UPDATE 15/05– DO NOT BUY FROM PEOPLE PRODUCTING MODIFIED CARTS, the readme file specifically bans making money from this patch. Since this work is given away entirely for free, a modified cart is worth the same as an unmodified one. If you buy from someone making carts to sell, then you’re supporting the idea that profiteers should be able to make money on other peoples work, that exploiting community goodwill is OK.
Opinions have long been divided on this, but while Metal Slug X is a revised, recoloured, extended and rearranged version of Metal Slug 2, I’m one of those people who just felt that Metal Slug 2 held together better as a game. I prefer the times of day (changed in X) and I prefer the boss ordering and I prefer the level of detail. For example in the below picture, the sand in the background of stage 1 is actually animated in MS2 but static in MSX. Metal Slug 2 is on the left.
However Metal Slug 2 has one big problem – slowdown, and lots of it. Half of the game has to be played at a crippling pace unless you overclock your MVS system, and even then it’s still not as quick as other games in the series. I don’t know why SNK never addressed this, but it was fixed in X, and it was also fixed in some of the newer port releases SNK have made over the years.
That doesn’t help arcade collectors though who want to play the game on original hardware, and overclocking the MVS isn’t really my preferred solution to the problem. Over the years on and off I’ve looked into it and never really gone much further, but the most solid information I could find was that there was a problem in the code causing game logic to get updated twice for every graphical frame.
I don’t know any 68k assembly language, but I know a man who does and I was finally able to get some of his time to look at the problem. Unfortunately, the logic happening twice – isn’t the case. However one thing he did spot was the 30 fps lock code was causing extra frames to be dropped. If the game was missing one frame it would miss two. If it would miss three it would instead miss four. So, code fix developed it’s time to try it out on a real Metal Slug 2 cartridge.
This is my world weary Metal Slug 2 cart – like so many others a victim of operators removing serial numbers so the cart couldn’t be traced – selling them across borders was against the copyright/usage terms. Still, it was very cheap.
I’ll have to admit I took that photo after I’d finished, you can tell – you’ll see why later. Remove the 4 screws and then take out the top layer board, which has the code ROM on and looks like this:
The code we need to fix is in the 241-P1 ROM. An equivalent EPROM part number would be M27C800, so you’ll need a blank 42 pin 8mbit EPROM of ideally 100ns – they’re not very expensive on ebay. When you program this with the updated code, it will also change the NGH (unique game ID every game has) to 941, and change the game name on the SOFT DIP settings page to “METALSLUG2 TURBO”. This was done so people can differentiate unmodified and original carts without having an obnoxious splash screen or similar.
Desolder the original 241-p1 ROM and put it somewhere safe. The fixed code is distributed as a binary patch file with patch utilities for Windows and Linux, please download and follow the instructions in the README.txt file.
When you’ve burned the 941-p1.p1 image to the 27C800 and verified it, you can solder it into the P1 position. Note that there is not enough space in the cart to fit this with a socket, so make sure you’ve verified the chip before soldering it in. If you really do want to use a socket as I needed to in case this didn’t work, you’ll have to dremel some of the inner cart vent plastic away which is hard to do cleanly. Your CPU board should look like this:
Then just bolt it back together – you can see in this photo that I’d dremelled the cart vents to make it fit with a socket. It’s nicer not to, I wouldn’t expect this ROM to be changed in future so you should be fine to just solder it in.
With this fixed the game still slows down as often as it used to and in the same places, but the actual delay between frames is reduced by 1 across all speeds. To improve things more would mean actually rewriting chunks of code as apparently there are many slow functions in there and the reason MSX is so much faster is because they’d actually re-written the engine rather than just fixing MS2, which was based on the original Metal Slug code. Here’s a video showing the difference, nearly 20 seconds just across the first level despite some mistakes on the ‘turbo’ run.
If anyone from SNK wishes to contact me to request removal, please contact me on the shmups.system11.org or neo-geo.com forums, user ‘system11’. This has purely been provided to improve one of your classics for owners of classic arcade hardware, and no harm is intended.
The world is freakingoutaboutblockchain and I have been sucked in. From day 1 of my exploration into the space, it has been enormously difficult to navigate the intersection of technology, politics, finance and the ensuing hype to get a direct answer to my fundamental question of “when should I be considering blockchain as a solution?” Several months later I finally have been able to get some clarity on how to evaluate it purely as a technology — dispassionately detached from its goal of being a vehicle for global change and disruption
Blockchain as a Database
Step one is to figure out a framework for analyzing blockchain. Fortunately, it falls into a very mature and well studied category: backend databases. Very simply, a blockchain is a database — it allows you to persistently store data and retrieve it later. Now the question is what kind of database is it?
It’s important to note that there’s no such thing as an innately useful or useless database. Every database chooses a different set of trade-offs giving it certain properties that may be useful for certain problems. If you’ve ever used a database that sucked, it’s likely that it was the wrong choice for your application.
Well what kind of database is it?
As a distributed system, databases are constrained by the CAP Theorem and have to choose between certain capabilities. Blockchains fall into the “eventually consistent” subcategory of databases that choose to sacrifice total consistency of their data. What this means is all the nodes in the database aren’t guaranteed to always have the exact same and up to date information.
Typically, this guarantee is sacrificed to support higher throughput for heavy workloads and high availability. Eventually consistent databases like Cassandra, CouchDB, and Riak are usually found tackling problems of scale. By contrast, blockchain does not have the capability to support anywhere near the throughput of these traditional databases.
The other challenge in any eventually consistent database is that the following scenario can happen:
User-A connects to a node in the USA. They write an amazing blog post on blockchain.
There is a network disruption between USA and Europe
User-A sends a link to their blog post to their German friend, Üser-B who connects to a node in Europe and cannot find the post. The update has not yet made it from the USA.
The problem that all eventually consistent systems have to deal with regardless of whether the disruption was for a second or for several hours is how to merge the two out of sync databases once they’re able to communicate again.
In this scenario, conflict resolution is easy. The post from the USA can just be inserted in Europe since it never existed there. However, what if the two users were collaborating on the same blog post during the network disruption? Two versions of the blog post exist until the disruption ends and they have to be merged into one.
Databases like Cassandra for instance simply decide the last modified version of the entity is chosen as the current state. While this is not ideal since one user can lose their changes, it is an acceptable loss since in most domains it is unlikely that two users in different locations are modifying the same entity at the same time. The two databases in Europe and USA can merge their data entity by entity, overwriting data only when it happens to have been modified in both places.
Blockchain, however, handles conflict resolution in quite a different way. If there is a net-split between Europe and the USA and two versions of the database emerge, it simply decides on re-connection to keep the entirety of the version that has received more traffic during the disruption (aka the longer chain). This means if the USA version wins, all of the modifications in the European version, even if there aren’t conflicts, are discarded. To reiterate, this means even if most of the interactions in Europe were just with other users in Europe and not in conflict with the USA version, all of those writes are thrown away regardless.
At this point it seems like blockchain is an inferior database when compared to others ones in the category. However, as I mentioned before there is no such thing as a useless database. For everything Blockchain does worse than other databases, it must be getting something in return for those trade-offs.
Byzantine Fault Tolerance
Remember these guys?
Typically, when you setup a database cluster you are in control of every node that belongs to it. Byzantine Fault Tolerance allows for systems to exist where multiple parties (basically anyone) can contribute nodes to the cluster. The complexity that arises with this is that there may be bad actors who try to corrupt the data with false information. BFT systems are able to tolerate bad actors to some degree. If you would like a deep dive on BFT the Wikipedia entry is actually quite approachable.
This is the core feature that blockchain is offering. It is the only thing that it does better than every other databases and should be the main reason why you choose blockchain for your application. If BFT does not create a huge advantage for your use-case, it is unlikely blockchain makes sense to consider over a traditional database. Decentralization is not free and must be a fundamental requirement of your product to justify its use. If it’s simply a cool twist on an existing concept, the non-decentralized version is always going to be better as it does not have to deal with the same constraints.
Now that we’ve narrowed down the advantage of blockchain to this singular trait, we can zoom out from an engineering perspective back into the real world. Decentralization is incredibly interesting to me from a philosophical perspective. A system that’s run by disconnected parties all contributing resources toward a common goal is innately appealing. No one wants to be at the mercy of large centralized entities.
But that’s just a personal affinity. The question of how BFT objectively provides a measurable technological advantage in the industries that blockchain is touted to revolutionize remains to be answered. The old, entrenched systems controlled by banks and governments are not going to risk the arduous path towards migrating to blockchain and all its trade-offs simply for philosophical reasons. The formula of “<old idea> now powered by blockchain” is doing wonders for cryptocurrency’s price in the short term but has not yet generated the value it needs to in order to be sustainable in the long term.
We are a group of software engineers that help companies execute on their technology goals. If you’re interested in building something with us please shoot an email to hello@ironbay.digital
The Python community has been discussing removing the Global Interpreter Lock for
a long time.
There have been various attempts at removing it:
Jython or IronPython successfully removed it with the help of the underlying
platform, and some have yet to bear fruit, like gilectomy. Since our February sprint in Leysin,
we have experimented with the topic of GIL removal in the PyPy project.
We believe that the work done in IronPython or Jython can be reproduced with
only a bit more effort in PyPy. Compared to that, removing the GIL in CPython is a much
harder topic, since it also requires tackling the problem of multi-threaded reference
counting. See the section below for further details.
As we announced at EuroPython, what we have so far is a GIL-less PyPy
which can run very simple multi-threaded, nicely parallelized, programs.
At the moment, more complicated programs probably segfault. The
remaining 90% (and another 90%) of work is with putting locks in strategic
places so PyPy does not segfault during concurrent accesses to
data structures.
Since such work would complicate the PyPy code base and our day-to-day work,
we would like to judge the interest of the community and the commercial
partners to make it happen (we are not looking for individual
donations at this point). We estimate a total cost of $50k,
out of which we already have backing for about 1/3 (with a possible 1/3
extra from the STM money, see below). This would give us a good
shot at delivering a good proof-of-concept working PyPy with no GIL. If we can get a $100k
contract, we will deliver a fully working PyPy interpreter with no GIL as a release,
possibly separate from the default PyPy release.
People asked several questions, so I'll try to answer the technical parts
here.
What would the plan entail?
We've already done the work on the Garbage Collector to allow doing multi-
threaded programs in RPython. "All" that is left is adding locks on mutable
data structures everywhere in the PyPy codebase. Since it would significantly complicate
our workflow, we require real interest in that topic, backed up by
commercial contracts in order to justify the added maintenance burden.
Why did the STM effort not work out?
STM was a research project that proved that the idea is possible. However,
the amount of user effort that is required to make programs run in a
parallelizable way is significant, and we never managed to develop tools
that would help in doing so. At the moment we're not sure if more work
spent on tooling would improve the situation or if the whole idea is really doomed.
The approach also ended up adding significant overhead on single threaded programs,
so in the end it is very easy to make your programs slower. (We have some money
left in the donation pot for STM which we are not using; according to the rules, we
could declare the STM attempt failed and channel that money towards the present
GIL removal proposal.)
Wouldn't subinterpreters be a better idea?
Python is a very mutable language - there are tons of mutable state and
basic objects (classes, functions,...) that are compile-time in other
language but runtime and fully mutable in Python. In the end, sharing
things between subinterpreters would be restricted to basic immutable
data structures, which defeats the point. Subinterpreters suffers from the same problems as
multiprocessing with no additional benefits.
We believe that reducing mutability to implement subinterpreters is not viable without seriously impacting the
semantics of the language (a conclusion which applies to many other
approaches too).
Why is it easier to do in PyPy than CPython?
Removing the GIL in CPython has two problems:
how do we guard access to mutable data structures with locks and
what to do with reference counting that needs to be guarded.
PyPy only has the former problem; the latter doesn't exist,
due to a different garbage collector approach. Of course the first problem
is a mess too, but at least we are already half-way there. Compared to Jython
or IronPython, PyPy lacks some data structures that are provided by JVM or .NET,
which we would need to implement, hence the problem is a little harder
than on an existing multithreaded platform. However, there is good research
and we know how that problem can be solved.
A consortium of German universities, research institutes and public libraries has rejected the latest offer from Dutch publishing giant Elsevier for a new country-wide licensing agreement for its research portfolio. Germany’s chief negotiator says the offer does not meet the requirements of German researchers.
The rejection in early July, comes after nearly a year of negotiations during which time rock-hard positions on both sides have scarcely budged, leaving a huge gap yet to be bridged. The German side, represented by a consortium founded in 2014 called Project DEAL, includes the German Research Foundation (DFG), the Fraunhofer–Gesellschaft, the German National Academy of Sciences Leopoldina, the Helmholtz and the Leibniz associations, and the Max Planck Society. Backed by these research giants plus dozens of universities, Project DEAL is demanding a nationwide contract from Elsevier that includes fair pricing, open access in Germany to all papers authored by researchers at German institutions, and permanent full-text access to all electronic journals published by Elsevier. Project DEAL will also lead negotiations for nationwide licensing agreements with Springer Nature and Wiley.
Horst Hippler, a physical chemist and chief negotiator for Project DEAL, tells Chemistry World that after a year of negotiation with Elsevier, the consortium had expected to ‘finally receive’ a proposal that could serve as a basis for further discussion in early July. But he said the offer ‘does not meet any of the requirements and expectations of the German scientific community’.
Hippler, who is also president of the German Rectors’ Conference (HRK), Germany’s main university association, says Project DEAL submitted a ‘fair and transparent’ proposal to Elsevier in July. ‘We asked Elsevier to finally enter into serious discussions on the basis of our principles and our proposal but we are still waiting for an answer for that. Elsevier is constantly trying to talk institutions into individual negotiations.’
Chemistry World contacted Elsevier for comment but did not receive a response.
Pressure building
As the negotiations between Germany and Elsevier now enter the second year, both sides will be feeling mounting pressure to reach agreement. Late last year, more than 70 universities, institutes and public libraries cancelled contracts with Elsevier to ‘improve their negotiating power’. Earlier this year, the institutions went several weeks without access to Elsevier’s portfolio before the publisher restored access in February ‘while good-faith discussions about a nationwide contract carry on’.
However, Project DEAL’s negotiating stance remained firm and Elsevier’s public statements indicated a growing frustration with the lack of progress. In late June, Project DEAL received a huge boost when three highly influential Berlin universities and Charite university hospital announced that they would cancel Elsevier contracts at the end of 2017. A few days later nine universities, including heavyweights Freiburg, Heidelberg and the Karlsruhe Institute of Technology (KIT), made similar pledges.
Tim Gowers, a mathematician at the University of Cambridge and an open access supporter who led a boycott against Elsevier in 2012, tells Chemistry World that he is ‘following the situation in Germany with great interest’. ‘I am very impressed that the German negotiators have had the courage and vision to stand up to the bullying tactics of Elsevier, and that they have had the necessary support from researchers who use the journals.’
Gowers is critical of the agreements that Dutch and UK research institutions have reached with Elsevier. He argues that UK negotiators ‘failed to obtain, significant changes’ and have ‘a lot to learn from the German example’. ‘We should be aiming for radically cheaper deals, rather than slightly improved versions of the current deals.’
Gowers hopes that German negotiators and Elsevier will both ‘refuse to budge’ and that contract talks break with no agreement. Under such a scenario he believes it will become clear that Germany’s researchers have not suffered any serious inconvenience. ‘This, I believe, is what would truly embolden other countries and lead to a collapse of the current system.’
Global reach
Hippler says that Project DEAL is in ‘close contact with many nations’ in Europe and the US too. ‘We are receiving a lot of positive feedback and recognition, especially regarding our negotiating goals for transformation to open access and for a fair and sustainable price model,’ he says. Project DEAL is open to compromise Hippler says, but compromise must be fair for both parties. He says that Elsevier thus far has not even addressed Project DEAL’s content requirements for a Germany-wide licence that reflects open access and the rapidly changing scientific landscape.
‘In the course of digitisation, science communication is undergoing a fundamental transformation process,’ he says. ‘Comprehensive, free and – above all – sustainable access to scientific publications is of immense importance to our researchers. We therefore will actively pursue the transformation to open access, which is an important building block in the concept of open science. To this end, we want to create a fair and sustainable basis through appropriate licensing agreements with Elsevier and other scientific publishers.’
‘There can be no mistaking how serious we are about this,’ he adds.
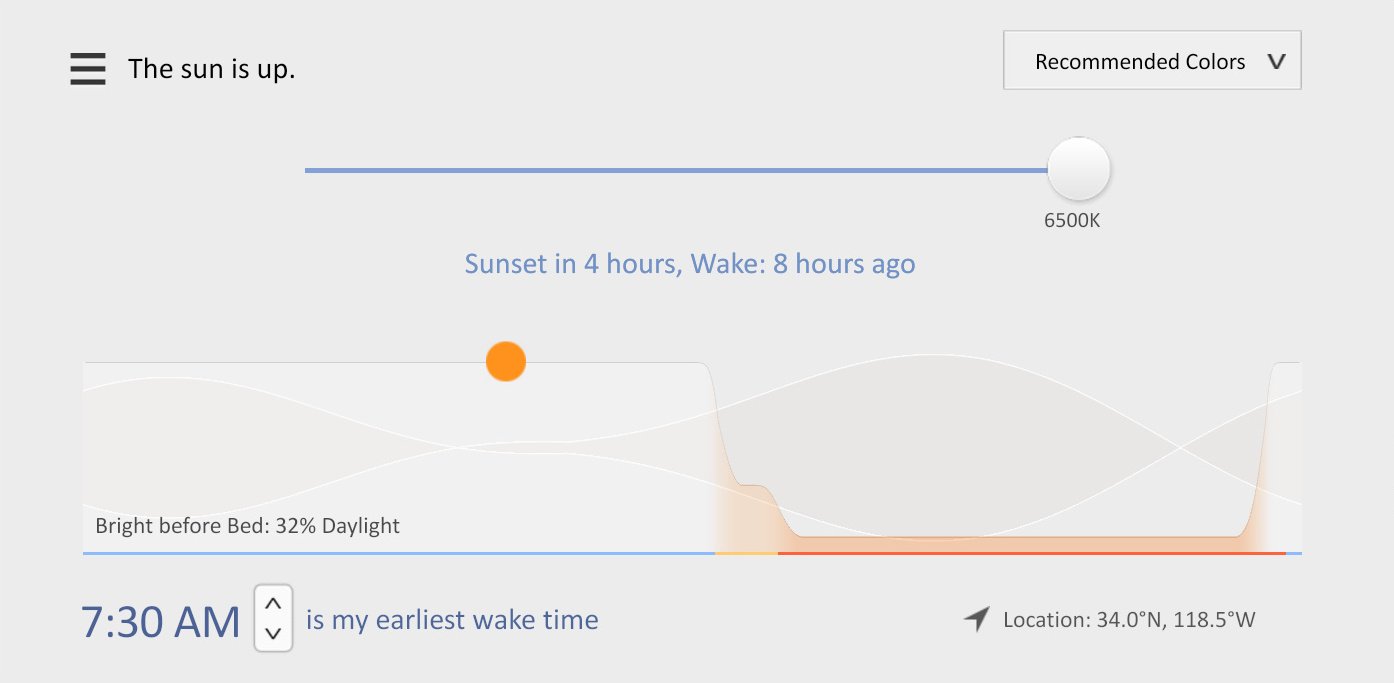
It’s well known that NGINX uses an asynchronous, event‑driven approach to handling connections. This means that instead of creating another dedicated process or thread for each request (like servers with a traditional architecture), it handles multiple connections and requests in one worker process. To achieve this, NGINX works with sockets in a non‑blocking mode and uses efficient methods such as epoll and kqueue.
Because the number of full‑weight processes is small (usually only one per CPU core) and constant, much less memory is consumed and CPU cycles aren’t wasted on task switching. The advantages of such an approach are well‑known through the example of NGINX itself. It successfully handles millions of simultaneous requests and scales very well.
Each process consumes additional memory, and each switch between them consumes CPU cycles and trashes L‑caches
But the asynchronous, event‑driven approach still has a problem. Or, as I like to think of it, an “enemy”. And the name of the enemy is: blocking. Unfortunately, many third‑party modules use blocking calls, and users (and sometimes even the developers of the modules) aren’t aware of the drawbacks. Blocking operations can ruin NGINX performance and must be avoided at all costs.
Even in the current official NGINX code it’s not possible to avoid blocking operations in every case, and to solve this problem the new “thread pools” mechanism was implemented in NGINX version 1.7.11 and NGINX Plus Release 7. What it is and how it supposed to be used, we will cover later. Now let’s meet face to face with our enemy.
For detailed discussions of other new features in NGINX Plus R7, see these related blog posts:
The Problem
First, for better understanding of the problem a few words about how NGINX works.
In general, NGINX is an event handler, a controller that receives information from the kernel about all events occurring on connections and then gives commands to the operating system about what to do. In fact, NGINX does all the hard work by orchestrating the operating system, while the operating system does the routine work of reading and sending bytes. So it’s very important for NGINX to respond fast and in a timely manner.
The worker process listens for and processes events from the kernel
The events can be timeouts, notifications about sockets ready to read or to write, or notifications about an error that occurred. NGINX receives a bunch of events and then processes them one by one, doing the necessary actions. Thus all the processing is done in a simple loop over a queue in one thread. NGINX dequeues an event from the queue and then reacts to it by, for example, writing or reading a socket. In most cases, this is extremely quick (perhaps just requiring a few CPU cycles to copy some data in memory) and NGINX proceeds through all of the events in the queue in an instant.
All processing is done in a simple loop by one thread
But what will happen if some long and heavy operation has occurred? The whole cycle of event processing will get stuck waiting for this operation to finish.
So, by saying “a blocking operation” we mean any operation that stops the cycle of handling events for a significant amount of time. Operations can be blocking for various reasons. For example, NGINX might be busy with lengthy, CPU‑intensive processing, or it might have to wait to access a resource (such as a hard drive, or a mutex or library function call that gets responses from a database in a synchronous manner, etc.). The key point is that while processing such operations, the worker process cannot do anything else and cannot handle other events, even if there are more system resources available and some events in the queue could utilize those resources.
Imagine a salesperson in a store with a long queue in front of him. The first guy in the queue asks for something that is not in the store but is in the warehouse. The salesperson goes to the warehouse to deliver the goods. Now the entire queue must wait a couple of hours for this delivery and everyone in the queue is unhappy. Can you imagine the reaction of the people? The waiting time of every person in the queue is increased by these hours, but the items they intend to buy might be right there in the shop.
Everyone in the queue has to wait for the first person’s order
Nearly the same situation happens with NGINX when it asks to read a file that isn’t cached in memory, but needs to be read from disk. Hard drives are slow (especially the spinning ones), and while the other requests waiting in the queue might not need access to the drive, they are forced to wait anyway. As a result, latencies increase and system resources are not fully utilized.
Just one blocking operation can delay all following operations for a significant time
Some operating systems provide an asynchronous interface for reading and sending files and NGINX can use this interface (see the aio directive). A good example here is FreeBSD. Unfortunately, we can’t say the same about Linux. Although Linux provides a kind of asynchronous interface for reading files, it has a couple of significant drawbacks. One of them is alignment requirements for file access and buffers, but NGINX handles that well. But the second problem is worse. The asynchronous interface requires the O_DIRECT flag to be set on the file descriptor, which means that any access to the file will bypass the cache in memory and increase load on the hard disks. That definitely doesn’t make it optimal for many cases.
To solve this problem in particular, thread pools were introduced in NGINX 1.7.11 and NGINX Plus Release 7.
Now let’s dive into what thread pools are about and how they work.
Thread Pools
Let’s return to our poor sales assistant who delivers goods from a faraway warehouse. But he has become smarter (or maybe he became smarter after being beaten by the crowd of angry clients?) and hired a delivery service. Now when somebody asks for something from the faraway warehouse, instead of going to the warehouse himself, he just drops an order to a delivery service and they will handle the order while our sales assistant will continue serving other customers. Thus only those clients whose goods aren’t in the store are waiting for delivery, while others can be served immediately.
Passing an order to the delivery service unblocks the queue
In terms of NGINX, the thread pool is performing the functions of the delivery service. It consists of a task queue and a number of threads that handle the queue. When a worker process needs to do a potentially long operation, instead of processing the operation by itself it puts a task in the pool’s queue, from which it can be taken and processed by any free thread.
The worker process offloads blocking operations to the thread pool
It seems then we have another queue. Right. But in this case the queue is limited by a specific resource. We can’t read from a drive faster than the drive is capable of producing data. Now at least the drive doesn’t delay processing of other events and only the requests that need to access files are waiting.
The “reading from disk” operation is often used as the most common example of a blocking operation, but actually the thread pools implementation in NGINX can be used for any tasks that aren’t appropriate to process in the main working cycle.
At the moment, offloading to thread pools is implemented only for three essential operations: the read() syscall on most operating systems, sendfile() on Linux, and aio_write() on Linux which is used when writing some temporary files such as those for the cache. We will continue to test and benchmark the implementation, and we may offload other operations to the thread pools in future releases if there’s a clear benefit.
It’s time to move from theory to practice. To demonstrate the effect of using thread pools we are going to perform a synthetic benchmark that simulates the worst mix of blocking and nonblocking operations.
It requires a data set that is guaranteed not to fit in memory. On a machine with 48 GB of RAM, we have generated 256 GB of random data in 4‑MB files, and then have configured NGINX 1.9.0 to serve it.
The configuration is pretty simple:
worker_processes 16;
events { accept_mutex off; }
http { include mime.types; default_type application/octet-stream;
As you can see, to achieve better performance some tuning was done: logging and accept_mutex were disabled, sendfile was enabled, and sendfile_max_chunk was set. The last directive can reduce the maximum time spent in blocking sendfile() calls, since NGINX won’t try to send the whole file at once, but will do it in 512‑KB chunks.
The machine has two Intel Xeon E5645 (12 cores, 24 HT‑threads in total) processors and a 10‑Gbps network interface. The disk subsystem is represented by four Western Digital WD1003FBYX hard drives arranged in a RAID10 array. All of this hardware is powered by Ubuntu Server 14.04.1 LTS.
Configuration of load generators and NGINX for the benchmark
The clients are represented by two machines with the same specifications. On one of these machines, wrk creates load using a Lua script. The script requests files from our server in a random order using 200 parallel connections, and each request is likely to result in a cache miss and a blocking read from disk. Let’s call this load the random load.
On the second client machine we will run another copy of wrk that will request the same file multiple times using 50 parallel connections. Since this file will be frequently accessed, it will remain in memory all the time. In normal circumstances, NGINX would serve these requests very quickly, but performance will fall if the worker processes are blocked by other requests. Let’s call this load the constant load.
The performance will be measured by monitoring throughput of the server machine using ifstat and by obtaining wrk results from the second client.
Now, the first run without thread pools does not give us very exciting results:
As you can see, with this configuration the server is able to produce about 1 Gbps of traffic in total. In the output from top, we can see that all of worker processes spend most of the time in blocking I/O (they are in a D state):
In this case the throughput is limited by the disk subsystem, while the CPU is idle most of the time. The results from wrk are also very low:
Running 1m test @ http://192.0.2.1:8000/1/1/1 12 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 7.42s 5.31s 24.41s 74.73% Req/Sec 0.15 0.36 1.00 84.62% 488 requests in 1.01m, 2.01GB read Requests/sec: 8.08 Transfer/sec: 34.07MB
And remember, this is for the file that should be served from memory! The excessively large latencies are because all the worker processes are busy with reading files from the drives to serve the random load created by 200 connections from the first client, and cannot handle our requests in good time.
It’s time to put our thread pools in play. For this we just add the aiothreads directive to the location block:
Now our server produces 9.5 Gbps, compared to ~1 Gbps without thread pools!
It probably could produce even more, but it has already reached the practical maximum network capacity, so in this test NGINX is limited by the network interface. The worker processes spend most of the time just sleeping and waiting for new events (they are in S state in top):
Running 1m test @ http://192.0.2.1:8000/1/1/1 12 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 226.32ms 392.76ms 1.72s 93.48% Req/Sec 20.02 10.84 59.00 65.91% 15045 requests in 1.00m, 58.86GB read Requests/sec: 250.57 Transfer/sec: 0.98GB
The average time to serve a 4‑MB file has been reduced from 7.42 seconds to 226.32 milliseconds (33 times less), and the number of requests per second has increased by 31 times (250 vs 8)!
The explanation is that our requests no longer wait in the events queue for processing while worker processes are blocked on reading, but are handled by free threads. As long as the disk subsystem is doing its job as best it can serving our random load from the first client machine, NGINX uses the rest of the CPU resources and network capacity to serve requests of the second client from memory.
Still Not a Silver Bullet
After all our fears about blocking operations and some exciting results, probably most of you already are going to configure thread pools on your servers. Don’t hurry.
The truth is that fortunately most read and send file operations do not deal with slow hard drives. If you have enough RAM to store the data set, then an operating system will be clever enough to cache frequently used files in a so‑called “page cache”.
The page cache works pretty well and allows NGINX to demonstrate great performance in almost all common use cases. Reading from the page cache is quite quick and no one can call such operations “blocking.” On the other hand, offloading to a thread pool has some overhead.
So if you have a reasonable amount of RAM and your working data set isn’t very big, then NGINX already works in the most optimal way without using thread pools.
Offloading read operations to the thread pool is a technique applicable to very specific tasks. It is most useful where the volume of frequently requested content doesn’t fit into the operating system’s VM cache. This might be the case with, for instance, a heavily loaded NGINX‑based streaming media server. This is the situation we’ve simulated in our benchmark.
It would be great if we could improve the offloading of read operations into thread pools. All we need is an efficient way to know if the needed file data is in memory or not, and only in the latter case should the reading operation be offloaded to a separate thread.
Turning back to our sales analogy, currently the salesman cannot know if the requested item is in the store and must either always pass all orders to the delivery service or always handle them himself.
The culprit is that operating systems are missing this feature. The first attempts to add it to Linux as the fincore() syscall were in 2010 but that didn’t happen. Later there were a number of attempts to implement it as a new preadv2() syscall with the RWF_NONBLOCK flag (see Nonblocking buffered file read operations and Asynchronous buffered read operations at LWN.net for details). The fate of all these patches is still unclear. The sad point here is that it seems the main reason why these patches haven’t been accepted yet to the kernel is continuous bikeshedding.
On the other hand, users of FreeBSD don’t need to worry at all. FreeBSD already has a sufficiently good asynchronous interface for reading files, which you should use instead of thread pools.
Configuring Thread Pools
So if you are sure that you can get some benefit out of using thread pools in your use case, then it’s time to dive deep into configuration.
The configuration is quite easy and flexible. The first thing you should have is NGINX version 1.7.11 or later, compiled with the --with-threads argument to the configure command. NGINX Plus users need Release 7 or later. In the simplest case, the configuration looks very plain. All you need is to include the aiothreads directive in the appropriate context:
# in the 'http', 'server', or 'location' context aio threads;
This is the minimal possible configuration of thread pools. In fact, it’s a short version of the following configuration:
# in the 'main' context thread_pool default threads=32 max_queue=65536;
# in the 'http', 'server', or 'location' context aio threads=default;
It defines a thread pool called default with 32 working threads and a maximum length for the task queue of 65536 tasks. If the task queue is overloaded, NGINX rejects the request and logs this error:
thread pool "NAME" queue overflow: N tasks waiting
The error means it’s possible that the threads aren’t able to handle the work as quickly as it is added to the queue. You can try increasing the maximum queue size, but if that doesn’t help, then it indicates that your system is not capable of serving so many requests.
As you already noticed, with the thread_pool directive you can configure the number of threads, the maximum length of the queue, and the name of a specific thread pool. The last implies that you can configure several independent thread pools and use them in different places of your configuration file to serve different purposes:
# in the 'main' context thread_pool one threads=128 max_queue=0; thread_pool two threads=32;
http { server { location /one { aio threads=one; }
location /two { aio threads=two; }
} # ... }
If the max_queue parameter isn’t specified, the value 65536 is used by default. As shown, it’s possible to set max_queue to zero. In this case the thread pool will only be able to handle as many tasks as there are threads configured; no tasks will wait in the queue.
Now let’s imagine you have a server with three hard drives and you want this server to work as a “caching proxy” that caches all responses from your backends. The expected amount of cached data far exceeds the available RAM. It’s actually a caching node for your personal CDN. Of course in this case the most important thing is to achieve maximum performance from the drives.
One of your options is to configure a RAID array. This approach has its pros and cons. Now with NGINX you can take another one:
# We assume that each of the hard drives is mounted on one of these directories: # /mnt/disk1, /mnt/disk2, or /mnt/disk3
# in the 'main' context thread_pool pool_1 threads=16; thread_pool pool_2 threads=16; thread_pool pool_3 threads=16;
In this configuration, the thread_pool directives define a dedicated, independent thread pool for each disk, and the proxy_cache_path directives define an dedicated, independent cache on each disk.
The split_clients module is used for load balancing between the caches (and as a result between the disks), which perfectly fits this task.
The use_temp_path=off parameter to the proxy_cache_path directive instructs NGINX to save temporary files into the same directories where the corresponding cache data is located. It is needed to avoid copying response data between the hard drives when updating our caches.
All this together allows us to get maximum performance out of the current disk subsystem, because NGINX through separate thread pools interacts with the drives in parallel and independently. Each of the drives is served by 16 independent threads with a dedicated task queue for reading and sending files.
I bet your clients like this custom‑tailored approach. Be sure that your hard drives like it too.
This example is a good demonstration of how flexibly NGINX can be tuned specifically for your hardware. It’s like you are giving instructions to NGINX about the best way to interact with the machine and your data set. And by fine‑tuning NGINX in user space, you can ensure that your software, operating system, and hardware work together in the most optimal mode to utilize all the system resources as effectively as possible.
Conclusion
Summing up, thread pools is a great feature that pushes NGINX to new levels of performance by eliminating one of its well‑known and long‑time enemies – blocking – especially when we are speaking about really large volumes of content.
And there is even more to come. As previously mentioned, this brand‑new interface potentially allows offloading of any long and blocking operation without any loss of performance. NGINX opens up new horizons in terms of having a mass of new modules and functionality. Lots of popular libraries still do not provide an asynchronous nonblocking interface, which previously made them incompatible with NGINX. We may spend a lot of time and resources on developing our own nonblocking prototype of some library, but will it always be worth the effort? Now, with thread pools on board, it is possible to use such libraries relatively easily, making such modules without an impact on performance.
Stay tuned.
Try out thread pools in NGINX Plus for yourself – start your free 30-day trial today or contact us for a live demo.
It’s Never too late to Learn Guitar. The Blogging Musician @ adamharkus.com. Photo by Cristian Newman on Unsplash
While there are many musicians that start learning the guitar at an early age, there are also many excellent guitar players who start out in their 30s, 40s and even 50s. Some even start later, and manage to do an amazing job anyway.
It’s not always right to start playing as a child, and learning guitar later has its benefits as well. Playing guitar isn’t about age or talent; it’s about passion, creativity and love for music. As an adult, you probably have the right motivation and more emotional baggage and life experience; all of this will impact your learning, playing and perhaps songwriting.
Learn the Basics
Learning the basic elements of guitar as soon as possible provides a good foundation for efficiently learning the instrument. Explore whether you want to play acoustic guitar or electric guitar and learn how they differ from one another. Learn how to change your guitar strings and how to tune them. Learn about general guitar maintenance and care, such as protecting your guitar from humidity. Finally, research the gear you need, such as amplifiers, picks and pedals.
Be sure to pick up the basic things you need, such as a tuner, picks and a capo, which allows you to play songs in any key easily by moving it up and down the fretboard.
Set Realistic Expectations
It’s ok to feel stiff and clumsy at first, but it doesn’t take long to acquire the motor skills you need to play. Untrained fingers take a while to get used to chord positions, so it’s perfectly normal for your playing to be slow at first.
Aim to practice daily and your speed will soon pick up. Expect very sore fingers at the beginning, due to the unusual pressure and movements you’re subjecting them to. This will eventually subside and your fingers will develop calluses to protect them as you learn guitar. Don’t be afraid to take a day off if the pain is too much to bear. Playing through the pain may sound like a rocker’s lifestyle but it’s definitely not recommended.
Practice, Practice Practice
The best guitarists practice for hours every day; talent can impact a guitarist’s ability, but it’s always practice that makes the difference. Good guitar playing doesn’t just happen; there’s a lot of work behind it. Aim to practice at least for 10 to 15 minutes every single day to build up your calluses and to help you feel more comfortable with your instrument. Practicing every day for a short time is much more effective than practising once a week for hours, as the learning process is not as effective.
Find a Good Teacher
The best way to learn guitar is through one-on-one lessons. Private lessons will give you extra motivation and also help you correct mistakes in technique and posture. Probably one of the best ways to find a teacher is by word of mouth, but you should also consider investigating music conservatories, as students who are getting close to their final degree often start teaching and are usually more inexpensive than experienced teachers.
Go for a teacher that suits your style. For example, if you want to learn jazz guitar, you should search for a teacher specialised in jazz rather than a rocker. It’s very hard to find a teacher that can do everything, so choose carefully. If you’re a complete beginner, style doesn’t matter enormously. The important thing is to find a teacher who will give you a good foundation so you can then move on to any other style.
Interview your prospective teachers but also go with your gut instinct; it’s important to find a teacher with whom you feel comfortable and at ease, as you will be expressing your emotions and feelings through music.
How often you take lessons depends on your schedule; in general, a weekly lesson is a good choice. However, if you have a very busy career, you’re in college full-time, you’re raising a family or in general you don’t have that much time to practice, you should opt for a lesson every two weeks. Remember that guitar lessons taken every three or four weeks will not be successful; lessons need to be closer together in order to be effective and stimulate learning.
Learning an Instrument Trains Your Brain
If you’re still on the fence about whether to start playing guitar or not, consider this: learning to play an instrument has been shown to be one of the most effective forms of brain training there is. It improves your cognitive performance and induces various changes in the brain, leading to an enhancement in verbal memory, spatial reasoning and literacy skills.
Learning to play the guitar is really not as complicated as it seems, and it can ultimately lead to a lot of fun and a number of other benefits on the side.
What are you still waiting for? Pick up your guitar and start learning today.
Months before social-media company Snap Inc. publicly disclosed slowing user growth, rival Facebook Inc. already knew.
Late last year, Facebook employees used an internal database of a sampling of mobile users’ activity to observe that usage of Snap’s flagship app, Snapchat, wasn’t growing as quickly as before, people familiar with the matter said. They saw that the shift occurred after Facebook’s Instagram app launched Stories, a...
Once I was about a thousand words into describing background for GEMM, it became pretty clear that it made more sense to group the numerical math papers into one post, so here goes the (out-of-order) numerical linear algebra special issue.
You might wonder: why do we care about matrix multiplication in particular so much? Who is it who’s doing these giant matrix multiplies? If you’re a customer of a linear algebra library, it’s not unlikely that you’re never calling GEMM (GEneral Matrix Multiply, the customary name for matrix multiply kernels, thanks to FORTRAN 77’s 6-character limit for function names) at all. So what gives?
Well, if you’re calling into a linear algebra library, odds are you want to solve a linear system of equations (which usually turns into a pivoted LU decomposition plus a solve step), a linear least-squares problem (depending on the problem and your accuracy requirements, this might turn either into a Cholesky decomposition or a QR decomposition, again followed by a solve step), or you want something fancier like the SVD (yet another matrix decomposition, and you probably still eventually want to solve a linear system – but you’re using the SVD because it’s noisy or ill-conditioned and you want to munge around with the singular values a bit).
What’s with all the focus on “decompositions”? Are numerical analysts secretly the world’s most pocket-protected goth band? No: a matrix decomposition (or factorization) expresses a more general matrix as the product of several special matrices that have some desirable structure. For example, the LU decomposition turns our general matrix into a product where is a unit lower triangular matrix and is upper triangular (note: I’ll be ignoring pivoting in this post for simplicity). The LU decomposition is the industrial-strength counterpart of the Gaussian Elimination process you might have learned in school, but with some side benefits: you can decompose the matrix once and then reuse the factorization multiple times if you’re solving the same system many times with different right-hand sides (this is common in applications), and it also happens to be really nice to have the whole process in a form that can be manipulated algebraically, which we’ll be using in a moment.
But why does this decomposition help? Well, suppose we have a toy system with 3 equations and 3 unknowns, which can be written as a matrix equation where is a 3×3 matrix of coefficients and and are 3-element column vectors. If we have a LU decomposition for A, this turns into
How does this help? Well, we can’t solve the full thing yet, but we now have two fairly simply matrices. For now, let’s focus on the left matrix and treat as an unknown:
Well, this one’s easy: the first row just states that . The second row states that , and we know everything but , so we can rearrange this to . With this, the final row poses no problems either, yielding . So just falls out, given we can compute , and given both we can compute . This is called “forward substitution”. Note that we’re just computing here. However, we’re never forming the inverse of L explicitly! This is important. In numerical LA, when you see an inverse, that means you’re supposed to use the corresponding “solve” routine. Actually computing the inverse matrix is generally both inefficient and inaccurate and to be avoided whenever possible.
Anyway, now that we have , we can write out the we defined it as, and use that to solve for the we actually wanted:
This time, we’re going backwards: , , and . You will not be surprised to learn that this is called “backwards substitution”. Again, we’re just calculating , which does not actually use a matrix inversion when U is triangular.
And that’s how you solve a linear system given a LU decomposition. In BLAS-ese, solving a triangular system using forwards or backwards substitution for one right-hand side is called a TRSV (TRiangular Solve for a single Vector) – that single routine handles both types. It’s what’s called a level-2 BLAS operation. Level-1 operations are between two vectors, level-2 operations work on a matrix and a vector, and level-3 operations work on two matrices. More about “levels” in a bit.
That’s all dandy, but what does any of this have to do with GEMM? Hang on, we’re getting close. Let’s first generalize slightly: what if we want to solve multiple systems with the same A all at once? Say we want to solve two systems
at once (using superscripts to denote the separate vectors, since I’m already using subscripts to denote components of a vector or matrix). It turns out that you can just write this as a single matrix equation
where we just group the column vectors for x into one matrix X, and the column vectors for b into another matrix B. Again we can solve this for a LU-decomposed A by forward and back substitution (remember, still not actually forming inverses!)
note that we already know one direct way to do this type of equation: loop over the columns of X (and B) and solve them one by one, as above. This kind of operation is called a TRSM: TRianguler Solve for Multiple right-hand sides, or TRiangular Solve for Matrix, our first level-3 BLAS operation.
Just to get used to the idea of dealing with multiple right-hand sides at once, let’s write down the full matrix equation form for a 6 equations, 6 unknowns unit lower triangular system with two separate right-hand sides explicitly:
As before, the first row tells us that ; the second row mutliplied out gives , and so forth, which we solve the exact same way as before, only now we’re always multiplying (and summing) short row vectors instead of single scalars.
But 6×6 is still really small as far as real-world systems of equations go and this is already getting really unwieldy. It’s time to chop the matrix into pieces! (You can always do that, and then work on blocks instead of scalars. This is really important to know.) Let’s just draw some lines and then cut up the matrices involved into parts:
turns into the matrix equation
where and are unit lower triangular, and is just a general matrix. If we just multiply the matrix product out by blocks (again, the blocks behave like they’re scalars in a larger matrix, but you need to make sure the matrix product sizes match and be careful about order of multiplication because matrix multiplication doesn’t commute) we get two matrix equations:
The first of these is just a smaller TRSM with a 2×2 system, and in the second we can bring the term to the right-hand side, yielding
On the right-hand side, we have a matrix multiply of values we already know (we computed with the smaller TRSM, and everything else is given). Compute the result of that, and we have another TRSM, this time with a 4×4 system.
The matrix multiply here is one instance of a GEneral Matrix Multiply (GEMM). The corresponding BLAS function computes , where the left arrow denotes assignment, A, B, and C are matrices, and α and β are scalar values. In this particular case, we would have , , , and .
So we cut the matrix into two parts, did a bit of algebra, and saw that our TRSM with a 6×6 L can be turned into a 2×2 TRSM, a GEMM of a 4×2 by a 2×2 matrix, and finally a 4×4 TRSM. Note the function of the matrix multiply: once we’ve computed two unknowns, we need to subtract out their contributions from every single equation that follows. That’s what the GEMM does. It’s the first matrix multiply we’ve seen, but does it matter?
Well, the next thing to realize is that we can do the splitting trick again for the 4×4 TRSM, turning it into 2 even smaller TRSM, plus another GEMM. But now that we’ve establishes the idea of using blocks, let’s skip to a somewhat more serious problem size, so it becomes clear why this is interesting.
Let’s say our A is 1000×1000 (so 1000 equations in 1000 unknowns); its LU factors are the same size. This time, let’s say we’re doing 20 right-hand sides at once, and working in blocks of 30×30. We have the same equation as before:
but this time is 30×30 unit lower triangular, is 970×30, is 970×970 unit lower triangular, and are 30×20, and and are 970×20. Again we do the same 3 steps:
(TRSM, 30×30 matrix times 30×20 RHS)
(GEMM, 970×30 times 30×30)
(TRSM, 970×970 times 970×30)
Now the computational cost of both a m×n-by-n×p TRSM and a m×n-by-n×p GEMM (the middle dimensions always have to match) are both roughly 2×m×n×p floating-point operations (flops, not to be confused with all-uppercase FLOPS, which conventionally denote flops/s, because nomenclature is stupid sometimes). Which means the first step above (the medium TRSM) has on the order of 1800 flops, while the second step (the GEMM) takes 873000 flops. In short, of these two steps, step 1 is basically a rounding error in terms of execution time.
And note that we’re splitting a large × TRSM into a medium × medium TRSM, a large × small GEMM, and a final large × large (but smaller than the original) TRSM. And we can keep doing the same splitting process to that remaining large TRSM, until it becomes small as well. In short, this process allows us to turn a large TRSM into a sequence of medium-size TRSM (always the same size), alternating with large-size GEMMs (which keep getting smaller as we proceed down). And what happens if you look at the matrix as a whole is that we end up doing a small amount of actual TRSM work near the diagonal, while the rest of the matrix gets carpet-bombed with GEMMs.
In short, even though what we wanted to do was solve a pre-factored linear systems for a bunch of different right-hand sides, what the computer actually ended up spending its time computing was mostly matrix multiplies. The GEMM calls are coming from inside the solver! (Cue scary music.)
Alright. At this point you might say, “fair enough, that may indeed be what happens if you use this TRSM thing that for all we know you just made up, but I for one am not ever asking the computer to solve the same equation with 50 different right-hand sides in a batch, so how does this apply to me?” Okay then, let’s have a look at how LU factorizations (which so far I’ve assumed we just have lying around) are actually computed, shall we? (And again, note I’m ignoring pivoting here, for simplicity.)
What we want to do is factor our matrix A into a unit lower triangular and an upper triangular factor:
So, how do we do that? Just keep staring at that equation for a minute longer, see if it flinches first! It doesn’t? Bugger. Okay, plan B: apply our new favorite trick, splitting a matrix into blocks, to play for time until we get a brilliant idea:
Our top-left block needs to be square (same number of rows as columns), else this isn’t right, but it can be any size. This makes square as well, and the other blocks are rectangular. The zeros are there because we want L and U to be lower and upper triangular respectively, and their entire top-right respectively bottom-left blocks better be all zero. Furthermore, and are also unit lower triangular (like the bigger L we carved them out of), and likewise and are upper triangular. About the remaining and , we can’t say much.
Still drawing blanks on the ideas front. But let’s just keep going for now: if we multiply out that matrix equation, we get
Wait a second. That first line is a smaller LU decomposition, which we’re trying to figure out how to compute. But suppose we knew for now, and we had something that gave us and . Then that second line is really just . That’s a TRSM, we just went over that. And the third line is , which is also a TRSM (of a shape we haven’t seen before, but it works the same way). Once we have and , our hand is forced with regards to these two matrices; for the factorization to multiply to the correct result A, we need them to be the things I just wrote down. And if we know these two matrices, we can attack that last equation by moving their product to the left-hand side:
Hey look, we do a big GEMM and then resume with computing a LU decomposition of the remainder – we’ve seen that kind of structure before! Great. This is how to do a block LU decomposition: compute a LU decomposition of the top-left block, two TRSMs, one GEMM to update the bottom-right part, then keep decomposing that. And this time the TRSMs are on medium × medium × large problems, while the GEMM is on large × medium × large, so again the bulk of the computation is going to be spent in the GEMM part.
But we still don’t know how to compute the LU decomposition of that top-left block. No worries: if in doubt, go for a cheap shot. We don’t know how to do this for an arbitrary block. But what if we make our partition really silly? For is a 1×1 element “matrix” levels of silly? (That is, we’re just splitting off one row and one column at the top left.)
Then is a no-brainer; all three of these matrices are 1×1, and we require to be “unit” (ones on the diagonal), which for a 1×1 matrix just means that . Therefore . Ta-daa! We “solved” a 1×1 LU decomposition. But that’s all we really need. Because once we have that one value determined, we can crank through our other 3 formulas, which give us (the rest of the top row of U), (the rest of the left column of L), and updates the rest of the matrix to eliminate the one variable we just computed. To compute a LU decomposition of a block, we simply keep peeling off 1×1 sub-blocks until we run out of matrix to decompose.
This description covers both “regular” and block LU decompositions (in fact we just do blocks and then get the regular decomposition as a special case when we do 1×1 blocks, at which point the problem becomes trivial), and not a single index or elementary row operation was harmed in the preceding text.
Note that this time, we turned LU decomposition (i.e. Gaussian elimination) into mostly-GEMMs-and-some-block-TRSMs, and we already saw earlier that block TRSMs turn into mostly-GEMMs-and-some-small-TRSMs. Therefore, the entire process of factoring a linear system and then solving it turns into… mostly GEMMs.
And that’s why everyone cares about GEMMs so much. (And also, you may now see why even if you don’t use TRSMs, math libraries still include them, because the solvers your app code calls want to call them internally!)
This pattern is not just specific to Gaussian Elimination-type algorithms, either. Block Householder for QR decompositions? Heavy on GEMMs. Hessenberg reduction for Eigenvalue problems? Basically Householder, which is mostly GEMMs. Computation of the Singular Value Decomposition (either for solvers or to get PCAs)? Generally starts with Golub-Kahan Bidiagonalization or one of its relatives, which is a somewhat fancier version of the QR decomposition algorithm, and yup, lots of GEMMs again. Then the actual singular value computation is iterative on that bidiagonal matrix, but that part tends to take less time than the non-iterative parts surrounding it, because the iteration is only iterating on a matrix reduced to 2 diagonals, whereas everything else works with the whole matrix.
In fact, what we’ve seen so far is a pattern of various matrix operations turning into smaller versions of themselves, plus maybe some other matrix operations, plus a GEMM. Guess what happens with a GEMM itself? If your guess was “GEMMs all the way down”, you’re right. It’s like a weed. (And turning GEMMs into smaller GEMMs is, in fact, quite important – but that’s in the paper, so I won’t talk about it here.)
This concludes our brief foray into dense numerical LA and why HPC people are so obsessed about GEMM performance. Note that dense problems are basically the easy case, at least from a high-level point of view; many of the things that are really interesting are huge (millions of equations and variables) but sparse and with exploitable structure, and these take a lot more care from the user, as well as more sophisticated algorithms. (That will nevertheless usually end up calling into a dense LA library for their bulk computations.)
Now that I’ve hopefully satisfyingly answered why GEMM, let’s talk a bit about the actual paper. The presentation I gave you of splitting up a matrix into blocks wasn’t just for notational convenience; that’s how these algorithms tend to work internally. The reason is that large matrices are, well, large. There’s an inherent 2D structure to these algorithms and completely looping over one axis of a giant matrix tends to thrash the cache, which in turn means there are suddenly lots of main memory accesses, and at that point you lose, because current computers can do way more computation per unit of time than they can do memory-to-cache transfers. If you truly want to do high-performance computation, then you have to worry about memory access patterns. (In fact, that’s most of what you do.)
That is something I pushed on the stack earlier in this post: different BLAS levels. This is an old chestnut, but it’s worth repeating: level-1 BLAS operations are vector-vector; something like say a big dot product (DOT in BLAS). Doing a dot product between two N-element vectors is on the order of 2N flops, and 2N memory operations (memops) to load the elements of the two vectors. 1:1 flops to memops – no good! Level-2 BLAS operations are matrix-vector; take say M×N matrix by M-element vector multiplication (GEMV, GEneral Matrix times Vector). Does 2MN flops, M×(N+2) memops (load all matrix elements once, load each vector element once, store each vector element once); closer to 2:1 flops to memops, which is an improvement, but still bad if you have the SIMD units to compute 32 single-precision flops per cycle and core and the main memory bandwidth to load half a float per cycle and core (the size of this gap is similar for CPUs and GPUs, for what it’s worth). It just means that your performance drops off a cliff once you’re working on data larger than your cache size.
Level-3 BLAS operations like GEMM, however, have 2MNP flops to MN+NP+MP necessary memops (load each matrix element once, store the result). That means the flops to memops ratio can in principle get arbitrarily large if only the matrices are big enough. Which in turn means that high-performance GEMMs are all about making sure that they do, in fact, reuse matrix elements extensively once they’re in the cache, and making sure that all the different cache levels are happy.
The way this works is interesting and worth studying, and that’s why that paper was on my list. Whew.
According to my headings, all of the above was about the matrix multiplication paper. Well, what can I say? I was lying.
That whole business with deriving our LU decomposition by partitioning our matrix into blocks, writing down equations for the individual block elements, and then winging our way towards a solution? That’s, essentially, this paper. Except the real paper is a lot more rigorous and consequently with a lot less “winging it”.
Partitioning matrices into blocks for fun and profit is a numerical linear algebra mainstay. I saw it done for a few algorithms at university. The work of this group at UT Austin (especially the stuff following from this paper) is what made me realize just how general and systematic it can be when it’s done right.
For a large class of dense LA algorithms, this procedure is well-specified enough to derive a working algorithm automatically from a problem description, complete with correctness and numerical stability analysis, within seconds; no inspiration required. It’s an algorithm-derivation algorithm. For a very limited (and fairly rigidly structured) problem domain, but still!
The moves, which include easing a cap on how many stations a broadcaster can own, have opened up lucrative opportunities for Mr. Smith, among them a $3.9 billion bid to buy Tribune Media, another large owner of stations.
Mr. Pai’s deregulatory drive has also helped win him a following as a champion of pro-business, conservative causes — even leading some Republicans to approach him since he was first named to the F.C.C. in 2012 about running for elected office.
The Sinclair Broadcast Group owns or operates 173 television stations across the country, almost three times the number it had in 2010. If a proposed merger with Tribune Media is approved, Sinclair would add 42 stations in spots across the United States, making its reach even broader.
Television stations owned or operated by the Sinclair Broadcast Group
Stations fully owned and
operated by Sinclair
Operated under a shared
services agreement
Operated under a local
marketing agreement
50 percent owned
by Sinclair
After potential merger with Tribune Media:
Television stations owned or operated
by the Sinclair Broadcast Group
After potential merger with Tribune Media:
Stations fully owned and
operated by Sinclair
Operated under a shared
services agreement
Operated under a local
marketing agreement
50 percent owned
by Sinclair
An examination of the F.C.C. records shows that the Smith-Pai alliance does not follow the familiar script of a lobbyist with deep pockets influencing policy. Instead, it is a case of a powerful regulator and an industry giant sharing a political ideology, and suddenly, with the election of Mr. Trump, having free rein to pursue it — with both Mr. Smith, 66, and Mr. Pai, 44, reaping rewards.
Neither Mr. Pai nor Mr. Smith would comment for this article.
Associates say both men believe that local television stations, which fall under the commission’s rules because they broadcast over federally owned airwaves, are at a disadvantage when competing against cable companies and online streaming services like Comcast and Netflix.
Tina Pelkey, spokeswoman for Mr. Pai, said the new chairman had not taken steps to help Sinclair specifically; his concerns relate to the broadcast industry generally.
“It has nothing to do with any one company,” Ms. Pelkey said.
Other broadcast companies, as well as the National Association of Broadcasters, have pushed for some of the same changes that have benefited Sinclair.
Loosened regulatory requirements, Sinclair executives said, will help even the playing field and benefit millions of Americans who rely on broadcast stations for news and entertainment by allowing the companies to invest in new equipment and technology.
“Thankfully we’ve got Chairman Pai, who’s launched an action to look at antiquated rules,” Christopher S. Ripley, who became Sinclair’s chief executive in mid-January, said in a recent speech, adding that the rules had “artificially tipped the playing field away from TV broadcast.”
But critics say the rollback undermines the heart of the F.C.C. mission to protect diversity, competition and local control in broadcast media. It also gives an increasingly prominent conservative voice in broadcast television — Sinclair has become known for its right-leaning commentary— an unparalleled national platform, as television remains the preferred source for most Americans of news, according to Pew.
A merger with Tribune would transform Sinclair into a media juggernaut, with reach into seven out of 10 homes through more than 200 stations in cities as diverse as Eureka, Calif., and Huntsville, Ala. The company would have a significant presence in important markets in several electoral swing states, including Pennsylvania, Ohio and North Carolina, and would gain entry into the biggest urban markets: New York, Los Angeles and Chicago.
PhotoAjit V. Pai, named chairman of the Federal Communications Commission in January, has pursued a deregulatory blitz at the agency.Credit
Eric Thayer for The New York Times
The result would illustrate the real-world stakes of the Trump administration’s pursuit of dismantling regulations across government. The rollback at the F.C.C., a microcosm of the broader effort, pleases business interests and many Republicans who complain that regulators are heavy-handed and hostile in their approach. It raises alarms among free-speech advocates and many Democrats who say consumers suffer without aggressive oversight.
“I worry that our democracy is at stake because democracy depends on a diversity of voices and competition of news outlets,” said Representative Frank Pallone Jr. of New Jersey, the top Democrat on the House Energy and Commerce Committee.
If Sinclair’s past is any guide, the changes for viewers could be profound.
The company has a history of cutting staffs and shaving costs by requiring stations to share news coverage, in that way reducing unique local content. And it has required stations to air conservative-leaning segments, including law-and-order features from its “Terrorism Alert Desk,” as well as punditry from Republicans like Boris Epshteyn, a former surrogate to Mr. Trump, who was still seen visiting the White House after joining Sinclair.
In the political battleground state of Wisconsin, a merger would give Sinclair six stations in the biggest markets — Milwaukee, Green Bay and Madison — causing some journalists to fear a statewide, coordinated corporate news strategy that would tilt right.
“We’ve moved from a high-quality independent news ownership structure to one where a few companies have outsized influence,” said Lewis A. Friedland, a professor of journalism at the University of Wisconsin-Madison.
Mr. Friedland previously worked as a news manager at WITI, the current Fox affiliate in Milwaukee. It is owned by Tribune and would become part of the Sinclair empire if the merger is approved, as expected.
Sinclair rejects suggestions that its stations push right-leaning views, and says the company’s mission is to be objective in its news coverage.
“We are proud to offer a range of perspectives, both conservative and liberal — to our consumers — on our Sinclair broadcast stations each day,” Scott Livingston, Sinclair’s vice president for news, wrote in a July memo to staff members. “It is unfortunate that so many of our competitors do not provide the same marketplace of ideas.”
PhotoCredit
Doug Wells/The Des Moines Register, via Associated Press
An Opposition Voice Rises
Though Sinclair is not a household name like the conservative cable TV channel Fox News, it has been a powerful operator in Washington, with a decades-long history of courting Republicans and Democrats even as regulators accused it of flouting broadcast rules.
Sinclair was founded in 1971 by Mr. Smith’s father, Julian Sinclair Smith, an electrical engineer with a deep curiosity about new broadcasting technology. At the time, the company consisted of a radio station and a single UHF station in Baltimore, but it wasn’t long before it embarked on an ambitious growth strategy.
With more stations, Sinclair could command more lucrative advertising, and later, higher fees from cable and satellite companies that retransmitted its broadcasts.
Sinclair helped pioneer a range of creative growth techniques that the company insisted were both legal and good for television viewers.
Most notable was its use of so-called joint sales agreements, which allowed it to work around ownership rules that prevented any one company from owning multiple top-rated channels in a single market.
The practice started in 1991 in Pittsburgh as a game of ownership hot potato, when Sinclair sold its station there to an employee, Edwin Edwards, and retained ownership of a second station. The two stations then shared resources and programming, but on paper they remained under separate ownership. David Smith’s mother, Carolyn Smith, later helped fund Mr. Edwards’s company and took a stake in it.
Consumer advocates long complained about the maneuver, and by President Obama’s second term, regulators at the F.C.C., then led by Democrats, were taking a hard look at it.
That is when, records show, Mr. Pai first met with Sinclair’s top lawyers.
Mr. Pai was a fresh Republican face on the commission. He had an impressive background: degrees from Harvard and the University of Chicago Law School, and stints at the Department of Justice, at the general counsel’s office of the F.C.C. and at the Senate Judiciary Committee, as an aide to Sam Brownback, then a Republican senator from Kansas and now the state’s governor.
The child of immigrants from India, he liked to tell the story of how his parents arrived in the United States with nothing but $10 and a transistor radio.
Perhaps most appealing to Sinclair and other TV station owners, Mr. Pai exhibited blanket empathy for the broadcasting industry, both television and radio.
“I’ve been listening carefully to what you have to say,” Mr. Pai told broadcast executives in late 2012. “Unfortunately, it seems there’s a widespread perception that today’s F.C.C. is largely indifferent to the fate of your business.”
An enthusiastic purveyor of free-market philosophy, Mr. Pai quickly became a dependable opponent to regulations created by the F.C.C.’s Democratic majority. He promised to take a “weed whacker” to regulations if he ever became chairman.
“The commission,” he told the broadcast executives, “can do a better job of focusing on what’s important to broadcasters.”
An Alliance Is Forged
Just seven months into Mr. Pai’s tenure, in December 2012, he welcomed a group of visitors to his office: Barry M. Faber, Sinclair’s general counsel, and two of the company’s Washington-based corporate lawyers.
“Television stations have utilized J.S.A.s for at least 10 years,” Mr. Faber told Mr. Pai according to records of the meeting filed with the F.C.C., referring to the joint sales agreements that Sinclair utilized in Pittsburgh and elsewhere.
Mr. Faber added that “to his knowledge, not a single example of harm to program diversity or competition for viewers resulting from J.S.A.s has been documented.”
Many have wondered why HMS Queen Elizabeth has two ‘islands’. Here we consider why she is the first aircraft carrier in the world to adopt this unique arrangement and the benefits it brings.
Redundancy and separation can be good
In a moment of inspiration back in 2001, an RN officer serving with the Thales CVF design team developing initial concepts for what became the Queen Elizabeth Class, hit upon the idea of separate islands. There are several advantages to this design but the most compelling reason for the twin islands is to space out the funnels, allowing greater separation between the engines below. QEC has duplicated main and secondary machinery in two complexes with independent uptakes and downtakes in each of the two islands. The separation provides a measure of redundancy, it increases the chances one propulsion system will remain operational in the event of action damage to the other. Gas turbine engines (situated in the sponsons directly below each island of the QEC) by their nature require larger funnels and downtakes than the diesel engines (in the bottom of the ship). The twin island design helps minimise their impact on the internal layout.
In a conventional single-island carrier design, either you have to have a very long island (like the Invincible class) which reduces flight deck space or, the exhaust trunkings have to be channelled up into a smaller space. There are limits to the angles this pipework may take which can affect the space available for the hangar. The uptakes can also create vulnerabilities, the third HMS Ark Royal was lost to a single torpedo hit in 1941, partly due to progressive engine room flooding through funnel uptakes.
The twin island design has several other benefits. Wind tunnel testing has proved that the air turbulence over the flight deck caused by the wind and the ship’s movement, is reduced by having two islands instead of one large one. Turbulent air is a hindrance to flight operations and aircraft carrier designers always have to contend with this problem. Twin islands allow greater flight deck area because the combined footprint of the two small islands is less than that of a single larger one. By having two smaller islands it allowed each to be constructed as a single block and then shipped to Rosyth to be lifted onto the hull. The forward island was built in Portsmouth and the aft island built in Glasgow.
This arrangement solves another problem by providing good separation for the main radars. The Type 1046 long range air surveillance radar is mounted forward while the Type 997 Artisan 3D medium range radar is aft. Powerful radars, even operating on different frequencies, can cause mutual interference or blind spots if the aerials are mounted too close together. Apart from a slim communications mast, both the Artisan and 1046 have clear, unobstructed arcs.
The flag bridge below the main bridge can be clearly seen in the forward island. The emergency conning position and the large Flyco can be seen in the aft island. Note the tall funnels designed to keep exhaust gasses away from the flight deck
Bridge – forward
With separate islands it is possible to site the bridge further forward than in a conventional single-island design. This gives the officer of the watch (OOW) a better view of the bows and what is immediately ahead, especially useful when in confined waters. The QEC bridge is spacious and has very large windows with a wide field of view, similar to the Type 45 destroyers. Carpeted with a dark blue-grey finish and wooden trim around the control panels, it has a very different feel to the cream and pale grey interior of preceding Invincible class carriers. The QEC are fitted with a state of the art Sperry Marine Integrated Navigation Bridge System (INBS) including the Naval Electronic Chart Display and Information System (ECDIS-N).
The captain has a day cabin just behind the bridge for use at sea but as is usual on a carrier, his spacious main cabin is down aft with the other officer accommodation. There is a small lift that allows him to quickly get up or down from the bridge to the operations room which is situated seven decks below.
Like the Invincible class, the QEC has facilities for the Admiral commanding the carrier group and has use of his own ‘flag bridge’ below the main navigation bridge. It offers a good view and a useful space for his staff, away from the ship’s personnel.
When no admiral is embarked, the flag bridge is available for the ship to use and is a convenient place for meetings and to entertain guests. Note the circular wooden table, inlaid with the ship’s crest. US Navy photo.
The steering position on the bridge of fifth HMS Ark Royal seen in 2009, complete with classic chintzy seat cover.
Steering HMS Queen Elizabeth, 2017
Flyco – aft
The QEC aircraft control position, known as flyco is a major change in design philosophy. Instead of being just an appendage to the navigation bridge it has been designed in partnership with Tex ATC Ltd, one of the world’s leading providers of military and civilian airfield control towers. By siting the Flyco separately, it can be positioned in the optimum place to view aircraft as they approach the ship for landing. This is the moment when the pilot requires most help from the ship and a dedicated aircraft controller sitting in Flyco (usually a former pilot) can help talk the plane down if needed. The QEC flyco projects out from the aft island and has enormous 3-metre tall windows with providing a 290º view over the flight deck. Such tall windows allow a good view of high flying aircraft for all, including for the personnel sitting in the small raised gallery at the back of the Flyco. In some older ships, the cramped flyco position looked like an afterthought it was sometimes necessary to get right up close to the small windows to see high flying aircraft.
The 3 metre high, multi-layered armoured glass panels are slightly tinted for protection against glare and are strong enough to withstand a direct hit from the rotating blade of a Chinook helicopter.
Flyco can issue instructions to the aircraft handlers on the flight deck via their headsets or using large LED displays mounted on the side of the aft island. It is also connected to the hangar control room below where orders are issued to prepare aircraft to be brought on deck. The Commander Air, “Wings” gets a day cabin in the aft island but does not have his own lift, like the Captain up forward. The aft island also features a ‘bridge’ which has replica ship controls and, in the event of damage to the forward island, could be used as the emergency conning position.
The new Project 23000E “Shtorm” concept from the Russian Krylov State Research Center (KSRC) for a 95,000 ton conventionally-powered aircraft carrier has copied the twin island design. Shtorm is a Putin fantasy, unlikely ever to be realised as Russia has not managed to build a surface ship larger than a frigate since the 1990s. Italy is also building a new LHD ‘flat top’ with twin islands.
Drawbacks?
For aircraft carrier veterans the completely separated bridge and flyco will take some adjustment. Because the ship’s course and speed need to be carefully coordinated with flying operations, the close proximity of the OOW to the flight controllers helped them work together. In the new arrangement, they will not be able to see each other and are reliant on the intercom. No doubt everyone will quickly adapt and the benefits of additional space for both navigators and flight controllers will outweigh any disadvantages. It is highly subjective, but some carrier ‘purists’ have said the twin islands make the QEC look “ugly”. Others see the QEC as quite beautiful and despite their quite angular shapes, represent just another step in the evolution of carrier design appropriate for the 21st Century.
The QEC will benefit from a ski-ramp to assist aircraft on take off and twin islands, both of which were invented by the RN. It is encouraging to see the RN retaining its place at the forefront of aircraft carrier innovation.
I built a simple extension in order to understand how to listen to DOM changes. I started using the old way and then refactored the code to use Mutation Observers. The key difference is that if you are observing a node for changes, your callback will not be fired until the DOM has finished changing. That’s a huge efficiency improvement.
Previously on DOM3
Listening to DOM changes was possible with the past DOM3 specification, but it didn’t have good, specific API: you needed to use event listeners.
This was called Mutation Events and it exposed a list of events you were able to listen to:
In the following example I’m listening to a DOMNodeInserted event.
Meet the DOM4 Mutation Observers
Now we have a better API in the DOM4 specification, MutationObservers. This specification became a W3C recommendation on 19 November 2015.
MutationObservers has a more complex API than the previous method, but it’s specifically designed for the requirements. The good thing here is that you specify which DOM changes you will be observing when instanciating the observer.
In my case I will be observing the DOM mutations when the subtree is changed.
An implementation example:
Simple MutationObserver implementation
Browser support
The good news is that this DOM feature is widely implemented. Microsoft added the support for IE11 last year, and the new versions of Edge already supports it.
Building a PoC extension
I built a small Chrome extension (it may be moved to be a WebExtension now, as they already work on Firefox stable now) that simply counts the number of replies a tweet has. This is done by observing a div (the twitter popup) and counting the number of subtree modifications (each modification is a reply).
Extension example usage
The counter goes up as the new mentions are insterted in the DOM.
Content script
This script is injected when the page is loaded:
Note that I’m using chrome.extension.sendMessage so I can send a message to the background-script. The background-script is able to use many of the browser APIs that are not available on the injected script (content-script).
Background script
On the background-script I listen to that message and change the badge text. That’s all.
Wrapping up
Recently the Atom team shipped a new release of their text editor with significant performance improvements. One of the changes they did is to replace a MutationObserver with both the IntersectionObserver and the ResizeObserver APIs. They did that in order to get a sane approach to detecting changes to editor dimensions and visibility in a fine-grained way. This is an example on how youcan get deeper in order to keep improving performance for special use cases. I recommend you to have a look at their post explaining how they started with their new approach to text rendering.
It’s great to see how the browsers’ APIs are getting more powerful and easy to use… keeping in mind that the Web can run anywhere!
By far the most well-known “game” in game theory is the Prisoners’ Dilemma. Albert Tucker, who formalized the game and gave it its name in 1950, described it as such:
Two members of a criminal gang are arrested and imprisoned. Each prisoner is in solitary confinement with no means of communicating with the other. The prosecutors lack sufficient evidence to convict the pair on the principal charge. They hope to get both sentenced to a year in prison on a lesser charge. Simultaneously, the prosecutors offer each prisoner a bargain. Each prisoner is given the opportunity either to: betray the other by testifying that the other committed the crime, or to cooperate with the other by remaining silent. The offer is:
If A and B each betray the other, each of them serves 2 years in prison
If A betrays B but B remains silent, A will be set free and B will serve 3 years in prison (and vice versa)
If A and B both remain silent, both of them will only serve 1 year in prison (on the lesser charge)
The dilemma is normally presented in a payoff matrix like the following:
What makes the Prisoners’ Dilemma so fascinating is that the result of both prisoners behaving rationally — that is betraying the other, which always leads to a better outcome for the individual — is a worse outcome overall: two years in prison instead of only one (had both prisoners behaved irrationally and stayed silent). To put it in more technical terms, mutual betrayal is the only Nash equilibrium: once both prisoners realize that betrayal is the optimal individual strategy, there is no gain to unilaterally changing it.
TIT FOR TAT
What, though, if you played the game multiple times in a row, with full memory of what had occurred previously (this is known as an iterated game)? To test what would happen, Robert Axelrod set up a tournament and invited fourteen game theorists to submit computer programs with the algorithm of their choice; Axelrod described the winner in The Evolution of Cooperation:
TIT FOR TAT, submitted by Professor Anatol Rapoport of the University of Toronto, won the tournament. This was the simplest of all submitted programs and it turned out to be the best! TIT FOR TAT, of course, starts with a cooperative choice, and thereafter does what the other player did on the previous move…
Analysis of the results showed that neither the discipline of the author, the brevity of the program—nor its length—accounts for a rule’s relative success…Surprisingly, there is a single property which distinguishes the relatively high-scoring entries from the relatively low-scoring entries. This is the property of being nice, which is to say never being the first to defect.
This is the exact opposite outcome of a single-shot Prisoners’ Dilemma, where the rational strategy is to be mean; when you’re playing for the long run it is better to be nice — you’ll make up any short-term losses with long-term gains.
Silicon Valley’s Iterated Game
What happens in Silicon Valley is far more complex than what can be described in a simple game of Prisoners’ Dilemma: instead of two actors, there are millions, and “games” are witnessed by even more. That, though, accentuates the degree to which Silicon Valley as a whole is an iterated game writ large: sure, short-term outcomes matter, but long-term outcomes matter most of all.
That, for example, is why few folks are willing to criticize their colleagues or former companies:1 today’s former co-worker or former manager is tomorrow’s angel investor or job reference, and memories are long and reputations longer.2 That holds particularly true for venture capitalists: as Marc Andreessen told Barry Ritholtz on a recent podcast, “We make our money on the [startups] that work and we make our reputation on the ones that don’t.”
Note the use of plurals: a venture capitalist will invest in tens if not hundreds of companies over their career, while most founders will only ever start one company; that means that for the venture capitalist investing is an iterated game. Sure, there may be short-term gain in screwing over a founder or bailing on a floundering company, but it simply is not worth it in the long-run: word will spread, and a venture capitalists’ deal flow is only as good as their reputation.
The most famous example of this is cemented in Valley lore. From The Facebook Effect:
Facebook’s success was beginning to make waves. And in Silicon Valley, success attracts money. More and more investors were calling. Zuckerberg was uninterested. One of the supplicants was Sequoia Capital. Among the bluest of blue chip VCs, Sequoia had funded a string of giants—Apple, Cisco, Google, Oracle, PayPal, Yahoo, and YouTube, among many others. The firm is known in the Valley for a certain humorlessness and a willingness to play hardball. Sequoia eminence grise and consummate power player Michael Moritz had been on Plaxo’s board and was well acquainted with Sean Parker. It was not a mutual admiration society. Parker saw Moritz as having contributed to his downfall. [Parker was fired from the company he founded by the board, including Moritz] “There was no way we were ever going to take money from Sequoia, given what they’d done to me,” says Parker.
Plaxo raised a total of $19.3 million in the rounds in which Sequoia participated; was whatever percentage of that $19.3 million Sequoia put in worth missing out on the chance to invest in one of the greatest grand slams in the history of venture investing?
The entire point of venture investing is to hit grand slams, and that calls for more swings of the bat. After all, the most a venture capitalist might lose on a deal — beyond time and opportunity cost, of course — is however much they invested; the downside is capped. Potential returns, though, can be many multiples of that investment. That is why, particularly as capital has flooded the Valley over the last decade, preserving the chance to make grand slam investments has been paramount. No venture capitalist wants to repeat Sequoia’s mistake: better to be “nice”, or, as they say in the Valley, “founder friendly.”
Benchmark Sues Kalanick
This is why what happened last week was so shocking: the venture capital firm Benchmark Capital filed suit against former Uber CEO Travis Kalanick for fraud, break of contract, and breach of fiduciary duty. From Axios:
The suit revolves around the June 2016 decision to expand the size of Uber’s board of voting directors from eight to 11, with Kalanick having the sole right to designate those seats. Kalanick would later name himself to one of those seats following his resignation, since his prior board seat was reserved for the company’s CEO. The other two seats remain unfilled. Benchmark argues that it never would have granted Kalanick those three extra seats had it known about his “gross mismanagement and other misconduct at Uber” — which Benchmark claims included “pervasive gender discrimination and sexual harassment,” and the existence of confidential findings (a.k.a. The Stroz Report) that recently-acquired self-driving startup Otto had “allegedly harbored trade secrets stolen from a competitor.” Benchmark argues that this alleged nondisclosure of material information invalidates Benchmark’s vote to enlarge the board.
Moreover, Benchmark alleges that Kalanick pledged in writing — as part of his resignation agreement — that the two empty board seats would be independent and subject to approval by the entire board (something Benchmark says was the reason it didn’t sue for fraud at the time). But, according to the complaint, Kalanick has not been willing to codify those changes via an amended voting agreement.
Giving three extra seats on the board to the CEO was certainly founder friendly; that the expansion happened at the same time Uber accepted a $3.5 billion investment from Saudi Arabia’s Public Investment Fund, which came with a board seat, suggests Benchmark viewed the board expansion as a way to protect its own interests and influence as well. After all, longtime Benchmark general partner and Uber board member Bill Gurley had been pursuing ride-sharing years before Uber came along, and the investor had penned multiple essays on his widely-read blog defending and extolling Kalanick and company.
Then again, by June 2016, when the board was expanded and the Saudi investment was announced, Gurley’s posts had taken a much sterner tone: specifically, in February 2015 Gurley warned that late-stage financing was very different than an IPO, and that it had “perverse effects on a company’s operating discipline.” A year later, in April 2016, Gurley said that the “Unicorn financing market just became dangerous…for all involved”, and that included Benchmark:
For the most part, early investors in Unicorns are in the same position as founders and employees. This is because these companies have raised so much capital that the early investor is no longer a substantial portion of the voting rights or the liquidation preference stack. As a result, most of their interests are aligned with the common, and key decisions about return and liquidity are the same as for the founder. This investor will also be wary of the dirty term sheet which has the ability to wrestle away control of the entire company. This investor will also have sufficient angst about the difference between paper return and real return, and the lack of overall liquidity in the market. Or at least they should.
I suspect this, more than anything, explains this unprecedented lawsuit.
The Uber Outlier
Benchmark is one of those most successful venture firms ever. Founded in 1995 with a commitment to early stage funding, the firm has, going by this chart from CB Insights been an investor in 14 IPOs, 11 in the last five years (the chart shows 13 and 10; I added Snapchat, which IPO’d earlier this year).
The company’s investments include Twitter, Dropbox, Instagram, Zendesk, Hortonworks, New Relic, WeWork, Zendesk, Grubhub, OpenTable, and many more; according to CB Insight, since 2007, the companies Benchmark has invested in have exited (via IPO or acquisition) for a combined $75.96 billion.3
That, though, simply highlights what an outlier Uber is, at least on paper. Uber’s most recent valuation of $68.5 billion nearly matches the worth of every successful Benchmark-funded startup since 2007. Sure, it might make sense to treat company X and founder Y with deference; after all, there are other fish in the pond. Uber, though, is not another fish: it is the catch of a lifetime.
That almost assuredly changed Benchmark’s internal calculus when it came to filing this lawsuit. Does it give the firm a bad reputation, potentially keeping it out of the next Facebook? Unquestionably. The sheer size of Uber though, and the potential return it represents, means that Benchmark is no longer playing an iterated game. The point now is not to get access to the next Facebook: it is to ensure the firm captures its share of the current one.
This, I would note, is a lesson founders should learn: Kalanick was resolutely opposed to an IPO, claiming he would wait “as long as humanly possible”; his delay, though, completely flipped the incentives of Kalanick and his early investors. While in most companies the venture capitalists have to worry about their reputation along with their capital, in the case of Uber there is simply too much money at stake: transforming a $68 billion paper return to a real return (and guaranteeing a per partner return in the nine figures) is worth whatever reputational damage is incurred along the way.
In other words, an iterated game is good for founders: it ensures venture capitalists are nice. Single move games, though, which Uber has become, often end badly for everyone, particularly founders.
Diminished Uber
Understanding that Benchmark is focused on achieving liquidity on its all-time greatest investment suggests two potential outcomes:
The most straightforward is that Benchmark hopes to push Uber to an IPO sooner-rather-than-later; clearly Kalanick was an obstacle as CEO, and according to reports, has sought to reestablish control of the company via his control of the board, driving away Meg Whitman, who was reportedly Benchmark’s choice for CEO.4 This also explains the urgency of this suit: Benchmark is trying to prevent Kalanick from naming two more members to the board, further complicating the CEO selection process.
The other potential outcome is that Benchmark is looking for an exit. Softbank, which is looking to dominate car-sharing globally, has reportedly had discussions with Benchmark and other investors about buying their shares; reports have been mixed as to who wants to make a deal — Kalanick or Benchmark — but if it is the latter a lawsuit is an excellent way of getting the former to agree to a sale.
There is a third possibility: that Uber broadly and Kalanick specifically are in big trouble when it comes to Waymo’s lawsuit against the company, and that Benchmark is making clear that it is not culpable. A full six pages of Benchmark’s lawsuit were dedicated to describing Kalanick’s role in the Otto acquisition and Benchmark’s obliviousness to alleged wrongdoing; I noted when the lawsuit was filed that it, more than any of Uber’s scandals, had the potential to be Kalanick’s doom, and apparently Benchmark agrees (although, of course, one should question why Gurley, then an Uber board member, apparently declined to do more digging on a $680 million acquisition).
What is without question, though, is that whatever outcome results from this mess will be a suboptimal one; most Uber critics still fail to appreciate that the ride-sharing market is demand driven, which meant Uber really did have a chance to be the transportation behemoth of much of the world. Now the company is retreating throughout Asia, is on the regulatory run in Europe, and stuck in a fight it should have never drawn out with Lyft in the United States. Perhaps Benchmark will get its all-time great return, reputations be damned. It seems unlikely its return will be what it once might have been.
This isn’t always a good thing: one reason serious issues like sexual harassment by venture capitalists go underreported is that the harassed worry about the long-term effect on their reputation — will future investors simply see them as trouble? [↩]
According to CB Insight, IPO valuation is based on first day closing price; acquisition valuation is based on public pronouncements or whisper valuations [↩]
Whitman is most famous for her stewardship of eBay, Benchmark’s first big breakthrough investment [↩]
We ran into a big blocker when designing SpriteBox Coding, a learn-to-code game for kids ages 5+. For some kids, code was simply unapproachable.
With our previous game LightBot, we’d already proven that kids ages 5+ were capable of writing complex programs with icons. The goal for our next title was to get kids engaged and acquainted with ‘real’ text programming so that they could advance to real programming languages.
Problem is, many newcomers, kids and adults alike, believe that code is inherently complex simply because it lookscomplex. Our first challenge became ‘How do we make code look friendly?’
Source: “Please Don’t Learn to Code” TechCrunch
We guessed that the likely culprits were the unusual symbols you see. We thought we’d succeed if we got rid of anything atypical, adopted simple vocabulary and used an interface that didn’t allow for syntax errors. We’d soon find out that this wasn’t the case. Here is what we came up with:
Textual Code in SpriteBox : Code Hour, our first try at the app
We showed the above to playtesters (kids and parents) who told us what we didn’t want to hear: the game looks complicated. The text deterred player confidence and lead to confusion more than anything.
We couldn’t believe it. From our perspective, we’d simplified the code to what looks like plain English. When we asked parents what they imagined the target age group for the app to be, we got responses that estimated ages 9, 10 and up- much older than the demographic we wanted to hit.
As a test, we replaced the text with icons, and many playtesters’ initial fears dissipated. Players were more confident in approaching the game and parents estimated that the target age for the app was much lower.
Icons in LightBot vs Icons in SpriteBox : Code Hour
It dawned on us that, for some people, the problem was simply that text itself was intimidating. It felt somewhat silly, and yet, learning textual code was the mental blocker for a good portion of our playtesters.
Coding is hard because text is scary.
At this point, we looked to draw inspiration from other educational games. In particular, we looked at DragonBox Algebra: a game for teaching algebra for young kids. The team there seemed to find that numbers and variables were intimidating for their players if introduced early on.
Consequently, DragonBox Algebra starts players off with pictures and explains the mechanics of algebra in an icons-only environment. As the game progresses, it phases those pictures out for numbers and variables.
This approach was so effective, a study was done that showed that 92.9% of kids using the app achieved mastery of basic algebra after 1.5 hours of play.
We wondered if we could model SpriteBox Coding similarly. We would keep the early game icons-only…
… but transition to textual code later. Icons would simply be “phased out”.
The response to this version was pronouncedly more positive. Playtesters felt less intimidated and were engaged longer. Little by little, SpriteBox swaps out all icons for instructions written in text format.
SpriteBox Coding with Swift syntax
So why does this work? We believe that by focusing on icons first, players don’t have to juggle learning two things at once, instead learning programming logic first and textual representation after. Moreover, when text code is introduced, players’ previous knowledge of the game’s mechanics keeps their confidence up as they solve familiar puzzles.
Could this approach work for other educational games? How many more kids could we get engaged in maths, science and programming by using perceptually simpler visuals first, and avoiding text until the last minute?
We’re excited to be launching SpriteBox Coding soon for iOS and Android (Windows, Mac and Linux to follow)! If you’d like to be alerted at launch day, please subscribe at https://goo.gl/forms/B6JTwtNRPIrvlBxp2
Hi everyone - we’ve improved tons of things since our last major release four years ago.
Now f.lux can adapt to your schedule, so by telling it when you wake up, f.lux will automatically adjust throughout the seasons to help you synchronize to the day.
We’ve also tried to explain a really big topic: how light affects your body. So there are some numbers in f.lux now that indicate how bright your screen is, compared to standing outside on a bright day.
We’ve improved performance, so f.lux will have much less impact on your system and on games especially. Here’s a bigger list!
New in version 4 (2017)
Features:
Bedtime mode: a warmer mode gets you ready for sleep
Predictions of how light affects your body
Backwards alarm clock: reminder not to stay up late
Presets to help adjust your settings
Color filters for eyestrain and other uses
Wider range of color settings
New hotkeys to adjust color (alt+shift+PgUp and alt+shift+PgDn)
Changes:
Better performance with games (no stutter)
Resolution independent interface, for high DPI displays
DisplayLink (USB adapters) works in a lot more cases
Smart Lighting:
Hue integration now supports more light types and uses a more advanced schedule
LAN API with support for telling other devices when f.lux changes
Old new stuff (2013)
f.lux can go warmer than 3400K now, down to 2700K. Or even 1200K if you really want it to.
Support for color profiles from a hardware calibrator
Movie mode. This setting warms up your display, but it preserves shadow detail, skintones, and sky colors better than f.lux’s typical colors. It lasts 2½ hours, which lets you watch most feature films
Disable until morning, for late-night crunch mode
A new “darkroom” mode, which inverts colors and gets very red
A map to help you find your location
Hotkeys to dim your display (Alt-PgDn, Alt-PgUp) late at night, so desktop users can dim too
A hotkey to disable/enable f.lux quickly: Alt-End
If you have a laptop, f.lux gets warmer when your backlight dims, like an incandescent lamp
A simple schedule for Philips Hue, so you can f.lux your house
Some more fixes
Safe mode for playing video games without hiccups
Bugs fixed with Intel chipsets
Smoother animations and fading
Better support for Windows 7 & 8
Thanks for using f.lux, and if you need help with the new features, please join us on our support page here: http://justgetflux.com/faq.html.
My Hungarian-Czech grandmother, an otherwise goodhearted and generous
woman, had a notoriously lax attitude toward property rules: bank pens,
ashtrays, and hospital slippers all were fair for the taking. One
minute, she’d be giving a bus driver brooches “for his vife”; the next,
she’d be stomping down a stranger’s front path to help herself to an
enormous bough of blossom while my sister and I, technically her
accomplices, hid behind parked cars, pretending not to know her.
I’ve tried to lead an honest life, in accordance with the 1968 Theft
Act; also, I’m a conscientious elder child and easily embarrassed. But
one’s fate is difficult to dodge; ask Oedipus. My own weakness, unlike Grandma’s, is limited to fruit. In the school fiction of yesteryear,
“scrumping” was what schoolboys, primarily, did in orchards. Nowadays,
with fried-chicken shops on every corner, the art of fruitnapping is
lost. Not, however, by me.
There’s no English word for the frenzied state into which I’m thrown
when I see a tree thick with crab apples, or greengages, or pears. Are
you seriously expecting me, a greedy person, to ignore the deliciously
bitter Morello cherries near the station, or the neglected grape vine by
that garage, or the vast banks of blackberries that litter Britain’s
parks and heaths, largely overlooked except by the occasional elderly
Pole or Czech, similarly purple-stained, with whom I exchange a brief,
competitive glance?
Although I enjoy the camaraderie, beware any fellow-foragers who happen
to stray near me on one particular, sacred day. This is my annual
secret visit to a forgotten damson tree, bearing concealed Tupperware,
dark clothes, and an expression of barely suppressed excitement.
“I’ll just be half an hour,” I say to my picnicking family. Poor fools,
they still believe me. They don’t realize that absolutely nothing
compares to the thrill of fruit-hunting: the covert slipping through the
foliage; the scanning for a telltale glisten of color; the way
that—deep in the hedgerow, scratched and juice-streaked, breath held as
one searches for another dusty bitter plum, then another—time stops.
When it comes to semi-legal harvesting, I am daring, virtually
buccaneering: qualities we novelists usually lack. Whether snatching fat
Spanish sweet chestnuts, glossy as horses’ flanks, from beneath the feet
of walkers on Hampstead Heath, or wild strawberries from the urns
outside the British Library, I stop at nothing and know no shame.
Because, as they say in the London Metropolitan Police, I have previous.
My first victim was an ancient black-mulberry tree in the grounds of St.
John’s College, Oxford. My father taught there, despite the fact that he
was not a floppy-haired blond aristocrat but instead a poor widow’s only
son, who had heaved himself from her dark London basement into a life of
Latin prayers and the boundary disputes of minor nation states. Usually,
despite the beard, he blended in with the port-drinkers and
philosophers, but, once a year, he persuaded the college porter to allow
his children, badly dressed even by Oxford standards, through the
hallowed gates.
Mulberries don’t travel. They are too juicily fragile-skinned for shops
to stock; to try them, one must pick one’s own. Their rich taste is
unforgettable: like the best blackberry crossed with the sweetest
raspberry—the platonic ideal of fruit. But picking them requires
courage, and compliant children dressed in their most terrible clothes.
The berries grew high on gnarled branches, which our father forced us to
climb and shake onto sheets spread below. Within five minutes, my sister
and I would be splotched with pink; after ten we’d have frightened Lady
Macbeth.
“Can we go home now?”
“No.”
“Now?”
“No.”
He was a man possessed, and this is the reason: mulberry gin. All you do
is stuff the fruits into a gin bottle with sugar, and wait: ambrosia will
follow. But at what cost? The cycle ride home, our tiny sweatshirts
crimson-splashed, dripping juice from wobbling plastic bags, scarred us.
My father got his gin; we kids got nothing but scratches and twiggy
hair.
Which is perhaps why, the moment I heard that my daughter’s school
contained a small mulberry tree, I did unto her precisely what was done
unto me.
These are external links and will open in a new window
Image caption
Marcus Hutchins was arrested by the FBI on 2 August
The British cyber-security researcher, charged in the US with creating and selling malware, has returned to Twitter to thank his supporters.
It is the first time Marcus Hutchins has spoken publicly since his arrest earlier this month in Las Vegas.
Earlier on Monday the 23-year-old pleaded "not guilty" during a court hearing in Milwaukee, Wisconsin.
A trial has been scheduled for October. The court gave Mr Hutchins permission to work and use the internet again.
However, he will not be allowed access to the server he used to stop WannaCry spreading.
He must surrender his passport and will be tracked in the US via GPS during his release.
Posting on Twitter as @MalwareTechBlog, Mr Hutchins said: "There's a lot of people I'd like to thank for amazing support over the past 11 days, which I will do when I get a chance to publish my blog."
He added: "I'm still on trial, still not allowed to go home, still on house arrest; but now i am allowed online. Will get my computers back soon."
He also listed a list of "things to do" at Def Con, the hacking conference he attended in Las Vegas prior to his arrest.
The list read: "Attend parties; visit red rock canyon; go shooting; be indicted by the FBI; rent supercars."
Mr Hutchins shot to fame after helping to stall the WannaCry ransomware cyber-attack that struck the NHS and affected many other organisations around the world in May.
'Brilliant young man'
Mr Hutchins faces six charges relating to the development and distribution of Kronos, a well-known piece of malware that gathered financial information from infected computers. He was arrested by the FBI on 2 August.
A second defendant, who has not yet been named, was included in the federal indictment against Mr Hutchins.
"Marcus Hutchins is a brilliant young man and a hero," said Marcia Hoffman, one of his lawyers, who was speaking outside the court after the hearing.
"He is going to vigorously defend himself against these charges and when the evidence comes to light we are confident that he will be fully vindicated."
Brian Klein, a second lawyer, added: "We are very pleased today that the court modified his terms, allowing him to return to his important work."
Mr Hutchins was arrested shortly after visiting the Black Hat and Def Con cyber-security conferences in Las Vegas.
The cyber-security researcher is from Ilfracombe, Devon and works for LA-based firm Kryptos Logic.
He was granted bail on 5 August after $30,000 (£23,000) was raised by friends and family.
Freeciv WebGL has been released with a new version today, which supports Anaglyph 3D with red and cyan 3D glasses. This was made possible thanks to the Three.js 3D engine which is used by Freeciv WebGL.
“Anaglyph 3D is the name given to the stereoscopic 3D effect achieved by means of encoding each eye’s image using filters of different (usually chromatically opposite) colors, typically red and cyan. Anaglyph 3D images contain two differently filtered colored images, one for each eye. When viewed through the “color-coded” “anaglyph glasses”, each of the two images reaches the eye it’s intended for, revealing an integrated stereoscopic image. The visual cortex of the brain fuses this into the perception of a three-dimensional scene or composition.”, accoding to Wikipedia.
To play Freeciv WebGL in anaglyph 3D mode, enable it in the settings dialog and play with 3D glasses such as these:
Snap’s Spectacles sunglasses may prove to be more of a fad than a must-have device. Snap revealed during its call following weak Q2 earnings that it generated $5.4 million in “Other” revenue, which would equate to around 41,500 pairs of its Spectacles camera sunglasses at a $130 price point. That’s compared to $8.3 million in Other revenue in Q1, or fewer than 64,000 pairs, meaning Spectacles sales have declined roughly 35 percent.
Snap recently began selling Spectacles on Amazon and in other companies’ retail stores, like Harrod’s, but those sales won’t show up til Q3 earnings. Snap did start selling Spectacles online and through its Snapbot vending machines in Europe for the first time back in June. That means the 41,500 number may have been propped up by this expansion, and sales in the U.S. may have slipped further.
Snap may either need a radically different, AR-equipped version 2 of Spectacles to reinvigorate interest, or it may need to look to other cameras to sell. It recently acquired Zero Robotics, a Chinese maker of the Hover selfie drone, for between $150 million and $200 million. Sources told TechCrunch today that the deal is complete. But more potential may lie in a camera people can fit in their pockets, like a 360 camera.
For the past several months, DreamHost has been working with the Department of Justice to comply with legal process, including a Search Warrant (PDF) seeking information about one of our customers’ websites.
At the center of the requests is disruptj20.org, a website that organized participants of political protests against the current United States administration. While we have no insight into the affidavit for the search warrant (those records are sealed), the DOJ has recently asked DreamHost to provide all information available to us about this website, its owner, and, more importantly, its visitors.
Records Requests
DreamHost, like many online service providers, is approached by law enforcement regularly to provide information about customers who may be the subject of criminal investigations. These types of requests are not uncommon; our legal department reviews and scrutinizes each request and, when necessary, rejects and challenges vague or faulty orders. You would be shocked to see just how many of these challenges we’re obligated to mount every year!
Chris Ghazarian, our General Counsel, has taken issue with this particular search warrant for being a highly untargeted demand that chills free association and the right of free speech afforded by the Constitution.
Demand for Information
The request from the DOJ demands that DreamHost hand over 1.3 million visitor IP addresses — in addition to contact information, email content, and photos of thousands of people— in an effort to determine who simply visited the website. (Our customer has also been notified of the pending warrant on the account.)
That information could be used to identify any individuals who used this site to exercise and express political speech protected under the Constitution’s First Amendment. That should be enough to set alarm bells off in anyone’s mind.
This is, in our opinion, a strong example of investigatory overreach and a clear abuse of government authority.
As we do in all such cases where the improper collection of data is concerned, we challenged the Department of Justice on its warrant and attempted to quash its demands for this information through reason, logic, and legal process.
Instead of responding to our inquiries regarding the overbreadth of the warrant, the DOJ filed a motion (PDF) in the Washington, D.C. Superior Court, asking for an order to compel DreamHost to produce the records.
Our Opposition
Last Friday Mr. Ghazarian, with the help of his legal team and outside counsel, filed legal arguments in opposition (PDF) of the DOJ’s request for access to this trove of personally identifiable information.
This motion is our latest salvo in what has become a months-long battle to protect the identities of thousands of unwitting internet users. Mr. Ghazarian will attend a court hearing on the matter on August 18 in Washington, D.C.
We’ve been working closely with the Electronic Frontier Foundation and their counsel throughout this process. They’ve been nothing but supportive and helpful throughout, and we’re honored to have them in our corner.
Why Bother?
The internet was founded— and continues to survive, in the main— on its democratizing ability to facilitate a free exchange of ideas. Internet users have a reasonable expectation that they will not get swept up in criminal investigations simply by exercising their right to political speech against the government.
We intend to take whatever steps are necessary to support and shield these users from what is, in our view, a very unfocused search and an unlawful request for their personal information.






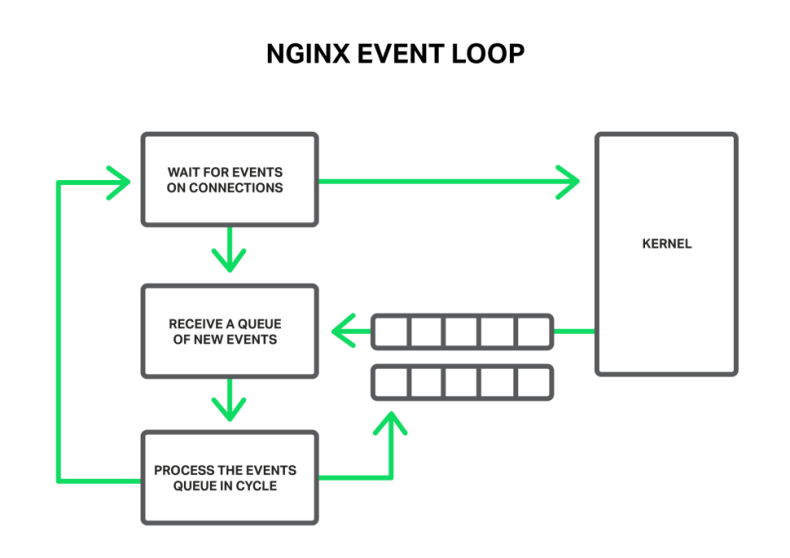
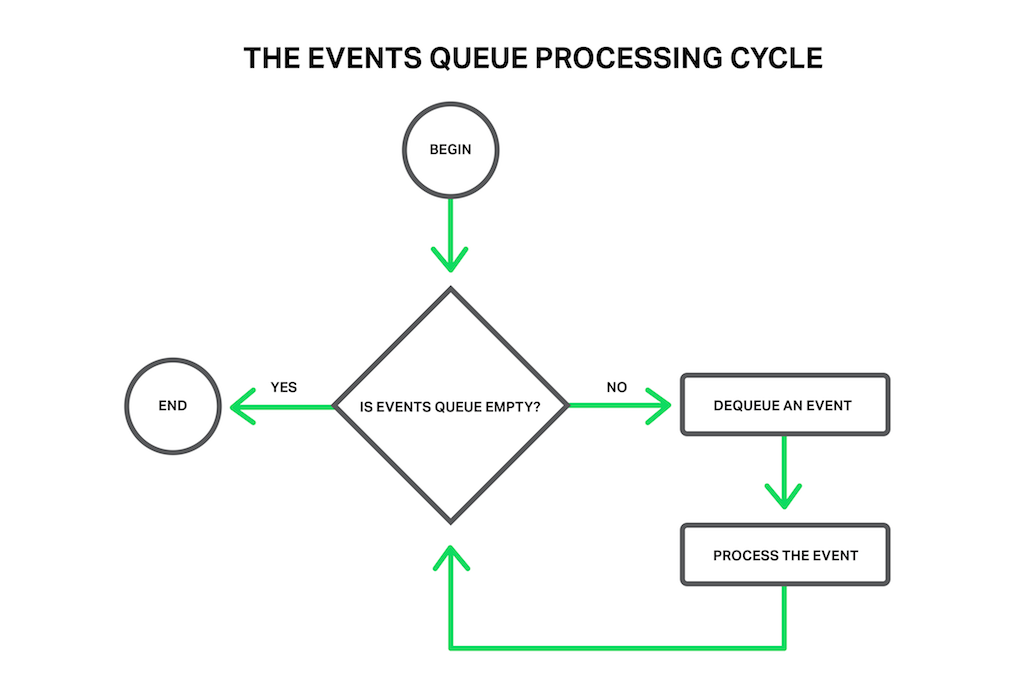
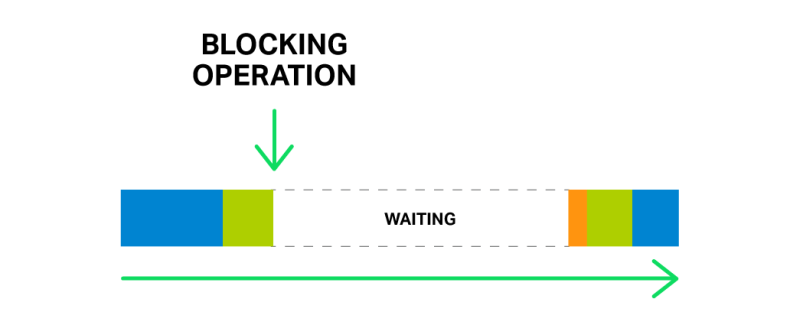
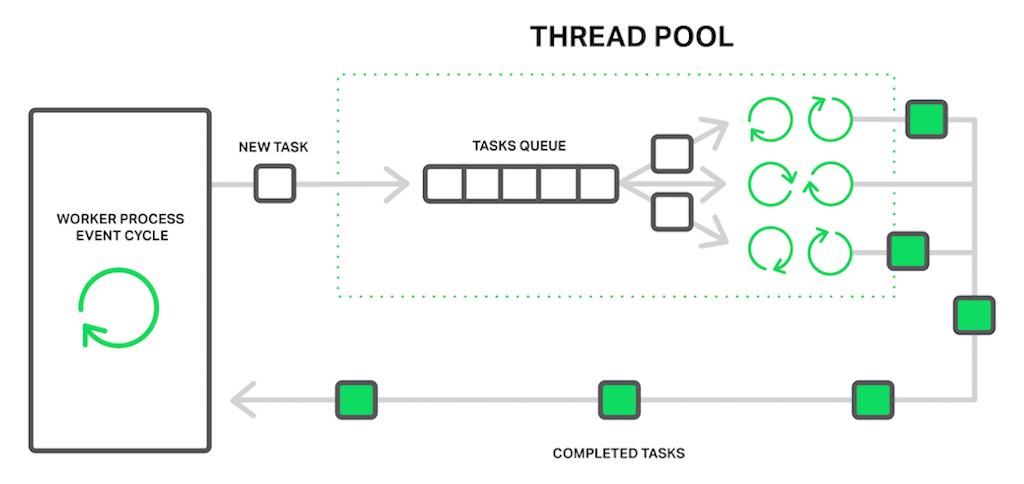


 as the product of several special matrices that have some desirable structure. For example, the LU decomposition turns our general matrix into a product
as the product of several special matrices that have some desirable structure. For example, the LU decomposition turns our general matrix into a product  where
where  is a
is a  is upper triangular (note: I’ll be ignoring pivoting in this post for simplicity). The LU decomposition is the industrial-strength counterpart of the Gaussian Elimination process you might have learned in school, but with some side benefits: you can decompose the matrix once and then reuse the factorization multiple times if you’re solving the same system many times with different right-hand sides (this is common in applications), and it also happens to be really nice to have the whole process in a form that can be manipulated algebraically, which we’ll be using in a moment.
is upper triangular (note: I’ll be ignoring pivoting in this post for simplicity). The LU decomposition is the industrial-strength counterpart of the Gaussian Elimination process you might have learned in school, but with some side benefits: you can decompose the matrix once and then reuse the factorization multiple times if you’re solving the same system many times with different right-hand sides (this is common in applications), and it also happens to be really nice to have the whole process in a form that can be manipulated algebraically, which we’ll be using in a moment. where
where  and
and  are 3-element column vectors. If we have a LU decomposition for A, this turns into
are 3-element column vectors. If we have a LU decomposition for A, this turns into
 as an unknown:
as an unknown:
 . The second row states that
. The second row states that  , and we know everything but
, and we know everything but  , so we can rearrange this to
, so we can rearrange this to  . With this, the final row
. With this, the final row  poses no problems either, yielding
poses no problems either, yielding  . So
. So  just falls out, given
just falls out, given  . This is called “forward substitution”. Note that we’re just computing
. This is called “forward substitution”. Note that we’re just computing  here. However, we’re never forming the inverse of L explicitly! This is important. In numerical LA, when you see an inverse, that means you’re supposed to use the corresponding “solve” routine. Actually computing the inverse matrix is generally both inefficient and inaccurate and to be avoided whenever possible.
here. However, we’re never forming the inverse of L explicitly! This is important. In numerical LA, when you see an inverse, that means you’re supposed to use the corresponding “solve” routine. Actually computing the inverse matrix is generally both inefficient and inaccurate and to be avoided whenever possible. , we can write out the
, we can write out the 
 ,
,  / u_{22}") , and
, and  / u_{11}") . You will not be surprised to learn that this is called “backwards substitution”. Again, we’re just calculating
. You will not be surprised to learn that this is called “backwards substitution”. Again, we’re just calculating  , which does not actually use a matrix inversion when U is triangular.
, which does not actually use a matrix inversion when U is triangular. 
 = \left(\begin{array}{c|c} b^1 & b^2 \end{array}\right) = B")


 ; the second row mutliplied out gives
; the second row mutliplied out gives  , and so forth, which we solve the exact same way as before, only now we’re always multiplying (and summing) short row vectors instead of single scalars.
, and so forth, which we solve the exact same way as before, only now we’re always multiplying (and summing) short row vectors instead of single scalars. \begin{pmatrix} x_{11} & x_{12} \\ x_{21} & x_{22} \\ \hline x_{31} & x_{32} \\ x_{41} & x_{42} \\ x_{51} & x_{52} \\ x_{61} & x_{62} \end{pmatrix} = \begin{pmatrix} b_{11} & b_{12} \\ b_{21} & b_{22} \\ \hline b_{31} & b_{32} \\ b_{41} & b_{42} \\ b_{51} & b_{52} \\ b_{61} & b_{62} \end{pmatrix}")

 and
and  are unit lower triangular, and
are unit lower triangular, and  is just a general matrix. If we just multiply the matrix product out by blocks (again, the blocks behave like they’re scalars in a larger matrix, but you need to make sure the matrix product sizes match and be careful about order of multiplication because matrix multiplication doesn’t commute) we get two matrix equations:
is just a general matrix. If we just multiply the matrix product out by blocks (again, the blocks behave like they’re scalars in a larger matrix, but you need to make sure the matrix product sizes match and be careful about order of multiplication because matrix multiplication doesn’t commute) we get two matrix equations:
 term to the right-hand side, yielding
term to the right-hand side, yielding
 , where the left arrow denotes assignment, A, B, and C are matrices, and α and β are scalar values. In this particular case, we would have
, where the left arrow denotes assignment, A, B, and C are matrices, and α and β are scalar values. In this particular case, we would have  ,
,  ,
,  ,
,  and
and  .
. are 30×20, and
are 30×20, and  are 970×20. Again we do the same 3 steps:
are 970×20. Again we do the same 3 steps: (TRSM, 30×30 matrix times 30×20 RHS)
(TRSM, 30×30 matrix times 30×20 RHS) (GEMM, 970×30 times 30×30)
(GEMM, 970×30 times 30×30) (TRSM, 970×970 times 970×30)
(TRSM, 970×970 times 970×30)

 needs to be square (same number of rows as columns), else this isn’t right, but it can be any size. This makes
needs to be square (same number of rows as columns), else this isn’t right, but it can be any size. This makes  square as well, and the other blocks are rectangular. The zeros are there because we want L and U to be lower and upper triangular respectively, and their entire top-right respectively bottom-left blocks better be all zero. Furthermore,
square as well, and the other blocks are rectangular. The zeros are there because we want L and U to be lower and upper triangular respectively, and their entire top-right respectively bottom-left blocks better be all zero. Furthermore,  and
and  are upper triangular. About the remaining
are upper triangular. About the remaining  , we can’t say much.
, we can’t say much.
 . That’s a TRSM, we just went over that. And the third line is
. That’s a TRSM, we just went over that. And the third line is  , which is also a TRSM (of a shape we haven’t seen before, but it works the same way). Once we have
, which is also a TRSM (of a shape we haven’t seen before, but it works the same way). Once we have 
 is a no-brainer; all three of these matrices are 1×1, and we require
is a no-brainer; all three of these matrices are 1×1, and we require  . Therefore
. Therefore  . Ta-daa! We “solved” a 1×1 LU decomposition. But that’s all we really need. Because once we have that one value
. Ta-daa! We “solved” a 1×1 LU decomposition. But that’s all we really need. Because once we have that one value