We have this handy fusion reactor in the sky.
You don’t have to do anything, it just works.
— Elon Musk —
As we briefly discussed in Part I of this mini-series [NoBugs17], message-passing technologies such as (Re)Actors (a.k.a. Actors, Reactors, ad hoc FSMs, and event-driven programs) have numerous advantages, ranging from being debuggable (including post-factum production debugging), to providing better overall performance. In[NoBugs17], we discussed an approach to handling allocations for (Re)Actors – and were able to reach kinda-safety at least in what we named ‘kinda-safe’ and ‘safe with relocation’ mode. Unfortunately, kinda-safety didn’t really provide the Holy Grail™ of safety against memory corruptions. Now, we can extend our allocation model with a few additional guidelines, and as long as we’re following these rules/ guidelines, our C++ programs WILL become perfectly safe against memory corruptions.
#define (Re)Actors
To make this article self-contained and make sure that we’re all on the same page with terminology, let’s repeat the definition of what we’re considering: (Re)Actors [NoBugs17].
Let’s begin with a common denominator for all our (Re)Actors: a
GenericReactor. GenericReactor is just an abstract class – and
has a pure virtual function react():
class GenericReactor {
virtual void react(const Event& ev) = 0;
}
Let’s define what we will refer to as ‘infrastructure code’: a piece of code
which calls GenericReactor’s react(). Quite often this call will be
within a so-called ‘event loop’ (Listing 1).
//Listing 1
std::unique_ptr r = reactorFactory.createReactor(...);
while(true) { //event loop
Event ev = get_event();
//from select(), libuv, ...
r->react(ev);
}
Let’s note that the get_event() function can obtain events from wherever we want; anything from select() (which is quite typical for servers) to libraries such as libuv (which is common for clients). Also let’s note that an event loop, such as the one above, is certainly not the only way to call react(): I’ve seen implementations of infrastructure code ranging from one running multiple (Re)Actors within the same thread, to another which deserialized (Re)Actor from DB, then called react() and then serialized (Re)Actor back to a database. What’s important, though, is that even if react() can be called from different threads, it MUST be called as if it is one single thread (if necessary, all thread sync should be done OUTSIDE of our (Re)Actor, so react() doesn’t need to bother about thread sync regardless of the infrastructure
code in use).
Finally, let’s refer to any specific derivative from GenericReactor (which implements our react() function) as a SpecificReactor:
class SpecificReactor : public GenericReactor {
void react(const Event& ev) override;
};
In addition, let’s observe that whenever (Re)Actor needs to communicate with another (Re)Actor – adhering to the ‘Do not communicate by sharing memory; instead, share memory by communicating’ principle – it merely sends a message, and it is only this message which will be shared between (Re)Actors. In turn, this means that we can (and should) use singlethreaded allocation for all (Re)Actor purposes – except for allocation of those messages intended for inter-(Re)Actor communications.
Rules to ensure memory safety
With (Re)Actors defined, we can formulate our rules to make our (Re)Actor code (Reactor::react() and all the stuff called from it) perfectly safe.
First, let’s postulate that there are three different types of pointers in our program: ‘owning’ pointers, ‘soft’ pointers, and ‘naked’ pointers. ‘Owning’ pointers delete their contents in destructors, and within our rules, should comply with the following:
- an ‘owning’ pointer is a template, semantically similar to std::unique_ptr<>
- ‘owning’ pointers are obtained only from operator new
- copying ‘owning’ pointers is not possible, but moving them is perfectly fine
- there is no explicit delete; however, there is a way to assign nullptr to the ‘owning’ pointer, effectively calling destructor and deleting the object. However, while the destructor will be called right away, implementation of our allocator will ensure that actual freeing of the memory will be postponed until the point when we’re out of Reactor::react(). As we’ll see below, it is important to ensure safety in cases when there is a ‘naked’ pointer to the object being deleted.
![Inquisitive hare:]() “Whenever we’re trying to access an already deleted object via a ‘soft’ pointer (or create a ‘naked’ pointer from a ‘soft’ pointer which points to an already deleted object) – we are guaranteed to get an exception.‘Soft’ pointers are obtained from ‘owning’ ones. Whenever we’re trying to access an already deleted object via a ‘soft’ pointer (or create a ‘naked’ pointer from a ‘soft’ pointer which points to an already deleted object) – we are guaranteed to get an exception. ‘Soft’ pointers should comply with the following:
“Whenever we’re trying to access an already deleted object via a ‘soft’ pointer (or create a ‘naked’ pointer from a ‘soft’ pointer which points to an already deleted object) – we are guaranteed to get an exception.‘Soft’ pointers are obtained from ‘owning’ ones. Whenever we’re trying to access an already deleted object via a ‘soft’ pointer (or create a ‘naked’ pointer from a ‘soft’ pointer which points to an already deleted object) – we are guaranteed to get an exception. ‘Soft’ pointers should comply with the following:
- a ‘soft’ pointer is also a template, somewhat similar to std::weak_ptr<>
- ‘soft’ pointers are obtained from an ‘owning’ pointer, or as a copy of an existing ‘soft’ pointer
- both copying and moving ‘soft’ pointers is ok
- ‘soft’ pointers can be implemented either using tombstones (with reference counting for the tombstones), or using the ID-comparison-based technique described in [NoBugs17].
‘Naked’ pointers are our usual C-style pointers – and are inherently very dangerous as a result. Apparently, we can still handle them in a safe manner, as long as the following rules are followed:
- our ‘naked’ pointers are obtained only from ‘owning’ pointers, from ‘soft’ pointers, or by taking an address of an existing on-stack object. This implies (a) that all pointer arithmetic is prohibited, and (b) that all casts which result in a pointer (except for dynamic_cast<>) are prohibited too.
- We are allowed to copy our ‘naked’ pointers into another ‘naked’ pointer of the same type (or a parent type); however, whenever we’re copying a ‘naked’ pointer, we MUST ensure that the lifetime of the copy is not longer than the lifetime of the original pointer.
The most reliable way to enforce the ‘lifetime is never extended’ rule above is to say that all copying of ‘naked’ pointers is prohibited, except for a few well-defined cases:
- Calling a function passing the pointer as a parameter, is ok. NB: double-naked-pointers and references to naked pointers effectively allow to us to return the pointer back (see on returning ‘naked’ pointer below) – so assigning to such *ptrs should be prohibited.
- Creating an on-stack copy of a ‘naked’ pointer (initialized from another pointer: ‘owning’, ‘soft’, or ‘naked’) of is generally ok too.
On the other hand, the following constructs are known to violate the ‘lifetime is never extended’ rule, and are therefore prohibited:
Note that the respective lists of ways to create pointers are exhaustive; in other words: the ONLY way to create an ‘owning’ pointer is from operator new of the same type; the ONLY ways to create a ‘safe’ pointer is (a) from an ‘owning’ pointer of the same base type, or (b) as a copy of a ‘safe’ pointer of the same type; and the ONLY way to create a ‘naked’ pointer is from {‘owning’|‘soft’|‘naked’} pointer as long as the ‘naked’ pointer doesn’t extend the lifetime of the original pointer.
This implies prohibiting casting to pointers (and also prohibits C-style cast and static_cast with respect to pointers; however, implicit pointer casts and dynamic_cast are ok). Note that although casting from pointers won’t cause memory corruption, it is not a good idea in general.
This also implies that assigning the result of new to anything except an ‘owning’ pointer is prohibited.
Implementations for both ‘owning’ and ‘safe’ pointers should take into account that their methods may be invoked after their destructor is called (see discussion in (*) paragraph below); in this case, we’ll either guarantee that no pointer to a non-existing object will be returned, or (even better) will throw an exception.
Note that for the time being, we do NOT handle collections and arrays; in particular, we have to prohibit indexed dereferencing (a[i] is inherently dangerous unless we’re ensuring boundary checks). That’s it – we’ve got our perfectly safe dialect of C++, and while it doesn’t deal with arrays or collections, it is a very good foundation for further
refinements.
Proof sketch
The formal proof of the program under the rules above is going to be lengthy and, well, formal, but a sketch of such a proof is as follows.
![Hare thumb up:]() “our rules do NOT allow the creation of any pointers, unless it is a pointer to an existing on-heap object, or an on-stack object (the latter is for ‘naked’ pointers only).First, let’s note that our rules do NOT allow the creation of any pointers, unless it is a pointer to an existing on-heap object, or an on-stack object (the latter is for ‘naked’ pointers only). NB: if we also want to deal with globals, this is trivial too, but for the time being let’s prohibit globals within (Re)Actors, which is good practice anyway.
“our rules do NOT allow the creation of any pointers, unless it is a pointer to an existing on-heap object, or an on-stack object (the latter is for ‘naked’ pointers only).First, let’s note that our rules do NOT allow the creation of any pointers, unless it is a pointer to an existing on-heap object, or an on-stack object (the latter is for ‘naked’ pointers only). NB: if we also want to deal with globals, this is trivial too, but for the time being let’s prohibit globals within (Re)Actors, which is good practice anyway.
As a result, there is no risk of the pointer pointing somewhere where there was never an object, and the only risks we’re facing are about the pointers to objects which did exist but don’t exist anymore. We have two types of such objects: on-stack objects, and on-heap ones.
For on-stack objects which don’t exist anymore:
- To start with, only ‘naked’ pointers can possibly point to on-stack objects
- Due to our ‘the lifetime of a ‘naked’ pointer never extends’ rule, we’re guaranteed that a ‘naked’ pointer will be destroyed not later than the object it points to, which means that we cannot possibly corrupt memory using it.
For on-heap objects which don’t exist anymore:
- ‘owning’ pointers are inherently safe (according to our rules, there is no way to delete an object while an ‘owning’ pointer still points there)
- ‘soft’ pointers are safe because of the runtime checks we’re doing every time we’re dereferencing them or converting them into a ‘naked’ pointer (and throwing an exception if the object they’re pointing to doesn’t exist anymore).
- ‘naked’ pointers to on-heap objects are safe because of the same ‘the lifetime never extends’ rule and because of the postponing the freeing of memory until we’re outside Reactor::react(). Elaborating on it a bit: as we know that at the moment of conversion from an ‘owning’ pointer or a ‘soft’ pointer to a ‘naked’ pointer, the object did exist, and the memory won’t be actually freed until we’re outside of Reactor::react(), this means that we’re fine until we’re outside of Reactor::react(); and as soon as we’re outside of Reactor::react(), as discussed above, there are no ‘naked’ pointers anymore, so there is no risk of them dereferencing the memory which we’re going to free.
(*) Note that via ‘naked’ pointers, we are still able to access objects which have already had their destructors called (but memory unreleased); this means that to ensure safety, those objects from supporting libraries which don’t follow the rules above themselves (in particular, collections) must ensure that their destructors leave the object in a ‘safe’ state (at least with no ‘dangling’ pointers left behind; more formally: there should be a firm guarantee that any operation over a destructed object cannot possibly cause memory corruption or return a pointer which is not a nullptr, though ideally it should cause an exception).
Phew. Unless I’m mistaken somewhere, it seems that we got our perfectly safe dialect of C++ (without collections, that is).
Enter collections
[Enter Romeo and Juliet]
Romeo: Speak your mind. You are as worried as the sum of yourself
and the difference between my small smooth hamster and my nose.
Speak your mind!
Juliet: Speak YOUR mind! You are as bad as Hamlet!
You are as small as the difference between the square of the difference
between my little pony and your big hairy hound
and the cube of your sorry little codpiece. Speak your mind!
[Exit Romeo]
— Program in The Shakespeare Programming Language —
As noted above, collections (including arrays) are not covered by our original rules above. However, it is relatively easy to add them, by adding a few additional rules with regards to collections. First, we will NOT use the usual iterators (including pointers within arrays); instead, we’re using ‘safe iterators’. A ‘safe iterator’ (or ‘safe range’) is a tuple/struct/class/… which contains:
- An {‘owning’|’soft’|’naked’} pointer/reference to the collection
- An iterator (or range) within the collection pointed out by the pointer above
The second rule about collections is that all the access to the collections (including iterator dereferencing) MUST be written in a way which guarantees safety.
For example, if we’re trying to access an element of the array via our ‘safe iterator’, it is the job of the operator* of our ‘safe iterator’ to ensure that it stays within the array (and to throw an exception otherwise).
This is certainly possible:
- For arrays, we can always store the size of the array within our array collection, and check the validity of our ‘safe iterator’ before dereferencing/indexing.
- Then, as all the std:: collections are implemented either on top of single objects or on top of arrays, rewriting them in a safe manner is always possible based on the techniques which we already discussed.
- On the other hand, more optimal implementations seem to be possible for specific collections. As one example, deque<> can be implemented without following the rules discussed above within its implementation, and simply checking range of the iterator instead. In another example, tree-based collections can be optimized too.
This way, whenever we want to use such a ‘safe iterator’/‘safe range’, first we’ll reach the collection (relying on our usual safety guarantees for our {‘owning’|’soft’|’naked’} pointers), and then the collection itself will guarantee that its own iterator is valid before dereferencing it.
Different approaches to safety in infrastructure code
and Reactor code
20% of people consume 80% of beer
— Pareto principle as applied to beer consumption —
An observation (*) above, as well as the discussion about optimized collections, highlights one important property of our Perfectly Safe Reactors:
we can (and often SHOULD) have different approaches to safety of the Reactor::react() and the rest of the code.
This dichotomy between infrastructure code and Reactor code is actually very important in practice. Infrastructure code (including supporting libraries such as collections, etc.) is:
- written once – and then stays pretty much unchanged
- usually relatively small compared to the business-logic stuff
- called over and over
- often fits into the 5% of the code which takes 95% of the execution time
In contrast, (Re)Actor code:
- contains business logic, which has a tendency to be changed several times a day
- as with any business logic, its code base can be huuuuge
- most of this code is called only occasionally compared to the Infrastructure Code
- 90% of it is glue code, which very rarely causes any performance issues
![Hare pointing out:]() “in the case of our rules, the expected performance hit is pretty much negligibleAs a result, we can observe that for small, never-changing, and performance-critical Infrastructure Code, it is both feasible and desirable to provide safe highly-optimized versions (which may or may not follow our rules above in the name of performance). On the other hand, for (Re)Actor Code, formal safety is usually much more important than bare performance. This is especially so as, in the case of our rules, the expected performance hit is pretty much negligible: the only two runtime checks we’re doing happen at ‘safe’ pointer to ‘naked’ pointer conversion (or at ‘safe’ pointer dereferencing), and at collection accesses; neither of them is expected to be noticeable (except in some very performance-critical code).
“in the case of our rules, the expected performance hit is pretty much negligibleAs a result, we can observe that for small, never-changing, and performance-critical Infrastructure Code, it is both feasible and desirable to provide safe highly-optimized versions (which may or may not follow our rules above in the name of performance). On the other hand, for (Re)Actor Code, formal safety is usually much more important than bare performance. This is especially so as, in the case of our rules, the expected performance hit is pretty much negligible: the only two runtime checks we’re doing happen at ‘safe’ pointer to ‘naked’ pointer conversion (or at ‘safe’ pointer dereferencing), and at collection accesses; neither of them is expected to be noticeable (except in some very performance-critical code).
Generalizing this point further, we can split our code base into a small performance critical part (which we’ll handle without our safety rules, but which is small enough to be scrutinized in a less formal manner), and a large performance-agnostic part (which we’ll handle according to the safety rules above); however, in practice, these lines will be usually very close to the lines between Infrastructure Code and (Re)Actor Code.
One important thing to keep in mind when writing those Infrastructure objects which are intended to be called from (Re)Actors is ensuring that they’re safe even after their destructor is called (as discussed in the (*) paragraph above). On the other hand, if our object follows our safety rules above, this will be achieved automagically.
All our rules are very local, which enables
automated checks
One further very important property of our safety rules is that
Indeed, all the rules above can be validated within the scope of one single function. In other words, it is possible to find whether our function f() is compliant with our safety rules using function f() and only function f().
![Hare with smiley sign:]() “This not only allows for simple code reviews, but also means that this process can be automated relatively easily. This not only allows for simple code reviews, but also means that this process can be automated relatively easily. Implementing such a tool is a different story (and it is still going to take a while) but is perfectly feasible (well, as long as we find a tool to parse C++ and get some kind of AST, but these days at least Clang does provide this kind of functionality).
“This not only allows for simple code reviews, but also means that this process can be automated relatively easily. This not only allows for simple code reviews, but also means that this process can be automated relatively easily. Implementing such a tool is a different story (and it is still going to take a while) but is perfectly feasible (well, as long as we find a tool to parse C++ and get some kind of AST, but these days at least Clang does provide this kind of functionality).
As soon as such an automated check tool is implemented, development will become a breeze:
- We separate our code into ‘safe’ code and ‘unsafe’ code (usually, though not strictly necessary, along the lines of the (Re)Actor::react()).
- For ‘safe’ code, such an automated check tool becomes a part of the build
- As a result, as long as ‘unsafe’ code is not changed (i.e. only ‘safe’ code is changed) there can be no possible regressions which can cause memory corruptions.
While this is not a real ‘silver bullet’ (nothing really is – in fact, the safety of theoretically safe languages also hinges on the safety of their compilers and standard libraries), this approach is expected to improve memory safety of the common business-level code by orders of magnitude (and even if your code is already perfectly safe, this approach will provide all the necessary peace of mind with regards to safety).
Conclusion
That’s pretty much it – we DID get a perfectly usable C++ dialect which is also 100% safe against memory corruption and against memory leaks. BTW, if necessary our approach can easily be extended to a more flexible model which relies on semantics similar to that of std:shared_ptr<> and std::weak_ptr<>; while I am not a fan of reference-counted semantics (from my experience, reference counting causes much more trouble than it is worth – and simplistic ‘owning’ pointers are more straightforward and are perfectly usable for millions of LOC projects) – it is perfectly feasible to implement shared ownership along the same lines as discussed above; the only substantial twist on this way is that as std::shared_ptr<> (unlike our model above) does allow for circular references and resulting memory leaks, we will probably need to detect them (which can be done, for example, by running some kind of incremental garbage collection at those points where we’re waiting for the input, sitting outside of Reactor::react()).
Phew. BTW, as the whole thing is quite complicated, please make sure to email me if you find any problem with the approach above (while I’m sure that it is possible to achieve safety along the lines discussed above, C++ is complicated enough we might need another restriction or two on this method).
[+]References
[+]Disclaimer
Acknowledgements
This article has been originally published in Overload Journal #140 in August 2017 and is also available separately on ACCU web site. Re-posted here with a kind permission of Overload. The article has been re-formatted to fit your screen.
Cartoons by Sergey Gordeev![IRL]() from Gordeev Animation Graphics, Prague.
from Gordeev Animation Graphics, Prague.
![]()



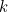 is Boltzmann's constant from thermodynamics, and is the Planck length. (You can read more about Bekenstein's work
is Boltzmann's constant from thermodynamics, and is the Planck length. (You can read more about Bekenstein's work 
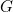 and the area of the black hole
and the area of the black hole 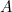 ), quantum physics (the Planck constant
), quantum physics (the Planck constant 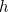 ) and thermodynamics (Boltzmann's constant
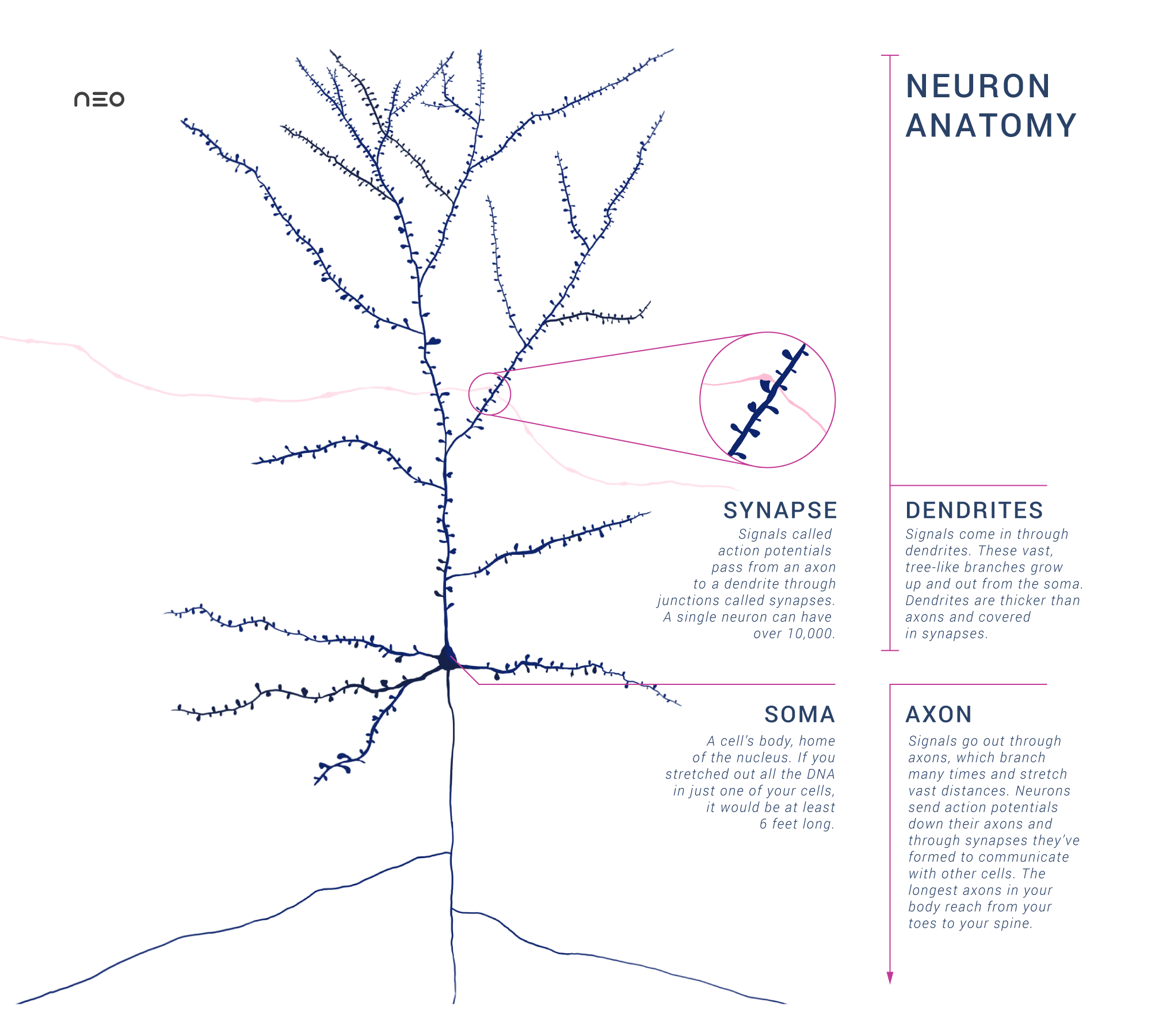
) and thermodynamics (Boltzmann's constant  ). Rees goes on to say that Hawking radiation had very deep implications for mathematical physics and is still a focus of theoretical interest, a topic of debate and controversy more than 40 years after his discovery.
). Rees goes on to say that Hawking radiation had very deep implications for mathematical physics and is still a focus of theoretical interest, a topic of debate and controversy more than 40 years after his discovery.













 from last year’s numbers—a 15 percent decrease –according to figures from an official Mexican government count in the winter of 2017. These numbers underscore how at risk the iconic animal is, with a possible collapse of migration if populations are critically low.
from last year’s numbers—a 15 percent decrease –according to figures from an official Mexican government count in the winter of 2017. These numbers underscore how at risk the iconic animal is, with a possible collapse of migration if populations are critically low.

 It should be evident to anyone viewing this website that I have a bit of a vintage computer obsession. And regular readers who’ve been paying attention over the past year and a half or so likely know that my other obsession is the space exploration game
It should be evident to anyone viewing this website that I have a bit of a vintage computer obsession. And regular readers who’ve been paying attention over the past year and a half or so likely know that my other obsession is the space exploration game 









