Over the past couple of months, we have implemented support for BigInts in V8, as currently specified by this proposal, to be included in a future version of ECMAScript. The following post tells the story of our adventures.
TL;DR
As a JavaScript programmer, you now1 have integers with arbitrary2 precision in your toolbox:
const a = 2172141653n;const b = 15346349309n;
a * b;// → 33334444555566667777n // Yay!Number(a) * Number(b);// → 33334444555566670000 // Boo!const such_many = 2n ** 222n;// → 6739986666787659948666753771754907668409286105635143120275902562304n
For details about the new functionality and how it could be used, refer to our in-depth Web Fundamentals article on BigInt. We are looking forward to seeing the awesome things you’ll build with them!
1Now if you run Chrome Beta, Dev, or Canary, or a preview Node.js version, otherwise soon (Chrome 67, Node.js master probably around the same time).
2 Arbitrary up to an implementation-defined limit. Sorry, we haven’t yet figured out how to squeeze an infinite amount of data into your computer’s finite amount of memory.
Representing BigInts in memory
Typically, computers store integers in their CPU’s registers (which nowadays are usually 32 or 64 bits wide), or in register-sized chunks of memory. This leads to the minimum and maximum values you might be familiar with. For example, a 32-bit signed integer can hold values from -2,147,483,648 to 2,147,483,647. The idea of BigInts, however, is to not be restricted by such limits.
So how can one store a BigInt with a hundred, or a thousand, or a million bits? It can’t fit in a register, so we allocate an object in memory. We make it large enough to hold all the BigInt’s bits, in a series of chunks, which we call “digits” — because this is conceptually very similar to how one can write bigger numbers than “9” by using more digits, like in “10”; except where the decimal system uses digits from 0 to 9, our BigInts use digits from 0 to 4294967295 (i.e. 2**32-1). That’s the value range of a 32-bit CPU register3, without a sign bit; we store the sign bit separately. In pseudo-code, a BigInt object with 3*32 = 96 bits looks like this:
3 On 64-bit machines, we use 64-bit digits, i.e. from 0 to 18446744073709551615 (i.e. 2n**64n-1n).
Back to school, and back to Knuth
Working with integers kept in CPU registers is really easy: to e.g. multiply two of them, there’s a machine instruction which software can use to tell the CPU “multiply the contents of these two registers!”, and the CPU will do it. For BigInt arithmetic, we have to come up with our own solution. Thankfully this particular task is something that quite literally every child at some point learns how to solve: remember what you did back in school when you had to multiply 345 * 678 and weren’t allowed to use a calculator?
That’s exactly how V8 multiplies BigInts: one digit at a time, adding up the intermediate results. The algorithm works just as well for 0 to 9 as it does for a BigInt’s much bigger digits.
Donald Knuth published a specific implementation of multiplication and division of large numbers made up of smaller chunks in Volume 2 of his classic The Art of Computer Programming, all the way back in 1969. V8’s implementation follows this book, which shows that this a pretty timeless piece of computer science.
“Less desugaring” == more sweets?
Perhaps surprisingly, we had to spend quite a bit of effort on getting seemingly simple unary operations, like -x, to work. So far, -x did exactly the same as x * (-1), so to simplify things, V8 applied precisely this replacement as early as possible when processing JavaScript, namely in the parser. This approach is called “desugaring”, because it treats an expression like -x as “syntactic sugar” for x * (-1). Other components (the interpreter, the compiler, the entire runtime system) didn’t even need to know what a unary operation is, because they only ever saw the multiplication, which of course they must support anyway.
With BigInts, however, this implementation suddenly becomes invalid, because multiplying a BigInt with a Number (like -1) must throw a TypeError4. The parser would have to desugar -x to x * (-1n) if x is a BigInt — but the parser has no way of knowing what x will evaluate to. So we had to stop relying on this early desugaring, and instead add proper support for unary operations on both Numbers and BigInts everywhere.
4 Mixing BigInt and Number operand types is generally not allowed. That’s somewhat unusual for JavaScript, but there is an explanation for this decision.
A bit of fun with bitwise ops
Most computer systems in use today store signed integers using a neat trick called “two’s complement”, which has the nice properties that the first bit indicates the sign, and adding 1 to the bit pattern always increments the number by 1, taking care of the sign bit automatically. For example, for 8-bit integers:
10000000 is -128, the lowest representable number,
10000001 is -127,
11111111 is -1,
00000000 is 0,
00000001 is 1,
01111111 is 127, the highest representable number.
This encoding is so common that many programmers expect it and rely on it, and the BigInt specification reflects this fact by prescribing that BigInts must act as if they used two’s complement representation. As described above, V8’s BigInts don’t!
To perform bitwise operations according to spec, our BigInts therefore must pretend to be using two’s complement under the hood. For positive values, it doesn’t make a difference, but negative numbers must do extra work to accomplish this. That has the somewhat surprising effect that a & b, if a and b are both negative BigInts, actually performs four steps (as opposed to just one if they were both positive): both inputs are converted to fake-two’s-complement format, then the actual operation is done, then the result is converted back to our real representation. Why the back-and-forth, you might ask? Because all the non-bitwise operations are much easier that way.
Two new types of TypedArrays
The BigInt proposal includes two new TypedArray flavors: BigInt64Array and BigUint64Array. We can have TypedArrays with 64-bit wide integer elements now that BigInts provide a natural way to read and write all the bits in those elements, whereas if one tried to use Numbers for that, some bits might get lost. That’s why the new arrays aren’t quite like the existing 8/16/32-bit integer TypedArrays: accessing their elements is always done with BigInts; trying to use Numbers throws an exception.
> const big_array = new BigInt64Array(1);> big_array[0] = 123n; // OK> big_array[0]123n> big_array[0] = 456;TypeError: Cannot convert 456 to a BigInt> big_array[0] = BigInt(456); // OK
Just like JavaScript code working with these types of arrays looks and works a bit different from traditional TypedArray code, we had to generalize our TypedArray implementation to behave differently for the two newcomers.
Optimization considerations
For now, we are shipping a baseline implementation of BigInts. It is functionally complete and should provide solid performance (a little bit faster than existing userland libraries), but it is not particularly optimized. The reason is that, in line with our aim to prioritize real-world applications over artificial benchmarks, we first want to see how you will use BigInts, so that we can then optimize precisely the cases you care about!
For example, if we see that relatively small BigInts (up to 64 bits) are an important use case, we could make those more memory-efficient by using a special representation for them:
{
type: 'BigInt-Int64',
value: 0x12…,
}
One of the details that remain to be seen is whether we should do this for “int64” value ranges, “uint64” ranges, or both — keeping in mind having to support fewer fast paths means that we can ship them sooner, and also that every additional fast path ironically makes everything else a bit slower, because affected operations always have to check whether it is applicable.
Another story is support for BigInts in the optimizing compiler. For computationally heavy applications operating on 64-bit values and running on 64-bit hardware, keeping those values in registers would be much more efficient than allocating them as objects on the heap as we currently do. We have plans for how we would implement such support, but it is another case where we would first like to find out whether that is really what you, our users, care about the most; or whether we should spend our time on something else instead.
Please send us feedback on what you’re using BigInts for, and any issues you encounter! You can reach us at our bug tracker crbug.com/v8/new, via mail to v8-users@googlegroups.com, or @v8js on Twitter.
“ Google Maps Platform was
almost a foregone conclusion due to its familiarity, reliability, accuracy,
flexibility, ongoing innovation, and relationships with other data providers. It met
all our requirements and provided virtually limitless integration
capabilities.”
Dean Peck, Senior Business Solutions Analyst and Project
Manager
Otherwise, grab the latest version -[picoLisp.tgz] - unpack it, follow the
instructions from the INSTALL file,
and then check out the tutorial.
Or maybe you like to do a little research
before diving in. In that case...
Keep Scrollin'
PicoLisp has a few features that make it especially nifty.
An integrated database
Awesome C / Java interop
It's really simple
Besides, it's free (MIT/X11 License). The documentation is pretty
great, too.
Integrated Database
Build large, distributed databases with fewer headaches and fewer
dependencies
Database functionality is built
into the core of the VM, making PicoLisp a language for querying and
manipulating databases.
For that, PicoLisp includes a built-inapplication framework andProlog engine
so you can create, organize, inspect and change (and even build a fancy UI
for) your data - all with a uniform and concise
syntax.
And when it's time to scale, PicoLisp has you covered - creating networks
of distributed databases is built into the core as well. It's simple and
powerful, and makes few assumptions about your application architecture.
Native C calls and Java interop
The intention of PicoLisp is to avoid writing extensive libraries. So we
give you easy, transparent access to all your favorite software.
Leverage any C library function, manipulate C data structures
in memory, call lisp functions from your C code - all that
interactively from the REPL.
# call the 'MD5' function from 'libcrypto.so'
(let Str "The quick brown fox jumped over the lazy dog's back"
(pack
(mapcar '((B) (pad 2 (hex B)))
(native "libcrypto.so" "MD5"
'(B . 16) Str (length Str) '(NIL (16)) ) ) ) )
-> "E38CA1D920C4B8B8D3946B2C72F01680"
PicoLisp can even interface directly to a running JVM, giving you dynamic
access to everything Java.
Beneath the surface of the language lies the PicoLisp virtual machine.
At the lowest level, the VM operates on a single data structure -the cell.
+-----+-----+
| CAR | CDR |
+-----+-----+
A cell is just a pair of pointers, 'CAR' and 'CDR'.
All functions and
data in the system are stored in cells, which simply point to each other
to form arbitrarily complex structures.
From these cells, we contruct three base data types -Numbers, Symbols, and Lists -
and from those, the rest of our universe.
So once you grok the underlying cell structure (which you pretty much
already have), you just need to explore asmall but powerful set of functions
that do cool things with those cells.
It's that simple!
Other Features
Flexibility
It's lisp, afterall. It's a language best suited for reprogrammingitself.
Into functional programming? Rock on. OOP? PicoLisp has an elegant,
unobtrusive, totally optionalobject system. Explore a syntax of nested
function calls, bend the language to the task at hand, metaprogram yourself
to the moon. We'll help you build a rocket.
Expressiveness
PicoLisp programs are often much shorter than
equivalent programs written in other languages.
Examples of various programming tasks and their solutions can be found atrosettacode.org.
Efficiency
PicoLisp uses very little memory, on
disk as well as in memory (heap space).
The tarball size of the whole system - including the interpreter, database,
HTTP server, HTML and JavaScript application framework, and the debugger - is
just a few hundred kilobytes.
Download
If the following command makes sense for your setup, go ahead and run it.
$ sudo apt-get install picolisp
If not, you'll have to build it from source. But that's easy, too!
Grab the tarball - [picoLisp.tgz] -
unpack it, and follow the instructions from theINSTALL file.
Learn More!
The documentation page has many examples and tutorials to get you started.
It is our pleasure to announce that Project Jupyter has been awarded the 2017 ACM Software System Award, a significant honor for the project. We are humbled to join an illustrious list of projects that contains major highlights of computing history, including Unix, TeX, S (R’s predecessor), the Web, Mosaic, Java, INGRES (modern databases) and more.
Officially, the recipients of the award are the fifteen members of the Jupyter steering council as of November 2016, the date of nomination (listed in chronological order of joining the project): Fernando Pérez, Brian Granger, Min Ragan-Kelley, Paul Ivanov, Thomas Kluyver, Jason Grout, Matthias Bussonnier, Damián Avila, Steven Silvester, Jonathan Frederic, Kyle Kelley, Jessica Hamrick, Carol Willing, Sylvain Corlay and Peter Parente.
A tiny subset of the Jupyter contributors and users that made Jupyter possible — Biannual development meeting, 2016, LBNL.
This is the largest team ever to receive this award, and we are delighted that the ACM was willing to recognize that modern collaborative projects are created by large teams, and should be rewarded as such. Still, we emphasize that Jupyter is made possible by many more people than these fifteen recipients. This award honors the large group of contributors and users that has made IPython and Jupyter what they are today. The recipients are stewards of this common good, and it is our responsibility to help this broader community continue to thrive.
Below, we’ll summarize the story of our journey, including the technical and human sides of this effort. You can learn more about Jupyter from our website, and you can meet the vibrant Jupyter community by attending JupyterCon, August 21–25, 2018, in New York City.
In the beginning
Project Jupyter was officially unveiled with its current name in 2014 at the SciPy scientific Python conference. However, Jupyter’s roots date back nearly 17 years to when Fernando Pérez announced his open source IPython project as a graduate student in 2001. IPython provided tools for interactive computing in the Python language (the ‘I’ is for ‘Interactive’), with an emphasis on the exploratory workflow of scientists: run some code, plot and examine some results, think about the next step based on these outcomes, and iterate. IPython itself was born out of merging an initial prototype with Nathan Gray’s LazyPython and Janko Hauser’s IPP, inspired by a 2001 O’Reilly Radar post — collaboration has been part of our DNA since day one.
From those humble beginnings, a community of like-minded scientists grew around IPython. Some contributors have moved on to other endeavors, while others are still at the heart of the project. For example, Brian Granger and Min Ragan-Kelley joined the effort around 2004 and today lead multiple areas of the project. Our team gradually grew, both with members who were able to dedicate significant amounts of effort to the project as well as a larger, but equally significant, “long tail” community of users and contributors.
In 2011, after development of our first interactive client-server tool (our Qt Console), multiple notebook prototypes, and a summer-long coding sprint by Brian Granger, we were able to release the first version of the IPython Notebook. This effort paved the path to our modern architecture and vision of Jupyter.
What is Jupyter?
Project Jupyter develops open source software, standardizes protocols for interactive computing across dozens of programming languages, and defines open formats for communicating results with others.
Interactive computation
On the technical front, Jupyter occupies an interesting area of today’s computing landscape. Our world is flooded with data that requires computers to process, analyze, and manipulate, yet the questions and insights are still the purview of humans. Our tools are explicitly designed for the task of computing interactively, that is, where a human executes code, looks at the results of this execution, and decides the next steps based on these outcomes. Jupyter has become an important part of the daily workflow in research, education, journalism, and industry.
Whether running a quick script at the IPython terminal, or doing a deep dive into a dataset in a Jupyter notebook, our tools aim to make this workflow as fluid, pleasant, and effective as possible. For example, we built powerful completion tools to help you discover the structure of your code and data, a flexible display protocol to show results enriched by the multimedia capabilities of your web browser, and an interactive widget system to let you easily create GUI controls like sliders to explore parameters of your computation. All these tools have evolved from their IPython origins into open, documented protocols that can be implemented in any programming language as a “Jupyter kernel”. There are over 100 Jupyter kernels today, created by many members of the community.
Exploring a large dataset interactively using the widget protocol and tools.
Our experience building and using the Jupyter Notebook application for the last few years has now led to its next-generation successor, JupyterLab, which is now ready for users. JupyterLab is a web application that exposes all the elements above not only as an end-user application, but also as interoperable building blocks designed to enable entirely new workflows. JupyterLab has already been adopted by large scientific projects such as the Large Synoptic Survey Telescope project.
Communicating results
In today’s data-rich world, working with the computer is only half of the picture. Its complement is working with other humans, be it your partners, colleagues, students, clients, or even your future self months down the road. The open Jupyter notebook file format is designed to capture, display and share natural language, code, and results in a single computational narrative. These narratives exist in the tradition of literate programming that dates back to Knuth’s work, but here the focus is weaving computation and data specific to a given problem, in what we sometimes refer to as literate computing. While existing computational systems like Maple, Mathematica and SageMath all informed our experience, our focus in Jupyter has been on the creation of open standardized formats that can benefit the entire scientific community and support the long-term sharing and archiving of computational knowledge, regardless of programming language.
We have also built tools to support Jupyter deployment in multi-user environments, whether a single server in your group or a large cloud deployment supporting thousands of students. JupyterHub and projects that build upon it, like Binder and BinderHub, now support industry deployments, large-scale education, reproducible research, and the seamless sharing of live computational environments.
Data Science class at UC Berkeley, taught using Jupyter.
We are delighted to see, for example, how the LIGO Collaboration, awarded the 2017 Nobel Prize in Physics for the observation of gravitational waves, offers their data and analysis code for the public in the form of Jupyter Notebooks hosted on Binder at their Open Science Center.
In Project Jupyter, we have concentrated on standardizing protocols and formats evolved from community needs, independent of any specific implementation. The stability and interoperability of open standards provides a foundation for others to experiment, collaborate, and build tools inspired by their unique goals and perspectives.
For example, while we provide the nbviewer service that renders notebooks from any online source for convenient sharing, many people would rather see their notebooks directly on GitHub. This was not possible originally, but the existence of a well-documented notebook format enabled GitHub to develop their own rendering pipeline, which now shows HTML versions of notebooks rendered in a way that conforms to their security requirements.
Similarly, there exist multiple client applications in addition to the Jupyter Notebook and JupyterLab to create and execute notebooks, each with its own use case and focus: the open source nteract project develops a lightweight desktop application to run notebooks; CoCalc, a startup founded by William Stein, the creator of SageMath, offers a web-based client with real-time collaboration that includes Jupyter alongside SageMath, LaTeX, and tools focused on education; and Google now provides Colaboratory, another web notebook frontend that runs alongside the rest of the Google Documents suite, with execution in the Google Cloud.
These are only a few examples, but they illustrate the value of open protocols and standards: they serve open-source communities, startups, and large corporations equally well. We hope that as the project grows, interested parties will continue to engage with us so we can keep refining these ideas and developing new ones in support of a more interoperable and open ecosystem.
Growing a community
IPython and Jupyter have grown to be the product of thousands of contributors, and the ACM Software System Award should be seen as a recognition of this combined work. Over the years, we evolved from the typical pattern of an ad-hoc assembly of interested people loosely coordinating on a mailing list to a much more structured project. We formalized our governance model and instituted a Steering Council. We continue to evolve these ideas as the project grows, always seeking to ensure the project is welcoming, supports an increasingly diverse community, and helps solidify a foundation for it to be sustainable. This process isn’t unique to Jupyter, and we’ve learned from other larger projects such as Python itself.
Jupyter exists at the intersection of distributed open source development, university-centered research and education, and industry engagement. While the original team came mostly from the academic world, from the start we’ve recognized the value of engaging industry and other partners. This led, for example, to our BSD licensing choice, best articulated by the late John Hunter in 2004. Beyond licensing, we’ve actively sought to maintain a dialog with all these stakeholders:
We are part of the NumFOCUS Foundation, working as part of a rich tapestry of other scientifically-focused open source projects. Jupyter is a portal to many of these tools, and we need the entire ecosystem to remain healthy.
We have obtained significant funding from the Alfred P. Sloan Foundation, the Gordon and Betty Moore Foundation, and the Helmsley Trust.
We engage directly with industry partners. Many of our developers hail from industry: we have ongoing active collaborations with companies such as Bloomberg and Quansight on the development of JupyterLab, and with O’Reilly Media on JupyterCon. We have received funding and direct support in the past from Bloomberg, Microsoft, Google, Anaconda, and others.
The problem of sustainably developing open source software systems of lasting intellectual and technical value, that serve users as diverse as high-school educators, large universities, Nobel prize-winning science teams, startups, and the largest technology companies in the world, is an ongoing challenge. We need to build healthy communities, find significant resources, provide organizational infrastructure, and value professional and personal time invested in open source. There is a rising awareness among volunteers, business leaders, academic promotion and tenure boards, professional organizations, government agencies, and others of the need to support and sustain critical open source projects. We invite you to engage with us as we continue to explore solutions to these needs and build these foundations for the future.
Acknowledgments
The award was given to the above fifteen members of the Steering Council. But this award truly belongs to the community, and we’d like to thank all that have made Jupyter possible, from newcomers to long-term contributors. The project exists to serve the community and wouldn’t be possible without you.
We are grateful for the generous support of our funders. Jupyter’s scale and complexity require dedicated effort, and this would be impossible without the financial resources provided (now and in the past) by the Alfred P. Sloan Foundation, the Gordon and Betty Moore Foundation, the Helmsley Trust, the Simons Foundation, Lawrence Berkeley National Laboratory, the European Union Horizon 2020 program, Anaconda Inc, Bloomberg, Enthought, Google, Microsoft, Rackspace, and O’Reilly Media. Finally, the recipients of the award have been supported by our employers, who often have put faith in the long-term value of this type of work well before the outcomes were evident: Anaconda, Berkeley Lab, Bloomberg, CalPoly, DeepMind, European XFEL, Google, JP Morgan, Netflix, QuantStack, Simula Research Lab, UC Berkeley and Valassis Digital.
On 7/19/2017 12:15 PM, Larry Hastings wrote:>>> On 07/19/2017 05:59 AM, Victor Stinner wrote:>> Mercurial startup time is already 45.8x slower than Git whereas tested>> Mercurial runs on Python 2.7.12. Now try to sell Python 3 to Mercurial>> developers, with a startup time 2x - 3x slower...>> When Matt Mackall spoke at the Python Language Summit some years back, I> recall that he specifically complained about Python startup time. He
> said Python 3 "didn't solve any problems for [them]"--they'd already> solved their Unicode hygiene problems--and that Python's slow startup> time was already a big problem for them. Python 3 being /even slower/
> to start was absolutely one of the reasons why they didn't want to upgrade.>> You might think "what's a few milliseconds matter". But if you run
> hundreds of commands in a shell script it adds up. git's speed is one
> of the few bright spots in its UX, and hg's comparative slowness here is> a palpable disadvantage.>>>> So please continue efforts for make Python startup even faster to beat>> all other programming languages, and finally convince Mercurial to>> upgrade ;-)>> I believe Mercurial is, finally, slowly porting to Python 3.>>https://www.mercurial-scm.org/wiki/Python3>> Nevertheless, I can't really be annoyed or upset at them moving slowly> to adopt Python 3, as Matt's objections were entirely legitimate.
I just now found found this thread when searching the archive for
threads about startup time. And I was searching for threads about
startup time because Mercurial's startup time has been getting slower
over the past few months and this is causing substantial pain.
As I posted back in 2014 [1], CPython's startup overhead was >10% of the
total CPU time in Mercurial's test suite. And when you factor in the
time to import modules that get Mercurial to a point where it can run
commands, it was more like 30%!
Mercurial's full test suite currently runs `hg` ~25,000 times. Using
Victor's startup time numbers of 6.4ms for 2.7 and 14.5ms for
3.7/master, Python startup overhead contributes ~160s on 2.7 and ~360s
on 3.7/master. Even if you divide this by the number of available CPU
cores, we're talking dozens of seconds of wall time just waiting for
CPython to get to a place where Mercurial's first bytecode can execute.
And the problem is worse when you factor in the time it takes to import
Mercurial's own modules.
As a concrete example, I recently landed a Mercurial patch [2] that
stubs out zope.interface to prevent the import of 9 modules on every
`hg` invocation. This "only" saved ~6.94ms for a typical `hg`
invocation. But this decreased the CPU time required to run the test
suite on my i7-6700K from ~4450s to ~3980s (~89.5% of original) - a
reduction of almost 8 minutes of CPU time (and over 1 minute of wall time)!
By the time CPython gets Mercurial to a point where we can run useful
code, we've already blown most of or past the time budget where humans
perceive an action/command as instantaneous. If you ignore startup
overhead, Mercurial's performance compares quite well to Git's for many
operations. But the reality is that CPython startup overhead makes it
look like Mercurial is non-instantaneous before Mercurial even has the
opportunity to execute meaningful code!
Mercurial provides a `chg` program that essentially spins up a daemon
`hg` process running a "command server" so the `chg` program [written in
C - no startup overhead] can dispatch commands to an already-running
Python/`hg` process and avoid paying the startup overhead cost. When you
run Mercurial's test suite using `chg`, it completes *minutes* faster.
`chg` exists mainly as a workaround for slow startup overhead.
Changing gears, my day job is maintaining Firefox's build system. We use
Python heavily in the build system. And again, Python startup overhead
is problematic. I don't have numbers offhand, but we invoke likely a few
hundred Python processes as part of building Firefox. It should be
several thousand. But, we've had to "hack" parts of the build system to
"batch" certain build actions in single process invocations in order to
avoid Python startup overhead. This undermines the ability of some build
tools to formulate a reasonable understanding of the DAG and it causes a
bit of pain for build system developers and makes it difficult to
achieve "no-op" and fast incremental builds because we're always
invoking certain Python processes because we've had to move DAG
awareness out of the build backend and into Python. At some point, we'll
likely replace Python code with Rust so the build system is more "pure"
and easier to maintain and reason about.
I've seen posts in this thread and elsewhere in the CPython development
universe that challenge whether milliseconds in startup time matter.
Speaking as a Mercurial and Firefox build system developer,
*milliseconds absolutely matter*. Going further, *fractions of
milliseconds matter*. For Mercurial's test suite with its ~25,000 Python
process invocations, 1ms translates to ~25s of CPU time. With 2.7,
Mercurial can dispatch commands in ~50ms. When you load common
extensions, it isn't uncommon to see process startup overhead of
100-150ms! A millisecond here. A millisecond there. Before you know it,
we're talking *minutes* of CPU (and potentially wall) time in order to
run Mercurial's test suite (or build Firefox, or ...).
>From my perspective, Python process startup and module import overheadis a severe problem for Python. I don't say this lightly, but in my mind
the problem causes me to question the viability of Python for popular
use cases, such as CLI applications. When choosing a programming
language, I want one that will scale as a project grows. Vanilla process
overhead has Python starting off significantly slower than compiled code
(or even Perl) and adding module import overhead into the mix makes
Python slower and slower as projects grow. As someone who has to deal
with this slowness on a daily basis, I can tell you that it is extremely
frustrating and it does matter. I hope that the importance of the
problem will be acknowledged (milliseconds *do* matter) and that
creative minds will band together to address it. Since I am
disproportionately impacted by this issue, if there's anything I can do
to help, let me know.
Gregory
[1] https://mail.python.org/pipermail/python-dev/2014-May/134528.html
[2] https://www.mercurial-scm.org/repo/hg/rev/856f381ad74b
GitHub has partnered with Let’s Encrypt, which is a free, open and automated certificate authority (CA). It is run by the Internet Security Research Group (ISRG), which is a public benefit corporationfunded by donations and a bunch of large corporations and non-profits.
The goal of this initiative is to secure the web by making it very easy to obtain a free, trusted SSL certificate. Moreover, it lets web servers run a piece of software that not only gets a valid SSL certificate, but will also configure your web server and automatically renew the certificate when it expires.
It works by running a bit of software on your web server, a certificate management agent. This agent software has two tasks: it proves to the Let’s Encrypt certificate authority that it controls the domain, and it requests, renews and revokes certificates for the domain it controls.
Validating a domain
Similar to a traditional process of obtaining a certificate for a domain, where you create an account with the CA and add domains you control, the certificate management agent needs to perform a test to prove that it controls the domain.
The agent will ask the Let’s Encrypt CA what it needs to do to prove that it is, effectively, in control of the domain. The CA will look at the domain, and issue one or more challenges to the agent it needs to complete to prove that it has control over the domain. For example, it can ask the agent to provision a particular DNS record under the domain, or make an HTTP resource available under a particular URL. With these challenges, it provides the agent with a nonce (some random number that can only be used once for verification purposes).
CA issuing a challenge to the certificate management agent (image taken from https://letsencrypt.org/how-it-works/)
In the image above, the agent creates a file on a specified path on the web server (in this case, on https://example.com/8303). It creates a key pair it will use to identify itself with the CA, and signs the nonce received from the CA with the private key. Then, it notifies the CA that it has completed the challenge by sending back the signed nonce and is ready for validation. The CA then validates the completion of the challenge by attempting to download the file from the web server and verify that it contains the expected content.
Certificate management agent completing a challenge (image taken from https://letsencrypt.org/how-it-works/)
If the signed nonce is valid, and the challenge is completed successfully, the agent identified by the public key is officially authorized to manage valid SSL certificates for the domain.
Certificate management
So, what does that mean? By having validated the agent by its public key, the CA can now validate that messages sent to the CA are actually sent by the certificate management agent.
It can send a Certificate Signing Request (CSR) to the CA to request it to issue a SSL certificate for the domain, signed with the authorized key. Let’s Encrypt will only have to validate the signatures, and if those check out, a certificate will be issued.
Issuing a certificate (image taken from https://letsencrypt.org/how-it-works/)
Let’s Encrypt will add the certificate to the appropriate channels, so that browsers will know that the CA has validated the certificate, and will display that coveted green lock to your users!
Right, that’s how we got started. The awesome thing about Let’s Encrypt is that it is automated, so all this handshaking and verifying happens behind the scenes, without you having to be involved.
In the previous post we saw how to set up a CNAME file for your custom domain. That’s it. Done. Works out of the box.
Optionally, you can enforce HTTPS in the settings of your repository. This will upgrade all users requesting stuff from your site over HTTP to be automatically redirected to HTTPS.
If you use A records to route traffic to your website, you need to update your DNS settings at your registrar. These IP addresses are new, and have an added benefit of putting your static site behind a CDN (just like we did with Cloudflare in the previous post).
Let’s Encrypt makes securing the web easy. More and more websites are served over HTTPS only, so it is getting increasingly difficult for script kiddies to sniff your web traffic on free WiFi networks. Moreover, they provide this service world-wide, to anyone, for free. Help them help you (and the rest of the world), and buy them a coffee!
The Vatican Secret Archives is one of the grandest historical collections in the world. It’s also one of the most useless.
The grandeur is obvious. Located within the Vatican’s walls, next door to the Apostolic Library and just north of the Sistine Chapel, the VSA houses 53 linear miles of shelving dating back more than 12 centuries. It includes gems like the papal bull that excommunicated Martin Luther and the pleas for help that Mary Queen of Scots sent to Pope Sixtus V before her execution. In size and scope, the collection is almost peerless.
That said, the VSA isn’t much use to modern scholars, because it’s so inaccessible. Of those 53 miles, just a few millimeters’ worth of pages have been scanned and made available online. Even fewer pages have been transcribed into computer text and made searchable. If you want to peruse anything else, you have to apply for special access, schlep all the way to Rome, and go through every page by hand.
But a new project could change all that. Known as In Codice Ratio, it uses a combination of artificial intelligence and optical-character-recognition (OCR) software to scour these neglected texts and make their transcripts available for the very first time. If successful, the technology could also open up untold numbers of other documents at historical archives around the world.
OCR has been used to scan books and other printed documents for years, but it’s not well suited for the material in the Secret Archives. Traditional OCR breaks words down into a series of letter-images by looking for the spaces between letters. It then compares each letter-image to the bank of letters in its memory. After deciding which letter best matches the image, the software translates the letter into computer code (ASCII) and thereby makes the text searchable.
This process, however, really only works on typeset text. It’s lousy for anything written by hand—like the vast majority of old Vatican documents. Here’s an example from the early 1200s, written in what’s called Caroline minuscule script, which looks like a mix of calligraphy and cursive:
In Codice Ratio
The main problem in this example is the lack of space between letters (so-called dirty segmentation). OCR can’t tell where one letter stops and another starts, and therefore doesn’t know how many letters there are. The result is a computational deadlock, sometimes referred to as Sayre’s paradox: OCR software needs to segment a word into individual letters before it can recognize them, but in handwritten texts with connected letters, the software needs to recognize the letters in order to segment them. It’s a catch-22.
Some computer scientists have tried to get around this problem by developing OCR to recognize whole words instead of letters. This works fine technologically—computers don’t “care” whether they’re parsing words or letters. But getting these systems up and running is a bear, because they require gargantuan memory banks. Rather than a few dozen alphabet letters, these systems have to recognize images of thousands upon thousands of common words. Which means you need a whole platoon of scholars with expertise in medieval Latin to go through old documents and capture images of each word. In fact, you need several images of each, to account for quirks in handwriting or bad lighting and other variables. It’s a daunting task.
In Codice Ratio sidesteps these problems through a new approach to handwritten OCR. The four main scientists behind the project—Paolo Merialdo, Donatella Firmani, and Elena Nieddu at Roma Tre University, and Marco Maiorino at the VSA—skirt Sayre’s paradox with an innovation called jigsaw segmentation. This process, as the team recently outlined in a paper, breaks words down not into letters but something closer to individual pen strokes. The OCR does this by dividing each word into a series of vertical and horizontal bands and looking for local minimums—the thinner portions, where there’s less ink (or really, fewer pixels). The software then carves the letters at these joints. The end result is a series of jigsaw pieces:
In Codice Ratio
By themselves, the jigsaw pieces aren’t tremendously useful. But the software can chunk them together in various ways to make possible letters. It just needs to know which groups of chunks represent real letters and which are bogus.
To teach the software this, the researchers turned to an unusual source of help: high schoolers. The team recruited students at 24 schools in Italy to build the projects’ memory banks. The students logged onto a website, where they found a screen with three sections:
In Codice Ratio
The green bar along the top contains nice, clean examples of letters from a medieval Latin text—in this case, the letter g. The red bar in the middle contains spurious examples of g, what the Codice scientists call “false friends.” The grid at the bottom is the meat of the program. Each of the images there is composed of a few jigsaw pieces that the OCR software chunked together—its guess at a plausible letter. The students then judged the OCR’s efforts, telling it which guesses were good and which were bad. They did so by comparing each image to the platonically perfect green letters and clicking a checkbox when they saw a match.
Image by image, click by click, the students taught the software what each of the 22 characters in the medieval Latin alphabet (a–i, l–u, plus some alternative forms of s and d) looks like.
The setup did require some expert input: Scholars had to pick out the perfect examples in green, as well as the false friends in red. But once they did this, there was no more need for them. The students didn’t even need to be able to read Latin. All they had to do is match visual patterns. At first, “the idea of involving high-school students was considered foolish,” says Merialdo, who dreamed up In Codice Ratio. “But now the machine is learning thanks to their efforts. I like that a small and simple contribution by many people can indeed contribute to the solution of a complex problem.”
Eventually, of course, the students stepped aside as well. Once they’d voted yes on enough examples, the software started chunking jigsaw pieces together independently and judging for itself what letters were there. The software itself became an expert—it became artificially intelligent.
At least, sort of. It turned out that chunking jigsaw pieces into plausible letters wasn’t enough. The computer still needed additional tools to untangle the knots of handwritten text. Imagine you’re reading a letter, and you come across this line:
Sam Kean
Is it “clear” to them or “dear” to them? Hard to say, since the strokes that make up “d” and “cl” are virtually the same. OCR software faces the same problem, especially with a highly stylized script like Caroline minuscule. Try deciphering this word:
In Codice Ratio
After running through different jigsaw combinations, the OCR threw up its hands. Guesses included aimo, amio, aniio, aiino, and even the Old MacDonald’s Farm–ish aiiiio. The word is anno, Latin for “year,” and the software nailed the a and o. But those four parallel columns in the middle flummoxed it.
To get around this problem, the In Codice Ratio team had to teach their software some common sense—practical intelligence. They found a corpus of 1.5 million already-digitized Latin words, and examined them in two- and three-letter combinations. From this, they determined which combinations of letters are common, and which never occur. The OCR software could then use those statistics to assign probabilities to different strings of letters. As a result, the software learned that nn is far more likely than iiii.
With this refinement in place, the OCR was finally ready to read some texts on its own. The team decided to feed it some documents from the Vatican Registers, a more than 18,000-page subset of the Secret Archives consisting of letters to European kings, rulings on legal matters, and other correspondence.
The initial results were mixed. In texts transcribed so far, a full one-third of the words contained one or more typos, places where the OCR guessed the wrong letter. If yov were tryinj to read those lnies in a bock, that would gct very aiiiioying. (The most common typos involved m/n/i confusion and another commonly confused pair: the letter f and an archaic, elongated form of s.) Still, the software got 96 percent of all handwritten letters correct. And even “imperfect transcriptions can provide enough information and context about the manuscript at hand” to be useful, says Merialdo.
Like all artificial intelligence, the software will improve over time, as it digests more text. Even more exciting, the general strategy of In Codice Ratio—jigsaw segmentation, plus crowdsourced training of the software—could easily be adapted to read texts in other languages. This could potentially do for handwritten documents what Google Books did for printed matter: open up letters, journals, diaries, and other papers to researchers around the world, making it far easier to both read these documents and search for relevant material.
That said, relying on artificial intelligence does have limitations, says Rega Wood, a historian of philosophy and paleographer (expert on ancient handwriting) at Indiana University. It “will be problematic for manuscripts that are not professionally written but copied by nonprofessionals,” she says, since the handwriting and letter shapes will vary far more in those documents, making it harder to teach the OCR. In addition, in cases where there’s only a small sample size of material to work with, “it is not only more accurate, but just as quick to make transcriptions without such technology.”
Pace Dan Brown, the “secret” in the Vatican Secret Archives’ name doesn’t refer to anything clandestine or conspiratorial. It merely means that the archives are the personal property of the pope; “private archives” would probably be a better translation of the original name, Archivum Secretum. Still, until recently, the VSA might as well have been secret to most of the world—locked away and largely inaccessible. “It is amazing for us to bring these manuscripts back to life,” Merialdo says, “and make their comprehension available to everybody.”
reported its Q1 2018 earnings today, posting adjusted losses of $3.35 per share with revenues on $3.4 billion. This is a beat, as analysts expected Tesla to report a loss of $3.48 a share with revenues of $3.22 billion, up from $2.7 billion a year ago. Last quarter, Tesla reported revenues of $3.29 billion. Tesla also ended Q1 with $2.7 billion in cash.
In September 2017, Tesla stock hit a record high of $389.61 a share. At market close today, Tesla was trading at $301.15. In after-hours, Tesla is trading around $305.
Tesla also provided some updates to its Model 3 production, noting it hit 2,270 cars produced per week for three straight weeks in April.
“Even at this stage of the ramp, Model 3 is already on the cusp of becoming the best-selling mid-sized premium sedan in the US, and our deliveries continue to increase,” Tesla CEO Elon Musk and CFO Deepak Ahuja wrote in a letter to investors. “Consumers have clearly shown that electric vehicles are simply more desirable when priced on par with their internal combustion engine competitors while offering better technology, performance and user experience.”
Model 3 production updates
Just as Tesla did in Q1, it plans to take planned downtime as part of its Model 3 production process. Prior to the downtime in April, Tesla said it had hit a record of producing 4,750 Model 3 vehicles in two weeks.
Once Tesla hits its ideal production rate of 5,000 Model 3 cars per week, which the company expects to do within about two months, the plan is to increase that goal to 10,000 Model 3 cars produced per week.
“In the end, this is all about having factories that are producing the world’s highest quality cars as quickly and as cost-effectively as possible, and with as close to zero injuries as we can possibly get,” the investor letter states. “Our automation strategy is key to this and we are as committed to it as ever.”
However, Musk has previously said that Tesla over-relied on automation for the production of Model 3 cars. That’s something he still stands by, saying Tesla mistakenly added “too much automation too quickly” early in the process.
Musk and Ahuja added:
In those select areas where we have had challenges ramping fully automated processes, such as portions of the battery module line, part of the material flow system, and two steps of general assembly, we have temporarily dialed back automation and introduced certain semi-automated or manual processes while we work to eventually have full automation take back over.
Model S and Model X demand is “very strong”
Tesla Model S
Although much attention has been paid to the Model 3, Tesla said demand for the Model S and Model X is still quite strong. In Q1, Tesla had its highest order number ever, with demand exceeding supply. Tesla said it produced 24,728 Model S cars and X vehicles, while delivering a total of 21,815 of them.
“Short-term operational and logistical issues led to an increase in the number of Model S and Model X vehicles in transit to customers at the end of Q1,” the letter states.
Looking forward into Q2, Tesla expects Model S and X deliveries to be similar to the ones in Q1. But Tesla said that number will increase in Q3 in order for Tesla to hit its goal of 100,000 deliveries for 2018.
Tesla expects to be profitable in Q3
Assuming Tesla hits its 5,000 Model 3 cars produced per week goal, Tesla expects to be profitable in Q3 and Q4, excluding non-cash, stock-based compensation. Tesla also expects to achieve full GAAP profitability in Q3 and Q4 as well.
Analysts, regulators and customers alike have been paying close attention to Tesla over the past few months. In March, a Tesla owner died following a car crash that involved the Model X’s Autopilot mode. In April, after cooperating with the National Transportation Safety Board for the investigation, the NTSB removed Tesla as a party. That’s because the NTSB was unhappy with the way Tesla released information pertaining to the crash to the public.
“The NTSB took this action because Tesla violated the party agreement by releasing investigative information before it was vetted and confirmed by the NTSB,” the NTSB wrote in a press release. “Such releases of incomplete information often lead to speculation and incorrect assumptions about the probable cause of a crash, which does a disservice to the investigative process and the traveling public.”
With the introduction of the iMac Pro by Apple in late December 2017, a number of brand-new features premiered on the macOS platform. While Apple had already introduced a dedicated security coprocessor with the inclusion of the T1 processor in the late 2016 MacBook Pro with Touch Bar, it served only a few specific tasks like driving the Touch Bar display and touch screen, reading fingerprints from the Touch ID sensor and storing fingerprint data in the T1’s Secure Enclave Processor or SEP.
In keeping with its limited system architecture role, the T1 Application Processor or AP was based on a 32-bit ARMv7 processor similar to the S1 AP used in the Apple Watch. Its dedicated watchOS-based OS is named BridgeOS, while the hardware identifier is iBridge.
The announcement of the iMac Pro made reference to the presence of another security processor but also mentioned a number of changes to system security. Touch ID would not be present and. while rumored to be an option, Face ID was also not present. Instead of focusing on mobile-friendly security features like touch or facial recognition, Apple instead used the next-generation T2 coprocessor to implement an overhauled boot security system, which it named Secure Boot.
Due to the increased reliance on a security coprocessor, Apple decided to give the T2 coprocessor a significant performance bump by basing it on the same AP core as the one found in the Apple A10 processor, a 64-bit ARMv8 processor also found in the iPhone 7 and 7 Plus. The T2 coprocessor is not exactly the same as the A10 processor since it incorporates only one of the T801x cores that make up the A10 package, but is a significant step up in capabilities from the earlier T1 AP. Apple gave the AP the model number T8012, references to which can be found throughout BridgeOS. A separate Secure Enclave Processor or SEP is also found in the T2, similar to that in the T1.
Given all of these changes, we wanted to explore how the T2 coprocessor was being used by Apple and how it currently fits into the larger system security model, as well as how this may evolve in the future. What follows is the first part of this exploration where we describe how the T2 coprocessor is used to implement Secure Boot on the iMac Pro, as well as comparing and contrasting this Secure Boot approach to those that have been present in Apple’s iDevices for a number of years.
Storage and the T2
First, we need to understand the role the T2 coprocessor plays in the security of the data stored on a system and understand the tasks that have been delegated to it from the main CPU. What follows is a technical walk through of what we discovered during our analysis and the conclusions we have drawn from it.
By significantly stepping up the performance of the T2 coprocessor in order to handle early boot tasks, the T2 coprocessor also gained a number of abilities that can be leveraged to enhance the security of at-rest data storage for the iMac Pro. Apple announced its improved security capabilities on the iMac Pro’s official product page:
“T2 also makes iMac Pro even more secure, thanks to a Secure Enclave coprocessor that provides the foundation for new encrypted storage and secure boot capabilities. The data on your SSD is encrypted using dedicated AES hardware with no effect on the SSD’s performance, while keeping the Intel Xeon processor free for your compute tasks.”
“Data on your iMac Pro built-in, solid-state drive (SSD) is encrypted using a hardware accelerated AES engine built into the T2 chip. The encryption is performed with 256 bit keys tied to a unique identifier within the T2 chip.”
These claims are backed up by what we found in BridgeOS itself when we looked at the com.apple.iokit.IOCryptoAcceleratorFamily.kext kernel extension which implements a number of cryptographic acceleration methods. Specifically, the IOAESAccelerator class is what helps to offload the work previously done by the AES-XTS support built into x86 CPUs, as documented here:
“The IOAESAccelerator service provides hardware-accelerated AES encryption/decryption functions in CBC mode. It also provides access to the secure UID (2000) and GID (1000) keys, and the generated securityd (2101/0x835) and various firmware encryption keys.”
But Apple went further than simply offloading the main CPU-bound AES encryption work to the T2 coprocessor as dedicated security coprocessor. In order to make it harder for an attacker with physical access to an iMac Pro to gain access to data stored on the internal storage, Apple implemented what appears to be encrypted storage in a way that puts the T2 coprocessor squarely in the middle of the I/O path instead of giving the main CPU access via the normal PCIe/NVMe path.
Further evidence about the use of dedicated encryption acceleration hardware and software can be found by taking a look at SEPOS since the decryption key for the SEPOS image found on the iPhone 5s became available in August 2017.
Apple NVMe
In order to understand Apple’s decision to switch from the older Serial ATA (SATA) interface to the higher-performing Non-Volatile Memory Express or NVMe, we recommend reading Ramtin Amin’s excellent deep-dive into its implementation. The main advantages of using NVMe to provide SSD storage access are that by using all the available parallel operations possible with modern flash-based storage over a four-lane PCIe connection, much better I/O speeds can be achieved compared to older HDD-specific interfaces.
In a nutshell, NVMe was designed with solid state storage as a central design goal, unlike older interfaces like SATA that were designed to meet the needs of spinning platter hard disks. NVMe support on both macOS and BridgeOS is handled by the com.apple.iokit.IONVMeFamily.kext kernel extension. When we take a look at the IORegistry layout for the iMac Pro’s SSD storage device, we can see this more clearly:
In the above diagram, we can see the Apple SSD AP1024M Media device as it is visible to the user in macOS. This device is made available as a regular block storage device via the IOStorageFamily.kext kernel extension, which, in its place, is support by the NVMe kernel extension. Meanwhile, the Apple ANS2 (Apple NAND Storage) controller appears to be only found on recent iOS devices such as the iPad Pro, iPhone 7, 8 and X. Inspection of Apple’s “iOS Security Guide” white paper gives some further insight into this:
“Every iOS device has a dedicated AES-256 crypto engine built into the DMA path between the flash storage and main system memory, making file encryption highly efficient. On A9 or later A-series processors, the flash storage subsystem is on an isolated bus that is only granted access to memory containing user data via the DMA crypto engine.”
This statement confirms what we’ve seen in the BridgeOS code itself, as well as what is known about the T2 coprocessor external connectivity: the pair of physical SSD memory chips that are exposed as a single device to macOS are directly connected via dual x4 PCIe lanes to the SoC where they are uniquely paired to the AP and at-rest encryption is enabled by default. Apple confirms this as well in the white paper:
“The device’s unique ID (UID) and a device group ID (GID) are AES 256-bit keys fused (UID) or compiled (GID) into the application processor and Secure Enclave during manufacturing. No software or firmware can read them directly; they can see only the results of encryption or decryption operations performed by dedicated AES engines implemented in silicon using the UID or GID as a key. Additionally, the Secure Enclave’s UID and GID can only be used by the AES engine dedicated to the Secure Enclave.”
The unique pairing here provides some very important security properties that prevent the memory chips that comprise the SSD itself from being physically removed from the system and connected to a different system, or from having their contents extracted from the chips and flashed onto SSD chips in another system. Apple states in further detail the way in which the T2 coprocessor and the SSD chips are uniquely bound together to provide these protections when the SSD chips are first initialized:
“On T1, S2, S3, and A9 or later A-series processors, each Secure Enclave generates its own UID (Unique ID). [...] The UID allows data to be cryptographically tied to a particular device. For example, the key hierarchy protecting the file system includes the UID, so if the memory chips are physically moved from one device to another, the files are inaccessible.”
At the time of last publication, Apple had not yet updated the information for the T2 coprocessor, but our research shows that the above largely applies to its implementation as well.
By further exploring the complete output of the IODeviceTree plane of IORegistry (which can be retrieved from BridgeOS running on the T2 coprocessor using sysdiagnose -c), we can see the logical hierarchy of the AES crypto engine and the ANS2 device that sits behind it.
macOS Device Discovery
On the macOS side, it’s interesting to see how the AppleNVMeFamily-backed storage device is exposed over a single x4 PCIe lane to the x86 CPU itself. As far as the x86 CPU and macOS running on it are concerned, the iMac Pro’s SSD storage is just a regular NVMe-compatible storage device when discovered; yet we’ve seen a number of transparent processes will have occurred and continue to occur during normal use in order to encrypt data as it written to the SSD’s memory chips.
The hierarchical view of the storage device that as we
have now learned is actively managed by the T2 coprocessor and BridgeOS is as follows:
Filevault and Secure Storage
By now, we’ve learned that by default, the iMac Pro’s storage is encrypted using a unique identifier stored in its T2 coprocessor. This prevents physical attacks involving removing the SSD memory chips, thus making them useless when installed anywhere but the iMac Pro they were original paired with.
In order to also protect against physical attacks on the same physical machine, full-disk encryption (FDE) comes into play. Apple has implemented FDE for a number of years through its FileVault feature. FileVault is a fully capable FDE system that has gone through a number of evolutions since its introduction in Mac OS X 10.7.
Originally, FileVault only encrypted the user’s home folder as a disk image. FileVault 2 fully encrypted volumes at the block level using AES-XTS and 128 bit blocks with a 256-bit key by leveraging its CoreStorage logical volume management. A more in-depth description of the FileVault 2 architecture can be found in this archived document from Apple’s Training website.
With the introduction of macOS 10.13 High Sierra, Apple introduced another evolution of FileVault that was mostly unseen but leverages the new APFS filesystem’s native encryption capabilities to allow for instant-on FDE and more streamlined enrollment of additional users.
We believe that, with the introduction of always-on disk encryption in the iMac Pro, the FileVault activation process is now essentially identical to how a passcode protects an iOS device. When enabled, the user’s passphrase is entangled with the device’s hardware UID and used to create further derived keys that are used to encrypt and decrypt. The Apple iOS Security white paper goes into more detail, but our findings corroborate that the iMac Pro’s T2 coprocessor operates in the same way. The Passcode key that is derived from the user’s passphrase is stored in the Secure Enclave that is part of the T2 coprocessor and not accessible through unprivileged means.
Conclusion
This is the first in a series of research articles about the iMac Pro and its new security features that we plan to publish in future installments. We decided to take a closer look at its storage security improvements first since it is prominently featured in Apple’s marketing for the iMac Pro.
With the inclusion of its next generation of security coprocessors, Apple has set the standard for what to expect for the future of the Mac platform. By taking their proven success and leadership on the iOS platform with respect to security and privacy, Apple has been able to fast-track catching up with competing platforms that already implement modern hardware security features.
Windows and ChromeOS’s support for TPMs, Universal 2nd Factor (U2F) and Universal Authentication Factor (UAF)/Webauthn have made them popular choices for security-minded customers. We hope that Apple pays close attention to these technologies as well, as they are quickly gaining adoption by the larger community, in addition to further improving its own proven platform security strength.
We expect to see future Mac models adopting many, if not all, of these security features while further iterating on them as well.
Without subscribers, LWN would simply not exist. Please considersigning up for a subscription and helping
to keep LWN publishing
By Jonathan Corbet April 18, 2018
Developers of database management systems are, by necessity, concerned
about getting data safely to persistent storage. So when the PostgreSQL
community found out that the way the kernel handles I/O errors could result
in data being lost without any errors being reported to user space, a fair
amount of unhappiness resulted. The problem, which is exacerbated by the
way PostgreSQL performs buffered I/O, turns out not to be unique to Linux,
and will not be easy to solve even there.
Craig Ringer first reported the problem to
the pgsql-hackers mailing list at the end of March. In short, PostgreSQL
assumes that a successful call to fsync() indicates that all data
written since the last successful call made it safely to persistent
storage. But that is not what the kernel actually does. When a buffered
I/O write fails due to a hardware-level error, filesystems will respond
differently, but that behavior usually includes discarding the data in the
affected pages and marking them as being clean. So a read of the blocks that
were just written will likely return something other than the data that was
written.
What about error status reporting? One year ago, the Linux Filesystem,
Storage, and Memory-Management Summit (LSFMM) included a session on error reporting, wherein it was
described as "a mess"; errors could easily be lost so that no
application would ever see them. Some
patches merged during the 4.13 development cycle improved the situation
somewhat (and 4.16 had some changes to improve it further), but there are
still ways for error notifications to be lost, as
will be described below. If
that happens to a PostgreSQL server, the result can be silent corruption of
the database.
PostgreSQL developers were not pleased. Tom Lane described it as "kernel brain
damage", while Robert Haas called it
"100% unreasonable". In the early part of the discussion, the
PostgreSQL developers were clear enough on what they thought the kernel's
behavior should be: pages that fail to be written out should be kept in
memory in the "dirty" state (for later retries), and the relevant file
descriptor should be put into a permanent error state so that the
PostgreSQL server cannot miss the existence of a problem.
Where things go wrong
Even before the kernel community came into the discussion, though, it
started to become clear that the situation was not quite as simple as it
might seem. Thomas Munro reported that
Linux is not unique in behaving this way; OpenBSD and NetBSD can also fail
to report write errors to user space. And, as it turns out, the way that
PostgreSQL handles buffered I/O complicates the picture considerably.
That mechanism was described in detail by
Haas. The PostgreSQL server runs as a collection of processes, many of
which can perform I/O to the database files. The job of callingfsync(), however, is handled in a single "checkpointer" process,
which is concerned with keeping on-disk storage in a consistent state that
can recover from failures. The checkpointer doesn't normally keep all of
the relevant files open, so it often has to open a file before callingfsync() on it. That is where the problem comes in: even in 4.13
and later kernels, the checkpointer will not see any errors that happened
before it opened the file. If something bad happens before the
checkpointer's open() call, the
subsequent fsync() call will return successfully. There are a
number of ways in which an I/O error can happen outside of anfsync() call; the kernel could encounter one while performing
background writeback, for example. Somebody calling sync() could
also encounter an I/O error — and consume the resulting error status.
Haas described this behavior as failing to live up to what PostgreSQL
expects:
What you have (or someone has) basically done here is made an
undocumented assumption about which file descriptors might care
about a particular error, but it just so happens that PostgreSQL
has never conformed to that assumption. You can keep on saying the
problem is with our assumptions, but it doesn't seem like a very
good guess to me to suppose that we're the only program that has
ever made them.
Joshua Drake eventually moved the
conversation over to the ext4 development list, bringing in part of the
kernel development community. Dave Chinner quickly described this behavior as "a recipe for
disaster, especially on cross-platform code where every OS platform behaves
differently and almost never to expectation". Ted Ts'o, instead, explained why the affected pages are marked
clean after an I/O error occurs; in short, the most common cause of I/O
errors, by far, is a user pulling out a USB drive at the wrong time. If
some process was copying a lot of data to that drive, the result will be an
accumulation of dirty pages in memory, perhaps to the point that the system
as a whole runs out of memory for anything else. So those pages cannot be
kept if the user wants the system to remain usable after such an event.
Both Chinner and Ts'o, along with others, said that the proper solution is
for PostgreSQL to move to direct I/O (DIO) instead. Using DIO gives a
greater level of control over writeback and I/O in general; that includes
access to information on exactly which I/O operations might have failed.
Andres Freund, like a number of other PostgreSQL developers, has acknowledged that DIO is the best long-term
solution. But he also noted that getting there is "a metric ton of
work" that isn't going to happen anytime soon. Meanwhile, he said, there are other programs (he mentioneddpkg) that are also affected by this behavior.
Toward a short-term solution
As the discussion went on, a fair amount of attention was paid to the
idea that write failures should result in the affected pages being kept in
memory, in their dirty state. But the PostgreSQL developers had quickly
moved on from
that idea and were not asking for it. What they really need, in the end,
is a reliable way to know that something has gone wrong. Given that, the
normal PostgreSQL mechanisms for dealing with errors can take over; in its
absence, though, there is little that can be done.
One idea that came up a few times was to respond to an I/O error by marking
the file itself (in the inode) as being in a persistent error state. Such
a change, though, would take Linux behavior further away from what POSIX
mandates and would raise some other questions, including: when and how
would that flag ever be cleared? So this change seems unlikely to happen.
At one point in the discussion, Ts'o mentioned that Google has its own mechanism
for handling I/O errors. The
kernel has been instrumented to report I/O errors via a netlink socket; a
dedicated process gets those notifications and responds accordingly. This
mechanism has never made it upstream, though. Freund indicated that this kind of mechanism would be
"perfect" for PostgreSQL, so it may make a public appearance
in the near future.
Meanwhile, Jeff Layton pondered another
idea: setting a flag in the filesystem superblock when an I/O error
occurs. A call to syncfs() would then clear that flag and return
an error if it had been set. The PostgreSQL checkpointer could make an
occasional syncfs() call as a way of polling for errors on the
filesystem holding the database. Freund agreed that this might be a viable solution to
the problem.
Any such mechanism will only appear in new kernels, of course; meanwhile,
PostgreSQL installations tend to run on old kernels maintained by
enterprise distributions. Those kernels are likely to lack even the
improvements merged in 4.13. For such systems, there is little that can be
done to help PostgreSQL detect I/O errors. It may come down to running a
daemon that scans the system log, looking for reports of I/O errors there.
Not the most elegant solution, and one that is complicated by the fact that
different block drivers and filesystems tend to report errors differently,
but it may be the best option available.
The next step is likely to be a discussion at the 2018 LSFMM event, which
happens to start on April 23. With luck, some sort of solution will
emerge that will work for the parties involved. One thing that will not
change, though, is the simple fact that error handling is hard to get
right.
SAN FRANCISCO — Most big banks have tried to stay far away from the scandal-tainted virtual currency Bitcoin.
But Goldman Sachs, perhaps the most storied name in finance, is bucking the risks and moving ahead with plans to set up what appears to be the first Bitcoin trading operation at a Wall Street bank.
In a step that is likely to lend legitimacy to virtual currencies — and create new concerns for Goldman — the bank is about to begin using its own money to trade with clients in a variety of contracts linked to the price of Bitcoin.
While Goldman will not initially be buying and selling actual Bitcoins, a team at the bank is looking at going in that direction if it can get regulatory approval and figure out how to deal with the additional risks associated with holding the virtual currency.
Rana Yared, one of the Goldman executives overseeing the creation of the trading operation, said the bank was cleareyed about what it was getting itself into.
“I would not describe myself as a true believer who wakes up thinking Bitcoin will take over the world,” Ms. Yared said. “For almost every person involved, there has been personal skepticism brought to the table.”
Still, the suggestion that Goldman Sachs, among the most vaunted banks on Wall Street and a frequent target for criticism, would even consider trading Bitcoin would have been viewed as preposterous a few years ago, when Bitcoin was primarily known as a way to buy drugs online.
Bitcoin was created in 2009 by an anonymous figure going by the name Satoshi Nakamoto, who talked about replacing Wall Street banks — not giving them a new revenue line.
Over the last two years, however, a growing number of hedge funds and other large investors around the world have expressed an interest in virtual currencies. Tech companies like Square have begun offering Bitcoin services to their customers, and the commodity exchanges in Chicago started allowing customers to trade Bitcoin futures contracts in December.
But until now, regulated financial institutions have steered clear of Bitcoin, with some going so far as to shut down the accounts of customers who traded Bitcoin. Jamie Dimon, the chief executive of JPMorgan Chase, famously called it a fraud, and many other bank chief executives have said Bitcoin is nothing more than a speculative bubble.
Ms. Yared said Goldman had concluded that Bitcoin is not a fraud and does not have the characteristics of a currency. But a number of clients wanted to hold it as a valuable commodity, similar to gold, given the limited quantity of Bitcoin that can ever be “mined” in a complex, virtual system.
“It resonates with us when a client says, ‘I want to hold Bitcoin or Bitcoin futures because I think it is an alternate store of value,’” she said.
Ms. Yared said the bank had received inquiries from hedge funds, as well as endowments and foundations that received virtual currency donations from newly minted Bitcoin millionaires and didn’t know how to handle them. The ultimate decision to begin trading Bitcoin contracts was approved by Goldman’s board of directors.
The step comes with plenty of uncertainties. Bitcoin prices are primarily set on unregulated exchanges in other countries where there are few measures in place to prevent market manipulation.
Since the beginning of the year, the price of Bitcoin has plunged — and recovered significantly — as traders have faced uncertainty about how regulators will deal with virtual currencies.
“It is not a new risk that we don’t understand,” Ms. Yared said. “It is just a heightened risk that we need to be extra aware of here.”
Goldman has already been doing more than most banks in the area, clearing trades for customers who want to buy and sell Bitcoin futures on the Chicago Mercantile Exchange and the Chicago Board Options Exchange.
In the next few weeks — the exact start date has not been set — Goldman will begin using its own money to trade Bitcoin futures contracts on behalf of clients. It will also create its own, more flexible version of a future, known as a non-deliverable forward, which it will offer to clients.
The bank’s first “digital asset” trader, Justin Schmidt, joined Goldman two weeks ago to handle the day-to-day operations, a hiring that was first reported by Tearsheet. In his last job, Mr. Schmidt, 38, was an electronic trader at the hedge fund Seven Eight Capital. In 2017, he left that job to trade virtual currencies on his own.
He will initially be placed on Goldman’s foreign currency desk because Bitcoin trading has the most similarity to movements in emerging market currencies, Ms. Yared said.
Mr. Schmidt is looking at trading actual Bitcoin — or physical Bitcoin, as it is somewhat ironically called — if the bank can secure regulatory approval from the Federal Reserve and New York authorities.
The firm also has to find a way to confidently hold Bitcoin for customers without its being stolen by hackers, as has happened to many Bitcoin exchanges. Mr. Schmidt and Ms. Yared said the current options for holding Bitcoin for clients did not yet meet Wall Street standards.
Goldman is known for pushing the envelope in the trading of complicated products. The firm faced significant criticism after the financial crisis for its profitable trading of so-called synthetic derivatives tied to the subprime mortgage markets.
Since the crisis, Goldman has made a big push to position itself as the most technologically sophisticated firm on Wall Street. Among other things, it has started an online lending service, known as Marcus, that has brought the firm into contact with retail customers for the first time. The virtual currency trading, though, will be available only to big institutional investors.
Mr. Schmidt said Goldman’s sophistication was a big part of the reason he was open to the job, despite many other opportunities in the virtual currency world.
“In terms of having a trusted institutional player, it has been something I have been looking for in my own crypto trading — but it didn’t exist,” he said.
Interersting, mine doesn't say that. In fact I have no entries for dns either. Byproduct of passthrough mode maybe? Actually, looks like you're on dsl, i'm on fiber. That might be why I don't have that entry.
Interersting, mine doesn't say that. In fact I have no entries for dns either. Byproduct of passthrough mode maybe? Actually, looks like you're on dsl, i'm on fiber. That might be why I don't have that entry.
Yes. I was getting very poor l2tp/ipsec speeds. I run sophos utm behind the bgw210 (in passthrough mode). After much experimentation, dropping mtu on all the interfaces (wan/lan and rg) to 1472 (from 1500 bytes) was the fix.
Still on 1.3.12 here in Michigan. Even did a firmware update on my router and decided to factory reset and reconfigure my 210 as well. Still on 1.3.12. Although i have to say my network is working very well.
Still 1.3.13 for me in Central Arkansas. I think it was about a week or two after seeing the first post about 1.3.13 before I got it, so I'm guessing any night now my gateway will reboot.
Received my update last night and now I cannot connect to 1.1.1.1 or 1.0.0.1. Makes you wonder why AT&T would be continuing to roll this out knowing they are blocking DNS servers. I wonder if it's on purpose due to the added privacy offered by 1.1.1.1?
Updated overnight to 1.5.11 from 1.3.12. My first clue this had happened was when I had issues connecting to the internet with my phone. (I had changed my DNS to the new service provided by Cloudfare.)
I then picked up my iPad and expected to see the same issue, but surprisingly it worked. I checked the DNS settings and saw that I had only entered the IPv6 numbers!
To spare you from having to look it up, here they are: 2606:4700:4700::1111 and 2606:4700:4700::1001
Assuming you have IPv6 in your area, it appears this works.
Just received mine (Cleveland Ohio) what exactly is Lightspeed, is it any different than fast path?
Hi, JimPap:
I do not know for sure, but, I believe "Project Lightspeed" was the original name of "U-Verse." With this new firmware, I don't know if this, actually, signifies a technical-based change or a change in name, only.
NuCypher is a data privacy layer for blockchain, decentralized applications, and other distributed systems. We're back by Y Combinator (S16), Polychain Capital, and many other leading investors.
We're looking for a scientist with expertise in fully homomorphic encryption (FHE) to assist with our research efforts on performance improvements and potential applications for smart contracts. Familiarity with related technologies like proxy re-encryption (PRE) and multi-party computation (MPC) is helpful.
Ideally, candidates have an understanding of the surrounding issues and problems and have an interest in identifying potential solutions. Due to the unproven and highly theoretical nature of these schemes, candidates should be willing to pivot research when practical solutions cannot be found. Qualified candidates are likely (but not required) to have a PhD or similarly extensive experience in cryptography.
Please email founders@nucypher.com with your CV and any previous research/publications you're able to share.
With traditional containers, the kernel imposes some limits on the resources the application can access. These limits are implemented through the use of Linux cgroups and namespaces, but not all resources can be controlled via these mechanisms. Furthermore, even with these limits, the kernel still exposes a large surface area that malicious applications can attack directly.
Kernel features like seccomp filters can provide better isolation between the application and host kernel, but they require the user to create a predefined whitelist of system calls. In practice, it’s often difficult to know which system calls will be required by an application beforehand. Filters also provide little help when a vulnerability is discovered in a system call that your application requires.
Existing VM-based container technology
One approach to improve container isolation is to run each container in its own virtual machine (VM). This gives each container its own "machine," including kernel and virtualized devices, completely separate from the host. Even if there is a vulnerability in the guest, the hypervisor still isolates the host, as well as other applications/containers running on the host. Running containers in distinct VMs provides great isolation, compatibility, and performance, but may also require a larger resource footprint.
Kata containers is an open-source project that uses stripped-down VMs to keep the resource footprint minimal and maximize performance for container isolation. Like gVisor, Kata contains an Open Container Initiative (OCI) runtime that is compatible with Docker and Kubernetes.
Sandboxed containers with gVisor
gVisor is more lightweight than a VM while maintaining a similar level of isolation. The core of gVisor is a kernel that runs as a normal, unprivileged process that supports most Linux system calls. This kernel is written in Go, which was chosen for its memory- and type-safety. Just like within a VM, an application running in a gVisor sandbox gets its own kernel and set of virtualized devices, distinct from the host and other sandboxes. gVisor provides a strong isolation boundary by intercepting application system calls and acting as the guest kernel, all while running in user-space. Unlike a VM which requires a fixed set of resources on creation, gVisor can accommodate changing resources over time, as most normal Linux processes do. gVisor can be thought of as an extremely paravirtualized operating system with a flexible resource footprint and lower fixed cost than a full VM. However, this flexibility comes at the price of higher per-system call overhead and application compatibility—more on that below.
"Secure workloads are a priority for the industry. We are encouraged to see innovative approaches like gVisor and look forward to collaborating on specification clarifications and making improvements to joint technical components in order to bring additional security to the ecosystem." — Samuel Ortiz, member of the Kata Technical Steering Committee and Principal Engineer at Intel Corporation
“Hyper is encouraged to see gVisor’s novel approach to container isolation. The industry requires a robust ecosystem of secure container technologies, and we look forward to collaborating on gVisor to help bring secure containers into the mainstream.” — Xu Wang, member of the Kata Technical Steering Committee and CTO at Hyper.sh
Integrated with Docker and Kubernetes
The gVisor runtime integrates seamlessly with Docker and Kubernetes though runsc (short for "run Sandboxed Container"), which conforms to the OCI runtime API.
The runsc runtime is interchangeable with runc, Docker's default container runtime. Installation is simple; once installed it only takes a single additional flag to run a sandboxed container in Docker:
$ docker run --runtime=runsc hello-world
$ docker run --runtime=runsc -p 3306:3306 mysql
In Kubernetes, most resource isolation occurs at the pod level, making the pod a natural fit for a gVisor sandbox boundary. The Kubernetes community is currently formalizing the sandbox pod API, but experimental support is available today.
The runsc runtime can run sandboxed pods in a Kubernetes cluster through the use of either the cri-o or cri-containerd projects, which convert messages from the Kubelet into OCI runtime commands.
gVisor implements a large part of the Linux system API (200 system calls and counting), but not all. Some system calls and arguments are not currently supported, as are some parts of the /proc and /sys filesystems. As a result, not all applications will run inside gVisor, but many will run just fine, including Node.js, Java 8, MySQL, Jenkins, Apache, Redis, MongoDB, and many more.
Getting started
As developers, we want the best of both worlds: the ease of use and portability of containers, and the resource isolation of VMs. We think gVisor is a great step in that direction. Check out our repo on GitHub to find how to get started with gVisor and to learn more of the technical details behind it. And be sure to join our Google group to take part in the discussion!
If you’re at KubeCon in Copenhagen join us at our booth for a deep dive demo and discussion.
Also check out an interview with the gVisor PM to learn more.
Learn more about gVisor, the new sandboxed container runtime via this demo.
Today, Google is launching a new investment program for early-stage startups working to broaden Google Assistant hardware or features. The new program provides financial resources, early access to Google features and tools, access to the Google Cloud Platform, and promotional support in efforts to bolster young companies. Google says its investment program will also support startups focussing on Google Assistant‘s use in travel, hospitality, or games industries.
The startups will receive advice from Google engineers, product managers, and design experts who will guide the young companies through technical and product development. Google notes it’s looking at creating new devices and ideas that use Google Assistant in fresh ways.
“We’re opening a new investment program for early-stage startups that share our passion for the digital assistant ecosystem, helping to push new ideas forward and advance the possibilities of what digital assistants can do,” wrote Nick Fox, VP of search and Google Assistant, and Sanjay Kapoor, VP of corporate development at Google, in a statement.
The following four companies are the first to receive investments under Google’s new program:
GoMoment, a company that makes a 24/7 concierge service called Ivy. Ivy can give instant answers to common questions like “can I get a late checkout?” Responses that need human input are sent to hotel staff for a quick turnaround.
Edwin, a personal AI-powered English tutor which helps students preparing to take foreign language tests with tailored lessons. Users can prepare for tests on Facebook Messenger and have the flexibility to study whenever and wherever they want.
BotSociety, a tool for developers to test and design voice interfaces.
Pulse Labs, an application that helps developers test their voice service apps using real people.
Google didn’t disclose how much the investments are worth, but says companies interested in a partnership can apply online.
Google’s parent company Alphabet also has a venture capital investment arm called GV, which has invested in over 300 companies. Google’s previous investment endeavors include Neverware, a software platform that converts old computers into Chromebooks, and Senosis, an app that uses a smartphone’s accelerometer, microphone, and camera for health diagnostics.
Editor's Note:Nicolas Dessaigne is Co-Founder & CEO at Algolia. Julien Lemoine is Co-Founder & CTO at Algolia. They are both originally from Paris, France and now reside in San Francisco, CA.
Algolia started out as a mobile SDK for apps that wanted better offline search. After customers starting asking for a hosted search product, they quickly realized that it could be an opportunity for them to move beyond just mobile apps. They now power search for a host of web apps including Pebble, WeFunder, CodeCombat and HackerNews. We sat down with them to learn more about their search product and the technology behind it.
StackShare: Let’s just start with how Algolia got started. Where did the idea come from?
Julien: It all started with consulting missions for startups in the Bay Area. One of them was using Google App Engine and they were developing their search feature using App Engine indexing. The problem is that App Engine only provides a classical document search engine and is not adapted to perform search “as you type” on small records, stored in databases, such as names of people or song titles. As I had developed three search engines in the past, they asked me to develop a very small search data structure that would fit their needs.
Nicolas: Julien has been working on information retrieval and natural language processing for more than 10 years, and me, for more than 15 years.
SS: So you had been working in search for a long time and then you thought there needed to be a better way to do search?
N: What Julien built for this consulting mission was a very lightweight search engine, and we realized that it could be a very good fit for mobile applications. This intuition was confirmed when we saw on Stack Overflow many unanswered questions about embedding a search engine directly in a mobile app. People wanted to embed Lucene and didn’t have any success with that. That was our “go” to start developing this search engine SDK embeddable in mobile apps. So that was actually our first product: an offline search engine.
J: The original idea was that developers could use this SDK in their mobile app. They had to be able to integrate it in their applications in only a few minutes without any specific search background.
N: So we started the company with this product in 2012 with iOS, Android and Windows Phone availability. It actually was a huge tech success, people loved it, but there was just no market for it.
SS: What kind of companies were using the SDK?
N: It was basically consumer apps, mainly apps with offline data. For example, a travel guide. Let’s say you are traveling to Paris and once there, you want to be able to look for local information but you don’t want to pay for the roaming fees. You simply download the guide on your mobile device and once you are in Paris you can search it offline. In that case it brings a lot of value.
The problem we had was that developers, especially on Android, were not ready to pay for an SDK. Few apps rely on offline data and they prefer to have a very basic search using SQLite.
N: At the same time, we got a lot of feedback from people who loved the experience but they wanted an online version of the engine so they could offer the same search experience on all their data.
We had built the search engine with mobile in mind, search needing to be instantaneous and tolerate typos which are so frequent on smartphone keyboards.
But this search experience is something that is incredibly difficult to build for any developer, not only those working on mobile apps. So they really saw the value of an easy to use REST API on their online data.
That was basically the time when we decided to build this SaaS version. It was early 2013. We started to build it in March and got a lot of very good feedback. We discovered that we had a solution for a problem that was very common. So we started to dedicate our work to this differentiation, targeting databases rather than documents.
SS: So it was really because you started on mobile that you made the decision to focus on the databases as opposed to documents, right?
N: Correct. What had led us to mobile was the nature of the data we were searching for. On a mobile device you search for contacts, for places, ... You don’t search for big documents because that is not the way you use a mobile device. This is what we optimized the engine for and we used the same core technology when we moved to the SaaS version. The fit was really good to perform full-text search in a database. Our core value, the value of the engine, is that it was designed and optimized for database records. Everything we have built ever since was always done keeping in mind that our target was databases.
SS: Can you explain the differences in terms of experience? Focusing on databases results in faster queries, can you talk a little more about the difference between the two and how you guys view the two?
N: Yes, there are not so many people talking about the two kinds of search, so it’s important to really explain the difference. Most engines have been designed to search in documents.
What that means is that when you want to rank results, you are using ranking rules that have been designed for documents. This ranking counts the occurrences of the terms of the queries inside each document and uses statistics based on TF-IDF. You want documents that contain many times the query terms you typed to be ranked higher. And this is a statistical formula that will generate a score for each document. This score is a bit cryptic, you can tune the formula, adapt it a little bit. But in the end you get a score that is very difficult to understand. It’s very difficult to tune a working formula for a document search engine. And that works well with full words but it doesn’t work well with prefixes, like when you are not typing the word completely.
So you need to do some hacks to get something approximately correct.
J: It’s because it was designed to search in big chunks of text, such as web pages like Wikipedia where you have a huge amount of text, for which these statistics make sense. In our case, on databases, it's very different. If you are searching for a simple product name, you do not have such constraints.
N: Because the data is different, we needed to come up with a totally different way of ranking the results, closer to the way people think. For example, if you search for an iPhone on an e-commerce website, you just want to find the word iPhone in the title and not at the end of the description. So the position of the word in the results is much more important than the number of occurrences.
You also don’t want the iPhone 3G, you want the latest iPhone 5S, the most popular one. So the advantage of having this database focus is that we can consider this kind of information, which is very difficult to do with a document search engine.
You also want to take into account other factors such as did I misspell my query? If you are an e-commerce company you may want to get the best sales first in your set of results. So you want to combine all these together and this mix is too complex with a document search engine. So we have developed a different approach that takes all these criteria into account in a very explicit way, everyone can easily understand why you get a certain set of results and why they were ranked that way.
SS: And a lot of this has to be customized, right? A lot of this is very specific to your app. How do you deal with that?
J: We have a customization that is very easy compared to other engines. We have a few settings compared to several thousands that you can customize in other solutions. So this is easier to customize and we also explain to our users how to get a good search experience on their data.
N: We consider that our default ranking is a good fit for 90% of the use cases. You basically have two settings to configure to have a good search:
1) Specify the importance of the attributes you want to index. For example, the names of products being more important the descriptions or the comments.
2) Define the popularity of the objects. For example the number of sales or the number of likes.
With these two settings you basically get an engine that is already extremely good in terms of relevancy.
J: For example one of the use cases that we show on our demo page is a search engine for TV series. The first setting specifies that the name of the TV show is more important than the the name of the actor and the second setting specifies that the popularity is defined by the number of followers. With these two settings, you get relevant results at the first keystroke.
N: And if they want to go further, such as showing the matching categories as you type, of course you can get advanced settings for the API. We also have an administration interface where you can configure every setting online.
SS: Very cool. So let's talk about the tech behind it.
J: So basically we have two big parts: an API that is used by our customers. And we have the website with the administration interface. These two parts are very different in terms of architecture.
So if we look first on the website and the administration interface, we are using Rails with bootstrap for the UI. We are using AWS for the hosting with RDS (MySQL) and EC2 in two different availability zones with an ELB for load balancing. Our AWS instances are located in U.S-East and we are using CloudFront to store all assets in order to provide a good experience anywhere in the world.
J: The dashboard uses our own REST API via the Javascript client to navigate and use your data. We also display real-time analytics and usage information that come directly from the API.
On the API servers, we store some real-time data using Redis and keep logs of the last API calls for each user. We also store the API counts in real-time, so each time you perform an action we increment a counter in Redis, to be able to give you this real-time information.
SS: Can you talk a bit about how the data is stored?
J: When you send your data to our API, we replicate the data on three different hosts which are the API servers. So indexing is done on three different hosts. They use a consensus algorithm to be sure to be synchronized, which is RAFT. It’s a kind of Paxos algorithm.
It’s the same kind of algorithm Amazon S3 or Google App Engine use. You need to be sure that your three different clusters are fully synchronized. Even if one is down for some time, even if you have a reboot or anything happens, you have to be sure they are fully synchronized.
When you send a write action to the API, we will send it to the three different servers and we will affect an ID of transaction to this write. This ID is an increasing integer across the cluster of three hosts decided via a consensus. The API call returns a taskID when the job is written on at least two hosts. You will be able to check when the job is indexed using the taskID.
N: You’ve got to ensure not only that you have replicated the data, but that it is in the same exact order, so these three hosts must always be synchronized and in the same state.
J: We are doing that for high availability. And even if one host is down, even if our provider has an availability zone which is down, the service needs to be up and running. So exactly like S3, we replicate three times the information to be sure you always have something running.
We also use this redundancy for performance because we share the queries across the three different hosts. For example if we receive one thousand queries per second, we send 33% of these queries to each host.
Our search engine is a C++ module which is directly embedded inside Nginx. So when the query enters Nginx, we directly run it through the search engine and send it back to the client.
There is no layer that slows down the process. It’s extremely optimized for the queries.
SS: So would you explain how the data flows end-to-end?
J: We have different clusters in different data centers, each of them is composed of three different hosts. Most of our clusters are multi-tenancy and host several clients.
These are very high-end machines. It’s basically a server with 256 Gigabytes of RAM, about 1T of SSD in Raid-0, 16 physical cores >= 3.5Ghz. We are not relying on EC2, we are using dedicated servers and several providers.
We also have very good bandwidth associated to these clusters: we usually have 4.5 Gbps of dedicated bandwidth per cluster because we really want a high quality of service. We did not make any compromise on the hardware and the bandwidth in order to offer the best service.
Each index is a binary file in our own format. We put the information in a specific order so that it is very fast to perform queries on it. This is the algorithm that we have developed for mobile.
Our Nginx C++ module will directly open the index file in memory-mapped mode in order to share memory between the different Nginx processes and will apply the query on the memory-mapped data structure.
To do the load balancing between these three different servers, we use load balancing directly in the API client code (Javascript for example). In the JavaScript code that you embed, we select a random server and fail over on another one if necessary.
N: It’s not rocket science, but it’s a nice way to avoid a SPOF in a hardware load-balancer. All our API clients are released on GitHub under the MIT license, so everything is accessible on GitHub.
In your backend, you will use the API client that matches the programming language of your backend. We recommend to use it to index and push the data but to perform queries, we strongly recommend to use the Javascript client for web applications (or Objective-c for iOS and C# for Windows Phone) in order to directly send the query from your end-user’s browser to our servers and avoid any slowdown because of an intermediate hop.
J: It’s a way to have very good performance. We've optimized everything at the Nginx layer. But if you have something in the middle, for example your own server, then you do not have the same experience. So this is why we really want people to use our JavaScript client.
SS: Is there some sort of queue for the index jobs?
J: It’s not exactly a queue, but it is a consensus. Each server has a builder process that receives indexing jobs from nginx. When you add an indexing job, the nginx that receives the job sends it to the three different builder processes and launches a consensus. It’s a vote between the three different builders to have an unique ID. The consensus is based on an election algorithm, at one point in time, we need to have one master builder and two slave builders. If the master is down the two remaining slaves will automatically elect a new master between them. The master performs the unique ID allocation and moves the temporary job in the indexing queue on all the builders. When two out of the three hosts have finished this operation, we acknowledge the user. There is an open source software that you can use for this kind of ID allocation, the most popular being Zookeeper. Zookeeper is a small layer that you can use to have distributed information in your cluster. So you can, for example, share the information on who the master is in your cluster.
The problem with Zookeeper is that a change in the topology can take a lot of time to be detected. For example, if a host is down, it can take up to several seconds to be detected. This is way too long for us, as in one second will have potentially thousands of indexing jobs to process on the cluster and we need to have a master that attributes an ID to be able to handle them. So we have built our own election algorithm based on RAFT. With this algorithm we ensure that we have one consistent ID allocator across the three different hosts. And if this leader is down, you elect another one within milliseconds.
The deployment process is very easy. We kill the build process and do a hot reload on Nginx process via signals. By killing the build process, we automatically test our election algorithm all the time and do not wait to have a host down to test it. This approach is similar to the Chaos Monkey approach of Netflix that stops production process in a random mode.
SS: That makes sense. So that takes care of how data is indexed and then also queried.
J: We have a third part in the architecture which is not important for production, but is important for testing.
SS: Yeah, I was going to say we should probably get into your build, deploy, and test process.
J: We provide a status page of the API with realtime metrics about the service. To do that, we have developed probes running on Google App Engine. These probes are performing indexing and queries all the time on all our clusters and they automatically detect any kind of problems.
We also offer a dedicated status page for specific users. For example we have a specific status page for Hacker News. That’s also the case for large enterprise customers who want their own infrastructure. If they want dedicated servers, we provide them with a dedicated status page as well.
And there is deployment: there are three of us pushing code to GitHub. We have continuous integration mainly for the API clients with a set of unit tests and non-regression tests. All the tests are applied at commit time using Travis CI, we are also using Code Climate to test code quality and Coveralls for code coverage.
For production, we have an automatic deployment script that applies a big set of unit tests and non-regression tests before deployment. We also have an automatic script for rollback operation if a problem is found with the new version.
SS: And then do you have a staging environment?
J: Yes, we have a cluster which is just for testing. And we have several kinds of production. We have critical production clusters and others for staging.
N: Depending on the importance of the updates, we will not start with the most critical clusters.
J: We haven’t had any search downtime for the moment. We have only had one indexing incident that lasted eight minutes since our launch in September 2013. Since our launch we’ve served close to 4 billion API calls.
N: This downtime was just for indexing and not for searching and only on one cluster, so not all customers were impacted. Maybe 15 to 20 customers were impacted during those eight minutes. So we quickly reached out to these customers and only two out of the 20 had actually noticed the problem. And these two were really happy with the way we handled the situation.
J: We believe in transparency. We wanted to explain what happened and how we solved it.
N: So we wrote a post-mortem blog post.
SS: Do you gusy provide any logging?
J: We use Redis to keep the last logs of users, the last error logs, and the counters. In fact, on the API server we only keep the last activities of all our users. We then have a dedicated cluster that processes all the logs to provide statistics and analytics on the users’ dashboards.
N: There are two kinds of analytics. There are the raw analytics that give you the response times you can see in your dashboard today. You can get response times as well as the 99% percentile of response time, ...
And we are working on more high-level analytics on the content of the queries. The idea is to know what are the most frequent queries, the most frequent queries without results, ... We’re working on it and it should be ready soon.
SS: In terms of monitoring, what sort of server monitoring do you guys use?
J: We are using Server Density to monitor our servers. And for the front end we also use CloudWatch.
SS: Any other services that you guys are using?
N: In each cluster, there are three hosts but we can also do search across many data centers (Europe, US, Asia). You can distribute this search on these different data centers. So the end-users would query the clusters closest to them. And we’re doing that using Route 53.
J: Yes, it really depends on the location of the end-user. Route 53 detects the closest server and directs the user to it. This is what we are using for the demos on our website, you always get a good response time.
J: We're using Intercom for user onboarding in the dashboard and we use Google Analytics and KISSmetrics to track our growth metrics and identify the steps we can improve in our funnel.
We use HipChat internally and we have a specific room for the website that dumps all sorts of data such as exceptions, new signups, payments, ... All of that is pretty common, but we are also using HipChat for support. If you go to the website, you can chat with us. In the chat room many people can join at the same time in the same room. We can chat with the customers and can even past some code with highlighting. It’s pretty nice when doing support for developers.
We are also using Twilio to send SMS when a probe detects an issue, Stripe for payments, as well as a handful of others (see the full list below).
SS: Are there any open source tools or libraries that are important and really helpful for you guys that you haven’t already mentioned?
J: We are also using quite a lot Google SparseHash library. It’s a very low-level and very high performance hash table that we are using in all the low level C++ code. It’s very efficient.
We're using tons of open source libraries, it would be quite long to list them all! :)
And then we are doing a few things to help the developer community. The last thing we have done is Depstack. It’s a tool to find and vote for popular libraries. What we are doing behind the scenes is we index all the different libraries we can find for different languages (Ruby, Python, Go, ...). Then, as a user, you can sign up with GitHub and vote for libraries. We also detect which GitHub projects are using other libraries and count a vote for them.
By doing that we are trying to help people identify the best and most used libraries.
SS: Very cool, sounds familiar :)
J: So we will continue to support the community with initiatives like Depstack. Oh and we also provide Algolia for free for community projects.
Selling drugs is a relationship business. It’s best to do it in person. That is why, on a summer evening in 2012, Alec Burlakoff was out for dinner with Steven Chun, the owner of Sarasota Pain Associates. Burlakoff was a sales manager for Insys Therapeutics, an Arizona-based pharmaceutical company with only one branded product, a new and highly potent opioid painkiller called Subsys. Chun was a doctor who prescribed a lot of opioids.
The location was a moderately expensive seafood restaurant in Sarasota, Fla., with linen tablecloths and large windows overlooking the bay. The sun was still high in the sky. Gleaming powerboats lined the docks outside, and a warm breeze rippled the water. On one side of the table were Burlakoff and Tracy Krane, an Insys sales representative. Krane was a newcomer to the industry, tall with dark brown hair in a bob. Burlakoff, then 38, with a slight frame and a boyish restlessness, was her new boss. He had years of experience in the opioid market. Colleagues marveled over his shameless push to make the sale, but he had a charisma that was hard to resist. Even people who didn’t trust him couldn’t help liking him.
Krane was there to learn the business, and the meeting made a vivid impression. Chun, then 49 and stout, had impeccable credentials: He was trained at the University of Washington, Cornell Medical College and the Memorial Sloan Kettering Cancer Center. He had been married at the Fifth Avenue Presbyterian Church in Manhattan, to a Juilliard-trained violinist who is the daughter of a former chief executive of Korean Air, but had since divorced. At Burlakoff’s invitation, he had brought his girlfriend at the time, a woman in her mid-20s, to dinner.
For Insys, Chun was just the right kind of doctor to pursue. In the late 1990s, sales of prescription opioids began a steep climb. But by the time Subsys came to market in 2012, mounting regulatory scrutiny and changing medical opinion were thinning the ranks of prolific opioid prescribers. Chun was one of the holdouts, a true believer in treating pain with narcotics. He operated a busy practice, and 95 percent of the Medicare patients he saw in 2015 had at least one opioid script filled. Chun was also a top prescriber of a small class of painkillers whose active ingredient is fentanyl, which is 50 to 100 times as powerful as morphine. Burlakoff’s product was a new entry to that class. On a “target list,” derived from industry data that circulated internally at Insys, Chun was placed at No. 3. The word inside the company for a doctor like Chun was a “whale.”
In the few months since Subsys was introduced, demand was not meeting expectations. Some of the sales staff had already been fired. If Burlakoff and Krane could persuade Chun to become a Subsys loyalist, it would be a coup for them and for the entire company. The drug was so expensive that a single clinic, led by a motivated doctor, could generate millions of dollars in revenue.
Over dinner, Burlakoff grew expansive, Krane recalled. She marveled at the way he drew on a wealth of information about the doctor — intelligence gathered over the course of years — without letting on just how much he knew. Before he worked for Insys, Burlakoff worked for Cephalon, Insys’s chief competitor, and he knew a bit about Chun’s romantic history, Krane said. He also knew that Chun liked to visit the casinos up in Tampa, so Burlakoff made a point of talking about his own penchant for gambling, according to Krane. She had no idea if he was telling the truth.
It is unclear whether Burlakoff knew that Chun was also, at that moment, in the middle of an expensive legal battle. The previous year, two nurses who formerly worked for him secretly filed a whistle-blower suit charging “widespread billing schemes” intended to defraud the government, and federal agents executed a search warrant on his clinic. (Chun would later pay $750,000 to the Department of Justice to resolve the claims. He was never charged with a crime and denies all wrongdoing.)
What is clear is that Burlakoff thought that Chun was a tremendous prize. After briefly extolling the virtues of Subsys, Krane recalled, Burlakoff finally arrived at the true purpose of the dinner. He had a proposition to make. Insys wanted to sign Chun up, he said, for the company’s speaker program, which was just getting underway.
Speaker programs are a widely used marketing tool in the pharmaceutical business. Drug makers enlist doctors to give paid talks about the benefits of a product to other potential prescribers, at a clinic or over dinner in a private room at a restaurant. But Krane and some fellow rookie reps were already getting a clear message from Burlakoff, she said, that his idea of a speaker program was something else, and they were concerned: It sounded a lot like a bribery scheme.
Burlakoff left the dinner in a great mood, Krane said, confident that Chun would come on board. The doctor did become an Insys speaker later that year, and sales did improve, not only in Chun’s Florida office but also around the country, as more doctors signed on. By the next year, according to the company, net revenue from Subsys sales would increase by more than 1,000 percent, to $95.7 million.
But the new reps were right to be worried. The Insys speaker program was central to Insys’ rapid rise as a Wall Street darling, and it was also central to the onslaught of legal troubles that now surround the company. Most notable, seven former top executives, including Burlakoff and the billionaire founder of Insys, John Kapoor, now await trial on racketeering charges in federal court in Boston. The company itself, remarkably, is still operating.
The reporting for this article involved interviews with, among other sources, seven former Insys employees, among them sales managers, sales reps and an insurance-authorization employee, some of whom have testified before a grand jury about what they witnessed. This account also draws on filings from a galaxy of Insys-related litigation: civil suits filed by state attorneys general, whistle-blower and shareholder suits and federal criminal cases. Some are pending, while others have led to settlements, plea deals and guilty verdicts.
To build the sales force, Insys hired a number of notably attractive people in their 20s and 30s, mostly women - not an uncommon tactic in the industry.Illustration by Francesco Francavilla
In the Insys case, prosecutors are looking to break new ground in holding the pharmaceutical and medical industry accountable in connection with the current opioid crisis. They’re attacking both ends of the pharma sales transaction; 11 prescribers face charges or have been convicted over their ties to Insys, and Chun has recently been subpoenaed for medical records related to Subsys. In looking into Insys’s relationship to providers like him, investigators are revealing just how opioids are sold at the point they first enter the national bloodstream — in the doctor’s office.
The opioid crisis, now the deadliest drug epidemic in American history, has evolved significantly over the course of the last two decades. What began as a sharp rise in prescription-drug overdoses has been eclipsed by a terrifying spike in deaths driven primarily by illicitly manufactured synthetic opioids and heroin, with overall opioid deaths climbing to 42,249 in 2016 from 33,091 in 2015. But prescription drugs and the marketing programs that fuel their sales remain an important contributor to the larger crisis. Heroin accounted for roughly 15,000 of the opioid deaths in 2016, for instance, but as many as four out of five heroin users started out by misusing prescription opioids.
By the time Subsys arrived in 2012, the pharmaceutical industry had been battling authorities for years over its role in promoting the spread of addictive painkillers. The authorities were trying to confine opioids to a select population of pain patients who desperately needed them, but manufacturers were pushing legal boundaries — sometimes to the breaking point — to get their products out to a wider market.
Even as legal penalties accrued, the industry thrived. In 2007, three senior executives of Purdue Pharma pleaded guilty in connection with a marketing effort that relied on misrepresenting the dangers of OxyContin, and the company agreed to pay a $600 million settlement. But Purdue continued booking more than $1 billion in annual sales on the drug. In 2008, Cephalon likewise entered a criminal plea and agreed to pay $425 million for promoting an opioid called Actiq and two other drugs “off-label” — that is, for unapproved uses. That did not stop Cephalon from being acquired three years later, for $6.8 billion.
Subsys and Actiq belong to a class of fentanyl products called TIRF drugs. They are approved exclusively for the treatment of “breakthrough” cancer pain — flares of pain that break through the effects of the longer-acting opioids the cancer patient is already taking around the clock. TIRFs are niche products, but the niche can be lucrative because the drugs command such a high price. A single patient can produce six figures of revenue.
Fentanyl is extremely powerful — illicitly manufactured variations, often spiked into heroin or pressed into counterfeit pills, have become the leading killers in the opioid crisis — and regulators have made special efforts to restrict prescription fentanyl products. In 2008, for instance, the F.D.A. rebuffed Cephalon’s application to expand the approved use for a TIRF called Fentora; in the company’s clinical trials, the subjects who did not have cancer demonstrated much more addictive behavior and propensity to substance abuse, which are “rarely seen in clinical trials,” F.D.A. officials concluded. An F.D.A. advisory committee reported that, during the trials, some of the Fentora was stolen. The agency later developed a special protocol for all TIRF drugs that required practitioners to undergo online training and certify that they understood the narrow approved use and the risks.
Despite these government efforts, TIRF drugs were being widely prescribed to patients without cancer. Pain doctors, not oncologists, were the dominant players. This was common knowledge in the industry. Although it is illegal for a manufacturer to promote drugs for off-label use, it is perfectly legal for doctors to prescribe any drug off-label, on their own judgment. This allows drug makers like Insys to use a narrow F.D.A. approval as a “crowbar,” as a former employee put it, to reach a much broader group of people.
That points to a major vulnerability in policing the opioid crisis: Doctors have a great deal of power. The F.D.A. regulates drug makers but not practitioners, who enjoy a wide latitude in prescribing that pharmaceutical companies can easily exploit. A respected doctor who advocates eloquently for wider prescribing can quickly become a “key opinion leader”; invited out on the lucrative lecture circuit. And any doctor who exercises a free hand with opioids can attract a flood of pain patients and income. Fellow doctors rarely blow the whistle, and some state medical boards exercise timid oversight, allowing unethical doctors to continue to operate. An assistant district attorney coping with opioids in upstate New York told me that it’s easy to identify a pill-mill doctor, but “it can take five years to get to that guy.” In the meantime, drug manufacturers are still seeing revenue, and that doctor is still seeing patients, one after another, day after day.
John Kapoor, the founder of Insys, has flirted with legal trouble throughout his long career as a pharmaceutical entrepreneur. Raised in India, where he was the first in his family to go to college, he immigrated to the United States to pursue a doctorate, he has said, with five dollars in his pocket. He amassed a fortune with a series of pharmaceutical ventures, mostly in the unglamorous arena of generic drugs. One of his companies, Lyphomed, drew sanctions from the F.D.A. related to manufacturing problems, leading to recalls and a consent decree. After he sold Lyphomed to a Japanese firm in 1990, personally reaping more than $100 million, the buyer sued him, claiming that he had been deceptive about the company’s regulatory difficulties. He settled out of court. Another of Kapoor’s big investments, Akorn, was delisted from Nasdaq during his tenure as chief executive for filing unaudited financial statements, but his stake, held in trust, is now worth hundreds of millions, despite new controversy over possible breaches of F.D.A. requirements at the company.
Kapoor, now 74, bankrolled Insys almost entirely on his own for over a decade, shepherding Subsys on the long road to approval by the Food and Drug Administration. What motivated him, he has often said, was seeing his wife, Editha, suffering from metastatic breast cancer, before her death in 2005 at 54.
Often called Dr. Kapoor, he more closely resembles an academic than a business titan, with glasses and a signature mop of graying hair. But employees found that Kapoor could be aggressive and unyielding. At Insys he was known to pound the table; he dressed down a manager in front of colleagues. People who worked for him speak of the need to “survive” him.
Kapoor believed that he had the best product in its class. All the TIRF drugs — for transmucosal immediate-release fentanyl — deliver fentanyl through the mucous membranes lining the mouth or nose, but the specific method differs from product to product. Actiq, the first TIRF drug, is a lozenge on a stick. Cephalon’s follow-up, Fentora — the branded market leader when Subsys arrived — is a tablet meant to be held in the cheek as it dissolves. Subsys is a spray that the patient applies under the tongue. Spraying a fine mist at the permeable mouth floor makes for a rapid onset of action, trials showed.
Once the F.D.A. gave final approval to Subsys in early 2012, the fate of Insys Therapeutics rested on selling it in the field. The industry still relies heavily on the old-fashioned way of making sales; drug manufacturers blanket the country with representatives who call on prescribers face to face, often coming to develop personal relationships with them over time.
To carry out a delicate sales campaign, Insys made some unusual choices. Overseeing the launch under Kapoor, then the executive chairman, would be his 36-year-old protégé, Michael Babich, who had been named the Insys chief executive. A tall Chicagoan, Babich had worked for Kapoor in various roles since he was in his 20s, when Kapoor recruited him from an asset-management firm. Kapoor introduced Babich to the staff as a rising talent, but he had never led a sales effort for an F.D.A.-approved drug. According to former Insys managers, Babich tended to defer to Kapoor, who was, after all, putting up his own money.
To build the sales force, Insys hired a number of notably attractive people in their 20s and 30s, mostly women — not an uncommon tactic in the industry. But Insys reps tended to be particularly inexperienced, often with no background in pharmaceutical sales. “They were hiring people straight out of college,” said Jim Coffman, who worked as a regional sales trainer at Insys in 2012. “So there was a certain naïveté, which played into their objectives and goals.” The company was offering salaries well below market rates — typically paying a rep $40,000 when other companies would offer twice that amount — but dangling the lure of stock options and unusually large commissions.
Examining detailed TIRF sales data purchased from third parties, Insys executives zeroed in on an important fact: The entire market was anchored by a relatively small pool of prescribers. Winning the business of a handful of carefully selected practitioners per state could be enough to make Insys the market leader. The names at the top of the chart were well known in the field.
Insys managers divided the existing base of TIRF prescribers into deciles, according to how many scripts they wrote. The “high decile” practitioners tended not to specialize in treating cancer pain, according to the Boston indictment, but Insys went right after them. Sales reps were instructed to call on them multiple times a week, to the point of sitting in their waiting rooms for hours, angling for a moment with the doctor. As one manager told me, “You fish where the fish are.”
A speaker program was in the works at Insys from the start, but in the first months after Subsys hit the market, it had not gotten underway. During that period, Kapoor was disappointed by the sales of the drug, according to former employees. Managers thought the expectations were unrealistic, given that the company had beginner reps and entrenched competitors, but Kapoor didn’t want to hear it. He and Babich would soon meet with each regional sales manager one on one at the home office, and some meetings would be contentious. Turnover in the sales staff was running high.
It was then that Alec Burlakoff arrived, asking about a job. Burlakoff had a history that might have put off some potential employers. In 2002, Eli Lilly fired him as a sales rep amid an investigation by the Florida attorney general’s office into a supposed scheme to send unsolicited pills — a slow-release form of Prozac — to patients through the mail. When Burlakoff and two other fired employees sued Lilly in return, claiming the plan was approved by management, they gained media attention nationwide. Burlakoff said in a court filing that his reputation in the industry was permanently scarred. (The case was settled.) When Burlakoff later sold Actiq and Fentora at Cephalon, he was based in the Southeast region, a hot spot in the investigations into the promotion of both those drugs.
Former Insys employees consistently describe Burlakoff’s arrival as a turning point. Insys initially hired him to head the Southeast region, but within three months, he was promoted to run the entire sales force. The speaker program swiftly became the centerpiece of the sales effort, and Burlakoff made it clear how he wanted it to work.
He explained it all to Tracy Krane on the first day they met, she told me, while they were sitting in her white Cadillac CTS. It was a conversation she later recounted, she said, in a grand-jury proceeding in connection with the Boston criminal case. Burlakoff had traveled to her territory to join her on a “ride along,” coaching her through sales calls on an oppressively sunny day, and they had just left Chun’s office. The ostensible purpose of a pharma-speaker program, as Krane understood it, was to spread the word about the drug through peer-to-peer marketing. With “honorariums” changing hands, the potential for a subtle corruption is clear, but Burlakoff was not subtle. He told Krane, she said, that the real target was not the audience but the speaker himself, who would keep getting paid to do programs if and only if he showed loyalty to Subsys. It was a quid pro quo or, as the Department of Justice later called it, a kickback. “He boiled it right down,” Krane recalled: We pay doctors to write scripts. That’s what the speaker program is.
Krane didn’t know all the rules, she told me, but this didn’t sound right. She turned to Burlakoff and asked, “Isn’t that illegal?”
He brushed off the question, Krane said, with a tone she likened to patting a child on the head and telling her not to worry — the worst that could happen was the company would have to pay a settlement. If Burlakoff in fact said this, he had some reason. It was during his time at Cephalon that the company handily survived its penalty for engaging in illegal promotional schemes.
Emails that have surfaced in court and public-records requests give the flavor of the sales messages that top executives were sending. One week after Burlakoff was hired, Babich, the chief executive, wrote an email to his sales managers, directing them to make sure that reps understood “the important nature of having one of their top targets as a speaker. It can pay big dividends for them.” Burlakoff urged on his sales staff, peppering them with emails and texts that alternated between the tropes of motivational speaking (“we are all starting a new opportunity to be our very best when we get out of bed tomorrow!”) and arm-twisting reminiscent of “Glengarry Glen Ross.” “PROGRAMS ARE THE ONLY THING THAT MATTERS,” he wrote. “WHY DO SOME OF YOU REFUSE TO ACKNOWLEDGE THIS PROVEN FACT?”
The speaker events themselves were often a sham, as top prescribers and reps have admitted in court. Frequently, they consisted of a nice dinner with the sales rep and perhaps the doctor’s support staff and friends, but no other licensed prescriber in attendance to learn about the drug. One doctor did cocaine in the bathroom of a New York City restaurant at his own event, according to a federal indictment. Some prescribers were paid four figures to “speak” to an audience of zero.
Burlakoff appears at first to have tried to shield Kapoor from the details of the Insys speaker programs, or I.S.P.s, as they were sometimes called in-house. “I need your guidance on how to present to Dr. Kapoor I.S.P.’s in a way — where he won’t get involved,” he wrote to Babich in an email obtained through a public-records request. Babich replied, “You got it.” Top executives, however, soon prepared documents for Kapoor, according to the Boston indictment, that explicitly calculated the I.S.P. “return on investment” for each speaker and indicated that underperformers could be culled from the program. Prosecutors have not yet presented evidence that Kapoor in fact saw the documents.
An Insys rep wrote to Kapoor that it was ‘so not right’ that one high-prescribing doctor was ‘getting $2,500 a pop to eat at fancy steakhouses in NYC often,’ adding, ‘I don’t think anyone even goes to his “programs.” ’Illustration by Francesco Francavilla
But Kapoor also had a direct contact out in the field, a New Jersey rep at the bottom of the hierarchy named Susan Beisler, who left a paper trail that could present legal difficulties for Kapoor. Beisler, then in her late 30s, seems to have had a close relationship with Kapoor, signing one email “many hugs and kisses,” according to a pending lawsuit filed by the New Jersey attorney general. Beisler complained to Kapoor that the speaker money “being thrown” at certain doctors was giving an unfair edge to their reps, particularly Burlakoff’s “friends,” according to the suit. Burlakoff had hired a number of Cephalon alumni he knew, reps who had pre-existing relationships with key doctors. As early as the summer of 2013, according to a federal indictment, an Insys rep — possibly Beisler — wrote to Kapoor that it was “so not right” that one high-prescribing doctor was “getting $2,500 a pop to eat at fancy steakhouses in NYC often,” adding, “I don’t think anyone even goes to his ‘programs.” The following year, according to the Boston indictment, Insys quadrupled the budget devoted to the speaker program to $10 million. In the end, the Top 10 speakers each made more than $200,000.
Insys wasn’t just winning over top TIRF prescribers from the competition. It was creating new ones. One star rep in Florida, later promoted to upper management, told another rep that when she went in search of potential speakers, she didn’t restrict herself to the top names, because, after all, any doctor can write scripts, and “the company does not give a [expletive] where they come from.” (Some dentists and podiatrists prescribed Subsys.) She looked for people, she said, “that are just going through divorce, or doctors opening up a new clinic, doctors who are procedure-heavy. All those guys are money hungry.” If you float the idea of becoming a paid speaker “and there is a light in their eyes that goes off, you know that’s your guy,” she said. (These remarks, recorded by the rep on the other end of the line, emerged in a later investigation.)
Unsurprisingly, tactics like these attracted some questionable figures to the program. In an email that surfaced in a lawsuit brought by the Illinois attorney general, a sales rep in the state reported directly to Babich about a pain-management doctor named Paul Madison: “Dr. Madison runs a very shady pill mill that only accepts cash,” the rep wrote. “He is extremely moody, lazy and inattentive. He basically just shows up to write his name on the prescription pad, if he shows up at all.” Insys was not deterred, it appears. According to the Boston indictment, Babich and Burlakoff hired a former exotic dancer named Sunrise Lee as a sales manager, and she helped court Madison as an Insys speaker. The company paid Madison tens of thousands dollars even after he was indicted on insurance-fraud charges that are still pending. (He pleaded not guilty.) According to the Illinois suit, which Insys later settled, he single-handedly accounted for 58 percent of the Subsys prescribed in Illinois over a three-year period.
In a March 2013 email to the sales force, Burlakoff singled out five reps at the top of the company leader board and noted that they “literally have their entire business being driven by basically one customer.” These “customers” were the top five Subsys prescribers in the nation, according to a pending lawsuit brought by the state of Arizona, and all were well-compensated Insys speakers. Three have been convicted of felonies; one has not been charged but had his license revoked. Only one remains in practice.
As a result of Insys’s approach to targeting doctors, its potent opioid was prescribed to patients it was never approved to treat — not occasionally, but tens of thousands of times. It is impossible to determine how many Subsys patients, under Kapoor, actually suffered from breakthrough cancer pain, but most estimates in court filings have put the number at roughly 20 percent. According to Iqvia data through September 2016, only 4 percent of all Subsys prescriptions were written by oncologists.
Jeff Buchalter, 34, a decorated Iraq war veteran, was one off-label Subsys patient. His doctor, William Tham, a paid Insys speaker, prescribed the drug to treat pain stemming from Buchalter’s wartime injuries, eventually raising the dose well beyond the maximum amount indicated by the F.D.A. Buchalter was taking it 12 times a day, not four to six, and alternating between the two highest doses, a medical chart from Tham’s clinic shows. Eventually, he had to be put under sedation in intensive care at Fort Belvoir, Va., while he went through withdrawal from Subsys and other prescription drugs. “I am frankly astonished at the amount of opioids the patient has been prescribed,” a hospital specialist noted in his records. Buchalter is suing Insys and Tham. (Tham’s lawyer, Andrew Vernick, told me, “He has done nothing wrong in this case, and he is not involved in any of the allegations that have been raised against Insys throughout the country.”)
Buchalter said Subsys gave him relief from pain, but it changed him into someone he did not recognize. He had always defined himself as a hard worker with integrity. With his eyes darting around the room as he spoke, he told me he became an addict, his day revolving around the next dose: He slept under his desk at the office, where boxes of Subsys filled the drawers, and his house went into foreclosure. Buchalter looked troubled and tired when we met. His hands were visibly dirty. “I’ve been absent from my life for years,” he told me. “What I remember is who I was when my daughter was born, and when I was a soldier.”
The prevalence of off-label prescribing, while legal, did initially present Insys with a challenge. Owing to the risk and expense of Subsys, nearly all health insurers required prior authorization and would pay for the drug only for its sole approved use: breakthrough cancer pain. Only about one-third of Subsys prescriptions were being approved for reimbursement in late 2012. So Insys created an internal division dedicated to improving that number.
According to a former employee and multiple court filings, including a manager’s guilty plea, the company offered to relieve doctors’ offices of insurance hassles and take on the task of getting prescriptions covered. Insys’ “prior authorization specialists” — workers who the company motivated with bonuses — would contact insurers or their contractors, giving the impression they were calling from the prescribing doctor’s office. They used what managers called “the spiel,” which led insurers to believe that patients had cancer when they did not. Sometimes they would falsify medical charts and outright lie, former staff members have acknowledged. Babich, the chief executive, was involved in arranging for this unit’s phone system to block Caller ID to disguise the fact that calls were not coming from the doctor’s office, according to the Boston indictment.
The initiative worked. By the following spring, a company estimate pegged the approval rate for commercial insurers at 87 percent.
With insurance approval now catching up with prescriptions, Insys revenue and market share were climbing sharply, but a serious threat was brewing within. Within six months of the Subsys launch, one rep based in Texas, Ray Furchak, started to consider reporting Insys to government authorities. The speaker program, he felt, amounted to a thinly disguised kickback scheme, and he was also concerned that management was pushing an overly high dose of Subsys to first-time patients, despite boldface F.D.A. warnings of the dangers. Furchak began to collect emails and texts as evidence.
He soon filed a whistle-blower complaint against the company, as well as John Kapoor. But the defendants did not know they had been sued for months — the case proceeded under seal.
While Insys’s fortunes were on the rise, Furchak’s suit was under review at the Justice Department. In cases like his, called qui tams, a whistle-blower sues on behalf of the government, claiming fraud, and stands to share in any recovered funds. Justice Department lawyers quietly conducted interviews, weighing whether to intervene and join the plaintiff in the suit. It was one of hundreds of decisions like it that qui tam investigators face at any given time. An investigator at the Department of Health and Human Services, Michael Cohen, told me the federal government faces an overwhelming amount of health care fraud: “We call it a tsunami.”
Fortunately for Insys, the Justice Department declined to intervene in Furchak’s case. A lawyer familiar with the decision cited the difficulty of proving significant damages; Insys was not a big fish yet. Furchak did what most people do in this situation: He dropped the suit. The judge ordered his complaint unsealed, but the media took no notice at the time. Insys was free to go on doing what it was doing. It would be a long time before the law caught up to it.
In May 2013, two months after the Justice Department decision, the company went public. At an event at the Nasdaq MarketSite in Times Square, Kapoor and Babich stood smiling, surrounded by a group of cheering Insys executives.
By the end of 2013, Subsys would become the most widely prescribed branded TIRF, according to a company S.E.C. filing. In an ebullient “State of the Union” message to the sales force that October, Babich joked about hiring midget wrestlers to perform at the next national sales meeting. Now the competition was going to come after Insys, he said. “One problem they have ... they don’t have a chance in hell!”
Insys became the year’s best-performing initial public offering, on a gain of over 400 percent. That December, the company disclosed that it had received a subpoena from the Office of the Inspector General at Health and Human Services, an ominous sign. But a CNBC interviewer made no mention of it when he interviewed Babich a few weeks later. Instead he said, “Tell us what it is about Insys that has investors so excited.”
By then, though, Insys management had identified a potential worry in the Southeast region. Xiulu Ruan and John Patrick Couch, each a well-compensated Insys speaker, jointly owned and operated a pain clinic in Mobile, Ala., that served thousands of clients. Their main location occupied a one-story brown building on a commercial strip on the western outskirts of the city, adjacent to a Shell station.
Ruan was able to successfully recommend an Insys rep for their territory, a 27-year-old named Natalie Perhacs. Ruan had been asking her out to dinner for several months, to no avail; now she would be in his clinic several times a week. In her previous job, Perhacs’s salary was just over $30,000, but in two years selling Subsys almost exclusively to Ruan and Couch, she made $700,000. (Perhacs later pleaded guilty to conspiracy to violate a federal anti-kickback statute.)
Ruan and Couch had many patients legitimately in need of pain treatment. But it would be difficult to miss, from regularly visiting the clinic or from prescribing data alone, that something was awry. “Oh, everybody knew it,” a nurse at a different Mobile practice told me.
In 2014, the doctors each averaged one prescription for a controlled substance roughly every four minutes, figuring on a 40-hour week. A typical pill mill makes its money from patients paying in cash for their appointments, but Ruan and Couch had a different model: A majority of their scripts were filled at a pharmacy adjacent to their clinic called C&R — for Couch and Ruan — where they took home most of the profits. The pharmacy sold more than $570,000 of Subsys in a single month, according to Perhacs’s criminal plea. Together the two men amassed a collection of 23 luxury cars.
Two former patients told me that people approached them to buy or sell prescription drugs in the clinic’s parking lot. “There was always one or two out there,” Alice Byrd Jordan said.
One patient, Keith Bumpers, told me that he had thought his doctor at the clinic was “Dr. Justin.” Justin Palmer was a nurse practitioner who testified that he routinely forged Couch’s name on prescriptions. He was one of three medical staff members at the clinic who were personally misusing painkillers at work. One of them died by suicide; the other two admitted seeing patients while impaired. A patient named Tamisan Witherspoon, who was prescribed Subsys off-label and became addicted, testified that a nurse practitioner at the clinic, Bridgette Parker, spoke incoherently and collapsed asleep in an exam room in front of her. Witherspoon recognized the state Parker was in, because she had been there herself, she said, from taking Subsys. “I started to cry,” Witherspoon said on the witness stand, “because I realized that she was in trouble and so was I.”
In court testimony, Perhacs acknowledged that in late 2013, there was a “sense of panic” at Insys regarding the situation at the clinic in Mobile. The problem was that the clinic wasn’t generating enough money for the company.
“Dr. Ruan and Dr. Couch are way down,” Burlakoff wrote to Perhacs. “Can you assist please. ... This was the topic of conversation today with Dr. Kapoor and Mike.”
In fact, Couch and Ruan were still writing a lot of Subsys scripts. But they had started prolifically prescribing a Subsys competitor too: Abstral, then made by Galena Biopharma. One reason Insys was losing out on potential sales, according to the Boston indictment, was that C&R Pharmacy was having trouble getting enough Subsys from distributors to keep it in stock — because of measures designed to combat the opioid crisis.
Seven former Insys executives not only face criminal prosecution but stand accused of racketeering under the RICO Act, a law more commonly invoked against organized-crime families and drug gangs. The industry will be paying attention.Illustration by Francesco Francavilla
The flow of controlled substances through distributors, which are the middlemen between drug companies and pharmacies, is strictly regulated, and distributors have paid hefty settlements for failing to notify the Drug Enforcement Administration of “suspicious orders” of controlled substances from particular pharmacies. Couch and Ruan’s pharmacy was hitting caps with their distributor, according to Perhacs’s testimony — an “enormous barrier,” a manager wrote to her. In internal emails cited in the Boston indictment, leadership scrambled to find a way to beat the competition and get around the caps at the same time. One executive wrote that “certain parties would be at risk” if they were not careful. Sales reps in the region felt they needed assistance. A manager wrote to Perhacs, “Hopefully with a little help from above we can land this.”
On Feb. 13, 2014, the help arrived. Two men flew to Alabama to have dinner at a steakhouse with Couch and Ruan and their pharmacists, booking rooms for the night at the Renaissance Hotel by the Mobile River. The two men who flew to Mobile for this meeting were the chief executive, Michael Babich, and the billionaire founder of Insys Therapeutics, John Kapoor.
Over dinner, according to the Boston indictment, Kapoor and Babich struck a remarkable agreement with the pharmacists and the doctors, who were operating a clinic rife with opioid addiction among the staff: Insys would ship Subsys directly to C&R Pharmacy. An arrangement like this is “highly unusual” and a “red flag,” according to testimony from a D.E.A. investigator in a related trial. As part of the terms of the deal, the pharmacy would make more money on selling the drug, with no distributor in the loop. And there would be another anticipated benefit for all involved: Everyone could sell more Subsys without triggering an alert to the D.E.A.
It was not long after that dinner in Alabama that the troubles at Insys came more clearly into public view. Early in 2014, according to a former employee at Insys headquarters cited in a shareholder suit, top executives learned that a major Subsys “whale” based in Michigan, Gavin Awerbuch, was under investigation. Awerbuch was a well-paid speaker and, by a large margin, the top prescriber of Subsys to Medicare patients. Further details have emerged in the Boston indictment and other court filings. Burlakoff had personally cultivated Awerbuch, flying to Michigan to take him out to dinner and then writing an email to colleagues: “Expect a nice ‘bump’ fellas.”
As it turned out, unfortunately for Insys, Awerbuch was under the eye of authorities even before Subsys went on the market. He was submitting insurance claims for bogus tests and liberally writing opioid scripts. As investigators closed in on him, his fondness for a new drug called Subsys caught their eye. He prescribed it to one patient complaining of mild to moderate back pain. That patient was an undercover agent.
Awerbuch was arrested in May 2014 and charged with illegally prescribing Subsys and insurance fraud. Insys’s stock took an immediate hit, on heavy trading volume.
In an email the previous September, Burlakoff had written to Babich and others, “Let’s make some money,” adding that it was the Awerbuchs “of the world that keep us in business, let’s get a few more.” Now Insys executives scrambled to distance themselves from the doctor. Subsys was not sold directly to doctors, who make their own decisions, they explained in a news release: “Insys only sells Subsys through D.E.A. approved wholesalers who monitor and track prescribing activity.”
With news of Awerbuch’s arrest, the New Jersey sales rep Susan Beisler wrote to a friend: “Yup. [Expletive].” When the friend responded that it was bad for the doctor but not for Insys, Beisler replied: “The thing is they bribed the [expletive] out of that guy to write. The complaint shows ten other docs they also bribed.”
It was a telling remark: In fact, the Awerbuch criminal complaint merely presented a chart of the Top 10 Subsys prescribers to Medicare patients. Names were withheld, but other details were provided. An executive at Galena, then the maker of Abstral, sent a screenshot of the list to Ruan, who was easily identifiable. The next day, Ruan began redirecting his Insys speaker fees to philanthropic purposes. “He runs away from that Insys money as fast as he can,” the assistant United States attorney Christopher Bodnar later told a jury.
With Awerbuch’s fall, Beisler apparently thought that Insys was done, but for her bosses, and for their investors, this wasn’t over. After a dip, revenues recovered and the stock resumed its climb. Insys kept paying speaker fees to physicians with disciplinary histories — and doing so out in the open, because a newly implemented provision of the Affordable Care Act meant that drug makers’ payments to doctors were now publicly posted. Burlakoff continued on the job for more than a year. Investors shrugged over the Awerbuch news and the bad press surrounding the speaker program. The subpoena Insys had received about its sales practices was “not particularly unusual,” one bullish Wall Street analysis noted later that year, adding, “we’re pretty sure that the worst-case outcome for Insys is some sort of fine.” The first hard-hitting report of several by Roddy Boyd of the Southern Investigative Reporting Foundation, in April 2015, jolted the stock, but again it recovered and moved higher, with sales still climbing.
Insys sustained another blow when federal agents descended on Ruan and Couch’s clinic in Mobile in May 2015. They were there to seize evidence and arrest the doctors, Kapoor and Babich’s dinner companions the previous year.
The local medical community felt the impact of the raid. Because refills are generally not allowed on controlled substances, patients typically visited the clinic every month. For days, dozens of them lined up outside in the morning, fruitlessly trying to get prescriptions from the remaining staff or at least retrieve their medical records to take elsewhere. But other providers were either booked up or would not take these patients. “Nobody was willing to give the amount of drugs they were on,” a nurse in the city said. Melissa Costello, who heads the emergency room at Mobile Infirmary, said her staff saw a surge of patients from the clinic in the ensuing weeks, at least a hundred, who were going through agonizing withdrawal.
Two months after the raid in Mobile, Insys’ stock reached an all-time high.
At dawn one morning last October, several S.U.V.s entered a gated community in Phoenix and drove up a mountainside road. Federal agents climbed out and entered a sprawling house with their weapons drawn. They took John Kapoor into custody at 7 a.m. When he appeared eight hours later in federal court, surrounded by indigent defendants being arraigned at the same time, he was wearing untied running shoes and gym shorts that appeared to be on backward.
Prosecutors had advanced from targeting lower-level employees toward the heart of the company, securing some guilty pleas along the way, including one from Michael Babich’s wife, Natalie Levine, a former Insys rep, on bribery charges. Babich, Burlakoff, Sunrise Lee and three other former senior Insys executives were indicted simultaneously on bribery and fraud charges, and months passed while Insys insiders wondered whether Kapoor would go untouched. Now they had their answer.
Kapoor and the six other executives charged in Boston have pleaded not guilty and await trial, scheduled for January. For prosecutors at the Department of Justice, this is uncharted territory. When pharmaceutical companies have been heavily penalized over marketing schemes and fraud, their leaders have typically settled the cases — or, more rarely, pleaded to misdemeanors — and walked away. The Insys defendants not only face criminal prosecution but stand accused of racketeering under the RICO Act, a law more commonly invoked against organized-crime families and drug gangs. The industry will be paying attention.
Kapoor’s lawyer, Beth Wilkinson, declined to comment in detail on the case, but did say, “We will vigorously defend Dr. Kapoor in court.” Lawyers for Burlakoff, Babich, Lee, Levine and Madison either declined or did not respond to detailed requests for comment. A lawyer for Beisler, who has not been charged with a crime, also declined to comment. Awerbuch pleaded guilty to accepting bribes and health care fraud and has been sentenced to jail time. Ruan and Couch were convicted on multiple felony counts and are in prison. They have appealed. Krane was fired by Insys in November 2012; the company cited poor sales performance. She no longer works in the drug industry.
Insys itself is still producing Subsys, though sales have fallen considerably. (Overall demand for TIRFs has declined industrywide.) The company is now marketing what it calls the “first and only F.D.A.-approved liquid dronabinol,” a synthetic cannabinoid, and is developing several other new drugs. Some analysts like the look of the company’s pipeline of new drugs and rate the stock a “buy.” In a statement, the company said its new management team consists of “responsible and ethical business leaders” committed to effective compliance. Most of its more than 300 employees are new to the company since 2015, and its sales force is focused on physicians “whose prescribing patterns support our products’ approved indications,” the company said. Insys has ended its speaker program for Subsys.
In Florida, Dr. Steven Chun is still seeing patients. The indictment against the Insys executives details the company’s relationship to 10 unnamed Subsys prescribers. Having worked to identify all of them, I was virtually certain that Chun is “Practitioner #9.” Three others have already been sentenced to prison time; Chun has not been charged with any crime. In February, after multiple attempts to contact him, I visited his Florida clinic unannounced.
Chun works out of the third floor of a two-tone stucco building flanked by palm trees, in prosperous Lakewood Ranch, a master-planned community. Adjacent to the medical complex housing his clinic is a tidy outdoor retail and entertainment area called Main Street at Lakewood Ranch. In Chun’s orderly waiting room, when I visited, an elderly man with a walker and a plaid shirt sat silently under the fluorescent lights. The clinic looked nothing like the pill mill that I had stopped by a few days earlier. It looked like a doctor’s office.
I did not expect Chun to agree to see me, but I was led down a long hallway into his personal office. Wearing dark blue scrubs with his name embroidered at the breast, he shook my hand and motioned for me to sit on a red leather sofa while he sat back in his chair, taking a sip from a thermos. A framed diploma hung on the wall behind him.
The practice of pain management has changed since Chun was in training in the 1990s, he said. There are so many regulations. People in pain have fewer and fewer places to go. And now, he said, he’s caught up in this Insys case.
Chun said that his prescribing of Subsys had nothing to do with the money that Insys paid him (more than $275,000, according to the Boston indictment). He believed in the product and he enjoyed doing the speaker programs. It suited his ego to take a teaching role, he said, smiling.
Asked for comment at press time, Chun defended his practice, saying he has never been accused of malpractice or disciplined by the state of Florida. He has complied with subpoenas related to Subsys, he said, and he has not been contacted directly by investigators in connection with Insys. He said a vast majority of his TIRF prescriptions are on-label, for patients with cancer or a history of cancer. He said he always tells patients, “Unless you have cancer, I’m not going to prescribe this for you.”
Chun said Subsys prescriptions went up 10 percent at most after he joined the speaker program. (The Boston indictment contradicts this account.) He said he only heard about the Insys “scam” after he left the program and saw no reason he was being associated with doctors who participated. He concluded, “I follow the rules.”
While Chun and I were speaking, staff members knocked on the door and entered every 30 minutes or so, carrying pieces of paper for Chun to sign. Chun explained that the nurse practitioner he worked with is not licensed to prescribe Schedule II controlled substances, the most tightly regulated category of legal drugs. The sheets of paper were prescriptions, and he signed them two to four at a time without pausing to read them over. As soon as the knock came on the door, without looking down, he would make a swift motion with his hand to retrieve his pen from his breast pocket and click the button on the top.
Down the hall, patients were presumably making the trip, in that cycle familiar to us all, from the waiting room to the exam room and finally home. Naturally the patient in the next room had no idea what Chun and I were discussing. He probably did not see that a sales rep stopped by and brought lunch for the clinic staff, getting a wave from Chun through the open door. It’s very likely that a pharmacy rang up a prescription for that patient on his way home, but the real sale had already happened, out of his sight.
In a rare piece of good news for whales, humpbacks who live and breed in the southern oceans near Antarctica appear to be making a comeback, with females in recent years having a high pregnancy rate and giving birth to more calves.
Humpback whales were nearly hunted out of existence in the late 19th and most of the 20th centuries until treaties were signed to stop killing them and protections were put in place for the world’s coldest, least accessible continent.
The end of hunting has fostered the recovery of the school-bus-sized animals whose life spans are roughly comparable to ours, according to Ari Friedlaender, an associate researcher at the University of California Santa Cruz, who led the new study.
The population was believed to have been reduced to less than 10 percent of it pre-whaling levels.
To determine gender, identity and pregnancy rates, the scientists, led by Logan Pallin, a doctoral student working with Dr. Friedlaender, used darts to take small skin and blubber samples from 239 males and 268 females from 2010 to 2016 around the Western Antarctic Peninsula.
As the researchers took their surveys, the whales were often just as curious about the team as it was about them. They would swim alongside the team’s vessel, some with their babies.
Slightly more than 60 percent of the females had high progesterone levels in their blubber, indicating that they were pregnant, according to the new study, published today in the journal Royal Society Open Science. There were more pregnant whales in recent years than earlier, according to the research. Genetic analysis indicated gender and enabled the scientists to avoid counting the same whale twice.
Although some other whale species also appear to be rebounding in the southern oceans, humpbacks seem to be faring the best, Dr. Friedlaender said. It may have been easier for the humpbacks to recover than the bigger fin and blue whales because the humpbacks mature faster,have a short period between pregnancies, and have centralized breeding grounds. Fin and blue whales mate in the open ocean, making it harder for them to find a match, he said.
A moratorium on commercial whaling took effect in the early 1980s, though some whaling regulations had been imposed as early as the 1940s. Twelve countries signed a treaty in 1959 to protect the Antarctic Peninsula. Humpback whales south of the Equator are no longer considered endangered, though. A few northern populations remain on the National Oceanic and Atmospheric Administration’s list of endangered animals.
It is likely that a large portion of the animals alive today were born after the age of whale hunting ended, Dr. Friedlaender said.
So far, climate change around the Antarctic Peninsula has been beneficial for humpbacks, he said, providing about 80 more ice-free days per year when these whales that prefer open water can feed on abundant stocks of tiny shrimplike crustaceans called krill.
Whale researchers are concerned that this moment of health and easy access to food will be short-lived. Krill stock around Antarctica is being fished by some countries, and threatened by climate change.
Additionally, reduction in sea ice endangers krill, which feed on the underside of sea ice, said Sean Todd, the chair in marine sciences at the College of the Atlantic in Bar Harbor, Me., who was not involved in the new research.
Dr. Todd said his repeated trips to Antarctica have proven to him that krill are essential to life in the southern oceans. “You either eat krill, or you eat something that eats krill,” he said. “If krill stocks collapse, then there’ll be profound changes to that region.”
Dr. Todd said the new study confirmed the growing abundance of humpbacks that he had noticed on annual trips to Antarctica. When he first started going in the early 2000s, he would see a few humpbacks every trip in February and March. Now, he sees them as early as December, he said, “to the point that you can lose count of how many are around you.”
He said he had also seen a smaller but obvious rebound among fin and blue whales – the planet’s largest animals – as well as the Southern right whale, a cousin to the highly endangered Northern Right Whale.
There have been a number of mentions of an attack thatEran Tromer found
against Ray Ozzie'sCLEAR
protocol, including in
Steven Levy'sWired
article
and onmy blog.
However, there haven't been any clear descriptions of it.
Eran has kindly given me his description of it, with permission to
publish it on my blog. The text below is his.
A fundamental issue with CLEAR approach is that it effectively tells
law enforcement officers to trust phones handed to them by criminals,
and give such phones whatever unlock keys they request. This provides
a powerful avenue of attack for an adversary who uses phones as a
Trojan horse.
For example, the following "man-in-the-middle" attack can let a
criminal unlock a victim's phone that reached their possession, if
that phone is CLEAR-compliant. The criminal would turn on the victim
phone, perform the requisite gesture to display the "device unlock
request" QR code, and copy this code. They would then program a new
"relay" phone to impersonate the victim phone: when the relay phone
is turned on, it shows the victim's QR code instead of its own.
(This behavior is not CLEAR-compliant, but that's not much of a barrier:
the criminal can just buy a non-compliant phone or cobble one from
readily-available components). The criminal would plant the relay
phone in some place where law enforcement is likely to take keen
interet in it, such as a staged crime scene or near a foreign
embassy. Law enforcement would diligently collect the phone and,
under the CLEAR procedure, turn it on to retrieve the "device unlock
request" QR code (which, unbeknownst to them, is actually the
victim's code). Law enforcement would then obtain a corresponding
search warrant, retrieve the unlock code from the vendor, and
helpfully present it to the relay phone — which will promptly relay
the code to the criminal, who can then enter the same code into the
victim's phone. The victim's code, upon receiving this code, will
spill all its secrets to the criminal. The relay phone can even
present law enforcement with a fake view of its own contents, so
that no anomaly is apparent.
The good news is that this attack requires the criminal to go through
the motions anew for for every victim phone, so it cannot easily
unlock phones en masse. Still, this would provide little consolation
to, say, a victim whose company secrets or cryptocurrency assets
have been stolen by a targeted attack.
It it plausible that such man-in-the-middle attacks can be mitigated
by modern cryptographic authentication protocols coupled with
physical measures such as tamper-resistant hardware or communication
latency measurements. But this is a difficult challenge that requires
careful design and review, and would introduce extra assumptions,
costs and fragility into the system.
Blocking communication (e.g.,
using Faraday cages) is also a possible measure, though notoriously
difficult, unwieldy and expensive.
Another problem is that CLEAR phones must resist "jailbreaking",
i.e., must not let phone owners modify the operating system or
firmware on their own phones. This is because CLEAR critically
relies on users not being able to tamper with their phones' unlocking
functionality, and this functionality would surely be implemented
in software, as part of the operating system or firmware, due to
its sheer complexity (e.g., it includes the "device unlock request"
screen, QR code recognition, crytographic verification of unlock
codes, and transmission of data dumps). In practice, it is well-nigh
impossible to prevent jailbreaking in complex consumer devices, and
even for state-of-the-art locked-down platforms such as Apple's
iOS, jailbreak methods are typically discovered and widely circulated
soon after every operating system update. Note that jailbreaking
also exacerbates the aforementioned man-in-the-middle attack: to
create the relay phone, the criminal may pick any burner phone from
a nearby store, and even if such phones are CLEAR-compliant by
decree, jailbreaking them would allow them to be reprogrammed as a
relay.
Additional risks stem from having an attacker-controlled electronics
operating within law enforcement premises. A phone can eavesdrop
on investigators's conversations, or even steal private cryptographic
keys from investigator's computers. For examples of the how the
latter may be done using a plain smartphone or hardware hidden that
can fit in a customized phone, seehttp://cs.tau.ac.il/~tromer/acoustic,http://www.cs.tau.ac.il/~tromer/radioexp,
andhttp://www.cs.tau.ac.il/~tromer/mobilesc.
While prudent forensics
procedures can mitigate this risk, these too would introduce new
costs and complexity.
These are powerful avenues of attack, because phones are flexible
devices with the capability to display arbitrary information,
communicate wirelessly with adversaries, and spy on their environment.
In a critical forensic investigation, you would never want to turn
on a phone and run whatever nefarious or self-destructing software
may be programmed in it. Moreover, the last thing you'd do is let
a phone found on the street issue requests to a highly sensitive
system that dispenses unlock codes (even if these requests are
issued indirectly, through a well-meaning but hapless law enforcement
officer who's just following procedure).
Indeed, in computer forensics, a basic precaution against such
attacks is to never turn on the computer in an uncontrolled fashion;
rather, you would extract its storage data and analyze it on a
different, trustworthy computer. But the CLEAR scheme relies on
keeping the phone intact, and even turning it on and trusting it
to communicate as intended during the recovery procedure. Telling
the guards of Troy to bring any suspicious wooden horse into the
city walls, and to grant it an audience with the king, may not be
the best policy solution to "Going Greek" debate.
Animation software brings together data to tell a molecular story
Advertisement
Animation is a powerful medium—it transports us to another time or place, or tells gripping stories. It can also help us visualize biological processes we would never otherwise see. Decades of research have pieced together the stages of the HIV life cycle, but because the it’s so small, no one has seen the virus hijack a cell to reproduce itself as it happens. Janet Iwasa, a biology professor at the University of Utah, uses advanced animation software to bring data to life in this video for Science of HIV, a project dedicated to visualizing the virus.
The views expressed are those of the author(s) and are not necessarily those of Scientific American.
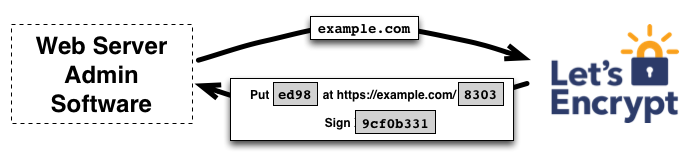
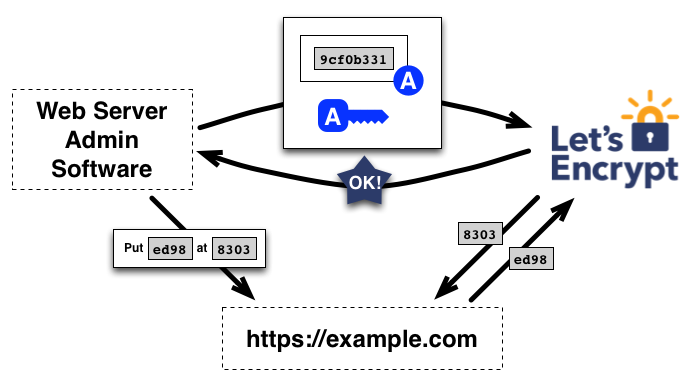
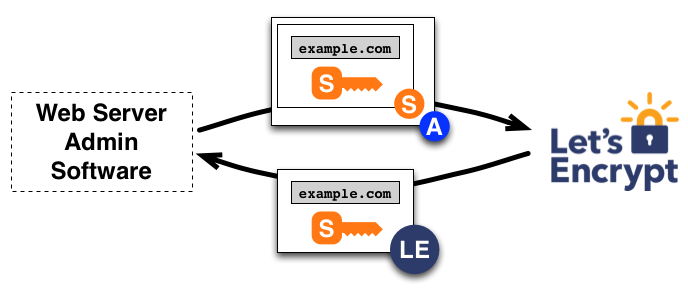



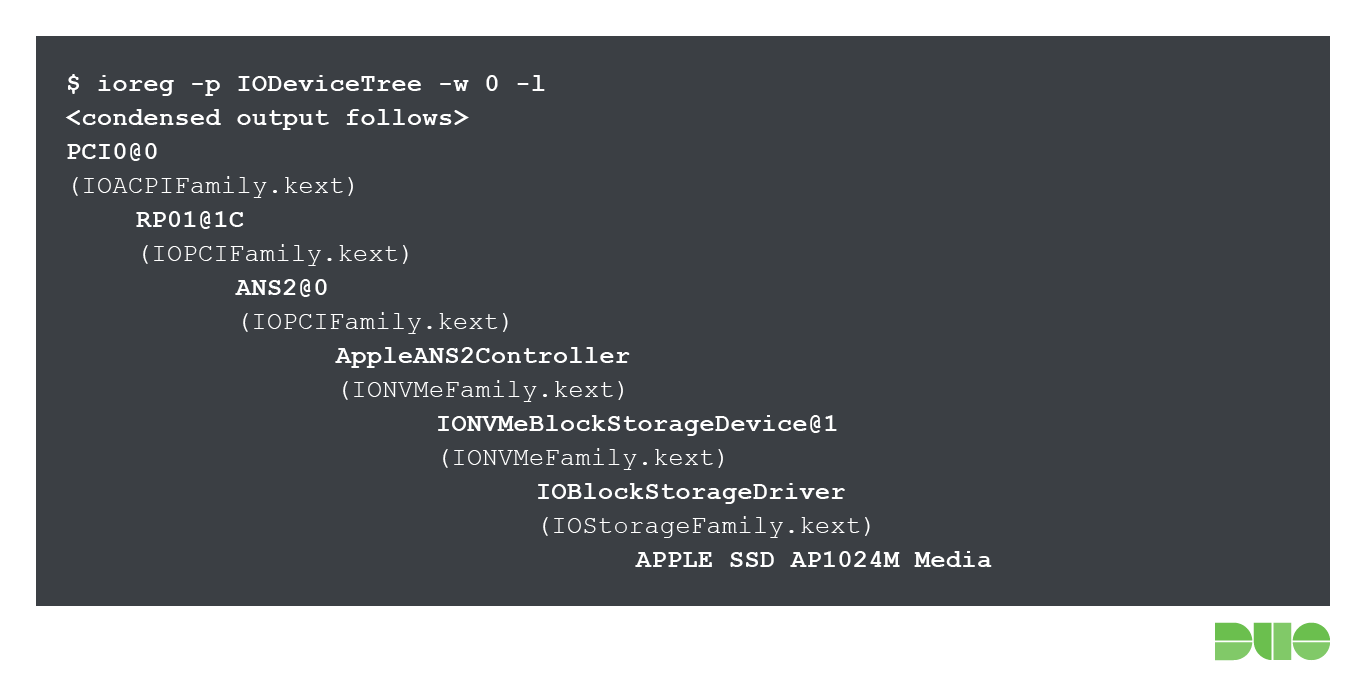
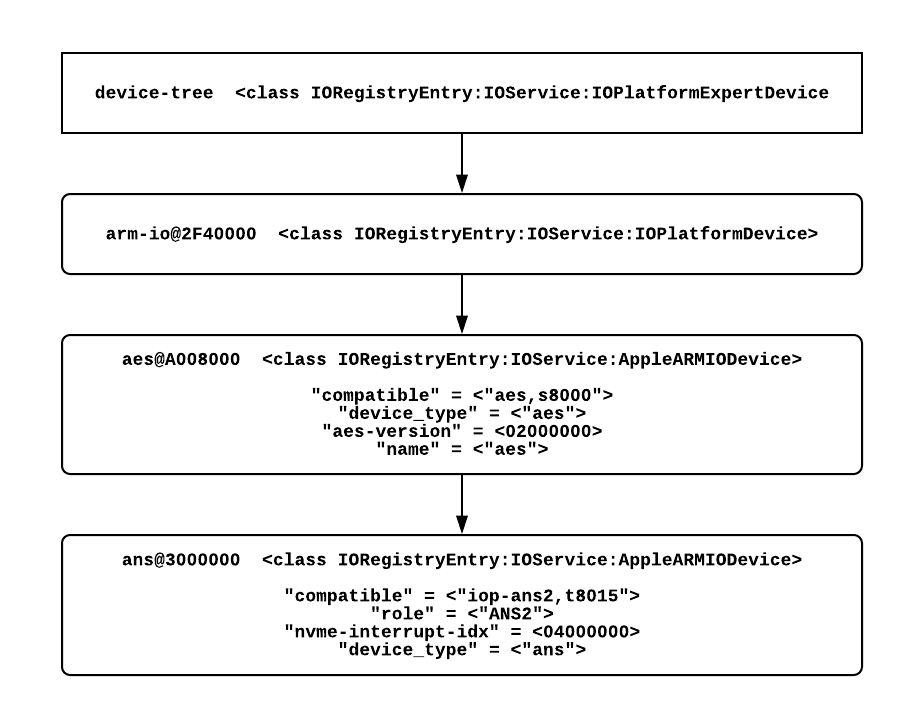
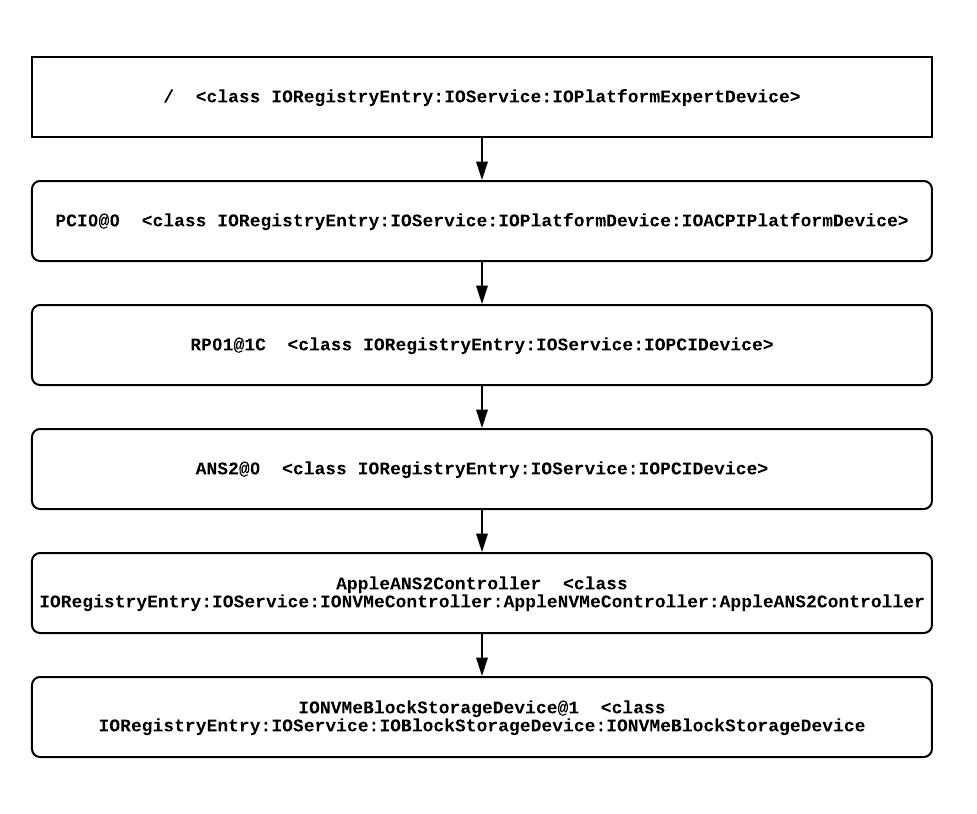
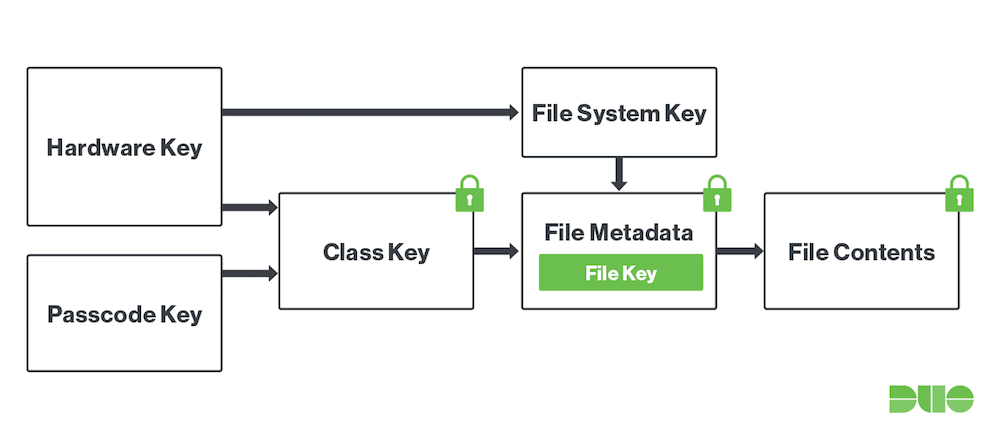

 ·
·

