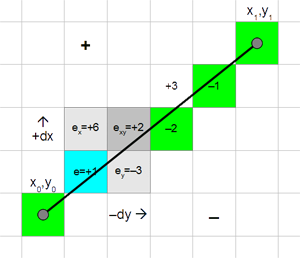
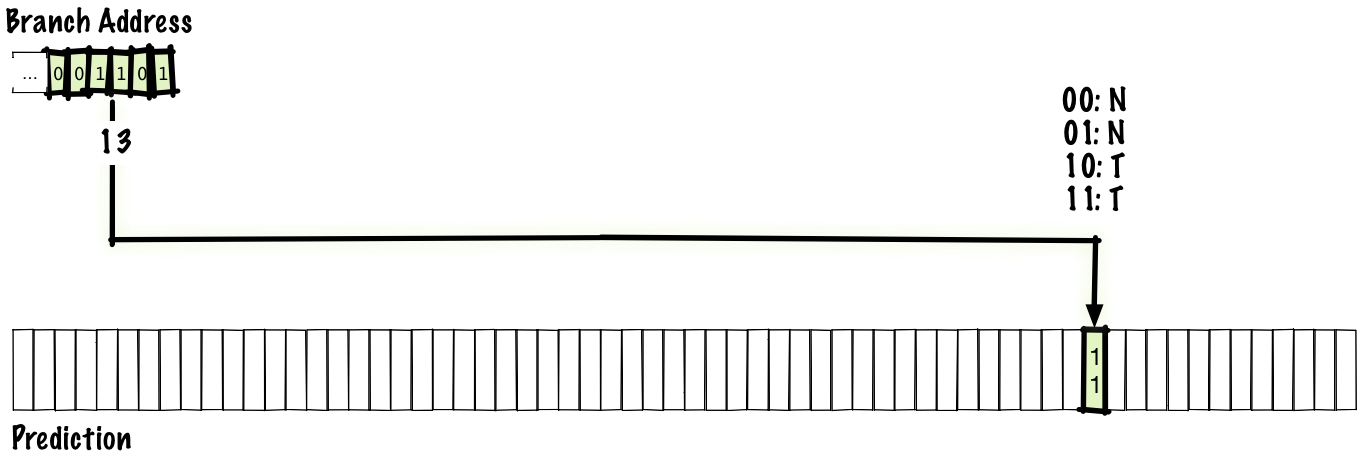
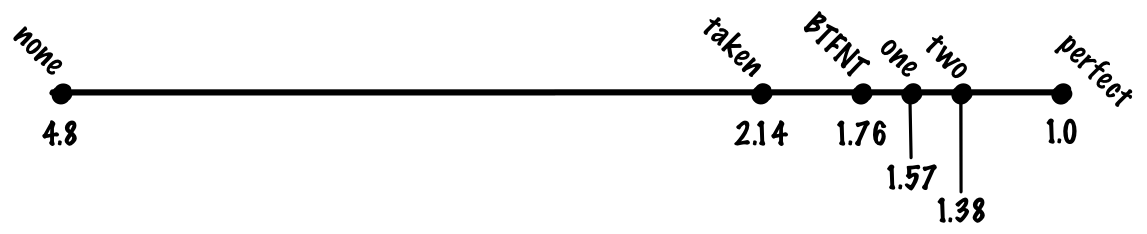
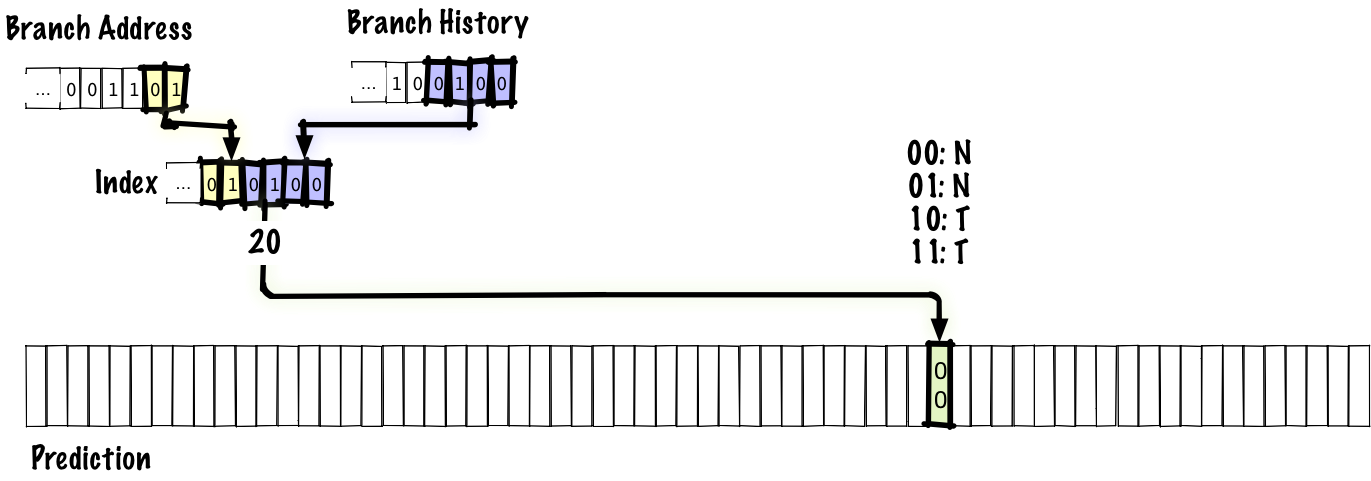
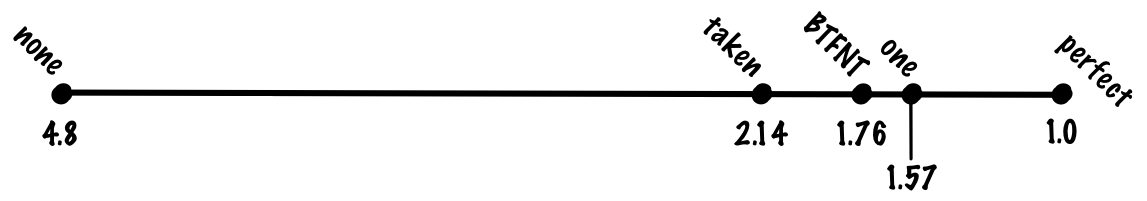This is an implementation of the circle algorithm.
voidplotCircle(int xm, int ym, int r)
{
int x = -r, y = 0, err = 2-2*r; /* II. Quadrant */ do {
setPixel(xm-x, ym+y); /* I. Quadrant */setPixel(xm-y, ym-x); /* II. Quadrant */setPixel(xm+x, ym-y); /* III. Quadrant */setPixel(xm+y, ym+x); /* IV. Quadrant */
r = err;
if (r <= y) err += ++y*2+1; /* e_xy+e_y < 0 */if (r > x || err > y) err += ++x*2+1; /* e_xy+e_x > 0 or no 2nd y-step */
} while (x < 0);
}
You may have heard of Project Quantum… it’s a major rewrite of Firefox’s internals to make Firefox fast. We’re swapping in parts from our experimental browser, Servo, and making massive improvements to other parts of the engine.
The project has been compared to replacing a jet engine while the jet is still in flight. We’re making the changes in place, component by component, so that you can see the effects in Firefox as soon as each component is ready.
And the first major component from Servo—a new CSS engine called Quantum CSS (previously known as Stylo)—is now available for testing in our Nightly version. You can make sure that it’s turned on for you by going to about:config and setting layout.css.servo.enabled to true.
This new engine brings together state-of-the-art innovations from four different browsers to create a new super CSS engine.
It takes advantage of modern hardware, parallelizing the work across all of the cores in your machine. This means it can run up to 2 or 4 or even 18 times faster.
On top of that, it combines existing state-of-the-art optimizations from other browsers. So even if it weren’t running in parallel, it would still be one fast CSS engine.
But what does the CSS engine do? First let’s look at the CSS engine and how it fits into the rest of the browser. Then we can look at how Quantum CSS makes it all faster.
What does the CSS engine do?
The CSS engine is part of the browser’s rendering engine. The rendering engine takes the website’s HTML and CSS files and turns them into pixels on the screen.
Each browser has a rendering engine. In Chrome, it’s called Blink. In Edge, it’s called EdgeHTML. In Safari, it’s called WebKit. And in Firefox, it’s called Gecko.
To get from files to pixels, all of these rendering engines basically do the same things:
Parse the files into objects the browser can understand, including the DOM. At this point, the DOM knows about the structure of the page. It knows about parent/child relationships between elements. It doesn’t know what those elements should look like, though.
Figure out what the elements should look like. For each DOM node, the CSS engine figures out which CSS rules apply. Then it figures out values for each CSS property for that DOM node.
Figure out dimensions for each node and where it goes on the screen. Boxes are created for each thing that will show up on the screen. The boxes don’t just represent DOM nodes… you will also have boxes for things inside the DOM nodes, like lines of text.
Paint the different boxes. This can happen on multiple layers. I think of this like old-time hand drawn animation, with onionskin layers of paper. That makes it possible to just change one layer without having to repaint things on other layers.
Take those different painted layers, apply any compositor-only properties like transforms, and turn them into one image. This is basically like taking a picture of the layers stacked together. This image will then be rendered on the screen.
This means when it starts calculating the styles, the CSS engine has two things:
a DOM tree
a list of style rules
It goes through each DOM node, one by one, and figures out the styles for that DOM node. As part of this, it gives the DOM node a value for each and every CSS property, even if the stylesheets don’t declare a value for that property.
I think of it kind of like somebody going through and filling out a form. They need to fill out one of these forms for each DOM node. And for each form field, they need to have an answer.
To do this, the CSS engine needs to do two things:
figure out which rules apply to the node — aka selector matching
fill in any missing values with values from the parent or a default value—aka the cascade
Selector matching
For this step, we’ll add any rule that matches the DOM node to a list. Because multiple rules can match, there may be multiple declarations for the same property.
Plus, the browser itself adds some default CSS (called user agent style sheets). How does the CSS engine know which value to pick?
This is where specificity rules come in. The CSS engine basically creates a spreadsheet. Then it sorts the declarations based on different columns.
The rule that has the highest specificity wins. So based on this spreadsheet, the CSS engine fills out the values that it can.
For the rest, we’ll use the cascade.
The cascade
The cascade makes CSS easier to write and maintain. Because of the cascade, you can set the color property on the body and know that text in p, and span, and li elements will all use that color (unless you have a more specific override).
To do this, the CSS engine looks at the blank boxes on its form. If the property inherits by default, then the CSS engine walks up the tree to see if one of the ancestors has a value. If none of the ancestors have a value, or if the property does not inherit, it will get a default value.
So now all of the styles have been computed for this DOM node.
A sidenote: style struct sharing
The form that I’ve been showing you is a little misrepresentative. CSS has hundreds of properties. If the CSS engine held on to a value for each property for each DOM node, it would soon run out of memory.
Instead, engines usually do something called style struct sharing. They store data that usually goes together (like font properties) in a different object called a style struct. Then, instead of having all of the properties in the same object, the computed styles object just has pointers. For each category, there’s a pointer to the style struct that has the right values for this DOM node.
This ends up saving both memory and time. Nodes that have similar properties (like siblings) can just point to the same structs for the properties they share. And because many properties are inherited, an ancestor can share a struct with any descendants that don’t specify their own overrides.
Now, how do we make that fast?
So that is what style computation looks like when you haven’t optimized it.
There’s a lot of work happening here. And it doesn’t just need to happen on the first page load. It happens over and over again as users interact with the page, hovering over elements or making changes to the DOM, triggering a restyle.
This means that CSS style computation is a great candidate for optimization… and browsers have been testing out different strategies to optimize it for the past 20 years. What Quantum CSS does is take the best of these strategies from different engines and combine them to create a superfast new engine.
So let’s look at the details of how these all work together.
Run it all in parallel
The Servo project (which Quantum CSS comes from) is an experimental browser that’s trying to parallelize all of the different parts of rendering a web page. What does that mean?
A computer is like a brain. There’s a part that does the thinking (the ALU). Near that, there’s some short term memory (the registers). These are grouped together on the CPU. Then there’s longer term memory, which is RAM.
Early computers could only think one thing at a time using this CPU. But over the last decade, CPUs have shifted to having multiple ALUs and registers, grouped together in cores. This means that the CPU can think multiple things at once — in parallel.
Quantum CSS makes use of this recent feature of computers by splitting up style computation for the different DOM nodes across the different cores.
This might seem like an easy thing to do… just split up the branches of the tree and do them on different cores. It’s actually much harder than that for a few reasons. One reason is that DOM trees are often uneven. That means that one core will have a lot more work to do than others.
To balance the work more evenly, Quantum CSS uses a technique called work stealing. When a DOM node is being processed, the code takes its direct children and splits them up into 1 or more “work units”. These work units get put into a queue.
When one core is done with the work in its queue, it can look in the other queues to find more work to do. This means we can evenly divide the work without taking time up front to walk the tree and figure out how to balance it ahead of time.
In most browsers, it would be hard to get this right. Parallelism is a known hard problem, and the CSS engine is very complex. It’s also sitting between the two other most complex parts of the rendering engine — the DOM and layout. So it would be easy to introduce a bug, and parallelism can result in bugs that are very hard to track down, called data races. I explain more about these kinds of bugs in another article.
If you’re accepting contributions from hundreds or thousands of engineers, how can you program in parallel without fear? That’s what we have Rust for.
With Rust, you can statically verify that you don’t have data races. This means you avoid tricky-to-debug bugs by just not letting them into your code in the first place. The compiler won’t let you do it. I’ll be writing more about this in a future article. In the meantime, you can watch this intro video about parallelism in Rust or this more in-depth talk about work stealing.
With this, CSS style computation becomes what’s called an embarrassingly parallel problem — there’s very little keeping you from running it efficiently in parallel. This means that we can get close to linear speed ups. If you have 4 cores on your machine, then it will run close to 4 times faster.
Speed up restyles with the Rule Tree
For each DOM node, the CSS engine needs to go through all of the rules to do selector matching. For most nodes, this matching likely won’t change very often. For example, if the user hovers over a parent, the rules that match it may change. We still need to recompute style for its descendants to handle property inheritance, but the rules that match those descendants probably won’t change.
It would be nice if we could just make a note of which rules match those descendants so we don’t have to do selector matching for them again… and that’s what the rule tree—borrowed from Firefox’s previous CSS engine— does.
The CSS engine will go through the process of figuring out the selectors that match, and then sorting them by specificity. From this, it creates a linked list of rules.
This list is going to be added to the tree.
The CSS engine tries to keep the number of branches in the tree to a minimum. To do this, it will try to reuse a branch wherever it can.
If most of the selectors in the list are the same as an existing branch, then it will follow the same path. But it might reach a point where the next rule in the list isn’t in this branch of the tree. Only at that point will it add a new branch.
The DOM node will get a pointer to the rule that was inserted last (in this example, the div#warning rule). This is the most specific one.
On restyle, the engine does a quick check to see whether the change to the parent could potentially change the rules that match children. If not, then for any descendants, the engine can just follow the pointer on the descendant node to get to that rule. From there, it can follow the tree back up to the root to get the full list of matching rules, from most specific to least specific. This means it can skip selector matching and sorting completely.
So this helps reduce the work needed during restyle. But it’s still a lot of work during initial styling. If you have 10,000 nodes, you still need to do selector matching 10,000 times. But there’s another way to speed that up.
Speed up initial render (and the cascade) with the style sharing cache
Think about a page with thousands of nodes. Many of those nodes will match the same rules. For example, think of a long Wikipedia page… the paragraphs in the main content area should all end up matching the exact same rules, and have the exact same computed styles.
If there’s no optimization, then the CSS engine has to match selectors and compute styles for each paragraph individually. But if there was a way to prove that the styles will be the same from paragraph to paragraph, then the engine could just do that work once and point each paragraph node to the same computed style.
That’s what the style sharing cache—inspired by Safari and Chrome—does. After it’s done processing a node, it puts the computed style into the cache. Then, before it starts computing styles on the next node, it runs a few checks to see whether it can use something from the cache.
Those checks are:
Do the 2 nodes have the same ids, classes, etc? If so, then they would match the same rules.
For anything that isn’t selector based—inline styles, for example—do the nodes have the same values? If so, then the rules from above either won’t be overridden, or will be overridden in the same way.
Do both parents point to the same computed style object? If so, then the inherited values will also be the same.
Those checks have been in earlier style sharing caches since the beginning. But there are a lot of other little cases where styles might not match. For example, if a CSS rule uses the :first-child selector, then two paragraphs might not match, even though the checks above suggest that they should.
In WebKit and Blink, the style sharing cache would give up in these cases and not use the cache. As more sites use these modern selectors, the optimization was becoming less and less useful, so the Blink team recently removed it. But it turns out there is a way for the style sharing cache to keep up with these changes.
In Quantum CSS, we gather up all of those weird selectors and check whether they apply to the DOM node. Then we store the answers as ones and zeros. If the two elements have the same ones and zeros, we know they definitely match.
If a DOM node can share styles that have already been computed, you can skip pretty much all of the work. Because pages often have many DOM nodes with the same styles, this style sharing cache can save on memory and also really speed things up.
Conclusion
This is the first big technology transfer of Servo tech to Firefox. Along the way, we’ve learned a lot about how to bring modern, high-performance code written in Rust into the core of Firefox.
We’re very excited to have this big chunk of Project Quantum ready for users to experience first-hand. We’d be happy to have you try it out, and let us know if you find any issues.
Lin is an engineer on the Mozilla Developer Relations team. She tinkers with JavaScript, WebAssembly, Rust, and Servo, and also draws code cartoons.
Are you tired of waiting for the next GOT book to come out? I know that I am, which is why I decided to train a RNN on the first five GOT books and use predictions from the network to create the sixth book in the series. The first five chapters of the generated sixth book are now available and are packed with as many twists and turns as the books we've all come to know and love. Here's the sparknotes summary:
Sansa is actualy a Baratheon and Jaime fears her because she is one of the second sons of the onion concubine...
“I feared Master Sansa, Ser,” Ser Jaime reminded her. “She Baratheon is one of the crossing. The second sons of your onion concubine.”
Reek is still annoying people...
“Some must, for you,” a woman’s voiced up lazily. “Gods, Reek.”
A new protagonist named Greenbeard is intorduced to the plot...
“Aye, Pate.” the tall man raised a sword and beckoned him back and pushed the big steel throne to where the girl came forward. Greenbeard was waiting toward the gates, big blind bearded pimple with his fallen body scraped his finger from a ring of white apple. It was half-buried mad on honey of a dried brain, of two rangers, a heavy frey.
Hodor comes back and can say something other than "Hodor!"
Hodor looked at them bellowing, “which road you should be home.”
Ned is still alive and Jon is a Lannister!
At once they were back there and they realize the way they wanted him to answer. When Jon Lannister staggered backward, Ned saw his axe and left hand in his head.
Varys poisons Daenerys and a dead man.
Varys poisoned Daenerys and another of the dead men. As he woke, it was a peaceful song, and now the low and the dawn was breaking up and there no smaller, robar the broken bones.
John rides a dragon and starts to get a little preverted...
Jon rode the dragons in a steep circle, buried fingers in the sand and there a burnt slope. “With a man should leave us clean, wench,” he said. “Stop him. Is that much? Until you’re at Winterfell simply get inside ’em o’ wildlings, or on the sound of a bastard dies.”
Lord Friendzone is off eating stew with chunks of butter...
Ser Jorah lingered to where the banners wending their descent down a long ways of rain. The marsh was ladling out beef-and-barley stew, cold as shy of three colors, chunks of butter.
Jaime kills Cersei and Jon becomes the wolf...
Jaime killed Cersei and was cold and full of words, and Jon thought he was the wolf now, and white harbor... Something about the day made the butt of her grow from the hem, half the white dogs running between two of Hizdahr’s arms.
They decide to let the dogs make decisions...
“Ask the dogs.”
It ends on a weird note during a winter storm with Jon's Targaryen side coming out in full color...
Once, she thought, it was wrong, climbing through the cloudless terrible light noise that was no last snow. Jon did not need to share a cup or part of it, but maybe this, a fat little blind girl.
There are still so many unanswered questions. Is Jon actually a Lannister-Targaryen? How will the dogs rule the seven kingdoms? Why did Varys poison Daenerys? Who are the seconds sons of the onion concubine?
If you would like to help sing the song of fire and ice, feel free to use this repository, put up pull requests, and offer advice on how to improve the model. I'm still fairly new to neural networks, so any help would be greatly appreciated.
We know IT admins face the challenge of managing a broad range of devices in today’s business landscape. And it’s critical to have the power to manage all devices using a single unified endpoint management solution. Which is why Chrome Enterprise now gives customers the ability to manage all their Chrome devices from a single management solution.
VMware Workspace ONE powered by VMware AirWatch will be the first third party solution provider to manage Chrome devices. Workspace ONE will provide a centralized approach to managing corporate-owned or bring-your-own device. This collaboration combines the speed, simplicity and security of Chrome with the cloud-based unified endpoint management of VMware AirWatch.
The compatibility of Chrome Enterprise with VMware Workspace ONE will enable organizations to deliver device policies using customizable assignment of groups based on geography, device platform, department, role, and more – simplifying policy enforcement across the company. Building on previously released integrations of Workspace ONE with Chrome OS, IT admins can also provide employees with access to all enterprise applications – cloud, web, native Android, virtual Windows – from a single app catalog to deliver a consistent experience to employees anywhere, anytime, on any device. Chrome device users can even access full Windows desktops and applications, helping to accelerate the adoption of Chrome devices in the enterprise.
“The consumerization of the enterprise has left IT managing multiple operating systems on a variety of devices—some provided by the business and others brought in by employees. As Chrome OS continues to gain momentum, our customers are eager to manage these devices consistently along with all other endpoints including mobile devices,” explains Sumit Dhawan, senior vice president and general manager, End-User Computing, VMware.“Using Workspace ONE, our customers will be able to securely manage the lifecycle of Chromebooks along with all their other end points giving them better security and a consistent user experience across all devices.”
Every morning, as soon as he wakes up,
Iñaki de la Parra,
an endurance athlete from Mexico, uses a heart-rate monitor he straps to his chest and an app on his smartphone to measure the tiny variations in the intervals between his heartbeats.
Like a growing number of athletes, Mr. de la Parra uses these measures of his heart-rate variability, or HRV, to help tailor his workout regimen—with high variability indicating his body is prepared for strenuous exercise and low HRV signaling that his body would benefit from a lighter workout or a break.
Since he started using HRV measurements to help guide his training a year and a half ago, Mr. de la Parra shaved five hours off his previous time in the Ultraman triathlon, winning the 2016 event by completing the 6.2-mile swim, 261-mile bike ride and 62-mile run in 22 hours, 34 minutes.
“HRV is a great tool that’s really helped my training,” he says.
Endurance athletes, however, aren’t the only ones finding benefits from HRV data. Thanks in part to the availability of accurate heart-rate data on wearable devices, it’s being used in training by soccer, basketball and football players, among others, from the elite to the weekend warrior. Psychologists are using it to train golfers and tennis players to control their heartbeats so they’re calmer under pressure. And some see managing heart-rate variability as a way for nonathletes to deal with stress.
By learning how to control their respiration with slow, rhythmical breaths, people can temporarily increase their heart-rate variability, which some medical experts say can help lower blood pressure and reduce stress and anxiety. This technique has also been used to treat everything from stage fright to irritable bowel syndrome.
While your heartbeat might seem steady at any given time—whether your heart is beating fast because of strenuous activity or slower because you’re at rest—there are actually tiny variations in the time between beats. That variability is due to the interplay of the two arms of the autonomic nervous system, the part of the nervous system that controls bodily functions, including the heartbeat, without a person’s conscious direction.
Those two arms are the parasympathetic and the sympathetic nervous systems, says
Lawrence Creswell,
a cardiac surgeon in Jackson, Miss., who studies sports cardiology. “The sympathetic arm has to do with getting adrenaline flowing, revving up the heartbeat,” Dr. Creswell says. “The parasympathetic autonomic system is the brakes and pulls down the heart rate.”
The balance between those two systems is in constant flux. After a hard workout, the parasympathetic system dominates as the body demands rest. This is associated with a decline in heart-rate variability. As the body gets the rest it needs, the sympathetic nervous system takes the upper hand, preparing the body for renewed activity. When that happens, heart-rate variability increases. Dr. Creswell says that in sports training, the idea is to have your heaviest workouts when your heart is most recovered—when your HRV is at its highest.
That number won’t be the same for everyone. The range of HRV numbers differs from person to person.
Alan Couzens,
a Boulder, Colo., coach who trains competitive athletes, says it takes about a month of monitoring your HRV to establish a baseline before you can use it to determine your recovery status.
Mr. Couzens uses HRV data that athletes send him to help set their training schedules. On days when an athlete’s HRV number is down, he orders up a light training day or, rarely, a day off—because low HRV is a sign that the body is still stressed, and pushing it too hard in that state might result in physical damage. “I think it’s a good measure of the health of the athlete,” Mr. Couzens says. “A drop in HRV often precedes injuries.”
Doctors and psychologists, meanwhile, have been studying HRV as an indicator of physical and mental health, and how altering it can benefit patients.
Richard Gevirtz,
a professor of health psychology at Alliant International University in San Diego, says training people to raise their HRV is being used successfully to treat stress-related disorders like anxiety, gastrointestinal problems such as irritable bowel syndrome, and work issues like fear of giving a speech.
Dr. Gevirtz has developed a program that uses slow, methodical breathing to increase HRV. He says studies show that each individual has a different breathing rate, usually between five and seven breaths a minute, at which they obtain maximum HRV, which has a calming effect. The research has shown that breathing at that rate can raise a person’s average HRV by 25% over time, he says.
An analysis of several peer-reviewed studies of heart-rate training using rhythmic breathing was published in March in the journal Psychological Medicine. It concluded that “HRV biofeedback training is associated with a large reduction in self-reported stress and anxiety.”
Harry van der Lei,
co-founder of the Hourglass Performance Institute in Atlanta, says training to control HRV with breathing can improve performance in golf, tennis and shooting—sports where performance anxiety can cause even seasoned pros to miss shots. “By increasing your HRV, you are increasing your stress-management capacity,” he says.
Mr. van der Lei’s company teaches golfers how to improve their HRV under conditions of pressure and stress such as tournaments. But he adds that while HRV training can enhance skills an athlete already has, it isn’t a substitute for those skills.
Measuring HRV is simple. Several smartphone apps provide detailed HRV measures and tracking using data from wearable heart-rate monitors. Another alternative is an earlobe clip called Inner Balance, which plugs into a smartphone and displays HRV data on-screen.
There are also several apps people can use to train themselves to regulate their breathing to raise their HRV and lower stress and anxiety. Practitioners recommend 20 minutes a day of breathing practice to obtain the full benefit.
Mr. Wallace is a writer in New York. He can be reached atreports@wsj.com.
Vice Chief of Naval Operations Adm. William “Bill” Moran who said that in total close to a dozen sailors aboard the USS Fitzgerald would face administrative punishment. (U.S. Navy photo by Gary Nichols/Released)
“You gotta challenge all assumptions. If you don’t, what is doctrine on day one becomes dogma forever after.” Colonel John Boyd, USAF
By Captain John Konrad (gCaptain) Last week the Secretary of the U.S. Navy released a 41 page inquiry report on the “Deaths of Seven Sailors Aboard The USS Fitzgerald” alongside comments from the Navy leadership which fail to discuss the cause of the tragedy and blames both vessels for exhibiting “poor seamanship” in the moments leading up to the collision. The inquiry continues with damage photos, diagrams, an emotionally heart wrenching narrative and overwhelming praise for the damage control efforts of (mostly) enlisted sailors among her crew.
The question is… why was this document released and to what benefit? The answer is that this document was written and released for one primary purpose: Public Relations.
Decades ago each major media outlet had dock reporters; journalists who wrote exclusively on maritime affairs and had an extensive list of high level maritime contacts as well as a working knowledge of ships. Today I only know of one journalist with this background, Carl Nolte of the San Francisco Chronicle. All the rest are generalists who are too easily confused by complicated facts and too susceptible to emotional triggers. As Ryan Holiday, author of “Trust Me, I’m Lying: Confessions of a Media Manipulator” says in this bestselling book… “today’s most effective public relations firms oversimplify facts and compensate by giving the public what it craves: an emotionally compelling story.”
The US Navy’s “Deaths of Seven Sailors Aboard The USS Fitzgerald” is just that, the vapid telling of a story about a few brave and honorable sailors fighting floods, destruction and death itself with a cursory acknowledgement of fault. It does nothing to prevent future collisions at sea and everything to send the message to the fleet that mistakes will not be tolerated and junior officers will be punished.
As a work of fiction it would be praised for pitting man against machine and for well painted characters – with strong wills and moral courage – placed in extraordinary circumstances to save the lives of shipmates and friends. But this is not a work of fiction or, at least, it is not supposed to be. It is supposed to be a preliminary investigation report filled with hard facts and harder questions that remain unanswered. This report contains very little of either.
I have no doubt that the ad hominem attacks directed at myself and gCaptain from US military personnel will continue. Like the report, they are devoid of meaning and attempt to engage the emotions. I will not apologize. No one should apologize for being right. Also unlikely is that I will ever apologize for saying this: the Navy has blamed the wrong people.
Last week, after releasing the report, Admiral Bill Moran, deputy chief of naval operations, told reporters the ship’s commanding officer, executive officer and master chief petty officer would be removed from the vessel because “we’ve lost trust and confidence in their ability to lead.” Moran said that, in total, close to a dozen sailors would face administrative punishment and left open the possibility for further action. But are the USS Fitzgerald’s officers and even some of the enlisted members at fault for not being able to avoid a relatively slow and highly unmaneuverable unarmed merchant ship? Are they at fault for the deaths of seven sailors? I do not believe they are.
It is maritime tradition which states the Captain is the primary party at fault for all failures aboard ship and for good reason. But maritime tradition does not extend blame down the ranks and not to non-commissioned officers like the USS Fitzgerald’s master chief petty officer who has been removed by Admiral Moran.
Those who are responsible for the events leading up to the collision, not just those involved in the collision, are those who steered the naval fleet towards these errors. The U.S. Navy has experienced four major failures in navigation this year alone. The men who are cumulatively responsible for these incidents are the same men who are responsible for other troublesome oversights, like the widespread and pervading ignorance of US Naval Officers as to how merchant ships operate at sea. These men have not been called to face “administrative punishment”. At the very least they include Adm. John Richardson, Adm. Bill Moran, Admiral Scott Swift and, the author of the Damage Control Inquiry, Rear Adm. Charles Williams.
With four collisions in under ten months, when is the Navy going to “lose confidence” in it’s own ability to decide who should be in command?
Those I interviewed for this article who defend the inquiry point to the fact that this document was not written to find the cause of the collision nor was it written to cast blame. It was written as the result of an investigation to evaluate the crew’s damage control activities.
This is a poor excuse. If this document has nothing to do with the collision itself then why release it alongside statements conceding “poor seamanship” and a loss of faith in leadership ability of the ship’s officers?
If the document is supposed to provide a focused look at “the crew’s damage control activities” then why is it so lacking in information about the challenges and failures the crew experienced after the incident?
Numerous problems of significant scope and size where barely mentioned in the report. Major problems, such as number 16: “The collision resulted in a loss of external communication and a loss of power in the forward portion of the ship”, are not explained at all. The most basic of commercial ships are required to have redundant emergency power systems. How then does half of the complex ship loose power completely? More importantly, why is this not explained? What lessons learned about this power loss could have been transmitted to the USS McCain? And how, in 2017, when any civilian can purchase a handheld Iridium satellite phone for less than the price of the latest iPhone and a portable EPIRB for much less, could the communications system of a US Naval warship be so damaged and the ship’s leadership so shaken, that it takes the ship a full thirty minutes to transmit a Mayday (via Cell Phone no less)?
Another important question that goes unanswered is… did the damage control efforts result in a reduced situational awareness after the collision? If not then why did it take two and a half hours to identify the name of the ship they collided with? What would have happened to damage control efforts if this had been a terrorist attack or enemy combatant?
Those facts are not even the most troubling. Both the civilian and military continue to fail to consider the design and construction of the ship itself. No experts from the vessel’s builder, Bath Iron Works, or the architect or the Admirals in charge of approving the Arleigh Burke-class destroyer design were mentioned. The report completely fails to mention the damage control done aboard the ACX Crystal because that ship suffered relatively minor damage. What design and construction tradeoffs were made that resulted in a the hull of a billion dollar warship having much less intrinsic strength than a Korean built containership that was delivered for a fraction of the cost?
Where is the independent analysis? Were damage control experts from the Japanese Navy consulted? What about the Japanese Coast Guard? Did salvage masters take a look? Where are the stability calculations? Where is the Coast Guard report? Perhaps these will all follow in the full report, but I doubt it. A comparable civilian report would contain testimony from dozens of the top experts in their field and nearly every organization associated with both vessels would be invited to participate. Because, one thing we have learned during the past few centuries is this: no organization can work alone, no ship owner – not Olympic Steamship, not Tote and certainly not the US Navy – can be 100% objective when investigating itself. Any attempt to do so is the result of ignorance or corruption or both.
Now before my inbox is flooded by another deluge of angry email I do want to say that the contents of the report are important. The damage control team absolutely deserves to be commended for their bravery, exceptional skill and unwavering dedication to their shipmates. Many well deserved medals will likely be given to USS Fitzgerald sailors. And that is exactly where the emotionally heart wrenching contents of this report belongs, inside public letters of commendation given to these sailors, not in an official preliminary incident report.
Official reports need hard information, important data and straight forward acknowledgment of the failures experienced by a heroic crew. This report contains very little… and no lessons learned which could have been of use to the crew of the USS McCain.
This incident, like all maritime incidents before it, was the result of an insidious compilation of events (e.g. AIS systems or steering gear malfunctions) coupled in time with human mistakes and failure. But the mistakes of the junior officers pale in comparison to the mistakes made by senior Naval leadership (e.g. ignoring the concerns of junior officers and American merchant mariners) and, unlike the chain of command above Master, many of those junior officers are young and have time left in their career to learn from those mistakes and share them after being reassigned to another place in the fleet.
That is, if they were given the chance. Given the current leadership’s lack of “confidence in their ability,” that chance appears to be highly unlikely.
Xcode 9 includes a brand new refactoring engine. It can transform code locally
within a single Swift source file, or globally, such as renaming a method or property
that occurs in multiple files and even different languages. The logic behind local refactorings is
implemented entirely in the compiler and SourceKit, and is now open source in
the swift repository. Therefore, any Swift enthusiast can
contribute refactoring actions to the language. This post discusses how
a simple refactoring can be implemented and surfaced in Xcode.
Kinds of Refactorings
A local refactoring occurs within the confines of a single file.
Examples of local refactoring include Extract Method and Extract Repeated Expression.Global refactorings, which change code cross multiple files
(such as Global Rename), currently require special coordination by Xcode and currently
cannot be implemented on their own within the Swift codebase. This post focuses on
local refactorings, which can be quite powerful in their own right.
A refactoring action is initiated by a user’s cursor selection in the editor.
According to how they are initialized, we categorize refactoring actions as cursor-based
or range-based. Cursor-based refactoring has a refactoring target sufficiently
specified by a cursor position in a Swift source file, such as rename refactoring.
In contrast, range-based refactoring needs a start and end position to specify
its target, such as Extract Method refactoring. To facilitate the implementation
of these two categories, the Swift repository provides pre-analyzed results calledSemaToken and RangeInfo to answer several common questions about a cursor
position or a range in a Swift source file.
For instance, SemaToken can tell us whether a location in the source file
points to the start of an expression and, if so, provide the corresponding compiler object of that
expression. Alternatively, if the cursor points to a name, SemaToken gives
us the declaration corresponding to that name. Similarly, RangeInfo encapsulates
information about a given source range, such as whether the range has multiple entry or exit points.
To implement a new refactoring for Swift, we don’t
need to start from the raw representation of a cursor or a range position;
instead, we can start with SemaToken and RangeInfo upon which a refactoring-specific
analysis can be derived.
Cursor-based Refactoring
Cursor-based refactoring is initiated by a cursor location in a Swift source file.
Refactoring actions implement methods that the refactoring engine uses to display the available actions
on the IDE and to perform the transformations.
Specifically, for displaying the available actions:
The user selects a location from the Xcode editor.
Xcode makes a request to sourcekitd to see what available refactoring actions exist for that location.
Each implemented refactoring action is queried with a SemaToken object to see if the action is applicable for that location.
The list of applicable actions is returned as response from sourcekitd and displayed to the user by Xcode.
When the user selects one of the available actions:
Xcode makes a request to sourcekitd to perform the selected action on the source location.
The specific refactoring action is queried with a SemaToken object, derived from the same location, to verify that the action is applicable.
The refactoring action is asked to perform the transformation with textual source edits.
The source edits are returned as response from sourcekitd and are applied by the Xcode editor.
To implement String Localization refactoring, we need to first declare this
refactoring in the RefactoringKinds.def file with an entry like:
CURSOR_REFACTORING specifies that this refactoring is initialized at a cursor
location and thus will use SemaToken in the implementation. The first field,LocalizeString, specifies the internal name of this refactoring in the Swift
codebase. In this example, the class corresponding to this refactoring is namedRefactoringActionLocalizeString. The string literal "Localize String" is the
display name for this refactoring to be presented to users in the UI. Finally,
“localize.string” is a stable key that identifies the refactoring action, which
the Swift toolchain uses in communication with the source editor.
This entry also allows
the C++ compiler to generate the class stub for the String Localization refactoring
and its callers. Therefore, we can focus on the implementation of the
required functions.
After specifying this entry, we need to implement two functions to
teach Xcode:
When it is appropriate to show the refactoring action.
What code change should be applied when a user invokes this refactoring action.
Both declarations are automatically generated from the
aforementioned entry. To fulfill (1), we need to implement the isApplicable function
of RefactoringActionLocalizeString in Refactoring.cpp, as below:
1boolRefactoringActionLocalizeString::2isApplicable(SemaTokenSemaTok){3if(SemaTok.Kind==SemaTokenKind::ExprStart){4if(auto*Literal=dyn_cast<StringLiteralExpr>(SemaTok.TrailingExpr){5return!Literal->hasInterpolation();// Not real API.6}7}8}
Taking a SemaToken object as input, it’s almost trivial to check
when to populate the available refactoring menu with
“localize string”. In this case, checking that the cursor points to the start of
an expression (Line 3), and the expression is a string literal (Line 4) without
interpolation (Line 5) is sufficient.
Next, we need to implement how the code under the cursor should be
changed if the refactoring action is applied. To do this, we
have to implement the performChange method of RefactoringActionLocalizeString.
In the implementation of performChange, we can access the same SemaToken object that isApplicable received.
1boolRefactoringActionLocalizeString::2performChange(){3EditConsumer.insert(SM,Cursor.TrailingExpr->getStartLoc(),"NSLocalizedString(");4EditConsumer.insertAfter(SM,Cursor.TrailingExpr->getEndLoc(),", comment: \"\")");5returnfalse;// Return true if code change aborted.6}
Still using String Localization as an example, the performChange function
is fairly straightforward to implement. In the function body, we
can use EditConsumer to issue textual edits around the expression pointed by
the cursor with the appropriate Foundation API calls, as Lines 3 and 4 illustrate.
Range-based Refactoring
As the above figure shows, range-based refactoring is initiated by selecting a
continuous range of code in a Swift source file. Taking the implementation of the Extract Expression
refactoring as an example, we first need to declare the following item inRefactoringKinds.def.
This entry declares that the Extract Expression refactoring is initiated by a range selection,
named internally as ExtractExpr, using "Extract Expression" as display name, and with
a stable key of “extract.expr” for service communication purposes.
To teach Xcode when this refactoring should be available, we
also need to implement isApplicable for this refactoring in Refactoring.cpp,
with the slight difference that the input is a RangeInfo instead of a SemaToken .
Though a little more complex than its counterpart in the aforementioned String
Localization refactoring, this implementation is self-explaining too. Lines 3
to 4 check the kind of the given range, which has to be a single expression
to proceed with the extraction. Lines 5 to 7 ensure the extracted expression has
a well-formed type. Further conditions that need to be checked are ommitted in
the example for now. Interested readers can refer to Refactoring.cpp for
more details. For the code change part, we can use the same RangeInfo instance
to emit textual edits:
1boolRefactoringActionExtractExprBase::performChange(){2llvm::SmallString<64>DeclBuffer;3llvm::raw_svector_ostreamOS(DeclBuffer);4OS<<tok::kw_let<<" ";5OS<<PreferredName;6OS<<TyBuffer.str()<<" = "<<RangeInfo.ContentRange.str()<<"\n";7Expr*E=RangeInfo.ContainedNodes[0].get<Expr*>();8EditConsumer.insert(SM,InsertLoc,DeclBuffer.str());9EditConsumer.insert(SM,10Lexer::getCharSourceRangeFromSourceRange(SM,E->getSourceRange()),11PreferredName)12returnfalse;// Return true if code change aborted.13}
Lines 2 to 6 construct the declaration of a local variable with the initialized
value of the expression under extraction, e.g. let extractedExpr = foo(). Line
8 inserts the declaration at the proper source location in the local context, and
Line 9 replaces the original occurrence of the expression with a reference to
the newly declared variable. As demonstrated by the code example, within the
function body of performChange, we can access not only the originalRangeInfo for the user’s selection, but also other important utilities such
as the edit consumer and source manager, making the implementation more convenient.
Diagnostics
A refactoring action may need to be aborted during automated code change for various reasons.
When this happens, a refactoring implementation can communicate via diagnostics the cause of such failures to the user.
Refactoring diagnostics employ the same mechanism as the compiler itself.
Taking rename refactoring as an example, we would like to issue
an error message if the given new name is an invalid Swift identifier. To do so,
we first need to declare the following entry for the diagnostics inDiagnosticsRefactoring.def.
ERROR(invalid_name,none,"'%0' is not a valid name",(StringRef))
After declaring it, we can use the diagnostic in either isApplicable orperformChange. For Local Rename refactoring, emitting the diagnostic inRefactoring.cpp would look something like:
1boolRefactoringActionLocalRename::performChange(){...2if(!DeclNameViewer(PreferredName).isValid()){3DiagEngine.diagnose(SourceLoc(),diag::invalid_name,PreferredName);4returntrue;// Return true if code change aborted.5}...6}
Testing
Corresponding to the two steps in implementing a new
refactoring action, we need to test that:
The contextually available refactorings are
populated properly.
The automated code change updates the user’s codebase correctly.
These two parts are both tested using the swift-refactor command line utility which
is built alongside the compiler.
Let’s again take String Localization as an example. The above code
snippet is a test for contextual refactoring actions.
Similar tests can be found in test/refactoring/RefactoringKind/.
Let’s take a look at the RUN line in more detail, starting with the use of the %refactor utility:
This line will dump the display names for all applicable refactorings when a user points the cursor to the string literal “Hello World!”.
%refactor is an alias that gets substituted by the test runner to give the full path to swift-refactor when the tests get run.-pos gives the cursor position where contextual refactoring actions should be pulled from. SinceString Localization refactoring is cursor-based, specifying -pos alone will be
sufficient. To test range-based refactorings, we need to specify-end-pos to indicate the end location of the refactoring target as well. All positions are
in the format of line:column.
To make sure the output of the tool is the expected one, we use the %FileCheck utility:
%FileCheck%s-check-prefix=CHECK-LOCALIZE-STRING
This will check the output text from %refactor
against all following lines with prefix CHECK-LOCALIZE-STRING. In this case, it will
check whether the available refactorings include Localize String. In addition to
testing that we show the right actions at the right cursor positions, we also need to
test available refactorings are not wrongly populated in situations like string literals
with interpolation.
Code Transformation Test
We should also test that when applying the refactoring, the automated code
change matches our expectations. As a preparation, we need to teach swift-refactor
a refactoring kind flag to specify the action we are testing with. To achieve this,
the following entry is added in swift-refactor.cpp:
With such an entry, swift-refactor can test the code transformation part of
String Localization specifically. A typical code transformation test consists of two parts:
The code snippet before refactoring.
The expected output after transformation.
The test performs the designated refactoring in (1) and compares the result
with (2). It passes if the two are identical, otherwise the test fails.
The above two code snippets comprise a meaningful code transformation test.
Line 4 prepares a temporary source directory
for the code resulting from the refactoring; using the newly added -localize-string,
Line 5 performs the refactoring code change at the start position of "Hello World!" and
dumps the result to the temporary directory; finally, Line 6 compares the result
with the expected output illustrated in the second code example.
Integrating with Xcode
After implementing all of above pieces in the Swift codebase, we
are ready to test/use the newly added refactoring in Xcode by integrating with
a locally-built open source toolchain.
Run build-toolchain
to build the open source toolchain locally.
Untar and copy the toolchain to /Library/Developer/Toolchains/.
Specify the local toolchain for Xcode’s use via Xcode->Toolchains, like the
following figure illustrates.
Potential Local Refactoring Ideas
This post just touches on some of the things that are now possible to implement in the new refactoring engine.
If you are excited about extending the refactoring engine to implement additional transformations,
Swift’s issue database contains several ideas of refactoring transformations awaiting implementations.
For further help with implementing refactoring transformations, please see the documentation or feel free to ask questions on the swift-dev mailing list.
It has been a century since Einstein published his mind- and space-bending theory of general relativity. When it passed its first real test during the total solar eclipse of 1919, where the bending of light from distant stars around our sun was exactly as general relativity predicted, Einstein became an international celebrity. General relativity replaced Newton’s model of gravity as a simple force with the revolutionary idea of curved spacetime that responds dynamically to mass and energy.
Since then, and especially in the last few decades, general relativity has elegantly explained the gravitational nature of our universe from the earliest times and at the largest scales in cosmology, to the compact and extremely warped regions of spacetime near black holes and neutron stars (as near as we have yet been able to measure), and even here throughout our solar system, where general relativity allows atomic clocks to keep perfect and synchronized time and thus for GPS devices to provide our locations to within a few meters. Time and again general relativity has been tested with ever improving precision using new and inventive astronomical observations, and each time Einstein’s theory has withstood the test. Yet surprisingly, there is a broad scientific consensus that general relativity is almost certainly not the final answer on gravity: that at some scale, under some circumstances, the theory of general relativity will break down.
The problem is the apparent conflict between general relativity and the other dominant and successful theory of physics, quantum mechanics. The quantum world, while perhaps even more counter-intuitive than relativity, has been tested to exquisite precision and both explains the nature of matter and predicts its behavior at the level of subatomic particles, atoms, and molecules; it underlies chemistry, the nature of materials, and all of the technologies that power our modern society. The pervasive nature of quantum mechanics in all aspects of modern physics except gravity strongly suggests that gravity should be part of the same fold—that matter on a planetary or galactic scale should not behave differently than matter on an atomic scale.
Image courtesy of NRAO/AUI and Harry Morton (NRAO)
One good example of the apparent gap between general relativity and quantum mechanics comes from modern cosmology. Increasingly detailed satellite measurements of the cosmic microwave background—the relic radiation left over from the Big Bang—combined with ground- and space-based observations of supernovae and the large-scale structures in the universe have led to a consensus model based firmly on general relativity that beautifully explains the observations. Yet the model suggests that over 95 percent of the “stuff” in our universe is currently a complete mystery to us, the famous dark matter and dark energy. Is general relativity showing us the way to new physics via that 95 percent? Or is it pointing us to flaws in general relativity?
Another aspect of the dilemma is the expectation that general relativity’s spacetime, since it responds to mass and energy that are quantized, should also display quantum characteristics. But the curved, smoothly varying spacetime of general relativity has resisted decades of attempts at quantization. Even so there are hints, such as Stephan Hawking’s still-untested prediction of quantum-mechanically generated radiation from black holes. So scientists continue to push on the theory, looking at extremes of scale or curvature where it might begin to break down. To take the next big step in fundamental physics, in effect, scientists now need to find the limitations of Einstein’s theory. The opportunity to do that, and to re-invent or refine the theory of gravity, now seems increasingly immanent.
Direct observation of the event horizon holds the answers to some of the most fundamental questions we can ask.
The opportunity stems primarily from several next-generation efforts to detect and measure gravitational waves or to directly image the effects of strongly curved spacetime. Gravitational waves are the only remaining prediction of general relativity that has not been observed, and if their characteristics differ from what general relativity predicts—or if they don’t exist—then the door to new physics is wide open. An early test will come from ground-based laser interferometers, such as LIGO (Laser Interferometer Gravitational-Wave Observatory), which seeks to detect gravitational waves with millisecond periods coming from pairs of black holes or neutron stars as they orbit closer and closer to each other before coalescence. According to general relativity, pairs of moving masses will emit gravitational waves in spacetime much like moving boats cause ripples in the surface of a pond. The waves carry energy and momentum away from the systems, causing the orbits to shrink, a prediction of general relativity that has been confirmed by timing pulses from pulsars in compact binary systems. While the direct detection of gravitational waves would be another confirmation of Einstein’s theory, the detailed shapes of the waveforms could potentially point to problems with general relativity.
Beyond LIGO there are a series of planned attempts to test general relativity more directly, some quite expensive and lengthy big science projects, others much less expensive and potentially capable of more rapid results. These include:
A major international project to build a space-based gravitational wave interferometer called LISA, which would provide very precise gravity wave measurements from massive black hole systems; the United States has recently withdrawn from this project, but a scaled-down version, called eLISA, is being planned in Europe for development in the 2020s and launch in the mid-2030s. It would detect waves with hour-long periods from thousands of emitting systems.
A very different ground-based mega-science project, the Square Kilometer Array, has tests of general relativity as one of its major scientific objectives. This continent-sized network of radio telescopes will be able to track pulsars—rotating neutron stars—in binary systems very precisely and also to detect very long wavelength gravitational waves from pairs of super-massive black holes orbiting each other in the centers of other galaxies. Phase one of the SKA is expected to be operational only in 2024 and the full array not before 2030. The U.S. is not currently involved in the SKA.
The Event Horizon Telescope (EHT) uses a network of atomic clocks to precisely synchronize existing radio telescopes around the planet, turning them into an Earth-sized virtual telescope. With the greatest magnifying power ever achieved in astronomy, the EHT is on track to make the first image of a black hole, and thereby test general relativity theory within the most extreme environment in the cosmos. The U.S. leads this international effort to “see the un-seeable,” which could alter our ideas of gravity and quantum mechanics, and prove, once and for all, that black holes exist.
A similar effort called NANOGrav is attempting to directly detect very low-frequency gravitational waves by precisely timing pulsars and looking for deviations in these otherwise extremely regular radio beacons. It has the potential to detect these waves at modest cost and within a few years. The effort, part of a larger international collaboration, uses the existing Green Bank and Arecibo radio telescopes currently funded by the National Science Foundation, but will need additional support.
Einstein’s theory of general relativity is most deservedly a central pillar in the framework of modern physics. Yet the lack of a quantum version of general relativity suggests to many scientists that experiments in the future will find its limitations. While proving Einstein “wrong” would be a sad moment, creating a new, quantum-friendly theory of gravity would also mark a monumental achievement for the progress of fundamental physics.
Image courtesy of Sheperd Doeleman
Measuring the Shadow of a Massive Black Hole
A long-standing goal in astronomy, math, and physics is to image and time-resolve the boundary of a black hole—the event horizon—where intense gravity prevents even light from escaping. If it were possible to zoom in to the event horizon, general relativity predicts that we would see a "shadow" against a backdrop of glowing super-hot gas as the black hole absorbs and bends the light surrounding it. Direct observation of this unique signature holds the answers to some of the most fundamental questions we can ask: Do black holes exist? Does general relativity hold in the strongest gravity environment? How do supermassive black holes affect the evolution of entire galaxies?
The Event Horizon Telescope (EHT) project is aimed at realizing this goal through the technique of Very Long Baseline Interferometry (VLBI): combining simultaneous observations across a global network of radio dishes to forge an Earth-sized telescope. By leveraging advanced electronics to build a new generation of VLBI instrumentation, the project will achieve a magnifying power 2,000 times finer than the Hubble Space Telescope. A prime target is Sagittarius A*, the supermassive black hole in the center of the Milky Way that has a mass of about 4 million suns, and which has the largest apparent event horizon in the sky. Observations with a prototype EHT have confirmed the size of SgrA* to be very close to the predicted value by general relativity, and this proof of concept has brought the project to a tipping point: Over the next few years, the prospects for imaging this black hole and tracking the dynamics of in-falling matter are excellent.
The main EHT challenge is in forming the electronic "lens" that combines data captured at all the geographic sites, in much the same way a mirror focuses optical light in a conventional telescope. Currently, these data streams are combined in a modest purpose-built computer cluster. But data rates at each site are to exceed 8 GBytes/second within two years, so a next-generation system that can handle this torrent of data is needed. An investment of $7 million would ensure completion of this EHT lens, including refinement of algorithms to efficiently form images. With funding already in hand from the NSF and international partners to support work at the individual telescopes, an investment on this scale would have considerable leverage, and would ensure continued U.S. leadership of the project.
Scott Ransom is an astronomer at the National Radio Astronomy Observatory and a professor at the University of Virginia.
In the 1950s, Philip Anderson, a physicist at Bell Laboratories, discovered a strange phenomenon. In some situations where it seems as though waves should advance freely, they just stop — like a tsunami halting in the middle of the ocean.
Anderson won the 1977 Nobel Prize in physics for his discovery of what is now called Anderson localization, a term that refers to waves that stay in some “local” region rather than propagating the way you’d expect. He studied the phenomenon in the context of electrons moving through impure materials (electrons behave as both particles and waves), but under certain circumstances it can happen with other types of waves as well.
Even after Anderson’s discovery, much about localization remained mysterious. Although researchers were able to prove that localization does indeed occur, they had a very limited ability to predict when and where it might happen. It was as if you were standing on one side of a room, expecting a sound wave to reach your ear, but it never did. Even if, after Anderson, you knew that the reason it didn’t was that it had localized somewhere on its way, you’d still like to figure out exactly where it had gone. And for decades, that’s what mathematicians and physicists struggled to explain.
This is where Svitlana Mayboroda comes in. Mayboroda, 36, is a mathematician at the University of Minnesota. Five years ago, she began to untangle the long-standing puzzle of localization. She came up with a mathematical formula called the “landscape function” that predicts exactly where waves will localize and what form they’ll take when they do.
“You want to know how to find these areas of localization,” Mayboroda said. “The naive approach is difficult. The landscape function magically gives a way of doing it.”
Her work began in the realm of pure mathematics, but unlike most mathematical advances, which might find a practical use after decades, if ever, her work is already being applied by physicists. In particular, LED lights — or light-emitting diodes — depend on the phenomenon of localization. They light up when electrons in a semiconducting material, having started out in a position of higher energy, get trapped (or “localize”) in a position of lower energy and emit the difference as a photon of light. LEDs are still a work in progress: Engineers need to build LEDs that more efficiently convert electrons into light, if the devices are to become the future of artificial lighting, as many expect they will. If physicists can gain a better understanding of the mathematics of localization, engineers can build better LEDs — and with the help of Mayboroda’s mathematics, that effort is already under way.
Rogue Waves
Localization is not an intuitive concept. Imagine you stood on one side of a room and watched someone ring a bell, only the sound never reached your ears. Now imagine that the reason it didn’t is that the sound had fallen into an architectural trap, like the sound of the sea bottled in a shell.
Of course, in an ordinary room that never happens: Sound waves propagate freely until they hit your eardrums, or get absorbed into the walls, or dissipate in collisions with molecules in the air. But Anderson realized that when waves move through highly complex or disordered spaces, like a room with very irregular walls, the waves can trap themselves in place.
Anderson studied localization in electrons moving through a material. He realized that if the material is well-ordered, like a crystal, with its atoms evenly distributed, the electrons move freely as waves. But if the material’s atomic structure is more random — with some atoms here, and a whole bunch over there, as is the case in many industrially manufactured alloys — then the electron waves scatter and reflect in highly complicated ways that can lead the waves to disappear altogether.
“Disorder is inevitable in the way these materials are created, there’s no way to escape it,” said Marcel Filoche, a physicist at the École Polytechnique outside Paris and a close collaborator of Mayboroda’s. “The only thing to hope is that you can play with it, control it.”
Physicists have long understood that localization is related to wave interference. If the peaks of one wave align with the troughs of another, you get destructive interference, and the two waves will cancel each other out.
Localization takes place when waves cancel each other out everywhere except in a few isolated places. For such nearly complete cancellation to occur, you need the waves to be moving in a complicated space that breaks the waves into a huge variety of sizes. These waves then interfere with each other in a bewildering number of ways. And, just as you can combine every color to get black, when you combine such a complicated mix of sound waves you get silence.
The principle is simple. The calculations are not. Understanding localization has always required simulating the infinite variety of wave sizes and exploring every possible way those waves could interfere with each other. It’s an overwhelming calculation that can take researchers months to carry out in the kinds of three-dimensional materials physicists actually want to understand. With some materials, it’s altogether impossible.
Unless you have the landscape function.
The Lay of the Landscape
In 2009 Mayboroda went to France and presented research she’d been doing on the mathematics of thin plates. She explained that when the plates have a complicated shape, and you apply some pressure from one side, the plates may flex in very irregular ways — bulging out in unexpected places, while remaining almost flat in others.
Filoche was in the audience. He had spent more than a decade studying the localization of vibrations, and his research had led to the construction of a prototype noise-abating barrier called “Fractal Wall” for use along highways. After Mayboroda’s talk, the two started speculating whether the irregular bulging patterns in Mayboroda’s plates might be related to the way Filoche’s vibrations localized in some places and disappeared in others.
Over the next three years they found that the two phenomena were indeed related. In a 2012 paper, Filoche and Mayboroda introduced a way to mathematically perceive the terrain the way a wave would see it. The resulting “landscape” function interprets information about the geometry and material a wave is moving through and uses it to draw the boundaries of localization. Previous efforts to pinpoint localized waves had failed due to the complexity of considering all possible waves, but Mayboroda and Filoche found a way to reduce the problem to a single mathematical expression.
To see how the landscape function works, think about a thin plate with a complex outer boundary. Imagine striking it with a rod. It might remain silent in some places and ring in others. How do you know what’s going to happen and where?
The landscape function considers how the plate flexes under uniform pressure. The places it bulges when placed under pressure aren’t visible, but the vibrations perceive those bulges and so does the landscape function: The bulges are where the plate will ring, and the lines around the bulges are precisely the lines of localization drawn by the function.
“Imagine a plate, subject it to air pressure on one side, push it, then measure the nonuniformity of how much points are bulging out. That’s the landscape function, that’s it,” said David Jerison, a mathematician at the Massachusetts Institute of Technology and a collaborator on the landscape function work.
Following their 2012 paper, Mayboroda and Filoche looked for ways to extend the landscape function from mechanical vibrations to the quantum world of electron waves.
Electrons are unique among wavelike phenomena. Instead of picturing a wave, think of them as having more or less energy depending on where they’re located in the atomic structure of a material. For a given material there’s a map, called the potential (as in “potential energy”), that tells you the energy. The potential is relatively easy to draw for materials like conductors that have an orderly atomic structure, but it’s very difficult to calculate in materials with highly irregular atomic structures. These disordered materials are precisely the ones in which electron waves will undergo localization.
“The randomness of the material makes prediction of the potential map very difficult,” Filoche explained in an email. “Moreover, this potential map also depends on the location of the moving electrons, while the motion of the electrons depends in turn on the potential.”
Another challenge in drawing the potential for a disordered material is that when waves localize in a region, they’re not actually confined completely to that area, and they gradually vanish as they get farther away from the localization region. In mechanical systems, such as a vibrating plate, these distant traces of a wave can be safely ignored. But in quantum systems filled with hypersensitive electrons, those traces matter.
“If you have an electron here and another there and they’re localized in different places, the only way they’ll interact will be by their exponentially decaying tails. For interacting quantum systems, you absolutely need [to be able to describe] this,” Filoche said.
At the beginning of the year, Medium announced a big change: 50 staffers were being laid off as the company shifted away from what founder Ev Williams called the "broken system (of) ad-driven media."
At the time, it wasn't clear how the company planned to solve the broken economics of internet publishing. Today, that vision is a little clearer.
This afternoon, Medium announced a new way for creators on Medium to receive money from people who appreciate their work. In a blog post, Medium Head of Product Michael Sippey announced that the company is beginning to give a small group of creators the ability to publish their stories to a members-only section and receive payment based on engagement. Here's how it works, according to Sippey:
For the creators in the program, each month you will be paid based on the level of engagement your stories get from Medium members. Essentially, we look at the engagement of each individual member (claps being the primary signal) and allocate their monthly subscription fee based on that engagement. This is one of the reasons we love Claps — it helps us measure the depth of appreciation that a member has for each individual post. (For our members, we’re excited to give you more meaningful control over the stories you support. The more claps you give a locked post, the more share of your membership fee that author will get.)
The new strategy calls to mind two big questions: How much will creators get paid? And does Medium have enough members to support a community of creators? Through a spokesperson, the company declined to provide specifics on either. But Sippey, who joined Medium in July after the company acquired his "texting-in-public messaging app," acknowledged that "there is a lot we need to figure out to make this work right."
These are just the early days of what we consider a grand experiment. Imagine a day when anyone with the skills and willingness to put in the effort can write something useful, insightful, or moving and be compensated based on its value to others. There is a lot we need to figure out to make this work right. But we are convinced that by joining forces, we can make a new economic model for quality content. We hope you’ll join us in this experiment.
The most important unit of engagement that Medium will use to determine how much publishers get paid through this program are called "claps." Introduced by Medium earlier this month, claps are a clicky way for users to show appreciation for content that they like. Readers can give unlimited claps, but the claps are measured relative to the number of claps that a user typically gives, according to Medium.
The philosophy behind claps (explained at length here) gives a behind-the-scenes look at how Medium is rethinking the business that underpins publishing on the internet. Rather than a simple "like," Medium wanted to give readers a way to express the true depth of their satisfaction for a piece of content. By doing this, Medium hoped to come up with a better representation of actual value than pageviews and unique visitors, which still control the business of internet publishing:
Since day one, Medium has had a goal of measuring value. The problem, as we saw it, with much of the media/web ecosystem is that the things that are measured and optimized for were not necessarily the things that reflected true value to people. For example, a pageview is a pageview, whether it’s a 3-second bounce (clickbait) or a 5-minute, informative story you read to the end. As a result, we got a lot more of the former.
To make its new pay-by-engagement initiative work, Medium needs to get enough people to shell out the $5/per month membership fee. To do that, Medium also announced this afternoon a tweak to its subscription paywall, which was announced in March. The paywall will now be metered, mirroring similar paywalls at The New York Times and The Washington Post, allowing non-members a limited amount of locked stories each month.
Also new today is a rebranding of Medium. The old Medium logo, the three-shaded "M," has been replaced by a more straightforward "wordmark" consisting of the company's name. That change will be accompanied by a new, expanded, color palette that's being rolled out across the company's portfolio of products. A branding statement from Medium shared with Poynter says the new wordmark and branding system "reflects the unique and dynamic nature of the ideas you can find on Medium without compromising the voices and stories shared."
In this document I'll explore an optimal stopping problem that occurs in popular dungeons and dragons games. It features probability theory and the python itertools package.
Screenshot
This is a screenshot of a video game I used to play when I was 12. This is the character screen and you can see the attributes of the hero. Depending on the class of the hero you typically value certain attributes over others. This screenshot shows a lot of value in strength and constitution so it is probably a brawler of some sort instead of a wizard who prefers intelligence.
When you create a character in this video game, which is based off of dungeons and dragons, you need to roll dice which determine how many points in total you can allocate to your character. There is no penalty for rerolling besides the time that you've wasted rerolling. I couldn't be too bother back when I was twelve but there are people who celebrate a high roll with videos on youtube and there are forums with plenty of discussions.
Stochastics
There's something stochastic which is interesting about this dice rolling problem. You want to have a high score but you don't want to end up rerolling a lot. So what is a good strategy?
This got me googling, again, for a fan website which had the rules for character generation. It seems that the system that generates scores is defined via three rules.
1. Roll 4 six sided dice, remove the lowest die. Do this 6 times (for each stat).
2. If none of the stats are higher than a 13, start over at step 1.
3. If the total modifiers are 0 or less, start over at step 1
(I belive this translates to the score needing to be greater than 60 ).
Let's turn this system into a game. You are allowed to reroll, but everytime you do the score you get will get subtracted by one. What would be the optimal stopping strategy?
We need to infer some probabilities first and there's two methods of getting them.
Approach 1: Simulation
It feels like we may need to consider $(6^4)^6$ different combinations that are possible so we could avoid enumeration via simulation. The following code will give us approximate probabilities that should work reasonably well.
Give it some thought and you may actually be able to iterate through all this. It won't be effortless but you could go there.
You may wonder how though. After all we need to roll 4 normal dice for every attribute and we need to do this for each of the six attributes. This sounds like you need to evaluated $(6^4)^6$ possible dice outcomes. Sure you may be able to filter some of the results away, but it is still a scary upper limit. Right?
To show why this is pessimistic, let's first consider all the dice combinations for a single attribute. We could enumerate them via;
This roll_counter object now contains all the possible rolls and counts them. In total it has the expected $6^4=1296$ different tuples. We don't want to consider all these possible rolls though. We will throw away the lowest scoring roll. Let's accomodate for that.
roll_counter = Counter((tuple(sorted(_)[1:]) for _ in it.product(d,d,d,d)))
This small change causes our roll_counter object to only have 56 keys. The upper limit of what we need to evaluate then is $56^6 = 30.840.979.456$. That's a lot better. We can reduce our key even further though.
roll_counter = Counter((sum(sorted(_)[1:]) for _ in it.product(d,d,d,d)))
This object only has 16 keys. Why can we do this? It's because we are not interested in individual dice rolls but we're interested in the scores that are rolled per attribute. By counting the scores we still keep track of the likelihood of each score without having to remember all of the dice rolls. This brings us to $16^6=16.777.216$ we may need to evaluate which is a number we can deal with on a single machine. We will even filter some of the rolls away because we need to reroll when the total scores are less than 60.
How many total objects do we need to consider?
k = roll_counter.items()
def roll_gt(tups, n):
min([_[0] for _ in tups]) > 13
return sum([_[0] for _ in tups]) > 60
sum(1 for comb in it.product(k,k,k,k,k,k) if roll_gt(comb, 60))
Turns out we only need to iterate over 9.822.736 items because many of the rolls are infeasible.
This should be doable, but let's be careful that we apply maths correctly.
def map_vals(tups):
rolled_value = sum([_[0] for _ in tups])
how_often = reduce(lambda x,y:x*y, [_[1] for _ in tups])
return Counter({rolled_value: how_often})
At this stage it is not a bad idea to check if I've not made a mathematical error. Let's compare the two plots.
Nothing jumps out as extraordinary so I think I'm good. I'll use the enumerated probabilities for all steps to come.
Toward Decision Theory
We need to calculate the probability that you'll get a higher score if you roll again.
The goal is not to get a higher score in this one next roll, but a higher score in any roll that comes after. Intuitively this probability is defined via;
$$
\begin{split}
\mathbb{P}(\text{higher than } s_0 \text{at roll } r) = & \mathbb{P}(s_1 > s_0 + r + 1) + \\& \mathbb{P}(s_2 > s_0 + r + 2)\mathbb{P}(s_1 \leq s_0 + r + 1) + \\& \mathbb{P}(s_3 > s_0 + r + 3)\mathbb{P}(s_2 \leq s_1 + r + 1)\mathbb{P}(s_1 \leq s_0 + r + 1) + \\& \mathbb{P}(s_4 > s_0 + r + 4)\mathbb{P}(s_3 \leq s_2 + r + 1)\mathbb{P}(s_2 \leq s_1 + r + 1)\mathbb{P}(s_1 \leq s_0 + r + 1) + \\& ...
\end{split}
$$
We need to abstract this away into some python code. But it is not too hard. I'll use numba.jit to make some parts a bit quicker though.
importnumbaasnbdefp_higher_next(val,probs):returnsum([vfork,vinprobs.items()ifk>=val])defprob_higher(score,n_rolls,probs):ifscore<=60:raiseValueError("score must be > 60")p=0forrollinrange(n_rolls+1,max(probs.keys())+1):higher_p=p_higher_next(score+roll,probs)fails_p=reduce(lambdaa,b:a*b,[1]+[1-p_higher_next(score+_,probs)for_inrange(roll-n_rolls-1)])p+=higher_p*fails_preturnp@nb.jitdefdecisions_matrix(probs,choice=lambdax:x):matrix=[]forscoreinreversed(list(probs.keys())):row=[]forrollinrange(1,25):output=prob_higher(score,roll,probs)output=choice(output)row.append(output)matrix.append(row)returnmatrixdefplot_decisions(probs,choice=lambdax:x,title=""):mat=decisions_matrix(probs,choice)plt.imshow(mat,interpolation='none',extent=[1,len(mat_p[0]),min(probs.keys()),max(probs.keys())])plt.title(title)_=plt.colorbar();
All this code will generate the probabilities we want and we can visualise the results.
The first plot demonstrates the probability of getting a higher score given a current score and the number of rolls you currently have.
The second plot rounds these probabilities, giving us a decision boundary.
The third plot rounds these probabilities but assumes we are less risk averse. We add 0.1 mass to each probability.
The third plot does the same but even more risk seeking. We add 0.3 mass to each probability.
You may notice that it seems like adding more probability mass doesn't change the behavior much. This is partly due to the visual bias in the y-axis (the odds of ever getting a score >90 are slim indeed). Another reason is that the switchpoint of the decision making region is very steep. So you'd need to really bias the risk if you want to see a change in decision making. These plots might shed some light on that phenomenon.
At this point, I was content with my work but then I had a discussion with a student who suggested a much simpler tactic.
Making the model too simple
The student suggest that the solution could be much simpler. Namely we merely needed to optimise;
$$ \text{argmax } v(a| s, t)=
\begin{cases}
s - t,& \text{if } a\\
\mathbb{E}(s) - t - 1 & \text{if not } a
\end{cases}
$$
Where $s$ is the current score, $t$ is the number of turns we've currently rerolled and $a$ denotes the action of stopping.
This suggests optimising a linear system based on expected value. To demonstrate that this is wrong, let's first calculate the expected value.
> sum([k*v for k,v in probs_iter.items()])
74.03527564970476
Let's now compare how this decision rule compares to our previous decision rule. The linear tactic is shown with a red line.
The naive model seems to fail to recognize that early on, re-rolling is usually a good tactic. The linear model only compares to getting a higher probability in the next reroll, not all rerolls that will happen in the future. If the student would have picked to optimise the following, it would have been fine;
$$ \text{argmax } v(a| s, t)=
\begin{cases}
s - t,& \text{if } a\\
\mathbb{E}(s, t) - 1 & \text{if not } a
\end{cases}
$$
It can be easy to make mistakes while optimising the correct model, but the easiest mistake is to pick the wrong model to start with.
I like this result and I hope it serves as a fun example on decision theory. I've made some assumptions on the D&D rules though because I didn't feel like reading all of the rules involved with rolling. It is safe to assume that my model is flawed by definition.
This "icewind dale problem" is very similar to the "secretary problem" or the "dating problem". All these problem focus on finding the right moment to stop and reap the benefits. The problems differ on a few things which can make the problem harder:
in our problem we are always able to reroll, you could imagine a situation where there is a chance of being able to reroll
we knew the stochastic process that generates scores beforehand, you could imagine that if we do not know how the attribute scores are generated that the problem becomes a whole lot harder too
Then looking back at how I solved this problem I'd like to mention a few observations too.
This is a rare case where you are able to enumerate the probabilities instead of simulating them. I find that you should celebrate these moments by doing the actual work to get the actual probabilities out. It requires more mental capacity though, initially working with simulations may also just be fine if you're just exploring.
I took the proper math path and I showed that the $\text{argmax } \mathbb{E}(s)$ expected value heuristic is flawed, albeit not too far off. If you only want to spend 5 minutes on the problem I guess simulation simulation and the expected value heuristic heuristic should get you 80% of the way for 5% of the time though.
You don't always need numeric libraries like numpy. What makes python great for these sorts of things is that I did not need to make custom objects because I was able to make use of the great little libraries in the standardlib. Tools like functools.reduce, collections.Counter and itertools really make solving these problems fun.
From here there are many other cool things you could calculate though. Given that you want at least a score of 88, how long do you expect to be rolling? If you feel like continueing my work, feel free to grab the notebook I used here.
Desks that can be adjusted to rise and fall as workers get up and sit down again are the fastest growing office perk in the U.S., offered, according to one poll, by 44 percent of companies, a tripling since 2013. They are already common in Scandinavia, and about 16 percent of German workers have them. Soon enough, some of these desks will be fitted with sensors that monitor sitting time and vibrate softly to nudge users who have been on their behinds too long. One aficionado — James Levine, the doctor who coined the admonition “sitting is the new smoking” — pushed the trend further by inventing the treadmill desk, which like the standing desk has been embraced by some users and abandoned by others.
The many people now toiling on their feet may not realize it, but they’re standing in the footsteps of their 19th-century office-worker forebears, who used high desks constantly, with no option to sit. In modern times, Winston Churchill, Ernest Hemingway and Donald Rumsfeld all worked on their feet, but the trend toward sitting picked up steam in the 20th-century, as fewer and fewer people made their living by physical labor. Public health experts have been sounding alarms practically ever since. A study comparing drivers with conductors working for the London Transport Executive, conducted from 1949 to 1952, found that the more active conductors had a much lower risk of heart disease. That just stands to reason: When a body sits for an extended time, blood pools in the legs, and the arteries there lose some of their ability to dilate. Metabolism slows, and with it the healthy functioning of various biochemical operations. That in turn leaves the body more vulnerable to the physical and psychological effects of sedentary living. Standing desks are meant to help office workers dodge this fate, but avoiding so much sitting isn’t the same thing as moving around.
The Argument
Cut sitting time to less than three hours a day, one group of researchers found, and you could lengthen your life expectancy by two years. Some researchers have found connections between sitting too long and disease even in runners and other active people. But contradictory research — also well conducted — has found that sitting is bad only for total couch potatoes, that vigorous exercise, even if it’s only for a couple of hours on the weekend, actually can eliminate the risk of death associated with sitting. Researchers also disagree on whether standing desks do anything to help workers burn more calories, or boost their productivity. Some point out that standing too long creates problems of its own: swollen ankles, leg cramps, varicose veins, posture problems, lasting muscle fatigue and back pain. Also, it turns out that some people who use standing desks at work compensate for their efforts by exercising less in their free time. The best way for desk jockeys to avoid the sitting trap, research shows, is to not just stand but walk around — for a couple of minutes once an hour, or for five or 10 minutes a few times a day. This gets the blood and breath flowing moderately. Toe tapping and other kinds of fidgeting help, as well, whether sitting or standing.
A history of branch prediction from 1500000 BC to 1995A history of branch prediction from 1500000 BC to 1995
This is a pseudo-transcript for a talk on branch prediction given at localhost, a new talk series organized by RC. This talk was given at Two Sigma Ventures on 8/22/2017.
How many of you use branches in your code? Could you please raise your hand if you use if statements or pattern matching?
Most of the audience raises their hands
I won’t ask you to raise your hands for this next part, but my guess is that if I asked, how many of you feel like you have a good understanding of what your CPU does when it executes a branch and what the performance implications are, and how many of you feel like you could understand a modern paper on branch prediction, fewer people would raise their hands.
The purpose of this talk is to explain how and why CPUs do “branch prediction” and then explain enough about classic branch prediction algorithms that you could read a modern paper on branch prediction and basically know what’s going on.
Before we talk about branch prediction, let’s talk about why CPUs do branch prediction. To do that, we’ll need to know a bit about how CPUs work.
For the purposes of this talk, you can think of your computer as a CPU plus some memory. The instructions live in memory and the CPU executes a sequence of instructions from memory, where instructions are things like “add two numbers”, “move a chunk of data from memory to the processor”. Normally, after executing one instruction, the CPU will execute the instruction that’s at the next sequential address. However, there are instructions called “branches” that let you change the address next instruction comes from.
Here’s an abstract diagram of a CPU executing some instructions. The x-axis is time and the y-axis distinguishes different instructions.
Here, we execute instruction A, followed by instruction B, followed by instruction C, followed by instruction D.
One way you might design a CPU is to have the CPU do all of the work for one instruction, then move on to the next instruction, do all of the work for the next instruction, and so on. There’s nothing wrong with this; a lot of older CPUs did this, and some modern very low-cost CPUs still do this. But if you want to make a faster CPU, you might make a CPU that works like an assembly line. That is, you break the CPU up into two parts, so that half the CPU can do the “front half” of the work for an instruction while half the CPU works on the “back half” of the work for an instruction, like an assembly line. This is typically called a pipelined CPU.
If you do this, the execution might look something like the above. After the first half of instruction A is complete, the CPU can work on the second half of instruction A while the first half of instruction B runs. And when the second half of A finishes, the CPU can start on both the second half of B and the first half of C. In this diagram, you can see that the pipelined CPU can execute twice as many instructions per unit time as the unpipelined CPU above.
There’s no reason that a CPU can only be broken up into two parts. We could break the CPU into three parts, and get a 3x speedup, or four parts and get a 4x speedup. This isn’t strictly true, and we generally get less than a 3x speedup for a three-stage pipeline or 4x speedup for a 4-stage pipeline because there’s overhead in breaking the CPU up into more parts and having a deeper pipeline.
One source of overhead is how branches are handled. One of the first things the CPU has to do for an instruction is to get the instruction; to do that, it has to know where the instruction is. For example, consider the following code:
if (x == 0) {
// Do stuff
} else {
// Do other stuff (things)
}
// Whatever happens later
This might turn into assembly that looks something like
branch_if_not_equal x, 0, else_label
// Do stuff
goto end_label
else_label:
// Do things
end_label:
// whatever happens later
In this example, we compare x to 0. if_not_equal, then we branch to else_label and execute the code in the else block. If that comparison fails (i.e., if x is 0), we fall through, execute the code in the if block, and then jump to end_label in order to avoid executing the code in else block.
The particular sequence of instructions that’s problematic for pipelining is
branch_if_not_equal x, 0, else_label
???
The CPU doesn’t know if this is going to be
branch_if_not_equal x, 0, else_label
// Do stuff
or
branch_if_not_equal x, 0, else_label
// Do things
until the branch has finished (or nearly finished) executing. Since one of the first things the CPU needs to do for an instruction is to get the instruction from memory, and we don’t know which instruction ??? is going to be, we can’t even start on ??? until the previous instruction is nearly finished.
Earlier, when we said that we’d get a 3x speedup for a 3-stage pipeline or a 20x speedup for a 20-stage pipeline, that assumed that you could start a new instruction every cycle, but in this case the two instructions are nearly serialized.
One way around this problem is to use branch prediction. When a branch shows up, the CPU will guess if the branch was taken or not taken.
In this case, the CPU predicts that the branch won’t be taken and starts executing the first half of stuff while it’s executing the second half of the branch. If the prediction is correct, the CPU will execute the second half of stuff and can start another instruction while it’s executing the second half of stuff, like we saw in the first pipeline diagram.
If the prediction is wrong, when the branch finishes executing, the CPU will throw away the result from stuff.1 and start executing the correct instructions instead of the wrong instructions. Since we would’ve stalled the processor and not executed any instructions if we didn’t have branch prediction, we’re no worse off than we would’ve been had we not made a prediction (at least at the level of detail we’re looking at).
What’s the performance impact of doing this? To make an estimate, we’ll need a performance model and a workload. For the purposes of this talk, our cartoon model of a CPU will be a pipelined CPU where non-branches take an average of one instruction per clock, unpredicted or mispredicted branches take 20 cycles, and correctly predicted branches take one cycle.
If we look at the most commonly used benchmark of “workstation” integer workloads, SPECint, the composition is maybe 20% branches, and 80% other operations. Without branch prediction, we then expect the “average” instruction to take branch_pct * 1 + non_branch_pct * 20 = 0.8 * 1 + 0.2 * 20 = 0.8 + 4 = 4.8 cycles. With perfect, 100% accurate, branch prediction, we’d expect the average instruction to take 0.8 * 1 + 0.2 * 1 = 1 cycle, a 4.8x speedup! Another way to look at it is that if we have a pipeline with a 20-cycle branch misprediction penalty, we have nearly a 5x overhead from our ideal pipelining speedup just from branches alone.
Let’s see what we can do about this. We’ll start with the most naive things someone might do and work our way up to something better.
Predict taken
Instead of predicting randomly, we could look at all branches in the execution of all programs. If we do this, we’ll see that taken and not not-taken branches aren’t exactly balanced – there are substantially more taken branches than not-taken branches. One reason for this is that loop branches are often taken.
If we predict that every branch is taken, we might get 70% accuracy, which means we’ll pay the the misprediction cost for 30% of branches, making the cost of of an average instruction (0.8 + 0.7 * 0.2) * 1 + 0.3 * 0.2 * 20 = 0.94 + 1.2. = 2.14. If we compare always predicting taken to no prediction and perfect prediction, always predicting taken gets a large fraction of the benefit of perfect prediction despite being a very simple algorithm.
Backwards taken forwards not taken (BTFNT)
Predicting branches as taken works well for loops, but not so great for all branches. If we look at whether or not branches are taken based on whether or not the branch is forward (skips over code) or backwards (goes back to previous code), we can see that backwards branches are taken more often than forward branches, so we could try a predictor which predicts that backward branches are taken and forward branches aren’t taken (BTFNT). If we implement this scheme in hardware, compiler writers will conspire with us to arrange code such that branches the compiler thinks will be taken will be backwards branches and branches the compiler thinks won’t be taken will be forward branches.
If we do this, we might get something like 80% prediction accuracy, making our cost function (0.8 + 0.8 * 0.2) * 1 + 0.2 * 0.2 * 20 = 0.96 + 0.8 = 1.76 cycles per instruction.
Used by
PPC 601(1993): also uses compiler generated branch hints
PPC 603
One-bit
So far, we’ve look at schemes that don’t store any state, i.e., schemes where the prediction ignores the program’s execution history. These are called static branch prediction schemes in the literature. These schemes have the advantage of being simple but they have the disadvantage of being bad at predicting branches whose behavior change over time. If you want an example of a branch whose behavior changes over time, you might imagine some code like
if (flag) {
// things
}
Over the course of the program, we might have one phase of the program where the flag is set and the branch is taken and another phase of the program where flag isn’t set and the branch isn’t taken. There’s no way for a static scheme to make good predictions for a branch like that, so let’s consider dynamic branch prediction schemes, where the prediction can change based on the program history.
One of the simplest things we might do is to make a prediction based on the last result of the branch, i.e., we predict taken if the branch was taken last time and we predict not taken if the branch wasn’t taken last time.
Since having one bit for every possible branch is too many bits to feasibly store, we’ll keep a table of some number of branches we’ve seen and their last results. For this talk, let’s store not taken as 0 and taken as 1.
In this case, just to make things fit on a diagram, we have a 64-entry table, which mean that we can index into the table with 6 bits, so we index into the table with the low 6 bits of the branch address. After we execute a branch, we update the entry in the prediction table (highlighted below) and the next time the branch is executed again, we index into the same entry and use the updated value for the prediction.
It’s possible that we’ll observe aliasing and two branches in two different locations will map to the same location. This isn’t ideal, but there’s a tradeoff between table speed & cost vs. size that effectively limits the size of the table.
If we use a one-bit scheme, we might get 85% accuracy, a cost of (0.8 + 0.85 * 0.2) * 1 + 0.15 * 0.2 * 20 = 0.97 + 0.6 = 1.57 cycles per instruction.
A one-bit scheme works fine for patterns like TTTTTTTT… or NNNNNNN… but will have a misprediction for a stream of branches that’s mostly taken but has one branch that’s not taken, ...TTTNTTT... This can be fixed by adding second bit for each address and implementing a saturating counter. Let’s arbitrarily say that we count down when a branch is not taken and count up when it’s taken. If we look at the binary values, we’ll then end up with:
00: predict Not
01: predict Not
10: predict Taken
11: predict Taken
The “saturating” part of saturating counter means that if we count down from 00, instead of underflowing, we stay at 00, and similar for counting up from 11 staying at 11. This scheme is identical to the one-bit scheme, except that each entry in the prediction table is two bits instead of one bit.
Compared to a one-bit scheme, a two-bit scheme can have half as many entries at the size size/cost (if we only consider the cost of storage and ignore the cost of the logic for the saturating counter), but even so, for most reasonable table sizes a two-bit scheme provides better accuracy.
Despite being simple, this works quite well, and we might expect to see something like 90% accuracy for a two bit predictor, which gives us a cost of 1.38 cycles per instruction.
One natural thing to do would be to generalize the scheme to an n-bit saturating counter, but it turns out that adding more bits has a relatively small effect on accuracy. We haven’t really discussed the cost of the branch predictor, but going from 2 bits to 3 bits per branch increases the table size by 1.5x for little gain, which makes it not worth the cost in most cases. The simplest and most common things that we won’t predict well with a two-bit scheme are patterns like NTNTNTNTNT... or NNTNNTNNT…, but going to n-bits won’t let us predict those patterns well either!
Used by
LLNL S-1 (1977)
CDC Cyber? (early 80s)
Burroughs B4900 (1982): state stored in instruction stream; hardware would over-write instruction to update branch state
Intel Pentium (1993)
PPC 604 (1994)
DEC EV45 (1993)
DEC EV5 (1995)
PA 8000 (1996): actually implemented as a 3-bit shift register with majority vote
That code will produce a pattern of branches like TTTNTTTNTTTN....
If we know the last three executions of the branch, we should be able to predict the next execution of the branch:
TTT:N
TTN:T
TNT:T
NTT:T
The previous schemes we’ve considered use the branch address to index into a table that tells us if the branch is, according to recent history, more likely to be taken or not taken. That tells us which direction the branch is biased towards, but it can’t tell us that we’re in the middle of a repetitive pattern. To fix that, we’ll store the history of the most recent branches as well as a table of predictions.
In this example, we concatenate 4 bits of branch history together with 2 bits of branch address to index into the prediction table. As before, the prediction comes from a 2-bit saturating counter. We don’t want to only use the branch history to index into our prediction table since, if we did that, any two branches with the same history would alias to the same table entry. In a real predictor, we’d probably have a larger table and use more bits of branch address, but in order to fit the table on a slide, we have an index that’s only 6 bits long.
Below, we’ll see what gets updated when we execute a branch.
The bolded parts are the parts that were updated. In this diagram, we shift new bits of branch history in from right to left, updating the branch history. Because the branch history is updated, the low bits of the index into the prediction table are updated, so the next time we take the same branch again, we’ll use a different entry in the table to make the prediction, unlike in previous schemes where the index is fixed by the branch address. The old entry’s value is updated so that the next time we take the same branch again with the same branch history, we’ll have the updated prediction.
Since the history in this scheme is global, this will correctly predict patterns like NTNTNTNT… in inner loops, but may not always correct make predictions for higher-level branches because the history is global and will be contaminated with information from other branches. However, the tradeoff here is that keeping a global history is cheaper than keeping a table of local histories. Additionally, using a global history lets us correctly predict correlated branches. For example, we might have something like:
if x > 0:
x -= 1
if y > 0:
y -= 1
if x * y > 0:
foo()
If either the first branch or the next branch isn’t taken, then the third branch definitely will not be taken.
With this scheme, we might get 93% accuracy, giving us 1.27 cycles per instruction.
As mentioned above, an issue with the global history scheme is that the branch history for local branches that could be predicted cleanly gets contaminated by other branches.
One way to get good local predictions is to keep separate branch histories for separate branches.
Instead of keeping a single global history, we keep a table of local histories, index by the branch address. This scheme is identical to the global scheme we just looked at, except that we keep multiple branch histories. One way to think about this is that having global history is a special case of local history, where the number of histories we keep track of is 1.
With this scheme, we might get something like 94% accuracy, which gives us a cost of 1.23 cycles per instruction.
Used by
gshare
One tradeoff a global two-level scheme has to make is that, for a fixed size prediction table size, bits must be dedicated to either the branch history or the branch address. We’d like to give more bits to the branch history because that allows correlations across greater “distance” as well as tracking more complicated patterns and we’d like to give more bits to the branch address to avoid interference between unrelated branches.
We can try to get the best of both worlds by hashing both the branch history and the branch address instead of concatenating them. One of the simplest reasonable things one might do, and the first proposed mechanism was to xor them together. This two-level adaptive scheme, where we xorthe bits together is called gshare.
With this scheme, we might see something like 94% accuracy. That’s the accuracy we got from the local scheme we just looked at, but gshare avoids having to keep a large table of local histories; getting the same accuracy while having to track less state is a significant improvement.
One reason for branch mispredictions is interference between different branches that alias to the same location. There are many ways to reduce interference between branches that alias to the same predictor table entry. In fact, the reason this talk only runs into schemes invented in the 90s is because a wide variety of interference-reducing schemes were proposed and there are too many to cover in half an hour.
We’ll look at one scheme which might give you an idea of what an interference-reducing scheme could look like, the “agree” predictor. When two branch-history pairs collide, the predictions either match or they don’t. If they match, we’ll call that neutral interference and if they don’t, we’ll call that negative interference. The idea is that most branches tend to be strongly biased (that is, if we use two-bit entries in the predictor table, we expect that, without interference, most entries will be 00 or 11 most of the time, not 01 or 10). For each branch in the program, we’ll store one bit, which we call the “bias”. The table of predictions will, instead of storing the absolute branch predictions, store whether or not the prediction matches or does not match the bias.
If we look at how this works, the predictor is identical to a gshare predictor, except that we make the changes mentioned above – the prediction is agree/disagree instead of taken/not-taken and we have a bias bit that’s indexed by the branch address, which gives us something to agree or disagree with. In the original paper, they propose using the first thing you see as the bias and other people have proposed using profile-guided optimization (basically running the program and feeding the data back to the compiler) to determine the bias.
Note that, when we execute a branch and then later come back around to the same branch, we’ll use the same bias bit because the bias is indexed by the branch address, but we’ll use a different predictor table entry because that’s indexed by both the branch address and the branch history.
If it seems weird that this would do anything, let’s look at a concrete example. Say we have two branches, branch A which is taken with 90% probability and branch B which is taken with 10% probability. If those two branches alias and we assume the probabilities that each branch is taken are independent, the probability that they disagree and negatively interfere is P(A taken) * P(B not taken) + P(A not taken) + P(B taken) = (0.9 * 0.9) + (0.1 * 0.1) = 0.82.
If we use the agree scheme, we can re-do the calculation above, but the probability that the two branches disagree and negatively interfere is P(A agree) * P(B disagree) + P(A disagree) * P(B agree) = P(A taken) * P(B taken) + P(A not taken) * P(B taken) = (0.9 * 0.1) + (0.1 * 0.9) = 0.18. Another way to look at it is, to have destructive interference, one of the branches must disagree with its bias. By definition, if we’ve correctly determined the bias, this cannot be likely to happen.
With this scheme, we might get something like 95% accuracy, giving us 1.19 cycles per instruction.
As we’ve seen, local predictors can predict some kinds of branches well (e.g., inner loops) and global predictors can predict some kinds of branches well (e.g., some correlated branches). One way to try to get the best of both worlds is to have both predictors, then have a meta predictor that predicts if the local or the global predictor should be used. A simple way to do this is to have the meta-predictor use the same scheme as the two-bit predictor above, except that instead of predicting taken or not taken it predicts local predictor or global predictor
Just as there are many possible interference-reducing schemes, of which the agree predictor, above is one, there are many possible hybrid schemes. We could use any two predictors, not just a local and global predictor, and we could even use more than two predictors.
If we use a local and global predictor, we might get something like 96% accuracy, giving us 1.15 cycles per instruction.
Used by
DEC EV6 (1998): combination of local (1k entries, 10 history bits, 3 bit counter) & global (4k entries, 12 history bits, 2 bit counter) predictors
IBM POWER4 (2001): local (16k entries) & gshare (16k entries, 11 history bits, xor with branch address, 16k selector table)
IBM POWER5 (2004): combination of bimodal (not covered) and two-level adaptive
IBM POWER7(2010)
Not covered
There are a lot of things we didn’t cover in this talk! As you might expect, the set of material that we didn’t cover is much larger than what we did cover. I’ll briefly describe a few things we didn’t cover, with references, so you can look them up if you’re interested in learning more.
Branch target prediction is expensive enough that some early CPUs had a branch prediction policy of “always predict not taken” because a branch target isn’t necessary when you predict the branch won’t be taken! Always predicting not taken has poor accuracy, but it’s still better than making no prediction at all.
Among the interference reducing predictors we didn’t discuss are bi-mode, gskew, and YAGS. Very briefly, bi-mode is somewhat like agree in that it tries to seperate out branches based on direction, but the mechanism used in bi-mode is that we keep multiple predictor tables and a third predictor based on the branch address is used to predict which predictor table gets use for the particular combination of branch and branch history. Bi-mode appears to be more successful than agree in that it’s seen wider use. With gksew, we keep at least three predictor tables and use a different hash to index into each table. The idea is that, even if two branches alias, those two branches will only alias in one of the tables, so we can use a vote and the result from the other two tables will override the potentially bad result from the aliasing table. I don’t know how to describe YAGS very briefly :-).
Because we didn’t take about speed (as in latency), a prediction strategy we didn’t talk about is to have a small/fast predictor that can be overridden by a slower and more accurate predictor when the slower predictor computes its result.
Some modern CPUs have completely different branch predictors; AMD Zen (2017) and AMD Bulldozer (2011) chips appear to use perceptron based branch predictors. Perceptrons are single-layer neural nets.
It’s been argued that Intel Haswell (2013) uses a variant of a TAGE predictor. TAGE stands for TAgged GEometric history length predictor. If we look at the predictors we’ve covered and look at actual executions of programs to see which branches we’re not predicting correctly, one major class of branches are branches that need a lot of history – a significant number of branches need tens or hundreds of bits of history and some even need more than a thousand bits of branch history. If we have a single predictor or even a hybrid predictor that combines a few different predictors, it’s counterproductive to keep a thousand bts of history because that will make predictions worse for the branches which need a relatively small amount of history (especially relative to the cost), which is most branches. One of the ideas in the TAGE predictor is that, by keeping a geometric series of history lengths, each branch can use the appropriate history. That explains the GE. The TA part is that branches are tagged, which is a mechanism we don’t discuss that the predictor uses to track which branches should use which set of history.
Modern CPUs often have specialized predictors, e.g., a loop predictor can accurately predict loop branches in cases where a generalized branch predictor couldn’t reasonably store enough history to make perfect predictions for every iteration of the loop.
We didn’t talk at all about the tradeoff between using up more space and getting better predictions. Not only does changing the size of the table change the performance of a predictor, it also changes which predictors are better relative to each other.
We also didn’t talk at all about how different workloads affect different branch predictors. Predictor performance varies not only based on table size but also based on which particular program is run.
We’ve also talked about branch misprediction cost as if it’s a fixed thing, but it is not, and for that matter, the cost of non-branch instructions also varies widely between different worklaods.
I tried to avoid introducing non-self-explanatory terminology when possible, so if you read the literature, terminology will be somewhat different.
Conclusion
We’ve looked at a variety of classic branch predictors and very briefly discussed a couple of newer predictors. Some of the classic predictors we discussed are still used in CPUs today, and if this were an hour long talk instead of a half-hour long talk, we could have discussed state-of-the-art predictors. I think that a lot of people have an idea that CPUs are mysterious and hard to understand, but I think that CPUs are actually easier to understand than software. I might be biased because I used to work on CPUs, but I think that this is not a result of my bias but something fundamental.
If you think about the complexity of software, the main limiting factor on complexity is your imagination. If you can imagine something in enough detail that you can write it down, you can make it. Of course there are cases where that’s not the limiting factor and there’s something more practical (e.g., the performance of large scale applications), but I think that most of us spend most of our time writing software where the limiting factor is the ability to create and manage complexity.
Hardware is quite different from this in that there are forces that push back against complexity. Every chunk of hardware you implement costs money, so you want to implement as little hardware as possible. Additionally, performance matters for most hardware (whether that’s absolute performance or performance per dollar or per watt or per other cost), and adding complexity makes hardware slower, which limits performance. Today, you can buy an off-the-shelf CPU for $300 which can be overclocked to 5 GHz. At 5 GHz, one unit of work is one-fifth of one nanosecond. For reference, light travels roughly one foot in one nanosecond. Another limiting factor is that people get pretty upset when CPUs don’t work perfectly all of the time. Although CPUs do have bugs, the rate of bugs is much lower than in almost all software, i.e., the standard to which they’re verified/tested is much higher. Adding complexity makes things harder to test and verify. Because CPUs are held to a higher correctness standard than most software, adding complexity creates a much higher test/verification burden on CPUs, which makes adding a similar amount of complexity much more expensive in hardware than in software, even ignoring the other factors we discussed.
A side effect of these factors that push back against chip complexity is that, for any particular “high-level” general purpose CPU feature, it is generally conceptually simple enough that it can be described in a half-hour or hour-long talk. CPUs are simpler than many programmers think! BTW, I say “high-level” to rule out things like how transistors and circuit design, which can require a fair amount of low-level (physics or solid-state) background to understand.
Thanks to Leah Hanson, Hari Angepat, and Nick Bergson-Shilcock for reviewing practice versions of the talk. Apologies for the somewhat slapdash state of this post – I wrote it quickly so that people who attended the talk could refer to the “transcript ” soon afterwards and look up references, but this means that there are probably more than the usual number of errors and that the organization isn’t as nice as it would be for a normal blog post. In particular, things that were explained using a series of animations in the talk are not explained in the same level of detail and on skimming this, I notice that there’s less explanation of what sorts of branches each predictor doesn’t handle well, and hence less motivation for each predictor. I may try to go back and add more motivation, but I’m unlikely to restructure the post completely and generate a new set of graphics that better convey concepts when there are a couple of still graphics next to text
Matthias Felleisen jested "Why are you still using CL when Scrbl/Racket is so much better :-)" ?
My response was as follows:
Dear Matthias,
you are right Racket is so much better in so many dimensions. I use Lisp because I just can't bear programming in a language without proper syntactic abstraction, and that is a dimension where Racket is far ahead of Common Lisp (CL), which sadly also remains far ahead of the rest of competition. Racket also has managed to grow a remarkable way to mix typed and untyped program fragments, which sets it ahead of most. But I am under the impression that there are still many dimensions in which Racket lags behind other languages and Common Lisp (CL) in particular.
The Common Lisp Object System (CLOS) has multiple-inheritance, multi-methods, method combinations, introspection and extensibility via the MOP, generic functions that work on builtin classes, support for dynamic instance class change (change-class, update-instance-for-changed-class) and class redefinition (defclass, update-instance-for-redefined-class), a semi-decent story for combining parametric polymorphism and ad hoc polymorphism (my own lisp-interface-library), etc. Racket seems to still be playing catch-up with respect to ad hoc polymorphism, and is lacking a set of good data structure libraries that take advantage of both functional and object-oriented programming (a good target is Scala's scalaz or its rival cats).
While the ubiquity of global side-effects in CL is very bad, the facts that all objects that matter are addressable by a path from some global namespace and that live redefinition is actively supported makes debugging and maintaining long-lived systems with in-image persistent data more doable (see again CLOS's update-instance-for-redefined-class). This is in contrast with the Racket IDE which drops live data when you recompile the code, which is fine for student exercises, but probably wrong for live systems. CL is one of the few languages that takes long-term data seriously (though not quite as seriously as Erlang).
Libraries. CL seems to have much more libraries than Racket, and though the quality varies, these libraries seem to often have more feature coverage and more focus on production quality. From a cursory look, Racket libraries seem to often stop at "good enough for demo". An effort on curating libraries, homogenizing namespaces, etc., could also help Racket (I consider CL rather bad in this respect, yet Racket seems worse). My recent experience with acmart, my first maintained Racket library, makes me think that writing libraries is even higher overhead in Racket than in CL, which is already mediocre.
Speedwise, SBCL still produces code that runs noticeably faster than Racket (as long as you don't need full delimited control, which would requires a much slower CL-to-CL compiler like hu.dwim.delico). This difference may be reduced as Racket adopts the notoriously fast Chez Scheme as a backend (or not). Actually, the announcement of the new Racket backend really makes me eager to jump ship.
As for startup latency, Common Lisp is also pretty good with its saved images (they start in tens of milliseconds on my laptop), making it practical to write trivial utilities for interactive use from the shell command-line with an "instantaneous" feel. Racket takes hundreds of milliseconds at startup which puts it (barely) in the "noticeable delay" category (though nowhere near as bad as anything JVM-based).
All these reasons, in addition to inertia (and a non-negligible code-base and mind-base), have made me stick to CL — for now. I think Racket is the future of Lisp (at least for me), I just haven't jumped ship right yet. If and when I do, I'll probably be working on some of these issues.
PS (still 2017-03): Here are ways that Racket is indeed vastly superior to CL, that make me believe it's the future of Lisp:
First and foremost, Racket keeps evolving, and not just "above" the base language, but importantly below. This alone makes it vastly superior to CL (that has evolved tremendously "above" its base abstractions, but hasn't evolved "below", except for FFI purpose, in the last 20 years), which itself remains superior to most languages (that tend to not evolve much "above", and not at all "below" their base abstractions).
Racket is by far ahead of the pack in terms of Syntactic abstraction
Racket has a decent module system, including build and phase separation, and symbol selection and renaming.
Racket has typed modules, and a good interface between typed and untyped modules.
Racket has lots of great teaching material.
Racket has a one-stop-shop for documentation, though it isn't always easy to navigate and often lack examples. That still puts it far ahead of CL and a lot of languages.
Racket provides purity by default a decent set of data structures.
Racket has many primitives for concurrency, virtualization, sandboxing.
Racket has standard primitives for laziness, pattern-matching, etc.
Racket has a standard, portable, gui.
Racket has a lively, healthy, user and developer community.
I probably forget more.
PS (2017-08-23):
A few months onward, I've mostly jumped ship from Common Lisp... but to Gerbil Scheme, not Racket.
As ASDF 3.3.0 gets released (imminently), I don't intend to code much more in Common Lisp, except to minimally maintain my existing code base until it gets replaced by Gerbil programs (if ever). (There's also a syntax-control branch of ASDF I'd like to update and merge someday, but it's been sitting for 3 years already and can wait for more.)
What is Gerbil?
Gerbil Scheme started as an actor system
that vyzo wrote over 10 years ago at MIT,
that once ran on top of PLT Scheme.
vyzo was dissatisfied with some aspects of PLT Scheme (now Racket),
notably regarding performance for low-level system code and concurrency (at the time at least),
but loved the module system (for good reasons),
so when he eventually jumped ship to Gambit
(that had great performance and was good for system programming,
with its C backend),
he of course first reimplemented the PLT module system on top of Gambit,
or at least the essential features of it.
(The two module systems were never fully compatible, and have diverged since,
but they remain conceptually close, and I suppose if and when the need arise,
Gerbil could be made to converge towards PLT in terms of features and/or semantics.)
Why did I choose Gerbil instead of Racket, like I intended?
A big reason why I did is that I have a great rapport with the author, vyzo,
a like mind whom I befriended back in those days.
A lot of our concerns and sense of aesthetics are very much in synch,
and that matters both for what there is and what may come to be.
Conversely, the bigger features that Racket has that Gerbil is lacking
(e.g. a gui) are those that matter less to me at this point.
What there is, the module system, the actor system, the object system, the libraries, is far from as complete as I could wish,
but it is all in good taste, and with the promise
that they can be molded to what we both want in the future.
While the code base is smaller than in PLT,
it is also more consistent and with a coherent sense of aesthetics,
being implemented by one man (so far).
It also happens to cover the kind of domains I'm most in need libraries for,
and it also has a bias towards industrial applicability
that you can't expect from PLT and its legion of academics and interns
(see my discussion of PLT above).
Sitting on top of Gambit does not just mean relatively efficient code
(as far as Scheme is concerned), but it also means enjoying the portability of its GVM, and some of these properties are especially interesting to me:
its observability.
Observability is the property (whose name I coined in my PhD thesis) whereby you can interrupt the execution of the program and observe it at the level of abstraction
of your language (in this case, the GVM).
This already allows Gambit to migrate processes
from one machine to the other,
even though the machines may be using completely different backends (C on ia32, C on AA64, JS, PHP, Java, etc.)
For my thesis, I want to generalize observability from the GVM to arbitrary virtual machines written on top of it for arbitrary languages,
with plenty of cool implications
(including e.g. Erlang-style robustness; see said thesis).
Working on the GVM will save me having to care about plenty
of CPU- or VM- dependent backends that I would have to deal with
if I wanted to write a compiler from scratch or reuse an existing one.
I notably tried to read the source of Chez Scheme,
that PLT Racket is adopting as a new backend
(moving from its own horribly complex yet ultimately slow C codebase);
but it is largely inscrutable,
and with its tens of backends would require much more work
before a prototype is achieved.
I therefore have a lot of personal reasons to adopt Gerbil.
I understand that Gerbil in its current state,
is no rival to Racket for most people in most situations.
Yet there are probably other people for whom it is a better fit,
as it is for me;
and I invite these people to come join forces and enjoy writing in Gerbil.
It's still barebones in many ways, yet already quite a pleasure to work with,
at least for me.
TL;DR: Almost everyone seem to be using Git like CVS, while it was created to
be used like in Linux kernel development.
What are you doing wrong
You can take the developer out of the CVS, but you can’t take the CVS out of the developer.
– me, in this post
Maybe I’m arrogant, but I think almost everyone are using Git incorrectly. Or,
to say it in a less click-bait way: sub-optimally.
How do you know if you, your team, or your organization use Git wrong?
Answer the following questions:
You have one online repository for every project (or even the entire code in
case of a monorepo).
Your repository/repositories have one branch that everyone branch from and
develop their changes against. (Release branches don’t count.)
You have one process that everyone have to follow to review the code; one
review system and one place that runs all your tests.
If the answer to all of them is yes, I’m afraid this is you:
CVS vs DCVS
Do you remember CVS? It stands for Concurrent Versions System. Concurrent
is the keyword here. If everything you do around your source control is
centralized, then concurrency is as far as you can go.
Git on the other hand implements Distributed version control, also known asdistributed revision control system (DRCS), or a distributed version control
system (DVCS).
Somewhere during popularization of Git people forgot what was the original
reason to create it, and now they use it as weird-CVS that wastes disk space, by
coping the whole code history everywhere.
My main point is: the difference between Git (and alikes) and previous
generation of source control tools is the difference between concurrent
model: creating changes to the shared codebase at the same time,
and distributed model: developing code independently and sharing changes.
It’s a fundamental difference. In a distributed model each developer should be
as autonomous and self-reliant as possible, and consensus should come from
communication, and not be centrally controlled fact.
This difference might initially seem rather insignificant, but it
affects the whole software engineering culture. It changes
what gets revisioned in the source control system in the first place, how you
create your build system, how you communicate, how you review changes, how you
setup testing and infrastructure.
DVCS is a superset of CVS. You don’t have to apply every aspect of DVSC model,
but it’s good to know it exists.
Signs that there is a problem
Have you ever did a code review, and gave feedback that was longer than doing the fix
yourself, while you’re at it?
Did you ever had a fix that your colleges are waiting for, but they couldn’t use
it until you passed all the code-review checks to actually get it “merged
into master”, while passing it out-of-band was an extra-hassle with your tools
and procedures actively getting in a way?
Did you encounter bugs in master branch, that affect only some developers, or
are failing intermittently, and slipped through automated tests?
Have you ever were unable to do something, because “master is broken”?
How you should use Git
Your software development model should embrace Linux kernel
development model. It was the whole reason Git was created, and got so popular.
It enables efficient, asynchronous code development collaboration between
many people.
It works well for > 15 million lines of code, thousands of developers:
paid and unpaid, professional and amateurs alike. So it can
benefit your projects as well.
Changing code
There should be no “one master branch” that everyone uses, since it’s a point of
contention and a single point of failure. And when stuff breaks in “one master
branch” your whole organization is affected.
Changes to the code should flow freely between people. Developers and teams
should exchange patches or whole branches as they find optimal for a situation
at hand. Generally, they should be organically propagating from the bottom-up
and across. This gives them time to mature, be battle tested on many
setups and situations before they land in anything that you would consider
“the master branch”.
Examples!
Bottom-up: Junior developers should push their changes to senior
developers, that truly review them (as opposed to just “glance over and point
out mistakes” - more on it later), and if accepted, they include them in their
own branches then push to team leaders, and then release managers and so on.
Across: UI team might be exchanging patches, reviewing and testing continuously within
the team, and periodically asking release manager to merge them. Backend
developers can maintain their changes, on top of current UI changes they depend
on, or the other way around.
Mixed: Cross-project feature contributors, send their changes to owners of
given project/components.
It might seem like chaos, but it is not. It is just fluid synchronization, or
to put differently: eventual consistency system.
Also, it is worth noting that every time changes are propagated, some code review
and testing is involved. More on it below.
Reviews
I am really at odds with how typically code reviews are organized.
I think the cost of any barrier to “getting the job done” in software development
is greatly underestimated.
Obviously, you don’t want a buggy code in production, and developers are only humans:
they make mistakes all the time. You need peer reviews for this and many other reasons.
But if your developers (even subconsciously) think that doing something will
involve unpleasant emotions like frustration, critique, etc. their productivity
will inevitably drop.
And code-reviews are where such barriers are naturally placed. They usually
involve:
crude, arcane, organization-specific tools to orchestrate it
ugly and clunky web UIs
bureaucracy level 9000
slowdowns due to rounds of reviews and follow up fixes with other bureaucracy compounding
First, developers already have git and their development environment. That’s all
they need for changing the code, which involves reading the existing code.
So why would they use anything else, for reading the code, when doing the code review?
Making them learn and then deal with yet another software is a distraction, at best.
And why would you force everyone
to review code the same way? Do you really think that everyone enjoys the
same color scheme and web interface of one tool that was picked for everyone?
Do you force everyone to use the same text editor, with the same color scheme too?
In an organization that uses truly distributed model, every developer
should be able to use their preferred tools for everything, code review included.
The way code review is done: by looking
on an output of diff command, pretty-printed in a web-browser, and pointing
out obvious mistakes is very inefficient and fundamentally insufficient. For
a developer to truly review a change, the developer should download
it locally, do git checkout on
it, open in IDE/text editor of their choice with or along diff viewer, jump
around the new code, run tests and even write some new ones, toy with it,
execute etc. Only then the change has been “reviewed” as opposed to “glanced
over”.
Review should be more about communication and collaboration, rather
than just one way critique. If problems were found the reviewer can fix them
immediately and send back the fixes. It’s usually much faster anyway, compared
to writing long comments, explaining what changes are required through some web
form and doing the review again, after the original author implemented requested
changes (often resulting in multiple round-trips like that). Also, “this is a change
with how I’d improve your code” feedback, is much nicer than “your stuff is
wrong, go fix it”, no matter how politely you go about it.
Testing
You should treat your developers as a distributed testing network
and not relay on a central testing system to do everything and catch
every issue. Sure, central, mandatory and automatic testing is a great last line of
defense, but before any change reaches that point, it should have been already
tested many, many times, locally by the developers propagating it.
This increases chances of catching stuff failing intermittently or only in
particular setups, before it hits everyone.
For this approach to be effective, it is vitally important that you make local testing
as efficient, natural and useful as possible. Developers should be intimate
with testing and run routinely and locally as much tests as possible.
Your testing suite should be created for humans, and not for a big,
inhuman, black-box, automation system. It should be natural and intuitive to
run specific subsets of your tests. Being able to tell what and where failed is
important.
But, I don’t like what you’re proposing
Sure, not all that is applicable in every situation. And you might just
not be enthusiastic about that “distributed” idea at all. Maybe more top-heavy,
centralized system is actually what you need.
But then, maybe CVS-es (like Subversion) could be a better choice for
you.
Mental model of using CVS-es is easier.
You don’t make your developers download the whole history. They can’t do
much being offline anyway, since everything that is important is happening
in a central location.
You get features like: locking
files
or checking out sub-tree of your project (especially useful for big mono-repos).
Anyway, I think it’s worth to know how things could be, even if
you don’t plan to use them right now, or even disagree with them altogether.
Y Combinator is not just the most prestigious accelerator out there, it’s also the largest. And so, as has been the case for the past several years, there were too many companies to jam them all into one day.
As a result, we once again braved the traffic of the 101 to bring you all the companies presenting on the second of Y Combinator’s day of demos, for what is the 25th batch of startups that have gone through the program.
Standard Cognition is using machine vision to build the checkout of the future. Called autonomous checkout, the technology will allow shoppers to grab what they want and walk out of a store without having to go to a cashier. Standard Cognition believes it tech will enable those companies to save money and reduce theft.
—
Modern Fertility– At-home test to check and monitor your fertility
Modern Fertility is selling home fertility tests for women to provide transparency at a fraction of the cost of traditional fertility clinics. Having launched just a week and a half ago, Modern Fertility has managed 70,000 pre-orders and it expects each customer to test on a yearly basis. The company is currently selling direct to consumer but also sees potential in selling to businesses. Businesses like AngelList, Plaid and OpenDoor have expressed interest in sponsoring home fertility care for employees.
Dharma Labs is building what it calls the first “protocol for debt on blockchains.” Citing the popularity of ICOs, the startup believes that there’s a “proven demand for cryptoassets that look and act much like equity.” So Dharma has built a mechanism for decentralized peer-to-peer lending. “Anyone in the world can borrow and anyone in the world can lend.”
—
Caelum Health– Replace prescription drugs with software
Sometimes physicians prescribe drugs because they work, and other times it’s because they’re easy. Caelum Health wants to use software to improve people’s health without prescribing them drugs. It’s starting with irritable bowel syndrome, which affects 20 percent of americans and leads to $55 billion worth of prescriptions. Caelum provides behavioral health treatments that it says are 3x more effective than prescription drugs, and has pilots with 7 of the top 10 health systems.
Greo wants to disrupt Twitter and other online forums by creating a better home for healthy intellectual debate. Created by a team of Stanford students, Greo counts about 850 users. The number is small, but the aim seems to be quality over quantity. By forcing people to use their real identity and exposing people to contrasting opinions, Greo thinks it can fill a growing social niche in an age of partisanship.
—
WheelStreet– India’s largest motorbike rental marketplace
WheelStreet claims to be “India’s largest motorbike rental marketplace.” The startup estimates that of the 600 million people commuting via motorbike, the majority don’t own one. WheelStreet is looking to bring rental inventory online and make it more affordable for everyone. The team works with rental shops and takes a 20% transaction fee. While WheelStreet only has $32,000 in monthly revenue right now, the team expects this to be a $6 billion market opportunity.
Warren wants to automate the process of making B2B payments. For most companies, going through the payment flow requires multiple steps to get vendors onboarded and get purchase orders approved. By automating those processes, Warren can reduce costs for businesses thanks to new APIs that make payments easy. In the US alone, there are 2 billion B2B payments made each year, and Warren wants to charge $0.50 each to ease that pain.
As Salesforce grows larger and larger, there’s still no shortage of startups digging for overlooked opportunities. OneLocal is the salesforce for (wait for it) local businesses. The reality is that small businesses don’t keep good tabs on their customers — they’re not as easy to corral as customers, but ignored they are. OneLocal has signed up 115 businesses to the tune of $24,000 in monthly recurring revenue. Like Salesforce, OneLocal aims to up-sell with new enterprise apps, designed specifically to solve problems faced by SMBs.
Flowspace is on-demand warehousing for businesses. The startup claims that “there are no good options for short-term warehouse space.” From candy manufacturers ramping up for Halloween season to fast-growing clothing companies, Flowspace believes that there is a market opportunity for temporary warehouses. They estimate that 400,000 companies in the U.S. are in need of flexible warehousing and that the market opportunity is $3.3 billion.
Goosebump is a messenger app that helps users find live music events online. There are two trends driving more live music entertainment: first, the move to listening to new artists online, as well as the need for musicians to make money through live performance. Goosebump is already taking advantage of these trends, with 6,000 weekly active users in Paris. And the company is growing 13 percent week over week, with 44 percent of users active weeks after they’ve joined.
Nimble is building an applicant tracking system designed specifically for schools. Rather than offering just a dressed up spreadsheet, Nimble is offering a predictive tool to help inform hiring decisions. The team didn’t go into too many details, but it’s clear that the system as it is is very broken. A paid pilot is coming this fall and the folks behind Nimble say that they have two letters of intent in hand for said pilots.
Retool markets itself as “a faster way to build internal tools.” The startup estimates that about half of all the code in the world is used for internal company procedures, yet most of the process is continuously replicated because the code is so similar. These companies are “writing the same code over and over again” and wasting time, Retool claims. The team says it has built a tool that makes building this code faster. Retool says they’ve already signed on a large enterprise customer in a paid pilot worth $1.5 million.
—
Dahmakan– Full stack food delivery for Southeast Asia
Dahmakan delivers ready-to-eat meals in SE Asia, controlling the entire process from food production to delivery. Because cities in Asia have 4x higher urban density than cities in the US and have 1/10 the labor costs, Dahmakan has been able to reach a 37 percent gross margin after food, labor, packaging and delivery costs. After launching in Kuala Lumpur, the company is on a $1.8 million revenue run rate and has plans to expand to eight more markets.
Communities are very powerful in the world of marketplaces. Covetly is looking to build an eBay competitor on the back of niche collectors. With 13,000 monthly active users and just six sellers, the platform has seen $4,000 in sales. The hope seems to be that increasing the number of sellers from six to 500 will drastically increase sales to cannibalize more of the $10 billion collector market.
Original Tech– Software for banks to accept loan/account applications online
Original Tech is software for banks to accept loan and other account applications online. The team says that they are putting an end to paper applications and helping lenders digitize their financial technology through its mobile-first white label platform. They have signed up 13 contracts in two months and believe this is a $1.5 billion market opportunity.
Vanido– Vanido is your personal AI music teacher, starting with singing
Vanido wants to be your AI-based music teacher, starting with helping users learn to sing. Americans spend $1.2 billion on singing lessons every year, and Vanido wants to make those lessons accessible to anyone with a smartphone. Users sing into their smartphone, and the app listens to their voices and corrects them, helping users to improve their signing by 34 percent. Already the company has more than 25,000 monthly active users who have completed 2 million exercises so far.
—
Entocycle– Sustainable insect protein for farm animals
Entocycle is building an automated factory to produce fish protein feed. The market sounds almost comically niche, but we were reassured that the space is valued at a robust $15 billion. Entocycle’s automated factory actually produces insects. The group feeds waste to the bugs and then, when it’s grown enough, it sells the insects to farms to feed animals. Prices have been steadily increasing for this feed, so the startup believes it can capture a meaningful portion of the market by cutting its own costs and selling to its customers at 20 percent below market rate.
Guilded built what they’re calling “team management for eSports.” On games like League of Legends and Overwatch, users play in groups and Guilded believes that these teams are looking for help in recruiting and organizing. Guilded says its recently-launched app is already the #1 app for Overwatch teams and claims that they can ultimately reach up to 700 million gamers. The founder previously worked on the growth team at Instagram.
Lambda School– An online code bootcamp with no upfront cost
Lambda School trains people to be software engineers in live online classes. Those classes are free to students, and the company makes money off employee referrals to companies looking to hire developers who have graduated. The company has signed up 50 hiring partners who are waiting to snap up graduating students. Its 170 students currently enrolled represent $4 million in future revenue. The company has just a 3 percent approval rate and its costs are less than $3,000 per student, including acquisition costs.
Between the major cloud providers, there are already a myriad of natural language processing tools available for machine learning developers. Unafraid, Plasticity is moving full steam ahead to become the Twilio of NLP. It has a signed letter of intent from Duck Duck Go worth $1.2 million and interest from others in using the Plasticity API for automating message replies.
Piggy is an app for Indians to invest in their retirement savings. Calling themselves the “Vanguard for India,” they allow users to invest in over 2000 mutual funds. Estimating that there will be over 600 billion invested in Indian retirement accounts by 2025, Piggy believes that that there is a large market opportunity. The team has already accrued $30 million in assets and claims to be growing 90% month-over-month. Piggy says it has been able to grow entirely through word-of-mouth because the commission-free service allows users to earn 1% more annually.
Fat Lama is a fully insured peer-to-peer rental marketplace for high-value items. Because all items made available are insured, users are ok with putting expensive DJ equipment, photography equipment and active sports gear on the site. As a result the company was able to do $21,000 in net revenue on more than $80,000 in GMV last month. Also, the company is growing 60 percent month over month, thanks to a trend away from ownership and a move toward borrowing high-value goods on-demand.
Solve– Airport concierge for international travellers
Traveling through airports hasn’t evoked the nostalgia of the golden age of air travel for quite some time. Lines are long, logistics are complex and security is tight. Solve promises to save travelers time in airports. At $125 per person, Solve will handle your luggage, coordinate vehicles and manage arrivals, departures and connections. The service is available in 500 airports and the team is expecting $16,000 in revenue this month.
Sunfolding is building “next-generation infrastructure for solar farms.” The team is creating what they are calling the “next generation of trackers,” with machines that are faster and cheaper than the solar trackers of generations past. The startup is marketing itself as a business “replacing complex machinery with air” and has signed up $1.5 million in projects for 2017.
Enzyme is building software to help life sciences companies with FDA approval and regulatory compliance. Using Enzyme’s software, those companies can avoid spending money on costly consultants which in turn can reduce their compliance costs by up to 50 percent. Since 10 percent of all personnel in biopharma and life sciences companies are related to regulatory issues, it can lower headcount as well. Perhaps most importantly, Enzyme can also make it easier and faster for those companies to bring their products to market.
—
Surematics– Software that helps structure commercial insurance contracts
Surematics is helping commercial insurance brokers structure complicated deals online. Homeowners and car insurance is enough of a nightmare for most of us to handle but Surematics is targeting even more difficult cases — awkward expensive items like oil rigs. With a dash of blockchain, the startup wants to allow companies to collaborate together to create enforceable contracts.
—
Templarbit– Protects applications from malicious activity
Templarbit is a startup for protecting applications from malicious activity known as “xss attacks.” The team estimates that these cyber threats count for almost 50% of all security issues. In the first month, the startup has already signed up 15 customers, including Match.com, AdRoll and Mercedes-Benz. The team says their early traction is because they’ve taken a “difficult, manual process” and made it so that just one line of code is needed.
—
Just Appraised– Better appraisal software for governments
Every year, local governments have to appraise properties to determine their value. Since about a third of all local government revenues come from property taxes, they rely on that data, but collecting the information is inefficient and frequently inaccurate. Just Appraised uses machine learning to evaluate public and private data, which enables it to build a comprehensive proprietary dataset. In addition to money it makes from local governments, that dataset can be resold to other companies relying on property value information in the real estate industry.
Advano is building lithium ion batteries that can store more energy at higher density using silicon-based additives. The team of nine scientists says that it has long been known that adding silicon to batteries allows them to store more energy. But unfortunately this has always come with sacrifices in battery life. Advano’s technology does away with this compromise. The company’s letters of intent are valued at $4.2 million and include requests for both both IoT batteries and 9.6MWh battery packs.
AutoHub is creating a marketplace for car dealers to buy and sell used cars from each other. Previously, dealers relied on offline auctions for the roughly eight cars they were buying every week. AutoHub says there is typically an added cost of $850 per car sold, but that its marketplace will charge less than half of that at $400 per car. The team believes that replacing offline auctions is an $8 billion addressable market. So far, AutoHub has sold $400,000 worth of cars in its first six weeks.
Enterprises like to say they’re data driven, but for many that data is a mess spread across the organization. Quilt wants to help businesses integrate their data sources to make sure everyone in the company is on the same page, and has already been adopted by some of the largest banks. By defining data “packages,” Quilt wants to become a sort of Docker for data, making it more discoverable and actionable across its clients.
Automated resume reviews are horrible. Large Fortune 500 companies receive millions of job applications each year and the review process is so poor that great apps are missed on the regular. Headstart is adding machine learning into the mix to automatically rank applicants to assist human hiring teams. This tool alone promises to cut hiring time by 60 percent. With $325,000 in annual recurring revenue, Headstart is already making progress capturing the $4 billion market.
BillionToOne is trying to be a “safe prenatal genetic test for all mothers.” The blood test helps check for fetal disorders like sickle cell and beta-thalassemia, without the miscarriage risk that comes through amniocentesis tests. The team claims that the first test they’ve developed is at least 99% accurate. BillionToOne is launching in the U.S. in 2018 and will expand globally, with a focus on market opportunities in India and China.
Bxblue provides a marketplace for personal loans in Brazil, focused on pensioners and government employees. Those borrowers can get secured loans because they have guaranteed income, and banks love these loans because they can deduct payments direct from borrower’s paychecks. Today the market is almost entirely offline, making it difficult for borrowers to compare rates . It’s a $4 billion market opportunity, with the potential of 42 million Brazilian borrowers Bxblue could go after.
Gameday thinks Draft Kings and FanDuel have completely ignored casual fantasy sports players. To fill that void, the startup is simplifying fantasy sports and integrating with Facebook messenger. About 70 percent of the company’s 50,000 weekly active users are first time players of fantasy sports and 60 percent of them have continued to use Gameday over a 20 week period. Eventually Gameday wants to grow to accommodate as many leagues as it can as it aims to grow the entire fantasy space.
VIDA & Co.– Marketplace for apparel designed on-demand by artists.
VIDA & Co. is a marketplace for “unique products” built on-demand and at scale. The “millennial generation is rejecting the standardized mass produced goods” and so customized products has become a $140 billion market, the startup claims. VIDA & Co. has created a platform for these personalized items. The team is targeting creative people like Instagram photographers or graphic designers and helps them turn their visions into products. VIDA & Co. has already worked with big brands like Steve Madden, HSN and the Golden Globe Awards.
LotusPay wants to become the infrastructure small and medium-sized businesses in India use to power recurring payments. In India, 75 percent of recurring payments are made by consumers who line up to pay with cash or check. But that’s changing, thanks to the government launching e-mandate, a new system that allows consumers to allow businesses to automatically debit their bank accounts. LotusPay has built the payments infrastructure that can be used by businesses to avoid having to build it out themselves, and has an addressable market for 5 million SMEs.
The fact that large construction projects are delayed by complex payment processes isn’t surprising. Contract Simply is building a platform to expedite the payment process that can involve a complex array of stakeholders. At its core, Contract Simply is a cloud-based workflow management tool that allows for faster capital deployment. The startup counts seven pilot users and projects $4 million in annual recurring revenue.
—
PreDxion Bio– A blood test to save critically ill patients in the ER.
PreDxion Bio believes that it has a blood test that could cut down on deaths in emergency rooms. The team says that previous blood tests often took over three days to get back and that about half a million people die per year because of the delays. They’ve built a test that can help doctors gain insight into inflammatory biomarkers, making it easier to treat things like trauma and burns. The startup is starting clinical trials this fall at UCSF, Mayo Clinic and Mount Sinai hospitals.
CarDash is a managed marketplace for auto service, going after the $170 billion market for maintenance and repairs in the U.S. The company believes that a managed marketplace is the future of the industry because it inspires trust, provides convenience and offers transparent pricing to consumers. For mechanics, the company provides free software and a line of new customers, also helping to automate the customer service experience for all involved. To date the company has grown by promoting itself as a workplace benefit provided to consumers by their employers, but also offers service direct to consumers.
HotelFlex– Check into your hotel room at anytime you want
We have all flown into a city on a red eye and landed at an early hour wanting nothing more than a bed and a few pillows. Alas, most hotels have strict check in policies that prevent this from happening. Hotels are complex operations and upending cleaning and other key logistical procedures for convenience isn’t easy. HotelFlex provides infrastructure for hotel guests to pay a premium for more flexible check-in. At a 15 percent up charge, 9 percent of guests were willing to pay the premium. This translates into $170 per room per year in revenue. HotelFlex has an initial pilot with a hotel chain valued at $2 million in annual recurring revenue.
Muzmatch is an app where single Muslims meet. The startup estimates that there are 400 million single Muslims worldwide and that they are spending $7.2 billion on matchmaking. Muzmatch launched two years ago and has attracted 220,000 users, with 56,000 of them still coming back monthly. Some have gone off the service because they’ve found a match. 6,250 couples have met on the service and they are already plenty of “Muzmatch babies.”
Leon & George sells plants online for homes and offices, helping users to find the right plants given a certain environment. The plant industry accounts for $40 billion in sales each year. Plants are everywhere and demand is growing, but they can’t be served by traditional ecommerce platforms and don’t work with the existing delivery infrastructure. As a result, Leon & George is expecting to do $55,000 in revenue this month and has a 57% gross margin.
—
Value Voting– Tech to defeat extremism in US politics
Value Voting is looking to catalyze action in politics by increasing the power of advocacy organizations. The Value Voting platform helps independent advocacy groups share data and collaborate. The team didn’t disclose revenue or growth numbers but insisted that it fully intends to be a for-profit company.
AssemblyAI is API for speech recognition. They’ve built “accurate, simple and customizable” technology that the team claims is what “Stripe did to payments,” but for speech. The voice technology industry is growing fast, due to the popularity of Siri, Alexa and Google Home. AssemblyAI believes that 50% of searches will be made by your voice by 2020. “Every single product is going to use voice in some way.” They hope that AssemblyAI’s technology, which can be customized in just one line of code, will gain traction.
Loop Support provides customer support as a service to companies. Using a combination of humans and AI, the company is able to solve tickets faster and cheaper than most companies’ in-house support teams. Reps trains themselves using Loop Support’s software, and can serve companies in their spare time. That allows its clients to scale their support teams up or down at will. The result is a business that is growing 84 percent month over month.
The former Facebook team behind FriendSpot believes that fear of missing out is a key emotion that can form the underpinnings of an entirely new social network. Their idea is to allow users to form specific event-centric chat groups. As more people join each group, incentives increase for others to join. The network is growing by 40 percent per week with 33 percent retention over a 28 period.
Disclosures.io builds software to help real estate agents manage property disclosures such as leaking roofs and broken sewer lines. Hoping to become the “system of record for all real estate transaction data,” the startup says it is going after real estate agents because they spend about $1 billion per year to manage disclosure documents. Since launching in January, they’ve attracted 615 customers and are working with big names in real estate like Sotheby’s and Pacific Union. Ultimately, the team wants to “build software to support their entire workflow, not just disclosures.”
Helix Nanotechnologies uses artificial intelligence to help cure genetic diseases. Errors in DNA causes cancer in cells, but by using cutting edge AI, Helix is trying to unlock the nucleus of cells and deliver new DNA. Already, it’s licensing its technology to four major firms, but looking to develop its own cell therapy. With just a shot in the arm a couple of times a year, Helix believes it could build a platform to cure and prevent all genetic diseases.
India is facing a massive shortage of dermatologists. There simply are not enough doctors to address the existing needs of the massive Indian market. CureSkin is using computer vision to recommend treatment to patients who don’t have access to trained professionals. With just a photo, CureSkin can diagnose approximately 80 percent of skin conditions and recommend treatment regimens. 7,000 patients are using CureSkin each week and half of those users come back for issues later on.
Py is an app for teaching coders new skills. From Python to iOS development, they help software engineers learn and also match them with jobs. With a ranking system that can identify strengths in categories like data science and app development, Py believes that it will help job seekers demonstrate what they’re good at. With 100,000 monthly active users, Py hopes to make a dent in what it estimates is a $3 billion market opportunity.
HealthWiz– SaaS platform for lowering employer healthcare costs
HealthWiz lowers health costs for businesses while also helping their employees find better care. Every year, employers waste $4,000 in healthcare costs due to their employees not choosing the right care providers. When providing HealthWiz as a benefit, their employees can find cheaper and faster ways to get a prescription. The company is going after a market that affects 50 million potential employees and it’s already testing with thousands of users.
CocuSocial managed to build the largest marketplace for cooking classes in New York City in just a year of operation. With that as a starting point, the company hopes to spread across the country providing wine tasting, painting classes, dance classes and floral design instruction. Swallowing the entirety of the $27 billion market opportunity might not be feasible in the short term but the team is taking in what it can manage with $21,000 in monthly net revenue on 58 percent month over month growth.
Rev Genomics thinks that it can create the best marijuana with biotechnology. Using everything from CRISPR to genomic selection, the startup believes that it has what it takes to make the “best cannabis in the world.” They are also targeting Botrytis, a fungus which can destroy cannabis crops. By “quantifying the gene expression levels of all 30,000 genes in the cannabis genome,” Rev Genomics says it will create plants with higher yields. The startup hopes to someday be the “Monsanto of Cannibis.”
Tpaga is looking to own the mobile wallet space in Latin America. The founding team is responsible for Columbia’s largest taxi app. Following in the path of other taxi apps that have added mobile wallets, its 50,000 taxi drivers will serve as the initial users of Tpaga. After that, Tpaga hopes to add a large super market chain, a large gas station chain, 10 cell phone carriers and 25 utilities providers. The app is set to launch on October 1st and the team is using the runway between now and then to ensure a market exists for new users.
—
NextDrop– The private water marketplace for urban India
NextDrop connects water buyers with water sellers in India, where private water is often delivered by truck. The cost of water has tripled in the last decade and continues to go up, making it more expensive than electricity now. NextDrop launched over the summer, has 3 pilot apartment customers, and is going after a billion-dollar market in urban India.
Mystery Science aims to fix STEM education by giving elementary school teachers a virtual science expert to co-teach classes. Estimating that 94% of elementary schools don’t have science teachers, Mystery Science says that it is addressing this problem with experts Skyping into classrooms everyday. Launched last year, they already brought in $1.4 million in ARR, by convincing schools to pay for its services. This year the startup is forecasting $3.5 million in ARR, with $1.5 million in profit. Mystery Science also plans to expand beyond schools and complete with Discovery and National Geographic with its direct-to-consumer product.
James Damore, the author of the notorious Google memo, has had his 15 minutes of fame. In six months, few of us will be able to remember his name. But Google will remember -- not the company, but the search engine. For the rest of his life, every time he meets someone new or applies for a job, the first thing they will learn about him, and probably the only thing, is that he wrote a document that caused an internet uproar.
The internet did not invent the public relations disaster, or the summary firing to make said disaster go away. What the internet changed is the scale of the disasters, and the number of people who are vulnerable to them, and the cold implacable permanence of the wreckage they leave behind.
Try to imagine the Damore story happening 20 years ago. It’s nearly impossible, isn’t it? Take a company of similar scope and power to Google -- Microsoft, say. Would any reporter in 1997 have cared that some Microsoft engineer she’d never heard of had written a memo his co-workers considered sexist? Probably not. It was more likely a problem for Microsoft HR, or just angry water-cooler conversations.
Even if the reporter had cared, what editor would have run the story? On an executive, absolutely -- but a random engineer who had no power over corporate policy? No one would have wasted precious, expensive column inches reporting it. And if for some reason they had, no other papers would have picked it up. Maybe the engineer would have been fired, maybe not, but he’d have gotten another job, having probably learned to be a little more careful about what he said to co-workers.
Compare to what has happened in this internet era: The memo became public, and the internet erupted against the author, quite publicly executing his economic and social prospects. I doubt Damore will ever again be employable at anything resembling his old salary and status. (Unless maybe a supporter hires him to make a political statement.)
This kind of private coercion is not entirely new, of course. Community outrage cost plenty of people their jobs or their businesses in the old days. But those were local scandals. Rarely would someone's notoriety follow them if they moved to another city.
Over time more and more people have suffered national stigma that outlasts their 15 minutes of fame. Cable news accelerated this: Think of Monica Lewinsky in 1998. The internet transformed the degree of scrutiny, the extent of its reach, and the shelf life of the scandal, so much as to make it different not just in degree, but in kind.
Whenever a new form of power arises, we need to think about how to safeguard individual liberty against it.
In the early days of Twitter, I used to say that it was a bit like I imagined living in a forager band to be: You were immersed in a constant stream of conversation from the people you knew.
Ten years later, I still think that’s the right metaphor, but not in the way that I meant it then. Back then I saw Twitter as a tool for building social bonds. These days, I see it as a tool for social coercion.
Forager bands do not have or need police. They have social coercion so powerful that it is just as effective as a gun to the head. If people don’t like you, they might not take care of you when you’re injured, at which point, you’ll die. Or they won’t share food with you when your hunting doesn’t go well, at which point, you’ll die. Or they’ll shun you, at which point … you get the idea.
We now effectively live in a forager band filled with people we don’t know. It's like the world’s biggest small town, replete with all the things that mid-century writers hated about small-town life: the constant gossip, the prying into your neighbor’s business, the small quarrels that blow up into lifelong feuds. We’ve replicated all of the worst features of those communities without any of the saving graces, like the mercy that one human being naturally offers another when you’re face to face and can see their suffering.
And, of course, you can't move away. There’s only one internet, and we’re all stuck here for the rest of our lives.
Private coercion starts looking less and less like a necessary, if sometimes regrettably deployed, tool of local community-building. Without the tempering instincts of intimate contact, without the ability to exit, it looks a lot more like brute, impersonal government coercion -- the sort that the earliest and highest U.S. laws were written to restrain.
Given the way the internet is transforming private coercion, I’m not sure we can maintain the hard, bright line that classical liberalism drew between state coercion and private versions. We may have to start talking about two kinds of problematic coercion:
Government coercion, which is still the worst, because it is backed up with guns, but is also the most readily addressed because we have a legal framework to limit government power.
Mass private coercion, which even if not quite as bad, still needs to have safeguards put in place to protect individual liberty. But we have no legal or social framework for those.
I find myself in more and more conversations that sound as if we’re living in one of the later-stage Communist regimes. Not the ones that shot people, but the ones that discovered you didn’t need to shoot dissidents, as long as you could make them pariahs -- no job, no apartment, no one willing to be seen talking to them in public.
The people I have these conversations with are terrified that something they say will inadvertently offend the self-appointed powers-that-be. They’re afraid that their email will be hacked, and stray snippets will make them the next one in the internet stocks. They’re worried that some opinion they hold now will unexpectedly be declared anathema, forcing them to issue a humiliating public recantation, or risk losing their friends and their livelihood.
Social media mobs are not, of course, as pervasive and terrifying as the Communist Party spies. But the Soviet Union is no more, and the mobs are very much with us, so it’s their power we need to think about.
That power keeps growing, as does the number of subjects they want to declare off-limits to discussion. And unless it is checked, where does it lead? To something depressingly like the old Communist states: a place where your true opinions about anything more important than tea cozies are only ever aired to a tiny circle of highly trusted friends; where all statements made to or by the people outside that circle are assumed by everyone to be lies; where almost every conversation is a guessing game that both sides lose. It is one element of Margaret Atwood's "A Handmaid's Tale" that does resonate today: Any two acquaintances must remain so mutually suspicious that every day, they can discuss only the pleasant weather and their common fealty to the regime.
It’s some comfort that the social media mobs don’t have guns. But that raises the most troubling question of all: how to disarm them.
This column does not necessarily reflect the opinion of the editorial board or Bloomberg LP and its owners.
I had written five books for Scott Moyers, following him as he moved from editing jobs at Scribner’s to Random House and then to Penguin Press. We worked well together, and in part thanks to his strong editing hand, my last three books had been bestsellers.
So what happened when I finished years of work and sent him the manuscript of my sixth book stunned me. In fact, I was in for a series of surprises.
They began about 18 months ago, after I emailed to him that manuscript, a dual appreciation of Winston Churchill and George Orwell. When I had begun work on it, in 2013, some old friends of mine thought the subject was a bit obscure. Why would anyone care how two long-dead Englishmen, a conservative politician and a socialist journalist who never met, had dealt with the polarized political turmoil of the 1930s and the world war that followed? By 2016, as people on both the American left and right increasingly seemed to favor opinion over fact, the book had become more timely.
But two weeks after I sent him the manuscript, I received a most unhappy e-mail back from him. “I fear that the disconnect over what this book should be might be fundamental,” Scott wrote to me, clearly pained to do so. What I had sent him was exactly the book he had told me not to write. He had warned me, he reminded me, against writing an extended book review that leaned on the weak reed of themes rather than stood on a strong foundation of narrative. I had put the works before the two men, he told me, and that would not do.
There was more. But in short, he pissed all over it. It was not that he disliked it. It was that he fucking hated it. I was taken aback—I had enjoyed the process of researching and writing the book. So, I had expected, a reader would too. No, Scott said, the way you’ve done this doesn’t work.
Partly, I was crushed. But even more, I was puzzled. How could I have been so off in my perception of my manuscript? This wasn’t a hurried work of a few months. For three years, I had steeped myself in Churchill, Orwell, and their times, reading hundreds of books, which were scattered in piles across the floor of my office in the attic of my home in Maine. The biggest of the piles was books by Churchill himself. The second biggest was diaries, memoirs, and collected letters by British politicians and writers of the 1930s and ’40s.
Scott followed up with a lengthy letter—I think it was about 10 pages—detailing his concerns. I live on an island on the coast of Maine. I received the letter the day before a major snowstorm. A few hours after it arrived, several old trees along the road downed power lines, taking the internet with them.
Cut off from email and other off-island communication, I spent that snowy day reading and rereading Scott’s letter. The next morning dawned crystalline and blue. I climbed into my pickup truck and drove slowly over 15 miles of icy backroads to the library in Blue Hill, on the mainland, where the internet was still working. The whole world was sparkling. I sat down in the sun-splashed reading room of the library, powered up my laptop, and sent a note to my literary agent, Andrew Wylie, asking him if Scott, being so negative, actually wanted to back out of the book altogether. If he really wanted out, then I didn’t want to dive into the job of rewriting if it.
Andrew’s reply came flying back, within minutes. (He may be the world’s fastest email replier.) He also knows Scott well. No, Andrew replied, Scott is just trying to emphasize to you how much work you have ahead of you to make this a good book. I found this reassuring. I even felt contented, for reasons I don’t completely understand. If Scott was still on board, well then so was I.
* * *
I spent the next five months, from mid-January to mid-June of 2016, redoing the whole book, rethinking it from top to bottom.
I began by taking his letter and his marked-up version of the manuscript with me to Austin, Texas, where my wife and I were taking a break in February from the long Maine winter. (Austin is a great town for live music, food, and hiking—and its winter feels to me like Maine in the summer.) I sat in the backyard and read and reread Scott’s comments. I didn’t argue with them. Rather, I pondered them. If he thinks that, I would ask myself, how can I address the problem? I underlined sections. At one point he pleaded in a note scrawled in the margin, “If you would only defer to the narrative, you could get away with murder.” I liked that comment so much I typed it across the top of the first page of the second draft, so I would see it every morning as I began my day’s work.
The next surprise, about three weeks into this process, was coming to realize, over the days of thinking about it, that Scott’s criticisms were spot-on. I saw that if I followed his suggestions and revamped the book, with a new structure that emphasized biography and told the stories of the two men chronologically, the book would be much better. I emailed a note to Scott. “You are right,” it said. This wasn’t so much an apology as the beginning of the next phase of work.
“Only a good writer would be able to say that,” he graciously responded.
Next, I disassembled the manuscript. Writing is a lot like carpentry, hammering and sawing and sanding. In this case, I was like a builder taking down a house I had just finished constructing. Scott had persuaded me that my blueprint was off, so I disassembled the whole thing. I stacked my lumber, bricks, window frames, glass, and cement. And then, after a couple more weeks of taking notes on how to do it differently, writing signposts on my new blueprint, I set to reconstruction.
I dug a new foundation, lining it with solid chronology. I wrote a second note to myself at the top of the manuscript: “If it is not chronological, why not?” That is, I would permit myself on occasion to deviate from the march of time, but I needed to articulate a pretty strong reason before doing so.
That brought the third surprise. Making the text follow the order of events was easier than I had expected—and it made more sense. Anecdotes that I had thought could only go in one place, in a discussion of a theme, actually would fit easily into other places, where they fit in time. In fact, they tended to work better when they appeared in the order in which they had occurred in reality. They often slipped in seamlessly, not needing to be hammered in with an introduction or explanation. Like a board prepared for a well-constructed floor, they just slid into place.
The fourth surprise was how much I came to enjoy the rewrite job. In fact, during that time of redrafting, from winter through spring and into summer in 2016, my wife often remarked on how happy I was. When it was time for me to make lunch—usually I’d defrost a homemade soup—I’d come down from my attic office with a smile on my face.
Over the following months the new version of the book fell into place. I still needed help from my “critical readers”—trusted friends with writing skills and different perspectives who also read the manuscript at about this time.
One old friend, a seasoned magazine editor, basically told me that Scott was entirely right: Get out of the way and let the stories tell themselves. Another reader, a San Francisco lawyer specializing in software and communications law, pushed me to patch the holes in the logic of some of my arguments. Two journalist friends, one a writer on secondary education, the other an editor at Politico, helped me think my way through to a new conclusion that wove together the strands of the book—and, oddly enough, took me to Martin Luther King Jr.’s “Letter From Birmingham City Jail,” an essay solidly in the tradition of Orwell’s best commentary. All of them made me think through again what I was trying to say, and why I thought that was important.
In the process, I went back and reread a lot of Churchill and even more of Orwell. The latter was the tougher nut. Churchill’s subject ultimately always was himself, so he lends himself to narrative. Orwell’s subject was the world, so he gave away little of himself in his essays and novels, and not even much in his diaries. In his daily entries there, he was more likely to note the health of his chickens than he was that of his wife, who would die of cancer at an early age, during World War II. But with time I learned to read better between Orwell’s lines. I also went back to the works of Malcolm Muggeridge and other intellectuals and literary journalists of mid-20th century Britain for more context. I think I found what I needed. It felt like good, honest work, like I had not only rebuilt that house but had used an improved design that made it more durable, and easier to use.
* * *
I sent the new manuscript to Scott in June of 2016, a bit over a year ago. This time he loved it.
In July, when I was in New Haven for a few days, I took the train down to New York’s Pennsylvania Station to talk to him, to do some planning, and to celebrate. We met at an ancient steakhouse in midtown Manhattan. It was a summertime Monday, and the joint was empty. Hundreds of clay pipes hung from the low ceiling, one of them supposedly belonging to Abraham Lincoln.
Over our Caesar salads with sliced steak, I asked Scott why he had been so rough on me the previous winter. “Sometimes my job is to be an asshole,” he explained with equanimity. I wasn’t startled at this. At one point on an earlier book, when I told him how stressed I was feeling, he had replied, a bit airily, I thought, “Oh, every good book has at least one nervous breakdown in it.”
Near the end of our lunch, Scott offered one more wise observation about the writing process: “The first draft is for the writer. The second draft is for the editor. The last draft is for the reader.”
At that lunch, he knew how grateful I was to him. Churchill and Orwell: The Fight for Freedom is a much better book for his powerful intervention. In retrospect, that first draft was herky-jerky and sometimes portentous. It also frequently was hard to read without rewarding the reader for making the effort. The final version, published in May of this year, pops right along.
That’s not just me who says so. Many reviewers have commented on how cleanly the book is written. So, contrary to my initial expectation, the hardest book for me to write became the easiest one to read. Readers seem to agree, recently putting this dual biography of two long-dead Englishmen on the list of bestsellers in hardcover nonfiction.
Most art has a public face—music is played, paintings are displayed, plays are enacted, movies are filmed and often watched by groups. Books tend to be more private, from one person’s act of writing to another’s act of reading. Most mysterious of all is the hidden middle stage, the offstage act of editing. Yet sometimes it can make all the difference.
Saving for retirement is not an area of financial strength for Americans. Too often, meeting the financial demands of today means delaying, diminishing or simply never starting to save for tomorrow.
“There are plenty of obstacles Americans claim are in their way when it comes to saving for retirement: credit card debt, student loan debt, low wages, the need to save for a child’s college education, and the list goes on,” said Cameron Huddleston, Life + Money columnist for GOBankingRates. “Although all of these things can put a strain on our budgets, they don’t necessarily make it impossible to save for retirement.”
GOBankingRates asked Americans how much money they have saved for retirement and found that most people are behind on their retirement savings. These survey findings also provide a helpful benchmark against which readers can compare their own retirement savings balances and progress.
Survey: How Much Americans Have Saved for Retirement
The GOBankingRates survey was conducted as three Google Consumer Surveys, each targeted at one of three age groups: millennials, Generation Xers, and baby boomers and seniors. Each age group was asked the same question, “By your best estimate, how much money do you have saved for retirement?” Respondents could select one of the options as displayed below:
Less than $10K
$10K to $49K
$50K to $99K
$100K to $199K
$200 to $299K
$300K or more
I don’t have retirement savings.
GOBankingRates analyzed the survey results to reveal key insights into how Americans of all ages are saving for retirement. Whether due to various economic factors or not correctly prioritizing finances, many people are not on track to have enough money to cover their expenses during retirement.
56% of Americans Have Less Than $10,000 Saved for Retirement
Most Americans are falling short of the amount of savings required for a comfortable retirement ― if they are saving at all. The most common responses to the question of what people have saved for retirement across all age groups are “I don’t have retirement savings” and “less than $10K,” breaking down as follows:
One-third of Americans report they have no retirement savings.
23 percent have less than $10,000 saved.
This lack of savings indicates that just getting started on retirement planning is a significant obstacle for many people. This difficulty can be due to a lack of education on the importance of retirement savings, said Kristen Bonner, the GOBankingRates research lead for this survey. “Americans might also be feeling as though their employer match ― or lack of ― is not enough to make it worth it to open an account, as well the growing trend of changing jobs every couple years and not wanting to deal with rolling over funds from one account to another,” Bonner said.
After “less than $10K,” the most common balance Americans have saved for retirement is “$300K or more.”
A significant 13 percent of Americans’ retirement savings balances are in the top bracket.
“The fact that so many Americans do have $300,000 or more saved for retirement goes to show just how easily the amount of money in your retirement fund can grow over time if you are dedicated to contributing regularly,” Bonner said.
Women More Likely Than Men to Have No Retirement Savings
The gap between men’s and women’s retirement savings is cause for concern for anyone planning for retirement. It’s as much as 26 percent, according to the 2015 Gender Pay Gap in Financial Wellness report from financial education company Financial Finesse. Overall, GOBankingRates’ survey findings show that women are significantly less likely to be sufficiently saving for retirement:
Women are 27 percent more likely than men to say they have no retirement savings.
Two-thirds of women (63 percent) say they have no savings or less than $10,000 in retirement savings, compared with just over half (52 percent) of men.
The gap between men’s and women’s retirement savings widens as balances get higher: Whereas men and women are about as likely to have $10,000 to $99,000 saved for retirement, men are twice as likely as women to have savings balances of $200,000 or more.
One reason women fall behind is the gender pay gap. “Women cannot save as much for retirement because they are not earning as much,” Bonner said, citing 2015 U.S. Census Bureau data that shows women earned $0.79 for every $1 men earned in full-time positions. Families trying to prepare for retirement need to factor such deficits into their financial plans.
“Women also are more likely to have gaps in employment to raise children and might not be contributing to retirement accounts during those periods when they’re not working,” Huddleston said.
Women’s retirement savings needs are also greater than men’s. “Women not only need to catch up with men but they also need to save more because their medical costs tend to be higher in retirement,” Huddleston said. Women are also more likely to live longer, increasing their chances of outliving retirement funds.
To make up for anemic earnings and plan for their higher retirement costs, women need to be proactive and save aggressively. “Financial experts typically recommend saving 10 percent to 15 percent of your annual pay, so women should aim for that higher percentage to close the retirement savings gap,” Huddleston said.
Retirement Savings Correlate Closely to Age
Retirement savings are closely tied to savers’ stages of life. For young people just starting their careers, simply saving at all could be a sufficient goal, while those nearing retirement will likely want to have at least a few hundred thousands of dollars in their retirement accounts.
GOBankingRates conducted this survey in three different parts aimed at specific generational age ranges ― millennials ages 18 to 34, Gen Xers ages 35 to 54, and baby boomers and seniors ages 55 and over ― to get an accurate picture of how Americans’ savings differ by life stage:
Millennials are 40 percent more likely to not have retirement savings than Gen Xers and 50 percent more likely than people age 55 and over.
About half of Gen X is making a significant effort to save for retirement ― 48.2 percent have saved over $10,000, including 26.7 percent who have saved $100,000 or more.
Boomers and seniors are 85 percent more likely than Gen Xers to have $300,000 or more in retirement accounts and 4.6 times more likely than millennials to have saved this amount.
3 of 5 Millennials Have Started a Retirement Fund
As the youngest group surveyed, millennials are the least likely to have substantial retirement savings. Three in four (72 percent) of millennials have saved less than $10,000 or nothing at all.
Additional findings show how millennials’ retirement savings reflect their life stage:
42 percent of millennials indicated they have no retirement savings.
The number of millennials with no retirement savings yet is 52 percent for younger millennials ages 18 to 24 but a more reasonable 36 percent for older millennials ages 25 to 34.
The most common balances that younger millennials have saved are “less than $10K,” at 30 percent, and “$10K to $49K,” at 11 percent.
Older millennials are twice as likely as younger millennials to have saved $10,000 to $49,000, at 14 percent versus 7 percent, respectively.
Overall, fewer millennials are saving for retirement than should be, but many millennials’ retirement savings are actually on track, especially among the those ages 25 to 34. For this group, saving now and saving regularly will make all the difference.
“The earlier you start saving, the easier it is ― really,” Huddleston said. “Thanks to the power of compounding, if you start regularly setting aside even small amounts as soon as you start working, you could easily have enough for a comfortable retirement.”
Saving as little as 5 percent of your income can make a big difference long term, Bonner added. “Make sure to always take advantage of any employer matches, and automatically transfer funds from your paycheck to your retirement fund so that you do not even think of that money as disposable income,” she said.
Gen X Still Playing Catch-Up on Retirement After Great Recession
Although some Gen Xers are hitting their retirement savings goals, just over half (52 percent) still have less than $10,000 in retirement savings. A big contributor to this low amount could be the Great Recession, which hit Gen X the hardest, costing members of this generation 45 percent of their net wealth on average, according to The Fiscal Times. This loss was a major setback for a generation that is saddled with a wide range of financial obligations, from mortgages to aging parents and children entering adulthood.
Younger Gen Xers are falling further behind on retirement savings than their older counterparts, who are twice as likely to have retirement savings with high balances:
Both younger Gen Xers (ages 35 to 44) and older Gen Xers (45 to 54) are equally as likely to not have a retirement account, at 31 percent.
Among younger Gen Xers who have a retirement account, most have lower balances of less than $50,000.
Older Gen Xers’ balances reflect good starting contributions that could earn considerable compound interest over time:
An impressive 40 percent of older Gen Xers have managed to save $50,000 or more in retirement accounts.
Over half of those older Gen Xers in that 40 percent have balances of $200,000 to $299,000 (7 percent) or $300,000 or more (15 percent).
“These figures are encouraging,” Huddleston said, “but this generation still could be setting aside a lot more if they actually want to have a comfortable retirement.”
Only 1 in 4 People Age 55 and Over Has More Than $300K Saved
As respondents get older, the gap between the savers and the save-nots widens. Although a larger portion of people age 55 and over report high-balance retirement funds, there remains a significant subgroup that has little to no retirement savings:
About 3 in 10 of respondents age 55 and over have no retirement savings.
26 percent report retirement savings with balances of under $50,000, an amount that is insufficient for people nearing retirement age.
Over half (54 percent) of people age 55 and over have balances far behind typical retirement fund benchmarks for their age group.
Some of those 55 and over who lack savings might not need them, Huddleston pointed out. “[They] might be among the dwindling group of Americans who will get a pension and will benefit from having an employer who set aside retirement funds for them.”
More likely, however, those without retirement savings couldn’t or didn’t make saving for retirement a financial priority. “Without savings of their own, they’ll have to rely solely on Social Security,” Huddleston said. Baby boomers most often cited Social Security as their expected primary source of retirement income (35 percent), according to a 2015 report from the Transamerica Center for Retirement Studies, whereas Gen Xers and millennials expected retirement accounts like 401ks or IRAs to be their main source of retirement income.
On the other end of the spectrum, many baby boomers and seniors have successfully socked away substantial savings in retirement accounts:
26 percent of baby boomers nearing retirement (ages 55 to 64) report healthy retirement savings with balances of $200,000 or more.
31 percent of seniors at or above the retirement age (65 and over) have balances of $200,000 or more.
“Those who have saved more than $300,000 have clearly made saving for retirement a priority and want a more comfortable lifestyle in retirement than what Social Security benefits will afford them,” Huddleston said.
About 75% of Americans Over 40 Are Behind on Saving for Retirement
Using this survey data as a snapshot of Americans’ retirement savings progress ― or lack thereof ― GOBankingRates sought to get a better look at how many people are actually on track to retire comfortably. To do so, GOBankingRates compared survey responses to key retirement savings benchmarks based on a savings rate of 5 percent of income and checkpoints sourced from J.P. Morgan Asset Management, as well as Census Bureau data on median incomes by age range. Based on those data sets, GOBankingRates determined that people of the following ages, representative of the survey age groups, are on track or behind at the following rates:
Age
Median Income
Retirement Savings Benchmark
Percentage on Track
Percentage Behind
24
$34,605
Started a retirement fund
48%
52%
30
$54,243
$16,272.90
33%
67%
40
$66,693
$100,039.50
20%
80%
50
$70,832
$212,496.00
22%
78%
60
$60,580
$260,494.00
26%
74%
A little less than half of people ages 18 to 24 are on track simply by having started a retirement fund. Among the people just a few years ahead of them, around age 30, significantly more ― two-thirds ― are already behind on saving for retirement.
Younger people are in the best position to recover if they’ve fallen behind because they have more time to use compound interest to their advantage. “Those who are in their 20s and 30s with $10,000 or less in retirement savings still have time to catch up if they make saving a priority,” Huddleston said.
For those age 40 and over, however, the picture is bleaker: Among those in their 40s and 50s, four in five savers have balances that fall behind the benchmarks for their age groups, which means only about 20 percent are on track for retirement. Among those 60 and over, about a quarter have sufficient retirement savings, but the other 74 percent are still behind.
“The real problem is procrastination,” Huddleston said. “People naturally tend to focus on the bills that are due today ― and the things they want now ― and assume they’ll have time to save for retirement later. But, before you know it, 20 or 30 years have passed; you’re approaching retirement age but you don’t have enough saved to retire.”
How to Catch Up If You’re Behind on Retirement Savings
With less time to save as each year passes, these older age groups need to reevaluate their financial priorities. The large majority of Americans age 40 and over who are behind on retirement savings can potentially catch up or compensate for their anemic retirement accounts by making changes to their savings plans now.
1. Stick to a Routine
The first step is to start saving regularly. Consistent savings, even in just small amounts, is the best way to ensure a retirement fund is growing. “Day to day, it might not seem as if the balance in your 401k or IRA is increasing significantly, but 10, 20, 30 years from now, your future self will be thanking you,” Bonner said.
If money is put into high-yield accounts or invested wisely, compound interest on small savings can help produce a sizable nest egg. “If you wait until you’re 40 or so to start saving, you’d have to save three or four times as much ― or more ― each month to accumulate the same amount as those who start saving earlier,” Huddleston said.
2. Prioritize Changes That Have Long-Term Benefits
Upping retirement savings contributions is also necessary to catch up. People age 50 and over can make catch-up contributions of $6,000 to a traditional 401k, for example, in addition to the regular $18,000 annual 401k contribution limit, according to the IRS.
Those nearing retirement can also help prepare for retirement by reducing spending and paying down debt, which will trim monthly expenses and enable them to stretch their savings further once they retire.
3. Save Like You’ll Retire Tomorrow
Lastly, those nearing retirement might need to adjust their expectations, Huddleston said. “Older Americans with little saved will have to work a lot harder to set aside more and likely will have to work longer ― or never fully retire,” she said.
Many Americans do not recognize retirement savings should be an urgent priority in their lives, according to Bonner. “The trending attitude today is to ‘enjoy life to the fullest,'” she said. “However, even though retirement seems far away to many people, and they think that there is still plenty of time to begin saving, Americans must make their future selves a priority and take all necessary steps to set themselves up for a comfortable financial future.”
Sponsored Links by Zergnet
People who view retirement as something that is just around the corner can help themselves stay on top of their retirement contributions so that they don’t fall behind. By keeping retirement at the top of the financial priority list, it can become less of a far-off dream and more of a soon-to-be reality.
Methodology: GOBankingRates’ survey posed the question, “By your best estimate, how much money do you have saved for retirement?” Respondents could select one of the following answer options: 1) “Less than $10K,” 2) “$10K to $49K,” 3) “$50K to $99K,” 4) “$100K to $199K,” 5) “$200K to $299K,” 6) “$300K or more,” or 7) “I don’t have retirement savings.” Responses were collected through three separate Google Consumer Surveys conducted simultaneously Jan. 21-23, 2016, and responses are representative of the U.S. online population.
Each survey targeted one of three age groups: 1) ages 18 to 34, which collected 1,502 responses with a 2.3 percent margin of error; 2) ages 35 to 54, which collected 1,500 responses with a 1.2 percent margin of error; and 3) age 55 and over, which collected 1,504 responses with a 4.3 percent margin of error. The overall and gender-based analysis looked at the combined responses provided in all three surveys; for the gender analysis, only responses for which gender demographic information was provided were included.
When you first sit in the cockpit of an electric-powered airplane, you see nothing out of the ordinary. However, touch the Start button and it strikes you immediately: an eerie silence. There is no roar, no engine vibration, just the hum of electricity and the soft whoosh of the propeller. You can converse easily with the person in the next seat, without headphones. The silence is a boon to both those in the cockpit and those on the ground below.
You rev the motor not with a throttle but a rheostat, and its high torque, available over a magnificently wide band of motor speeds, is conveyed to the propeller directly, with no power-sapping transmission. At 20 kilograms (45 pounds), the motor can be held in two hands, and it measures only 10 centimeters deep and 30 cm in diameter. An equivalent internal-combustion engine weighs about seven times as much and occupies some 120 by 90 by 90 cm. In part because of the motor’s wonderful efficiency—it turns 95 percent of its electrical energy directly into work—an hour’s flight in this electric plane consumes just US $3 worth of electricity, versus $40 worth of gasoline in a single-engine airplane. With one moving part in the electric motor, e-planes also cost less to maintain and, in the two-seater category, less to buy in the first place.
It’s the cost advantage, even more than the silent operation, that is most striking to a professional pilot. Flying is an expensive business. And, as technologists have shown time and again, if you bring down the cost of a product dramatically, you effectively create an entirely new product. Look no further than the $300 supercomputer in your pocket.
At my company, Bye Aerospace, in Englewood, Colo., we have designed and built a two-seat aircraft called the Sun Flyer that runs on electricity alone. We expect to fly the plane, with the specs described above, later this year. We designed the aircraft for the niche application of pilot training, where the inability to carry a heavy payload or fly for more than 3 hours straight is not a problem and where cost is a major factor. But we believe that pilot training will be just the beginning of electric aviation. As batteries advance and as engineers begin designing hybrid propulsion systems pairing motors with engines, larger aircraft will make the transition to electricity. Such planes will eventually take over most short-hop, hub-and-spoke commuter flights, creating an affordable and quiet air service that will eventually reach right into urban areas, thereby giving rise to an entirely new category of convenient, low-cost aviation.
Photo: Bye AerospaceBatteries are Included: The Sun Flyer fills the perfect electric-plane niche, that of the trainer craft. Such airplanes fly for a relatively short time, carry only two people, and are quiet enough to be based near populated areas. The key to the airplane’s feasibility is the development of more powerful batteries, more efficient motors, and power-saving tricks, such as turning off the motor when it’s not needed and using it to recover energy while descending or slowing down.
I will never forget my first experience with electric propulsion, during the early days of Tesla Motors, in the mid-2000s. I was a guest, visiting Tesla’s research warehouse in the San Francisco Bay Area, and there I rode along with a test driver in the prototype of the company’s first Roadster. Looking over the electric components then available—the motor was large and heavy, and the gearbox, inverter, and batteries were all relatively crude—I found it hard to imagine why anyone would take an electric car over a gasoline-powered one. But then the driver’s foot hit the accelerator, the car lunged forward like a rocket, and I was a believer.
Electric flight has advanced on the backs of such efforts, themselves the beneficiaries of the cellphone industry’s work on battery technology and power-management software. I founded Bye Aerospace in 2007 to build electric planes and capitalize on three advances in particular. The first one is improved lithium-ion batteries. The second is efficient and lightweight electric motors and controllers. And the third is aerodynamic design—specifically a long, low-drag fuselage with efficient long-wing aerodynamics, constructed with a very lightweight and strong carbon composite.
Our first project was the Silent Falcon, a 14-kg (30-lb.) solar-electric fixed-wing drone. We optimized the power system for long-duration flight by including only enough lithium-ion batteries to supply peak power for climbing. We designed and built a pneumatic rail launcher so that the plane does not have to take off under its own power. When it reaches the desired altitude, it can cruise for 5 to 7 hours, supplementing a trickle of battery power with electricity from solar panels spanning the 4.2-meter (14-foot) wings. The solar panels turn sunlight into electricity with 11 percent efficiency, effectively doubling the flight time that the batteries alone could provide. Nowadays, the best solar cells are rated at 26 percent efficiency, and they will allow the plane to stay up for 10 to 12 hours.
The Silent Falcon can carry various payloads, including conventional and infrared cameras and sensors useful for surveilling border areas, inspecting power lines, gathering information on forest fires, and many other uses. It flies with a completely autonomous plan. You give it a general order—where you want it to go, how high, and over what location—and then hit the Send button. The Silent Falcon started production in 2015, becoming the world’s first commercial solar-electric unmanned aerial vehicle, or UAV.
Our next project was to develop, with the help of subcontractors around the world, an electric propulsion system for use in an existing full-size airplane: the Cessna 172 four-seater, the most popular airplane in the world. After flying the converted Cessna for a few dozen short hops, we followed up with a purpose-built, single-seat electric airplane. We’ve taken each of these test planes on 20-odd test flights.
Our first problem was finding a suitably light, efficient motor. Years ago, in the early days of electric flight, we encountered aviators who considered dropping (or actually did drop) a conventional electric motor into an airplane. But it weighed too much because of the heavy motor casings, the elaborate liquid-cooling systems, and the complex gearboxes. Our approach has been to work with such companies as Enstroj, Geiger, Siemens, and UQM, which have designed electric motors specifically for aerospace applications.
These aviation-optimized motors differ in several respects from the conventional sort. They can weigh less because they don’t need as much starting power at low revolutions per minute. An airplane has far less inertia to overcome while slowly accelerating along a runway than a car does as it kicks off from a stoplight. Aviation motors can dispense with the heavy motor casing because they don’t need to be as rugged as auto motors, which are frequently jostled by ruts and potholes and stressed by vibration and high torque.
In a Tesla, the power might peak at around 7,000 rpm, and that is fine for driving a car. But when you’re turning a propeller, you need the power curve to peak much sooner, at one-third the revs— about 2,000 rpm. It would be a shame to achieve the shape of that power curve at that lower speed by adding the deadweight of a complex gearbox; therefore, our supplier furnishes us with motors that have the appropriate windings and a motor controller programmed to deliver such a power curve. At 2,000 rpm, the motor can thus directly drive the propeller. As a result, we’ve been able to progress from power plants that developed just 1 to 2 kilowatts per kilogram to models generating more than 5 kW/kg.
Even more important was the lithium-ion battery technology, the steady improvement of which over the past 15 years was key to making our project possible. Bye Aerospace has worked with Panasonic and Dow Kokam; currently we use a battery pack composed of LG Chem’s 18650 lithium-ion batteries, so called because they’re 18 millimeters in diameter and 65 mm long, or a little larger than a standard AA battery. LG Chem’s cell has a record-breaking energy density of 260 watt-hours per kilogram, about 2.5 times as great as the batteries we had when we began working on electric aviation. Each cell also has a robust discharge capability, up to about 10 amperes. Our 330-kg battery pack easily allows normal flight, putting out a steady 18 to 25 kW and up to 80 kW during takeoff. The total energy storage capacity of the battery pack is 83 kWh.
That peak power rating is generally most needed toward the end of a flight, when the state of charge drops and voltage gets low. Just as important, the battery can charge quite rapidly; all we need is the kind of supercharging outlets now available for electric cars.
To use lithium-ion batteries in an airplane, you must take safety precautions beyond those required for a car. For example, we use a packaging system to contain heat and at the same time allow the venting of any vapors that may be created. An electronic safety system monitors each cell during operations, avoiding both under- and overcharges. Our battery-management system monitors all these elements and feeds the corresponding data to the overall information-management system in the cockpit.
Should something go wrong with the batteries in midflight, an alarm light flashes in the cockpit and the pilot can disconnect the batteries, either electronically or mechanically. If this happens, the pilot can then glide back to the airfield, which the plane will always be near, given that it is serving as a trainer.
A key precaution, pioneered in the original Tesla Roadster, is to separate the individual cells with an air gap, so that if one cell overheats, the problem can’t easily propagate to its neighbors. Air cooling is sufficient for the batteries, but we use liquid cooling for the motor and controller, which throw off a lot of heat in certain situations (such as a full-power takeoff and climb-out from a Phoenix airport).
The airframe design takes advantage of advanced composites, which allowed us to produce a wing and fuselage design that is both lightweight and strong. We used advanced aerodynamics design tools to shape the fuselage airfoils and wing for a very low drag without compromising easy handling.
Much of the aerodynamic payoff of our electric propulsion system is centered in the cowling area in the airplane’s nose. The motor sits in this space, between the propeller and the cockpit, and it is so small that we could squeeze the cowling down to an elegant taper, smoothing airflow along the entire fuselage. This allows us to reduce air resistance by 15 percent, as compared with what a conventional plane such as a single-engine Cessna would offer. Also, because the electric motor throws off a lot less heat than a gasoline engine, you need less air cooling and thus can manage with smaller air inlets. The result is less parasitic cooling drag and a nicer appearance (if we do say so ourselves).
The sleek airplane nose also increases propeller efficiency. On a conventional airplane, much of the inner span of the propeller is blocked because of the large motor behind it. In a properly designed electric airplane, the entire propeller blade is in open air, producing considerably more thrust. A bonus: The airplane can regenerate energy during braking, just as electric cars do. When the pilot slows down or descends, the propeller becomes a windmill, running the motor as a generator to recharge the batteries. In the sort of airport traffic pattern typical for general aviation and student-pilot training, this energy savings comes to about 13 percent. In other words, if a plane lands having apparently used 8.7 kWh during the flight, it has actually used 10 kWh—the propeller-recoup system put back roughly 1.3 kWh while flying in the traffic pattern.
The commercial rationale for training aircraft like the Sun Flyer is the projected crisis in the supply of qualified airline pilots. Last year, Boeing made a staggering projection: The world will need an additional 617,000 commercial pilots by the year 2035. To put that in perspective, the total number of commercial pilots in the world today has been estimated at 130,000.
The growing scarcity of pilots has various causes. Fewer trained pilots are coming out of the world’s large militaries. At the same time, it’s increasingly expensive to obtain a commercial airline pilot’s license from civilian pilot schools, as more hours of flight time are now required, some 1,500 flight hours in total. On top of that, the age of the typical training aircraft—in the United States, it’s probably a Cessna or a Piper—now averages 50 years, according to the General Aviation Manufacturers Association.
The Sun Flyer, manufactured by our Aero Electric Aircraft Corp. (AEAC) division, is currently one of a kind, but it won’t be much longer. NASA has announced a project to develop an experimental electric airplane, the X-57 Electric Research Plane, which would be the first new experimental aircraft the agency has designed in five years. (Because NASA is a government agency, its plane would not be a commercial competitor of the Sun Flyer.) Airbus has flown a small experimental electric aircraft several times over the last few years, but it now focuses on hybrid-electric commercial transport (which I’ll discuss in a moment). Pipistrel, a Slovenian maker of gliders and light-sport aircraft (LSA), has flown experimental electric prototypes for several years. However, the future of such craft is unclear because the U.S. Federal Aviation Administration and the European equivalent, EASA, do not now allow any LSAs, electric or otherwise, to be used as commercial trainers.
For now, we are sticking to our niche in training. AEAC is working with Redbird Flight Simulations, in Austin, Texas, to offer a comprehensive training system. The Spartan College of Aeronautics and Technology, in Tulsa, Okla., has placed a deposit toward the purchase of 25 of our Sun Flyers, and it has also signed a training-related agreement that will help us to develop a complete training system. Other flight schools and individual pilots have made deposits and options to buy, bringing the total to more than 100 Sun Flyer deposits and options; another 100 deposits are in various stages of negotiation.
The Sun Flyer aircraft will be FAA certified in the United States according to standard-category, day-night visual flight rules with a target gross weight of less than 864 kg (1,900 lb.). And the airplane will not compromise on performance: We are aiming for a climb rate of 430 meters (1,450 feet) per minute; for comparison, a Cessna 172 climbs at about 210 meters (700 feet) per minute.
Photo: Bye Aerospace
Why aren’t we pursuing a larger commercial electric airplane? The main reason is the energy-to-speed ratio. The bigger and faster an electric airplane gets, the greater the number of batteries it needs and the greater the share of its weight those batteries constitute. The underlying problem is the same for any moving object: The drag on a vehicle goes up as the square of speed. If you double speed, you increase drag by a factor of four. In a relatively slow airplane, like a flight trainer, electric aviation is a serious contender, but it will take years before batteries have enough energy density to power airplanes that are substantially faster and heavier than our models.
While we wait for pure-electric technology to mature, we can use hybrid-electric solutions, which operate in planes on the same principle as they do in cars. Because you need about four times as much energy during takeoff as when cruising, you can get that extra burst of energy by running the electric motor at peak power; this is possible because motors have such a wide band of efficiency. Then, we could use a small internal-combustion engine running at optimal rpm to recharge the battery and sustain cruising speed. As a side benefit, relying on the electric motor for takeoff spares the neighbors a lot of noise.
We are in the midst of the monumental task of making the two-seat Sun Flyer 2 and the four-seat Sun Flyer 4 a viable, commercial reality. Some still say it can’t be done. I counter that nothing of any fundamental and lasting value can be accomplished without trying things that have never been done before. Thanks to visionaries and pioneers, electric airplanes are not just an intriguing possibility. They are a reality.
This article appears in the September 2017 print issue as “Fly the Electric Skies.”