EX-99.1 | | | | | | |
| | ![LOGO]()
| | | Exhibit 99.1 | |
To our shareowners:
The
American Customer Satisfaction Index recently announced the results of its annual survey, and for the 8th year in a row customers ranked Amazon #1. The United Kingdom has a similar index, The U.K.
Customer Satisfaction Index, put out by the Institute of Customer Service. For the 5th time in a row Amazon U.K. ranked #1 in that survey. Amazon was also just named the #1 business on
LinkedIns 2018 Top Companies list, which ranks the most sought after places to work for professionals in the United States. And just a few weeks ago, Harris Poll released its annual Reputation Quotient, which surveys over 25,000 consumers on a
broad range of topics from workplace environment to social responsibility to products and services, and for the 3rd year in a row Amazon ranked #1.
Congratulations and thank you to the now over 560,000 Amazonians who come to work every day with unrelenting customer obsession, ingenuity, and commitment to
operational excellence. And on behalf of Amazonians everywhere, I want to extend a huge thank you to customers. Its incredibly energizing for us to see your responses to these surveys.
One thing I love about customers is that they are divinely discontent. Their expectations are never static they go up. Its human nature. We
didnt ascend from our hunter-gatherer days by being satisfied. People have a voracious appetite for a better way, and yesterdays wow quickly becomes todays ordinary. I see that cycle of improvement happening
at a faster rate than ever before. It may be because customers have such easy access to more information than ever before in only a few seconds and with a couple taps on their phones, customers can read reviews, compare prices from multiple
retailers, see whether somethings in stock, find out how fast it will ship or be available forpick-up, and more. These examples are from retail, but I sense that the same customer empowerment phenomenon
is happening broadly across everything we do at Amazon and most other industries as well. You cannot rest on your laurels in this world. Customers wont have it.
How do you stay ahead of ever-rising customer expectations? Theres no single way to do it its a combination of many things. But high
standards (widely deployed and at all levels of detail) are certainly a big part of it. Weve had some successes over the years in our quest to meet the high expectations of customers. Weve also had billions of dollars worth of
failures along the way. With those experiences as backdrop, Id like to share with you the essentials of what weve learned (so far) about high standards inside an organization.
Intrinsic or Teachable?
First, theres a
foundational question: are high standards intrinsic or teachable? If you take me on your basketball team, you can teach me many things, but you cant teach me to be taller. Do we first and foremost need to select for high
standards people? If so, this letter would need to be mostly about hiring practices, but I dont think so. I believe high standards are teachable. In fact, people are pretty good at learning high standards simply through exposure. High
standards are contagious. Bring a new person onto a high standards team, and theyll quickly adapt. The opposite is also true. If low standards prevail, those too will quickly spread. And though exposure works well to teach high standards, I
believe you can accelerate that rate of learning by articulating a few core principles of high standards, which I hope to share in this letter.
Universal or Domain Specific?
Another important
question is whether high standards are universal or domain specific. In other words, if you have high standards in one area, do you automatically have high standards elsewhere? I believe high standards are domain specific, and that you have to learn
high standards separately in every arena of interest. When I started Amazon, I had high standards on inventing, on customer care, and (thankfully) on hiring. But I didnt have high standards on operational process: how to keep fixed problems
fixed, how to eliminate defects at the root, how to inspect processes, and much more. I had to learn and develop high standards on all of that (my colleagues were my tutors).
Understanding this point is important because it keeps you humble. You can consider yourself a person of high
standards in general and still have debilitating blind spots. There can be whole arenas of endeavor where you may not even know that your standards are low or non-existent, and certainly not
world class. Its critical to be open to that likelihood.
Recognition and Scope
What do you need to achieve high standards in a particular domain area? First, you have to be able to recognize what good looks like in that domain.
Second, you must have realistic expectations for how hard it should be (how much work it will take) to achieve that result the scope.
Let
me give you two examples. One is a sort of toy illustration but it makes the point clearly, and another is a real one that comes up at Amazon all the time.
Perfect Handstands
A close friend recently decided to
learn to do a perfect free-standing handstand. No leaning against a wall. Not for just a few seconds. Instagram good. She decided to start her journey by taking a handstand workshop at her yoga studio. She then practiced for a while but wasnt
getting the results she wanted. So, she hired a handstand coach. Yes, I know what youre thinking, but evidently this is an actual thing that exists. In the very first lesson, the coach gave her some wonderful advice. Most people,
he said, think that if they work hard, they should be able to master a handstand in about two weeks. The reality is that it takes about six months of daily practice. If you think you should be able to do it in two weeks, youre just going
to end up quitting. Unrealistic beliefs on scope often hidden and undiscussed kill high standards. To achieve high standards yourself or as part of a team, you need to form and proactively communicate realistic beliefs about how
hard something is going to be something this coach understood well.
Six-Page Narratives
We dont do PowerPoint (or any other slide-oriented) presentations at Amazon. Instead, we write narratively structured
six-page memos. We silently read one at the beginning of each meeting in a kind of study hall. Not surprisingly, the quality of these memos varies widely. Some have the clarity of angels singing.
They are brilliant and thoughtful and set up the meeting for high-quality discussion. Sometimes they come in at the other end of the spectrum.
In the
handstand example, its pretty straightforward to recognize high standards. It wouldnt be difficult to lay out in detail the requirements of a well-executed handstand, and then youre either doing it or youre not. The
writing example is very different. The difference between a great memo and an average one is much squishier. It would be extremely hard to write down the detailed requirements that make up a great memo. Nevertheless, I find that much of the time,
readers react to great memos very similarly. They know it when they see it. The standard is there, and it is real, even if its not easily describable.
Heres what weve figured out. Often, when a memo isnt great, its not the writers inability to recognize the high standard,
but instead a wrong expectation on scope: they mistakenly believe a high-standards, six-page memo can be written in one or two days or even a few hours, when really it might take a week or more!
Theyre trying to perfect a handstand in just two weeks, and were not coaching them right. The great memos are written and re-written, shared with colleagues who are asked to improve the work, set
aside for a couple of days, and then edited again with a fresh mind. They simply cant be done in a day or two. The key point here is that you can improve results through the simple act of teaching scope that a great memo probably should
take a week or more.
Skill
Beyond recognizing the
standard and having realistic expectations on scope, how about skill? Surely to write a world class memo, you have to be an extremely skilled writer? Is it another required element? In my view, not so much, at least not for the individual in
the context of teams. The football coach doesnt need to be able to throw, and a film director doesnt need to be able to act. But they both do need to recognize high standards for those things and teach realistic expectations on scope.
Even in the example of writing a six-page memo, thats
teamwork. Someone on the team needs to have the skill, but it doesnt have to be you. (As a side note, by tradition at Amazon, authors names never appear on the memos the
memo is from the whole team.)
Benefits of High Standards
Building a culture of high standards is well worth the effort, and there are many benefits. Naturally and most obviously, youre going to build better
products and services for customers this would be reason enough! Perhaps a little less obvious: people are drawn to high standards they help with recruiting and retention. More subtle: a culture of high standards is protective of all
the invisible but crucial work that goes on in every company. Im talking about the work that no one sees. The work that gets done when no one is watching. In a high standards culture, doing that work well is its own reward
its part of what it means to be a professional.
And finally, high standards are fun! Once youve tasted high standards, theres no going
back.
So, the four elements of high standards as we see it: they are teachable, they are domain specific, you must recognize them,
and you must explicitly coach realistic scope. For us, these work at all levels of detail. Everything from writing memos to whole new, clean-sheet business initiatives. We hope they help you too.
Insist on the Highest Standards
Leaders have
relentlessly high standards many people may think these standards are unreasonably high.
-- from the Amazon Leadership Principles
Recent Milestones
The high standards our leaders strive
for have served us well. And while I certainly cant do a handstand myself, Im extremely proud to share some of the milestones we hit last year, each of which represents the fruition of many years of collective effort. We take none of
them for granted.
| | | | Prime 13 years post-launch, we have exceeded 100 million paid Prime members globally. In 2017 Amazon shipped more than five billion items with Prime worldwide, and more new members joined Prime than
in any previous year both worldwide and in the U.S. Members in the U.S. now receive unlimited free two-day shipping on over 100 million different items. We expanded Prime to Mexico, Singapore, the
Netherlands, and Luxembourg, and introduced Business Prime Shipping in the U.S. and Germany. We keep making Prime shipping faster as well, with Prime Free Same-Day and Prime FreeOne-Day delivery now in more than 8,000 cities and towns. Prime Now is available in more than 50 cities worldwide across nine countries. Prime Day 2017 was our biggest global shopping event ever (until
surpassed by Cyber Monday), with more new Prime members joining Prime than any other day in our history. |
| | | | AWS Its exciting to see Amazon Web Services, a $20 billion revenue run rate business, accelerate its already healthy growth. AWS has also accelerated its pace of innovation especially in
new areas such as machine learning and artificial intelligence, Internet of Things, and serverless computing. In 2017, AWS announced more than 1,400 significant services and features, including Amazon SageMaker, which radically changes the
accessibility and ease of use for everyday developers to build sophisticated machine learning models. Tens of thousands of customers are also using a broad range of AWS machine learning services, with active users increasing more than
250 percent in the last year, spurred by the broad adoption of Amazon SageMaker. And in November, we held our sixth re:Invent conference with more than 40,000 attendees and over 60,000 streaming participants. |
| | | | Marketplace In 2017, for the first time in our history, more than half of the units sold on Amazon worldwide were from our third-party sellers, including small and
medium-sized businesses (SMBs). Over 300,000 U.S.-based SMBs started selling on Amazon in 2017, and Fulfillment by Amazon shipped billions of items for SMBs worldwide. Customers ordered more than
40 million items from SMBs worldwide during Prime Day 2017, growing their sales by more than 60 percent over Prime Day 2016. Our Global Selling program (enabling SMBs to sell products across national borders) grew by over 50% in 2017 and
cross-border ecommerce by SMBs now represents more than 25% of total third-party sales. |
| | | | Alexa Customer embrace of Alexa continues, with Alexa-enabled devices among the best-selling items across all of Amazon. Were seeing extremely strong adoption by other companies and developers that
want to create their own experiences with Alexa. There are now more than 30,000 skills for Alexa from outside developers, and customers can control more than 4,000 smart home devices from 1,200 unique brands with Alexa. The foundations of Alexa
continue to get smarter every day too. Weve developed and implemented an on-device fingerprinting technique, which keeps your device from waking up when it hears an Alexa commercial on TV. (This
technology ensured that our Alexa Super Bowl commercial didnt wake up millions of devices.) Far-field speech recognition (already very good) has improved by 15% over the last year; and in the U.S., U.K.,
and Germany, weve improved Alexas spoken language understanding by more than 25% over the last 12 months through enhancements in Alexas machine learning components and the use of semi-supervised learning techniques. (These
semi-supervised learning techniques reduced the amount of labeled data needed to achieve the same accuracy improvement by 40 times!) Finally, weve dramatically reduced the amount of time required to teach Alexa new languages by using machine
translation and transfer learning techniques, which allows us to serve customers in more countries (like India and Japan). |
| | | | Amazon devices 2017 was our best year yet for hardware sales. Customers bought tens of millions of Echo devices, and Echo Dot and Fire TV Stick with Alexa were the best-selling products across all of
Amazon across all categories and all manufacturers. Customers bought twice as many Fire TV Sticks and Kids Edition Fire Tablets this holiday season versus last year. 2017 marked the release of our
all-new Echo with an improved design, better sound, and a lower price; Echo Plus with a built-in smart home hub; and Echo Spot, which is compact and beautiful with a
circular screen. We released our next generation Fire TV, featuring 4K Ultra HD and HDR; and the Fire HD 10 Tablet, with 1080p Full HD display. And we celebrated the 10th anniversary of
Kindle by releasing the all-new Kindle Oasis, our most advanced reader ever. Its waterproof take it in the bathtub with a bigger 7 high-resolution 300 ppi display and has built-in audio so you can also listen to your books with Audible. |
| | | | Prime Video Prime Video continues to drive Prime member adoption and retention. In the last year we made Prime Video even better for customers by adding new, award-winning Prime Originals to the
service, like The Marvelous Mrs. Maisel, winner of two Critics Choice Awards and two Golden Globes, and the Oscar-nominated movie The Big Sick. Weve expanded our slate of programming across
the globe, launching new seasons of Bosch and Sneaky Pete from the U.S., The Grand Tour from the U.K., and You Are Wanted from Germany, while adding new
Sentosha shows from Japan, along with Breathe and the award-winning Inside Edge from India. Also this year, we expanded our Prime Channels offerings, adding CBS All Access in the U.S. and launching
Channels in the U.K. and Germany. We debuted NFL Thursday Night Football on Prime Video, with more than 18 million total viewers over 11 games. In 2017, Prime Video Direct secured subscription video rights for more
than 3,000 feature films and committed over $18 million in royalties to independent filmmakers and other rights holders. Looking forward, were also excited about our upcoming Prime Original series pipeline, which
includes Tom Clancys Jack Ryan starring John Krasinski; King Lear, starring Anthony Hopkins and Emma Thompson; The Romanoffs, executive produced by
Matt Weiner; Carnival Row starring Orlando Bloom and Cara Delevingne; Good Omens starring Jon Hamm; and Homecoming, executive produced by Sam Esmail and starring Julia Roberts in her first
television series. We acquired the global television rights for a multi-season production of The Lord of the Rings, as well as Cortés, a miniseries based on the epic saga of Hernán
Cortés from executive producer Steven Spielberg, starring Javier Bardem, and we look forward to beginning work on those shows this year. |
| | | | Amazon Music Amazon Music continues to grow fast and now has tens of millions of paid customers. Amazon Music Unlimited, our on-demand,ad-free offering, expanded to more than 30 new countries in 2017, and membership has more than doubled over the past six months. |
| | | | Fashion Amazon has become the destination for tens of millions of customers to shop for fashion. In
2017, we introduced our first fashion-oriented Prime benefit, Prime Wardrobe a new service that brings the fitting room directly to the homes of Prime members so they can try on the latest styles before they buy. We introduced Nike and UGG on
Amazon along with new celebrity collections by Drew Barrymore and Dwyane Wade, as well as dozens of new private brands, like Goodthreads and |
| |
Core10. Were also continuing to enable thousands of designers and artists to offer their exclusive designs and prints on demand through Merch by Amazon. We finished 2017 with the launch of
our interactive shopping experience with Calvin Klein, including pop-up shops, on-site product customization, and fitting rooms with Alexa-controlled lighting, music,
and more. |
| | | | Whole Foods When we closed our acquisition of Whole Foods Market last year, we announced our commitment to making high-quality, natural and organic food available for everyone, then immediately lowered
prices on a selection of best-selling grocery staples, including avocados, organic brown eggs, and responsibly-farmed salmon. We followed this with a second round of price reductions in November, and our Prime member exclusive promotion broke Whole
Foods all-time record for turkeys sold during the Thanksgiving season. In February, we introduced free two-hour delivery on orders over $35 for Prime members in
select cities, followed by additional cities in March and April, and plan continued expansion across the U.S. throughout this year. We also expanded the benefits of the Amazon Prime Rewards Visa Card, enabling Prime members to get 5% back when
shopping at Whole Foods Market. Beyond that, customers can purchase Whole Foods private label products like 365 Everyday Value on Amazon, purchase Echo and other Amazon devices in over a hundred Whole Foods stores, and pick-up or return Amazon packages at Amazon Lockers in hundreds of Whole Foods stores. Weve also begun the technical work needed to recognize Prime members at the point of sale and look forward to offering
more Prime benefits to Whole Foods shoppers once that work is completed. |
| | | | Amazon Go Amazon Go, a new kind of store with no checkout required, opened to the public in January in Seattle. Since opening, weve been thrilled to hear many customers refer to their shopping
experience as magical. What makes the magic possible is a custom-built combination of computer vision, sensor fusion, and deep learning, which come together to create Just Walk Out shopping. With JWO, customers are able to grab their
favorite breakfast, lunch, dinner, snack, and grocery essentials more conveniently than ever before. Some of our top-selling items are not surprising caffeinated beverages and water are popular
but our customers also love the Chicken Banh Mi sandwich, chocolate chip cookies, cut fruit, gummy bears, and our Amazon Meal Kits. |
| | | | Treasure Truck Treasure Truck expanded from a single truck in Seattle to a fleet of 35 trucks across 25 U.S. cities and 12 U.K. cities. Our bubble-blowing, music-pumping trucks fulfilled hundreds of
thousands of orders, from porterhouse steaks to the latest Nintendo releases. Throughout the year, Treasure Truck also partnered with local communities to lift spirits and help those in need, including donating and delivering hundreds of car seats,
thousands of toys, tens of thousands of socks, and many other essentials to community members needing relief, from those displaced by Hurricane Harvey, to the homeless, to kids needing holiday cheer. |
| | | | India Amazon.in is the fastest growing marketplace in India, and the most visited site on both desktop and mobile, according to comScore and SimilarWeb. The Amazon.in mobile shopping app was also the
most downloaded shopping app in India in 2017, according to App Annie. Prime added more members in India in its first year than any previous geography in Amazons history. Prime selection in India now includes more than 40 million local
products from third-party sellers, and Prime Video is investing in India original video content in a big way, including two recent premiers and over a dozen new shows in production. |
| | | | Sustainability We are committed to minimizing carbon emissions by optimizing our transportation
network, improving product packaging, and enhancing energy efficiency in our operations, and we have a long-term goal to power our global infrastructure using 100% renewable energy. We recently launched Amazon Wind Farm Texas, our largest wind farm
yet, which generates more than 1,000,000 megawatt hours of clean energy annually from over 100 turbines. We have plans to host solar energy systems at 50 fulfillment centers by 2020, and have launched 24 wind and solar projects across the U.S. with
more than 29 additional projects to come. Together, Amazons renewable energy projects now produce enough clean energy to power over 330,000 homes annually. In 2017 we celebrated the 10-year anniversary
of Frustration-Free Packaging, the first of a suite of sustainable packaging initiatives that have eliminated more than 244,000 tons of packaging materials over the past 10 years. In addition, in 2017 alone our programs significantly reduced
packaging waste, eliminating the |
| |
equivalent of 305 million shipping boxes. And across the world, Amazon is contracting with our service providers to launch our first low-pollution
last-mile fleet. Already today, a portion of our European delivery fleet is comprised of low-pollution electric and natural gas vans and cars, and we have over 40 electric scooters and e-cargo bikes that complete local urban deliveries. |
| | | | Empowering Small Business Millions of small and medium-sized businesses worldwide now sell their products through Amazon to reach new customers around the globe.
SMBs selling on Amazon come from every state in the U.S., and from more than 130 different countries around the world. More than 140,000 SMBs surpassed $100,000 in sales on Amazon in 2017, and over a thousand independent authors surpassed $100,000
in royalties in 2017 through Kindle Direct Publishing. |
| | | | Investment & Job Creation Since 2011, we have invested over $150 billion worldwide in our fulfillment networks, transportation capabilities, and technology infrastructure,
including AWS data centers. Amazon has created over 1.7 million direct and indirect jobs around the world. In 2017 alone, we directly created more than 130,000 new Amazon jobs, not including acquisitions, bringing our global employee base to
over 560,000. Our new jobs cover a wide range of professions, from artificial intelligence scientists to packaging specialists to fulfillment center associates. In addition to these direct hires, we estimate that Amazon Marketplace has created
900,000 more jobs worldwide, and that Amazons investments have created an additional 260,000 jobs in areas like construction, logistics, and other professional services. |
| | | | Career Choice One employee program were particularly proud of is Amazon Career Choice. For hourly associates with more than one year of tenure, we pre-pay 95%
of tuition, fees, and textbooks (up to $12,000) for certificates and associate degrees in high-demand occupations such as aircraft mechanics, computer-aided design, machine tool technologies, medical lab technologies, and nursing. We fund education
in areas that are in high demand and do so regardless of whether those skills are relevant to a career at Amazon. Globally more than 16,000 associates (including more than 12,000 in the U.S.) have joined Career Choice since the program launched in
2012. Career Choice is live in ten countries and expanding to South Africa, Costa Rica, and Slovakia later this year. Commercial truck driving, healthcare, and information technology are the programs most popular fields of study. Weve
built 39 Career Choice classrooms so far, and we locate them behind glass walls in high traffic areas inside our fulfillment centers so associates can be inspired by seeing their peers pursue new skills. |
The credit for these milestones is deserved by many. Amazon is 560,000 employees. Its also 2 million sellers, hundreds of thousands of authors,
millions of AWS developers, and hundreds of millions of divinely discontent customers around the world who push to make us better each and every day.
Path Ahead
This year marks the 20th anniversary of our
first shareholder letter, and our core values and approach remain unchanged. We continue to aspire to be Earths most customer-centric company, and we recognize this to be no small or easy challenge. We know there is much we can do better, and
we find tremendous energy in the many challenges and opportunities that lie ahead.
A huge thank you to each and every customer for allowing us to serve
you, to our shareowners for your support, and to Amazonians everywhere for your ingenuity, your passion, and your high standards.
As always, I attach a
copy of our original 1997 letter. It remains Day 1.
Sincerely,
![LOGO]()
Jeffrey P. Bezos
Founder and
Chief Executive Officer
Amazon.com, Inc.
![LOGO]()
1997 LETTER TO
SHAREHOLDERS
(Reprinted from the 1997 Annual Report)
To our shareholders:
Amazon.com passed many milestones in 1997: by year-end, we had served more than 1.5 million customers, yielding 838% revenue growth to
$147.8 million, and extended our market leadership despite aggressive competitive entry.
But this is Day 1 for the Internet and, if we execute well, for Amazon.com. Today, online commerce saves customers money and precious time. Tomorrow, through personalization, online commerce will
accelerate the very process of discovery. Amazon.com uses the Internet to create real value for its customers and, by doing so, hopes to create an enduring franchise, even in established and large markets.
We have a window of opportunity as larger players marshal the
resources to pursue the online opportunity and as customers, new to purchasing online, are receptive to forming new relationships. The competitive landscape has continued to evolve at a fast pace. Many large players have moved online with credible
offerings and have devoted substantial energy and resources to building awareness, traffic, and sales. Our goal is to move quickly to solidify and extend our current position while we begin to pursue the online commerce opportunities in other areas.
We see substantial opportunity in the large markets we are targeting. This strategy is not without risk: it requires serious investment and crisp execution against established franchise leaders.
Its All About the Long Term
We believe that a fundamental measure of our success will be
the shareholder value we create over the long term. This value will be a direct result of our ability to extend and solidify our current market leadership position. The stronger our market leadership, the more powerful our economic model.
Market leadership can translate directly to higher revenue, higher profitability, greater capital velocity, and correspondingly stronger returns on invested capital.
Our decisions have consistently reflected this focus. We
first measure ourselves in terms of the metrics most indicative of our market leadership: customer and revenue growth, the degree to which our customers continue to purchase from us on a repeat basis, and the strength of our brand. We have invested
and will continue to invest aggressively to expand and leverage our customer base, brand, and infrastructure as we move to establish an enduring franchise.
Because of our emphasis on the long term, we may make decisions and weigh tradeoffs differently than some companies. Accordingly, we want
to share with you our fundamental management and decision-making approach so that you, our shareholders, may confirm that it is consistent with your investment philosophy:
| | | | We will continue to focus relentlessly on our customers. |
| | | | We will continue to make investment decisions in light of long-term market leadership considerations rather than short-term profitability
considerations or short-term Wall Street reactions. |
| | | | We will continue to measure our programs and the effectiveness of our investments analytically, to jettison those that do not provide acceptable
returns, and to step up our investment in those that work best. We will continue to learn from both our successes and our failures. |
| | | | We will make bold rather than timid investment decisions where we see a sufficient probability of gaining market leadership advantages. Some of these
investments will pay off, others will not, and we will have learned another valuable lesson in either case. |
| | | | When forced to choose between optimizing the appearance of our GAAP accounting and maximizing the present value of future cash flows, well take
the cash flows. |
| | | | We will share our strategic thought processes with you when we make bold choices (to the extent competitive pressures allow), so that you may evaluate
for yourselves whether we are making rational long-term leadership investments. |
| | | | We will work hard to spend wisely and maintain our lean culture. We understand the importance of continually reinforcing a cost-conscious culture,
particularly in a business incurring net losses. |
| | | | We will balance our focus on growth with emphasis on long-term profitability and capital management. At this stage, we choose to prioritize growth
because we believe that scale is central to achieving the potential of our business model. |
| | | | We will continue to focus on hiring and retaining versatile and talented employees, and continue to weight their compensation to stock options rather
than cash. We know our success will be largely affected by our ability to attract and retain a motivated employee base, each of whom must think like, and therefore must actually be, an owner. |
We arent so bold as to claim that the above is the
right investment philosophy, but its ours, and we would be remiss if we werent clear in the approach we have taken and will continue to take.
With this foundation, we would like to turn to a review of
our business focus, our progress in 1997, and our outlook for the future.
Obsess Over Customers
From the beginning, our focus has been on offering our customers compelling value. We realized that the Web was, and still is, the World Wide Wait. Therefore, we set out to offer customers something they
simply could not get any other way, and began serving them with books. We brought them much more selection than was possible in a physical store (our store would now occupy 6 football fields), and presented it in a useful, easy-to-search, and
easy-to-browse format in a store open 365 days a year, 24 hours a day. We maintained a dogged focus on improving the shopping experience, and in 1997 substantially enhanced our store. We now offer customers gift certificates, 1-ClickSM shopping, and vastly more reviews, content, browsing options, and
recommendation features. We dramatically lowered prices, further increasing customer value. Word of mouth remains the most powerful customer acquisition tool we have, and we are grateful for the trust our customers have placed in us. Repeat
purchases and word of mouth have combined to make Amazon.com the market leader in online bookselling.
By many measures, Amazon.com came a long way in 1997:
| | | | Sales grew from $15.7 million in 1996 to $147.8 million an 838% increase. |
| | | | Cumulative customer accounts grew from 180,000 to 1,510,000 a 738% increase. |
| | | | The percentage of orders from repeat customers grew from over 46% in the fourth quarter of 1996 to over 58% in the same period in 1997. |
| | | | In terms of audience reach, per Media Metrix, our Web site went from a rank of 90th to within the top 20. |
| | | | We established long-term relationships with many important strategic partners, including America Online, Yahoo!, Excite, Netscape, GeoCities,
AltaVista, @Home, and Prodigy. |
Infrastructure
During 1997, we worked hard to expand our business
infrastructure to support these greatly increased traffic, sales, and service levels:
| | | | Amazon.coms employee base grew from 158 to 614, and we significantly strengthened our management team. |
| | | | Distribution center capacity grew from 50,000 to 285,000 square feet, including a 70% expansion of our Seattle facilities and the launch of our second
distribution center in Delaware in November. |
| | | | Inventories rose to over 200,000 titles at year-end, enabling us to improve availability for our customers. |
| | | | Our cash and investment balances at year-end were $125 million, thanks to our initial public offering in May 1997 and our $75 million loan, affording
us substantial strategic flexibility. |
Our Employees
The past years success is the product of a talented, smart, hard-working group, and I take great pride in being a part of this team. Setting the bar high in our approach to hiring has been, and will
continue to be, the single most important element of Amazon.coms success.
Its not easy to work here (when I interview people I tell them, You can work long, hard, or smart, but at Amazon.com you cant choose two out of three), but we are working to build
something important, something that matters to our customers, something that we can all tell our grandchildren about. Such things arent meant to be easy. We are incredibly fortunate to have this group of dedicated employees whose sacrifices
and passion build Amazon.com.
Goals for 1998
We are still in the early stages of learning
how to bring new value to our customers through Internet commerce and merchandising. Our goal remains to continue to solidify and extend our brand and customer base. This requires sustained investment in systems and infrastructure to support
outstanding customer convenience, selection, and service while we grow. We are planning to add music to our product offering, and over time we believe that other products may be prudent investments. We also believe there are significant
opportunities to better serve our customers overseas, such as reducing delivery times and better tailoring the customer experience. To be certain, a big part of the challenge for us will lie not in finding new ways to expand our business, but in
prioritizing our investments.
We now know vastly
more about online commerce than when Amazon.com was founded, but we still have so much to learn. Though we are optimistic, we must remain vigilant and maintain a sense of urgency. The challenges and hurdles we will face to make our long-term vision
for Amazon.com a reality are several: aggressive, capable, well-funded competition; considerable growth challenges and execution risk; the risks of product and geographic expansion; and the need for large continuing investments to meet an expanding
market opportunity. However, as weve long said, online bookselling, and online commerce in general, should prove to be a very large market, and its likely that a number of companies will see significant benefit. We feel good about what
weve done, and even more excited about what we want to do.
1997 was indeed an incredible year. We at Amazon.com are grateful to our customers for their business and trust, to each other for our hard work, and to our shareholders for their support and
encouragement.
![LOGO]()
Jeffrey
P. Bezos
Founder and Chief Executive Officer
Amazon.com, Inc.
![]()



 Reuse content
Reuse content
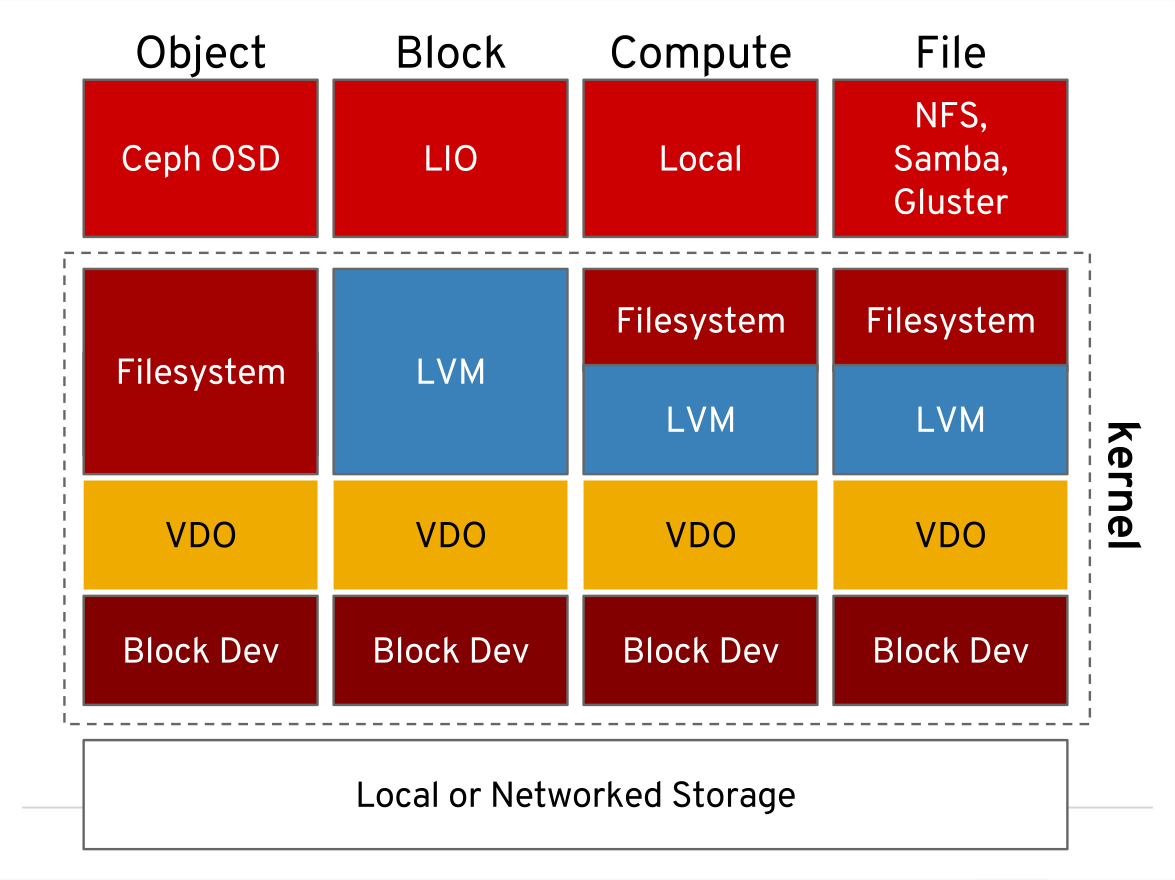
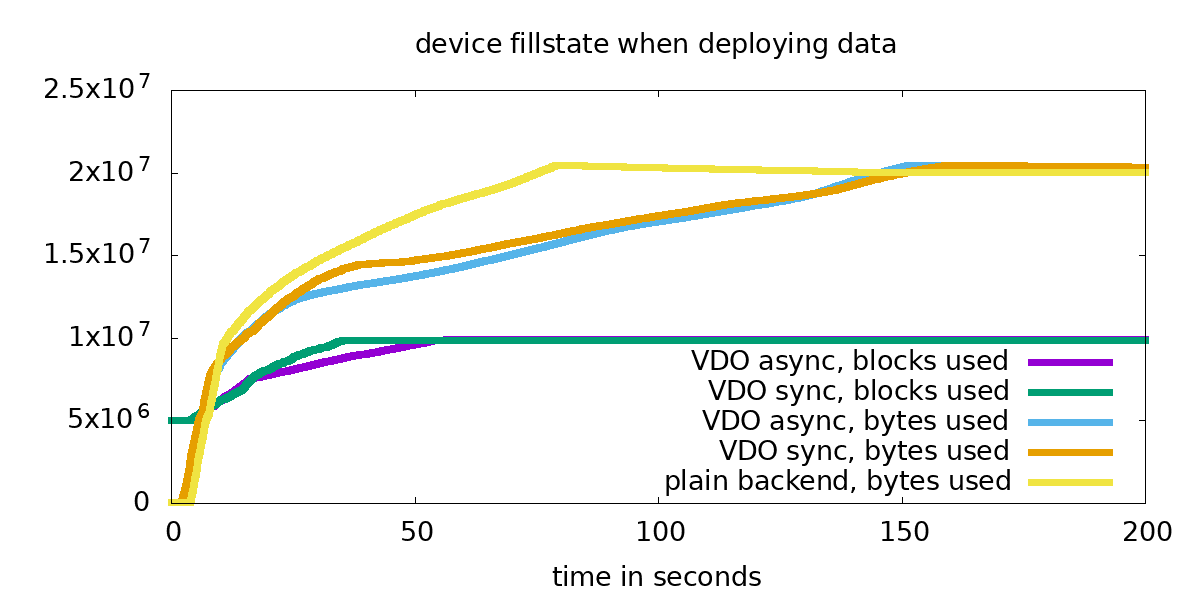
 Christian Horn is a Red Hat TAM based in Tokyo, working with partners and customers. In his work as Linux Engineer/Architect in Germany since 2001, later as Red Hat TAM in Munich and Tokyo, Virtualization, operations and performance tuning are among the returning topics of this daily work. In his spare time, Christian works on improving his Japanese, cycles to Tokyo’s green spots and enjoys onsen, Japanese bathes. More posts from Christian are
Christian Horn is a Red Hat TAM based in Tokyo, working with partners and customers. In his work as Linux Engineer/Architect in Germany since 2001, later as Red Hat TAM in Munich and Tokyo, Virtualization, operations and performance tuning are among the returning topics of this daily work. In his spare time, Christian works on improving his Japanese, cycles to Tokyo’s green spots and enjoys onsen, Japanese bathes. More posts from Christian are 
















