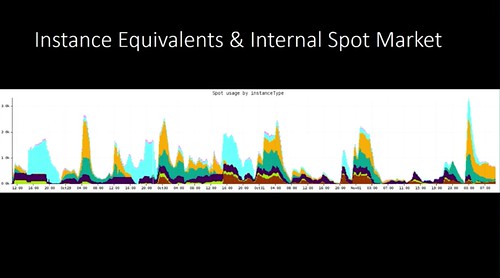
You've started a new project. When should you start using it "in
anger", "for real", "in production"? My advice is to do so as early as you can.
I did this for my newest project. I've been developing it slowly, and
things had matured enough that it could now actually do things. I set
up two instances doing things that I, and my company, now rely on. If
the software breaks, I will need to take action (disable the broken
instances, do things in another way until I fix the software).
The point of doing this early is that it gives me quick feedback on
whether the software works at all, and makes it easy to add new
features, and makes it easier for others to try out the software.
(When I announce it publically, which I'm not yet doing.)
I see quickly if something doesn't work. (For now, it does.)
I see at once if there's a missing feature that I urgently need. (I
have found two bugs yesterday.)
I see what is awkward and cumbersome for configuring, deploying the
software. (So many interacting components.)
I see if it's nice to actually use. (I need to find someone to write
a web interface, and need to improve the command line tool.)
I see if the performance is adequate and get an idea what the actual
resource requirements are. (Not many resources needed for now. Even
the cheapest VM I could choose is adequate.)
I get more confident in the software the more I actually use it.
Writing a test suite is good, but real use is better. Real use
always comes up with things you didn't think about writing tests
for.
In order to set up not just one but two instances, I had to make the
deployment automated. (I'm that lazy, and I don't apologise for
that.)
Thanks to an automated setup, when I add features or fix bugs,
they're easy to roll out. It's now almost as easy as just running
the program from the source tree.
My development process is now, I write tests; I write code; tests
pass; I tag a release; I let CI build it; and I run Ansible to upgrade
everywhere. About 15 seconds of work once the tests pass, though it
takes a couple of minutes of wall-clock time, since I run CI on my
laptop.
Apart from the benefits that come from the features of the
software itself, getting to this stage is emotionally very rewarding. In
one day, my little pet project went from "I like this idea" to "it's a
thing".
I recommend you start using your stuff in production earlier rather
than later. Do it now, do it every day.
Traditionally, a lot of companies rely on Mixpanel for product analytics to understand each user’s journey. However, if your product becomes a success and your volume of events is getting high, Mixpanel may become somewhat expensive. In this post we are going to review one of our projects with Jelly Button to design their own event-analytics solution based on Google Cloud Platform in a very efficient way and which is going to save Jelly Button about quarter million dollars each year.
Jelly Button Games develops and publishes interactive mobile and web games. It was founded in 2011 and the company’s flagship title is Pirate Kings, where players battle their friends to conquer exotic islands, amass gold, and become the lord of the high seas in what Jelly Button Games calls a “mingle-player” experience. Launched in 2014, the game has achieved around 70 million downloads across iOS, Android, and Facebook.
Here at DoiT International, we help startups to architect, build and operate perfectly robust data solutions based on Google Cloud Platform and Amazon Web Services. Together with Jelly Button’s team led by Meir Shitrit and Nir Shney-Dor, we have build a global, robust and secure data pipeline solution which processes and stores millions of events every hour.
Google Reference Architecture for Mobile Gaming Analytics
The Requirements
Jelly Button are building games which are played by over 70 millions of people using their smartphones. Each player is sending game-related events to the analytics backend. These events should be stored for later processing and analysis. Jelly Button uses this data for game analytics, research and marketing.
This backend should maintain a very low latency so that the mobile application has minimal time to wait when sending these events as well as processing as many events as possible every second. Having said that, the event data is crucial and no data loss can be tolerated.
Finally the event data must be available for analysis as soon as possible and the millions of events coming in every hour must not make it hard to perform complex analysis.
The Solution
From the start, it was obvious that the best tool to store and analyze this kind of data is Google BigQuery as it allows virtually unlimited storage, blazing fast queries and have built-in ingestion mechanism allowing to insert up to 100K records per second per table.
On the other hand we needed a fast, global and robust backend infrastructure that could be automatically scaled up to support low latency for millions of users or scaled down to keep the cost to the minimum. We have decided to use Google Container Engine (GKE) which is managed Kubernetes cluster.
Using Kubernetes we managed to set up very efficient backend deployed as a federated cluster— one cluster in United States and additional cluster in Europe, both serving traffic coming from a single global Google HTTP/S Load Balancer with a built in geo-awareness, thus providing a minimal latency to mobile clients.
Another challenge we had was about relaying the events received by the backend and reliably storing them in Google BigQuery. To keep the backend’s low latency, we decided to use Google Cloud Pub/Sub. The Pub/Sub gives us a very fast messaging medium supporting unlimited rate with guaranteed worldwide delivery as well as up to 7 days of message persistency.
Cloud Pub/Sub publish subscribe model with persistent storage
The final component we needed was an ETL that can handle the large amount of messages coming from Google PubSub and perform filtering, mapping and aggregations on the raw data before storing it in Google BigQuery for analysis. Luckily for us, Google Dataflow provides a fully managed cluster of workers that can run our ETL in streaming mode to handle these transformations and aggregations in near realtime, making the data available for analysis almost instantly.
Solution Overview
Kubernetes
In our setup, each pod contains two containers. An nginx container and a nodejs container with the backend code.
The backend code is essentially a simple nodejs based server
The backend simply adds some metadata and pushes the payload along with it to Google PubSub. No extra work is done here to maintain low latency.
Most of the transformation and aggregation logic that is required is being done inside the Dataflow pipeline. This way it could be executed in an asynchronous, non-blocking way using Dataflow’s distributed computing cluster.
The basic pipeline simply parses messages coming from Google PubSub and embeds some of the fields into BigQuery columns while preserving the rest of the data as a json object stored in a BigQuery as a string column.
To add more functionality, usually we only need to edit the relevant Mapping class
Please, note the line:
options.setStreaming(true);
This makes the Dataflow pipeline to start in streaming mode. It will not stop until manually stopped and the pipeline will keep processing messages as they arrive to Google Pub/Sub in near realtime.
Costs
Jelly Button has started this journey of building their own data pipeline to cut down the costs of the Mixpanel and build more flexible data analytics pipeline.
During July 2017, our new data analytics pipeline was processing about 500 events every second. Here is the summary of Our Google Cloud Platform costs:
About $500 for Google Cloud Dataflow
About $500 for Google Container Engine
About $200 for Google Pub/Sub
About $100 for Google BigQuery
Jelly Button are using reOptimize — a free cost tracking and optimization tool, to track and control Google Cloud Platform costs. This is how Jelly Button’s daily average spend looks like:
Summary
The whole project took us about 5 weeks to complete. We have spent a significant amount of time together with Jelly Button to architect the solution, build a proof of concept and finally code and test it with real traffic. It’s been running in production for couple of months now and we are confident Jelly Button now have robust analytics pipeline to support many new millions of people playing Pirate Kings and other games to come.
Crusader Kings 2 was the last PC game that I bought on disk before surrendering fully to the Steam Gods. I played much of it in the days when I had a severely limited internet connection which is why I have "only" 190 hours clocked up in game. Unlike other Paradox titles such as Stellaris or Europa Universalis 4, or other strategy titles like the Civilisation series, instead of playing as the abstract notion of a "nation" CK2 puts you as the head of a landed dynasty in the medieval world. Time passes day by day, the character you are playing marries, has children, fights wars, contracts diseases, has affairs, appoints councils and eventually dies. The titles this character held pass to the next in line through the often complicated succession laws of the time and you take control of that characters heir who may have inherited some or all of their predecessors land. And so the game continues. You lose the game if your starting dynasty loses all its counties or all members of the dynasty die out.
Click to open in new window.
The long form game lasts from the year 769 until 1453. There are over 1300 individual counties in the game, all ruled by a Count, and these merge in various ways into Duchies which merge into Kingdoms which merge into Empires, all of which rise and fall and are fought over throughout the 700 or so years that the game lasts. The starting conditions are true to real world history; if you take the 1066 start then William the Bastard is Duke of Normandy and can be chosen by the player. Once the game starts and runs for a few years things often diverge dramatically from real world history and there is even one expansion for the game in which the Aztecs invade Europe and North Africa from the West. The game has its own subreddit which is full of awesome images and stories that players have experienced, and lots of memes.
Like all Paradox titles the game contains a massive amount of data. Clicking on a character in game allows you to see portraits representing their parents, spouse, siblings and children. Clicking on any of these allows you to do the same for them. You can click on any county and get a chronological list of every character that held it and the same goes for Duchies, Kingdoms and Empires. I realised that the game must be storing these details in the save file and in a relational format that could be used to build a network. I had already done a project in which I pulled data from a Caves of Qud save file and I wanted to see if the same could be done here.
A non-Ironman, uncompressed CK2 save file can be opened with a text editor. Each character is represented by an entry that includes a unique identifier and values for the unique identifier of their father, mother and dynasty if those exist. It also includes details like how the character died, if they were murdered or died in battle who was responsible and data on their religion and culture. There are details on all dynasties such as their culture and religion and for each title there are details on who held the title, how they got it (inheritance, election, conquest etc) and when their reign started.
I wrote a script that would pull out this data and store it in MongoDB. This script and the ones used for the below data can be found on my GitHub account. I allowed a full game to play out in observer mode from 769 but the game doesn’t end at 1453 in this mode so I stopped on the 1st of January 1460. You can click here to download a zip of the save file I used to make these networks. The save file is from version 2.7.2, the version before the Jade Dragon expansion released in November. I decided to use the previous version of the game as with Jade Dragon China tends to expand quickly and creates a lot of dynasties in the Western Protectorate that tend to die out in a generation or two.
I was able to build 2 main types of networks from the save game data; marriage networks and kill networks. Links to interactive versions of all of the networks built with linkurious.js can be found here. Due to the size of these networks they can take a few seconds to load.
Marriage Networks
Marriage is a very important tool in CK2 for a number of different reasons, mainly to provide legitimate children to succeed your current ruler and to secure alliances with your inlaws. Unlike in other games where you can sign treaties with those you are on good terms with you can often only form alliances with those you have close marriage ties with in CK2. Marrying members of your immediate family into the powerful dynasty threatening your border may make them like you more and forming an alliance may stave off an invasion and provide you with an ally to attack your rivals.
I wrote some code that took all characters in the game who had a dynasty and a spouse and built a network of all the dynasties with weighted edges existing between those where a character from each had married each other. Clusters form in the network around geography and religion and the below image shows the network colored using the modularity statistic in Gephi. The Indian subcontinent is isolated in the top right and Europe is in the bottom left in orange with Italy splitting out into a cluster of its own just above it. The brown cluster above this is the Greek dynasties of Byzantium which converted early in the game to Islam and expanded massively. The light blue cluster represents the dynasties of the Middle East and North Africa, the dark green cluster to the right is Spain and West Africa and the light green cluster in the middle is the pagan dynasties of Eastern Europe and the Steppes. An interactive version of this network can be found here.
Click to open in new window.
This is the largest connected component in the network and consist of almost 10,000 of the 29,000 dynasties that appear in the game. There are many smaller components consisting of only a handful of dynasties and they do not appear here. Dynasties will cluster closer together if there are more edges (marriages) between them and will be far away if there are less. While there may be few marriages between Irish dynasties (on the right of the bottom orange cluster) and the Italian/Lombard dynasties (the smaller orange cluster to the left) they both marry into French and German dynasties and are therefore closer to each other than they are to the dynasties of distant India in the top right. There is also an interactive verison of this network colored by culture and by religion.
The above network shows all marriages between all dynasties but I wanted to see how the most powerful dynasties acted. I wrote code to find every character who had held a Kingdom or Empire level title and then got all their children. I then built a marriage network for them and an interactive version can be found here showing dynasties that held titles in orange and those that didn’t in blue. Again Europe and India are separated on the left and right. The nodes are sized by PageRank, a measure of the nodes popularity. The large orange nodes have clusters of blue nodes connected into them but there are no large blue nodes that provide spouses to the reigning dynasties often. There are few blue nodes which sit between the larger clusters but there are a number of marriages between ruling dynasties that cross religious divides. In the central column of clusters the top are the pagan dynasties, in the middle is Greece on the left and the Middle East on the right, on the bottom is Spain and North Africa.
Kill Networks
Characters can also be killed in the game. Battle, poison, a lone arrow or a basement full of manure and a lit match can all bring a life to an end early. When assassinations are carried out there’s a chance that the character ordering the killing will go undiscovered. Even if this happens the save file still registers, in the victims data, the unique identifier of their killer. The kill networks are built using this data. An edge exists between two dynasties where a member of one killed a member of the other. While it would make more sense for this to be a directed graph, indicating which dynasty did the killing and which the being killed, this caused difficulty when trying to pull out the largest connected component using networkx. What I should have done is build the network undirected, taken out the largest component and then rebuilt a directed network using only these nodes and this is something I might do in future.
The kill networks (colored by cluster, by culture or by religion) follows along the same lines as the marriage networks. India is isolated in the top right, Europe in the bottom left. Greece is to its right and many of the pagan dynasties are above it to the left. Spain is in the centre, the Middle East is above them and North Africa is to the right. These networks take in all killings and a lot of killings are carried out due to rivalry or spite. Religious leaders will demand their liege to burn heretics alive or often prisoners constitutions will not prove up to the task of surviving prison. Here is the code I used to focus just on those killed in battle. During a battle there is a chance that a named character on one side will kill a named character on the other side. On occasion kings will fall in battle, as happened with Conlang De Vannes, the founder of the Kingdom of Ireland. I built a network showing the connections between dynasties who killed a member of another dynasty in battle, again this should be directed to make more sense, and took the largest component. Click here to see the network colored by culture, here by religion.
Click to open in new window.
India forms a closed circle in the top right while small clusters form around the rest of the network, mainly consisting of multiple religions. Religious wars break out when a member of a religion declares a Holy War to take land belonging to a different faith. Members of both religions can flock to the aid of the attacker or defender. As the name of the game suggests the Pope can call Crusades for the conquest of lands not in Catholic control and it is in this fashion that the Republic of Greece, after electing an Islamic leader, was conquered by England in this game. Members of the same religion will also go to war with each other to enforce claims.
Character Statistics
There are generally only a small number of characters involved in a battle and only a small change of a killing happening so it is rare to rack up multiple kills during a military career. Here I pulled out all characters who had been killed in battle and grouped by their killer. Both Mahipala Mahipalid and Samir Samirid had 4 kills during their lives. The Ayudha of northern India had the most kills of any dynasty with 18 but suffered heavy loses along with the southern Vengi Chalukya dynasty. There is also a list of all the knights who killed and were then killed themselves in battle, a number of them achieved 2 kills before falling.
While building out the kill networks I also looked at the top killers in the game. Jochi Jochid, the Emperor of the Mongol Empire was responsible for the deaths of 36 people, most of them dying in his prison. Not to be outdone his son and successor Bilge finished off another 42! The save file also contains data on a character’s father and "rfat" or real father in the event that they are born out of marriage. That sort of thing was important back in the days of hereditary titles. If a character has both a fat and rfat value it means the person bringing them up, their father, isn’t their real father. In this notebook I got details on which characters had the most children. Uways Abbasid was bringing up 17 children who had an rfat value meaning he wasn’t their father. On the other hand Abdul-Razzaq Hasan had 22 children with married women and the children were being brought up as belonging to the husband. Amaneus de Carcassonne had 19 children, either with unmarried women or with women who were married but the affair was discovered. In total Muhammad Aleppo was the father of 44 children with 34 mothers and Angilbert Bouvinid had 41 children with 35 different mothers. It must be hard to remember all those birthdays!
Women don’t tend to have as many children as men but Piratamatevi Ay found time to have 10 children in between conquering south India and establishing the Ay as a major power. Amalfrida Liutprandingi had 6 children and was married to the Bishop of Oderzo. Chlotsuintha Lambertingi married the Mayor of Genoa and had 6 children. In both cases the husbands were not the fathers.
Charlemagne
Finally, I’ll end where I began. At the start I aimed to focus mainly on the Irish dynasties in the game (and did up marriage networks of them). When I was writing out the code with only a few years worth of data there weren’t any powerful Irish rulers and so I used Charlemagne to test if what I was trying to do was even possible. There are 2 notebooks based around using MongoDB’s $graphLookup on Charlemagne. The second one takes a full count of all his direct descendents through the male and female lines. By the end of the game almost 50,000 characters have been born who are descendants of Charlemagne. Over 700 of them are members of the Italian Alachisling dynasty, 613 are members of the Greek Isauros that ruled Byzantium before its conversion to Islam and 506 are members of the Penikis dynasty that controls Finland, Rus and much of North Eastern Europe. There is also a few cells of code that find all descendants in common between two characters. I chose Charlemagne and Cobthach of the Eóganacht-Locha Léin dynasty, count of Thomand (Clare/Limerick) until his death in 789. Cobthach has over 14,000 descendants himself and he and Charlemagne share 10,000 in common.
Click to open in new window.
Conclusion
Crusader Kings 2 has a wealth of information that can be used for building networks and finding out interesting statistics about a game. While I mainly let the game run away on its own in observer mode I did watch the progress of the Kingdom of Italy and the Knights Hospitaller who controlled most of Germany. The networks and statistics pulled from the game tell that there was an interesting story going on in India.
I’m happy with the way the networks turned out. It was my first time using Sigma.js and I don’t have much experience with Javascript. The colors don’t look great; bright colors looked fine in Gephi but where much too bright when drawn with Sigma.js. The culture networks had over 80 nodes which each needed a distinct color so I got the palette to auto generate colors for a dark background. While I’m happy to have gotten to use Sigma.js I needed tooltips for the nodes and could only get these working by using linkurious.js which is a fork of Sigma. Linkurious is deprecated and is no longer being developed and Bokeh in python doesn’t have as much functionality as Sigma for drawing networks so I’m not fully sure what to focus on next.
I’m going to amend the code in the notebooks shortly to work with Jade Dragon as well. I’m also going to see about rebuilding the kill and battle networks as directed networks. I started this project on the 2nd of October so I have been working on it for a long time and am glad to be finished. The Social Network of the 1916 Rising project I did before this was a great help and I reused some of the code for getting the centrality measures.
If you have any suggestions on improvements or on other measures or statistics that could be drawn from the data please suggest them. I’d love to hear about other video games that have save files which allow for data science to be applied in a similar way.
NORILSK, Russia — Blessed with a cornucopia of precious metals buried beneath a desert of snow, but so bereft of sunlight that nights in winter never end, Norilsk, 200 miles north of the Arctic Circle, is a place of brutal extremes. It is Russia’s coldest and most polluted industrial city, and its richest — at least when measured by the value of its vast deposits of palladium, a rare mineral used in cellphones that sells for more than $1,000 an ounce.
It is also dark. Starting about now, the sun stops rising, leaving Norilsk shrouded in the perpetual night of polar winter. This year that blackout began last Wednesday.
Built on the bones of slave prison laborers, Norilsk began as an outpost of Stalin’s Gulag, a place so harsh that, according to one estimate, of 650,000 prisoners who were sent here between 1935 and 1956, around 250,000 died from cold, starvation or overwork. But more than 80 years after Norilsk became part of the Gulag Archipelago, nobody really knows exactly how many people labored there in penal servitude or how many died.
The Norilsk camp system, known as Norillag, shut down in 1956, when Nikita Khrushchev began to dismantle the worst excesses of Stalinism. The legacy of repressive control, though, lives on in tight restrictions on access to the city. All foreigners are barred from visiting without a permit from Russia’s Federal Security Service, the post-Soviet successor to the K.G.B.
A signpost showing the distance to the closest cities. Norilsk is one of the most isolated spots on earth, accessible only by plane or boat.
Norilsk has prospered as the world’s largest producer of palladium, but workers pay a price in the brutal cold, winter darkness and isolation.
Participants in a painting class. Because of the isolation and harsh climate, cultural pursuits are popular in Norilsk.
“Norilsk is a unique city, it was put here by force,” said Alexander Kharitonov, owner of a printing house in the city. “It is like a survivor. If it had not been for Norilsk, there would have been another principle of life in the Arctic: You came, you worked, you froze — and you left.”
The residents of Norilsk have stayed, turning what until the 1930s had been an Arctic wilderness inhabited only by a scattering of indigenous peoples into an industrial city dotted with smoke-belching chimneys amid crumbling Soviet-era apartment blocks and the ruins of former prison barracks.
The population dropped sharply after the 1991 collapse of the Soviet Union, which sent the economy into a tailspin. It has risen again, along with Russia’s economic fortunes. Around 175,000 people now live year-round in Norilsk.
Beyond the city, which is 1,800 miles northeast of Moscow in northern Siberia, extends an endless, mostly uninhabited wilderness.
Russians are famed for swimming in any weather, even in Norilsk, 200 miles north of the Arctic Circle. Here, people at the swimming club Walruses of Taimyr emerging from a sauna to take a dip.
“Everything else is a vast wild land with a wild nature and no people,” said Vladimir Larin, a scientist who lives in Norilsk. “This is where the last wild mammoths died. When they dug the foundations of the buildings, they found the bones of mammoths.”
The bones of former prisoners also keep resurfacing, appearing each year when winter finally breaks in June and the melting snow carries to the surface these buried remains of the city’s grim and, in official accounts at least, still mostly smothered past.
“After bathing, I have the feeling that I have been on vacation for a week,” said Natalia Karpushkina, a 42-year-old who runs a local walrus club.
Some residents are the descendants of former slave laborers who stayed on simply because it was too hard to leave a place so remote that locals refer to the rest of Russia as “the mainland.” There are no roads or railway lines connecting Norilsk to parts of Russia outside the Arctic. The only way to get in or out is by plane or by boat on the Arctic Ocean.
Many residents, however, came voluntarily, lured by the promise of relatively high salaries and steady work in the city’s metallurgical industry, a sprawling complex of mines and smelters owned by Norilsk Nickel. The business is a privatized former state company that is the world’s largest producer of palladium and also a major supplier of nickel, copper and other metals.
It is also one of the world’s biggest producers of pollution, turning an area twice the size of Rhode Island into a dead zone of lifeless tree trunks, mud and snow. At one point, the company belched more sulfur dioxide a year than all of France. It has since taken some steps to reduce its output of toxic waste but was last year blamed for turning the Daldykan, a river that runs by the plant, into a flow of red goo. Locals called it “blood river.”
People hurrying through the streets in Norilsk, which is pitched into perpetual darkness for two months of the year.
Workers on their way to the city of Norilsk. It can get so cold that people cannot wait at a bus stop for fear of freezing to death.
The barracks that housed the slave laborers who built Norilsk in the 1930s, at least 250,000 of whom died there.
The company gets its products to market through a port at Dudinka on the Yenisei River, the largest of three great Siberian rivers that flow north into the Arctic Ocean.
Dudinka, as well as providing Norilsk’s main outlet to the outside world, also offers a glimpse of the region’s past. The settlement’s natural history museum displays tents used by the four main indigenous peoples in the area. The biggest of these today are the Dolgans, a nomadic Turkic people that used to live off hunting and reindeer herding but were themselves herded into collective farms during the Soviet era.
“When they dug the foundations of the buildings, they found the bones of mammoths,” said Vladimir Larin, a scientist who lives in Norilsk.
There are now around 7,000 Dolgans, many of whom have given up their ancestors’ shamanistic beliefs in favor of Christianity. Smaller native groups include the Entsi, of which there are only around 227 left in the region, which is known as Taimyr.
Traditional belief in shamanism has been steadily eroded by the Russian Orthodox Church, which has been sending priests into the area since the 19th century and in 2000 built a new church on a bluff overlooking Dudinka port.
“Our children study their native language as if it were a foreign tongue,” said Svetlana Moibovna, who is a member of the Nganasan indigenous group. “Many local people were persecuted for shamanism. One shaman in his dreams saw that the Russian god would defeat the shaman god and that only the Russian god would rule in Taimyr.”
Dudinka, a small port city on the Yenisei River, is the main transportation hub for the palladium, nickel, copper and other metals produced in Norilsk.
Newlyweds being greeted by family members in Norilsk.
Girls practicing classic dance at the Norilsk College of Arts. There is plenty of time for indoor activities in Norilsk.
Despite the horrendously harsh climate, choking pollution and absence of sunlight from late November until January, many residents are fiercely proud of Norilsk — and their own ability to survive in an environment that even the hardiest of Russians living elsewhere would find intolerable.
Last winter, temperatures plunged to minus 62 Celsius (minus 80 Fahrenheit), and early winter this year has also been unforgiving, with temperatures in November already falling to around minus 20 Celsius, about 4 below Fahrenheit.
Most of the work and leisure takes place indoors, particularly in the winter period of perpetual darkness.
The cold has spawned a booming freelance taxi business because it is too cold to walk even short distances. Taxis charge a fixed price of 100 rubles (about $1.70) to go anywhere in the city. There are also buses, but it is too cold to wait outside so passengers crowd into nearby shops to shelter until their bus arrives.
But even the bitter cold is for some a source of delight, with the frigid waters of Lake Dolgoye attracting swimmers who revel in the bracing experience of bathing in ice. “After bathing, I have the feeling that I have been on vacation for a week,” said Natalia Karpushkina, a 42-year-old who runs a local walrus club. The lake freezes only partially because of hot water pipes from a nearby power plant.
The city also has a large indoor swimming pool for those less keen on bathing in ice water.
An aerial view of Norilsk, where most people still live in Soviet-era apartment buildings.
Young people listening to a rock band at the popular Zaboi (The Face) bar, the only establishment in the city that has its own brewery.
A man waiting for the bus inside a grocery store.
Most of the work and leisure takes place indoors, particularly in the winter period of perpetual darkness. Life inside became considerably less monotonous recently thanks to a long-awaited breakthrough: After decades of serving the digital economy by providing materials needed to make cellphones and computers, Norilsk got its first reliable internet service.
But even without the internet, it had replicated as best it could the amenities of a normal Russia city. The Norilsk College of Arts offers ballet lessons. Norilsk Greenhouse, a local company, grows cucumbers in heated shelters, while the Zaboi Bar offers revelers home brew and live music.
The bar’s 30-year-old manager, Anton Palukhin, who moved to Norilsk with his parents from Kazakhstan when he was 5, said that he still struggles with the climate and that whenever he travels to warmer parts of Russia on vacation, dreads having to return to the Arctic.
“I really do not want to go back and am ready to give anything so that I don’t have to fly,” he said. All the same, he keeps coming back.
Never a bad moment for a dip in Lake Dolgoye, which is prevented from freezing over by hot water pipes from a power plant and other nearby facilities.
That a group composed not just of biology Ph.D.s but also chemists, electrical engineers, a schoolteacher and a physicist, among others, would be the ones to do such groundbreaking research did not surprise Dave Goulson, a bee expert at the University of Sussex, and co-author of a scientific article based on the group’s research and published this fall.
PhotoThe all-volunteer society shocked the world by documenting a 75 percent drop in flying insect populations.Credit
Gordon Welters for The New York Times
“In this field, amateurs are often the experts,” he said. “Most people don’t really pay attention to insects. With the exception of butterflies, because they’re pretty.”
Bugs have long gotten short shrift, scientifically. Estimated to make up more than half of all animal life, only about 10 percent of insect species are thought to have even been named.
In addition, raw data about the creatures is hard to come by. “This kind of monitoring is unspectacular, so it usually doesn’t get done,” said Teja Tscharntke, a professor of agro-ecology at the University of Göttingen. “That’s where the hobbyists from Krefeld come in.”
Their study looks at 63 nature preserves mostly in the area around Krefeld. But experts say it is likely to reflect the insect situation in places like North America, where monoculture and pesticide use are widespread.
“People have been saying, ‘There just doesn’t seem to be as many ‘X’ as there used to be,’” said Steve Heydon, senior scientist at the University of California, Davis’s Bohart Museum of Entomology, of the Krefeld study. “It’s nice to have it documented. Figures change it from an opinion to a fact.”
Mr. Tscharntke agreed. “I was a little surprised, but it fits with what we know about, say, insect-eating birds disappearing,” he said.
Calling the Krefelders’ data “a rich treasure trove,” Mr. Tscharntke warned that entomology hobbyists are themselves a dying species. “These days, people who spend their free time looking at ladybugs and flies are about as common as stamp collectors.”
PhotoMembers of the society use traps installed all over western Germany to track insect populations.Credit
Gordon Welters for The New York Times
In Germany and around the world, members of entomological societies tend to be elderly. And, in a field that has seen very little in the way of high-tech digitization, their expertise often dies with them.
In many ways, the Krefelders buck these trends. For one thing, the society, which is more than 100 years old, is keen on archiving.
“In a lot of places, everything gets thrown out — the papers, the insect collection,” said Martin Sorg, a longstanding member of the Krefeld society whose expertise includes wasps.
Gesturing around the group’s book-lined headquarters, Mr. Sorg said things were different, here. “When one of our members dies, we keep everything, even handwritten notes.”
They also focus on the future. About a third of the society’s 59 members are newbies, and children as young as 12 can join the society’s adults in poring over unsorted trays of translucent wings and delicate thoraxes, or carefully rifle through the wooden cabinets that hold over a million pinned wasps, bees, ants, sawflies, beetles, flies, mosquitoes, butterflies, moths, dragonflies, crickets, true bugs, lacewings and caddis flies.
Experienced entomologists take beginners on expeditions, and train them in the complex art of identifying insects. “Knowledge is passed down, from one generation to the next,” said Thomas Hörren, who is 28 and wears a large tattoo of his favorite insect, the beetle, on his neck. “Growing up, there was nobody to guide me.”
Krefeld’s youngest official member is 14. “He’s an ant guy,” said Mr. Schwan, himself a childhood bug lover. It was not until his late 20s that he discovered Krefeld’s entomological society and started learning about caterpillars.
PhotoThe society maintains meticulous records.Credit
Gordon Welters for The New York Times
Back then, members, along with their bugs, met every two weeks at Krefeld pubs.
Gazing into a glass-covered box of ants, Mr. Schwan smiled and said he planned to take the teenager and the ants along to an coming entomological conference in Düsseldorf. There, an ant expert from Wuppertal promised to identify the boy’s specimens.
Harald Ebner, a pesticide expert and politician with Germany’s Green Party, said it was “typically German” for people to spend free time doing club-based volunteer work.
“Without the efforts of the Krefeld insect researchers, we would only have the observation that, these days, your car’s windshield is almost totally free of insects,” wrote Mr. Ebner, in an email. “On the other hand, the lack of interest on the part of the state is horrifying, especially in a country where just about everything else is so precisely tested, overseen and counted.”
But Josef Tumbrinck, a society member who works as an environmental lobbyist, thinks the plight of insects is going to interest a wider audience soon.
“Right now, it’s ‘those nutty entomologists,’” Mr. Tumbrinck said. “But I think this is going to get more and more attention, not just from crazy people with long hair.”
Setting a glass box down on the table, he pointed to a hand-size butterfly that his wife hatched from eggs for the school where she teaches. Mr. Tumbrinck’s 10-year-old son tugged on his sleeve. “And I found this one in the lamp,” he whispered, pointing to a little gray moth mounted next to it.
As the scent of 82 proof alcohol that preserves the bugs wafted, just a little, through the room, a reporter asked if, at this rate, all the insects were going to disappear.
“Oh, don’t worry,” said Mr. Sorg, the wasp expert. “All the vertebrates will die before that.”
The slowdown in server sales ahead of Intel’s July launch of the “Skylake” Xeon SP was real, and if the figures from the third quarter of this year are any guide, then it looks like that slump is over. Plenty of customers wanted the shiny new Skylake gear, and we think a fair number of them also wanted to buy older-generation “Broadwell” Xeons and the “Grantley” server platform given the premium that Intel is charging for Skylake processors and their “Purley” platform.
Server makers with older Broadwell machinery in the barn were no doubt happy to oblige customers and clear out the older inventory – a story we keep hearing again and again – as well as sell new Skylake systems. It is a win-win for server makers, and in the short term it is good for Intel, too, at least on paper. If the hyperscalers and cloud builders that are driving the server market are just getting deeper discounts, as we think is probably the case, then what it means is that Intel is shifting the burden of extracting profits to enterprise clients who individually buy far less iron but that collectively still buy more gear than the hyperscalers and cloud builders. This shift would be happening as sales of systems to enterprises is still in a slump and customers are also reeling from higher prices on main memory and flash storage.
In the short run, this situation is tenable, but over the long haul, it will just drive more customers to clouds, not only because enterprises can’t compete on technology and flexibility, but because they cannot compete on price when it comes to building and running their own infrastructure. This, over the long haul, is not something that Intel wants to see. Intel needs tens of millions of companies to still buy servers and tens of thousands of midrange and large enterprises to still buy clusters if it is to retain its profit margins.
This seems increasingly unlikely given the situation and given the improving CPU alternatives from AMD, Cavium, Qualcomm, and IBM. But for now, according to the latest statistics from IDC showing what it thinks happened in the server market in the third quarter, it is all boom town.
In the quarter ended in September, which ended only nine weeks after AMD rolled out the Epyc chips, only six weeks after Intel launched the Skylake Xeons, and only two weeks after IBM started shipping its System z14 mainframes, both the X86 and mainframe parts of the business both skyrocketed after being in the doldrums for several quarters. IDC has restated its numbers for the year-ago period, showing that the original design manufacturers (ODMs) have made more sales than originally anticipated, and even with that restating, IDC believes that server revenues in Q3 2017 rose by an astounding 19.9 percent to just a hair under $17 billion, the highest level for any quarter that we can remember, and shipments rose by 11.1 percent to 2.67 million units, the highest level we can recall as well and besting the 2.6 million units shipped in the fourth quarter of 2015 when the “Haswell” Xeons were selling like hotcakes despite the impending Broadwell launch the following March.
Sometimes, the hyperscalers and cloud builders can wait, and sometimes they cannot.
For a while there, it looked like we might be repeating the slowdown in server sales from early 2011 through early 2014, when the “Sandy Bridge” Xeons were pushed out a bit and the “Ivy Bridge” Xeons were similarly delayed. But Haswell Xeons saved the day, even if there was a flattening during the Broadwell generation. We think the elimination of uncertainty – not the Skylake Xeon launch per se– is what has unleashed some pent up demand for servers. People now know what to do, based on the feeds, speeds, and needs. And the prices, at the list ceilings and out on the streets.
A couple of things stand out in the figures for the third quarter from IDC. Take a look at the revenue numbers by vendor:
And then the shipments by vendor:
Something very profound is going on at Dell, and we think it is more than benefitting from any synergies from its combination with enterprise storage juggernaut EMC and enterprise server virtualization behemoth VMware. We suspect that more than a few hyperscalers and cloud builders are buying machines from Dell’s custom server business unit, and the leverage it has with Intel because it sells both PCs and servers based on the X86 architecture – unlike IBM and now Hewlett Packard Enterprise – is one reason it can be so aggressive in the server racket. In the quarter ended in September, Dell grew its server unit shipments by 11.2 percent to 503,000 machines, beating HPE (along with its H3C Group partnership in China), which shipped 501,400 machines according to IDC, down 1.7 percent year on year. This is the first time that Dell has beaten HPE or its predecessors since the Compaq merger in 2001. And while HPE/H3C saw revenues decline by 1.1 percent in the period, Dell saw them rise by 37.9 percent to $3.07 billion, right on the heels of the $3.32 billion that HPE/H3C together raked in during the quarter.
Closing that much of the revenue gap should have taken years, and should have taken a lot more servers, we think. So Dell must be selling a lot of beefy machines to someone. To a lot of someones. And moreover, Dell’s average selling price is up by around 24 percent, and that probably means it sold a lot of really cheap boxes and a lot of really expensive ones, perhaps laden with GPU and FPGA accelerators and lots of memory.
The other thing that jumps out, especially in the following chart that plots server revenues since the end of the Great Recession, is the giant spike in ODM server sales – as we said, up 45.3 percent even after a significantly large restatement for Q3 2016. Look at that spike:
We think that IDC will eventually make public its restatement of ODM revenues for Q4 2016 and Q1 2017, but we do not have that data yet. This will smooth out that thick green curve, which is growing fast and shows again that the ODMs, as a group, push more iron than any single vendor in the market – HPE or Dell. This has been true since the second quarter of this year, by IDC’s reckoning. And that ODM figure is understated, we think, because parts of Dell, Lenovo, HPE, Inspur, and Sugon act like ODMs more than like traditional OEMs.
If you want to know why Meg Whitman is stepping down as CEO at HPE, it is not so much that the turnaround is done as it is that HPE and its Foxconn partnership has not helped boost its presence at hyperscalers and cloud builders, and Dell is making huge inroads along with the ODMs and the Chinese OEMs. Every one of these players is eating HPE’s server lunch right now, and it is a problem that HPE’s new CEO, Antonio Neri, is going to have to tackle.
IBM is back above $1 billion in sales in the third quarter, mostly because it closed so many System z14 mainframe deals in the quarter to ship a bunch of machines in the last two weeks of September, which allowed it to book $673 million in System z revenues, up 63.8 percent year-on-year. If you do the math, that means IBM’s Power Systems business generated $421 million in sales, down 7.2 percent. IBM is getting ready to fire off its first salvo of Power9 systems for commercial customers, and has already begun shipping Power9 iron for the “Summit” and “Sierra” supercomputers for the US Department of Energy, although the numbers are modest.
On the shipment side of the server business, Lenovo contracted by a gut-wrenching 33.1 percent while Inspur rose by 37.9 percent, and the two companies are neck-and-neck for the number three position in the market in terms of systems sold rather than revenues generated. Supermicro and Huawei Technologies are, technically speaking, in a statistical four-way tie with Lenovo and Inspur by IDC’s standards, which is when the vendors are within one point of share across vendors. By this metric, in terms of boxes shipped, Dell and HPE/H3C are tied, too.
Thanks to the System z spike, sales of non-X86 servers rose by 15.1 percent to $1.5 billion in the quarter, but sales of X86 servers grew at a faster pace of 20.4 percent to reach $15.4 billion.
The big question is what will happen in Q4 and beyond, and if this new level of shipment and revenues represents an apex or a new floor. The average ODM server price has been raised in the IDC numbers, which reflects, we think, the heftier GPU laden machines that hyperscalers and cloud builders are buying as well as more than a few HPC centers. But the ASP for ODMs did not really grow year on year – around $6,200 per node on average. We think there are plenty of $2,000 infrastructure boxes in that mix and a smaller but significant number of systems with lots of GPUs that probably cost out at something more like $50,000.
This may be the shape of things to come for all server buyers. But it has as much to do with the reaction to Intel’s Skylake Xeons as it does with the Skylake Xeons themselves.
Sysdig is routinely praised by users for the richness of the data it’s able to capture and for the ability to store system, application and container that data into capture files that can be easily shared with other people.
However, extracting insights from rich data can be hard. Mastering the art of analyzing sysdig capture files requires dedication and skills. This is why we constantly try to improve workflows around sysdig and find ways to get better insights with less effort. Today, we bring these efforts to a new level with the release of Sysdig Inspect.
Sysdig Inspect is a powerful, intuitive tool for sysdig capture analysis that runs natively on your Mac or your Linux PC, with a user interface that has been designed for performance and security investigation.
Sysdig Inspect, and the experience of using it, are really best explained by trying it, which requires just a 30 second installation. But in case that’s too much for you, here’s a one minute video to get you started:
Let me share a few of the principles that we used to guide the design of Sysdig Inspect.
Instant highlights
The overview page offers an out of the box, at a glance summary of the content of the capture file. Content is organized in tiles, each of which shows the value of a relevant metric and its trend. Tiles are organized in categories to surface useful information more clearly and are starting point for investigation and drill down.
Sub-second microtrends and metric correlation
Once you click on a tile, you will see the sub-second trend of the metric shown by the tile. Yes, sub-second. You will be amazed at how different your system, containers and applications look at this level of granularity. Multiple tiles can be selected to see how metrics correlate to each other and identify hot spots.
Intuitive drill-down-oriented workflow
You can drill down into any tile to see the data behind it and start investigating. At this point you can either use the timeline to restrict what data you are seeing, or further drill down by double clicking on any line of data. You will be able to see processes, files, network connections and much more.
All the details when you need them
Every single byte of data that is read or written to a file, to a network connection to a pipe is recorded in the capture file and Sysdig Inspect makes it easy to observe it. Do you need to troubleshoot an intermittent network issue or determine what a malware wrote to the file system? All the data you need is there. And, of course, you can switch at any time into sysdig mode and look at every single system call.
Conclusion
Most of all, the guiding principle when designing Sysdig Inspect was: make troubleshooting and security investigation easy, effective and, as much as possible, a pleasure. Either if you took the capture file manually or you used Sysdig Monitor to launch a capture just when an alert triggered, we aim at providing all the tools you need to monitor, troubleshoot and do forensics in your container platform. Did we succeed achieving this goal? You can judge by yourself by trying it! To make your life easy, here are some capture files that you can use to play with it.
BEIJING — Reading headlines from the World Internet Conference in China, the casual reader might have come away a little confused. China was opening its doors to the global Internet, some media outlets optimistically declared, while others said Beijing was defending its system of censorship and state control.
And perhaps most confusing of all, Apple’s CEO Tim Cook stood up and celebrated China’s vision of an open Internet.
Say what?
China has more than 730 million Internet users, boast the largest e-commerce market in the world and consumers who enthusiastically embrace mobile digital technology. But it censors many foreign news websites and keeps most Western social media companies out.
The World Internet Conference held in the eastern Chinese city of Wuzhen is meant to promote China’s vision of “cyber-sovereignty” — the idea that governments all over the world should have the right to control what appears on the Internet in their countries.
In practice, in China, that amounts to the largest system of censorship and digital surveillance in the world, where criticism of the Communist Party is sharply curtailed and can even land you in jail.
But that wasn’t mentioned when Cook delivered a keynote speech on the opening day of the gathering Sunday.
“The theme of this conference — developing a digital economy for openness and shared benefits — is a vision we at Apple share,” Cook said, in widely reported remarks. “We are proud to have worked alongside many of our partners in China to help build a community that will join a common future in cyberspace.”
Alongside Cook in endorsing China’s digital vision were officials from countries such as Saudi Arabia and Serbia, it noted.
Free speech and human rights advocates were less impressed.
“Cook’s appearance lends credibility to a state that aggressively censors the internet, throws people in jail for being critical about social ills, and is building artificial intelligence systems that monitors everyone and targets dissent,” Maya Wang at Human Rights Watch in Hong Kong wrote in an email.
“The version of cyberspace the Chinese government is building is a decidedly dystopian one, and I don’t think anyone would want to share in this ‘common future.’ Apple should have spoken out against it, not endorsed it.”
And it wasn’t just Cook who some critics accused of indulging in a little doublespeak.
China’s President Xi Jinping opened the conference with written remarks that led to a flurry of arguably misleading headlines.
“The development of China’s cyberspace is entering a fast lane,” he said in remarks read out by an official. “China's doors will only become more and more open.”
Yet the audience was soon reminded that nothing that could possibly threaten the Communist Party would be allowed through those supposedly open doors.
China has tightened censorship and controls of cyberspace under Xi, with a new cybersecurity law requiring foreign firms to store data locally and submit to domestic surveillance.
Wang Huning, who serves as a member of the Communist Party’s elite standing committee and is Xi’s top ideologue, defended China’s system and even suggested that more controls could be in the offing.
“China stands ready to develop new rules and systems of internet governance to serve all parties and counteract current imbalances,” he said to the conference, according to Reuters.
But it was Cook’s words that prompted the strongest reaction, coming after Apple has also come under fire for its actions in China.
In a written response to questions from Senators Patrick J. Leahy (D-Vt.) and Ted Cruz of (R-Tex.) last month, Apple said that it had removed 674 VPN apps from its app store in China this year — tools that allow users to circumvent censorship by routing traffic abroad — to comply with local laws. Skype was also removed from Apple’s China store, the New York Times reported.
In August, Cook said Apple hadn’t wanted to remove the apps but had to follow local laws wherever it does business.
“We strongly believe that participating in markets and bringing benefits to consumers is in the best interests of folks there and in other countries as well,” Cook said. “We believe in engaging in governments even when we disagree.”
But Greatfire.org, a group that combats Chinese censorship, argued Apple’s decision to agree to censorship put pressure on other companies to follow suit and could even mean that Chinese citizens could ultimately be subjected to Chinese censorship when they travel abroad.
“It is undeniable that Tim Cook and Xi Jinping have a shared vision of the internet. Xi wants to be able to control all information and silence those who may threaten his leadership. Cook helps him with vast, unaccountable, implementation of censorship across Apple products,” the group wrote to The Washington Post.
Critics saw simple business calculations in Cook’s appearance in Wuzhen.
“Cook Kisses the Ring,’ Bloomberg columnist Tim Culpan wrote, arguing that Cook was “desperate to hold onto any remaining scraps of the China market” in the face of stiff competition from local rivals.
The head honchos of China’s main digital and Internet companies, Huawei, Baidu and Tencent, “ought to have been grinning like Cheshire cats,” Culpan added, since censorship has kept foreign companies like Facebook, Google and Twitter out of China and served as a “handy little tool of trade protectionism.”
Nor did it matter if Cook’s tongue was in his cheek, for his presence at the conference, along with Google’s Sundar Pichai and CISCO Systems’ Chuck Robbins, not only gave legitimacy to the authorities but also sent a signal to domestic Chinese rivals that their turf is safe, Culpan wrote.
Rights group Freedom House last month branded China the worst abuser of Internet freedom among 65 countries surveyed, followed by Syria and Ethiopia.
But in Wuzhen, that report was not about to be discussed.
Instead, a top state-backed Chinese think tank declared that the host nation ranked fifth among 38 nations globally in standards of cyber governance, as it called for a ‘democratic’ Internet governance system to eradicate inequalities that it said had marginalized developing nations.
“We should promote the establishment of a multinational, democratic and transparent global internet governance system,” the Chinese Academy of Cyberspace Studies said in a report, according to Reuters.
After 8+ years, I have concluded that it is a bad idea to use Mz as my handle on HN. Also, I am generally moving towards using my real full name more, both online and off, for professional reasons.
Details as to why I am retiring the Mz handle were posted elsewhere. For a longer explanation as to why I am suddenly using my actual name on the internet, you might find this post relevant.
I had hoped to be low key about the whole thing, but the matter is coming up repeatedly in comments, though it has only been a week. Hopefully, this post will help cut back on that. I consider it to be a derail in conversation.
This is a longstanding problem that I have. Other people ask me personal questions in forums. If I don't answer them, it is drama and I am accused of being rude, among other things. If I do answer them, it is drama and I am accused of making things about me, among other things.
So, I don't have a good solution here. I muddle through as best I can.
Historically, different answers to this question – that is,
different visions of computing – have helped inspire and
determine the computing systems humanity has ultimately
built. Consider the early electronic computers. ENIAC, the
world’s first general-purpose electronic computer, was
commissioned to compute artillery firing tables for the United
States Army. Other early computers were also used to solve
numerical problems, such as simulating nuclear explosions,
predicting the weather, and planning the motion of rockets. The
machines operated in a batch mode, using crude input and output
devices, and without any real-time interaction. It was a vision
of computers as number-crunching machines, used to speed up
calculations that would formerly have taken weeks, months, or more
for a team of humans.
In the 1950s a different vision of what computers are for began to
develop. That vision was crystallized in 1962, when Douglas
Engelbart proposed that computers could be used as a way
of augmenting human
intellect. In this view, computers weren’t primarily
tools for solving number-crunching problems. Rather, they were
real-time interactive systems, with rich inputs and outputs, that
humans could work with to support and expand their own
problem-solving process. This vision of intelligence augmentation
(IA) deeply influenced many others, including researchers such as
Alan Kay at Xerox PARC, entrepreneurs such as Steve Jobs at Apple,
and led to many of the key ideas of modern computing systems. Its
ideas have also deeply influenced digital art and music, and
fields such as interaction design, data visualization,
computational creativity, and human-computer interaction.
Research on IA has often been in competition with research on
artificial intelligence (AI): competition for funding, competition
for the interest of talented researchers. Although there has
always been overlap between the fields, IA has typically focused
on building systems which put humans and machines to work
together, while AI has focused on complete outsourcing of
intellectual tasks to machines. In particular, problems in AI are
often framed in terms of matching or surpassing human performance:
beating humans at chess or Go; learning to recognize speech and
images or translating language as well as humans; and so on.
This essay describes a new field, emerging today out of a
synthesis of AI and IA. For this field, we suggest the
name artificial intelligence augmentation (AIA): the use
of AI systems to help develop new methods for intelligence
augmentation. This new field introduces important new fundamental
questions, questions not associated to either parent field. We
believe the principles and systems of AIA will be radically
different to most existing systems.
Our essay begins with a survey of recent technical work hinting at
artificial intelligence augmentation, including work
on generative interfaces– that is, interfaces
which can be used to explore and visualize generative machine
learning models. Such interfaces develop a kind of cartography of
generative models, ways for humans to explore and make meaning
from those models, and to incorporate what those models
“know” into their creative work.
Our essay is not just a survey of technical work. We believe now
is a good time to identify some of the broad, fundamental
questions at the foundation of this emerging field. To what
extent are these new tools enabling creativity? Can they be used
to generate ideas which are truly surprising and new, or are the
ideas cliches, based on trivial recombinations of existing ideas?
Can such systems be used to develop fundamental new interface
primitives? How will those new primitives change and expand the
way humans think?
Using generative models to invent meaningful creative operations
Let’s look at an example where a machine learning model makes a
new type of interface possible. To understand the interface,
imagine you’re a type designer, working on creating a new
fontWe shall egregiously abuse the distinction between
a font and a typeface. Apologies to any type designers who may be
reading.. After sketching some initial designs, you
wish to experiment with bold, italic, and condensed variations.
Let’s examine a tool to generate and explore such variations, from
any initial design. For reasons that will soon be explained the
quality of results is quite crude; please bear with us.
Of course, varying the bolding (i.e., the weight), italicization
and width are just three ways you can vary a font. Imagine that
instead of building specialized tools, users could build their own
tool merely by choosing examples of existing fonts. For instance,
suppose you wanted to variy the degree of serifing on a font. In
the following, please select 5 to 10 sans-serif fonts from the top
box, and drag them to the box on the left. Select 5 to 10 serif
fonts and drag them to the box on the right. As you do this, a
machine learning model running in your browser will automatically
infer from these examples how to interpolate your starting font in
either the serif or sans-serif direction:
In fact, we used this same technique to build the earlier bolding
italicization, and condensing tool. To do so, we used the
following examples of bold and non-bold fonts, of italic and
non-italic fonts, and of condensed and non-condensed fonts:
To build these tools, we used what’s called a generative
model; the particular model we use was trained
by James Wexler. To
understand generative models, consider that a priori
describing a font appears to require a lot of data. For
instance, if the font is 64 by 64 pixels, then we’d expect
to need 64×64=4,096 parameters to describe a single
glyph. But we can use a generative model to find a much simpler
description.
We do this by building a neural network which takes a small number
of input variables, called latent variables, and produces
as output the entire glyph. For the particular model we use, we
have 40 latent space dimensions, and map that into the4,096-dimensional space describing all the pixels in the glyph.
In other words, the idea is to map a low-dimensional space into a
higher-dimensional space:
The generative model we use is a type of neural network known as
a variational autoencoder
(VAE). For our purposes, the details of the generative
model aren’t so important. The important thing is that by
changing the latent variables used as input, it’s possible to get
different fonts as output. So one choice of latent variables will
give one font, while another choice will give a different font:
You can think of the latent variables as a compact, high-level
representation of the font. The neural network takes that
high-level representation and converts it into the full pixel
data. It’s remarkable that just 40 numbers can capture the
apparent complexity in a glyph, which originally required 4,096
variables.
The generative model we use is learnt from a training set of more
than 50 thousand
fonts Bernhardsson
scraped from the open web. During training, the weights and
biases in the network are adjusted so that the network can output
a close approximation to any desired font from the training set,
provided a suitable choice of latent variables is made. In some
sense, the model is learning a highly compressed representation of
all the training fonts.
In fact, the model doesn’t just reproduce the training fonts. It
can also generalize, producing fonts not seen in training. By
being forced to find a compact description of the training
examples, the neural net learns an abstract, higher-level model of
what a font is. That higher-level model makes it possible to
generalize beyond the training examples already seen, to produce
realistic-looking fonts.
Ideally, a good generative model would be exposed to a relatively
small number of training examples, and use that exposure to
generalize to the space of all possible human-readable fonts.
That is, for any conceivable font – whether existing or
perhaps even imagined in the future – it would be possible
to find latent variables corresponding exactly to that font. Of
course, the model we’re using falls far short of this ideal
– a particularly egregious failure is that many fonts
generated by the model omit the tail on the capital
“Q” (you can see this in the examples above). Still,
it’s useful to keep in mind what an ideal generative model would
do.
Such generative models are similar in some ways to how scientific
theories work. Scientific theories often greatly simplify the
description of what appear to be complex phenomena, reducing large
numbers of variables to just a few variables from which many
aspects of system behaviour can be deduced. Furthermore, good
scientific theories sometimes enable us to generalize to discover
new phenomena.
As an example, consider ordinary material objects. Such objects
have what physicists call a phase– they may be a
liquid, a solid, a gas, or perhaps something more exotic, like a
superconductor
or Bose-Einstein
condensate. A priori, such systems seem immensely
complex, involving perhaps 1023 or so molecules. But the
laws of thermodynamics and statistical mechanics enable us to find
a simpler description, reducing that complexity to just a few
variables (temperature, pressure, and so on), which encompass much
of the behaviour of the system. Furthermore, sometimes it’s
possible to generalize, predicting unexpected new phases of
matter. For example, in 1924, physicists used thermodynamics and
statistical mechanics to predict a remarkable new phase of matter,
Bose-Einstein condensation, in which a collection of atoms may all
occupy identical quantum states, leading to surprising large-scale
quantum interference effects. We’ll come back to this predictive
ability in our later discussion of creativity and generative
models.
Returning to the nuts and bolts of generative models, how can we
use such models to do example-based reasoning like that in the
tool shown above? Let’s consider the case of the bolding tool. In
that instance, we take the average of all the latent vectors for
the user-specified bold fonts, and the average for all the
user-specified non-bold fonts. We then compute the difference
between these two average vectors:
We’ll refer to this as the bolding vector. To make some
given font bolder, we simply add a little of the bolding vector to
the corresponding latent vector, with the amount of bolding vector
added controlling the boldness of the resultIn
practice, sometimes a slightly different procedure is used. In
some generative models the latent vectors satisfy some constraints– for instance, they may all be of the same length. When
that’s the case, as in our model, a more sophisticated
“adding” operation must be used, to ensure the length
remains the same. But conceptually, the picture of adding the
bolding vector is the right way to think.:
This technique was introduced
by Larsen et al, and
vectors like the bolding vector are sometimes calledattribute vectors. The same idea is use to implement all
the tools we’ve shown. That is, we use example fonts to creating
a bolding vector, an italicizing vector, a condensing vector, and
a user-defined serif vector. The interface thus provides a way of
exploring the latent space in those four directions.
The tools we’ve shown have many drawbacks. Consider the following
example, where we start with an example glyph, in the middle, and
either increase or decrease the bolding (on the right and left,
respectively):
Examining the glyphs on the left and right we see many unfortunate
artifacts. Particularly for the rightmost glyph, the edges start to get
rough, and the serifs begin to disappear. A better generative
model would reduce those artifacts. That’s a good long-term
research program, posing many intriguing problems. But even with
the model we have, there are also some striking benefits to the
use of the generative model.
To understand these benefits, consider a naive approach to
bolding, in which we simply add some extra pixels around a glyph’s
edges, thickening it up. While this thickening perhaps matches a
non-expert’s way of thinking about type design, an expert does
something much more involved. In the following we show the
results of this naive thickening procedure versus what is actually
done, for Georgia and Helvetica:
As you can see, the naive bolding procedure produces quite
different results, in both cases. For example, in Georgia, the
left stroke is only changed slightly by bolding, while the right
stroke is greatly enlargened, but only on one side. In both
fonts, bolding doesn’t change the height of the font, while the
naive approach does.
As these examples show, good bolding is not a trivial
process of thickening up a font. Expert type designers have many
heuristics for bolding, heuristics inferred from much previous
experimentation, and careful study of historical
examples. Capturing all those heuristics in a conventional program
would involve immense work. The benefit of using the generative
model is that it automatically learns many such heuristics.
For example, a naive bolding tool would rapidly fill in the
enclosed negative space in the enclosed upper region of the letter
“A”. The font tool doesn’t do this. Instead, it goes
to some trouble to preserve the enclosed negative space, moving
the A’s bar down, and filling out the interior strokes more slowly
than the exterior. This principle is evident in the examples
shown above, especially Helvetica, and it can also be seen in the
operation of the font tool:
The heuristic of preserving enclosed negative space is not a
priori obvious. However, it’s done in many professionally
designed fonts. If you examine examples like those shown above
it’s easy to see why: it improves legibility. During training,
our generative model has automatically inferred this principle
from the examples it’s seen. And our bolding interface then makes
this available to the user.
In fact, the model captures many other heuristics. For instance,
in the above examples the heights of the fonts are (roughly)
preserved, which is the norm in professional font design. Again,
what’s going on isn’t just a thickening of the font, but rather
the application of a more subtle heuristic inferred by the
generative model. Such heuristics can be used to create fonts
with properties which would otherwise be unlikely to occur to
users. Thus, the tool expands ordinary people’s ability to
explore the space of meaningful fonts.
The font tool is an example of a kind of cognitive technology. In
particular, the primitive operations it contains can be
internalized as part of how a user thinks. In this it resembles a
program such as Photoshop or a spreadsheet or 3D graphics
programs. Each provides a novel set of interface primitives,
primitives which can be internalized by the user as fundamental
new elements in their thinking. This act of internalization of new
primitives is fundamental to much work on intelligence
augmentation.
The ideas shown in the font tool can be extended to other domains.
Using the same interface, we can use a generative model to
manipulate images of human faces using qualities such as
expression, gender, or hair color. Or to manipulate sentences
using length, sarcasm, or tone. Or to manipulate molecules using
chemical properties:
Such generative interfaces provide a kind of cartography of
generative models, ways for humans to explore and make meaning
using those models.
We saw earlier that the font model automatically infers relatively
deep principles about font design, and makes them available to
users. While it’s great that such deep principles can be
inferred, sometimes such models infer other things that are wrong,
or undesirable. For example, White
points out the addition of a smile vector in some face
models will make faces not just smile more, but also appear more
feminine. Why? Because in the training data more women than men
were smiling. So these models may not just learn deep facts about
the world, they may also internalize prejudices or erroneous
beliefs. Once such a bias is known, it is often possible to make
corrections. But to find those biases requires careful auditing
of the models, and it is not yet clear how we can ensure such
audits are exhaustive.
More broadly, we can ask why attribute vectors work, when they
work, and when they fail? At the moment, the answers to these
questions are poorly understood.
For the attribute vector to work requires that taking any starting
font, we can construct the corresponding bold version by adding
the same vector in the latent space. However, a
priori there is no reason using a single constant vector to
displace will work. It may be that we should displace in many
different ways. For instance, the heuristics used to bold serif
and sans-serif fonts are quite different, and so it seems likely
that very different displacements would be involved:
Of course, we could do something more sophisticated than using a
single constant attribute vector. Given pairs of example fonts
(unbold, bold) we could train a machine learning algorithm to take
as input the latent vector for the unbolded version and output the
latent vector for the bolded version. With additional training
data about font weights, the machine learning algorithm could
learn to generate fonts of arbitrary weight. Attribute vectors
are just an extremely simple approach to doing these kinds of
operation.
For these reasons, it seems unlikely that attribute vectors will
last as an approach to manipulating high-level features. Over the
next few years much better approaches will be developed. However,
we can still expect interfaces offering operations broadly similar
to those sketched above, allowing access to high-level and
potentially user-defined concepts. That interface pattern doesn’t
depend on the technical details of attribute vectors.
Interactive Generative Adversarial Models
Let’s look at another example using machine learning models to
augment human creativity. It’s the interactive generative
adversarial networks, or iGANs, introduced
by Zhu et al in 2016.
One of the examples of Zhu et al is the use of iGANs in
an interface to generate images of consumer products such as
shoes. Conventionally, such an interface would require the
programmer to write a program containing a great deal of knowledge
about shoes: soles, laces, heels, and so on. Instead of doing
this, Zhu et al train a generative model using 50
thousand images of shoes, downloaded from Zappos. They then use
that generative model to build an interface that lets a user
roughly sketch the shape of a shoe, the sole, the laces, and so
on:
Excerpted from Zhu et
al.
The visual quality is low, in part because the generative model
Zhu et al used is outdated by modern (2017) standards– with more modern models, the visual quality would be much
higher.
But the visual quality is not the point. Many interesting things
are going on in this prototype. For instance, notice how the
overall shape of the shoe changes considerably when the sole isfilled in – it becomes narrower and sleeker. Many small
details are filled in, like the black piping on the top of the
white sole, and the red colouring filled in everywhere on the
shoe’s upper. These and other facts are automatically deduced
from the underlying generative model, in a way we’ll describe
shortly.
The same interface may be used to sketch landscapes. The only
difference is that the underlying generative model has been
trained on landscape images rather than images of shoes. In this
case it becomes possible to sketch in just the colors associated
to a landscape. For example, here’s a user sketching in some green
grass, the outline of a mountain, some blue sky, and snow on the
mountain:
Excerpted from Zhu et
al.
The generative models used in these interfaces are different than
for our font model. Rather than using variational autoencoders,
they’re based on generative
adversarial networks (GANs). But the underlying idea is
still to find a low-dimensional latent space which can be used to
represent (say) all landscape images, and map that latent space to
a corresponding image. Again, we can think of points in the
latent space as a compact way of describing landscape images.
Roughly speaking, the way the iGANs works is as follows. Whatever
the current image is, it corresponds to some point in the latent
space:
Suppose, as happened in the earlier video, the user now sketches
in a stroke outlining the mountain shape. We can think of the
stroke as a constraint on the image, picking out a subspace of the
latent space, consisting of all points in the latent space whose
image matches that outline:
The way the interface works is to find a point in the latent space
which is near to the current image, so the image is not changed
too much, but also coming close to satisfying the imposed
constraints. This is done by optimizing an objective function
which combines the distance to each of the imposed constraints, as
well as the distance moved from the current point. If there’s
just a single constraint, say, corresponding to the mountain
stroke, this looks something like the following:
We can think of this, then, as a way of applying constraints to
the latent space to move the image around in meaningful ways.
The iGANs have much in common with the font tool we showed
earlier. Both make available operations that encode much subtle
knowledge about the world, whether it be learning to understand
what a mountain looks like, or inferring that enclosed negative
space should be preserved when bolding a font. Both the iGANs and
the font tool provide ways of understanding and navigating a
high-dimensional space, keeping us on the natural space of fonts
or shoes or landscapes. As Zhu et al remark:
[F]or most of us, even a simple image manipulation in Photoshop
presents insurmountable difficulties… any less-than-perfect
edit immediately makes the image look completely unrealistic. To
put another way, classic visual manipulation paradigm does not
prevent the user from “falling off” the manifold of
natural images.
Like the font tool, the iGANs is a cognitive technology. Users
can internalize the interface operations as new primitive elements
in their thinking. In the case of shoes, for example, they can
learn to think in terms of the difference they want to apply,
adding a heel, or a higher top, or a special highlight. This is
richer than the traditional way non-experts think about shoes
(“Size 11, black” etc). To the extent that
non-experts do think in more sophisticated ways –
“make the top a little higher and sleeker” –
they get little practice in thinking this way, or seeing the
consequences of their choices. Having an interface like this
enables easier exploration, the ability to develop idioms and the
ability to plan, to swap ideas with friends, and so on.
Two models of computation
Let’s revisit the question we began the essay with, the question
of what computers are for, and how this relates to intelligence
augmentation.
One common conception of computers is that they’re problem-solving
machines: “computer, what is the result of firing this
artillery shell in such-and-such a wind [and so on]?”;
“computer, what will the maximum temperature in Tokyo be in
5 days?”; “computer, what is the best move to take
when the Go board is in this position?”; “computer,
how should this image be classified?”; and so on.
This is a conception common to both the early view of computers as
number-crunchers, and also in much work on AI, both historically
and today. It’s a model of a computer as a way of outsourcing
cognition. In speculative depictions of possible future AI,
this cognitive outsourcing model often shows up in the
view of an AI as an oracle, able to solve some large class of
problems with better-than-human performance.
But a very different conception of what computers are for is
possible, a conception much more congruent with work on
intelligence augmentation.
To understand this alternate view, consider our subjective
experience of thought. For many people, that experience is verbal:
they think using language, forming chains of words in their heads,
similar to sentences in speech or written on a page. For other
people, thinking is a more visual experience, incorporating
representations such as graphs and maps. Still other people mix
mathematics into their thinking, using algebraic expressions or
diagrammatic techniques, such as Feynman diagrams and Penrose
diagrams.
In each case, we’re thinking using representations invented by
other people: words, graphs, maps, algebra, mathematical diagrams,
and so on. We internalize these cognitive technologies as we grow
up, and come to use them as a kind of substrate for our thinking.
For most of history, the range of available cognitive technologies
has changed slowly and incrementally. A new word will be
introduced, or a new mathematical symbol. More rarely, a radical
new cognitive technology will be developed. For example, in 1637
Descartes published his “Discourse on Method”,
explaining how to represent geometric ideas using algebra, and
vice versa:
This enabled a radical change and expansion in how we think about
both geometry and algebra.
Historically, lasting cognitive technologies have been invented
only rarely. But modern computers are a meta-medium enabling the
rapid invention of many new cognitive techologies. Consider a
relatively banal example, such
as Photoshop. Adept Photoshop users routinely
have formerly impossible thoughts such as: “let’s apply the
clone stamp to the such-and-such layer.”. That’s an
instance of a more general class of thought: “computer, [new
type of action] this [new type of representation for a newly
imagined class of object]”. When that happens, we’re using
computers to expand the range of thoughts we can think.
It’s this kind of cognitive transformation model which
underlies much of the deepest work on intelligence augmentation.
Rather than outsourcing cognition, it’s about changing the
operations and representations we use to think; it’s about
changing the substrate of thought itself. And so while cognitive
outsourcing is important, this cognitive transformation view
offers a much more profound model of intelligence augmentation.
It’s a view in which computers are a means to change and expand
human thought itself.
Historically, cognitive technologies were developed by human
inventors, ranging from the invention of writing in Sumeria and
Mesoamerica, to the modern interfaces of designers such as Douglas
Engelbart, Alan Kay, and others.
Examples such as those described in this essay suggest that AI
systems can enable the creation of new cognitive technologies.
Things like the font tool aren’t just oracles to be consulted when
you want a new font. Rather, they can be used to explore and
discover, to provide new representations and operations, which can
be internalized as part of the user’s own thinking. And while
these examples are in their early stages, they suggest AI is not
just about cognitive outsourcing. A different view of AI is
possible, one where it helps us invent new cognitive technologies
which transform the way we think.
In this essay we’ve focused on a small number of examples, mostly
involving exploration of the latent space. There are many other
examples of artificial intelligence augmentation. To give some
flavour, without being comprehensive:
the sketch-rnn system, for neural
network assisted drawing;
the Wekinator, which enables
users to rapidly build new musical instruments and artistic
systems; TopoSketch, for developing
animations by exploring latent spaces; machine learning models for
designing overall typographic
layout; and a generative model which enables
interpolation between musical
phrases. In each case, the systems use machine learning
to enable new primitives which can be integrated into the user’s
thinking. More broadly, artificial intelligence augmentation will
draw on fields such as computational
creativity and interactive machine
learning.
Finding powerful new primitives of thought
We’ve argued that machine learning systems can help create
representations and operations which serve as new primitives in
human thought. What properties should we look for in such new
primitives? This is too large a question to be answered
comprehensively in a short essay. But we will explore it briefly.
Historically, important new media forms often seem strange when
introduced. Many such stories have passed into popular culture:
the near riot at the premiere of Stravinsky and Nijinksy’s
“Rite of Spring”; the consternation caused by the
early cubist paintings, leading
The New York Timesto
comment: “What do they mean? Have those
responsible for them taken leave of their senses? Is it art or
madness? Who knows?”
Another example comes from physics. In the 1940s, different
formulations of the theory of quantum electrodynamics were
developed independently by the physicists Julian Schwinger,
Shin’ichirō Tomonaga, and Richard Feynman. In their work,
Schwinger and Tomonaga used a conventional algebraic approach,
along lines similar to the rest of physics. Feynman used a more
radical approach, based on what are now known as Feynman diagrams,
for depicting the interaction of light and matter:
Image by Joel
Holdsworth), licensed under a Creative Commons
Attribution-Share Alike 3.0 Unported license
Initially, the Schwinger-Tomonaga approach was easier for other
physicists to understand. When Feynman and Schwinger presented
their work at a 1948 workshop, Schwinger was immediately
acclaimed. By contrast, Feynman left his audience mystified. As
James Gleick put it in his biography of
Feynman:
It struck Feynman that everyone had a favorite principle or
theorem and he was violating them all… Feynman knew he had
failed. At the time, he was in anguish. Later he said simply:
“I had too much stuff. My machines came from too far
away.”
Of course, strangeness for strangeness’s sake alone is not
useful. But these examples suggest that breakthroughs in
representation often appear strange at first. Is there any
underlying reason that is true?
Part of the reason is because if some representation is truly new,
then it will appear different than anything you’ve ever seen
before. Feynman’s diagrams, Picasso’s paintings, Stravinsky’s
music: all revealed genuinely new ways of making meaning. Good
representations sharpen up such insights, eliding the familiar to
show that which is new as vividly as possible. But because of
that emphasis on unfamiliarity, the representation will seem
strange: it shows relationships you’ve never seen before. In some
sense, the task of the designer is to identify that core
strangeness, and to amplify it as much as possible.
Strange representations are often difficult to understand. At
first, physicists preferred Schwinger-Tomonaga to Feynman. But as
Feynman’s approach was slowly understood by physicists, they
realized that although Schwinger-Tomonaga and Feynman were
mathematically equivalent, Feynman was more powerful. As Gleick
puts it:
Schwinger’s students at Harvard were put at a competitive
disadvantage, or so it seemed to their fellows elsewhere, who
suspected them of surreptitiously using the diagrams anyway. This
was sometimes true… Murray Gell-Mann later spent a semester
staying in Schwinger’s house and loved to say afterward that he
had searched everywhere for the Feynman diagrams. He had not
found any, but one room had been locked…
These ideas are true not just of historical representations, but
also of computer interfaces. However, our advocacy of strangeness
in representation contradicts much conventional wisdom about
interfaces, especially the widely-held belief that they should be“user friendly”, i.e., simple and immediately useable
by novices. That most often means the interface is cliched, built
from conventional elements combined in standard ways. But while
using a cliched interface may be easy and fun, it’s an ease
similar to reading a formulaic romance novel. It means the
interface does not reveal anything truly surprising about its
subject area. And so it will do little to deepen the user’s
understanding, or to change the way they think. For mundane tasks
that is fine, but for deeper tasks, and for the longer term, you
want a better interface.
Ideally, an interface will surface the deepest principles
underlying a subject, revealing a new world to the user. When you
learn such an interface, you internalize those principles, giving
you more powerful ways of reasoning about that world. Those
principles are the diffs in your understanding. They’re all you
really want to see, everything else is at best support, at worst
unimportant dross. The purpose of the best interfaces isn’t to be
user-friendly in some shallow sense. It’s to be user-friendly in
a much stronger sense, reifying deep
principles about the world, making them the working
conditions in which users live and create. At that point what once
appeared strange can instead becomes comfortable and familiar,
part of the pattern of thoughtA powerful instance of
these ideas is when an interface reifies general-purpose
principles. An example is an
interface one of us developed
based on the principle of conservation of energy. Such
general-purpose principles generate multiple unexpected
relationships between the entities of a subject, and so are a
particularly rich source of insights when reified in an
interface..
What does this mean for the use of AI models for intelligence
augmentation?
Aspirationally, as we’ve seen, our machine learning models will
help us build interfaces which reify deep principles in ways
meaningful to the user. For that to happen, the models have to
discover deep principles about the world, recognize those
principles, and then surface them as vividly as possible in an
interface, in a way comprehensible by the user.
Of course, this is a tall order! The examples we’ve shown are just
barely beginning to do this. It’s true that our models do
sometimes discover relatively deep principles, like the
preservation of enclosed negative space when bolding a font. But
this is merely implicit in the model. And while we’ve built a tool
which takes advantage of such principles, it’d be better if the
model automatically inferred the important principles learned, and
found ways of explicitly surfacing them through the interface.
(Encouraging progress toward this has been made
by InfoGANs, which use
information-theoretic ideas to find structure in the latent
space.) Ideally, such models would start to get at true
explanations, not just in a static form, but in a dynamic form,
manipulable by the user. But we’re a long way from that point.
Do these interfaces inhibit creativity?
It’s tempting to be skeptical of the expressiveness of the
interfaces we’ve described. If an interface constrains us to
explore only the natural space of images, does that mean we’re
merely doing the expected? Does it mean these interfaces can only
be used to generate visual cliches? Does it prevent us from
generating anything truly new, from doing truly creative work?
To answer these questions, it’s helpful to identify two different
modes of creativity. This two-mode model is over-simplified:
creativity doesn’t fit so neatly into two distinct categories. Yet
the model nonetheless clarifies the role of new interfaces in
creative work.
The first mode of creativity is the everyday creativity of a
craftsperson engaged in their craft. Much of the work of a font
designer, for example, consists of competent recombination of the
best existing practices. Such work typically involves many
creative choices to meet the intended design goals, but not
developing key new underlying principles.
For such work, the generative interfaces we’ve been discussing are
promising. While they currently have many limitations, future
research will identity and fix many deficiencies. This is
happening rapidly with GANs: the original
GANs had many limitations,
but models soon appeared that were better adapted to
images, improved the
resolution, reduced artifactsSo much work has been
done on improving resolution and reducing artifacts it seems
unfair to single out any small set of papers, and to omit the many
others., and so on. With enough iterations it’s
plausible these generative interfaces will become powerful tools
for craft work.
The second mode of creativity aims toward developing new
principles that fundamentally change the range of creative
expression. One sees this in the work of artists such as Picasso
or Monet, who violated existing principles of painting, developing
new principles which enabled people to see in new ways.
Is it possible to do such creative work, while using a generative
interface? Don’t such interfaces constrain us to the space of
natural images, or natural fonts, and thus actively prevent us
from exploring the most interesting new directions in creative
work?
The situation is more complex than this.
In part, this is a question about the power of our generative
models. In some cases, the model can only generate recombinations
of existing ideas. This is a limitation of an ideal GAN, since a
perfectly trained GAN generator will reproduce the training
distribution. Such a model can’t directly generate an image based
on new fundamental principles, because such an image wouldn’t look
anything like it’s seen in its training data.
Artists such as Mario
Klingemann and Mike
Tyka are now using GANs to create interesting
artwork. They’re doing that using “imperfect” GAN
models, which they seem to be able to use to explore interesting
new principles; it’s perhaps the case that bad GANs may be more
artistically interesting than ideal GANs. Furthermore, nothing
says an interface must only help us explore the latent space.
Perhaps operations can be added which deliberately take us out
of the latent space, or to less probable (and so more
surprising) parts of the space of natural images.
Of course, GANs are not the only generative models. In a
sufficiently powerful generative model, the generalizations
discovered by the model may contain ideas going beyond what humans
have discovered. In that case, exploration of the latent space may
enable us to discover new fundamental principles. The model would
have discovered stronger abstractions than human experts. Imagine
a generative model trained on paintings up until just before the
time of the cubists; might it be that by exploring that model it
would be possible to discover cubism? It would be an analogue to
something like the prediction of Bose-Einstein condensation, as
discussed earlier in the essay. Such invention is beyond today’s
generative models, but seems a worthwhile aspiration for future
models.
Our examples so far have all been based on generative models. But
there are some illuminating examples which are not based on
generative models. Consider the pix2pix system developed
by Isola et al. This
system is trained on pairs of images, e.g., pairs showing the
edges of a cat, and the actual corresponding cat. Once trained,
it can be shown a set of edges and asked to generate an image for
an actual corresponding cat. It often does this quite well:
When supplied with unusual constraints, pix2pix can produce
striking images:
This is perhaps not high creativity of a Picasso-esque level. But
it is still surprising. It’s certainly unlike images most of us
have ever seen before. How does pix2pix and its human user achieve
this kind of result?
Unlike our earlier examples, pix2pix is not a generative model.
This means it does not have a latent space or a corresponding
space of natural images. Instead, there is a neural network,
called, confusingly, a generator – this is not meant in the
same sense as our earlier generative models – that takes as
input the constraint image, and produces as output the filled-in
image.
The generator is trained adversarially against a discriminator
network, whose job is to distinguish between pairs of images
generated from real data, and pairs of images generated by the
generator.
While this sounds similar to a conventional GAN, there is a
crucial difference: there is no latent vector input to the
generatorActually, Isola et
al experimented with adding such a latent vector to
the generator, but found it made little difference to the
resulting images.. Rather, there is simply an input
constraint. When a human inputs a constraint unlike anything seen
in training, the network is forced to improvise, doing the best it
can to interpret that constraint according to the rules it has
previously learned. The creativity is the result of a forced
merger of knowledge inferred from the training data, together with
novel constraints provided by the user. As a result, even
relatively simple ideas – like the bread- and beholder-cats
– can result in striking new types of images, images not
within what we would previously have considered the space of
natural images.
Conclusion
It is conventional wisdom that AI will change how we interact with
computers. Unfortunately, many in the AI community greatly
underestimate the depth of interface design, often regarding it as
a simple problem, mostly about making things pretty or
easy-to-use. In this view, interface design is a problem to be
handed off to others, while the hard work is to train some machine
learning system.
This view is incorrect. At its deepest, interface design means
developing the fundamental primitives human beings think and
create with. This is a problem whose intellectual genesis goes
back to the inventors of the alphabet, of cartography, and of
musical notation, as well as modern giants such as Descartes,
Playfair, Feynman, Engelbart, and Kay. It is one of the hardest,
most important and most fundamental problems humanity grapples
with.
As discussed earlier, in one common view of AI our computers will
continue to get better at solving problems, but human beings will
remain largely unchanged. In a second common view, human beings
will be modified at the hardware level, perhaps directly through
neural interfaces, or indirectly through whole brain emulation.
We’ve described a third view, in which AIs actually change
humanity, helping us invent new cognitive technologies, which
expand the range of human thought. Perhaps one day those
cognitive technologies will, in turn, speed up the development of
AI, in a virtuous feedback cycle:
It would not be a Singularity in machines. Rather, it would be a
Singularity in humanity’s range of thought. Of course, this loop
is at present extremely speculative. The systems we’ve described
can help develop more powerful ways of thinking, but there’s at
most an indirect sense in which those ways of thinking are being
used in turn to develop new AI systems.
Of course, over the long run it’s possible that machines will
exceed humans on all or most cognitive tasks. Even if that’s the
case, cognitive transformation will still be a valuable end, worth
pursuing in its own right. There is pleasure and value involved
in learning to play chess or Go well, even if machines do it
better. And in activities such as story-telling the benefit often
isn’t so much the artifact produced as the process of construction
itself, and the relationships forged. There is intrinsic value in
personal change and growth, apart from instrumental benefits.
The interface-oriented work we’ve discussed is outside the
narrative used to judge most existing work in artifical
intelligence. It doesn’t involve beating some benchmark for a
classification or regression problem. It doesn’t involve
impressive feats like beating human champions at games such as
Go. Rather, it involves a much more subjective and
difficult-to-measure criterion: is it helping humans think and
create in new ways?
This creates difficulties for doing this kind of work,
particularly in a research setting. Where should one publish?
What community does one belong to? What standards should be
applied to judge such work? What distinguishes good work from
bad?
We believe that over the next few years a community will emerge
which answers these questions. It will run workshops and
conferences. It will publish work in venues such as Distill. Its
standards will draw from many different communities: from the
artistic and design and musical communities; from the mathematical
community’s taste in abstraction and good definition; as well as
from the existing AI and IA communities, including work on
computational creativity and human-computer interaction. The
long-term test of success will be the development of tools which
are widely used by creators. Are artists using these tools to
develop remarkable new styles? Are scientists in other fields
using them to develop understanding in ways not otherwise
possible? These are great aspirations, and require an approach
that builds on conventional AI work, but also incorporates very
different norms.
From The Lord of the Rings: The Fellowship of the Ring by J.R.R. Tolkien
Barliman News
4 December 2016
Barliman overview
Barliman is a prototype "smart editor" that performs real-time program synthesis to try to make the programmer's life a little easier. Barliman has several unusual features:
Given a set of tests for some function foo, Barliman tries to "guess" how to fill in an partially-specified definition of foo to make all of the tests pass;
Given a set of tests for some function foo, Barliman tries to prove that a partially-specified definition of foo is inconsistent with one or more of the tests;
Given a fully or mostly-specified definition of some function foo, Barliman will attempt to prove that a partially-specified test is consistent with, or inconsistent with, the definition of foo.
Barliman is general enough to handle multiple programming languages. In fact, the user can even specify their own programming language, or change the semantics or syntax of one of the default languages that come with Barliman. The default language for Barliman is a small but Turing-complete subset of side-effect-free Scheme that supports recursion, list operations, higher-order functions, multi-argument and variadic functions, and a few other features.
Purpose of Barliman
Test the hypothesis that even very modest or slow program synthesis can be useful, if it is part of an interactive conversation with a programmer.
Explore utility of interactive synthesis.
Explore design for such an interactive tool.
Try to inspire others to build similar tools, perhaps using radically different implementation techniques.
Barliman in action
Here are a few screenshots of Barliman, using the Mac implementation as of June 4, 2016:
Update: I've added a few newer screenshots from June 16, 2016. Once Barliman stops changing as rapidly I'll update all the screenshots.
Update – 10 October 2016: Please see the interesting_examples directory for more recent examples and screenshots.
Update – 4 December 2016: The Clojure/conj 2016 talk is currently the best source of up-to-date information on Barliman.
The following descriptions are based on an older and far less capable version. TODO: update them.
The first screenshot shows the main editor window. The Scheme Definition edit pane contains the complete (fully instantiated) and correct definition of append, the list concatenation function in Barliman's default "miniScheme" language. append will be our simple running example in these screenshots. The edit window also contains three tests; each test contains an input expression, and the expected value of that expression. The Best Guess pane, which is not editable by the user, contains the same fully instantiated definition of append as in the Scheme Definition edit pane.
All the text in the editor window is black, indicating that all the information in the editor is consistent and valid. The definition of append is a valid symbolic expression (s-expression), and is indeed a syntactically valid miniScheme definition. The test expressions and expected values are syntactically valid, and consistent with each other.
The editor window displayed in this first screeenshot is similar in spirit to a modern integrated development environment (IDE) that runs tests whenever the code to be tested is modified.
Let's see how we might have gotten to the final version of append using Barliman.
Screenshot 1: Fully instantiated definition of append:
Screenshot 2 shows the empty main editor window, immediately after starting Barliman. We know we want to define append, so in true test-drived development style we begin by writing our tests cases.
Screenshot 2:
Screenshot 3 shows the main editor window with our three tests. The first test says that if we append the empty list to the empty list, we should get back the empty list. You should be able to figure out the other two tests.
The text for all three tests are red, indicating that none of the tests pass. This isn't surprising, perhaps, since we haven't started to define the append function.
(From an interface design standpoint, whether to use colors, which colors to use, which text fields to hilight, etc., are all open questions in my mind. Over time I hope to make it much more clear exactly which part of the code is failing, and why.)
Screenshot 3:
Screenshot 4 shows the main editor window after we have begun defining append in the Scheme Definition edit pane. Our parentheses are not balanced – we haven't yet typed a closing parenthesis for the define form. Because of the missing parenthesis, the definition is not a legal Scheme s-expression. The tests cannot pass, of course, since append isn't even an s-expression. Barliman recognizes this, and turns the text in the Scheme Definition edit pane, and the text in the test edit fields, a sickly green color.
(Future versions of Barliman should include a structured editor that will automatically insert balanced parentheses.)
Screenshot 4:
Screenshot 5 shows the main editor window after we have added the closing parenthesis in our partial definition of append in the Scheme Definition edit pane. The partial definition of append is now a legal s-expression. However, the definition of append is not syntactically valid according to the rules of miniScheme. Of course, this invalid definition of append causes all the tests to fail as well. Barliman recognizes this, and turns the text in the Scheme Definition edit pane, and the text in the test edit fields, red.
(Currently Barliman doesn't actually check that definitions are grammatically correct. Rather, Barliman uses evaluation of the tests to check whether code is semantically legal, rather than syntactically legal. Future versions of Barliman will probably include explicit grammars that are checked, in addition to semantic rules.) (Update: Barliman now includes a relational parser for the miniScheme language, as is shown in the newer screenshots at the end.)
Screenshot 5:
In screenshot 6 we can see that the programmer has partially specified the defintion of append. The definition is a syntactally-correct s-expression, and indeed is a syntactically correct use of miniScheme's define form. Importantly, the definition of append is only partially specified, and contains four (logic) variables (A, B, C, and D) representing unknown subexpressions. In Barliman variables representing unknown subexpressions are single-letter upper-case variables A through Z. (Note to Schemers: The comma (,) that usually occurs before these letters is necessary because the code in the Scheme Definition edit pane is implicitly quasiqoted.)
Given the partially-specified defintion of append in the Scheme Definition edit pane, along with the three tests, Barliman is able to correctly "guess" the code corresponding to these variables. The correct and complete definition of append is displayed in the Best Guess pane. Barliman guesses the correct code in this case in a second or less. All of the text in the main editor window is black, indicating that all of the code is syntactically correct, and that all three tests pass given the completed definition of append shown in the Best Guess pane.
Screenshot 6:
Screenshot 7 shows an incorrect partial definition of append. As in the previous screenshot, the partial definition of append contains variables representing unknown subexpressions (the A and B and C). However, in this case the first argument to cons is incorrect. The first argument to cons should be (car l), as shown in screenshot 1. Alternatively, the first argument to cons could be an incomplete expression containing a variable representating an unknown subexpression, such as (car ,B) from screenshot 6, provided that this incomplete expression is consistent with the expression (car l). Here, however, the first argument to cons is the expression (cdr l). The red text for tests 2 and 3 indicate that these tests are incompatible with the partial definition of append in the Scheme Definition edit pane. That is, there are no legal miniScheme expressions that could be substituted for the variables A, B, and C that would make tests 2 and 3 pass.
The spinning progress indicator to the upper-right of the Best Guess pane indicates that Barliman is trying to find expressions for variables A, B, and C that will make all of the tests pass. Of course this is impossible – Barliman should be a little smarter, and cut off the Best Guess computation when one of the individual tests fails.
The important thing about this example is that Barliman was able to prove that the partial definition of append is incorrect, without append being fully defined. More precisely, the partial definition of append is inconsistent with respect to tests 1 through 3 and the semantics of miniScheme (which can be edited by the programmer).
Screenshot 7:
Screenshot 8 shows another partially-instantiated, but incorrect, definition of append. The base case of append should be s instead of l, yet all the text is in black, indicating that the individual tests are compatible with the definition so far. The problem is that we don't have a test that exposes that this partial definition is wrong. We'll fix this in the next screenshot.
This is one danger of using tests for feedback, of course – in general, no finite number of tests is sufficient to prove our definition is correct. I hope that future versions of Barliman will include other ways to specify the behavior of programs, which might include specifying program properties, or providing a "reference" implementation of a function that is being redefined to perform faster, etc.
Screenshot 8:
In screenshot 9 we add a new test, test 4, that shows that the base case of append is incorrect. Sure enough, test 4's text immediately turns red, indicating it is incompatible with our partial definition.
Screenshot 9:
Screenshot 10 shows a limitation of Barliman's program synthesis. Here the partially-specified definition of append contains only a single variable, A, representing an unknown subexpression. Ideally Barliman would quickly figure out that A should be the expression (cdr l). However, for this example Barliman seems to get "stuck" – we can see the spinning progress indicators to the upper-right of the Best Guess pane and the Test 2 and Test 3 edit fields, indicating that Barliman is still "thinking". I let Barliman run for a minute or two, but it didn't find a value for A in that time. (Adding the notion of "parsimony" to Barliman, so it tries to generate the smallest terms first, might help with this example.)
We could allow Barliman to keep thinking – perhaps it would find the answer in five minutes, or in an hour (provided our computer has enough RAM!). However, in practice we would probably try filling in A manually. If we were to type (cdr ,B) in place of ,A, Barliman would immedialy guess in the correct, trivial subexpression l for the variable B.
This example shows how program synthesis in Barliman can be much slower than we might hope in certain cases. However, since Barliman is a text editor, and since multicore computers with lots of RAM are now ubiquitous, I see these examples from a "glass half full" perspective. Sometimes Barliman can help you, either by guessing the rest of your incomplete definition, or by proving that there is no completion for your partially-specified definition that is consistent with your tests. In this case you win. Sometimes Barliman can't help you, in which case you use it like a regular text editor. In this case you use more CPU cyles and RAM on your machine, but otherwise edit text normally.
Of course, Barliman isn't currently a particularly good text editor, especially compared to Emacs with paredit mode, to take one example. This problem is only a matter of engineering – in fact, Barliman-like functionality could be added to Emacs, or to another editor. Or Barliman could get more sophisticated editing abilities.
A bigger drawback is that the semantics for the language you are writing in must be specified in miniKanren. This is fine if you are writing in a minimal Scheme subset, such as miniScheme. This isn't so great if you want to program in full Clojure or Racket or Javascript or Ruby. Finding ways to scale this technology is an open problem. The solution may not be miniKanren or constraint logic programming, but rather another synthesis approach. I don't know. I do hope, however, that Barliman will make people think about how synthesis capabilities can be integrated into editors, especially for dynamic languages.
Screenshot 10:
Update: Here are a few newer screenshots, as of June 16, 2016, that show off the relational parser for miniScheme that I added a couple of days ago.
Screenshot 11 is an updated version of screenshot 5, showing the new relational parser at work. The definition of append is syntactically incorrect, which is represented by the purple text in the Scheme Definition edit pane. The tests are syntactically correct, but fail, and are therefore shown in red text.
Screenshot 11:
Screenshot 12, like screenshot 11, shows a syntactically incorrect definition of append. In this case the keyword lambda appears as the body of a lambda expression. In miniScheme, as in Scheme, lambda is a special form rather than a function; the keyword lambda cannot appear "by itself". Hence the purple text in the Scheme Definition edit pane.
Once again, the tests are syntactically valid, but fail, and so are shown in red text.
Screenshot 12:
Screenshot 13 is identical to screenshot 12, except that the formal parameter to the lambda expression in the Scheme Definition edit pane has been changed from x to lambda. This formal parameter shadows the lambda keyword, allowing lambda to appear by itself in the body of the lambda expression.
Once again, the tests are syntactically valid, but fail, and so are shown in red text.
This example shows that the relational parser keeps track of the environment, variable scope, and shadowing.
Screenshot 13:
Screenshot 14 shows a syntactically legal partial definition of append in the Scheme Definition edit pane. Three of the tests are syntactically legal, and are (individually) consistent with the partial definition of append; therefore, the text for these tests are shown in black.
The third test, however, is syntactically incorrect. This is because in miniScheme, as in Scheme, and is a special form rather than a function, and therefore cannot be passed into the call to append. Since the third test is syntactically illegal, it is shown in purple text.
Screenshot 14:
Advantages and limitations of Barliman
Advantages of Barliman
Barliman is flexible. Barliman can handle operational semantics for various programming languges. Users can add their own semantics, or modify the semantics for languages that are included with Barliman. Barliman does not require the language be statically typed, or that the user has supplied enough tests to fully synthesize the function being defined.
Barliman is interactive. Any change to the definition of a function, the corresponding tests, or even the semantics immediately re-triggers the program synthesis solver.
Limitations of Barliman
Barliman can be extremely slow when it comes to program synthesis, and can easily get "stuck", possibly taking hours and tens of gigabytes of RAM to synthesize small fragments of code. Since the default "miniScheme" language is dynamically typed, Barliman cannot take advantage of types to limit the space of programs to be considered during synthesis. There are other synthesis tools that can synthesize the complete definition of append, for example, given append's type signature along with tests that properly cover the behavior of append. (In fact, Michael Ballantyne has been able to synthesize append by integrating types into a tiny Scheme-like languge, which I'd like to explore in the context of Barliman.)
To me this is a tradeoff. Barliman is very flexible in its handling of languages and synthesis problems. At the same time, Barliman's synthesis is slow, which is why the tool is designed to work interactively with a programmer. I think this is a reasonable tradoff to explore, since there are plenty of dynamically-typed languages in use (Javascript, Python, Ruby, Scheme/Racket/Clojure/Lisp, etc.). Also, Barliman doesn't require that the user specify every test necessary to synthesize the complete definition of the function being considered, which reduces the burden on the programmer.
In short, Barliman is flexible, and can handle Turing-complete dynamically-typed higer-order languages, and under-specified synthesis problems, but the tradeoff is that Barliman's synthesis is slow.
Barliman works best for big-step operational semantics. It is possible to implement small-step semantics in Barliman. However, the synthesis features of Barliman are likely to work poorly compared with semantics written in a big-step style.
Similarly, Barliman works best for side-effect-free languages, such as a pure subset of Scheme. Once again, Barliman can handle languages with side effects, such as variable mutation. However, Barliman's synthesis abilities are likely to suffer as a result.
I do not know how large a language, or how large a definition, Barliman can handle in practice. I will be experimenting with this...
Barliman can be resource hungry. Given six example programs and a definition, Barliman will launch eight instances of Chez Scheme, all running in parallel. Barliman tries to kill these processes when they are not needed, but it is possible for these processes to run for long periods of time (like, forever) and take up unbounded amounts of RAM.
Barliman currently isn't a very good at standard text editing. For example, anyone used to paredit or structured text editing will miss those features in Barliman, at least for now. I do want to add these features to Barliman, especially since I expect they will make the synthesis aspects easier to explore.
Barliman currently doesn't support saving or loading files, definitions, tests, or anything else. I plan to add this feature soon.
Barliman is changing quickly, and definitely contains errors and interface quirks. To the best of my knowledge none of these problems are inherent in the design of Barliman, or the technology being used for synthesis. Still, since this is a rapidly evolving prototype, I expect I will be introducing errors about as quickly as I remove them, at least for a while.
Chez Scheme in turn uses the miniKanren implementation and relational interpreter implementation contained in the mk-and-rel-interp directory.
The default "miniScheme" language
(give grammar and semantics for the default language)
As in Scheme, in miniScheme duplicate variable names of definitions at the same scoping level, or duplicate lambda or letrec bindings, are illegal. However, Barliman does not currently detect these violations. For example, Barliman will not complain about the expression ((lambda (x x) x) 3 4), the behavior of which is unspecified. Probably the parser should enforce that the variable names are distinct.
The lambda and letrec forms do not contain an implicit begin.
The lambda form supports multiple arguments, (lambda (x y z) y), and a single "variadic" argument, (lambda x x), but currently doesn't support the full Scheme variadic syntax, (lambda (x y . z) x).
Barliman implementation details
The cocoa version of the editor is written in Swift, and has been tested under OS X 10.11.4 and XCode 7.3.1. Eventually the editor will be crossplatform. I'm starting with cocoa since I'm developing on a Mac, and I want to make sure I don't box myself into a corner with the user interface/performance as I experiment with the design and the interface. The cocoa version of Barliman calls out to Chez Scheme (https://github.com/cisco/ChezScheme), which must be installed separately, and which is assumed to reside in /usr/local/bin/scheme.
IMPORTANT: The cocoa version of Barliman does its best to clean up the Scheme processes it launches. However, it is wise to run top -o cpu from the terminal after playing with Barliman, to make sure errant Scheme processes aren't running in the background. If these tasks are running, you can kill them using kill -9 <pid>, where <pid> is the process identifier listed from the top command.
To use the cocoa version of Barliman, first build and launch the application from XCode. The application currently has a single window, with a single editable pane. Enter Scheme expressions that run in the relational Scheme interpreter, such as:
((lambda (x) x) 5)
Each time the text changes, a Chez Scheme process will be launched, attempting to evaluate the expression in the relational Scheme interpreter. If the expression is not a valid Scheme s-expression, Chez will complain, an Baliman will display the code in red. If the expression is a legal s-expression, and the corresponding miniKanren query to the relational interpeter succeeds, the value of the query will be displayed below the editable text box. If the query fails, the empty list will be displayed in the text box.
For more interesting answers, you can use the logic variables A through G, upper-case. Make sure to unquote the logic variables:
((lambda (x) ,A) ,B)
Acknowledgements and thanks
Thanks to Michael Ballantyne, Kenichi Asai, Alan Borning, Nada Amin, Guannan Wei, Pierce Darragh, Alex Warth, Michael Adams, Tim Johnson, Evan Czaplicki, Stephanie Weirich, Molly Feldman, Joe Osborn, Nehal Patel, Andrea Magnorsky, Reid McKenzie, Emina Torlak, Chas Emerick, Martin Clausen, Devon Zuegel, Daniel Selifonov, Greg Rosenblatt, Michael Nielsen, David Kahn, Brian Mastenbrook, Orchid Hybrid, Rob Zinkov, Margaret Staples, Ziyao Wei, Matt Hammer, Hunter Hutchinson, Bryan Joseph, Cesar Marinho, Michael Bernstein, Bodil Stokke, Dan Friedman, Ron Garcia, Rich Hickey, Phil Wadler, Tom Gilray, Dakota Fisher, Gavin Whelan, Devon Zeugel, Jonas Kölker, Matt Might, participants of my 2016 PEPM tutorial on miniKanren, and particants of the 'As We May Thunk' group (http://webyrd.net/thunk.html), for suggestions, encouragement, and inspiration.
Thanks to Kent Dybvig, Andy Keep, and Cisco Systems for releasing Chez Scheme under an open source license.
The definition of letrec in the main interpreter is based based on Dan Friedman's code, using the "half-closure" approach from Reynold's definitional interpreters.
Greg Rosenblatt has been improving the search and the miniScheme interpreter to improve synthesis performance, greatly improving performance on many of the synthesis problems.
Matt Might suggests using properties like (append (cons a l) s) == (cons a (append l s)) for synthesizing append.
Devon Zeugel suggests using a monospace font, and perhaps swapping the tests and the definitions in the main window. Devon suggests using the number of tests that pass to guide search for auto-repair or other synthesis. Or, to try to maximize the number of tests that pass, then have the user take over. Maybe use the number of tests that pass as a score/heuristic for stochastic search.
Tom Gilray suggests being able to hover over a ,A logic variable to select/approve a suggested/guessed value for that particular subexpression. Michael Ballantyne and other people have suggested similar notions, including a scrubber for scrubbing over/selecting a generated/guessed value for a subexpression.
replace test input/output edit fields with multi-line edit capabilities similar to that of the 'Definitions' pane
add paren hilighting to editor
add "smart delete" of parens
add add auto-indent
add forward/backward s-expression
add transpose s-expression
add pretty printing of "Best Guess" definitions
add smart editing/auto insert of gensyms in the test edit panes, similar to how smart editing/auto insert of logic variables works in the Definitions edit pane
for 'syntax error' and 'illegal sexpression' messages for a test, potentially show whether the input, the output, or both is the problem (could be complicated in that the output might be an illegal sexpression, while the input is a syntax error, for example)
have Barliman attempt to guess the result of a test, as the programmer types in the test (thanks Ziyao Wei!)
show the definition guessed for each individual successful test
show reified test inputs and outputs upon success, for all tests (would allow queries like 'quines')
mouse hover over ,A variable should display the variable's "Best Guess" value
allow resizing of Barliman main window
add let and cond.
add better error message for 'invalid syntax', at least indicating whether there is an unexpected paren/missing end paren
Possibly replace list call in the "best quess" query with nested cons calls instead. (Need to time this again with Greg's new improvements to the search.) This can be an order of magnitude faster in some cases, according to my testing (variadic application is more expensive than 'cons' in the current miniScheme interpreter, apparently: see times for append-gensym-synthesis-with-cons-1 versus append-gensym-synthesis-with-list-1 tests in test-interp.scm).
add an implicit begin to lambda, letrec, and let forms.
parser should enforce that the variable names are distinct in lambda formals, letrec bindings and formals, and define's within the same scope.
create a version of Barliman on an open platform (Electron, Clojurescript, Lighttable, whatever). Any help would be appreciated! :)
consider using ulimit or some other capability for keeping the running Scheme processes under control/keep them from using all the RAM and CPU cycles
consider adding fields for seeing the ground results of partially-instantiated test inputs/outputs
add full variadic syntax: (lambda (x y . z) x)
consider turning the background of the "guess" pane green, or otherwise indicting the user, when a guess can be made. Could also potentially change the code in the main definition edit pane, although this may not be friendly.
add STLC as an example, complete with type inferencer
perhaps be able to drag and drop subexpressions from the best guess pane onto variables in the definition pane. And also be able to replace an extort subexpression in the definition pane with a logic variable.
think about contextual menus/right click and also drag and shift-drag. What should these do?
make sure Semantics and the main Barliman windows can be reopened if the user closes them! Currently there doesn't seem to be a way to get the window back. Perhaps allow the user to hide the windows, but not close them? What is the preferred Mac way?
for the case in which a simple function is being used to generate test inputs and answers for a more complex version of the same function, may need or want a grounder to make sure answers are fully ground. May also want a grounder for code, esp for the best guess pane. Although grounding code may not be necessary or ideal.
would be smart to only re-run Scheme processes when the Scheme code actually changes– for example, white space characters outside of an S-expr shouldn't trigger re-evaluation. One way would be to compare "before" and "after" S-exprs to see if anything has changed. Could run a single Scheme instance and call equal? to see if the code has actually changed. This could be a big win for expensive computations.
add ability to save and load examples/tests/semantics, and include interesting examples, such as a tiny Scheme interpreter written in Scheme, state machine using mutual recursion, examples from pearls, etc.
add structured editor for semantics and for type inferencer (as an alternative to/in addition to the free-form editor)
possibly move as much work as possible into NSTasks, such as loading files.
possibly add pairs of tests as processes, once individual tests complete successfully
add syntax-directed auto-indentation of code
figure out how to do syntax-directed hilighlighting, and precise hilighting of syntax errors. May not be as important if I go the structured editor route. Although perhaps this should be an option, either way.
add documentation/tutorial
add paper prototype for desired features
move 'barliman-query.scm' temporary file to a more suitable location than 'Documents' directory, or get rid of the temp file entirely
experiment with store passing style and small step interpreters
get rid of hardcoded path to Chez executable
add input/output examples
find a cleaner and more flexible way to construct the program sent to Chez
add "accept suggested completion" button
would be smarter/less resource intense to not launch all the tests again when the text in a single test changes. Only that test and allTests need be re-run, in theory. Getting the UI to display the state of everything properly may be a little subtle, though.
differential relational interpreters
use a meta-interpreter to let the programmer know the deepest part of the search path upon failure, to try to give a better hint as to what went wrong (thanks Nada! and halp! :))
mousing over a failing test should highlight subexpressions in the Definitions pane that are incompatible with that test.
mousing over a subexpression should hilight any tests which would be incompatible with the definitions, were a logic variable to be substututed for the expression being moused over. (perhaps do this only if a modifier key is help down)
improve editor so that typing '(' 'cons' auto completes to '(cons ,A ,B)', based on arity of cons (unless cons is shadowed).
consider placing each of the 'definition' forms in its own edit window, with 'uses mutattion', 'uses call/cc', 'well-typed' checkboxes for each definition (inspired by Kenichi Asai's tool for teaching functional programming).
try adding contracts/properties/specs. For example, for append, could add the property that the sum of (length l) and (length s) must be equal to (length (append l s)). This could work with randomized testing, even for partially-instantiated definitions. In the case of length, would either need to use Oleg numbers, or CLP(FD).
related to properties, might want generators, such as a loso that generates flat lists of symbols, for example, or lovo, that generates flat lists of values, or treevo, that generates trees of values. Could use these generators for specifying and testing properties. One simple, "type" property is that append should work on any two lovos, and, in this case, return of lovo. Could extend this to talk about the lengths of the lovos, etc. Could then either enumerate or randomly generate lovos QuickCheck style to try to find counter-examples with respect to the current partial (or complete) definition, or perhaps to help with synthesizing the actual code.
automatic test generation/fuzzing
add arithmetic to the main interpreter
explore incremental computing with the editor
add type inferencer
test generation of typed test programs
partial evaluation of the interpreter to speed up evaluation
write simple implementation of a function, generate test from that function, then use those tests to guide the more sophisticated implementation. Or more generally, continually test the partially-implemented function vs the fully implemented but perhaps less efficient function.
Matt Might suggests as a use case, "automatic program repair after bug discovery," and points to work by Stephanie Forrest. I really like this idea. Here's how the use case might work:
You write tests and code. The tests pass. Later you find an error in the code, so you go back and add more tests, which fail.
Click a Barliman 'auto-repair' button. Barliman tries, in parallel, removing each subexpression and trying synthesis to fill in the rest.
If Barliman could use a Amazon server with dozens of hardware cores and 2TB RAM (like the new X1 server on AWS), this really could be done in parallel.
Or run locally until there's a timeout, then run again with the holes in other places. Could even try pairs of holes to keep the synthesis problem as small as possible.
Or, perhaps more practical short term until Barliman's synthesis improves...
Have Barliman try removing each subexpression and then check if any of the tests still fail. Then hilight these known bad subexpressions to help guide the user.
Greg Rosenblatt's suggestion for auto-repair: "The user may also want to mark some regions of the code as suspect, which would prioritize the area searched for problematic sub-expressions. If the user is right, the fix could be found much sooner."
SUSPECT IDEAS:
could just call out to Scheme one the program becomes grounded. However, the semantics and even the grammar may not match that of the interpreter used by miniKanren, so this seems difficult or impossible to do properly. However, could call a (non-relational) interpreter for miniScheme.
INTERESTING IDEAS:
Tom Gilray suggests using a simplified intermediate representation (IR) that disallows shadowing, has if but not cond, etc. Could have the IR be the macro expanded code. Could possibly reverse engineer/infer macro calls that could have produced the IR.
Tom Gilray suggests changing the interface to just have a single editor window, which allows for definitions and for test calls/results. I suspect this is the right way to go, although it will involve significant changes to Barliman. Tom also suggests having arrows to the right of each logic variable, showing the current value of each variable.
perhaps use delayed goals to implement arithmetic over floating point numbers, and other tricky operations. If the arguments do not become instantiated enough, Barliman should be non-commital (can't synthesize code, and can't prove tests are not consistent with the code until the code is more instantiated).
Greg Ronsenblatt suggests dividing tests into a 'training' set and a 'test' set, as is done in machine learning to avoid overfitting. Of course this could also lead into 'propety-based testing', generators, etc.
Jonas Kölker suggests synthesizing multiple definitions, or perhaps even all of the Haskell Prelude-style list functions, simultaneously, based on the relationships between the functions, and their Quickcheck-style properties. He also suggests using properties like reverse (xs++ys) == reverse ys ++ reverse xs and map f (xs++ys) == map f xs ++ map f ys for synthesis.
KNOWN LIMITATIONS:
The Best Guess pane cannot be resized vertically, which sometimes cuts off text.
Non-specific error indication (the color changes for the text, but does not show which part of the text caused the error)
Currently the UI only supports 6 tests. Should allow more tests to be added.
Test inputs and outputs are NSTextFields rather than NSTextViews, which makes writing longer and more complicated tests awkward.
KNOWN ERRORS:
let expressions are not parsed properly. In particular (let ((x)) y) parses. Probably other expressions are also parsed a little too laxly.
Shadowing of syntax is no longer working. (and and #t) => #t should result in a syntax error, unless the Definitions pane contains a defn named 'and': (define and (lambda x x)). In which case, (and and #t) should be legal syntax. (Wonder if we broke this when we messed with the environment in evalo.)
It is possible, rarely, to exit Barliman and still have a Scheme process running in the background. Need a way to better track which processes have been started and make sure to kill them. Or potentially use something like ulimit when launching a process.
The miniKanren queries constructed by Barliman expose several local variable names and a number of global variable names that could accidentally or intentionally be used by the programmer. Need to tighten this up.
closing one of the windows means the window cannot be reopened! Oops. I'm not going to worry about this until I decide what to do with the Semantics window.
sometimes the spinners stop spinning but are still visible
DONE (features on the TODO list implemented since the original release of Barliman)
Implemented monospace font, as recommended by Devon Zeugel.
Fixed error: An illegal s-expression in the 'Definitions' edit pane will make test input/output expressions that are legal expressions appear to be illegal.
Fixed error (by removing auto-insert of right parens): auto-insert of right parens and auto-insert of logic variables breaks 'undo'. Guess I need to learn how 'undo' works in Cocoa...
Fixed error: The '0' key no longer seems to work.
Fixed error: (lambda (,A ,B) ...) should always produce a disequality constraint between A and B.
Fixed error: Will modified the miniKanren reifier to remove unnecessary constraints involving gensyms. Alas, he goofed it, and the reifier removes too many constraints, including some =/= and absento constraints in play when gensyms are used.
Fixed error: scoping problem introduced by optimizing variable lookup.
Fixed error: Inserting a new logic variable with Control- doesn't replace highlighted text. Instead, it adds the variable and keeps the hilighted text.
changed reifier and main edit window to display constraints separately from "best guess" definition(s).
fixed: quickly tab-deleting a test with a syntax error (for example) can leave the 'syntax error message' on an empty test
added automatic addition of right parens, and auto-addition of logic variables (thanks Michael Ballantyne, Guannan Wei, Pierce Darragh, Michael Adams, for discussions on how this might work)
changed reifier so that constraints involving gensym are not displayed.
Fixed error: even if the "best guess" query terminates with success, individual test processes may still keep running, since those tests don't "know" that the best guess involving all the tests has succeed. If the best guess query terminates with success, the individual test processes should be killed, and marked as successful (black text, stop the progress spinner).
updated letrec to allow for zero or more bindings, and updated begin to allow for zero or more definitions; this allows the creation of mutually-recursive functions.
define grammar for microScheme (and the other languages) as a miniKanren relation, and use this grammar to separately check and report whether the definition is grammatically correct.
cancel the allTests operation if any single test fails, since in that case allTests cannot possibly succeed
wait part of a second to see if there are more keystrokes before launching Scheme processes. Sort of like XCode (I assume XCode is doing this). Would be more resource friendly, less distracting, and would make typing quickly more responsive. Could probably do this using an timer.
add ability to change the evaluator rules and perhaps an explicit grammar as well
It turns out that while they were publicly crisscrossing America, they were also privately holding meetings with some of the wealthiest individuals and families in the country, urging them to not only invest in a new fund but become partners with some of the companies that will benefit from it.
On Tuesday, the fund, called Rise of the Rest, will disclose its investors, which has turned into a Who’s Who of American business. Among them: Jeff Bezos, the founder of Amazon and now the world’s richest person; Eric Schmidt, chairman of Google’s parent, Alphabet; Howard Schultz, chairman of Starbucks; Tory Burch, the fashion mogul; Ray Dalio, founder of the hedge fund Bridgewater Associates; Dan Gilbert, the founder of Quicken Loans who has remade Detroit; Henry Kravis, the co-founder of KKR; David Rubenstein, the co-founder of Carlyle Group; Michael Milken, the financier and philanthropist; John Doerr, the venture capitalist; Jim Breyer, one of the first investors in Facebook; as well as members of three wealthy families: the Waltons, the Kochs and the Pritzkers.
Also on the list are Sean Parker, a former president of Facebook; Sara Blakely, the founder of Spanx; Ted Leonsis, the sports team owner and investor; Jeff Vinik, the Florida billionaire and sports franchise owner; Byron Trott, Warren Buffett’s favorite banker; and Adebayo Ogunlesi, the lead director of Goldman Sachs and a large infrastructure investor. All told, it may be the greatest concentration of American wealth and power in one investment fund.
PhotoMr. Case, right, aboard a bus in Columbus, Ohio, during a barnstorming tour to promote start-ups in the middle of the country. “While the network in Silicon Valley is obviously something that is great, it can also have an exclusionary effect,” he said.Credit
Maddie McGarvey for The New York Times
The idea — far grander than the money itself, which is only $150 million to start, pocket money for most of the investors — was to assemble a dream team and create a network effect for entrepreneurs in the middle of the country to align with the biggest names in business.
The fund, said Mr. Vance, was meant to construct an ecosystem like the one in Silicon Valley that will provide support and connections to entrepreneurs in small towns.
“People tend to follow their networks,” said Mr. Vance, who was recruited to the effort by Mr. Case. “While the network in Silicon Valley is obviously something that is great, it can also have an exclusionary effect that prevents investors from looking at and finding opportunities that exist outside of their networks and outside of their geographies.”
Mr. Case and Mr. Vance hope to seed investments in start-ups in underserved cities and then bring in some of their big names to invest even more money in them. “We’ll be curating interesting companies,” Mr. Case said.
In other words, if they discover a nascent but promising e-commerce company in Allentown, Pa., they will not only invest in it, but they might also help it establish a relationship with one of the fund’s investors — Mr. Bezos, for example — who might invest even more.
Mr. Case was quick to say that the new enterprise should not be considered a social impact fund, which has become the hot nomenclature for investors seeking to do good. Some consider social impact investing a sort of pseudophilanthropy because the returns aren’t always the main goal.
Mr. Case said he would only succeed in changing the way investors think about the rest of the country if he can produce significant financial success stories.
“We’re fans of impact investing,” he said. “But we actually didn’t position this as an impact fund. First and foremost, our goal was to generate top returns.”
Mr. Schmidt of Alphabet said he was sold on the idea from the moment he first heard about it. “I felt it was a no-brainer,” he said. “There is a large selection of relatively undervalued businesses in the heartland between the coasts, some of which can scale quickly.”
PhotoMr. Case said the fund would be “curating interesting companies” for its investors, but should not be considered an exercise in social impact investing. “First and foremost, our goal was to generate top returns,” he said.Credit
Maddie McGarvey for The New York Times
And while it isn’t an altruistic investment, he said he hoped the effort creates “more jobs, more wealth, better products and helps our society deal with a lot of jarring employment changes.”
One of the great questions about American capitalism is why big investors, who are always looking for opportunities and are often willing to fly halfway around the world to find them in places like China and India, put so little effort into finding investment in the middle of the country. California, New York and Massachusetts attract 76 percent of all venture capital money, according to the National Venture Capital Association.
One answer may be that the nation’s top talent is drawn to the coasts, but Mr. Breyer said he has seen that changing.
“Entrepreneurs are now creating start-ups in lots of places,” he said. “The confluence of social networking technologies and cloud services makes it easier and less costly than ever before to develop and bring new technologies to market” for entrepreneurs outside of centers like Silicon Valley.
One example of a company that could be a model for the fund is one that Mr. Case has already invested in: 75f, located in Burnside, Minn., which works to make commercial buildings more comfortable and energy-efficient.
Critics may argue that the fund is a marketing exercise for elites trying to fix a problem of their own making. And there may be some truth to that. But like most great entrepreneurs, these investors have a genuine interest in finding the next Facebook or Google, and they get excited about the prospect of discovering a needle in the start-up haystack.
And they recognize that the next big idea may come from someplace totally unexpected — somewhere not on either coast or in one of the other pockets of entrepreneurship.
“There’s still more talent (engineers, execs) — and resources (funding), but the costs and competition for talent and housing are extreme” in Silicon Valley, Mr. Doerr wrote in an email, suggesting perhaps that it may be a less attractive location than before.
“In the end, don’t think of ‘the Valley’ as some ZIP codes in California,” he wrote. “It is a state of mind that can be anywhere, for everyone. Increasingly, for all of the rest of us.”
I stumbled upon an article the other day where Rob Pike implements a rudimentary regular expression engine in c. I converted his code to Javascript and added test specs so that someone can self-guide themselves through the creation of the regex engine. The specs and solution can be found in this GitHub repository. This blog post walks through my solution.
The Problem
Our regex engine will support the following syntax:
Syntax
Meaning
Example
matches
a
Matches the specified character literal
q
q
*
Matches 0 or more of the previous character
a*
“”, a, aa, aaa
?
Matches 0 or 1 of the previous character
a?
“”, a
.
Matches any character literal
.
a, b, c, d, e …
^
Matches the start of a string
^c
c, ca, caa, cbb …
$
Matches the end of a string
a$
ba, baaa, qwerta …
The goal is to provide a syntax robust enough to match a large portion of regex use cases with minimal code.
Matching One Character
The first step is to write a function that takes in a one character pattern and a one character text string and returns a boolean indicating if they match. A pattern of . is considered a wildcard and matches against any character literal.
Now we want to add support for patterns and text strings of greater length. For now, let’s only consider a pattern/text pair of the same length. I happen to know that the solution lends itself very naturally to recursion, so we will use it here. We are going to want to repeatedly invoke matchOne on successive pairs of characters from the pattern/text combination.
The above code advances character by character across the the pattern/text pair. It first compares pattern[0] to text[0] and then pattern[1] to text[1] and continues comparing pattern[i] to text[i] until i === pattern.length - 1. If they ever don’t match, then we know that the pattern cannot match the text.
Let’s take an example. Suppose we invoke match('a.c', 'abc'), which returns matchOne('a', 'a') && match('.c', 'bc').
If we continue evaluating these functions, we get matchOne('a', 'a') && matchOne('.', 'b') && matchOne('c', 'c') && match("", ""), which is just equal to true && true && true && true, So we have a match!
The $ Character
Let’s add support for the special pattern character $ that allows us to match the end of a string. The solution simply requires adding an additional base case to the match function.
Let’s add support for the special pattern character ^ that allows us to match the beginning of a string. I’m going to introduce a new function called search.
1
2
3
4
5
functionsearch(pattern, text) {
if (pattern[0] === "^") {
return match(pattern.slice(1), text)
}
}
This function will be the new entry point to our code. Up till this point, we were only matching patterns that began at the beginning of the text. We are simply making that more clear now by forcing the user to preface the pattern with a ^. But how do we support patterns that appear anywhere within the text?
Matches Starting Anywhere
Currently, the following return true
search("^abc", "abc") search("^abcd", "abcd")
But search("bc", "abcd") will just return undefined. We want it to return true
If the user does not specify that the pattern matches the beginning of the text, then we want to search for that pattern at every possible starting point within the text. We will default to this behavior if the pattern does not begin with ^1.
1
2
3
4
5
6
7
8
9
10
11
functionsearch(pattern, text) {
if (pattern[0] === "^") {
return match(pattern.slice(1), text)
} else {
return text.split("").some((_, index) => {
return match(pattern, text.slice(index))
})
}
}
The ? Character
We want to be able to match 0 to 1 of the character before ?.
The first step is to modify match to detect when a ? character is present and then delegate to the matchQuestion function, which we will define shortly.
Where the character before the ? is not matched but the text matches the remainder of the pattern (everything after the ?).
Where the character before the ? is matched and the rest of the text (minus the 1 matched character) matches the remainder of the pattern.
If either of these cases is truthy, then matchQuestion can return true.
Let’s consider the first case. How do we check if the text matches everything in the pattern except the _? syntax? In order words, how do we check if the character before the ? appears 0 times? We strip 2 characters off the pattern (the first character is the one before the ? and the second is the ? itself) and invoke the match function.
1
2
3
functionmatchQuestion(pattern, text) {
return match(pattern.slice(2), text);
}
The second case is a little more challenging, but just like before, it reuses functions we’ve already written
1
2
3
4
5
6
7
functionmatchQuestion(pattern, text) {
if (matchOne(pattern[0], text[0]) && match(pattern.slice(2), text.slice(1))) {
returntrue;
} else {
return match(pattern.slice(2), text);
}
}
If the text[0] matches pattern[0], and the rest of the text (minus the part that is matched by matchOne) matches the remainder of the pattern, then we are golden. Note that we could rewrite the code like this:
The one thing I like about this latter approach is that the boolean OR makes it explicitly clear that there are two cases, either of which may be true.
The * Character
We want to be able to match the character before the * 0 or more times.
matchStar, like matchQuestion, also needs to handle two cases:
Where the character before the * is not matched but the text matches the remainder of the pattern (everything after the *).
Where the character before the * is matched one or more times and the rest of the text matches the remainder of the pattern.
Since there are two cases that both result in a match (0 matches OR more matches), we know that matchStar can be implemented with a boolean OR. Furthermore, case 1 for matchStar is exactly the same as it was for matchQuestion and can be implemented identically using match(pattern.slice(2), text). That means we only need to formulate an expression that satisfies case 2.
We can now go back and cleverly simplify search using a trick I learned in Peter Norvig’s class.
1
2
3
4
5
6
7
functionsearch(pattern, text) {
if (pattern[0] === "^") {
return match(pattern.slice(1), text)
} else {
return match(".*" + pattern, text)
}
}
We use the * character itself to allow for the pattern to appear anywhere in the string. The prepended .* says that any number of any character can appear before the pattern we wish to match.
Conclusion
It’s remarkable how simple and elegant the code for such a sophisticated and generalized program can be. The full source is available in this GitHub repository
1: There is a small bug in this code that I’m choosing to ignore. We don’t account for the case that text is an empty string. Currently when text === '', text.split("") will return [] and will not appropriately call match.
When I moved to Rome from Washington, DC, one sight struck me more than any ancient column or grand basilica: people doing nothing.
I’d frequently glimpse old women leaning out of their windows, watching people pass below, or families on their evening strolls, stopping every so often to greet friends. Even office life proved different. Forget the rushed desk-side sandwich. Come lunchtime, restaurants filled up with professionals tucking into proper meals.
Of course, ever since Grand Tourists began penning their observations in the seventeenth century, outsiders have stereotyped the idea of Italian ‘indolence’. And it isn’t the whole story. The same friends who headed home on their scooters for a leisurely lunch often returned to the office to work until 8pm.
Even so, the apparent belief in balancing hard work with il dolce far niente, the sweetness of doing nothing, always struck me. After all, doing nothing appears to be the opposite of being productive. And productivity, whether creative, intellectual or industrial, is the ultimate use of our time.
As we fill our days with more and more ‘doing’, many of us are finding that going non-stop isn’t the apotheosis of productivity. It is its adversary
But as we fill our days with more and more ‘doing’, many of us are finding that non-stop activity isn’t the apotheosis of productivity. It is its adversary.
Researchers are learning that it doesn’t just mean that the work we produce at the end of a 14-hour day is of worse quality than when we’re fresh. This pattern of working also undermines our creativity and our cognition. Over time, it can make us feel physically sick – and even, ironically, as if we have no purpose.
Think of mental work as doing push-ups, says Josh Davis, author of Two Awesome Hours. Say you want to do 10,000. The most ‘efficient’ way would be to do them all at once without a break. We know instinctively, though, that that is impossible. Instead, if we did just a few at a time, between other activities and stretched out over weeks, hitting 10,000 would become far more feasible.
“The brain is very much like a muscle in this respect,” Davis writes. “Set up the wrong conditions through constant work and we can accomplish little. Set up the right conditions and there is probably little we can’t do.”
Do or die
Many of us, though, tend to think of our brains not as muscles, but as a computer: a machine capable of constant work. Not only is that untrue, but pushing ourselves to work for hours without a break can be harmful, some experts say.
People who worked more than 11 hours a day were almost 2.5 times more likely to have a major depressive episode than those who worked seven to eight
“The idea that you can indefinitely stretch out your deep focus and productivity time to these arbitrary limits is really wrong. It’s self-defeating,” says research scientist Andrew Smart, author of Autopilot. “If you’re constantly putting yourself into this cognitive debt, where your physiology is saying ‘I need a break’ but you keep pushing yourself, you get this low-level stress response that’s chronic – and, over time, extraordinarily dangerous.”
If you’re wondering if this means that you might want to consider taking that long-overdue holiday, the answer may be yes. One study of businessmen in Helsinki found that over 26 years, executives and businessmen who took fewer holidays in midlife predicted both earlier deaths and worse health in old age.
Holidays also can literally pay off. One study of more than 5,000 full-time American workers found that people who took fewer than 10 of their paid holiday days a year had a little more than a one-in-three chance of getting a pay rise or a bonus over three years. People who took more than 10 days? A two in three chance.
Productivity provenance
It’s easy to think that efficiency and productivity is an entirely new obsession. But philosopher Bertrand Russell would have disagreed.
“It will be said that while a little leisure is pleasant, men would not know how to fill their days if they had only four hours’ work out of the 24,” Russell wrote in 1932, adding, “it would not have been true at any earlier period. There was formerly a capacity for light-heartedness and play which has been to some extent inhibited by the cult of efficiency. The modern man thinks that everything ought to be done for the sake of something else, and never for its own sake.”
It will be said that while a little leisure is pleasant, men would not know how to fill their days if they had only four hours’ work out of the 24 – Bertrand Russell
That said, some of the world’s most creative, productive people realised the importance of doing less. They had a strong work ethic – but also remained dedicated to rest and play.
“Work on one thing at a time until finished,” wrote artist and writer Henry Miller in his 11 commandments on writing. “Stop at the appointed time!... Keep human! See people, go places, drink if you feel like it.”
Even US founding father, Benjamin Franklin, a model of industriousness, devoted large swathes of his time to being idle. Every day he had a two-hour lunch break, free evenings and a full night’s sleep. Instead of working non-stop at his career as a printer, which paid the bills, he spent “huge amounts of time” on hobbies and socialising. “In fact, the very interests that took him away from his primary profession led to so many of the wonderful things he’s known for, like inventing the Franklin stove and the lightning rod,” writes Davis.
Even on a global level, there is no clear correlation between a country’s productivity and average working hours. With a 38.6-hour work week, for example, the average US employee works 4.6 hours a week longer than a Norwegian. But by GDP, Norway’s workers contribute the equivalent of $78.70 per hour – compared to the US’s $69.60.
The very interests that took him away from his primary profession led to so many of the wonderful things he’s known for - Josh Davis
As for Italy, that home of ildolce far niente? With an average 35.5-hour work week, it produces almost 40% more per hour than Turkey, where people work an average of 47.9 hours per week. It even edges the United Kingdom, where people work 36.5 hours.
All of those coffee breaks, it seems, may not be so bad.
Brain wave
The reason we have eight-hour work days at all was because companies found that cutting employees’ hours had the reverse effect they expected: it upped their productivity.
During the Industrial Revolution, 10-to-16-hour days were normal. Ford was the first company to experiment with an eight-hour day – and found its workers were more productive not only per hour, but overall. Within two years, their profit margins doubled.
One survey of almost 2,000 full-time office workers in the UK found that people were only productive for 2 hours and 53 minutes out of an eight-hour day
This seems borne out by how people behave during the working day. One survey of almost 2,000 full-time office workers in the UK found that people were only productive for 2 hours and 53 minutes out of an eight-hour day. The rest of the time was spent checking social media, reading the news, having non-work-related chats with colleagues, eating – and even searching for new jobs.
When we’re pushing ourselves to the edge of our capabilities, we need more breaks than we think. Most people can only handle an hour of deliberate practice without taking a rest
We can focus for an even shorter period of time when we’re pushing ourselves to the edge of our capabilities. Researchers like Stockholm University psychologist K Anders Ericsson have found that when engaging in the kind of ‘deliberate practice’ necessary to truly master any skill, we need more breaks than we think. Most people can only handle an hour without taking a rest. And many at the top, like elite musicians, authors and athletes, never dedicate more than five hours a day consistently to their craft.
The other practice they share? Their “increased tendency to take recuperative naps,” Ericsson writes – one way, of course, to rest both brain and body.
Other studies have also found that taking short breaks from a task helped participants maintain their focus and continue performing at a high level. Not taking breaks made their performance worse.
Active rest
But ‘rest’, as some researchers point out, isn’t necessarily the best word for what we’re doing when we think we’re doing nothing.
In other words, if this network were switched off, we might struggle to remember, foresee consequences, grasp social interactions, understand ourselves, act ethically or empathise with others – all of the things that make us not only functional in the workplace, but in life.
“It helps you recognise the deeper importance of situations. It helps you make meaning out of things. When you’re not making meaning out of things, you’re just reacting and acting in the moment, and you’re subject to many kinds of cognitive and emotional maladaptive behaviours and beliefs,” says Mary Helen Immordino-Yang, a neuroscientist and researcher at the University of Southern California’s Brain and Creativity Institute.
If, like Archimedes, you got your last good idea while in the bath or on a stroll, you have your biology to thank
We also wouldn’t be able to come up with new ideas or connections. The birthplace of creativity, the DMN lights up when you’re making associations between seemingly unrelated subjects or coming upwithoriginal ideas. It is also the place where your ‘ah-ha’ moments lurk – which means if, like Archimedes, you got your last good idea while in the bath or on a stroll, you have your biology to thank.
Perhaps most importantly of all, if we don’t take time to turn our attention inward, we lose a crucial element of happiness.
“We’re just doing things without making meaning out of it a lot of the time,” Immordino-Yang says. “When you don’t have the ability to embed your actions into a broader cause, they feel purposeless over time, and empty, and not connected to your broader sense of self. And we know that not having a purpose over time is connected to not having optimal psychological and physiological health.”
Monkey mind
But as anyone who has tried meditation knows, doing nothing is surprisingly difficult. How many of us, after 30 seconds of downtime, reach for our phones?
In fact, it makes us so uncomfortable that we’d rather hurt ourselves. Literally. Across 11 different studies, researchers found that participants would rather do anything– even administer themselves electric shocks – instead of nothing. And it wasn’t as if they were asked to sit still for long: between six and 15 minutes.
The good news is that you don’t have to do absolutely nothing to reap benefits. It’s true that rest is important. But so is active reflection, chewing through an issue you have or thinking about an idea.
In fact, anything that requires visualising hypothetical outcomes or imagined scenarios – like discussing a problem with friends, or getting lost in a good book – also helps, Immordino-Yang says. If you’re purposeful, you even can engage your DMN if you’re looking at social media.
“If you’re just looking at a pretty photo, it’s de-activated. But if you’re pausing and allowing yourself to internally riff on the broader story of why that person in the photo is feeling that way, crafting a narrative around it, then you may very well be activating those networks,” she says.
Even taking just one walk, preferably outside, has been proven to significantly increase creativity
It also doesn’t take much time to undo the detrimental effects of constant activity. When both adults and children were sent outdoors, without their devices, for four days, their performance on a task that measured both creativity and problem-solving improved by 50%. Even taking just one walk, preferably outside, has been proven to significantly increase creativity.
Another highly effective method of repairing the damage is meditation: as little as a week of practice for subjects who never meditated before, or a single session for experienced practitioners, can improve creativity, mood, memory and focus.
Any other tasks that don’t require 100% concentration also can help, like knitting or doodling. As Virginia Woolf wrote in a Room of One’s Own: “Drawing pictures was an idle way of finishing an unprofitable morning’s work. Yet it is in our idleness, in our dreams, that the submerged truth sometimes comes to the top.”
Time out
Whether it’s walking away from your desk for 15 minutes or logging out of your inbox for the night, part of our struggle is control – the fear that if we relax a grip for a moment, everything will come crashing down.
That’s all wrong, says poet, entrepreneur and life coach Janne Robinson. “The metaphor I like to use is of a fire. We start a business, and then after a year, it’s like, when can we take a week off, or hire someone to come in? Most of us don’t trust someone to come in for us. We’re like, ‘The fire will go out’,” she says.
“What if we just trusted that those embers are so hot, we can walk away, someone can throw a log on and it’ll burst into flames?”
That isn’t easy for those of us who feel like we have to constantly ‘do’. But in order to do more, it seems, we may have to become comfortable with doing less.
To comment on this story or anything else you have seen on BBC Capital, please head over to ourFacebook page or message us on Twitter.
If you liked this story, sign up for the weekly bbc.com features newsletter called "If You Only Read 6 Things This Week". A handpicked selection of stories from BBC Future, Culture, Capital and Travel, delivered to your inbox every Friday.
I am a language addict ~ I love learning new languages, spoken ones and those you can do funny things with on a computer. As part of an MSc degree, I have picked the ”Programming Paradigms and Languages” module offered by Birkbeck University of London, and nicely delivered by Keith Mannock and Trevor Fenner. The aim of the module was to enable students to understand the fundamental differences between various programming paradigms and the applicability of these paradigms to different programming problems.
This module was the reason why I fell in love with Prolog, a logic programming language heavily used in computational linguistics and artificial intelligence in general.
In this post, I am going to provide a short introduction to the language and its essential features. After reading the post, you should be able to write simple programs in Prolog and understand the language’s underlying primary principles.
Installation
First things first, let us get a working Prolog installation to begin with. As far as this blog post is concerned I am going to use SWI-Prolog (Version 7.2.3), please be aware that Prolog dialects may vary. MacOS and Windows user can download executables here. On Ubuntu or any other Debian-based distribution, you can use apt-get.
Alternatively, you can also use the official docker image.
docker run -it swipl:stable
docker run -it swipl:latest
Now that we have the stage set let us dive into Prolog. However, before it gets technical whats the motivation behind it?
Motivation to learn Prolog (or any other language)
Why should you even bother to learn Prolog at all? Well, there are a couple of reasons, but at this point, I instead like to refer to “The Pragmatic Programmer”.
Tip #8 “Invest Regularly in Your Knowledge Portfolio”:
Learn at least one new language every year. Different languages solve the same problems in different ways. By learning several different approaches, you can help broaden your thinking and avoid getting stuck in a rut. Additionally, learning many languages is far easier now, thanks to the wealth of freely available software on the Internet.
Having said that, try to solve a Sudoku puzzle for example in Java or C ~ in Prolog you can do that in few lines of code.
Cool eh, I can sense that you are getting excited .
However, before we dive into Prolog let’s lay down the base for any further considerations. To start with, what is “Logical programming”?
Logical programming
Say what you want, not how you want it done.
Logical programming is a programming paradigm which has its foundations in mathematical logic. In contrast to languages like Java or C, programs written in a logic programming languages such as Prolog are not composed of sequences of instructions but of a set of axioms, or rules which define relationships between objects. They also follow a declarative rather than an imperative approach. However, what does that mean?
Imperative vs declarative programming
Let us consider the “coffee-order” metaphor to make sure we are on the same page. Imagine you walk into your favourite coffee place and that you like to order some coffee .
The imperative approach:
Enter the coffee shop
Queue in the line and wait for the barista asking you for your order
Order
Yes, for takeaway, please
Pay
Present your loyalty card to collect points
Take your order and walk out
The declarative approach:
A large latte for takeaway, please
So rather than providing a step by step instruction to archive x or y (imperative), you tell the system what you need and let it try to come up with a solution (declarative).
About Prolog
Prolog is based on Horn clauses (a subset of first-order logic) and it is probably the most famous language in the logic programming family. It was a collaborative project by Alain Colmerauer, Phillipe Roussel (both University of Aix-Marseille) and Robert Kowalski (University of Edinburgh) and has been around for quite a while. Its first version appeared, like Smalltalk and C, in 1972. The name is an abbreviation for “Programmation en logique” (French for programming in logic).
Prolog has been enormously influential in the domains of theorem proving, expert systems, natural language processing and in the field of artificial intelligence (notably IBM’s Watson) in general. It also significantly influenced the development of Erlang programming language.
Language Constructs
One thing in particular which appealed to me is its ridiculous simple execution model. Prolog has four building block, logical or, logical and, term rewriting and unification. By combining these four blocks, we can perform any computation we care about.
Prolog, like SQL, has two main aspects, one to express the data and another to query it. The basic constructs of logic programming, terms and statements, are inherited from logic. There are three basic statements:
Facts are fundamental assertions about the problem domain (e.g. “Socrates is a man”)
Rules are inferences about facts in the domain (e.g. “All men are mortal.“)
Queries are questions about that domain (e.g. “Is Socrates mortal?“)
Facts and rules are stored in a knowledge base, which the Prolog compiler transpiles into a form which is more efficient to query against. When we “ask” a question, Prolog does an exhaustive search through the “database” of facts and rules until it finds a result, using backtracking internally.
Basic facts and queries
Prolog has a straightforward syntax. You will pick up the few rules very quickly. Let us transform the Socrates example from earlier into an actual Prolog program and analyse what is happing inside the compiler.
The first line reads as “Socrates is a man”, it is a base clause, which represents a simple fact. The second line is a rule and translates to, “X is mortal if X is a man” or, “All men are mortal.” This rule is for determining when its input X is “mortal”. Rules are a key concept of the language and allow us to make general statements about objects and their relationships. They consist of a head and a body connected by the turnstile symbol :- (pronounced “if”). The third line reads as “Is Socrates mortal?”, the ?- is the Prolog prompt for a question.
If you have read those three lines of code thoughtfully, you may have observed the case-sensitivity. In contrast to most other languages capitalisation matters in Prolog. Strings starting with a lowercase character are immutable and called atoms, you can compare them with the symbol type in Ruby. Strings starting with an uppercase character or an underscore are variables and can change their value. In our example socrates is an atom and the uppercase X a variable. Also, note that the full stop after each clause is mandatory.
Let us ask Prolog another question using our previously defined knowledge base.
Prolog will, of course, respond false, because we do not have Plato defined in our knowledge base. What about the next question:
That is, “Who (X) is mortal?“. Prolog will respond X = socrates and bound Socrates to the variable X. Have you noticed the tremendous difference between imperative and declarative style?
In contrast to the imperative way of programming, we have not provided any instructions to the program how exactly the variable should be defined. We have just asked the engine a question, and it automatically bound a value to our variable X! This process of matching variables with items is called unification and is precisely where logic programming has its strengths.
Unification
The assignment statement is fundamental to most imperative programming languages. In Java or Ruby, the expression x = 10 means that the value 10 is assigned to the variable x. Variables in both languages are mutable, meaning that x = 20 re-assigns the value 20 to the variable and the previous value is lost. In Prolog and other declarative languages, variables are only “variable” until they have been bound for the first time and become one with which they were unified. Hence we are using the term unification: the process of being united or made into a whole. We can find applications of unification also in imperative languages where it is typically used to enable type inference.
Let us have a look at an example to make sure we get the idea.
The =/2 predicate determines whether the two given arguments unify. Hence both arguments in the first example are the same atom Prolog returns true and false in the second case.
Hint: Most constructs in Prolog use prefix syntax by default. There are a couple of built-in predicates such as <, >, = which use infix notation and you can even define your own pre-, in- and postfix operators. The above example could have also been written as aristotle = aristotle..
What about:
Well, that is an easy one. Both terms are variables, of course, they unify with each other (depending on your Prolog implementation you get true back). When Prolog resolves queries to come up with a conclusion, it tries to unify terms. Therefore a possible definition could be:
Two terms unify if they are the same term or if they contain variables that can be uniformly instantiated with terms in such a way that the resulting terms are equal.
Lists
Hitherto we have only considered basic terms such as atoms, variables, integers and floating point numbers as arguments for our programs. However, in Prolog, like in other logic programming languages, the most common data-structure is the list. Lists in Prolog are a special case of terms. The syntax is identical to Python, they start and end with square brackets, and a comma separates each list item. Here is a simple list:
['ancient philosophy',1, socrates,1.23,['an atom in a nested list']].
Prolog provides a special facility to split the first part of the list (called the head) away from the rest of the list (known as the tail). We can place a special symbol | (pronounced ‘bar’) in the list to distinguish between the first item in the list and the remaining list. For example, consider the following.
The unification here succeeds, H is bound to the first item in the list and T to the remaining list.
Prolog provides a bunch of handy operations for list manipulation such as append, flatten reverse etc. I will not go into more details here, just have a look at the docs before you start writing your own predicates.
One notion of the Prolog shell. If you have tried to run the above snippets, you may have stumbled across the “Undefined procedure” error.
?-man(socrates).ERROR: top-level:Undefined procedure:man/1(DWIM could not correct goal)
The error is caused because of Prolog’s interactive top-level mode in which you are only allowed to query the knowledge base. To define facts and rules in the shell, you have to specify them either in a sperate file and call consult['my_knowledge_base.pl'] ., use assert (assert(man(socrates)).) or consult user by typing [user] like in the following snippet:
?-[user].man(socrates).|: true .
So far so good, we have seen the language’s basics and can now express our problem in Prolog using simple facts and rules. We have also learned how to write queries for asking fundamental questions and how the engine derives conclusions by applying unification.
Let us now have a look at a slightly more specific problem and also introduce recursion, another fundamental concept in the language and logic programming in general.
Recursion
As is commonly the case in many programming tasks, we often like to perform certain operations repeatedly either over a whole data-structure or until certain conditions are met. The way we typically do this in logic programming languages is by recursion. It merely means a program calls itself typically until some final point is reached.
In Prolog what this means is that we have a first fact that acts as a guard condition followed up by some rules that perform some operation before reinvoking itself.
Four colour theorem
One classic application is the four colour theorem (sometimes called Guthrie’s problem), which remained unsolved for approximately 124 years and was considered to be a hard problem till Kenneth Appel and Wolfgang Haken came finally up with a solution. The theorem states that, given any separation of a plane into contiguous regions, producing a plane map, no more than four colours are required to tint the regions of the map so that no two adjacent regions have the same colour. Two regions are called adjacent if they share a common boundary that is not a corner, where corners are the points shared by three or more regions.
So let us try to tint the map of all member states of the European Union using the four colour theorem.
First, we start with defining the land borders of each member country as facts in our knowledge base. The predicate neighbours/2 determines the list of neighbours of a country.
The predicate colour_countries/1 is our main entry-point which we will later use to invoke the program. It first uses setof/3 to create a list of terms in the form Country/Var. It then uses colours/2 to bind each Var in this list to an appropriate colour.
The predicate colours/1 just returns true if there are no elements in a given list.
For a list of head Country/Colour and tail Rest, the predicate colours/2 colours all the Rest. Then selects a value for Colour from the list of candidates, then check that there is no country in Rest which neighbours the Country just coloured and had the same Colour.
The member/2 predicate we have used in colours/1 and neighbours/2 is just a standard membership utility function which checks if X is a member of a given list.
That is really all, with a couple of lines of code we are done! The logic is ridiculously simple, and yet the program is still easy to follow. Think about how much code you would need to express the same problem in your favourite programming language!
Let us visually check if our program has concluded a correct solution and plot a map with the colour results retrieved from the colour_countries/1 predicate. Observe that no two adjacent regions have the same colour. You can have a try if you can solve the problem with for example just three colours!
The complete “Four Colour Theorem” code example is also available on my github account.
What Next?
If you find it as mind-blowing as I do with how few lines you can write reasonable programs why don’t you try to solve one of those classic puzzles like for example the ”Tower of Hanoi” or the ”Escape from Zurg” on your own? Alternatively, try to solve one of the 99 Prolog problems as your daily Kata.
Over the past 15 years, HAProxy has become well known for its reliability, superior performance, extensible features, and advanced security. It is relatively less known that one of HAProxy’s core building blocks is the Runtime API which provides very powerful dynamic configuration capabilities with no service reloads or restarts.
The early improvements to the Runtime API’s dynamic configuration capabilities were driven by requests from advanced HAProxy users such as Airbnb and Yelp through their development of SmartStack, a pioneering automated service discovery and registration platform. Since then, we have been strongly committed to evolving the Runtime API based on feedback from our users, as exemplified by our recent blog post “Dynamic Scaling for Microservices with the HAProxy Runtime API” and the release of HAProxy version 1.8.
In this blog post we are going to take you on a tour of the HAProxy Runtime API and some of its key features, such as the ability to dynamically configure backend servers, maps, ACLs, stick tables, and TLS ticket keys. These features allow for improved integration with service discovery tools and orchestration systems, enhance geolocation functionality, enable adaptive security policies, increase the efficiency of SSL/TLS clusters, and much more.
Getting Started
The HAProxy Runtime API traces its origins back to our wishes to create a complete configuration and statistics API for HAProxy, whose commands would all take effect immediately, during runtime. One of our early features in this API was of course the ability to retrieve detailed real-time statistics. Also, unlike typical newer APIs which only support HTTP, the HAProxy Runtime API was always accessible through TCP and Unix sockets. That is why we sometimes still refer to it as the HAProxy “stats socket” or just “socket”, and why the configuration directive for enabling the Runtime API bears the same name.
The Runtime API is enabled in the HAProxy configuration by using the following example:
If you are not using HAProxy Enterprise Edition, the default Unix socket name in your installation might be named “/var/run/haproxy.sock” instead of “/var/run/hapee-lb.sock”.
Then, for testing or executing commands interactively, the Runtime API can be conveniently accessed using the interactive command prompt provided by “socat”:
$ socat readline /var/run/hapee-lb.sock
$ socat readline tcp4-connect:127.0.0.1:9999
> help
Please note that for the above to work, your version of “socat” needs to be compiled with GNU Readline support. This could be verified by running “socat -V | grep READLINE”. If the output of “socat -V” doesn’t mention “READLINE”, or it mentions “undef READLINE”, or running the actual command produces an error “unknown device/address “readline””, it means you have a version without readline support.
For accessing the Runtime API from scripts, or as an alternative to the interactive use shown above, the following command could be used:
And finally, as an alternative to “socat” altogether, command “nc” from the package “netcat” could be used. In that case, please use the”netcat-openbsd” version of “netcat”; it also supports the option “nc -U” for connecting to Unix domain sockets.
The best way to start with the Runtime API is to execute a simple request returning a list of all available commands. This is done by sending “help” or any unknown command to the API. Here is the actual output from “help”, executed on HAProxy version 1.8-dev2. If your HAProxy is missing any particular commands or options, please make sure you are using a recent HAProxy or HAPEE release.
> help
help : this message
prompt : toggle interactive mode with prompt
quit : disconnect
show errors : report last request and response errors for each proxy
clear counters : clear max statistics counters (add 'all' for all counters)
show info : report information about the running process
show stat : report counters for each proxy and server
show schema json : report schema used for stats
disable agent : disable agent checks (use 'set server' instead)
disable health : disable health checks (use 'set server' instead)
disable server : disable a server for maintenance (use 'set server' instead)
enable agent : enable agent checks (use 'set server' instead)
enable health : enable health checks (use 'set server' instead)
enable server : enable a disabled server (use 'set server' instead)
set maxconn server : change a server's maxconn setting
set server : change a server's state, weight or address
get weight : report a server's current weight
set weight : change a server's weight (deprecated)
show sess [id] : report the list of current sessions or dump this session
shutdown session : kill a specific session
shutdown sessions server : kill sessions on a server
clear table : remove an entry from a table
set table [id] : update or create a table entry's data
show table [id]: report table usage stats or dump this table's contents
disable frontend : temporarily disable specific frontend
enable frontend : re-enable specific frontend
set maxconn frontend : change a frontend's maxconn setting
show servers state [id]: dump volatile server information (for backend )
show backend : list backends in the current running config
shutdown frontend : stop a specific frontend
set dynamic-cookie-key backend : change a backend secret key for dynamic cookies
enable dynamic-cookie backend : enable dynamic cookies on a specific backend
disable dynamic-cookie backend : disable dynamic cookies on a specific backend
show stat resolvers [id]: dumps counters from all resolvers section and
associated name servers
set maxconn global : change the per-process maxconn setting
set rate-limit : change a rate limiting value
set timeout : change a timeout setting
show env [var] : dump environment variables known to the process
show cli sockets : dump list of cli sockets
add acl : add acl entry
clear acl : clear the content of this acl
del acl : delete acl entry
get acl : report the patterns matching a sample for an ACL
show acl [id] : report available acls or dump an acl's contents
add map : add map entry
clear map : clear the content of this map
del map : delete map entry
get map : report the keys and values matching a sample for a map
set map : modify map entry
show map [id] : report available maps or dump a map's contents
show pools : report information about the memory pools usage
Retrieving Statistics
For a light introduction before going into the Runtime API’s more powerful commands, let’s demonstrate the method for obtaining real-time statistics from HAProxy.
(One of the already well known methods for retrieving real-time statistics is through the HAProxy’s built-in, HTML web page. These statistics, formatted in a simple and straightforward way, can be obtained after configuring the “stats uri” in HAProxy and visiting the statistics URL.)
The same complete and raw information can also be obtained through the HAProxy Runtime API. The API command is named “show stat”:
> show stat
The command’s output will be provided in CSV format. Support for JSON output has been included in HAProxy version 1.8 and HAProxy Enterprise Edition version 1.7r2.
The statistics output contains more than 80 different metrics. To quickly convert it to a shorter and human readable output, we could use standard command line tools. Here is an example that shows a chosen subset of data and refreshes it every 2 seconds:
The topic of using the HAProxy Runtime API for dynamically scaling backend servers was covered in one of our previous blog posts titled “Dynamic Scaling for Microservices with the HAProxy Runtime API“. Please refer to it for the complete treatment of the subject, especially for use in microservices environments where the rate of changes is very high and where configuration updates must be done during runtime with absolutely no impact on user experience. A brief summary is included here for completeness.
The Runtime API allows changing backend server addresses, ports, weights, and states, and enabling and disabling backends.
The following configuration directives help us implement dynamic scaling using the Runtime API:
First, we could use “server templates” to quickly define template/placeholder slots for up to n backend servers:
This configuration is equal to writing out server websrvX 192.168.122.1:8080 check disabled 100 times, but automatically replacing X with a number incrementing from 1 to 100, inclusive. The servers are added in the disabled state, and it is expected that your server template range (“1-100”) will be larger than the number of servers you currently have to allow for runtime/dynamic scaling to up to n configured backend servers.
Then, after the backend servers are in place (either by using server-template or defining them manually), we could use the Runtime API to configure or update the servers. For example, we could update the IP address and port of ‘websrv1’, and change it from a ‘disabled’ to a ‘ready’ state:
> set server be_template/websrv1 addr 192.168.122.42 port 8080
> set server be_template/websrv1 state ready
In addition, we are also going to ensure that any runtime changes are written out to the state file, and that the state file is loaded on reload/restart:
Please note that the state file is not updated automatically. To save state, you would run echo “show servers state” | socat stdio /var/run/hapee-lb.sock > /etc/hapee/haproxy.state after making changes to the states and before invoking an HAProxy reload or restart.
Maps in HAProxy are a general mechanism for converting sets of input values onto corresponding output values. Maps are used in numerous cases, including for converting HTTP “Host” header values into backend (application) names and for mapping ranges of IP addresses to geographical locations. In the blog post titled “Web Application Name to Backend Mapping in HAProxy“, we have shown practical examples of using the map files and we have mentioned the standalone tool lb-update that can be used to periodically and automatically update map and ACL files. A similar functionality could be obtained by using the HAProxy Runtime API.
The process of updating map contents via the HAProxy Runtime API is simple: we are going to list maps and map contents, identify the entries we want to modify, and then perform the actual modifications. Modifications to the existing entries in the Runtime API generally consist of of two steps – first adding a new value, then deleting the old one to complete the transition.
A complete session for modifying the contents of a map could look like the following:
# List maps
> show map
# id (file) description
-1 (/etc/hapee/domain2backend.map) pattern loaded from file '/etc/hapee/domain2backend.map' used by map at file '/etc/hapee/hapee-lb.cfg' line 64
-1 (/etc/hapee/domain2redirect.map) pattern loaded from file '/etc/hapee/domain2redirect.map' used by map at file '/etc/hapee1/hapee-lb.cfg' line 65
# Display contents of a particular map
> show map /etc/hapee/domain2backend.map
0x2163350 app1.domain1.com bk_app1
0x21633d0 app1.domain2.com bk_app1
0x2163450 app2.domain1.com bk_app2
0x21634d0 app2.domain2.com bk_app2
0x2163550 app.domain.com bk_app1
# Replace the last entry "app.domain.com bk_app1" with "app.domain.com bk_app2"
# Perform the replacement by adding a new value, then deleting the old one
> add map /etc/hapee/domain2backend.map app.domain.com bk_app2
> del map /etc/hapee/domain2backend.map #0x2163550
# Verify new contents of the map
> show map /etc/hapee/domain2backend.map
0x2163350 app1.domain1.com bk_app1
0x21633d0 app1.domain2.com bk_app1
0x2163450 app2.domain1.com bk_app2
0x21634d0 app2.domain2.com bk_app2
0x2163550 app.domain.com bk_app2
Updating GeoIP Databases
GeoIP databases map IP address ranges to geographical locations. Such databases can be used in HAProxy for different purposes. Often times, they are used for performing GeoIP lookups natively within HAProxy and serving the data to backend servers. The backend servers can then depend on the information being available as part of incoming requests, requiring no specific GeoIP code nor causing any slowdowns in the application code itself.
More information about using GeoIP with HAProxy can be found in one of our previous blog posts titled “Using GeoIP Databases with HAProxy“. Another common use case for GeoIP is to include the client country code in the HAProxy logs. This could be achieved using the following log-format directive:
The above line will use the map_ip converter in order to get the country code from the map file “ip-country.lst”. Logs based on this format will then look like the following:
We could easily add them to the running configuration using the Runtime API command “add map”. Also, instead of adding entries one by one, we are going to use a little bit of bash shell scripting to automate the data import:
# Loop through the map entries on disk and add them to the running configuration
$ IFS=$'\n'
$ for ip_country in $(cat /tmp/more-ip-countries.lst); do
echo "add map /tmp/ip-country.lst $ip_country"
done | socat stdio /var/run/hapee-lb.sock
Updating Stick Tables
Stick tables are yet another very powerful and very applicable, but simple to use feature in HAProxy. Stick tables allow keeping track of arbitrary client information across requests, so they are used for purposes such as creating “sticky” sessions, implementing security protections, setting limits, and maintaining arbitrary counters and lists.
Stick tables (along with timers, schedulers, ACLs, and many other features and tools) are based on high-performance Elastic Binary Trees, invented by our HAProxy Technologies CTO, Willy Tarreau. Ebtrees allow these tables to contain millions of records while maintaining extremely fast speed of access. We have blogged about stick tables and their uses in many of our previous blog posts, including:
The Runtime API allows stick table entries to be added, removed, searched, and updated during runtime. In the following example, we are going to create a stick table of 1 million entries to keep track of the request rates coming from individual client IPs. We will impose a limit of a maximum 5 requests per second, and the IP addresses which keep sending requests with a rate above that limit over a period of 10 seconds will be denied further requests for a period of 15 minutes.
frontend ft_web
bind 0.0.0.0:8080
# Stick table definition
stick-table type ip size 1m expire 15m store gpt0,http_req_rate(10s)
http-request allow if { src -f /etc/hapee/whitelist.lst }
http-request track-sc0 src
acl abuse src_http_req_rate ge 5
http-request sc-set-gpt0(0) 1 if abuse
http-request deny if { sc0_get_gpt0 ge 1 }
As mentioned, the above stick table can store up to 1 million entries, and each entry will contain 3 values: an IP address, the determined average HTTP request rate over 10 seconds, and a general purpose tag “GPT0”, which will have a value of “1” if the requests are to be denied. Entries in the table will be removed to not occupy space if the client IP makes no further requests within the configured expiration period (in our example, 15 minutes). Requests coming from the whitelisted IPs will be passed through without imposing any restrictions on them.
All of this will work automatically and require no manual intervention, thanks just to the configuration lines above.
However, we might still want to be able to manipulate the stick table during runtime, for example to change the entries’ GPT0 flag, to remove entries altogether, or to list currently blocked IPs. This can again be done using the Runtime API:
# List the contents of the stick table
> show table ft_web
# table: ft_web, type: ip, size:1048576, used:2
0x1c1efe0: key=127.0.0.1 use=0 exp=5600 gpt0=1 http_req_rate(10000)=50
0x1c0d8e0: key=192.168.122.1 use=0 exp=7713 gpt0=0 http_req_rate(10000)=1
# Set an entry's GPT0 value to 0
> set table ft_web key 127.0.0.1 data.gpt0 0
# Delete the entry
> clear table ft_web key 127.0.0.1
# Verify successful deletion
> show table ft_web
# table: ft_web, type: ip, size:1048576, used:2
0x1c0d8e0: key=192.168.122.1 use=0 exp=7700 gpt0=0 http_req_rate(10000)=0
# List remaining blocked client IPs (those with tag GPT0 value greater than 0)
> show table ft_web data.gpt0 gt 0
Updating ACLs
To extend the above example of rate-limiting the incoming HTTP requests, let’s assume we would now want to change the existing rate limit from 10 to 60 requests per second.
To do so, the HAProxy Runtime API will certainly allow us to change the ACLs during runtime. We will execute the command “show acl” to see the configured ACLs, then identify the one we want to modify, and finally perform the actual modification. The modification will consist of adding a new value and then deleting the old one to complete the transition.
A complete session could look like the following:
> show acl
# id (file) description
0 () acl 'path_beg' file '/etc/hapee/hapee-lb.cfg' line 60
1 () acl 'nbsrv' file '/etc/hapee/hapee-lb.cfg' line 61
2 (/etc/hapee/whitelist.lst) pattern loaded from file '/etc/hapee/whitelist.lst' used by acl at file '/etc/hapee/hapee-lb.cfg' line 67
3 () acl 'src' file '/etc/hapee/hapee-lb.cfg' line 67
4 () acl 'src_http_req_rate' file '/etc/hapee/hapee-lb.cfg' line 69
5 () acl 'sc0_get_gpt0' file '/etc/hapee/hapee-lb.cfg' line 71
6 () acl 'path_beg' file '/etc/hapee/hapee-lb.cfg' line 80
7 () acl 'always_true' file '/etc/hapee/hapee-lb.cfg' line 106
# We are interested in the 5th ACL (ID #4)
# Display the ACL's current settings
> show acl #4
0xc9a3e0 10
# Verify that the rate is 10, and will now add a new rate of 60
> add acl #4 60
# Verify that both values are now present
> show acl #4
0xc9a3e0 10
0xce8f10 60
# Delete the old value in any of the following two ways - by value, or by using the reference number
> del acl #4 10
> del acl #4 #0xc9a3e0
# Verify that only one value now remains in effect
> show acl #4
0xce8f10 60
Updating Whitelists and Blacklists
Again extending our original rate limiting example, please notice that we have used the following configuration directive to provision for whitelisted IP addresses:
http-request allow if { src -f /etc/hapee/whitelist.lst }
This configuration line tells HAProxy to fetch the source IP, check it against the list of IP addresses that were loaded from whitelist.lst, and pass the request through without further checks if the IP address is found in the list.
In this example we are going to modify the contents of the whitelist by using the Runtime API – we will be changing an IP address entry from “192.168.1.6” to “192.168.1.9”. As usual, to do so we are going to list the ACLs, identify the entries we want to modify, and then perform the actual modification. The modification will consist of adding the new value and then deleting the old one to complete the transition.
A complete session could look like the following:
> show acl
# id (file) description
0 () acl 'path_beg' file '/etc/hapee/hapee-lb.cfg' line 60
1 () acl 'nbsrv' file '/etc/hapee/hapee-lb.cfg' line 61
2 (/etc/hapee/whitelist.lst) pattern loaded from file '/etc/hapee/whitelist.lst' used by acl at file '/etc/hapee/hapee-lb.cfg' line 67
3 () acl 'src' file '/etc/hapee/hapee-lb.cfg' line 67
4 () acl 'src_http_req_rate' file '/etc/hapee/hapee-lb.cfg' line 69
5 () acl 'sc0_get_gpt0' file '/etc/hapee/hapee-lb.cfg' line 71
6 () acl 'path_beg' file '/etc/hapee/hapee-lb.cfg' line 80
7 () acl 'always_true' file '/etc/hapee/hapee-lb.cfg' line 106
# We are interested in the third entry (ID #2)
# Display its content
> show acl #2
0x24de920 191.168.1.1
0x24de960 191.168.1.2
0x24de9a0 191.168.1.3
0x24de9e0 191.168.1.4
0x24dcf10 191.168.1.5
0x24de300 191.168.1.6
0x24de340 191.168.1.7
# Add the new entry
> add acl #2 192.168.1.9
# Delete the old entry
> del acl #2 #0x24de300
# Verify the result
> show acl #2
0x24de920 191.168.1.1
0x24de960 191.168.1.2
0x24de9a0 191.168.1.3
0x24de9e0 191.168.1.4
0x24dcf10 191.168.1.5
0x24de340 191.168.1.7
0x24de300 192.168.1.9
SSL/TLS
Updating TLS Tickets
HAProxy uses tls-ticket-keys to avoid the expensive key renegotiation when an existing client wants to start a new session after closing the previous one. If a client supports session tickets, HAProxy will send it a new session ticket record containing all of the negotiated session data (cipher suite, master secret, etc.). The record will be encrypted with a secret key only known to the HAProxy process, ensuring that the data won’t be read or modified by the client.
The secrets used to encrypt the TLS tickets are generated on HAProxy startup. If an active-active HAProxy cluster is set up and a client moves between nodes, it will have to renegotiate the keys often because the tickets, encrypted with node-specific keys, will not be understood by other nodes in the cluster. In order to avoid this, it is possible to place secrets in a file and also periodically rotate them to maintain perfect forward secrecy. That way all nodes in the cluster will use exactly the same set of secrets and clients will be able to move between HAProxy nodes without any side effects.
This could be done by updating the file containing the keys and reloading HAProxy manually, but it can also be done during runtime by using the HAProxy Runtime API.
A complete session could look like the following:
# List keys files
> show tls-keys
# id (file)
0 (/dev/shm/hapee_ticket_keys.txt)
# List keys in a particular file
> show tls-keys #0
# id secret
# 0 (/dev/shm/hapee_ticket_keys.txt)
0.0 vaL65b3ns0mAJbiQRGiQZ84H4C9N1dZAyDYrHXVqG6KRDuXCo8mpwfk6+xPtlM1m
0.1 fQxhSJT8sBKNb6JAFZT11UkzplfXEI1uUijPQUTBysZpNqzT26s2RVARxCoo5E52
0.2 QtxrjBbPrX6z/PljdHIFqmHMH2/Rc5zZzIKklcfBPJa01G6PU9Dp9ixcibeisZxU
# Update key
> set ssl tls-keys #0 CaF7HpWr0gUByzxDqlbvYXCFT2zqmhnKFAdbM4MyQHfty974QO31Pn1OLJIR92rk
TLS ticket key updated!
# Verify successful update
> show tls-keys #0
# id secret
# 0 (/dev/shm/hapee_ticket_keys.txt)
0.0 fQxhSJT8sBKNb6JAFZT11UkzplfXEI1uUijPQUTBysZpNqzT26s2RVARxCoo5E52
0.1 QtxrjBbPrX6z/PljdHIFqmHMH2/Rc5zZzIKklcfBPJa01G6PU9Dp9ixcibeisZxU
0.2 CaF7HpWr0gUByzxDqlbvYXCFT2zqmhnKFAdbM4MyQHfty974QO31Pn1OLJIR92rk
Configuring OCSP Responses
HAProxy also supports the TLS Certificate Status Request extension, also known as “OCSP stapling”. For more information on configuring the OCSP responses, please see the documentation section 5.1 – crt. OCSP stapling allows HAProxy to send certificate status information to the clients. The information is a signed OCSP response and will avoid the need for a client to send a separate request to the OCSP service hosted by the issuing Certificate Authority. Here is an example of a command used to display the OCSP response from a server:
$ openssl s_client -servername hapee-mh -connect 127.0.0.1:443 -tlsextdebug -status
CONNECTED(00000003)
TLS server extension "server name" (id=0), len=0
TLS server extension "renegotiation info" (id=65281), len=1
0001 - <SPACES/NULS>
TLS server extension "EC point formats" (id=11), len=4
0000 - 03 00 01 02 ....
TLS server extension "session ticket" (id=35), len=0
TLS server extension "status request" (id=5), len=0
TLS server extension "heartbeat" (id=15), len=1
0000 - 01 .
depth=2 C = FR, ST = France, O = MMH-LAB, OU = SERVER, CN = MMH-CA
verify error:num=19:self signed certificate in certificate chain
verify return:0
OCSP response:
======================================
OCSP Response Data:
OCSP Response Status: successful (0x0)
Response Type: Basic OCSP Response
Version: 1 (0x0)
Responder Id: C = FR, ST = France, O = MMH-LAB, OU = SERVER, CN = MMH-OCSP
Produced At: Nov 20 16:00:00 2017 GMT
Responses:
Certificate ID:
Hash Algorithm: sha1
Issuer Name Hash: 1A7A927EC43135F4B6FF62065A09E1C7FD02557B
Issuer Key Hash: A45FE1C0DDC03B42C34306A08DF14ED33B74B86C
Serial Number: 1000
Cert Status: good
This Update: Nov 20 16:00:00 2017 GMT
Next Update: Nov 30 16:00:00 2017 GMT
Near the end of the output, we can see the information “Cert Status: Good”. We can also see in the last line of output that the next update is expected in 10 days.
Now, if we would want to update the OCSP response in order to change the next update time from 10 to 20 days, we could prepare the response and then load it into the running HAProxy instance by using the Runtime API:
$ openssl ocsp -CAfile intermediate/certs/ca-chain.cert.pem -issuer intermediate/certs/intermediate.cert.pem -cert intermediate/certs/hapee-mmh.cert.pem -url http://localhost:8080 -respout /tmp/ocsp-resp.der
Response verify OK
intermediate/certs/hapee-mmh.cert.pem: good
This Update: Nov 20 16:00:00 2017 GMT
Next Update: Dec 10 16:00:00 2017 GMT
$ echo "set ssl ocsp-response $(base64 -w 10000 /tmp/ocsp-resp.der)" | socat stdio /var/run/hapee-lb.sock
OCSP Response updated!
And using the same approach as above, we can verify that HAProxy is now serving the updated response:
$ openssl s_client -servername hapee-mh -connect 127.0.0.1:443 -tlsextdebug -status
CONNECTED(00000003)
...
...
OCSP response:
======================================
...
...
Cert Status: good
This Update: Nov 20 16:00:00 2017 GMT
Next Update: Dec 10 16:00:00 2017 GMT
Troubleshooting
When it comes to troubleshooting the configuration or observed application behavior, looking into the HAProxy log files is probably one of the most common courses of action. And it is certainly a good one – HAProxy logs contain all sorts of information, including data about timers, sizes, connection counters, etc. But from time to time we may come across complicated issues or even bugs that need more detailed debugging output than even logs can provide.
Displaying Errors
As mentioned, HAProxy logs errors to log files, as documented in the section 1.3.1. The Response line. For example, if we send it simple, invalid traffic such as the following:
$ echo "This is invalid traffic\n\nMore invalid traffic" | nc -v hapee-lab 80
Connection to hapee-lab 80 port [tcp/http] succeeded!
HTTP/1.0 400 Bad request
Cache-Control: no-cache
Connection: close
Content-Type: text/html
400 Bad Request
Your browser sent an invalid request.
But to get even more information about the request in question and even see the contents of the request, we can use the Runtime API command “show errors”:
> show errors
Total events captured on [10/Nov/2017:13:41:58.421] : 3
[10/Nov/2017:13:41:43.328] frontend fe_main (#2): invalid request
backend (#-1), server (#-1), event #2
src 192.168.122.1:54154, session #15, session flags 0x00000080
HTTP msg state MSG_RQVER(6), msg flags 0x00000000, tx flags 0x00000000
HTTP chunk len 0 bytes, HTTP body len 0 bytes
buffer flags 0x00808002, out 0 bytes, total 46 bytes
pending 46 bytes, wrapping at 16384, error at position 8:
00000 This is invalid traffic\n
00024 \n
00025 More invalid traffic\n
Dumping Sessions
Depending on the logging configuration, all connections can be logged to HAProxy’s log files – but, as usual, they are logged only after HAProxy gets a reply from the backend servers or when one of its timers expires. In situations where long timeouts are involved or where sessions are taking long to complete, this might cause the logs to never seem to arrive. In such situations, the Runtime API command “show sess” may be used to dump all current sessions and their related information:
In the above example, we can see two sessions: the first one is an IPv4 session; the second is a session related to our invoking of the Runtime API. From looking into the output, we can, for example, identify that the IPv4 session is in an early stage of processing because no backend (“be=”) was selected yet. Also, to help us further in troubleshooting complex issues, we may use the command “show sess” with a session ID provided as an argument (“show sess ID”) to get even more details about a particular session.
Closing Sessions
In addition to displaying active sessions using “show sess”, we can also use the Runtime API to close sessions at will by using “shutdown session”:
> shutdown session 0xd38210
Such sessions will appear in the logs containing the flag “K”, indicating they were shut down.
We hope you have enjoyed this blog post providing an introduction to the HAProxy Runtime API and showing some of its most common and practical use cases. The complete HAProxy Runtime API documentation can be found in the HAProxy Management Guide, section 9.3.
If you have a subscription to HAProxy Enterprise Edition, we can provide you with authoritative support, scripts, and modules that will help you make the best use of the Runtime API, including its most advanced features listed among the commands but not specifically elaborated in this blog post.
The Runtime API is evolving along with all other features and improvements that we are adding to HAProxy. One of the planned Runtime API improvements is an HTTP REST interface to complement the existing access methods. Let us know what other features and improvements you would like to see included!
The formalism of Hierarchical State Machines (aka statecharts) makes the state machine approach truly applicable to real-life embedded systems.
In State Machines for Event-Driven Systems, I touched on the benefits of using state machines in programming reactive (event-driven) systems. However, while the traditional Finite State Machines (FSMs) are an excellent tool for tackling smaller problems, it's also generally known that they tend to become unmanageable even for moderately involved systems. Due to the phenomenon known as "state explosion," the complexity of a traditional FSM tends to grow much faster than the complexity of the reactive system it describes. This happens because the traditional state machine formalism inflicts repetitions.
For example, if you try to represent the behavior of just about any nontrivial system (such as the calculator I described in State Machines for Event-Driven Systems) with a traditional FSM, you'll immediately notice that many events (e.g., the Clear event) are handled identically in many states. A conventional FSM, however, has no means of capturing such a commonality and requires repeating the same actions and transitions in many states. What's missing in the traditional state machines is the mechanism for factoring out the common behavior in order to share it across many states.
The formalism of statecharts, invented by David Harel in the 1980s, addresses exactly this shortcoming of the conventional FSMs.1 Statecharts provide a very efficient way of sharing behavior, so that the complexity of a statechart no longer explodes but tends to faithfully represent the complexity of the reactive system it describes. Obviously, formalism like this is a godsend to embedded systems programmers (or any programmers working on reactive systems), because it makes the state machine approach truly applicable to real-life problems.
Reuse of behavior in reactive systems
All reactive systems seem to reuse behavior in a similar way. For example, the characteristic look-and-feel of all Graphical User Interfaces (GUIs) results from the same pattern, which Charles Petzold calls the "Ultimate Hook".2 The pattern is brilliantly simple. A GUI system dispatches every event first to the application (e.g., Windows calls a specific function inside the application, passing the event as an argument). If not handled by the application, the event flows back to the system. This establishes a hierarchical order of event processing. The application, which is conceptually at a lower level of the hierarchy, has the first shot at every event; thus, the application can customize every aspect of its behavior. At the same time, all unhandled events flow back to the higher level (i.e., to the GUI system), where they are processed according to the standard look-and-feel. This is an example of programming-by-difference because the application programmer needs to code only the differences from the standard system behavior.
Harel statecharts bring the "Ultimate Hook" pattern to the logical conclusion by combining it with the state machine formalism. The most important innovation of statecharts over the classical FSMs is the introduction of hierarchically nested states (that's why statecharts are also called hierarchical state machines).
Figure 1. (a) UML notation for hierarchically nested states; (b) UML state diagram of a PELICAN crossing, in which states vehiclesEnabled and pedestriansEnabled share the common transition OFF to the off state.
The semantics associated with state nesting (shown in Figure 1(a)) are as follows: If a system is in the nested state s11 (called a substate), it also (implicitly) is in the surrounding state s1 (the superstate). This state machine will attempt to handle any event in the context of state s11 (which is at the lower level of the hierarchy). However, if state s11 does not prescribe how to handle the event, the event is not quietly discarded (as in a traditional "flat" state machine); rather, it is automatically handled at the higher level context of state s1. This is what is meant by the system being in state s11 as well as s1. Of course, state nesting is not limited to one level only, and the simple rule of event processing applies recursively to any level of nesting.
As you can see, the semantics of hierarchical state decomposition are designed to facilitate sharing of behavior through the direct support for the "Ultimate Hook" pattern. The substates (nested states) need only define the differences from the superstates (surrounding states). A substate can easily reuse the common behavior from its superstate(s) by simply ignoring commonly handled events, which are then automatically handled by higher level states. In this manner, the substates can share all aspects of behavior with their superstates. For example, in a state model of a PELICAN (PEdestrian LIght CONtrolled) crossing shown in Figure 1(b), states vehiclesEnabled and pedestriansEnabled share a common transition OFF to the off state, defined in their common superstate operational.3
Behavioral inheritance
The fundamental character of state nesting in Hierarchical State Machines (HSMs) comes from combining hierarchy with programming-by-difference, which is otherwise known in software as inheritance. In Object-Oriented Programming (OOP), the concept of class inheritance lets you define a new kind of class rapidly in terms of an old one by specifying only how the new class differs from the old class. State nesting introduces another fundamental type of inheritance, called behavioral inheritance.4 Behavioral inheritance lets you define a new state as a specific kind of another state, by specifying only the differences from the existing state rather than defining the whole new state from scratch.5
As class inheritance allows subclasses to adapt to new environments, behavioral inheritance allows substates to mutate by adding new behavior or by overriding existing behavior. Nested states can introduce new behavior by adding new state transitions or reactions (also known as internal transitions) for events that are not recognized by superstates. This corresponds to adding new methods to a subclass. Alternatively, a substate may also process the same events as the superstates but will do it in a different way. In this manner, the substate can override the inherited behavior, which corresponds to a subclass overriding a (virtual in C++) method defined by its parents. In both cases, overriding the inherited behavior leads to polymorphism.
Liskov substitution principle (LSP) for states
Because behavioral inheritance is just a specific kind of inheritance, the universal law of generalization—the Liskov Substitution Principle (LSP)—should be applicable to state hierarchies as well as class taxonomies. In its traditional formulation for classes, LSP requires that every instance of a subclass must continue to act as though it were also an instance of the superclass. From the programming standpoint, LSP means that any code designed to work with the instance of the superclass should continue to work correctly if an instance of the subclass is used instead.
Figure 2. Complete UML state diagram of the PELICAN crossing.
The LSP extends naturally for hierarchical states and requires in this case that every substate continue to behave as though it were also the superstate. For example, all substates nested inside the vehiclesEnabled state of the PELICAN crossing (such as vehiclesGreen or vehiclesYellow, shown in Figure 2) should share the same basic characteristics of the vehiclesEnabled state. In particular, being in the vehiclesEnabled state means that the vehicles are allowed (by a green or yellow light) and simultaneously the pedestrians are not allowed (by the DON'T WALK signal). To be compliant with the LSP, none of the substates of vehiclesEnabled should disable the vehicles or enable the pedestrians. In particular, disabling vehicles (by switching the red light), or enabling the pedestrians (by displaying the WALK signal) in any of the nested states vehiclesGreen or vehiclesYellow would be inconsistent with being in the superstate vehiclesEnabled and would be a violation of the LSP (it will also be a safety hazard in this case).
Compliance with the LSP allows you to build better (correct) state hierarchies and make efficient use of abstraction. For example, in an LSP-compliant state hierarchy, you can safely "zoom out" and work at the higher level of the vehiclesEnabled state (thus abstracting away the specifics of vehiclesGreen and vehiclesYellow). As long as all the substates are consistent with their superstate, such abstraction is meaningful. On the other hand, if the substates violate basic assumptions of being in the superstate, zooming out and ignoring specifics of the substates will be incorrect.
Guaranteed initialization and cleanup
Every state in a UML statechart can have optional entry actions, which are executed upon entry to a state, as well as optional exit actions, which are executed upon exit from a state.6 Entry and exit actions are associated with states, not transitions. Regardless of how a state is entered or exited, all of its entry and exit actions will be executed.
The value of entry and exit actions is often underestimated. However, entry and exit actions are as important in HSMs as class constructors and destructors are in OOP because they provide for guaranteed initialization and cleanup. For example, consider the vehiclesEnabled state from Figure 1(b), which corresponds to the traffic lights configuration that enables vehicles and disables pedestrians. This state has a very important safety-critical requirement: always disable the pedestrians (by turning on the DON'T WALK signal) when vehicles are enabled. Of course, you could arrange for such a behavior by adding an appropriate action (switching the DON'T WALK signal) to every transition path leading into the vehiclesEnabled state. However, such a solution would potentially cause the repetition of this action on many transitions. More importantly, such an approach is error-prone in view of changes to the state machine. For instance, a programmer upgrading a PELICAN crossing to a PUFFIN (Pedestrian User Friendly INtelligent) crossing might simply forget to turn on the DON'T WALK signal on all transitions into the vehiclesEnabled state or any of its substates.
Entry and exit actions allow you to implement the desired behavior in a safer, simpler, and more intuitive way. You could specify turning on the DON'T WALK signal upon the entry to vehiclesEnabled. This solution is superior because it avoids potential repetitions of this action on transitions and eliminates the basic safety hazard of leaving the WALK signal turned on while vehicles may be allowed into the crossing. The semantics of entry actions guarantees that, regardless of the transition path, the DON'T WALK signal will be turned on when the traffic controller is in the vehiclesEnabled state. (Note that an equally correct alternative design is to switch the DON'T WALK signal in the exit action from pedestriansEnabled and to switch the red light for vehicles in the exit action from vehiclesEnabled.)
Obviously, you can also use entry and exit actions in the classical (nonhierarchical) FSMs. In fact, the lack of hierarchy in this case makes the implementation of this feature almost trivial. For instance, one way of implementing entry and exit actions is to dispatch reserved signals (e.g., ENTRY_SIG and EXIT_SIG) to the state machine. The FsmTran_() method (see State Machines for Event-Driven Systems) could dispatch the EXIT_SIG signal to the current state (transition source) and then dispatch the ENTRY_SIG signal to the target. Such an implementation of the FsmTran_() method might look as follows (the complete source code in C and C++ is available with QP-nano downloads and further described in an application note):
static Event const entryEvt = { ENTRY_SIG };
static Event const exitEvt = { EXIT_SIG };
void FsmTran_(Fsm *me, State target)
{
FsmDispatch(me, &exitEvt); /* exit the source */
me->state__ = target; /* change current state */
FsmDispatch(me, &entryEvt); /* enter the target */
}
However, entry and exit actions are particularly important and powerful in HSMs because they often determine the identity of hierarchical states. For example, the identity of the vehiclesEnabled state is determined by the fact that the vehicles are enabled and pedestrians disabled. These conditions must be established before entering any substate of vehiclesEnabled because entry actions to a substate, such as vehiclesGreen (see Figure 2), rely on proper initialization of the vehiclesEnabled superstate and perform only the differences from this initialization. Consequently, the order of execution of entry actions must always proceed from the outermost state to the innermost state. Not surprisingly, this order is analogous to the order in which class constructors are invoked. Construction of a class always starts at the top of the class hierarchy and follows through all inheritance levels down to the class being instantiated. The execution of exit actions, which corresponds to destructor invocation, proceeds in the exact reverse order, starting from the innermost state (corresponding to the most derived class).
Hint:
Try to make your state machine as much a Moore automaton as possible. (Moore automata associate actions with states rather than transitions.) That way you achieve a safer design (in view of future modifications) and your states will have better-defined identity.
A closer look at the Pelican HSM
Figure 2 shows a complete UML state diagram of the PELICAN crossing (a "zoomed in" version of the diagram from Figure 1(b)). I believe that this HSM represents quite faithfully the behavior of the pedestrian crossing in front of the midtown shopping center on Middlefield Road in Palo Alto. I have tested the crossing several times (the drivers sure loved me for it) and have determined that it operates as follows. Nominally, vehicles are enabled and pedestrians disabled. To activate the traffic light switch, a pedestrian must push a button (let's call this event PEDESTRIAN_WAITING). In response, the vehicles get the yellow light. After a few seconds, vehicles get a red light and pedestrians get the WALK signal, which shortly thereafter changes to a flashing DON'T WALK signal. When the DON'T WALK signal stops flashing, vehicles get the green light. After this cycle, the traffic lights don't respond to the PEDESTRIAN_WAITING event immediately, although the button "remembers" that it has been pushed. The traffic light controller always gives the vehicles a minimum of several seconds of green light before repeating the cycle.
Perhaps the most interesting element of the state model from Figure 2 (except the aforementioned use of entry actions to avoid basic safety hazards) is the way it guarantees the minimal green light time for the vehicles. The HSM models it with two states, vehiclesGreen and vehiclesGreenInt, as well as with the isPedestrianWaiting flag. The state vehiclesGreen corresponds to the uninterruptible green light for the vehicles. The occurrence of the PEDESTRIAN_WAITING event in this state doesn't trigger any transition but merely sets the isPedestrianWaiting flag to "remember" that the button was pressed. The only criterion for exiting vehiclesGreen is the occurrence of the TIMEOUT event, which triggers a transition either to vehiclesYellow (if the isPedestrianWaiting flag is set) or to the vehiclesGreenInt state, the latter corresponding to the interruptible green light for vehicles.
Another interesting aspect of this state model is the generation of the TIMEOUT events by means of only one timer object. (A timer is a facility that dispatches an event to the state machine after a preprogrammed time interval.) Typically, timers are scarce system resources that need to be allocated (here indicated by the SetTimer() action) and recycled (by the KillTimer() action). Note how the state machine enables using only one TIMEOUT event (different states handle the same event differently), and how entry and exit actions help to initialize and clean up the timer. In particular, please note that the timer is never leaked, even in the case of the always enabled OFF transition inherited from the operational superstate.
HSMs in C and C++
If I left this quick introduction to HSMs only at the level of the state diagram from Figure 2, you would probably walk away with the impression that the whole approach is just a pie-in-the-sky. The diagram in Figure 2 might look clever, perhaps, but how does it lead to better code?
Contrary to a widespread misconception, you don't need sophisticated CASE tools to translate UML state diagrams to efficient and highly maintainable C or C++.
Figure 3. A GUI application representing the PELICAN crossing. The traffic signals are activated by pedestrians pushing the control button. Pane (a) shows the GUI in the vehiclesEnabled state. Pane (b) shows the GUI in the pedestriansEnabled state.
I have embedded the HSM into a Windows application (see Figure 3), because I needed a timer to dispatch TIMEOUT events to the state machine. Note, however, that the underlying coding technique is not at all Windows- or GUI-specific. In particular, the HSM implementation can be used in embedded systems in conjunction with any infrastructure to execute state machines.
Exercise:
Test the GUI application (either C or C++ version) and correlate its behavior with the state diagram from Figure 2 (you might find the current state display handy). Subsequently, set breakpoints at all exit actions from states and convince yourself that the application never leaks the Windows timer.
While I don't have here room for a detailed discussion of the HSM implementation that you'll find online, I'd only like to mention that it is a straightforward extension of the FSM technique I presented in State Machines for Event-Driven Systems. As before, State is defined as a pointer-to-function in C (and pointer-to-member-function in C++), however the signature of state handler methods has changed. In an HSM, the state handler additionally returns the superstate, thus providing information about the nesting of a given state. More precisely, a state handler method must return a pointer to the superstate handler, if it doesn't handle the event, or NULL if it does. To guarantee that all states have superstates, the QHsm class (base class for derivation of HSMs, analogous to the Fsm class from State Machines for Event-Driven Systems) provides the top state as the ultimate root of the state hierarchy. The top state handler cannot be overridden and always returns NULL. These conventions make the implementation of the QHsmDispatch() method simple:
As you can see, every event dispatched to an HSM passes through a chain of state handlers until a state handler returns NULL, which indicates that either the event has been handled or the top state has been reached.
As a client programmer, you don't need to know the internal details of the QHsm class. The main point is that the resulting HSM implementation provides a very straightforward mapping between the diagram and the code, and it is easy to modify at any stage of the development process. I encourage you to undertake the following two exercises:
Exercise:
Modify the state machine to implement the alternative design of switching the DON'T WALK signal in the exit action from pedestriansEnabled and switching the red light for vehicles in the exit action from vehiclesEnabled. Recompile and test.
Exercise:
Modify the initial transition in the vehiclesEnabled state to enter the vehiclesGreenInt substate. In addition, change the target of the TIMEOUT transition for state pedestriansFlash from vehiclesEnabled to vehiclesGreen.
Finally, I hope you experienced a strange feeling of deja vu when you read about programming-by-difference, inheritance, guaranteed initialization and cleanup, and the LSP in the context of state machines. Such a close analogy between the fundamental concepts of OOP and HSMs is truly remarkable. Indeed, the analogy adds another dimension to the OOP. The traditional OO method seems to stop short at the boundary of a class, leaving the internal implementation of individual class methods to mostly procedural techniques. The concept of behavioral inheritance goes beyond that frontier. Behavioral inheritance allows applying the OO concepts inside reactive classes.
There is a lot more information about building embedded software out of state machines at www.state-machine.com.
5. Many writings about HSMs cautiously use the term "inheritance" to describe sharing of behavior between substates and superstates (e.g., see the Object Management Group's UML Specification Version 2.2). Please note, however, that the term behavioral inheritance is not part of the UML vocabulary and should not be confused with the traditional (class) inheritance applied to entire state machines (classes that internally embed state machines). [back]
6. While some embedded programmers seem intimidated by Unified Modeling Language (UML), the concerns are largely exaggerated. It takes just a few hours to get acquainted with the most basic UML diagrams. (I get the most mileage from the sequence diagram, state diagram, and class diagram.) The ability to read basic UML diagrams belongs to every embedded programmer's skill set in the same way as the ability to read schematics. If I were to recommend a book, I'd probably start with: Fowler, Martin. UML Distilled: A Brief Guide to the Standard Object Modeling Language (3rd Edition). Addison-Wesley, 2003. [back]
While the Republican tax overhaul would add up to an overall tax cut for individual taxpayers, at least through 2025, millions could still immediately receive a tax increase. For many, particularly those in Democratic areas who earn $200,000 or more, the increase would come from the repeal of the state and local tax deduction, known as SALT.
Average State and Local Tax Deduction for High-Income Taxpayers
Margin of support in 2016 presidential election
◄ MORE REPUBLICAN MORE DEMOCRATIC ►
Highly-populated counties in Democratic-leaning states like California and New York tend to claim much higher SALT deductions.
Note: Tax returns for filers earning $200,000 or more. Circle size is proportional to the number of tax returns filed in each county in 2015.
Because Democratic voters are more concentrated in high-tax states like New York and California, taxpayers in counties that voted for Hillary Clinton take much larger SALT deductions on average. Upper-class taxpayers are much more likely to claim more than the higher proposed standard deduction (roughly $24,000 for couples in both versions of the bill).
States with the Highest Average SALT Deduction for Households Earning $200,000 or More
State
Average deduction
2016 margin
New York
$84,964
Clinton +22%
California
$64,771
Clinton +30%
Connecticut
$61,997
Clinton +14%
New Jersey
$51,259
Clinton +14%
Washington, D.C.
$51,202
Clinton +87%
Minnesota
$46,591
Clinton +2%
Oregon
$44,928
Clinton +11%
Massachusetts
$42,890
Clinton +27%
Vermont
$41,641
Clinton +26%
Maryland
$41,622
Clinton +26%
Wisconsin
$40,962
Trump +0.8%
Rhode Island
$39,394
Clinton +16%
Maine
$38,089
Clinton +3%
Hawaii
$37,219
Clinton +32%
Idaho
$36,641
Trump +32%
Illinois
$36,374
Clinton +17%
Nebraska
$35,957
Trump +25%
Montana
$35,823
Trump +20%
Arkansas
$35,755
Trump +27%
Ohio
$35,666
Trump +8%
Missouri
$35,459
Trump +19%
Kentucky
$35,172
Trump +30%
Iowa
$32,939
Trump +9%
Georgia
$32,881
Trump +5%
North Carolina
$32,574
Trump +4%
Delaware
$31,950
Clinton +11%
Pennsylvania
$31,708
Trump +0.7%
Virginia
$31,643
Clinton +5%
West Virginia
$31,387
Trump +42%
Utah
$30,959
Trump +18%
Michigan
$30,204
Trump +0.2%
South Carolina
$29,916
Trump +14%
Indiana
$29,044
Trump +19%
Kansas
$27,867
Trump +20%
Oklahoma
$27,798
Trump +36%
Colorado
$27,644
Clinton +5%
Florida
$25,974
Trump +1.2%
Wyoming
$25,952
Trump +46%
Arizona
$25,855
Trump +4%
Mississippi
$24,109
Trump +18%
New Hampshire
$23,495
Clinton +0.4%
New Mexico
$23,471
Clinton +8%
Nevada
$23,300
Clinton +2%
Louisiana
$23,220
Trump +20%
North Dakota
$21,454
Trump +36%
Alabama
$21,218
Trump +28%
Texas
$18,214
Trump +9%
Washington
$16,392
Clinton +16%
South Dakota
$15,943
Trump +30%
Tennessee
$15,886
Trump +26%
Alaska
$9,131
Trump +15%
There are a handful of Republican counties, particularly in New York and New Jersey, that claim high amounts of SALT deductions. Many of the 13 Republican representatives who voted against the House version of the tax bill cited the SALT changes.
The issue has been less controversial among Republican members in the Senate, because none of the senators representing the top 10 states taking the SALT deduction are Republicans.
Why the Wealthiest Are Hit Hardest
Even as it repeals several itemized deductions, the bill nearly doubles the standard deduction to roughly $12,000 for individuals and $24,000 for couples.
While many lower-income people take the SALT deduction, many would end up better off under the bill because the new standard deduction would be worth more than what they deducted in SALT and other itemizations. Experts predict that the share of taxpayers who itemize their deductions will fall to less than 10 percent from 30 percent currently.
Taxpayers earning $200,000 or more, who make up 4.5 percent of all returns, are at the highest risk of a tax increase from the SALT repeal, because many currently deduct much more in state and local taxes than the bill’s new standard deduction.
But not all groups above that income threshold would fare the same. Taxpayers earning from about $500,000 to $1,000,000 are most likely to pay the Alternative Minimum Tax (AMT), an alternative income tax calculation that ensures high-earners pay a minimum amount of taxes. The AMT does not allow the state and local tax deduction, so those who pay it are likely to be hurt less by the SALT repeal because they are not currently receiving the full benefit of the deduction.
Income vs. Property Taxes
The initial version of the Senate bill repealed all of the SALT deductions — for income, property and other taxes. But Senator Susan Collins of Maine, a critical Republican vote, pushed to retain a property tax deduction of up to $10,000, a provision also included in the House bill.
But the income tax deduction would be repealed in its entirety. There are several states, like Tennessee, Texas and Florida, that have no income tax, so people there do not currently benefit from that deduction unless they pay taxes on income earned elsewhere.
Average Income Tax Deduction for High-Income Taxpayers
Margin of support in 2016 presidential election
◄ MORE REPUBLICAN MORE DEMOCRATIC ►
Florida taxpayers that take the deduction pay taxes on income earned elsewhere.
Note: Tax returns for filers earning $200,000 or more. Circle size is proportional to the number of tax returns filed in each county in 2015.
The property tax deduction is claimed by many more people in places that voted for President Trump, like in Texas and Florida. Those who claim more than $10,000 — the new limit in the bill — are at the highest risk of seeing a tax increase.
Average Property Tax Deduction for High-Income Taxpayers
Margin of support in 2016 presidential election
◄ MORE REPUBLICAN MORE DEMOCRATIC ►
Note: Tax returns for filers earning $200,000 or more. Circle size is proportional to the number of tax returns filed in each county in 2015.
Netflix used their internal spot market to save 92% on video encoding costs. The story of how is told by Dave Hahn in his now annual A Day in the Life of a Netflix Engineer. Netflix first talked about their spot market in a pair of articles published in 2015: Creating Your Own EC2 Spot Market Part 1 and Part 2.
The idea is simple:
Netflix runs out of three AWS regions and uses hundreds of thousands of EC2 instances; many are underutilized at various parts in the day.
Video encoding is 70% of Netflix’s computing needs, running on 300,000 CPUs in over 1000 different autoscaling groups.
So why not create a spot market to process video encoding?
As background, Dave explained the video encoding process:
Netflix gets video from production houses and studios. First, Netflix validates the source file, looking for missing frames, digital artifacts, color changes, and any other problems. If problems are found, the video is rejected.
Video files are huge. Many many terabytes in size. Processing a single multi-terabyte sized video file is not reasonable, so it’s broken up into chunks so it can be operated on in parallel.
Chunks are sent through the media pipeline. There’s lots of encoding work to do. Netflix supports 2200 devices and lots of different codecs, so video is needed in many different file formats.
Once the chunks are encoded, they’re validated again to make sure new problems haven’t been introduced. The chunks are assembled back into a file and validated again.
Over 70 different pieces of software are involved with the pipeline.
Netflix believes static encoding produces a higher quality video viewing experience than dynamic encoding. The result is a lot of files.
Stranger Things season 2 is shot in 8K and has nine episodes. The source files are terabytes and terabytes of data. Each season required 190,000 CPU hours to encode. That’s the equivalent of running 2,965 m4.16xlarge instances for an hour. The static encoding process creates 9,570 different video, audio, and text files.
How do you encode video? There are two possible approaches.
The most obvious approach is setting up a static farm of instances reserved only for media encoding. The win of this approach is you always have the resources you need available.
But if you look, encoding has a bursty workload pattern. That means the farm would be underutilized a lot of the time.
Whenever you see bursty workloads the idea of leveraging the spot market should burst immediately to mind.
AWS has a spot market, why not use that?
Netflix has a huge baseline capacity of reserved instances. They autoscale in and out 10,000s of instances a day from this pool. When Netflix autoscales down they have unused capacity.
So Netflix did a genius thing, they built their own internal spot market to process the chunked encoding jobs. The Engineering Tools team built an API exposing real time unused reservations at the minute level.
What were the cost savings of using an internal spot market versus a static encoding farm? 92%!
It's All About the Economics
Netflix started their own internal spot market for the same reason Amazon did; cloud economics are all about driving higher machine utilization. Reserving instances saves a lot of money in AWS, it makes sense to extract the most value as possible out of those instances. Every microsecond CPUs are not working is a waste of money.
My favorite was creating a secondary market so developers could resell the unused capacity on their instances. Utilization of VMs is still abysmally low. There’s lots of unused CPU, network, and memory capacity on instances. So it seemed like a good idea. A cloud within a cloud.
The kicker was security. Who would run code and put their data on an a random machine without a security guarantee? This was before containers. Though I had used Jails on FreeBSD to good effect, the idea of containers never occurred to me.
I thought GAE would completely lose the instance image concept all together in favor of applications being written on one giant task queue container.
The basis of this conjecture/vision is the development and evolution of one of GAE's most innovative and far reaching features: task queues. It's a great feature that allows applications to be decomposed into asynchronous flows. Work is queued and executed at some later time. Instead the monolithic and synchronous model used originally by GAE, an application can be completely asynchronous and can be run on any set of machines. For a while now it has been clear the monolithic front-end instances have become redundant with the fruition of task queues.
The problem is task queues are still image based. Operation are specified by a URL that terminate inside a run time instance whose code template is read from an image. An image contains all the code an application can execute. It's monolithic.
When a web client URL is invoked it executes code inside a monolithic image. It's these large images that must be managed by GAE and why Google needs to charge you more. They take resources to manage, time to initialize, and while running take memory even if your app isn't doing anything.
A different idea is to ask why can't a request terminate at a task queue work item instead? Then the monolithic image could be dropped infavor of an asynchronous coding model. Yes, GAE would have to still manage and distribute these code libraries in some fantastical way, no simple task, but this would solve the matching work to resources granularity problem that they instead solved by going the other direction, that is making images the unit of distribution and instances the unit of execution. We'll talk more about the granularity problem next.
So with this super cool task queue framework and programming model being developed I felt sure they were ready to announce that the monolithic images would disappear, instances would disappear, and there would be an even finer pay for what you use billing model as a replacement. I was wrong. Again.
It's A Problem Of Quanta Mechanics
Driving this upheaval is that programs run on an abstract machine that uses resources that are quantized differently than the underlying physical machines. A server comes with only so much memory and CPU. Running programs use memory even when a program is idle. Google must pay for the machine resources used by an instance. Charging only for the resources used by a program instead of all the resources used to host a program creates an unsustainable and unprofitable pricing friction between the two models.
In other words, programs are deployed in big quanta, but run in small quanta. A smaller work granularity would allow work to be schedule in idle times, which is why I think the task queue model is superior.
It’s nice to see those ideas eventually worked out.
But its popularity has underscored one of the technology's biggest downsides: its lack of scalability.
Etherscan has reported a sixfold increase in pending transactions on Ethereum since the game's release, by the Axiom Zen innovation studio, on 28 November.
"CryptoKitties has become so popular that it's taking up a significant amount of available space for transactions on the Ethereum platform," said Garrick Hileman, from the Cambridge Centre for Alternative Finance.
"Some people are concerned that a frivolous game is now going to be crowding out more serious, significant-seeming business uses."
An estimated $4.5m (£3.35m) has been spent on the cartoon cats at the time of writing, according to Crypto Kitty Sales.
Image copyrightwww.cryptokitties.coImage caption
CryptoKitties is the first game built on Ethereum
What is a CryptoKitty?
Think of these rather unpalatable cartoon kittens as unique digital Pokemon cards. The game's developers describe them as "breedable Beanie Babies", each with its own unique 256-bit genome.
These crypto-collectibles are also gender-fluid, able to play the role of either the "dame" or the "sire" when bred together. The kitties' unique DNA can lead to four billion possible genetic variations.
Some of the varieties created so far look lifelike, with grey striped fur and bulging green eyes. Others are speckled with neon-blue spots or magenta-patterned swirls.
Image copyrightwww.cryptokitties.coImage caption
One of the less attractive CryptoKitties
How much are CryptoKitties worth?
At the time of writing, the median, or mid-range, price of a CryptoKitty is approximately $23.06 (£17.19), according to Crypto Kitty Sales.
The game's top cat brought in $117,712.12 (£87,686.11) when it sold on Saturday, 2 December.
How can I pay for my own litter?
CryptoKitties can be bought using only Ether, a crypto-currency that acts as the fuel of the Ethereum blockchain network.
To get started, users must install a Chrome extension called MetaMask, which acts as a digital wallet and lets players send and receive Ether from their computers.
Ether must be purchased from a crypto-currency exchange before it can be added to MetaMask.
Image copyrightwww.cryptokitties.coImage caption
The sale page for a CryptoKitty
Where do the CryptoKitties come from?
Axiom Zen releases a new CryptoKitty every 15 minutes, but the rest of the supply is powered by the breeding of existing crypto-pets. Owners of kittens can put them up for sale and set their own price in ethers.
Why does it matter if CryptoKitties is slowing down Ethereum?
According to ETH Gas Station, the CryptoKitties game accounts for over 10% of network traffic on Ethereum. As traffic increases, transactions become more expensive to execute quickly.
"The real big issue is other major players looking for alternatives to Ethereum and moving to different systems," Mr Hileman said.
"There's definitely an urgency for Ethereum to try and address this issue."






























 .
. .
. The complete “Four Colour Theorem” code example is also available on my
The complete “Four Colour Theorem” code example is also available on my