Flaky failures are the worst. In this particular investigation, which spanned twenty months, we suspected hardware failure, compiler bugs, linker bugs, and other possibilities. Jumping too quickly to blaming hardware or build tools is a classic mistake, but in this case the mistake was that we weren’t thinking big enough. Yes, there was a linker bug, but we were also lucky enough to have hit a Windows kernel bug which is triggered by linkers!
In September of 2016 we started noticing random failures when building Chrome– 3 out of 200 builds of Chrome failed when protoc.exe, one of the executables that is part of the build, crashed with an access violation. That is, we would build protoc.exe, and then run it to generate header files for the next build stage, but it would crash instead.
The developers who investigated knew immediately that something weird was happening but they couldn’t reproduce the bug locally so they were forced to make guesses. A couple of speculative fixes (reordering the tool’s arguments and adding explicit dependencies) were made, and the second fix seemed to work. The bug went away for a year.
And then, a few days shy of its first birthday, the bug started happening again. A steady drumbeat of reports came in – ten separate bugs were merged into the master bug over the next few months, representing just a fraction of the crashes.
Local repros
I joined the investigation when I hit the bug on my workstation. I ran the bad binary under a debugger and saw this assembly language in the debugger:
Now we have a problem statement that we can reason about: why are large chunks of our code segment filled with zeroes?
I deleted the binary and relinked it and found that the zeroes were replaced with a series of five-byte jmp instructions. The long array of zeroes was in an array of thunks, used by VC++’s incremental linker so that it can more easily move functions around. It seemed quite obvious that we were hitting a bug in incremental linking. Incremental linking is an important build-time optimization for huge binaries like chrome.dll, but for tiny binaries like protoc.exe it is irrelevant, so the fix was obvious: disable incremental linking for the tiny binaries used in the build.
It turned out that this fix did work around an incremental linking bug, but it was not the bug we were looking for.
I then ignored the bug until I hit it on my workstation two weeks later. My fix had not worked. And, this time the array of zeroes was in a function, instead of in the incremental linking jump table.
I was still assuming that we were dealing with a linker bug so when another two weeks later I hit the problem again I was confused. I was confused because I was not using Microsoft’s linker anymore. I had switched to using lld-link (use_lld=true in my gn args). In fact, when the bug first hit we had been using the VC++ compiler and linker and I’d just hit it with the clang compiler and linker. If switching out your entire toolchain doesn’t fix a bug then it’s clearly not a toolchain bug – mass hysteria was starting to seem like the best explanation.
Science!
Up to this point I had been hitting this bug randomly. I was doing a lot of builds because I was doing build-speed investigations and these crashes were interfering with my ability to do measurements. It’s frustrating to leave your computer running tests overnight only to have crashes pollute the results. I decided it was time to try science.
Instead of doing a dozen builds in a night to test a new build optimization I changed my script to just build Chrome in a loop until it failed. With jumbodistributed builds and a minimal level of symbols I can, on a good day, build Chrome a dozen times in an hour. Even a rare and flaky bug like this one starts happening every single night when you do that. So do other bugs (zombies!) but that’s a different story.
And then, I got lucky. I logged on to my computer in the morning, saw that genmodule.exe had crashed overnight (the crashing binary varied), and decided to run it again, to get a live crash instead of looking at crash dumps. And it didn’t crash.
The crash dump (I have Windows Error Reporting configured to save local crash dumps, all Windows developers should do this) showed lots of all-zero instructions in the critical path. It was not possible for this binary to run correctly. I ran genmodule.exe under the debugger and halted on the function that had previously crashed – that had previously been all zeroes – and it was fine.
Apologies for the strong language, and women and children might want to skip the rest of this paragraph, but WTF?!?
I then loaded the crash dump into windbg and typed “!chkimg”. This command compares the code bytes in the crash dump (some of them are saved in the crash dump, just in case) against those on disk. This is helpful when a crash is caused by bad RAM or bad patching and it will sometimes report that a few dozen bytes have been changed. In this case it said that 9322 bytes in the code in the crash dump were wrong. Huh!
Now we have a new problem statement: why are we not running the code that the linker wrote to the file?
This was starting to look like a Windows file cache bug. It looked like the Windows loader was pulling in pages full of zeroes instead of the pages that we had just written. Maybe something to do with multi-socket coherency of the disk and cache or ???
My coworker Zach made the vital suggestion that I run the sysinternals sync command after linking binaries. I resisted at first because the sync command is quite heavyweight and requires administrative privileges, but eventually I ran a weekend long test where I built Chrome from scratch over 1,000 times, as admin, with various mitigations after running the linker:
Normal build: 3.5% failure rate
7-second sleep after linking exes: 2% failure rate
sync.exe after linking exes: 0% failure rate
Huzzah! Running sync.exe was not a feasible fix, but it was a proof of concept. The next step was a custom C++ program that opened the just-linked exe and called FlushFileBuffers on it. This is much lighter weight and doesn’t require administrative privileges and this also stopped the bug from happening. The final step was to convert this into Python, land the change, and then make my favorite under-appreciated tweet:
Later that day – before I’d had a chance to file an official bug report – I got an email from Mehmet, an ex-coworker at Microsoft, basically saying “Hey, how’s things? What’s this I hear about a kernel bug?”
I shared my results (the crash dumps are quite convincing) and my methodology. They were unable to reproduce the bug – probably due to not being able to build Chrome as many times per hour as I can. But, they helped me enable circular-buffer ETW tracing, rigged to save the trace buffers on a build failure. After some back-and-forth I managed to record a trace which contained enough information for them to understand the bug.
The underlying bug is that if a program writes a PE file (EXE or DLL) using memory mapped file I/O and if that program is then immediately executed (or loaded with LoadLibrary or LoadLibraryEx), and if the system is under very heavy disk I/O load, then a necessary file-buffer flush may fail. This is very rare and can realistically only happen on build machines, and even then only on monster 24-core machines like I use. They confirmed that my fix should mitigate the bug (I’d already noted that it had allowed ~600 clean builds in a row), and promised to create a proper fix in Windows.
Play along at home
You probably won’t be able to reproduce this bug but if you want to see an example crash dump you can find one (and the .exe and .pdb files) on github. You can load them into Visual Studio and see all the zero bytes in the disassembly, or load them into windbg to run !chkimg and see the !chkimg errors:
1) Building Chrome very quickly causes CcmExec.exe to leak process handles. Each build can leak up to 1,600 process handles and about 100 MB. That becomes a problem when you do 300+ builds in a weekend – bye bye to ~32 GB of RAM, consumed by zombies. I now run a loop that periodically kills CcmExec.exe to mitigate this, and Microsoft is working on a fix.
2) Most Windows developers have seen 0xC0000005 enough times to remember that it means Access Violation – it means that your program dereferenced memory that it should not have, or in a way that it should not have. But how many Windows programmers recognize the error codes 3221225477 or -1073741819? It turns out that these are the same value, printed as unsigned or signed decimal. But, not surprisingly, when developers see a number around negative one billion their eyes glaze over and the numbers all start to look the same. So when some of the crashes returned error code -1073740791 the difference was either not noticed, or was ignored.
3) That’s a shame because it turns out that there were two bugs. crbug.com/644525 is the Chromium bug for investigating what turned out to be this kernel bug. But, once I landed a workaround for that bug and reenabled incremental linking we started hitting different crashes – crbug.com/812421. Some developers were hitting error code –1073740791 which is 0xC0000409 which is STATUS_STACK_BUFFER_OVERRUN. I never saw this crash myself but I asked for a crash dump (I was terrified that crbug.com/644525 had returned) from a coworker and saw that ntdll.dll!RtlpHandleInvalidUserCallTarget was calling RtlFailFast2. I recognized this signature and knew that it had nothing to do with buffer overruns. It’s a Control Flow Guard violation, meaning that the OS thinks that your program is being exploited by bad people to do an illegal indirect function call.
It appears that if you use /incremental with /cfg then the Control Flow Guard information isn’t always updated during incremental linking. The simple fix was to update our build configurations to never use /incremental and /cfg at the same time– they aren’t a useful combination anyway.
We still don’t know what caused this bug to start showing up in the first place – maybe our switch to gn changed the ordering of build steps to make us more vulnerable?
We also don’t know why the bug disappeared for a year. Was the original bug something unrelated that was fixed by this change? Or did we just get lucky or oblivious?
Either way, whether we fixed two or three separate bugs, Chrome’s builds are much more reliable now and I can go back to doing build-performance testing without hitting failures.
The Chrome workaround is 100% reliable, and both lld-link.exe and Microsoft’s link.exe will be adding FlushFileBuffers calls as mitigations. If you work on a tool that creates binaries (Rust? I filed an internal bug for Go) using memory mapped files you should consider adding a FlushFileBuffers call just before closing the file. This bug shows up from Server 2008 R2 (Windows 7) up to the latest stable build of Windows 10 and OS fixes will take a while to propagate so you might as well be careful.
A global map showing where all fishing vessels were active during 2016. Dark circles show the vessels avoiding exclusive economic zones around islands, where they aren't allowed.
Global Fishing Watchhide caption
toggle caption
Global Fishing Watch
The fishing industry has long been hard to monitor. Its global footprint is difficult even to visualize. Much fishing takes place unobserved, far from land, and once the boats move on, they leave behind few visible traces of their activity.
But this week, the journal Sciencepublished some remarkable maps that help fill that gap. John Amos, president of an organization called SkyTruth, which helped produce them, issued a statement calling the maps "a stunning illustration of the vast scope of exploitation of the ocean."
SkyTruth and its collaborators tracked most of the world's fishing vessels through an entire year by monitoring radio transmissions that most vessels now emit automatically in order to avoid collisions with each other. The researchers were able to distinguish between different kinds of vessels — trawlers that drag nets behind them, for instance, versus vessels that deploy drifting "longlines" that often are used to catch tuna.
This map shows fishing by trawlers, which drag fishing nets behind them. They dominate fishing in coastal areas, such as fisheries near Europe and China.
Global Fishing Watchhide caption
toggle caption
Global Fishing Watch
The maps show the most intense fishing activity along the coasts of heavily populated areas like Europe and China. But fishing also covers much of the high seas. According to the researchers, commercial fishing operations covered at least 55 percent of the world's oceans. That area, it calculates, is four times larger than the area devoted to agriculture on land.
The researchers also were able to distinguish between fishing vessels from different countries. According to the study, five countries — China, Spain, Taiwan, Japan, and South Korea — accounted for 85 percent of all high-seas fishing.
This map shows activity of fishing vessels that use drifting longlines. They roamed the high seas, especially in tropical latitudes.
Global Fishing Watchhide caption
toggle caption
Global Fishing Watch
In addition to SkyTruth, researchers from Global Fishing Watch, the National Geographic Society's Pristine Seas project, University of California Santa Barbara, Dalhousie University, Google, and Stanford University collaborated on the study.
The “Oxidizing” article recounts my experience integrating Rust
(compiled to WebAssembly) into the source-map JavaScript
library. Although the JavaScript implementation was originally
authored in idiomatic JavaScript style, as we profiled and implemented speed
improvements, the code became hard to read and maintain. With Rust and its
zero-cost abstractions, we found that there was no trade-off between performance
and clean code.
mraleph is an established expert on JavaScript performance.
He specializes in Just-In-Time (JIT) compilers, and has contributed to Google’s
V8 JavaScript engine. Guided by profiling the JIT’s internals and emitted code,
he ultimately brought the JavaScript implementation’s performance on par with
the Rust and WebAssembly implementation:
The optimizations he implemented roughly fall into three buckets:
Algorithmic improvements.
Avoiding allocations to reduce garbage collections.
Staying on the JIT’s happy paths to gain compiler optimizations, and
subsequently avoiding falling off performance cliffs.
His article is well-measured and a great read. I particularly like it for three
reasons:
It is educational to peek into his profiling process, and he shares
JavaScript performance techniques that are just plain fun to read about.
The opportunities for algorithmic improvements that he noticed helped speed
up the Rust and WebAssembly implementation another 3x over what we had
previously seen. Thanks to his suggestions, the current version of thesource-map library is now 5.3x faster than the original JavaScript in
Chrome, 10.8x faster in Firefox, and 9.4x faster in Safari.
He perfectly demonstrates one of the points my “Oxidizing” article was
making: with Rust and WebAssembly we have reliable performance without
the wizard-level shenanigans that are required to get the same performance in
JavaScript.
Before continuing, I suggest that you go back and read the two articles if you
haven’t already.
Staying on the JIT’s Happy Paths
First, mraleph noticed that some sorting comparator functions had an arity of
three, the last parameter being optional, but were only ever actually invoked
with two arguments in hot code paths. In V8, this arity mismatch results in an
extra trampoline function in the emitted machine code, and fixing the arity
improved performance:
Just by fixing the arity mismatch we improved benchmark mean on V8 by 14% from
4774 ms to 4123 ms. If we profile the benchmark again we will discover thatArgumentsAdaptorTrampoline has completely disappeared from it. Why was it
there in the first place?
It turns out that ArgumentsAdaptorTrampoline is V8’s mechanism for coping
with JavaScript’s variadic calling convention: you can call function that has
3 parameters with 2 arguments - in which case the third parameter will be
filled with undefined. V8 does this by creating a new frame on the stack,
copying arguments down and then invoking the target function.
Impressive results for such a tiny change! But that’s also part of the problem:
the reasons for JavaScript’s good or bad performance don’t readily reveal
themselves to readers. Worse yet, what is fine in one engine’s JIT might be a
performance cliff in another engine’s JIT. This is the case with this arity
mismatch, as mraleph notes:
For what it is worth argument adaptation overhead seems to be highly V8
specific. When I benchmark my change against SpiderMonkey, I don’t see any
significant performance improvement from matching the arity.
Next, mraleph noticed that the generic sorting routine was not being
monomorphized, and the comparator functions passed to it were not being inlined.
To mold the JavaScript code into something that would match the JIT’s heuristics
for monomorphization and inlining, he stringified the functions to get their
source text and then re-evaluated that source text with new
Function(...). This causes the JavaScript engine to create distinct functions
with their own type inference records. Therefore, from the JIT’s point of view,
the types passed to the new functions are not intermingled with those passed to
the originals, and the JIT will monomorphize them in the machine code it emits.
Stringifying a function to get its source text and re-evaluating it is a very
clever trick, but it is not idiomatic JavaScript style. This introduces more
convolutions to the codebase for the sake of performance, and maintainability
suffers. Furthermore, although the code might match this JIT’s heuristics for
inlining and monomorphization today, those heuristics may change in the future,
and other JITs may use different heuristics altogether.
With Rust and WebAssembly, we have reliable speed without clever tricks.
WebAssembly is designed to perform well without relying on heuristic-based
optimizations, avoiding the performance cliffs that come if code doesn’t meet
those heuristics. It is expected that the compiler emitting the WebAssembly (in
this case rustc and LLVM) already has sophisticated optimization
infrastructure, that the engine is receiving WebAssembly code that has already
had optimization passes applied, and that the WebAssembly is close to its final
form.
Avoiding Allocation and Reducing Garbage Collection
The original JavaScript implementation parsed each mapping into a JavaScriptObject, which must be allocated by the garbage collector. To reduce GC
pressure during parsing, mraleph modified the parser so that, rather than
allocating Objects, it uses a linear typed array buffer and a pointer into
that buffer as a bump allocator. It writes parsed mappings into the typed array,
doubling the typed array’s size whenever it fills up.
Effectively, this technique is like writing C code in JavaScript, but without
even the abstractions that C provides. We can’t define any structs because
that implies a GC allocation in JavaScript. In some cases, JITs can optimize
away such allocations, but (once again) that depends on unreliable heuristics,
and JIT engines vary in their effectiveness at removing the allocations.
Since we can’t define any structs to name the records and their members in the
typed array, we must manually write, in mraleph’s words, “verbose and error
prone code” to read and write memory[pointer + static_offset_of_member]:
The final group of optimizations that mraleph implemented included two
algorithmic improvements to avoid sorting all mappings at once, and only sort
subsequences of mappings at a time.
First, mraleph noticed that the encoding for mappings means that they are
already sorted by generated line number as we parse them. It follows that, if we
wish to sort mappings by generated location (i.e. generated line and column,
breaking ties with original location), we only need to sort within each
generated line’s subsequence to sort the entire sequence by generated location.
Second, when sorting by original location, we can bucket mappings by their
source file, and then we only need to sort one source file’s bucket at a
time. Furthermore, we can lazily sort each source file’s bucket.
These algorithmic improvements aren’t providing fundamentally smaller big-O
running times. In the worst case, there is only one generated line and only one
original source file, which means that the subsequences we sort are actually the
full sequence in both cases. And this isn’t a terribly rare worst case either:
if you minify a single JavaScript file, you’ll likely create this scenario. But
in the large Scala.js source map that is an input to the benchmark, and I
suspect many other source maps found in the wild, both of these optimizations
pay off.
I implemented both subsequence sorting optimizations for the current Rust and
WebAssembly version of the source-map library, and then measured the “setting
a breakpoint for the first time” benchmark once more, using the same methods
and setup as in the “Oxidizing” article. Below are the results;
recall that lower values are better.
Speed improved another ~3x over what we had previously seen. The current
version of the source-map library is now 5.3x faster than the original
JavaScript in Chrome, 10.8x faster in Firefox, and 9.4x faster in Safari!
(mraleph did not publish his complete set of changes, so I could not
directly compare his improved JavaScript implementation’s speeds in this
graph.)
Conclusion
Most of the improvements that mraleph implemented are desirable regardless of
the programming language that is our medium. Excessive allocation rates make any
garbage collector (or malloc and free implementation) a bottleneck.
Monomorphization and inlining are crucial to eking out performance in both Rust
and JavaScript. Algorithms transcend programming languages.
But a distinction between JavaScript and Rust+WebAssembly emerges when we
consider the effort required to attain inlining and monomorphization, or to
avoid allocations. Rust lets us explicitly state our desires to the compiler, we
can rely on the optimizations occurring, and Rust’s natural idioms guide us
towards fast code, so we don’t have to be performance wizards to get
fast code. In JavaScript, on the other hand, we must communicate with oblique
incantations to match each JavaScript engine’s JIT’s heuristics.
mraleph concludes with a bit of sound engineering advice:
Obviously each developer and each team are free to choose between spending N
rigorous hours profiling and reading and thinking about their JavaScript code,
or to spend M hours rewriting their stuff in a language X.
I couldn’t agree more! It is important to remember that engineering choices have
trade-offs, and it is equally important to be cognizant of the choices in the
first place.
We chose to rewrite a portion of our library in Rust and WebAssembly not just
for the speed ups, although those are certainly nice, but also for
maintainability and to get rid of the kludges added to gain JIT
optimizations. We wanted to return to clean code and clearly expressed
intent. It has been a great success.
Rewriting the whole library from scratch would not have been tenable either. We
avoided that because Rust’s small runtime and freedom from a garbage collector
mean that incremental adoption is both possible and practical. We were able to
surgically replace just the hottest code paths with Rust and WebAssembly,
leaving the rest of the library’s code in place.
Finally, I’d like to re-broadcast mraleph’s points about profiling:
Profiling and fine grained performance tracking in various shapes and forms is
the best way to stay on top of the performance. It allows you to localize
hot-spots in your code and also reveals potential issues in the underlying
runtime. For this particular reason don’t shy away from using low-level
profiling tools like perf - “friendly” tools might not be telling you the
whole story because they hide lower level.
Different performance problems require different approaches to profiling and
visualizing collected profiles. Make sure to familiarize yourself with a wide
spectrum of available tools.
This is sage advice, and his article is an outstanding example of letting a
profiler lead your investigations.
Great cities attract ambitious people. You can sense it when you
walk around one. In a hundred subtle ways, the city sends you a
message: you could do more; you should try harder.
The surprising thing is how different these messages can be. New
York tells you, above all: you should make more money. There are
other messages too, of course. You should be hipper. You should
be better looking. But the clearest message is that you should be
richer.
What I like about Boston (or rather Cambridge) is that the message
there is: you should be smarter. You really should get around to
reading all those books you've been meaning to.
When you ask what message a city sends, you sometimes get surprising
answers. As much as they respect brains in Silicon Valley, the
message the Valley sends is: you should be more powerful.
That's not quite the same message New York sends. Power matters
in New York too of course, but New York is pretty impressed by a
billion dollars even if you merely inherited it. In Silicon Valley
no one would care except a few real estate agents. What matters
in Silicon Valley is how much effect you have on the world. The
reason people there care about Larry and Sergey is not their wealth
but the fact that they control Google, which affects practically
everyone.
_____
How much does it matter what message a city sends? Empirically,
the answer seems to be: a lot. You might think that if you had
enough strength of mind to do great things, you'd be able to transcend
your environment. Where you live should make at most a couple
percent difference. But if you look at the historical evidence,
it seems to matter more than that. Most people who did great things
were clumped together in a few places where that sort of thing was
done at the time.
You can see how powerful cities are from something I wrote aboutearlier: the case of the Milanese Leonardo.
Practically every
fifteenth century Italian painter you've heard of was from Florence,
even though Milan was just as big. People in Florence weren't
genetically different, so you have to assume there was someone born
in Milan with as much natural ability as Leonardo. What happened
to him?
If even someone with the same natural ability as Leonardo
couldn't beat the force of environment, do you suppose you can?
I don't. I'm fairly stubborn, but I wouldn't try to fight this
force. I'd rather use it. So I've thought a lot about where to
live.
I'd always imagined Berkeley would be the ideal place—that
it would basically be Cambridge with good weather. But when I
finally tried living there a couple years ago, it turned out not
to be. The message Berkeley sends is: you should live better. Life
in Berkeley is very civilized. It's probably the place in America
where someone from Northern Europe would feel most at home. But
it's not humming with ambition.
In retrospect it shouldn't have been surprising that a place so
pleasant would attract people interested above all in quality of
life. Cambridge with good weather, it turns out, is not Cambridge.
The people you find in Cambridge are not there by accident. You
have to make sacrifices to live there. It's expensive and somewhat
grubby, and the weather's often bad. So the kind of people you
find in Cambridge are the kind of people who want to live where the
smartest people are, even if that means living in an expensive,
grubby place with bad weather.
As of this writing, Cambridge seems to be the intellectual capital
of the world. I realize that seems a preposterous claim. What
makes it true is that it's more preposterous to claim about anywhere
else. American universities currently seem to be the best, judging
from the flow of ambitious students. And what US city has a stronger
claim? New York? A fair number of smart people, but diluted by a
much larger number of neanderthals in suits. The Bay Area has a
lot of smart people too, but again, diluted; there are two great
universities, but they're far apart. Harvard and MIT are practically
adjacent by West Coast standards, and they're surrounded by about
20 other colleges and universities.[1]
Cambridge as a result feels like a town whose main industry is
ideas, while New York's is finance and Silicon Valley's is startups.
_____
When you talk about cities in the sense we are, what you're really
talking about is collections of people. For a long time cities
were the only large collections of people, so you could use the two
ideas interchangeably. But we can see how much things are changing
from the examples I've mentioned. New York is a classic great city.
But Cambridge is just part of a city, and Silicon Valley is not
even that. (San Jose is not, as it sometimes claims, the capital
of Silicon Valley. It's just 178 square miles at one end of it.)
Maybe the Internet will change things further. Maybe one day the
most important community you belong to will be a virtual one, and
it won't matter where you live physically. But I wouldn't bet on
it. The physical world is very high bandwidth, and some of the
ways cities send you messages are quite subtle.
One of the exhilarating things about coming back to Cambridge every
spring is walking through the streets at dusk, when you can see
into the houses. When you walk through Palo Alto in the evening,
you see nothing but the blue glow of TVs. In Cambridge you see
shelves full of promising-looking books. Palo Alto was probably
much like Cambridge in 1960, but you'd never guess now that there
was a university nearby. Now it's just one of the richer neighborhoods
in Silicon Valley. [2]
A city speaks to you mostly by accident—in things you see
through windows, in conversations you overhear. It's not something
you have to seek out, but something you can't turn off. One of the
occupational hazards of living in Cambridge is overhearing the
conversations of people who use interrogative intonation in declarative
sentences. But on average I'll take Cambridge conversations over
New York or Silicon Valley ones.
A friend who moved to Silicon Valley in the late 90s said the worst
thing about living there was the low quality of the eavesdropping.
At the time I thought she was being deliberately eccentric. Sure,
it can be interesting to eavesdrop on people, but is good quality
eavesdropping so important that it would affect where you chose to
live? Now I understand what she meant. The conversations you
overhear tell you what sort of people you're among.
_____
No matter how determined you are, it's hard not to be influenced
by the people around you. It's not so much that you do whatever a
city expects of you, but that you get discouraged when no one around
you cares about the same things you do.
There's an imbalance between encouragement and discouragement like
that between gaining and losing money. Most people overvalue
negative amounts of money: they'll work much harder to avoid losing
a dollar than to gain one. Similarly, although there are plenty of
people strong enough to resist doing something just because that's
what one is supposed to do where they happen to be, there are few
strong enough to keep working on something no one around them cares
about.
Because ambitions are to some extent incompatible and admiration
is a zero-sum game, each city tends to focus on one type of ambition.
The reason Cambridge is the intellectual capital is not just that
there's a concentration of smart people there, but that there's
nothing else people there care about more. Professors in
New York and the Bay area are second class citizens—till they
start hedge funds or startups respectively.
This suggests an answer to a question people in New York have
wondered about since the Bubble: whether New York could grow into
a startup hub to rival Silicon Valley. One reason that's unlikely
is that someone starting a startup in New York would feel like a
second class citizen. [3]
There's already something else people in New York admire more.
In the long term, that could be a bad thing for New York. The power
of an important new technology does eventually convert to money.
So by caring more about money and less about power than Silicon
Valley, New York is recognizing the same thing, but slower.[4]
And in fact it has been losing to Silicon Valley at its own game:
the ratio of New York to California residents in the Forbes 400 has
decreased from 1.45 (81:56) when the list was first published in
1982 to .83 (73:88) in 2007.
_____
Not all cities send a message. Only those that are centers for
some type of ambition do. And it can be hard to tell exactly what
message a city sends without living there. I understand the messages
of New York, Cambridge, and Silicon Valley because I've lived for
several years in each of them. DC and LA seem to send messages
too, but I haven't spent long enough in either to say for sure what
they are.
The big thing in LA seems to be fame. There's an A List of people
who are most in demand right now, and what's most admired is to be
on it, or friends with those who are. Beneath that the message is
much like New York's, though perhaps with more emphasis on physical
attractiveness.
In DC the message seems to be that the most important thing is who
you know. You want to be an insider. In practice this seems to
work much as in LA. There's an A List and you want to be on it or
close to those who are. The only difference is how the A List is
selected. And even that is not that different.
At the moment, San Francisco's message seems to be the same as
Berkeley's: you should live better. But this will change if enough
startups choose SF over the Valley. During the Bubble that was a
predictor of failure—a self-indulgent choice, like buying
expensive office furniture. Even now I'm suspicious when startups
choose SF. But if enough good ones do, it stops being a self-indulgent
choice, because the center of gravity of Silicon Valley will shift
there.
I haven't found anything like Cambridge for intellectual ambition.
Oxford and Cambridge (England) feel like Ithaca or Hanover: the
message is there, but not as strong.
Paris was once a great intellectual center. If you went there in
1300, it might have sent the message Cambridge does now. But I
tried living there for a bit last year, and the ambitions of the
inhabitants are not intellectual ones. The message Paris sends now
is: do things with style. I liked that, actually. Paris is the
only city I've lived in where people genuinely cared about art. In
America only a few rich people buy original art, and even the more
sophisticated ones rarely get past judging it by the brand name of
the artist. But looking through windows at dusk in Paris you can
see that people there actually care what paintings look like.
Visually, Paris has the best eavesdropping I know. [5]
There's one more message I've heard from cities: in London you can
still (barely) hear the message that one should be more aristocratic.
If you listen for it you can also hear it in Paris, New York, and
Boston. But this message is everywhere very faint. It would have
been strong 100 years ago, but now I probably wouldn't have picked
it up at all if I hadn't deliberately tuned in to that wavelength
to see if there was any signal left.
_____
So far the complete list of messages I've picked up from cities is:
wealth, style, hipness, physical attractiveness, fame, political
power, economic power, intelligence, social class, and quality of
life.
My immediate reaction to this list is that it makes me slightly
queasy. I'd always considered ambition a good thing, but I realize
now that was because I'd always implicitly understood it to mean
ambition in the areas I cared about. When you list everything
ambitious people are ambitious about, it's not so pretty.
On closer examination I see a couple things on the list that are
surprising in the light of history. For example, physical
attractiveness wouldn't have been there 100 years ago (though it
might have been 2400 years ago). It has always mattered for women,
but in the late twentieth century it seems to have started to matter
for men as well. I'm not sure why—probably some combination
of the increasing power of women, the increasing influence of actors
as models, and the fact that so many people work in offices now:
you can't show off by wearing clothes too fancy to wear in a factory,
so you have to show off with your body instead.
Hipness is another thing you wouldn't have seen on the list 100
years ago. Or wouldn't you? What it means is to know what's what.
So maybe it has simply replaced the component of social class that
consisted of being "au fait." That could explain why hipness seems
particularly admired in London: it's version 2 of the traditional
English delight in obscure codes that only insiders understand.
Economic power would have been on the list 100 years ago, but what
we mean by it is changing. It used to mean the control of vast
human and material resources. But increasingly it means the ability
to direct the course of technology, and some of the people in a
position to do that are not even rich—leaders of important
open source projects, for example. The Captains of Industry of
times past had laboratories full of clever people cooking up new
technologies for them. The new breed are themselves those people.
As this force gets more attention, another is dropping off the list:
social class. I think the two changes are related. Economic power,
wealth, and social class are just names for the same thing at
different stages in its life: economic power converts to wealth,
and wealth to social class. So the focus of admiration is simply
shifting upstream.
_____
Does anyone who wants to do great work have to live in a great city?
No; all great cities inspire some sort of ambition, but they aren't
the only places that do. For some kinds of work, all you need is
a handful of talented colleagues.
What cities provide is an audience, and a funnel for peers. These
aren't so critical in something like math or physics, where no
audience matters except your peers, and judging ability is sufficiently
straightforward that hiring and admissions committees can do it
reliably. In a field like math or physics all you need is a
department with the right colleagues in it. It could be anywhere—in
Los Alamos, New Mexico, for example.
It's in fields like the arts or writing or technology that the
larger environment matters. In these the best practitioners aren't
conveniently collected in a few top university departments and
research labs—partly because talent is harder to judge, and
partly because people pay for these things, so one doesn't need to
rely on teaching or research funding to support oneself. It's in
these more chaotic fields that it helps most to be in a great city:
you need the encouragement of feeling that people around you care
about the kind of work you do, and since you have to find peers for
yourself, you need the much larger intake mechanism of a great city.
You don't have to live in a great city your whole life to benefit
from it. The critical years seem to be the early and middle ones
of your career. Clearly you don't have to grow up in a great city.
Nor does it seem to matter if you go to college in one. To most
college students a world of a few thousand people seems big enough.
Plus in college you don't yet have to face the hardest kind of
work—discovering new problems to solve.
It's when you move on to the next and much harder step that it helps
most to be in a place where you can find peers and encouragement.
You seem to be able to leave, if you want, once you've found both.
The Impressionists show the typical pattern: they were born all
over France (Pissarro was born in the Carribbean) and died all over
France, but what defined them were the years they spent together
in Paris.
_____
Unless you're sure what you want to do and where the leading center
for it is, your best bet is probably to try living in several
places when you're young. You can never tell what message a city
sends till you live there, or even whether it still sends one.
Often your information will be wrong: I tried living in Florence
when I was 25, thinking it would be an art center, but it turned
out I was 450 years too late.
Even when a city is still a live center of ambition, you won't know
for sure whether its message will resonate with you till you hear
it. When I moved to New York, I was very excited at first. It's
an exciting place. So it took me quite a while to realize I just
wasn't like the people there. I kept searching for the Cambridge
of New York. It turned out it was way, way uptown: an hour uptown
by air.
Some people know at 16 what sort of work they're going to do, but
in most ambitious kids, ambition seems to precede anything specific
to be ambitious about. They know they want to do something great.
They just haven't decided yet whether they're going to be a rock
star or a brain surgeon. There's nothing wrong with that. But it
means if you have this most common type of ambition, you'll probably
have to figure out where to live by trial and error. You'll
probably have to find the city where you feel at home to know what sort of
ambition you have.
Notes
[1]
This is one of the advantages of not having the universities
in your country controlled by the government. When governments
decide how to allocate resources, political deal-making causes
things to be spread out geographically. No central goverment would
put its two best universities in the same town, unless it was the
capital (which would cause other problems). But scholars seem to
like to cluster together as much as people in any other field, and
when given the freedom to they derive the same advantages from it.
[2]
There are still a few old professors in Palo Alto, but one by
one they die and their houses are transformed by developers into
McMansions and sold to VPs of Bus Dev.
[3]
How many times have you read about startup founders who continued
to live inexpensively as their companies took off? Who continued
to dress in jeans and t-shirts, to drive the old car they had in
grad school, and so on? If you did that in New York, people would
treat you like shit. If you walk into a fancy restaurant in San
Francisco wearing a jeans and a t-shirt, they're nice to you; who
knows who you might be? Not in New York.
One sign of a city's potential as a technology center is the number
of restaurants that still require jackets for men. According to
Zagat's there are none in San Francisco, LA, Boston, or Seattle,
4 in DC, 6 in Chicago, 8 in London, 13 in New York, and 20 in Paris.
(Zagat's lists the Ritz Carlton Dining Room in SF as requiring jackets
but I couldn't believe it, so I called to check and in fact they
don't. Apparently there's only one restaurant left on the entire West
Coast that still requires jackets: The French Laundry in Napa Valley.)
[4]
Ideas are one step upstream from economic power, so it's
conceivable that intellectual centers like Cambridge will one day
have an edge over Silicon Valley like the one the Valley has over
New York.
This seems unlikely at the moment; if anything Boston is falling
further and further behind. The only reason I even mention the
possibility is that the path from ideas to startups has recently
been getting smoother. It's a lot easier now for a couple of hackers
with no business experience to start a startup than it was 10 years
ago. If you extrapolate another 20 years, maybe the balance of
power will start to shift back. I wouldn't bet on it, but I wouldn't
bet against it either.
[5]
If Paris is where people care most about art, why is New York
the center of gravity of the art business? Because in the twentieth
century, art as brand split apart from art as stuff. New York is
where the richest buyers are, but all they demand from art is brand,
and since you can base brand on anything with a sufficiently
identifiable style, you may as well use the local stuff.
Thanks to Trevor Blackwell, Sarah Harlin, Jessica Livingston,
Jackie McDonough, Robert Morris, and David Sloo for reading drafts
of this.
You may have seen Boston Dynamic Dogs and the recently released Sony Aibo. They are supper cool but are too expensive to enjoy. I hope to provide some affordable alternatives that have most of their motion capabilities.
With very limited resources and knowledge, I started small. Smaller structure avoids a lot engineering problems of those larger models. It also allows faster iterations and optimization, just like rats adapt faster than elephants. Regardless the hardware, the major control algorithm could be shared once accurate mapping of DoFs is achieved. I derived a motion algorithm (with a dozen of parameters) for multiple gaits. The current fastest speed is achieved with trotting(2-leg-in-air). As I constantly add new components and change the CoM, while the adaptive part is not good enough, I reserve the tuning time for finalized models.
The motion algorithm is currently implemented on a 32KB,16MHz Arduino board, using up its system resources with algorithmic optimization almost everywhere. I'm going to switch to a 256KB,48MHz board to boost the performance of active adaption, as well as allowing additional codes by future users. The motion is actuated by hobby level (but still robust, digital & metal gear) servos considering price. Some elastic structures were introduced to damper the shock and protect the hardware.
On top of the motion module is a RasPi. The Pi takes no responsibility for controlling detailed limb movements. It focuses on more serious questions, such as "Who am I? Where do I come From? Where am I going?" It generates mind and sends string commands to the Arduino slave. New motion skills can also be sent to the Arduino in a slower manner. A human remote sits in the middle to intercept the robot's control of its own body. It will still hold certain instincts, like refusing to jump down a cliff.
Currently I have two functional prototypes:
* The mini model is a stand-alone 8-DoF (supports up to 16-DoF) Arduino motion module that holds all skills for multiple gaits and real-time adaptation. The codes are compatible with the full version, only to change one parameter. The mount dimension matches those of a RasPi board. So it can also be a "leg-hat" for your existing project. It's targeted at STEM education and Maker community. The price will be similar to some robotic car kits.
* The full version uses a Pi for more AI-enhanced perception and instructs an upgraded 16-DoF motion module. Besides Pi's wifi and bluetooth, it also carries ground contact, touch, infrared, distance, voice and night vision interfaces. All modules have been tested on its light weighted body. It also adopts some bionic skeleton designs to make it morphologically resembles a cat. It's targeted at consumer market with less tech backgrounds. You can imagine it as a legged Android phone or Alexa that has an app store for third party extensions. I also reserved some space below the spine for additional boards (such as a GPS). I have a regular routine for duplicating the model, but need better industrialization to reduce the labor. I expect the price to be close to a smartphone.
* I also have an obsolete version that uses only Pi for controlling both AI and motion. All code were written in Python. The movement is not as good if it's running intensive AI tasks.
I bought my first RasPi in Jun.2016 to learn coding hardware. This robot served as a playground for learning all the components in a regular RasPi beginner kit. I started from craft sticks, then switched to 3D printed frames for optimized performance and morphology. An Arduino was introduced in Jul.2017 for better movement. The 7 major iterations were made between Jul.2016 and Sep.2017. No significant progress was made since last September, when I got distracted from increasing job duties, company formation and patent writting.
I'm now teaching a university robotics class using the Mini kit. I hope to sell more kits to validate the market and bring in some revenue to keep the project going. The full version is yet to be polished. I'm also applying for several accelerators and will probably try Indiegogo. Depending on where the best support I could get, I may start a business or make the project completely open-souce.
I'm not saying I can reproduce the precise motions of those robotics giants. I'm just breaking down the barrier from million dollars to hundreds. I don't expect to send it to battlefield or other challenging realities. I just want to fit this naughty buddy in a clean, smart, yet too quiet house.
Currently it can continuously run at about 2.6 bodyLength/sec for 60 mins, or sit streaming videos for several hours. Users can focus on coding it on either motion (Arduino with C) or AI (Pi with Python) part. And the two can communicate through string tokens. It's pretty easy to teach new postures and behaviors with a couple lines of codes. I believe in the power of open-source if everyone could grab a robot and start to solder and code. Students can learn physics and coding on a new type of toy. Robotics experts can experiment with their own walking algorithms on a much cheaper platform. Software developers can write AI-enhanced applications on a pet-like robot, rather than a "wheeled ipad".
If you are interested in the cat and want to have one in hand, please like the video and share. I also love to see your comments to make it better. Your support will determine how soon it will be available on the market.
------------
I was amazed by your warm feedback. It's really encouraging! Here I want to answer some common questions:
----
* Sharing STL?
- The full version cat needs multiple precisely printed structures with various filament. It requires ~two day for printing and post processing (involving acetone). And they have to be assembled with specific accessories and tools. Some mechanisms are designed at <0.2mm precision and I'm currently tuning it by careful filing. Even an alternative way of soldering or wiring may cause trouble in assembling.
I think the most economic (and safe) way is to invest some expensive injection mold then go mass production, at least for the key mechanic parts. And I need time to put up a good documentation. The mini version should come out much earlier.
----
* Sharing Codes?
- The project is built upon some open-sourced libraries. I'm supposed to inherit their licenses. From another point of view, it's impossible for me to hide my codes once it's released. However, I do hope to organize my codes and plan better for the project. The cat is my baby and I want it stronger before leaving home.
----
* Open-source?
- Open-source also needs some commercial operations to keep healthy. I'll try my best to balance everything. They are out of my expertise and I have to learn. I do have to settle down and support my family, rather than sleeping lonely on a foreign land.
Sorry guys...I'm currently teaching 5 credits university classes only to pay-off my bills!
----
* Last question is for you:
- Could you suggest some semi-public platform (like forum, BBS) so that we can discuss the project in a better organized way? I'm receiving emails for collaborations and I hope everyone could get credit and keep track of others' contribution.
The phenomenon of women discriminating against other women in the workplace — particularly as they rise in seniority — has long been documented as the "queen bee syndrome." As women have increased their ranks in the workplace, most will admit to experiencing rude behavior and incivility.
Who is at fault for dishing out these mildly deviant behaviors? Has the syndrome grown more pervasive?
"Studies show women report more incivility experiences overall than men, but we wanted to find out who was targeting women with rude remarks," said Allison Gabriel, assistant professor of management and organizations in the University of Arizona's Eller College of Management.
Gabriel and her co-authors set out to answer that question across three studies. Men and women who were employed full time answered questions about the incivility they experienced at work during the last month. The questions were about co-workers who put them down or were condescending, made demeaning or derogatory remarks, ignored them in a meeting or addressed them in unprofessional terms. Each set of questions was answered twice, once for male co-workers and once for female co-workers.
"Across the three studies, we found consistent evidence that women reported higher levels of incivility from other women than their male counterparts," Gabriel said. "In other words, women are ruder to each other than they are to men, or than men are to women.
"This isn't to say men were off the hook or they weren't engaging in these behaviors," she noted. "But when we compared the average levels of incivility reported, female-instigated incivility was reported more often than male-instigated incivility by women in our three studies."
Participants also were asked to complete trait inventories of their personalities and behaviors to determine if there were any factors that contributed to women being treated uncivilly. The research showed that women who defied gender norms by being more assertive and dominant at work were more likely to be targeted by their female counterparts, compared to women who exhibited fewer of those traits.
The researchers also found that when men acted assertive and warm — in general, not considered the norm for male behavior — they reported lower incivility from their male counterparts. This suggests men actually get a social credit for partially deviating from their gender stereotypes, a benefit that women are not afforded.
Gabriel, whose co-authors are Marcus Butts from Southern Methodist University, Zhenyu Yuan of the University of Iowa, Rebecca Rosen of Indiana University and Michael Sliter of First Person Consulting, said the research is important not only from the standpoint of individual employee health but also in terms of organizational management.
Evidence emerged in the three studies that companies may face a greater risk of losing female employees who experience female-instigated incivility, as they reported less satisfaction at work and increased intentions to quit their current jobs in response to these unpleasant experiences. Paired with estimates that incivility can cost organizations an estimated $14,000 per employee, this presents a problem for organizations.
Gabriel noted that the findings are an opportunity for companies to re-evaluate their cultures and how they address this issue.
"Companies should be asking, 'What kinds of interventions can be put in place to really shift the narrative and reframe it?'" Gabriel said. "Making workplace interactions more positive and supportive for employees can go a long way toward creating a more positive, healthier environment that helps sustain the company in the long run. Organizations should make sure they also send signals that the ideas and opinions of all employees are valued, and that supporting others is crucial for business success — that is, acting assertively should not be viewed negatively, but as a positive way for employees to voice concerns and speak up."
The study, "Further Understanding Incivility in the Workplace: The Effects of Gender, Agency and Communion," is forthcoming in the Journal of Applied Psychology.
Computers that operate more like the human brain than computers—a field sometimes referred to as neuromorphic computing—have promised a new era of powerful computing.
While this all seems promising, one of the big shortcomings in neuromorphic computing has been that it doesn’t mimic the brain in a very important way. In the brain, for every neuron there are a thousand synapses—the electrical signal sent between the neurons of the brain. This poses a problem because a transistor only has a single terminal, hardly an accommodating architecture for multiplying signals.
Now researchers at Northwestern University, led by Mark Hersam, have developed a new device that combines memristors—two-terminal non-volatile memory devices based on resistance switching—with transistors to create what Hersam and his colleagues have dubbed a “memtransistor” that performs both memory storage and information processing.
This most recent research builds on work that Hersam and his team conducted back in 2015 in which the researchers developed a three-terminal, gate-tunable memristor that operated like a kind of synapse.
While this work was recognized as mimicking the low-power computing of the human brain, critics didn’t really believe that it was acting like a neuron since it could only transmit a signal from one artificial neuron to another. This was far short of a human brain that is capable of making tens of thousands of such connections.
“Traditional memristors are two-terminal devices, whereas our memtransistors combine the non-volatility of a two-terminal memristor with the gate-tunability of a three-terminal transistor,” said Hersam to IEEE Spectrum. “Our device design accommodates additional terminals, which mimic the multiple synapses in neurons.”
Hersam believes that these unique attributes of these multi-terminal memtransistors are likely to present a range of new opportunities for non-volatile memory and neuromorphic computing.
This schematic shows an integrated circuit with a new element—a “memtransistor”—that its inventors say could be useful in neuromorphic computing.
Hersam and his team used molybdenum disulfide in their work back in 2015. However, in that instance they just used flakes of the material. In this most recent work, they used a continuous film of polycrystalline molybdenum disulfide that includes a large number of smaller flakes. This made it possible to scale up the device from just a single flake to a number of devices across an entire wafer.
Once they had fabricated memtransistors uniformly across an entire wafer, Hersam and his colleagues added contacts.
“Thus far, we have demonstrated seven terminals (six terminals in direct contact with the molybdenum disulfide channel and a seventh gate terminal), but additional terminals should be achievable using higher resolution lithography,” said Hersam.
The multi-terminal memtransistors have distinctive electrical characteristics, according to Hersam. For one, they have gate-tunability that allows dynamic adjustment of the electrical characteristics through the application of a gate potential. They also have large on/off switching ratios with high cycling endurance and long-term retention of states.
Perhaps the key feature is that the multiple terminals mimic the multiple synapses in neurons and enable gates to be tuned in such a way that the memtransistor is capable of more functions than would be possible to achieve using standard two-terminal memristors.
“For example, the conductance between a pair of two floating electrodes (pre-synaptic and post-synaptic neurons) can be varied by an order of magnitude by applying voltage pulses to the modulatory terminals,” explained Hersam.
Hersam believes that these memtransistors can serve as a foundational circuit element for neuromorphic computing. Of course, scaling up from dozens of these devices to the billions that are available today in conventional transistors must still be done. But Hersam does not see any fundamental barriers to doing this. In fact, Hersam and his team are already moving toward this aim.
He added: “We are now working on making smaller and faster memtransistors, which should possess lower operating voltages and more efficient neuromorphic computation. We are also exploring the integration of memtransistors into more complicated circuits that are suitable for non-volatile memory and advanced neuromorphic architectures.”
“Any sufficiently complicated model class contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half of a state machine.”–Pete Forde
Domain models are representations of meaningful real-world concepts pertinent to sphere of knowledge, influence or activity (the “domain”) that need to be modelled in software. Doman models can represent concrete real-word objects, or more abstract things like meetings and incidents.
Forde’s insight was that most domain models end up having a representation of various states. Over time, they build up a lot of logic around how and when they transition between these states, and that logic is smeared across various methods where it becomes difficult to understand and modify.
By recognizing when domain models should be represented first and foremost as state machines–or recognizing when to refactor domain models into state machines–we keep our models understandable and workable. We tame their complexity.
So, what are state machines? And how do they help?
finite state machines
A finite state machine, or simply a state machine, is a mathematical model of computation. It is an abstract machine that can be in exactly one of a finite number of states at any given time.
A state machine can change from one state to another in response to some external inputs; the change from one state to another is called a transition. A state machine is defined by a list of its states, its initial state, and the conditions for each transition.–Wikipedia
Well, that’s a mouthful. To put it in context from a programming (as opposed to idealized model of computation) point of view, when we program with objects, we build little machines. They have internal state and respond to messages or events from the rest of the program via the mechanism of their methods. (JavaScript also permits direct access to properties, but let’s consider the subset of programs that only interact with objects via methods.)
Most objects are designed to encapsulate some kind of state. Stateless objects are certainly a thing, but let’s put them aside and consider only objects that have state. Some such objects can be considered State Machines, some cannot. What distinguishes them?
First, a state machine has a notion of a state. All stateful objects have some kind of “state,” but a state machine reifies this and gives it a name. Furthermore, there are a finite number of possible states that a state machine can be in, and it is always in exactly one of these states.
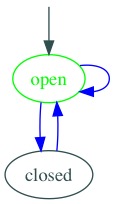
For example let’s say that a bank account has a balance and it can be be one of open, closed, or frozen. Its balance certainly is stateful, but it’s “state” from the perspective of a state machine is open, closed, or frozen.
Second, a state machine formally defines a starting state, and allowable transitions between states. The aforementioned bank account starts in open state. It can transition from open to closed, and from time to time, from closed back to open. Sometimes, it transitions from a state back to itself, which we see in an arrow from open back to open. This can be displayed with a diagram, and such diagrams are a helpful way to document or brainstorm behaviour:
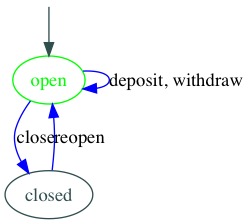
Third, a state machine transitions between states in response to events. Our bank account starts in open state. When open, a bank account responds to a close event by transitioning to the closed state. When closed, a bank account responds to the reopen event by transitioning to the open state. As noted, some transitions do not involve changes in state. When open, a bank account responds to deposit and withdraw events, and it transitions back to open state.
transitions
The events that trigger transitions are noted by labeling the transitions on the diagram:
We now have enough to create a naïve JavaScript object to represent what we know so far about a bank account. We will make each event a method, and the state will be a string:
letaccount={state:'open',balance:0,deposit(amount){if(this.state==='open'){this.balance=this.balance+amount;}else{throw'invalid event';}},withdraw(amount){if(this.state==='open'){this.balance=this.balance-amount;}else{throw'invalid event';}},close(){if(this.state==='open'){if(balance>0){// ...transfer balance to suspension account}this.state='closed';}else{throw'invalid event';}},reopen(){if(this.state==='closed'){// ...restore balance if applicablethis.state='open';}else{throw'invalid event';}}}account.state//=> openaccount.close();account.state//=> closed
The first thing we observe is that our bank account handles different events in different states. In the open state, it handles the deposit, withdraw, and close event. In the closed state, it only handles the reopen event. The natural way of implementing events is as methods on the object, but now we are imbedding in each method a responsibility for knowing what state the account is in and whether that transition can be allowed or not.
It’s also not clear from the code alone what all the possible states are, or how we transition. What is clear is what each method does, in isolation. This is one of the “affordances” of a typical object-with-methods design: It makes it very easy to see what an individual method does, but not to get a higher view of how the methods are elated to each other.
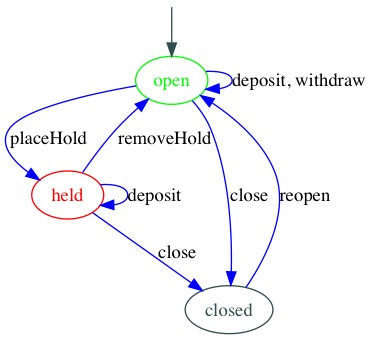
Let’s add a little functionality: A “hold” can be placed on accounts. Held accounts can accept deposits, but not withdrawals. And naturally, the hold can be removed. The new diagram looks like this:
And the code we end up with looks like this:
letaccount={state:'open',balance:0,deposit(amount){if(this.state==='open'||this.state==='held'){this.balance=this.balance+amount;}else{throw'invalid event';}},withdraw(amount){if(this.state==='open'){this.balance=this.balance-amount;}else{throw'invalid event';}},placeHold(){if(this.state==='open'){this.state='held';}else{throw'invalid event';}},removeHold(){if(this.state==='held'){this.state='open';}else{throw'invalid event';}},close(){if(this.state==='open'||this.state==='held'){if(balance>0){// ...transfer balance to suspension account}this.state='closed';}else{throw'invalid event';}},reopen(){if(this.state==='closed'){// ...restore balance if applicablethis.state='open';}else{throw'invalid event';}}}
To accomodate the new state, we had to update a number of different methods. This is not difficult when the requirements are in front of us, and it’s often a mistake to overemphasize whether it is easy or difficult to implement something when the requirements and the code are both well-understood.
However, we can see that the code does not do a very good job of documenting what is or isn’t possible for a held account. This organization makes it easy to see exactly what a deposit or withdraw does, at the expense of making it easy to see how held accounts work or the overall flow of accounts from state to state.
If we wanted to emphasize states, what could we do?
executable state descriptions
Directly compiling diagrams has been–so far–highly unproductive for programming. But there’s another representation of a state machine that can prove helpful: A transition table. Here’s our transition table for the naïve bank account:
open
held
closed
open
deposit, withdraw
place-hold
close
held
remove-hold
deposit
close
closed
reopen
In the leftmost column, we have the current state of the account. Each subsequent column is a destination state. At the intersection of the current state and a destination state, we have the event or events that transition the object from current to destination state. Thus, deposit and withdraw transition from open to open, while place-hold transitions the object from open to held. The start state is arbitrarily taken as the first state listed.
Like the state diagram, the transition table shows clearly which events are handled by which state, and the transitions between them. We can take this idea to our executable code: Here’s a version of our account that uses objects to represent table rows and columns.
constSTATES=Symbol("states");constSTARTING_STATE=Symbol("starting-state");constAccount={balance:0,STARTING_STATE:'open',STATES:{open:{open:{deposit(amount){this.balance=this.balance+amount;},withdraw(amount){this.balance=this.balance-amount;},},held:{placeHold(){}},closed:{close(){if(balance>0){// ...transfer balance to suspension account}}}},held:{open:{removeHold(){}},held:{deposit(amount){this.balance=this.balance+amount;}},closed:{close(){if(balance>0){// ...transfer balance to suspension account}}}},closed:{open:{reopen(){// ...restore balance if applicable}}}}};
This description isn’t executable, but it doesn’t take much to write an implementation organized along the same lines:
implementing a state machine that matches our description
In Mixins, Forwarding, and Delegation in JavaScript, we briefly touched on using late-bound delegation to create state machines. The principle is that instead of using strings for state, we’ll use objects that contain the methods we’re interested in. First, we’ll write out what those objects will look like:
constSTATE=Symbol("state");constSTATES=Symbol("states");constopen={deposit(amount){this.balance=this.balance+amount;},withdraw(amount){this.balance=this.balance-amount;},placeHold(){this[STATE]=this[STATES].held;},close(){if(balance>0){// ...transfer balance to suspension account}this[STATE]=this[STATES].closed;}};constheld={removeHold(){this[STATE]=this[STATES].open;},deposit(amount){this.balance=this.balance+amount;},close(){if(balance>0){// ...transfer balance to suspension account}this[STATE]=this[STATES].closed;}};constclosed={reopen(){// ...restore balance if applicablethis[STATE]=this[STATES].open;}};
Now our actual account object stores a state object rather than a state string, and delegates all methods to it. When an event is invalid, we’ll get an exception. That can be “fixed,” but let’s not worry about it now:
Unfortunately, this regresses: We’re littering the methods with state assignments. One of the benefits of transition tables and state diagrams is that they communicate both the from_and _to states of each transition. Assigning state within methods does not make this clear, and introduces an opportunity for error.
To fix this, we’ll write a transitionsTodecorator to handle the state changes.
constSTATE=Symbol("state");constSTATES=Symbol("states");functiontransitionsTo(stateName,fn){returnfunction(...args){constreturnValue=fn.apply(this,args);this[STATE]=this[STATES][stateName];returnreturnValue;};}constopen={deposit(amount){this.balance=this.balance+amount;},withdraw(amount){this.balance=this.balance-amount;},placeHold:transitionsTo('held',()=>undefined),close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})};constheld={removeHold:transitionsTo('open',()=>undefined),deposit(amount){this.balance=this.balance+amount;},close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})};constclosed={reopen:transitionsTo('open',function(){// ...restore balance if applicable})};constaccount={balance:0,[STATE]:open,[STATES]:{open,held,closed},deposit(...args){returnthis[STATE].deposit.apply(this,args);},withdraw(...args){returnthis[STATE].withdraw.apply(this,args);},close(...args){returnthis[STATE].close.apply(this,args);},placeHold(...args){returnthis[STATE].placeHold.apply(this,args);},removeHold(...args){returnthis[STATE].removeHold.apply(this,args);},reopen(...args){returnthis[STATE].reopen.apply(this,args);}};
Now we have made it quite clear which methods belong to which states, and which states they transition to.
We could stop right here if we wanted to: This is a pattern that is remarkably easy to write by hand, and for many cases, it is far easier to read and maintain than having various if and/or switch statements littering every method. But since we’re enjoying ourselves, what would it take to automate the process of implementing this naïve state machine pattern from descriptions?
compiling descriptions into state machines
Code that writes code does add a certain complexity, but it also enables us to arrange our code such that it is organized more appropriately for our problem domain. Managing stateful entities is one of the hardest problems in programming, so it’s often worth a investing in a little infrastructure work to arrive at an easier to understand and extend program.
The first thing we’ll do is “begin with the end in mind.” We wish to be able to write something like this:
constSTATES=Symbol("states");constSTARTING_STATE=Symbol("starting-state");functiontransitionsTo(stateName,fn){returnfunction(...args){constreturnValue=fn.apply(this,args);this[STATE]=this[STATES][stateName];returnreturnValue;};}constaccount=StateMachine({balance:0,[STARTING_STATE]:'open',[STATES]:{open:{deposit(amount){this.balance=this.balance+amount;},withdraw(amount){this.balance=this.balance-amount;},placeHold:transitionsTo('held',()=>undefined),close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})},held:{removeHold:transitionsTo('open',()=>undefined),deposit(amount){this.balance=this.balance+amount;},close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})},closed:{reopen:transitionsTo('open',function(){// ...restore balance if applicable})}}});
What does StateMachine do?
constRESERVED=[STARTING_STATE,STATES];functionStateMachine(description){constmachine={};// Handle all the initial states and/or methodsconstpropertiesAndMethods=Object.keys(description).filter(property=>!RESERVED.includes(property));for(constpropertyofpropertiesAndMethods){machine[property]=description[property];}// now its statesmachine[STATES]=description[STATES];// what event handlers does it have?consteventNames=Object.entries(description[STATES]).reduce((eventNames,[state,stateDescription])=>{consteventNamesForThisState=Object.keys(stateDescription);for(consteventNameofeventNamesForThisState){eventNames.add(eventName);}returneventNames;},newSet());// define the delegating methodsfor(consteventNameofeventNames){machine[eventName]=function(...args){consthandler=this[STATE][eventName];if(typeofhandler==='function'){returnthis[STATE][eventName].apply(this,args);}else{throw`invalid event ${eventName}`;}}}// set the starting statemachine[STATE]=description[STATES][description[STARTING_STATE]];// we're donereturnmachine;}
let’s summarize
We began with this simple code for a bank account that behaved like a state machine:
letaccount={state:'open',close(){if(this.state==='open'){if(balance>0){// ...transfer balance to suspension account}this.state='closed';}else{throw'invalid event';}},reopen(){if(this.state==='closed'){// ...restore balance if applicablethis.state='open';}else{throw'invalid event';}}};
Encumbering this simple example with meta-programming to declare a state machine may not have been worthwhile, so we won’t jump to the conclusion that we ought to have written it differently. However, code being code, requirements were discovered, and we ended up writing:
letaccount={state:'open',balance:0,deposit(amount){if(this.state==='open'){this.balance=this.balance+amount;}elseif(this.state==='held'){this.balance=this.balance+amount;}else{throw'invalid event';}},withdraw(amount){if(this.state==='open'){this.balance=this.balance-amount;}else{throw'invalid event';}},placeHold(){if(this.state==='open'){this.state='held';}else{throw'invalid event';}},removeHold(){if(this.state==='held'){this.state='open';}else{throw'invalid event';}},close(){if(this.state==='open'){if(balance>0){// ...transfer balance to suspension account}this.state='closed';}if(this.state==='held'){if(balance>0){// ...transfer balance to suspension account}this.state='closed';}else{throw'invalid event';}},reopen(){if(this.state==='open'){throw'invalid event';}elseif(this.state==='closed'){// ...restore balance if applicablethis.state='open';}}}
Faced with more complexity, and the dawning realization that things are going to inexorably become more complex over time, we refactored our code from an ad-hoc, informally-specified, bug-ridden, slow implementation of half of a state machine to this example:
constaccount=StateMachine({balance:0,[STARTING_STATE]:'open',[STATES]:{open:{deposit(amount){this.balance=this.balance+amount;},withdraw(amount){this.balance=this.balance-amount;},placeHold:transitionsTo('held',()=>undefined),close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})},held:{removeHold:transitionsTo('open',()=>undefined),deposit(amount){this.balance=this.balance+amount;},close:transitionsTo('closed',function(){if(balance>0){// ...transfer balance to suspension account}})},closed:{reopen:transitionsTo('open',function(){// ...restore balance if applicable})}}});
how does this help?
Let’s finish our examination of state machines with a small change. We wish to add an availableForWithdrawal method. It returns the balance (if positive and for accounts that are open and not on hold). The old way would be to write a single method with an if statement:
As discussed, this optimizes for understanding availableForWithdrawal, but makes it harder to understand how open and held accounts differ from each other. It combines multiple responsibilities in the availableForWithdrawal method: Understanding everything about account states, and implementing the functionality for each of the applicable states.
This emphasizes the different states and the characteristics of an account in each state, and it separates the responsibilities: States and transitions are handled by our “state machine” organization, and each of the two functions handles just the mechanics of reporting the correct amount available for withdrawal.
“So much complexity in software comes from trying to make one thing do two things.”–Ryan Singer
We can obviously extend our code to generate ES20165 classes, incorporate before- and after- method decorations, tackle validating models in general and transitions in particular, and so forth. Our code here was written to illustrate the basic idea, not to power the next Startup Unicorn.
But for now, our lessons are:
It isn’t always necessary to build architecture to handle every possible future requirement. But it is a good idea to recognize that as the code grows and evolves, we may wish to refactor to the correct choice in the future. While we don’t want to do it too early, we also don’t want to do it too late.
Organizing things that behave like state machines along state machine lines separates responsibilities and decomposes methods into smaller pieces, each of which is focused on implementing the correct behaviour for a single state.
p.s. State was popularized as one of the twenty-three design patterns articulated by the “Gang of Four.” The implementation examples tend to be somewhat specific to a certain style of OOP language, but it is well-worth a review.
Circle Internet Financial Ltd., a closely held mobile-payments firm backed by Goldman Sachs Group Inc., said it acquired Poloniex Inc., one of the larger digital-token exchanges.
Terms of the agreement weren’t disclosed. Fortune magazine reported earlier that the deal was for about $400 million, citing an unnamed person familiar with the transaction. Poloniex, ranked as the 14th largest crypto exchange by data tracker CoinMarketCap.com, says on its website that the U.S.-based company was formed in January 2014.
Circle’s mobile app lets people make instant money transfers. The company also has a trading operation, which handles about $2 billion in crypto trading a month with large institutional buyers and sellers. Minimum order size for the tradition side of the business is $250,000. Circle is also working on a mobile app that will let people easily invest in crypto assets.
Poloniex is already available in more than 100 countries, and Circle plans to scale it further, Circle co-founders Sean Neville and Jeremy Allaire said in a blog. Circle plans to increase its token listings, and explore the fiat connectivity to the dollar, euro and pound that Circle already offers through its mobile app, they said.
“We expect to grow the Poloniex platform beyond its current incarnation as an exchange for only crypto assets,” Neville and Allaire said. “We envision a robust multi-sided distributed marketplace that can host tokens which represent everything of value: physical goods, fundraising and equity, real estate, creative productions such as works of art, music and literature, service leases and time-based rentals, credit, futures, and more."
The combined companies will compete with large digital wallets and exchanges such as Coinbase Inc. The agreement comes as startups and corporations alike are trying to figure out whether to wade into cryptocurrencies. While many have been involved in blockchain for years, there has been more hesitancy around what to do with digital assets like Bitcoin due to volatility and a history of it being used in shady transactions like drugs and evading taxes.
Circle has raised nearly $140 million in funding from Goldman, General Catalyst and IDG Capital Partners, according to Crunchbase. Poloniex hasn’t disclosed any funding from venture capitalists or large institutions.
For more on cryptocurrencies, check out the Decrypted podcast:
We are thrilled to announce that as of Monday, February 26th, Visual China Group (VCG), a visual-content licensing and visual data technology company based in Beijing, has acquired 100% of 500px shares. VCG is among the top image licensing companies in the world, the go-to choice for creative and media professionals in China, and an award-winning leader in copyright protection.
Most importantly, VCG has been an invaluable partner to us since they became our lead investor in 2015, and we’ve since watched both 500px.com and 500px.me (the China-based counterpart of 500px.com) flourish.
For 500px photographers, this means a lot of exciting things are on the way. By joining forces with VCG, we’ll be able to consistently deliver more innovative features to help you amplify your personal brand, connect with millions of like-minded creatives, and inspire you to improve your skill set as a photographer, as well as reward your talent and creativity with new incentives.
New products and services rolling out this year include:
Better statistics to improve and understand the reach and impact of your photos;
Top charts and badges that will help expand your exposure and reward your achievements;
Private messaging to support meaningful communication between members;
Sub-communities that allow photographers to connect around shared interests, styles, and locations.
If you’re selling photos with us, you’ll be excited to hear that we will be announcing new partnerships that will give your photos an even greater reach, and new markets in which to sell.
We’re extremely proud of where we’ve taken 500px in recent years. We truly believe this acquisition is a great opportunity, and can’t wait to see the 500px community grow and prosper even more. We’re so honored to share the journey with all of you.
If you have any questions, please feel free to send us an email at community@500px.com.
The compiler tool chain is one of the largest and most complex components of any system, and increasingly will be based on open source code, either GCC or LLVM. On a Linux system only the operating system kernel and browser will have more lines of code. For a commercial system, the compiler has to be completely reliable—whatever the source code, it should produce correct, high performance binaries.
So how much does producing this large, complex and essential component cost? Thanks to open source not as much as you might think. In this post, I provide a real world case study, which shows how bringing up a new commercially robust compiler tool chain need not be a huge effort.
How much code?
An analysis by David A Wheeler’s SLOCCount shows that GCC is over 5 million lines. LLVM is smaller at 1.6 million lines, but is newer, supports only C and C++ by default and has around one third the number of architectures included as targets. However a useful tool chain needs many more components.
Debugger: Either GDB (800k lines) or LLDB (600k lines)
Linker: GNU ld (160k lines), gold (140k lines) or lld (60k lines)
Assembler/disassembler: GNU gas (850k lines) or the built in LLVM assembler
Binary utilities: GNU (90k lines) and/or LLVM (included in main LLVM source)
Emulation library: libgcc (included in GCC source) or CompilerRT (340k lines)
Standard C library: newlib (850k lines), glibc (1.2M lines), musl (82k lines) or uClibC-ng (251k lines)
In addition the tool chain needs testing. In most GNU tools, the regression test suite is included with the main source. However for LLVM, the regression tests are a separate code base of 500 thousand lines. Plus for any embedded system, it is likely a debug server will be needed to talk to the debugger to allow tests to be loaded.
What is involved in porting a compiler?
Our interest is in a port of the tool chain that is robust for commercial deployment. Many PhD students round the world port compilers for their research, but their effort is dedicated to exploring a particular research theme. The resulting compiler is often produced quickly, but is neither complete, nor reliable—since this is not the point of a research program.
This article is instead concerned with creating a set of tools which reliably produce correct and efficient binaries for any source program in a commercial/industrial environment.
Fortunately most of this huge code base is completely generic. All mainstream compiler tools go to considerable efforts to provide a clean separation of target specific code, so the task of porting a compiler tool chain to a new architecture is a manageable task. There are five stages in porting a compiler tool chain to a new target.
Proof of concept tool chain. Initial working ports of all components are created. This prototype is essential to identify areas of particular challenge during the full porting process and should be completed in the first few months of the project. At this point it will be possible to compile a set of representative programs to demonstrate the components will work together as expected.
Implementation of all functionality. All functionality of the compiler and other tools is completed. Attributes, builtin/intrinsic functions and emulations of missing functionality are completed. All relocations are added to the linker, the full C library board support package is written and custom options are added to tools as needed. At the end of this process, the customer will have a fullly functional tool chain. Most importantly, all the regression test suites will be running, with the great majority of tests running.
Production testing. This is often the largest part of the project. Testing must pass in three areas:
regression testing, to demonstrate that the tool chain has not broken anything which works on other architectures;
compliance testing, often using the customer’s tests to show that all required functionality is present; and
benchmarking, to demonstrate that the tool chain generates code which meets the required performance criteria, whether for execution speed, code size or energy efficiency.
Roll out. This is primarily about helping users understand their new compiler and how it differs from the previous tools, and usually involves written and video tutorials. While there will be real bugs uncovered in use, invariably there will also be numerous bug reports which amount to “this new compiler is different to the old one”. This is particularly pronounced where GCC and LLVM replace old proprietary compilers, because the step up in functionality is so great. Where there is a large user base, phased roll-out is essential to manage the initial support load.
Maintenance. LLVM and GCC are very active projects, and new functionality is always being added, both to support new language standards in the front end and to add new optimizations in the back end. The compiler will need to be kept up to date with these changes. Plus of course there will be new functionality specific to the target required and on such a large project bugs reported by users.
How much effort: the general case
Let us consider the general case. A new architecture with a large external user base, which must support C and C++ in both bare metal and embedded Linux targets. In this case it is likely that the architecture provides a range of implementations, from small processors used as bare metal or with RTOS in deeply embedded systems, to large processors capable of supporting a full application Linux environment.
Overall first production release of a such a tool chain takes 1-3 engineer years. The initial proof of concept tool chain should be completed in 3 months. Implementation of all the functionality then takes a further 6-9 months, with a further 3 months if both bare metal and Linux targets are to be supported.
Production testing takes at least 6 months, but with a large range of customer specific testing this can be as large as 12 months. Initial roll-out takes 3 months, but with a large user base, phased general release can take up to 9 months more.
Maintenance effort depends hugely on the size of the customer base reporting in issues and the number of new features needed. It can be as little as 0.5 engineer months per month, but is more usually 1 engineer month per month.
It is important to note that a complete team of engineers will work on this: compiler specialists, debugger experts, library implementation engineers and so on. Compiler engineering is one of the most technically demanding disciplines in computing, and no one engineer can have all the expertise needed.
How much effort: the simpler case
Not everyone needs a full compiler release for a large number of external users. There are numerous application specific processors, particularly DSPs which are used solely in-house by one engineering company. Where such processors have proved commercially successful they have been developed and what was a tiny core programmed in assembler by one engineer has become a much more powerful processor with a large team of assembler programmers. In such cases moving to C compilation would mean a great increase in productivity and reduction in cost.
For such use cases, the tool chain need only support C, not C++ and a minimal C library is sufficient. There may well be a pre-existing assembler and linker that can be reused. This greatly reduces the effort and timescales to as little as one engineer year for a full production compiler.
The proof-of-concept still takes 3 months, but then completing full functionality can be achieved in as little as 3 more months. Production testing is still the largest effort, taking 3-6 months, but with a small user base 3 months is more than sufficient for roll out.
The tool chain still needs to be maintained, but for this simpler system with a small user base, an effort of 0.25 engineer months/month is typically enough.
For the smallest customers, it can be sufficient to stop after completing full functionality. If there are only a handful of standard programs to be compiled, it may be enough to demonstrate that the compiler handles these well and efficiently without progressing to full production testing.
Case Study
In 2016, Embecosm was approached by an electronic design company, who for many years had used an in-house 16-bit word addressed DSP designed to meet the needs of their specialist area. This DSP was now on its third generation and they were conscious that they needed a great deal of assembler programming effort. This was aggravated by the standard codecs on which they relied having C reference implementations. They had an existing compiler, but it was very old and porting it to the new generation DSP was not feasible.
Embecosm were tasked with providing a LLVM based tool chain capable of compiling their C codecs and delivering high quality code. There was an assumption that this code would then be hand-modified if necessary. They had an existing assembler/linker, which worked by combining all the assembler into a single source file, resolving cross references and generating a binary file to load onto the DSP. The customer was also keen to build up in-house compiler expertise, so one of their engineers joined the Embecosm implementation team and has been maintaining the compiler since the end of the project.
In the first 3 months, we created a tool chain based on their existing assembler/disassembler. In order to use newlib, we created a pseudo-linker, which would extract the required files from newlib as source assembler to combine with the test program. Because silicon was not yet available, we tested against a Verilator model of the chip. For this we wrote a gdbserver, allowing GDB to talk to the model. In the absence of ELF, source level debugging was not possible, but GDB was capable of loading programs and determining results, sufficient for testing purpose. In the absence of 16-bit char support in LLVM, we used packed chars for the proof-of-concept. This meant many character based programs would not work, but was sufficient for this stage.
This allowed us to compile representative test programs and demonstrate that the compiler tool chain would work. It became clear that there were two major obstacles to achieving full-functionality: 1) lack of ELF binary support; and 2) lack of proper 16-bit character support.
For phase two, we implemented a GNU assembler/disassembler using CGEN, which required approximately 10 days of effort. We also implemented 16-bit character support for LLVM as documented in this blog post. With these two features, completing the tool chain functionality became much more straightfoward and we were able to run standard LLVM lit and GCC regression tests for the tool chain, the great majority of which passed. The DSP has a number of specialist modes for providing saturating fixed-point arithmetic. To support these we implemented specialist builtin and intrinsic functions.
At this point we had a compiler which correctly compiled the customer’s code. The ELF support meant techniques such as link-time optimization (LTO) and garbage collection of sections were possible, leading to successful optimization of the code so it met the memory constraints of the customer. With an investment of 120 engineer days, they had achieved their goal of being able to compile C code efficiently for their new DSP.
The customer decided they had all the functionality they needed by this point and decided no further work was required. Should they decide to make the compiler more widely available they have the option to continue with full production testing of the compiler tool chain.
Lessons learned
Two factors made it possible to deliver a fully functional compiler tool chain in 120 engineer days.
Using an open source compiler. The tools used in this project represent a cumulative effort of thousands of engineer years by the compiler community over three decades. Our customer was able to take advantage of this to acquire a state-of-the-art compiler tool chain.
An expert compiler team. Although this was a 120 days project, a team of five were involved, each bringing years of specialist expertise. No one individual could know everything about emulation, GDB, CGEN assemblers, the GNU linker and the LLVM compiler. But within Embecosm we have the skill set to deliver the full project.
If you would like to know more about bringing up a compiler tool chain for your processor, please get in touch.
“In ecology when you see something like this, it usually means there’s a cost-benefit trade-off,” Garnier said. “You try to understand: What is the benefit, and what is the cost?”
The cost, ecologists think, is that ants trapped in bridges aren’t available for other tasks, like foraging. At any time on a march, a colony might be maintaining 40 to 50 bridges, with as few as one and as many as 50 ants per bridge. In a 2015 paper, Garnier and his colleagues calculated that as much as 20 percent of the colony can be locked into bridges at a time. At this point, a shorter route just isn’t worth the extra ants it would take to create a longer bridge.
Except, of course, individual ants have no idea how many of their colony-mates are holding fast over a gap. And this is where the second rule kicks in. As individual ants run the “bridging” algorithm, they have a sensitivity to being stampeded. When traffic over their backs is above a certain level, they hold in place, but when it dips below some threshold — perhaps because too many other ants are now occupied in bridge-building themselves — the ant unfreezes and rejoins the march.
This new paper grew out of experiments conducted with army ants in the Panamanian jungle in 2014. Based on those observations, the researchers have created a model that quantifies ants’ sensitivity to foot traffic and predicts when a colony will bridge an obstacle and when it will decide, in a sense, that it’s better to go around.
“We’re trying to figure out if we can predict how much shortcutting ants will do given a geometry of their environment,” Garnier said.
Evolution has seemingly equipped army ants with just the right algorithm for on-the-go bridge building. Researchers working to build swarms of simple robots are still searching for the instructions that will allow their cheap machines to perform similar feats. One challenge they have to contend with is that nature makes ants more reliably, and at lower cost, than humans can fabricate swarm-bots, whose batteries tend to die. A second is that it’s very possible there’s more governing army ant behavior than two simple rules.
“We describe army ants as simple, but we don’t even understand what they’re doing. Yes, they’re simple, but maybe they’re not as simple as people think,” said Melvin Gauci, a researcher at Harvard University working on swarm robotics.
Hi HN! We're Jared and Gabe (YC W18), the founders of Pagedraw (https://pagedraw.io). Pagedraw is a UI builder that turns mockups into React code.
Pagedraw lets you annotate mockups with extra information (like how to connect to the backend, resize for different screens, etc.) to get full, presentational, React Components. They’re React Components just like any others, so they can be interleaved freely with handwritten ones. They don’t require any new dependencies and work well with any existing JSX build system.
You can import the mockups from Sketch or Figma, or draw them from scratch in Pagedraw.
Working as full stack devs, we constantly had to do this translation by hand. It was our least favorite part of our jobs, since the creative work had already been done by the mockup designer. It's so repetitive and mechanical that we decided to stop hand-coding divs and css and write a program to do it instead.
There have been many attempts to automate this stuff in the past. For 20 years, people have been trying to solve the problem with tools like Dreamweaver, Frontpage, and so on. Broadly speaking, they tended to fall into one of two buckets, each with their own problems. In one corner are tools like Dreamweaver, which can produce correct code but have to expose some of the underlying HTML model, making their users play a puzzle game to do something as simple as move an object around. In the other corner are freeform design tools that generate position:absolute code. That doesn’t work if you care about working on different screen sizes, or reflowing the layout around variable-length content as simple as “hello <username>”.
We think the problem is that you have to look at it like a compiler. Past tools never fully worked because they tried to unify two fundamentally different mental models: the designer’s mental model of a free form canvas like Sketch or Photoshop, and the DOM’s mental model of <div> followed by a <p> followed by an <img> and so on. What always happens is one of two things: either the computer’s mental model is imposed on the designer, or the designer’s mental model is imposed on the computer. The former results in a clunky design tool, and the latter results in position:absolute.
What we do instead is recognize that these are two fundamentally different models. Designers work with Sketch by saying “put this button at this pixel”. We can let them do that and still generate flexbox code without positon:absolute, and let everything resize and reflow correctly. Pagedraw does it by inferring constraints from the relative geometries in the mockup. For example, if object A is to the right of object B, we infer it should always remain to the right, regardless of resizing or content reflowing. Sometimes, the developer does have to ask the designer about their intent regarding resizing, which is why Pagedraw also needs you to annotate that information. We then compile those constraints, inferred and annotated, into HTML layout mechanisms like inline-block and flexbox.
It turns out that a lot of other nice things follow from a compiler-like architecture. For one, we separate codegen correctness from codegen prettiness by cleaning up the generated code in discrete optimization passes. Another is the ability to easily retarget for AngularJS, Backbone, React Native, and so on by just swapping the compiler backend. We even have some nice editor features that fell out from hacking a Lispy interpreter onto our internal representation.
We’re excited to see what you all think and hear about your experiences in this area! You can try it at https://pagedraw.io/
This post summarizes the result of our 2017 user survey along with commentary
and insights. It also draws key comparisons between the results of the 2016 and
2017 survey.
This year we had 6,173 survey respondents, 70% more than the 3,595 we had in theGo 2016 User Survey. In
addition, it also had a slightly higher completion rate (84% → 87%) and a
higher response rate to most of the questions. We believe that survey length is
the main cause of this improvement as the 2017 survey was shortened in response
to feedback that the 2016 survey was too long.
We are grateful to everyone who provided their feedback through the survey to
help shape the future of Go.
Programming background
For the first time, more survey respondents say they are paid to write Go
than say they write it outside work. This indicates a significant shift in
Go's user base and in its acceptance by companies for professional software
development.
The areas people who responded to the survey work in is mostly consistent with
last year, however, mobile and desktop applications have fallen significantly.
Another important shift: the #1 use of Go is now writing API/RPC services (65%,
up 5% over 2016), taking over the top spot from writing CLI tools in Go (63%).
Both take full advantage of Go's distinguishing features and are key elements of
modern cloud computing. As more companies adopt Go, we expect these two uses
of Go to continue to thrive.
Most of the metrics reaffirm things we have learned in prior years. Go
programmers still overwhelmingly prefer Go. As more time passes Go users are
deepening their experience in Go. While Go has increased its lead among Go
developers, the order of language rankings remains quite consistent with last
year.
Go usage
In nearly every question around the usage and perception of Go, Go has
demonstrated improvement over our prior survey. Users are happier using Go, and
a greater percentage prefer using Go for their next project.
When asked about the biggest challenges to their own personal use of Go, users
clearly conveyed that lack of dependency management and lack of generics were
their two biggest issues, consistent with 2016. In 2017 we laid a foundation to
be able to address these issues. We improved our proposal and development
process with the addition of
Experience Reports which is
enabling the project to gather and obtain feedback critical to making these
significant changes. We also made
sigificant changes under the hood in
how Go obtains, and builds packages. This is foundational work essential to
addressing our dependency management needs.
These two issues will continue to be a major focus of the project through 2018.
In this section we asked two new questions. Both center around what
developers are doing with Go in a more granular way than we've previously asked.
We hope this data will provide insights for the Go project and ecosystem.
Since last year there has been an increase of the percentage of people who
identified "Go lacks critical features" as the reason they don't use Go more and
a decreased percentage who identified "Go not being an appropriate fit". Other
than these changes, the list remains consistent with last year.
Reading the data: This question asked how strongly the respondent agreed or disagreed with the statement.
The responses for each statement are displayed as sections of a single bar, from “strongly disagree” in deep red on the left end
to “strongly agree” in deep blue on the right end. The bars use the same scale as the rest of the graphs,
so they can (and do, especially later in the survey) vary in overall length due to lack of responses.
The ratio after the text compares the number of respondents who agreed (including “somewhat agree” and “strongly agree”)
to those who disagreed (including “somewhat disagree” and “strongly disagree”).
For example, the ratio of respondents agreeing that they would recommend Go to respondents disagreeing was 19 to 1.
The second ratio (within the brackets) is simply a weighted ratio with each somewhat = 1, agree/disagree = 2, and strongly = 4.
Reading the data: This question asked for write-in responses.
The bars above show the fraction of surveys mentioning common words or phrases. Only words or phrases that
appeared in 20 or more surveys are listed, and meaningless common words or phrases like “the” or “to be” are omitted.
The displayed results do overlap: for example, the 402 responses that mentioned “management” do include the
266 listed separately that mentioned “dependency management” and the 79 listed separately that mentioned
“package management.”
However, nearly or completely redundant shorter entries are omitted: there are not twenty or more surveys that listed
“dependency” without mentioning “dependency management,” so there is no separate entry for “dependency.”
Development and deployment
We asked programmers which operating systems they develop Go on; the ratios of
their responses remain consistent with last year. 64% of respondents say
they use Linux, 49% use MacOS, and 18% use Windows, with multiple choices
allowed.
Continuing its explosive growth, VSCode is now the most popular editor among
Gophers. IntelliJ/GoLand also saw significant increase in usage. These largely
came at the expense of Atom and Submlime Text which saw relative usage drops.
This question had a 6% higher response rate from last year.
Survey respondents demonstrated significantly higher satisfaction with Go
support in their editors over 2016 with the ratio of satisfied to dissatisfied
doubling (9:1 → 18:1). Thank you to everyone who worked on Go editor support
for all your hard work.
Go deployment is roughly evenly split between privately managed servers and
hosted cloud servers. For Go applications, Google Cloud services saw significant
increase over 2016. For Non-Go applications, AWS Lambda saw the largest increase in use.
Working Effectively
We asked how strongly people agreed or disagreed with various statements about
Go. All questions are repeated from last year with the addition of one new
question which we introduced to add further clarifaction around how users are
able to both find and use Go libraries.
All responses either indicated a small improvement or are comparable to 2016.
As in 2016, the most commonly requested missing library for Go is one for
writing GUIs though the demand is not as pronounced as last year. No other
missing library registered a significant number of responses.
The primary sources for finding answers to Go questions are the Go web site,
Stack Overflow, and reading source code directly. Stack Overflow showed a small
increase from usage over last year.
The primary sources for Go news are still the Go blog, Reddit’s /r/golang and
Twitter; like last year, there may be some bias here since these are also how
the survey was announced.
The Go Project
59% of respondents expressed interest in contributing in some way to the Go
community and projects, up from 55% last year. Respondents also indicated that
they felt much more welcome to contribute than in 2016. Unfortunately,
respondents indicated only a very tiny improvement in understanding how to
contribute. We will be actively working with the community and its leaders
to make this a more accessible process.
Respondents showed an increase in agreement that they are confident in the
leadership of the Go project (9:1 → 11:1). They also showed a small increase in
agreement that the project leadership understands their needs (2.6:1 → 2.8:1)
and in agreement that they feel comfortable approaching project leadership with
questions and feedback (2.2:1 → 2.4:1). While improvements were made, this
continues to be an area of focus for the project and its leadership going
forward. We will continue to work to improve our understanding of user needs and
approachability.
We tried some new ways to engage
with users in 2017 and while progress was made, we are still working on making these
solutions scalable for our growing community.
Community
At the end of the survey, we asked some demographic questions.
The country distribution of responses is largely similar to last year with minor
fluctuations. Like last year, the distribution of countries is similar to the
visits to golang.org, though some Asian countries remain under-represented in
the survey.
Perhaps the most significant improvement over 2016 came from the question which
asked to what degree do respondents agreed with the statement, "I feel welcome
in the Go community". Last year the agreement to disagreement ratio was 15:1. In
2017 this ratio nearly doubled to 25:1.
An important part of a community is making everyone feel welcome, especially
people from under-represented demographics. We asked an optional question about
identification across a few underrepresented groups. We had a 4% increase in
response rate over last year. The percentage of each underrepresented group
increased over 2016, some quite significantly.
Like last year, we took the results of the statement “I feel welcome in the Go
community” and broke them down by responses to the various underrepresented
categories. Like the whole, most of the respondents who identified as
underrepresented also felt significantly more welcome in the Go community than
in 2016. Respondents who identified as a woman showed the most significant
improvement with an increase of over 400% in the ratio of agree:disagree to this
statement (3:1 → 13:1). People who identified as ethnically or racially
underrepresented had an increase of over 250% (7:1 → 18:1). Like last year,
those who identified as not underrepresented still had a much higher percentage
of agreement to this statement than those identifying from underrepresented
groups.
We are encouraged by this progress and hope that the momentum continues.
The final question on the survey was just for fun: what’s your favorite Go
keyword? Perhaps unsurprisingly, the most popular response was go, followed bydefer, func, interface, and select, unchanged from last year.
Finally, on behalf of the entire Go project, we are grateful for everyone who
has contributed to our project, whether by being a part of our great community,
by taking this survey or by taking an interest in Go.
U.S. Equal Opportunity Employment Information (Completion is voluntary)
Individuals seeking employment at Checkr are considered without regards
to race, color, religion, national origin, age, sex, marital status, ancestry, physical
or mental disability, veteran status, gender identity, or sexual orientation. You are
being given the opportunity to provide the following information in order to help us
comply with federal and state Equal Employment Opportunity/Affirmative Action record
keeping, reporting, and other legal requirements.
Completion of the form is entirely voluntary. Whatever your decision,
it will not be considered in the hiring process or thereafter. Any information that you
do provide will be recorded and maintained in a confidential file.
If you believe you belong to any of the categories of protected veterans listed below,
please indicate by making the appropriate selection. As a government contractor
subject to Vietnam Era Veterans Readjustment Assistance Act (VEVRAA), we request this
information in order to measure the effectiveness of the outreach and positive
recruitment efforts we undertake pursuant to VEVRAA. Classification of protected
categories is as follows:
A "disabled veteran" is one of the following: a veteran of the U.S. military, ground,
naval or air service who is entitled to compensation (or who but for the receipt of
military retired pay would be entitled to compensation) under laws administered by the
Secretary of Veterans Affairs; or a person who was discharged or released from active
duty because of a service-connected disability.
A "recently separated veteran" means any veteran during the three-year period beginning
on the date of such veteran's discharge or release from active duty in the U.S.
military, ground, naval, or air service.
An "active duty wartime or campaign badge veteran" means a veteran who served on active
duty in the U.S. military, ground, naval or air service during a war, or in a campaign
or expedition for which a campaign badge has been authorized under the laws
administered by the Department of Defense.
An "Armed forces service medal veteran" means a veteran who, while serving on active
duty in the U.S. military, ground, naval or air service, participated in a United
States military operation for which an Armed Forces service medal was awarded pursuant
to Executive Order 12985.
Form CC-305
OMB Control Number 1250-0005
Expires 1/31/2020
Why are you being asked to complete this form?
Because we do business with the government, we must reach out to, hire, and provide
equal opportunity to qualified people with disabilities1. To help us
measure how well we are doing, we are asking you to tell us if you have a disability or
if you ever had a disability. Completing this form is voluntary, but we hope that you
will choose to fill it out. If you are applying for a job, any answer you give will be
kept private and will not be used against you in any way.
If you already work for us, your answer will not be used against you in any way.
Because a person may become disabled at any time, we are required to ask all of our
employees to update their information every five years. You may voluntarily
self-identify as having a disability on this form without fear of any punishment
because you did not identify as having a disability earlier.
How do I know if I have a disability?
You are considered to have a disability if you have a physical or mental impairment or
medical condition that substantially limits a major life activity, or if you have a
history or record of such an impairment or medical condition.
Disabilities include, but are not limited to:
Blindness
Deafness
Cancer
Diabetes
Epilepsy
Autism
Cerebral palsy
HIV/AIDS
Schizophrenia
Muscular dystrophy
Bipolar disorder
Major depression
Multiple sclerosis (MS)
Missing limbs or partially missing limbs
Post-traumatic stress disorder (PTSD)
Obsessive compulsive disorder
Impairments requiring the use of a wheelchair
Intellectual disability (previously called mental retardation)
Reasonable Accommodation Notice
Federal law requires employers to provide reasonable accommodation to qualified
individuals with disabilities. Please tell us if you require a reasonable accommodation
to apply for a job or to perform your job. Examples of reasonable accommodation
include making a change to the application process or work procedures, providing
documents in an alternate format, using a sign language interpreter, or using
specialized equipment.
1Section 503 of the Rehabilitation Act of 1973, as amended. For more
information about this form or the equal employment obligations of Federal contractors,
visit the U.S. Department of Labor's Office of Federal Contract Compliance Programs
(OFCCP) website at www.dol.gov/ofccp.
PUBLIC BURDEN STATEMENT: According to the Paperwork Reduction Act of 1995 no persons
are required to respond to a collection of information unless such collection displays
a valid OMB control number. This survey should take about 5 minutes to complete.
Except for her family and closest friends, no one in Jennifer’s various circles knows that she is on the spectrum. Jennifer was not diagnosed with autism until she was 45 years old—and then only because she wanted confirmation of what she had figured out for herself over the previous decade. Most of her life, she says, she evaded a diagnosis by forcing herself to stop doing things her parents and others found strange or unacceptable. (Because of the stigma associated with autism, Jennifer asked to be identified only by her first name.)
Over several weeks of emailing back and forth, Jennifer confides in me some of the tricks she uses to mask her autism—for example, staring at the spot between someone’s eyes instead of into their eyes, which makes her uncomfortable. But when we speak for the first time over video chat one Friday afternoon in January, I cannot pick up on any of these ploys.
She confesses to being anxious. “I didn’t put on my interview face,” she says. But her nervousness, too, is hidden—at least until she tells me that she is tapping her foot off camera and biting down on the chewing gum in her mouth. The only possible “tell” I notice is that she gathers up hanks of her shoulder-length brown hair, pulls them back from her face, and then lets them drop—over and over again.
In the course of more than an hour, Jennifer, a 48-year-old writer, describes the intense social and communication difficulties she experiences almost daily. She can express herself easily in writing, she says, but becomes disoriented during face-to-face communication. “The immediacy of the interaction messes with my processing,” she says.
“Am I making any sense at all?” she suddenly bursts out. She is, but often fears she is not.
To compensate, Jennifer says she practices how to act. Before attending a birthday party with her son, for example, she prepares herself to be “on,” correcting her posture and habitual fidgeting. She demonstrates for me how she sits up straight and becomes still. Her face takes on a pleasant and engaged expression, one she might adopt during conversation with another parent. To keep a dialogue going, she might drop in a few well-rehearsed catchphrases, such as “good grief” or “go big or go home.” “I feel if I do the nods, they won’t feel I’m uninterested,” she says.
Over the past few years, scientists have discovered that, like Jennifer, many women on the spectrum “camouflage” the signs of their autism. This masking may explain at least in part why three to four times as many boys as girls are diagnosed with the condition. It might also account for why girls diagnosed young tend to show severe traits, and highly intelligent girls are often diagnosed late. (Men on the spectrum also camouflage, researchers have found, but not as commonly as women.)
Nearly everyone makes small adjustments to fit in better or conform to social norms, but camouflaging calls for constant and elaborate effort. It can help women with autism maintain their relationships and careers, but those gains often come at a heavy cost, including physical exhaustion and extreme anxiety.
“Camouflaging is often about a desperate and sometimes subconscious survival battle,” says Kajsa Igelström, an assistant professor of neuroscience at Linköping University in Sweden. “And this is an important point, I think—that camouflaging often develops as a natural adaptation strategy to navigate reality,” she says. “For many women, it’s not until they get properly diagnosed, recognized, and accepted that they can fully map out who they are.”
Even so, not all women who camouflage say they would have wanted to know about their autism earlier—and researchers acknowledge that the issue is fraught with complexities. Receiving a formal diagnosis often helps women understand themselves better and tap greater support, but some women say it comes with its own burdens, such as a stigmatizing label and lower expectations for achievement.
Because so many more boys are diagnosed with autism than girls are, clinicians don’t always think of autism when they see girls who are quiet or appear to be struggling socially. William Mandy, a clinical psychologist in London, says he and his colleagues routinely used to see girls who had been shuffled from one agency or doctor to another, often misdiagnosed with other conditions. “Initially, we had no clue they needed help or support with autism,” he says.
Over time, Mandy and others began to suspect that autism looks different in girls. When they interviewed girls or women on the spectrum, they couldn’t always see signs of their autism but got glimmers of a phenomenon they call “camouflaging” or “masking.” In a few small studies starting in 2016, the researchers confirmed that, at least among women with high intelligence quotients, camouflaging is common. They also noted possible gender differences that help girls escape clinicians’ notice: Whereas boys with autism might be overactive or appear to misbehave, girls more often seem anxious or depressed.
Last year, a team of researchers in the United States extended that work. They visited several school yards during recess and observed interactions among 48 boys and 48 girls, aged 7 or 8 on average, half of each group diagnosed with autism. They discovered that girls with autism tend to stay close to the other girls, weaving in and out of their activities. By contrast, boys with autism tend to play by themselves, off to the side. Clinicians and teachers look for social isolation, among other things, to spot children on the spectrum. But this study revealed that by using that criterion alone, they would miss many girls with autism.
Typical girls and boys play differently, says Connie Kasari, a researcher at UCLA who coled the study. While many boys are playing a sport, she says, girls are often talking and gossiping, and involved in intimate relationships. The typical girls in the study would flit from group to group, she says. The girls with autism appeared to be doing the same thing, but what was actually happening, the investigators learned, was different: The girls with autism were rejected repeatedly from the groups, but would persist or try to join another one. The scientists say these girls may be more motivated to fit in than the boys are, so they work harder at it.
Delaine Swearman, 38, says she wanted badly to fit in when she was about 10 or 11, but felt she was too different from the other girls in her school. She studied the girls she liked and concluded, “If I pretended to like everything they liked and to go along with everything, that maybe they would accept me,” she says. Her schoolmates were avid fans of the band New Kids on the Block. So Swearman, who says she had zero interest in the band, feigned a passion she did not feel. She made a few more friends, but felt she was never being herself. Swearman, like Jennifer, was not diagnosed until adulthood, when she was 30.
Even when teachers do flag girls for an autism evaluation, standard diagnostic measures may fail to pick up on their autism. For example, in a study last year, researchers looked at 114 boys and 114 girls with autism. They analyzed the children’s scores on the Autism Diagnostic Observation Schedule (ADOS) and on parent reports of autism traits and daily living skills, such as getting dressed. They found that even when the girls have ADOS scores similar to those of boys, they tend to be more severely impaired: The parents of girls included in the study had rated their daughters lower than the boys in terms of living skills and higher in terms of difficulties with social awareness and restricted interests or repetitive behaviors. The researchers say girls with less severe traits, especially those with high IQs, may not have scored high enough on the ADOS to be included in their sample in the first place.
These standard tests may miss many girls with autism because they were designed to detect the condition in boys, says the lead researcher, Allison Ratto, an assistant professor at the Center for Autism Spectrum Disorders at Children’s National Health System in Washington, D.C. For instance, the tests screen for restricted interests, but clinicians may not recognize the restricted interests girls with autism have. Boys with autism tend to obsess about things such as taxis, maps, or U.S. presidents, but girls on the spectrum are often drawn to animals, dolls, or celebrities—interests that closely resemble those of their typical peers and so fly under the radar. “We may need to rethink our measures,” Ratto says, “and perhaps use them in combination with other measures.”
Before scientists can create better screening tools, they need to characterize camouflaging more precisely. A study last year established a working definition for the purpose of research: Camouflaging is the difference between how people seem in social contexts and what’s happening to them on the inside. If, for example, someone has intense autism traits but tends not to show it in her behavior, the disparity means she is camouflaging, says Meng-Chuan Lai, an assistant professor of psychiatry at the University of Toronto in Canada, who worked on the study. The definition is necessarily broad, allowing for any effort to mask an autism feature, from suppressing repetitive behaviors known as stimming or talking about obsessive interests to pretending to follow a conversation or imitating neurotypical behavior.
To evaluate some of these methods, Mandy, Lai, and their colleagues in the United Kingdom surveyed 55 women, 30 men, and seven individuals who are either transgender or “other” gendered, all diagnosed with autism. They asked what motivates these individuals to mask their autism traits and what techniques they use to achieve their goal. Some of the participants reported that they camouflage in order to connect with friends, find a good job, or meet a romantic partner. “Camouflaging well can land you a lucrative job,” Jennifer says. “It helps you get through social interaction without there being a spotlight on your behavior or a giant letter A on your chest.” Others said they camouflage to avoid punishment, to protect themselves from being shunned or attacked, or simply to be seen as “normal.”
“I actually got told by a couple of my teachers that I needed to have ‘quiet hands,’” says Katherine Lawrence, a 33-year-old woman with autism in the United Kingdom. “So I had to resort to hiding my hands under the table and ensuring my foot tapping and leg jiggling remained out of sight as much as possible.” Lawrence, who was not diagnosed with autism until age 28, says she knew that otherwise, her classmates would think she was strange and her teachers would punish her for distracting others.
The adults in the survey described an imaginative store of tools they call upon in different situations to avoid pain and gain acceptance. If, for example, someone has trouble starting a conversation, she might practice smiling first, Lai says, or prepare jokes as an icebreaker. Many women develop a repertoire of personas for different audiences. Jennifer says she studies other people’s behavior and learns gestures or phrases that, to her, seem to project confidence; she often practices in front of a mirror.
Before a job interview, she writes down the questions she thinks she will be asked, and then writes down and memorizes the answers. She has also committed to memory four anecdotes she can tell about how she met a challenging deadline. The survey found that women on the spectrum often create similar rules and scripts for themselves for having conversations. To avoid speaking too much about a restricted interest, they may rehearse stories about other topics. To hide the full extent of her anxiety when she is “shaking inside” because, say, an event is not starting on time, Swearman has prepared herself to say, “I’m upset right now. I can’t focus; I can’t talk to you right now.”
Some women say that, in particular, they put in a great deal of effort into disguising their stimming. “For many people, stimming may be a way to self-soothe, self-regulate, and relieve anxiety, among other things,” Lai says. And yet these motions—which can include flapping hands, spinning, scratching, and head banging—can also readily “out” these people as having autism.
Igelström and her colleagues interviewed 342 people, mostly women and a few trans people, about camouflaging their stimming. Many of the participants had self-diagnosed, but 155 women have an official autism diagnosis. Nearly 80 percent of the participants had tried to implement strategies to make stimming less detectable, Igelström says. The most common method is redirecting their energy into less visible muscle movements, such as sucking and clenching their teeth or tensing and relaxing their thigh muscles. The majority also try to channel their need to stim into more socially acceptable movements, such as tapping a pen, doodling, or playing with objects under the table. Many try to confine their stimming to times when they are alone or in a safe place, such as with family. Igelström found that a few individuals try to prevent stimming altogether by way of sheer will or by restraining themselves—by sitting on their hands, for example.
For Lawrence, her need to fidget with her hands, tap her foot, or jiggle her leg feels too urgent to suppress. “I do it because if my brain doesn’t get frequent input from the respective body parts, it loses track of where in space that body part is,” she says. “It also helps me concentrate on what I am doing.”
All of these strategies call for considerable effort. Exhaustion was a near-universal response in the 2017 British survey: The adults interviewed described feeling utterly drained—mentally, physically, and emotionally. One woman, Mandy says, explained that after camouflaging for any length of time, she needs to curl up in the fetal position to recover. Others said they feel their friendships are not real because they are based on a lie, increasing their sense of loneliness. And many said they have played so many roles to disguise themselves through the years that they have lost sight of their true identity.
Igelström says some of the women in her study told her that suppressing repetitive movements feels “unhealthy” because the stimming helps them to regulate their emotions, sensory input, or ability to focus. Camouflaging feels unhealthy for Lawrence, too. She has to spend so much effort to fit in, she says, that she has little physical energy for tasks such as housework, little mental energy for processing her thoughts and interactions, and poor control over her emotions. The combination tips her into a volatile state in which “I am more likely to experience a meltdown or shutdown,” she says.
Lawrence says that if she’d been diagnosed as a child, her mother might have understood her better. She might have also avoided a long history of depression and self-harm. “One of the main reasons I went down that route was because I knew I was different but didn’t know why—I was bullied quite badly at school,” she says.
The vast majority of women diagnosed later in life say that not knowing early on that they have autism hurt them. In a small 2016 study, Mandy and his colleagues interviewed 14 young women not diagnosed with autism until late adolescence or adulthood. Many described experiences of sexual abuse. They also said that, had their condition been known, they would have been less misunderstood and alienated at school. They might have also received much-needed support sooner.
Others might have benefited from knowing themselves better. Swearman completed a master’s degree to be a physician assistant, but ultimately stopped because of issues related to her autism. “I was actually very good at what I did,” she says. But “it was too much social pressure, too much sensory stimulation, a lot of miscommunication and misinterpretation between myself and supervisors, due to thinking differences.” It was only after she stopped working that her counselor suggested she might have autism. She read up on it and discovered, “Oh, my gosh, that’s me!” she recalls. It was a major turning point: Everything started to make sense.
It’s only after a diagnosis that a woman may ask, “Which parts of myself are an act and which parts of me have been hidden? What do I have that’s valuable inside myself that can’t be expressed because I’m constantly and automatically camouflaging my autistic traits?,” Igelström says. “None of those questions can be processed without first getting diagnosed, or at least [self-identifying], and then replaying the past with this new insight. And for many women, this happens late in life after years of camouflaging in a very uncontrolled, destructive, and subconscious way, with many mental-health problems as a consequence.”
A diagnosis leads some women to abandon camouflaging. “Realizing that I am not broken, that I simply have a different neurology from the majority of the population and that there is nothing wrong with me the way I am means that I will not hide who I am just to fit in or make neurotypical people more comfortable,” Lawrence says.
Others learn to make camouflaging work for them, mitigating its negative effects. They may use masking techniques when they first make a new connection, but over time become more authentically themselves. Those who feel that camouflaging is within their control can plan to give themselves breaks, from going to the bathroom for a few minutes to leaving an event early or forgoing it entirely. “I learned to take care of myself better,” Swearman says. “The strategy is self-awareness.”
Jennifer concedes that knowing about her autism earlier would have helped her, and yet she is “torn” about whether it would have been better. Because she didn’t have a diagnosis, she says, she also had no excuses. “I had to suck it up and deal. It was a really difficult struggle, and I made loads of mistakes—still do—but there was simply no choice,” she says. “If I had been labeled as autistic, maybe I wouldn’t have tried so hard and achieved all the things I’ve achieved.”
She has achieved a great deal. During our video chat that snowy afternoon in January, it’s clear that one of her most significant accomplishments has been finding a balance in life that works for her. Her camouflaging skills allow her to put on a warm, personable exterior, one that has helped her build a successful career. But thanks to a few friends and a husband and son who love her for who she is, she can let that mask drop when it becomes too heavy.
Something bigger is afoot. Alexa has the best shot of becoming the third great consumer computing platform of this decade — next to iOS and Android, a computing service so ubiquitous that it sets a foundation for much of the rest of what happens in tech.
It is not a sure path. Amazon could screw this up, and rivals like Google have many cards to play to curb Alexa’s rise. Amazon’s strategy — something like a mix between Google’s plan for Android and Apple’s for the iPhone — is also unusual. And there are lingering social concerns about voice assistants and, as I discovered, their sometimes creepy possibilities. How many people, really, are willing to let an always-on device in their house?
Despite this, Alexa’s ubiquity is a plausible enough future that it is worth seriously pondering. In an effort to do so, I recently dived headlong into Alexa’s world. I tried just about every Alexa gadget I could get my hands on, including many not made by Amazon, such as an Alexa-enabled pickup truck, to see what life with her will be like once she’s everywhere.
What I found was a mess — many non-Amazon Alexa devices aren’t ready for prime time — but an inviting one. Late-night shrieks notwithstanding, one day very soon, Alexa or something like it will be everywhere — and computing will be better for it.
“We had a spectacular holiday,” Dave Limp, Amazon’s senior vice president of devices and services, said when I called last month to chat about the assistant’s future.
Amazon is famously cagey about sales numbers, but Mr. Limp braved a slight disclosure: “We’ve said we’ve sold tens of millions of Alexa-enabled devices, but I can assure you that last year we also sold tens of millions of just Echo devices. At that scale, it’s safe to now call this a category.”
Mr. Limp’s distinction is confusing but important. At Amazon, Alexa lives in two places. She is part of a device category, the Echo smart speaker, which now comes in a variety of permutations, from the $49 Echo Dot to the screen-bearing Echo Show, which sells for $229. (These prices are merely guidelines; in its bid for ubiquity, Amazon often offers steep discounts, with the Dot selling for $29 during last year’s holidays.)
But like Google’s Android operating system, Alexa is also a piece of software that Amazon makes available for free for other device makers to put into their products.
At least 50 devices are now powered by Alexa, and more keep coming. They include dozens of Echo-like smart speakers, home thermostats, light fixtures, dashboard cameras, smartphones, headphones, a smoke alarm and a very strange robot.
Alexa is spreading so quickly that even Amazon can’t keep track of it. Mr. Limp said that as he wandered the floor at the CES electronics trade show in Las Vegas this year, even he was surprised by the number of different Alexa devices.
“To me, that says the strategy is working,” he said.
There are some costs to this strategy, which prizes speed over polish. The universe of Alexa-enabled products is shaggy. Many third-party devices get low reviews on Amazon. Many don’t include some of Alexa’s key functions — I tested devices that don’t let you set reminders, one of the main reasons to use Alexa. Technical limitations also prevent non-Amazon devices from taking advantage of some of Alexa’s best new features, like the ability to call phones or other Alexas (creating a kind of home intercom system).
Mr. Limp said Amazon was aiming to fix these limitations, but conceded that its strategy necessarily led to some low-end devices. “You’re right, sometimes the ramifications of this will be that some devices will be out there that aren’t perfect,” he said.
PhotoAmazon’s Alexa voice assistant is part of Echo smart speakers like this one, but it is also a piece of software that other device makers can put into their products.Credit
Jens Mortensen for The New York Times
But there are also advantages to Alexa’s model for ubiquity. Imagine if you could gain access to your smartphone on just about any screen you encountered. Move from your phone to your TV to your laptop to your car, and wherever you went, you’d find all your apps, contacts and data just there, accessible through the same interface.
That model isn’t really possible for phones. But because Alexa runs in the cloud, it allows for a wondrously device-agnostic experience. Alexa on my Echo is the same as Alexa on my TV is the same as Alexa on my Sonos speaker.
And it’s the same even on devices not in your home. Ford — the first of several carmakers to offer Alexa integration in its vehicles — lent me an F-150 pickup outfitted with Alexa. The experience was joyously boring: I called up Alexa while barreling down the highway, and although she was slower to respond than at home, she worked just the same. She knew my musical tastes, my shopping list, the apps and smart-home services I had installed, and just about everything else.
It was the best showcase of the possibilities of always-on voice computing. In the future, wherever you go, you can expect to talk to a computer that knows you, one that can get stuff done for you without any hassle.
There’s a lot of money in the voice game. For Amazon, Alexa’s rise could lead to billions of dollars in additional sales to its store, Mark Mahaney, an analyst at RBC Capital Markets, predicted recently. Amazon is thus not the only company chasing the dream of everywhere voice computing.
Google, which is alive to the worry that Alexa will outpace it in the assistant game, is also offering its Google Assistant to other device makers. Though Amazon remains the leader in the business, there’s some evidence that Google’s devices gained market share over the holidays. (Apple, which just released a $349 smart speaker, HomePod, does not seem to be aiming for voice ubiquity.)
The emerging platform war between Amazon and Google could lead to fallout for users. But their platforms can also play together. Amazon’s and Google’s relationships with third-party companies are nonexclusive, which means that hardware makers are free to add both Alexa and Google Assistant to their products. Sonos, for instance, now integrates with Alexa, and is planning to add Google Assistant soon.
This is not the best outcome for the future; it would be better for all of us if the next computing platform didn’t come from one of the current tech giants, and if start-ups didn’t have to rely on Amazon or Google for this key piece of tech.
But that seems unlikely. If Alexa is headed for ubiquity, it’s good that Google may be, too.
This book helps you gain the foundational knowledge required to write an
operating system from scratch. Hence the title, 0 to 1.
After completing this book, at the very least you will learn:
How to write an operating system from scratch by reading hardware datasheets.
In the real world, it works like that. You won't be able to consult Google for
a quick answer.
A big picture of how each layer of a computer is related to the other, from hardware to software.
Write code independently. It's pointless to copy and paste code. Real learning
happens when you solve problems on your own. Some examples are given to kick
start, but most problems are yours to conquer. However, the solutions are
available online for you to examine after giving it a good try.
Linux as a development environment and how to use common tools for low-level
programming.
x86 assembly in-depth.
How a program is structured so that an operating system can run.
How to debug a program running directly on hardware with gdb and QEMU.
Linking and loading on bare metal x86_64, with pure C. No standard library. No
runtime overhead.
You give a poor man a fish and you feed him for a day. You teach him to fish
and you give him an occupation that will feed him for a lifetime.
This has been the guiding principle of the book when I was writing it. The book does
not try to teach you everything, but enough to enable you to learn by yourself.
The book itself, at this point, is quite "complete": once you master part 1 and
part 2 (which consist of 8 chapters), you can drop the book and learn by
yourself. At this point, smart readers should be able to continue on their own.
For example, they can continue their journeys
on OSDev wiki; in fact, after you study
everything in part 1 and part 2, you only meet
the minimum requirement by OSDev
Wiki (well, not quite, the book actually goes deeper for the suggested topics).
Or, if you consider developing an OS for fun is impractical, you can continue
with a Linux-specific book, such as this free
book Linux Insides, or other
popular Linux kernel books. The book tries hard to provide you a strong
foundation, and that's why part 1 and part 2 were released first.
The book teaches you core concepts, such as x86 Assembly, ELF, linking and
debugging on bare metal, etc., but more importantly, where such information
come from. For example, instead of just teaching x86 Assembly, it also teaches
how to use reference manuals from Intel. Learning to read the official
manuals is important because only the hardware manufacturers themselves
understand how their hardware work. If you only learn from the secondary
resources because it is easier, you will never gain a complete understanding of
the hardware you are programming for. Have you ever read a book on Assembly, and
wondered where all the information came from? How does the author know
everything he says is correct? And how one seems to magically know so much about
hardware programming? This book gives pointers to such questions.
As an example, you should skim through chapter 4, "x86 Assembly and C", to see
how it makes use of the Intel manual, Volume 2. And in
the process, it guides you how to use the official manuals.
Part 3 is planned as a series of specifications that a reader will implement to
complete each operating system component. It does not contain code aside from a
few examples. Part 3 is just there to shorten the reader's time when reading the
official manuals by giving hints where to read, explaining difficult concepts
and how to use the manuals to debug. In short, the implementation is up to the
reader to work on his or her own; the chapters are just like university assignments.
Know some circuit concepts:
Basic Concepts of Electricity: atoms, electrons, protons, neutrons, current flow.
Ohm's law
However, if you know absolutely nothing about electricity, you can quickly learn it here:http://www.allaboutcircuits.com/textbook/, by reading chapter 1 and chapter 2.
C programming. In particular:
Variable and function declarations/definitions
While and for loops
Pointers and function pointers
Fundamental algorithms and data structures in C
Linux basics:
Know how to navigate directory with the command line
Know how to invoke a command with options
Know how to pipe output to another program
Touch typing. Since we are going to use Linux, touch typing helps. I know typing
speed does not relate to problem-solving, but at least your typing speed should
be fast enough not to let it get it the way and degrade the learning experience.
In general, I assume that the reader has basic C programming knowledge, and can
use an IDE to build and run a program.
Part 1
Chapter 1: Complete
Chapter 2: Complete
Chapter 3: Almost. Currently, the book relies on the Intel Manual for fully explaining x86 execution environment.
Chapter 4: Complete
Chapter 5: Complete
Chapter 6: Complete
Part 2
Chapter 7: Complete
Chapter 8: Complete
Part 3
Chapter 9: Incomplete
Chapter 10: Incomplete
Chapter 11: Incomplete
Chapter 12: Incomplete
Chapter 13: Incomplete
... and future chapters not included yet ...
In the future, I hope to expand part 3 to cover more than the first 2 parts. But
for the time being, I will try to finish the above chapters first.
This repository is the sample OS of the
book that is intended as a reference material for part 3. It covers 10 chapters
of the "System Programming Guide" (Intel Manual Volume 3), along with a simple
keyboard and video driver for input and output. However, at the moment, only the
following features are implemented:
Protected mode.
Creating and managing processes with TSS (Task State Structure).
Interrupts
LAPIC.
Paging and I/O are not yet implemented. I will try to implement it as the book progresses.
If you find any grammatical issues, please report it using Github Issues. Or, if
some sentence or paragraph is difficult to understand, feel free to open an
issue with the following title format: [page number][type] Descriptive Title.
For example: [pg.9][grammar] Incorrect verb usage.
type can be one of the following:
Typo: indicates typing mistake.
Grammar: indicates incorrect grammar usage.
Style: indicates a style improvement.
Content: indicates problems with the content.
Even better, you can make a pull request with the provided book source. The main
content of the book is in the file "Operating Systems: From 0 to 1.lyx". You can
edit the .txt file, then I will integrate the changes manually. It is a
workaround for now since Lyx can cause a huge diff which makes it impossible to
review changes.
The book is in development, so please bear with me if the English irritates you.
I really appreciate it.
Finally, if you like the project and if it is possible, please donate to help
this project and keep it going.
If you have any question related to the material or the development of the book,
feel free to open a Github issue.
If you're going to commit an illegal act, it's best not to discuss it in e-mail. It's also best to Google tech instructions rather than asking someone else to do it:
One new detail from the indictment, however, points to just how unsophisticated Manafort seems to have been. Here's the relevant passage from the indictment. I've bolded the most important bits:
Manafort and Gates made numerous false and fraudulent representations to secure the loans. For example, Manafort provided the bank with doctored [profit and loss statements] for [Davis Manafort Inc.] for both 2015 and 2016, overstating its income by millions of dollars. The doctored 2015 DMI P&L submitted to Lender D was the same false statement previously submitted to Lender C, which overstated DMI's income by more than $4 million. The doctored 2016 DMI P&L was inflated by Manafort by more than $3.5 million. To create the false 2016 P&L, on or about October 21, 2016, Manafort emailed Gates a .pdf version of the real 2016 DMI P&L, which showed a loss of more than $600,000. Gates converted that .pdf into a "Word" document so that it could be edited, which Gates sent back to Manafort. Manafort altered that "Word" document by adding more than $3.5 million in income. He then sent this falsified P&L to Gates and asked that the "Word" document be converted back to a .pdf, which Gates did and returned to Manafort. Manafort then sent the falsified 2016 DMI P&L .pdf to Lender D.
So here's the essence of what went wrong for Manafort and Gates, according to Mueller's investigation: Manafort allegedly wanted to falsify his company's income, but he couldn't figure out how to edit the PDF. He therefore had Gates turn it into a Microsoft Word document for him, which led the two to bounce the documents back-and-forth over email. As attorney and blogger Susan Simpson notes on Twitter, Manafort's inability to complete a basic task on his own seems to have effectively "created an incriminating paper trail."
If there's a lesson here, it's that the Internet constantly generates data about what people are doing on it, and that data is all potential evidence. The FBI is 100% wrong that they're going dark; it's really the golden age of surveillance, and the FBI's panic is really just its own lack of technical sophistication.