August 27th marks five years since diaspora*, the open, privacy-oriented social network, was placed into the hands of its community by its founders. One year ago the community released diaspora* version 0.6, the result of a huge effort of refactoring the old code to make it perform better, as well as redesigning diaspora*'s interface and introducing new features. One year later, we are proud to announce the release of diaspora* version 0.7. Since the last major release, 28 contributors have added 28675 lines of code and removed 20019 lines, which marks the release of diaspora* version 0.7 as one of the biggest versions diaspora*’s community has ever released.
Our latest release contains some important changes, particularly ‘under the hood’.
It is now possible to mention people in comments as well as in posts – a long-awaited feature.
The markdown editor, with previews, is available on comments and conversations, bringing them into line with the publisher and making it a lot easier to add formatting, links and images to comments and conversations.
This markdown editor is now also available on the mobile version of diaspora*, for posts, comments and conversations!
And, last but certainly not least, this new release will include the first of the two steps towards a full account migration feature!
Version 0.2.0 of our federation protocol, created by Benjamin Neff (SuperTux88) with help from Senya (cmrd-senya), has started the process of including new functionality. It also provides underlying support for secure and reliable account migration.
Important reminder to podmins: This new federation protocol is incompatible with versions of diaspora* older than 0.6.3.0. If you are still running an earlier version, your server will no longer be able to fully communicate with servers running the latest software.
Senya has also been hard at work creating the first stages of the much-needed account migration feature! With the release of this version, it will be possible to fully export your account data which will become importable in a future diaspora* release. We also started working on implementing federation methods to enable pods to correctly handle account migrations. The next step will be to create this secure account importing, which can be introduced once the majority of pods in our network have updated to version 0.7. These steps cannot be introduced in the same release as the network first needs to upgrade so when the first users start to import their archives, a maximum of pods will be able to understand the migration message.
Since last year's launch of version 0.6.0.0, we achieved a pretty impressive list of changes!
Additions and enhancements since version 0.6.0.0:
Automatically pull new notifications every 5 minutes
Add a user setting for default post visibility
Use guid instead of id in permalinks and in single-post view
Links to streams of posts I have liked or commented on
Access to “My aspects” and “Followed tags” pages on mobile
Improve color themes and add a “Dark” color theme
Enable collapsing of notification threads in your mail client
OpenGraph video support
Improve error handling on mobile
Admin pages for mobile users
NodeInfo 2.0
Stop communication with pods that have been offline for an extended period of time
Support for an optional Content-Security-Policy header
Here’s a quick round-up of the major changes coming your way in version 0.7:
Interface
Mentions in comments
Improve Mentions: display @ before mentions; simplify mentions in the publisher
Internationalization for color themes
Refactoring single-post view interactions
Update help pages
Simplified publisher preview
Add markdown editor for comments and conversations
Support cmd+enter to submit posts, comments and conversations
Account migration
Update the user data export archive format
Reset stuck exports and handle errors
Add support for receiving account migrations
Federation
Switch to new federation protocol
Fix order of comments across pods
Mobile
Always link comment count text on mobile
Include count in mobile post action links
Support direct links to comments on mobile
Improve responsive header in desktop version
Add markdown editor for posts, comments and conversations on mobile
Mark as "Mobile Web App Capable" on Android
Internals
Upgrade to jQuery 3 and Rails 5.1
Send public profiles publicly
Change sender for mails
Add some missing indexes and clean up the data base if needed
Improve stream when ignoring a person who posts a lot of tagged posts
Update instructions are available as usual in the wiki. For those of you who have been testing the release candidate, run git checkout master before the update to get back to the stable release branch.
Proof of stake is a category of consensus algorithms for public blockchains, which Ethereum's upcoming Casper algorithm is a part of. It serves a similar function to the proof of work which underpins the security behind Bitcoin, the current version of Ethereum and many other blockchains, but has significant advantages in terms of security and energy efficiency.
In general, a proof of stake algorithm looks as follows. The blockchain keeps track of a set of validators, and anyone who holds the blockchain's base cryptocurrency (in Ethereum's case, ether) can become a validator by sending a special type of transaction that locks up their ether into a deposit. The process of creating and agreeing to new blocks is then done through a consensus algorithm that all current validators can participate in.
There are many kinds of consensus algorithms, and many ways to assign rewards to validators who participate in the consensus algorithm, so there are many "flavors" of proof of stake. From an algorithmic perspective, there are two major types: chain-based proof of stake and BFT-style proof of stake.
In chain-based proof of stake, the algorithm pseudo-randomly selects a validator during each time slot (eg. every period of 10 seconds might be a time slot), and assigns that validator the right to create a single block, and this block must point to some previous block (normally the block at the end of the previously longest chain), and so over time most blocks converge into a single constantly growing chain.
In BFT-style proof of stake, validators are randomly assigned the right to propose blocks, but agreeing on which block is canonical is done through a multi-round process where every validator sends a "vote" for some specific block during each round, and at the end of the process all (honest and online) validators permanently agree on whether or not any given block is part of the chain. Note that blocks may still be chained together; the key difference is that consensus on a block can come within one block, and does not depend on the length or size of the chain after it.
What are the benefits of proof of stake as opposed to proof of work?
No need to consume large quantities of electricity in order to secure a blockchain (eg. it's estimated that both Bitcoin and Ethereum burn over $1 million worth of electricity and hardware costs per day as part of their consensus mechanism).
Because of the lack of high electricity consumption, there is not as much need to issue as many new coins in order to motivate participants to keep participating in the network. It may theoretically even be possible to have negative net issuance, where a portion of transaction fees is "burned" and so the supply goes down over time.
Proof of stake opens the door to a wider array of techniques that use game-theoretic mechanism design in order to better discourage centralized cartels from forming and, if they do form, from acting in ways that are harmful to the network (eg. like selfish mining in proof of work).
Reduced centralization risks, as economies of scale are much less of an issue. $10 million of coins will get you exactly 10 times higher returns than $1 million of coins, without any additional disproportionate gains because at the higher level you can afford better mass-production equipment.
Ability to use economic penalties to make various forms of 51% attacks vastly more expensive to carry out than proof of work - to paraphrase Vlad Zamfir, "it's as though your ASIC farm burned down if you participated in a 51% attack".
How does proof of stake fit into traditional Byzantine fault tolerance research?
There are several fundamental results from Byzantine fault tolerance research that apply to all consensus algorithms, including traditional consensus algorithms like PBFT but also any proof of stake algorithm and, with the appropriate mathematical modeling, proof of work.
The key results include:
CAP theorem - "in the cases that a network partition takes place, you have to choose either consistency or availability, you cannot have both". The intuitive argument is simple: if the network splits in half, and in one half I send a transaction "send my 10 coins to A" and in the other I send a transaction "send my 10 coins to B", then either the system is unavailable, as one or both transactions will not be processed, or it becomes inconsistent, as one half of the network will see the first transaction completed and the other half will see the second transaction completed. Note that the CAP theorem has nothing to do with scalability; it applies to sharded and non-sharded systems equally.
FLP impossibility - in an asynchronous setting (ie. there are no guaranteed bounds on network latency even between correctly functioning nodes), it is not possible to create an algorithm which is guaranteed to reach consensus in any specific finite amount of time if even a single faulty/dishonest node is present. Note that this does NOT rule out "Las Vegas" algorithms that have some probability each round of achieving consensus and thus will achieve consensus within T second with probability exponentially approaching 1 as T grows; this is in fact the "escape hatch" that many successful consensus algorithms use.
Bounds on fault tolerance - from the DLS paper we have: (i) protocols running in a partially synchronous network model (ie. there is a bound on network latency but we do not know ahead of time what it is) can tolerate up to 1/3 arbitrary (ie. "Byzantine") faults, (ii) deterministic protocols in an asynchronous model (ie. no bounds on network latency) cannot tolerate faults (although their paper fails to mention that randomized algorithms can with up to 1/3 fault tolerance), (iii) protocols in a synchronous model (ie. network latency is guaranteed to be less than a known d) can, surprisingly, tolerate up to 100% fault tolerance, although there are restrictions on what can happen when more than or equal to 1/2 of nodes are faulty. Note that the "authenticated Byzantine" model is the one worth considering, not the "Byzantine" one; the "authenticated" part essentially means that we can use public key cryptography in our algorithms, which is in modern times very well-researched and very cheap.
Proof of work has been rigorously analyzed by Andrew Miller and others and fits into the picture as an algorithm reliant on a synchronous network model. We can model the network as being made up of a near-infinite number of nodes, with each node representing a very small unit of computing power and having a very small probability of being able to create a block in a given period. In this model, the protocol has 50% fault tolerance assuming zero network latency, ~46% (Ethereum) and ~49.5% (Bitcoin) fault tolerance under actually observed conditions, but goes down to 33% if network latency is equal to the block time, and reduces to zero as network latency approaches infinity.
Proof of stake consensus fits more directly into the Byzantine fault tolerant consensus mould, as all validators have known identities (stable Ethereum addresses) and the network keeps track of the total size of the validator set. There are two general lines of proof of stake research, one looking at synchronous network models and one looking at partially asynchronous network models. "Chain-based" proof of stake algorithms almost always rely on synchronous network models, and their security can be formally proven within these models similarly to how security of proof of work algorithms can be proven. A line of research connecting traditional Byzantine fault tolerant consensus in partially synchronous networks to proof of stake also exists, but is more complex to explain; it will be covered in more detail in later sections.
Proof of work algorithms and chain-based proof of stake algorithms choose availability over consistency, but BFT-style consensus algorithms lean more toward consistency; Tendermint chooses consistency explicitly, and Casper uses a hybrid model that prefers availability but provides as much consistency as possible and makes both on-chain applications and clients aware of how strong the consistency guarantee is at any given time.
Note that Ittay Eyal and Emin Gun Sirer's selfish mining discovery, which places 25% and 33% bounds on the incentive compatibility of Bitcoin mining depending on the network model (ie. mining is only incentive compatible if collusions larger than 25% or 33% are impossible) has NOTHING to do with results from traditional consensus algorithm research, which does not touch incentive compatibility.
What is the "nothing at stake" problem and how can it be fixed?
In many early (all chain-based) proof of stake algorithms, including Peercoin, there are only rewards for producing blocks, and no penalties. This has the unfortunate consequence that, in the case that there are multiple competing chains, it is in a validator's incentive to try to make blocks on top of every chain at once, just to be sure:
In proof of work, doing so would require splitting one's computing power in half, and so would not be lucrative:
The result is that if all actors are narrowly economically rational, then even if there are no attackers, a blockchain may never reach consensus. If there is an attacker, then the attacker need only overpower altruistic nodes (who would exclusively stake on the original chain), and not rational nodes (who would stake on both the original chain and the attacker's chain), in contrast to proof of work, where the attacker must overpower both altruists and rational nodes (or at least credibly threaten to: see P + epsilon attacks).
Some argue that stakeholders have an incentive to act correctly and only stake on the longest chain in order to "preserve the value of their investment", however this ignores that this incentive suffers from tragedy of the commons problems: each individual stakeholder might only have a 1% chance of being "pivotal" (ie. being in a situation where if they participate in an attack then it succeeds and if they do not participate it fails), and so the bribe needed to convince them personally to join an attack would be only 1% of the size of their deposit; hence, the required combined bribe would be only 0.5-1% of the total sum of all deposits. Additionally, this argument implies that any zero-chance-of-failure situation is not a stable equilibrium, as if the chance of failure is zero then everyone has a 0% chance of being pivotal.
This can be solved via two strategies. The first, described in broad terms under the name "Slasher" here and developed further by Iddo Bentov here, involves penalizing validators if they simultaneously create blocks on multiple chains, by means of including proof of misbehavior (ie. two conflicting signed block headers) into the blockchain as a later point in time at which point the malfeasant validator's deposit is deducted appropriately. This changes the incentive structure thus:
Note that for this algorithm to work, the validator set needs to be determined well ahead of time. Otherwise, if a validator has 1% of the stake, then if there are two branches A and B then 0.99% of the time the validator will be eligible to stake only on A and not on B, 0.99% of the time the validator will be eligible to stake on B and not on A, and only 0.01% of the time will the validator will be eligible to stake on both. Hence, the validator can with 99% efficiency probabilistically double-stake: stake on A if possible, stake on B if possible, and only if the choice between both is open stake on the longer chain. This can only be avoided if the validator selection is the same for every block on both branches, which requires the validators to be selected at a time before the fork takes place.
This has its own flaws, including requiring nodes to be frequently online to get a secure view of the blockchain, and opening up medium-range validator collusion risks (ie. situations where, for example, 25 out of 30 consecutive validators get together and agree ahead of time to implement a 51% attack on the previous 19 blocks), but if these risks are deemed acceptable then it works well.
The second strategy is to simply punish validators for creating blocks on the wrong chain. That is, if there are two competing chains, A and B, then if a validator creates a block on B, they get a reward of +R on B, but the block header can be included into A (in Casper this is called a "dunkle") and on A the validator suffers a penalty of -F (possibly F = R). This changes the economic calculation thus:
The intuition here is that we can replicate the economics of proof of work inside of proof of stake. In proof of work, there is also a penalty for creating a block on the wrong chain, but this penalty is implicit in the external environment: miners have to spend extra electricity and obtain or rent extra hardware. Here, we simply make the penalties explicit. This mechanism has the disadvantage that it imposes slightly more risk on validators (although the effect should be smoothed out over time), but has the advantage that it does not require validators to be known ahead of time.
That shows how chain-based algorithms solve nothing-at-stake. Now how do BFT-style proof of stake algorithms work?
BFT-style (partially synchronous) proof of stake algorithms allow validators to "vote" on blocks by sending one or more types of signed messages, and specify two kinds of rules:
Finality conditions - rules that determine when a given hash can be considered finalized.
Slashing conditions - rules that determine when a given validator can be deemed beyond reasonable doubt to have misbehaved (eg. voting for multiple conflicting blocks at the same time). If a validator triggers one of these rules, their entire deposit gets deleted.
To illustrate the different forms that slashing conditions can take, we will give two examples of slashing conditions (hereinafter, "2/3 of all validators" is shorthand for "2/3 of all validators weighted by deposited coins", and likewise for other fractions and percentages). In these examples, "PREPARE" and "COMMIT" should be understood as simply referring to two types of messages that validators can send.
If MESSAGES contains messages of the form ["COMMIT", HASH1, view] and ["COMMIT", HASH2, view] for the same view but differing HASH1 and HASH2 signed by the same validator, then that validator is slashed.
If MESSAGES contains a message of the form ["COMMIT", HASH, view1], then UNLESS either view1 = -1 or there also exist messages of the form ["PREPARE", HASH, view1, view2] for some specific view2, where view2 < view1, signed by 2/3 of all validators, then the validator that made the COMMIT is slashed.
There are two important desiderata for a suitable set of slashing conditions to have:
Accountable safety - if conflicting HASH1 and HASH2 (ie. HASH1 and HASH2 are different, and neither is a descendant of the other) are finalized, then at least 1/3 of all validators must have violated some slashing condition.
Plausible liveness - unless at least 1/3 of all validators have violated some slashing condition, there exists a set of messages that 2/3 of validators can produce that finalize some value.
If we have a set of slashing conditions that satisfies both properties, then we can incentivize participants to send messages, and start benefiting from economic finality.
What is "economic finality" in general?
Economic finality is the idea that once a block is finalized, or more generally once enough messages of certain types have been signed, then the only way that at any point in the future the canonical history will contain a conflicting block is if a large number of people are willing to burn very large amounts of money. If a node sees that this condition has been met for a given block, then they have a very economically strong assurance that that block will always be part of the canonical history that everyone agrees on.
There are two "flavors" of economic finality:
A block can be economically finalized if a sufficient number of validators have signed cryptoeconomic claims of the form "I agree to lose X in all histories where block B is not included". This gives clients assurance that either (i) B is part of the canonical chain, or (ii) validators lost a large amount of money in order to trick them into thinking that this is the case.
A block can be economically finalized if a sufficient number of validators have signed messages expressing support for block B, and there is a mathematical proof that if some B' != B is also finalized under the same definition then validators lose a large amount of money. If clients see this, and also validate the chain, and validity plus finality is a sufficient condition for precedence in the canonical fork choice rule, then they get an assurance that either (i) B is part of the canonical chain, or (ii) validators lost a large amount of money in making a conflicting chain that was also finalized.
The two approaches to finality inherit from the two solutions to the nothing at stake problem: finality by penalizing incorrectness, and finality by penalizing equivocation. The main benefit of the first approach is that it is more light-client friendly and is simpler to reason about, and the main benefits of the second approach are that (i) it's easier to see that honest validators will not be punished, and (ii) griefing factors are more favorable to honest validators.
Casper follows the second flavor, though it is possible that an on-chain mechanism will be added where validators can voluntarily opt-in to signing finality messages of the first flavor, thereby enabling much more efficient light clients.
So how does this relate to Byzantine fault tolerance theory?
Traditional byzantine fault tolerance theory posits similar safety and liveness desiderata, except with some differences. First of all, traditional byzantine fault tolerance theory simply requires that safety is achieved if 2/3 of validators are honest. This is a strictly easier model to work in; traditional fault tolerance tries to prove "if mechanism M has a safety failure, then at least 1/3 of nodes are faulty", whereas our model tries to prove "if mechanism M has a safety failure, then at least 1/3 of nodes are faulty, and you know which ones, even if you were offline at the time the failure took place". From a liveness perspective, our model is the easier one, as we do not demand a proof that the network will come to consensus, we just demand a proof that it does not get stuck.
Fortunately, we can show the additional accountability requirement is not a particularly difficult one; in fact, with the right "protocol armor", we can convert any traditional partially synchronous or asynchronous Byzantine fault-tolerant algorithm into an accountable algorithm. The proof of this basically boils down to the fact that faults can be exhaustively categorized into a few classes, and each one of these classes is either accountable (ie. if you commit that type of fault you can get caught, so we can make a slashing condition for it) or indistinguishable from latency (note that even the fault of sending messages too early is indistinguishable from latency, as one can model it by speeding up everyone's clocks and assigning the messages that weren't sent too early a higher latency).
What is "weak subjectivity"?
It is important to note that the mechanism of using deposits to ensure there is "something at stake" does lead to one change in the security model. Suppose that deposits are locked for four months, and can later be withdrawn. Suppose that an attempted 51% attack happens that reverts 10 days worth of transactions. The blocks created by the attackers can simply be imported into the main chain as proof-of-malfeasance (or "dunkles") and the validators can be punished. However, suppose that such an attack happens after six months. Then, even though the blocks can certainly be re-imported, by that time the malfeasant validators will be able to withdraw their deposits on the main chain, and so they cannot be punished.
To solve this problem, we introduce a "revert limit" - a rule that nodes must simply refuse to revert further back in time than the deposit length (ie. in our example, four months). Note that this rule is different from every other consensus rule in the protocol, in that it means that nodes may come to different conclusions depending on when they saw certain messages. The time that a node saw a given message may be different between different nodes; hence we consider this rule "subjective" (alternatively, one well-versed in Byzantine fault tolerance theory may view it as a kind of synchrony assumption).
However, the "subjectivity" here is very weak: in order for a node to get on the "wrong" chain, they must receive the original message four months later than they otherwise would have. This is only possible in two cases:
When a node connects to the blockchain for the first time.
If a node has been offline for more than four months.
We can solve (1) by making it the user's responsibility to authenticate the latest state out of band. They can do this by asking their friends, block explorers, businesses that they interact with, etc. for a recent block hash in the chain that they see as the canonical one. In practice, such a block hash may well simply come as part of the software they use to verify the blockchain; an attacker that can corrupt the checkpoint in the software can arguably just as easily corrupt the software itself, and no amount of pure cryptoeconomic verification can solve that problem.
Note that all of this is a problem only in the very limited case where a majority of previous stakeholders collude to attack the network and create an alternate chain; most of the time we expect there will only be one canonical chain to choose from.
Also, note that weak subjectivity assumptions exist in proof of work chains as well if the chain does any hard forks. Bitcoin has previously pulled off a hard fork with 2 months lead time through bitcoind 0.8.1, which fixed a database issue that made certain kinds of large blocks invalid and thereby allowed clients to process blocks that bitcoind 0.7 could not process, and so users had to download a new version of the software with 2 months' notice. This is itself a kind of weak subjectivity assumption, as users had to "log on" within that two-month period to download the update to stay on the correct chain.
Additionally, the social authentication can if needed even be automated in several ways. One is to bake it into natural user workflow: a BIP 70-style payment request could include a recent block hash, and the user's client software would make sure that they are on the same chain as the vendor before approving a payment (or for that matter, any on-chain interaction). The other is to use Jeff Coleman's universal hash time. If UHT is used, then a successful attack chain would need to be generated secretly at the same time as the legitimate chain was being built, requiring a majority of validators to secretly collude for that long.
Does weak subjectivity mean that a proof of stake chain must be "anchored" into a proof of work chain to be secure?
In short, no.
Elaborate?
Weak subjectivity by itself is a rather small addition to the security assumptions in a blockchain in practice, and definitely does not necessitate some proof-of-work-based outside source of truth to supplement it. To see why, consider the kind of situation where weak subjectivity by itself would compromise a blockchain's security. In such a world, powerful corporate or nation state actors would have the ability to somehow convince an entire community that block hash B was the block hash of block XXXYYY when most of them saw at the time and have stored in their own computers that the block hash of block XXXYYY was A, but for some reason such powerful actors would not have the ability to trick users into accepting a different location from where they download their client software.
Furthermore, the "anchoring" that advocates of such a scheme describe is not even all that secure. All anchoring proves is that a given block hash was produced at time T' < T; it does not prove that it was published at that time. Hence, a PoS chain anchored into a PoW chain could simply be attacked by a majority coalition that produces both chains in parallel, anchors both, publishes one, and then four months later publishes the other one.
One could get around this by embedding a fully-functional "light client" of the PoS chain into the PoW chain, which would reject the double-anchoring, but this would require the PoW chain to be feature-rich enough to be able to implement such a client - a property which most actually existing proof of work chains do not possess.
Can one economically penalize censorship in proof of stake?
Unlike reverts, censorship is much more difficult to prove. The blockchain itself cannot directly tell the difference between "user A tried to send transaction X but it was unfairly censored", "user A tried to send transaction X but it never got in because the transaction fee was insufficient" and "user A never tried to send transaction X at all". However, there are a number of techniques that can be used to mitigate censorship issues.
The first is censorship resistance by halting problem. In the weaker version of this scheme, the protocol is designed to be Turing-complete in such a way that a validator cannot even tell whether or not a given transaction will lead to an undesired action without spending a large amount of processing power executing the transaction, and thus opening itself up to denial-of-service attacks. This is what prevented the DAO soft fork.
In the stronger version of the scheme, transactions can trigger guaranteed effects at some point in the near to mid-term future. Hence, a user could send multiple transactions which interact with each other and with predicted third-party information to lead to some future event, but the validators cannot possibly tell that this is going to happen until the transactions are already included (and economically finalized) and it is far too late to stop them; even if all future transactions are excluded, the event that validators wish to halt would still take place. Note that in this scheme, validators could still try to prevent all transactions, or perhaps all transactions that do not come packaged with some formal proof that they do not lead to anything undesired, but this would entail forbidding a very wide class of transactions to the point of essentially breaking the entire system, which would cause validators to lose value as the price of the cryptocurrency in which their deposits are denominated would drop.
The second, described by Adam Back here, is to require transactions to be timelock-encrypted. Hence, validators will include the transactions without knowing the contents, and only later could the contents automatically be revealed, by which point once again it would be far too late to un-include the transactions. If validators were sufficiently malicious, however, they could simply only agree to include transactions that come with a cryptographic proof (eg. ZK-SNARK) of what the decrypted version is; this would force users to download new client software, but an adversary could conveniently provide such client software for easy download, and in a game-theoretic model users would have the incentive to play along.
Perhaps the best that can be said in a proof-of-stake context is that users could also install a software update that includes a hard fork that deletes the malicious validators and this is not that much harder than installing a software update to make their transactions "censorship-friendly". Hence, all in all this scheme is also moderately effective, though it does come at the cost of slowing interaction with the blockchain down (note that the scheme must be mandatory to be effective; otherwise malicious validators could much more easily simply filter encrypted transactions without filtering the quicker unencrypted transactions).
A third alternative is to include censorship detection in the fork choice rule. The idea is simple. Nodes watch the network for transactions, and if they see a transaction that has a sufficiently high fee for a sufficient amount of time, then they assign a lower "score" to blockchains that do not include this transaction. If all nodes follow this strategy, then eventually a minority chain would automatically coalesce that includes the transactions, and all honest online nodes would follow it. The main weakness of such a scheme is that offline nodes would still follow the majority branch, and if the censorship is temporary and they log back on after the censorship ends then they would end up on a different branch from online nodes. Hence, this scheme should be viewed more as a tool to facilitate automated emergency coordination on a hard fork than something that would play an active role in day-to-day fork choice.
How does validator selection work, and what is stake grinding?
In any chain-based proof of stake algorithm, there is a need for some mechanism which randomly selects which validator out of the currently active validator set can make the next block. For example, if the currently active validator set consists of Alice with 40 ether, Bob with 30 ether, Charlie with 20 ether and David with 10 ether, then you want there to be a 40% chance that Alice will be the next block creator, 30% chance that Bob will be, etc (in practice, you want to randomly select not just one validator, but rather an infinite sequence of validators, so that if Alice doesn't show up there is someone who can replace her after some time, but this doesn't change the fundamental problem). In non-chain-based algorithms randomness is also often needed for different reasons.
"Stake grinding" is a class of attack where a validator performs some computation or takes some other step to try to bias the randomness in their own favor. For example:
In Peercoin, a validator could "grind" through many combinations of parameters and find favorable parameters that would increase the probability of their coins generating a valid block.
In one now-defunct implementation, the randomness for block N+1 was dependent on the signature of block N. This allowed a validator to repeatedly produce new signatures until they found one that allowed them to get the next block, thereby seizing control of the system forever.
In NXT, the randomness for block N+1 is dependent on the validator that creates block N. This allows a validator to manipulate the randomness by simply skipping an opportunity to create a block. This carries an opportunity cost equal to the block reward, but sometimes the new random seed would give the validator an above-average number of blocks over the next few dozen blocks. See here for a more detailed analysis.
(1) and (2) are easy to solve; the general approach is to require validators to deposit their coins well in advance, and not to use information that can be easily manipulated as source data for the randomness. There are several main strategies for solving problems like (3). The first is to use schemes based on secret sharing or deterministic threshold signatures and have validators collaboratively generate the random value. These schemes are robust against all manipulation unless a majority of validators collude (in some cases though, depending on the implementation, between 33-50% of validators can interfere in the operation, leading to the protocol having a 67% liveness assumption).
The second is to use cryptoeconomic schemes where validators commit to information (ie. publish sha3(x)) well in advance, and then must publish x in the block; x is then added into the randomness pool. There are two theoretical attack vectors against this:
Manipulate x at commitment time. This is impractical because the randomness result would take many actors' values into account, and if even one of them is honest then the output will be a uniform distribution. A uniform distribution XORed together with arbitrarily many arbitrarily biased distributions still gives a uniform distribution.
Selectively avoid publishing blocks. However, this attack costs one block reward of opportunity cost, and because the scheme prevents anyone from seeing any future validators except for the next, it almost never provides more than one block reward worth of revenue. The only exception is the case where, if a validator skips, the next validator in line AND the first child of that validator will both be the same validator; if these situations are a grave concern then we can punish skipping further via an explicit skipping penalty.
The third is to use Iddo Bentov's "majority beacon", which generates a random number by taking the bit-majority of the previous N random numbers generated through some other beacon (ie. the first bit of the result is 1 if the majority of the first bits in the source numbers is 1 and otherwise it's 0, the second bit of the result is 1 if the majority of the second bits in the source numbers is 1 and otherwise it's 0, etc). This gives a cost-of-exploitation of ~C * sqrt(N) where C is the cost of exploitation of the underlying beacons. Hence, all in all, many known solutions to stake grinding exist; the problem is more like differential cryptanalysis than the halting problem - an annoyance that proof of stake designers eventually understood and now know how to overcome, not a fundamental and inescapable flaw.
What would the equivalent of a 51% attack against Casper look like?
The most basic form of "51% attack" is a simple finality reversion: validators that already finalized block A then finalize some competing block A', thereby breaking the blockchain's finality guarantee. In this case, there now exist two incompatible finalized histories, creating a split of the blockchain, that full nodes would be willing to accept, and so it is up to the community to coordinate out of band to focus on one of the branches and ignore the other(s).
This coordination could take place on social media, through private channels between block explorer providers, businesses and exchanges, various online discussion forms, and the like. The principle according to which the decision would be made is "whichever one was finalized first is the real one". Another alternative is to rely on "market consensus": both branches would be briefly being traded on exchanges for a very short period of time, until network effects rapidly make one branch much more valuable with the others. In this case, the "first finalized chain wins" principle would be a Schelling point for what the market would choose. It's very possible that a combination of both approaches will get used in practice.
Once there is consensus on which chain is real, users (ie. validators and light and full node operators) would be able to manually insert the winning block hash into their client software through a special option in the interface, and their nodes would then ignore all other chains. No matter which chain wins, there exists evidence that can immediately be used to destroy at least 1/3 of the validators' deposits.
Another kind of attack is liveness denial: instead of trying to revert blocks, a cartel of >=34% of validators could simply refuse to finalize any more blocks. In this case, blocks would never finalize. Casper uses a hybrid chain/BFT-style consensus, and so the blockchain would still grow, but it would have a much lower level of security. If no blocks are finalized for some long period of time (eg. 1 day), then there are several options:
The protocol can include an automatic feature to rotate the validator set. Blocks under the new validator set would finalize, but clients would get an indication that the new finalized blocks are in some sense suspect, as it's very possible that the old validator set will resume operating and finalize some other blocks. Clients could then manually override this warning once it's clear that the old validator set is not coming back online. There would be a protocol rule that under such an event all old validators that did not try to participate in the consensus process take a large penalty to their deposits.
A hard fork is used to add in new validators and delete the attackers' balances.
In case (2), the fork would once again be coordinated via social consensus and possibly via market consensus (ie. the branch with the old and new validator set briefly both being traded on exchanges). In the latter case, there is a strong argument that the market would want to choose the branch where "the good guys win", as such a chain has validators that have demonstrated their goodwill (or at least, their alignment with the interest of the users) and so is a more useful chain for application developers.
Note that there is a spectrum of response strategies here between social coordination and in-protocol automation, and it is generally considered desirable to push as far toward automated resolution as possible so as to minimize the risk of simultaneous 51% attacks and attacks on the social layer (and market consensus tools such as exchanges). One can imagine an implementation of (1) where nodes automatically accept a switch to a new validator set if they do not see a new block being committed for a long enough time, which would reduce the need for social coordination but at the cost of requiring those nodes that do not wish to rely on social coordination to remain constantly online. In either case, a solution can be designed where attackers take a large hit to their deposits.
A more insidious kind of attack is a censorship attack, where >= 34% of validators refuse to finalize blocks that contain certain kinds of transactions that they do not like, but otherwise the blockchain keeps going and blocks keep getting finalized. This could range from a mild censorship attack which only censors to interfere with a few specific applications (eg. selectively censoring transactions in something like Raiden or the lightning network is a fairly easy way for a cartel to steal money) to an attack that blocks all transactions.
There are two sub-cases. The first is where the attacker has 34-67% of the stake. Here, we can program validators to refuse to finalize or build on blocks that they subjectively believe are clearly censoring transactions, which turns this kind of attack into a more standard liveness attack. The more dangerous case is where the attacker has more than 67% of the stake. Here, the attacker can freely block any transactions they wish to block and refuse to build on any blocks that do contain such transactions.
There are two lines of defense. First, because Ethereum is Turing-complete it is naturally somewhat resistant to censorship as censoring transactions that have a certain effect is in some ways similar to solving the halting problem. Because there is a gas limit, it is not literally impossible, though the "easy" ways to do it do open up denial-of-service attack vulnerabilities.
This resistance is not perfect, and there are ways to improve it. The most interesting approach is to add in-protocol features where transactions can automatically schedule future events, as it would be extremely difficult to try to foresee what the result of executing scheduled events and the events resulting from those scheduled events would be ahead of time. Validators could then use obfuscated sequences of scheduled events to deposit their ether, and dilute the attacker to below 33%.
Second, one can introduce the notion of an "active fork choice rule", where part of the process for determining whether or not a given chain is valid is trying to interact with it and verifying that it is not trying to censor you. The most effective way to do this would be for nodes to repeatedly send a transaction to schedule depositing their ether and then cancel the deposit at the last moment. If nodes detect censorship, they could then follow through with the deposit, and so temporarily join the validator pool en masse, diluting the attacker to below 33%. If the validator cartel censors their attempts to deposit, then nodes running this "active fork choice rule" would not recognize the chain as valid; this would collapse the censorship attack into a liveness denial attack, at which point it can be resolved through the same means as other liveness denial attacks.
That sounds like a lot of reliance on out-of-band social coordination; is that not dangerous?
Attacks against Casper are extremely expensive; as we will see below, attacks against Casper cost as much, if not more, than the cost of buying enough mining power in a proof of work chain to permanently 51% attack it over and over again to the point of uselessness. Hence, the recovery techniques described above will only be used in very extreme circumstances; in fact, advocates of proof of work also generally express willingness to use social coordination in similar circumstances by, for example, changing the proof of work algorithm. Hence, it is not even clear that the need for social coordination in proof of stake is larger than it is in proof of work.
In reality, we expect the amount of social coordination required to be near-zero, as attackers will realize that it is not in their benefit to burn such large amounts of money to simply take a blockchain offline for one or two days.
Doesn't MC => MR mean that all consensus algorithms with a given security level are equally efficient (or in other words, equally wasteful)?
This is an argument that many have raised, perhaps best explained by Paul Sztorc in this article. Essentially, if you create a way for people to earn $100, then people will be willing to spend anywhere up to $99.9 (including the cost of their own labor) in order to get it; marginal cost approaches marginal revenue. Hence, the theory goes, any algorithm with a given block reward will be equally "wasteful" in terms of the quantity of socially unproductive activity that is carried out in order to try to get the reward.
There are three flaws with this:
It's not enough to simply say that marginal cost approaches marginal revenue; one must also posit a plausible mechanism by which someone can actually expend that cost. For example, if tomorrow I announce that every day from then on I will give $100 to a randomly selected one of a given list of ten people (using my laptop's /dev/urandom as randomness), then there is simply no way for anyone to send $99 to try to get at that randomness. Either they are not in the list of ten, in which case they have no chance no matter what they do, or they are in the list of ten, in which case they don't have any reasonable way to manipulate my randomness so they're stuck with getting the expected-value $10 per day.
MC => MR does NOT imply total cost approaches total revenue. For example, suppose that there is an algorithm which pseudorandomly selects 1000 validators out of some very large set (each validator getting a reward of $1), you have 10% of the stake so on average you get 100, and at a cost of $1 you can force the randomness to reset (and you can repeat this an unlimited number of times). Due to the central limit theorem, the standard deviation of your reward is $10, and based on other known results in math the expected maximum of N random samples is slightly under M + S * sqrt(2 * log(N)) where M is the mean and S is the standard deviation. Hence the reward for making additional trials (ie. increasing N) drops off sharply, eg. with 0 re-trials your expected reward is $100, with one re-trial it's $105.5, with two it's $108.5, with three it's $110.3, with four it's $111.6, with five it's $112.6 and with six it's $113.5. Hence, after five retrials it stops being worth it. As a result, an economically motivated attacker with ten percent of stake will inefficiently spend $5 to get an additional revenue of $13, though the total revenue is $113. If the exploitable mechanisms only expose small opportunities, the economic loss will be small; it is decidedly NOT the case that a single drop of exploitability brings the entire flood of PoW-level economic waste rushing back in. This point will also be very relevant in our below discussion on capital lockup costs.
Proof of stake can be secured with much lower total rewards than proof of work.
What about capital lockup costs?
Locking up X ether in a deposit is not free; it entails a sacrifice of optionality for the ether holder. Right now, if I have 1000 ether, I can do whatever I want with it; if I lock it up in a deposit, then it's stuck there for months, and I do not have, for example, the insurance utility of the money being there to pay for sudden unexpected expenses. I also lose some freedom to change my token allocations away from ether within that timeframe; I could simulate selling ether by shorting an amount equivalent to the deposit on an exchange, but this itself carries costs including exchange fees and paying interest. Some might argue: isn't this capital lockup inefficiency really just a highly indirect way of achieving the exact same level of economic inefficiency as exists in proof of work? The answer is no, for both reasons (2) and (3) above.
Let us start with (3) first. Consider a model where proof of stake deposits are infinite-term, ASICs last forever, ASIC technology is fixed (ie. no Moore's law) and electricity costs are zero. Let's say the equilibrium interest rate is 5% per annum. In a proof of work blockchain, I can take $1000, convert it into a miner, and the miner will pay me $50 in rewards per year forever. In a proof of stake blockchain, I would buy $1000 of coins, deposit them (ie. losing them forever), and get $50 in rewards per year forever. So far, the situation looks completely symmetrical (technically, even here, in the proof of stake case my destruction of coins isn't fully socially destructive as it makes others' coins worth more, but we can leave that aside for the moment). The cost of a "Maginot-line" 51% attack (ie. buying up more hardware than the rest of the network) increases by $1000 in both cases.
Now, let's perform the following changes to our model in turn:
Moore's law exists, ASICs depreciate by 50% every 2.772 years (that's a continuously-compounded 25% per annum; picked to make the numbers simpler). If I want to retain the same "pay once, get money forever" behavior, I can do so: I would put $1000 into a fund, where $167 would go into an ASIC and the remaining $833 would go into investments at 5% interest; the $41.67 dividends per year would be just enough to keep renewing the ASIC hardware (assuming technological development is fully continuous, once again to make the math simpler). Rewards would go down to $8.33 per year; hence, 83.3% of miners will drop out until the system comes back into equilibrium with me earning $50 per year, and so the Maginot-line cost of an attack on PoW given the same rewards drops by a factor of 6.
Electricity plus maintenance makes up 1/3 of mining costs. We estimate the 1/3 from recent mining statistics: one of Bitfury's new data centers consumes 0.06 joules per gigahash, or 60 J/TH or 0.000017 kWh/TH, and if we assume the entire Bitcoin network has similar efficiencies we get 27.9 kWh per second given 1.67 million TH/s total Bitcoin hashpower. Electricity in China costs $0.11 per kWh, so that's about $3 per second, or $260,000 per day. Bitcoin block rewards plus fees are $600 per BTC * 13 BTC per block * 144 blocks per day = $1.12m per day. Thus electricity itself would make up 23% of costs, and we can back-of-the-envelope estimate maintenance at 10% to give a clean 1/3 ongoing costs, 2/3 fixed costs split. This means that out of your $1000 fund, only $111 would go into the ASIC, $55 would go into paying ongoing costs, and $833 would go into hardware investments; hence the Maginot-line cost of attack is 9x lower than in our original setting.
Deposits are temporary, not permanent. Sure, if I voluntarily keep staking forever, then this changes nothing. However, I regain some of the optionality that I had before; I could quit within a medium timeframe (say, 4 months) at any time. This means that I would be willing to put more than $1000 of ether in for the $50 per year gain; perhaps in equilibrium it would be something like $3000. Hence, the cost of the Maginot line attack on PoS increases by a factor of three, and so on net PoS gives 27x more security than PoW for the same cost.
The above included a large amount of simplified modeling, however it serves to show how multiple factors stack up heavily in favor of PoS in such a way that PoS gets more bang for its buck in terms of security. The meta-argument for why this perhaps suspiciously multifactorial argument leans so heavily in favor of PoS is simple: in PoW, we are working directly with the laws of physics. In PoS, we are able to design the protocol in such a way that it has the precise properties that we want - in short, we can optimize the laws of physics in our favor. The "hidden trapdoor" that gives us (3) is the change in the security model, specifically the introduction of weak subjectivity.
Now, we can talk about the marginal/total distinction. In the case of capital lockup costs, this is very important. For example, consider a case where you have $100,000 of ether. You probably intend to hold a large portion of it for a long time; hence, locking up even $50,000 of the ether should be nearly free. Locking up $80,000 would be slightly more inconvenient, but $20,000 of breathing room still gives you a large space to maneuver. Locking up $90,000 is more problematic, $99,000 is very problematic, and locking up all $100,000 is absurd, as it means you would not even have a single bit of ether left to pay basic transaction fees. Hence, your marginal costs increase quickly. We can show the difference between this state of affairs and the state of affairs in proof of work as follows:
Hence, the total cost of proof of stake is potentially much lower than the marginal cost of depositing 1 more ETH into the system multiplied by the amount of ether currently deposited.
Note that this component of the argument unfortunately does not fully translate into reduction of the "safe level of issuance". It does help us because it shows that we can get substantial proof of stake participation even if we keep issuance very low; however, it also means that a large portion of the gains will simply be borne by validators as economic surplus.
Will exchanges in proof of stake pose a similar centralization risk to pools in proof of work?
From a centralization perspective, in both Bitcoin and Ethereum it's the case that roughly three pools are needed to coordinate on a 51% attack (4 in Bitcoin, 3 in Ethereum at the time of this writing). In PoS, if we assume 30% participation including all exchanges, then three exchanges would be enough to make a 51% attack; if participation goes up to 40% then the required number goes up to eight. However, exchanges will not be able to participate with all of their ether; the reason is that they need to accomodate withdrawals.
Additionally, pooling in PoS is discouraged because it has a much higher trust requirement - a proof of stake pool can pretend to be hacked, destroy its participants' deposits and claim a reward for it. On the other hand, the ability to earn interest on one's coins without oneself running a node, even if trust is required, is something that many may find attractive; all in all, the centralization balance is an empirical question for which the answer is unclear until the system is actually running for a substantial period of time. With sharding, we expect pooling incentives to reduce further, as (i) there is even less concern about variance, and (ii) in a sharded model, transaction verification load is proportional to the amount of capital that one puts in, and so there are no direct infrastructure savings from pooling.
A final point is that centralization is less harmful in proof of stake than in proof of work, as there are much cheaper ways to recover from successful 51% attacks; one does not need to switch to a new mining algorithm.
Can proof of stake be used in private/consortium chains?
Generally, yes; any proof of stake algorithm can be used as a consensus algorithm in private/consortium chain settings. The only change is that the way the validator set is selected would be different: it would start off as a set of trusted users that everyone agrees on, and then it would be up to the validator set to vote on adding in new validators.
It was April. Year was probably was 2010. The cold, snowy winter was finally coming to an end and the spring was almost in the air. I was preparing for my final exams. The review lectures were going on for the RDBMS course that I was enrolled in at my university.
Around the same time, I had started hearing and reading about the shinny, new technology that was going to change the way we use databases. The NoSQL movement was gaining momentum. I was reading blogs about how MongoDB is big time outperforming ancient, non web scale relational databases.
After the lecture, being a smart-ass that I’m, I asked my professor:
Me: So, between RDBMS and NoSQL databases, which one do you think is the best?
Professor: Well, it depends.
Me: Depends on what?
Professor: Depends on what you are trying to achieve. Both have their pros and cons. You pick the right tool for the job.
Me: But MySQL can’t really scale.
Professor: How do you think we got this far? Send me an email and I’ll send you some papers and practical uses of MySQL handling very high load.
SQL was hard for my brain, especially the joins. I loved NoSQL. Simple key->value model without any joins! Stone-aged RDBMS systems that were designed in 1960’s were simply not enough to keep up with modern demands. I had lost all interest in RDBMS and predicted they’ll just die off in the next few years.
I never emailed my professor.
It’s 2012. We’re redesigning my employer’s flagship product. The first version was a monolith that used the boring MySQL. Spending too much time reading blogs and Hacker News comments section, we convinced ourselves that we need to go big and modern:
Break monolith into service-oriented architecture, aka, the SOA.
Replace MySQL with Cassandra (MySQL to Redis to Cassandra)
And we built it.
There was nothing wrong with the new system… except one major flaw. It was too complex for a small startup team to maintain. We had built a Formula One race car, that makes frequent pit-stops and requires very specialized maintenance, when we needed a Toyota Corolla that goes on for years and years on just the oil change.
Fast forward to 2017. It feels like almost all software developers I interview these days, have hands-on experience with microservices architecture and many have even actually used it in production.
A grey San Francisco afternoon. I’m conducting an on-site interview. Masters degree and 3 years of experience at a startup that looked like it didn’t make it. I asked him to tell me about the system he built.
Guy: We built the system using the microservices architecture. We had lots of small services which made our life really easy…
Me: Go on…
Guy: Data was written to the BI system through a Kafka cluster. Hadoop and MapReduce system was built to process data for analytics. The system was super scalable.
I pressed him to tell me drawbacks of microservices architecture and problems it introduces. The guy tried to hand-wave his way through and was convinced, just like I was in 2010 about NoSQL databases, that there are absolutely no issues with microservices architecture.
I’m not saying microservices architecture is bad. It’s beneficial, but only to a few organizations in the world. Organizations who have very complex systems that justify the operational burden, the overhead, it introduces. Martin Fowler, who coined the term microservices, warns us of the “microservices premium”:
The fulcrum of whether or not to use microservices is the complexity of the system you’re contemplating. The microservices approach is all about handling a complex system, but in order to do so the approach introduces its own set of complexities. When you use microservices you have to work on automated deployment, monitoring, dealing with failure, eventual consistency, and other factors that a distributed system introduces. There are well-known ways to cope with all this, but it’s extra effort, and nobody I know in software development seems to have acres of free time.
So my primary guideline would be don’t even consider microservices unless you have a system that’s too complex to manage as a monolith. The majority of software systems should be built as a single monolithic application. Do pay attention to good modularity within that monolith, but don’t try to separate it into separate services.
Martin’s being generous. I believe that only very few, very large organizations really benefit from microservices. Netflix is one of such organizations. Their system grew too large and too complex to justify switching to microservices.
In almost all cases, you can’t go wrong by building a monolith first. You break your architecture into services-oriented or… microservices when the benefits outweigh the complexity.
Guy: Not a whole lot right now because we only have 3 customers. But the system could scale up to support millions and millions of users. Also, with both Kafka and Hadoop clusters, we get fool-proof fault-tolerance
Me: How big is the team and company?
Guy: Overall, I guess there were (less than 10) people in the company. Engineering was about 5.
At this point, I was tempted to ask if he had ever heard of YAGNI:
Yagni … stands for “You Aren’t Gonna Need It”. It is a mantra from Extreme Programming … It’s a statement that some capability we presume our software needs in the future should not be built now because “you aren’t gonna need it”.
People sometimes have honest intentions and they don’t introduce new tools, libraries, frameworks, just for the sake of enhancing their resumes. Sometimes they simply speculate enormous growth and try to do everything up front to not have to do this work later.
The common reason why people build presumptive features is because they think it will be cheaper to build it now rather than build it later. But that cost comparison has to be made at least against the cost of delay, preferably factoring in the probability that you’re building an unnecessary feature, for which your odds are at least ⅔.
People know complexity is bad. No one likes to see bugs filed on JIRA or get PagerDuty alerts at 3 a.m. that something is wrong with Cassandra cluster. But why do software developers still do it? Why do they choose to build complex systems without proper investigation?
Are there other reasons for building complex features besides preparing for a hypothetical future?
I’m sure majority of you are familiar with the term cargo cult software development. Teams who slavishly and blindly follow techniques of large companies they idolize like Google, Apple or Amazon, in the hopes that they’ll achieve similar success by emulating their idols.
Just like the South Sea natives who built primitive runways, prayed and performed rituals in the hopes that planes would come in and bring cargo, the food and supplies. Richard Feynman warned graduates at the California Institute of Technology to not fall victim to the cargo cult thinking:
In the South Seas there is a cargo cult of people. During the war they saw airplanes land with lots of good materials, and they want the same thing to happen now. So they’ve arranged to make things like runways, to put fires along the sides of the runways, to make a wooden hut for a man to sit in, with two wooden pieces on his head like headphones and bars of bamboo sticking out like antennas — he’s the controller — and they wait for the airplanes to land. They’re doing everything right. The form is perfect. It looks exactly the way it looked before. But it doesn’t work. No airplanes landed.
It reminded me of the time when we took a perfectly good monolith and created service-oriented architecture (SOA). It didn’t work. No planes landed.
Whatever the reasons:
not wanting to be left out: the new Javascript framework from this week will be the next hottest thing.
enhancing resume with buzzwords: Monolith won’t impress recruiters / interviewers.
imitating heroes: Facebook does it, Google does it, Twitter does it.
technology that could keep up with the projected 5000% YoY company growth: YAGNI.
latest tools to convince people that you’re a proper SF bay area tech company.
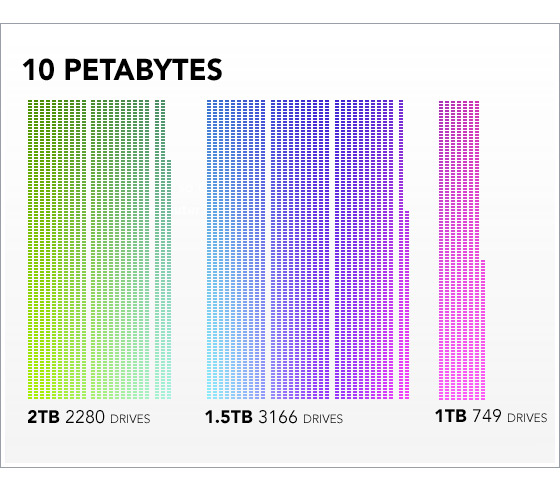
Cargo-cult engineering just doesn’t work. You are not Google. What works for them, may not work for your much smaller company. Google actually needed MapReduce because they wanted to regenerate indexes for the entire World Wide Web, or something like that. They needed fault tolerance from thousands of commodity servers. They had 20 petabytes of data to process.
20 petabytes is just enormous. In terms of the number of disk drives, here’s what half of that, 10 petabytes, would look like:
To avoid falling in the cargo-cult trap, I have learned to do the following:
Focus on the problem first, not the solution. Don’t pick any tool until you have fully understood what you are trying to achieve or solve. Don’t give up solving the actual problem and make it all about learning and using the shinny new tech.
Keep it simple. It’s an over-used term, but software developers still just don’t get it. Keep. It. Simple.
If you are leaning towards something that Twitter or Google uses, do your homework and understand the real reasons why they picked that technology.
When thinking of growth, understand that the chances of your startup growing to be the size of Facebook are slim to none. Even if your odds are huge, is it really worth all this effort to set-up a ‘world-class foundation’ now vs doing it later?
Weigh operational burden and complexity. Do you really need multi-region replication for fault-tolerance in return of making your DevOps life 2x more difficult?
Be selfish. Do you want to be woken up in the middle of night because something, somewhere stopped working? There is nothing wrong with learning the new JavaScript framework from last week. Create a new project and publish it on GitHub. Don’t build production systems just because you like it.
Think about people who’d have to live with your mess. Think about your legacy. Do people remember you as the guy who built rock-solid systems or someone who left a crazy mess behind?
Share your ideas with experts and veterans and let them criticize. Identify people in other teams who you respect and who’d disagree freely.
Don’t jump to conclusions on the results of quick experiments. HelloWorld prototypes of anything is easy. Real-life is very different from HelloWorld.
We discussed YAGNI in this post, but it is generally applied in the context of writing software, design patterns, frameworks, ORMs, etc. Things that are in control of one person.
YAGNI is coding what you need, as you need, refactoring your way through.
Back to the guy I interviewed. It’s highly unlikely, even for a small startup, that a software developer in the trenches was allowed to pick Hadoop, Kafka and microservices architecture. Cargo cult practices usually start from someone higher up the ranks. A tech leader who may be a very smart engineer, but very bad at making rational decisions. Someone who probably spends way too much time reading blogs and tries very hard keep up with the Amazon or Google way of building software.
2017 is almost over. NoSQL has matured. MongoDB is on its way out. DynamoDB is actually a very solid product and is maturing really well. RDBMS systems didn’t die. One can argue they are actually doing pretty good. StackOverflow is powered by just4 Microsoft SQL Servers. Uber runs on MySQL.
You may have great reasons to use MapReduce or microservices. What matters is how you arrive at your decision. Did you fell victim to the hype-cycle and picked up the technology just to jump on the bandwagon? Or did you carefully analyze the problem, and picked the best tool that gets the job done and you and your team can deal with it?
As the professor said: “Pick the right tool for the job.” I’ll also add: don’t build Formula One cars when you need a Corolla.
“The greatest single programming language ever designed.”— Alan Kay, on Lisp
“Lisp is worth learning for the profound enlightenment experience you will have when you finally get it; that experience will make you a better programmer for the rest of your days, even if you never actually use Lisp itself a lot.”— Eric Raymond, "How to Become a Hacker"
“One of the most important and fascinating of all computer languages is Lisp (standing for "List Processing"), which was invented by John McCarthy around the time Algol was invented.”— Douglas Hofstadter, Gödel, Escher, Bach
“Within a couple weeks of learning Lisp I found programming in any other language unbearably constraining.”— Paul Graham, Road to Lisp
“Lisp is the most sophisticated programming language I know. It is literally decades ahead of the competition ... it is not possible (as far as I know) to actually use Lisp seriously before reaching the point of no return.”— Christian Lynbech, Road to Lisp
“We were not out to win over the Lisp programmers; we were after the C++ programmers. We managed to drag a lot of them about halfway to Lisp. Aren't you happy?”— Guy Steele, Java spec co-author, LL1 mailing list, 2003
“Lisp has jokingly been called "the most intelligent way to misuse a computer". I think that description is a great compliment because it transmits the full flavor of liberation: it has assisted a number of our most gifted fellow humans in thinking previously impossible thoughts.”— Edsger Dijkstra, CACM, 15:10
“Historically, languages designed for other people to use have been bad: Cobol, PL/I, Pascal, Ada, C++. The good languages have been those that were designed for their own creators: C, Perl, Smalltalk, Lisp.”— Paul Graham
“Lisp ... made me aware that software could be close to executable mathematics.”— L. Peter Deutsch
“Will write code that writes code that writes code that writes code for money.”— on comp.lang.lisp
“I object to doing things that computers can do.”— Olin Shivers
“Lisp is a language for doing what you've been told is impossible.”— Kent Pitman
“Anyone could learn Lisp in one day, except that if they already knew Fortran, it would take three days.”— Marvin Minsky
“Programming in Lisp is like playing with the primordial forces of the universe. It feels like lightning between your fingertips. No other language even feels close.”— Glenn Ehrlich, Road to Lisp
The Web is a key space for civic debate and the current battleground for protecting freedom of expression. However, since its development, the Web has steadily evolved into an ecosystem of large, corporate-controlled mega-platforms which intermediate speech online. In many ways this has been a positive development; these platforms improved usability and enabled billions of people to publish and discover content without having to become experts on the Web’s intricate protocols.
But in other ways this development is alarming. Just a few large platforms drive most traffic to online news sources in the U.S., and thus have enormous influence over what sources of information the public consumes on a daily basis. The existence of these consolidated points of control is troubling for many reasons. A small number of stakeholders end up having outsized influence over the content the public can create and consume. This leads to problems ranging from censorship at the behest of national governments to more subtle, perhaps even unintentional, bias in the curation of content users see based on opaque, unaudited curation algorithms. The platforms that host our networked public sphere and inform us about the world are unelected, unaccountable, and often impossible to audit or oversee.
At the same time, there is growing excitement around the area of decentralized systems, which have grown in prominence over the past decade thanks to the popularity of the cryptocurrency Bitcoin. Bitcoin is a payment system that has no central points of control, and uses a novel peer-to-peer network protocol to agree on a distributed ledger of transactions, the blockchain. Bitcoin paints a picture of a world where untrusted networks of computers can coordinate to provide important infrastructure, like verifiable identity and distributed storage. Advocates of these decentralized systems propose related technology as the way forward to “re-decentralize” the Web, by shifting publishing and discovery out of the hands of a few corporations, and back into the hands of users. These types of code-based, structural interventions are appealing because in theory, they are less corruptible and resistant to corporate or political regulation. Surprisingly, low-level, decentralized systems don’t necessarily translate into decreased market consolidation around user-facing mega-platforms.
In this report, we explore two important ways structurally decentralized systems could help address the risks of mega-platform consolidation: First, these systems can help users directly publish and discover content directly, without intermediaries, and thus without censorship. All of the systems we evaluate advertise censorship-resistance as a major benefit. Second, these systems could indirectly enable greater competition and user choice, by lowering the barrier to entry for new platforms. As it stands, it is difficult for users to switch between platforms (they must recreate all their data when moving to a new service) and most mega-platforms do not interoperate, so switching means leaving behind your social network. Some systems we evaluate directly address the issues of data portability and interoperability in an effort to support greater competition.
We offer case studies of the following decentralized publishing projects:
Freedom Box, a system for personal publishing
Diaspora, a federated social network
Mastodon, a federated Twitter-like service
Blockstack, a distributed system for online identity services
IPFS (Interplanetary File System), a distributed storage service with a proposed mechanism to incentivize resource sharing
Solid (Social Linked Data), a linked-data protocol that could act as a back-end for data sharing between social media networks
Appcoins, a digital currency framework that enables users to financially participate in ownership of platforms and protocols
Steemit, an online community that uses an appcoin to incentivize development and community participation in a social network
Considering these projects as a whole, we found a robust and fertile community of experimenters developing promising software. Many of the projects in this report are working on deeply exciting new ideas. Easy to use, peer-to-peer distributed storage systems change the landscape for content censorship and archiving. Appcoins may transform how new projects are launched online, making it possible to fund open-source development teams focused on developing shared protocols instead of independent companies. There is also a renewed interest in creating interoperable standards and protocols that can cross platforms.
However, we have reason to doubt that these decentralized systems alone will address the problems of exclusion and bias caused by today’s mega-platforms. For example, distributed, censorship-resistant storage does not help address problems related to bias in curation algorithms – content that doesn’t appear at the top of your feed might as well be invisible, even if it’s technically accessible. And though censorship-resistance and decentralization are noble goals that will undoubtedly appeal to tech-savvy and politically inclined users, most users are not ideologically motivated and have no interest in shouldering the additional cost and responsibility of running these complex systems directly. They will want to engage with the Web through friendlier, third-party publishing platforms, and these platforms will suffer from the same forces that drive consolidation today.
It’s important to remember that today’s mega-platforms are built on top of the Web’s already distributed and open protocols. The real issue to address is this natural tendency towards market consolidation. Underlying these concerns is the predominant business model for platforms on the Web – user-targeted advertising. Advertising based business models encourage the consolidation and the hoarding of user views and data, driving platforms to become ever larger.
The challenges decentralized systems as a whole face are as follows:
User and developer adoption. Technical feasibility alone does not guarantee the sort of widespread adoption necessary to build a useful social network. Some of the more mature tools developed in this space have faced serious difficulties in attracting a permanent user base, and the problems those platforms suffer from may hinder the growth of new systems as well. Social networks, in particular, are difficult to bootstrap due to network effects. We generally join social networks because our friends are already there. Systems like Steemit and Diaspora are currently incompatible with existing social networks, planning to supersede existing communities like Reddit and Facebook, rather than integrate with them. Taking a competitive, rather than complementary, position in the market creates a difficult barrier to entry for new projects. Similarly, interoperable protocols require adoption at the developer level. Solid, which hopes to bridge between existing and novel social networks, faces a serious adoption challenge: Why should developers choose to switch to Solid’s new data model, and what's the incentive for Facebook to make their data interoperable without legal requirements forcing them to do so?
Security. Another major issue is security. “Decentralized” networks generally means anyone can join, which implies these systems have to take strong precautions to enforce security, usually by pushing the responsibility of security to users in the form of managing public key cryptography. It is extremely difficult to develop software that is both cryptographically secure and easy to use. Most of these systems, like IPFS and Blockstack, do not yet have a good story for how users will manage their private cryptographic keys and gain a good mental model of complex security protocols. As companies like Signal, an encrypted messaging service, have recently demonstrated, this is not impossible to achieve, but it requires an intense focus on usability that we did not see in many of the tools we review in this report.
Monetization and incentives. Given that user data is so important for monetizing these platforms, there is little incentive for the mega-platforms to adopt interoperable protocols – they would rather own all the data. Similarly, content that is viewed and clicked on the most generates the most advertising revenue, so mega-platforms have an incentive to prioritize viral, attention-grabbing or feel-good content. Steemit offers a fascinating alternative model to prioritizing and monetizing content. However, it replaces opacity with a semi-transparent free market model that concentrates power in a few hands and, if not carefully crafted, might even incentivize more clickbait. Designing robust reward mechanisms for community-governed content is still an open problem, but if solved, this could be integral to placing curation control in the hands of a community.
Resisting market consolidation? Platforms benefit from economies of scale in multiple ways – it’s cheaper to acquire resources like storage and servers in bulk and as platforms become larger they become more useful as a social network and usually, more profitable. Even in decentralized systems like Bitcoin, there has been a natural market consolidation in the form of large mining pools. This type of consolidation into a few super-participants might be inevitable due to economies of scale. We are increasingly persuaded that this isn't necessarily a bad thing, and that a more realistic goal might be the development of a robust, competitive marketplace that offers a range of ground rules for online speech, rather than a return to a purely peer-to-peer architecture for communication online.
Recommendations: We advise investors–whether motivated by civic or fiscal concerns–both to watch this space closely and to advocate for the pre-conditions that we believe will enable a healthier marketplace for online publishing. A precondition for the success of these distributed platforms is a shift towards user-controlled data, the ownership of a user’s social graph and her intellectual property created online. It will be difficult for new platforms to develop without widespread support for efforts towards data portability and rights over data ownership.
Data portability also enables new models for aggregation.
Small, thoughtfully curated news sources will be made more powerful by having access to the user data currently locked inside mega-platforms, but right now, federated clients that interoperate between different platforms are borderline illegal – fixing this may require adjusting overly broad regulations, like the Digital Millennium Copyright Act. We believe that these user-controlled data rights are essential to develop a more robust market and allow new efforts to emerge from existing communities. Though individual users might not directly care about or understand these rights, their adoption will free developers to create applications that leverage users’ existing data, so that they can provide compelling, interesting new experiences, even with a small user base.
In envisioning a marketplace for open speech platforms that support more generative and censorship-resistant discussions, we recommend focusing on supporting existing efforts that provide alternatives to Facebook’s opaque curation and ranking. These alternatives might look more like Reddit's sub-communities, with different rule sets to enable different types of conversation, overseen and administered by members of the community with a system for due process when contentious issues arise.
Funding developers directly to create a diverse ecosystem of publishing platforms and curation websites is another place to make a difference. In particular, foundations are in an excellent place to fund the development of user-friendly software to implement common security practices that are common across many applications. An example of this is Let’s Encrypt, which makes using secure HTTP (HTTPS) easier for small website administrators. Most small platforms do not have the resources to directly hire experts in usability and security.
Another fascinating space to watch and explore is that of Appcoins. Recently there has been a dramatic upsurge in the adoption of appcoins as a mechanism for funding new projects and platforms. Appcoins potentially provide a way to circumvent the existing open-source or VC-funded software development models to create systems where users collectively own their data. Creating an alternative business model to advertising could end up pushing the markets to create entirely new, different types of applications than the ones we’ve seen so far, which mainly rely on user data and views. New funding models means smaller projects could more easily bootstrap small, personalized communities. However, this space also has a lot of potential for scams, and it might be unreasonable to expect users to manage a financial stake in many different networks.
Some people can tell the most boring story and keep an audience on the edges of their seats. On the other hand, when I try to tell people about the most interesting things I've experienced (and there are some pretty interesting ones), it tends to land with a thud. I seem to have no natural talent for storytelling, but I'm hoping it's something I can learn to improve.
This applies to both spoken and written communication, in social and business contexts. I think there must be some foundational techniques for structuring and telling stories to make them effective, but I haven't really been able to reverse engineer them.
Are there books, websites, or other materials I should look at to learn this? Or do you have any specific tips or guidance for me?
If you know HTML, CSS, and Javascript, you know Marko
fast.
Faster loads via streaming and a tiny (~10kb gzip) runtime
progressive.
From simple HTML templates to powerful UI components
trusted.
Marko is powering high-traffic websites like ebay.com
Change the data backing a view and Marko will automatically and efficiently update the resulting HTML
class{
onCreate(){
this.state={ count:0};
}
increment(){
this.state.count++;
}
}
style{
.count{
color:#09c;
font-size:3em;
}
.example-button{
font-size:1em;
padding:0.5em;
}
}
<div.count>
${state.count}
</div>
<button.example-buttonon-click('increment')>
Click me!
</button>
Write in a familiar HTML-like style or drop the angle brackets and use Marko's concise syntax
<!doctype html>
<html>
<head>
<title>Hello Marko</title>
</head>
<body>
<h1>My favorite colors</h1>
<ul.colors>
<lifor(color ininput.colors)>
${color}
</li>
</ul>
</body>
</html>
⇄
<!doctype html>
html
head
title-- Hello Marko
body
h1-- My favorite colors
ul.colors
lifor(color ininput.colors)
--${color}
Fast enough to power animations at 60FPS
The above animation is <div> tags. No SVG, no CSS transitions/animations. It's all powered by Marko which does a full re-render every frame.
Marko provides first-class support for the Atom editor with syntax highlighting, Autocomplete for both HTML and custom tags, Hyperclick to quickly jump to referenced files and methods, and Pretty printing to keep your code readable.
Community plugins also provide syntax highlighting for Sublime, VS Code, Webstorm & others!
This benchmark measures the time it takes to cycle through 133 colors. The selected color index changes every cycle. When the selected color index changes three things happen:
The new selected color is highlighted
The old selected color is unhighlighted
The selected color's name is shown at the end
This benchmark measures how well a large render tree is optimized when only a few nodes actually need to be updated.
Do you like thinking, writing, and teaching others about Internet security? Have you worked as a software engineer?
Aptible is hiring an expert in web security and software development to help make the Internet safe for sensitive data.
It's true: software is eating the world, powered by the Internet. A growing wave of developers all over the world are using web-scale technology to build and deploy health care, fintech, banking, payments, IoT, blockchain, machine learning, and other B2B applications.
Security and compliance are mandatory from day one for these teams of developers, but many of them struggle. When their teams are small, they can’t afford to hire full-time for security or compliance. When they scale, they find that existing security and compliance management tools suck.
At Aptible, we make people-centered security products that help developer teams build security into their architecture and their organization’s culture:
Enclave is a container orchestration platform built for developers that automates security best practices and controls needed for deploying and scaling Dockerized apps in regulated industries.
Gridiron is like the missing QuickBooks for security management. It helps developers design and run security management programs that meet and exceed requirements like HIPAA, SOC 2, and ISO 27001. Customers use it to build trust with their own customers and partners, and prepare for certifications.
This role involves working on both product and growth/marketing.
Please be sure to include a cover letter and samples of previous work that demonstrate why you will be a good fit for this role.
The ultimate replacement for spreadsheets, mind mappers, outliners, PIMs, text editors and small databases.
Suitable for any kind of data organization, such as Todo lists, calendars, project management, brainstorming, organizing ideas, planning, requirements gathering, presentation of information, etc.
It's like a spreadsheet, immediately familiar, but much more suitable for complex data because it's hierarchical. It's like a mind mapper, but more organized and compact. It's like an outliner, but in more than one dimension. It's like a text editor, but with structure.
Have a quick look at what the application looks like on the screenshots page, see how easy it is to use in the tutorial, then give it a download (above).
TreeSheets is exceptionally small & fast, so can sit in your system tray at all times: with several documents loaded representing the equivalent of almost 100 pages of text, it uses only 5MB of memory on Windows 7 (!)
TreeSheets is free & open source. Enjoy!
Visit this google group for discussion, bug reports and news updates / releases. Grab the source code from GitHub. google moderator can be used for feature suggestions. Please donate if you enjoy using this software. contact the author (Wouter van Oortmerssen) personally.
Presented with these two scenarios, most adults did indeed explain the events by talking about a single block, or about Sally’s traits — they gave the obvious explanation.
Then we added a twist. Another group of participants saw the same scenarios, but this time they saw an additional set of facts that made the unusual explanation more likely than the more obvious one. Would the participants go with the obvious explanation, or try something new?
When it came to explaining the physical machine, the pattern was straightforward. The preschoolers were most likely to come up with the creative, unusual explanation. The school-age children were somewhat less creative. And there was a dramatic drop at adolescence. Both the teenagers and the adults were the most likely to stick with the obvious explanation even when it didn’t fit the data.
But there was a different pattern when it came to the social problems. Once again the preschoolers were more likely to give the creative explanation than were the 6-year-olds or adults. Now, however, the teenagers were the most creative group of all. They were more likely to choose the unusual explanation than were either the 6-year-olds or the adults.
Why does creativity generally tend to decline as we age? One reason may be that as we grow older, we know more. That’s mostly an advantage, of course. But it also may lead us to ignore evidence that contradicts what we already think. We become too set in our ways to change.
Relatedly, the explanation may have to do with a tension between two kinds of thinking: what computer scientists call exploration and exploitation. When we face a new problem, we adults usually exploit the knowledge about the world we have acquired so far. We try to quickly find a pretty good solution that is close to the solutions we already have. On the other hand, exploration — trying something new — may lead us to a more unusual idea, a less obvious solution, a new piece of knowledge. But it may also mean that we waste time considering crazy possibilities that will never work, something both preschoolers and teenagers have been known to do.
This idea suggests a solution to the evolutionary paradox that is human childhood and adolescence. We humans have an exceptionally long childhood and prolonged adolescence. Why make human children so helpless for so long, and make human adults invest so much time and effort into caring for them?
The answer: Childhood and adolescence may, at least in part, be designed to resolve the tension between exploration and exploitation. Those periods of our life give us time to explore before we have to face the stern and earnest realities of grown-up life. Teenagers may no longer care all that much about how the physical world works. But they care a lot about exploring all the ways that the social world can be organized. And that may help each new generation change the world.
YANFF is a set of libraries for creating and deploying cloud-native Network
Functions (NFs). It simplifies the creation of network functions without
sacrificing performance. Network functions are written in Go using high-level
abstractions like flows and packets.
YANFF is an Open Source BSD licensed project that runs mostly in Linux user
land. The most recent patches and enhancements provided by the community are
available in the master branch.
Getting YANFF
Use the go get command to download YANFF. You must first set your GOPATH
export GOPATH=/my/local/directory
go get -v -d github.com/intel-go/yanff
Go will download the sources into $GOPATH/src. It will try to build YANFF and
fail with a message:
can't load package: package github.com/intel-go/yanff: no buildable Go source files in /localdisk/work/rscohn1/ws/yanff-test/src/github.com/intel-go/yanff
Ignore the message for now. We need to install some dependencies before you can
build.
Working with a github fork
If you are working on a fork, then the go get command will not put yanff in
$GOPATH/src/github.com/intel-go. However, imports will continue to reference
githb.com/intel-go. This is a feature of Go and not a problem in the way yanff
is written. See stackoverflow
article
for a discussion. A simple way to resolve the problem is to use a symlink. If
you are rscohn2 on github, and you forked yanff into your personal account,
then do this:
cd $GOPATH/src/github.com
mkdir intel-go
cd intel-go
ln -s ../rscohn2/yanff .
The kernel module, which is required for DPDK user-mode drivers, is built but
not installed into kernel directory. You can load it using the full path to the
module file:
$GOPATH/src/github.com/intel-go/yanff/test/dpdk/dpdk-17.02/x86_64-native-linuxapp-gcc/kmod/igb_uio.ko
Go
Use Go version 1.8 or higher. To check the version of Go, do:
to generate full documentation. Alternatively, you can do:
godoc -http=:6060
and browse the following URLs:
Tests
Invoking make in the top-level directory builds the testing framework and
examples. YANFF distributed tests are packaged inside of Docker container
images. There are also single node unit tests in some packages that you can
run using the command:
make testing
Docker images
To create Docker images on the local default target (either the default UNIX
socket in /var/run/docker.sock or whatever is defined in the DOCKER_HOST
variable), use the make images command.
To deploy Docker images for use in distributed testing, use the make deploy
command. This command requires two environment variables:
YANFF_HOSTS="hostname1 hostname2 ... hostnameN"* - a list of all hostnames for deployed test Docker images
DOCKER_PORT=2375* - the port number to connect to Docker daemons running on hosts in the YANFF_HOSTS variable
To delete generated images in the default Docker target, use the make
clean-images command.
Running tests
After the Docker images are deployed on all test hosts, you can run distributed
network tests. The test framework is located in the test/main directory and
accepts a JSON file with a test specification. There are predefined configs for
performance and stability tests in the same directory. To run these tests,
change hostname1 and hostname2 to the hosts from the YANFF_HOSTS list
in these JSON files.
Cleaning-up
To clean all generated binaries, use the make clean command. To delete all
deployed images listed in YANFF_HOSTS, use the make cleanall command.
Changing the DPDK sources
If you use the make command from YANFF directories, the DPDK driver is
downloaded and patched automatically. To use different sources, apply the
patch from test/dpdk/DPDK_17_02.patch. The patch makes it impossible to use
indirect mbufs due to data races, but it improves YANFF performance. YANFF
doesn't use indirect mbufs.
Contributing
If you want to contribute to YANFF, check our Contributing
guide. We also
recommend checking the 'janitorial' bugs in our list of open issues; these bugs
can be solved without an extensive knowledge of YANFF. We would love to help
you start contributing.
You can reach the YANFF development team via our mailing
list.
About five years ago John Lees-Miller and I had a trip to forget to San Francisco. We had made it through to the interview stage at YC with our collaborative writing platform, called WriteLaTeX.
TL;DR – Things didn’t go well in the interview, but we pressed on regardless and today have a successful, investor-backed business that now serves over two million users worldwide.
If you have similar / different stories of how you got started, feel free to post them in the comments here or on the blog post linked above. If you’re in London on the 25th September and are working in the science / research / publishing space, you should definitely come to our next #FuturePub event that evening.
We still have some speaking slots available if you fancy giving a lightning talk — just let me know 🙂
Game downloads on PS4 have a reputation of being very slow, with many people
reporting downloads being an order of magnitude faster on Steam or
Xbox. This had long been on my list of things to look into, but at
a pretty low priority. After all, the PS4 operating system is
based on a reasonably modern FreeBSD (9.0), so there should not be
any crippling issues in the TCP stack. The implication is that the
problem is something boring, like an inadequately dimensioned CDN.
But then I heard that people were successfully using local HTTP
proxies as a workaround. It should be pretty rare for that to
actually help with download speeds, which made this sound like a
much more interesting problem.
This is going to be a long-winded technical post. If you're not
interested in the details of the investigation but just want a
recommendation on speeding up PS4 downloads, skip straight to theconclusions.
Background
Before running any experiments, it's good to have a mental model
of how the thing we're testing works, and where the problems might
be. If nothing else, it will guide the initial experiment design.
The speed of a steady-state TCP connection is basically defined by
three numbers. The amount of data the client is will to receive on
a single round-trip (TCP receive window), the amount of data the
server is willing to send on a single round-trip (TCP congestion
window), and the round trip latency between the client and the server (RTT).
To a first approximation, the connection speed will be:
speed = min(rwin, cwin) / RTT
With this model, how could a proxy speed up the connection? Well,
with a proxy the original connection will be split into two mostly
independent parts; one connection between the client and the
proxy, and another between the proxy and the server. The speed of
the end-to-end connection will be determined by the slower of
those two independent connections:
With a local proxy the client-proxy RTT will be very low; that
connection is almost guaranteed to be the faster one. The
improvement will have to be from the server-proxy connection being
somehow better than the direct client-server one. The RTT will not
change, so there are just two options: either the client has a
much smaller receive window than the proxy, or the client is
somehow causing the server's congestion window to
decrease. (E.g. the client is randomly dropping received packets,
while the proxy isn't).
Out of these two theories, the receive window one should be much
more likely, so we should concentrate on it first. But that just
replaces our original question with a new one: why would the
client's receive window be so low that it becomes a noticeable
bottleneck? There's a fairly limited number of causes for low
receive windows that I've seen in the wild, and they don't really
seem to fit here.
Maybe the client doesn't support the TCP window scaling option,
while the proxy does. Without window scaling, the receive window
will be limited to 64kB. But since we know Sony started with a
TCP stack that supports window scaling, they would have had to
go out of their way to disable it. Slow downloads, for no benefit.
Maybe the actual downloader application is very slow. The operating
system is supposed to have a certain amount of buffer space available
for each connection. If the network is delivering data to the OS
faster than the application is reading it, the buffer will start to
fill up, and the OS will reduce the receive window as a form
of back-pressure. But this can't be the reason; if the application
is the bottleneck, it'll be a bottleneck with or without the
proxy.
The operating system is trying to dynamically scale the
receive window to match the actual network conditions, but
something is going wrong. This would be interesting, so it's
what we're hoping to find.
The initial theories are in place, let's get digging.
Experiment #1
For our first experiment, we'll start a PSN download on a baseline
non-Slim PS4, firmware 4.73. The network connection of the PS4 is
bridged through a Linux machine, where we can add latency to the
network using tc netem. By varying the added latency,
we should be able to find out two things: whether the receive
window really is the bottleneck, and whether the receive window
is being automatically scaled by the operating system.
This is what the client-server RTTs (measured from a packet
capture using TCP timestamps) look like for the experimental
period. Each dot represents 10 seconds of time for a single
connection, with the Y axis showing the minimum RTT seen for that
connection in those 10 seconds.
The next graph shows the amount of data sent by the server in one
round trip in red, and the receive windows advertised by the
client in blue.
First, since the blue dots are staying constantly at about 128kB,
the operating system doesn't appear to be doing any kind of
receive window scaling based on the RTT. (So much for that
theory). Though at the very right end of the graph the receive
window shoots out to 650kB, so it isn't totally
fixed either.
Second, is the receive window the bottleneck here? If so, the
blue dots would be close to the red dots. This is the case
until about 10:50. And then mysteriously the bottleneck moves to
the server.
So we didn't find quite what we were looking for, but there are a
couple of very interesting things that are correlated with events
on the PS4.
The download was in the foreground for the whole duration of the
test. But that doesn't mean it was the only thing running on the
machine. The Netflix app was still running in the background,
completely idle [1]. When the background app was
closed at 11:00, the receive window increased dramatically. This
suggests a second experiment, where different applications are
opened / closed / left running in the background.
The time where the receive window stops being the bottleneck is
very close to the PS4 entering rest mode. That looks like another
thing worth investigating. Unfortunately, that's not true, and
rest mode is a red herring here. [2]
Experiment #2
Below is a graph of the receive windows for a second download,
annotated with the timing of various noteworthy events.
The differences in receive windows at different times are
striking. And more important, the changes in the receive
windows correspond very well to specific things I did on
the PS4.
When the download was started, the game Styx: Shards of
Darkness was running in the background (just idling in the title
screen). The download was limited by a receive window of under
7kB. This is an incredibly low value; it's basically going to
cause the downloads to take 100 times longer than they should.
And this was not a coincidence, whenever that game
was running, the receive window would be that low.
Having an app running (e.g. Netflix, Spotify) limited the
receive window to 128kB, for about a 5x reduction in potential
download speed.
Moving apps, games, or the download window to the foreground
or background didn't have any effect on the receive window.
Launching some other games (Horizon: Zero Dawn, Uncharted 4,
Dreadnought) seemed to have the same effect as running an app.
Playing an online match in a networked game (Dreadnought) caused the
receive window to be artificially limited to 7kB.
Playing around in a non-networked game (Horizon: Zero Dawn)
had a very inconsistent effect on the receive window, with the
effect seemingly depending on the intensity of gameplay. This
looks like a genuine resource restriction (download process
getting variable amounts of CPU), rather than an artificial
limit.
I ran a speedtest at a time when downloads were limited to
7kB receive window. It got a decent receive window of over
400kB; the conclusion is that the artificial receive window
limit appears to only apply to PSN downloads.
Putting the PS4 into rest mode had no effect.
Built-in features of the PS4 UI, like the web browser,
do not count as apps.
When a game was started (causing the previously running game
to be stopped automatically), the receive window could increase
to 650kB for a very brief period of time. Basically it appears
that the receive window gets unclamped when the old game stops,
and then clamped again a few seconds later when the new game
actually starts up.
I did a few more test runs, and all of them seemed
to support the above findings. The only additional information
from that testing is that the rest mode behavior was dependent
on the PS4 settings. Originally I had it set up to suspend apps
when in rest mode. If that setting was disabled, the apps would
be closed when entering in rest mode, and the downloads would
proceed at full speed.
A 7kB receive window will be absolutely crippling for any user.
A 128kB window might be ok for users who have CDN servers very
close by, or who don't have a particularly fast internet. For
example at my location, a 128kB receive window would cap the downloads at about
35Mbp to 75Mbps depending on which CDN the DNS RNG happens to give me.
The lowest two speed tiers for my ISP are 50Mbps and 200Mbps.
So either the 128kB would not be a noticeable problem (50Mbps) or it'd mean
that downloads are artificially limited to to 25% speed (200Mbps).
Conclusions
If any applications are running, the PS4 appears to change the
settings for PSN store downloads, artificially restricting their
speed. Closing the other applications will remove the limit. There
are a few important details:
Just leaving the other applications running in the background willnot help. The exact same limit is applied whether the download
progress bar is in the foreground or not.
Putting the PS4 into rest mode might or might not help,
depending on your system settings.
The artificial limit applies only to the PSN store downloads.
It does not affect e.g. the built-in speedtest. This
is why the speedtest might report much higher speeds than the
actual downloads, even though both are delivered from the same
CDN servers.
Not all applications are equal; most of them will cause the
connections to slow down by up to a factor of 5. Some
games will cause a difference of about a factor of 100. Some
games will start off with the factor of 5, and then migrate to
the factor of 100 once you leave the start menu and start playing.
The above limits are artificial. In addition to that,
actively playing a game can cause game downloads to slow down.
This appears to be due to a genuine lack of CPU resources (with
the game understandably having top priority).
So if you're seeing slow downloads, just closing all the running
applications might be worth a shot. (But it's obviously not
guaranteed to help. There are other causes for slow downloads as
well, this will just remove one potential bottleneck).
To close the running applications, you'll need to
long-press the PS button on the controller, and then select "Close
applications" from the menu.
The PS4 doesn't make it very obvious exactly what programs are
running. For games, the interaction model is that opening a new
game closes the previously running one. This is not how other apps
work; they remain in the background indefinitely until you
explicitly close them.
And it's gets worse than that. If your PS4 is configured to
suspend any running apps when put to rest mode, you can seemingly
power on the machine into a clean state, and still have a hidden
background app that's causing the OS to limit your PSN download
speeds.
This might explain some of the superstitions about this on the
Internet. There are people who swear that putting the machine to
rest mode helps with speeds, others who say it does nothing. Or
how after every firmware update people will report increased
download speeds. Odds are that nothing actually changed in the
firmware; it's just that those people had done their first full
reboot in a while, and finally had a system without a background
app running.
Speculation
Those were the facts as I see them. Unfortunately this raises some
new questions, which can't be answered experimentally. With no
facts, there's no option except to speculate wildly!
Q: Is this an intentional feature? If so, what its purpose?
Yes, it must be intentional. The receive window changes very
rapidly when applications or games are opened/closed, but not for
any other reason. It's not any kind of subtle operating system
level behavior; it's most likely the PS4 UI explicitly
manipulating the socket receive buffers.
But why? I think the idea here must be to not allow the network
traffic of background downloads to take resources away from the
foreground use of the PS4. For example if I'm playing an online
shooter, it makes sense to harshly limit the background download
speeds to make sure the game is getting ping times that are
both low and predictable. So there's at least some point in that
7kB receive window limit in some circumstances.
It's harder to see what the point of the 128kB receive window
limit for running any app is. A single game download from some
random CDN isn't going to muscle out Netflix or Youtube... The
only thing I can think of is that they're afraid that multiple
simultaneous downloads, e.g. due to automatic updates, might cause
problems for playing video. But even that seems like a stretch.
There's an alternate theory that this is due to some non-network
resource constraints (e.g. CPU, memory, disk). I don't think that
works. If the CPU or disk were the constraint, just having the
appropriate priorities in place would automatically take care of
this. If the download process gets starved of CPU or disk
bandwidth due to a low priority, the receive buffer would fill up
and the receive window would scale down dynamically, exactly when
needed. And the amounts of RAM we're talking about here are
miniscule on a machine with 8GB of RAM; less than a megabyte.
Q: Is this feature implemented well?
Oh dear God, no. It's hard to believe just how sloppy this
implementation is.
The biggest problem is that the limits get applied based just on
what games/applications are currently running. That's just
insane; what matters should be which games/applications someone is
currently using. Especially in a console UI, it's a totally
reasonable expectation that the foreground application gets
priority. If I've got the download progress bar in the foreground,
the system had damn well give that download priority. Not some
application that was started a month ago, and hasn't been used
since. Applying these limits in rest mode with suspended
apps is beyond insane.
Second, these limits get applied per-connection. So if you've got
a single download going, it'll get limited to 128kB of receive
window. If you've got five downloads, they'll all get 128kB, for a
total of 640kB. That means the efficiency of the "make sure downloads
don't clog the network" policy depends purely on how many downloads
are active. That's rubbish. This is all controlled on the
application level, and the application knows how many downloads
are active. If there really were an optimal static receive window
X, it should just be split evenly across all the downloads.
Third, the core idea of applying a static receive window as a
means of fighting bufferbloat is just fundamentally broken.
Using the receive window as the rate limiting mechanism just
means that the actual transfer rate will depend on the RTT
(this is why a local proxy helps). For this kind of thing to
work well, you can't have the rate limit depend on the
RTT. You also can't just have somebody come up with a number
once, and apply that limit to everyone. The limit needs to
depend on the actual network conditions.
There are ways to detect how congested the downlink is in the
client-side TCP stack. The proper fix would be to implement them,
and adjust the receive window of low-priority background downloads
if and only if congestion becomes an issue. That would actually be
a pretty valuable feature for this kind of appliance. But I can
kind of forgive this one; it's not an off the shelf feature, and
maybe Sony doesn't employ any TCP kernel hackers.
Fourth, whatever method is being used to decide on whether a game
is network-latency sensitive is broken. It's absurd that a demo of
a single-player game idling in the initial title screen would
cause the download speeds to be totally crippled. This really
should be limited to actual multiplayer titles, and ideally just
to periods where someone is actually playing the game online.
Just having the game running should not be enough.
Q: How can this still be a problem, 4 years after launch?
I have no idea. Sony must know that the PSN download speeds have
been a butt of jokes for years. It's probably the biggest
complaint people have with the system. So it's hard to believe
that nobody was ever given the task of figuring out why it's
slow. And this is not rocket science; anyone bothering to look
into it would find these problems in a day.
But it seems equally impossible that they know of the cause, but
decided not to apply any of the the trivial fixes to it. (Hell, it
wouldn't even need to be a proper technical fix. It could just be
a piece of text saying that downloads will work faster with all
other apps closed).
So while it's possible to speculate in an informed manner about
other things, this particular question will remain as an open
mystery. Big companies don't always get things done very
efficiently, eh?
Developing VST Plugins for Linux is something that has always been of great interest to me personally. There never seemed to be a framework that was easily portable to Linux aside from JUCE. Why not use JUCE you ask? Don’t get me wrong, JUCE is an excellent framework full of a multitude of useful libraries, but the licensing fees are too high for an independent developer like me. Then there is WDL which I used for a while, but unfortunately, it has been orphaned so future developments are unlikely unless you do them yourself. WDL also doesn’t have support for Linux, and in my experience, it can be a nightmare to manage the projects. I could go on and on comparing JUCE, WDL, and Dplug but I will save that for a later post. In this post, I want to tell my story of why I switched to the new kid on the block: Dplug.
Begin long story…
Sometime about 6 or 7 months ago, I started learning a new language just for fun called D. It was a language that had caught my interest from various blog entries and youtube videos. One of the beautiful things about D is the package manager made for it called Dub. Just out of curiosity I searched the Dub package repository for “vst” and was shocked when “dplug” came up.
So what is Dplug? Dplug is an open source library written entirely in D that can build plugins for Windows and Mac in VST format and Audio Unit format. At first, this seemed too good to be true. I cloned the GitHub repository and followed the instructions in the README for building a sample plugin. I went to the distort example, opened a terminal, and typed in “dub”. Much to my surprise, the plugin built like it was magic. There wasn’t any frustration over using an IDE, no build errors, nothing. Surely something must have gone wrong, it’s never that easy. So I moved the resulting DLL over to my plugins folder and opened my host. Once again I was shocked to see the example plugin open and run beautifully.
At this point I was sold on Dplug, but there was just one thing that still bothered me. Just like WDL, there was no Linux support. After asking the author Guillaume Piolat about the state of Linux support, he mentioned that he had once attempted to add Linux support in the past but ran into problems with x11 and hosts not find the plugins’ entry points (D and the libraries written in it have matured a lot since that time). Guillaume decided to appoint a programmer named Rikki to add support for x11 windowing. Again I was shocked. There was a library for VST/AU plugins that is maintained extremely well and frequently.
Rikki is great when it comes to this sort of task. If you need any work done, especially in D or with windowing, I highly recommend him. http://cattermole.co.nz/
In just a short amount of time, Rikki finished up X11 windowing for Dplug and had a working standalone example. I could hardly contain my excitement to finally see my plugins run on Linux. The plugins didn’t work right off the bat unfortunately. This was due to the plugins not getting a handle on the window to draw to and also not receiving events for the X server. We handled this by having Dplug create its own window and then creating a separate thread to dispatch events and redraw the UI. After a few small changes, we had the plugins opening and properly handling X events.
Conclusion
Finally, there is an open source framework for creating VST plug-ins in Linux. There are no licensing fees to worry about and development is very active.
Dplug is exactly what I was looking for, but I’m not going to say that is the ultimate library for creating audio plugins. The library is still actively being developed so it doesn’t have support for formats like AAX or VST3. Also even though D has a syntax similar to C and C++, it may take a while to adapt to using a different language. If this doesn’t scare you away then I strongly encourage you to give Dplug a chance!
In the following months, if there is enough interest, I may begin a series of tutorials about writing plugins with Dplug. If you are interested in joining our discussion about Dplug, we have a discord server here https://discord.gg/V5xDwFP
If you are interested in seeing what kind of plugins can be made with Dplug, then you should certainly checkout Auburn Sounds. They use Dplug exclusively. https://www.auburnsounds.com/
As always feel free to contact me at ctrecordingslive@gmail.com
Eclipse Ceylon is a modern statically-typed programming language for the Java, Android, and JavaScript virtual machines. The language features a unique and uncommonly elegant static type system, a flexible and very readable syntax, a powerful module architecture, a modular SDK, smooth interoperation with native Java and JavaScript, and with Maven and npm, excellent command-line tooling, and a full-featured IDE.
The Ceylon language is defined by a complete, but very readable specification.
Development of Ceylon ramped up in 2011, with the first major release 1.0 in 2013. Ceylon 1.1 was released in 2014, 1.2 in 2015, and 1.3 in 2016. Ceylon has a very active user community, with most interaction occurring in the various Gitter channels associated with the project.
The Ceylon project has already significantly advanced the state of the art in the Java/C# language family, and in the field of statically-typed languages in general. Innovations seen first in the Ceylon project are already being adopted in the type systems other new programming languages. Ceylon was the first language to demonstrate practical applications of free-form union and intersection types, and alerted the programming language community to the importance of these constructs. Ceylon was also either the first language, or at least one of the first two languages, to feature flow-sensitive typing, a concept which has now been adopted by a number of other languages. Furthermore, Ceylon has the most sophisticated and cleanly-integrated module system of any programming language.