In 1992, three Canadians, inspired by their country’s 125th birthday celebration, thought up a crazy plan. What if they could connect all of Canada’s hiking trails, footpaths, rail trails, and boardwalks and into one giant mega-trail that snaked from coast to coast?
It’s now 2017. Canada has celebrated its 150th birthday. And on August 26th, those three dreamers—along with the thousands of volunteers who helped clear brush, fix planks, put up signs, and do all the other little tasks that make wilderness passable—celebrated the coast-to-coast connection of what they’re calling the Great Trail.
As MTLBlog reports, the trail can be used for biking, hiking, and horseback riding in the summer, and cross-country skiing and snowmobiling in the winter. “First you build it, then get people using it and then it becomes an icon that will hopefully last forever,” Paul LaBarge, one of the original founders, told the Globe and Mail.
The path stretches 24,000 kilometers, or nearly 15,000 miles, criss-crossing southern Canada before forming a huge loop in the Northwest. A quarter of this length is water—wetland and river routes where hikers will have to trade boots for boats.
It’s almost four times as long as the Grand Italian trail, which covers all of Italy. It’s also over five times as long as the West Coast’s famed Pacific Crest Trail, and over six times as long as the Appalachian. (In case you were wondering, it would take a roller-grill hot dog 76 years and 256 days to travel the entire trail network.)
The trail is far from finished. As LaBarge tells the Globe and Mail, connection is merely “phase one.” Now, signs must be added, more funds must be raised for upkeep, and—most importantly—people must be brought out to actually use it.
After a few news articles jumped the gun and called the trail “complete,” the Trail’s twitter account jumped in to correct them: “It is not, it is CONNECTED,” it clarified. “Work remains to be done but it’s time to 🎉.” (That emoji is presumably a cone of trail mix.) If you’d like to join in, this map will tell you the closest spot to hop on. Happy hiking!
Every day, we track down a fleeting wonder—something amazing that’s only happening right now. Have a tip for us? Tell us about it! Send your temporary miracles to [email protected].
This story was originally published on Civil Eats.
I could spend all day collecting day-olds from bakeries for the community meals program I run. The donuts, danishes, and buttery rolls look luscious, but our guests have plenty of access to refined foods. I want to offer healthier options, so I started to think more about what all this extra bread does to all of us — not just those who rely on emergency feeding programs, but also to the average eater, and bakers, too.
This surplus breaks my heart. I like baking so much that I wrote a book about flour, and spent years learning about how much work goes into getting grain from the field to the mill. That work is not reflected in the cost of flour, which is insulated by economies of scale, the pennies game of milling, and government subsidies ($40 billion between 1995 and 2014). No wonder this ingredient seems disposable.
There’s also the fact that, except in the most exclusive bakeries, a bare shelf is a no-no. Customers expect fresh bread and lots of it. Sugar and fat are also relatively inexpensive, so it is safer to make too much and donate the leftovers than it is to risk running out.
The problem of plenty isn’t exclusive to America. In France and Germany, small bakeries are closing, partially because of the ubiquity of supermarket bread. Baker Pascal Rigo, who reinvented the baked goods at Starbucks, is now building a network of microboulangeries in France, hoping to revive the traditions of local baking. I think we should take a page from this model, and scale back bread production, too.
I’m not saying we should harken back to another era entirely. Before factory bread was the norm in America, many women spent their only day off baking large batches of bread. Yet the solution, which began with horse-drawn carts delivering factory-baked bread, has ballooned, bringing with it all kinds of industrial-scale problems. Even in the manufacturing process, this kind of bread can generate great waste. If one machine on the line breaks down, 90,000 pounds of dough can suddenly go “off-track,” destined to be sold into animal feed or other secondary markets.
Managing excess dough and baked goods in smaller-scale bakeries is not as clumsy, but still a part of business. And these businesses expect charities to absorb the extra. But people living in poverty already have access to easy calories, and even large operations like mine limit what we accept. Our shelf space is limited, and produce is heavy, perishable, and needs a lot of handling.
For instance, I recently sorted through a case of clementines, removing the ones that had burst, and rinsing the rest. The task didn’t take long but it did take time, and not all of our volunteers know how to look at dubious fruit and decide what’s worth saving. But the bread and sweets we pick up are always attractive and ready to serve.
What would happen if we made a lot less bread — and fewer donuts?
What if supermarket bakeries shrank their offerings, creating a sense of abundance in tighter real estate? What if independent bakeries baked only what they thought they could sell and no more? Some high-end bakeries sell out of their legendary treats, and they survive customer disappointment. Some even thrive on it.
What if we had to order bread like we order birthday cakes? In some circuits, this is the standard. Community supported bakeries (CSBs) sell subscriptions to loaves, just as community supported agriculture (CSA) farms sell seasonal subscriptions to a farm’s products. Sarah Owens, a James Beard Award-winning cookbook author, ran BK17 Bakery from her Brooklyn apartment that way. Many microbakery enterprises like hers only bake the loaves that people pre-order. I know these models can’t replace the way most of us buy our bread, but they suggest efficiencies that can help trim production and shift the burden of excess food further upstream.
As a home baker, I can’t bear to let any of the bread I bake go to waste. The remnants become breadcrumbs, and end up in macaroni and cheese, inside fish cakes, and even in sweet cakes, between berries and whipped cream. Such frugality is evident in old cookbooks, which use breadcrumbs galore. One baker who was trained in Germany once told me that his first task as an apprentice was grinding leftover bread to use in more dough.
Here’s another solution: Toast Ale, the brainchild of food waste activist Tristram Stuart. Launched in England, and now coming to the United States via Chelsea Brewing, the beer is made using 40 percent surplus bread. It replaces fresh grains in the brewing formula, so it preserves resources that would normally go into growing and malting barley, in addition to keeping bread out of the waste stream.
Once upon a time, bread was valuable because it was hard to make. Wheat was tough to grow and mill. Baking bread took time and resources.
Breaking bread remains a symbol of the shared labors involved, and of the necessity of our cooperation. If we could see the work invested by bakers, millers and farmers, whether small-scale or industrial, that symbol might gain real meaning again. And feeding each other, especially the poorest among us, would mean more than disposing of surplus foods.
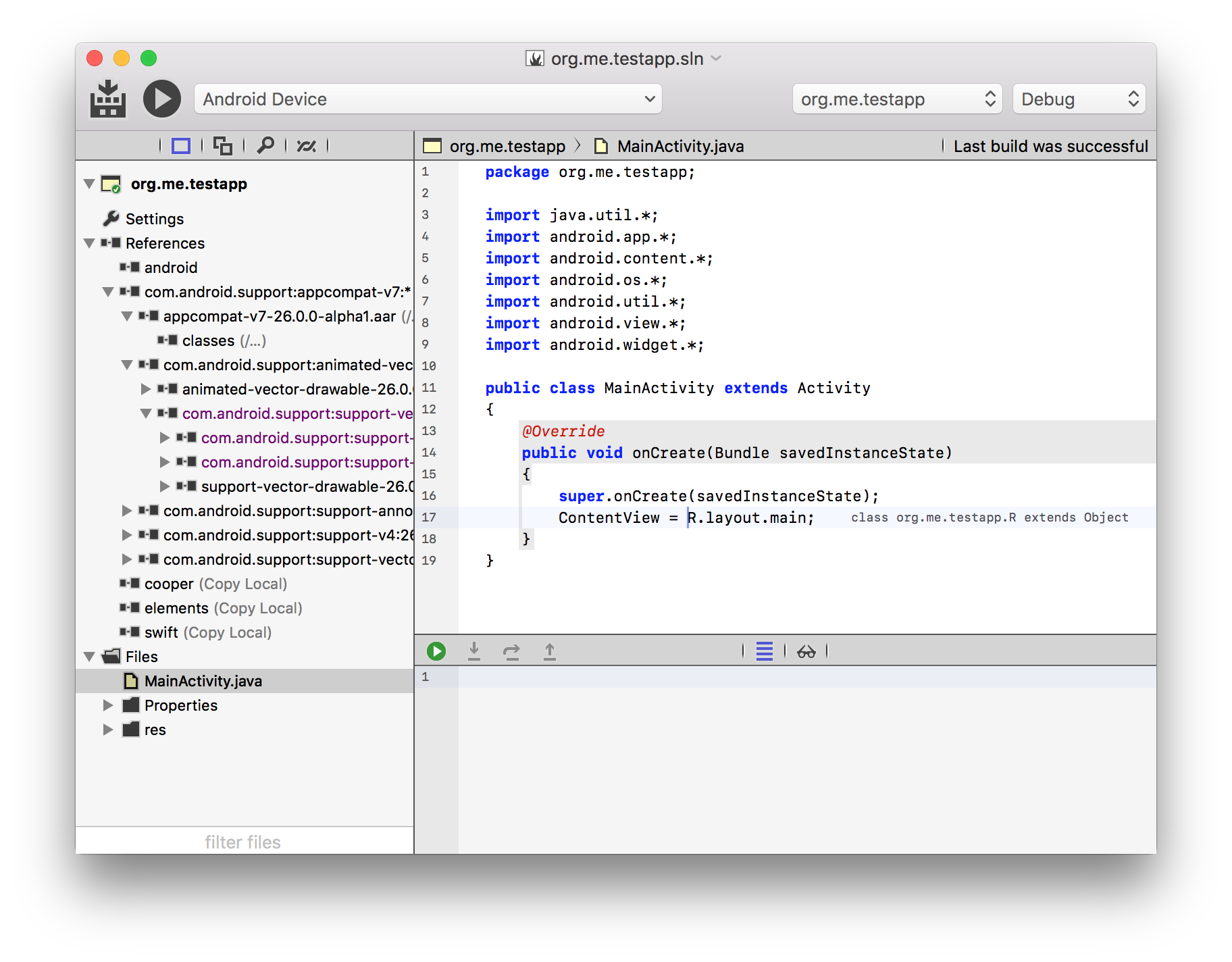
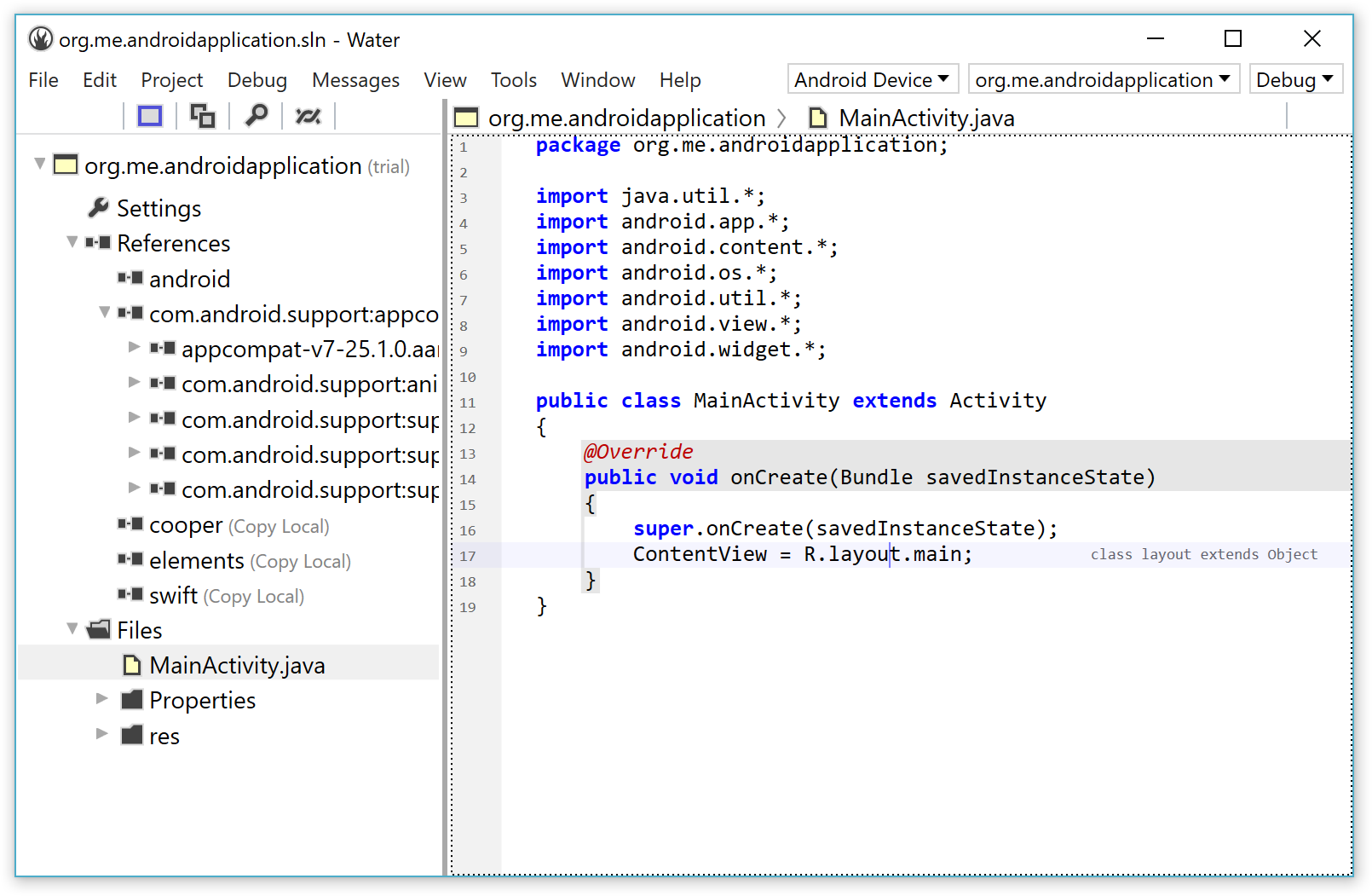
Last week we Announced Elements 9.2, and one of the major new features in this release is Iodine, our new Java Language compiler front-end.
While a major focus is using the Java language on other platforms (a topic i'll cover in my next post), the goal with Iodine is also to provide a great/better Java development experience for existing Java developers who target the JVM or Android. So even if you could not care less about using Java on .NET, Cocoa or native platforms, we believe Iodine has a lot offer!
1. A Better Language
Iodine is a full superset of regular Java, but provides enhanced abilities that will make writing Java code easier and more productive. All your existing Java code should compile right away (just copy it over), and you can start making use of the enhancements, right away.
Cocoa-style multi-part method names (aka named parameters)
and the list will continue expanding, with support for structs/records and easy property definitions, for example, coming in version 9.3. Read about all the language extensions here.
Iodine also does away with some silly limitations that plague Java developers, such as being limited to having one class per file (or, indeed, one file per class) or having to match the package/namespace structure of your code with folders on disk.
Of course Iodine will also keep in sync as the Java language as defined by Oracle itself evolves, for Java 9 and beyond.
2. A Better IDE Experience
Let's face it: Nobody loves working in Android Studio, Eclipse, or NetBeans – the IDEs are bloated, clunky and unintuitive.
Iodine comes with a range of great IDE options.
On Mac, we have Fire, our own IDE that's lightweight, simple and does not get in your way. Our customers that have been using Fire other languages absolutely love it.
On Windows, fully integrates with Visual Studio, Microsoft's flag-ship IDE. We also have Water, our own Windows IDE, coming out later this year (and usable as early Preview right now); Water is designed around the same principles that make Fire great, but also designed decidedly for Windows.
3. A Better Tool Chain
Iodine comes with a great build tool chain to take your project from source code to final executable – be it .jar or .apk. The core compile is fast, and has great error reporting, including auto-fix-its and recoverable errors for common trivial mistakes (such as wrong case or a missing semicolon. Gradle/Maven package resolution is build deeply into the IDEs and build chain, with no need to manually tweak .gradle script files. And coming in version 10 later this year, our new EBuild build chain will take things to the next level.
Another cool benefit is that, because Iodine is part of the four-language family of Elements, you can exult mix in code written in Swift, C# or Oxygene (on a file-by-file basis within the same project) and compile that into your Java or Android project, as well. That's great for re-using code snippets you find online in the "wrong" language.
Iodine is a great tool chain for developing Java and Android apps using the Java language – with a better compiler, faster IDEs and a more sophisticated over-all tool chain. If you are frustrated at all with your current Java IDE, or tool chain, check it out!
Did you receive this newsletter as a forward? Subscribe here
GE discovers that industrial IoT doesn't scale
By Stacey Higginbotham
This week Reuters did a deep dive into problems with GE's industrial IoT efforts. The company had taken a two-month "time out" to fix problems with its Predix software platform designed for the industrial IoT and has asked executives to cut costs. GE is also backing off selling the platform to all industries, and will instead focus on oil & gas, aviation and energy.
Since launching its industrial IoT effort five years ago, GE has spent billions selling the internet of things to investors, analysts and customers. The idea of adding sensors to its equipment, analyzing the data captured from those sensors and using that to generate business insights wasn't new, but GE made a huge effort to commercialize it.
GE is learning that the industrial IoT isn't a problem that can be tackled as a horizontal platform play. Five years after it began, GE is learning lessons that almost every industrial IoT platform I've spoken with is also learning. The industrial IoT doesn't scale horizontally. Nor can a platform provider compete at every layer.
For example, Samsara, a startup that formed in 2015, aimed to build a wide-scale industrial IoT platform that started with generic sensors. It has since narrowed its focus to fleet monitoring and cold-chain assurance, which is how some of the earliest users of its product used it.
Helium is another company that had a similar vision. It makes sensors and sends data over a proprietary wireless network to a gateway or (originally) the Helium cloud. The original plan was that companies would buy the sensors and build out rules in the cloud. But that was too open-ended, and Helium now has decided to link data from its sensors to other provider's clouds. It is also focusing on managing those sensors from a Dashboard setup.
In Samsara's case, the company went from a broad focus to a few specific industries. In Helium's case, it decided to stop building out a cloud where industrial customers could host their data so it could focus on management software and act as a connector between customers' data and their cloud of choice.
GE's decisions are similar.
A year ago it decided to stop building out its own cloud data centers and started signing partnerships so customers could run Predix in Amazon's or Microsoft's clouds. As part of the current refocusing, it appears to be narrowing its customer focus to industries where it already has customers using its equipment.
This makes sense. When I began covering the industrial and enterprise internet of things it quickly became clear that while IT could be generic, the data analytics elements and the real-world devices in the field that were being monitored would require specialized knowledge. What has happened is that at the computing (and even device management layer) larger cloud providers like Microsoft and Amazon are winning.
I think we'll see connectivity also steer toward the big platforms, whether its cable providers offering LoRa networks, cellular companies, or a few of the specialized low power wide area network providers. The hardware will likely be dominated by bigger companies such as Intel, Dell, HPE and those with established IT credibility. We'll also see industrial gateways from the likes of Advantech and Eurotech.
But it's the many areas of specialization here the industrial IoT gets interesting. I think we're going to see startups emerge around data analytics and AI such as Uptake, C3, SightMachine Flutura, and Foghorn. Many of these will have specific areas of expertise such as C3 with energy and Flutura with oil and gas.
There's also a role for specialization in building the overall IoT solution for companies. A hospital aiming to connect patient rooms needs a different set of knowledge around regulation and security than a company trying to create connected conference rooms needs. Today, those areas of specialization are ripe for startups.
Rick Bullota, who founded Thingworx which was sold to PTC, said that he anticipates a lot of M&A in the coming 12-24 months as more businesses embrace the insights and business transformation enabled by the industrial IoT. He also says that the buyers of industrial IoT products are coming more from the business side than the tech side, which means that the overall package of technology will become more important, rather than the individual pieces.
Get ready to hear more about end-to-end solutions.
Meanwhile, GE's software and industrial IoT efforts are still impressive. While it planned on revenue of $15 billion by 2020, it is now scaling that down to $12 billion in part to clarify what is software versus connected hardware it sells to industrial clients. Back in 2015, GE's Kate Johnson, then-CEO of Intelligent Platforms, told me GE reported $4 billion in software sales in 2014 and expected $7 billion in 2016. (Johnson left in July to work at Microsoft.)
So when it comes to the industrial IoT, the opportunity is big. It's just taking a while to figure out how to attack the market. Step one is realizing that it's silly to take on the big cloud and connectivity providers. Step two is quitting the platform dreams and focusing on a specific area of expertise.
Startup Profile: Runtime has built an OS for things
Bear with me because with this week's startup profile we are going deep into the weed of IoT enabling technology.
Runtime, a company that is building an operating system for microcontrollers, has raised $7.5 million in first round funding from NEA, Foundation Capital and Danhua Capital.
These microcontroller operating systems handle the basics of how a chip implements security, communicates with networking chips and handles higher level software. Runtime's innovation could make it much faster and cheaper for product companies to build and manage chips for connected devices.
Let's dig in. The OSes for lower-level Microcontroller Units (MCUs) used in sensors, wearables and other battery-powered devices are known as real-time operating systems because they handle data coming at them as it comes in. There are dozens of Realtime Operating Systems (RTOSes), which makes building IoT devices complicated. That's a problem companies like ARM have tried to solve by creating a unified RTOS for IoT, but for now most companies use a proprietary variant based on the type of chip they buy, or they use FreeRTOS, an open source project.
So the market is still fragmented which means if Whirlpool wants to build a connected appliance, it has to buy the MCU from a vendor, buy the connectivity radio and hire a few engineers to put everything together. If Whirlpool switches the underlying chip in later products it will still need the original expertise on the original chip's RTOS to ensure its older machines stay updated.
Runtime offers a twist on this scenario. It is following in the footsteps of FreeRTOS and ARM with Apache Mynewt, an open source OS under the Linux Foundation. But the aim is to provide more than the bare-bones elements of an RTOS by adding things like software to connect the MCU to a radio, security elements and the ability to run file systems.
The idea was to build a modular, fully functioning OS for microcontrollers that also has the benefit of breaking up elements such as secure boot loaders or radio connectivity. That makes it highly configurable without requiring a lot of the extra engineering time. It also means the component parts can spread more widely, offering a new source of business for Runtime.
Runtime has built a cloud that can manage devices that use the Mynewt OS, which is how it hopes to make its money. Companies can hire Runtime for consulting, support and also cloud management for Mynewt devices. CEO James Pace says the company has $1 million in bookings and between 5 million and 10 million devices in its cloud today.
Pace has been thinking about this problem for years as a member of the team that started Silver Springs Networks. In 2015 he formed Runtime to build Mynewt and help lower the complexity associated with building connected devices. With a more configurable and fully functioning OS, designers can build exactly the features they need into a MCU and save room on the chip for more application-specific needs.
For example, Pace says one customer purchased an MCU from a vendor where 90% of the available memory was taken up by the vendor's own code. By putting Mynewt on the chip instead, the vendor was able to claw back 30% more space for its own software. This is a big deal for companies trying to create more customizable hardware.
Better software on the chip can increase battery life, enable special functions or just make things faster. And with the ability to use the same underlying code even if you buy chips from another vendor, this feels like a good solution for companies wanting to build their own connected devices.
However, there is plenty of competition, both from chip vendors who have their own RTOSes and also from module vendors such as Particle and Electric Imp, which are solving the same problem but in different ways. My hunch is the big enterprises that want to build connectivity into their existing product lines may veer toward modules, while companies trying to build hundreds of millions of connected devices will look closely at something like Mynewt.
News of The Week
After Hurricane Harvey hit Houston open data helped: As someone who grew up in a now-flooded suburb of Houston, I watched Harvey with my heart in my mouth all week. I watched flooding on connected stream gauges transmitting their data every hour and scoured Google Maps/Waze for open evacuation routes to help friends find their way out of the city. It turns out the city itself is a fan of open data and this story shows how various groups used that to help city residents, volunteers and first responders plot safe routes, direct resources and even manage donations in the aftermath. This story highlights why smart cities aren't just connected but open. (Medium)
Why edge computing is the new cloud: I've been thinking about this idea for the last few weeks, and plan to write something in more depth soon, but in the meantime here's a nice encapsulation of why the edge (the real edge, not IoT gateways) is becoming more relevant for people thinking about IoT architectures. Yes, the cloud still matters, so don't freak out. (Medium)
Even cloud software project OpenStack is excited about the edge: OpenStack, an open source software project that helps companies build massive cloud infrastructure like Amazon, Microsoft and Google, has set it sights on edge computing with its latest release. OpenStack users like Verizon, Inmarsat and Walmart are looking to build out Openstack for some seriously cool edge computing cases. I'm going to find out more, but in the meantime, this looks like something to watch. (TechCrunch)
Blockchain to prevent food poisoning? Forget digital currencies. I've been excited about the blockchain for its ability to provide scalable accountability for years. Amidst the Bitcoin and initial coin offering hype, here comes a compelling use case of the digital ledger's ability to track a highly distributed system--the food supply. Walmart, Kroger, Nestle and IBM have created a blockchain-based accountability program to track foodborne illness and trace it back to the source. (Coindesk)
What is happening with Z-wave? The challenge of heading out on summer vacation is you miss stories, such as this one from July 26 about Sigma Designs, the maker of Z-wave chips, hiring a bank to sell the company. There is a ton of consolidation in the chip space, but as the provider of Z-wave chips, this doesn't feel like a great sign for the technology. Z-wave is still in a lot of sensors but feels less relevant as most consumers reject hubs and other wireless technologies improve their resiliency and range. (Sigma Designs)
The business world wakes up to Comcast's goals: The business press is waking up to Comcast's smart home designs. I've covered them here and am really interested to see how the battle for monitored home security shakes out between ADT, Ring and Comcast. If you want to revisit the topic, check out the Reuters article or any of mine linked above. (Reuters)
Austin's School District is using telemedicine to cut down on nurses: We often talk about connected medicine as a way to deliver care to rural areas, but another element is the elimination of certain jobs. In this case, one nurse will now oversee medical aides working at six schools, up from one nurse covering three schools. (Austin American-Statesman)
Talk to your health provider about the risk of this software patch: This week the FDA warned almost 500,000 patients who have one of four Abbot Labs' pacemakers that their devices had software vulnerabilities. Two of the pacemakers didn't store patient information or transmit it in an encrypted format. All of them had vulnerabilities that could result in repeated radio calls to drain the battery or issue unauthorized commands. While control of the pacemaker isn't easy to exploit, the fact that the patch requires patients to visit their doctor's office for a software patch that may or may not cause problems with their device changes the risk equation. The FDA's advice? Update it in the physician's office and talk to your doctor to see if this patch makes sense to you. I bet cardiologists are really excited to have this new role. (ICS-CERT)
There's a cheaper, new Nest thermostat: I think the frosted front makes it pretty ugly. For the same $169 price tag of the cheaper Nest, just buy the Ecobee Lite. (Ars Technica)
Speaking of connected thermostats: The government of Ontario, through Green Ontario Fund, plans to buy up to 100,000 connected thermostats for residents and install them through 2018. It plans to install 30,000 this year and the remaining 70,000 in 2018 to help reduce energy use in homes and small businesses. Residents can choose Honeywell, Ecobee and Nest thermostats, but my hunch is Canadian company Ecobee may get a hometown advantage. (MobileSyrup)
Two IoT standards groups are teaming up: The Industrial Internet Consortium (IIC) and the Manufacturing Enterprise Solutions Association (MESA) International are going to work together. The IIC has been working with a variety of companies to build reference frameworks for a variety of scenarios. These aren't standards, just models of how different connected systems might work together. (Smart Cities World)
Two good stories on design and UX for IoT: Designing interfaces for connected products involves hardware, software and perhaps even a service component. This makes it exceptionally difficult, especially if the product manufacturer doesn't get the designers involved early. The story from Machine Design goes into exhaustive detail on design considerations for connected devices, while the article from Fast Company talks about the disturbing trend of manipulative design and what it means when we combine physical products with software. (Machine Design, Fast Company)
If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware.
If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices.
We recently had quite a spectacle in the United States, with a Solar Eclipse reaching totality throughout a large portion of the United States. Being that this was the first solar eclipse passing through the Continental US since 1979, excitement ran wild on capturing this natural event using the best camera gear available.
But with such excitement, came a treasure trove of warnings. Warnings that this event can easily damage your camera, your lens, and your eyes if you do not have the proper protection. With all of our rentals leading up to this event, we warned everyone to view the event with appropriate eyewear and to attach a solar filter to the end of their lenses to protect the lens elements and camera sensor.
But despite our warnings, we still expected gear to come back damaged and destroyed. And as evidence to our past posts of broken gear being disassembled and repaired, we figured you’d all want to see some of the gear that we got back and hear what went wrong. But please keep in mind, this post is for your entertainment, and not to be critical of our fantastic customer base. Things happen, and that’s why we have a repair department. And furthermore, we found this to be far more exciting than we were disappointed. With this being the first solar eclipse for Lensrentals, we didn’t know what to expect and were surprised with how little of our gear came back damaged. So without further ado, here are some of the pieces of equipment that we got back, destroyed by the Solar Eclipse of 2017.
Melted Sensors
The most common problem we’ve encountered with damage done by the eclipse was sensors being destroyed by the heat. We warned everyone in a blog post to buy a solar filter for your lens, and also sent out mass emails and fliers explaining what you need to adequately protect the equipment. But not everyone follows the rules, and as a result, we have quite a few destroyed sensors. To my personal surprise, this damage was far more visually apparent than I even expected, and the photos below really make it visible.
Burn damage through the shutter system of the camera.
Burning of the shutter system
Under the shutter, you can see the additional damage on the sensor.
Damage to the sensor is really apparent even through visual inspection.
Mirror Damage
The images above are likely created because people were shooting in Live View mode, allowing them to compose the image using the back of their screen, instead of risking damage to their eyes by looking through the viewfinder. However, those who didn’t use live view (and hopefully guess and checked instead of staring through the viewfinder), were more likely to face damage to their camera’s mirror. While this damage was far rarer, we did get one particular camera with a damaged mirror box caused by the sun.
Damaged mirror on a Nikon D500 resulting from the eclipse.
Lens Iris Damage
Another common problem we’ve had sent back is the lens iris being destroyed from the heat and brightness of the solar eclipse. In short, the lens iris is the mechanic piece that changes the amount of light that enters the camera, or in simpler terms, the aperture adjustment. Apertures are usually made from 8-12 pieces of black plastic or metal and are susceptible to heat damage. In one particular case below, a customer used a drop in solar filter to protect the camera from being damaged by the eclipse. He was right, the camera was protected….but the lens iris was not protected, and was destroyed.
From the outside, this 600mm looks fine. But quick inspection shows the aperture system is destroyed thanks to the eclipse.
Another angle of the damaged iris of the Canon 600mm f/4L IS II USM
A partially disassembled image of the Canon 600mm from above.
ND System Damage
Filed under the unexpected, we also received a built in ND filter system damaged in one of our cinema camera systems. Most cinema cameras are equipped with a built in ND system that slides over the sensor, allowing them to adjust f-stop and shutter speeds to work better with their frame rate and shooting style. However, a common misconception is that an ND filter could properly protect the camera from the heat and light when shooting the solar eclipse. It doesn’t, and as a result, the damage is similar to that shown above with the sensors.
Canon C300 Mark II with a Damaged Built in ND Filter
Overall, we were really impressed with how few pieces of gear we got back damaged. And of the things returned, we were equally impressed with our customer-base, and their guilt and owning up to the damage. Unfortunately, these types of damage are considered neglect, as warnings were given out to customers before the solar eclipse. Our LensCap insurance plan, which can be added to rentals for a small nominal fee, does not protect from neglect but is an excellent tool for those who are worried about their rental and want to protect themselves from any accidental damage. This is just a few of the pieces of gear we’ve gotten back that have shown damage from the eclipse, and will hopefully serve as a warning to those who are already prepping for the next eclipse in 2024.
I’m Zach and I’m the editor and a frequent writer here at Lensrentals.com. I’m also an editorial and portrait photographer in Los Angeles, CA, and offer educational workshops on photography and lighting all over North America.
Media captionNorth Korean state media announces "hydrogen bomb" test
North Korea says it has successfully tested a nuclear weapon that could be loaded on to a long-range missile.
The secretive communist state said its sixth nuclear test was a "perfect success", hours after seismologists had detected an earth tremor.
Pyongyang said it had tested a hydrogen bomb - a device many times more powerful than an atomic bomb.
Analysts say the claims should be treated with caution, but its nuclear capability is clearly advancing.
North Korea last carried out a nuclear test in September 2016. It has defied UN sanctions and international pressure to develop nuclear weapons and to test missiles which could potentially reach the mainland US.
South Korean officials said the latest test took place in Kilju County, where the North's Punggye-ri nuclear test site is situated.
The "artificial quake" was 9.8 times more powerful than the tremor from the North's fifth test, the state weather agency said.
It came hours after Pyongyang said it had miniaturised a hydrogen bomb for use on a long-range missile, and North Korean leader Kim Jong-un was pictured with what state media said was a new type of hydrogen bomb. State media said the device could be loaded on to a ballistic missile.
What does the test tell us?
A series of recent missile tests has caused growing international unease.
In a report on Sunday, the North's state news agency KCNA said Kim Jong-un had visited scientists at the nuclear weapons institute and "guided the work for nuclear weaponisation".
Image copyrightReuters/KCNAImage caption
The news came hours after state media showed North Korean leader Kim Jong-un inspecting what it said was a hydrogen bomb
The North has previously claimed to have miniaturised a nuclear weapon, but experts have cast doubt on this. There is also scepticism about the North's claims to have developed a hydrogen bomb.
However, this does appears to be the biggest and most successful nuclear test by North Korea to date - and the messaging is clear. North Korea wants to demonstrate it knows what makes a credible nuclear warhead.
Nuclear weapons expert Catherine Dill told the BBC it was not yet clear exactly what nuclear weapon design was tested.
"But based on the seismic signature, the yield of this test definitely is an order of magnitude higher than the yields of the previous tests."
Current information did not definitively indicate that a thermonuclear weapon had been tested "but it appears to be a likely possibility at this point", she said.
Hydrogen bombs use fusion - the merging of atoms - to unleash huge amounts of energy, whereas atomic bombs use nuclear fission, or the splitting of atoms.
What has the reaction been?
South Korean President Moon Jae-in said North Korea's sixth nuclear test should be met with the "strongest possible" response, including new United Nations Security Council sanctions to "completely isolate" the country.
China, North Korea's only major ally, condemned the test.
North Korea "has ignored the international community's widespread opposition, again carrying out a nuclear test. China's government expresses resolute opposition and strong condemnation toward this," the foreign ministry said in a statement.
Japan's Chief Cabinet Secretary Yoshihide Suga said sanctions against North Korea should include restrictions on the trade of oil products.
Russia meanwhile said the test defied international law and urged all sides involved to hold talks, saying this was the only way to resolve the Korean peninsula's problems.
The head of the International Atomic Energy Agency, the global nuclear watchdog, described the test as "an extremely regrettable act".
Yukiya Amano added: "This new test, which follows the two tests last year and is the sixth since 2006, is in complete disregard of the repeated demands of the international community."
How can the world respond?
Jonathan Marcus, BBC defence and diplomatic correspondent
North Korea's sixth nuclear test - probably its largest so far - sends out one clear political signal.
Despite the bluster and threats from the Trump administration in Washington and near-universal condemnation from around the world, Pyongyang is not going to halt or constrain its nuclear activities.
Worryingly, it also suggests that this is a programme that is progressing on all fronts at a faster rate than many had expected. So far all efforts to pressure North Korea - sanctions, isolation, and military threats - have all failed to move Pyongyang.
Could more be done? Certainly, but the harshest economic pressure would potentially cripple the regime and push it towards catastrophe - something China is unwilling to countenance.
Containment and deterrence will now come to the fore as the world adjusts its policy from seeking to roll-back Pyongyang's weapons programme to living with a nuclear-armed North Korea.
How did news of the test emerge?
The first suggestion that this was to be a far from normal Sunday in the region came when seismologists' equipment started picking up readings of an earth tremor in the area where North Korea has conducted nuclear tests before.
Initial reports from the US Geological Survey put the tremor at 5.6 magnitude with a depth of 10km (six miles) but this was later upgraded to 6.3 magnitude at 0km.
Image copyrightEPA/USGSImage caption
The USGS put the site of the quake near the Punggye-ri test site
Then Japanese Foreign Minister Taro Kono said there was no doubt this was North Korea's sixth nuclear test.
Finally, in a radio broadcast that had been trailed as a "major announcement", North Korean state media confirmed this was no earthquake.
China embarrassed
Robin Brant, BBC News, Shanghai
North Korea's sixth nuclear weapons test is an utter rejection of all that its only ally has called for.
Beijing's response was predictable: condemnation, urging an end to provocation and dialogue. But it also spoke of urging North Korea to "face up to the firm will" of the international community to see denuclearisation on the Korean peninsula.
There is no sign though that China is willing yet to see that firm will go beyond UN sanctions, which recently clamped down on seafood and iron ore exports, in addition to the coal and minerals that are already banned from crossing the border.
It is noteworthy also that this test took place just as the Chinese president was about to welcome a handful of world leaders to the two-day showpiece Brics summit on China's east coast.
Even the state-controlled media will find it hard to ignore the fact that their man has been upstaged - embarrassed too - by its almost universally ostracised ally and neighbour.
Menlo Park, Calif. — Researchers from the Department of Energy’s SLAC National Accelerator Laboratory and Stanford University have for the first time shown that neural networks – a form of artificial intelligence – can accurately analyze the complex distortions in spacetime known as gravitational lenses 10 million times faster than traditional methods.
“Analyses that typically take weeks to months to complete, that require the input of experts and that are computationally demanding, can be done by neural nets within a fraction of a second, in a fully automated way and, in principle, on a cell phone’s computer chip,” said postdoctoral fellow Laurence Perreault Levasseur, a co-author of a study published today in Nature.
KIPAC scientists have for the first time used artificial neural networks to analyze complex distortions in spacetime, called gravitational lenses, demonstrating that the method is 10 million times faster than traditional analyses. (Greg Stewart/SLAC National Accelerator Laboratory)
Lightning Fast Complex Analysis
The team at the Kavli Institute for Particle Astrophysics and Cosmology (KIPAC), a joint institute of SLAC and Stanford, used neural networks to analyze images of strong gravitational lensing, where the image of a faraway galaxy is multiplied and distorted into rings and arcs by the gravity of a massive object, such as a galaxy cluster, that’s closer to us. The distortions provide important clues about how mass is distributed in space and how that distribution changes over time – properties linked to invisible dark matter that makes up 85 percent of all matter in the universe and to dark energy that’s accelerating the expansion of the universe.
Until now this type of analysis has been a tedious process that involves comparing actual images of lenses with a large number of computer simulations of mathematical lensing models. This can take weeks to months for a single lens.
But with the neural networks, the researchers were able to do the same analysis in a few seconds, which they demonstrated using real images from NASA’s Hubble Space Telescope and simulated ones.
To train the neural networks in what to look for, the researchers showed them about half a million simulated images of gravitational lenses for about a day. Once trained, the networks were able to analyze new lenses almost instantaneously with a precision that was comparable to traditional analysis methods. In a separate paper, submitted to The Astrophysical Journal Letters, the team reports how these networks can also determine the uncertainties of their analyses.
KIPAC researcher Phil Marshall explains the optical principles of gravitational lensing using a wineglass. (Brad Plummer/SLAC National Accelerator Laboratory)
Prepared for Data Floods of the Future
“The neural networks we tested – three publicly available neural nets and one that we developed ourselves – were able to determine the properties of each lens, including how its mass was distributed and how much it magnified the image of the background galaxy,” said the study’s lead author Yashar Hezaveh, a NASA Hubble postdoctoral fellow at KIPAC.
This goes far beyond recent applications of neural networks in astrophysics, which were limited to solving classification problems, such as determining whether an image shows a gravitational lens or not.
The ability to sift through large amounts of data and perform complex analyses very quickly and in a fully automated fashion could transform astrophysics in a way that is much needed for future sky surveys that will look deeper into the universe – and produce more data – than ever before.
The Large Synoptic Survey Telescope (LSST), for example, whose 3.2-gigapixel camera is currently under construction at SLAC, will provide unparalleled views of the universe and is expected to increase the number of known strong gravitational lenses from a few hundred today to tens of thousands.
“We won’t have enough people to analyze all these data in a timely manner with the traditional methods,” Perreault Levasseur said. “Neural networks will help us identify interesting objects and analyze them quickly. This will give us more time to ask the right questions about the universe.”
KIPAC researchers used images of strongly lensed galaxies taken with the Hubble Space Telescope to test the performance of neural networks, which promise to speed up complex astrophysical analyses tremendously. (Yashar Hezaveh/Laurence Perreault Levasseur/Phil Marshall/Stanford/SLAC National Accelerator Laboratory; NASA/ESA)
A Revolutionary Approach
Neural networks are inspired by the architecture of the human brain, in which a dense network of neurons quickly processes and analyzes information.
In the artificial version, the “neurons” are single computational units that are associated with the pixels of the image being analyzed. The neurons are organized into layers, up to hundreds of layers deep. Each layer searches for features in the image. Once the first layer has found a certain feature, it transmits the information to the next layer, which then searches for another feature within that feature, and so on.
“The amazing thing is that neural networks learn by themselves what features to look for,” said KIPAC staff scientist Phil Marshall, a co-author of the paper. “This is comparable to the way small children learn to recognize objects. You don’t tell them exactly what a dog is; you just show them pictures of dogs.”
But in this case, Hezaveh said, “It’s as if they not only picked photos of dogs from a pile of photos, but also returned information about the dogs’ weight, height and age.”
Scheme of an artificial neural network, with individual computational units organized into hundreds of layers. Each layer searches for certain features in the input image (at left). The last layer provides the result of the analysis. The researchers used particular kinds of neural networks, called convolutional neural networks, in which individual computational units (neurons, gray spheres) of each layer are also organized into 2-D slabs that bundle information about the original image into larger computational units. (Greg Stewart/SLAC National Accelerator Laboratory)
Although the KIPAC scientists ran their tests on the Sherlock high-performance computing cluster at the Stanford Research Computing Center, they could have done their computations on a laptop or even on a cell phone, they said. In fact, one of the neural networks they tested was designed to work on iPhones.
“Neural nets have been applied to astrophysical problems in the past with mixed outcomes,” said KIPAC faculty member Roger Blandford, who was not a co-author on the paper. “But new algorithms combined with modern graphics processing units, or GPUs, can produce extremely fast and reliable results, as the gravitational lens problem tackled in this paper dramatically demonstrates. There is considerable optimism that this will become the approach of choice for many more data processing and analysis problems in astrophysics and other fields.”
Part of this work was funded by the DOE Office of Science.
-Written by Manuel Gnida
Citation: Y.D. Hezaveh, L. Perreault Levasseur, P.J. Marshall, Nature, 30 August 2017 (10.1038/nature23463)
SLAC is a multi-program laboratory exploring frontier questions in photon science, astrophysics, particle physics and accelerator research. Located in Menlo Park, California, SLAC is operated by Stanford University for the U.S. Department of Energy Office of Science. To learn more, please visit www.slac.stanford.edu.
SLAC National Accelerator Laboratory is supported by the Office of Science of the U.S. Department of Energy. The Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov.
Hi folks,
As promised, here's a quick summary of what was discussed at the 2038
BoF session I ran in Montréal.
Thanks to the awesome efforts of our video team, the session is
already online [1]. I've taken a copy of the Gobby notes too,
alongside my small set of slides for the session. [2]
We had a conversation about the coming End of The World, the 2038 problem.
What's the problem?
-------------------
UNIX time_t is 31 bits (signed), counting seconds since Jan 1,
1970. It's going to wrap.. It's used *everywhere* in UNIX-based
systems. Imagine the effects of Y2K, but worse.
What could go wrong?
--------------------
All kinds if disasters! We're not trying to exaggerate this *too*
much, but it's likely to be a significat problem. For most of the
things that needed fixing for Y2K, they were on big obvious computers,
typically mainframes. Y2K was solved by people doing a lot of work; to
many outside of the direct work, it almost came to be an anti-climax.
In 20 years' time, the systems that we will be trying to fix for the
2038 problem are likely to be much harder to track. They're typically
not even going to look like computers - look at the IoT devices
available today, and extrapolate. Imagine all kinds of devices with
embedded computers that we won't know how to talk to, let alone verify
their software.
When does it happen?
--------------------
Pick the example from the date(1) man page:
$ date --date=@$((2**31-1))
Tue 19 Jan 03:14:07 GMT 2038
At that point, lots of software will believe it's suddenly 1902...
What needs doing?
-----------------
Lots of fixes are going to be needed all the way up the stack.
Data formats are often not 2038-safe. The filesystems in use today are
typically not ready. Modern ext4 *is*, using 34 bits for seconds and
30 bits for nanoseconds. btrfs uses a 64-bit second counter. But data
on older filesystems will need to be migrated.
There are many places in the Linux kernel where 32-bit time_t is
used. This is being worked on, and so are the interfaces that expose
32-bit time_t.
Lots of libraries use 32-bit time_t, even in places where it might not
be obvious. Finally, applications will need fixing.
Linux kernel
------------
There's project underway to fix Linux time-handling, led by Deepa
Dinamani and Arnd Bergmann. There's a web site describing the efforts
at https://kernelnewbies.org/y2038 and a mailing list at
y2038@lists.linaro.org. They are using the y2038 project as a good way
to get new developers involved in the Linux kernel, and those people
are working on fixing things in a number of areas: adding core 64-bit
time support, fixing drivers, and adding new versions of interfaces
(syscalls, ioctls).
We can't just replace all the existing interfaces with 64-bit
versions, of course - we need to continue suporting the existing
interfaces for existing code.
There are lots of tasks here where people can join in and help.
Glibc
-----
Glibc is the next obvious piece of the puzzle - almost everything
depends on it. Planning is ongoing at
https://sourceware.org/glibc/wiki/Y2038ProofnessDesign
to provide 64-bit time_t support without breaking the existing 32-bit
code. There's more coverage in LWN at
https://lwn.net/Articles/664800/
The glibc developers are obviously going to need the kernel to provide
64-bit interfaces to make much progress. Again, there's lot of work to
be done here and help will be welcome.
Elsewhere?
----------
If you're working further up the stack, it's hard to make many fixes
when the lower levels are not yet done.
Kernels other than Linux are also going to have the same problems to
solve - not really looked at them in much detail. As the old time_t
interfaces are POSIX-specified, hopefully we'll get equivalent new
64-bit interfaces that will be standard across systems.
Massive numbers of libraries are going to need updates, possibly more
than people realise. Anything embedding a time_t will obviously need
changing. However, many more structures will embed a timeval or
timespec and they're also broken. Almost anything that embeds
libc-exposed timing functions will need updating.
We're going to need mass rebuilds to find things that break with new
interfaces, and to ensure that old interfaces still work. An obvious
thing to do here also is automated scanning for ABI compliance as
things change.
Things to do now
----------------
Firstly: developers trying to be *too* clever are likely to only make
things worse - don't do it! Whatever you do in your code, don't bodge
around the 32-bit time_t problem. *Don't* store time values in weird
formats, and don't assume things about it to "avoid" porting
problems. These are all going to cause pain in the future as we try to
fix problems.
For the time being in your code, *use* time_t and expect an ABI break
down the road. This is the best plan *for now*.
In terms of things like on-disk data structures, don't try to
second-guess future interfaces by simply adding padding space for a
64-bit time_t or equivalent. The final solution for time handling may
not be what you expect and you might just make things worse.
Dive in and help the kernel and glibc folks if you can!
Next, check your code and the dependencies of your code to see if
there are any bodges or breakages that you *can* fix now.
Discussion
----------
It's a shame to spoil the future pensions of people by trying to fix
this problem early! :-)
There are various license checkers already in use today - could the
same technology help finding time junk? Similarly, are any of the
static analysis tools likely to help. It's believed that Coverity (for
example) may be looking into the static analysis component of
this. There's plenty of scope for developers to help work in these
areas too.
Do we need to worry about *unsigned* time_t usage too (good to 2106)?
As an example, OpenPGP packets use that. This gives us a little bit
longer, but will still need to be considered. The main point to
consider is fixing things *properly*, don't just hack around things by
moving the epoch or something similarly short-term.
It's important that we work on fixing issues *now* to stop people
building broken things that will bite us. We all expect that our own
computer systems will be fine by 2038; Debian systems will be fixed
and working! We'll have rebuilt the world with new interfaces and
found the issues. The issues are going to be in the IoT, with systems
that we won't be able to simply rebuild/verify/test - they'll fail. We
need to get the underlying systems right ASAP for those systems.
2038 is the problem we're looking at now, but we're going to start
seeing issues well before then - think repeating calendar entries.
Libraries often don't need to expose any time_t style information, but
it's something to be careful about. If people have worked things out
well, changing the internal implementation of a delay function should
not pollute up the stack. But it's easy to pick up changes without
realising - think about select() in the event loop, for example.
Statically linked things (e.g. the Go ecosystem) are likely to bite -
we need to make sure that the libraries that they embed are fixed
early, before we can rebuild that stack upwards.
How can we enforec the ability to upgrade and get support for IoT
products so that they don't just brick themselves in future? GPL
violations play into this because the sources are unavailable - i.e.,
no way to rebuild and upgrade. Ancient vendor kernels are a major
PITA, and only make things more urgent.
If you're designing your own data format without reference to current
or upcoming standards, then of course consider the need for better
time handling. Conversions will be needed anyway.
Main takeaways:
* This is a real problem
* We need to fix the problem *early*
* People are working on this already, and there's plenty of tasks to
help with
[1] http://meetings-archive.debian.net/pub/debian-meetings/2017/debconf17/it-s-the-end-of-the-world-in-21-years.vp8.webm
[2] https://www.einval.com/~steve/talks/Debconf17-eotw-2038/
--
Steve McIntyre, Cambridge, UK. steve@einval.com
"...In the UNIX world, people tend to interpret `non-technical user'
as meaning someone who's only ever written one device driver." -- Daniel Pead
This post is by Tanya O’Carroll, Adviser Tech and Human Rights, Amnesty International; Danna Ingleton, Adviser, Human Rights Defenders; and Jun Matsushita, Founder and CEO, iilab.
In 2012, Amnesty International, with support from our partners at iilab, The Engine Room and Frontline Defenders, began developing a tool that would provide human rights defenders with an alert system in their pocket: the Panic Button app. Now, we’ve made the decision to cease ongoing support for the app. Here, we share the lessons learned and what it means for the future of developing security tools for human rights activists. .
The origins of Panic Button
When we first called on the tech community to help us use technology to prevent unlawful detentions — back in 2012 — we always knew we would be trying something different. That was Amnesty International’s first Open Innovation Challenge; it was the first time the organization attempted to use technology to address human rights abuses directly.
Our dream was to develop a smart and simple tool that would provide human rights defenders (HRDs) with an alert system in their pocket: the panic button app.
A huge, collaborative effort came out of that dream. About 350 designers and developers took part in an open design process, and multiple hackathons and codejams over a year and a half to prototype and develop the app. There were three iterations of the UX as we responded to the feedback and input of human rights defenders in Amnesty’s networks. 120 HRDs from 17 countries took part in in a six-month pilot and helped us understand how the app was working – or not working! – for them in practice (an evaluation of the pilot can be found here).
From the outset, all those involved knew this was about much more than an app. At its centre, the Panic Button project aimed to develop a model for strong peer-to-peer emergency response between HRDs and their networks. We worked closely with defenders from across the world to understand and build upon their existing security practices, designing a flexible security framework that would help them prepare for and manage physical threats. We called this security framework the PACT so that HRDs and their networks would be “Prepared to ACT.”
A participant at a Panic Button workshop creates a map of countries where we tested Panic Button in partnership with the East and Horn of Africa Human Rights Defenders Project in 2014.
Why we are sunsetting Panic Button
Five years later and we have many stories of successes, failures and lessons learned. It would be worrying if we didn’t; it would mean that we hadn’t really tried anything new. We are proud of what we achieved with the PACT — and the training kit that supports it — which represent an innovative approach to emergency response planning with HRDs. This has been confirmed over and over again in the feedback we have received from activists in trainings (some of the testimony from HRDs can be found here in our training diary).
Unfortunately, despite a huge collective effort, we have had to come to terms with the fact that the Panic Button app has not become the tool we hoped it would be. That’s why today we are making the painful decision, after months of pursuing all other avenues, to cease our support for the Panic Button app.
We arrived at that decision for three reasons:
Despite our best efforts, we have not been able to secure any substantial external funding for the project since being awarded £100,000 as runners-up in the Google Global Impact Award in June 2013. In part, this is due to what in hindsight was a short-lived boom in funding and excitement around “tech 4 good.”
Without adequate resourcing, we have not been able to resolve a major technical issue with the app: a false alert problem caused by “false positives” when the phone thinks the power button has been triggered.
Also linked to resourcing, we have not been able to keep up with the level of human resources needed to maintain our engagement with users.
We think a lot of our experiences will be familiar to others who have experimented with developing tech for social good. We also think that failures too often get swept under the carpet. We don’t want to do that. Two months ago, we joined a session at the Internet Freedom Festival in Valencia to share lessons from the Panic Button experience. This post builds off the discussions we had with many of you there.
We also think that failures too often get swept under the carpet. We don’t want to do that.
We hope our experience provides useful lessons for app developers, human rights technologists and funders, and contributes towards tech initiatives that are scalable, sustainable and socially impactful.
Increasingly we run our Perl programs inside docker containers,
because there are advantages in terms of isolation and deployment.
Containers provide applications with an idealized view of the OS -
they see their own filesystem, their own networking stack, and their
own set of processes.
Running the application as PID 1 inside the container comes withwell-documented challenges around child process zombie
reaping,
but we knew about that and understood it. However, it turns out there
is a separate issue with signal handling, which we had not fully
appreciated.
The problem: shutting down gracefully
Recently we moved one of our Perl daemon processes to run inside
docker - this is a system which has a few dozen worker instances
running, consuming jobs from a queue.
The problem was, it was taking a long time to deploy all of these
instances - each one would take 10 seconds to shut down. On closer
inspection, ‘docker stop’ was waiting for them to terminate
gracefully, then after 10 seconds giving up and sending a kill signal.
We reproduced this with a one-liner:
$ docker run debian perl -E 'sleep 300'
^C
[refuses to die]
(Of course, Ctrl+C sends SIGINT rather than SIGTERM, but sending
SIGTERM manually had the same effect. ‘docker stop’ could shut it
down, but only after the timeout and sending a SIGKILL.)
This confused us.
What’s going on: PID 1 signal handling
Adding a signal handler shows that the signal is actually received by
the script:
$ docker run debian perl -E '$|=1; $SIG{TERM}=sub{say "Received SIGTERM"}; sleep 300 while 1'
[Send SIGTERM from other terminal]
Received SIGTERM
So although under normal circumstances an unhandled SIGTERM would mean
the program shuts down, when running as PID 1 this is not true.
In other words, while normally the kernel would apply default
behaviour if our process received a TERM or INT signal that it wasn’t
handling, when running as PID 1 this is not applied.
Why this confused us: Golang is special
Why did it take us so long to notice this behaviour? We’ve been using
docker for ages.
Other than adding signal handlers to all of our applications, we could
instead use an init daemon such asdumb-init, or since Docker 1.13
you can pass an ‘–init’ flag to make docker run do something similar.
Another alternative would be to use a system other than docker - rkt
runs container processes as PID 2 rather than PID 1, which is looking
increasingly sensible given the special handling by the kernel.
As hard as you try, some personally identifiable information may remain. This could be something as simple as your name on a message.
You have little control over this or what others share about you in future. The most you can realistically do is ask your friends to respect your privacy.
Data shared with apps and advertisers is with them forever. As a Facebook user you are leaving behind a valuable personal data footprint.
Enjoy Your Freedom
‘And remember, where you have a concentration of power in a few hands, all too frequently men with the mentality of gangsters get control. History has proven that. All power corrupts; absolute power corrupts absolutely.’— Sir John Dalberg-Acton.
There hasn't been any official announcement from Oracle, but unconfirmed reports put it at 1,000~1,500 Oracle staff losing their jobs, particularly in the Solaris and SPARC divisions.
Solaris has been slowly dieing and these latest layoffs seem to further reinforce that and some anonymous reports as well that Solaris 11.4 isn't going to happen, or at least not as planned, and Solaris 12 can definitely be kissed goodbye.
One now former Oracle/Sun developer even said, "For real. Oracle RIF'd most of Solaris (and others) today." [RIF is "Reduction In Force"] That was from an Oracle formerly Sun developer who had been at the company since 2004 and then let go on Friday.
Another tweeting, "One of the saddest days in my professional life. There is a rich and deep UNIX, systems, OS, platform and processor talent pool available. 😢"
And it even looks like Sun's longtime X11 developer and former X.Org Foundation board member seems to have also been impacted with these latest cuts.
Those wanting to read more anonymous reports from reported former Oracle employees can find a ton more content this weekend over on thelayoff.com/oracle.
Svelte is not a framework like the other conventional Javascript frameworks. Svelte is an Ahead Of Time (AOT) compiler, so in the end the code that get shipped is just plain old Javascript with minimal runtime overhead. This is one of the reasons why Svelte is so fast, in some cases my entire Svelte application is smaller than the entire React library.
To use Svelte, you can install its cli tool or if you just want to experiment, you can make use of its online REPL. For our setup we will make use of the online REPL.
Lets get started with Svelte by creating our first small widget.
Our widget will be a filter list component like that you see on web applications like Slack with its channel chooser.
We will start writing our HTML code in the App.html section of the Svelte REPL. As we go along you will notice I will define some classes on each HTML element for styling the component later on.
The elements we will need for this widget is an input field for us to type our value into:
Now that we have our input field, we can start adding some Svelte specific properties to it in order to make the value entered dynamic and available later on in our app. For this we will add the bind:value property with a value of q.
<input bind:value="q" type="text" class="search">
For a quick test to see how this works, lets add this bit of code below the filter-search closing div tag.
You may notice a side-effect of using a value in bind:value that is not defined, by default the value q is undefined and such will be outputted on the screen. Assign q to an empty string over in the panel on the bottom right where it says name in the REPL.
Now as you type into the input field, you should see the value getting printed out below as you type.
So now we need a list for the input value to filter through.
<div class="filtering-list"><div class="filter-search"><input bind:value="q" type="text" class="search"></div><ul class="filter-list">
{{#each list as name}}<li>#{{name}}</li>
{{/each}}</ul></div>
Same as earlier, also assign list to an empty array over in the panel on the bottom right in the REPL. Otherwise this will throw an error in the REPL.
With this now in place, we have most of our user interface setup and ready to receive values. But you may have noticed that there is currently no association between the bind:value of q and the list. This is where we will start writing actual Javascript code.
One of the nice things about Svelte components is that you write all your HTML, CSS and Javascript code in the same file or in this instance in the same column in the REPL.
The first piece of code we need is to export the object we will write out Svelte related Javascript code in.
<script>
export default {
}</script>
You might have noticed the script tag and be wondering, why are we writing our Javascript inline again, I thought that was a bad thing? well luckily in the case of Svelte, this is not a bad thing as our component once completed will be loaded as an external file in our actual final product.
Earlier we defined the q and the list in the bottom right column of the REPL, but I would normally move this into this part of our code to give the widget a default state if its loaded with no values assigned.
Change the value of list in the panel on the bottom right to something like ["angular","backbone", "ember", "glimmer", "react", "svelte", "vue"]
Now that we have our initial state for our application, we can go ahead and add in code for the filtering to work as expected. To carry out this task we will use Svelte’s computed properties.
We named our computed property filteredList and it is keeping watch of our two initial values, whenever one of these value’s change, our computed property will run. Now even with this we still won’t see any changes as we type a value into the field.
We can now go back to our template from earlier and change {{#each list as name}} to {{#each filteredList as name}}. Our complete code should now look like below.
We now have a working application doing what we had set out for it to do in the beginning. We can go on to styling it to look better and also do some code refactoring. Here is a link to the final widget with some CSS applied and the filter code refactored.
One of the questions some people might ask is, why use Svelte over any of the others available on the market, well with Svelte you can create Universal widgets that are not tied to any Javascript framework, since the end result from Svelte is plain old Javascript and no runtime library (this is subjective since the runtime library is minimal and part of the actual output code) necessary to run it, you can drop it into any other projects you have.
I hope you enjoyed your first experience with Svelte and will continue your journey from here on out.
It was 1998 and the dot-com boom was in full effect. I was making websites as a 22 year old freelance programmer in NYC. I charged my first client $1,400. My second client paid $5,400. The next paid $24,000. I remember the exact amounts – they were the largest checks I’d seen up til that point.
Then I wrote a proposal for $340,000 to help an online grocery store with their website. I had 5 full time engineers at that point (all working from my apartment) but it was still a ton of dough. The client approved, but wanted me to sign a contract – everything had been handshakes up til then.
No prob. Sent the contract to my lawyer. She marked it up, sent it to the client. Then the client marked it up and sent it back to my lawyer. And so on, back and forth for almost a month. I was inexperienced and believed that this is just how business was done.
Annoyed by my lawyering, the client eventually gave up and hired someone else.
Dang.
But lucky enough, another big company came knocking. A fortune 500 company needed an e-commerce site. I wrote a $400,000 proposal (ahh, the boom days…). The client okay’d it and gave me a contract to sign.
This time, instead of sending it to my lawyer, I sent it to my Dad – a lifelong entrepreneur.
“Just sign it,” he said, calmly.
“But it has all kinds of crazy stuff in it!” I replied. “It says I’m personally liable if anything goes wrong! It says I owe them money if it’s late!” and so on.
“Just sign it,” he said.
“But what if something happens?? What if the site crashes? What if I’m late? What if..??”
“Do you think any of that stuff is going to happen?” he asked.
“Probably not. But what if it does?”
“Then you know what you do?” he said. “Tell them, ‘fucking sue me.’”
He was right. I got the job, they paid, things went well, nobody got sued.
Then there was the time I wanted to hire my first full time employee. I was apprehensive to do it because I only had enough money to pay him for 2 months, unless I got another client fast.
“Worry about that in 2 months,” Dad said.
He worked for me for several years.
This lesson in total disregard for risk served me well. They say entrepreneurs are risk takers. I think of myself as too lazy and irresponsible to fully understand the risk.
We are building an alternative to Android and other mobile operating systems by not forking but bending the time-provenAlpine Linux distribution to fit our purpose. Instead of using Android's build process, we build small software packages that can be installed with Alpine's package manager. To minimize the amount of effort for maintenance, we want every device to require only one device-specific package and share everything else.
At this point our OS is only suitable for fellow hackers who enjoy using the command-line and want to improve postmarketOS. Telephony or other typical smartphone tasks are not working yet.
Why We Evolve in Many Directions
Why don't we focus on one "flagship" device and stop making blog posts until it can be used as daily driver?
Our philosophy is that community-based FLOSS projects need to become known during the development phase to fellow developers. Our way of doing that is through periodically posting reports summarizing our real progress.
The postmarketOS community is a collective group of hackers who contribute to this project in their free time. We won't tell someone who wants to, for example, extend postmarketOS to run Doom on their smartwatch that their idea has no benefit to the project's vision. Such activities demonstrate the flexibility of postmarketOS and oftentimes leads to improvements to the project's codebase as new requirements are implemented to cover previously unforeseen use cases. In addition, these fun activities also increase our collective knowledge about the software and hardware we work with. But most importantly we don't want to, or plan to, take the fun away. Because without being fun and rewarding, a free time project becomes a dead project.
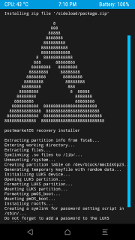
The idea of providing a device specific package for QEMU was introduced back in July "so it will be easier to try the project and/or develop userspace". Although the initial PR #56 didn't make it, the idea got picked up again and today we can provide you with an implementation of exactly that vision. All you need to dive right into running postmarketOS on QEMU is to install Python (3.4+), git, QEMU, and run the following commands. As expected, pmbootstrap does everything in chroots in the install step, so your host operating system does not get touched.
Since postmarketOS was released, we have been using Wayland's reference compositor Weston as a UI. However, as stated in #62, it "is a cool demo, but far from a usable day-to-day shell people can work with. We need to provide a sane UI."
plasma-mobile (KDE's plasma desktop for phones)
Alpine Linux does not have any KDE programs or libraries packaged yet, so @PureTryOut went through the colossal task of packaging, looking for patches, compiling and debugging more than 80 pieces of plasma-mobile related software. This is the very minimum to get the mobile version of KDE's Plasma desktop running. Alpine provided quite a few challenges along the way, such as the usage of the more standards compliant musl libc instead of the commonly used glibc. Luckily @mpynealready provided patches in KDE's bugtracker that we were able to use. @bshah not only helped us with the port, but also mentioned postmarketOS in his plasma-mobile talk at KDE's Akademy 2017!
This is definitely a huge step in the direction towards making plasma-mobile work on postmarketOS! We're excited to see where this is heading, and would greatly appreciate any help from interested developers. Jump right in with QEMU and the unofficial binary packages for KDE/Plasma!
The popular Nokia N900 originally shipped with a desktop called Hildon, which ran on its Debian-based Maemo operating system. @NotKit started a port currently containing the minimum packages required to get working: a modified, mobile friendly, GTK+2 and 12 other packages.
A modernized GTK+3 version of Hildon is being worked on at talk.maemo.org, which we could package in the future. While Hildon is based on X11 instead of Wayland, it is still a lightweight phone interface suitable for older devices.
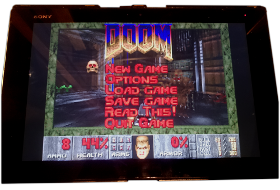
Speaking of classic interfaces, @Opendata26 made an obligatory Doom port. In the photo is his Xperia Z2 tablet with a 4.3 kernel and the open source userspace driver freedreno. In addition to running Doom, he also enabled the driver upstream in Alpine's mesa package so that all Alpine users can benefit from it! Check out his /r/postmarketOS post for more photos of other games running. Even though freedreno provides a FOSS implementation of the userspace portion of the driver, it still requires a proprietary firmware file for 3D acceleration. This test was made with X11, as it currently does not work with a Wayland compositor. Further debug will be required to determine why this is the case!
Next up is @Bloo, who decided to port postmarketOS to his LG G Watch R, giving us the first smartwatch port! In order to take out the watch and shout "It's time to play Doom!" whenever asked for the time, he decided to compile and run it on his device too. In the photo on the right, Doom is running in its native resolution of 320x240 (compare to the watch at 320x320) in Weston through XWayland. For both the Xperia Z2 and LG G Watch R, Chocolate Doom was used and is being packaged for postmarketOS now.
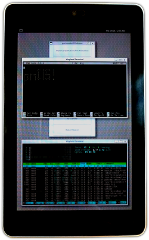
The initramfs is a small filesystem with an init.sh file that prepares the environment before it passes control to the init system running in the real root partition. For postmarketOS we use it to find and optionally unlock the root partition.
@craftyguy and @MartijnBraam have started to write a new on-screen keyboard named osk-sdl from scratch because we couldn't find an existing one that did not depend on heavy GUI libraries. osk-sdl will allow us to unlock the root filesystem directly with the device's touch screen or physical keyboard (if applicable). It is currently in the process of being integrated into postmarketOS, after which it will fully replace the current method of unlocking via telnet. If unlocking via telnet is a requirement for you, please reach out to us and let us know!
To work around the tight size limitations on some devices which do not support having a large boot.img file, @drebrez implemented the initramfs-extras trick: a second initramfs file stores all the big files and is placed in the unencrypted boot partition. The real initramfs then detects this file by its label and extracts everything from initramfs-extras. At this point the init script works like before and has all files it needs!
Speaking of small size: the system image generated in the installation step doesn't have a fixed size anymore, it now adjusts dynamically! After flashing and booting, the initramfs will check whether the flashed image takes up all available space of the system partition and, if it does not, automatically resizes the partition to use all available space.
Check out that cool new splash screen (#206)! It gets built dynamically for the device's screen size whenever we build the initramfs. So it always fits perfectly! And in case you don't like it, it comes with a customizable config!
Last but not least we did a lot of refactoring, such as placing the deviceinfo file inside the initramfs for easy access to device-specific settings and adding support for a configfs-based USB network setup to help out some devices that need it.
With all the recent device porting we have learned that there are many different flashing methods required for different devices. In some cases it isn't even possible to directly write to the system partition on a device but it is possible to flash a recovery zip through a recovery operating system, such as the popular TWRP. @ata2001 made it possible to create such an image with pmbootstrap install --android-recovery-zip. This allows flashing a device by sideloading this image while TWRP is running with pmbootstrap flasher --method=adb sideload!
Some older Samsung phones are not fastboot compatible, but their bootloader implements a so-called odin-mode. Samsung expects people to install their proprietary, Windows-only Odin program to be able to flash images in this mode. The protocol has been reverse engineered for some devices and can be used with the open source heimdall program, which has been wrapped with our pmbootstrap. But for some older phones the necessary reverse engineering work has not been done and you still have to run the proprietary program to get anything working at all. @drebrez has implemented an Odin-compatible export option to help out folks in this situation: pmbootstrap flasher export --odin.
One of our previously stated goals is using the mainline Linux kernel on as many mobile devices as possible. This is not as easy as it might sound, since many Linux-based smartphones (Android) require binary drivers which depend on very specific kernel versions. It's a tremendous task to rewrite these drivers to work with the current kernel APIs. Nevertheless, some people have been doing that since long before postmarketOS existed. In the case of the Nokia N900 this has been going on for some number of years and almost all components are now supported in the mainline kernel. This has allowed us to use the mainline kernel as the default kernel for the N900, jumping from Maemo's 2.6.x to mainline 4.12!
Most desktop Linux distributions not only provide the kernel from the same source code but also use one binary kernel package for multiple devices for systems of the same CPU architecture. Since this makes maintenance easier, we follow that approach with our linux-postmarketos package. This package configures the kernel to support multiple devices at once, currently the N900 and QEMU, by supporting kernel modules and multiple device trees. On a side note, it is currently not possible for us to use Alpine's kernels because they do not have support for many components found in smartphones and we wouldn't be as flexible as we are now with temporarily applying patches.
We now have several different key pieces of infrastructure in place to support ongoing project development! The first and most obvious if you are a returning reader: we have a brand new homepage that hosts both our main landing page, this blog, and has links to all of our online resources. You might have also seen our new logo which - besides looking great - is rendered programatically!
Travis CI now verifies the checksums of downloads in our package recipes and also runs shellcheck over more scripts across the source tree. With these changes, in combination with numerous bug fixes and requiring that nearly all changes to the master branch are presented as PRs for review, pmbootstrap runs pretty stable now.
With over 100 people in the Matrix/IRC channel and lots of messages coming in every day, we decided to create ##postmarketOS-offtopic to keep the backlog in #postmarketOS a bit shorter.
What you see here is only the tip of the iceberg. So much work has gone into fixing bugs, and little improvements, that it would be ridiculous to go through the effort and list them all. The community has grown so fast in such a short time and we have people with all kinds of skills on board, ranging from Linux experts to kernel hackers to people who reverse engineer bootloaders (hi @McBitter!). We collaborate with people from other projects as well, such as @pavelmalchek, who is close to using his N900 as a daily driver with his own distribution, recently just reached out to us.
So if you read through the whole post, you are probably interested in what we do. Consider contributing to the project, the entry barrier is really low. pmbootstrap automates everything for you and we are more than happy to help you through any issues you encounter in the chat. There are also a lot of opportunities to help with development, so there's plenty to do. And plenty of fun to have. Join us and tell your friends!
In Emacs today, there’s no way to find all the callers of a function
or macro. Most Emacsers just grab their favourite text search tool.
Sadly, dumb text search knows nothing of syntax.
We can do better. It just wouldn’t be Emacs without a little fanatical
tool building. Let’s make this happen.
Parsing
Everyone know how to parse lisp, right? It’s just read.
It turns out that a homoiconic language is hard to parse when you want
to know where you found the code in the first place. In a language
with a separate AST, the AST type includes file positions. In
lisp, you just have… a list. No frills.
I briefly explored writing my own parser before coming to my
senses. Did you know the following is legal elisp?
;; Variables can start with numbers:(let((0x01));; And a backquote does not have to immediately precede the;; expression it's quoting:`;; foo(+,0x0))
Cripes.
Anyway, I totally ripped off was inspired by similar functionality
in el-search. read
moves point to the end of the expression read, and you can usescan-sexps to find the beginning. Using this technique
recursively, you can find the position of every form in a file.
Analysing
OK, we’ve parsed our code, preserving positions. Which forms actually
look like function calls?
This requires a little thought. Here are some tricky examples:
;; Not references to `foo' as a function.(defunsome-func(foo))(lambda(foo))(let(foo))(let((foo)));; Calls to `foo'.(foo)(lambda(x)(foo))(let(x)(foo))(let((x(foo)))(foo))(funcall'foo);; Not necessarily a call, but definitely a reference to ;; the function `foo'.(a-func#'foo)
We can’t simply walk the list: (foo) may or may not be a function
call, depending on context. To model context, we build a ‘path’ that
describes the contextual position of the current form.
A path is just a list that shows the first element of all the
enclosing forms, plus our position within it. For example, given the
code (let (x) (bar) (setq x (foo))), we build a path ((setq . 2)
(let . 3)) when looking at the (foo).
This gives us enough context to recognise function calls in normal
code. “Aha!”, says the experienced lisper. “What about macros?”
Well, elisp-refs understands a few common macros. Most macros just
evaluate most of their arguments. This means we can just walk the
form and spot most function calls.
This isn’t perfect, but it works very well in practice. We also
provide an elisp-refs-symbol command that finds all references to a
symbol, regardless of its position in forms.
Performance
It turns out that Emacs has a ton of elisp. My current instance
has loaded three quarters of a million lines of code. Emacs actually
lazily loads files, so that’s only the functionality that I use!
So, uh, a little optimisation was needed. I wrote a benchmark script
and learnt how to make elisp fast.
Firstly, avoid doing work. elisp-refs needs to calculate form
positions, so users can jump to the file at the correct
location. However, if a form doesn’t contain any matches, we don’t
need to do this expensive calculation at all.
Secondly, find shortcuts. Emacs has a little-known variable
called read-with-symbol-positions. This variable reports all the
symbols read when parsing a form. If we’re looking for function calls
to some-func, and there’s no reference to the symbol some-func, we
can skip that form entirely.
Thirdly, use C functions. CS algorithms says that building a hash
map gives you fast lookup. In elisp-refs, we use assoc with small
alists, because C functions are fast and most lists weren’t big enough
to benefit from the O(1) lookup.
Fourthly, write impure functions. Elisp provides various ways to
preserve the state of the current buffer, particularlysave-excursion and with-current-buffer. This bookkeeping is
expensive, so elisp-refs just creates its own temporary buffers and
dirties them.
When all else fails, cheat. elisp-refs reports its progress, which
doesn’t make it faster, but it certainly feels like it.
Display
We have something that works, and we can search in all the code in in
the current Emacs instance in less than 10 seconds. How do we display
results?
first prototype, showing the matching forms in isolation
Initially, I just displayed each form in the results buffer. It turns
out that the context is useful, so added the rest of the matching lines
too. To avoid confusion, I underlined the section of the code that
matched the search.
second prototype, adding context and custom faces
The second prototype also had some custom faces for styling. This was
an improvement, but it forces all Emacs theme authors to add support
for the faces defined in our package.
It still didn’t work as well as I’d hoped. When I get stuck with UI,
I ask ‘what would magit do?’. I decided that magit would take
advantage of existing Emacs faces.
final UI, using normal syntax highlighting
The final version uses standard elisp highlighting, but highlights the
surrounding context as comments. This means it will match your
favourite colour scheme, and new users should find the UI familiar.
I added a few other flourishes too. You can see that results in the
second prototype were often very indented. The final version unindents
each result, to make the matches easier to read quickly.
Shirod Ince sat at the front of a line of more than 100 people, mostly guys in their early 20s, on a Friday evening last month. For two days, he and his friends had been taking turns waiting outside a Foot Locker in Harlem to buy the new LeBron sneaker. Through the long, restless hours, they had sustained themselves on Popeye’s, McDonald’s and a belief that it would all pay off in the end.
Ince had no plans to wear the new Nikes. No, for the past two years, the 22-year-old basketball coach has been reselling the sneakers he waits for. And he thought he could double, triple, possibly even quadruple his money for this particular pair, getting anywhere between $500 and $900 for a sneaker that was selling for $250 retail.
“I’ve been here since Wednesday. I have to get it,” he said. “It’s going to be crazy in the morning.”
Ince thinks of himself as a small-time entrepreneur, but in reality he’s part of a complex, rubber-soled mini economy — one with “buyers, sellers, brokers, market-makers and third-party valuation services,” said Josh Luber, who founded Campless, a blog about sneaker data.
Luber, 36, understands this market better than anyone. Since 2012, he has compiled data on more than 13 million eBay auctions and posted his analysis on Campless, creating a price guide he calls the Kelley Blue Book of sneakers. The site tracks the prices of more than 1,100 pairs of collectible sneakers — that is, sneakers that sell on the secondary market above their primary market, or retail, price.
The markup can be astonishing. The average eBay price of the LeBron 10 What the MVP sneaker? $2,086. The Nike Air MAG Back to the Future? $5,718. How about the Air Yeezy 2 Red October, designed by Kanye West and released by Nike this year for $250 retail? It sold on eBay for an average price of $2,958, with almost two dozen people paying at least $8,000, Luber said.1
Luber — a fanatical sneaker collector himself, with 178 pairs on display in his home — says eBay’s sneaker business totaled $338 million in the last year, up 31 percent from the year before. Sneakers, he says, have become “boxes of cash” for many people. As soon as Foot Lockers across the country open each Saturday, thousands of pairs are on eBay.
None of this happens, of course, without the complicity of Nike, which is on track to hit $30 billion in sales this year. By inventing the concept of a limited sneaker, the company helped spawn a secondary market that puts money in the pockets of Ince and other investors.
It’s puzzling behavior for a money-making behemoth. So lately Luber has been fixated on a complicated question: Is Nike leaving money on the table — and giving up profits to the secondary market — by limiting the supply of certain lines of its sneakers? And if so, why?
When I visited Luber at his Philadelphia apartment in July, he came to the front door unshaven, wearing sweatpants and a Nike shirt — and no shoes. He prefers to go barefoot around the house.
And yet shoes are his obsession. They’re displayed on custom-built shelves in his basement, which also happens to be the guest bedroom, his daughter’s playroom and his wife’s office. “Basically anywhere we’ve lived there’s been a shoe wall,” said his wife, Patricia Luber.2 In Atlanta, the sneakers lined glass shelves and were lit up by rope lighting. And they found space in their small New York City apartment for a “mini shoe wall.” But the current display “is the grandest showcasing to date,” she said.
Josh — who actually wears his shoes and has never resold a pair — also keeps an assortment of brand-new sneakers near his desk at home, and slips them on as he works. (They migrate to the shoe wall only after he’s worn them outdoors for the first time.)
None of Patricia’s shoes (Nike or otherwise) has ever been allowed on the wall — there really isn’t room, Josh says — but he’s made an exception for their 2-year-old daughter’s.
“I bought my daughter a couple of pairs of Jordans till my wife found out how much they cost,” said Luber, who spent between $60 and $75 on each pair.
Luber grew up in the ‘80s and ‘90s, dreaming of basketball greatness. He played high school ball and plastered the walls of his bedroom with posters and Sports Illustrated covers of his favorite players. It was the Michael Jordan era, and all Luber wanted to do was wear Air Jordans.
But the sneakers were expensive — $100 at the time — so it wasn’t until after he graduated from college and was working that he bought his first pair, the Air Jordan 11 Concord.
He pulled them off his shoe wall to show me. The sneaker is mostly white, with black patent leather wrapping around the bottom half. Luber’s pair is in surprisingly good shape.
“When I first bought these sneakers in 2000, I literally walked into Foot Locker a couple of weeks after they were released and bought them, because back then, sneakers used to sit on shelves for a while. … We didn’t have the resale market,” he said. “The last time they were released in 2011, there were riots.”
Josh Luber in front of his shoe wall at his home in Philadelphia on Sept. 13, 2014.
Rebecca Greenfield
Capitalizing on the power of the Jordan brand, Nike has been re-releasing the classic Air Jordans (models 1 through 14) over and over again. The Air Jordan 11, for example, has been released some 40 times over nearly 20 years — in different colors. Take all those classic models and colors, release them dozens of times in limited quantities, and you’ve got lines outside Foot Locker and other Nike retailers every Saturday morning. (The original 1995 pair, if unworn, sells on eBay for an average price of $479. Luber’s 2000 version sells for $351.)
“Michael Jordan is, without a doubt, the father of the sneakerhead culture, and still even today,” Luber said.
The lord of the Concord is 51 now and hasn’t played professionally in more than a decade, but his brand continues to be a huge part of Nike’s business. Jordan footwear makes up nearly a quarter of the company’s shoe revenue. It makes up an even bigger part of the secondary market. Luber estimates that about half of all money spent on sneakers on eBay is for the Jordan brand.
Luber’s obsession is what compels him to stay up until 3 a.m. most nights — outside his full-time job as a strategy consultant at IBM — collecting data on sneakers. Using eBay’s public API, he can crunch the sales numbers in spreadsheets and learn all sorts of things about the secondary sneaker market. With sneakerheads on Instagram stoking consumer desire, Luber says it’s the perfect moment for him. “So the timing worked out really well,” he said. “My obsession with sneakers and obsession with data were growing at the same time.”
Luber tried to think of everything when he created his price guide. To get a sneaker’s true value, you have to make sure you’re looking only at eBay auctions that end in a sale — about half don’t — and auctions of authentic, name-brand sneakers. Lots of fakes are sold on eBay — accounting for about 10 percent of sales, Luber estimates — and their prices would corrupt the price guide.
Luber has created some rules for eliminating fakes from his calculations: First, he sets a floor and a ceiling on the price of a sneaker3; second, he throws out any outliers, i.e. prices that are more than two standard deviations from the mean; and third, he excludes auctions that have words like “replica,” “fake,” “AAA” and “variant” in the title. (The market has grown so big that some sellers specialize in good-quality fakes.4)
Another challenge is figuring out which sneaker — which model, size, color and release year — is actually for sale in a given auction. “An eBay auction has a lot of noise in it,” Luber said. Sellers throw in keywords just to get their auction to pop up in search results. Luber has to have faith in his system, because with 13 million auctions and counting, there’s no way he can check every one.
Using data from eBay and other sources, Luber also tries to answer all sorts of questions about the secondary market: Do sneakers behave more like stocks or drugs? What’s the most expensive sneaker size? Who’s the typical sneakerhead?
A lot of resellers take orders from customers before shoes are even released. Luber has noticed that prices tend to be high before the release date, when the hype is loudest. They generally fall when the shoe comes out, then rise steadily after that.
“There’s only so much to talk about with sneakers — when it’s coming out, how much does it cost, how do I get a pair,” Luber said. “This expands that. It adds a layer of content to the community that didn’t exist before.”
Luber has a dozen people who help him on Campless — his younger brother, a handful of data nerds and entrepreneur types like him, and several sneakerheads he has met through the site. All volunteer their time. Often, Luber says, they have “philosophical debates,” such as whether to include shipping in the price people pay for shoes. Say the sneaker sells for $100 but the seller is charging $70 for shipping. Is the sneaker’s true value $100 or $170? In the end, Luber’s team decided to include shipping.
You hear of lucrative secondary markets in stocks, bonds and options, but rarely do you hear of them in material things.5 That’s because companies normally price their goods and supply the market to meet consumer demand, as a way of maximizing profit.
The existence of a secondary market in sneakers raises questions for economists and people like Luber: Is it rational to sell a sneaker for $250 and let the buyer resell it for $8,000, earning a 3,000 percent return on his or her money? Could Nike capture any of that money?
“This is kind of the holy grail of sneakerhead questions,” Luber said. It’s the central question of all his research — it comes up, in some form, every time he analyzes any aspect of the secondary market. “It’s a really complicated question,” he said.
To start answering it, you first have to know this: How much money, exactly, is Nike letting the resellers walk away with?
Luber has a good handle on how much eBay resellers in particular are earning over and above sneakers’ retail price: In 2013, they made about $60 million in combined profits.6 But to arrive at a figure representing profits of the entire secondary market in sneakers, Luber has to make a big assumption about the size of eBay’s role. People also buy and sell sneakers at consignment shops such as Flight Club, blogs such as Sole Collector, forums such as NikeTalk, and of course, on Craigslist, Instagram, Twitter, Facebook, and in face-to-face deals at sneaker shows or on the street.
Based on interviews with people knowledgeable about the industry, and on sales data from some of these outlets, Luber believes eBay’s collectible sneaker market represents a quarter of the secondary market — an estimate he calls conservative.7 This suggests that resellers made $240 million last year, all but $10 million of it on Nike products. That $230 million is equivalent to 8.5 percent of Nike’s earnings in fiscal 2014. Knowing how difficult it is for a large company like Nike to add even 1 percentage point to its bottom line, Luber said, this isn’t a number to ignore.
To know whether Nike could capture any of the millions of dollars consumers spend in the secondary market, it helps to understand why people want these sneakers in the first place.
While the Jordan brand continues to dominate, Nike makes sure it cultivates deals with other fan favorites: LeBron James, Kobe Bryant and Kevin Durant all have their own sneaker lines. Last year, Nike spent $3 billion on what it calls “demand creation” — marketing — which is more than the total revenue of Under Armour, a competitor that started offering basketball footwear four years ago.
By restricting the supply of its popular brands, Luber says, Nike is tapping into another consumer desire: to have something no one else has.
On that Friday night at the Harlem Foot Locker, I met several sneakerheads who confirmed this sentiment. But they also went much deeper into the psychology of consumers like them.
Frank Taylor, who is 23 and lives in the Bronx, had already been waiting several hours when I caught up with him. He had come with his friends and had a spot somewhere in the front third of the line. He wore a white hoodie and, standing well over six feet, he towered over the crowd. He said he owns about 150 pairs of sneakers, having collected them over a dozen years.
These days, a lot of people use bots to buy shoes online as soon as they’re released. Others exploit an inside connection; Foot Locker employees are kings in the secondary marketplace. Taylor is old school and only buys retail. Sneakerheads take pride in having bought new shoes from the store, because camping out in long lines shows commitment.
“You get respect from the sneaker community,” Taylor said. “People are like, wow, how’d you get those?”
After I did the math on Taylor’s collection — 150 sneakers at about $250 a pair — I asked him whether it was possible he’d spent nearly $40,000 on shoes. “Easy, easy,” he said.
“Some people spend that money on weed,” he said. “I decide to spend mine on sneakers.”
Farther back in the line, I met 23-year-old Quay Johnson, who told me he has more than 200 pairs — half of which he hasn’t worn — and that he’s been collecting sneakers since he was 8 years old.
“My grandmother always says when I die, she’s going to bury me, going to put my sneakers in the ground with me,” he said.
Like most of the people in this line, Johnson, who works at a drugstore and in construction, wasn’t interested in reselling his pair.
“I just want it for me,” he said.
So owning a scarce resource taps into a basic desire to hoard things of value. It gets you respect. But it does something else, too. Nike’s strategy of limiting supply creates a gap — sometime a significant one — between what a shoe costs (at retail) and what it’s worth.
That differential allows people to buy something on the cheap but feel like they’re wearing a luxury item.
“So even if you paid $100, you’ve got $800 on your feet. It’s like having Gucci,” Taylor said.
As he explained this, he realized that wearing a limited-edition LeBron sneaker may in fact be better. The moment you walk out the door wearing a pair of Gucci shoes, it’s worth less. “You can’t sell it for what you paid,” Taylor said. But with certain Nike sneakers, you can buy them, wear them all day, and still sell them for a profit.
That’s because within hours (sometimes minutes) of Nike’s release of a limited-edition sneaker, the shoe is gone — totally sold out at retail outlets. It lives only in the secondary market. And so, Taylor said, people who want the shoe have no choice but to buy what’s already been obtained by someone else.
Why isn’t Taylor selling his shoes, if he could make such huge premiums on them? “If you talk down a car and you get it for a good deal, you’re not going to sell it. You’re going to drive it,” he said.
Sneakers have become like art for a lot of these men. Some want to buy low and sell high, to make a profit, but most just want to hold and admire — and sometimes show off.
Nike may be leaving money on the table, but the company certainly isn’t suffering. In fiscal 2014, it did $27.8 billion in sales — an increase of about 10 percent from the previous year, not easy for a big company. Western Europe accounts for a lot of that growth, but North America, Nike’s largest market, also saw 10 percent growth.
“How much bigger can Nike get in the United States?” asked Sam Poser, an equity analyst at the brokerage firm Sterne, Agee & Leach. “They can get bigger.”
When you ask Wall Street analysts why Nike allows resellers to pocket the profits from shoes, many say it’s great marketing: It fuels excitement about the brand, and it rewards the company’s most loyal customers. “They’re exceptionally good at keeping people hungry,” Poser, who has been following Nike for more than a decade, said. “They understand the cool factor, and they know how to stay cool. And if they don’t stay cool they know this business dries up, because this is fashion.”
Cool — especially to sneakerheads — often refers to something that’s hard to get. Nike has also made basketball shoes cool through its pricing. Air Jordans and LeBrons typically retail between $150 and $275.
“Because it’s expensive, it makes [Nike] a lot of money. And because it sells out in a heartbeat, it makes everybody a lot of money,” said Poser, who used to work as a footwear buyer for Bloomingdale’s, Champs Sports and The Sports Authority. “If you talk to the retailers, they always want more [pairs]. They’re never satisfied but they also understand that if they got too much, it could kill the golden goose.”
Another benefit to keeping supply tight is that Nike doesn’t have to discount sneakers to move inventory, said Paul Swinand, an analyst with Morningstar. Doing so could cheapen the brand’s perceived value.
And yet I wondered whether there was such a thing as keeping supply too tight, and giving up too much money to resellers. The retail market operates almost inversely to the secondary market. Think about it this way: If Nike produced only a single pair of sneakers every year — call it the Air Only — the retail price would be, say, $300. But whoever bought the pair for $300 could probably resell it for some astronomical amount. That was pretty much the case with the Air Yeezy 2 Red October, the Kanye West sneakers, which had an average resale markup of 1,083 percent.
When I asked whether there’s a point at which Nike gives up too much profit to resellers, Poser paused and said, “I don’t know the answer to that question.”
He saw only the benefits of a robust secondary market. Resellers are essentially doing PR for Nike; they’re curators. And Nike, he said, understands that to sell stuff it needs strong curators — whether that’s Foot Locker, Michael Jordan or some of the guys waiting in line in Harlem.
Sneaker re-sellers are increasingly finding their buyers through Instagram.
Of course, most people in the Saturday morning lines at Foot Locker just want to wear the shoes. Luber says that underscores one of the challenges Nike would face if it tried to stifle the secondary market by raising prices or increasing supply.
Luber says only 1 percent of Air Jordans sold at retail end up on eBay, based on his analysis of retail and eBay sales data. Again, assuming eBay makes up a quarter of the secondary market, then presumably 4 percent of Air Jordans sold at retail end up on the secondary market. That suggests 96 percent of consumers buying Air Jordans are paying the average retail price of $170, instead of the average secondary-market price, which Luber says is $265.
So, how many of those customers would Nike lose if it raised the retail price or increased supply?
The answer depends on several things. First, how much do the retail customers care about price? The more price-sensitive they are, the more Nike risks losing them if it charges more. Second, how much do these customers care about that gap between what the sneakers cost and what they’re worth? The more they care, the better the chance Nike would scare them away with higher prices or more supply.
And the third but perhaps most important issue: How critical are these intensely loyal retail customers to Nike’s business? Could Nike stand to lose some of them, but potentially gain a lot of other customers — perhaps a much bigger group of people — who aren’t willing to wait in line?
Nike presumably knows these answers, but a spokesman said by email that the company didn’t want to comment for this article.
In Luber’s mind, it’s not worth it for Nike to lose the serious sneakerheads in favor of other customers who will buy sneakers only once or twice a year. Nike captures that second group anyway — with its ubiquitous Nike Air Monarchs, which retail for as little as $50.
“They would rather err on the side of leaving money on the table than risk disrupting the secondary market and all the marketing, brand cachet, PR and hype that comes with having a really vibrant secondary market,” Luber said.
And yet, there are some recent signs that Nike executives are curious about the secondary market. In June, the company announced that eBay’s CEO, John Donahoe, had joined Nike’s board. Nike has also been tinkering with its level of production and pricing, with second rounds of sales of limited-release sneakers (what it calls restocking), as well as more frequent re-releases of Air Jordans. Also, starting next year, Nike is expected to raise the price of some of its Air Jordans 10 percent to 15 percent, because it says it’s using higher-quality material to make the sneakers more like their original versions. This increase far exceeds typical price increases for Air Jordans, which have tracked closely with inflation.
After waiting in line for more than two days, Shirod Ince buys the LeBron 11 What The LeBron in Harlem, New York, on Sept. 13, 2014.
Rebecca Greenfield
When the Foot Locker in Harlem opened a little after 8 a.m. that Saturday, clerks lifted a metal gate just high enough that people had to crouch down to get inside. At one point, guys were yelling and pushing each other against the gate, and within minutes eight police cars showed up to calm everybody down.
After days of waiting, Shirod Ince needed only a couple of minutes to buy his sneakers. He walked out with the LeBron 11 What the LeBron, in a size 12. Within an hour of the store opening, all shoes under size 10 were sold out.
Some of the speculators worried that the lines for this release were shorter than usual, suggesting the demand for this shoe might not be as strong as expected. Josh Luber saw this coming. He had been watching eBay’s average price for pre-orders of the sneaker, and it had fallen rapidly. In April, people were pre-ordering the LeBron shoe for $1,006. By early September, the price had dropped to $430.
It was expected to be an extremely limited sneaker, but as it became clear that more retailers were carrying it — two weeks before any release, stores start to advertise that they’ll be selling a sneaker — the market started to wise up.
I called Ince later to see how things had gone for him. He told me he’d sold the shoe to a South Carolina buyer who had seen his post on Instagram. His sale price was $500 — almost double the retail price, but at the bottom of the range he had expected.
“My priority was to get a buyer. I wasn’t trying to be greedy or anything,” he said.
Given how much time he had spent in line, however, I wondered how he felt about earning the equivalent of minimum wage.
No problem, he said. He’s hoping to start his own consignment shop and sees the long waits as practice toward delivering on his promises.
“For me, I think it’s worth it.”
CORRECTION (October 17, 10:30 a.m.): A label on an earlier version of a chart in this article misstated the percentage of sneakerheads who sell their sneakers for strategic purposes. It is 25 percent, not 33 percent.
A compiler is a computer program that takes a program as input, does some sort of transformation on it, and returns another program. Most of the time, we think of a compiler as something that translates code from a higher-level language (such as, for instance, Rust, Racket, or JavaScript) to a lower-level language (such as, for instance, LLVM IR or x86-64 assembly), but this doesn’t necessarily have to be the case.
Around 2013 or so, it started to become fashionable to use the word “transpiler” for certain kinds of compilers. When people say “transpiler”, what kind of compiler do they mean?
According to Wikipedia, a transpiler is a compiler that “translates between programming languages that operate at approximately the same level of abstraction”. JavaScript is a popular target language for these kinds of compilers, because every mainstream web browser can now execute JavaScript efficiently (and is getting better at it all the time, thanks to significant investment from browser vendors and fierce competition among them). Lots of people want their code to run in every mainstream web browser, and not all of those people want to write JavaScript. Hence we have compilers that transform code from various other high-level input languages to JavaScript.1
A source-to-source compiler, transcompiler or transpiler is a type of compiler that takes the source code of a program written in one programming language as its input and produces the equivalent source code in another programming language. A source-to-source compiler translates between programming languages that operate at approximately the same level of abstraction, while a traditional compiler translates from a higher level programming language to a lower level programming language.
Interestingly, this definition says that “transpiler” and “source-to-source compiler” are synonyms: it says that they both mean a compiler with input and target languages that are approximately the same level of abstraction. But a “source-to-source compiler” sounds like it ought to be something more specific than that. It sounds like a compiler for which the input and target languages not only operate at similar levels of abstraction, but also both operate at high levels of abstraction (because a language that we’d call a “source” language is presumably high-level). This definition coincides with “translates between programming languages that operate at approximately the same level of abstraction” only if we assume that all compilers have a high-level input language.
There are other ways of defining “transpiler” that overlap with the Wikipedia definition, but don’t coincide with it. Some people seem to use “transpiler” to mean “compiler with a high-level target language”, without saying anything in particular about the level of abstraction of the input language. For instance, Emscripten— which compiles LLVM bitcode, a relatively low-level language, to JavaScript, a relatively high-level language — is often called a transpiler. In fact, Wikipedia even cites Emscripten as an example of a transpiler, even though it contradicts the “approximately the same level of abstraction” part of the Wikipedia definition.
In other contexts, “transpiler” might imply “compiler with relatively human-readable output”, which is yet another overlapping-but-different definition. This definition would rule out Emscripten, because although Emscripten’s output is JavaScript, readability of the output isn’t a priority. TypeScript and CoffeeScript, on the other hand, are high-level, JavaScript-like languages that get compiled to JavaScript by a compiler that tries to more or less preserve readability, and Wikipedia calls them transpiled languages, too.
So, we’ve got several overlapping-but-different definitions for “transpiler”:
compiler that translates between languages that operate at similar levels of abstraction (the Wikipedia definition)
compiler with high-level languages as its input and target languages (which is what I think “source-to-source compiler” sounds like)
compiler that targets a high-level language (examples include Emscripten, TypeScript, and CoffeeScript)
compiler that produces readable output in a high-level target language (examples include TypeScript and CoffeeScript, but not Emscripten)
In a recent conversation with a friend, I learned about yet another connotation that “transpiler” might have. Compiling from a high-level input language all the way to assembly removes certain opportunities for language interoperability; if you want to link together components that are written in different input languages, then it can be easier to do that if the input languages’ compilers both target the same intermediate language. (Microsoft’s Common Intermediate Language is an example of an intermediate language that compilers for various input languages target, and that was designed with language interoperability in mind.) It’s useful to have a word for compilers that make a point of making interoperability easy in this way, and for my friend, the word “transpiler” serves that purpose. So we have yet another overlapping-but-not-quite-coinciding definition:
compiler that targets a relatively high-level language for the purpose of facilitating interoperability between different input languages
I don’t think many people use “transpiler” to mean this, but at least one language implementer that I know does.
By now, I hope it’s clear that “transpiler” means different things to different people, and that the definitions are fuzzy and have weird edge cases. Furthermore, even if two people agree that “transpiler” means, say, “compiler that targets a high-level language” or “compiler with input and target languages at similar levels of abstraction”, there’s still room for misunderstanding: “high-level” and “low-level” are relative, and whether or not any given two languages operate at “similar levels of abstraction” isn’t necessarily a cut-and-dried matter. There isn’t a total ordering on languages by level of abstraction. Language constructs that operate at different levels of abstraction can coexist in the same language, making it simultaneously “higher-level” and “lower-level” than another language that has only language constructs that are somewhere in between.
When I wrote the first, unpublished draft of this post a few years ago, it was called “Stop saying ‘transpiler’”. I decided not to call it that, because I’m trying to lay off the prescriptivism (and I have a policy against writing blog posts with “stop doing X” titles now, anyway); I understand that people are using “transpiler” because, for them, it describes something that it’s convenient to have a word for. I do think, though, that before saying “transpiler”, it’s useful to think about what exactly one means by it, and whether the people one is communicating with are going to agree with that meaning. For me, any convenience that might be gained by saying “transpiler” is rarely worth the potential for confusion.