It's a little known fact that the PostGIS geography type since PostGIS 2.2 (well was introduced in 2.1 I think but had a bug in it until 2.1.4 or so), supports any spheroidal spatial reference system that measures in degrees. When an srid is not specified, it defaults to using 4326, Earth WGS 84 long lat.
Here is an example to demonstrate. Suppose you were doing research about Mars and all your observations on Mars are in longitude/latitude of Mars. You would add an entry such as this one to your spatial_ref_sys table, using this code:
Given that Mars is a smaller planet than earth, you would expect any distance between two locations on the planet to be lower than same on Earth.
We'll test this out.
If you’ve read an article or two about economic inequality in the United States at any point in the past decade, chances are you’ve come across a chart like this:
The left-leaning Economic Policy Institute has been producing that graphic, and ones like it, for years now. It shows that in the aftermath of World War II through the early 1970s, workers got paid more as the economy grew. Median hourly compensation rose in tandem with productivity (the amount of economic output workers could produce per hour).
But something changed in 1973 or thereabouts. While productivity kept growing, and the economy as a whole did too (with some temporary setbacks during recessions), the average worker’s pay package did not. The implication is clear: The economy broke at a certain point, and now workers are getting screwed.
The point is especially powerful when you consider that the share of income going to the top 1 percent, and particularly the top 0.1 percent and top 0.01 percent, has skyrocketed:
Now there’s a new graph to add to the pile, one that is uncommonly thorough and precise and gives a portrait of how incomes have grown for each segment of the population from 1913 to the present. Produced by Berkeley economist Emmanuel Saez and his frequent collaborators Thomas Piketty (EHESS), and Gabriel Zucman (Berkeley), and using a mix of tax and survey data, it shows compellingly that income gains in recent decades have gone overwhelmingly to the ultrarich, not the middle class:
This is not just another chart. The data it uses directly answers conservative attempts to claim that middle-class incomes really have grown substantially, and that the rich aren’t taking all the economic gains. The conservatives argued that the standard data used to illustrate inequality is incomplete; Saez, Piketty, and Zucman have completed it, and demonstrated that income growth has been quite low for the middle class and very unequally distributed between them and the wealthy.
The background context for the new research is that a growing number of conservative economists and policy analysts, most notably Cornell’s Richard Burkhauser and the Joint Economic Committee’s Scott Winship, have argued that even though the data is right, the takeaway message (that the middle class has barely benefited since the 1970s, or that it’s gained a lot less than it should given productivity growth) is false.
They argue that charts like the first two above make a number of choices that cause them to understate how much things have improved for poor and middle-class households. Among them:
They don’t include taxes (including refundable tax credits like the earned income tax credit) or transfer programs (food stamps, Medicaid, etc.) Those help poor and middle-class people more than the rich, and so including them reveals more income growth for people at the bottom and middle.
The charts adjust for inflation using the Consumer Price Index (CPI), which many economists believe overstates inflation. A slower-growing inflation measure, like the Personal Consumption Expenditures (PCE) index, shows incomes rising more because less of the increase from the rise in incomes from the 1970s to the present is attributable to inflation.
Many charts about inequality, like the Piketty/Saez one above showing growth in the top 0.1 percent’s share of income, use data from IRS tax returns. That’s great in some ways (you get more data than if you just take a survey, and tax records are more accurate than people’s self-reported incomes), but it necessarily leaves out nontaxable benefits that people get from their employers, like health insurance or pension contributions. A tax return can also come from a single person, a couple with no kids, or a couple with many kids. Because of declining fertility, the number of people in each “tax unit” has declined over the years, meaning more income growth per person than tax data on its own implies.
When you put those factors together, the conservatives’ contention is things aren’t all that bad — the standard of living of middle-class families has grown quite a bit from the 1970s to the present.
Most liberals and leftists concerned with inequality have argued with this not by disputing the underlying numbers but by pointing out that it’s a rather odd conservative defense of the way the economy works.
“So the argument (of the right) has to be: cash market income of the bottom 99 percent of adults has stagnated but the bottom 99 percent get much more expensive private and government provided health care benefits, some more government transfers, and they have fewer kids,” Saez, who pioneered the use of tax data to study inequality, told the New York Times’s Thomas Edsall in 2012. “This does not seem like a great situation, especially from a conservative point of view.”
But the new research by Saez, Piketty, and Zucman suggests that might have been conceding too much. They attempt to track down where all the income in the United States from 1913 to the present has gone: how much has gone to the bottom 20 percent, how much to the top 1 percent, how much to everyone in between.
With the results, called “distributional national accounts,” researchers can see exactly where economic growth is going, and how much each group is seeing its income rise relative to the overall economy.
Crucially, the way that Saez, Piketty, and Zucman calculated the numbers answers basically all of the conservative critiques. They use tax data on incomes as their base, but then fold in the cost of employer-provided health care, pensions, and other benefits, as measured by survey data. They also add in the effect of all taxes and government transfer programs like food stamps or Medicaid. They measure changes in income among adults, rather than households or tax units, meaning changes in family size don’t matter. And they use the slower-growing inflation metric, rather than CPI.
The chart above shows how much the incomes of each group grew, on average, every year from 1980 to 2014. The two lines show both pre- and post-tax incomes.
The implication is clear. People at or below the median income saw their incomes rise by 1 percent or less every year during that period. That isn’t nothing, but it’s hardly great. At the very bottom, some people have seen incomes fall pre-tax; while most poor households get government assistance to help with that, programs like food stamps or the earned income tax credit fail to reach about 20 to 25 percent of the people they’re meant to help.
But the rich? Boy, the rich made out like bandits. The top 1 percent, but really the top 0.1, top 0.01, and even top 0.001 percent (that last group included only 2,344 adults in 2014) saw really fast, dramatic growth in their incomes after 1980. Contrary to some recent commentary, the large increase in inequality isn’t due to the top 20 percent; affluent, educated professionals with low-six-figure salaries and nice homes in good suburbs aren’t driving this. Their incomes are growing about 1.5 percent a year — not bad, but not that much better than the middle class either. The major spike is in the top 1 percent (adults receiving an average of $1.31 million per year each out of national income) and above, where annual income grew by 3, 4, 5, even 6 percent.
This doesn’t appear to have been the way the economy worked from, say, 1946 to 1980. On the request of the New York Times’s David Leonhardt (who has a knack for smart suggestions for research from empirically minded economists), Piketty, Saez, and Zucman reproduced the same graph for every 34-year period from 1946 to the present. Here’s how the 1946-1980 graph compares to the 1980-2014 graph:
If the 1980-2014 graph was staggering, the 1946-1980 one is even more so. It shows that the uneven distribution of economic growth in recent decades is not the way things have always been.
In the 1950s and ’60s, poor and middle-income Americans actually saw greater income growth than rich ones. The big fat spike at the end of the chart doesn’t exist in that period. The richest of the rich got rather muted increases in income. And everyone’s incomerose a great deal faster from 1946 to 1980 than the bottom 95 percent’s did from 1980 to 2014. The rich saw incomes rise more slowly then, but their incomes were still growing much faster than those of today’s middle class.
What explains this dramatic change? That part is much less well-known. But one theory, which Saez, Piketty, and Harvard economist Stefanie Stantcheva have floated, holds that very high marginal tax rates (the top rate on wages was 91 percent for most of the 1950s) discouraged the rich from making very large salaries. In particular, it prevented them from bargaining with their employers to divert money from shareholders or lower-ranked staffers into higher executive compensation.
Think of it this way. In 2017, the top federal income tax rate is 39.6 percent. So if a CEO convinces his company to raise his pay from $5 million to $6 million, he’ll get to keep $604,000 of that raise (I’m ignoring state and payroll taxes for the sake of simplicity). That’s a really healthy after-tax raise, so that CEO has a very big incentive to lobby for pay hikes like that. But in 1955, the top federal income tax rate was 91 percent. So that same pay raise would only net him $90,000. Not nothing, but a way, way smaller windfall. So back then, executives had less reason to try to fight to earn more, which kept down inequality.
Saez, Piketty, and Stantcheva argue that the main effect was to deter wage bargaining— that is, high earners used to be much less aggressive about fighting for raises. They don’t think the high tax rates actually stopped high earners from engaging in useful economic activity, or did much to harm economic growth.
Conservative and libertarian economists, naturally, disagree, and contend that rates that high have massive economic costs. The actual average tax rate that the richest Americans paid in the 1950s was only slightly higher than the average rate today (42 percent then versus 36.4 percent now); because there was less inequality, very few people were rich enough to pay the top rates, and there were many more deductions and loopholes. That also limited the amount of revenue the tax rates could raise for social programs.
But if nothing else, the Saez, Piketty, and Zucman research confirms that something really did change in the 1970s and ’80s, to make the economy less rewarding to the middle-class and poor and more rewarding to the rich. That’s an important finding, and given how careful their latest work is to include all sources of income, it’s going to be a hard one to rebut.
Tomorrow I head for “Sci Foo” at the Googleplex. I proposed a discussion session there, “Are We Becoming Less Cooperative? If So, Why?” and I’d like to use today’s blog to help me formulate my ideas for this session. So here it goes.
The title of this blog is a paraphrase of a 1995 article by Robert Putnam, “The Strange Disappearance of Civic America.” Robert Putnam is a political scientist at Harvard who over the last 20 years has been documenting the decline of ‘social capital’ in America.
Putnam has argued, in particular, that last several decades saw lower levels of trust in government, lower levels of civic participation, lower connectedness among ordinary Americans, and lower social cooperation.
This is a puzzling development, because from its inception the American society was characterized, to an unusual degree, by the density of associational ties and an abundance of social capital. Almost 200 years ago that discerning observer of social life, Alexis de Tocqueville, wrote about the exceptional ability of Americans to form voluntary associations and, more generally, to cooperate in solving problems that required concerted collective action. This capacity for cooperation apparently lasted into the post-World War II era, but several indicators suggest that during the last 3-4 decades it has been unraveling.
Robert Putnam points to such indicators as the participation rate in voluntary organizations (Masonic lodges, Parent-Teacher Associations, sports clubs and bowling leagues…):
If between 1900 and 1960 the general trend for the mean membership rate was to increase, during the 1970s this trend reversed itself. Participation has been declining ever since. Another indicator is the level of generalized trust, including trust in such institutions as the state:
Putnam’s thesis has been quite controversial. But during the two decades since he first proposed it various measures of social capital continued to decline, strengthening his case. In some cases there were substantial up and down fluctuations, as with trust in government (the graph above). Yet note how each trough is lower than the preceding one, and peaks reach nowhere near the level of confidence last observed during the 1960s.
While Putnam’s focus was primarily on the associational life of ordinary Americans, the changes that he documented about unraveling social cooperation have affected American social life at all levels, including state and federal governance and relations between economic classes (e.g., employers and employees).
One important factor, closely related to social cooperation, is the degree of economic inequality. Both general theories of social evolution and empirical studies suggest that inequality is corrosive of cooperation. As Emmanuel Saez, Thomas Piketty, and coworkers have demonstrated using sophisticated analyses of income tax returns, income inequality declined during most of the twentieth century, but it turned a corner in the 1970s and has been increasing ever since:
Furthermore, as I have shown in my own research, such cycles in economic inequality are actually recurrent features in the history of complex societies. More details are available in my Aeon article and in The Double Helix of Inequality and Well-Being.
In these articles I argue that general well-being (and high levels of social cooperation) tends to move in the opposite direction from inequality. During the ‘disintegrative phases’ inequality is high while well-being and cooperation are low. During the ‘integrative phases’ inequality is low, while well-being and cooperation are high. This antagonistic association produces a characteristic ‘double helix’ pattern in the data on well-being and inequality:
The cyclic pattern of cooperation versus discord is reflected in the ‘polarization index’ developed by political scientists Keith Poole and Howard Rosenthal:
This graph shows that there were two periods of unusually low polarization and high cooperation among the elites: the 1820s (also known as the ‘Era of Good Feelings’) and the 1950s. In contrast, the Gilded Age (1870-1900) and the last three decades since 1980 (which many commentators have dubbed ‘The Second Gilded Age’) were both periods of growing economic inequality and declining cooperation among the political elites.
You may think that political polarization is not so bad. What’s wrong with different political parties holding strong opinions about how this country should be governed? The problem is, the clash of ideas inevitably leads to the clash of personalities. As political positions become separated by a deep ideological gulf the capacity for compromise disappears and political leaders become increasingly intransigent. The end result is political gridlock, something that became abundantly clear in the last few years, but has been developing over the last few decades. Take a look at this graph, showing the proportion of legislation that was either filibustered in the Senate, or threatened with a filibuster:
Source: Sinclair, Barbara. 2006. Party wars: polarization and the politics of national policy making. Norman: University of Oklahoma Press.
The change is from 7 to 70 percent! Or the confirmation rates for judicial nominations:
Did they decrease from nearly 100 percent in the 1960s to around 40 percent today because the judges today are more corrupt and incompetent? Or is it a reflection of an increasing political gridlock – the failure of cooperation among the governing elites?
To anybody who reads political news regularly there can be no doubt that cooperation among the American political elites has been unraveling. This is clear from the quantitative proxies I plotted above, and it is also evident from simply hearing what our political leaders say about each other.
In addition to the collapse of cooperation among the political elites and growing divisions between the elites and general population, we also see the relations between employers and employees becoming less cooperative and more antagonistic. I have addressed this issue in my blog A Proxy for Non-Market Forces (Why Real Wages Stopped Growing III).
What we have then, is a ‘strange disappearance’ of cooperation at all levels within the American society: from the neighborhood bowling leagues to the national-level economic and political institutes. What’s worse, it is disappearing from our lexicon:
In our search of explanations (which is the first and necessary step before proposing remedies) we need to look for fundamental factors that affect social cooperation. Yes, Americans watch more TV, but is this really why they bowl together less? Yes, news media is reducing everything to five-second sound bites, but is this why we have the political gridlock? Social cooperation waxes and wanes in most complex societies, following a long cycle. This is a generic pattern in not only our own society but also in ancient and medieval empires. Where there are recurrent empirical patterns, there must be general explanations. This means that things are not hopeless – we can figure out why cooperation is declining, and how to fix this problem.
Notes on the margin: after Sci Foo I go to the Evolution meetings in Snowbird, Utah. As I will be away from home for a week, I am taking a short break from blogging.
In my first decade writing Makefiles, I developed the bad habit of
liberally using GNU Make’s extensions. I didn’t know the line between
GNU Make and the portable features guaranteed by POSIX. Usually it
didn’t matter much, but it would become an annoyance when building on
non-Linux systems, such as on the various BSDs. I’d have to specifically
install GNU Make, then remember to invoke it (i.e. as gmake) instead
of the system’s make.
I’ve since become familiar and comfortable with make’s official
specification, and I’ve spend the last year writing strictly
portable Makefiles. Not only has are my builds now portable across all
unix-like systems, my Makefiles are cleaner and more robust. Many of the
common make extensions — conditionals in particular — lead to fragile,
complicated Makefiles and are best avoided anyway. It’s important to be
able to trust your build system to do its job correctly.
This tutorial should be suitable for make beginners who have never
written their own Makefiles before, as well as experienced developers
who want to learn how to write portable Makefiles. Regardless, in
order to understand the examples you must be familiar with the usual
steps for building programs on the command line (compiler, linker,
object files, etc.). I’m not going to suggest any fancy tricks nor
provide any sort of standard starting template. Makefiles should be dead
simple when the project is small, and grow in a predictable, clean
fashion alongside the project.
I’m not going to cover every feature. You’ll need to read the
specification for yourself to learn it all. This tutorial will go over
the important features as well as the common conventions. It’s important
to follow established conventions so that people using your Makefiles
will know what to expect and how to accomplish the basic tasks.
If you’re running Debian, or a Debian derivative such as Ubuntu, the
bmake and freebsd-buildutils packages will provide the bmake andfmake programs respectively. These alternative make implementations
are very useful for testing your Makefiles’ portability, should you
accidentally make use of a GNU Make feature. It’s not perfect since each
implements some of the same extensions as GNU Make, but it will catch
some common mistakes.
What’s in a Makefile?
I am free, no matter what rules surround me. If I find them tolerable,
I tolerate them; if I find them too obnoxious, I break them. I am free
because I know that I alone am morally responsible for everything I
do. ―Robert A. Heinlein
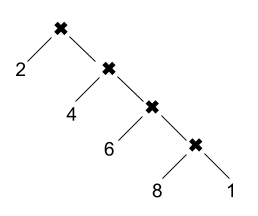
At make’s core are one or more dependency trees, constructed from
rules. Each vertex in the tree is called a target. The final
products of the build (executable, document, etc.) are the tree roots. A
Makefile specifies the dependency trees and supplies the shell commands
to produce a target from its prerequisites.
In this illustration, the “.c” files are source files that are written
by hand, not generated by commands, so they have no prerequisites. The
syntax for specifying one or more edges in this dependency tree is
simple:
target [target...]: [prerequisite...]
While technically multiple targets can be specified in a single rule,
this is unusual. Typically each target is specified in its own rule. To
specify the tree in the illustration above:
The order of these rules doesn’t matter. The entire Makefile is parsed
before any actions are taken, so the tree’s vertices and edges can be
specified in any order. There’s one exception: the first non-special
target in a Makefile is the default target. This target is selected
implicitly when make is invoked without choosing a target. It should be
something sensible, so that a user can blindly run make and get a useful
result.
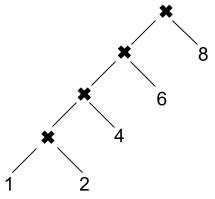
A target can be specified more than once. Any new prerequisites are
appended to the previously-given prerequisites. For example, this
Makefile is identical to the previous, though it’s typically not written
this way:
There are six special targets that are used to change the behavior
of make itself. All have uppercase names and start with a period.
Names fitting this pattern are reserved for use by make. According to
the standard, in order to get reliable POSIX behavior, the first
non-comment line of the Makefile must be .POSIX. Since this is a
special target, it’s not a candidate for the default target, so game
will remain the default target:
In practice, even a simple program will have header files, and sources
that include a header file should also have an edge on the dependency
tree for it. If the header file changes, targets that include it should
also be rebuilt.
We’ve constructed a dependency tree, but we still haven’t told make how
to actually build any targets from its prerequisites. The rules also
need to specify the shell commands that produce a target from its
prerequisites.
If you were to create the source files in the example and invoke make,
you will find that it actually does know how to build the object
files. This is because make is initially configured with certaininference rules, a topic which will be covered later. For now, we’ll
add the .SUFFIXES special target to the top, erasing all the built-in
inference rules.
Commands immediately follow the target/prerequisite line in a rule. Each
command line must start with a tab character. This can be awkward if
your text editor isn’t configured for it, and it will be awkward if you
try to copy the examples from this page.
Each line is run in its own shell, so be mindful of using commands likecd, which won’t affect later lines.
The simplest thing to do is literally specify the same commands you’d
type at the shell:
I tried to walk into Target, but I missed. ―Mitch Hedberg
When invoking make, it accepts zero or more targets from the dependency
tree, and it will build these targets — e.g. run the commands in the
target’s rule — if the target is out-of-date. A target is out-of-date
if it is older than any of its prerequisites.
# build the "game" binary (default target)
$ make
# build just the object files
$ make graphics.o physics.o input.o
This effect cascades up the dependency tree and causes further targets
to be rebuilt until all of the requested targets are up-to-date. There’s
a lot of room for parallelism since different branches of the tree can
be updated independently. It’s common for make implementations to
support parallel builds with the -j option. This is non-standard, but
it’s a fantastic feature that doesn’t require anything special in the
Makefile to work correctly.
Similar to parallel builds is make’s -k (“keep going”) option, which
is standard. This tells make not to stop on the first error, and to
continue updating targets that are unaffected by the error. This is nice
for fully populating Vim’s quickfix list or Emacs’ compilation
buffer.
It’s common to have multiple targets that should be built by default. If
the first rule selects the default target, how do we solve the problem
of needing multiple default targets? The convention is to use phony
targets. These are called “phony” because there is no corresponding
file, and so phony targets are never up-to-date. It’s convention for a
phony “all” target to be the default target.
I’ll make game a prerequisite of a new “all” target. More real targets
could be added as necessary to turn them into defaults. Users of this
Makefile will also expect make all to build the entire project.
Another common phony target is “clean” which removes all of the built
files. Users will expect make clean to delete all generated files.
So far the Makefile hardcodes cc as the compiler, and doesn’t use any
compiler flags (warnings, optimization, hardening, etc.). The user
should be able to easily control all these things, but right now they’d
have to edit the entire Makefile to do so. Perhaps the user has both
gcc and clang installed, and wants to choose one or the other
without changing which is installed as cc.
To solve this, make has macros that expand into strings when
referenced. The convention is to use the macro named CC when talking
about the C compiler, CFLAGS when talking about flags passed to the C
compiler, LDFLAGS for flags passed to the C compiler when linking, andLDLIBS for flags about libraries when linking. The Makefile should
supply defaults as needed.
A macro is expanded with $(...). It’s valid (and normal) to reference
a macro that hasn’t been defined, which will be an empty string. This
will be the case with LDFLAGS below.
Macro values can contain other macros, which will be expanded
recursively each time the macro is expanded. Some make implementations
allow the name of the macro being expanded to itself be a macro, whichis turing complete, but this behavior is non-standard.
Macros are overridden by macro definitions given as command line
arguments in the form name=value. This allows the user to select their
own build configuration. This is one of make’s most powerful and
under-appreciated features.
$ make CC=clang CFLAGS='-O3 -march=native'
If the user doesn’t want to specify these macros on every invocation,
they can (cautiously) use make’s -e flag to set overriding macros
definitions from the environment.
$ export CC=clang
$ export CFLAGS=-O3
$ make -e all
Some make implementations have other special kinds of macro assignment
operators beyond simple assignment (=). These are unnecessary, so
don’t worry about them.
Inference rules so that you can stop repeating yourself
The road itself tells us far more than signs do. ―Tom Vanderbilt,
Traffic: Why We Drive the Way We Do
There’s repetition across the three different object files. Wouldn’t it
be nice if there was a way to communicate this pattern? Fortunately
there is, in the form of inference rules. It says that a target with
a certain extension, with a prerequisite with another certain extension,
is built a certain way. This will make more sense with an example.
In an inference rule, the target indicates the extensions. The $<
macro expands to the prerequisite, which is essential to making
inference rules work generically. Unfortunately this macro is not
available in target rules, as much as that would be useful.
For example, here’s an inference rule that teaches make how to build an
object file from a C source file. This particular rule is one that
is pre-defined by make, so you’ll never need to write this one yourself.
I’ll include it for completeness.
.c.o:$(CC)$(CFLAGS)-c$<
These extensions must be added to .SUFFIXES before they will work.
With that, the commands for the rules about object files can be omitted.
The first empty .SUFFIXES clears the suffix list. The second one adds.c and .o to the now-empty suffix list.
Other target conventions
Conventions are, indeed, all that shield us from the shivering void,
though often they do so but poorly and desperately. ―Robert Aickman
Users usually expect an “install” target that installs the built
program, libraries, man pages, etc. By convention this target should use
the PREFIX and DESTDIR macros.
The PREFIX macro should default to /usr/local, and since it’s a
macro the user can override it to install elsewhere, such as in their
home directory. The user should override it for both building and
installing, since the prefix may need to be built into the binary (e.g.-DPREFIX=$(PREFIX)).
The DESTDIR is macro is used for staged builds, so that it gets
installed under a fake root directory for the sake of packaging. Unlike
PREFIX, it will not actually be run from this directory.
You may also want to provide an “uninstall” phony target that does the
opposite.
make PREFIX=$HOME/.local install
Other common targets are “mostlyclean” (like “clean” but don’t delete
some slow-to-build targets), “distclean” (delete even more than
“clean”), “test” (run the test suite), and “dist” (create a package).
Complexity and growing pains
One of make’s big weak points is scaling up as a project grows in size.
Recursive Makefiles
As your growing project is broken into subdirectories, you may be
tempted to put a Makefile in each subdirectory and invoke them
recursively.
Don’t use recursive Makefiles. It breaks the dependency
tree across separate instances of make and typically results in a
fragile build. There’s nothing good about it. Have one Makefile at the
root of your project and invoke make there. You may have to teach your
text editor how to do this.
When talking about files in subdirectories, just include the
subdirectory in the name. Everything will work the same as far as make
is concerned, including inference rules.
Keeping your object files separate from your source files is a nice
idea. When it comes to make, there’s good news and bad news.
The good news is that make can do this. You can pick whatever file names
you like for targets and prerequisites.
The bad news is that inference rules are not compatible with
out-of-source builds. You’ll need to repeat the same commands for each
rule as if inference rules didn’t exist. This is tedious for large
projects, so you may want to have some sort of “configure” script, even
if hand-written, to generate all this for you. This is essentially what
CMake is all about. That, plus dependency management.
Dependency management
Another problem with scaling up is tracking the project’s ever-changing
dependencies across all the source files. Missing a dependency means the
build may not be correct unless you make clean first.
If you go the route of using a script to generate the tedious parts of
the Makefile, both GCC and Clang have a nice feature for generating all
the Makefile dependencies for you (-MM, -MT), at least for C and
C++. There are lots of tutorials for doing this dependency generation on
the fly as part of the build, but it’s fragile and slow. Much better to
do it all up front and “bake” the dependencies into the Makefile so that
make can do its job properly. If the dependencies change, rebuild your
Makefile.
For example, here’s what it looks like invoking gcc’s dependency
generator against the imaginary input.c for an out-of-source build:
Unfortunately this feature strips the leading paths from the target, so,
in practice, using it is always more complicated than it should be (e.g.
it requires the use of -MT).
Microsoft’s Nmake
Microsoft has an implementation of make called Nmake, which comes with
Visual Studio. It’s nearly a POSIX-compatible make, but
necessarily breaks from the standard in some places. Their cl.exe
compiler uses .obj as the object file extension and .exe for
binaries, both of which differ from the unix world, so it has different
built-in inference rules. Windows also lacks a Bourne shell and the
standard unix tools, so all of the commands will necessarily be
different.
There’s no equivalent of rm -f on Windows, so good luck writing a
proper “clean” target. No, del /f isn’t the same.
So while it’s close to POSIX make, it’s not practical to write a
Makefile that will simultaneously work properly with both POSIX make
and Nmake. These need to be separate Makefiles.
May your Makefiles be portable
It’s nice to have reliable, portable Makefiles that just work anywhere.
Code to the standards and you don’t need feature tests or
other sorts of special treatment.
If you think that Rails and Sinatra are the two most popular Ruby web frameworks, you’re probably right. Thanks to a big community and numerous gems, Rails is the biggest and most popular Ruby framework for now. Sinatra is also quite popular… but generally for smaller web apps. If you have ever tried to build something with it – it’s quite hard to build something big.
There are also two less popular frameworks – Pardino and Lotus. Well, Lotus is no longer Lotus – now it’s called Hanami. I thought, that since Lotus changed its name, maybe they also added a lot of new features and improvements and maybe we can begin to count it as a Rails rival.
In this article, I want to compare Hanami to Rails and write a little about its features. I also wanted to share my feelings after spending some time building a test application.
What is Hanami?
First of all – what is Hanami? Hanami is a full-stack Ruby web framework built by Luca Guidi, made up of simple, small Ruby libraries. As the Hanami Team writes on their page, Hanami’s goal is to build lightweight apps which consume less memory than other Ruby web frameworks (they probably had in mind Rails).
Let’s look up at Hanami’s core. It’s built of 9 main parts:
Hanami::Model– Persistence with entities, repositories and data mapper
Hanami::View– Presentation with a separation between views and templates
Hanami::Controller– Full featured, fast and testable actions for Rack
Hanami::Validations– Validations mixin for Ruby objects
Hanami::Router– Rack compatible HTTP router for Ruby
Hanami::Helpers– View helpers for Ruby applications
Hanami::Mailer– Mail for Ruby applications
Hanami::Assets– Assets management for Ruby
Hanami::Utils– Ruby core extensions and class utilities
As you can see, these parts look similar to the Rails core:
Hanami::Model -> ActiveModel
Hanami::View -> ActionView
Hanami::Controller -> ActionController
Hanami::Validations -> ActiveModel::Validations
Hanami::Router -> ActionDispatch::Routing
Hanami::Helpers -> ActionController::Helpers
Hanami::Mailer -> ActionMailer
Hanami::Assets -> The Asset Pipeline
Hanami::Utils -> ActiveSupport
Architecture
First of all, there is a physical separation in a file’s structure between what happens on the front-end and the back-end. Controllers, which are responsible for processing requests, manage response logic and provide data to views. They are included in apps/web.
Views are also stored there, but we can divide them into templates and views. Templates are normal .html.erb views, while views are something like helpers. You can write a helper which builds a full HTML form and include it in a template. Moreover, under the web/config folder, you can find a router which includes all routes.
Also, as in Rails, all assets like images, javascript files, and CSS files are located under web/assets folder.
Everything that is connected to the back-end logic, like models and mailers, are stored in the lib/app_name folder. It’s pretty logical.
What’s more interesting is that models are divided into two classes – entities and repositories. Entities are plain, Ruby objects which define all instance methods, while repositories are classes responsible for defining database associations, scopes, query construction and defining a connection with the database.
What’s more, Hanami allows you to create many applications under one application. What does it mean? For instance, you have an application for admins and users, different dashboards and actions – you can create them under one app. Admins’ app will be located under the lib/admins, while users’ app under the lib/users. In Rails, we can achieve it by using namespaces.
Generators
Hanami has built in generators like Rails. A lot of things also look similar, for instance:
$hanami generate model model_name
$hanami generate migration migration_name
Also, we can run a console, server or database console using the hanami command:
But if you want to migrate a database, you don’t need to run Rake, instead use:
Code-reloading
In Rails, we have a great feature which reloads our code in a background without needing to restart a server. Hanami also has the same feature. It uses a gem called Shotgun to auto-reload any code modifications in the background.
Models
What is different and maybe even better in Hanami? First of all, in Rails, a database table is represented as a model. By default, everything is there and should be defined there. As I mentioned before, in Hanami, models are divided into Entities and Repositories. Moreover, they are located in the lib folder, not an app like in Rails.
What is the difference and for what are they used? Well, Entities are pure Ruby object which collects data returned by a repository from a database. You can’t establish a connection to a table while calling a model like MyModel.create. If you want to do so, you need to use a repository.
Repositories are objects which get data from a database and as a result, return a collection of models. For example, if you want to get data from the database, you should run MyModelRepository.new.all. Every time when you want to access the database, you should create a new instance of a repository object.
Moreover, in repositories, we keep all logic connected with a database – queries, scopes and associations, like:
classFlightRepository<Hanami::Repository
has_many:passengers
defmost_recent_flights(limit=10)
.order(Sequel.desc(:flights__departure_at))
.limit(limit)
What is funny? The fact that, by default, something like MyModelRepository.new.count doesn’t work – you need to define the count method in order to get COUNT(*), like in the code above. In models, everything stays connected with objects – like instance methods.
Honestly, IMHO this division is a great thing, the two layers of logic connected with models are separated and the code is cleaner. We know where we should put a new logic.
What is bad? In the following beta version, the Hanami Team added new relations like belongs_to, has_one and has_many :through. For me it’s like a base for models, without this it’s really hard to define any relation in a database – and yes, the live version doesn’t have it yet.
Controllers
Controllers look similar to the Rails’ – they are stored in the web/controllers folder. What is different? Well, in Hanami there isn’t a single controller for an each resource, like BooksController. Also, all actions connected to a resource aren’t in one file. Each action of the controller has its own file. This file and class name equal to the an action name. There is only one method called call– which handles all logic.
There are a couple of important things. First, each file should be in a controller namespace, like: Web::Controllers::Home. Second, instance variables are not shared between views, to access it in a view, you’ll need to expose it, using the expose method, like:
moduleWeb::Controllers::Home
includeWeb::Action
@airports=AirportRepository.new.all
Views
As I said before, views are divided into two types – templates and views. Templates are ordinary .html.erb files, where you can keep the complete HTML, while views are like Rails helpers. You can define their Ruby methods which can be accessible in a template. Like controllers, each action has its own template and view.
This is how a template looks:
<divclass="col-md-8">
<divclass="jumbotron">
<h1>Searchforflights:</h1>
<%=search_form%>
This is how a view looks:
includeWeb::View
form_for:search,'/search',method::getdo
divclass:'form-group'do
label:departure_airport_id
select:departure_airport_id,airports.map{|a|[a.name_with_code,a.id]},class:'form-control',options:{prompt:'Select a departure airport...'}
divclass:'form-group'do
label:arrival_aiport_id
select:arrival_aiport_id,airports.map{|a|[a.name_with_code,a.id]},class:'form-control',options:{prompt:'Select an arrival airport...'}
divclass:'form-group'do
label:departure_date
date_field:departure_date,class:'form-control'
submit'Search',class:'btn btn-success'
Well, this structure looks very organized to me. Each action has its own separate file, so everything looks clear and files aren’t too big. That’s the plus for Hanami! But on the other hand, this division isn’t something new, we have it already in Rails divided into views and helpers.
Migrations
Like Rails, Hanami also provides database migrations which help manage any changes in a database table. They look pretty similar to Rail’s migrations but IMHO they are more clear – their syntax.
Hanami::Model.migrationdo
create_table:airportsdo
primary_key:id
column:code,String,null:false,unique:true,size:3
column:name,String,null:false,unique:true
column:city,String,null:false
column:country,String,null:false
column:created_at,DateTime,null:false
column:updated_at,DateTime,null:false
index:code,unique:true
index:name,unique:true
My thoughts and feelings
I tried to make a sample application in Hanami to check how this framework really looks. You know, in the documentation everything can be beautiful and easy. I gave myself a 6-hour limit to create something that really works.
I wanted to create an application which searches for flights by specified departure and arrival airports and also by a date. A flight can be booked by a passenger. Everything is saved in a database. Well, I’m not saying that it’s easy to achieve in 6 hours but I think that a similar MVP in Rails is creatable in 6. You just create all models and a search method which looks for a specified flight in a database (you have dummy data) and later you can book it. Yeah, it’s not so complicated and we try to keep it as simple as it could be. Of course, we don’t add any custom styles and tests, just plain Bootstrap. And before we start, a database schema is ready, so we know all associations.
So here is my story about how it looked like in Hanami. First of all, I started from creating models. That was really easy – I created all needed migrations, entities and repositories. Migrated everything together and created a service, which seeds my database with dummy data – in Hanami there isn’t something like rake db:seeds in Rails.
When I had everything ready, I started creating the main controller, which is responsible for getting all available airports from the database and creating a search form. That wasn’t so hard but here I learned that instance variables are shared with views. You need to explicitly define which variable is shared with a view. I also learned here, that you can’t think like in Rails, you need to get data from a model’s repository, not directly from a model – what is more, we don’t have them in Hanami. I also added the first method in an entity, which was responsible for formatting data and was shown on the front-end. Wohooo, I used all models mechanisms that Hanami provides!
I also learned here, that you can’t think like in Rails, you need to get data from a model’s repository, not directly from a model – moreover, we don’t have them in Hanami. I also added the first method in an entity, which was responsible for formatting data and was shown on the front-end. Wohooo, I used all models mechanisms that Hanami provides!
After this part, I started defining associations in the repositories and defining the scopes. The first weird thing was the fact, that Hanami doesn’t provide built in count method, you need to define it by yourself. Ok, I thought that it’s not something hard and bad at all, you can define it in 10 seconds. But the next weird thing was the fact, that Hanami doesn’t provide the belongs_to association. I was digging in the source code and other libraries, like Sequel to find out why that doesn’t work. Yeah, Hanami doesn’t have belongs_to or has_one associations (one to many!).
Another thing was the fact, that without it, it’s hard for me to query needed fields – you need to write a pure SQL query to get it. Yeah, you use a library to use pure SQL – pretty normal, right? What’s more, for me their documentation at some level really sucks. There are like one or two examples and that’s everything. You need to guess how to use a function or dig into the source code to check all available options. Imagine how much time you will waste when you need to research every function like this, its behavior etc.
What’s even funnier, is the fact that in a simple SQL query I needed to use a Sequel method, to get what I needed.
When I was somehow done with this part, I moved on to the views. I had some problems defining a route in a form, and yes, I followed the documentation. All the time I was getting the same error, the route is not found. I was googling and digging in the source code without any success. Then I realized that I spent like 2-3 hours to get what I needed. Yeah, at this point I saw that simple things in Hanami took too much time.
Conclusion
For me, Hanami is a great project and idea! Its architecture is planned really well and it’s really clear. But there is a big problem – for now, it is a lack of really good documentation with more complex examples. What’s more, the community isn’t big at the moment, so if you think that you’ll find an answer for your problem on StackOverflow or in Google or in the documentation, you’re probably wrong.
The biggest problem is the fact that the most Ruby gems aren’t created or designed with Hanami use in mind. So if you want to create a fast MVP and you don’t have a big budget or long timeline, you probably shouldn’t create an app with Hanami. As for me, it’s not ready for big production apps yet. You can build simple apps like a blog or something similar.
I hope that you like this article. Remember one big, important thing! I didn’t spend a lot of time developing web-apps with Hanami so I might be wrong, but at the first sight, I would still choose Rails and for me, it’s not well-documented yet.
Engineer @ Google working on Lighthouse, Web Components, Chrome, and the web
TL;DR
With Custom Elements, web developers can create new HTML tags,
beef-up existing HTML tags, or extend the components other developers have
authored. The API is the foundation of web
components. It brings a web
standards-based way to create reusable components using nothing more than
vanilla JS/HTML/CSS. The result is less code, modular code, and more reuse in
our apps.
Introduction
The browser gives us an excellent tool for structuring web applications. It's
called HTML. You may have heard of it! It's declarative, portable, well
supported, and easy to work with. Great as HTML may be, its vocabulary and
extensibility are limited. The HTML living
standard has always lacked a way to
automatically associate JS behavior with your markup... until now.
Custom elements are the answer to modernizing HTML, filling in the missing
pieces, and bundling structure with behavior. If HTML doesn't provide the
solution to a problem, we can create a custom element that does. Custom
elements teach the browser new tricks while preserving the benefits of HTML.
Defining a new element
To define a new HTML element we need the power of JavaScript!
The customElements global is used for defining a custom element and teaching
the browser about a new tag. Call customElements.define() with the tag name
you want to create and a JavaScript class that extends the base HTMLElement.
Example - defining a mobile drawer panel, <app-drawer>:
class AppDrawer extends HTMLElement {...}
window.customElements.define('app-drawer', AppDrawer);
// Or use an anonymous class if you don't want a named constructor in current scope.
window.customElements.define('app-drawer', class extends HTMLElement {...});
Example usage:
<app-drawer></app-drawer>
It's important to remember that using a custom element is no different than
using a <div> or any other element. Instances can be declared on the page,
created dynamically in JavaScript, event listeners can be attached, etc. Keep
reading for more examples.
Defining an element's JavaScript API
The functionality of a custom element is defined using an ES2015class
which extends HTMLElement. Extending HTMLElement ensures the custom element
inherits the entire DOM API and means any properties/methods that you add to the
class become part of the element's DOM interface. Essentially, use the class to
create a public JavaScript API for your tag.
Example - defining the DOM interface of <app-drawer>:
class AppDrawer extends HTMLElement {
// A getter/setter for an open property.
get open() {
return this.hasAttribute('open');
}
set open(val) {
// Reflect the value of the open property as an HTML attribute.
if (val) {
this.setAttribute('open', '');
} else {
this.removeAttribute('open');
}
this.toggleDrawer();
}
// A getter/setter for a disabled property.
get disabled() {
return this.hasAttribute('disabled');
}
set disabled(val) {
// Reflect the value of the disabled property as an HTML attribute.
if (val) {
this.setAttribute('disabled', '');
} else {
this.removeAttribute('disabled');
}
}
// Can define constructor arguments if you wish.
constructor() {
// If you define a ctor, always call super() first!
// This is specific to CE and required by the spec.
super();
// Setup a click listener on <app-drawer> itself.
this.addEventListener('click', e => {
// Don't toggle the drawer if it's disabled.
if (this.disabled) {
return;
}
this.toggleDrawer();
});
}
toggleDrawer() {
...
}
}
customElements.define('app-drawer', AppDrawer);
In this example, we're creating a drawer that has an open property, disabled
property, and a toggleDrawer() method. It also reflects properties as HTML
attributes.
A neat feature of custom elements is that this inside a class definition
refers to the DOM element itself i.e. the instance of the class. In our
example, this refers to <app-drawer>. This (😉) is how the element can
attach a click listener to itself! And you're not limited to event listeners.
The entire DOM API is available inside element code. Use this to access the
element's properties, inspect its children (this.children), query nodes
(this.querySelectorAll('.items')), etc.
Rules on creating custom elements
The name of a custom element must contain a dash (-). So <x-tags>,<my-element>, and <my-awesome-app> are all valid names, while <tabs>
and <foo_bar> are not. This requirement is so the HTML parser can
distinguish custom elements from regular elements. It also ensures forward
compatibility when new tags are added to HTML.
You can't register the same tag more than once. Attempting to do so will
throw a DOMException. Once you've told the browser about a new tag, that's
it. No take backs.
Custom elements cannot be self-closing because HTML only allows a few
elements
to be self-closing. Always write a closing tag
(<app-drawer></app-drawer>).
Extending elements
The Custom Elements API is useful for creating new HTML elements, but it's also
useful for extending other custom elements or even the browser's built-in HTML.
Extending a custom element
Extending another custom element is done by extending its class definition.
Example - create <fancy-app-drawer> that extends <app-drawer>:
class FancyDrawer extends AppDrawer {
constructor() {
super(); // always call super() first in the ctor. This also calls the extended class' ctor.
...
}
toggleDrawer() {
// Possibly different toggle implementation?
// Use ES2015 if you need to call the parent method.
// super.toggleDrawer()
}
anotherMethod() {
...
}
}
customElements.define('fancy-app-drawer', FancyDrawer);
Extending native HTML elements
Let's say you wanted to create a fancier <button>. Instead of replicating the
behavior and functionality of <button>, a better option is to progressively
enhance the existing element using custom elements.
A customized built-in element is a custom element that extends one of the
browser's built-in HTML tags. The primary benefit of extending an existing
element is to gain all of its features (DOM properties, methods, accessibility).
There's no better way to write a progressive web
app than to progressively enhance existing HTML
elements.
To extend an element, you'll need to create a class definition that inherits
from the correct DOM interface. For example, a custom element that extends<button> needs to inherit from HTMLButtonElement instead of HTMLElement.
Similarly, an element that extends <img> needs to extend HTMLImageElement.
Example - extending <button>:
// See https://html.spec.whatwg.org/multipage/indices.html#element-interfaces
// for the list of other DOM interfaces.
class FancyButton extends HTMLButtonElement {
constructor() {
super(); // always call super() first in the ctor.
this.addEventListener('click', e => this.drawRipple(e.offsetX, e.offsetY));
}
// Material design ripple animation.
drawRipple(x, y) {
let div = document.createElement('div');
div.classList.add('ripple');
this.appendChild(div);
div.style.top = `${y - div.clientHeight/2}px`;
div.style.left = `${x - div.clientWidth/2}px`;
div.style.backgroundColor = 'currentColor';
div.classList.add('run');
div.addEventListener('transitionend', e => div.remove());
}
}
customElements.define('fancy-button', FancyButton, {extends: 'button'});
Notice that the call to define() changes slightly when extending a native
element. The required third parameter tells the browser which tag you're
extending. This is necessary because many HTML tags share the same DOM
interface. <section>, <address>, and <em> (among others) all shareHTMLElement; both <q> and <blockquote> share HTMLQuoteElement; etc..
Specifying {extends: 'blockquote'} lets the browser know you're creating a
souped-up <blockquote> instead of a <q>. See the HTML
spec
for the full list of HTML's DOM interfaces.
Consumers of a customized built-in element can use it in several ways. They can
declare it by adding the is="" attribute on the native tag:
<!-- This <button> is a fancy button. --><button is="fancy-button" disabled>Fancy button!</button>
create an instance in JavaScript:
// Custom elements overload createElement() to support the is="" attribute.
let button = document.createElement('button', {is: 'fancy-button'});
button.textContent = 'Fancy button!';
button.disabled = true;
document.body.appendChild(button);
or use the new operator:
let button = new FancyButton();
button.textContent = 'Fancy button!';
button.disabled = true;
Here's another example that extends <img>.
Example - extending <img>:
customElements.define('bigger-img', class extends Image {
// Give img default size if users don't specify.
constructor(width=50, height=50) {
super(width * 10, height * 10);
}
}, {extends: 'img'});
Users declare this component as:
<!-- This <img> is a bigger img. --><img is="bigger-img" width="15" height="20">
A custom element can define special lifecycle hooks for running code during
interesting times of its existence. These are called custom element
reactions.
Name
Called when
constructor
An instance of the element is
created or upgraded. Useful for initializing state,
settings up event listeners, or creating shadow dom.
See the spec
for restrictions on what you can do in the constructor.
connectedCallback
Called every time the
element is inserted into the DOM. Useful for running setup code, such as
fetching resources or rendering. Generally, you should try to delay work until
this time.
disconnectedCallback
Called every time the element is removed from the DOM. Useful for running
clean up code (removing event listeners, etc.).
An attribute was added, removed, updated, or replaced. Also called for
initial values when an element is created by the parser, or upgraded. Note: only attributes listed in theobservedAttributes property will receive this callback.
adoptedCallback()
The custom element has
been moved into a new document (e.g. someone calleddocument.adoptNode(el)).
The browser calls the attributeChangedCallback() for any attributes
whitelisted in the observedAttributes array (see Observing changes to
attributes). Essentially, this is a performance optimization.
When users change a common attribute like style or class, you don't want to
be spammed with tons of callbacks.
Reaction callbacks are synchronous. If someone calls el.setAttribute()
on your element, the browser will immediately call attributeChangedCallback().
Similarly, you'll receive a disconnectedCallback() right after your element is
removed from the DOM (e.g. the user calls el.remove()).
Example: adding custom element reactions to <app-drawer>:
class AppDrawer extends HTMLElement {
constructor() {
super(); // always call super() first in the ctor.
...
}
connectedCallback() {
...
}
disconnectedCallback() {
...
}
attributeChangedCallback(attrName, oldVal, newVal) {
...
}
}
Define reactions if/when it make senses. If your element is sufficiently complex
and opens a connection to IndexedDB in connectedCallback(), do the necessary
cleanup work in disconnectedCallback(). But be careful! You can't rely on your
element being removed from the DOM in all circumstances. For example,disconnectedCallback() will never be called if the user closes the tab.
Example: moving a custom element into another document, observing itsadoptedCallback():
function createWindow(srcdoc) {
let p = new Promise(resolve => {
let f = document.createElement('iframe');
f.srcdoc = srcdoc || '';
f.onload = e => {
resolve(f.contentWindow);
};
document.body.appendChild(f);
});
return p;
}
// 1. Create two iframes, w1 and w2.
Promise.all([createWindow(), createWindow()])
.then(([w1, w2]) => {
// 2. Define a custom element in w1.
w1.customElements.define('x-adopt', class extends w1.HTMLElement {
adoptedCallback() {
console.log('Adopted!');
}
});
let a = w1.document.createElement('x-adopt');
// 3. Adopts the custom element into w2 and invokes its adoptedCallback().
w2.document.body.appendChild(a);
});
Properties and attributes
Reflecting properties to attributes
It's common for HTML properties to reflect their value back to the DOM as an
HTML attribute. For example, when the values of hidden or id are changed in
JS:
div.id = 'my-id';
div.hidden = true;
the values are applied to the live DOM as attributes:
<div id="my-id" hidden>
This is called "reflecting properties to
attributes".
Almost every property in HTML does this. Why? Attributes are also useful for
configuring an element declaratively and certain APIs like accessibility and CSS
selectors rely on attributes to work.
Reflecting a property is useful anywhere you want to keep the element's DOM
representation in sync with its JavaScript state. One reason you might want to
reflect a property is so user-defined styling applies when JS state changes.
Recall our <app-drawer>. A consumer of this component may want to fade it out
and/or prevent user interaction when it's disabled:
When the disabled property is changed in JS, we want that attribute to be
added to the DOM so the user's selector matches. The element can provide that
behavior by reflecting the value to an attribute of the same name:
...
get disabled() {
return this.hasAttribute('disabled');
}
set disabled(val) {
// Reflect the value of `disabled` as an attribute.
if (val) {
this.setAttribute('disabled', '');
} else {
this.removeAttribute('disabled');
}
this.toggleDrawer();
}
Observing changes to attributes
HTML attributes are a convenient way for users to declare initial state:
<app-drawer open disabled></app-drawer>
Elements can react to attribute changes by defining aattributeChangedCallback. The browser will call this method for every change
to attributes listed in the observedAttributes array.
class AppDrawer extends HTMLElement {
...
static get observedAttributes() {
return ['disabled', 'open'];
}
get disabled() {
return this.hasAttribute('disabled');
}
set disabled(val) {
if (val) {
this.setAttribute('disabled', '');
} else {
this.removeAttribute('disabled');
}
}
// Only called for the disabled and open attributes due to observedAttributes
attributeChangedCallback(name, oldValue, newValue) {
// When the drawer is disabled, update keyboard/screen reader behavior.
if (this.disabled) {
this.setAttribute('tabindex', '-1');
this.setAttribute('aria-disabled', 'true');
} else {
this.setAttribute('tabindex', '0');
this.setAttribute('aria-disabled', 'false');
}
// TODO: also react to the open attribute changing.
}
}
In the example, we're setting additional attributes on the <app-drawer> when adisabled attribute is changed. Although we're not doing it here, you could
also use the attributeChangedCallback to keep a JS property in sync with its
attribute.
Element upgrades
Progressively enhanced HTML
We've already learned that custom elements are defined by callingcustomElements.define(). But this doesn't mean you have to define + register a
custom element all in one go.
Custom elements can be used before their definition is registered.
Progressive enhancement is a feature of custom elements. In other words, you can
declare a bunch of <app-drawer> elements on the page and never invokecustomElements.define('app-drawer', ...) until much later. This is because the
browser treats potential custom elements differently thanks to unknown
tags. The process of calling define() and endowing an existing
element with a class definition is called "element upgrades".
To know when a tag name becomes defined, you can usewindow.customElements.whenDefined(). It vends a Promise that resolves when the
element becomes defined.
Example - delay work until a set of child elements are upgraded
<share-buttons><social-button type="twitter"><a href="...">Twitter</a></social-button><social-button type="fb"><a href="...">Facebook</a></social-button><social-button type="plus"><a href="...">G+</a></social-button></share-buttons>
// Fetch all the children of <share-buttons> that are not defined yet.
let undefinedButtons = buttons.querySelectorAll(':not(:defined)');
let promises = [...undefinedButtons].map(socialButton => {
return customElements.whenDefined(socialButton.localName);
));
// Wait for all the social-buttons to be upgraded.
Promise.all(promises).then(() => {
// All social-button children are ready.
});
Element-defined content
Custom elements can manage their own content by using the DOM APIs inside
element code. Reactions come in handy for this.
Example - create an element with some default HTML:
customElements.define('x-foo-with-markup', class extends HTMLElement {
connectedCallback() {
this.innerHTML = "<b>I'm an x-foo-with-markup!</b>";
}
...
});
Declaring this tag will produce:
<x-foo-with-markup><b>I'm an x-foo-with-markup!</b></x-foo-with-markup>
Creating an element that uses Shadow DOM
Shadow DOM provides a way for an element to own, render, and style a chunk of
DOM that's separate from the rest of the page. Heck, you could even hide away an
entire app within a single tag:
<!-- chat-app's implementation details are hidden away in Shadow DOM. --><chat-app></chat-app>
To use Shadow DOM in a custom element, call this.attachShadow inside yourconstructor:
customElements.define('x-foo-shadowdom', class extends HTMLElement {
constructor() {
super(); // always call super() first in the ctor.
// Attach a shadow root to the element.
let shadowRoot = this.attachShadow({mode: 'open'});
shadowRoot.innerHTML = `
<style>:host { ... }</style> <!-- look ma, scoped styles --><b>I'm in shadow dom!</b><slot></slot>
`;
}
...
});
Example usage:
<x-foo-shadowdom><p><b>User's</b> custom text</p></x-foo-shadowdom><!-- renders as --><x-foo-shadowdom><b>I'm in shadow dom!</b><slot></slot></x-foo-shadowdom>
Creating elements from a <template>
For those unfamiliar, the <template>
element
allows you to declare fragments of DOM which are parsed, inert at page load, and
can be activated later at runtime. It's another API primitive in the web
components family. Templates are an ideal placeholder for declaring the
structure of a custom element.
Example: registering an element with Shadow DOM content created from a<template>:
<template id="x-foo-from-template"><style>
p { color: orange; }</style><p>I'm in Shadow DOM. My markup was stamped from a <template>.</p></template><script>
customElements.define('x-foo-from-template', class extends HTMLElement {
constructor() {
super(); // always call super() first in the ctor.
let shadowRoot = this.attachShadow({mode: 'open'});
const t = document.querySelector('#x-foo-from-template');
const instance = t.content.cloneNode(true);
shadowRoot.appendChild(instance);
}
...
});</script>
These few lines of code pack a punch. Let's understanding the key things going
on:
We're defining a new element in HTML: <x-foo-from-template>
The element's Shadow DOM is created from a <template>
The element's DOM is local to the element thanks to Shadow DOM
The element's internal CSS is scoped to the element thanks to Shadow DOM
Styling a custom element
Even if your element defines its own styling using Shadow DOM, users can style
your custom element from their page. These are called "user-defined styles".
You might be asking yourself how CSS specificity works if the element has styles
defined within Shadow DOM. In terms of specificity, user styles win. They'll
always override element-defined styling. See the section on Creating an element
that uses Shadow DOM.
Pre-styling unregistered elements
Before an element is upgraded you can target it in CSS using the:defined pseudo-class. This is useful for pre-styling a component. For
example, you may wish to prevent layout or other visual FOUC by hiding undefined
components and fading them in when they become defined.
After <app-drawer> becomes defined, the selector (app-drawer:not(:defined))
no longer matches.
Misc details
Unknown elements vs. undefined custom elements
HTML is lenient and flexible to work with. For example, declare<randomtagthatdoesntexist> on a page and the browser is perfectly happy
accepting it. Why do non-standard tags work? The answer is the HTML
specification
allows it. Elements that are not defined by the specification get parsed asHTMLUnknownElement.
The same is not true for custom elements. Potential custom elements are parsed
as an HTMLElement if they're created with a valid name (includes a "-"). You
can check this in a browser that supports custom elements. Fire up the Console:Ctrl+Shift+J (or Cmd+Opt+J on Mac) and paste in the
following lines of code:
// "tabs" is not a valid custom element name
document.createElement('tabs') instanceof HTMLUnknownElement === true
// "x-tabs" is a valid custom element name
document.createElement('x-tabs') instanceof HTMLElement === true
API reference
The customElements global defines useful methods for working with custom
elements.
define(tagName, constructor, options)
Defines a new custom element in the browser.
Example
customElements.define('my-app', class extends HTMLElement { ... });
customElements.define(
'fancy-button', class extends HTMLButtonElement { ... }, {extends: 'button'});
get(tagName)
Given a valid custom element tag name, returns the element's constructor.
Returns undefined if no element definition has been registered.
Example
let Drawer = customElements.get('app-drawer');
let drawer = new Drawer();
whenDefined(tagName)
Returns a Promise that resolves when the custom element is defined. If the
element is already defined, resolve immediately. Rejects if the tag name is not
a valid custom element name
If you've been following web components for the last couple of years, you'll
know that Chrome 36+ implemented a version of the Custom Elements API that usesdocument.registerElement() instead of customElements.define(). That's now
considered a deprecated version of the standard, called v0.customElements.define() is the new hotness and what browser vendors are
starting to implement. It's called Custom Elements v1.
If you happen to be interested in the old v0 spec, check out the html5rocks
article.
function loadScript(src) {
return new Promise(function(resolve, reject) {
const script = document.createElement('script');
script.src = src;
script.onload = resolve;
script.onerror = reject;
document.head.appendChild(script);
});
}
// Lazy load the polyfill if necessary.
if (!supportsCustomElementsV1) {
loadScript('/bower_components/custom-elements/custom-elements.min.js').then(e => {
// Polyfill loaded.
});
} else {
// Native support. Good to go.
}
Conclusion
Custom elements give us a new tool for defining new HTML tags in the browser and
creating reusable components. Combine them with the other new platform
primitives like Shadow DOM and <template>, and we start to realize the grand
picture of Web Components:
Cross-browser (web standard) for creating and extending reusable components.
Requires no library or framework to get started. Vanilla JS/HTML FTW!
Provides a familiar programming model. It's just DOM/CSS/HTML.
Works well with other new web platform features (Shadow DOM, <template>, CSS
custom properties, etc.)
Welcome to Angrave's crowd-sourced System Programming wiki-book!
This wiki is being built by students and faculty from the University of Illinois and is a crowd-source authoring experiment by Lawrence Angrave from CS @ Illinois.
Rather than requiring an existing paper-based book this semester, we will build our own set of resources here.
Warning these are good practice but not comprehensive. The CS241 final assumes you fully understand and can apply all topics of the course. Questions will focus mostly but not entirely on topics that you have used in the lab and programming assignments.
When you observe a solar eclipse—with great care, of course—what you see is a thin, red crescent outlining the blocked-out Sun and, extending beyond it, a stark white mane. This is the corona, an aura millions of miles thick of superheated plasma.
It’s natural to assume the corona is cooler than the sun’s blazing surface. But in fact it gets hotter as it ranges outward. The Sun’s surface temperature is about 10,000 degrees Fahrenheit. The corona can get as hot as 5.4 million degrees Fahrenheit. This phenomenon, known as the “coronal heating problem,” “remains one of the great unsolved problems in space science,” says James A. Klimchuk, research astrophysicist at the NASA Goddard Space Flight Center.
Scientists still don’t quite understand why the corona is so toasty. But at least they accept that it is hotter. Which was not the case for a long chapter in science history. It took a little-known Swede, Hannes Alfvén, an electrical engineer by training, to convince the world of the corona’s hotness.
Around the early 1940s, there was no coronal heating problem. That’s because scientists were confident the corona’s temperature was lower, or not drastically higher, than the sun’s surface temperature. One estimate, by Swedish astronomer Bengt Edlén in 1943, was 450,000 degrees Fahrenheit. If you look up the discovery of the corona’s extraordinary heat—in reviews and textbooks from the last 50 years, even NASA’s website—you’ll generally come across only Edlén’s name.
Alfvén’s “extraordinary physical intuition,” concerning how a form of wave could move through any ionized gas, “was, for several years, condescendingly dismissed.”
But two years before Edlén made his estimate, Alfvén published a paper on the topic in an obscure Swedish journal. He theorized that the sun’s magnetic field, interacting with charged particles, plays a crucial role in the corona’s bewildering heat, overcoming presumed thermodynamic limits—that heat cannot be transported from a cool to a hot body. While his contemporaries didn’t dare to draw such a conclusion, Alfvén boldly declared that the corona is “heated to an extremely high temperature.”
A year later, Alfvén showed the existence of a special wave associated with plasmas, pioneering the field of plasma astrophysics. The waves came to be known as Alfvén waves. When Alfvén’s discovery of the waves won him the Nobel Prize, in 1970 (which he shared with a solid state physicist), an article was published in Science with the title, “Swedish Iconoclast Recognized after Many Years of Rejection and Obscurity.” The article’s author, a solar physicist named Alex Dessler, wrote that Alfvén’s “extraordinary physical intuition,” concerning how a form of wave could move through any ionized gas, “was, for several years, condescendingly dismissed.” Later, Alfvén postulated these waves caused the corona’s immense heat. Excited by perturbations in the Sun’s magnetic field, the waves propagate upwards carrying, Alfvén reasoned, 1 percent of the Sun’s radiated energy.
As discoveries become common knowledge, “often the person who first changed a paradigm gets forgotten,” wrote solar physicists Hardi Peter and Bhola N. Dwivedi, in Frontiers in Astronomy and Space Sciences, in 2014. “One such case is the discovery that the Sun’s corona is a million degrees hot.” Seven decades later, they went on, and scientists are still investigating how much these waves heat it, “first explicitly argued for by Alfvén himself.”
Indeed, in 2015, in a study published in The Astrophysical Journal, a team of researchers wrote that observations from a pair of satellite telescopes provided “direct evidence” for Alfvén’s idea, narrowing “down to unparalleled levels” the evidence for Alfvén wave heating of the corona.
Alfvén passed away in 1995, but perhaps the evidence that his waves cause the corona’s wild heat will help the iconoclast stave off obscurity.
Virat Markandeya is a freelance science writer based in Delhi. Follow him on Twitter @Viratmarkandeya.
Get the Nautilus newsletter
The newest and most popular articles delivered right to your inbox!
WATCH: The Columbia University astrophysicist Daniel Wolf Savin on what star formation teaches us about the universe.
This classic Facts So Romantic post was originally published in April 2016.
Paul Miller shares a joke with his grandson, Max. They play poker together, but as a numbers guy, Miller is hard to beat.
LA Johnson/NPRhide caption
toggle caption
LA Johnson/NPR
Most teachers these days last no more than five to 10 years in the classroom, but Paul Miller taught math for nearly 80. At one point, he was considered the "oldest active accredited teacher" in the U.S.
His career started in his hometown of Baltimore. It was 1934, the Dust Bowl was wreaking havoc in the Plains, Bonnie and Clyde were gunned down by police in Louisiana, and a thuggish politician named Adolf Hitler became president of Germany.
Miller taught elementary school kids by day, college students at night and his mother on weekends.
"I had to teach her how to write her name and the address of her house," he says.
His parents, Jewish immigrants from Lithuania, had very little schooling. They had arrived in the U.S. long before the Nazis occupied their country in 1941.
"My parents spoke Yiddish," says Miller. "They didn't know any English at all."
Lisa, Miller's youngest daughter, talks about her father's career as documented through newspaper clippings and photographs on display in his room.
LA Johnson/NPRhide caption
toggle caption
LA Johnson/NPR
Miller didn't know English very well himself when he started grammar school. But he went on to do well and enrolled in the only college he could afford, a teachers school. It turned out to be a good decision because teaching was one of the few jobs available during the Great Depression. Every dollar Miller made as a teacher he gave to his parents — until he got married.
Miller and his wife raised seven children during some pretty tough times. The family struggled on his teacher wages, but Lisa, Miller's youngest child, remembers that as long as her dad was teaching, he was happy.
"I don't think he ever considered it work because he loved what he was doing," she says.
Miller was inducted into the National Teachers Hall of Fame in 2011, an honor he never expected. "If you become a teacher to become famous, forget it," he says.
Courtesy of Lisa Millerhide caption
toggle caption
Courtesy of Lisa Miller
These days Miller, who has lost most of his hearing, stays in an assisted living facility in Baltimore where his family visits him often. His grandkids, Ilana and Max, call him "Papa." Miller loves playing poker with them, but he is hard to beat.
"Until I met Mr. Miller in 1978, I always thought math was boring," says one of his former students, John Shapiro. A computer engineer, Shapiro heard we were profiling his all-time favorite teacher and says he had to come by and explain why he liked Mr. Miller so much.
"He had a way of making it very easy, very simple," he says. "It worked for me, that's for sure."
Miller says he lights up when former students come by to see him, bringing back wonderful memories and reminding him of the impact he has had.
The key to teaching math, says Miller, boils down to one thing — repetition. "Repetition is one of the foundations of learning."
Repetition and rote memorization aren't exactly cutting edge these days, but it's hard to disagree with the advice Miller gives teachers who are just starting out: "Be sure that you know your subject."
You have to wonder though, is that enough? I remind Miller that even talented teachers who know their stuff are leaving the profession in droves these days. So I ask him whether in his 78-year career, there ever was a time he felt like leaving the profession.
"Any time you have a bad day you think of that," says Miller. "The next morning, it's all forgotten."
Miller chuckles. It's clear he still misses being in the classroom. Even a heart attack at age 84 didn't stop him from going back to teaching. Miller continued for 14 more years.
By the time he retired in 2014, he had written a college math textbook and become the first Maryland teacher to be inducted into the National Teachers Hall of Fame.
It was a long overdue recognition that Miller wasn't sure he deserved and certainly never expected.
"If you become a teacher to become famous, forget it," he says laughing.
This year has been enjoyably eventful for processor releases. Intel launched their 7th Generation processors, Kaby Lake, in January. Then we had AMD release their new high-performance microarchitecture in Ryzen, EPYC and Threadripper. Intel then launched their Skylake-SP Xeon Scalable Platform, based on an upgraded 6th Generation core design, and we’re expecting new AMD APUs for mobile later this year.
And adding to that list this morning is once again is Intel. Today the company is launching its new 8th Generation family of processors, starting with four CPUs for the 15W mobile family. The launch of these processors was perhaps spoiled by Intel jumping the gun a few days ago and listing the processors on its own public price list, but also we have started to see laptop and mobile designs being listed at various retailers before the official announcement.
There are two elements that make the launch of these 8th Gen processors different. First is that the 8th Gen is at a high enough level, running basically the same microarchitecture as the 7th Gen – more on this below. But the key element is that, at the same price and power where a user would get a dual core i5-U or i7-U in their laptop, Intel will now be bumping those product lines up to quad-cores with hyperthreading. This gives a 100% gain in cores and 100% gain in threads.
Obviously nothing is for free, so despite Intel stating that they’ve made minor tweaks to the microarchitecture and manufacturing to get better performing silicon, the base frequencies are down slightly. Turbo modes are still high, ensuring a similar user experience in most computing tasks. Memory support is similar – DDR4 and LPDDR3 are supported, but not LPDDR4 – although DDR4 moves up to DDR4-2400 from DDR4-2133.
Specifications of Intel Core i5/i7 U-series CPUs
7th Generation
8th Generation
Cores
Freq +
Turbo
L3
Price
Cores
Freq +
Turbo
L3
Price
i7-7660U
2/4
2.5/4.0 GHz
4 MB
$415
i7-8650U
4/8
1.9/4.2 GHz
8 MB
$409
i7-7560U
2.4/3.8 GHz
$415
i7-8550U
1.8/4.0 GHz
$409
i5-7360U
2/4
2.3/3.6 GHz
3 MB
$304
i5-8350U
4/8
1.7/3.6 GHz
6 MB
$297
i5-7260U
2.2/3.4 GHz
$304
i5-8250U
1.6/3.4 GHz
$297
Another change from 7th Gen to 8th Gen will be in the graphics. Intel is upgrading the nomenclature of the integrated graphics from HD 620 to UHD 620, indicating that the silicon is suited for 4K playback and processing. During our pre-briefing it was categorically stated several times that there was no change between the two, however we have since confirmed that the new chips will come with HDMI 2.0/HDCP 2.2 support as standard, removing the need for an external LSPCON for this feature. Other than this display controller change however, it appears that these new UHD iGPUs are architecturally the same as their HD predecessors.
Fundamentally these are what Intel calls a ‘4+2’ silicon design, featuring four cores and GT2 integrated graphics, whereas the last generation used 2+2 designs. The 4+2 design was also used in the mainstream desktop processors, suggesting that Intel is using those dies now for their 15W products rather than their 45W+ products. That being said, Intel is likely to have created new masks and revisions for this silicon to account for the lower power window as well as implementing HDCP 2.2 support and other minor fixes.
Now by having quad-core parts in the 15W form factor, performance on the new chips is expected to excel beyond what has been available from the previous generation of Core i5-U and Core i7-U processors. However Intel and its OEMs have a tight balancing act to walk here, as 15W is not a lot of thermal headroom for a two core CPU, let alone a four core one. At the same time we have started to see the 15W U-series parts find their way into smaller and even fanless notebook designs, which are more prone to throttling under sustained workloads, and quad core CPUs in this segment could exacerbate the issue. However, for the larger 13-15-inch designs with active cooling, moving down from a 35W-45W quad core processor down to 15W will likely offer substantially better battery life during intense loading, should OEMs swap out H-series chips for the new U-series chips in their designs.
Intel’s big aim with the new processors is, as always, to tackle the growing market of 3-5+ year old devices still being used today, quoting better performance, a better user experience, longer battery life, and fundamentally new experiences when using newer hardware. Two years ago Intel quoted 300 million units fit into this 3-5+ year window; now that number is 450 million.
Intel provided this shot of a wafer containing these new refresh dies, which by my math gives 22 x 32.7 dies per wafer. Giving some margin for die spacing, this correlates to a 13.6 x 9.1 mm die, at 124 mm2 and 478 full dies per wafer. At a tray cost of $409 per Core i7, and running at ~124mm2 per die, that makes an interesting metric of $3.30 per square millimeter. Intel no longer officially provides die sizes or transistor counts, though a list of $/mm2 would be interesting to compile - for reference some of the high-end Xeons push north of $19/mm2.
Kaby Lake Refresh? 14+? Where’s my Coffee (Lake)?
So despite Intel launching its 7th Generation family in January, today Intel is formally launching the 8th Generation only eight months later. To explain why Intel is breaking the usual 12-18 month cadence for the generation product, it comes down to product positioning.
In the past we are used to a new numbered generation to come with a new core microarchitecture design. But this time Intel is improving a core design, calling it a refresh, and only releasing a few processors for the mobile family. We expect that Intel’s 8th Generation will eventually contain three core designs of product on three different process design nodes: the launch today is Kaby Lake Refresh on 14+, and in the future we will see Coffee Lake on 14++ become part of the 8th Gen, as well as Cannon Lake on 10nm.
Intel's Core Architecture Cadence (8/20)
Core Generation
Microarchitecture
Process Node
Release Year
2nd
Sandy Bridge
32nm
2011
3rd
Ivy Bridge
22nm
2012
4th
Haswell
22nm
2013
5th
Broadwell
14nm
2014
6th
Skylake
14nm
2015
7th
Kaby Lake
14nm+
2016
8th
Kaby Lake Refresh
Coffee Lake
Cannon Lake
14nm+
14nm++
10nm
2017
2017?
2018?
9th
Ice Lake?
...
10nm+
2018?
Unknown
Cascade Lake (Server)
?
?
Now the Generation name is no longer in direct correlation with underlying core microarchitecture or lithography process. This is going to confuse some users and anger others, although Intel’s official line is along the lines of the fact that lithography process nodes are harder to optimize, smaller nodes benefit in yield from smaller cores and as such their product portfolio has to expand beyond traditional naming in order to provide the appropriate product and the appropriate price point.
In our pre-briefings, Intel only mentioned Coffee Lake in the context of the fact that today’s launch is not Coffee Lake. Because media were expecting this to be Coffee Lake (and expecting it to be a desktop processor launch), the question ‘is this Coffee Lake’ was actually asked several times, and the answer had to be repeated. These four new CPUs are still Kaby Lake CPUs built on the same 14+ technology, with minor updates, and bringing quad cores to 15W.
So when is Coffee Lake on 14++ (or Cannon Lake) coming? Intel only stated that other members of the 8th Generation family (which contains Kaby Lake Refresh, Coffee Lake and Cannon Lake) are coming later this year. Desktop will come in the autumn, and additional products for enterprise, workstation and enthusiast notebooks will also happen. As for today's 8th Generation U-series announcement, Intel tells us that we should start seeing laptops using the new CPUs hit the market in September.
Update: Along with the product specs for the new mobile SKUs, Intel has also uploaded the new box art for the desktop 8th Gen Core parts to their website. The boxes confirm, among other things, that once these desktop parts will launch they'll have 6 cores (with HT for the i7) and require 300 series motherboards.
Hello Neighbor’s experience reflects the rise of video sites like YouTube as an accelerant for the video game business. Big-budget video game studios are courting popular YouTubers by sending them early review copies of games or paying them to make positive videos, and the impact can be even more significant for independent games with little money to spend on marketing.
YouTube, in particular, has a strong reach with younger audiences, who watch more than twice as much online video content as they do television. According to YouTube, hundreds of millions of people watch more than 246 billion minutes of videos about gaming on its service every month, with 70 percent of the viewers younger than 34.
For some video game developers, the goal is to gain the attention of someone like Felix Kjellberg, a Swede better known by his YouTube alias PewDiePie, whose channel has more than 56 million subscribers. Earlier this year, Mr. Kjellberg was embroiled in a controversy over posting anti-Semitic videos, but he is still regarded as so influential that developers sometimes refer to his impact as “the PewDiePie Effect.”
Ryan Clark, who designed an independent video game called Crypt of the Necrodancer, experienced that effect firsthand. After a glowing PewDiePie video about the game in 2015, Crypt of the Necrodancer saw an immediate $60,000 increase in sales. Factoring in the halo effect of the PewDiePie video, Mr. Clark estimated the total value of the video at more than $100,000.
In 2013, attention from PewDiePie and other YouTubers also helped Surgeon Simulator, a game made by the London-based Bossa Studios, become a global phenomenon that has sold more than 3.5 million copies.
“It’s something that has become really important to how we think about how we market our games going forward,” Tracey McGarrigan, the chief marketing officer of Bossa Studios, said of YouTube.
But some game developers warn that YouTube exposure is not a magic bullet that translates into sales, even if millions of people are watching.
When Lurking, a horror game made by four students in Singapore, caught the attention of PewDiePie and Markiplier, another well-known YouTube personality, their videos amassed more than 7 million views. But the results were marginal; one video about the game with 1.5 million views spurred only 8,000 downloads, even though Lurking was free.
Justin Ng, one of the creators of Lurking, said that when YouTubers make videos featuring a complete play-through of a game, it can potentially hurt sales, especially if the game is focused on a linear story.
Play-throughs can “spoil the narrative experience,” Mr. Ng said. “The game mechanics need to seem interesting enough for me to want to experience it for myself and not vicariously.”
While top-tier YouTube influencers can help put a game in front of tens of millions of eyes, their celebrity can also be a double-edged sword when fans are more interested in watching the player than buying the game.
What really drives sales, some developers said, is not just one-and-done attention from the most popular YouTubers, but creating communities of broader support from other content creators who are devoted to the game — and whose audiences are as well.
In some cases, smaller YouTube channels that focus on specific games can grow alongside them, creating positive attention and community for both. For example, Mr. Nichiporchik said he has seen some YouTubers who had 5,000 subscribers grow that to 200,000 subscribers over the course of playing Hello Neighbor.
“That’s a good lesson for a lot of indie developers: Don’t always go for the top-tier guys,” said Brendan Greene, creator of PlayerUnknown’s Battlegrounds, a battle royale-style multiplayer survival game. “Go for the midlevel guys who are looking for something to get behind.”
He added, “If you find those people, they will walk through fire to help you out and it’s a great thing to have.”
Exclusive! PlayerUnknown's Battlegrounds official trailerVideo by PC Gamer
Mr. Greene, who spent years cultivating relationships with video game streamers, knew he wanted to get the streamers involved before releasing Battlegrounds this year. So over the course of a few months, his team interviewed top streamers of other battle royale games to hear what they wanted to play. Later, as a sweetener, Mr. Greene offered some streamers their own server computers where they could host customized versions of Battlegrounds for other players to try out.
The moves worked. After a preliminary “early access” version of Battlegrounds went on sale in March, it sold more than 6 million copies in four months.
“I owe a large part of my success to streamers,” Mr. Greene said. “I wouldn’t be here today making my own game without the support of the content creator community.”
Dynamic Pixels and tinyBuild have also worked to keep the Hello Neighbor community that was fostered by YouTube and Twitch viewers engaged. They have regularly offered updated demos of the game to customers who pre-ordered it, for instance. And when the game’s final version becomes available at the end of the month, it will allow players to enter the one room that they could not reach before: the basement.
“People get really into the game trying to figure out exactly what is in the basement,” Mr. Nichiporchik said. “That creates a community effect that makes people want to participate, and participating means playing.”
After a recent outage, we wondered how hard it would be to replaceCloudflare and their robot-protection code.
Once that worked, we realized that we had a decent front-end for websockets
to operate at scale.
This codebase is a full stack for delivering web apps. It uses NGINX
as the web server, and extends it with lots of custom Lua code. The Lua code
runs inside the memory of the Nginx workers, and provides the following services:
fake browser detection and blocking.
basic session cookies.
websocket fan-out / message passing
content cache from redis and/or disk
generalized virtual hosting: a single IP can host many domains
It can serve static content, dynamic content via FastCGI
for each virtual host, and also serve static/cached content from Redis.
Live Demo
Visit cloudfire-demo.coinkite.com for a quick
demo. It's quite basic: just a basic chat application with a simple robot.
How It Works
DDoS Protection
It's great to be able to "curl" your website, but when others are doing it
as a DDoS, it's less fun. The Lua code in this project checks all accesses
to the web server. If the new visitor does not have a session cookie
(managed by Lua, not your app), then a boring HTML page is rendered. That HTML
page contains Javascript to do a "proof of work" exercise and then posts the
result back to Lua. If the proof-of-work verifies, the user gets a cookie and
can proceed onto their usual content.
For real visitors, they have a Javascript-capable browser, so they are delayed
but not blocked and no captcha is needed.
For the PoW test, we're using SHA1 of a random seed (provided by the Lua code, so
it cannot be pre-computed) and a simple counter as a nonce. We want to see a
specific bit pattern anywhere in the hash hex. This is a simple check that both
the browser and server can do easily, but takes quite a few interations. A typical
browser can complete the task in a few seconds. If someone were to develop custom
ASICs to solve these PoW problems, we'll increase the difficulty... In fact, the
Lua code could do that automatically when it senses that new incoming traffic is
coming too fast.
Dynamic Content vs. Caching
We use Redis to share state between FastCGI dynamic websites
and the Lua Code. All incoming URL's are checked against Redis to see if we should
provide a cached response. It's up the dynamic stuff to control what URL's are
in Redis for caching purposes. This system does only explicit caching at this point.
Boring redirects and smaller CSS/JS files can be put into Redis for
direct handling by the Lua code. For larger objects, contents are
served from disk based on the record found in Redis. This unlocks
the many features of Nginx, like Etags and Range requests, which
you want for larger objects.
Because this caching is explicit, you can upload an entire static website and
serve it directly from Nginx/Lua/Redis. See the python
helper program "upload.py" to enable this.
There is no cache expiration, although if a key were to have limited
lifetime in Redis, you would get the same effect.
Websockets
It's 2015, so we want to make modern websites that push data to the browser
as real-time events happen. We currently use Pubnub
at Coinkite, and they've never let us down. However, since we have Redis and Lua
in place, why not connect them? Then a CloudFIRE front-end can be the fan-out we
need for Websockets. Websockets, in my opinion, are ready to come of
age and be deployed more widely. CloudFIRE does not attempt any backwards compatibity
with older browsers w.r.t websockets. This looks safe based on our
research at caniuse.com.
CloudFIRE accepts new websocket connections and implements them in Lua. (They are
rate-limited and managed via the same session cookies as normal HTTP traffic.)
Incoming traffic (from browser to server) is pushed onto a per-virtualhost
Redis list, which is easy to read
and decouples processing time from data rates (via BLPOP).
To send data from the server to
clients, the Lua code subscribes (SUBSCRIBE)
to a few specific channels, each of which can be written by the backend.
To do all this, the backend dynamic code must be connected to Redis and FastCGI.
The demo code does exactly this, using a few additions to the usual python/Flask setup.
We've provided Redis channels to send messages to every socket (broadcast),
only those of a single browser (session) or only to a specific web socket. When messages
are received from browsers, they are securely tracked as to their origin, so the
backend can be trust the origins of each message. (Be sure not to trust the contents
of the message though!)
Backend Options
There is no requirement to use Python and Flask in the backend. Any
dynamic web server could be used as long as it can do FastCGI and
Redis. There is no need for complex async networking code, since
it will be only doing PUBLISH and BRPOP Redis commands for websockets.
In the FreeBSD directory, you'll find some deployment notes because
we used FreeBSD 10.1 to host this project.
Usage Notes
Your backends should run as different users from the front end. They will communicate
with CloudFIRE via Redis and FastCGI which is easily done via TCP on localhost.
Each visitor will consume two sockets: one websocket and one connection to Redis.
We haven't experimented yet with this "at scale" to see how well that works.
You'll need to understand how to use NGINX effectively to be able to deploy this.
Please use SSL for everything; we didn't for this demo to keep it simple.
This code is just experimental at this point; we aren't using it in production.
I think most CSRF issues would be solved by accepting form data via websocket only?!
Lots more DDoS features could be added at the Lua layer. Like checking IP address
black/white listing and rate limiting.
Big props to the folks at openresty.org who created all
the Lua tools we used this project.
Future Directions
Some things we might do if we had more time...
Lua placeholder HTML templates should be uploadable or fetched from Redis.
This would allow each vhost to customize the branding shown in their 404/502 pages.
The present upload.py code is poor and needs a rewrite. It should probably post to
an admin URL instead of using a mixture of Redis and admin URL's.
The Flask code could be greatly improved with better integrate between CloudFIRE and
the python code. For example, it could automatically upload all the static content
based on standard flask configuration values.
More statistics. The Lua code should collect stats and provide them via an admin URL
or Redis.
Imagine a warehouse, just like the one pictured below, packed with thousands and thousands of boxes.
Now imagine not one, but a vast network of such warehouses, each containing thousands and thousands of boxes and new ones arriving every day. Currently warehouse workers walk from one aisle to another, manually count the number of boxes on a given shelf, record the data and verify that this number corresponds with the quantity in the database.
As you can imagine, this is a very time consuming and costly process. Workers have to spend hours every day walking and counting the various amounts of boxes. Also, since there is a human component involved, it is easier to make a mistake while counting, recording erroneous information and other possible mistakes which can wreak havoc in the warehouse.
What if we told you, that we are working on a state-of-the-art AI-powered robot which will optimize cycle counting by eliminating the need to manually count all of the inventory and input it into the system by hand. The robot will do everything for you. Imagine how much time and money this can save you. Even though this may sound like something out of a sci-fi movie, Innovecs is making it a reality. We already have a prototype developed and the robot itself will be fully operational in 6 months.
Project Goals
The goal of the project is to develop software which will allow a robot to calculate the number of boxes within an image by employing OpenCV and Tesseract technologies. These boxes will be stored in a huge warehouse and the rows of the warehouse will have labels on them such as the one below.
The robot must be able to:
Read the barcode and letters on the warehouse shelf which contains information about the quantity of boxes located in a particular aisle or shelf.
Identify the object in the image (pellet, box, label, etc.)
Count the number of boxes in the image
Verify that the number of boxes in the image matches the number stored in the database
Challenges which We Need to Overcome
Creating a robot which can accomplish the above stated goals poses difficult, yet interesting challenges. Namely:
Detecting, identifying and quantifying objects in an image.
Synchronizing information received with the overall database.
Reading and recognizing the bar code on warehouse shelf containing relevant data.
The boxes are stored in a warehouse in subzero conditions, -30°C, meaning that the camera must be operable in such temperature.
The warehouse is equipped with low lighting, so the camera must be able to detect objects in the image and count them using a low amount of light.
Object Detection and Object Analysis
The two major components of the project are to create a robot that can first of all detect an image and then be able to analyze that image. These are two very different steps.
For object detection, we are simply trying to find out whether the object is in the frame and its approximate location. We use OpenCV for this since its features are better suited. For analysis, we use Tesseract, since OpenCV does not include OCR libraries. There are two general settings where OCR is applied: Controlled- Images taken from a scanner or something similar, where the target is a document and things like font, perspective, orientation, background consistency are mild in nature.
Uncontrolled: More natural, outside photos taken from a camera where you are trying to identify a traffic light, a stop sign etc.
Tesseract is better when used in a controlled setting, such as a warehouse and this is why we decided to use it. Generally, retraining OCR will not directly improve detection, but may improve recognition, especially for scene OCR.
The Final Product
The final product will be an robot powered by artificial intelligence, which will be placed on a forklift, like the illustration below.
It will fulfill all our project goal and reduce our client’s labor costs and provide a better, more efficient way to keep track of inventory.
This only one example of innovative software solutions Innovecs is creating for our clients. We are always open to new, exciting and challenging projects where we can create cutting edge software solutions. Partner with Innovecs and discover for yourself the Innovecs difference.
Dmytro has PhD in Engineering in the field of Artificial Intelligence. His professional experience includes over 10 years in teaching and scientific activities (Kyiv Polytechnic Institute, Institute for Applied Systems Analysis; Taras Shevchenko National University of Kyiv, Faculty of Cybernetics). Additionally, he has more than a decade of project management experience in product R&D companies (Finance, Logistics) as well as big outsourcing programs (Deutsche Bank, LG Electronics).
This is a (very) rare work-related entry. I mostly work on the compiler for a programming language named “Go”, and one of the problems we face is if and how we should add “generics” to a future version of Go. I can’t possibly summarize easily for a non-technical reader, but the TLDR version is (1) lots of other languages have generics (2) we’re pretty sure they’re useful (3) but they come with associated costs and complexity and we’re not sure they’re worth it. Also, “generics” is not just a single thing, there’s several semantic variants and several ways to implement them (for example, erased versus dictionary-passing versus template-stamping). So our team is collecting example stories of how Go generics would be useful in various situations — the jargon term for this is “use case”. Here’s mine:
The Go compiler uses maps fairly often, but map iteration order changes from one program execution to the next (and there are good reasons for this). It is a requirement that the Go compiler always generate the same output given the same program input, which means that any time the iteration order for a map would affect program output, we can’t directly use it.
The way we usually deal with this is to also build a slice of the elements in the map, where each time a new element is inserted in the map (each time insertion changes its size), that element is also appended to the slice, thus giving us an insertion-ordered map. This makes the code slightly clunkier and also adds a speed bump for new work on the compiler (and especially for new contributors to the compiler), where new code is first expressed plainly in idiomatic Go, but the idiomatic Go lacks a constant order, and then the order is cleaned up in a second pass.
We could also solve our problem with a datastructure handling interface{} elements, but this would add a bit of storage overhead (storing 2-element interfaces instead of 1-element pointers) and a little bit of time overhead, and our users are, for better or worse, remarkably sensitive to the time it takes to compile their programs.
With generics (either templated or dictionary-passing; templated would provide the best performance for us) we could define, say, OrderedMap[[T,U]], that would take care of all the order bookkeepping, be space efficient, and fast. If we could arrange for some “sensible” overloading, the difference between idiomatic Go and the correct Go for compiler implementation would be only the declaration of the data structure itself. I think that the overloading has to be part of the use case; if we have to use different syntax for something that is map-like, and thus could not update a program by updating just the declaration/allocation, that’s not as good.
By sensible overloading, I mean that we could define a generic interface type, say MapLike[[T,U]] with methods Get(T)U, GetOk(T)U,bool, Put(T,U), Delete(T), and Len()int, and any data type that supplied those methods could be manipulated using existing Go map syntax.
Iteration methods are also required, but trickier; a fully general solution would use an iteration state with its own methods, or we could declare that iteration state fits in an integer, which constrains the possible map implementations (though would be a very Go thing to do). The integer version could use three methods on the data structure itself, say, FirstOk(int)int,bool, NextOk(int)int,bool, and GetAt(int)T,U. The you-get-an-integer approach is a little interesting because it allows recursive subdivision as well as iteration, if NextOk works properly given an input that is not itself a valid index.
The iterator-state version could instead use the map method Begin()Iterator[[T,U]] and iterator methods Iterator[[T,U]].Nonempty()bool, Iterator[[T,U]].Next(), Iterator[[T,U]].Key()T, Iterator[[T,U]].Value()U. This doesn’t by itself support recursive subdivision; that would require more methods, perhaps one to split the iterator into a pair of iterators at a point and another to report the length of the iterator itself.
I wrote a small command-line text processing program in four different ML-derived languages, to try to get a feel for how they compare in terms of syntax, library, and build-run cycles.
ML is a family of functional programming languages that have grown up during the past 40 years and more, with strong static typing, type inference, and eager evaluation. I tried out Standard ML, OCaml, Yeti, and F#, all compiling and running from a shell prompt on Linux.
The job was to write a utility that:
accepts the name of a CSV (comma-separated values) file as a command-line argument
reads all the lines from that file, each consisting of the same number of numeric columns
sums each column and prints out a single CSV line with the results
handles large inputs
fails if it finds a non-numeric column value or an inconsistent number of columns across lines (an uncaught exception is acceptable)
A toy exercise, but one that touches on file I/O, library support, string processing and numeric type conversion, error handling, and the build-invocation cycle.
I tested on a random Big Data CSV file that I had to hand; running the wc (word count) utility on it gives the size and a plausible lower bound for our program’s runtime:
$ time wc big-data.csv
337024 337024 315322496 big-data.csv
real 0m3.086s
user 0m3.050s
sys 0m0.037s
$
I’ve included timings throughout because I thought a couple of them were interesting, but they don’t tell us much except that none of the languages performed badly (with the slowest taking about 16 seconds on this file).
Finally I wrote the same thing in Python as well for comparison.
Practical disclaimer: If you actually have a CSV file you want to do things like this with, don’t use any of these languages. Do it with R instead, where this exercise takes three lines including file I/O. Or at least use an existing CSV-mangling library.
Here are the programs I ended up with, and my impressions.
Standard ML
Standard ML, or SML, is the oldest and “smallest” of the four and the only one to have a formal standard, fixed since 1997. Its standard library (the Basis library) is a more recent addition.
funfold_stream f acc stream =
caseTextIO.inputLine stream of
SOME line => fold_stream f (f (line, acc)) stream
| NONE => acc
funto_number str =
caseReal.fromString str of
SOME r => r
| NONE => raise Fail ("Invalid real: " ^ str)
funvalues_of_line line =
letvalfields = String.fields (fn c => c = #",") line in
map to_number fields
endfunadd_to [] values = values
| add_to totals values =
if length totals = length values thenListPair.map (Real.+) (totals, values)
elseraise Fail "Inconsistent-length rows"funsum_stream stream =
fold_stream (fn (line, tot) => add_to tot (values_of_line line)) [] stream
funsum_and_print_file filename =
letvalstream = TextIO.openIn filename inletvalresult = sum_stream stream in
print ((String.concatWith "," (map Real.toString result)) ^ "\n")
end;
TextIO.closeIn stream
endfunmain () =
caseCommandLine.arguments () of [filename] => sum_and_print_file filename
| _ => raise Fail "Exactly 1 filename must be given"val () = main ()
(Note that although I haven’t included any type annotations, like all ML variants this is statically typed and the compiler enforces type consistency. There are no runtime type errors.)
This is the first SML program I’ve written since 23 years ago. I enjoyed writing it, even though it’s longer than I’d hoped. The Basis library doesn’t offer a whole lot, but it’s nicely structured and easy to understand. To my eye the syntax is fairly clear. I had some minor problems getting the syntax right first time—I kept itching to add end or semicolons in unnecessary places—but once written, it worked, and my first attempt was fine with very large input files.
I had fun messing around with a few different function compositions before settling on the one above, which takes the view that, since summing up a list is habitually expressed in functional languages as an application of fold, we could start with a function to apply a fold over the sequence of lines in a file.
More abstractly, there’s something delightful about writing a language with a small syntax that was fixed and standardised 18 years ago and that has more than one conforming implementation to choose from. C++ programmers (like me) have spent much of those 18 years worrying about which bits of which sprawling standards are available in which compiler. And let’s not talk about the lifespans of web development frameworks.
To build and run it I used the MLton native-code compiler:
$ time mlton -output sum-sml sum.sml
real 0m2.295s
user 0m2.160s
sys 0m0.103s
$ time ./sum-sml big-data.csv
150.595368855,68.9467923856,[...]
real 0m16.383s
user 0m16.370s
sys 0m0.027s
$
The executable was a 336K native binary with dependencies on libm, libgmp, and libc. Although the compiler has a good reputation, this was (spoiler alert!) the slowest of these language examples both to build and to run. I also tried the PolyML compiler, with which it took less than a tenth of a second to compile but 26 seconds to run, and Moscow ML, which was also fast to compile but much slower to run.
OCaml
OCaml is a more recent language, from the same root but with a more freewheeling style. It seems to have more library support than SML and, almost certainly, more users. I started taking an interest in it recently because of its use in the Mirage OS unikernel project—but of these examples it’s the one in which I’m least confident in my ability to write idiomatic code.
(Edit: at least two commenters below have posted improved versions of this—thanks!)
openStrlet read_line chan =
trySome (input_line chan)
withEnd_of_file -> Noneletrec fold_channel f acc chan =
match read_line chan with
| Some line -> fold_channel f (f line acc) chan
| None -> acc
let values_of_line line =
let fields = Str.split (Str.regexp ",") line inList.map float_of_string fields
let add_to totals values =
match totals with
| [] -> values
| _ ->
ifList.length totals = List.length values thenList.map2 (+.) totals values
else failwith "Inconsistent-length rows"let sum_channel chan =
let folder line tot = add_to tot (values_of_line line) in
fold_channel folder [] chan
let sum_and_print_file filename =
let chan = open_in filename in
(let result = sum_channel chan in
print_string ((String.concat "," (List.map string_of_float result)) ^ "\n");
close_in chan)
let main () =
matchSys.argv with
| [| _; filename |] -> sum_and_print_file filename
| _ -> failwith "Exactly 1 filename must be given"let() = main ()
I’m in two minds about this code. I don’t much like the way it looks and reads. Syntax-wise there are an awful lot of lets; I prefer the way SML uses fun for top-level function declarations and saves let for scoped bindings. OCaml has a more extensive but scruffier library than SML and although there’s lots of documentation, I didn’t find it all that simple to navigate—as a result I’m not sure I’m using the most suitable tools here. There is probably a shorter simpler way. And my first attempt didn’t work for long files: caught out by the fact that input_line throws an exception at end of file (ugh), I broke tail-recursion optimisation by adding an exception handler.
On the other hand, writing this after the SML and Yeti versions, I found it very easy to write syntax that worked, even when I wasn’t quite clear in my head what the syntax was supposed to look like. (At one point I started to worry that the compiler wasn’t working, because it took no time to run and printed no errors.)
I didn’t spot at first that OCaml ships with separate bytecode and optimising native-code compilers, so my first tests seemed a bit slow. In fact it was very fast indeed:
$ time ocamlopt -o sum-ocaml str.cmxa sum.ml
real 0m0.073s
user 0m0.063s
sys 0m0.003s
$ time ./sum-ocaml big-data.csv
150.595368855,68.9467923856,[...]
real 0m7.761s
user 0m7.740s
sys 0m0.027s
$
The OCaml native binary was 339K and depended only on libm, libdl, and libc.
Yeti
Yeti is an ML-derived language for the Java virtual machine. I’ve written about it a couple of timesbefore.
I love Yeti’s dismissive approach to function and binding declaration syntax—no let or fun keywords at all. Psychologically, this is great when you’re staring at an empty REPL prompt trying to decide where to start: no syntax to forget, the first thing you need to type is whatever it is that you want your function to produce.
The disadvantage of losing let and fun is that Yeti needs semicolons to separate bindings. It also makes for a visually rather irregular source file.
As OCaml is like a pragmatic SML, so Yeti seems like a pragmatic OCaml. It provides some useful tools for a task like this one. Although the language is eagerly evaluated, lazy lists have language support and are interchangeable with standard lists, so the standard library can expose the lines of a text file as a lazy list making a fold over it very straightforward. The default map and map2 functions produce lazy lists.
Unfortunately, this nice feature then bit me on the bottom in my first draft, as the use of a lazy map2 in line 6 blew the stack with large inputs (why? not completely sure yet). The standard library has an eager map as well as a lazy one but lacks an eager map2, so I fixed this by converting the number row to an array (arguably the more natural type for it).
The Yeti compiler runs very quickly and compiles to Java .class files. With a small program like this, I would usually just invoke it and have the compiler build and run it in one go:
$ time yc ./sum.yeti big-data.csv
150.59536885458684,68.9467923856445,[...]
real 0m14.440s
user 0m26.867s
sys 0m0.423s
$
Those timings are interesting, because this is the only example to use more than one processor—the JVM uses a second thread for garbage collection. So it took more time than the MLton binary, but finished quicker…
F♯
F♯ is an ML-style language developed at Microsoft and subsequently open-sourced, with a substantial level of integration with the .NET platform and libraries.
(Edit: as with the OCaml example, you’ll find suggestions for alternative ways to write this in the comments below.)
let addTo totals row =
match totals with
| [||] -> row
| _ ->
ifArray.length totals = Array.length row thenArray.map2 (+) totals row
else failwith "Inconsistent-length rows"let sumOfFields fields =
let rows = Seq.map (Array.map float) fields inSeq.fold addTo [||] rows
let fieldsOfFile filename =
seq { use s = System.IO.File.OpenText(filename)
whilenot s.EndOfStreamdoyield s.ReadLine().Split',' }
let sumAndPrintFile filename =
let result = fieldsOfFile filename |> sumOfFields in
printfn "%s" (String.concat "," (Array.map string result))
[<EntryPoint>]
let main argv =
match argv with
| [|filename|] -> (sumAndPrintFile filename; 0)
| _ -> failwith "Exactly 1 filename must be given"
F♯ also has language support for lazy lists, but with different syntax (they’re called sequences) and providing a Python-style yield keyword to generate them via continuations. The sequence generator here came from one of the example tutorials.
A lot of real F♯ code looks like it’s mostly plugging together .NET calls, and there are a lot of capital letters going around, but the basic functional syntax is almost exactly OCaml. It’s interesting that the fundamental unit of text output seems to be the formatted print (printfn). I gather F♯ programmers are fond of their |> operator, so I threw in one of those.
I’m running Linux so I used the open source edition of the F♯ compiler:
$ time fsharpc -o sum-fs.exe sum.fs
F# Compiler for F# 3.1 (Open Source Edition)
Freely distributed under the Apache 2.0 Open Source License
real 0m2.115s
user 0m2.037s
sys 0m0.063s
$ time ./sum-fs.exe big-data.csv
150.595368854587,68.9467923856445,[...]
real 0m13.944s
user 0m13.863s
sys 0m0.070s
$
The compiler produced a mere 7680-byte .NET assembly, that of course (like Yeti) requires a substantial managed runtime. Performance seems pretty good.
Python
Python is not an ML-like language; I include it just for comparison.
importsysdefadd_to(totals, values):
n = len(totals)
if n == 0:
return values
elif n == len(values):
return [totals[i] + values[i] for i inrange(n)]
else:
raise RuntimeError("Inconsistent-length rows")
defadd_line_to(totals, line):
values = [float(s) for s in line.strip().split(',')]
return add_to(totals, values)
defsum_file(filename):
f = open(filename, 'r')
totals = []
for line in f:
totals = add_line_to(totals, line)
f.close()
return totals
if __name__ == '__main__':
iflen(sys.argv) != 2:
raise RuntimeError("Exactly 1 filename must be given")
result = sum_file(sys.argv[1])
print(','.join([str(v) for v in result]))
Feels odd having to use the return keyword again, after using languages in which one just leaves the result at the end of the function.
This is compact and readable. A big difference from the above languages is invisible—it’s dynamically typed, without any compile-time type checking.
To build and run this, I just invoked Python on it:
$ time python ./sum.py ./big-data.csv
150.59536885458684,68.9467923856445,[...]
real 0m10.939s
user 0m10.853s
sys 0m0.060s
$
That’s Python 3. Python 2 was about a second faster. I was quite impressed by this result, having expected to suffer from my decision to always return new lists of totals rather than updating the values in them.
Any conclusions?
Well, it was a fun exercise. Although I’ve written more in these languages than appears here, and read quite a bit about all of them, I’m still pretty ignorant about the library possibilities for most of them, as well as about the object support in OCaml and F♯.
I am naively impressed by the OCaml compiler. For language “feel”, it gave me the least favourable first impression but I can imagine it being pleasant to use daily.
F♯ on Linux proved unexpectedly straightforward (and fast). Could be a nice choice for web and server applications.
I have made small web and server applications using Yeti and enjoyed the experience. Being able to integrate with existing Java code is good, though of course doubly so when the available libraries in the language itself are so limited.
Standard ML has a clarity and simplicity I really like, and I’d still love to try to use it for something serious. It’s just, well, nobody else seems to—I bet quite a lot of people have learned the language as undergrads (as I did) but it doesn’t seem to be the popular choice outside it. Hardly anyone uses Yeti either, but the Java interoperability means you aren’t so dependent on other developers.
Practically speaking, for jobs like this, and where you want to run something yourself or give someone the source, there’s not much here to recommend anything other than Python. Of course I do appreciate both compile-time typechecking and (for some problems) a more functional style, which is why I’m writing this at all.
But the fact that compilers for both SML and OCaml can generate compact and quick native binaries is interesting, and Yeti and F♯ are notable for their engagement with other existing frameworks.
If you’ve any thoughts or suggestions, do leave a comment.
At a recent security conference, a new research has been presented by the experts from an Israeli university that showed a possible attack scenario that involves replacement parts to carry out attacks on smartphones and other smart devices.
The attack has been described as chip-in-the-middle, and it works on the assumption that a malicious actor is capable of mass-manufacturing electronic spare parts which have an extra chip for intercepting a device’s inner communications but is also capable of issuing malicious commands.
The researchers made their theory into a reality by building the malicious spare parts and then using them to gain control over a test smartphone. At the end of the article, you will find video proof of their hack.
Although the attack seems complex, according to the researchers that conducted the experiment, they only used off-the-shelf electronics that summed up to a total cost of $10. Even though there are practical skills required for some of the operations in this hack, the attack is far from sophistication that it exudes and involves no complex machinery often installed in high-tech factories.
The researchers said that they found two ways in which they could exploit the malicious spare attacks they manufacture.
The one way is a basic command injection into the communication streams between the phone and the spare component. The attack in question works best with malicious touchscreen displays since it lets the attacker pose as the phone user by mimicking touch actions and exfiltrating data.
The second way is a buffer overflow attack that works by targeting a vulnerability in the touch controller device driver embedded within the operating system kernel. By exploiting this flaw, attackers get elevated privileges on the phone and carry out attacks on the OS itself, no need to mimic touch gestures needed. This attack doesn’t work universally though since it is specific to one set of device drivers.
The experts from the Ben-Gurion University of the Negev in Israel that formed the research team that carried out the hack have presented multiple hardware-based countermeasures for preventing attacks via spare parts in their research paper.
Their paper is titled “Shattered Trust: When Replacement Smartphone Components Attack” and the countermeasures and other details can be found on these two addresses: first and the second one. Researchers presented their work at the recently concluded USENIX W00T ’17 security conference.
Below you can find videos that show how the experts carried out their hacks on smartphones.
Summary
Article Name
An Easily Made Malicious Chip can Spy and Take Over Your Phone
Description
At a recent security conference, a new research has been presented by the experts from an Israeli university that showed a possible attack scenario that involves replacement parts to carry out attacks on smartphones and other smart devices.
A "fold" is a fundamental primitive in defining operations on data structures;
it's particularly important in functional languages where recursion is the
default tool to express repetition. In this article I'll present how left and
right folds work and how they map to some fundamental recursive patterns.
The article starts with Python, which should be (or at least look) familiar to
most programmers. It then switches to Haskell for a discussion of more advanced
topics like the connection between folding and laziness, as well as monoids.
foldr - fold right
Generalizations like transform make functional programming fun and powerful,
since they let us express complex ideas with the help of relatively few building
blocks. Let's take this idea further, by generalizing transform even more.
The main insight guiding us is that the mapping and the combination don't even
have to be separate functions. A single function can play both roles.
In the definition of transform, combination is applied to:
The result of calling mapping on the current sequence value.
The recursive application of the transformation to the rest of the sequence.
We can encapsulate both in a function we call the "reduction function". This
reduction function takes two arguments: the current sequence value (item), and
the result of applying the full transfromation to the rest of the sequence. The
driving transformation that uses this reduction function is called "a right
fold" (or foldr):
The key here is the func argument. In the case of product, it "reduces"
the current sequence value with the "accumulator" (the result of the overall
transformation invoked on the rest of the sequence) by multiplying them
together. The overall result is a product of all the elements in the list.
Let's trace the calls to see the recursion pattern. I'll be using the tracing
technique described in this post.
For this purpose I hoisted the reducing function into a standalone function
called product_reducer:
The recursion first builds a full stack of calls for every element in the
sequence, until the base case (empty list) is reached. Then the calls toproduct_reducer start executing. The first reduces 8 (the last element in
the list) with 1 (the result of the base case). The second reduces this result
with 6 (the second-to-last element in the list), and so on until we reach the
final result.
Since foldr is just a generic traversal pattern, we can say that the real
work here happens in the reducers. If we build a tree of invocations ofproduct_reducer, we get:
And this is why it's called the right fold. It takes the rightmost element and
combines it with init. Then it takes the result and combines it with the
second rightmost element, and so on until the first element is reached.
More general operations with foldr
We've seen how foldr can implement all kinds of functions on lists by
encapsulating a fundamental recursive pattern. Let's see a couple more examples.
The function double shown above is just a special case of the functionalmap primitive:
Instead of applying a hardcoded "multiply by 2" function to each element in the
sequence, map applies a user-provided unary function. Here's map
implemented in terms of foldr:
Another functional primitive that we can implement with foldr is filter.
This one is just a bit trickier because we sometimes want to "skip" a value
based on what the filtering predicate returns:
Note how similar it is to map_with_foldr; only the order of concatenation is
flipped.
Left-associative operations and foldl
Let's probe at some of the apparent limitations of foldr. We've seen how it
can be used to easily compute the product of numbers in a sequence. What about a
ratio? For the list [3, 2, 2] the ratio is "3 divided by 2, divided by 2",
or 0.75 .
If we take product_with_foldr from above and replace * by /, we get:
What gives? The problem here is the associativity of the operator /. Take
another look at the call tree diagram shown above. It's obvious this diagram
represents a right-associative evaluation. In other words, what our attempt at a
ratio did is compute 3 / (2 / 2), which is indeed 3.0; instead, what we'd
like is (3 / 2) / 2. But foldr is fundamentally folding the expressionfrom the right. This works well for associative operations like + or *
(operations that don't care about the order in which they are applied to a
sequence), and also for right-associative operations like exponentiation, but it
doesn't work that well for left-associative operations like / or -.
This is where the left fold comes in. It does precisely what you'd expect -
folds a sequence from the left, rather than from the right. I'm going to leave
the division operation for later and use another example of a
left-associative operation: converting a sequence of digits into a number. For
example [2, 3] represents 23, [3, 4, 5, 6] represents 3456, etc. (a
related problem which is more common in introductory programming is converting a
string that contains a number into an integer).
The basic reducing operation we'll use here is: acc * 10 + sequence value.
To get 3456 from [3, 4, 5, 6] we'll compute:
(((((3 * 10) + 4) * 10) + 5) * 10) + 6
Note how this operation is left-associative. Reorganizing the parens to a
rightmost-first evaluation would give us a completely different result.
Note that the order of calls between the recursive call to itself and the call
to func is reversed vs. foldr. This is also why it's customary to putacc first and seqval second in the reducing functions passed tofoldl.
Contrary to the right fold, the reduction function here is called immediately
for each recursive step, rather than waiting for the recursion to reach the end
of the sequence first. Let's draw the call graph to make the
folding-from-the-left obvious:
Now, to implement the digits-to-a-number function task described earlier, we'll
write:
Stepping it up a notch - function composition with foldr
Since we're looking at functional programming primitives, it's only natural to
consider how to put higher order functions to more use in combination with
folds. Let's see how to express function composition; the input is a sequence of
unary functions: [f, g, h] and the output is a single function that
implements f(g(h(...))). Note this operation is right-associative, so it's a
natural candidate for foldr:
In this case seqval and acc are both functions. Each step in the fold
consumes a new function from the sequence and composes it on top of the
accumulator (which is the function composed so far). The initial value for this
fold has to be the identity for the composition operation, which just happens to
be the identity function.
Let's take this trick one step farther. Recall how I said foldr is limited
to right-associative operations? Well, I lied a little. While it's true that the
fundamental recursive pattern expressed by foldr is right-associative, we
can use the function composition trick to evaluate some operation on a sequence
in a left-associative way. Here's the digits-to-a-number function withfoldr:
To understand what's going on, manually trace the invocation of this
function on some simple sequence like [1, 2, 3]. The key to this approach
is to recall that foldr gets to the end of the list before it actually
starts applying the function it folds. The following is a careful trace of what
happens, with the folded function replaced by g for clarify.
Now things become a bit trickier to track because of the different anonymous
functions and their bound variables. It helps to give these function names.
In other words, the actual computation passed to that final identity is:
Which is the left-associative application of the folded function.
Expressing foldl with foldr
After the last example, it's not very surprising that we can take this approach
to its logical conclusion and express the general foldl by using foldr.
It's just a generalization of digits2num_with_foldr:
In fact, the pattern expressed by foldr is very close to what is calledprimitive recursionby Stephen Kleene in his 1952 bookIntroduction to Metamathematics. In other words, foldr can be used to
express a wide range of recursive patterns. I won't get into the theory here,
but Graham Hutton's article A tutorial on the universality and expressiveness
of fold is a good read.
foldr and foldl in Haskell
Now I'll switch gears a bit and talk about Haskell. Writing transformations with
folds is not really Pythonic, but it's very much the default Haskell style. In
Haskell recursion is the way to iterate.
Haskell is a lazily evaluated language, which makes the discussion of folds a
bit more interesting. While this behavior isn't hard to emulate in Python, the
Haskell code dealing with folds on lazy sequences is pleasantly concise and
clear.
Let's starts by implementing product and double - the functions this
article started with. Here's the function computing a product of a sequence of
numbers:
myproduct[]=1myproduct(x:xs)=x*myproductxs
And a sample invocation:
*Main> myproduct [2,4,6,8]
384
The function doubling every element in a sequence:
mydouble[]=[]mydouble(x:xs)=[2*x]++mydoublexs
Sample invocation:
*Main> mydouble [2,4,6,8]
[4,8,12,16]
IMHO, the Haskell variants of these functions make it very obvious that a
right-fold recursive pattern is in play. The pattern matching idiom of(x:xs) on sequences splits the "head" from the "tail" of the sequence, and
the combining function is applied between the head and the result of the
transformation on the tail. Here's foldr in Haskell, with a type declaration
that should help clarify what goes where:
If you're not familiar with Haskell this code may look foreign, but it's really
a one-to-one mapping of the Python code for foldr, using some Haskell idioms
like pattern matching.
These are the product and doubling functions implemented with myfoldr,
using currying to avoid specifying the last parameter:
And this is how we'd write the left-associative function to convert a sequence
of digits into a number using this left fold:
digitsToNumWithFoldl=myfoldl(\accx->acc*10+x)0
Folds, laziness and infinite lists
Haskell evaluates all expressions lazily by default, which can be either a
blessing or a curse for folds, depending on what we need to do exactly. Let's
start by looking at the cool applications of laziness with foldr.
Given infinite lists (yes, Haskell easily supports infinite lists because of
laziness), it's fairly easy to run short-circuiting algorithms on them withfoldr. By short-circuiting I mean an algorithm that terminates the recursion
at some point throughout the list, based on a condition.
As a silly but educational example, consider doubling every element in a
sequence but only until a 5 is encountered, at which point we stop:
It terminates and returns the right answer! Even though our earlier stack trace
of folding makes it appear like we iterate all the way to the end of the input
list, this is not the case for our folding function. Since the folding function
doesn't use acc when x == 5, Haskell won't evaluate the recursive fold
further .
The same trick will not work with foldl, since foldl is not lazy in
its second argument. Because of this, Haskell programmers are usually pointed tofoldl', the eager version of foldl, as the better option. foldl'
evaluates its arguments eagerly, meaning that:
It won't support infinite sequences (but neither does foldl!)
It's significantly more efficient than foldl because it can be easily
turned into a loop (note that the recursion in foldl is a tail call, and
the eager foldl' doesn't have to build a thunk of increasing size due to
laziness in the first argument).
There is also an eager version of the right fold - foldr', which can be more
efficient than foldr in some cases; it's not in Prelude but can be
imported from Data.Foldable .
Folding vs. reducing
Our earlier discussion of folds may have reminded you of the reduce built-in
function, which seems to be doing something similar. In fact, Python'sreduce implements the left fold where the first element in the sequence is
used as the zero value. One nice property of reduce is that it doesn't
require an explicit zero value (though it does support it via an optional
parameter - this can be useful when the sequence is empty, for example).
Haskell has its own variations of folds that implement reduce - they have
the digit 1 as suffix: foldl1 is the more direct equivalent of Python'sreduce - it doesn't need an initializer and folds the sequence from the
left. foldr1 is similar, but folds from the right. Both have eager variants:foldl1' and foldr1'.
I promised to revisit calculating the ratio of a sequence; here's a way, in
Haskell:
myratioWithFoldl=foldl1(/)
The problem with using a regular foldl is that there's no natural identity
value to use on the leftmost side of a ratio (on the rightmost side 1 works, but
the associativity is wrong). This is not an issue for foldl1, which starts
the recursion with the first item in the sequence, rather than an explicit
initial value.
*Main> myratioWithFoldl [3,2,2]
0.75
Note that foldl1 will throw an exception if the given sequence is empty,
since it needs at least one item in there.
Folding arbitrary data structures
The built-in folds in Haskell are defined on lists. However, lists are not the
only data structure we should be able to fold. Why can't we fold maps (say,
summing up all the keys), or even custom data structures? What is the minimum
amount of abstraction we can extract to enable folding?
Let's start by defining a simple binary tree data structure:
dataTreea=Empty|Leafa|Nodea(Treea)(Treea)derivingShow-- A sample tree with a few nodest1=Node10(Node20(Leaf4)(Leaf6))(Leaf7)
Suppose we want to fold the tree with (+), summing up all the values
contained within it. How do we go about it? foldr or foldl won't cut it
here - they expect [a], not Tree a. We could try to write our own foldr:
There's a problem, however. Since we want to support an arbitrary folding
result, we're not quite sure what to substitute for the ??s in the code
above. In foldr, the folding function takes the accumulator and the next
value in the sequence, but for trees it's not so simple. We may encounter a
single leaf, and we may encounter several values to summarize; for the latter
we have to invoke f on x as well as on the result of folding left
and right. So it's not clear what the type of f should be - (b -> a ->
a) doesn't appear to work .
A useful Haskell abstraction that can help us solve this problem is Monoid.
A monoid is any data type that has an identity element (called mempty) and
an associative binary operation called mappend. Monoids are, therefore,
amenable to "summarization".
We no longer need to pass in an explicit zero element: since a is aMonoid, we have its mempty. Also, we can now apply a single (b -> a)
function onto every element in the tree, and combine the results together into a
summary using a's mappend (<> is the infix synonym of mappend).
The challenge of using foldTree is that we now actually need to use a unary
function that returns a Monoid. Luckily, Haskell has some useful built-in
monoids. For example, Data.Monoid.Sum wraps numbers into monoids under
addition. We can find the sum of all elements in our tree t1 usingfoldTree and Sum:
>foldrTreeSumt1Sum{getSum=47}
Similarly, Data.Monoid.Product wraps numbers into monoids under
multiplication:
>foldrTreeProductt1Product{getProduct=33600}
Haskell provides a built-in typeclass named Data.Foldable that only requires
us to implement a similar mapping function, and then takes care of defining many
folding methods. Here's the instance for our tree:
And we'll automatically have foldr, foldl and other folding methods
available on Tree objects:
>Data.Foldable.foldr(+)0t147
Note that we can pass a regular binary (+) here; Data.Foldable employs
a bit of magic to turn this into a properly monadic operation. We get many more
useful methods on trees just from implementing foldMap:
It's possible that for some special data structure these methods can be
implemented more efficiently than by inference from foldMap, but nothing is
stopping us from redefining specific methods in our Foldable instance. It's
pretty cool, however, to see just how much functionality can be derived from
having a single mapping method (and the Monoid guarantees) defined. See the
documentation of Data.Foldable for more details.
In December 2010, Sheryl Sandberg gave a talk about women’s leadership in which she mentioned “sitting at the table.” Women, she said, have to pull up a chair and sit at the conference-room table rather than clinging to the edges of the room, “because no one gets to the corner office by sitting on the side.”
Less than a year later, I would take those words to heart. I had been working for six years at the Silicon Valley firm Kleiner Perkins Caufield & Byers as a junior partner and chief of staff for managing partner John Doerr. Kleiner was then one of the three most powerful venture-capital firms in the world. One day, I was part of a small group flying from San Francisco to New York on the private jet of another managing partner, Ted Schlein. I was the first to arrive at Hayward Airport. The main cabin of the plane was set up with four chairs in pairs facing each other. Usually the most powerful seat faces forward, looking at the TV screen, with the second most powerful next to it. Then came the seats facing backward. I was sure the white men booked on the flight (Ted, senior partner Matt Murphy, a tech CEO, and a tech investor) would be taking those four seats and I would end up on the couch in back. But Sheryl’s words echoed in my mind, and I moved to one of the power seats — the fourth, backward-facing seat, but at the table nonetheless. The rest of the folks filed in one by one. Ted sat across from me, the CEO next to him, and the tech investor next to me on my right. Matt ended up with what would have been my original seat on the couch.
Once we were airborne, the CEO, who’d brought along a few bottles of wine, started bragging about meeting Jenna Jameson, talking about her career as the world’s greatest porn star and how he had taken a photo with her at the Playboy Mansion. He asked if I knew who she was and then proceeded to describe her pay-per-view series (Jenna’s American Sex Star), on which women competed for porn-movie contracts by performing sex acts before a live audience.
“Nope,” I said. “Not a show I’m familiar with.”
Then the CEO switched topics. To sex workers. He asked Ted what kind of “girls” he liked. Ted said that he preferred white girls — Eastern European, to be specific.
Eventually we all moved to the couch for a working session to help the tech CEO; he was trying to recruit a woman to his all-male board. I suggested Marissa Mayer, but the CEO looked at me and dismissively said, “Nah, too controversial.” Then he grinned at Ted and added, “Though I would let her join the board because she’s hot.”
Somehow, I got the distinct vibe that the group couldn’t wait to ditch me. And once we landed at Teterboro, the guys made plans to go to a club, while I headed into Manhattan alone. Taking your seat at the table doesn’t work so well, I thought, when no one wants you there. (When Sandberg’s book Lean In came out, that same Jenna Jameson–obsessed CEO became a vocal spokesperson for it.)
Seven months later, I would sue Kleiner Perkins for sexual harassment and discrimination in a widely publicized case in which I was often cast as the villain — incompetent, greedy, aggressive, and cold. My husband and I were both dragged through the mud, our privacy destroyed. For a long time I didn’t challenge those stories, because I wasn’t ready to talk about my experience in detail. Now I am.
When I first got the three pages of specs for a chief-of-staff position at Kleiner Perkins in 2005, it was almost as if someone had copied my résumé. The list of requirements was comically long: an engineering degree (only in computer science or electrical engineering), a law degree and a business degree (only from top schools), management-consulting experience (only at Booz Allen or Bain), start-up experience (only at a top start-up), enterprise-software-company experience (only at a big established player known for training employees) … oh, and fluency in Mandarin.
John Doerr wanted his new chief of staff to “leverage his time,” which he valued at $200,000 per hour. I liked John. People sometimes compare him to Woody Allen, because he has that strange mixture of nervous energy, nerdy charm, and awkwardness, though John was also an unapologetic salesman. His pitch to me: I would be senior to others in this role; Kleiner Perkins was one of the few VC firms with women, and he wanted to bring even more onboard; diversity was important to him.
In retrospect, there were some early warning signs, like when John declared that he’d specifically requested an Asian woman for my position. He liked the idea of a “Tiger Mom–raised” woman. He usually had two chiefs of staff at a time, one of each gender, but the male one seemed to focus mostly on investing and the female one did more of the grunt work and traveled with him. “There are certain things I am just more comfortable asking a woman to do,” John once told me matter-of-factly.
Still, my new job felt thrilling. At Kleiner, we focused on the really big ideas: the companies that were trying to transform an industry or revolutionize daily life. And John was king of kingmakers. He had some early hits: Genentech, Intuit, Amazon. He was one of the first to invest in the internet, with Netscape, and cemented his online reputation later with Google.
In venture capital, a ton of power is concentrated in just a few people who all know one another. Tips and information are exchanged at all-male dinners, outings to Vegas, and sports events. Networks are important inside a VC firm, too. One secret of the venture-capital world is that many firms run on vote trading. A person might offer to vote in favor of investing in another partner’s investment so that partner will support his upcoming investment. Many firms, including Kleiner, also had a veto rule: Any one person could veto another member’s investment. No one ever exercised a veto while I was there, but fear of it motivated us to practice the California art of superficial collegiality, where everything seems tan and shiny on the outside but behind closed doors, people would trash your investment, block it, or send you on unending “rock fetches” — time-consuming, unproductive tasks to stall you until you gave up.
Venture capital’s underbelly of competitiveness exists in part because the more I invest, the less money for you, my partner, to make your investments. And we’re all trying to make as many investments as possible because chances are low that any one investment is going to be successful. Partners can increase their own odds by excluding all of your investments. And as a junior partner you faced another dilemma: Your investments could be poached by senior partners. You wanted to pitch your venture so it would be supported but not so much that it would be stolen. Once a senior partner laid claim to a venture you were driving, you were better off just keeping quiet. Otherwise, you could be branded as having sharp elbows and not being a good team player. But this was true, I noticed, only for women. Junior men could sometimes even take ventures from senior partners.
Predicting who will succeed is an imperfect art, but also, sometimes, a self-fulfilling prophecy. When venture capitalists say — and they do say — “We think it’s young white men, ideally Ivy League dropouts, who are the safest bets,” then invest only in young white men with Ivy League backgrounds, of course young white men with Ivy League backgrounds are the only ones who make money for them. They’re also the only ones who lose money for them.
Sometimes the whole world felt like a nerdy frat house. People in the venture world spoke fondly about the early shenanigans at big companies. A friend told me how he sublet office space to Facebook, only to find people having sex there on the floor of the main public area. They wanted to see if the Reactrix — an interactive floor display hooked up to light sensors — would enhance their experience. At VC meetings, male partners frequently spoke over female colleagues or repeated what the women said and took the credit. Women were admonished when they “raised their voices” yet chastised when they couldn’t “own the room.” When I was still relatively new, a male partner made a big show of passing a plate of cookies around the table — but curiously ignored me and the woman next to him. Part of me thought, They’re just cookies. But after everyone left, my co-worker turned to me and shrugged. “It’s like we don’t exist,” she said.
Then, in 2006, I took a fateful business trip. Ajit Nazre, a fellow partner, had asked me to go with him on a tour of German green-tech start-ups. Every time we were alone in the evening, he would tell me that he and his wife had a terrible relationship, that he was desperately lonely, and that he and I would be good together.
Honestly, I might have considered dating him had he been less arrogant and less married. I was awfully lonely too. After our last set of meetings, Ajit asked for my room number. Since he and I were leaving the next morning, I figured he might want to coordinate our departure for the airport. So I told him the number. But I must have subconsciously given him the wrong one. The next morning at checkout, he was livid. It seemed he’d gone to what he thought was my room and I wasn’t there. He stormed off to the airport by himself.
After the trip, I tried to placate Ajit by sending a couple of friendly emails. He slowly became friendlier; then we worked on a project together, and he was actually helpful. I tried to keep the relationship professional, but he soon started saying that he and his wife were having problems again. I kept up my mantra: “You should do counseling.” Until, one day, he said, “I wanted you to know that my wife and I have separated. We’re getting divorced. I want to be with you.” He’d never said anything like that before. I felt a dash of hope that this could be a real thing.
We started seeing each other and had what eventually amounted to a short-lived, sporadic fling. It was fun bonding over work. Ajit told me the history of the firm and gave me the scoop on departed partners, and I felt like I was at last being let in on company secrets. Finally I had someone who was willing to talk about the dysfunction we saw in our workplace, and to be honest about how decisions were really made.
Then one day in a meeting, one of the managing partners, oblivious to my relationship with Ajit, said, “Can you believe my weekend? I was in a suite at the Ritz-Carlton at Half Moon Bay, standing on the balcony in my bathrobe, and who did I see? Ajit and his wife walking across the lawn!” I broke it off with Ajit, but I was hopeful we could move past it personally and professionally.
As it turned out, I would soon meet and fall in love with the man I would marry, Buddy Fletcher. He was a financial arbitrageur who’d helped fund the first professorship for LGBTQ studies at Harvard. During our first date in New York, he told me during hours of conversation that he had previously been with men, something I never had a problem with but which would later be used in the press as evidence that our marriage was a sham. We got engaged just six weeks after we met.
My newly joyous home life was a liability in one sense, though: It made me recognize how very uncomfortable my work situation had become. Ajit had grown increasingly hostile toward me, excluding me from information and meetings. Even with other managers, I often got ignored or interrupted. At one point, John had a suggestion for how I could get more airtime. He wanted me to go to school — to learn to be a stand-up comic.
Partners had become so aggressive about pursuing ventures I was working on that CEOs started to point it out. One CEO I had been working with, Mike McCue, called me to relate how John and another managing partner, Bing Gordon, had met with him and asked to invest more money in his start-up Flipboard. Just a few months earlier, I had lobbied hard for the firm to go all in and invest a large amount in Flipboard, but had been pushed to take a smaller investment. “They offered to pay $15 million for another 5 percent,” Mike told me. That price worked out to 20 percent higher than in the latest round. When Mike told them he was done raising, they upped their offer to $25 million for 5 percent. I gasped inwardly. We’d had a chance to buy the same number of shares for only $10 million just a month ago.
“Then,” he continued, “Bing asked for a board seat for himself or John. I said no. You know I don’t want anyone but you on my board right now. What is going on?” Now I understood why they hadn’t invited me to the meeting or even told me about it. I had made the initial investment and was a board member, so standard practice would have been for me to be part of any discussions about Flipboard. After the call, I confronted the two partners with Mike’s account. John seemed sheepish and blamed the gambit on Bing. Bing just looked alarmed. I don’t think he ever expected to fail in his bid or be held accountable for his bad manners. I didn’t get an apology, but the look of shock on his face was almost enough to make me feel better. And I could console myself with the knowledge that at least I had relationships worth trying to steal.
Of the few women I encountered at or above my professional level, almost none had young families. One partner told me that when she happily announced her third pregnancy, a male senior partner responded, “I don’t know any professional working woman who has three kids.”
When I gave birth to my first child, some partners at work treated my taking maternity leave as the equivalent of abandoning a ship in the middle of a typhoon to get a manicure. Juliet de Baubigny, one of the partners who had helped recruit me, had warned me that taking time off would put my companies at risk of being commandeered by another partner. I knew two other women who had board seats taken away during their maternity leaves. Juliet coached me on how to keep at least one company by leading their search for a CEO even though technically I was on leave. I’d arranged to take four months off, but after three I felt pressure to return.
Back at Kleiner, I continued to have a huge problem with Ajit. Not only was he blocking my work, he had been promoted to a position of even greater responsibility and was giving me negative reviews. I started to lodge formal complaints about him. In response, the firm suggested I transfer to the China office.
It wasn’t until the spring of 2011 that I finally told a few colleagues about my harassment by Ajit. One instructed me never to mention it again. But when I told fellow junior partner Trae Vassallo, she grew uncharacteristically quiet. Then she said something I never expected: She had been harassed by Ajit, too. He’d asked her out for drinks to talk shop, and in the course of the evening he started touching her with his leg under the table. Then I said something I still feel bad about. I recommended that she not report it. I had, and had been paying the price ever since.
Fortunately, Trae didn’t take my advice. She reported Ajit’s behavior soon after, when she found out he was about to do her review. She was promised that the firm would keep an eye on it, but no other action was taken.
In that round of summer reviews, Kleiner had six junior partners who had worked there for four or more years. The women had twice as many years at Kleiner, but only the men got promoted.
Around the end of November, Ajit persuaded Trae to go to New York with him for an important work trip. He said they’d be having dinner with a CEO who might be able to help one of Trae’s companies. But when they arrived, Trae saw that the table was set for two. The trip was just her and Ajit, in a hotel together for the weekend. Later that night he came to her room in his bathrobe, asking to be let in. She eventually had to push him out the door. Later, when she told one of the managing partners about the fake trip, he said, “You should feel flattered.”
It was now clear to me that the firm was unwilling to take the difficult actions needed to fix its problems. On January 4, 2012, I sent an email to the managing partners presenting all the facts as clearly as I could and asking for substantive changes and either protection from further ostracism or help with an exit.
After more than a month, the company put Ajit on leave. Two tense months after that, he finally left. When I spoke to the COO, he asked how much I wanted in order to quietly leave. “I want no less than what Ajit gets,” I said — which I suspected was around $10 million. The COO gasped.
Life at Kleiner got progressively worse. At one point I found out the partners had taken some CEOs and founders on an all-male ski trip. They spent $50,000 on the private jet to and from Vail. I was later told that they didn’t invite any women because women probably wouldn’t want to share a condo with men.
Finally, an outside independent investigator looked into Trae’s complaint and the issues I’d raised in my memo. Almost all of the women came to me after their interviews with him and said the same thing: “He really didn’t ask questions. He asked if we had ever seen porn in the office.” He didn’t seem interested in finding out about actual discrimination, bias, or harassment.
In my own interview, when I mentioned that my colleagues had talked about a porn star when we were on a plane together, the investigator asked if it was Sasha Grey. I said no. He pressed the point, saying that Sasha Grey was crossing over into legitimate acting. At another point, the investigator asked, in a “gotcha” tone, “Well, if they look down on women so much, if they block you from opportunities, they don’t include you at their events, why do they even keep you around in the first place?”
I hadn’t thought about it before. I replied slowly as the answer crystallized in my mind: If you had the opportunity to have workers who were overeducated, underpaid, and highly experienced, whom you could dump all the menial tasks you didn’t want to do on, whom you could get to clean up all the problems, and whom you could create a second class out of, wouldn’t you want them to stay?
I noticed he didn’t write that down in his notebook. Among the other things the investigator did not write down: that there was no sexual-harassment training, not even a line in the hiring paperwork saying: Hey, be appropriate. Don’t do things that make people feel uncomfortable. Don’t touch people. Kleiner’s managing partners flouted hiring rules, too, asking inappropriate questions in interviews like: Are you married? Do you have kids? How old are you? Are you thinking about having kids? What does your husband do? What did your ex-husband do? It was noted at some point that such questions created a giant legal risk, and the response was, effectively, Well, who’s going to sue us?
Apparently, me. My claim — 12 pages covering everything that had happened to me over seven years at Kleiner — specified gender discrimination in promotion and pay, and retaliation against me after I reported the harassment. I asked for damages to cover the lost pay and to prevent them from doing it again. Meanwhile, Kleiner had notified me that its investigation was done: The finding was that there had been no retaliation or discrimination.
In response to my suit, Kleiner hired a powerful crisis-management PR firm, Brunswick. On their website, they bragged about having troll farms — “integrated networks of influence,” used in part for “reputation management” — and I believe they enlisted one to defame me online. Dozens, then thousands, of messages a day derided me as bad at my job, crazy, an embarrassment. Repeatedly, Kleiner called me a “poor performer.” A Vanity Fair story implied that Buddy was gay, a fraud, and a fake husband.
My lawyer said my case would be stronger if I continued to work at Kleiner. The general partners sometimes had long meetings to discuss the lawsuit; the ten of them would file into one of the large, windowed conference rooms. I could see them hunched around the table looking annoyed as a team of lawyers blared over the speakerphone. If I walked down the hall, the room would fall silent and their eyes would follow me until I was out of sight.
I tried to stay focused on my personal life. After a lot of trying, I was pregnant with our second child. Still, the negativity wore me down. Then in June 2012, during a regular checkup, my doctor looked at the sonogram and I could tell something was wrong. I’d had a miscarriage.
“When I saw all the horrible things being said about you,” he said, “I was worried about you and the baby. Stress can be a factor.” He was referring to an article in the New York Times in which an expert was quoted saying he was skeptical about my claims because he hadn’t ever heard of mistreatment of women in Silicon Valley. I felt, in that moment, that Kleiner had taken everything from me.
Then I had my summer review. Ted and Matt told me that CEOs had complained about my board performance. When I asked which ones, Matt just said, “All of them.”
A few months later, Matt asked me to leave, claiming I hadn’t improved since my last review. I was told to be out of the office by the end of the day. On the drive home, I wept. Some of it was sorrow. Most of it was relief.
The trial would last five weeks. Lynne Hermle of Orrick, Kleiner’s defense attorney, had once been so intense during another case that she’d made an opponent vomit in the courtroom, and she wasted no time in painting a picture of me as talentless, stupid, and greedy. “She did not have the necessary skills for the job,” she said. “She did not even come close.”
At other times, the trial was almost gratifying. The CFO, who was also still at Kleiner, admitted that until 2012 the company didn’t even have an HR department and didn’t provide employees with an anti-discrimination policy; they hadn’t had one until Trae and I formally raised our concerns. When Hermle tried to show that women did rise at Kleiner, we pointed out that nearly all those promotions had happened since I brought up these issues. At the start of 2012, when Trae and I had lodged our complaint, only one woman in the firm’s 40-year history had ever been promoted to senior partner.
And anomalies in reviews were finally cleared up: It turned out that Ted had set up a process designed to make me look bad. He started with the standard procedure: I was asked to list people I had worked with; our outside consultant asked everyone on my list to review me; she organized their feedback and sent it to Ted. Ted then solicited negative feedback from phantom reviewers — people I had not worked closely with, who were not on my list, and whom he didn’t list as reviewers in the final document. The everyone-hates-you feedback Ted had delivered was in fact from a board-member crony of his and another venture capitalist I had not worked with much at all.
I’d be lying if I said it wasn’t a thrill to hear Ted questioned by one of my lawyers, Alan Exelrod, about the positive feedback he’d hidden from me and excluded from my review. Had we not gone to trial, it would never have surfaced.
Alan: He said that “She was very engaged and proactive,” correct?
Ted: Yes.
Alan: And that “She tries very hard to be helpful”?
Ted: Correct.
Alan: “100 percent behind the company”?
Ted: Yes.
Alan: “She is one of the three people I call from the board for her advice”?
Ted: Correct.
Such satisfaction was short-lived. The verdict came down on March 27, 2015: I had lost on all four counts.
Before suing, I’d consulted other women who had sued big, powerful companies over harassment and discrimination, and they all gave me pretty much the same advice: “Don’t do it.” One woman told me, “It’s a complete mismatch of resources. They don’t fight fair. Even if you win, it will destroy your reputation.”
Renée Fassbender Amochaev, an investment adviser, told me she’d been miserable from the moment she filed her lawsuit. She became an outcast and a target. Her co-workers started a petition to have her leave. Every morning, she would get to the parking lot and throw up.
“You have to prepare for it to be harder than you can even imagine,” she said. “Do you regret it?” I asked. There was a pause. “No,” she said.
Losing my suit hurt, but I didn’t have regrets either. I could have received millions from Kleiner if I would just have signed a non-disparagement contract; I turned it down so I could finally share my story, which I have been doing by speaking at events across the country and through Project Include— a nonprofit I co-founded to give everyone a fair shot to succeed in tech. I started it with an impressive group of women from the tech industry, many of whom shared similarly painful experiences.
We channeled our frustration with the tepid “diversity solutions” prevalent in the industry, ones focused on PR-oriented initiatives that spend more time outlining the problems than implementing solutions. To become truly inclusive, companies needed solutions that included all people, covered everything a company does, and used detailed metrics to hold leaders accountable. So we decided to give CEOs and start-ups just that. We launched on May 3, 2016, with 87 recommendations. Since then, more than 1,500 people have signed up in support of our efforts, including 100 tech CEOs. Soon after, we partnered with ten start-up CEOs who were far along in their understanding of diversity and inclusion to help them address these issues in their own companies. We’ve had to reassure some of them that we aren’t out to shame them; we just offer a starting point and a supportive community. We’ve also partnered with 16 tech-focused investment firms; through them, we’ll be collecting industrywide diversity data to help set benchmarks across the tech sector.
It was a huge relief to be past the explain-define-and-prove-the-problem-exists conversations my co-founders and I had each gotten dragged into too many times. Over the past year, despite the ongoing public exposure of the ways both the president and tech companies like Uber discourage diversity and inclusion, we’ve seen results that give us hope. More personally, I’ve come out of the experience with great friends and supporters. We’ve changed jobs, started companies, taken time off, moved across the country, and switched careers. I’ve watched as each of us — myself included — has become more vocal, more open, and more courageous in advocating for change in tech.
In the wake of my suit, I often heard people say that my case was a matter of “right issues, wrong plaintiff,” or that the reason I lost was because I wasn’t a “perfect victim.” I’ll grant that only someone a little bit masochistic would sign up for the onslaught of personal attacks that comes with a high-profile case, but I reject the argument that I wasn’t the right person to bring suit. I was one of the only people who had the resources and the position to do so. I believed I had an obligation to speak out about what I’d seen.
Since the trial, I have had time to think of all the things I wished I’d done differently. I might have had better luck with public opinion, for instance, if I’d spent more time with the press and prepared a few pages of talking points every day, like Kleiner had. But Kleiner also had tremendous resources that I couldn’t match, and it made a difference. For example, I didn’t have time to go through all my emails to figure out which ones to give Kleiner, so during the discovery process we gave them practically everything, some 700,000 emails — most of which we could have legally withheld. Kleiner meanwhile handed over just 5,000 emails, claiming they didn’t have the resources to search for anything other than emails that we specifically requested. They did have the resources to pick over my emails, though — I heard they hired a team in India to read and sort through every single one. Their work would show: During depositions, they brought up everything from my nanny’s contract to an exercise I’d done in therapy where I listed resentments. Emails to friends, emails to my husband, emails to other family members, even emails to my lawyers.
In retrospect, the most painful part of the trial was being cross-examined by Kleiner’s lawyer. At one point, she claimed I’d never invested in a woman’s company. “You’ve never done anything for women, have you?” she said snidely. I’d been instructed by my lawyers not to respond to comments like that, because it might open me up to more criticism — jurors could find me difficult or aggressive, the very things Kleiner was trying so hard to portray me as in court. I ended up coming across as distant, even a bit robotic, as I tried to keep my answers noncombative. But it hurt to leave that one unchallenged. It was patently false. At Kleiner, I helped drive investments in six women founders. A few months after I was fired by Kleiner, I invested in ten companies with my own money; five had women CEOs. But I didn’t say any of that. I just sat there.
Before my suit was over, though, other women had begun to sue tech companies with public filings. One of my lawyers represented a Taiwanese woman who sued Facebook for discrimination; her suit alleged that she was given menial tasks like serving drinks to the men on the team. Another lawyer at the firm represented Whitney Wolfe, one of the co-founders at Tinder, who sued for sexual harassment. Both of those suits settled, but others, against Microsoft and Twitter, are ongoing. Some reporters even came up with a name for the phenomenon of women or minorities in tech suing or speaking up. They called it the “Pao effect.”
Did you know that it was possible to extract your google chrome cookies to use them in a script?
This can be a great way of automating interaction with a website when you don't want to bother automating the login flow.
There is a great python library to do that called browsercookie. Browsercookie works on Linux, Mac OSX, and Windows and can extract
cookies from Chrome and Firefox.
I have been learning Clojure for the past month and I decided to reimplement the same functionality as browsercookie as an exercise!
I built a command line tool to print decrypted Chrome cookies as a JSON on OSX. This article will walk you through the implementation.
Even if you don't know a thing about Clojure you should be able to understand the process and learn a few things along the way; enjoy!
The full code for this project is available on github.
Context: how does Chrome store cookies?
Chrome store its cookies in a SQLite database, in the cookies table. The actual content of the cookies is encrypted with AES using a key stored in the user's keychain.
Architecture
Here is a diagram of the architecture (in orange, are the side effects and green pure computation):High-level architecture of the code
This translates to what the main function does:
(defn -main
[&args]
(if (not= 1 (count args))
(.println*err*"Usage ./program <site-url>")
(let [site-url (first args)aes-key (build-decryption-key (get-chrome-password-osx))db-spec {:dbtype"sqlite":dbname (temp-file-copy-ofcookies-file-osx)}query (str "select * from cookies where host_key like '"site-url"'")cookies (jdbc/querydb-spec [query])]
(println
(json/write-str
(map (partial decrypt-cookieaes-key) cookies)))
(System/exit0))))
Let's explore how each part works, dividing the process into three steps:
Step 1 — Building the cookies decryption key
This is a two step process: reading the key from the keychain and making it suitable to use for AES.
To read a key from the keychain, MacOS provide a command line utility called =security=:
To get the chrome key you can do:
security find-generic-password -a "Chrome" -w
Which can express this in Clojure:
(defn get-chrome-rawkey-osx"Get the chrome raw decryption key using the `security` cli on OSX"
[]
(-> (shell/sh"security""find-generic-password""-a""Chrome""-w":out-enc"UTF-8")
(:out)
(clojure.string/trim)
(.toCharArray)))
The Clojure syntax (-> x (a) (b k)) would translate to b(a(x), k) in python, it allows chaining of operations in a very readable way.
Note how we can easily mix Clojure function and Java functions that start with a =.= character.
We can then build a key suitable for AES decryption:
(defn build-decryption-key"Given a chrome raw key, construct a decryption key for the cookies"
[raw-key]
(let [salt (.getBytes"saltysalt")]
(-> (SecretKeyFactory/getInstance"pbkdf2withhmacsha1")
(.generateSecret (PBEKeySpec.raw-keysalt1003128))
(.getEncoded)
(SecretKeySpec."AES"))))
To decrypt AES, we need the key and a salt. saltysalt is the salt used by Chrome (I copied this from browsercookie).
Again note that methods starting with . are Java methods. We use the Java interop and the javax.crypto library to build this key.
Now that we have a decryption key, let's see how we can read the cookies and decrypt them!
Step 2 — Reading the encrypted cookies
The cookies are stored in a SQLite database at a known location on OSX.
Each row in the cookies table corresponds to a cookie:
if the encrypted_value fields start with v10, it is an encrypted cookie (again according to the reference implementation browsercookie).
otherwise, the value field contains the value of the cookie.
Let's start with a utility function to return the path of the cookie database:
(def cookies-file-osx"Return the path to the cookie store on OSX"
(str
(System/getProperty"user.home")"/Library/Application Support/Google/Chrome/Default/Cookies"))
Since we don't want to work directly on the real cookie database, we can make a copy of it to a temp file using another function:
(defn temp-file-copy-of"Create a copy of file as a temp file that will be removed when the program exits, return its path"
[file]
(let [tempfile (java.io.File/createTempFile"store""db")]
(.deleteOnExittempfile)
(io/copy (io/filefile) (io/filetempfile))tempfile))
We can use these two functions to query all the cookies from the database matching the domain name the user requested:
(let [site-url (first args)db-spec {:dbtype"sqlite":dbname (temp-file-copy-ofcookies-file-osx)}query (str "select * from cookies where host_key like '"site-url"'")]...;; Do something with cookies)
At this point, we have extracted all the relevant cookies from the SQLite database and have a decryption key ready, let's decrypt and print the cookies!
Step 3 - Decrypting the cookies and printing them
In this step we will build the decrypt-cookie function.
Given a cookie like:
How do we know if a cookie is encrypted? As we said above, a cookie is encrypted if its encrypted_value field starts with v10.
Let's use the -> macro to express this in the is-encrypted? function:
(defn is-encrypted?"Returns true if the provided encrypted value (bytes[]) is an encrypted value by Chrome that is, if it starts with v10"
[cookie]
(-> cookie
(:encrypted_value)
(String."UTF-8")
(clojure.string/starts-with?"v10")))
But how do we decrypt an encrypted value?
Since we use CBC, we need to combine the AES key and an initialization vector (again taken from the reference implementation) and build a cipher.
Using this cipher we decrypt the encrypted text in the decrypt function:
(defn decrypt [aeskeytext]"Decrypt AES encrypted text given an aes key"
(let [ivsbytes (-> (repeat 16" ") (clojure.string/join) (.getBytes))iv (IvParameterSpec.ivsbytes)cipher (Cipher/getInstance"AES/CBC/PKCS5Padding")_ (.initcipherCipher/DECRYPT_MODEaeskeyiv)]
(String. (.doFinalciphertext))))
This is a little terse but can easily be decomposed into three steps:
Building the initial vector for the AES decryption (let block omitted):
This is a little ugly, because .init is used only for its side effect and we ignore its result ...
Decrypting the text:
(String. (.doFinalciphertext))
Now that we know how to decrypt a value and detect encrypted values, we can put it all together into decrypt-cookie, a function that decrypts a cookie:
(defn decrypt-cookie"Given a cookie, return a cookie with decrypted value"
[aes-keycookie]
(-> cookie
(assoc :value
(if (is-encrypted?cookie);; Drop 3 removes the leading "v10"
(->>cookie (:encrypted_value) (drop 3) (byte-array) (decryptaes-key))
(-> cookie (:value))));; Remove the unused :encrypted_value entry
(dissoc :encrypted_value)))
Note that we use the ->> macro instead of -> that we used before.
Instead of threading the expression as the first argument of each function like ->, ->> threads the expression as the last argument.
Putting it all together
It all comes together in the main function that we showed above:
(defn -main
[&args]
(if (not= 1 (count args))
(.println*err*"Usage ./program <site-url>")
(let [site-url (first args)aes-key (build-decryption-key (get-chrome-password-osx))db-spec {:dbtype"sqlite":dbname (temp-file-copy-ofcookies-file-osx)}query (str "select * from cookies where host_key like '"site-url"'")cookies (jdbc/querydb-spec [query])]
(println
(json/write-str
(map (partial decrypt-cookieaes-key) cookies)))
(System/exit0))))
Here we map over all the relevant cookies from the database using a function to decrypt the cookies. We use partial to build a function with the first argument aes-key locked in.
Conclusion
In this guide, we covered how to extract and decrypt Chrome cookies. We also looked at some Clojure idioms.
Again if you want to use this in python you should check out browsercookie.
The full code for this project is available on github.