↧
The Sims Game Design Documents
↧
Steadying the Mouse for People with Parkinson's Disease and Multiple Sclerosis
SteadyMouse is assistive software, designed from the ground up to be your fierce ally against Essential Tremor and the variants that often accompany Parkinson's disease and Multiple Sclerosis.
By detecting and removing shaking motion before it reaches your cursor, and by blocking accidental clicks, the entire mouse experience goes from a chaotic battle to an enjoyable reality.
- Anti-tremor filtering to remove shaking motion
- Automatic blocking of unintentional mouse clicks
- A unique Icon Targeting System to snap your cursor to where it was trying to go with the tap of a button
- An easy global on/off toggle via the scroll-lock key
With SteadyMouse, you can finally stop thinking about tremor and just use your mouse. It takes care of the heavy lifting for you, so while your hand may shake, your cursor will be nice and stable! You can rest your mind and focus on better things.
↧
↧
Show HN: Unlimited UI design
+
When you've joined Fairpixels Pro, you'll get an email address of your dedicated designer. You'll be able to directly send your UI design projects to your designer.
When you deliver your rough wireframes and/or screen descriptions as well as other project details, your designer will get to work and deliver your Sketch files within days.
You can review the work, provide feedback if you need changes or start implementing the designs to your development work. No matter how many projects or revisions you need, you'll only pay a low flat-monthly-fee.
↧
Google Doesn't Want What's Best for Us
Google processes more than three billion search queries a day. It has altered our notions of privacy, tracking what we buy, what we search for online — and even our physical location at every moment of the day. Every business trying to reach mass-market consumer demand online knows that Google is the gatekeeper.
The fact that it is a monopoly, with an almost 90 percent share of the search advertising business, is a given that we have all come to accept. It’s Google’s world; we just live in it. So it matters how this company works — who it hires, who it fires and why.
When a company is dominant enough, it sets the tone for an entire era. In the fall of 1985, I was working as a vice president in the media mergers and acquisitions group at Merrill Lynch in Los Angeles. I would occasionally have to show up for a meeting at 5 a.m. in the Beverly Hills office of Drexel Burnham Lambert. I would do this because Mike Milken, the king of junk bonds at Drexel, would demand it — once the trading day started at 6:30 a.m., he was unavailable.
Executives were terrified that Drexel would start a raid on their companies. Politicians would seek Mr. Milken’s counsel and his money. His “who’s going to stop me?” attitude was the perfect libertarian credo for the Reagan era of deregulation. Drexel gave us culture, too — “Barbarians at the Gate,” “The Bonfire of the Vanities” and Gordon Gekko in “Wall Street” telling us that “greed is good.” But Drexel flew too close to the sun. Mr. Milken went to prison and Drexel is no more.
Today, the great fortunes are not made at companies like Drexel but at companies like Google, Facebook and Amazon. And the rules set by Google are the rules we all abide by.
Last week, Google fired a software engineer for writing a memo that questioned the company’s gender diversity policies and made statements about women’s biological suitability for technical jobs.
“Portions of the memo violate our code of conduct and cross the line by advancing harmful gender stereotypes in our workplace,” Google’s chief executive, Sundar Pichai, wrote in a companywide email.
It’s impossible to believe that Google or other large tech companies a few years ago would have reacted like this to such a memo. In 2011 when CNN filed a Freedom of Information Act request for the workplace diversity data on big tech companies, Google, among others, asked the Department of Labor for its data to be excluded. The company said that releasing that information would cause “competitive harm.” It was not until 2014 that Google began to disclose statistics showing that only 17 percent of its technical work force was female.
The rise of Google and the other giant businesses of Silicon Valley have been driven by a libertarian culture that paid only lip service to notions of diversity. Peter Thiel, one of the ideological leaders in the Valley, wrote in 2009 on a blog affiliated with the Cato Institute that “since 1920, the vast increase in welfare beneficiaries and the extension of the franchise to women — two constituencies that are notoriously tough for libertarians — have rendered the notion of ‘capitalist democracy’ into an oxymoron.”
If women should not even have the vote, why should we worry about gender diversity in the engineering ranks?
Today Google is under growing scrutiny, and the cognitive dissonance between the outward-facing “Don’t be evil” stance and the internal misogynistic “brogrammer” rhetoric was too extreme.
Google had to fire the offending engineer, James Damore, but anyone who spends time on the message boards frequented by Valley engineers will know that the “bro” culture that gave us Gamergate — an online movement that targeted women in the video game industry — is much more prevalent than Mr. Pichai wants to acknowledge.
Google employees who opposed Mr. Damore found their internal company profile pictures posted on Breitbart, the Verge reported. “What really gets me is that when Googlers leaked these screenshots, they knew this was the element of the internet they were leaking it to,” a former Google employee said. “They knew they were subjecting their colleagues to this type of abuse.”
The company canceled a planned all-hands meeting on Thursday, citing concern about harassment.
For much of the short life of Silicon Valley, America has held a largely romantic view of the tech industry. Men like Steve Jobs and Bill Gates were held in high esteem. But increasingly, companies like Google, Amazon and Facebook are coming under the same cultural microscope that questioned the “greed is good” culture of the 1980s. Viewers of the comedy series “Silicon Valley” note that uber-libertarianism and uber-geek machismo go hand in hand. And certainly Mark Zuckerberg was not happy with his portrayal in David Fincher’s “The Social Network,” nor could anyone in the Valley be happy with Dave Eggers’s novel “The Circle” or Don DeLillo’s “Zero K.”
The effects of the darker side of tech culture reach well beyond the Valley. It starts with an unwillingness to control fake news and pervasive sexism that no doubt contributes to the gender pay gap. But it will soon involve the heart of Google’s business: surveillance capitalism. The trope that “if you are not paying for it, you aren’t the customer — you’re the product” has been around for a while. But now the European Union has passed the General Data Protection Regulation, which will go into effect next May. This regulation aims to give people more control over their data, so search engines can’t follow them everywhere they roam online. It will be an arrow to the heart of Google’s business.
We have an obligation to care about the values of the people who run Google, because we’ve given Google enormous control over our lives and the lives of our children. As the former Google design ethicist Tristan Harris points out, “Without realizing the implications, a handful of tech leaders at Google and Facebook have built the most pervasive, centralized systems for steering human attention that has ever existed, while enabling skilled actors (addictive apps, bots, foreign governments) to hijack our attention for manipulative ends.”
The future implications of a couple of companies’ having such deep influence on our attention and our behavior are only beginning to be felt. The rise of artificial intelligence combined with Google’s omnipresence in our lives is an issue that is not well understood by politicians or regulators.
America is slowly waking up both culturally and politically to the takeover of our economy by a few tech monopolies. We know we are being driven by men like Peter Thiel and Jeff Bezos toward a future that will be better for them. We are not sure that it will be better for us.
As George Packer, writing in The New Yorker in 2011, put it, “In Thiel’s techno-utopia, a few thousand Americans might own robot-driven cars and live to 150, while millions of others lose their jobs to computers that are far smarter than they are, then perish at 60.”
Somehow the citizens of the world have been left out of this discussion of our future. Because tools like Google and Facebook have become so essential and because we have almost no choice in whether to use them, we need to consider the role they play in our lives.
By giving networks like Google and Facebook control of the present, we cede our freedom to choose our future.
↧
Hunting Malicious npm Packages
Last week, a tweet was posted showing that multiple packages were published to npm, a Javascript package manager, that stole users’ environment variables:
The names of these malicious packages were typosquats of popular legitimate packages. In this case, the attackers relied on developers incorrectly typing in the name of the package when they ran npm install.
This is dangerous because many environments store secret keys or other sensitive bits of information in environment variables. If administrators mistakenly installed these malicious packages, these keys would be harvested and sent to the attacker. And, in this particular attack, the malicious packages were listed to "depend" on the legitimate counterparts, so the correct package would eventually be installed and the developer would be none the wiser.
With npm having a history of dealing with malicious packages - either hijacked legitimate packages or malicious packages created from scratch - we decided to analyze the entire npm package repository for other malicious packages.
This Isn't npm's First Rodeo
This isn't the first time npm has had incidents like this. In 2016, an author unpublished their npm packages in response to a naming dispute. Some of these packages were listed as dependencies in many other npm packages, causing widescale disruption and concerns around possible hijacking of the packages by attackers.
In another study published earlier this year, a security researcher was able to gain direct access to 14% of all npm packages (and indirect access to 54% of packages) by either brute-forcing weak credentials or by reusing passwords discovered from other unrelated breaches, leading to mass password resets across npm.
The impact of hijacked or malicious packages is compounded by how npm is structured. Npm encourages making small packages that aim to solve a single problem. This leads to a network of small packages that each depend on many other packages. In the case of the credential compromise research, the author was able to gain access to some of the most highly depended-upon packages, giving them a much wider reach than they would have otherwise had.
For example, here's a map showing the dependency graph of the top 100 npm packages (source: GraphCommons)

How Malicious npm Packages Take Over Systems
In both of the previous cases, access to the packages was gained by researchers. However, the question stands - what if an attacker gained access to the packages? How can they use this access to gain control of systems?
The easiest way, which was also the way leveraged by the malicious typosquat packages, is to abuse the ability for npm to run preinstall or postinstall scripts. These are arbitrary system commands specified in the npm package's package.json file to be run either before or after the package is installed. These commands can be anything.
Having this ability is not, by itself, an issue. In fact, these installation scripts are often used to help set up packages in complex ways. However, they are an easy way for attackers to leverage access to packages - hijacked or created - in order to easily compromise systems.
With this in mind, let's analyze the entire npm space to hunt down other potentially malicious packages.
Hunting for Malicious npm Packages
Getting the Packages
The first step in our analysis is getting the package information. The npm registry runs on CouchDB at registry.npmjs.org. There used to be an endpoint at /-/all that returned all the package information as JSON, but it has since been deprecated.
Instead, we can leverage a replica instance of the registry at replicate.npmjs.org. We can use the same technique leveraged by other libraries to get a copy of the JSON data for every package:
curl https://replicate.npmjs.com/registry/_design/scratch/_view/byField > npm.jsonThen, we can use the JSON processing tool jq to parse out the package name, the scripts, and the download URL with this nifty one-liner:
cat npm.json | jq '[.rows | to_entries[] | .value | objects | {"name": .value.name, "scripts": .value.scripts, "tarball": .value.dist.tarball}]' > npm_scripts.jsonTo make analysis easier, we'll write a quick Python script to find packages with preinstall, postinstall, or install scripts; find files executed by the script; and search those files for strings that could indicate suspicious activity.
Findings
PoC Packages
Developers have known about the potential implications of installation scripts for quite a while. One of the first things we noticed when doing this research were packages that aimed to show the impact of these exact issues in a seemingly benign way:
Tracking Scripts
The next thing we found were scripts that tracked when the packages were installed. Npm provides some download metrics on the package listing itself, but it appears that some authors wanted more granular data, causing potential concerns around user privacy. Here are some packages using Google Analytics or Piwik to track installations:
Some packages were less obvious about their tracking, in that they hid the tracking scripts within Javascript installation files rather than just embedding shell commands in the package.json.
Here are the other tracking packages we discovered:
Malicious Scripts
Finally, we looked for packages that had installation scripts that were obviously malicious in nature. If installed, these packages could have disastrous effects on the user's system.
The Case of mr_robot
Digging into the remaining packages, we came across an interesting installation script in the shrugging-logging package. The package's claims are simple: it adds the ASCII shrug, ¯_(ツ)_/¯, to log messages. But, it also includes a nasty postinstall script which adds the package's author, mr-robot, to every npm package owned by the person who ran npm install.
Here's a relevant snippet. You can find the full function listing here.
This script first uses the npm whoami command to get the current user’s username. Then, it scrapes the npmjs.org website for any packages owned by this user. Finally, it uses the npm owner add command to add mr_robot as an owner to all of these packages.
This author has also published these packages, which include the same backdoor:
test-module-apandora-doomsday
Worming into Local Packages
The last malicious package we discovered had code that was, in many ways, identical to the packages from mr_robot, but had a different trick up its sleeve. Instead of just modifying the owners of any locally-owned npm packages, the sdfjghlkfjdshlkjdhsfg module shows a proof of concept of how to infect and re-publish these local packages.
The sdfjghlkfjdshlkjdhsfg installation script shows what this process would look like by modifying and re-publishing itself:
You can find the full source here.
While this is a proof-of-concept, this exact technique can be easily modified to worm into any local package owned by the person doing the install.
Conclusion
It’s important to note that these issues don't just apply to npm. Most, if not all, package managers allow maintainers to specify commands to be executed when a package is installed. This issue is just arguably more impactful to npm simply due to the dependency structure discussed earlier.
In addition to this, it's important to note that this is a hard problem to solve. Static analysis of npm packages as they are uploaded is difficult - so much so that there are companies dedicated to solving the problem.
There are also reports from npm developers that suggests there may be work being done to leverage various metrics to help prevent users from downloading malicious packages:
In the meantime, it's recommended to continue being cautious when adding dependencies to projects. In addition to minimizing the number of dependencies, we recommend enforcing strict versioning and integrity checking of all dependencies, which can be done natively using yarn or using the npm shrinkwrap command. This is an easy way to get peace of mind that the code used in development will be the same used in production.
↧
↧
Not even remotely possible

Down with the tyranny of geography. Down with commuting, “the daily activity most injurious to human happiness.” Down with allegedly “collaborative” open floor plans built such that “high-level executives […] are exempt from this collaborative environment.” Up with more time, greater flexibility, and, believe it or not, higher productivity.
I’m talking about remote work, of course, a subject that provokes surprising vituperation whenever I write about it. (Armchair-psychologist theory: people get very angry at notions which imply they have spent much of their lives needlessly making themselves very unhappy.) It’s also a subject I know more than a little something about: we at HappyFunCorp have been building software with all-remote and/or partly-remote teams for seven years now. I’ve seen what works and what doesn’t.
What doesn’t work includes confusing physical presence with checked-in code, or in-person meetings with productive communications, or valuing the starry-eyed magic of “serendipitous collisions” above all else and/or common sense. Don’t get me wrong, I’m not saying remote work is a panacea. It too has its failure modes. But the assumption that its failure modes are worse than those of office work, just because office work is the historical default, is sheer intellectual laziness.
We at HFC do have a headquarters in Brooklyn, where a plurality of us labor, but I’ve worked successfully with teams scattered across New Delhi, Milan, New York, Berlin, Campina Grande, and San Francisco. In this era of Slack, Skype, and Github, a team of a dozen capable people across a dozen time zones can run like a well-oiled machine.
Quite apart from the time and rent saved, there’s growing evidence that remote teams can be more productive than in-person ones. Consider: “We found massive, massive improvement in performance — a 13% improvement in performance from people working at home.” Consider companies like Automattic, Gitlab, InVision, and Zapier, all of which thrive as fully remote companies.
And if still seems bizarre, weird, or experimental, consider this:
Surveys done by Gallup indicate that in 2016, the proportion of Americans who did some or all of their work from home was 43%, up from 39% in 2012. Over the same period, the proportion who only work remotely went to 20% from 15%
The biggest transition from office to remote work isn’t the geography; that’s incidental. The biggest transition is the mode of communication, which goes from default-synchronous (walk over to your colleague’s desk) to default-asynchronous (PM them on Slack.) I certainly concede that certain forms of work, and certain people, benefit more from synchronous communications; but I put it to you that “most kinds of software development” is not among them1, and that an ever-increasing fraction of the world’s work can be described as “most kinds of software development.”
However. Having said all that. Remote work is not without its flaws and challenges. Some people prefer a tight-knit work community to the broader but more loose-knit ones that remote work fosters, which is fair enough. “Serendipitous collisions” can and do happen among asynchronous communicators, too — posts on shared Slack channels can snowball into full-scale internal projects with surprising ease — but I think it’s fair to say that they’re more likely to occur in-person. And even the largest of all-remote companies have populations measured in the hundreds, not the thousands; once you hit a certain size you need a physical footprint.
The biggest problem of all, though, is that it’s much harder for (many) junior people to learn from asynchronous rather than synchronous communication. There are exceptions, the kinds of people who learn better from textbooks than from classes; but as a general rule, in my experience, remote work is for people who are already fairly capable and experienced. That’s fine for HFC and companies like us, we have the luxury of limiting ourselves to senior developers and/or the exceptions among juniors, but that solution doesn’t scale.
Looking at the increasing numbers, though, it seems awfully apparent that remote work is the future for a substantial fraction of the modern work force. I still find it bizarre that the notion apparently makes so many people so angry.
1Pair programming has its place in this world, but I spent six months working at a 100% pair-programming shop once, and it was one of the least pleasant experiences of my professional career. I recognize and celebrate that for many people it is excellent! For most of the rest of us, however, it is the polar opposite.
Featured Image: PxHere UNDER A CC0 Public Domain LICENSE↧
Boring Company to use Tesla’s technology for its tunnel project under LA
Elon Musk’s Boring Company, supposedly a “small project with a few engineers and interns”, is quickly working toward its goal, which is officially “to solve the problem of soul-destroying traffic.”
After several announcements of upcoming large scale projects, like a network of tunnels under Los Angeles and an underground hyperloop between New York and Washington DC, the company is now presenting its R&D tunnel project underneath Hawthorne.
They plan to test boring techniques in the tunnel as well as Tesla’s autonomous driving and powertrain technologies on electric platforms to move vehicles.
In April, Musk’s new startup took delivery of their first boring machine and started digging in the parking lot of SpaceX’s headquarters.
They already obtained a permit for a 305-feet (100 meters) tunnel at the location, which they reportedly already completed.
Now they presented the second phase of the tunnel at a special meeting of the Hawthorne city council last week.
The current tunnel links SpaceX’s parking lot to 120th street and the second phase would follow the street over 2 miles (3.2 km) all the way to Hawthorne Boulevard.

At the presentation before the Hawthorne city council, Brett Horton, Senior Director of Facilities and Construction for both SpaceX and Boring Company, said that the tunnel would only be for research and development and not to transport people or cargo.
They aim to test their boring machine and find ways to improve it:
“It is a research and development tunnel meant for us to learn about our tunneling machine (Godot), understand the technology and where we can improve it, and also test and prove out the transportation system.”
Horton also explains that the transportation system will use Tesla’s autonomous driving technology and electric powertrain technology:
“To speak very quickly about how the transportation works and how we are going to be testing it in this tunnel, it is based on Tesla technology. We all know about autonomous driving and the capabilities we’ve seen demonstrated in various videos. We are going to use that technology, but instead of an enclosed Tesla, it’s going to be an electric skate.”
He said to imagine a Tesla Model S drivetrain, but with a platform instead of a cabin on top.
The Boring Company has so far been mostly associated with Elon Musk’s SpaceX so it’s interesting to see that Tesla, Musk other main company, is also being involved.
They have also been using Tesla vehicles in their demonstation videos.
The rest of Horton’s presentation revolved around safety requirements for building the tunnel. He went through several safety measures that the Boring Company is taking to ensure that it will be safe. It ranges from simple checks for gas lines, sewage, and optic cables, to more high-tech systems to monitor surface disruption from their tunneling efforts.
They aim to have no impact at the surface by digging just about 20 feet (6 meters) in the ground.
The meeting was to familiarize the members of the council with the project, which they now seek to expedite. City Manager Arnold Shadbehr was appointed to negotiate the terms for granting the permits for the project.
There’s a transcript of the full presentation via ticklestuff) and here’s a video of the presentation:
↧
How to program an NES game in C
Thanks for visiting. Come back again, because I will make updates from time to time. All files updated, 02/09/2017. See Update link for details.
Vigilante Ninja 2 – my NES game is complete!
13. Sprite 0 Trick / Debugging
24. MMC3, Bank-switching, IRQs
25. Importing a MIDI to Famitracker
I’ve decided to add some examples, using the neslib code.
Sprite Collision, and Controllers
↧
Split User Stories Ruthlessly – And Get Value Earlier
Why do you need to split user stories?
Often, you hear that it is important to split user stories. You read articles that say it should be possible to complete a user story within a single sprint, ideally within a few days. That’s entirely accurate.
But the main benefit of splitting user stories is that you will deliver value faster!
Let’s take a look at an example. Say, we are developing a time tracking tool. Its main purpose is to analyse time spent on different projects.
Let’s also assume that we already have a prioritised backlog that looks like this:
- Enter timesheets
- Approve timesheets
- View time spent by project
At the first glance, the backlog looks reasonable. It appears to be prioritised and the user stories look small enough. But the devil is in the details. When you look at the the first story - ‘Enter timesheets’, you’ll see the following:
As a developer
I want to be able to log time spent on projects
So that the company could analyse time spent on different projects
**Acceptance criteria**
* Users select a project and enter hours spent for each day
* Users can add more lines for other projects
* Users can delete lines for projects
* If a user presses [delete] on an item with hours,
there has to be a confirmation pop-up
* There should be an area where a user can see total time spent per day
* We want a user to avoid making mistakes. If time soent is less or more than
8 hours per day it has to be coloured in red.
If it’s 8 hours plus/minus one hour, it should be coloured in green.
There’s also a mockup attached.

Well, that’s escalated quickly! A simple story has turned out into a collection of business rules!
It may seem that each rule is small enough and can be easily implemented. But don’t give in to that temptation!
Each rule is small enough, but in total they all will make up to a substantial amount of time to develop. That will, in turn, require a good amount of testing, as well.
So, let’s stop and think. What’s the proposition behind your product? It is analysis of time spent on different projects. There is even a user story for that. So, why don’t we go to that user story as fast as possible?!
And what is the main premise of the ‘Enter timesheets’ story? Well, that’s an ability to enter timesheets! So, let’s focus on that activity and try to move other bits into separate user stories.
If we look at the acceptance criteria, we’ll see that most of it is not about entering timesheets, but related functionality. For example, we want to have a variable number of activities (lines) per week. Then, we would like to see nice visual cues, if hours entered look wrong.
Those are great ideas, but do they help us to achive the overacrching product goal? No. So, let’s focus on what is really important. And split the user story into:
- Enter timesheets (3 activities per week)
- Visual cues when the hours entered doesn’t look right
- Have more than 3 activities per week
Now, we should go back to our backlog and re-prioritise it. We want to put the last two stories to the bottom of the backlog. At the end your backlog should look like:
- Enter timesheets (3 activities per week)
- Approve timesheets
- View time spent by project
- Visual cues when the hours entered doesn’t look right
- Have more than 3 activities per week
Always re-prioritise the backlog after splitting user stories. Otherwise, you would do the same things in the initial order and wouldn’t move towards your product goals fast enough.
Splitting user stories allows you to prioritise what is really important. And achieve the product goals faster.
You’ll probably have to repeat this exercise for ‘Approve Timesheets’ and ‘View time spent by project’. But I guess you’ve got the idea. You’ll end up with the Prioritise - Split - Prioritise cycle.

Another good way to look at is to revisit the famous picture of the iterative Mona Lisa (pictures below are credit of Jeff Patton - the inventor of User Story Maps)
Incremental Mona Lisa

Iterative Mona Lisa

Indeed, you don’t want to spend time painting the perfect top-left corner of the picture (the original ‘Enter Timesheets’ story). Instead, you want to sketch out the whole piece. That will already give users and stakeholders something to play with. Such early deliver will allow you to get feedback from users and learn from that.
I’ve focused on the benefits of splitting user stories here. But if you want to know more about techniques for splitting user stories and prioritising backlogs, then I would suggest the following reading:
↧
↧
An Intro to Compilers
How to Speak to Computers, Pre-Siri
August 13, 2017
tl;dr:Learning new meanings for front-end and back-end.
A compiler is just a program that translates other programs. Traditional compilers translate source code into executable machine code that your computer understands. (Some compilers translate source code into another programming language. These compilers are called source-to-source translators or transpilers.) LLVM is a widely used compiler project, consisting of many modular compiler tools.
Traditional compiler design comprises three parts:
- The Frontend translates source code into an intermediate representation (IR)*.
clangis LLVM’s frontend for the C family of languages. - The Optimizer analyzes the IR and translates it into a more efficient form.
optis the LLVM optimizer tool. - The Backend generates machine code by mapping the IR to the target hardware instruction set.
llcis the LLVM backend tool.
* LLVM IR is a low-level language that is similar to assembly. However, it abstracts away hardware-specific information.
Below is a simple C program that prints “Hello, Compiler!” to stdout. The C syntax is human-readable, but my computer wouldn’t know what to do with it. I’m going to walk through the three compilation phases to make this program machine-executable.
// compile_me.c
// Wave to the compiler. The world can wait.#include <stdio.h>intmain(){printf("Hello, Compiler!\n");return0;}The Frontend
As I mentioned above, clang is LLVM’s frontend for the C family of languages. Clang consists of a C preprocessor, lexer, parser, semantic analyzer, and IR generator.
The C Preprocessor modifies the source code before beginning the translation to IR. The preprocessor handles including external files, like
#include <stdio.h>above. It will replace that line with the entire contents of thestdio.hC standard library file, which will include the declaration of theprintffunction.See the output of the preprocessor step by running:
clang -E compile_me.c -o preprocessed.iThe Lexer (or scanner or tokenizer) converts a string of characters to a string of words. Each word, or token, is assigned to one of five syntactic categories: punctuation, keyword, identifier, literal, or comment.
Tolkenization of compile_me.c
![]()
The Parser determines whether or not the stream of words consists of valid sentences in the source language. After analyzing the grammar of the token stream, it outputs an abstract syntax tree (AST). Nodes in a Clang AST represent declarations, statements, and types.
The AST of compile_me.c


The Semantic Analyzer traverses the AST, determining if code sentences have valid meaning. This phase checks for type errors. If the main function in compile_me.c returned
"zero"instead of0, the semantic analyzer would throw an error because"zero"is not of typeint.The IR Generator translates the AST to IR.
Run the clang frontend on compile_me.c to generate LLVM IR:
clang -S -emit-llvm -o llvm_ir.ll compile_me.cThe main function in llvm_ir.ll
1
2
3
4
5
6
7
8
9
10
11
12
; llvm_ir.ll@.str=privateunnamed_addrconstant[18xi8]c"Hello, Compiler!\0A\00",align1definei32@main(){%1=allocai32,align4; <- memory allocated on the stackstorei320,i32*%1,align4%2=calli32(i8*,...)@printf(i8*getelementptrinbounds([18xi8],[18xi8]*@.str,i320,i320))reti320}declarei32@printf(i8*,...)
The Optimizer
The job of the optimizer is to improve code efficiency based on it’s understanding of the program’s runtime behavior. The optimizer takes IR as input and produces improved IR as output. LLVM’s optimizer tool, opt, will optimize for processor speed with the flag -O2 (capital o, two) and for size with the flag -Os (capital o, s).
Take a look at the difference between the LLVM IR code our frontend generated above and the result of running:
opt -O2 llvm_ir.ll -o optimized.llThe main function in optimized.ll
1
2
3
4
5
6
7
8
9
10
; optimized.ll@str=privateunnamed_addrconstant[17xi8]c"Hello, Compiler!\00"definei32@main(){%puts=tailcalli32@puts(i8*getelementptrinbounds([17xi8],[17xi8]*@str,i640,i640))reti320}declarei32@puts(i8*nocapturereadonly)
In the optimized version, main doesn’t allocate memory on the stack, since it doesn’t use any memory. The optimized code also calls puts instead of printf because none of printf’s formatting functionality was used.
Of course, the optimizer does more than just know when to use puts in lieu of printf. The optimizer also unrolls loops and inlines the results of simple calculations. Consider the program below, which adds two integers and prints the result.
// add.c#include <stdio.h>intmain(){inta=5,b=10,c=a+b;printf("%i + %i = %i\n",a,b,c);}Here is the unoptimized LLVM IR:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@.str=privateunnamed_addrconstant[14xi8]c"%i + %i = %i\0A\00",align1definei32@main(){%1=allocai32,align4; <- allocate stack space for var a%2=allocai32,align4; <- allocate stack space for var b%3=allocai32,align4; <- allocate stack space for var cstorei325,i32*%1,align4; <- store 5 at memory location %1storei3210,i32*%2,align4; <- store 10 at memory location %2%4=loadi32,i32*%1,align4; <- load the value at memory address %1 into register %4%5=loadi32,i32*%2,align4; <- load the value at memory address %2 into register %5%6=addnswi32%4,%5; <- add the values in registers %4 and %5. put the result in register %6storei32%6,i32*%3,align4; <- put the value of register %6 into memory address %3%7=loadi32,i32*%1,align4; <- load the value at memory address %1 into register %7%8=loadi32,i32*%2,align4; <- load the value at memory address %2 into register %8%9=loadi32,i32*%3,align4; <- load the value at memory address %3 into register %9%10=calli32(i8*,...)@printf(i8*getelementptrinbounds([14xi8],[14xi8]*@.str,i320,i320),i32%7,i32%8,i32%9)reti320}declarei32@printf(i8*,...)
Here is the optimized LLVM IR:
1
2
3
4
5
6
7
8
@.str=privateunnamed_addrconstant[14xi8]c"%i + %i = %i\0A\00",align1definei32@main(){%1=tailcalli32(i8*,...)@printf(i8*getelementptrinbounds([14xi8],[14xi8]*@.str,i640,i640),i325,i3210,i3215)reti320}declarei32@printf(i8*nocapturereadonly,...)
Our optimized main function is essentially lines 17 and 18 of the unoptimized version, with the variable values inlined. opt calculated the addition because all of the variables were constant. Pretty cool, huh?
The Backend
LLVM’s backend tool is llc. It generates machine code from LLVM IR input in three phases:
Instruction selection is the mapping of IR instructions to the instruction-set of the target machine. This step uses an infinite namespace of virtual registers.
Register allocation is the mapping of virtual registers to actual registers on your target architecture. My CPU has an x86 architecture, which is limited to 16 registers. However, the compiler will use as few registers as possible.
Instruction scheduling is the reordering of operations to reflect the target machine’s performance constraints.
Running this command will produce some machine code!
llc -o compiled-assembly.s optimized.ll_main:
pushq %rbp
movq %rsp, %rbp
leaq L_str(%rip), %rdi
callq _puts
xorl %eax, %eax
popq %rbp
retq
L_str:
.asciz "Hello, Compiler!"This program is x86 assembly language, which is the human readable syntax for the language my computer speaks. Someone finally understands me 🙌
Resources
↧
GoCardless (YC S11) Is Hiring Software Engineers/SREs/Data Scientists/PMs(London)
GoCardless Ltd. 338-346 Goswell Road, London, EC1V 7LQ, United Kingdom
GoCardless (company registration number 07495895) is authorised by the Financial Conduct Authority under the Payment Services Regulations 2009, registration number 597190, for the provision of payment services.
By continuing your visit to this site, you agree to the use of cookies. Learn more
↧
Why Women Had Better Sex Under Socialism
Ms. Durcheva was a single mother for many years, but she insisted that her life before 1989 was more gratifying than the stressful existence of her daughter, who was born in the late 1970s.
“All she does is work and work,” Ms. Durcheva told me in 2013, “and when she comes home at night she is too tired to be with her husband. But it doesn’t matter, because he is tired, too. They sit together in front of the television like zombies. When I was her age, we had much more fun.”
Last year in Jena, a university town in the former East Germany, I spoke with a recently married 30-something named Daniela Gruber. Her own mother — born and raised under the Communist system — was putting pressure on Ms. Gruber to have a baby.
“She doesn’t understand how much harder it is now — it was so easy for women before the Wall fell,” she told me, referring to the dismantling of the Berlin Wall in 1989. “They had kindergartens and crèches, and they could take maternity leave and have their jobs held for them. I work contract to contract, and don’t have time to get pregnant.”
This generational divide between daughters and mothers who reached adulthood on either side of 1989 supports the idea that women had more fulfilling lives during the Communist era. And they owed this quality of life, in part, to the fact that these regimes saw women’s emancipation as central to advanced “scientific socialist” societies, as they saw themselves.
Although East European Communist states needed women’s labor to realize their programs for rapid industrialization after World War II, the ideological foundation for women’s equality with men was laid by August Bebel and Friedrich Engels in the 19th century. After the Bolshevik takeover, Vladimir Lenin and Aleksandra Kollontai enabled a sexual revolution in the early years of the Soviet Union, with Kollontai arguing that love should be freed from economic considerations.
The Soviets extended full suffrage to women in 1917, three years before the United States did. The Bolsheviks also liberalized divorce laws, guaranteed reproductive rights and attempted to socialize domestic labor by investing in public laundries and people’s canteens. Women were mobilized into the labor force and became financially untethered from men.
In Central Asia in the 1920s, Russian women crusaded for the liberation of Muslim women. This top-down campaign met a violent backlash from local patriarchs not keen to see their sisters, wives and daughters freed from the shackles of tradition.
In the 1930s, Joseph Stalin reversed much of the Soviet Union’s early progress in women’s rights — outlawing abortion and promoting the nuclear family. However, the acute male labor shortages that followed World War II spurred other Communist governments to push forward with various programs for women’s emancipation, including state-sponsored research on the mysteries of female sexuality. Most Eastern European women could not travel to the West or read a free press, but scientific socialism did come with some benefits.
“As early as 1952, Czechoslovak sexologists started doing research on the female orgasm, and in 1961 they held a conference solely devoted to the topic,” Katerina Liskova, a professor at Masaryk University in the Czech Republic, told me. “They focused on the importance of the equality between men and women as a core component of female pleasure. Some even argued that men need to share housework and child rearing, otherwise there would be no good sex.”
Agnieszka Koscianska, an associate professor of anthropology at the University of Warsaw, told me that pre-1989 Polish sexologists “didn’t limit sex to bodily experiences and stressed the importance of social and cultural contexts for sexual pleasure.” It was state socialism’s answer to work-life balance: “Even the best stimulation, they argued, will not help to achieve pleasure if a woman is stressed or overworked, worried about her future and financial stability.”
In all the Warsaw Pact countries, the imposition of one-party rule precipitated a sweeping overhaul of laws regarding the family. Communists invested major resources in the education and training of women and in guaranteeing their employment. State-run women’s committees sought to re-educate boys to accept girls as full comrades, and they attempted to convince their compatriots that male chauvinism was a remnant of the pre-socialist past.
Although gender wage disparities and labor segregation persisted, and although the Communists never fully reformed domestic patriarchy, Communist women enjoyed a degree of self-sufficiency that few Western women could have imagined. Eastern bloc women did not need to marry, or have sex, for money. The socialist state met their basic needs and countries such as Bulgaria, Poland, Hungary, Czechoslovakia and East Germany committed extra resources to support single mothers, divorcées and widows. With the noted exceptions of Romania, Albania and Stalin’s Soviet Union, most Eastern European countries guaranteed access to sex education and abortion. This reduced the social costs of accidental pregnancy and lowered the opportunity costs of becoming a mother.
Some liberal feminists in the West grudgingly acknowledged those accomplishments but were critical of the achievements of state socialism because they did not emerge from independent women’s movements, but represented a type of emancipation from above. Many academic feminists today celebrate choice but also embrace a cultural relativism dictated by the imperatives of intersectionality. Any top-down political program that seeks to impose a universalist set of values like equal rights for women is seriously out of fashion.
The result, unfortunately, has been that many of the advances of women’s liberation in the former Warsaw Pact countries have been lost or reversed. Ms. Durcheva’s adult daughter and the younger Ms. Gruber now struggle to resolve the work-life problems that Communist governments had once solved for their mothers.
“The Republic gave me my freedom,” Ms. Durcheva once told me, referring to the People’s Republic of Bulgaria. “Democracy took some of that freedom away.”
As for Ms. Gruber, she has no illusions about the brutalities of East German Communism; she just wishes “things weren’t so much harder now.”
Because they championed sexual equality — at work, at home and in the bedroom — and were willing to enforce it, Communist women who occupied positions in the state apparatus could be called cultural imperialists. But the liberation they imposed radically transformed millions of lives across the globe, including those of many women who still walk among us as the mothers and grandmothers of adults in the now democratic member states of the European Union. Those comrades’ insistence on government intervention may seem heavy-handed to our postmodern sensibilities, but sometimes necessary social change — which soon comes to be seen as the natural order of things — needs an emancipation proclamation from above.
Continue reading the main story↧
Why Genghis Khan’s tomb can’t be found
This is an outsized land for outsized legends. No roads, no permanent buildings; just unfurling sky, tufted dry grass and streaming wind. We stopped to drink salted milk tea in nomads’ round ger tents and to snap pictures of roaming horses and goats. Sometimes we stopped just for the sake of stopping ‒ Ömnögovi Province, Mongolia, is endless by car. I couldn’t imagine tackling it on a horse.
But this is the country of Genghis Khan, the warrior who conquered the world on horseback. His story is full of kidnappings, bloodshed, love and revenge.
That’s just history. The legend begins with his death.
You might also like:
‒ Where the Earth’s mightiest army roamed
‒ Mongolia’s 6,000-year tradition
‒ A disappearing desert oasis
Genghis Khan (known in Mongolia as Chinggis Khaan) once ruled everything between the Pacific Ocean and the Caspian Sea. Upon his death he asked to be buried in secret. A grieving army carried his body home, killing anyone it met to hide the route. When the emperor was finally laid to rest, his soldiers rode 1,000 horses over his grave to destroy any remaining trace.
In the 800 years since Genghis Khan’s death, no-one has found his tomb.
Foreign-led expeditions have pursued the grave through historical texts, across the landscape and even from space ‒ National Geographic’s Valley of the Khans Project used satellite imagery in a mass hunt for the gravesite. But most interest in locating the tomb is international; Mongolians don’t want it found.
It’s not that Genghis Khan isn’t significant in his homeland ‒ quite the reverse. His face is on the money and on the vodka; he probably hasn’t been this popular since his death in 1227. So it can be difficult for outsiders to understand why it’s considered taboo to seek his grave.
Genghis Khan did not want to be found
The reluctance is often romanticised by foreign media as a curse, a belief that the world will end if Genghis Khan’s tomb is discovered. This echoes the legend of Tamarlane, a 14th-Century Turkic-Mongolian king whose tomb was opened in 1941 by Soviet archaeologists. Immediately following the tomb’s disturbance, Nazi soldiers invaded the Soviet Union, launching World War II’s bloody Eastern Front. Superstitious people might call that cause and effect.
But Uelun, my translator, was having none of it. A young Mongolian with a degree in international relations from Buryat State University in Ulan-Ude, Russia, she did not seem superstitious. In her opinion, it is about respect. Genghis Khan did not want to be found.
“They went through all that effort to hide his tomb,” she pointed out. Opening it now would violate his wishes.
This was a common sentiment. Mongolia is a country of long traditions and deep pride. Many families hang tapestries or portraits of the Grand Khan. Some identify themselves as ‘Golden Descendants’, tracing their ancestry to the royal family. Throughout Mongolia, the warrior remains a powerful icon.
The search for Genghis Khan’s tomb
Beyond cultural pressures to honour Genghis Khan’s dying wish for secrecy, a host of technical problems hinder the search for his tomb. Mongolia is huge and underdeveloped ‒ more than seven times the size of Great Britain with only 2% of its roads. The population density is so low that only Greenland and a few remote islands can beat it. As such, every view is epic wilderness. Humanity, it seems, is just there to provide scale: the distant, white curve of a herdsman’s ger, or a rock shrine fluttering with prayer flags. Such a landscape holds on to its secrets.
Dr Diimaajav Erdenebaatar has made a career overcoming such challenges in pursuit of archaeology. Head of the Department of Archaeology at Ulaanbaatar State University in Mongolia’s capital city, Dr Erdenebaatar was part of the first joint expedition to find the tomb. The Japanese-Mongolian project called Gurvan Gol (meaning ‘Three Rivers’) focused on Genghis Khan’s birthplace in Khentii Province where the Onon, Kherlen and Tuul rivers flow. That was in 1990, the same year as the Mongolian Democratic Revolution, when the country peacefully rejected its communist government for a new democratic system. It also rejected the search for Genghis Khan, and public protests halted the Gurvan Gol project.
Uelun and I met Dr Erdenebaatar at Ulaanbaatar State University to talk tombs ‒ specifically similarities between his current project and the resting place of Genghis Khan. Since 2001 Dr Erdenebaatar has been excavating a 2,000-year-old cemetery of Xiongnu kings in central Mongolia’s Arkhangai Province. Dr Erdenebaatar believes the Xiongnu were ancestors of the Mongols ‒ a theory Genghis Khan himself shared. This could mean similar burial practices, and the Xiongnu graves may illustrate what Genghis Khan’s tomb looked like.
Xiongnu kings were buried more than 20m underground in log chambers, with the sites marked above ground with a square of stones. It took Dr Erdenebaatar 10 summers to excavate the first tomb, which had already been hit by robbers. Despite this, it contained a wealth of precious goods indicating the Xiongnu’s diplomatic reach: a Chinese chariot, Roman glassware and plenty of precious metals.
Dr Erdenebaatar took me to the university’s tiny archaeology museum to see the artefacts. Gold and silver ornaments were buried with the horses sacrificed at the gravesite. He pointed out leopards and unicorns within the designs ‒ royal imagery also used by Genghis Khan and his descendants.
There already aren’t enough lifetimes for this work ‒ history is too big
Many believe Genghis Khan’s tomb will be filled with similar treasures gathered from across the Mongol Empire. It’s one reason foreign interest remains strong. But if the Grand Khaan was buried in the Xiongnu style, it may be difficult ‒ if not impossible ‒ to know for sure. Such a tomb could be hidden by simply removing the marker stones. With the main chamber 20m down, it would be impossible to find in the vastness of Mongolia.
When I asked Dr Erdenebaatar if he thought Genghis Khan would ever be found, he responded with a calm, almost indifferent, shrug. There already aren’t enough lifetimes for his work. History is too big.
A possible lead in a forbidden location
Folklore holds that Genghis Khan was buried on a peak in the Khentii Mountains called Burkhan Khaldun, roughly 160km north-east of Ulaanbaatar. He had hidden from enemies on that mountain as a young man and pledged to return there in death. Yet there’s dissent among scholars as to precisely where on the mountain he’d be ‒ if at all.
“It is a sacred mountain,” acknowledged Dr Sodnom Tsolmon, professor of history at Ulaanbaatar State University with an expertise in 13th-Century Mongolian history. “It doesn’t mean he’s buried there.”
Scholars use historical accounts to puzzle out the location of Genghis Khan’s tomb. Yet the pictures they create are often contradictory. The 1,000 running horses indicate a valley or plain, as at the Xiongnu graveyard. Yet his pledge pins it to a mountain. To complicate matters further, Mongolian ethnologist S Badamkhatan identified five mountains historically called Burkhan Khaldun (though he concluded that the modern Burkhan Khaldun is probably correct).
Theories as to Genghis Khan’s whereabouts hang in unprovable limbo
Neither Dr Tsolmon nor I could climb Burkhan Khaldun; women aren’t welcome on the sacred mountain. Even the surrounding area was once closed to everyone but royal family. Once known as the Ikh Khorig, or ‘Great Taboo’, is now the Khan Khentii Strictly Protected Area and a Unesco World Heritage site. Since achieving this designation, Burkhan Khaldun has been off-limits to researchers, which means any theories as to Genghis Khan’s whereabouts hang in unprovable limbo.
Honouring a warrior’s final wish
With the tomb seemingly out of reach, why does it remain such a controversial issue in Mongolia?
Genghis Khan is simply Mongolia’s greatest hero. The West recalls only what he conquered, but Mongolians remember what he created. His empire connected East and West, allowing the Silk Road to flourish. His rule enshrined the concepts of diplomatic immunity and religious freedom. He established a reliable postal service and the use of paper money. Genghis Khan didn’t just conquer the world, he civilised it.
Genghis Khan didn’t just conquer the world, he civilised it
He remains to this day a figure of enormous respect ‒ which is why Mongolians like Uelun want his tomb to remain undisturbed.
“If they’d wanted us to find it, they would have left some sign.”
That is her final word.
Join over three million BBC Travel fans by liking us on Facebook, or follow us on Twitter and Instagram.
If you liked this story, sign up for the weekly bbc.com features newsletter called "If You Only Read 6 Things This Week". A handpicked selection of stories from BBC Future, Earth, Culture, Capital and Travel, delivered to your inbox every Friday.
↧
↧
The Last American Baseball-Glove Maker Refuses to Die
This little brick factory isn’t supposed to be here. It should be in the Philippines, or Vietnam, maybe China. Not here, in the heart of Texas.
Baseball gloves, like many other things, aren’t really made in America anymore. In the 1960s, production shifted to Asia and never came back. It might be America’s favorite pastime, and few things are more personal to baseball-lovers than their first glove — the smell, the feel, the memory of childhood summers. But most gloves are stitched together thousands of miles away by people who couldn’t afford a ticket at Fenway Park.
The Nokona manufacturing facility in Nocona, Texas.
Photographer: Cooper Neill/Bloomberg
One company didn’t get the memo. Since the Great Depression, Nokona has been making gloves in a small town outside Dallas with a long history of producing boots and whips for cowboys. There’s a livestock-feed store next door to the factory, which offers $5 tours for visitors who want to see how the “last American ball glove” is made. You can watch employees weave the webbing by hand, feed the laces through the holes with needles, and pound the pocket into shape with a rounded hammer. The American flag gets stitched into the hide — and that, they say at Nokona, is more than just a business matter.
“Made in America means you believe in our country,” said Carla Yeargin, a glove inspector and tour guide at Nokona, where she worked her way up from janitor. “We have the love for the ballglove, because we made it here.”
And the final product could cost you 25 times more than a foreign-made version at the local discount store. Yes, that’s partly a reflection of the premium nature of the Nokona line but still it represents a huge challenge for the company, as well as for Donald Trump.
An employee uses a hammer-like machine to shape a glove.
Photographer: Cooper Neill/Bloomberg
“Making it here” is a big deal for the president. Last month Trump staged a week of events to celebrate U.S. manufacturing, showcasing products from Campbell’s soup to Caterpillar construction gear. July 17 was declared “Made in America Day.”
“Restoring American manufacturing will not only restore our wealth, it will restore our pride,” Trump said.
The president loves to use his bully pulpit to advance the cause, but it doesn’t always work. Trump threatened Ford over its plan to shift assembly of Focus cars to Mexico — and so the automaker moved operations to China instead. Plus, modern factories rely more on automation than ever, so even if production comes back, it might be done by robots.
There’s nostalgia in Trump’s rhetoric — critics would call it fantasy. He harkens to a time when the U.S. was the world’s biggest manufacturer, and Fords rolled off the assembly line into the driveways of upwardly mobile households.
By now, though, “supply chains have been so heavily outsourced that it’s no longer possible to buy American for some products,” said Mark Muro, a senior fellow at the Brookings Institution in Washington who studies advances in manufacturing. “The suppliers don’t exist. In some instances, it’s too little, too late.”
Trump’s message also represents a break from the globalization gospel preached by his predecessors, as they pushed for trade deals that would bring emerging giants such as China into the capitalist fold. Offshoring production was seen as acceptable, because it would make American economies more competitive. That, added to cheap imports, would leave the U.S. economy better off.
Economists are waking up to the limits of that logic. Voters have been awake for a while — especially in the Rust Belt towns, hollowed out by industrial decline, which swung last year’s election for Trump.
“For 30 years, this country all but neglected any serious challenge to a globalist view of sourcing,” Muro said.
Nokona refused to follow the herd.
A Nokona employee assembles a ballglove.
Photographer: Cooper Neill/Bloomberg
After the Civil War, ranchers drove longhorn cattle through Montague County to livestock markets in the north. The town of Nocona, located some 100 miles northwest of Dallas and named after a Comanche chief (hence the Native American-in-headdress logo on Nokona gloves), developed a reputation as a leather-goods hub.
The company’s name is spelled with a “k” because it was told in the 1930s that the town’s name couldn’t be trademarked. Today, Nocona is home to about 3,000 people and a few stoplights. “God Bless America” banners line the street, and locals wish you a “blessed day.”
Founded in 1926, the company originally made wallets and purses. It was a former Rice University baseball player named Roberts Storey who steered Nokona into ballgloves.
In the early days of baseball, it was considered unmanly to use a glove. Broken bones were common. The first mass-produced gloves had little padding and no fingers. In the 1920s and ’30s, companies started producing gloves with a web between the thumb and forefinger, to create a pocket.
The shift to Asia in the 1960s nearly put Nokona out of business. Storey wouldn’t budge. “It hit him all wrong that we would have to go to Japan,” said his grandson Rob Storey, now the company’s executive vice president. “One of his favorite sayings was: ‘If I have to tell my employees we’re closing up and they don’t have jobs any more, I may as well get a bucket of worms and go fishing’.”
An employee shapes a Nokona glove on hot steel fingers.
Photographer: Cooper Neill/Bloomberg
It hasn’t been an easy faith to keep. The company went bankrupt in 2010, but kept producing after a Phoenix-based maker of football gloves bought a majority stake. And cracks are starting to show in Nokona’s claim to be all-American. It recently started importing partially assembled gloves from China, made of Kip leather, a luxury cowhide.
Still, 98 percent of its gloves are made at the factory in Nocona. The nutty scent of leather fills the place. In the lobby, samples of the company’s work over the decades are displayed on the wall, from wallets to football pads. When you buy a glove, the cashier Helen — who’s worked there for 55 years — writes out a receipt by hand.
Making a glove involves about 40 steps and can take four hours. Hides, mostly from Chicago or Milwaukee, are tested for temper and thickness. Workers lower presses onto metal dies to cut the leather. The pieces — some models require 25 of them — are sewn together, joining the inner and outer halves. The product is turned right-side-out and shaped on hot steel fingers. A grease used during World War II to clean rifles is lathered under the pocket, to keep it flexible.
The company emphasizes the craft that goes into each glove, and that’s reflected in the bill. Rawlings has gloves for all budgets: Its top-end models cost plenty, but you can get a 9-inch children’s version for less than $8. Nokona’s equivalent-sized mitt costs $220, and its pro model runs to $500.
A finished glove waits to be packaged.
Photographer: Cooper Neill/Bloomberg
Like many made-in America holdouts, they’re always going to be niche products. Making them isn’t going to generate jobs on the scale Trump wants.
Nokona ships about 40,000 gloves a year, a fraction of the 6.2 million sold annually in the U.S. It employs about 35 people at the Texas plant. Storey won’t disclose the privately held company’s revenue. “Will we ever be Nike? No.” But he says it’s profitable. Trump got 88 percent of votes in the county and Storey counts himself a supporter. He welcomes White House support for domestic manufacturers: “It’s music to our ears.”
It’s also hard to compete with the big brands — Rawlings, Wilson, Mizuno — for Major League endorsements. Some companies pay players to use their gloves. Nokona has one superstar admirer: Texan legend and Hall of Famer Nolan Ryan, whose first glove was a Nokona, and who’s appeared in the company’s ads. But it only has about a dozen current top-level players signed up.
Up against so many odds, why doesn’t Nokona give in and go offshore?
“Because I’m crazy,” says Storey. “This is all I know how to do.”
↧
Make flexible road routing at least 15 times faster
The latest release 0.9.0 has a new “landmark algorithm”. We introduced it as a new, third option and called it “hybrid mode” as it combines the advantages of the flexible and the speed mode. The initial algorithm was implemented fast but the implementation details got very tricky at the end and so this took several months before we could include this feature in a release.
Let us introduce you to the old routing “modes” of the GraphHopper routing engine first, before we explain the meaning and details of the new landmark algorithm.
Flexible Routing Algorithm
The GraphHopper routing engine comes with the Dijkstra algorithm exploring a road network, where every junction is a node and roads connecting the junctions are the edges in the mathematical graph model. The Dijkstra algorithm has nice properties like being optimal fast for what it does and most importantly being able to change requirements per request. So if you want to route from A to B and you want to avoid motorways or tolls or both you can easily change these requirements per request. There are also the faster, still optimal bidirectional or goal directed variants. The speed up there is approx. 4 times. Note that this speed-up is often very similar to the explored nodes in the graph and so here we do a comparison of the different algorithms based on the visited nodes via a ~130km example route:
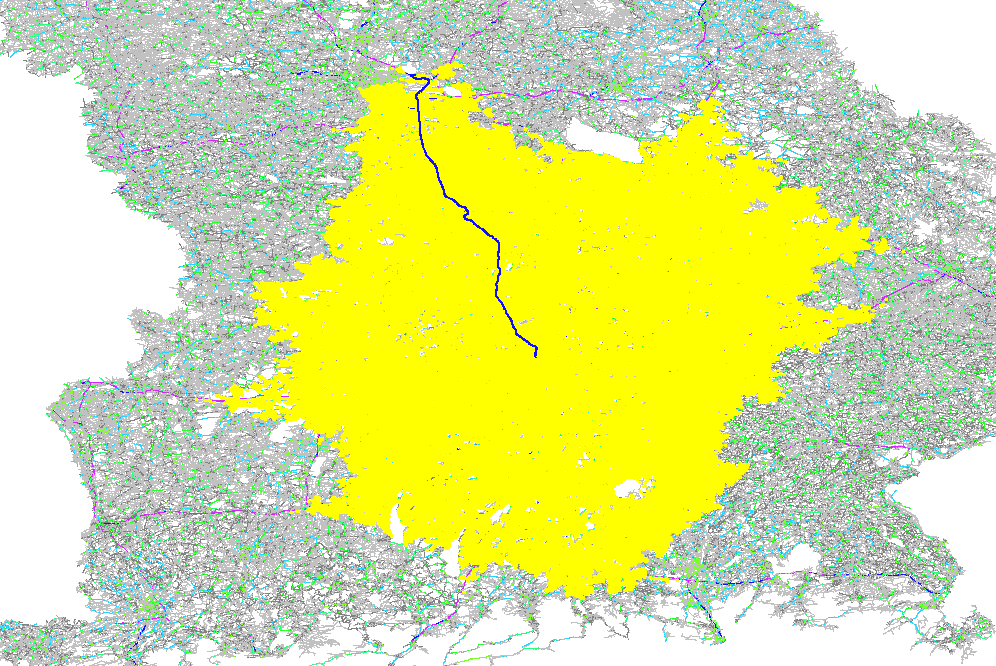
Unidirectional Dijkstra with 500K visited nodes
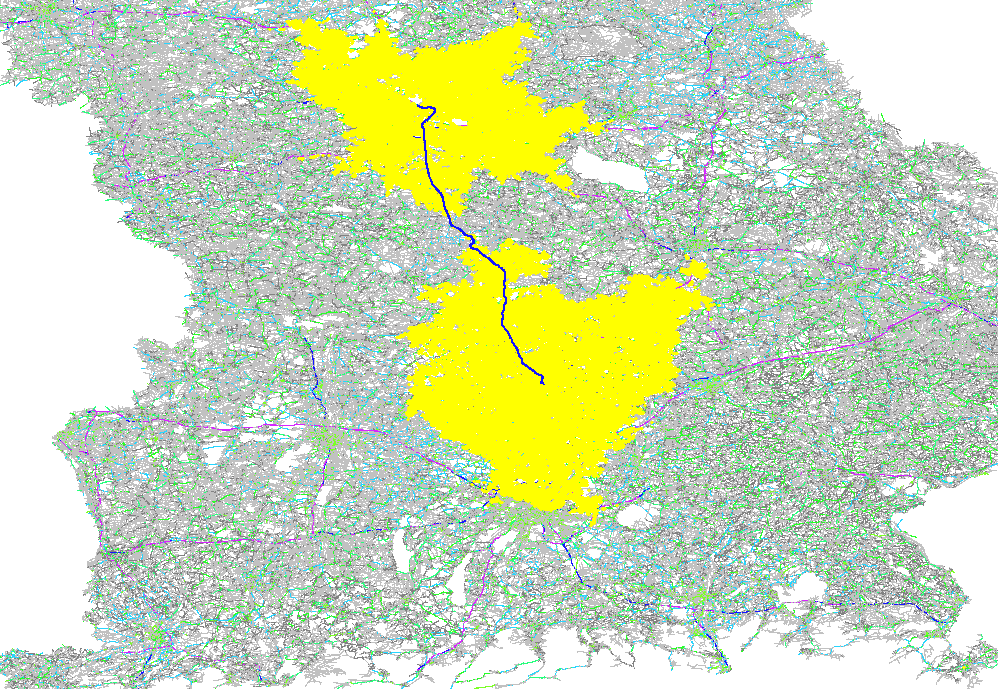
Bidirectional Dijkstra with 220K visited nodes
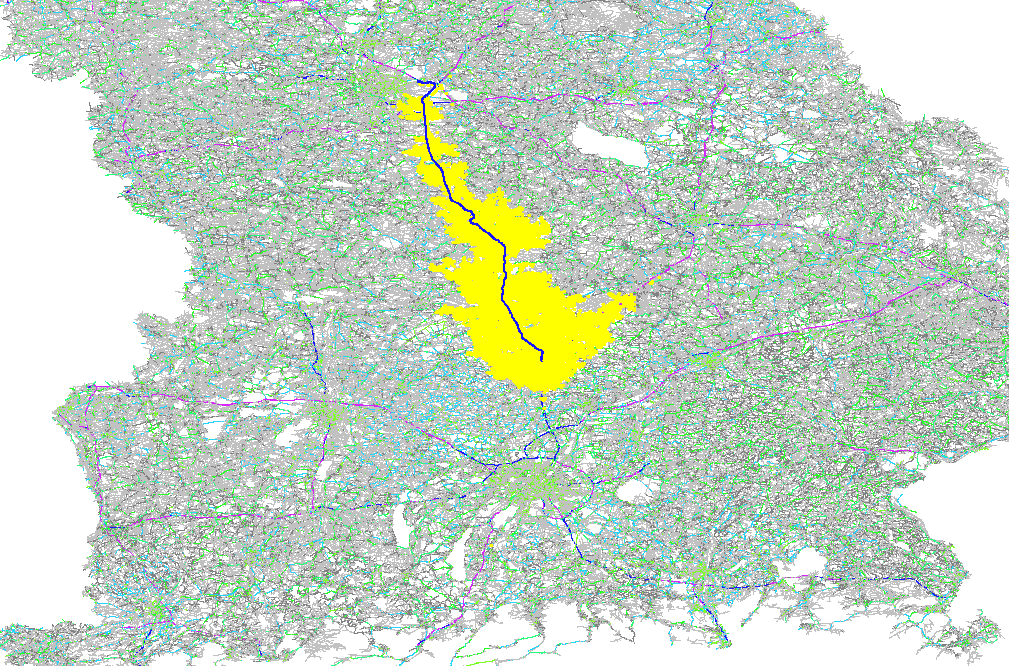
Unidirectional A* with 50K visited nodes
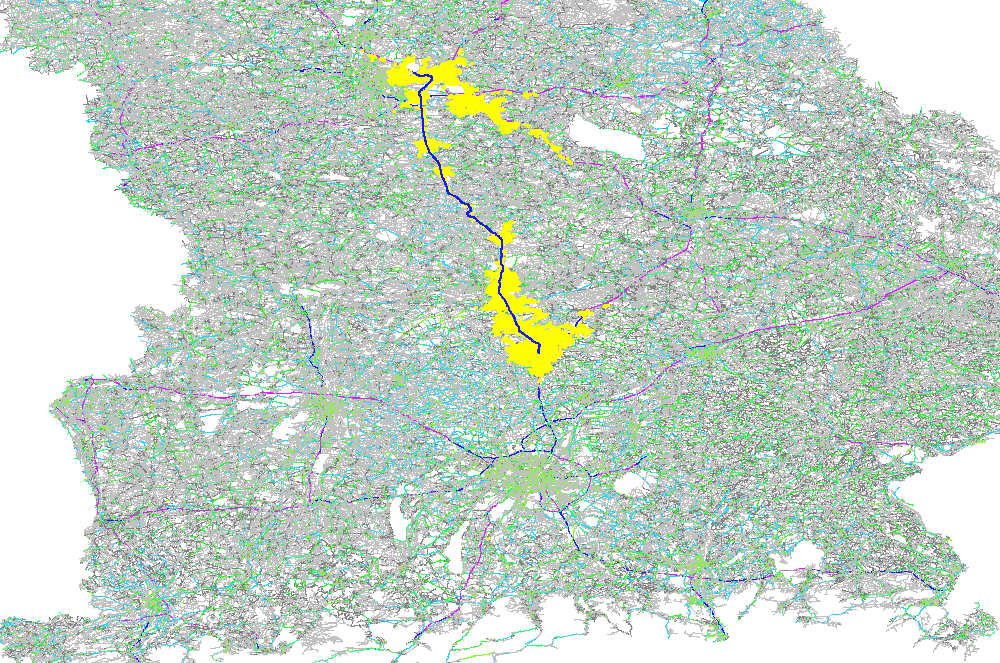
Bidirectional A* with ~25K visited nodes
Note that GraphHopper is able to change the cost function used to calculate the best path on the fly, e.g. you can change the shortest or fastest path per request. This cost function is called the “weighting” internally which is independent of the calculation used for the time of the route.
The problem with Dijkstra and also A* is that these algorithms are still too slow for most real world graphs. GraphHopper does its best and serves responses for A* in roughly a second on average even for longer country wide routes, but tuning it lower than this is hard if you want to keep flexibility and optimality. And routing through a continent or several countries is only reasonably doable if you tune your algorithm to special use cases or if you sacrifice optimality. Even with current hardware.
Fast Routing Algorithm
Researchers of the KIT have invented many nice routing algorithms and one of them was “Contraction Hierarchies” (CH), which is still a bidirectional Dijkstra but works on a “shortcut graph” giving response times of under 100ms for routes across a whole continent. Some researchers might be nitpicking and say we have a slow implementation but probably they measure response times for just the distance calculation. Here we are talking about the full route calculation, with getting the instructions and geometry (without latency) in under 100ms and of course this is much faster for country-wide queries.
The visited nodes picture looks very sparse:
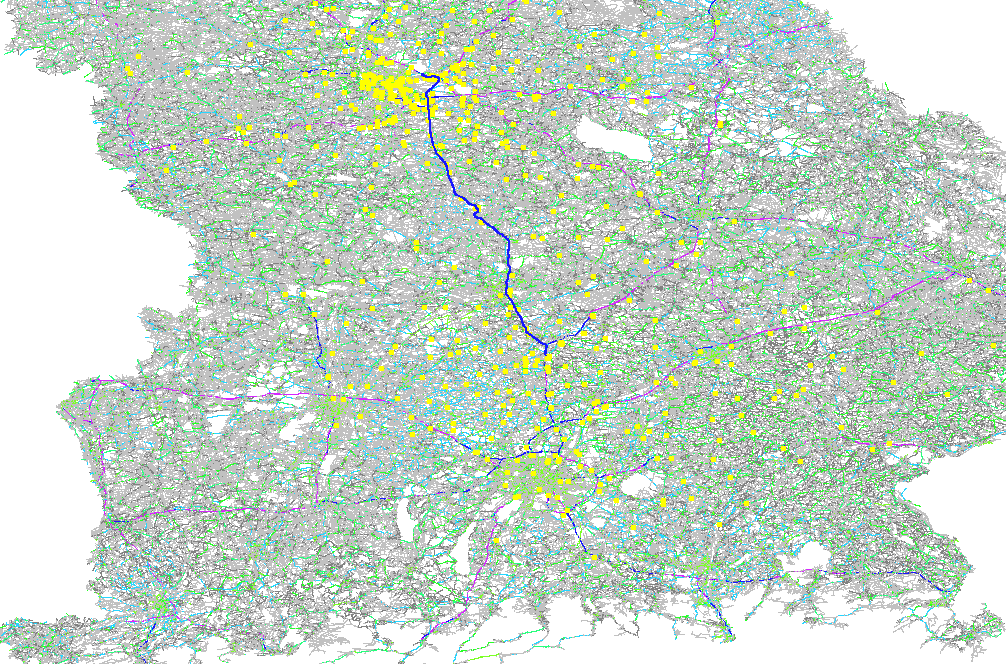
Contraction Hierarchies with ~600 visited nodes
Our new kid on the road: landmark algorithm
The newly developed landmark algorithm is an algorithm using A* with a new heuristic based on landmarks and the triangle inequality for the goal direction. Note that despite using this heuristic the algorithm still returns optimal routes. Also, this algorithm was developed earlier than CH so only “new” in GraphHopper.
The idea
For this algorithm we need a few landmarks that indicate where the graph “looks” beneficial to explore. A landmark can be any node of the graph and to make the algorithm work we have to calculate distances from these landmarks to all nodes of the graph. So assume the following graph, where the number between the nodes is the distance (“edge weight”) and node 1 and 4 are our two landmarks:
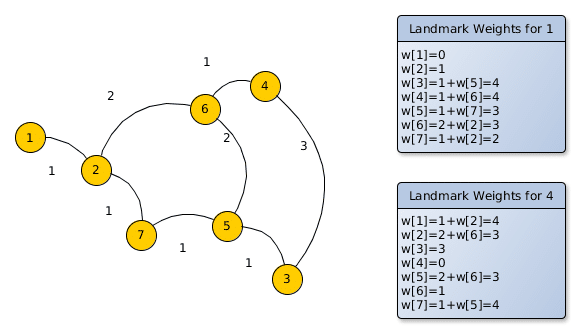
The tables on the right show the distances for the two landmarks to all the other nodes. For example the pre-calculated weight for landmark “node 1” from node 2 is 1km, from node 3 it is 4km and so on. The same for the landmark “node 4”: the weight from node 1 is 4km, from node 2 it is 3km and so on. This means if you want to route from node 3 to the landmark “node 4” you already know the best weight, which is 3km or from node 3 to the landmark “node 1” it is 4km. But how would you use these landmark weights for arbitrary queries? The idea is to use A* which requires a weight approximation and you normally get the approximation w(XD) to the destination D via beeline estimates, now in this algorithm the triangle inequality is used. The only requirement is that this weight should not be overestimated:
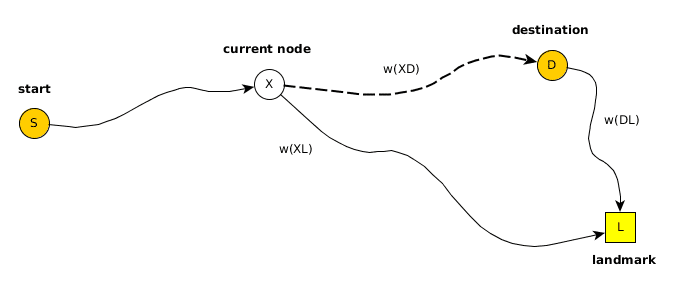
w(XD) + w(DL) >= w(XL)
w(XD) >= w(XL) – w(DL)
In real world we can pre-calculate w(DL) for all landmarks. The rest of the implementation is a bit more complex as the graph is directed and you have more landmarks, and other stuff that we’ll highlight later on. The good news is that we are allowed to pick the maximum of all calculated values for the different landmarks.
Here it is important to highlight the limitation of this algorithm compared to the flexible mode: without recalculating the landmark weight tables we can only increase an edge weight. If we would do a decrease the resulting routes could be suboptimal. But for most scenarios this works nicely (traffic jams make your weights higher) or you can invert the requirement to make the rest slower. Furthermore for all the other scenarios where this is not possible or to complex a recalculation of the landmark weights is fast even in the world wide case and can be made parallel.
How to pick the best landmarks?
To pick the best landmarks we are not using a completely random algorithm, which would be fast but we would get no real speedup. Instead we pick only the first node at random, then search the farthest node which is our first landmark. Then start from this landmark 1 to search again the farthest node being our landmark 2. And now we put these two landmarks as start in our graph search to search landmark 3 which is farthest from 1 and 2. And so on. This results in landmarks at the boundary of our graph and roughly equally spread, which is exactly what we need.
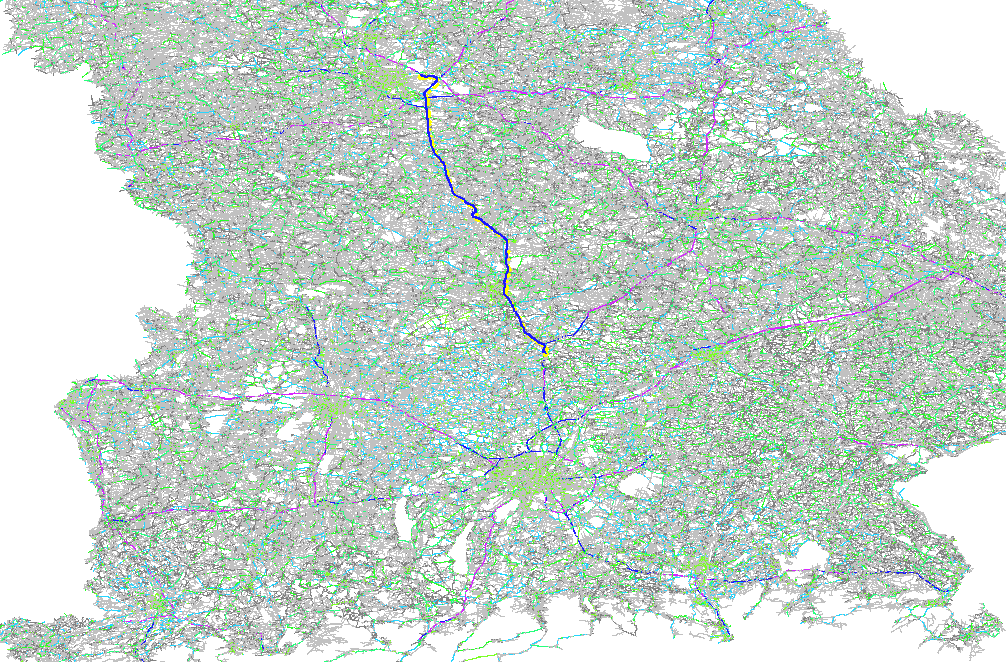
This search can be independent on the used weighting. We initially started with shortest and it works mostly, but for bigger continental scale it was producing strange clustered landmarks leading to slower results compared to handpicked landmarks. So what we really wanted is not a ‘farthest’ in terms of geometry but ‘farthest’ in terms of the density or topology of the graph. I.e. an equal distance between the nodes and so a simple breadth-first search resulted in the best quality. Here is an example of Bavaria a part of south Germany:
Automatic Landmark Selection for Bavaria, Germany
For every request it turns out that not all landmarks are equally usable and we pick a set of active landmarks. This could be dynamically changed but in our tests this didn’t improve the query speed consistently.
Visited Nodes
As we picked a bit extreme example route the visited nodes for the landmark algorithm look even better than that of the CH calculation, which is not the case on average:
landmark algorithm with only ~300 visited nodes
Here we’d like to highlight again that the landmark algorithm can be very efficient compared to the normal A*:
Bidirectional A* with ~25K visited nodes
QueryGraph
As already mentioned above our underlying data structure knows only nodes that are junctions. But how would we handle a start or destination that starts somehow on an edge? We introduce so called “virtual nodes” (and virtual edges) in our graph that live only in an isolated QueryGraph for the time span of the request. With this concept the underlying algorithm does not need to know about such virtual query nodes (and edges). The problem for the approximated weights for the landmarks algorithm is that the pre-calculated values are only done for the junction nodes and we have to carefully pick the correct weight of the neighboring junction node to maintain correctness. So the approximation procedure needs to be aware of virtual nodes, which is a bit unsatisfying but seems to be necessary.
Subnetworks
You have to calculate landmarks for every subnetwork. We had the subnetwork algorithm already there (Tarjan) and reused this algorithm. Coming to this conclusion was the trickiest conclusion, as we previously assumed a simple connectivity check would be sufficient, but real world showed it was not.
Storage
You can calculate the storage requirement as follows. A good start are 16 landmarks and lets say we use Germany. Germany has roughly 9 mio edges and we store the distance in a short (2 bytes) and this is necessary for forward and backward direction of every edge, then we need 2*2*16*9mio bytes, i.e. ~550MB just for this speedup data which is twice as large as the speedup data for CH but the 16 landmarks are created faster. Although GraphHopper supports memory mapping you should use the default “in-memory” configuration to keep everything fast. And because of this we cannot waste memory and have to make compromises on the way to achieve this, just to make it working on a global scale.
One of the compromise is to store every distance in a short. This is not easy if you have both: short edges and long ferry ways across a continent. And so we artificially disallow routing across certain borders e.g. currently only within Europe, within Africa, Russia and South-East Asia. We think this cutting is reasonable for now and are then able to store 16 landmarks in ~5GB of memory for the world wide case per precomputed vehicle profile.
Results
The query speed for cross country are as follows where we always picked 8 as active landmarks.
| Landmarks | Average Speed/ms | Speed up compared to A* (~1.2s) |
| 16 | 72 | 17x |
| 32 | 46 | 26x |
| 64 | 33 | 36x |
For this specific test we used the OpenStreetMap data from 16.02.2017 for Germany with 8.6 mio nodes and 10.9 mio edges in the road network.
Conclusion
This is a really good speed improvement compared to the flexible routing with Dijkstra or A*. Still the speed of contraction hierarchies is ~10 times faster on average. The speed advantage of CH gets lost as soon as we go into a more dynamic scenario like with traffic information or blocking certain roads and also handling other scenarios where we consider the heading of a vehicle are straightforward to implement with the landmarks algorithm but complex with CH.
The downsides of this new ‘hybrid mode’ compared to the flexible mode are that it requires substantially more memory and changing edge weights has to be done carefully. Furthermore if you force the algorithm to take completely different routes than the best ones, e.g. with a per-request requirement to avoid a whole country, then the performance degrades to the one of A*.
↧
Snapchat now lets you Pikachu yourself

Snapchat is teaming up with The Pokémon Company to introduce a new Pikachu filter to the app. The official Pikachu filter applies the electric mouse’s trademark rosy cheeks, pointy ears, black nose and big eyes to faces in the app, and when users open their mouth the iconic Pikachu cry rings out as an animated version of the characters leaps into frame.
The Pikachu filter is a pretty perfect tie-in for Snapchat, which aims at a demographic that is already pretty gaga for the most recognizable of Nintendo’s pocket monsters. Plus, Snapchat could use some brand juice, and Pokémon and Pikachu have prove to offer that for a lot of other platforms, including any of Nintendo’s hardware consoles and even AR via Pokémon Go.
Snapchat’s Pikachu filter is a limited run option, so if you want to capture yourself looking like Ash’s best pal you’d better get on it. The best strategy is probably to stockpile a wide range of selfies of yourself as Pika so you have one for every possible emotional response you can possibly make.
Will Snapchat Pika reach the lofty heights of Dancing Hot Dog? Only time will tell.
↧
Amazon recalls eclipse glasses
Amazon issues recall for some eclipse glasses
PORTLAND, Ore. – On Saturday, KGW’s photography staff received an email from Amazon, explaining the solar filters the station purchased for the Aug. 21 total solar eclipse were not confirmed safe for viewing.
The lens caps had the proper ISO number, 12312-2, which has been verified to comply with international safety standards. Amazon on Saturday said the supplier could not confirm the item came from a recommended manufacturer.
“We recommend that you DO NOT use this product to view the sun or the eclipse,” Amazon wrote.
Many other people received similar emails from Amazon for eclipse glasses, as stores are selling out of the hot-ticket items with one week to go before the eclipse. But some verified sellers of glasses say their products are under an Amazon recall, and they're stunned by the corporation's actions just one week before the eclipse takes place.
Amazon recalls eclipse glasses out of 'caution'
At least a dozen KGW viewers said they received recall notices from Amazon Saturday.
Portland resident Dan Fellini bought a pack of four solar eclipse glasses with his wife and a friend.
“Just last night we were talking about the glasses, and thinking maybe we shouldn't trust them, even though the Amazon page made it fairly clear they were legit,” he said.
At 2:05 a.m. Fellini received a recall email from Amazon.
Another Portland resident, Will Clark, bought eclipse glasses billed as “CE and ISO tested, safe solar viewing.” He received a recall email Saturday morning at 7:28 a.m.
KGW viewer Heather Andersen said she bought two separate sets of solar glasses and learned both were not verified.
“I give up,” she tweeted.
Amazon is issuing full refunds. An Amazon spokesperson said Amazon is responding "out of an abundance of caution."
"Safety is among our highest priorities. Out of an abundance of caution, we have proactively reached out to customers and provided refunds for eclipse glasses that may not comply with industry standards. We want customers to buy with confidence anytime they make a purchase on Amazon.com and eclipse glasses sold on Amazon.com are required to comply with the relevant ISO standard," the company said in a statement.
Amazon said customers who did not receive an email purchased glasses that were safe to use. The company did not reveal how many glasses were recalled or how much money was refunded.
Anyone who is concerned about their eclipse glasses but did not receive an email about the recall can reach out to Amazon customer service.
Amazon suggested customers refer to the NASA and AAS websites for more information about safely viewing the solar eclipse.
Recall stuns U.S. Amazon sellers
Two separate Amazon solar eclipse glasses sellers called KGW Saturday following Amazon's recall. Both said their products were verified as safe and manufactured by companies approved by NASA. But their glasses are still under a recall.
Manish Panjwani's Los Angeles-based astronomy product business, AgenaAstro, has sold three times its average monthly revenue in the past month. Ninety-five percent is related to the solar eclipse. He hired seven extra temporary workers just to help with the pre-eclipse boom.
Panjwani's eclipse glasses come from two NASA-approved sellers: Thousand Oaks Optical in Arizona and Baader Planetarium in Germany. He said he provided documentation to Amazon proving the products' authenticity weeks ago, with no response from Amazon.
On Saturday morning, he woke up to 100 emails from customers after Amazon issued a recall for his products.
"People have some of the best glasses in the world in their hands right now and they don't believe in that product," he said. "They're out there looking for something inferior."
Panjwani said Amazon is temporarily retaining some of his profits because of the recall.He also has almost 5,000 glasses at an Amazon warehouse, which customers can no longer purchase.
"That's just sitting there. I cannot sell it and I cannot get it back in time for the eclipse," he said.
Amazon sent Panjwani this statement following the recall:
“Due to the evolving circumstances around Eclipse glasses, it’s important that you have funds available to address customer returns. We will be holding back a portion of your funds from prior sales of Eclipse glasses and will continue to evaluate the need to hold a reserve for these funds. As we learn more about the safety concerns related to Eclipse glasses, we'll assess changes regarding your disbursement reserve balance."
A second eclipse glasses seller based in Tucson, Ariz., Lunt Solar System, said their products are also verified but under a recall anyway.
Amazon did not respond to KGW's specific questions about the sellers.
"Customers may have purchased counterfeit versions of legitimate products," an Amazon spokesperson said when asked about the issue.
Approximately 1 million people are expected to travel to Oregon for the eclipse. The path of totality runs through Lincoln City, Salem, Madras and John Day.
NASA list of reputable solar eclipse glasses sellers
Published August 12, 2017
↧
↧
SoftBank’s $100B fund is in a league of its own

For the average American, the name “SoftBank” doesn’t mean much.
It’s neither soft nor, technically, a bank. It’s a sprawling Japanese mobile carrier, internet service provider and holding company for other businesses ranging from cloud services and self-driving cars to energy trading. And its investment arm has bankrolled some of the world’s largest and most successful upstart technology companies, including many with serious name recognition here in the U.S.
Like many large corporations, SoftBank invests its cash across a broad portfolio of asset classes. It also invests some of its substantial capital reserves in earlier-stage technology companies. So where does that cash go, and how is it doled out to startups across the globe?
SoftBank is not your typical CVC setup
In most cases, corporate venture capital funds (CVCs) are named after their corporate parents. True to the parental metaphor, most of these CVCs receive an ongoing allowance from their corporate sponsors, with no outside money joining the capital pool. Accordingly, it’s often thought that CVCs are beholden only to the corporation and its strategic initiatives.
This is not necessarily the case with SoftBank’s investment arm. Although SoftBank does invest its own money in startups, and it has been doing so since 1995 under the aegis of SoftBank Capital, a new fund raised by the company’s founder and CEO, Masayoshi Son, blurs the traditional CVC model.
According to research done by the Financial Times, Softbank’s new fund, called the “Vision Fund,” has raised quite a bit of money from partners, including:
- $45 billion from Saudi Arabia’s Public Investment Fund.
- $15 billion from Abu Dhabi’s Mubadala Investment Company.
- $1 billion from Apple.
- $1 billion from Sharp.
- $3 billion from Qualcomm, Foxconn and Oracle founder Larry Ellison’s family office.
- $28 billion of SoftBank’s own capital.
According to June 2017 SEC filings, that’s some $93 billion in total. That leaves $7 billion to go to meet a publicly stated target fund size of $100 billion by November 2017, six months after the initial close. Crunchbase News has learned that the fund is intended to be deployed over five years, with anywhere between seven and nine years to mature before distributing assets back to investors.
This mixing of assets from multiple partners — both strategic and not — combined with an unorthodox leveraged financial structure and a decision-making framework that makes Masayoshi Son the final arbiter of deals, to say nothing of the sheer scale of the fund, is unusual.
From an outside perspective, it seems like Son has made a kind of Faustian bargain. SoftBank has partnered with some of the world’s most influential investors in the interest of furthering his 300-year plan to build the largest company on the planet. In doing so, SoftBank runs the very real risk of overwhelming markets for late-stage venture capital, private equity and post-IPO equity deals, which already have a lot of cash chasing relatively few opportunities.
In the following sections, we’ll compare SoftBank’s investing style to other CVC groups, chart the growth of its venture capital and private equity investments over time and discuss some of the challenges SoftBank’s Vision Fund may face over its 12-year cycle.
Even with a unique CVC structure, SoftBank doesn’t break the mold
As mentioned earlier, SoftBank began its corporate venture capital practice — SoftBank Capital — in 1995. It quickly found success with early investments in Yahoo, Alibaba and Huffington Post, among other notable deals.
For a 20-year run between 1995 and 2015, when SoftBank’s then newly appointed president Nikesh Arora made the decision to start winding down SoftBank Capital, SoftBank Capital was one of the top CVC shops around.
Even over the last five years, including the two years where SoftBank Capital was on its way out, the company’s early-stage investing style didn’t meaningfully deviate from other CVCs at leading technology companies. Based on Crunchbase data for 1,200 deals made by SoftBank and four of the other most active corporate venture groups backed by big tech conglomerates, we can see that SoftBank ranks among the most active CVCs.

In terms of the rounds that have been publicly surfaced, we can see that SoftBank may not have been the most active CVC. Regardless, it’s in the top 2 percent of corporate investors by VC, private equity, venture debt and post-IPO financing activity overall.
In early-stage, SoftBank was about average
Although SoftBank has lately been swimming in deeper capital pools, its early-stage investing practice hasn’t been all that different from other leaders of the CVC pack. Here’s a chart which averages out 799 Seed, Series A, Series B and Series C deals led or participated in by these top five corporate venture investors between January 2012 and August 2, 2017.

On average, the size of SoftBank’s early-stage venture capital deals were more or less in line with the company’s CVC peers, at least in terms of straight averages.
So, at least for SoftBank’s early-stage investing practice, the firm really was just another garden variety CVC. However, with the decline of SoftBank Capital and the rise of the new Vision Fund, early-stage investments would be “more of the exception than the rule,” Arora told ReCode in an interview announcing the decision.
SoftBank’s investment pivot
The Vision Fund is a significant departure from SoftBank’s previous investing style, even when including other CVCs. Although the new $100 billion fund was just announced in the late Spring of 2017, the decision to wind down early-stage venture capital investing was made in 2015. In the same interview with ReCode, Arora suggested that “the way to preserve the long-term sustainability of SoftBank is to be large minority shareholders of many assets.”
And it’s possible to see, in the intervening years between largely ending its early-stage investing initiatives and announcing the Vision Fund, that SoftBank had been busy establishing a track record of playing in what Arora characterized as “the large-check marketplace.” Although it’s hard to know exactly how much capital SoftBank has invested in individual rounds, we can sum the total amount of capital raised in VC and PE rounds in which SoftBank was either a participant or the lead investor.

Year-to-date in 2017, SoftBank was a lead or participant in over $14 billion worth of venture capital and private equity rounds alone. This does not account for SoftBank’s $4 billion post-IPO investment in Nvidia in May, any non-PE or VC financings or other funding events that haven’t yet been announced. And given that SoftBank seems to be announcing new deals every week or two these days, the chart above is likely to be out of date very soon. (Update: Softbank didn’t take long to prove us right.)
Visualized a different way, we can see how SoftBank has consistently ramped up the size of checks it’s willing to write. Below is a logarithmically scaled (i.e. by powers of 10) plot of SoftBank’s VC, PE and post-IPO financing events since the beginning of 2012.

To put this in perspective, in just five short years, the average round in which SoftBank invests has grown by approximately two orders of magnitude, from the low seven figures to the mid-to-upper nine figures.
Deploying $100 billion is harder than it looks
The challenge, of course, is that SoftBank now has to deploy two pools of capital: the Vision Fund and its own corporate cash. Crunchbase News has learned that Vision Fund will be SoftBank’s primary investment vehicle, with preferred access to deals over $100 million. SoftBank declined to comment on the record.
At the time of writing, Crunchbase data shows that, globally, there were just 126 VC, PE and post-IPO equity financing rounds larger than $250 million. (We chose $250 million because it’s a round number and also the amount SoftBank invested in business lending platform Kabbage’s Series F.) In U.S.-based companies, there were just 50 rounds of that size closed in 2016.
Even if the global venture capital and private equity markets continue to recover from their mid-2016 lows, and there are more of these quarter-billion-plus rounds, it’s still going to be difficult to invest that capital judiciously. In a good year, $100 billion is about the size of the entire global VC market. To fill out the rest of the Vision Fund, it’s likely we’re going to see more deals like the $32 billion all-cash buyout of ARM that SoftBank completed in July 2016. As it stands, the Vision Fund now holds 25 percent of ARM, the now $5 billion stake of Nvidia, as well as equity stakes in a few startups financed directly by Vision Fund. It’s also possible that marginal shares of other recent large-dollar investments previously made by SoftBank could be absorbed into Vision Fund.
Arora told Recode the large-check marketplace is “less crowded,” noting that “it’s a smaller universe of companies we have to understand and support.” What he didn’t say, though, was that a constrained universe of big deals is a kind of double-edged sword. This being said, SoftBank shows no indication it’s going to be falling on it anytime soon.
Featured Image: iStockPhoot UNDER A winhorse LICENSE↧
Efficient Immutable Collections [pdf]
↧
The AMD Radeon RX Vega 64 and RX Vega 56 Review: Vega Burning Bright
We’ve seen the architecture. We’ve seen the teasers. We’ve seen the Frontier. And we’ve seen the specifications. Now the end game for AMD’s Radeon RX Vega release is finally upon us: the actual launch of the hardware. Today is AMD’s moment to shine, as for the first time in over a year, they are back in the high-end video card market. And whether their drip feeding marketing strategy has ultimately succeeded in building up consumer hype or burnt everyone out prematurely, I think it’s safe to say that everyone is eager to see what AMD can do with their best foot forward on the GPU front.
Launching today is the AMD Radeon RX Vega 64, or just Vega 64 for short. Based on a fully enabled Vega 10 GPU, the Vega 64 will come in two physical variants: air cooled and liquid cooled. The air cooled card is your traditional blower-based design, and depending on the specific SKU, is either available in AMD’s traditional RX-style shroud, or a brushed-aluminum shroud for the aptly named Limited Edition.
Meanwhile the Vega 64 Liquid Cooled card is larger, more powerful, and more power hungry, utilizing a Radeon R9 Fury X-style external radiator as part of a closed loop liquid cooling setup in order to maximize cooling performance, and in turn clockspeeds. You actually won’t see AMD playing this card up too much – AMD considers the air cooled Vega 64 to be their baseline – but for gamers who seek the best Vega possible, AMD has put together quite a stunner.
Also having its embargo lifted today, but not launching until August 28th, is the cut-down AMD Radeon RX Vega 56. This card features lower clockspeeds and fewer enabled CUs – 56 out of 64, appropriately enough – however it also features lower power consumption and a lower price to match. Interestingly enough, going into today’s release of the Vega 64, it’s the Vega 56 that AMD has put the bulk of their marketing muscle behind.
| AMD Radeon RX Series Specification Comparison | ||||||
| AMD Radeon RX Vega 64 Liquid | AMD Radeon RX Vega 64 | AMD Radeon RX Vega 56 | AMD Radeon R9 Fury X | |||
| Stream Processors | 4096 (64 CUs) | 4096 (64 CUs) | 3585 (56 CUs) | 4096 (64 CUs) | ||
| Texture Units | 256 | 256 | 224 | 256 | ||
| ROPs | 64 | 64 | 64 | 64 | ||
| Base Clock | 1406MHz | 1247MHz | 1156MHz | N/A | ||
| Boost Clock | 1677MHz | 1546MHz | 1471MHz | 1050MHz | ||
| Memory Clock | 1.89Gbps HBM2 | 1.89Gbps HBM2 | 1.6Gbps HBM2 | 1Gbps HBM | ||
| Memory Bus Width | 2048-bit | 2048-bit | 2048-bit | 4096-bit | ||
| VRAM | 8GB | 8GB | 8GB | 4GB | ||
| Transistor Count | 12.5B | 12.5B | 12.5B | 8.9B | ||
| Board Power | 345W | 295W | 210W | 275W (Typical) | ||
| Manufacturing Process | GloFo 14nm | GloFo 14nm | GloFo 14nm | TSMC 28nm | ||
| Architecture | Vega (GCN 5) | Vega (GCN 5) | Vega (GCN 5) | GCN 3 | ||
| GPU | Vega 10 | Vega 10 | Vega 10 | Fiji | ||
| Launch Date | 08/14/2017 | 08/14/2017 | 08/28/2017 | 06/24/2015 | ||
| Launch Price | $699* | $499/599* | $399/499* | $649 | ||
Between these SKUs, AMD is looking to take on NVIDIA’s longstanding gaming champions, the GeForce GTX 1080 and the GeForce GTX 1070. In both performance and pricing, AMD expects to be able to bring NVIDIA’s cards to a draw, if not pulling out a victory for Team Red. This means we’ll see the $500 Vega 64 set against the GTX 1080, while the $400 Vega 56 goes up against the GTX 1070. At the same time however, the dark specter of cryptocurrency mining hangs over the gaming video card market, threatening to disrupt pricing, availability, and the best-laid plans of vendors and consumers alike. Suffice it to say, this is a launch like no other in a time like no other.
Overall it has been an interesting past year and a half to say the least. With a finite capacity to design chips, AMD’s decision to focus on the mid-range market with the Polaris series meant that the company effectively ceded the high-end video card market to NVIDIA once the latter’s GeForce GTX 1080 and GTX 1070 launched. This has meant that for the past 15 months, NVIDIA has had free run of the high-end market. Meanwhile AMD’s efforts to focus on the mid-range market to win back market share meant that AMD initially got the jump on NVIDIA in this market by releasing Polaris ahead of NVIDIA’s answer, and their market share has recovered some. However it’s a constant fight against the dominating NVIDIA, and one that’s been made harder by essentially being invisible to the few high-end buyers and the many window shoppers. That is a problem that ends today with the launch of the Vega 64.

I’d like to say that today’s launch is AMD landing a decisive blow in the video card marketplace, but the truth of the matter is that while AMD PR puts on their best face, there are signs that behind the scenes things are more chaotic than anyone would care for. Vega video cards were originally supposed to be out in the first-half of this year, and while AMD technically made that with the launch of the Vega Frontier Edition cards, it’s just that: a technicality. It was certainly not the launch that anyone was expecting at the start of 2017, especially since some of Vega’s new architectural functionality wasn’t even enabled at the time.
More recently, AMD’s focus on product promotion and on product sampling has been erratic. We’ve only had the Vega 64 since Thursday, giving us less than 4 days to completely evaluate the thing. Adding to the chaos, Thursday evening AMD informed us that we’d receive the Vega 56 on Friday, and encouraging us to focus on that instead. The reasoning behind this is complex – I don’t think AMD knew if it could have Vega 56 samples ready, for a start – but ultimately boils down to AMD wanting to put their best foot forward. And right now, the company believes that the Vega 56 will do better against the GTX 1070 than the Vega 64 will do against the GTX 1080.
Regardless, it means that we’ve only had a very limited amount of time to evaluate the performance and architectural aspects of AMD’s new cards, and even less time to write about them. Never mind chasing down interesting odds & ends. So while this is a full review of the Vega 64 and Vega 56, there’s some further investigating left to do once we recover from this blitz of a weekend and get our bearings back.
So without further ado, let’s dig into AMD return to the high-end market with their Vega architecture, Vega 10 GPU, and the Vega 64 & Vega 56 video cards.
↧