↧
Facebook Patent: Socioeconomic group classification based on user features [pdf]
↧
Minecraft players exposed to malicious code in modified “skins”
Close to 50,000 Minecraft accounts infected with malware designed to reformat hard-drives and more.
Nearly 50,000 Minecraft accounts have been infected with malware designed to reformat hard-drives and delete backup data and system programs, according to Avast data from the last 30 days. The malicious Powershell script identified by researchers from Avast’s Threat Labs uses Minecraft “skins” created in PNG file format as the distribution vehicle. Skins are a popular feature that modify the look of a Minecraft player’s Avatar. They can be uploaded to the Minecraft site from various online resources.

The malicious code is largely unimpressive and can be found on sites that provide step-by-step instructions on how to create viruses with Notepad. While it is fair to assume that those responsible are not professional cybercriminals, the bigger concern is why the infected skins could be legitimately uploaded to the Minecraft website. With the malware hosted on the official Minecraft domain, any detection triggered could be misinterpreted by users as a false positive.
 Hosted URL of malicious skin
Hosted URL of malicious skin
We have contacted Mojang, the creator of Minecraft, and they are working on fixing the vulnerability.
Why Minecraft?
As of January 2018, Minecraft had 74 million players around the globe - an increase of almost 20 million year-on-year. However, only a small percentage of the total user base actively uploads modified skins. Most players use the default versions provided by Minecraft. This explains the low registration of infections. Over the course of 10 days, we’ve blocked 14,500 infection attempts. Despite the low number, the scope for escalation is high given the number of active players globally.
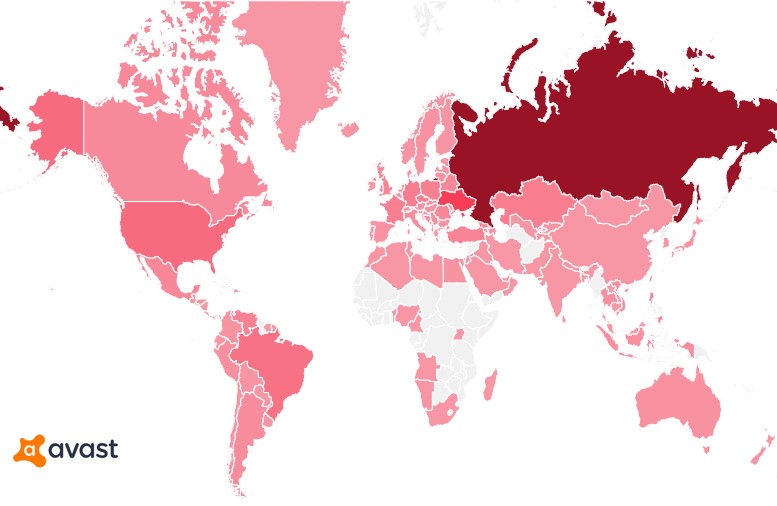
Detection heatmap
Although Minecraft is played by individuals across a broad demographic spectrum, the largest demographic is 15-21 year olds, which accounts for 43% of the user base. The bad actors may have looked to capitalize on a more vulnerable group of unsuspecting users that play a game trusted by parents and guardians. Pentesting is another possibility, but it’s more likely that the vulnerability was exposed for amusement - a more common mindset adopted by script kiddies.
How identifiable is the threat?
Users can identify the threat in a number of ways. The malware is included in skins available on the Minecraft website. Three examples that contain the malware can be seen below.
Not all skins are malicious, but if you’ve downloaded one similar to those featured below, we would recommend you run an antivirus scan.

Users may also receive unusual messages in their account inbox. Some examples identified are:
“You Are Nailed, Buy A New Computer This Is A Piece Of Sh*t”
“You have maxed your internet usage for a lifetime”
“Your a** got glued”

Other evidence of infection includes system performance issues caused by a simple tourstart.exe loop or an error message related to disk formatting.

How can users protect themselves?
Scanning your machine with a strong antivirus (AV) such as Avast Free Antivirus will detect the malicious files and remove them. However, in some cases, the Minecraft application may require reinstallation. In more extreme circumstances where user machines have already been infected with the malware and systems files have been deleted, data restoration is recommended.
↧
↧
YouTube promises expansion of sponsorships, monetization tools for creators
YouTube says it’s rolling out more tools to help its creators make money from their videos. The changes are meant to address creators’ complaints over YouTube’s new monetization policies announced earlier this year. Those policies were designed to make the site more advertiser-friendly following a series of controversies over video content from top creators, including videos from Logan Paul, who had filmed a suicide victim, and PewDiePie, who repeatedly used racial slurs, for example.
The company then decided to set a higher bar to join its YouTube Partner Program, which is what allows video publishers to make money through advertising. Previously, creators only needed 10,000 total views to join; they now need at least 1,000 subscribers and 4,000 hours of view time over the past year to join. This resulted in wide-scale demonetization of videos that previously relied on ads.
The company has also increased policing of video content in recent months, but its systems haven’t always been accurate.
YouTube said in February it was working on better systems for reviewing video content when a video is demonetized over its content. One such change, enacted at the time, involved the use of machine learning technology to address misclassifications of videos related to this policy. This, in turn, has reduced the number of appeals from creators who want a human review of their video content instead.
According to YouTube CEO Susan Wojcicki, the volume of appeals is down by 50 percent as a result.
Wojcicki also announced another new program related to video monetization which is launching into pilot testing with a small number of creators starting this month.
This system will allow creators to disclose, specifically, what sort of content is in their video during the upload process, as it relates to YouTube’s advertiser-friendly guidelines.
“In an ideal world, we’ll eventually get to a state where creators across the platform are able to accurately represent what’s in their videos so that their insights, combined with those of our algorithmic classifiers and human reviewers, will make the monetization process much smoother with fewer false positive demonetizations,” said Wojcicki.
Essentially, this system would rely on self-disclosure regarding content, which would then be factored in as another signal for YouTube’s monetization algorithms to consider. This was something YouTube had also said in February was in the works.
Because not all videos will be brand-safe or meet the requirements to become a YouTube Partner, YouTube now says it will also roll out alternative means of making money from videos.

This includes an expansion of “sponsorships,” which have been in testing since last fall with a select group of creators.
Similar to Twitch subscriptions, sponsorships were introduced to the YouTube Gaming community as a way to support favorites creators through monthly subscriptions (at $4.99/mo), while also receiving various perks like custom emoji and a custom badge for live chat.
Now YouTube says “many more creators” will gain access to sponsorships in the months ahead, but it’s not yet saying how those creators will be selected, or if they’ll have to meet certain requirements, as well. It’s also unclear if YouTube will roll these out more broadly to its community, outside of gaming.
Wojcicki gave updates on various other changes YouTube has enacted in recent months. For example, she said that YouTube’s new moderation tools have led to a 75-plus percent decline in comment flags on channels, where enabled, and these will now be expanded to 10 languages. YouTube’s newer social network-inspired Community feature has also been expanded to more channels, she noted.
The company also patted itself on the back for its improved communication with the wider creator community, saying that this year it has increased replies by 600 percent and improved its reply rate by 75 percent to tweets addressed to its official handles: @TeamYouTube, @YTCreators, and @YouTube.
While that may be true, it’s notable that YouTube isn’t publicly addressing the growing number of complaints from creators who – rightly or wrongly – believe their channel has been somehow “downgraded” by YouTube’s recommendation algorithms, resulting in declining views and loss of subscribers.
This is the issue that led the disturbed individual, Nasim Najafi Aghdam, to attack YouTube’s headquarters earlier this month. Police said that Aghdam, who shot at YouTube employees before killing herself, was “upset with the policies and practices of YouTube.”
It’s obvious, then, why YouTube is likely proceeding with extreme caution when it comes to communicating its policy changes, and isn’t directly addressing complaints similar to Aghdam’s from others in the community.
But the creator backlash is still making itself known. Just read the Twitter replies or comment thread on Wojcicki’s announcement. YouTube’s smaller creators feel they’ve been unfairly punished because of the misdeeds of a few high-profile stars. They’re angry that they don’t have visibility into why their videos are seeing reduced viewership – they only know that something changed.
YouTube glosses over this by touting the successes of its bigger channels.
“Over the last year, channels earning five figures annually grew more than 35 percent, while channels earning six figures annually grew more than 40 percent,” Wojcicki said, highlighting YouTube’s growth.
In fairness, however, YouTube is in a tough place. Its site became so successful over the years, that it became impossible for it to police all the uploads manually. At first, this was the cause for celebration and the chance to put Google’s advanced engineering and technology to work. But these days, as with other sites of similar scale, the challenging of policing bad actors among billions of users, is becoming a Herculean task – and one companies are failing at, too.
YouTube’s over-reliance on algorithms and technology has allowed for a lot of awful content to see daylight – including inappropriate videos aimed a children, disturbing videos, terrorist propaganda, hate speech, fake news and conspiracy theories, unlabeled ads disguised as product reviews or as “fun” content, videos of kids that attract pedophiles, and commenting systems that allowed for harassment and trolling at scale.
To name a few.
YouTube may have woken up late to its numerous issues, but it’s not ignorant of them, at least.
“We know the last year has not been easy for many of you. But we’re committed to listening and using your feedback to help YouTube thrive,” Wojcicki said. “While we’re proud of this progress, I know we have more work to do.”
That’s putting it mildly.
↧
Cloud SQL for PostgreSQL now generally available
Among open-source relational databases, PostgreSQL is one of the most popular—and the most sought-after by Google Cloud Platform (GCP) users. Today, we’re thrilled to announce that PostgreSQL is now generally available and fully supported for all customers on our Cloud SQL fully-managed database service.
Backed by Google’s 24x7 SRE team, high availability with automatic failover, and our SLA, Cloud SQL for PostgreSQL is ready for the demands of your production workloads. It’s built on the strength and reliability of Google Cloud’s infrastructure, scales to support critical workloads and automates all of your backups, replication, patches and updates while ensuring greater than 99.95% availability anywhere in the world. Cloud SQL lets you focus on your application, not your IT operations.
While Cloud SQL for PostgreSQL was in beta, we added high availability and replication, higher performance instances with up to 416GB of RAM, and support for 19 additional extensions. It also joined the Google Cloud Business Associates Agreement (BAA) for HIPAA-covered customers.
Cloud SQL for PostgreSQL runs standard PostgreSQL to maintain compatibility. And when we make improvements to PostgreSQL, we make them available for everyone by contributing to the open source community.
Throughout beta, thousands of customers from a variety of industries such as commercial real estate, satellite imagery, and online retail, deployed workloads on Cloud SQL for PostgreSQL. Here’s how one customer is using Cloud SQL for PostgreSQL to decentralize their data management and scale their business.
How OneMarket decentralizes data management with Cloud SQL
OneMarket is reshaping the way the world shops. Through the power of data, technology, and cross-industry collaboration, OneMarket’s goal is to create better end-to-end retail experiences for consumers.
Built out of Westfield Labs and Westfield Retail Solutions, OneMarket unites retailers, brands, venues and partners to facilitate collaboration on data insights and implement new technologies, such as natural language processing, artificial intelligence and augmented reality at scale.
To build the platform for a network of retailers, venues and technology partners, OneMarket selected GCP, citing its global locations and managed services such as Kubernetes Engine and Cloud SQL.
"I want to focus on business problems. My team uses managed services, like Cloud SQL for PostgreSQL, so we can focus on shipping better quality code and improve our time to market. If we had to worry about servers and systems, we would be spending a lot more time on important, but somewhat insignificant management tasks. As our CTO says, we don’t want to build the plumbing, we want to build the house."
— Peter McInerney, Senior Director of Technical Operations at OneMarket
The OneMarket team employs a microservices architecture to develop, deploy and update parts of their platform quickly and safely. Each microservice is backed by an independent storage service. Cloud SQL for PostgreSQL instances back many of the platform’s 15 microservices, decentralizing data management and ensuring that each service is independently scalable.
"I sometimes reflect on where we were with Westfield Digital in 2008 and 2009. The team was constantly in the datacenter to maintain servers and manage failed disks. Now, it is so easy to scale."
— Peter McInerney
Because the team was able to focus on data models rather than database management, developing the OneMarket platform proceeded smoothly and is now in production, reliably processing transactions for its global customers. Using BigQuery and Cloud SQL for PostgreSQL, OneMarket analyzes data and provides insights into consumer behavior and intent to retailers around the world.
Peter’s advice for companies evaluating cloud solutions like Cloud SQL for PostgreSQL: “You just have to give it a go. Pick a non-critical service and get it running in the cloud to begin building confidence.”
Getting started with Cloud SQL for PostgreSQL
Connecting to a Google Cloud SQL database is the same as connecting to a PostgreSQL database—you use standard connectors and standard tools such as pg_dump to migrate data. If you need assistance, our partner ecosystem can help you get acquainted with Cloud SQL for PostgreSQL. To streamline data transfer, reach out to Google Cloud partners Alooma, Informatica, Segment, Stitch, Talend and Xplenty. For help with visualizing analytics data, try ChartIO, iCharts, Looker, Metabase, and Zoomdata.
Sign up for a $300 credit to try Cloud SQL and the rest of GCP. You can start with inexpensive micro instances for testing and development, and scale them up to serve performance-intensive applications when you’re ready.
Cloud SQL for PostgreSQL reaching general availability is a huge milestone and the best is still to come. Let us know what other features and capabilities you need with our Issue Tracker and by joining the Cloud SQL discussion group. We’re glad you’re along for the ride, and look forward to your feedback!
↧
Upgradeable smart contracts in Ethereum
Imagine a world where a software is maintaining millions of dollars worth of money, but there is an exploit which allows the hacker to take all that money away. Now imagine you can't do much about it because you can't update your software, so all you can do is wait and watch or pull the plug of the whole server.
This is a world we are living in with the software/contracts being developed for the Ethereum blockchain.
Immutability of blockchain has its advantages in making sure that things are tamper proof and the whole history of change can be seen publicly and audited. When it comes to smart contracts, immutability of the contract code has its disadvantages which makes it hard to update in case of bugs. The DAO and the Parity Wallet exploit are a good example of why smart contracts should have the capability to upgrade.
There is no de facto way of upgrading a contract. Several approaches have been developed and I'm going to discuss one of the better ones in my opinion.
Understanding how contracts are called
In Ethereum virtual machine (EVM) there are various ways by which contract A can invoke some function in contract B. Lets go over them
call: This calls the contract B at the given address with provided data, gas and ether. When the call is made the context is changed to this contract B context i.e. the storage used will be of the called contract. The
msg.senderwill be the calling contract A and not the originalmsg.sender.callcode: This is similar to call but the only difference is that the context will be of original contract A so the storage will not be changed to that of the called contract B. This means the code in the contract B can essentially manipulate storage of the contract A. The
msg.senderwill be the calling contract A and not the originalmsg.sender.delegatecall: This is similar to callcode but here the
msg.senderandmsg.valuewill be the original ones. It's as if the user called this contract B directly.
Here delegatecall seems of interest, as this can allow us to proxy a call from the user to a different contract. Now we need to build a contract that allows us to do that.
Upgradeable smart contract
We will write a smart contract that has an owner and it proxies all calls to a different contract address. The owner should be able to upgrade the contract address to which the code proxies to.

This is what that contract would look like
Let's dissect the code
Let's dissect above code. function () payable public is the fallback function. When a user calls a contract without a function call (when sending ether) or a function call that is not implemented, it all gets routed to the fallback function. The function can do whatever it wants to. As we don't know what functions our contracts will have, nor how will it change so this is the ideal place where we route all calls made by user to the required contract address.

Inside this function we have some EVM assembly, as what we want to do is not currently directly available in Solidity.
let ptr := mload(0x40)
calldatacopy(ptr, 0, calldatasize) As the user can send data which would contain information about which function to call and what are the arguments of that function so we also need to send it to our implementation contract. In Solidity the address to free memory is stored at location 0x40. We load the data at 0x40 address and assign it name ptr. Then we call calldatacopy to copy all the data passed in by user to memory starting from ptr address.
let result := delegatecall(gas, _impl, ptr, calldatasize, 0, 0) Here we use the delegatecall as discussed before to call the contract. The result returned is either 0 or 1. 0 means that there was some failure so we need to revert. 1 means the contract code execution was successful.
let size := returndatasize
returndatacopy(ptr, 0, size) As the execution of code might have returned some data so we need to return it back to user, here we copy the returned data to memory starting at ptr address.
switch result
case 0 { revert(ptr, size) }
case 1 { return(ptr, size) } Lastly we just decided whether to return or revert based on the result of delegatecall.
We inherit the contract from Ownable so the contract will have an owner. We expose updateImplementation(address) function to update the implementation and it can only be executed by the owner of contract.
Deploy an upgradeable contract
First deploy the UpgradeableContractProxy contract. Let's say we have a global calculator contract, which has list of numbers in storage and we can get the sum of all numbers in it.
Let's take that contract and deploy it. It should give us some address, now use that address as one of the parameters to call updateImplementation of the previously deployed UpgradeableContractProxy contract. Now our proxy should point to the deployed GlobalCalculator_V1 contract.
Now use the GlobalCalculator_V1 contract interface (ABI) to call the proxy contract. So if you are using web3js then you can do the following
const myGlobalCalculator = new web3.eth.Contract(GlobalCalculator_V1_JSON, 'PROXY_CONTRACT_ADDRESS'); Now when you make a function call to proxy, it will delegate the call to your global calculator contract. Let say you called few addNum(uint) to add numbers to the _nums list in storage and now it has [2, 5] as value.
Let's add a multiplication functionality in your updated contract. We create a new contract which inherits from GlobalCalculator_V1 and add that feature.
Let's deploy GlobalCalculator_V2 contract and call updateImplementation(address) of the proxy to point to this newly deployed contract address.
You can use the GlobalCalculator_V2 contract interface (ABI) to call same proxy contract which would route the call to new implementation.
const myGlobalCalculator_v2 = new web3.eth.Contract(GlobalCalculator_V2_JSON, 'PROXY_CONTRACT_ADDRESS'); You should have the ability to call getMul() now. One thing to notice is that if I call getSum it will return 7 as the _nums in storage is still the same as the old one and have value [2, 5]. So in this way our storage is maintained and we can add more functionality to our contract. The users also don't have to change the address as they always call the proxy contract which delegates it to other contracts.
Pros
- Ability to upgrade code.
- Ability to retain storage, no need to move data.
- Easy to change and fix.
Cons
- As we use fallback function to delegate so ether can't be directly sent to contract (due to not enough gas when using
.transferor.send). We need to have a specific function that needs to be called for receiving ether. - There is some gas cost for executing the proxy logic.
- Your updated codes needs to be backwards compatible.
- The update capability is controlled by one entity. This can be solved by writing a contract that uses tokens and voting mechanism to allow the community to decide whether to update or not.
If you want to look at an example project using truffle which is testing an upgradeable contract see this.
Disclaimer
Don't use the above contract for production as it's not audited for exploits. It is only provided here for educational purpose.
Reference
↧
↧
Google shuttering domain fronting, Signal moving to souqcdn.com
↧
The End of Software: Will Programming Become Obsolete?
Tell a crowd of nerds that software is coming to an end, and you’ll get laughed out of the bar. The very notion that the amount of software and software development in the world will do anything besides continue on an exponential growth curve is unthinkable in most circles. Examine any industry data and you’ll see the same thing – software content is up and to the right. For decades, the trend in system design has been toward increasing the proportion of functionality implemented in software versus hardware, and the makeup of engineering teams has followed suit. It is not uncommon these days to see a 10:1 ratio of software versus hardware engineers on an electronic system development project. And that doesn’t count the scores of applications developed these days that are software alone.
Yep, it’s all coming to an end.
But, software is one of those five immutable elements, isn’t it – fire, water, earth, air, and code? Practically nothing exists in our technological world today without software. Rip out software and you have taken away the very essence of technology – its intelligence – its functionality – its soul.
Is software really all that important?
Let’s back up a bit. Every application, every system is designed to solve a problem. The solution to that problem can generally be broken down into two parts: the algorithm and the data. It is important to understand that the actual answer always lies within the data. The job of the algorithm is simply to find that answer amongst the data as efficiently as possible. Most systems today further break the algorithm portion of that down into two parts: hardware and software. Those elements, of course, form the basis of just about every computing system we design – which comprises most of modern technology.
We all know that, if the algorithm is simple enough, you can sometimes skip the software part. Many algorithms can be implemented in hardware that processes the data and finds the solution directly, with no software required. The original hand calculators, the early arcade video games, and many other “intelligent” devices have used this approach. If you’re not doing anything more complex than multiplication or maybe the occasional quadratic formula, bring on the TTL gates!
The problem with implementing algorithms directly in hardware, though, is that the complexity of the hardware scales with the complexity of the algorithm. Every computation or branch takes more physical logic gates. Back in the earliest days of Moore’s Law, that meant we had very, very tight restrictions on what could be done in optimized hardware. It didn’t take much complexity to strain the limits of what we were willing and able to solder onto a circuit board with discrete logic gates. “Pong” was pushing it. Anything more complicated than that and we leapt blissfully from the reckless optimism of Moore into the warm and comfortable arms of Turing and von Neumann.
The conventional von Neumann processor architecture uses “stored programs” (yep, there it is, software) to allow us to handle arbitrarily complex algorithms without increasing the complexity of our hardware. We can design one standard piece of hardware – the processor, and using that we can execute any number of arbitrarily complex algorithms. Hooray!
But every good thing comes at a price, doesn’t it? The price of programmability is probably somewhere between three and four orders of magnitude. Yep. Your algorithm might run somewhere between 100 and 10,000 times as fast if it were implemented in optimized hardware compared with software on a conventional processor. All of that business with program counters and fetching instructions is really a lot of overhead on top of the real work. And, because of the sequential nature of software, pure von Neumann machines trudge along doing things one at a time that could easily be done simultaneously.
The performance cost of software programmability is huge, but the benefits are, as well. Both hardware cost and engineering productivity are orders of magnitude better. An algorithm you could implement in a few hours in software might require months of development time to create in optimized hardware – if you could do it at all. This tradeoff is so attractive, in fact, that the world has spent over half a century optimizing it. And, during that half century, Moore’s Law has caused the underlying hardware implementation technology to explode exponentially.
The surface of software development has remained remarkably calm considering the turbulence created by Moore’s Law below. The number of components we can cram onto integrated circuits has increased by something like eight orders of magnitude since 1965, and yet we still write and debug code one line at a time. Given tens of millions of times the transistors, processors have remained surprisingly steady as well. Evolution has taken microprocessors from four to sixty-four bits, from one core to many, and has added numerous performance-enhancing features such as caches, pipelines, hardware arithmetic, predictive execution, and so forth, but the basic von Neumann architecture remains largely unchanged.
It’s important to note that all of the enhancements to processor architecture have done – all they ever can do – is to mitigate some of the penalty of programmability. We can make a processor marginally closer to the performance of optimized hardware, but we can never get there – or even close.
Of course, those eight orders of magnitude Moore’s Law has given us in transistor count also mean that the complexity of the algorithms we could implement directly in optimized hardware has similarly increased. If you’re willing and able to make a custom optimized chip to run your specific algorithm, it will always give 100x or more the performance of a software version running on a processor using similarly less energy. The problem there, of course, is the enormous cost and development effort required. Your algorithm has to be pretty important to justify the ~24-month development cycle and most likely eight-figure investment to develop an ASIC.
During that same time, however, we have seen the advent of programmable hardware, in the form of devices such as FPGAs. Now, we can implement our algorithm in something like optimized hardware using a general purpose device (an FPGA) with a penalty of about one order of magnitude compared with actual optimized hardware. This has raised the bar somewhat on the complexity of algorithms (or portions thereof) that can be done without software. In practical terms, however, the complexity of the computing problems we are trying to solve has far outpaced our ability to do them in any kind of custom hardware – including FPGAs. Instead, FPGAs and ASICs are relegated to the role of “accelerators” for key computationally intensive (but less complex) portions of algorithms that are still primarily implemented in software.
Nevertheless, we have a steadily rising level of algorithmic complexity where solutions can be implemented without software. Above that level – start coding. But there is also a level of complexity where software starts to fail as well. Humans can create algorithms only for problems they know how to solve. Yes, we can break complex problems down hierarchically into smaller, solvable units and divide those portions up among teams or individuals with various forms of expertise, but when we reach a problem we do not know how to solve, we cannot write an algorithm to do it.
As a brilliant engineer once told me, “There is no number of 140 IQ people that will replace a 160 IQ person.” OK, this person DID have a 160 IQ (so maybe there was bias in play) but the concept is solid. We cannot write a program to solve a problem we are not smart enough to solve ourselves.
Until AI.
With deep learning, for example, we are basically bypassing the software stage and letting the data itself create the algorithm. We give our system a pile of data and tell it the kind of answer we’re looking for, and the system itself divines the method. And, in most cases, we don’t know how it’s doing it. AI may be able to look at images of a thousand faces and tell us accurately which ones are lying, but we don’t know if it’s going by the angle of the eyebrows, the amount of perspiration, the curl of the lip, or the flaring of the nostrils. Most likely, it is a subtle and complex combination of those.
We now have the role of software bounded – both on the low- and high-complexity sides. If the problem is too simple, it may be subsumed by much more efficient dedicated hardware. If it’s too complex, it may be taken over by AI at a much lower development cost. And the trendlines for each of those is moving toward the center – slowly reducing the role of classical software.
As we build more and more dedicated hardware to accelerate high compute load algorithms, and as we evolve the architectures for AI to expand the scope of problems it can solve, we could well slowly reduce the role of traditional software to nothing. We’d have a world without code.
I wouldn’t go back to bartending school just yet, though. While the von Neumann architecture is under assault from all sides, it has a heck of a moat built for itself. We are likely to see the rapid acceleration of software IP and the continued evolution of programming methods toward higher levels of abstraction and increased productivity for software engineers. Data science will merge with computer science in yet-unforeseen ways, and there will always be demanding problems for bright minds to solve. It will be interesting to watch.
↧
WaystoCap (YC W17) Is Unlocking African Trade. Full Stack Developer? Join Us
A bit about us:
Hi! We're WaystoCap a Y Combinator startup backed by a top tier VC: Battery Ventures; and we are building the future trading platform of B2B in Africa.
We are on a mission to unlock trade in Africa, by creating transparency and trust in international trade.
Our headquarters are in: Morocco and Spain; with offices in the UK and Benin too!
We use the most up-to-date technologies, and we are looking for software developers to help us develop our trading platform and extend our micro services architecture.
Please note as we are still a small company we are looking for people to join us on our journey in the office in Marbella, Spain. We believe building a great company culture starts working together!
A little more about what we do:
Our mission is to help businesses in Africa work with trusted partners globally and grow their company. We are building a trust platform, as its the missing component in any trade! We do more than just a listing or marketplace site, and help our buyers and sellers go through the entire trade process more easily, efficiently, and improved with technology.
Here is a short video about us: The African Opportunity
We want every African business to be able to trade internationally, just like any company and take advantage of cutting edge tech to solve payments, logistics, and most importantly trust issues. In our first year of full operations (2017) we already grew 300%, and the sky is the limit!
Your challenge as a full stack developer:
You will be part of a cross functional agile team helping to build a strong and scalable products. The team will plan, design and build innovative solutions to unlock international trading in Africa. backed by a deep understanding of software engineering and best practices, your duties will include build, monitor and maintain scalable applications.
We are looking for full stack software engineers with:
- Exceptional ability to work anywhere in the technical stack, delivering quality code both on the frontend and backend.
- Fluency in any backend server language, and expertise in relational databases and schema design.
- Strong motivation to drive impact by making product improvements.
- An ability to share knowledge, and evangelize best practices.
- You should be proactive, with strong good communication skills and an ability to learn fast.
Requirements:
- More than 4 years professional experience
- Experience in programming with one of the following language: Golang, Node, Java, Scala
- Experience in software design and testing
- Experience in database and storage technologies (RDBMS, NoSQL,...)
- Experience in frontend technologies (PWA, ReactJS/angular/VueJs)
- Experience with CI/CD pipeline
- Experience working on an agile team
What we offer:
- Product ownership and decision making in the entire development process
- Work with a talented team and learn from international advisors and investors
- Work in sunny Marbella, with a great lifestyle and excellent quality of living
- Be involved in a fundamental company supporting development in Africa
- Very competitive salary and stock options in a Silicon Valley startup
- Regular afterwork drinks, company team buildings, celebrations
- Generous PTO
- Support for relocation (if needed)
- Company provided laptop and screens (you choose your set up!)
- Have a voice in what tools you want us to use
↧
Why does software cost so much?
Posted on by in Data Modeling and Analytics
By Robert Stoddard Principal Researcher Software Solutions Division
Cost estimation was cited by the Government Accountability Office (GAO) as one of the top two reasons why DoD programs continue to have cost overruns. How can we better estimate and manage the cost of systems that are increasingly software intensive? To contain costs, it is essential to understand the factors that drive costs and which ones can be controlled. Although we understand the relationships between certain factors, we do not yet separate the causal influences from non-causal statistical correlations. In this blog post, we explore how the use of an approach known as causal learning can help the DoD identify factors that actually cause software costs to soar and therefore provide more reliable guidance as to how to intervene to better control costs.
As the role of software in the DoD continues to increase so does the need to control the cost of software development and sustainment. Consider the following trends cited in a March 2017 report from the Institute for Defense Analysis:
- The National Research Council (2010) wrote that "The extent of the DoD code in service has been increasing by more than an order of magnitude every decade, and a similar growth pattern has been exhibited within individual, long-lived military systems."
- The Army (2011) estimated that the volume of code under Army depot maintenance (either post-deployment or post-production support) had increased from 5 million to 240 million SLOC between 1980 and 2009. This trend corresponds to approximately 15 percent annual growth.
- A December 2017 Selected Acquisition Report (SAR) showed cost growth in large-scale DoD programs is common, with a $91 billion cost growth to-date (engineering and estimating) in the DoD portfolio. Poor cost estimation, including early lifecycle estimates, represents almost $8 billion of the $91 billion.
The SEI has a long track record of cost-related research to help the DoD manage costs. In 2012, we introduced Quantifying Uncertainty in Early Lifecycle Cost Estimation (QUELCE) as a method for improving pre-Milestone-A software cost estimates through research designed to improve judgment regarding uncertainty in key assumptions (which we term "program change drivers"), the relationships among the program change drivers, and their impact on cost.
QUELCE synthesized scenario planning workshops, Bayesian Belief Network (BBN) modeling, and Monte Carlo simulation into an estimation method that quantifies uncertainties, allows subjective inputs, visually depicts influential relationships among program change drivers and outputs, and assists with the explicit description and documentation underlying an estimate. The outputs of QUELCE necessarily then feed the inputs to existing cost estimation machinery.
While QUELCE focused on early-lifecycle cost estimation (which is highly dependent on subjective expert judgment) to create a connected probabilistic model of change drivers, we realized that major portions of the model could be derived from causal learning of historical DoD program experiences. We found that several existing cost-estimation tools could go beyond traditional statistical correlation and regression and benefit from causal learning as well.
The focus on cost estimation alone does not require causal knowledge, as it is focused on prediction rather than intervention. When prediction is the goal, statistical and maximum likelihood (ML) estimation methods are suitable. If the goal, however, is to intervene to deliberately cause a change via policy or management action, causal learning is more suitable and offers benefits beyond statistical and machine learning methods.
The problem is that statistical correlation and regression alone do not reveal causation because correlation is only a noisy indicator of a causal connections. As a result, the relationships identified by traditional correlation-based statistical methods are of limited value for driving cost reductions. Moreover, the magnitude of cost reductions cannot be confidently derived from the current body of cost-estimation work.
At the SEI, I am working with a team of researchers including
- Mike Konrad, who has background in machine, causal, and deep learning and has recently co-developed measures and analytic tools for the Complexity and Safety, Architecture-Led Incremental System Assurance (ALISA), and other research projects,
- Dave Zubrow, who has an extensive background in statistical analysis and led the development of the SEI DoD Factbook, based on DoD Software Resource Data Report (SRDR) program reporting data, and
- Bill Nichols, who has extensive background with the Team Software Process (TSP) and Personal Software Process (PSP) frameworks, analyzing associated costs, and in designing an organizational dashboard to monitor their effectiveness and deployment.
Why Do We Care About Causal Learning?
If we want to proactively control outcomes, we would be far more effective if we knew which organizational, program, training, process, tool, and personnel factors actually caused the outcomes we care about. To know this information with any certainty, we must move beyond correlation and regression to the subject of causation. We also want to establish causation without the expense and challenge of conducting controlled experiments, the traditional approach to learning about causation within a domain. Establishing causation with observational data remains a vital need and a key technical challenge.
Different approaches have arisen to help determine which factors cause which outcomes from observational data. Some approaches are constraint-based, in which conditional independence tests reveal the graphical structure of the data (e.g., if two variables are independent conditioned on a third, there is no edge connecting them). Other approaches are score-based, in which causal graphs are incrementally grown and then shrunk to improve the score (likelihood-based) of how well the resulting graph fits the data. Such a categorization, however, barely does justice to the diversity of causal algorithms that have been developed to address non-linear--as well as linear--causal systems with Gaussian-- as well as non-Gaussian--error terms.
Judea Pearl, who is credited as the inventor of Bayesian Networks and one of the pioneers of the field, wrote the following about causal learning in Bayesian Networks to Causal and Counterfactual Reasoning:
The development of Bayesian Networks, so people tell me, marked a turning point in the way uncertainty is handled in computer systems. For me, this development was a stepping stone towards a more profound transition, from reasoning about beliefs to reasoning about casual and counterfactual relationships.
Causal learning has come of age from both a theoretical and practical tooling standpoint. Causal learning may be performed on data whether it is derived from experimentation or passive observation. Causal learning has been used recently to identify causal factors within domains such as energy economics, foreign investment benefits, and medical research.
For the past two years, our team has trained in causal learning (causal discovery and causal estimation) at Carnegie Mellon University (CMU) through workshops led by Dr. Richard Scheines, Dean of the Dietrich College of Humanities and Social Sciences, whose research examined graphical and statistical causal inference and foundations of causation. We have also trained and worked with several faculty and staff within the CMU Department of Philosophy led by Dr. David Danks, whose research focuses on causal learning (human and machine). Additional Department of Philosophy faculty and staff include Peter Spirtes, a professor of graphical and statistical modeling of causes; Kun Zhang, professor in time-series-oriented causal learning; Joseph Ramsey, the director of research computing; and Madelyn Glymour, causal analyst and co-author of a causal-learning primer.
What Are the Causal Factors Driving Software Cost?
Armed with this new approach, we are exploring causal factors driving software cost within DoD programs and systems. For example, vendor tools might identify anywhere between 25 and 45 inputs that are used to estimate software development. We believe that the great majority of these factors are not causal and thus distract program managers from identifying factors that should be controlled. For example, our approach may identify that one causal factor in software cost is the level of a programmer's experience. Such a result would allow the DoD to recommend and review the level of experience of programmers involved in a software-development project.
The first phase of our research began an initial assessment of causality at multiple levels of granularity to identify and evaluate families of factors related to causality (e.g., customer interface, team composition, experience with domain and tool, design and code complexity, and quality). We have begun to analyze and apply this approach to software development project data from several sources, including:
We are initiating collaborations with major commercial cost-estimation-tool vendors. Through these collaborations, the vendors will be instructed by our research team in conducting their own causal studies on their individual proprietary cost-estimation databases and sharing sanitized causal conclusions with our research team.
We are also working with two doctoral students advised by Dr. Barry Boehm, creator of the Constructive Cost Model (COCOMO) and founding director of the Center for Systems and Software Engineering at the University of Southern California (Los Angeles). Last year, our team trained these and other students in causal learning and began coaching them to analyze their tightly controlled COCOMO research data. An initial paper summarizing the work has been published and several other papers will be presented at the 2018 Acquisition Research Symposium.
The tooling for causal learning consists primarily of the Tetrad tool, an open-source program developed and maintained by CMU and University of Pittsburgh researchers, through the Center for Causal Discovery, that provides access to several dozen causal-learning algorithms to enable causal search, inference, and estimation. The aim of Tetrad is to provide a more complete set of causal search algorithms in a friendly graphical user interface requiring no programming knowledge.
Looking Ahead
While we are excited with the potential of causal learning, we are limited by the availability of relevant research data. In many cases, available data may not be shareable due to proprietary concerns or federal regulations governing the access to software project data. The SEI is currently participating in a pilot program through which more software program data may be made available for research. We continue to solicit additional research collaborators who have access to research or field data and who want to learn more about causal learning.
Having recently completed a first-year exploratory research project on applying causal learning, we just embarked on a three-year research project to explore more specific factors at greater depth including where alternative factors may identify more causal influences of DoD software program cost. These additional factors will then be incorporated into the causal model to provide a holistic causal cost model for further research and tool development, as well as guidance for software development and acquisition program managers.
Additional Resources
Learn more about Causal Learning:
CMU Open Learning Initiative: Causal & Statistical Reasoning
This tutorial on Causal Learning by Richard Scheines is part 1 of the Workshop on Case Studies of Causal Discovery with Model Search, held on October 25-27, 2013, at Carnegie Mellon University.
Center for Causal Discovery Summer Seminar 2016 Part 1: An Overview of Graphical Models, Loading Tetrad, Causal Graphs, and Interventions
Center for Causal Discovery Summer Seminar 2016 Part 2
Center for Causal Discovery Summer Seminar 2016 Part 3
Center for Causal Discovery Summer Seminar 2016 Part 4
Center for Causal Discovery Summer Seminar 2016 Part 5
Center for Causal Discovery Summer Seminar 2016 Part 6
Center for Causal Discovery Summer Seminar 2016 Part 7
Center for Causal Discovery Summer Seminar 2016 Part 8
Center for Causal Discovery Summer Seminar 2016 Part 9
Center for Causal Discovery Summer Seminar 2016 Part 10
Center for Causal Discovery Summer Seminar 2016 Part 11
Center for Causal Discovery Summer Seminar 2016 Part 12
Center for Causal Discovery Summer Seminar 2016 Part 13
The Book of Why: The New Science of Cause and Effect 1st Edition
Causal Inference in Statistics: A Primer
Counterfactuals and Causal Inference: Methods and Principles for Social Research (Analytical Methods for Social Research)
↧
↧
Python 3.7: Introducing Data Classes
Python 3.7 is set to be released this summer, let’s have a sneak peek at some of the new features! If you’d like to play along at home with PyCharm, make sure you get PyCharm 2018.1 (or later if you’re reading this from the future).
There are many new things in Python 3.7: various character set improvements, postponed evaluation of annotations, and more. One of the most exciting new features is support for the dataclass decorator.
Most Python developers will have written many classes which looks like:
def__init__(self,var_a,var_b): |
Data classes help you by automatically generating dunder methods for simple cases. For example, a __init__ which accepted those arguments and assigned each to self. The small example before could be rewritten like:
A key difference is that type hints are actually required for data classes. If you’ve never used a type hint before: they allow you to mark what type a certain variable _should_ be. At runtime, these types are not checked, but you can use PyCharm or a command-line tool like mypy to check your code statically.
So let’s have a look at how we can use this!
You know a movie’s fanbase is passionate when a fan creates a REST API with the movie’s data in it. One Star Wars fan has done exactly that, and created the Star Wars API. He’s actually gone even further, and created a Python wrapper library for it.
Let’s forget for a second that there’s already a wrapper out there, and see how we could write our own.
We can use the requests library to get a resource from the Star Wars API:
response=requests.get('https://swapi.co/api/films/1/') |
This endpoint (like all swapi endpoints) responds with a JSON message. Requests makes our life easier by offering JSON parsing:
dictionary=response.json() |
And at this point we have our data in a dictionary. Let’s have a look at it (shortened):
'characters':['https://swapi.co/api/people/1/', …], 'created':'2014-12-10T14:23:31.880000Z', 'director':'George Lucas', 'edited':'2015-04-11T09:46:52.774897Z', 'opening_crawl':'It is a period of civil war.\r\n … ', 'planets':['https://swapi.co/api/planets/2/', 'producer':'Gary Kurtz, Rick McCallum', 'release_date':'1977-05-25', 'species':['https://swapi.co/api/species/5/', ...], 'starships':['https://swapi.co/api/starships/2/', ...], 'url':'https://swapi.co/api/films/1/', 'vehicles':['https://swapi.co/api/vehicles/4/', ...] |
To properly wrap an API, we should create objects that our wrapper’s user can use in their application. So let’s define an object in Python 3.6 to contain the responses of requests to the /films/ endpoint:
title:str, episode_id:int, opening_crawl:str, director:str, producer:str, release_date:datetime, characters:List[str], planets:List[str], starships:List[str], vehicles:List[str], species:List[str], created:datetime, edited:datetime, url:str ): self.title=title self.episode_id=episode_id self.opening_crawl=opening_crawl self.director=director self.producer=producer self.release_date=release_date self.characters=characters self.planets=planets self.starships=starships self.vehicles=vehicles self.species=species self.created=created self.edited=edited self.url=url iftype(self.release_date)isstr: self.release_date=dateutil.parser.parse(self.release_date) iftype(self.created)isstr: self.created=dateutil.parser.parse(self.created) iftype(self.edited)isstr: self.edited=dateutil.parser.parse(self.edited) |
Careful readers may have noticed a little bit of duplicated code here. Not so careful readers may want to have a look at the complete Python 3.6 implementation: it’s not short.
This is a classic case of where the data class decorator can help you out. We’re creating a class that mostly holds data, and only does a little validation. So let’s have a look at what we need to change.
Firstly, data classes automatically generate several dunder methods. If we don’t specify any options to the dataclass decorator, the generated methods are: __init__, __eq__, and __repr__. Python by default (not just for data classes) will implement __str__ to return the output of __repr__ if you’ve defined __repr__ but not __str__. Therefore, you get four dunder methods implemented just by changing the code to:
release_date:datetime characters:List[str] starships:List[str] |
We removed the __init__ method here to make sure the data class decorator can add the one it generates. Unfortunately, we lost a bit of functionality in the process. Our Python 3.6 constructor didn’t just define all values, but it also attempted to parse dates. How can we do that with a data class?
If we were to override __init__, we’d lose the benefit of the data class. Therefore a new dunder method was defined for any additional processing: __post_init__. Let’s see what a __post_init__ method would look like for our wrapper class:
iftype(self.release_date)isstr: self.release_date=dateutil.parser.parse(self.release_date) iftype(self.created)isstr: self.created=dateutil.parser.parse(self.created) iftype(self.edited)isstr: self.edited=dateutil.parser.parse(self.edited) |
And that’s it! We could implement our class using the data class decorator in under a third of the number of lines as we could without the data class decorator.
By using options with the decorator, you can tailor data classes further for your use case. The default options are:
@dataclass(init=True,repr=True,eq=True,order=False,unsafe_hash=False,frozen=False) |
- init determines whether to generate the
__init__dunder method. - repr determines whether to generate the
__repr__dunder method. - eq does the same for the
__eq__dunder method, which determines the behavior for equality checks (your_class_instance == another_instance). - order actually creates four dunder methods, which determine the behavior for all lesser than and/or more than checks. If you set this to true, you can sort a list of your objects.
The last two options determine whether or not your object can be hashed. This is necessary (for example) if you want to use your class’ objects as dictionary keys. A hash function should remain constant for the life of the objects, otherwise the dictionary will not be able to find your objects anymore. The default implementation of a data class’ __hash__ function will return a hash over all objects in the data class. Therefore it’s only generated by default if you also make your objects read-only (by specifying frozen=True).
By setting frozen=True any write to your object will raise an error. If you think this is too draconian, but you still know it will never change, you could specify unsafe_hash=True instead. The authors of the data class decorator recommend you don’t though.
If you want to learn more about data classes, you can read the PEP or just get started and play with them yourself! Let us know in the comments what you’re using data classes for!
↧
Random Darknet Shopper: A Live Mail Art Piece
------------------------------------------------------------------------
RANDOM██████╗ █████╗ ██████╗ ██╗ ██╗███╗ ██╗███████╗████████╗
██╔══██╗██╔══██╗██╔══██╗██║ ██╔╝████╗ ██║██╔════╝╚══██╔══╝
██║ ██║███████║██████╔╝█████╔╝ ██╔██╗ ██║█████╗ ██║
██║ ██║██╔══██║██╔══██╗██╔═██╗ ██║╚██╗██║██╔══╝ ██║
██████╔╝██║ ██║██║ ██║██║ ██╗██║ ╚████║███████╗ ██║
╚═════╝ ╚═╝ ╚═╝╚═╝ ╚═╝╚═╝ ╚═╝╚═╝ ╚═══╝╚══════╝ ╚═╝
SHOPPER
Version 0.13 / Runs on AlphaBay Market
------------------------------------------------------------------------
DATE: 30.12.2015
ITEM NO: 18
------------------------------------------------------------------------
OPENING ALPHABAY MARKET - http://lo4wpvx3tcdbqra4.onion
CONNECTING VIA TOR (this might take a while)
------------------------------------------------------------------------
LOGIN
INEJECTING COOKIE
------------------------------------------------------------------------
CHOOSING RANDOM CATEGORY: Fraud > Personal Information & Scans > Personal Information & Scans
FILTERING ITEMS WHICH ARE SHIPPED TO UK & ARE BELOW 100 USD
COLLECTING ALL ITEMS IN CATEGORY
------------------------------------------------------------------------------------
NR | ITEM | VENDOR | BTC | USD |
------------------------------------------------------------------------------------
1 | Personal Information~SSN~DOB~ect... | BooMstick | 0.0005 |$ 0.2 |
2 | ( ^Θ^) ID Template and Scan Pack 13 GB ... | tastych... | 0.0006 |$ 0.25 |
3 | CreditCard Template Pack!!!!! | Halfman | 0.0007 |$ 0.28 |
4 | +++ 0.50 cents FRESH 2015 USA PROFILES... | wakawaka | 0.0012 |$ 0.5 |
5 | USA Full informations profile with SSN | bakov | 0.0012 |$ 0.5 |
6 | 1100+ Personal Information From USA, 45... | bestworks | 0.0012 |$ 0.5 |
7 | [MasterSplynter2] Florida Drivers Licen... | masters... | 0.0018 |$ 0.75 |
8 | Personal Information~SSN~DOB Fulls - ... | verdugin | 0.0019 |$ 0.8 |
9 | German Templates: CCs, Documents ++more | zZz | 0.0023 |$ 0.99 |
10 | ** DRIVER SCAN FLORIDA ** MEN | Dark-Eu... | 0.0024 |$ 1.0 |
11 | [GlobalData] USA Profile /w Background ... | globaldata | 0.0024 |$ 1.0 |
12 | Personal Inforamtion + | BooMstick | 0.0024 |$ 1.0 |
13 | APRIL 2015 FRESH USA PROFILES SSN/DOB | wakawaka | 0.0024 |$ 1.0 |
14 | National Identity Card (Italy) with SSN... | GrayFac... | 0.0024 |$ 1.0 |
15 | Bitcoin lottery | MoneyTr... | 0.0024 |$ 1.0 |
16 | Personal Information~SSN~DOB~ect... | BooMstick | 0.0005 |$ 0.2 |
17 | ( ^Θ^) ID Template and Scan Pack 13 GB ... | tastych... | 0.0006 |$ 0.25 |
18 | CreditCard Template Pack!!!!! | Halfman | 0.0007 |$ 0.28 |
19 | +++ 0.50 cents FRESH 2015 USA PROFILES... | wakawaka | 0.0012 |$ 0.5 |
20 | USA Full informations profile with SSN | bakov | 0.0012 |$ 0.5 |
21 | 1100+ Personal Information From USA, 45... | bestworks | 0.0012 |$ 0.5 |
22 | [MasterSplynter2] Florida Drivers Licen... | masters... | 0.0018 |$ 0.75 |
23 | Personal Information~SSN~DOB Fulls - ... | verdugin | 0.0019 |$ 0.8 |
24 | German Templates: CCs, Documents ++more | zZz | 0.0023 |$ 0.99 |
25 | ** DRIVER SCAN FLORIDA ** MEN | Dark-Eu... | 0.0024 |$ 1.0 |
26 | [GlobalData] USA Profile /w Background ... | globaldata | 0.0024 |$ 1.0 |
27 | Personal Inforamtion + | BooMstick | 0.0024 |$ 1.0 |
28 | APRIL 2015 FRESH USA PROFILES SSN/DOB | wakawaka | 0.0024 |$ 1.0 |
29 | National Identity Card (Italy) with SSN... | GrayFac... | 0.0024 |$ 1.0 |
30 | Bitcoin lottery | MoneyTr... | 0.0024 |$ 1.0 |
31 | [GlobalData] USA Profile /w Background ... | globaldata | 0.0024 |$ 1.0 |
32 | ** DRIVER SCAN FLORIDA ** MEN | Dark-Eu... | 0.0024 |$ 1.0 |
33 | |Ultra HQ Scan | Verification Documents... | Raven1 | 0.0024 |$ 1.0 |
34 | APRIL 2015 FRESH USA PROFILES SSN/DOB | wakawaka | 0.0024 |$ 1.0 |
35 | ✯ Premium HQ PSD Templates ✯ USA ✯ Phot... | Hund | 0.0025 |$ 1.05 |
36 | German ID And Other Scan | shonajaan | 0.0026 |$ 1.1 |
37 | 2015 FRESH SSN + DOB Fulls - All 50 Sta... | Andigatel | 0.003 |$ 1.25 |
38 | FBI,CIA and Other US Government Officia... | bestworks | 0.0033 |$ 1.4 |
39 | + USA PROFILES SSN/DOB/DL/BANK + FREE ... | wakawaka | 0.0036 |$ 1.5 |
40 | UK DEAD FULLZ/PROFILES | pringle... | 0.0036 |$ 1.5 |
41 | ★★★7 REASONS WHY THAT CVV YOUR USING GE... | GodsLef... | 0.0036 |$ 1.5 |
42 | [GlobalData] UK Profiles - 50% Discount! | globaldata | 0.0036 |$ 1.5 |
43 | [AUTOSHOP] UK LEADS NAME|ADDRESS|MOBILE... | UKDOCS | 0.0036 |$ 1.54 |
44 | ||Ultra HQ Scan|| Custom Passport, DL, ... | sky88 | 0.0047 |$ 2.0 |
45 | ** PASSPORT SCAN LITHUANIA ** MEN | Dark-Eu... | 0.0047 |$ 2.0 |
46 | ** PASSPORT SCAN LITHUANIA ** MEN | Dark-Eu... | 0.0047 |$ 2.0 |
47 | ||Ultra HQ Scan|| Custom Passport, DL, ... | sky88 | 0.0047 |$ 2.0 |
48 | $$ Highest Quality BANKING FULLZ USA $$ | Grimm | 0.0047 |$ 2.0 |
49 | ** ID CARD SCAN CHINA ** MEN ** | Dark-Eu... | 0.0047 |$ 2.0 |
50 | Business Profiles EIN + DOB + SSN ( Per... | Despot | 0.0047 |$ 2.0 |
51 | US Passport and Other Scan Read Full Li... | shonajaan | 0.0052 |$ 2.2 |
52 | 272 Passport Scans From 46 Countries | bestworks | 0.0066 |$ 2.8 |
53 | French Documents: IDs, Passports, Licen... | zZz | 0.0071 |$ 2.99 |
54 | ⚫⚫▶▶♕ ♕ HQ IDs and PASSPORTS ♕ ♕ | KingCarder | 0.0071 |$ 2.99 |
55 | How to to open your OWN Bank Drops **20... | 7awjn | 0.0071 |$ 3.0 |
56 | Wordlist for password bruteforce cracki... | Asphyxi... | 0.0071 |$ 3.0 |
57 | approximately 1000 onion sites | 7awjn | 0.0071 |$ 3.0 |
58 | ★★★LEARN HOW TO CREATE YOUR VERY OWN BA... | GodsLef... | 0.0071 |$ 3.0 |
59 | Hacked Email [ Email + Pass ] | Code | 0.0071 |$ 3.0 |
60 | UK Templates Bank Statment,Credit Card ... | shonajaan | 0.0078 |$ 3.3 |
61 | U.S. Passport & CC Templates | zZz | 0.0083 |$ 3.49 |
62 | Bitcoin lottery | MoneyTr... | 0.0095 |$ 4.0 |
63 | Valid SSN+MMN+DOB+E-mail+Phone number -... | Kingscan | 0.0095 |$ 4.0 |
64 | Make Your own BestBuy Receipt (PSD) | tkmremi | 0.0104 |$ 4.39 |
65 | Amazon Unlimited Money | COLOR | 0.0107 |$ 4.5 |
66 | ★Uk DOB Service 90% Success Rate★ | IcyEagle | 0.0118 |$ 4.99 |
67 | Unique UK Identity Set ( Passport+DL+Bi... | Kingscan | 0.0118 |$ 5.0 |
68 | Residential Lease Agreement - Use for Drop | GetVeri... | 0.0118 |$ 5.0 |
69 | BRITISH GAS UTILITY BILL "Template" [Au... | TheNice... | 0.0118 |$ 5.0 |
70 | [Editable] US Passport | Code | 0.0118 |$ 5.0 |
71 | HUGE e-mail list 500,000 emails SPAM TH... | nucleoide | 0.0118 |$ 5.0 |
72 | Aussie Email Logins ( @iinet.net.au / @... | OzRort | 0.0118 |$ 5.0 |
73 | ★★★WELLS FARGO CASHOUT GUIDE!!! LEARN H... | GodsLef... | 0.0118 |$ 5.0 |
74 | Canada Profiles / Personnal data (No cc) | REDF0X | 0.0118 |$ 5.0 |
75 | Link to US Automobile Database | GetVeri... | 0.0118 |$ 5.0 |
76 | German Documents Credit Cards Bills and... | magneto | 0.0118 |$ 5.0 |
77 | Unique BOA (Statment+CC) Custom Digital... | Kingscan | 0.0118 |$ 5.0 |
78 | ★★★WELLS FARGO CASHOUT GUIDE!!! LEARN H... | GodsLef... | 0.0118 |$ 5.0 |
79 | Link to US Automobile Database | GetVeri... | 0.0118 |$ 5.0 |
80 | [Editable] US Passport | Code | 0.0118 |$ 5.0 |
81 | USA PERSONAL PROFILES *BLACKSTAR* | BlackSt... | 0.0118 |$ 5.0 |
82 | BRITISH GAS UTILITY BILL "Template" [Au... | TheNice... | 0.0118 |$ 5.0 |
83 | ✯ Premium HQ PSD Templates ✯ German Pho... | Hund | 0.013 |$ 5.48 |
84 | USA Passport Template | adeadra... | 0.013 |$ 5.5 |
85 | Link to two (2) Databases to Find Most ... | itabraus2 | 0.0142 |$ 5.99 |
86 | ★★★HOW TO CREATE KEYGENS FOR YOUR FAVOR... | GodsLef... | 0.0142 |$ 6.0 |
87 | HQ Scans - German Passports or IDs | bakov | 0.0142 |$ 6.0 |
88 | ★★★HOW TO CARD AMAZON!!! LEARN HOW TO U... | GodsLef... | 0.0142 |$ 6.0 |
89 | SSN Social Security Number Template + B... | sexypanda | 0.0164 |$ 6.92 |
90 | **ULTIMATE MONEY MAKING PACKAGE** WELCO... | GodsLef... | 0.0166 |$ 6.99 |
91 | German ID Card - Deutscher Personalausw... | MadeInG... | 0.0169 |$ 7.13 |
92 | USA SSN+DOB Lookup | Raffi | 0.0171 |$ 7.22 |
93 | [NEW BATCH - AUTO] CANADA FULLZ CREDIT ... | phackman | 0.0171 |$ 7.22 |
94 | ★USA SSN + DOB + ADDRESS Service 90% Su... | IcyEagle | 0.0189 |$ 7.99 |
95 | ★★★WELLS FARGO TO BTC!! THIS GUIDE TEAC... | GodsLef... | 0.0189 |$ 8.0 |
96 | USA only SSN DOB Lookup. Almost 100% re... | verdugin | 0.0189 |$ 8.0 |
97 | California License - custom creation - ... | BTH-Ove... | 0.0189 |$ 8.0 |
98 | ✪✪✪✪✪ SSN Provision Service - Find SSN ... | verdugin | 0.0189 |$ 8.0 |
99 | 1 Driver's License Scan Canada Ontario | Passpor... | 0.0189 |$ 8.0 |
100| Passport scan of real person High Quali... | CardPass | 0.0189 |$ 8.0 |
101| Link to Top 2 Database to Find Most Ame... | verdugin | 0.0189 |$ 8.0 |
102| UK Birth Certificate PSD Template | S.O.M | 0.0199 |$ 8.39 |
103| ★★★MAKE THOUSANDS LEARNING HOW TO CASHO... | GodsLef... | 0.0213 |$ 9.0 |
104| HOW TO STEAL PEOPLE's INFORMATIONS ▄▀... | fake | 0.0213 |$ 9.0 |
105| PayPal VERIFIED accounts with BANK & CC... | GodsLef... | 0.0213 |$ 9.0 |
106| SUPREME FRAUD PACKAGE!!! I BRING YOU TH... | GodsLef... | 0.0225 |$ 9.5 |
107| 10x Freshly gathered USA fullz without ... | BlockKids | 0.0237 |$ 10.0 |
108| 1 Passport Scan of Canada + Matching pe... | Passpor... | 0.0237 |$ 10.0 |
109| USA SSN AND DOB SEARCH *BLACKSTAR* | BlackSt... | 0.0237 |$ 10.0 |
110| USA utility Bill digital document | LikeApr0 | 0.0237 |$ 10.0 |
111| USA Social Security Number SSN digital ... | LikeApr0 | 0.0237 |$ 10.0 |
112| ★★★CREDIT CARD FRAUD, A BEGINNERS GUIDE... | GodsLef... | 0.0237 |$ 10.0 |
113| Full USA FUllz (SSN,DOB,MMN) | QTwoTimes | 0.0237 |$ 10.0 |
114| Link to Top 2 Database to Find Most Ame... | GetVeri... | 0.0237 |$ 10.0 |
115| Aussie Docs | OzRort | 0.0237 |$ 10.0 |
116| Full USA FUllz (SSN,DOB,MMN) | QTwoTimes | 0.0237 |$ 10.0 |
117| ****GodsLeftNuts Carding Software****TH... | GodsLef... | 0.0237 |$ 10.0 |
118| CANADIAN DL SCAN REAL INFOS/DL+PASSPORT... | pringle... | 0.0237 |$ 10.0 |
119| COX.net Email Leads [Auto-... | Code | 0.0237 |$ 10.0 |
120| ★★★INTRODUCTION INTO EXPERT CARDING!!!!... | GodsLef... | 0.0237 |$ 10.0 |
121| US Bank Check Template | GetVeri... | 0.0237 |$ 10.0 |
122| ****GodsLeftNuts Carding Software****TH... | GodsLef... | 0.0237 |$ 10.0 |
123| ★ CHEAPEST PRICE Passport & Driving Lic... | Maddy1980 | 0.0237 |$ 10.0 |
124| Full USA FUllz (SSN,DOB,MMN) | QTwoTimes | 0.0237 |$ 10.0 |
125| Full USA FUllz (SSN,DOB,MMN) | QTwoTimes | 0.0237 |$ 10.0 |
126| USA utility Bill digital document | LikeApr0 | 0.0237 |$ 10.0 |
127| Full USA FUllz (SSN,DOB,MMN) | QTwoTimes | 0.0237 |$ 10.0 |
128| SSN Provision Service - Find SSN and DOB | GetVeri... | 0.0237 |$ 10.0 |
129| ★★★INTRODUCTION INTO EXPERT CARDING!!!!... | GodsLef... | 0.0237 |$ 10.0 |
130| USA Social Security Number SSN digital ... | LikeApr0 | 0.0237 |$ 10.0 |
131| UK SCANS SERVICE | datrude... | 0.0237 |$ 10.0 |
132| Find Anybody DOB 100% Accurate and Free | GetVeri... | 0.0237 |$ 10.0 |
133| UK utility Bill and template passport +... | theone | 0.0247 |$ 10.42 |
134| Custom pay stubs | Raffi | 0.0256 |$ 10.83 |
135| THE COOPERATIVE BANK STATEMENT "Templat... | Nesquik7 | 0.045 |$ 19.0 |
136| COMCAST - CUSTOM MADE UTILITY BILL | suzie | 0.026 |$ 11.0 |
137| BANK OF AMERICA - BANK STATEMENT | suzie | 0.026 |$ 11.0 |
138| SSN CARD SCAN | suzie | 0.026 |$ 11.0 |
139| Make Your own Fake Doctor Notes | tkmremi | 0.0264 |$ 11.15 |
140| EXIF data VERIFICATION BOOSTER | Battalion | 0.0267 |$ 11.26 |
141| 1 Romanian passport scan | Passpor... | 0.0284 |$ 12.0 |
142| BIG US & EU TEMPLATE PACK [PROMO PRICE] | yummy5656 | 0.0284 |$ 12.0 |
143| 1 Passport Scan of France | Passpor... | 0.0284 |$ 12.0 |
144| 1 Passport Scan of the USA | Passpor... | 0.0284 |$ 12.0 |
145| Wells Fargo VISA Bank Statement "Template" | Nesquik7 | 0.045 |$ 19.0 |
146| UK DOB SEARCH | datrude... | 0.0317 |$ 13.38 |
147| [Service] UK DOB SEARCH (Date Of Birth) | UKDOCS | 0.0324 |$ 13.69 |
148| 1 National Identity Card Scan Spain | Passpor... | 0.0332 |$ 14.0 |
149| Background Reports, Credit Reports! | sal | 0.0355 |$ 15.0 |
150| HQ DL+SIN+Passport Scan of Canadian cit... | ordapro... | 0.0355 |$ 15.0 |
151| British Gas bill - Create your own temp... | boggalertz | 0.0355 |$ 15.0 |
152| Uk British Gas electricity bill template | dilling... | 0.0355 |$ 15.0 |
153| Super HQ - Utility Bill Template - Unli... | GetVeri... | 0.0355 |$ 15.0 |
154| Water utility bill - Create your own te... | boggalertz | 0.0355 |$ 15.0 |
155| ***CERTIFIED ETHICAL HACKER OFFICIAL CO... | GodsLef... | 0.0355 |$ 15.0 |
156| Slovenian custom utility bill RTV | CardPass | 0.0355 |$ 15.0 |
157| █ █ CVV ssn dob + Background Check & Cr... | fake | 0.0355 |$ 15.0 |
158| HQ DL+SIN+Passport Scan of Canadian cit... | ordapro... | 0.0355 |$ 15.0 |
159| Uk Profile - good for finance | jojo100 | 0.0355 |$ 15.0 |
160| Custom Credit/Debit Physical Card Blanks | Kingscan | 0.0355 |$ 15.0 |
161| HQ DL+Passport scans of Canadian citize... | ordapro... | 0.0355 |$ 15.0 |
162| DL+Passport Scans of Canadian citizen. ... | ordapro... | 0.0355 |$ 15.0 |
163| German proof of Address - deutscher Adr... | DarkLor... | 0.0355 |$ 15.0 |
164| 1 Passport Scan from any Country you N... | Passpor... | 0.0355 |$ 15.0 |
165| HQ DL+SIN+Passport Scan of Canadian cit... | ordapro... | 0.0355 |$ 15.0 |
166| Uk Profile - good for finance | jojo100 | 0.0355 |$ 15.0 |
167| British Gas bill - Create your own temp... | boggalertz | 0.0355 |$ 15.0 |
168| Slovenian custom utility bill RTV | CardPass | 0.0355 |$ 15.0 |
169| Water utility bill - Create your own te... | boggalertz | 0.0355 |$ 15.0 |
170| [Service} UK MOBILE PHONE NUMBER SEARCH... | UKDOCS | 0.0366 |$ 15.47 |
171| 1 Driver Licence Scan of the U.K. | Passpor... | 0.0379 |$ 16.0 |
172| SCAN CNI FR + RIB FR | tutoFrP... | 0.039 |$ 16.47 |
173| 1 Passport Scan of the UK + tenancy agr... | Passpor... | 0.0403 |$ 17.0 |
174| UTILITY BILLS SCAN (USA,UK,FR,IT,DE,ES) | pringle... | 0.0414 |$ 17.5 |
175| Free Electoral Roll Search Tutorial - UK | Data_De... | 0.0426 |$ 18.0 |
176| [SERVICE] UK MMN SEARCH (Mother Maiden ... | UKDOCS | 0.0446 |$ 18.83 |
177| BRITISH GAS UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
178| AGL (AUS) Utility Bills "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
179| TALKTALK (UK) Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
180| HM Revenue & Customs TAX CODE UTILITY B... | Nesquik7 | 0.045 |$ 19.0 |
181| Vodafone (AUS) Utility Bills "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
182| Momentum (AUS) Utility Bills "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
183| United Utilities (UK) Utility Bill "Tem... | Nesquik7 | 0.045 |$ 19.0 |
184| Free (FRANCE) Utility Bills "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
185| RSB BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
186| LLOYDS BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
187| BRITISH GAS UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
188| Chase Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
189| TALKTALK (UK) Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
190| Entergy Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
191| Orange (FRANCE) Utility Bills "Template... | Nesquik7 | 0.045 |$ 19.0 |
192| Comcast Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
193| EDF (FRANCE) Utility Bills "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
194| Halifax (UK) Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
195| BT GROUP UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
196| BT GROUP UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
197| NATWEST BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
198| United Utilities (UK) Utility Bill "Tem... | Nesquik7 | 0.045 |$ 19.0 |
199| BRITISH GAS UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
200| Direct Energie (FRANCE) Utility Bills "... | Nesquik7 | 0.045 |$ 19.0 |
201| Chase Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
202| Orange (FRANCE) Utility Bills "Template... | Nesquik7 | 0.045 |$ 19.0 |
203| RSB BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
204| Canadian Fullz Credit Registration Etc | casa | 0.0473 |$ 19.99 |
205| Doxing Service | ULTIMATE BARGAIN PRICE... | HighPing | 0.0473 |$ 19.99 |
206| USA passport digital document | LikeApr0 | 0.0474 |$ 20.0 |
207| UK driver license digital document | LikeApr0 | 0.0474 |$ 20.0 |
208| UK Passport info Search | boggalertz | 0.0474 |$ 20.0 |
209| 700+ Credit Score Complete Fullz | HuggleB... | 0.0474 |$ 20.0 |
210| Background Report Service | GetVeri... | 0.0474 |$ 20.0 |
211| Standard US Drivers License Template (B... | motorhe... | 0.0474 |$ 20.0 |
212| 1x CHECKED FULLZ+BANK ACCOUNT from jaho... | jahoda | 0.0474 |$ 20.0 |
213| SPAIN ID CARD digital document DNI | LikeApr0 | 0.0474 |$ 20.0 |
214| Social Security Card Scan - HQ *Sample ... | GetVeri... | 0.0474 |$ 20.0 |
215| USA driver license digital document | LikeApr0 | 0.0474 |$ 20.0 |
216| Exteme ID Template Megapack! ALL 50 US ... | bartock | 0.0474 |$ 20.0 |
217| UK DOB LOOKUP - $20 | ScJ | 0.0474 |$ 20.0 |
218| Custom Social Security Number Card Scan... | Kingscan | 0.0474 |$ 20.0 |
219| custom amount of data | alphabase | 0.0474 |$ 20.0 |
220| PANAMA DRIVER LICENSE digital document | LikeApr0 | 0.0474 |$ 20.0 |
221| Aussie Passport Scans | OzRort | 0.0474 |$ 20.0 |
222| Utility Bill Scan *Sample Link Inside* | GetVeri... | 0.0474 |$ 20.0 |
223| EU Editable Photoshop Template HQ - Rom... | cyberpe... | 0.0474 |$ 20.0 |
224| UK Scan Service - Customized documents ... | boggalertz | 0.0474 |$ 20.0 |
225| Background Report Service | GetVeri... | 0.0474 |$ 20.0 |
226| Utility Bill Scan *Sample Link Inside* | GetVeri... | 0.0474 |$ 20.0 |
227| UK Scan Service - Customized documents ... | boggalertz | 0.0474 |$ 20.0 |
228| 700+ Credit Score Complete Fullz | HuggleB... | 0.0474 |$ 20.0 |
229| California State Drivers License Templa... | motorhe... | 0.0474 |$ 20.0 |
230| USA Documents Credit Cards Bills and Mo... | magneto | 0.0474 |$ 20.0 |
231| SPAIN ID CARD digital document DNI | LikeApr0 | 0.0474 |$ 20.0 |
232| UK DOB search -UK ONLY $20 each With fr... | boggalertz | 0.0474 |$ 20.0 |
233| USA driver license digital document | LikeApr0 | 0.0474 |$ 20.0 |
234| EU Editable Photoshop Template HQ - Rom... | cyberpe... | 0.0474 |$ 20.0 |
235| Social Security Card Template - SSN PSD... | GetVeri... | 0.0592 |$ 25.0 |
236| Aussie Drivers License Scans | OzRort | 0.0474 |$ 20.0 |
237| USA Frontier Communication Utility Bill... | mackay | 0.0485 |$ 20.5 |
238| [OFFICIAL] EQUIFAX/TRANSUNION CANADIAN ... | phackman | 0.0513 |$ 21.66 |
239| photos PHYSICAL CC/ID NEEDED FOR VERIF... | CINABICAB | 0.0534 |$ 22.57 |
240| photos PHYSICAL id/cc NEEDED FOR VERIF... | CINABICAB | 0.0534 |$ 22.57 |
241| 195 photos for fake ID : Man & Woman | FrenchyBoy | 0.0536 |$ 22.64 |
242| BARCLAYS BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.0545 |$ 23.0 |
243| ..::n0unit_Evo::..US fullz x50 | n0units | 0.0592 |$ 25.0 |
244| Arizona DL Scans | mackay | 0.0592 |$ 25.0 |
245| Florida DL Scans | mackay | 0.0592 |$ 25.0 |
246| USA CC Scans | mackay | 0.0592 |$ 25.0 |
247| Massachusetts DL Scans | mackay | 0.0592 |$ 25.0 |
248| Maryland DL scans | mackay | 0.0592 |$ 25.0 |
249| Minnesota DL Scans | mackay | 0.0592 |$ 25.0 |
250| La Caixa Payment Service Notification -... | mackay | 0.0592 |$ 25.0 |
251| Full Credit File/report 1 Star rating F... | boggalertz | 0.0592 |$ 25.0 |
252| [CA] Canadian Pros - Instant Delivery | ramboiler | 0.0592 |$ 25.0 |
253| PREMIUM Ally Bank drops | verdugin | 0.0592 |$ 25.0 |
254| USA DL/SSN scans | mackay | 0.0592 |$ 25.0 |
255| USA Chase Bank CC Statement scans | mackay | 0.0592 |$ 25.0 |
256| Massachusetts DL Scans | mackay | 0.0592 |$ 25.0 |
257| USA DiSH Bill scans - 100% Perfect Qual... | mackay | 0.0592 |$ 25.0 |
258| Iowa DL scans | mackay | 0.0592 |$ 25.0 |
259| Michigan DL Scans | mackay | 0.0592 |$ 25.0 |
260| Florida DL Scans | mackay | 0.0592 |$ 25.0 |
261| Minnesota DL Scans | mackay | 0.0592 |$ 25.0 |
262| 2013 BotNet LogFilez - 1 TXT with varia... | o-c-king | 0.0592 |$ 25.0 |
263| Maryland DL scans | mackay | 0.0592 |$ 25.0 |
264| USA Chase Bank CC Statement scans | mackay | 0.0592 |$ 25.0 |
265| USA DL/SSN scans | mackay | 0.0592 |$ 25.0 |
266| ..::n0unit_Evo::..US fullz x50 | n0units | 0.0592 |$ 25.0 |
267| [CA] Canadian Pros - Instant Delivery | ramboiler | 0.0592 |$ 25.0 |
268| ★ Driving Licence, Passports, Bank Stat... | tescovo... | 0.0592 |$ 25.0 |
269| Indiana DL scans | mackay | 0.0592 |$ 25.0 |
270| richtext - /virgin/ american ssn & *rea... | richtext | 0.0592 |$ 25.0 |
271| Idaho DL Scans | mackay | 0.0592 |$ 25.0 |
272| Utility Bill/Bank Statements Scans | mackay | 0.0592 |$ 25.0 |
273| USA Ally Bank Statement - 100% Perfect ... | mackay | 0.0592 |$ 25.0 |
274| custom listing for vbainf1000 | mackay | 0.0663 |$ 28.0 |
275| Scan personnalisé CNI Carte Identité Fr... | FrenchyBoy | 0.0593 |$ 25.04 |
276| UK ID Pack Templates | dilling... | 0.071 |$ 30.0 |
277| Michigan State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
278| USA Passport Card Scans | mackay | 0.071 |$ 30.0 |
279| South Dakota State Drivers License Temp... | motorhe... | 0.071 |$ 30.0 |
280| USA eBay Accounts With Feedback and Ema... | o-c-king | 0.071 |$ 30.0 |
281| SSN card template | dilling... | 0.071 |$ 30.0 |
282| Arkansas State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
283| North Carolina State Drivers License Te... | motorhe... | 0.071 |$ 30.0 |
284| USA Driver License Number | batard | 0.071 |$ 30.0 |
285| Custom United States Utility Bill Scan,... | Kingscan | 0.0829 |$ 35.0 |
286| Nevada State Drivers License | motorhe... | 0.071 |$ 30.0 |
287| Arizona State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
288| UK Middle Name search -UK ONLY $30 each... | boggalertz | 0.071 |$ 30.0 |
289| Georgia State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
290| ★WORLD FAMOUS™★INSTANT DELIVERY★CANADA ... | Thinkin... | 0.071 |$ 30.0 |
291| Ohio State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
292| American Express Template | motorhe... | 0.071 |$ 30.0 |
293| New Mexico Sate Drivers License Template | motorhe... | 0.071 |$ 30.0 |
294| California State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
295| New Jersey State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
296| Mississippi State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
297| Tennessee State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
298| Premier Platinum Credit Card | motorhe... | 0.071 |$ 30.0 |
299| UK Utility bill template, FULLY EDITABL... | boggalertz | 0.071 |$ 30.0 |
300| Premier Platinum mastercard | motorhe... | 0.071 |$ 30.0 |
301| BACKGROUND REPORT & CREDIT REPORT 30$ | suzie | 0.071 |$ 30.0 |
302| Kansas State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
303| [GlobalData] USA FICO CREDIT PROFILE - ... | globaldata | 0.071 |$ 30.0 |
304| template´s pack(Passport-ID-DL)--Easy ... | netfree | 0.071 |$ 30.0 |
305| ★WORLD FAMOUS™★INSTANT DELIVERY★CANADA ... | Thinkin... | 0.071 |$ 30.0 |
306| UK Profiles for applying for credit - C... | boggalertz | 0.071 |$ 30.0 |
307| American Express Template | motorhe... | 0.071 |$ 30.0 |
308| Pennsylvania State Drivers License Temp... | motorhe... | 0.071 |$ 30.0 |
309| New York State Drivers License Template | motorhe... | 0.071 |$ 30.0 |
310| Los Angeles Tax Certificate / Business ... | GetVeri... | 0.071 |$ 30.0 |
311| USA Passport Scans + High quality + Rea... | mackay | 0.071 |$ 30.0 |
312| 3x - HQ UK Passport/Driving Licence/NIN... | Grime | 0.0787 |$ 33.25 |
313| EVOscans custom made scan | Battalion | 0.0801 |$ 33.84 |
314| 100k worldwide emails, fresh leads. | BlockKids | 0.0829 |$ 35.0 |
315| Custom United States Passport Scan, Any... | Kingscan | 0.0829 |$ 35.0 |
316| PREMIUM Bank Of America Bank drops | verdugin | 0.0829 |$ 35.0 |
317| Capital One 360 Bank drops + FREE Bank ... | verdugin | 0.0829 |$ 35.0 |
318| Custom Germany Passport Scan, Any Details | Kingscan | 0.0829 |$ 35.0 |
319| Amazing! Selfie drawing service! 100% a... | ordapro... | 0.0829 |$ 35.0 |
320| Fidelity Bank Drops | verdugin | 0.0829 |$ 35.0 |
321| BB-Leads | UKDOCS | 0.0883 |$ 37.29 |
322| 25K Consumer Forex + Investment Product... | szadpl | 0.0895 |$ 37.78 |
323| **Custom this ANONYMOUS Reloadable Plas... | Darkcry... | 0.1373 |$ 58.0 |
324| 100 New Jersey Fullz | alphabase | 0.0947 |$ 40.0 |
325| 100 Massachusetts Fullz | alphabase | 0.0947 |$ 40.0 |
326| 100 Missouri Fullz | alphabase | 0.0947 |$ 40.0 |
327| 100 California Fullz | alphabase | 0.0947 |$ 40.0 |
328| ★INSTANT DELIVERY★FRANCE TEMPLATE MEGA ... | Thinkin... | 0.0947 |$ 40.0 |
329| 100 New Mexico Fullz | alphabase | 0.0947 |$ 40.0 |
330| 100 Nebraska Fullz | alphabase | 0.0947 |$ 40.0 |
331| 100 Montana Fullz | alphabase | 0.0947 |$ 40.0 |
332| 100 Georgia Fullz | alphabase | 0.0947 |$ 40.0 |
333| 100 Iowa Fullz | alphabase | 0.0947 |$ 40.0 |
334| 100 Delaware Fullz | alphabase | 0.0947 |$ 40.0 |
335| 100 Michigan Fullz | alphabase | 0.0947 |$ 40.0 |
336| 100 Mississippi Fullz | alphabase | 0.0947 |$ 40.0 |
337| 100 Washington Fullz | alphabase | 0.0947 |$ 40.0 |
338| 100 Illinois Fullz | alphabase | 0.0947 |$ 40.0 |
339| Drivers License Template - Most States ... | GetVeri... | 0.0947 |$ 40.0 |
340| 100 Maine Fullz | alphabase | 0.0947 |$ 40.0 |
341| 100 Connecticut Fullz | alphabase | 0.0947 |$ 40.0 |
342| ★INSTANT DELIVERY★ITALY TEMPLATE MEGA P... | Thinkin... | 0.0947 |$ 40.0 |
343| 100 South Carolina Fullz | alphabase | 0.0947 |$ 40.0 |
344| 100 Alabama Fullz | alphabase | 0.0947 |$ 40.0 |
345| High Quality US Passport scan template ... | dilling... | 0.0947 |$ 40.0 |
346| 100 Florida Fullz | alphabase | 0.0947 |$ 40.0 |
347| Doracard's USA Ready-made Real DL+SSN... | doracard | 0.0947 |$ 40.0 |
348| [Forged] 1 YEAR of California Medical M... | kaiba | 0.0947 |$ 40.0 |
349| Custom Germany Utility Bill Scan, Any D... | Kingscan | 0.0947 |$ 40.0 |
350| 100 North Carolina Fullz | alphabase | 0.0947 |$ 40.0 |
351| 100 New York Fullz | alphabase | 0.0947 |$ 40.0 |
352| 100 Kentucky Fullz | alphabase | 0.0947 |$ 40.0 |
353| Custom British Passport Scan, Any Details | Kingscan | 0.0947 |$ 40.0 |
354| 100 Ohio Fullz | alphabase | 0.0947 |$ 40.0 |
355| 100 Wyoming Fullz | alphabase | 0.0947 |$ 40.0 |
356| 100 Oklahoma Fullz | alphabase | 0.0947 |$ 40.0 |
357| 100 Idaho Fullz | alphabase | 0.0947 |$ 40.0 |
358| 100 Arizona Fullz | alphabase | 0.0947 |$ 40.0 |
359| 100 Wisconsin Fullz | alphabase | 0.0947 |$ 40.0 |
360| 100 Texas Fullz | alphabase | 0.0947 |$ 40.0 |
361| 100 Arkansas Fullz | alphabase | 0.0947 |$ 40.0 |
362| ( ^Θ^) 20x Canada Dead Fullz No Bank/C... | tastych... | 0.0947 |$ 40.0 |
363| 100 Oregon Fullz | alphabase | 0.0947 |$ 40.0 |
364| 100 Colorado Fullz | alphabase | 0.0947 |$ 40.0 |
365| 100 Nevada Fullz | alphabase | 0.0947 |$ 40.0 |
366| 100 Pennsylvania Fullz | alphabase | 0.0947 |$ 40.0 |
367| 100 Virginia Fullz | alphabase | 0.0947 |$ 40.0 |
368| 100 Tennessee Fullz | alphabase | 0.0947 |$ 40.0 |
369| ★INSTANT DELIVERY★LATVIA TEMPLATE MEGA ... | Thinkin... | 0.0947 |$ 40.0 |
370| 100 Alaska Fullz | alphabase | 0.0947 |$ 40.0 |
371| 100 Louisiana Fullz | alphabase | 0.0947 |$ 40.0 |
372| 100 Minnesota Fullz | alphabase | 0.0947 |$ 40.0 |
373| 100 Kansas Fullz | alphabase | 0.0947 |$ 40.0 |
374| 100 Maryland Fullz | alphabase | 0.0947 |$ 40.0 |
375| Custom Germany ID Scan, (PERSONALAUSWEI... | Kingscan | 0.0947 |$ 40.0 |
376| 100 Indiana Fullz | alphabase | 0.0947 |$ 40.0 |
377| 100 Utah Fullz | alphabase | 0.0947 |$ 40.0 |
378| High quality ID proof, PS work. Fake ID... | cashteam | 0.0947 |$ 40.0 |
379| Custom England Utility Bill Scan, Any D... | Kingscan | 0.0971 |$ 41.0 |
380| Wells Fargo Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
381| Huntington Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
382| RayBan Invoice Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
383| EON UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
384| NATIONWIDE BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
385| DOLCEVITA UTILITY BILLS "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
386| VIRGIN MEDIA UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
387| Cathay Pacific Flight Invoice Statement... | Nesquik7 | 0.045 |$ 19.0 |
388| West Texas Gas Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
389| FIRST DIRECT - BANK STATEMENT "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
390| Regions Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
391| The Bancorp Bank Statement "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
392| EDF UTILITY BILL "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
393| Peco Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
394| Edison California Utility Bills "TEMPLATE" | Nesquik7 | 0.045 |$ 19.0 |
395| DTE Energy Utility Bill "Template" ⇊ | Nesquik7 | 0.045 |$ 19.0 |
396| Fake passport scan Germany | EuroVCC | 0.1062 |$ 44.85 |
397| Custom Austria ID Scan, (PERSONALAUSWEI... | Kingscan | 0.1066 |$ 45.0 |
398| Fake ID scan Austria in HQ | EuroVCC | 0.1066 |$ 45.01 |
399| Custom USA SSN Social Security Number C... | LewisHa... | 0.1184 |$ 50.0 |
400| 2014 BotNet LogFilez - 1 TXT with varia... | o-c-king | 0.1184 |$ 50.0 |
401| Custom USA/UK Natwest Bank Statement Sc... | LewisHa... | 0.1184 |$ 50.0 |
402| Custom USA Bank of America Bank Stateme... | LewisHa... | 0.1184 |$ 50.0 |
403| Custom Canada Passport ID Scanned Verif... | LewisHa... | 0.1184 |$ 50.0 |
404| Full Credit File/report 4 Star rating F... | boggalertz | 0.1184 |$ 50.0 |
405| Custom UK Payslip Wage Slip Proof of Wa... | LewisHa... | 0.1184 |$ 50.0 |
406| Custom RBC Royal Canada Bank Statement ... | LewisHa... | 0.1184 |$ 50.0 |
407| Comcast Scam pages [ May 2015 ] | Code | 0.1184 |$ 50.0 |
408| Custom Malaysia Passport ID Scanned Ver... | LewisHa... | 0.1184 |$ 50.0 |
409| Custom Post 2007 USA Passport ID Scanne... | LewisHa... | 0.1184 |$ 50.0 |
410| Newest California Driver's License ID T... | GetVeri... | 0.1184 |$ 50.0 |
411| Custom Florida Driving License Scanned ... | LewisHa... | 0.1184 |$ 50.0 |
412| Custom USA Passport ID Card Scanned Ver... | LewisHa... | 0.1184 |$ 50.0 |
413| ★INSTANT DELIVERY★UNITED KINDOM TEMPLAT... | Thinkin... | 0.1184 |$ 50.0 |
414| Custom UK E-On Utility Bill Statement S... | LewisHa... | 0.1184 |$ 50.0 |
415| Custom USA Chase Bank Statement Scanned... | LewisHa... | 0.1184 |$ 50.0 |
416| Custom USA Verizon Telephone Utility Bi... | LewisHa... | 0.1184 |$ 50.0 |
417| US Chase Bank - FULL STATEMENTS SCAN W... | mikhalych | 0.1184 |$ 50.0 |
418| 10x FULLZ+BANK ACCOUNT from jahoda - EV... | jahoda | 0.1184 |$ 50.0 |
419| Custom India Passport ID Scanned Verifi... | LewisHa... | 0.1184 |$ 50.0 |
420| Custom UK Barclays Bank Statement Scann... | LewisHa... | 0.1184 |$ 50.0 |
421| ..::n0unit_Evo::..US fullz x100 | n0units | 0.1184 |$ 50.0 |
422| UK Mobile phone shop Profiles | boggalertz | 0.1184 |$ 50.0 |
423| High Quality CC scan template - Front -... | dilling... | 0.1184 |$ 50.0 |
424| Slovenian utility bill RTV TEMPLATE | CardPass | 0.1184 |$ 50.0 |
425| [Forged] 1 YEAR of Car Insurance ANY CO... | kaiba | 0.1184 |$ 50.0 |
426| Custom Canada Quebec Driving License Sc... | LewisHa... | 0.1184 |$ 50.0 |
427| UK CREDIT REPORTS (EXCELLENT+ Credit Ra... | ScJ | 0.1184 |$ 50.0 |
428| Custom UK HSBC Bank Statement Scanned V... | LewisHa... | 0.1184 |$ 50.0 |
429| Custom Austria Utility Bill Scan, Any D... | Kingscan | 0.1184 |$ 50.0 |
430| Custom USA USBank Bank Statement Scanne... | LewisHa... | 0.1184 |$ 50.0 |
431| Custom NY New York Driving License Scan... | LewisHa... | 0.1184 |$ 50.0 |
432| Custom Australia Passport ID Scanned Ve... | LewisHa... | 0.1184 |$ 50.0 |
433| Custom UK Passport ID Scanned Verificat... | LewisHa... | 0.1184 |$ 50.0 |
434| W2 Form TAX REFUND FRESH | UniccShop | 0.1184 |$ 50.0 |
435| Custom USA Passport ID Scanned Verifica... | LewisHa... | 0.1184 |$ 50.0 |
436| Custom USA Wells Fargo Bank Statement S... | LewisHa... | 0.1184 |$ 50.0 |
437| UK Profile With company info | typhoon06 | 0.1184 |$ 50.0 |
438| Custom CC Visa Mastercard Amex Credit C... | LewisHa... | 0.1184 |$ 50.0 |
439| Custom USA Xcel Energy Utility Bill Sta... | LewisHa... | 0.1184 |$ 50.0 |
440| Custom German Passport ID Card Scanned ... | LewisHa... | 0.1184 |$ 50.0 |
441| ★INSTANT DELIVERY★CANADA TEMPLATE MEGA ... | Thinkin... | 0.1184 |$ 50.0 |
442| Fresh Loan Applications + BGRs + Credit... | sal | 0.1184 |$ 50.0 |
443| Custom UK British Gas Utility Bill Scan... | LewisHa... | 0.1184 |$ 50.0 |
444| Custom Irish Utility Bill Scan, Any Det... | Kingscan | 0.1184 |$ 50.0 |
445| Custom UK Driving Licence ID Scanned Ve... | LewisHa... | 0.1184 |$ 50.0 |
446| Custom USA PPL Utility Bill Scanned Ver... | LewisHa... | 0.1184 |$ 50.0 |
447| ★INSTANT DELIVERY★USA TEMPLATE MEGA PAC... | Thinkin... | 0.1184 |$ 50.0 |
448| PSD HQ d'un chèque de banque (BNP) | FrenchyBoy | 0.1213 |$ 51.24 |
449| Custom Netherlands Utility Bill Scan, A... | Kingscan | 0.1255 |$ 53.0 |
450| Custom Spain Utility Bill Scan, Any Det... | Kingscan | 0.1255 |$ 53.0 |
451| Custom Poland Utility Bill Scan, Any De... | Kingscan | 0.1255 |$ 53.0 |
452| Custom Belgium Utility Bill Scan, Any D... | Kingscan | 0.1255 |$ 53.0 |
453| Custom France Utility Bill Scan, Any De... | Kingscan | 0.1302 |$ 55.0 |
454| Custom Pay Check Stub, Any Details | Kingscan | 0.1302 |$ 55.0 |
455| Customized HQ USA ID/DL + SSN Scan | Kingscan | 0.1302 |$ 55.0 |
456| Driver's License ID Scan | GetVeri... | 0.1421 |$ 60.0 |
457| 10 passport scans of real people Nether... | CardPass | 0.1421 |$ 60.0 |
458| Real Original ID Scan | sky88 | 0.1421 |$ 60.0 |
459| ( ^Θ^) 20x Canada Dead Fullz No Bank/C... | tastych... | 0.1421 |$ 60.0 |
460| 10 passport scans of real people France... | CardPass | 0.1421 |$ 60.0 |
461| 10 passport scans of real people UK Hig... | CardPass | 0.1421 |$ 60.0 |
462| High quality UK passport template+photo... | dilling... | 0.1421 |$ 60.0 |
463| Custom Portugal Utility Bill Scan, Any ... | Kingscan | 0.1539 |$ 65.0 |
464| FINLAND PASSPORT V1 "Template" ⇊ | Nesquik7 | 0.1634 |$ 69.0 |
465| AUSTRIA PASSPORT V1 "Template" ⇊ | Nesquik7 | 0.1634 |$ 69.0 |
466| Aussie ID - Passport AND Drivers | OzRort | 0.1658 |$ 70.0 |
467| custom ready | batard | 0.1658 |$ 70.0 |
468| Custom for Rod | batard | 0.1658 |$ 70.0 |
469| 10 Passport Scans of the USA | Passpor... | 0.1658 |$ 70.0 |
470| CUSTOM CREDIT REPORTS TO ORDER (Anyone ... | ScJ | 0.1776 |$ 75.0 |
471| Motor finance profiles, For obtaining c... | boggalertz | 0.1776 |$ 75.0 |
472| SWEDISH DRIVER LICENSE "Template" ⇊ | Nesquik7 | 0.1776 |$ 75.0 |
473| HIgh Credit Info 700+ (Good for Loans ... | el33tacid | 0.1776 |$ 75.0 |
474| ★WORLD FAMOUS™★ 23 GB OF PASSPORTS, BI... | Thinkin... | 0.1776 |$ 75.0 |
475| ITALY PASSPORT V1 "Template" ⇊ | Nesquik7 | 0.1776 |$ 75.0 |
476| Custom Australia ID Scan, (NSW) Any Det... | Kingscan | 0.1776 |$ 75.0 |
477| Scans Photos. Link to AUTO SHOP! | ilovechina | 0.1821 |$ 76.92 |
478| Custom Australia Utility Bill Scan, Any... | Kingscan | 0.1823 |$ 77.0 |
479| !!Premium Fullz with CS 750++, ALL FRES... | Darkcry... | 0.1871 |$ 79.0 |
480| 10 Passport Scans of France | Passpor... | 0.2013 |$ 85.0 |
481| Set of (3) Scans - SSN + Drivers Licens... | GetVeri... | 0.2131 |$ 90.0 |
482| USA Credit Score Complete Profiles. | batard | 0.2131 |$ 90.0 |
483| Splynter Paper v2.0 (PSD Template) | masters... | 0.2131 |$ 90.0 |
484| 10 Cartes Nationale D'identite Scan (Fr... | Passpor... | 0.225 |$ 95.0 |
485| 10 Italian Carta D'identita Scan Italy | Passpor... | 0.225 |$ 95.0 |
486| Custom listing 10 National Identity Car... | Passpor... | 0.225 |$ 95.0 |
487| USA MOTOR VEHICLE & DRIVER LICENSE & ... | livecar... | 0.2368 |$ 100.0 |
488| 47 Us states DL and IDs templates and m... | 7awjn | 0.2368 |$ 100.0 |
489| Chase Paper v3.0 (PSD Template) [Splynt... | masters... | 0.2368 |$ 100.0 |
490| katalyst's Credit Profiles (credit socr... | katalyst | 0.2368 |$ 100.0 |
491| 1,8 Million US Bank Clients Emails | bakov | 0.2368 |$ 100.0 |
492| Bulk Cpanel Deal | Code | 0.2368 |$ 100.0 |
493| USA MOTOR VEHICLE & DRIVER LICENSED A... | livecar... | 0.2368 |$ 100.0 |
494| [Forged] 1 YEAR of US Car Insurance! GE... | kaiba | 0.2368 |$ 100.0 |
495| 1.2 Million ATT & Bellsouth Emails Fresh | bakov | 0.2368 |$ 100.0 |
496| 1.825.000 USA Email Leads. ( May 2015) | Code | 0.2368 |$ 100.0 |
------------------------------------------------------------------------------------
CHOOSING A RANDOM ITEM
------------------------------------------------------------------------
WE HAVE A WINNER!
------------------------------------------------------------------------
CHOOSING SHIPPING OPTION
SELECTED: Default - 1 days - USD +0.00 / item
1.825.000 USA Email Leads. ( May 2015)
------------------------------------------------------------------------
CATEGORY: Fraud > Personal > Information > & > Scans > Personal > Information > & > Scans
PRICE USD: $ 100.0
PRICE BTC: 0.2368 BTC
VENDOR: Code
VENDOR RATING: Vendor Level 3
FROM: Worldwide
TO: Worldwide
URL: http://lo4wpvx3tcdbqra4.onion/listing.php?id=8583
------------------------------------------------------------------------
DESCRIPTION:
1.825.000 USA Email Leads. ( May
2015)--------------------------------------------------------Validity
percentage : 86%Counted Emails : 1.825.380Source :
SQL Dumps from several US Shopping sites.
↧
Show HN: IP Geolocation and Threat Data API
What is Ipdata?
It is an API to programmatically look up the locations of IP Addresses.
What would I use it for?
See a detailed answer on the main FAQs page
How do I test my GeoIP integration?
You can test whether users in different countries are seeing their local currency, weather or other geo-localised data using Geoscreenshot's awesome tool.
Can I update my card details?
Yes, send an email to support@ipdata.co requesting the change. You will receive a link from where you'll be able to securely update your details.
Can I cancel my subscription?
Yes, by sending an email to support@ipdata.co. Your request will be processed within 24hrs.
Can I get a refund?
Yes. Refunds will be prorated based on your period of usage.
What if I want to change plans?
Send an email to support requesting a cancellation of your existing plan and the plan you'd like to be upgraded to.
How long are your contracts?
You can upgrade, downgrade, or cancel your monthly account at any time with no further obligation.
Other questions?
We're always available at support@ipdata.co
↧
Giving meaning to 100B analytics events a day with Kafka, Dataflow and BigQuery
In this article, we describe how we orchestrate Kafka, Dataflow and BigQuery together to ingest and transform a large stream of events. When adding scale and latency constraints, reconciling and reordering them becomes a challenge, here is how we tackle it.
In digital advertising, day-to-day operations generate a lot of events we need to track in order to transparently report campaign’s performances. These events come from:
- Users’ interactions with the ads, sent by the browser. These events are called tracking events and can be standard (start, complete, pause, resume, etc.) or custom events coming from interactive creatives built with Teads Studio. We receive about 10 billion tracking events a day.
- Events coming from our back-ends, regarding ad auctions’ details for the most part (real-time bidding processes). We generate more than 60 billion of these events daily, before sampling, and should double this number in 2018.
In the article we focus on tracking events as they are on the most critical path of our business.
Tracking events are sent by the browser over HTTP to a dedicated component that, amongst other things, enqueues them in a Kafka topic. Analytics is one of the consumers of these events (more on that below).
We have an Analytics team whose mission is to take care of these events and is defined as follows:
We ingest the growing amount of logs,
We transform them into business-oriented data,
Which we serve efficiently and tailored for each audience.
To fulfill this mission, we build and maintain a set of processing tools and pipelines. Due to the organic growth of the company and new products requirements, we regularly challenge our architecture.
Why we moved to BigQuery
Back in 2016, our Analytics stack was based on a lambda architecture (Storm, Spark, Cassandra) and we were having several problems:
- The scale of data made it impossible to have it all in a single Cassandra table, which prevented efficient cross-querying,
- It was a complex infrastructure with code duplication for both batch and speed layers, preventing us from releasing new features efficiently,
- In the end it was difficult to scale and not cost efficient,
At that time we had several possible options. First, we could have built an enhanced lambda but it would have only postponed the problems we were facing.
We considered several promising alternatives like Druid and BigQuery. We finally chose to migrate to BigQuery because of its great set of features.
With BigQuery we are able to:
- Work with raw events,
- Use SQL as an efficient data processing language,
- Use BigQuery as the processing engine,
- Make explanatory access to date easier (compared to Spark SQL or Hive),
Thanks to a flat-rate plan, our intensive usage (query and storage-wise) is cost efficient.
However, our technical context wasn’t ideal for BigQuery. We wanted to use it to store and transform all our events coming from multiple Kafka topics. We couldn’t move our Kafka clusters away from AWS or use Pub/Sub, the managed equivalent of Kafka on GCP, since these clusters are used by some of our ad delivery components also hosted on AWS. As a result, we had to deal with the challenges of operating a multi-cloud infrastructure.
Today, BigQuery is our data warehouse system, where our tracking events are reconciled with other sources of data.
Ingestion
When dealing with tracking events, the first problem you face is the fact that you have to process them unordered, with unknown delays.
The difference between the time the event actually occurred (event time) and the time the event is observed by the system (processing time) ranges from the millisecond up to several hours. These large delays are not so rare and can happen when the user loses its connection or activates flight mode in between browsing sessions.
For further information about the challenges of streaming data processing, we recommend to have a look at Google Cloud Next ’17 talk « Moving back and forth between batch and stream processing » from Tyler Akidau (tech lead for data processing at Google) and Loïc Jaures (Teads’ co-founder and SVP Technology). The article is inspired by this talk.
The hard reality of streaming
Dataflow is a managed streaming system designed to address the challenges we face with the chaotic nature of the events. Dataflow has a unified streaming and batch programming model, streaming being the flagship feature.
We were sold on Dataflow’s promises and candidly tried streaming mode. Unfortunately, after opening it to real production traffic, we had an unpleasant surprise: BigQuery’s streaming insertion costs.
We had based our estimations on compressed data size (i.e. the actual volume of bytes that goes through the network), and not BigQuery’s raw data format size. Fortunately this is now documented for each data type so you can do the math.
Back then, we had underestimated this additional cost by a factor of 100, which almost doubled the cost of our entire ingestion pipeline (Dataflow + BigQuery). We also faced other limitations like the 100,000 events/s rate limit, which was dangerously close to what we were doing.
The good news was that there is a way to completely avoid streaming inserts limitation: batch load into BigQuery.
Ideally, we would have liked to use Dataflow in streaming mode with BigQuery in batch mode. At that time there was no BigQuery batch sink for unbounded data streams available in the Dataflow SDK.
We then considered developing our own custom sink. Unfortunately, it was impossible to add a custom sink to an unbounded data stream at the time (see Dataflow plans to add support for custom sinks that write unbounded data in a future release — it may be possible now that Beam is the official Dataflow SDK).
We had no choice but to switch our Dataflow job to batch mode. Thanks to Dataflow’s unified model it was only a matter of a few lines of code. And luckily for us, we could afford the additional data processing delay introduced by the switch to batch mode.
Moving forward, our current ingestion architecture is based on Scio, a Scala API for Dataflow open sourced by Spotify. As previously said, Dataflow natively supports Pub/Sub but Kafka integration was less mature. We had to extend Scio to enable offset checkpoint persistence and enable an efficient parallelism.
A micro batch pipeline
Our resulting architecture is a chain of 30 min Dataflow batch jobs, sequentially scheduled to read a Kafka topic and write to BigQuery using load jobs.
One of the key was finding the ideal batch duration. We found that there is a sweet spot to have the best trade-off between cost and reading performance (thus latency). The variable to adjust is the duration of the Kafka read phase.
To end up with the complete batch duration, you have to add the write to BigQuery phase (not proportional, but closely linked to the read duration), and a constant that is the boot and shutdown duration.
Worth noting:
- A too short reading phase will lower the ratio between reading and non-reading phases. In an ideal world, a 1:1 ratio would mean that you have to be able to read just as fast as you’re writing. In the example above, we have a 20 min read phase, for a 30 min batch (3:2 ratio). This means we have to be able to read 1.5x faster than we write. A small ratio means a need for bigger instances.
- A too long read phase will simply increase the latency between the time the event occurred and when it is available in BigQuery.
Performance tuning
Dataflow jobs are launched sequentially for simplicity reasons and easier failure management. It’s a latency trade-off we are willing to take. If a job fails we simply go back to the last commited Kafka offset.
We had to modify our Kafka clusters’ topology and increased the number of partitions to be able to unstack messages faster. Depending on the transformations you do in Dataflow, the limiting factor will most likely be the processing capacity or the network throughput. For efficient parallelism you should always try to keep a number of CPU threads that is a divisor of the number of partitions you have (corollary: it’s nice to have a number of Kafka partitions that is a highly composite number).
In the rare case of delays we are able to fine tune the job with longer read sequences. By using bigger batches, we are also able to catch up with the delay at the expense of latency.
To handle most of the situations we sized Dataflow to be able to read 3 times faster than the actual pace. A 20 min read with a single n1-highcpu-16instance can unstack 60 minutes of messages.
In our use case, we end up with a sawtooth latency that oscillates between 3 min (minimum duration of the Write BQ phase) and 30 min (total duration of a job).
Transformation
Raw data is inevitably bulky, we have too many events and cannot query them as is. We need to aggregate this raw data to keep a low read time and compact volumes. Here is how we do it in BigQuery:
Unlike traditional ETL processes where data is Transformed before it is Loaded, we choose to store it first (ELT), in a raw format.
It has two main benefits:
- It lets us have access to each and every raw event for fine analysis and debug purposes,
- It simplifies the entire chain by letting BigQuery do the transformations with a simple but powerful SQL dialect.
We would have liked to directly write into the raw events table that is daily partitioned. We couldn’t because a Dataflow batch has to be defined with a specific destination (table or partition) and could include data intended for different partitions. We solve this problem by loading each batch into a temporary table and then begin transforming it.
For each of these temporary batch tables, we run a set of transformations, materialized as SQL queries that output to other tables. One of these transformations simply append all the data to the big raw events table, partitioned by day.
Another of these transformations is the rollup: an aggregation of the data, given a set of dimensions. All these transformations are idempotent and can be re-run safely in case of error or need for data reprocessing.
Rollups
Querying the raw events table directly is nice for debugging and deep analysis purposes, but it’s impossible to achieve acceptable performance querying a table of this scale, not to mention the cost of such operation.
To give you an idea, this table has a retention of 4 months only, contains 1 trillion events, for a size close to 250TB.
In the example above we rollup event counts for 3 dimensions: Hour, Ad ID, Website ID. Events are also pivoted and transformed to columns. The example shows a 2.5x size reduction, whereas the reality is closer to 70x.
In BigQuery’s massively parallel context, query runtime isn’t much impacted, the improvement is measured on the number of slots used.
Rollups also let us partition data into small chunks: events are grouped into small tables for a given hour (hour of the event time, not the processing time). Therefore, if you need to query the data for a given hour, you’ll query a single table (<10M rows, <10GB).
Rollups are one kind of general purpose aggregation we do to be able to query all the events more efficiently, given a large set of dimensions. There are other use cases where we want dedicated views of the data. Each of them can implement a set of specific transformations to end up with a specialized and optimized table.
Limits of a managed service
BigQuery, as powerful as it can be, has its limits:
- BigQuery doesn’t allow queries to multiple tables that have different schemas (even if the query is not using the fields that differ). We have a script to bulk update hundreds of tables when we need to add a field.
- BigQuery doesn’t support column drop. Not a big deal, but not helping to pay the technical debt.
- Querying multiple hours: BigQuery supports wildcard in table name, but performance is so bad we have to generate queries that explicitly query each table with UNION ALL.
- We always need to join these events with data hosted on other databases (e.g. to hydrate events with more information about an advertising campaign), but BigQuery does not support it (yet). We currently have to regularly copy entire tables to BigQuery to be able to join the data within a single query.
Joys of inter-cloud data transfer
With Teads’ ad delivery infrastructure in AWS and a Kafka cluster shared with many other components, we have no choice but to move quite a lot of data between both AWS and GCP Clouds, which is not easy and certainly not cheap. We located our Dataflow instances (thus the main GCP entry point) as close as possible to our AWS infrastructure, and fortunately, the existing links between AWS and GCP are good enough so we can simply use managed VPNs.
Although we encountered some instability running these VPN, we managed to sort it out using a simple script that turns it off and on again. We have never faced big enough problems to justify the cost of a dedicated link.
Once again, cost is something you have to closely watch and, where egress is concerned, difficult to assess before you see the bill. Carefully choosing how you compress data is one of the best leverage to reduce these costs.
Only halfway there
Having all these events in BigQuery is not enough. In order to bring value to the business, data has to be hydrated with different rules and metrics. Besides, BigQuery isn’t tailored for real-time use cases.
Due to concurrency limits and incompressible query latency of 3 to 5 sec (acceptable and inherent to its design), BigQuery has to be compounded with other tools to serve apps (dashboards, web UIs, etc.).
This task is performed by our Analytics service, a Scala component that taps onto BigQuery to generate on-demand reports (spreadsheets) and tailored data marts (updated daily or hourly). This specific service is required to handle the business logic. It would be too hard to maintain as SQL and generate data marts using the pipeline transformation otherwise.
We chose AWS Redshiftto store and serve our data marts. Although it might not seem to be an obvious choice to serve user-facing apps, Redshift works for us because we have a limited number of concurrent users.
Also, using a key/value store would have required more development effort. By keeping an intermediate relational database, data marts consumption is made easier.
There is a lot to say on how we build, maintain and query those data marts at scale, but it will be the subject of another article.
↧
↧
Basis Protocol/Basecoin: the worst idea in cryptocurrency, reborn
See also Bitshares: Don’t walk away – run, Stablecoins are doomed to fail, Stablecoins are doomed to fail, part II, and Stablecoins are doomed to fail, part III.
UPDATE, 4/18/18 – it appears Basecoin has changed its name to “Basis Protocol” and has also raised $133 million from top Valley investors including A16Z, Bain, Lightspeed, and Google Ventures anyway. Despite the fact that it’s an economic dumpster fire.
Cryptocurrency today is borderline euphoric. As it should be, considering that many of its leading voices are printing money, having made investments in 2010 that have paid off at a rate of 65,000,000% as of earlier this morning. These same voices call to you now to join them in this revolution of personal investment and wealth generation driven by technology. This is the core underlying cause of the ICO mania.
I have been around “blockchain” for some time. Early enough to remember the prosperity gospel surrounding the first useless ICO craze in late 2013 and early 2014, where the celebrated cryptocoin projects were those that few if any of you have heard of today: such as Protoshares, Bitshares, MaidSafe, or others.
Today’s prosperity gospel features revamped, slicker, prettier, younger versions of those projects. Like Tezos (Ethereum 2: Electric Boogaloo), Eos (Also Ethereum 2: Electric Boogaloo), Cardano (also Ethereum 2: Electric Boogaloo), DFinity (again, Ethereum 2: Electric Boogaloo), Augur (Truthcoin 2: Electric Boogaloo), Gnosis (Augur 2: Electric Boogaloo), Filecoin (StorJ 2: Electric Boogaloo), and…
Basecoin
The latest of these is a proposed cryptocurrency called Basecoin (Bitshares 2: Electric Boogaloo) (edit: which appears to have renamed itself Basis?) which, we learn, has received investment from a smattering of reputable traditional VC firms (including Andreessen Horowitz and Bain Capital Ventures) as well as the top crypto-only outfits (Pantera, DCG and Polychain).
The product? To create what Coindesk calls
“the crypto holy grail: a stable token.”
This is an exceedingly bad idea.
The concept is so profoundly ill-conceived that I’d venture to say the “Stablecoin” is the closest thing the crypto world has for an answer to the Hitchiker’s Guide to the Galaxy’s Ravenous Bugblatter Beast from Traal, a creature known not only for being extremely vicious and hungry, but also for being denser than a neutron star. Which, for those of us not versed in stellar physics, is very dense indeed. In that series of books, the Traalbeast is regarded as the single dumbest creature in the entire universe, a failure of evolution so complete and irredeemable that it “believes if you can’t see it, it can’t see you.”
It’s thus with this pernicious idea of the stable coin: a free-floating digital commodity devoid of intrinsic value that doesn’t assume the market prices it, but rather that it prices for the market, and which only works by devouring new investment money at every available opportunity. This is far from the first time such a scheme has been attempted; the BitsharesX cryptocurrency, abandoned two years ago by its founder (Eos’ Dan Larimer) to work on other, more lucrative projects, claimed to possess a working asset peg that operates through a similar mechanism to that Basecoin proposes.
Bitshares’ stablecoin, “BitUSD,” has not been wildly successful; it manages to hold its peg but only on extremely thin trading which could quite easily be maintained through market manipulation.

Note, in 2014 Bitshares’ “BitUSD” dollar peg fell flat on its face less than 100 hours from launch, with the result that the core developers were forced to shut the thing off. I liveblogged it at the time so you can see for yourself how it all went down.
Basecoin claims to solve the problem of wildly fluctuating cryptocurrency prices through the issuance of a cryptocurrency for which “tokens can be robustly pegged to arbitrary assets or baskets of goods while remaining completely decentralized.” This is achieved, the paper states in its abstract, by the fact that “1 Basecoin can be pegged to always trade for 1 USD. In the future, Basecoin could potentially even eclipse the dollar and be updated to a peg to the CPI or basket of goods.”
(Interjecting, I once had a sit-down chat with A16Z. I have no idea how on Earth this startup got away with hyperbole like this. Guess I had the wrong approach.)
Continuing, Basecoin claims that it can “algorithmically adjust…the supply of Basecoin tokens in reponse to changes in, for example, the Basecoin-USD exchange rate… implementing a monetary policy similar to that executed by central banks around the world”.
Two points.
First, this is not how central banks manage the money supply. Something akin to a price-first approach (really a spending-first approach) to managing the money supply is known as Nominal GDP Targeting (NGDPT) and is currently in vogue among fringe libertarian groups like the Adam Smith Institute, which means we should probably expect it to be official policy of the Bank of England at some point in the next 10 years. Just not today.
But of course, Basecoin isn’t actually creating a monetary supply, which central banks will into existence and then use to buy assets, primarily debt securities. Basecoin works by creating an investable asset which the “central bank” (i.e. the algorithm, because it’s nothing like a central bank) issues to holders of the tokens which those token holders then sell to new entrants into the scheme.
Buying assets to create money vs. selling assets to obtain money. There’s a big difference.
Second,
We need to talk about how a peg does and doesn’t work

Convertibility, parity
Currently there are very efficient ways to peg the price of something to something else, let’s say (to keep it simple) $1. The first of these would be to execute a trust deed (cost: $0) saying that some entity, e.g. a bank, holds a set sum of money, say $1 billion, on trust absolutely for the holders of a token, which let’s call Dollarcoin for present purposes. If the token is redeemable at par from that bank (qua Trustee and not as depository), then the token ought to trade at close to $1, with perhaps a slight discount depending on the insolvency risk to which a Dollarcoin holder is exposed (although there are well-worn methods to keep the underlying dollars insolvency-remote, i.e. insulated from the risk of a collapse of that bank).
Put another way, there is a way to turn 1 dollarcoin into a $1 here. Easy-peasy, no questions asked, with ancient technology like paper and pens or SQL tables. The downside of course is that you need to 100% cash collateralize the system, which is (from a cost of capital perspective) rather expensive. This is the reason why fractional reserve banking exists.
Convertibility, no parity
Here is where we find the official pegs of the Zimbabwean Dollar or the Venezuelan bolívar. These currencies maintain official pegs (e.g. 710 bolívar: $1) which vastly overstate the value of the domestic national currency vis-à-vis their actual US dollar price on the free markets (e.g. 60,000 bolívar: $1) . More successful examples include the European ERM, although that too fell apart when George Soros took advantage of it to kick England’s ass in 1992.
These situations are an object lesson in why you don’t try to peg currencies: because you are unable to hold the peg any longer than you can afford to subsidize your differences of opinion with the market. Once you run out of firepower, the peg breaks, and ceases to have any useful meaning except perhaps to assuage the egos of delusional tyrants who insist on its continued maintenance.
But you need to study politics, economics and history to learn things like this, which I understand are not computer science and are therefore unpopular.
No convertibility, parity?
Alternatively, we could make something like Tether, which is sort of like Dollarcoin above but with one important qualification. Tether says its tokens, which are listed on a corporate affiliate’s exchange (Bitfinex), are backed 1:1 by USD in an account at an as-yet-unnamed bank, probably somewhere in Asia. Tether does not say that there is any contractual mechanism to convert these tokens into USD. The tokens trade at close to $1 despite the fact there is no way for most people to actually turn them into dollars, due in large part to banking issues a certain exchange has had lately. It is thus very much unlike Dollarcoin.
Put another way, there is not a way to turn 1 Tether into 1 dollar, yet somehow the thing trades at a dollar on the exchange run by its corporate parent. Sketchy, but I can trade that into Bitcoin, so what the hell. Party on.
No convertibility, no parity
This is where stablecoins go.
The third way might be called “the Bitshares way” (or the “Basecoin way” thanks to the fact that Bitshares really isn’t much of an actively developed project anymore). This approach involves having a bunch of cryptocurrency and then manipulating either (a) the supply of the cryptocurrency or (b) the supply of pools of collateral which “back” it in order to artificially support its price on off-chain markets.
This is why Basecoin (hereinafter “$BASE” or “BASE”) is not really one cryptocurrency. In fact, it is three cryptocurrencies in one.
But before we get to that, here’s a helpful chart I made for you, using fancy legal graphics software, summarizing what we’ve covered so far:

Down the rabbit hole: how Basecoin is supposed to work, in English
True to form, there’s a 19-page white paper running to 10,000 words and published with LaTeX, so it’s formatted like hot death and the font is too small. Fortunately, I can deal with it in about five hundred words.
To spare myself unnecessary typing, I will simply screen shot the white paper:

In English:
There’s a coin. Called BaseCoin. It should be worth, arguendo, $1 on the market at all times.
The decentralized protocol, which has no way of independently verifying what is going on in the outside world, relies on a third party’s computer to tell the protocol what 1 BASE is trading for on Kraken/Polo/whatever (also a third party) and to modify its new coin issuance by relying totally on that third party data feed. In other words, it’s not decentralized at all.
If the price of 1 BASE is above $1, the blockchain prints new $BASE to holders of “BASE Shares” (mother of god), a standalone cryptocurrency which is issued in the genesis block and held by early adopters, which then distributes new Basecoins to them as a “dividend.” Holders of “BASE Shares” are free to either hold onto their Dividend-Basecoins (thus not bringing the price down) or sell them into the market, pushing out the supply curve and bringing down 1 BASE’s price. This process continues until the price of 1 BASE drops to $1.
If the price of 1 BASE is below $1, the blockchain prints “BASE Bonds,” which aren’t really “bonds” at all but rather are BASE call option/future hybrid critters (feel free to amend the white paper, team Basecoin. No charge). If 1 BASE costs $0.80, for example, and the peg is $1.00, the “BASE Bondholder” spends $0.80 with a promise that once the peg is hit again the “bond” (again, really an option contract of sorts, and not a bond) will convert at 0.8:1. This is also supposed to be a standalone cryptocurrency of its own.
Oh, and “BASE Bond” holders are paid not pro rata and pari passu, which is what would happen with a class of bondholders who hold real bonds (which I used to draft for a living), but rather on a first-in first-out basis, like payments are made in a pyramid scheme. Which of course is all the more incentive for BASE Bondholders to “evangelize” after they buy.
As a result of all this we are told, again in CoinDesk, that
“…the basecoin protocol can be pegged to the value of any asset or basket of assets, dynamically adjusting its market price through the creative use of a combination of tokens… ‘(we aim to prove) this actually works and that the peg stays put no matter what'”.
Which it won’t, just like BitShares didn’t when the BitUSD market didn’t consist entirely of wash trades. But anyway, as part of proving their concept, there will presumably in the near future be a public-facing ICO where “Base Shares” will be sold and hey, better get in fast because Tim Draper was behind Tezos, and OMG A16Z INVESTED IN BASECOIN and everyone knows that A16Z is the only firm in town hotter than Draper’s.
It’ll work fine while we’re all going “to the moon.” On the way down, however, there will be insufficient new “bond collateral” entering the scheme to bring the price back up and the only way you can achieve stability is by way of massive buys on the part of insiders. Which speculators will trade against, as they did when they broke the Bank of England in 1992, and when they broke Paycoin in 2014. They will break Basecoin.
Dunning-Krugerrands
The rest of the paper is a lot of citation-needed, freshman-dorm-room economics. I mean, come on:
Conceptually, the Bond Queue is similar to the US national debt. Just like how the Basecoin system issues Base Bonds that go into the Bond Queue, the Fed issues Treasury bonds that add to the national debt.
When the national debt is too large, faith in Treasury bonds drops, resulting in higher borrowing costs that, if left unpaid, eventually manifest as future inflation, higher future taxes, or future default. By capping the size of the Bond Queue and defaulting on bonds that are too old, the Basecoin system disallows this tax on future stability. Instead, its fixed bond expiration transparently taxes the present. We propose a 5-year bond expiration that we have shown by rigorous analysis and simulation to result in a robust system with sufficiently high bond prices even in the face of wild price swings.
Except it’s nothing like that at all. Government bonds are obligations of governments. They function as money-substitutes while they remain outstanding, but they have nothing to do with the price of money itself – or money’s issuers, for that matter, who are independent central banks.
Central banks purchase bonds to create money in a process known as open market operations. They do not issue their own bonds in an effort to stabilize the currency they issue (in which the bond is denominated) as pegged to some second asset.
When the white paper’s authors speak of Fed “open market operations” as being the Fed creating bonds, or conflate monetary and fiscal policy, they betray an ignorance of finance requiring at least a two-year postgraduate master’s and several years’ work experience to cure. This lack of practical knowledge has led them to make assumptions so obviously faulty that the operating thesis of the entire project is undermined.
Due to the Basecoin team’s failure to ascertain the difference between the Treasury Department and the Federal Reserve System, the structure their “white paper” puts forward – which can be summarised as “I create a coin, which will always revert to a market price of $1 per coin regardless of quantity demanded, backed by bonds which I issue, which are denominated in the coins I just created, and redeemed for coins I will later create” – is recursive, or the financial equivalent of a perpetual motion machine.
The money to keep the machine going must come from somewhere, and in this case that somewhere is a new investor willing to subsidize profit-taking by earlier participants in the scheme by committing risk capital of his own. When he stops investing, Basecoin loses its ability to hold the peg.
How’s that for “rigorous analysis.”
Or this:
one day, Basecoin might become so widely used as a medium of exchange that it actually starts to displace the USD in transaction volume.
Please. Figure out what a government bond is, first. Then we can have a little chat about scalability.
All the above, mind you, is without conducting any securities law, Bank Secrecy Act, or international AML and terrorist financing analysis, on which I could write chapter and verse. But that’s a conversation for another day.
Mises wept
If this level of overwrought garbage is what one needs to get past a top VC’s investment committee these days, I weep for entrepreneurship.
Anyway. I’m at roughly 2,000 words, which is about 1,000 more than I set out to write an hour ago. So I’ll wrap up. It seems to me on this very cursory review that Basecoin depends on
- Printing free money and giving it to crypto-investors who are inclined to hold it and thus restrict supply;
- providing financial incentives to subsequent investors to introduce money into the scheme and subsidize the price of the scheme if the price of a coin should fall below a certain level (say, $1);
- with a not-at-all-decentralized reliance on price indicators provided by unsupervised, unregulated third-party markets already widely suspected of serious shenanigans;
- with the primary benefits accruing to early buyers in an unregulated ICO;
- which is completely dependent upon, and immediately falls apart without, new buyers for $BASE.
Similarly, a cascading margin call situation could lead to failure to hold the peg in such a way as to require a lot of new money and a very convoluted two-step investment process to recapture it. This, in a business where most users can’t even manage their private keys.
Investment schemes which are backed only by new investors and not by real assets go by a number of names. I leave it to you, dear reader, to decide what name you will choose to give to this one.
When dealing with crypto-assets, which are crazy enough already, trying to build for “stability” in relation some to third, highly liquid, mass-adopted asset like 1 USD is folly: even if this approach to setting prices of goods (what we want the goods to be priced, rather than the price of things being what purchasers are willing to pay for them) had ever worked in the 6,000 years of recorded history preceding us (it hasn’t), these things only work as long as the humans are playing along.
I don’t care how complex your algo is. If nobody’s buying, your network’s up a creek without a paddle. Today it’s within the realm of possibility that adoption is going to hockey stick like the price of Bitcoin. Perhaps it will. Maybe it’ll take awhile. Maybe some folks will go to jail along the way. But it won’t be able to do it forever, which is a problem given that eternal growth is precisely what is required in order for a scheme like Basecoin – which has no real income-generating assets backing it – to work. Which means, as would any scheme dependent on gobbling up the world to succeed, the Basis Protocol is doomed to failure.
For which reason I suspect that, before too long, we will relearn the lessons of the past, and that the laws of economics have not been suspended.
Postscript, 2 January 2018
It gets worse.
↧
Hello wasm-pack

As Lin Clark emphasizes in her article about Rust and WebAssembly: the goal of WebAssembly is not to replace JavaScript, but to be an awesome tool to use with JavaScript. Lots of amazing work has been done to simplify crossing the language boundary between JavaScript and WebAssembly, and you can read all about that in Alex Crichton’s post on wasm-bindgen. This post focuses on a different type of JavaScript/Rust integration: package ecosystem and developer workflows.
Both Rust and JavaScript have vibrant package ecosystems. Rust has cargo and crates.io. JavaScript has severalCLItools, including the npm CLI, that interface with the npm registry. In order for WebAssembly to be successful, we need these two systems to work well together, specifically:
- Rust developers should be able to produce WebAssembly packages for use in JavaScript without requiring a Node.js development environment
- JavaScript developers should be able to use WebAssembly without requiring a Rust development environment
✨📦 Enter: wasm-pack.
wasm-packis a tool for assembling and packaging Rust crates that target WebAssembly. These packages can be published to the npm Registry and used alongside other packages. This means you can use them side-by-side with JS and other packages, and in many kind of applications, be it a Node.js server side app, a client-side application bundled by Webpack, or any other sort of application that uses npm dependencies. You can find wasm-pack on crates.io and GitHub.
Development of this tooling has just begun and we’re excited to get more developers from both the Rust and JavaScript worlds involved. Both the JavaScript and Rust ecosystems are focused on developer experience. We know first hand that the key to a productive and happy ecosystem is good tools that automate the boring tasks and get out of the developer’s way. In this article, I’ll talk about where we are, where we’re headed, how to get started using the tooling now, and how to get involved in shaping its future.
💁 What it does today

Today, wasm-pack walks you through four basic steps to prepare your Rust code to be published as a WebAssembly package to the npm registry:
1. Compile to WebAssembly
wasm-pack will add the appropriate WebAssembly compilation target using rustup and will compile your Rust to Web Assembly in release mode.
To do this, wasm-pack will:
- Add the
wasm32-unknown-unknowncompilation target, if needed - Compile your Rust project for release using the wasm target
2. Run wasm-bindgen
wasm-pack wraps the CLI portion of the wasm-bindgen tool and runs it for you! This does things like wrapping your WebAssembly module in JS wrappers which make it easier for people to interact with your module. wasm-bindgen supports both ES6 modules and CommonJS and you can use wasm-pack to produce either type of package!
To do this, wasm-pack will:
- If needed, install and/or update
wasm-bindgen - Run
wasm-bindgen, generating a new.wasmfile and a.jsfile - Moves the generated files to a new
pkgdirectory
3. Generate package.json
wasm-pack reads your Cargo.toml and generates the package.json file necessary to publish your package to the npm registry. It will:
To do this, wasm-pack will:
- Copy over your project
nameanddescription - Link to your Rust project’s
repository - List the generated JavaScript files in the
fileskey. This ensures that those files, and only those files, are included in your npm package. This is particularly important for ensuring good performance if you intend to use this package, or a bundle including this package, in the browser!
4. Documentation
wasm-pack will copy your Rust project’s README.md to the npm package it produces. We’ve got a lot of great ideas about extending this further to support the Rust ecosystem’s documentation feature, rustdoc– more on the in the next section!
🔮 Future Plans
Integrate with rustdoc
The crates.io team surveyed developers, and learned that good documentation was the number one feature that developers looked for when evaluating the use of crate. Contributor Yoshua Wuyts introduced the brilliant idea of generating further README.md content by integrating wasm-pack with the Rust API documentation tool, rustdoc. The Rust-wasm team is committed to making Rust a first class way to write WebAssembly. Offering documentation for Rust-generated WebAssembly packages that’s both easy to write and easy to discover aligns neatly with our goals. Read more about the team’s thoughts in this issue and join in the discussion!
Manage and Optimize your Rust and JS dependency graphs
The next large piece of development work on wasm-pack will focus on using custom segments in compiled WebAssembly to declare dependencies on local Javascript files or other npm packages.
The preliminary work for this feature has already landed in wasm-bindgen, so the next step will be integrating it into wasm-pack. The naive integration won’t be too tricky- but we’re excited to explore the opportunities we have to streamline and optimize Rust dependency trees that contain npm dependencies on several levels! This work will be similar to the optimizations that bundlers like webpack deliver, but on the level of Rust dependencies.
There’s a lot of questions we still have to answer and there’s going be a lot of neat engineering work to do. In a few weeks there will be a full post on this topic, so keep an eye out!

Grow Node.js toolchain in Rust
The largest and most ambitious goal of this project is to rewrite the required npm login, npm pack and npm publish steps in Rust so that the required dependency on a Node.js development environment becomes optional for those who don’t currently use Node.js in their workflow. As we’ve said before, we want to ensure that both WebAssembly package producers and users can remain in their familiar workflows. Currently, that is true for JavaScript developers- they do not need to have a Rust development environment or any knowledge of Rust to get started using a Rust-generated WebAssembly module that’s been published with wasm-pack. However, Rust developers still need to install Node.js and npm to publish with wasm-pack, we’re excited to change that by writing a npm package publisher in Rust- and who knows, perhaps we can eventually integrate some Rust elements (perhaps compiled to WebAssembly!) into the npm client!
Further collaboration with npm and bundlers
We’re always communicating with the npm CLI team members Kat Marchan and Rebecca Turner, as well as the folks who work on webpack and Parcel– we’re excited to keep working with them to make it easy for developers to release and use WebAssembly code!
🛠 Start using it today!
wasm-pack is currently a command line tool distributed via Cargo. To install it, setup a Rust development environment, and then run:
cargo install wasm-packIf you aren’t sure where to start, we have a tutorial for you! This tutorial, by Michael Gattozzi and the Rust-wasm working group, walks you through:
- writing a small Rust library
- compiling it to WebAssembly, packaging, and publishing with
wasm-pack - bundling with webpack to produce a small website

👯♀️Contribute
The key to all excellent developer tooling is a short feedback cycle between developers of the tool and developers using the tool in their day to day workflows. In order to be successful with wasm-pack, and all of our WebAssembly developer tooling, we need developers of all skill levels and backgrounds to get involved!
Take a look at our Contributor Guidelines and our Issue Tracker (we regularly label things as “good first issue” and provide mentors and mentoring instructions!)- we’re excited to work with you!
Ashley Williams is an engineer at Integer32, contracting for Mozilla on the Rust Programming Language. She is a member of the Rust Core team, leads the Rust Community Team, and helps maintain Rust's package registry, crates.io. Previously, she worked as an engineer at npm, the package manager for Javascript, and currently is the Individual Membership Director on the Node.js Foundation Board of Directors. A long time teacher, Ashley has focused much of her energies on education programs for open source projects, founding NodeTogether in 2016 and currently leading the RustBridge initiative. She has represented teachers' perspectives at TC39 meetings to influence the growth of JavaScript and continues to be passionate about growing the web through her work on Web Assembly.
↧
The gene family that cheats Mendel (2017)
Many of the traits an individual has, from eye color to the risk of having certain diseases, are passed from parents to their children via their genes. In diploid organisms, such as humans, most cells contain two copies – or alleles – of every gene. The exceptions to this rule are gametes (that is, sperm and egg cells), which contain just one allele. According to Mendel’s famous law of segregation, half of the gametes will carry one allele for a given gene, and the other half will carry the other allele. Thus, both of the mother’s alleles have an equal chance of being passed on to her children, and likewise for the father’s alleles.
However, some alleles defy Mendel’s law and can increase their chances of being transmitted to the next generation by killing gametes that do not share the same alleles (Burt and Trivers, 2006). Genes harboring alleles that behave in this way have been identified in plants, fungi and animals – including humans – and are called by various names, including selfish drivers, gamete killers and spore killers.
There are many types of selfish drivers and much remains unclear about how they work, though they can generally be distinguished by the way they destroy other cells. In the ‘poison-antidote’ model, the selfish driver produces a poison that destroys all gametes unless an antidote is there to protect them from the effects of the poison (Figure 1A and B). In the ‘killer-target’ model, the selfish driver produces a poison that kills gametes that carry a specific target (Figure 1C).

The poison-antidote and killer-target models of selfish drivers.
In both models, a particular allele has an increased chance of being passed on to the next generation because it produces a toxin to kill gametes that do not carry it. (A, B) In the poison-antidote model, cells produce a toxin (shown as skull-and-crossbones) that can be neutralized by an antidote (shown as a pill); the alleles that do not code for either are shown in gray. In the single-gene model (A) the same gene codes for both the poison and the antidote through alternative transcription. Nuckolls et al. show that the gene wtf4 is a selfish driver in Schizosaccharomyces yeasts. Hu et al. show that two other genes in the wtf family (cw9 and cw27) are also selfish drivers. In the two-gene model (B) different genes produce the poison and antidote, as in the fungus Neurospora (Hammond et al., 2012). (C) In the killer-target model, the toxin only destroys cells that contain alleles with a specific target marker (shown here by concentric black circles). This is the case in Drosophila, where the segregation distortion (Sd) allele acts by killing gametes that contain a sensitive Responder (Rsps) marker (Larracuente and Presgraves, 2012).
Aiming to understand how selfish drivers have evolved and work, two research groups – one led by Sarah Zanders and Harmit Malik, the other by Li-Lin Du – turned to two species of fission yeast, Schizosaccharomyces kambucha and S. pombe. These two species are genetically nearly identical, and some researchers do not even consider them as separate species (Rhind et al., 2011), but hybrids between the two are often sterile. In previous studies, Zanders and co-workers discovered that S. kambucha has at least three selfish drivers that cause infertility in the hybrids (Zanders et al., 2014).
To unravel the genetic identity of these selfish drivers in yeast, Zanders, Malik and co-workers at the Stowers Institute for Medical Research, the Fred Hutchinson Cancer Research Center and the University of Kansas Medical Center – including Nicole Nuckolls and Maria Angelica Bravo Núñez as joint first authors – isolated a region on a chromosome that caused selfish drive (Nuckolls et al., 2017). Within this region, they found a selfish-driver gene called wtf4– a member of a large and cheekily-named gene family – which creates both a poison and an antidote.
To explore the underlying mechanisms in more detail, Nuckolls et al. created fluorescent versions of the poison and the antidote and mapped their location inside and around the gametes. These elegant experiments showed that wtf4’s poison can leave their originating cells and cross into surrounding cells while the antidote remains trapped inside the cells that produce it.
In an independent study, Du and co-workers at the National Institute of Biological Sciences in Beijing – including Wen Hu as first author – identified two other genes from the wtf gene family, named cw9 and cw27, as selfish drivers that also employ the poison-antidote model in crosses between different strains of S. pombe (Hu et al., 2017). They found that mutant diploid strains missing both copies of either cw9 or cw27 survived more than strains missing only one copy of the gene, indicating that both genes are selfish drivers. When they created diploid mutants missing a copy of cw9 and cw27, the yeast strains survived even less compared to strains missing a copy of only one of the two genes. This suggests that the two genes do not rescue each other and that they act independently to drive survival.
By identifying several genes within the same family that can kill cells that are different, and by exploring their mode of action, the work of these two groups enriches our understanding of the genes that break Mendel’s acclaimed genetic law. Future work in this area will help us to understand the impact of selfish elements on genetic diversity and may lead to a deeper understanding of how these mechanisms affect conditions such as infertility in species as diverse as plants, fungi and animals – including humans.
↧
Dataturks – ML data annotations and labeling doesn't need to suck
Pre-built support for all data annotation needs like image labeling, NLP tagging, classification etc.
Annotate all your data, Text, Image, Video, or Speech.
No more ad-hoc setups, or passing around excel sheets.
↧
↧
A constructive look at the Atari 2600 BASIC cartridge
A constructive look at the Atari 2600 BASIC cartridge
I installed Stella (an Atari 2600 VCS emulator), downloaded the Atari 2600 BASIC cartridge and have been playing around with it for the past few days. If I'm going to do some Stupid Twitter Trick™ with it, I might as well know how it works, right?
And thus, this review.
Honestly, I don't think the Atari 2600 BASIC has ever had a fair review. It's pretty much reviled as a horrible program, a horrible programming environment and practically useless. But I think that's selling it short. Yes, it's bad (and I'll get to that in a bit), but in using it for the past few days, there are some impressive features on a system where the RAM can't hold a full Tweet and half the CPU time is spent Racing The Beam. I'll get the bad out of the way first.
Input comes from the Atari Keypads, dual 12-button keypads. If that weren't bad enough,I'm using my keyboard as an emulated pair of Atari Keypads, where I have to keep this image open at all times.
Okay, here's how this works. I want to enter this line:
A←A+1
(Ah yes! The “left arrow” for assignment. Mathematicians rejoice!) Upon startup, the Atari 2600 BASIC cursor is white. This is important, because this tells you what mode you are in. Hit a key when the cursor is white, and you do the functions labeled in white above each key. To get an “A,” you hit the bottom center button on the left controller (the one with the arrow circling around it) until the cursor turns blue, then you can hit the upper left key on the left controller (labeled “STATUS + A IF”). It's a bit hard to see, but yes, that “A” is indeed blue.
To get the “←” symbol (it's the top right button on the left controller) you hit the bottom middle button the the left controller until the cursor cycles back to red, then hit the upper right button on the left controller. Then cycle the cursor back to blue to get the “A,” then cycle to red to get the “plus” and the “1” (top left button on the right controller).
That's probably bad enough on the real thing. On the simulated Atarti 2600? Okay, what key on my keyboard is the “cycle” key? Then what key is the “A” key? Here's what I have to type to get that line of code:
xx1xxx3x1xxx19
But to be honest, it's on par with other keyboards of the time and may be a bit better, having actual tactile feedback instead of a simple membrane. I'm also picky about keyboards so I'm always going to bitch about the keyboard unless it's an IBM model M.
And given that the Atari 2600 only has 128 bytes of memory, it's expected that the programs are going to be rather short. I at first thought that you had 64 bytes for the program, but no—it's 64 bytes for the program, variables and runtime expression evaluation! That actually surprised me. Even worse, running this program over and over again (spaces added for clarity):
1 A ← 1 2 B ← 2 3 PRINT A,B
leaks memory!
No, really, that program, if run multiple times, will eventually exhaust all of memory. But not all programs leak memory. This program, if run over and over again (more on this little program in a bit):
1 D ← 1 2 HOR1 ← HOR1 + D 3 IF HOR1 = 0 THEN GOTO 5 4 IF HOR1 ← 99 THEN GOTO 2 5 D ← 99 - D + 1 6 GOTO 2
won't leak so much as a byte. Go figure.
Worse though,
is that each variabled used in the program
(and it doesn't matter if it's a predefined variable like HOR1 or a user defined variable like A)
consumes three bytes out of the precious 64 bytes you get for your program!
On the plus side though,
unused variables (event the builtin ones) don't use space at all
(I figured this out by watching the RAM use in Stella).
The grahics are pretty pathetic as well.
There are two dots that can be manipulated.
The builtin variables HOR1 and VER1 control the horizontal and vertical position for one dot;HOR2 and VER2 are used for the other dot.
The colors are fixed.
Oh,
and if the builtin variable HIT is 1,
the two dots are in the same position.
The positions are themselves limited to 0 to 99, but that's because all variables are limited to the range 0 to 99. The values wrap though—add 1 to 99 and you get 0. Subtract 1 from 0 and you get 99.
Which leads us into the ugly.
Yes,
there are no negative values—everything is unsigned.
And the values are all limited from 0 to 99.
This stems from a unique feature of the Atari 2600 CPU,the 6507
(a cheaper variation on the 6502).
That CPU can do math in either binary orbinary-coded decimal
and the Atari 2600 BASIC uses the binary-coded decimal mode, which restricts the values from 0 to 99.
So while you don't have negative numbers,
you do in a way because of the way the math works.
99 plus 99 is 198,
but because the range is modulus 100,
the result is 98.
Add 99 again,
and you end up with 97.
I use this fact in the above program.
Line 5 negates D—it converts 99 to 1,
or 1 back to 99.
Essentially,
1 to -1 and back again,
causing the dot to slowly crawl back and forth across the screen.
But now we finally arrive at what's good, or rather, what's amazing about this program.
First and foremost, it's an IDE.
Seriously.
Dispite it being only 4,096 bytes, there's a pretty credible, windowed(!) integrated development environment in there. If you look back at the keypad, you'll notice the first six buttons on the left controller are labeled:
- STATUS
- PROGRAM
- STACK
- VARIABLES
- OUTPUT
- GRAPHICS
Those are the various “windows” (and technically, they are windows, even if they don't overlap but are instead, stacked vertically on the screen) and the buttons there toggle the “windows” on and off.
The “STATUS” window (you can see it in the screen shot from the other day) shows memory usage (how many bytes, called “symbols”) and how fast the program will run (1, 2, 4, 8, 15, 30 and 60 are the speed values and they reflect how often the interpreter is run—once a second, twice a second, on up to 60 times a second). The “PROGRAM” window obviously contains the program (all nine lines if you have that many—and the IDE automatically numbers the lines for you even though it doesn't use them or store them—more on that below).
The “VARIABLES” window contains a list of the variables used in the program, listed as:
A is 1 HOR1 is 40 B is 2
“OUTPUT” is the text output window;
output of PRINT. “GRAPHICS” is the laughable graphics screen.
Leaving the “STACK” window, which is a misnomer actually. It's not a true stack, since there is no concept of “subroutine” in the Atari 2600 BASIC. You could think of it as “TRON” as it actually shows you the execution of each statment that is abolutely amazing! Imagine each line below being shown one at a time and you'll get a feeling for how this works. We'll be following line 5 from the above program (assuming D is 1):
D D← D←99 D←99-D D←99-1 D←98 D←98+1 D←99
One more example, to show that the Atari 2600 BASIC also follows mathematical precedence. Here, A is 1, B is 2 and C is 3. The line of code we're following is:
D←A+B*C
and during execution:
D D← D←A D←1 D←1+B D←1+2 D←1+2*C D←1+2*3 D←1+6 D←7
Strange as it sounds, this blew me away. I don't think I've ever seen anything like this. Sure, in debuggers where you execute a line at a time. Or in assembly language, instruction by instruction. But never substeps in expression evaluation. And of course, you can always step through the code with the “STEP” button. I just find it amazing that all of this, as simple as it is, can fit in 4,096 bytes of code.
How it stores the code internally is interesting. Most BASICs I'm aware of store the line number as part of the program, but here, that's not done. Take this program for example:
1 A ← 1 2 HOR1 ← HOR1 + 1 3 A ← A + 5 4 GOTO 2
Internally in memory, it's stored:
| Byte | Symbol |
|---|---|
| BC | A |
| E8 | ← |
| 01 | 1 |
| F1 | <end of line> |
| B2 | HOR1 |
| E8 | ← |
| B2 | HOR1 |
| E3 | + |
| 01 | 1 |
| F1 | <end of line> |
| BC | A |
| E8 | ← |
| BC | A |
| E3 | + |
| 05 | 5 |
| F1 | <end of line> |
| A6 | GOTO |
| 02 | 2 |
| FF | <end of program> |
Not a line number in sight,
which means GOTO statements do a linear scan of the program
(a typical design choice of BASIC systems on 8-bit computers at the time)
but the end of each line is marked.
Weird,
but whatever works I guess.
Variables are stored after the program, sequentially:
| Byte | Symbol |
|---|---|
| B2 | HOR1 |
| EE | is (see below) |
| 02 | current value |
| BC | A |
| EE | is |
| 15 | current value |
As best as I can tell,
the value EE is used when displaying the variables on the “VARIABLES” window,
and probably means “is.” It's probably done that way to avoid a special case when displaying data—it can be treated the same when displaying the program.
I'm guessing there's not much space left what with the font data and code to support the IDE in addition to running a
(admittedly very simple) BASIC interpreter for special casing the variables.
As a “proof-of-concept” it's an amzing piece of work. As an actual product, yes, it sucks, mostly because of the limitations of the hardware. The ideas behind it are incredible though, and I think it's gotten short shrifted because of the limitations, which is sad. There is something to learn from here.
Update Wednesday, June 17th, 2015 at 1:56 AM
I almost forgot—the IF statement is an expression!
You can do the following:
A ← IF B = 15 THEN 40 ELSE 99
and A will be 40 if B is 15,
otherwise A will be 99.
There aren't many languages I've used that have allowed this.
↧
Google Grasshopper: Learn to Code for Free
Visual puzzles develop your problem-solving skills and solidify coding concepts.
Use industry-standard JavaScript with just a few taps on your phone.
Real-time feedback guides you like a teacher.
Collect achievements as you learn new skills.
↧
The Dow of Cities
The Dow Jones Industrial may be down, but the Dow of Cities is rising
The daily business news is obsessed with the price of stocks. Widely reported indicators like the Dow Jones Industrial average gauge the overall health of the US economy by how much, on any given day (or hour, or minute) investors are willing to pay for a bundle of stocks that represent the ownership of some of the nation’s biggest businesses. After peaking in January, investors have become decidedly skittish and pessimistic about the US economy, as evidenced by wild daily gyrations and an overall fall of almost 10 percent the Dow Jones Industrials (DJI).
 At City Observatory, we’ve applied the same idea–a broad market index of prices–to America’s cities. We’ve developed an indicator we call “The Dow of Cities.” Like the DJI, we look at the performance of a bundle of asset prices, in this case, the market values of homes in the nation’s densest urban neighborhoods. And because we’re focused on cities, we compare how prices for houses in cities compare with the price of houses in the more outlying portions of metro areas.
At City Observatory, we’ve applied the same idea–a broad market index of prices–to America’s cities. We’ve developed an indicator we call “The Dow of Cities.” Like the DJI, we look at the performance of a bundle of asset prices, in this case, the market values of homes in the nation’s densest urban neighborhoods. And because we’re focused on cities, we compare how prices for houses in cities compare with the price of houses in the more outlying portions of metro areas.
Here’s the simple number: since 2000, home prices in city centers have outperformed those in suburbs by 50 percent. In graphic terms, it looks like this:
The data were complied by Fitch–the investment rating agency, in a report released with the announcement that “U.S. Demand Pendulum Swinging Back to City Centers.” What the data show is that the dark blue line–which represents housing in city centers–is consistently outpacing the other lines–representing increasingly suburban rings of housing. The premium that the most urban houses command over the rest of the metro housing stock reflects the growing market value Americans attach to urban living.
If you care about cities, and you’re looking for definitive evidence of the verdict of the market on urbanism—this is it. But we are also resigned to the fact that we are geeks, and stuff that gets our blood-racing leaves most people cold. So I’m groping for an analogy: the most convenient one is to the stock market.
Image a CNN business reporter saying:
“In the market today, city centers were up strongly to a new high”
Or a Wall Street Journal headline
“A bull market for city centers”
That’s the news here. Just as with private companies this price index is a great indicator of market performance. Imagine for a moment if you were CEO of Widgets, Inc, a publicly traded company. Every day, you’d be getting feedback from the market on how well you were doing, and on investor’s expectations for your company’s future. If your stock price went up, it would be a good indication that you were doing better, and that expectations were rising for future performance. Especially if you had a sustained rise in your stock price, and if your company were regularly outperforming both other companies in the widget industry, and the overall stock market. The reason the investment world is gaga over Warren Buffet is pretty much because he’s been able to do just that with the portfolio of companies he’s assembled under the Berkshire-Hathaway banner.
Wouldn’t it be great if we had the same kind of clear cut financial market style indicator on the health and prospects of our nation’s center cities? Wouldn’t it be useful if we could show in a stark and quantitative way how city centers are performing relative to suburbs? That, in essence, is what the Fitch data shows. Fitch’s analysts looked at 25 years worth of zip code level home price data in 50 of the nation’s largest metropolitan areas to track how well city centers performed compared to surrounding neighborhoods and suburbs. They divided zip codes within metropolitan areas into four groups based on their proximity to the city center.
You can’t literally buy stock in a city, but buying a house is the closest thing imaginable. The price a buyer is willing to pay for a home in a particular city or neighborhood is a reflection both of the current value of that location, and the buyer’s expectations of the future character and performance of the neighborhood and city. Add up all the home values in the city, and you’ve got an indicator of the market for the city as a whole.
This Fitch chart is, in effect, a kind of Dow Jones Index for the performance of the nation’s center cities. It clearly shows that over the course of the last housing cycle—beginning before the big run up in housing prices, but then continuing through the housing bubble, and growing during the bust and recovery, is an ever wider edge of city center housing prices compared to more suburban, out-lying locations. And this isn’t a short term aberration or a recession artifact. The Fitch data show the trend emerging in the late 1990s, and growing steadily over time.
While there’s a growing recognition that cities are back, in some quarters there’s denial. The truly great thing about this measure its it definitively puts the lie to the claims by perennial city nay-sayers like Joel Kotkin that the overall growth or size of suburbs is somehow a manifestation of their revealed economic superiority. In economic terms, bigger doesn’t necessarily mean better. In the economic world, market prices, and particularly changes in relative market prices are the best indicator of what’s hot and what’s not. The new Fitch analysis make it abundantly clear that cities are hot, and suburbs are not.
The reason of course is that housing demand can (and is) changing much faster than supply—which is why prices are rising so much. Rising prices are both a positive indicator of the value consumers place on city center living, and a reminder that as we’ve said many times at City Observatory, we’re experiencing a shortage of cities. And the rising relative prices for city locations are the market’s way of saying “we want more housing in cities” and “we want more cities.” While the strength in the housing sector has been an urban focused boom in new rental apartments, the fact is that supply isn’t growing rapidly enough. We aren’t creating new San Franciscos and new dense, walkable, transit-served neighborhoods in other cities as fast as the demand for urban living is increasing—and that means that prices are continuing to rise.
↧