The open-source Trello-like kanban.

The open-source Trello-like kanban.
However, a fact that has been overlooked so far is that watermarks are typically added in a consistent manner to many images. We show that this consistency can be used to invert the watermarking process — that is, estimate the watermark image and its opacity, and recover the original, watermark-free image underneath. This can be all be done automatically, without any user intervention, and by only observing watermarked image collections publicly available online.
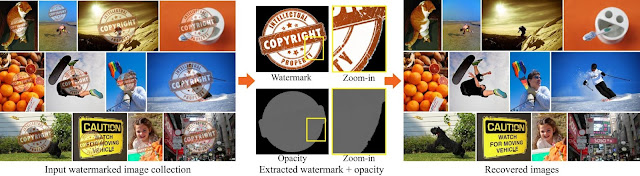 |
| The consistency of a watermark over many images allows to automatically remove it in mass scale. Left: input collection marked by the same watermark, middle: computed watermark and its opacity, right: recovered, watermark-free images. Image sources: COCO dataset, Copyright logo. |
 |
| Watermark extraction with increasing number of images. Left: watermarked input images, Middle: median intensities over the input images (up to the input image shown), Right: the corresponding estimated (matted) watermark. All images licensed from 123RF. |
Here are some more results, showing the estimated watermarks and example watermark-free results generated for several popular stock image services. We show many more results in our supplementary material on the project page.
 |
| Left column: Watermark estimated automatically from watermarked images online (rendered on a gray background). Middle colum: Input watermarked image. Right column: Automatically removed watermark. Image sources: Adobe Stock, Can Stock Photo, 123RF, Fotolia. |
 |
| Flipping between the original watermark and a slightly, randomly warped watermark that can improve its robustness |
Here are some more results on the images from above when using subtle, randomly warped versions of the watermarks. Notice again how visible artifacts remain when trying to remove the watermark in this case, compared to the accurate reconstructions that are achievable with current, consistent watermarks. More results and a detailed analysis can be found in our paper and project page.
 |
| Left column: Watermarked image, using subtle, random warping of the watermark. Right Column: Watermark removal result. |
While we cannot guarantee that there will not be a way to break such randomized watermarking schemes in the future, we believe (and our experiments show) that randomization will make watermarked collection attacks fundamentally more difficult. We hope that these findings will be helpful for the photography and stock image communities.
Acknowledgements
The research described in this post was performed by Tali Dekel, Michael Rubinstein, Ce Liu and Bill Freeman. We thank Aaron Maschinot for narrating our video.
When I started Essential, I did so with six core beliefs. Today, as we celebrate the launch of Essential Phone, I want to illustrate how we baked those principles into every facet of the device—and how all the choices we made along the way were done with you in mind.
At Essential, we are up against industry giants that employ tens of thousands of workers to develop and deploy smartphones around the world. There is a significant advantage to that kind of scale, but we also know that when a company gets to a certain size, the desire to create a customer-first experience sometimes takes a back seat to other considerations, like profits and corporate agendas. Our 100-person team is made up of people who believe in putting the best experience for you above all else. That’s why we’re working around the clock to create products designed to fit your life—never the other way around—with the spirit of American innovation and craftsmanship imbued in every part we design.
Devices are your personal property. We won’t force you to have anything you don’t want.
One of the first things you’ll notice about Essential Phone is that there’s no branding. That’s because we want it to be yours, not ours. And once you turn it on, you’ll find that there are a limited number of preloaded apps and no duplicative services.
We will always play well with others. Closed ecosystems are divisive and outdated.
Every year, like clockwork, manufacturers make “design tweaks” and launch new features and products that work well if you choose to stay in their ecosystem. You buy their phone, TV, speaker, and fridge with the promise of simplicity, but more and more often, this is a way to force loyalty. At Essential, it’s our goal to be the bridge between all these different ecosystems so you can pick and choose the products and services that work best for you, no matter who makes them.
We’re just getting started but we will always advocate for solutions that work well across all your devices. For instance, why limit who you can talk to by sticking to Facetime while there are so many alternatives out there -- from WhatsApp to WeChat -- that work across a wide range of mobile and desktop devices.
Premium materials and true craftsmanship shouldn’t just be for the few.
Our phones are with us all the time, and they are susceptible to wear and tear as they get shoved into pockets, tossed in bags, dropped on desks, and exposed to the elements. You deserve a phone that can resist the trials of everyday use. That’s why we made Essential Phone out of titanium and ceramic. These materials are harder, stronger, and more resistant to dents and scratches than the materials that make up most smartphones. And while costs for such finely crafted materials are usually reserved for high-priced, out-of-reach goods, we've tried to make our phone as affordable as possible.
Devices shouldn’t become outdated every year. They should evolve with you.
Technology moves so quickly that companies rush to release a new phone each year, but most times even that isn’t fast enough. This deluge of devices isn’t good for your wallet or for the planet. Essential Phone will get guaranteed Android OS updates for 2 years and will get monthly security updates for 3 years, so your phone will always be secure and have the latest features.
We also plan to release new wireless accessories (like our snap-on 360º Camera) every few months. That schedule ensures that the latest technology will always be in the palm of your hand without having to replace your phone. These accessories will also work with other products like Essential Home.
Technology should assist you so that you can get on with enjoying life.
Our phones are no longer just digital companions; they are the means by which we record and share our lives. Each and every day, we capture images and videos to share with friends, save for family, or post for the world to see. That’s why we put nearly a year’s worth of development into making a camera that integrates into the body of the phone (without the tell tale camera hump) while still taking great pictures. The dual camera system on Essential Phone shoots with both color and monochrome sensors to create a photograph with richer color and clarity, even in low-light situations. Now you can snap a photo and enjoy the moment––without worrying about picture quality.
With the 360º Camera, we’re also making it a lot easier for you to capture the world around you -- from group selfies to immersive sunsets on the beach. If a picture is worth a thousand words, 360º is worth a million.
Simple is always better.
The most consumer-friendly attribute of all is simplicity. That’s why we made something that works intuitively right out of the box, without complication or clutter. While the technology powering Essential Phone is cutting edge, the exterior and interface hide the complexity underneath; the result is a phone with a minimalist style designed to offer only what you need and nothing more.
At Essential, we believe that phones are at their best when they serve you, not a company. Our phone comes standard with 128GB of storage, because it’s a small cost for us to absorb and unlike most players in the market, we’re not out to charge customers for incremental upgrades. We’ve made a 360º camera because we want to unleash the creativity of our customers. And we’ve built in future-proof technology because we want Essential Phone to evolve with our customers’ needs. This is the phone we always wanted, but we didn’t just make it for ourselves. We designed it around you.
Available today. Compatible with all major networks.
Starting today, Essential Phone is available on Essential.com, Sprint and Best Buy. Essential Phone is compatible with all major carriers.
On Essential.com you can get an unlocked Essential Phone for just $699 and for a limited time you will be able to get Essential Phone and Essential 360 Camera as a bundle for $749.
Liquid biopsy for cancer
Credit: Reprinted with permission from Victor Velculescu et al., Science Translational Medicine 2017
In a bid to detect cancers early and in a noninvasive way, scientists at the Johns Hopkins Kimmel Cancer Center report they have developed a test that spots tiny amounts of cancer-specific DNA in blood and have used it to accurately identify more than half of 138 people with relatively early-stage colorectal, breast, lung and ovarian cancers. The test, the scientists say, is novel in that it can distinguish between DNA shed from tumors and other altered DNA that can be mistaken for cancer biomarkers.
A report on the research, performed on blood and tumor tissue samples from 200 people with all stages of cancer in the U.S., Denmark and the Netherlands, appears in the Aug. 16 issue of Science Translational Medicine.
“This study shows that identifying cancer early using DNA changes in the blood is feasible and that our high accuracy sequencing method is a promising approach to achieve this goal,” says Victor Velculescu, M.D., Ph.D., professor of oncology at the Johns Hopkins Kimmel Cancer Center.
Blood tests for cancer are a growing part of clinical oncology, but they remain in the early stages of development. To find small bits of cancer-derived DNA in the blood of cancer patients, scientists have frequently relied on DNA alterations found in patients’ biopsied tumor samples as guideposts for the genetic mistakes they should be looking for among the masses of DNA circulating in those patients’ blood samples.
To develop a cancer screening test that could be used to screen seemingly healthy people, scientists had to find novel ways to spot DNA alterations that could be lurking in a person’s blood but had not been previously identified.
“The challenge was to develop a blood test that could predict the probable presence of cancer without knowing the genetic mutations present in a person’s tumor,” says Velculescu.
The goal, adds Jillian Phallen, a graduate student at the Johns Hopkins Kimmel Cancer Center who was involved in the research, was to develop a screening test that is highly specific for cancer and accurate enough to detect the cancer when present, while reducing the risk of “false positive” results that often lead to unnecessary overtesting and overtreatments.
The task is notably complicated, says Phallen, by the need to sort between true cancer-derived mutations and genetic alterations that occur in blood cells and as part of normal, inherited variations in DNA.
As blood cells divide, for example, Velculescu says there is a chance these cells will acquire mistakes or mutations. In a small fraction of people, these changes will spur a blood cell to multiply faster than its neighboring cells, potentially leading to pre-leukemic conditions. However, most of the time, the blood-derived mutations are not cancer-initiating.
His team also ruled out so-called “germline” mutations. While germline mutations are indeed alterations in DNA, they occur as a result of normal variations between individuals, and are not usually linked to particular cancers.
To develop the new test, Velculescu, Phallen and their colleagues obtained blood samples from 200 patients with breast, lung, ovarian and colorectal cancer. The scientists’ blood test screened the patients’ blood samples for mutations within 58 genes widely linked to various cancers.
Overall, the scientists were able to detect 86 of 138 (62 percent) stage I and II cancers. More specifically, among 42 people with colorectal cancer, the test correctly predicted cancer in half of the eight patients with stage I disease, eight of nine (89 percent) with stage II disease, nine of 10 (90 percent) with stage III and 14 of 15 (93 percent) with stage IV disease. Of 71 people with lung cancer, the scientists’ test identified cancer among 13 of 29 (45 percent) with stage I disease, 23 of 32 (72 percent) with stage II disease, three of four (75 percent) with stage III disease and five of six (83 percent) with stage IV cancer. For 42 patients with ovarian cancer, 16 of 24 (67 percent) with stage I disease were correctly identified, as well as three of four (75 percent) with stage II disease, six of eight (75 percent) with stage III cancer and five of six (83 percent) with stage IV disease. Among 45 breast cancer patients, the test spotted cancer-derived mutations in two of three (67 percent) patients with stage I disease, 17 of 29 (59 percent) with stage II disease and six of 13 (46 percent) with stage III cancers.
They found none of the cancer-derived mutations among blood samples of 44 healthy individuals.
Despite these initial promising results for early detection, the blood test needs to be validated in studies of much larger numbers of people, say the scientists.
Velculescu and his team also performed independent genomic sequencing on available tumors removed from 100 of the 200 patients with cancer and found that 82 (82 percent) had mutations in their tumors that correlated with the genetic alterations found in the blood.
The Johns Hopkins-developed blood test uses a type of genomic sequencing the researchers call “targeted error correction sequencing.” The sequencing method is based on deep sequencing, which reads each chemical code in DNA 30,000 times. “We’re trying to find the needle in the haystack, so when we do find a DNA alteration, we want to make sure it is what we think it is,” says Velculescu.
Such deep sequencing, covering more than 80,000 base pairs of DNA, has the potential to be very costly, but Velculescu says sequencing technology is becoming cheaper, and his research team may eventually be able to reduce the number of DNA locations they screen while preserving the test’s accuracy.
He says the populations that could benefit most from such a DNA-based blood test include those at high risk for cancer including smokers — for whom standard computed tomography scans for identifying lung cancer often lead to false positives — and women with hereditary mutations for breast and ovarian cancer within BRCA1 and BRCA2 genes.
Scientists who contributed to the research include Mark Sausen, Derek Murphy, Sonya Parpart-Li, David Riley, Monica Nesselbush, Naomi Sengamalay, Andrew Georgiadis, Siân Jones and Sam Angiuoli from Personal Genome Diagnostics; Vilmos Adleff, Alessandro Leal, Carolyn Hruban, James White, Valsamo Anagnostou, Jacob Fiksel, Stephen Cristiano, Eniko Papp, Savannah Speir Qing Kay Li, Robert B Scharpf and Luis A. Diaz Jr. from Johns Hopkins; Thomas Reinert, Mai-Britt Worm Orntoft, Frank Viborg Mortensen, Torben Ørntoft and Claus Lindbjerg Andersen from Aarhus University Hospital, Denmark; Brian D Woodward and Hatim Husain from the University of California, San Diego; Mogens Rørbæk Madsen from the Herning Regional Hospital, Denmark; Joost Huiskens and Cornelis Punt from the University of Amsterdam, The Netherlands; Nicole van Grieken from the VU University Medical Center, The Netherlands; Remond Fijneman and Gerrit Meijer from The Netherlands Cancer Institute and Hans Jørgen Nielsen from Hvidovre Hospital, Denmark.
Funding for the study was provided by the Dr. Miriam and Sheldon G. Adelson Medical Research Foundation; the Stand Up to Cancer-Dutch Cancer Society International Translational Cancer Research Dream Team Grant; the Commonwealth Foundation; the Cigarette Restitution Fund Program; the Burroughs Wellcome Fund; the Maryland-Genetics, Epidemiology and Medicine Training Program; the International Association for the Study of Lung Cancer/Prevent Cancer Foundation; the National Institutes of Health’s National Cancer Institute (grants CA121113, CA006973 and CA180950); the Danish Council for Independent Research; the Danish Council for Strategic Research; the Novo Nordisk Foundation; and the Danish Cancer Society.
Phallen, Sausen, Diaz and Velculescu are inventors on patent applications related to this research. Velculescu, a founder of Personal Genome Diagnostics and a member of its scientific advisory board and board of directors, owns Personal Genome Diagnostics stock, which is subject to certain restrictions under university policy. Velculescu is also on the scientific advisory board for Ignyta. The terms of these arrangements are managed by The Johns Hopkins University in accordance with its conflict of interest policies.
August 15, 2017Timothy Prickett Morgan
One of the reasons that the University of California at Berkeley was been a hotbed of software technology back in the 1970s and 1980s is Michael Stonebraker, who was one of the pioneers in relational database technology and one of the industry’s biggest – and most vocal – shakers and movers and one of its most prolific serial entrepreneurs.
Like other database pioneers, Stonebraker read the early relational data model papers by IBMer Edgar Codd, and in 1973 started work on the Ingres database along IBM’s own System R database, which eventually became DB2, and Oracle’s eponymous database, which entered the field a few years later.
In the decades since the early database days, Stonebreaker helped create the Postgres follow-on to Ingres, which is commonly used today, and was also the CTO at relational database maker Informix, which was eaten by IBM many years ago and just recently mothballed. More importantly, he was one of the researchers on the the C-Store shared-nothing columnar database for data warehousing, which was eventually commercialized as Vertica, and a few years after that Stonebraker and friends started up the H-Store effort, a distributed, in-memory OLTP system that was eventually commercialized as VoltDB. Never one to sit still for long, Stonebraker led an effort to create an array-based database called SciDB that was explicitly tuned for the needs of technical applications, which think in terms of arrays, not tables as in the relational model.
That is an extremely abbreviated and oversimplified history of Stonebraker, who has been an adjunct professor of computer science at MIT since 2001 and who continues to shape the database world.
With so many new compute, storage, and networking technologies entering the field and so many different database and data store technologies available today, we thought it would be a good idea to touch base with Stonebraker to see what effect these might have on future databases.
Timothy Prickett Morgan: When it comes to data and storage, you have kind of seen it all, so I wanted to dive right in and get your sense of how the new compute and storage hardware that is coming to market particularly persistent memory – will affect the nature of databases in the near and far term. Let’s assume that DRAM and flash get cheaper again, unlike today, and that technologies like 3D XPoint come to market in both SSD and DIMM form factors. These make main memories larger and cheaper and flash gets even more data closer to compute than disk drives, no matter how you gang them up, ever could. Do we have to rethink the idea of cramming everything into main memory for performance reasons? The new technologies open up a lot of possibilities.
Michael Stonebraker: The issue is the changing storage hierarchy and what it has to do with databases. Let’s start with online transaction processing. In my opinion, this is a main memory system right now, and there are a bunch of NewSQL startups that are addressing this market. An OLTP database that is 1 TB in size is a really big one, and 1 TB of main memory is no big deal any more. So I think OLTP will entirely go to main memory for anybody who cares about performance. If you don’t care about performance, then run the database on your wristwatch or whatever.
In the data warehousing space, all of the traction is at the high end, where people are operating petascale data warehouses, so up there it is going to be a disk-based market indefinitely. The thing about business analysts and data scientists is that they have an insatiable desire to correlate more and more and more data. Data warehouses are therefore getting bigger at a rate that is faster than disk drives are getting cheaper.
Of course, the counter-example to this are companies like Facebook, and if you are a big enough whale, you might do things differently. Facebook has been investing like mad in SSDs as a level in their hierarchy. This is for active data. Cold data is going to be on disk forever, or until some other really cheap storage technology comes along.
If you have a 1 TB data warehouse, the Vertica Community Edition is free for this size, and the low-end system software are going to be essentially free. And if you care about performance, it is going to be in main memory and if you don’t care about performance, it will be on disk. It will be interesting to see if the data warehouse vendors invest more in multi-level storage hierarchies.
TPM: What happens when these persistent memory technologies, such as 3D XPoint or ReRAM, come into the mix?
Michael Stonebraker: I don’t see these are being that disruptive because all of them are not fast enough to replace main memory and they are not cheap enough to replace disks, and they are not cheap enough to replace flash. Now, it remains to be seen how fast 3D XPoint is going to be and how cheap it is going to be.
I foresee databases running on two-level stores and three-level stores, but I doubt they will be able to manage four-level stores because it is just too complicated to do the software. But there will be storage hierarchies and exactly what pieces will be in the storage hierarchy is yet to be determined. Main memory will be at the top and disk will be at the bottom, we know that, and there will be stuff in between for general purpose systems. For OLTP systems, there are going to be in main memory, end of story, and companies like VoltDB and MemSQL are main memory SQL engines that are blindingly fast.
The interesting thing to me, though, is that business intelligence is going to be replaced by data science as soon as we can train enough data scientists to do it. Business intelligence is SQL aggregates with a friendly face. Data science is predictive analytics, regression, K means clustering, and so on, and it is all essentially linear algebra on arrays. How data science is getting integrated into database systems is the key.
Right now, it is the wild west. The thing that is popular now is Spark, but it is disconnected from data storage completely. So one option is that data science will just be applications that are external to a database system.
Another option is that array-based database systems will become popular, and SciDB, TileDB, and Rasdaman are three such possibilities. It is not clear how widespread array databases will be, but they will certainly be popular in genomics, which is all using array data.
The other option is that the current data warehousing vendors will allow users to adopt data science features. They are already allowing user-defined functions in R. It remains to be seen what is going to happen to Spark – whatever it is today, it is going to be different tomorrow. So in data science, it is the wild west.
TPM: We talked about different technologies and how they might plug into the storage hierarchy. But what about the compute hierarchy? I am thinking about GPU-accelerated databases here specifically, such as MapD, Kinetica, BlazingDB, and Sqream.
Michael Stonebraker: This is one of the things that I am much more interested in. If you want to do a sequential scan or a floating point calculation, GPUs are blindingly fast. The problem with GPUs is if you get all of your data within GPU memory, they are really fast, otherwise you have to load it from somewhere else, and loading is the bottleneck. On small data that you can load into GPU memory, they will definitely find applications at the low end where you want ultra-high performance. The rest of the database space, it remains to be seen how prevalent GPUs are going to be.
The most interesting thing to me is that networking is getting faster at a pace that is higher than CPUs are getting beefier and memory is getting faster. Essentially all multi-node database systems have been designed under the premise that networking is the bottleneck. It turns out that no one can saturate 40 Gb/sec Ethernet. In point of fact, we have moved from 1 Gb/sec to 40 Gb/sec Ethernet in the past five years, and over that same time, clusters on the order of eight nodes have become somewhat faster, but nowhere near a factor of 40X, and memory is nowhere near this, either. So networking is probably not the bottleneck anymore.
TPM: Certainly not with 100 Gb/sec Ethernet getting traction and vendors demonstrating that they can deliver ASICs that can drive 200 Gb/sec or even 400 Gb/sec within the next year or two.
Michael Stonebraker: And that means essentially that everybody gets to rethink their fundamental partitioning architecture, and I think this will be a big deal.
TPM: When does that inflection point hit, and how much bandwidth is enough? And what does it mean when you can do 400 Gb/sec or even 800 Gb/sec, pick your protocol, with 300 nanosecond-ish latency?
Michael Stonebraker: Let’s look at Amazon Web Services as an example. The connections at the top of the rack are usually 10 Gb/sec. Figure it to be 1 GB/sec. There is a crosspoint between the nodes is infinitely fast by comparison. So fast can you get stuff out of storage? If it is coming off disk, every drive is 100 MB/sec, so ten of these ganged in parallel in a RAID configuration will just barely able to keep up. So the question is how fast is storage relative to networking.
My general suspicion is that networking advances will make it at least as beefy as the storage system, at which point database systems will not be network bound and there will be some other bottleneck. If you are doing data science, that bottleneck is going to be the CPU because you are doing a singular value decomposition, and that is a cubic operation relative to the number of cells that you look at. If you are doing conventional business intelligence, you are likely going to be storage bound, and if you doing OLTP you are already in main memory anyway.
With OLTP, if you want to do 1 million transactions per second, it is no big deal. Your favorite cluster will do that on things like VoltDB and MemSQL. Oracle, DB2, MySQL, SQL Server and the others can’t do 1 million transactions per second no matter what. There is just too much overhead in the software.
A bunch of us wrote a paper back in 2009, and we configured an open source database system and measured it in detail, and we assumed that all of the data fit in main memory. So basically everything is in the cache. And we wanted to measure how costly the different database functions were. In round numbers, managing the buffer pool was a big issue. The minute you have a buffer pool, then you have to get the data out of it, convert it to main memory format, operate on it, and then put it back if it is an update and figure out which blocks are dirty and keep an LRU list and all this stuff. So that is about a third of the overhead. Multithreading is about another third of the overhead, and database systems have tons of critical sections and with a bunch of CPUs, they all collide on critical sections and you end up just waiting. Writing the log in an OLTP world is like 15 percent, and you have to assemble the before image and the after image, and write it ahead of the data. So maybe 15 percent, with some other additional overhead, is actual useful work. These commercial relational databases are somewhere between 85 percent and 90 percent overhead.
To get rid of that overhead, you have to rearchitect everything, which is what the in-memory OLTP systems have done.
TPM: By comparison, how efficient are the array databases, and are they the answer for the long haul? Or are they not useful for OLTP systems?
Michael Stonebraker: Absolutely not. I wrote a paper over a decade ago explaining that one size database does not fit all, and my opinion has not changed at all on this.
It turns out that if you want to do OLTP, you want a row-based memory store, and if you want to do data warehousing, you want a disk-based column store. Those are fundamentally different things. And if you want to do data science, you want an array-based data model, not a table-based data model, and you want to optimize for regression and singular value decomposition and that stuff. If you want to do text mining, none of these work well. I think application-specific database systems for maybe a dozen classes of problems is going to be true as far as I can see into the future.
TPM: What about data stores for machine learning? The interesting thing to me is that the GPU accelerated database providers are all talking about how they will eventually support native formats for machine learning frameworks like TensorFlow. In fact, TensorFlow is all that they seem to care about. They want to try to bridge fast OLTP and machine learning on the same database platform.
Michael Stonebraker: So back up a second. Machine learning is all array-based calculation. TensorFlow is an array-oriented platform that allows you to assemble a bunch of primitive array operations into a workflow. If you have a table-based system and an array that is 1 million by 1 million, which is 1 trillion cells, if you store that as a table in any relational system, you are going to store three columns or one row and then another that has a huge blob with all of the values. In an array-based system, you store this puppy as an array, and you optimize storage that it is a big thing in both directions. Anybody who starts with a relational engine has got to cast tables to arrays in order to run TensorFlow or R or anything else that uses arrays, and that cast is expensive.
TPM: How much will that hinder performance? I assume it has to one at least one of the workloads, relational or array.
Michael Stonebraker: Let me give you two different answers. If we have a dense array, meaning that every cell is occupied, then this is going to be an expensive conversion. If we have a very sparse array, then encoding a sparse array as a table is not a bad idea at all. So it really depends on the details and it is completely application dependent, not machine learning framework dependent.
This comes back to what I was saying earlier: it is the wild west out there when it comes to doing data science and storage together.
TPM: So your answer, it would seem, is to use VoltDB on OLTP and SciDB on arrays. Are you done now?
Michael Stonebraker: Data integration seems to be a much bigger Achilles’ heel to corporations, and that is why I am involved with a third startup called Tamr, which was founded in 2013.
One of Tamr’s customers is General Electric, which has 75 different procurement systems, perhaps considerably more – they don’t really know how many they have got. The CFO at GE concluded that if these procurement systems could operate in tandem and demand most favored nation status with vendors, that would be worth about $1 billion in savings a year to the company. But they have to integrate 75 independently constructed supplier databases.
TPM: The presumption with tools like Tamr is that it is much easier to integrate disparate things than to try to pour it all into one giant database and rewrite applications or at least pick only one application.
Michael Stonebraker: Exactly. Enterprises are hugely siloed because they divide into business units so they can get stuff done, and integrating silos for the purposes of cross selling or aggregate buying or social networking, or even getting a single view of customers, is a huge deal.
Today, in partnership with B Lab, we're excited to officially launch support for Delaware public benefit corporations on Clerky.
Delaware PBCs are increasingly common with founders who want to run their startups not only for the benefit of stockholders, but also the broader public. While regular Delaware corporations are required to maximize stockholder value, Delaware PBCs must balance that interest against one or more specified public benefits, as well as anyone it materially affects. For founders, this means more freedom to use their startup as a force for good, which we are proud to support.
This launch marks the first time PBC startups can do the complete set of formation paperwork that investors and acquirers look for, entirely online. And as with regular startups, PBC startups that form on Clerky can go on to use our complete suite of products for fundraising and hiring as they grow. We're excited to bring to PBC startups our unique focus on doing paperwork correctly, in order to help avoid legal issues down the line.
We are also thrilled to be working with B Lab to help our PBC customers go on to become certified B Corporations. In order to be certified by B Lab, B Corporations are held to rigorous standards of social and environmental performance, accountability, and transparency. Certification as a B Corporation is a great tool for communicating values to potential customers, employees, investors, and partners.
Delaware enacted the legislation enabling PBCs four years ago, at the urging of B Lab. Back then, companies electing for PBC status were large and established, like Method, Kickstarter, and Plum Organics. Increasingly though, founders are incorporating their startups as PBCs from the start. Some startups that have already used Clerky to form as PBCs are:
Crowdbotics uses machine learning and on-demand software engineers to automate software development. Crowdbotics was founded by Anand Kulkarni, a serial entrepreneur who led his previous startup through Y Combinator to raise over $20 million in venture capital financing.
FreeWill provides users with a friendly and intuitive way to create high-quality legal wills, completely free. These tools make charitable giving within wills easier than ever, and the company aims to raise $1 trillion globally for nonprofit organizations. FreeWill is funded by Highland Capital Partners and Dorm Room Fund (run by First Round Capital), and was founded by Patrick Schmitt (former Head of Innovation at Change.org, a certified B Corporation), Jennifer Xia, Helen Zou, and Alexander Leishman.
As more founders aim to start PBCs, we're also developing resources to help them along the way. To that end, we've updated our Legal Concepts for Founders handbook to include an article about PBCs and B Corporations, and are happy to announce the addition of Rick Alexander, the Head of Legal Policy at B Lab, to the editorial board. Rick is widely recognized as one of the world's leading experts in Delaware corporate law.
We're excited to make it easier for founders to use their startups as a force for good, and are very much looking forward to seeing the impressive impact they will have.
Forever Labs, a startup in Y Combinator’s latest batch, is preserving adult stem cells with the aim to help you live longer and healthier.
Stem cells have the potential to become any type of cell needed in the body. It’s very helpful to have younger stem cells from your own body on hand should you ever need some type of medical intervention, like a bone marrow transplant as the risk of rejection is greatly reduced when the cells are yours.
Steven Clausnitzer spent the last 15 years studying stem cells. What he found is that not only do we have less of them the older we get, but they also lose their function as we age. So, he and his co-founders Edward Cibor and Mark Katakowski started looking at how to bank them while they were young.
Clausnitzer banked his cells two years ago at the age of 38. So, while he is biologically now age 40, his cells remain the age in which they were harvested — or as he calls it, “stem cell time travel.”
Steven Clausnitzer with his 38-year-old banked stem cells.
Stem cell banking isn’t new. In fact, a lot of parents are now opting to store their baby’s stem cells through cord blood banking. But that’s for newborns. For adults, it’s not so common, and there’s a lot of snake oil out there, Clausnitzer cautions.
“There are places offering stem cell therapy and Botox,” he said.
Forever Labs is backed by a team of Ivy League-trained scientists with decades of experience between them. Jason Camm, chief medical officer for Thiel Capital, is also one of the company’s medical advisors — however, the startup is quick to point out it is not associated with Thiel Capital.
The process involves using a patented device to collect the cells. Forever Labs can then grow and bank your cells for $2,500, plus another $250 for storage per year (or a flat fee of $7,000 for life).
The startup is FDA-approved to bank these cells and is offering the service in seven states. What it does not have FDA approval for is the modification of those cells for rejuvenation therapy.
Clausnitzer refers to what the company is doing as longevity as a service, with the goal being to eventually take your banked cells and modify them to reverse the biological clock.
But that may take a few years. There are hundreds of clinical trials looking at stem cell uses right now. Forever Labs has also proposed its own clinical trial to take your stem cells and give them to your older cells.
“You’ll essentially young-blood effect yourself,” Clausnitzer joked — of course, in this case, you’d be using your own blood made from your own stem cells, not the blood of random teens.
In a packed headquarters ballroom, Cisco Systems Inc.'s then-chief executive officer John Chambers offered a fond farewell to a star executive and friend, Jayshree Ullal. He celebrated her ability to make complicated things simple and wished her success in her next role.
He didn't expect that much success.
Within months of the 2008 party, Ms. Ullal became CEO of Arista Networks Inc., a small startup that has since snagged Cisco customers including Microsoft Corp. and Facebook Inc., and is eating into the share of the networking giant's most important business.
Mr. Chambers couldn't stand to lose sales, especially to someone he considered family and the rivalry has become personal, according to people close to both executives. Defeating Arista has become a priority for Cisco, a company more than 40 times bigger by annual revenue.
In 2013, Ms. Ullal's image appeared in an internal Cisco presentation pasted onto a bull's-eye pierced with arrows. "Arm the field, stop the bleeding and fire back," according to the presentation.
Now, the fighting is unfolding in court, where Cisco, once the world's most valuable company, has accused Arista of stealing its technology. Arista has denied the allegations, saying the Silicon Valley giant sued only because it lacked smart ideas to regain business. Each side has notched incremental wins over the past two and half years with no sign of a resolution.
Continue Reading Below
ADVERTISEMENT
Mr. Robbins said Cisco is now repositioning itself to build products with more automation and security.
"Because we see companies that get disrupted, you can disappear in a hurry in today's world," he said in a recent interview. In June, Cisco promoted a new line of automated and programmable switches. Mr. Robbins told a gathering of 28,000 partners and customers the company was on a journey "to change everything."
His predecessor, Mr. Chambers, has said he made mistakes during his tenure as CEO. Cisco, he said in court testimony, was too slow to react to a fast-changing market. He declined to be interviewed for this article, as did Ms. Ullal.
On Wednesday, Cisco reported that revenue fell for a seventh straight quarter.
This account of how a Cisco insider became one of its fiercest foes is based on interviews with current and former executives of Cisco and Arista, court testimony and records, and unpublished corporate documents and emails reviewed by The Wall Street Journal.
Mr. Chambers, 67, now Cisco's executive chairman, is credited with the company's extraordinary growth phase in the 1990s, largely by buying smaller companies, including Crescendo Communications where Ms. Ullal worked.
Ms. Ullal, who rose to become one of Cisco's most valuable executives over her 15 years at the company, ran the switching division, which allows companies to shuttle data at high speeds. By the time she left, switching was Cisco's biggest business, with more than $10 billion in annual revenue, a big reason why Cisco recovered from the dot-com bust.
Mr. Chambers and Ms. Ullal made a strong team, partly because they're both extremely competitive, according to former executives who worked with them. Their priorities and styles sometimes clashed. Mr. Chambers, a soft-spoken West Virginian, was a managerial guru and a salesman whose gracious manner skewed more senatorial than Silicon Valley. Ms. Ullal, raised in India, was an outspoken engineering and marketing whiz who disliked rigid rules.
Ms. Ullal grew frustrated as Cisco began moving beyond its core switching and routing business into areas such as high-end videoconferencing and consumer electronics, former executives who worked with her said. About a year before she left, Mr. Chambers had created dozens of internal councils and boards, which was at odds with her command-and-control approach.
Cisco's engineering team knew Ms. Ullal's departure would be bad news, say former co-workers.
Arista was a better fit. The Santa Clara, Calif., startup, founded in 2004 by former Cisco executives, was small and entrepreneurial. When Ms. Ullal joined as CEO in 2008, it had shipped its first product, an unusually fast networking switch for Wall Street trading networks. The market was worth only about $50 million but it gave Arista a foothold.
It was also a segment of the market Cisco hadn't prioritized. Ms. Ullal urged her employees to avoid attracting Cisco's attention at first, said a person familiar with her thinking. As the giant in the field, Cisco could have "destroyed us with a stray thought," this person said.
In public, Arista said it planned to focus on narrow markets such as high-frequency trading. Privately it was working on building a flexible and easy-to-program switch that could be sold to large internet companies that were Cisco customers.
Mr. Chambers didn't see his protégé as a threat until two years later, when it was too late. In 2010, Arista was on the verge of winning about $2 million of business from Microsoft, one of Cisco's biggest customers, according to a March 2011 briefing document for Mr. Chambers and his own court testimony. The amount was small, but to Cisco it was a "canary in the coal mine," the briefing document said.
The Arista product was faster at moving data than Cisco's hardware, and cost less, according to internal Cisco documents. Cisco feared that Arista could end up with as much as $100 million in future annual sales to Microsoft. Cisco was already concerned about losing business after missing its annual revenue estimate for the first time in eight years.
Microsoft remains a big Cisco customer. But for the past six years, Microsoft has been Arista's largest customer, accounting for 16% of its total revenue last year, or $181 million.
Mr. Chambers felt betrayed by Ms. Ullal, a former Cisco executive said. "To John, it was a relationship question -- 'Why would you do such a thing?' "
He told executives to keep Arista from winning any new business from Cisco customers, according to former executives. Mr. Chambers also sent a 1,500-word memo to employees in April 2011 saying Cisco was too slow to make decisions and lacked discipline.
That month, the sales team created a "Tiger Team" to track Arista's every move, thwart its marketing efforts and forestall its initial public offering plan, according to internal presentations and emails. As many as 70 salespeople and engineers participated in "war room" calls where no detail was too small.
In 2012, Mr. Chambers asked four top Cisco engineers who had created some of its past hit products to secretly start a new company to compete directly with Arista's offerings. Cisco invested $135 million in the company, Insieme Networks, and later bought it.
Arista's technology was faster, more flexible and less expensive than Cisco's, according to customers and internal sales documents. Facebook engineers described Cisco as "behind the curve and on target to become irrelevant" in the data center, according to a Cisco engineer's email to executives in March 2013. Facebook, now a customer of both Arista and Cisco, declined to comment.
A Cisco employee presented the slide deck with Ms. Ullal's photo on a bull's-eye a few months later, calling for "zero loss tolerance against Arista."
Other customers started complaining. An email from a customer support engineer in August 2013 to dozens of senior managers, including Mr. Robbins, the future CEO, said Morgan Stanley had lost confidence in one of the switching products "after more than 12 months of ongoing software defects, instability and a lack of needed features." The bank halted plans to use 400 Cisco switches and said it might turn to Arista.
Morgan Stanley declined to comment.
Cisco interviewed dozens of executives to understand the problem. The brutal conclusion in a September 2013 report: Cisco had good ideas and talented employees but a risk-averse culture, indecisive leaders and too big a focus on incremental products.
In November, Ms. Ullal ran into Mr. Chambers at a cocktail party in San Francisco, according to a person familiar with the encounter. The two hugged, and then Mr. Chambers joked to the former CEO of a big Cisco customer that his one-time treasured executive had become his toughest competitor.
"Don't buy from her," he said.
Ms. Ullal was irritated by the exchange and told her staff that Cisco's gloves were coming off, according to the person.
Inside Cisco, a "Beat Arista" document in January 2014 warned that the impending IPO would provide the upstart the cash to strike Cisco's most profitable product lines. "Time is now to target their top 100 accounts -- slow momentum, impact revenue & market share and help drive an unsatisfactory IPO," one slide said.
About six months later, Arista had an initial public offering on the New York Stock Exchange. Its shares jumped 35% on the first day of trading, making Ms. Ullal's 7% stake worth about $260 million, and climbed another 40% by November.
In December 2014, Mr. Chambers approved two lawsuits against Arista with the blessing of his operating committee. He struggled with the decision.
"It is hard to accuse people who are your friends -- and they are still my friends -- of stealing from you," Mr. Chambers said in court testimony. "But this was so blatant."
The lawsuits filed in U.S. District Court for the Northern District of California accused Arista of copying technology, infringing on 14 patents and taking copyrighted material.
Arista says the suits have no merit. "I'm disappointed at Cisco's tactics -- this is not the Cisco I knew," Ms. Ullal told reporters at the time. She later wrote on Arista's blog that older companies are "often in denial of new technologies and market disruptions until it's too late."
Arista prevailed over Cisco in a trial late last year over copyright claims and one patent claim in one of the lawsuits.
The other lawsuit is on hold pending related investigations being conducted by the International Trade Commission at Cisco's request. The ITC found that Arista infringed on three of the patents in dispute, leading it to redesign some products this year. But the company is appealing a ban by the agency on the import and sales of products in the U.S. related to two other patents.
Cisco, with a market value of $160 billion, remains the leader in the networking business, but the much smaller Arista is chipping away at the fastest-growing part of the switching business. Arista's share of the overall data-center switching market has grown from nothing in 2010 to over 9% in 2016, while Cisco's share has fallen from about 80% to about 58%, according to research firm International Data Corp.
Mr. Chambers and Ms. Ullal did not see each other again until last month at a wedding, according to a person familiar with the meeting. They embraced, chatted for several minutes -- though not about work -- and appeared in a photo together. Then they went their separate ways.
Write to Rachael King at rachael.king@wsj.com
(END) Dow Jones Newswires
August 17, 2017 10:47 ET (14:47 GMT)
Every so often, officials at Rockwell Collins Inc. pitch a one-day job offer to residents near its Winston-Salem, N.C. design center: Earn $100 for sitting in an airplane seat for eight hours.
Show up for the gig, and there’s nary a drinks cart or flight attendant in sight. The rows of seats are arrayed in a testing area at the company’s design and engineering complex. Even without engine hum or overhead bins, “it’s kind of like they’re on the plane,” says Alex Pozzi, vice president of research and development at the company’s campus here.
Over the years, seat researchers at B/E Aerospace, which Rockwell acquired in April for $8 billion, have gleaned a few insights about life in the air. Most people are just fine for two hours. As the third hour approaches, stiffness increases and comfort declines. At four hours, however, a sort of derièrre detente is achieved, and the levels of discomfort recede. After all, when you’re stuck inside a sealed, speeding tube at 35,000 feet, resistance is truly futile.
There are many reasons to despise flying, from delays, to fees, to overzealous TSA staff. But shrinking seats and the pain, claustrophobia, and rage they can trigger are arguably the biggest justification for airline loathing. The modern seat, with its power to pack more customers onto any given plane, is at the very heart of the industry’s 21st century economics. Slimmer seats and less legroom between rows—known as pitch—has enabled “cabin densification” across domestic and international fleets. More seats, quite simply, means more money and lower operating costs.
Aboard a Boeing Co. 737 Max.
Photographer: Luke MacGregor/Bloomberg
There are limits, however, even beyond physical constraints. Regulators mandate a certain ratio of attendants to seats, and carriers want to keep labor costs down. Still, the trend has clearly been moving toward scrunching you. While 34 to 35 inches of pitch was once common for economy class, the new normal is 30 to 31 inches, with several major carriers deploying 28 inches on short and medium flights. Soon, however, that squeeze-play may come to an end.
The seat factory in Winston-Salem is at the center of testing the physical limits of human tolerance. One part of its live studies involves giving only some participants Wi-Fi access, an exercise that typically reveals a direct relationship between distraction and seat-staying power. “You can easily see the difference in ratings for the exact same seat if you have entertainment,” says Pozzi.
Yes, a good sci-fi flick can ease the harshest heinie-holder, and it’s no coincidence that most seatbacks on long-haul flights have a screen. But this is small compensation for the sacrifices required of air travelers who, having run the gantlet of parking, ticketing, security, and terminal, visibly slump when they find that their assigned seat has gotten even smaller.
Let there be no doubt about the shrinking quarters in economy—space is tight. Reallocation of aircraft real estate has allowed airlines to install new, medium-tier cabins between first class and economy. The front of the plane where the big money sits remains largely unchanged when it comes to space. The shrinkage, unsurprisingly, has been in back.
Rockwell Collins’ research facility.
Photographer: Justin Bachman/Bloomberg
In recent years, the “slimline” seat has become the de facto standard by which airlines outfit economy cabins. This design is inches thinner than predecessors and markedly lighter, allowing carriers an additional cost-saver by reducing weight and thus fuel burn. Today, an economy seat that tips the scales above 9 kilograms (20 pounds) is, by an airline’s measure, too heavy to fly.
Carriers are “segmenting the economy cabin into two or three buckets,” said John Heimlich, chief economist at Airlines for America, the industry’s U.S. trade group. These efforts help “to minimize the market-share loss to ultra low-cost carriers [ULCC] or to other modes of transport.”
When Boeing Co. introduced the twin-aisle 777 in the mid-1990s, a nine-seat breadth was standard. Now, the aircraft—flown by carriers worldwide—often seats 10 across in economy, making life even more miserable for passengers. Boeing’s 787 Dreamliner has become notorious for its economy-class pinch with nine across-seating—and on some 787s, these seats are only 17 inches wide. (Airbus’s new A350 is also typically configured with nine seats across, but its cabin is about four feet wider, so it could fit 10.)
This cabin squeeze and seat-shrinking has helped increase earnings in an industry that’s gotten used to fiscal stability. But it occasionally results in some bad public relations. Two United passengers got into a kerfuffle in the summer of 2014 when a man stuck a “knee defender” device on the seat in front of him to prevent reclining, causing the seat’s occupant to grow irate. The crew diverted the Denver-bound flight to Chicago to eject both combatants.
In early May, news leaked that the world’s largest airline, American Airlines Group Inc., planned to add three rows of seats separated by only 29 inches of pitch on its new fleet of Boeing 737 Max, which arrives later this year. That arrangement would allow for an additional row of extra-legroom seats, which American calls main cabin extra, between first class and steerage. The move would have broken the current 30-inch pitch limit among the six-biggest U.S. airlines, putting it closer to no-frills carriers such as Spirit Airlines Inc., which offers a mere 28 inches.
Doug Parker, CEO of American Airlines Group Inc.
Photographer: Christopher Goodney/Bloomberg
Less than six weeks later, American reversed course—not because of passenger outrage, but because of flight attendants. American Chief Executive Officer Doug Parker said on July 28 that employees pushed back at having to be the front-line defender of a new level of cabin-class stratification. Parker said employees were telling him, “‘You’re going to put us in a position where we need to explain to these customers that indeed this is necessary so that we can have one more row of main cabin extra?’”
Parker explained the underlying calculation: “While we could convince ourselves that that might be able to produce somewhat higher revenues on the aircraft, what it was doing to our perception with our team wasn’t worth it.”
No airline has yet edged below 28-inches of legroom, although at least one major seat manufacturer, Zodiac Aerospace, has shown a prototype designed with just 27 inches. Italy-based Aviointeriors SpA gained attention in 2010 with a “standing” perch-style concept called SkyRider. That “seat” hasn’t passed regulatory muster, nor won any orders, although periodically a ULCC will speak favorably about such seating possibilities. Last month, South American carrier VivaColombia was the latest to raise the prospect of standing flights.
This rush to squeeze ever-more money out of passenger posture may soon slow. Carriers such as Delta Air Lines Inc. are looking to exploit this issue by retaining some creature comforts its competitors have ditched. It’s kept nine-across seating on its 777s, “one of the only in the world” to do so, says Joe Kiely, Delta’s managing director of product and customer experience. Delta has also led an industry trend to fly larger aircraft on more routes, reducing the role of regional jets. JetBlue Airways Corp. took pitch into consideration for its Airbus A320 fleet, which will see legroom shrink by more than an inch, to 32 inches, starting this fall. Despite the contraction, JetBlue wanted still to be able to advertise “the most legroom in coach.”
Meanwhile in Europe, low-fare king Ryanair Holdings Plc will pitch its 197 seats on the new 737 Max at 31 inches—one more than American, which plans for 30-inches of legroom in a slightly smaller version of the new 737 it begins flying in November. The battle over comfort, or more accurately less discomfort, is on.
Illustration: Scott Gelber
Smaller seats and legroom have come in for scrutiny by a powerful federal appeals court. A three-judge panel recently ruled that regulators must consider setting minimum space standards, agreeing with aspects of a consumer group lawsuit that warned safety is being compromised. In emergencies, the Federal Aviation Administration requires fully loaded planes be emptied in 90 seconds or less.
“This is the Case of the Incredible Shrinking Airline Seat,” U.S. Circuit Judge Patricia Ann Millett wrote in the July 28 ruling. Her court, the U.S. Court of Appeals for the District of Columbia, handles most cases involving federal regulators and rules, a fact that may give airlines pause as they decide whether to shrink seating further.
Flyers Rights, a nonprofit advocacy group, contends that seat space has shrunk at the same time passengers have gotten larger. Those developments could lead to a catastrophic outcome during evacuation, the group warns. It also points to a less dramatic peril exacerbated by tight quarters and longer flights: deep-vein thrombosis, or blood clots in the leg, which can kill.
“Our concern is that it will take a Titanic-type disaster to make a change if we don’t get regulation,” says Paul Hudson, the group’s president. The court decision may “give impetus to getting seats back to where they’re going to be both safe and potentially not unhealthy.”
Bills pending in both houses of Congress would mandate rules on minimum airline seat space. In the past, such efforts have failed; the U.S. Department of Transportation has likewise been reluctant to address the topic. Airlines frequently say that such regulatory moves targeting key revenue centers—baggage fees, seat space, ticket-change fees—could lead to higher fares. Hudson, who previously worked as an aviation attorney, dismissed the industry response as a knee-jerk reaction.
“I’ve never heard that argument not raised,” he says.
Airlines offer a few other rejoinders to the chorus of complaints. One is airfare: Faced with a choice between discomfort and higher fares, an overwhelming majority of travelers choose the former. Another is pricing-power. While industry consolidation did allow carriers to cut costs and command higher prices on some routes, average U.S. airfares have been one of the few consistent goods to hold firm against inflation over the past 20 years. Slimming the seats and tightening the space, the airlines argue, is a rational response.
The industry also points out that new seats, while thinner, are far superior to older models. Carriers’ zeal for lighter, durable, ergonomic seating has yielded engineering advances. Body shape and size, along with better materials and design, have become integral to airline seat manufacturing, and all four of the industry’s major players—Recaro GmbH, Thompson Aero Seating, Zodiac Aerospace, and Rockwell Collins—are fiercely competitive in such areas as materials and ergonomics.
The L-shaped seat of yore has morphed into something more akin to a pivoting cradle-chair, seat designers say. And the once-flat seat pan, the chair’s frame and source of much anguish, is now generally curved. The passenger’s lower back is also finding fresh support in the newer designs.
American noted repeatedly that its seat selection for the 737 Max is a newer Rockwell Collins design, called Meridian, that’s more comfortable than prior economy-class seats. That’s the same seat Southwest Airlines Co. chose for its 200 new Max aircraft and its current 737-800s. United Continental Holdings Inc. is also purchasing the Meridian seat for its Max 9.
During a tour of its Winston-Salem design complex in May, Rockwell Collins officials invited reporters to sit in a variety of newer seats, including the Meridian and Aspire, a model aimed at two-aisle aircraft on long-haul routes. Tom Plant, vice president and general manager of aircraft seating at the company’s Interior Systems unit, asked the “passengers” to guess how much legroom each seat had. The pitch was 29 inches, but all the guesses were too high, mostly 30 to 32 inches.
Designers had managed to create a clever illusion of space. And that illusion means money.
Developers, businesses, and individuals increasingly are using initial coin offerings, also called ICOs or token sales, to raise capital. These activities may provide fair and lawful investment opportunities. However, new technologies and financial products, such as those associated with ICOs, can be used improperly to entice investors with the promise of high returns in a new investment space. The SEC’s Office of Investor Education and Advocacy is issuing this Investor Bulletin to make investors aware of potential risks of participating in ICOs.
Background – Initial Coin Offerings
Virtual coins or tokens are created and disseminated using distributed ledger or blockchain technology. Recently promoters have been selling virtual coins or tokens in ICOs. Purchasers may use fiat currency (e.g., U.S. dollars) or virtual currencies to buy these virtual coins or tokens. Promoters may tell purchasers that the capital raised from the sales will be used to fund development of a digital platform, software, or other projects and that the virtual tokens or coins may be used to access the platform, use the software, or otherwise participate in the project. Some promoters and initial sellers may lead buyers of the virtual coins or tokens to expect a return on their investment or to participate in a share of the returns provided by the project. After they are issued, the virtual coins or tokens may be resold to others in a secondary market on virtual currency exchanges or other platforms.
Depending on the facts and circumstances of each individual ICO, the virtual coins or tokens that are offered or sold may be securities. If they are securities, the offer and sale of these virtual coins or tokens in an ICO are subject to the federal securities laws.
| On July 25, 2017, the SEC issued a Report of Investigation under Section 21(a) of the Securities Exchange Act of 1934 describing an SEC investigation of The DAO, a virtual organization, and its use of distributed ledger or blockchain technology to facilitate the offer and sale of DAO Tokens to raise capital. The Commission applied existing U.S. federal securities laws to this new paradigm, determining that DAO Tokens were securities. The Commission stressed that those who offer and sell securities in the U.S. are required to comply with federal securities laws, regardless of whether those securities are purchased with virtual currencies or distributed with blockchain technology. |
To facilitate understanding of this new and complex area, here are some basic concepts that you should understand before investing in virtual coins or tokens:
What is a blockchain?
A blockchain is an electronic distributed ledger or list of entries – much like a stock ledger – that is maintained by various participants in a network of computers. Blockchains use cryptography to process and verify transactions on the ledger, providing comfort to users and potential users of the blockchain that entries are secure. Some examples of blockchain are the Bitcoin and Ethereum blockchains, which are used to create and track transactions in bitcoin and ether, respectively.
What is a virtual currency or virtual token or coin?
A virtual currency is a digital representation of value that can be digitally traded and functions as a medium of exchange, unit of account, or store of value. Virtual tokens or coins may represent other rights as well. Accordingly, in certain cases, the tokens or coins will be securities and may not be lawfully sold without registration with the SEC or pursuant to an exemption from registration.
What is a virtual currency exchange?
A virtual currency exchange is a person or entity that exchanges virtual currency for fiat currency, funds, or other forms of virtual currency. Virtual currency exchanges typically charge fees for these services. Secondary market trading of virtual tokens or coins may also occur on an exchange. These exchanges may not be registered securities exchanges or alternative trading systems regulated under the federal securities laws. Accordingly, in purchasing and selling virtual coins and tokens, you may not have the same protections that would apply in the case of stocks listed on an exchange.
Who issues virtual tokens or coins?
Virtual tokens or coins may be issued by a virtual organization or other capital raising entity. A virtual organization is an organization embodied in computer code and executed on a distributed ledger or blockchain. The code, often called a “smart contract,” serves to automate certain functions of the organization, which may include the issuance of certain virtual coins or tokens. The DAO, which was a decentralized autonomous organization, is an example of a virtual organization.
Some Key Points to Consider When Determining Whether to Participate in an ICO
If you are thinking about participating in an ICO, here are some things you should consider.
Investing in an ICO may limit your recovery in the event of fraud or theft. While you may have rights under the federal securities laws, your ability to recover may be significantly limited.
If fraud or theft results in you or the organization that issued the virtual tokens or coins losing virtual tokens, virtual currency, or fiat currency, you may have limited recovery options. Third-party wallet services, payment processors, and virtual currency exchanges that play important roles in the use of virtual currencies may be located overseas or be operating unlawfully.
Law enforcement officials may face particular challenges when investigating ICOs and, as a result, investor remedies may be limited. These challenges include:
Be careful if you spot any of these potential warning signs of investment fraud.
***
Before making any investment, carefully read any materials you are given and verify the truth of every statement you are told about the investment. For more information about how to research an investment, read our publication Ask Questions. Investigate the individuals and firms offering the investment, and check out their backgrounds on Investor.gov and by contacting your state securities regulator. Many fraudulent investment schemes involve unlicensed individuals or unregistered firms.
Additional Resources
SEC Investor Alert: Bitcoin and Other Virtual Currency-Related Investments
SEC Investor Alert: Ponzi Schemes Using Virtual Currencies
SEC Investor Alert: Social Media and Investing – Avoiding Fraud

This document is published in the style of a "Swift evolution manifesto", outlining a long-term view of how to tackle a very large problem. It explores one possible approach to adding a first-class concurrency model to Swift, in an effort to catalyze positive discussion that leads us to a best-possible design. As such, it isn't an approved or finalized design prescriptive of what Swift will end up adopting. It is the job of public debate on the open source swift-evolution mailing list to discuss and iterate towards that ultimate answer, and we may end up with a completely different approach.
We focus on task-based concurrency abstractions commonly encountered in client and server applications, particularly those that are highly event driven (e.g. responding to UI events or requests from clients). This does not attempt to be a comprehensive survey of all possible options, nor does it attempt to solve all possible problems in the space of concurrency. Instead, it outlines a single coherent design thread that can be built over the span of years to incrementally drive Swift to further greatness.
So far, Swift was carefully designed to avoid most concurrency topics, because we specifically did not want to cut off any future directions. Instead, Swift programmers use OS abstractions (like GCD, pthreads, etc) to start and manage tasks. The design of GCD and Swift's trailing closure syntax fit well together, particularly after the major update to the GCD APIs in Swift 3.
While Swift has generally stayed away from concurrency topics, it has made some
concessions to practicality. For example, ARC reference count operations are atomic,
allowing references to classes to be shared between threads. Weak references are also
guaranteed to be thread atomic, Copy-On-Write (
Concurrency is a broad and sweeping concept that can cover a wide range of topics. To help scope this down a bit, here are some non-goals for this proposal:
So what are the actual goals? Well, because it is already possible to express concurrent apps with GCD, our goal is to make the experience far better than it is today by appealing to the core values of Swift: we should aim to reduce the programmer time necessary to get from idea to a working and efficient implementation. In particular, we aim to improve the concurrency story in Swift along these lines:
That said, it is absolutely essential that any new model coexists with existing concurrency constructs and existing APIs. We cannot build a conceptually beautiful new world without also building a pathway to get existing apps into it.
It is clear that the multicore world isn't the future: it is the present! As such, it is essential for Swift to make it straight-forward for programmers to take advantage of hardware that is already prevalent in the world. At the same time, it is already possible to write concurrent programs: since adding a concurrency model will make Swift more complicated, we need a strong justification for that complexity. To show opportunity for improvement, let's explore some of the pain that Swift developers face with the current approaches. Here we focus on GCD since almost all Swift programmers use it.
Modern Cocoa development involves a lot of asynchronous programming using closures and completion handlers, but these APIs are hard to use. This gets particularly problematic when many asynchronous operations are used, error handling is required, or control flow between asynchronous calls is non-trivial.
There are many problems in this space, including the "pyramid of doom" that frequently occurs:
funcprocessImageData1(completionBlock: (result: Image) ->Void) {loadWebResource("dataprofile.txt") { dataResource inloadWebResource("imagedata.dat") { imageResource indecodeImage(dataResource, imageResource) { imageTmp indewarpAndCleanupImage(imageTmp) { imageResult incompletionBlock(imageResult)
}
}
}
}
}Error handling is particularly ugly, because Swift's natural error handling mechanism cannot be used. You end up with code like this:
funcprocessImageData2(completionBlock: (result: Image?, error: Error?) ->Void) {loadWebResource("dataprofile.txt") { dataResource, error inguardlet dataResource = dataResource else {completionBlock(nil, error)return
}loadWebResource("imagedata.dat") { imageResource, error inguardlet imageResource = imageResource else {completionBlock(nil, error)return
}decodeImage(dataResource, imageResource) { imageTmp, error inguardlet imageTmp = imageTmp else {completionBlock(nil, error)return
}dewarpAndCleanupImage(imageTmp) { imageResult inguardlet imageResult = imageResult else {completionBlock(nil, error)return
}return imageResult
}
}
}
}
}Partially because asynchronous APIs are onerous to use, there are many APIs defined in a synchronous form that can block (e.g. UIImage(named: ...)), and many of these APIs have no asynchronous alternative. Having a natural and canonical way to define and use these APIs will allow them to become pervasive. This is particularly important for new initiatives like the Swift on Server group.
Beyond being syntactically inconvenient, completion handlers are problematic because their syntax suggests that they will be called on the current queue, but that is not always the case. For example, one of the top recommendations on Stack Overflow is to implement your own custom async operations with code like this (Objective-C syntax):
- (void)asynchronousTaskWithCompletion:(void (^)(void))completion;
{dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{// Some long running task you want on another threaddispatch_async(dispatch_get_main_queue(), ^{if (completion) {completion();
}
});
});
}Note how it is hard coded to call the completion handler on the main queue. This is an insidious problem that can lead to surprising results and bugs like race conditions. For example, since a lot of iOS code already runs on the main queue, you may have been using an API built like this with no problem. However, a simple refactor to move that code to a background queue will introduce a really nasty problem where the code will queue hop implicitly - introducing subtle undefined behavior!
There are several straight-forward ways to improve this situation like better documentation or better APIs in GCD. However, the fundamental problem here is that there is no apparent linkage between queues and the code that runs on them. This makes it difficult to design for, difficult to reason about and maintain existing code, and makes it more challenging to build tools to debug, profile, and reason about what is going wrong, etc.
Lets define "Shared mutable state" first: "state" is simply data used by the program. "Shared" means the data is shared across multiple tasks (threads, queues, or whatever other concurrency abstraction is used). State shared by itself is not harmful: so long as no-one is modifying the data, it is no problem having multiple readers of that data.
The concern is when the shared data is mutable, and therefore someone is changing it while others tasks are looking at it. This opens an enormous can of worms that the software world has been grappling with for many decades now. Given that there are multiple things looking at and changing the data, some sort of synchronization is required or else race conditions, semantic inconsistencies and other problems are raised.
The natural first step to start with are mutexes or locks. Without attempting to survey the
full body of work
around this, I'll claim that locking and mutexes introduce a number of problems: you need to
ensure that data is consistently protected by the right locks (or else bugs and memory safety
issues result), determine the granularity of locking, avoid deadlocks, and deal with many other
problems. There have been a number of attempts to improve this situation, notablysynchronized methods in Java (which were later imported into Objective-C). This sort of
thing improves the syntactic side of the equation but doesn't fix the underlying problem.
Once an app is working, you then run into performance problems, because mutexes are generally very inefficient - particularly when there are many cores and threads. Given decades of experience with this model, there are a number of attempts to solve certain corners of the problem, includingreaders-writer locks,double-checked locking, low-levelatomic operations and advanced techniques likeread/copy/update. Each of these improves on mutexes in some respect, but the incredible complexity, unsafety, and fragility of the resulting model is itself a sign of a problem.
With all that said, shared mutable state is incredibly important when you're working at the level of systems programming: e.g. if you're implementing the GCD API or a kernel in Swift, you absolutely must be able to have full ability to do this. This is why it is ultimately important for Swift to eventually define an opt-in memory consistency model for Swift code. While it is important to one day do this, doing so would be an orthogonal effort and thus is not the focus of this proposal.
I encourage anyone interested in this space to read Is Parallel Programming Hard, And, If So, What Can You Do About It?. It is a great survey developed by Paul E. McKenney who has been driving forward efforts to get the Linux kernel to scale to massively multicore machines (hundreds of cores). Besides being an impressive summary of hardware characteristics and software synchronization approaches, it also shows the massive complexity creep that happens when you start to care a lot about multicore scalability with pervasively shared mutable state.
On the hardware side of things, shared mutable state is problematic for a number of reasons. In brief, the present is pervasively multicore - but despite offering the ability to view these machines as shared memory devices, they are actually incrediblyNUMA / non-uniform.
To oversimplify a bit, consider what happens when two different cores are trying to read and write the same memory data: the cache lines that hold that data are arbitrated by (e.g.) theMESI protocol, which only allows a cache line to be mutable in a single processor's L1 cache. Because of this, performance quickly falls off of a cliff: the cache line starts ping-pong'ing between the cores, and mutations to the cache line have to be pushed out to other cores that are simply reading it.
This has a number of other knock on effects: processors have quickly moved to havingrelaxed consistency models which make shared memory programming even more complicated. Atomic accesses (and other concurrency-related primitives like compare/exchange) are now 20-100x slower than non-atomic accesses. These costs and problems continue to scale with core count, yet it isn't hard to find a large machine with dozens or hundreds of cores today.
If you look at the recent breakthroughs in hardware performance, they have come from hardware that has dropped the goal of shared memory. Notably,GPUs have been extremely successful at scaling to extremely high core counts, notably because they expose a programming model that encourages the use of fast local memory instead of shared global memory. Supercomputers frequently use MPI for explicitly managed memory transfers, etc. If you explore this from first principles, the speed of light and wire delay become an inherently limiting factor for very large shared memory systems.
The point of all of this is that it is highly desirable for Swift to move in a direction where Swift programs run great on large-scale multi-core machines. With any luck, this could unblock the next step in hardware evolution.
Ok, it is somewhat tautological, but any model built on shared mutable state doesn't work in the absence of shared memory.
Because of this, the software industry has a complexity explosion of systems for interprocess communication: things likesockets, signals, pipes, MIG, XPC, and many others. Operating systems then invariably introduce variants of the same abstractions that exist in a single process, including locks (file locking), shared mutable state (memory mapped files), etc. Beyond IPC, distributed computation and cloud APIs then reimplement the same abstractions in yet-another way, because shared memory is impractical in that setting.
The key observation here is simply that this is a really unfortunate state of
affairs. A better world would be for app developers to have a way to
build their data abstractions, concurrency abstractions, and reason about their
application in the large, even if it is running across multiple machines in a cloud ecosystem.
If you want your single process app to start running in an IPC or distributed setting, you
should only have to teach your types how to serialize/
After all, app developers don't design their API with JSON as the input and output format for each function, so why should cloud developers?
This manifesto outlines several major steps to address these problems, which can be added incrementally to Swift over the span of years. The first step is quite concrete, but subsequent steps get increasingly vague: this is an early manifesto and there is more design work to be done. Note that the goal here is not to come up with inherently novel ideas, it is to pull together the best ideas from wherever we can get them, and synthesize those ideas into something self-consistent that fits with the rest of Swift.
The overarching observation here is that there are four major abstractions in computation that are interesting to build a model on top of:
Swift already has a fully-developed model for the first point, incrementally refined and improved over the course of years, so we won't talk about it here. It is important to observe that the vast majority of low-level computation benefits from imperative control flow,mutation with value semantics, and yes, reference semantics with classes. These concepts are the important low-level primitives that computation is built on, and reflect the basic abstraction of CPUs.
Asynchrony is the next fundamental abstraction that must be tackled in Swift, because it is essential to programming in the real world where we are talking to other machines, to slow devices (spinning disks are still a thing!), and looking to achieve concurrency between multiple independent operations. Fortunately, Swift is not the first language to face these challenges: the industry as a whole has fought this dragon and settled onasync/await as the right abstraction. We propose adopting this proven concept outright (with a Swift spin on the syntax). Adopting async/await will dramatically improve existing Swift code, dovetailing with existing and future approaches to concurrency.
The next step is to define a programmer abstraction to define and model the independent tasks in a program, as well as the data that is owned by those tasks. We propose the introduction of a first-class actor model, which provides a way to define and reason about independent tasks who communicate between themselves with asynchronous message sending. The actor model has a deep history of strong academic work and was adopted and proven inErlang and Akka, which successfully power a large number of highly scalable and reliable systems. With the actor model as a baseline, we believe we can achieve data isolation by ensuring that messages sent to actors do not lead to shared mutable state.
Speaking of reliable systems, introducing an actor model is a good opportunity and excuse to introduce a mechanism for handling and partially recovering from runtime failures (like failed force-unwrap operations, out-of-bounds array accesses, etc). We explore several options that are possible to implement and make a recommendation that we think will be a good for for UI and server applications.
The final step is to tackle whole system problems by enabling actors to run in different processes or even on different machines, while still communicating asynchronously through message sends. This can extrapolate out to a number of interesting long term possibilities, which we briefly explore.
NOTE: This section is concrete enough to have a fully baked proposal from a complexity perspective, it is plausible to get into Swift 5, we just need to debate and refine it as a community.
No matter what global concurrency model is settled on for Swift, it is hard to ignore the glaring problems we have dealing with asynchronous APIs. Asynchronicity is unavoidable when dealing with independently executing systems: e.g. anything involving I/O (disks, networks, etc), a server, or even other processes on the same system. It is typically "not ok" to block the current thread of execution just because something is taking a while to load. Asynchronicity also comes up when dealing with multiple independent operations that can be performed in parallel on a multicore machine.
The current solution to this in Swift is to use "completion handlers" with closures. These arewell understood but also have a large number of well understood problems: they often stack up a pyramid of doom, make error handling awkward, and make control flow extremely difficult.
There is a well-known solution to this problem, calledasync/await. It is a popular programming style that was first introduced in C# and was later adopted in many other languages, including Python, Javascript, Scala, Hack, Dart, Kotlin ... etc. Given its widespread acceptance by the industry and combined with few other good solutions to these problems, I suggest that we do the obvious thing and support this in Swift.
The general design of async/await drops right into Swift, but a few tweaks makes it fit into
the rest of Swift more consistently. We suggest adding async as a function modifier akin
to the existing throws function modifier. Functions (and function types) can be declared asasync, and this indicates that the function is acoroutine. Coroutines are functions that may return
normally with a value, or may suspend themselves and internally return a continuation.
This approach allows the completion handler to be absorbed into the language. For example, before you might write:
funcloadWebResource(_path: String, completionBlock: (result: Resource) ->Void) { ... }funcdecodeImage(_r1: Resource, _r2: Resource, completionBlock: (result: Image) ->Void)funcdewarpAndCleanupImage(_i : Image, completionBlock: (result: Image) ->Void)funcprocessImageData1(completionBlock: (result: Image) ->Void) {loadWebResource("dataprofile.txt") { dataResource inloadWebResource("imagedata.dat") { imageResource indecodeImage(dataResource, imageResource) { imageTmp indewarpAndCleanupImage(imageTmp) { imageResult incompletionBlock(imageResult)
}
}
}
}
}whereas now you can write:
funcloadWebResource(_path: String) async -> ResourcefuncdecodeImage(_r1: Resource, _r2: Resource) async -> ImagefuncdewarpAndCleanupImage(_i : Image) async -> ImagefuncprocessImageData1() async -> Image {let dataResource = await loadWebResource("dataprofile.txt")let imageResource = await loadWebResource("imagedata.dat")let imageTmp = await decodeImage(dataResource, imageResource)let imageResult = await dewarpAndCleanupImage(imageTmp)return imageResult
}await is a keyword that works like the existing try keyword: it is a noop at runtime, but
indicate to a maintainer of the code that non-local control flow can happen at that point.
Besides the addition of the await keyword, the async/await model allows you to write
obvious and clean imperative code, and the compiler handles the generation of state
machines and callback handlers for you.
Overall, adding this will dramatically improve the experience of working with completion handlers, and provides a natural model to compose futures and other APIs on top of. More details are contained in the full proposal.
The introduction of async/await into the language is a great opportunity to introduce more asynchronous APIs to Cocoa and perhaps even entire new framework extensions (like a revised asynchronous file I/O API). The Server APIs Project is also actively working to define new Swift APIs, many of which are intrinsically asynchronous.
Given the ability define and use asynchronous APIs with expressive "imperative style" control flow, we now look to give developers a way to carve up their application into multiple concurrent tasks. We propose adopting the model ofactors: Actors naturally represent real-world concepts like "a document", "a device", "a network request", and are particularly well suited to event driven architectures like UI applications, servers, device drivers, etc.
So what is an actor? As a Swift programmer, it is easiest to think of an actor as a
combination of a DispatchQueue, the data that queue protects, and messages that can be
run on that queue. Because they are embodied by an (internal) queue abstraction, you
communicate with Actors asynchronously, and actors guarantee that the data they protect is
only touched by the code running on that queue. This provides an "island of serialization
in a sea of concurrency".
It is straight-forward to adapt legacy software to an actor interface, and it is possible to progressively adopt actors in a system that is already built on top of GCD or other concurrency primitives.
Actors have a deep theoretical basis and have been explored by academia since the 1970s - the wikipedia page on actors and thec2 wiki page are good places to start reading if you'd like to dive into some of the theoretical fundamentals that back the model. A challenge of this work (for Swift's purposes) is that academia assumes a pure actor model ("everything is an actor"), and assumes a model of communication so limited that it may not be acceptable for Swift. I'll provide a broad stroke summary of the advantages of this pure model, then talk about how to address the problems.
As Wikipedia says:
In response to a message that it receives, an actor can: make local decisions, create more actors, send more messages, and determine how to respond to the next message received. Actors may modify private state, but can only affect each other through messages (avoiding the need for any locks).
Actors are cheap to construct and you communicate with an actor using efficient unidirectional asynchronous message sends ("posting a message in a mailbox"). Because these messages are unidirectional, there is no waiting, and thus deadlocks are impossible. In the academic model, all data sent in these messages is deep copied, which means that there is no data sharing possible between actors. Because actors cannot touch each other's state (and have no access to global state), there is no need for any synchronization constructs, eliminating all of the problems with shared mutable state.
To make this work pragmatically in the context of Swift, we need to solve several problems:
There are several possible ways to manifest the idea of actors into Swift. For the purposes of this manifesto, I'll describe them as a new type in Swift because it is the least confusing way to explain the ideas and this isn't a formal proposal. I'll note right here up front that this is only one possible design: the right approach may be for actors to be a special kind of class, a model described below.
With this design approach, you'd define an actor with the actor keyword. An actor can
have any number of data members declared as instance members, can have normal methods,
and extensions work with them as you'd expect. Actors are reference types and have an
identity which can be passed around as a value. Actors can conform to protocols and
otherwise dovetail with existing Swift features as you'd expect.
We need a simple running example, so lets imagine we're building the data model for an app that has a tableview with a list of strings. The app has UI to add and manipulate the list. It might look something like this:
actor TableModel {let mainActor : TheMainActorvar theList : [String] = [] {didSet {
mainActor.updateTableView(theList)
}
}init(mainActor: TheMainActor) { self.mainActor= mainActor }// this checks to see if all the entries in the list are capitalized:// if so, it capitalize the string before returning it to encourage// capitalization consistency in the list.funcprettify(_x : String) ->String {// ... details omitted, it just pokes theList directly ... }
actor funcadd(entry: String) {
theList.append(prettify(entry))
}
}This illustrates the key points of an actor model:
mainActor and theList is the data in the actor.self actor.actor methods are the messages that actors accept. Marking a method as actor
imposes certain restrictions upon it, described below.let dataModel = TableModel(mainActor).actor methods are implicitly async, so they can
freely call async methods and await their results.It has been found in other actor systems that an actor abstraction like this encourage the "right" abstractions in applications, and map well to the conceptual way that programmers think about their data. For example, given this data model it is easy to create multiple instances of this actor, one for each document in an MDI application.
This is a straight-forward implementation of the actor model in Swift and is enough to achieve the basic advantages of the model. However, it is important to note that there are a number of limitations being imposed here that are not obvious, including:
actor method cannot return a value, throw an error, or have an inout parameter.actor methods may only be accessed by methods defined lexically
on the actor or in an extension to it (whether they are marked actor or otherwise).The first limitation (that actor methods cannot return values) is easy to address as we've
already discussed. Say the app developer needs a quick way to get the number of entries in
the list, a way that is visible to other actors they have running around. We should simply
allow them to define:
extensionTableModel {
actor funcgetNumberOfEntries() ->Int {return theList.count
}
}This allows them to await the result from other actors:
print(await dataModel.getNumberOfEntries())This dovetails perfectly with the rest of the async/await model. It is unrelated to this
manifesto, but we'll observe that it would be more idiomatic way to
define that specific example is as an actor var. Swift currently doesn't allow property
accessors to throw or be async. When this limitation is relaxed, it would be
straight-forward to allow actor vars to provide the more natural API.
Note that this extension makes the model far more usable in cases like this, but erodes the
"deadlock free" guarantee of the actor model. Continuing the analogy that each actor is
backed by a GCD queue, an await on an actor method becomes analogous to callingdispatch_sync on that queue. Because only one message is processed by the actor at a
time, if an actor waits on itself directly (possibly through a chain of references) a deadlock will
occur - in exactly the same way as it happens with dispatch_sync:
extensionTableModel {
actor funcf() {...let x = await self.getNumberOfEntries() // trivial deadlock....
}
}The trivial case like this can also be trivially diagnosed by the compiler. The complex case would ideally be diagnosed at runtime with a trap, depending on the runtime implementation model.
The solution for this is to encourage people to use Void-returning actor methods that "fire
and forget". There are several reasons to believe that these will be the most common: the
async/await model described syntactically encourages people not to use it (by requiring
marking, etc), many of the common applications of actors are event-driven applications
(which are inherently one way), the eventual design of UI and other system frameworks
can encourage the right patterns from app developers, and of course documentation can
describe best practices.
The example above shows mainActor being passed in, following theoretically pure actor
hygiene. However, the main thread in UIKit and AppKit are already global state, so we might
as well admit that and make code everywhere nicer. As such, it makes sense for AppKit and
UIKit to define and vend a public global constant actor reference, e.g. something like this:
public actor MainActor { // Bikeshed: could be named "actor UI {}"privateinit() {} // You can't make another one of these.// Helpful public stuff could be put here to make app developers happy. :-)}publiclet mainActor =MainActor()This would allow app developers to put their extensions on MainActor, making their code
more explicit and clear about what needs to be run on the main thread. If we got really
crazy, someday Swift should allow data members to be defined in extensions on classes,
and App developers would then be able to put their state that must be manipulated on the
main thread directly on the MainActor.
The way that actors eliminate shared mutable state and explicit synchronization is through deep copying all of the data that is passed to an actor in a message send, and preventing direct access to actor state without going through these message sends. This all composes nicely, but can quickly introduce inefficiencies in practice because of all the data copying that happens.
Swift is well positioned to deal with this for a number of reasons: its strong focus on value
semantics means that copying of these values is a core operation understood and known by
Swift programmers everywhere. Second, the use of Copy-On-Write (theList array back to the UI thread so it can
update itself. In Swift, this is a super efficient O(1) operation that does some ARC stuff: it
doesn't actually copy or touch the elements of the array.
The third piece, which is still in development, will come as a result of the work on addingownership semantics to Swift. When this is available, advanced programmers will have the ability to move complex values between actors, which is typically also a super-efficient O(1) operation.
This leaves us with three open issues: 1) how do we know whether something has proper value semantics, 2) what do we do about reference types (classes and closures), and 3) what do we do about global state. All three of these options should be explored in detail, because there are many different possible answers to these. I will explore a simple model below in order to provide an existence proof for a design, but I do not claim that it is the best model we can find.
This is something that many many Swift programmers have wanted to be able to know the answer to, for example when defining generic algorithms that are only correct in the face of proper value semantics. There have been numerous proposals for how to determine this, and I will not attempt to summarize them, instead I'll outline a simple proposal just to provide an existence proof for an answer:
protocol ValueSemantical { func valueSemanticCopy() -> Self }ValueSemantical. For example,
Array conforms when its elements conform - note that an array of reference types doesn't
always provide the semantics we need.ValueSemantical, just like we do for Codable.ValueSemantical protocol and
rejects any arguments and return values that do not conform.The reiterate, the name ValueSemantical really isn't the right name for this: things likeUnsafePointer, for example, shouldn't conform. Enumerating the possible options and
evaluating the naming tradeoffs between them is a project for another day though.
It is important to realize that this design does not guarantee memory safety. Someone
could implement the protocol in the wrong way (thus lying about satisfying the requirements)
and shared mutable state could occur. In the author's opinion, this is the right tradeoff:
solving this would require introducing onerous type system mechanics (e.g. something like
the capabilities system in the Pony language). Swift already
provides a model where memory safe APIs (e.g. Array) are implemented in terms of memory
unsafety (e.g. UnsafePointer), the approach described here is directly analogous.
Alternate Design: Another approach is to eliminate the requirement from the protocol: just use the protocol as a marker, which is applied to types that already have the right behavior. When it is necessary to customize the copy operation (e.g. for a reference type), the solution would be to box values of that type in a struct that provides the right value semantics. This would make it more awkward to conform, but this design eliminates having "another kind of copy" operation, and encourages more types to provide value semantics.
The solution to this is simple: classes need to conform to ValueSemantical (and
implement the requirement) properly, or else they cannot be passed as a parameter or result
of an actor method. In the author's opinion, giving classes proper value semantics will not
be that big of a deal in practice for a number of reasons:
Beyond that, when you start working with an actor system, it is an inherent part of the application design that you don't allocate and pass around big object graphs: you allocate them in the actor you intend to manipulate them with. This is something that has been found true in Scala/Akka for example.
It is not safe to pass an arbitrary value with function type across an actor message,
because it could close over arbitrary actor-local data. If that data is closed over
by-reference, then the recipient actor would have arbitrary access to data in the sending
actor's state. That said, there is at least one important exception that we should carve
out: it is safe to pass a closure literal when it is known that it only closes over
data by copy: using the same ValueSemantical copy semantics described above.
This happens to be an extremely useful carveout, because it permits some interesting "callback" abstractions to be naturally expressed without tight coupling between actors. Here is a silly example:
otherActor.doSomething { self.incrementCount($0) }In this case OtherActor doesn't have to know about incrementCount which is defined
on the self actor, reducing coupling between the actors.
Since we're friends, I'll be straight with you: there are no great answers here. Swift and C already support global mutable state, so the best we can do is discourage the use of it. We cannot automatically detect a problem because actors need to be able to transitively use random code that isn't defined on the actor. For example:
funccalculate(thing : Int) ->Int { ... }
actor Foo {
actor funcexampleOperation() {let x =calculate(thing: 42)...
}
}There is no practical way to know whether 'calculate' is thread-safe or not. The only solution is to scatter tons of annotations everywhere, including in headers for C code. I think that would be a non-starter.
In practice, this isn't as bad as it sounds, because the most common operations
that people use (e.g. print) are already internally synchronizing, largely because people are
already writing multithreaded code. While it would be nice to magically solve this long
standing problem with legacy systems, I think it is better to just completely ignore it and tell
developers not to define or use global variables (global lets are safe).
All hope is not lost though: Perhaps we could consider deprecating global vars from Swift
to further nudge people away from them. Also, any accesses to unsafe global global mutable
state from an actor context can and should be warned about. Taking some steps like this
should eliminate the most obvious bugs.
Thus far, we've dodged the question about how the actor runtime should be implemented.
This is intentional because I'm not a runtime expert! From my perspective, GCD is a
reasonable baseline to start from: it provides the right semantics, it has good low-level
performance, and it has advanced features like Quality of Service support which are just as
useful for actors as they are for anything else. It would be easy to provide access to these
advanced features by giving every actor a gimmeYourQueue() method.
The one problem I anticipate with GCD is that it doesn't scale well enough: server developers in particular will want to instantiate hundreds of thousands of actors in their application, at least one for every incoming network connection. The programming model is substantially harmed when you have to be afraid of creating too many actors: you have to start aggregating logically distinct stuff together to reduce # queues, which leads to complexity and loses some of the advantages of data isolation.
There are also questions about how actors are shut down. The conceptually ideal model is that actors are implicitly released when their reference count drops to zero and when the last enqueued message is completed. This will probably require some amount of runtime integration.
Another potential concern is that GCD queues have unbounded depth: if you have a producer/consumer situation, a fast producer can outpace the consumer and continuously grow the queue of work. It would be interesting to investigate options for providing bounded queues that throttle or block the producer in this sort of situation.
The design above is simple and self consistent, but may not be the right model, because actors have a ton of conceptual overlap with classes. Observe:
weak/unowned
references to them.However, actors are not simple classes: here are some differences:
actor methods on them. These methods have additional
requirements put on them in order to provide the safety in the programming model we seek.One important pivot-point in discussion is whether subclassing of actors is desirable. If so, modeling them as a special kind of class would be a very nice simplifying assumption, because a lot of complexity comes in with that (including all the initialization rules etc). If not, then defining them as a new kind of type is defensible, because they'd be very simple and being a separate type would more easily explain the additional rules imposed on them.
Syntactically, if we decided to make them classes, it makes sense for this to be a modifier on the class definition itself, since actorhood fundamentally alters the contract of the class, e.g.:
actor classDataModel : SomeBaseActor { ... }NOTE: This section should be expanded to show some of the more common design patterns so people have more of an intuitive feel of how things work. Suggestions are welcome!
Swift has many aspects of its design that encourages programmer errors (aka software bugs :-) to be caught at compile time: a static type system, optionals, encouraging covered switch cases, etc. However, some errors may only be caught at runtime, including things like out-of-bound array accesses, integer overflows, and force-unwraps of nil.
As described in the Swift Error Handling Rationale, there is a tradeoff that must be struck: it doesn't make sense to force programmers to write logic to handle every conceivable edge case: even discounting the boilerplate that would generate, that logic is likely to itself be poorly tested and therefore full of bugs. We must carefully weigh and tradeoff complex issues in order to get a balanced design. These tradeoffs are what led to Swift's approach that does force programmers to think about and write code to handle all potentially-nil pointer references, but not to have to think about integer overflow on every arithmetic operation. The new challenge is that integer overflow still must be detected and handled somehow, and the programmer hasn't written any recovery code.
Swift handles these with a fail fast philosophy: it is preferable to detect and report a programmer error as quickly as possible, rather than "blunder on" with the hope that the error won't matter. Combined with rigorous testing (and perhaps static analysis technology in the future), the goal is to make bugs shallow, and provide good stack traces and other information when they occur. This encourages them to be found and fixed quickly early in the development cycle. However, when the app ships, this philosophy is only great if all the bugs were actually found, because an undetected problem causes the app to suddenly terminate itself.
Sudden termination of a process is hugely problematic if it jeopardizes user data, or - in the
case of a server app - if there are hundreds of clients currently connected to the server at the
time. While it is impossible in general to do perfect resolution of an arbitrary programmer
error, there is prior art for how handle common problems gracefully. In the case of Cocoa,
for example, if an NSException propagates up to the top of the runloop, it is useful to try to
save any modified documents to a side location to avoid losing data. This isn't guaranteed
to work in every case, but when it does, the
user is very happy that they haven't lost their progress. Similarly, if a server crashes
handling one of its client's requests, a reasonable recovery scheme is to finish handling the
other established connections in the current process, but push off new connection requests
to a restarted instance of the server process.
The introduction of actors is a great opportunity to improve this situation, because actors provide an interesting granularity level between the "whole process" and "an individual class" where programmers think about the invariants they are maintaining. Indeed, there is a bunch of prior art in making reliable actor systems, and again, Erlang is one of the leaders. We'll start by sketching the basic model, then talk about a potential design approach.
The basic concept here is that an actor that fails has violated its own local invariants, but that the invariants in other actors still hold: this because we've defined away shared mutable state. This gives us the option of killing the individual actor that broke its invariants instead of taking down the entire process. Given the definition of the basic actor model with unidirectional async message sends, it is possible to have the runtime just drop any new messages sent to the actor, and the rest of the system can continue without even knowing that the actor crashed.
While this is a simple approach, there are two problems:
awaited, but if the
actor has crashed those awaits will never complete. actor Merge10Notifications {var counter :Int=0let otherActor =...// set up by the init. actor funcnotify() {
counter +=1if counter >=10 {
otherActor.notify()
}
}
}If one of the 10 actors feeding notifications into this one crashes, then the program will wait forever to get that 10th notification. Because of this, someone designing a "reliable" actor needs to think about more issues, and work slightly harder to achieve that reliability.
Given that a reliable actor requires more thought than building a simple actor, it is reasonable to look for opt-in models that provide progressive disclosure of complexity. The first thing you need is a way to opt in. As with actor syntax in general, there are two broad options: first-class actor syntax or a class declaration modifier, i.e., one of:
reliable actor Notifier { ... }
reliable actor classNotifier { ... }When one opts an actor into caring about reliability, a new requirement is imposed on allactor methods that return a value: they are now required to be declared throws as well.
This forces clients of the actor to be prepared for a failure when/if the actor crashes.
Implicitly dropping messages is still a problem. I'm not familiar with the approaches taken in other systems, but I imagine two potential solutions:
init() could
then use this API to register its failure handler the system.actor methods to throw, with the semantics that they only throw if the actor
has crashed. This forces clients of the reliable actor to handle a potential crash, and do so
on the granularity of all messages sent to that actor.Between the two, the first approach is more appealing to me, because it allows factoring out the common failure logic in one place, rather than having every caller have to write (hard to test) logic to handler the failure in a fine grained way. For example, a document actor could register a failure handler that attempts to save its data in a side location if it ever crashes.
That said, both approaches are feasible and should be explored in more detail.
Alternate design: An alternate approach is make all actors be "reliable" actors, by making
the additional constraints a simple part of the actor model. This reduces the number of
choices a Swift programmer gets-to/has-to make. If the async/await model ends up making
async imply throwing, then this is probably the right direction, because the await on a value
returning method would be implicitly a try marker as well.
Besides the high level semantic model that the programmer faces, there are also questions about what the runtime model is. When an actor crashes:
There are multiple possible designs, but I advocate for a design where no cleanup is performed: if an actor crashes, the runtime propagates that error to other actors and runs any recovery handlers (as described in the previous section) but that it should not attempt further clean up the resources owned by the actor.
There are a number of reasons for this, but the most important is that the failed actor just
violated its own consistency with whatever invalid operation it attempted to perform. At this
point, it may have started a transaction but not finished it, or may be in any other sort of
inconsistent or undefined state. Given the high likelihood for internal inconsistency, it is
probable that the high-level invariants of various classes aren't intact, which means it isn't
safe to run the deinit-ializers for the classes.
Beyond the semantic problems we face, there are also practical complexity and efficiency issues at stake: it takes code and metadata to be able to unwind the actor's stack and release active resources. This code and metadata takes space in the application, and it also takes time at compile time to generate it. As such, the choice to provide a model that attempted to recover from these sorts of failures would mean burning significant code size and compile time for something that isn't supposed to happen.
A final (and admittedly weak) reason for this approach is that a "too clean" cleanup runs the risk that programmers will start treating fail-fast conditions as a soft error that doesn't need to be handled with super-urgency. We really do want these bugs to be found and fixed in order to achieve the high reliability software systems that we seek.
As described in the motivation section, a single application process runs in the context of a larger system: one that often involves multiple processes (e.g. an app and an XPC daemon) communicating through IPC, clients and servers communicating through networks, and servers communicating with each other in "the cloud" (using JSON, protobufs, GRPC, etc...). The points of similarity across all of these are that they mostly consist of independent tasks that communicate with each other by sending structured data using asynchronous message sends, and that they cannot practically share mutable state. This is starting to sound familiar.
That said, there are differences as well, and attempting to papering over them (as was done in the older Objective-C "Distributed Objects" system) leads to serious problems:
Codable.In order to align with the goals of Swift, we cannot sweep these issues under the rug: we want to make the development process fast, but "getting something up and running" isn't the goal: it really needs to work - even in the failure cases.
The actor model is a well-known solution in this space, and has been deployed successfully in less-mainstream languages likeErlang. Bringing the ideas to Swift just requires that we make sure it fits cleanly into the existing design, taking advantage of the characteristics of Swift and ensuring that it stays true to the principles that guide it.
One of these principles is the concept of progressive disclosure of complexity: a Swift developer shouldn't have to worry about IPC or distributed compute if they don't care about it. This means that actors should opt-in through a new declaration modifier, aligning with the ultimate design of the actor model itself, i.e., one of:
distributed actor MyDistributedCache { ... }
distributed actor classMyDistributedCache { ... }Because it has done this, the actor is now subject to two additional requirements.
reliable actor, since adistributed actor is a further refinement of a reliable actor. This means that all
value returning actor methods must throw, for example.actor methods must conform to Codable.In addition, the author of the actor should consider whether the actor methods make
sense in a distributed setting, given the increased latency that may be faced. Using coarse
grain APIs could be a significant performance win.
With this done, the developer can write their actor like normal: no change of language or tools, no change of APIs, no massive new conceptual shifts. This is true regardless of whether you're talking to a cloud service endpoint over JSON or an optimized API using protobufs and/or GRPC. There are very few cracks that appear in the model, and the ones that do have pretty obvious reasons: code that mutates global state won't have that visible across the entire application architecture, files created in the file system will work in an IPC context, but not a distributed one, etc.
The app developer can now put their actor in a package, share it between their app and their
service. The major change in code is at the allocation site of MyDistributedCache, which
will now need to use an API to create the actor in another process instead of calling its
initializer directly. If you want to start using a standard cloud API, you should be able to
import a package that vends that API as an actor interface, allowing you to completely
eliminate your code that slings around JSON blobs.
The majority of the hard part of getting this to work is on the framework side, for example, it would be interesting to start building things like:
ValueSemantical. Heavy weight types can then opt into using it where it
makes sense.In any case, there is a bunch of work to do here, and it will take multiple years to prototype, build, iterate, and perfect it. It will be a beautiful day when we get here though.
Looking even farther down the road, there are even more opportunities to eliminate accidental complexity by removing arbitrary differences in our language, tools, and APIs. You can find these by looking for places with asynchronous communications patterns, message sending and event-driven models, and places where shared mutable state doesn't work well.
For example, GPU compute and DSP accelerators share all of these characteristics: the CPU talks to the GPU through asynchronous commands (e.g. sent over DMA requests and interrupts). It could make sense to use a subset of Swift code (with new APIs for GPU specific operations like texture fetches) for GPU compute tasks.
Another place to look is event-driven applications like interrupt handlers in embedded
systems, or asynchronous signals in Unix. If a Swift script wants to sign up for notifications
about SIGWINCH, for example, it should be easy to do this by registering your actor and
implementing the right method.
Going further, a model like this begs for re-evaluation of some long-held debates in the software community, such as the divide between microkernels and monolithic kernels. Microkernels are generally considered to be academically better (e.g. due to memory isolation of different pieces, independent development of drivers from the kernel core, etc), but monolithic kernels tend to be more pragmatic (e.g. more efficient). The proposed model allows some really interesting hybrid approaches, and allows subsystems to be moved "in process" of the main kernel when efficiency is needed, or pushed "out of process" when they are untrusted or when reliability is paramount, all without rewriting tons of code to achieve it. Swift's focus on stable APIs and API resilience also encourages and enables a split between the core kernel and driver development.
In any case, there is a lot of opportunity to make the software world better, but it is also a long path to carefully design and build each piece in a deliberate and intentional way. Let's take one step at a time, ensuring that each is as good as we can make it.
When designing a concurrency system for Swift, we should look at the designs of other languages to learn from them and ensure we have the best possible system. There are thousands of different programming languages, but most have very small communities, which makes it hard to draw practical lessons out from those communities. Here we look at a few different systems, focusing on how their concurrency design works, ignoring syntactic and other unrelated aspects of their design.
Perhaps the most relevant active research language is the Pony programming language. It is actor-based and uses them along with other techniques to provide a type-safe, memory-safe, deadlock-free, and datarace-free programming model. The biggest semantic difference between the Pony design and the Swift design is that Pony invests a lot of design complexity into providing capability-based security, which impose a high learning curve. In contrast, the model proposed here builds on Swift's mature system of value semantics. If transferring object graphs between actors (in a guaranteed memory safe way) becomes important in the future, we can investigate expanding the Swift Ownership Model to cover more of these use-cases.
Akka is a framework written in the Scala programming language, whose mission is to "Build powerful reactive, concurrent, and distributed applications more easily". The key to this is their well developedAkka actor system, which is the principle abstraction that developers use to realize these goals (and it, in turn, was heavily influenced by Erlang. One of the great things about Akka is that it is mature and widely used by a lot of different organizations and people. This means we can learn from its design, from the design patterns the community has explored, and from experience reports describing how well it works in practice.
The Akka design shares a lot of similarities to the design proposed here, because it is an implementation of the same actor model. It is built on futures, asynchronous message sends, each actor is a unit of concurrency, there are well-known patterns for when and how actor should communicate, and Akka supports easy distributed computation (which they call "location transparency").
One difference between Akka and the model described here is that Akka is a library feature,
not a language feature. This means that it can't provide additional type system and safety
features that the model we describe does. For example, it is possible to accidentally share
mutable state
which leads to bugs and erosion of the model. Their message loops are also manually written
loops with pattern matching, instead of being automatically dispatched to actor methods -
this leads to somewhat more boilerplate. Akka actor messages are untyped (marshalled
through an Any), which can lead to surprising bugs and difficulty reasoning about what the
API of an actor is. Beyond that though, the two models are very comparable - and, no, this
is not an accident.
Keeping these differences in mind, we can learn a lot about how well the model works in practice, by reading the numerous blog posts and other documents available online, including, for example:
Further, it is likely that some members of the Swift community have encountered this model, it would be great if they share their experiences, both positive and negative.
The Go programming language supports a first-class approach to
writing concurrent programs based on goroutines and (bidirectional) channels. This model
has been very popular in the Go community and directly reflects many of the core values of
the Go language, including simplicity and preference for programming with low levels of
abstraction. I have no evidence that this is the case, but I speculate that this model was
influenced by the domains that Go thrives in: the Go model of channels and communicating
independent goroutines almost directly reflects how servers communicate over network
connections (including core operations like select).
The proposed Swift design is higher abstraction than the Go model, but directly reflects one of the most common patterns seen in Go: a goroutine whose body is an infinite loop over a channel, decoding messages to the channel and acting on them. Perhaps the most simple example is this Go code (adapted from this blog post):
funcprinter(cchanstring) {for {msg:=<- c
fmt.Println(msg)
}
}... is basically analogous to this proposed Swift code:
actor Printer {
actor funcprint(message: String) {print(message)
}
}The Swift design is more declarative than the Go code, but doesn't show many advantages or disadvantages in something this small. However, with more realistic examples, the advantages of the higher-level declarative approach show benefit. For example, it is common for goroutines to listen on multiple channels, one for each message they respond to. This example (borrowed from this blog post) is fairly typical:
// Worker represents the worker that executes the jobtypeWorkerstruct {WorkerPoolchanchanJobJobChannelchanJob
quit chanbool
}funcNewWorker(workerPoolchanchanJob) Worker {return Worker{
JobChannel: make(chan Job),
quit: make(chanbool)}
}func(wWorker) Start() {gofunc() {for {select {casejob:=<-w.JobChannel:// ...case<-w.quit:// ...
}
}
}()
}// Stop signals the worker to stop listening for work requests.func(wWorker) Stop() {gofunc() {
w.quit<-true
}()
}This sort of thing is much more naturally expressed in our proposal model:
actor Worker {
actor funcdo(job: Job) {// ... }
actor funcstop() {// ... }
}That said, there are advantages and other tradeoffs to the Go model as well. Go builds onCSP, which allows more adhoc structures of communication. For example, because goroutines can listen to multiple channels it is occasionally easier to set up some (advanced) communication patterns. Synchronous messages to a channel can only be completely sent if there is something listening and waiting for them, which can lead to performance advantages (and some disadvantages). Go doesn't attempt to provide any sort of memory safety or data isolation, so goroutines have the usual assortment of mutexes and other APIs to use, and are subject to standard bugs like deadlocks and data races. Races can even break memory safety.
I think that the most important thing the Swift community can learn from Go's concurrency model is the huge benefit that comes from a highly scalable runtime model. It is common to have hundreds of thousands or even a million goroutines running around in a server. The ability to stop worrying about "running out of threads" is huge, and is one of the key decisions that contributed to the rise of Go in the cloud.
The other lesson is that (while it is important to have a "best default" solution to reach for in the world of concurrency) we shouldn't overly restrict the patterns that developers are allowed to express. This is a key reason why the async/await design is independent of futures or any other abstraction. A channel library in Swift will be as efficient as the one in Go, and if shared mutable state and channels are the best solution to some specific problem, then we should embrace that fact, not hide from it. That said, I expect these cases to be very rare :-)
Rust's approach to concurrency builds on the strengths of its ownership system to allow library-based concurrency patterns to be built on top. Rust supports message passing (through channels), but also support locks and other typical abstractions for shared mutable state. Rust's approaches are well suited for systems programmers, which are the primary target audience of Rust.
On the positive side, the Rust design provides a lot of flexibility, a wide range of different concurrency primitives to choose from, and familiar abstractions for C++ programmers.
On the downside, their ownership model has a higher learning curve than the design described here, their abstractions are typically very low level (great for systems programmers, but not as helpful for higher levels), and they don't provide much guidance for programmers about which abstractions to choose, how to structure an application, etc. Rust also doesn't provide an obvious model to scale into distributed applications.
That said, improving synchronization for Swift systems programmers will be a goal once the basics of the Swift Ownership Model come together. When that happens, it makes sense to take another look at the Rust abstractions to see which would make sense to bring over to Swift.
The FBI has been briefing private sector companies on intelligence claiming to show that the Moscow-based cybersecurity company Kaspersky Lab is an unacceptable threat to national security, current and former senior U.S. officials familiar with the matter tell CyberScoop.
The briefings are one part of an escalating conflict between the U.S. government and Kaspersky amid long-running suspicions among U.S. intelligence officials that Russian spy agencies use the company as an intelligence-gathering tool of global proportions.
The FBI’s goal is to have U.S. firms push Kaspersky out of their systems as soon as possible or refrain from using them in new products or other efforts, the current and former officials say.
The FBI’s counterintelligence section has been giving briefings since beginning of the year on a priority basis, prioritizing companies in the energy sector and those that use industrial control (ICS) and Supervisory Control and Data Acquisition (SCADA) systems.
In light of successive cyberattacks against the electric grid in Ukraine, the FBI has focused on this sector due to the critical infrastructure designation assigned to it by the Department of Homeland Security.
Additionally, the FBI has briefed large U.S. tech companies that have working partnerships or business arrangements with Kaspersky on products — from routers to virtual machines — that touch a wide range of American businesses and civilians.
In the briefings, FBI officials give companies a high-level overview of the threat assessment, including what the U.S. intelligence community says are the Kaspersky’s deep and active relationships with Russian intelligence. FBI officials point to multiple specific accusations of wrongdoing by Kaspersky, such as a well-known instance of allegedly faking malware.
In a statement to CyberScoop, a Kaspersky spokesperson blamed those particular accusations on “disgruntled, former company employees, whose accusations are meritless” while FBI officials say, in private and away from public scrutiny, they know the incident took place and was blessed by the company’s leadership.
The FBI’s briefings have seen mixed results. Companies that utilize ISC and SCADA systems have been relatively cooperative, one government official told CyberScoop, due in large part to what’s described as exceptional sense of urgency that dwarfs most other industries. Several of these companies have quietly moved forward on the FBI’s recommendations against Kaspersky by, for example, signing deals with Kaspersky competitors.
The firms the FBI have briefed include those that deal with nuclear power, a predictable target given the way the electric grid is increasingly at the center of catastrophic cybersecurity concerns.
The traditional tech giants have been less receptive and cooperative to the FBI’s pitch.
Earlier this year, a U.S. congressional panel asked federal government agencies to share documents on Kaspersky Lab because the firm’s products could be used to carry out “nefarious activities against the United States,” Reuters reported. That followed the General Services Administration removing Kaspersky from an approved-vendors list in early July and a congressional push to pass a law that would ban Kaspersky from being used by the Department of Defense.
Kaspersky, which has long denied ever helping any government with cyber-espionage efforts, reiterated those denials.
“If these briefings are actually occurring, it’s extremely disappointing that a government agency would take such actions against a law-abiding and ethical company like Kaspersky Lab,” a company representative told CyberScoop. “The company doesn’t have inappropriate ties with any government, which is why no credible evidence has been presented publicly by anyone or any organization to back up the false allegations made against Kaspersky Lab. The only conclusion seems to be that Kaspersky Lab, a private company, is caught in the middle of a geopolitical fight, and it’s being treated unfairly, even though the company has never helped, nor will help, any government in the world with its cyber-espionage or offensive cyber efforts.”
The U.S. government’s actions come as Russia is engaged in its own push to stamp American tech giants like Microsoft out of that country’s systems.
In the briefings, FBI officials also raise the issue of Russia’s increasingly expansive surveillance laws and what they charge is a distinct culture wherein powerful Russian intelligence agencies are easily able to reach into private sector firms like Kaspersky with little check on government power.
Of particular interest are the Yarovaya laws and the System for Operative Investigative Activities (SORM), among others, which mandate broad, legally vague and permissive Russian intelligence agency access to data moving inside Russia with retention periods extending to three years. Companies have little course to fight back. U.S officials point to the FSB, the KGB’s successor, as the cryptography regulator in Russia, and say it puts an office of active agents inside Russian companies.
A Kaspersky spokesperson emphasized that all information received by the company is “is protected in accordance with legal requirements and stringent industry standards, including encryption, digital certificates, firewalls and more” and insisted that “the company is not subject to these laws and other government tools” like SORM.
The law unquestionably does, however, impact Russian internet and communications providers, which Kaspersky uses. And, after all, it’s the Russian “legal requirements” that raise so many eyebrows.
“If it comes to the case of Kaspersky being induced to do something which is undocumented and illegal, it’s only then we’re in a slightly different domain [than in the West] and yes, you can assume the Russian government would have ways to induce private industry to do what it wants,” Keir Giles, a Russia expert with the British think tank Chatham House, told CyberScoop. “This is extremely hard to pin down because by this very nature this official encouragement is clandestine.”
By design, there is little visibility and public understanding of this opaque world. Many of the accusations pointed at Russia are met — by Kaspersky’s defenders as well as by civil liberties activists and technologists critical of what they view as gross U.S. government overreach — with fingers pointed right back at U.S. military and spy agencies.
Eva Galperin, the director of cybersecurity at the Electronic Frontier Foundation, believes Western intelligence agencies are engaged in many of the same tactics and must be similarly criticized but that “the legal and political landscape in Russia is very different.”
“The Yarovaya laws and many of the other internet-related laws in Russia were never meant to be implementable,” she told CyberScoop. “They were always meant to be overbroad, overreaching and impossible to comply with because this gives the Russian government a place to start whenever they come calling for your data. They show up, say ‘you’re already breaking the law, now what are you going to do for me?'”
Galperin’s observations on the Russian legal and political landscape mirrors what U.S. officials say in private about intentionally vague laws allowing intelligence officers to have broad abilities and authorities to conduct what U.S. officials see as malicious activity.
Throughout Kaspersky’s leadership ranks, including CEO and founder Eugene Kaspersky, the company is populated with Russian former intelligence officials, some of whom are accused by Western intelligence agencies of continuing in all but name to work for the Kremlin. This is a major point of contention, because Western cybersecurity firms are largely populated by ex-intelligence community employees as well.
While much of the public focus has understandably been on Eugene Kaspersky, the U.S. intelligence community places great focus on other executives, including Chief Legal Officer Igor Chekunov. Prior to joining the company, Chekunov was a KGB officer. U.S intelligence officials say in briefings they believe the list of individuals within Kaspersky cooperating with Russian intelligence is far longer, but they’ve offered no public evidence as proof.
“Once you serve in the [Russian] intelligence services, you’re always kind of linked to them,” Zachary Witlin, a Russia analyst at the Eurasia Group, told CyberScoop. “Kaspersky is an interesting case though. Eugene built this entire company there, he and plenty of other Russians want it to succeed as a global cybersecurity company because it showcases that Russia does have the talent to have world-class software products. I don’t think they would be immune from the same sorts of oversight that incredibly powerful Russian intelligence agencies have on the rest of the country, but they would have to make a calculation about whether or not they would be putting a major company like that at irreparable risk. In a situation like this, I’m not so sure.”
In closed congressional hearings, senators have responded with some punch to the FBI’s work. The chief criticism from Congress, which is anxious to take legislative action, is that the U.S. intelligence community didn’t speak up sooner about the problem. Earlier this year, senior U.S. intelligence officials slammed Kaspersky in an open congressional hearing; Eugene Kaspersky blamed it on “political reasons” rather than any wrongdoing by his own company.
In the years since suspicion has crept up against Kaspersky, the firm has repeatedly denied that it poses a threat to U.S. security or that it cooperates with Russia or any other government to spy on users. Efforts to reach out to American authorities have repeatedly been ignored or dismissed, the company told CyberScoop.
“CEO Eugene Kaspersky has repeatedly offered to meet with government officials, testify before the U.S. Congress and provide the company’s source code for an official audit to help address any questions the U.S. government has about the company, but unfortunately, Kaspersky Lab has not received a response to those offers,” a company spokesperson said.
“The company simply wants the opportunity to answer any questions and assist all concerned government organizations with any investigations, as Kaspersky Lab ardently believes a deeper examination of the company will confirm that these allegations are completely unfounded.”
The issue of a code audit was dismissed as a “publicity stunt” earlier this year by Jake Williams, an ex-NSA employee who has called the U.S. government’s efforts against Kaspersky “purely political.”
Beyond Kaspersky, U.S. intelligence officials see a problem that encompasses all of Russia and which, more broadly, impacts relations with tech firms from other countries, most notably China. As with so many other Washington, D.C., conversations of late, however, Russia has taken nearly sole possession of the spotlight that might otherwise be spread more globally.
Published on 15th of August 2017
In the last few years, I've had the pleasure to work with a lot of talented Software Engineers.
One thing that struck me is, that many of them did not have any working knowledge of Makefiles
and why they are useful.
When faced with the task to automate a build process, they often roll their own shell scripts.
Common culprits are called build.sh or run.sh or doall.sh etc.
They implement the same basic functionality over and over again:
Along the way, they keep doing the same basic mistakes:
If you think that make is scary, you probably think of complicated build machinery for bigsoftware projects.
It doesn't need to be that way. Let's hear what the author of make, Stuart Feldman has to say:
It began with an elaborate idea of a dependency analyzer, boiled down to something much simpler, and turned into Make that weekend. Use of tools that were still wet was part of the culture. Makefiles were text files, not magically encoded binaries, because that was the Unix ethos: printable, debuggable, understandable stuff.
Before I leave the house, I need to get dressed. I use the same simple routine every time: Underpants, trousers, shirt, pullover, socks, shoes, jacket. Most likely you also have a routine, even though yours might be different.
Some of these steps depend on each other.Make is good for handling dependencies.
Let's try to express my routine as a Makefile.
dress: trousers shoes jacket@echo "All done. Let's go outside!"jacket: pullover@echo "Putting on jacket."pullover: shirt@echo "Putting on pullover."shirt:@echo "Putting on shirt."trousers: underpants@echo "Putting on trousers."underpants:@echo "Putting on underpants."shoes: socks@echo "Putting on shoes."socks: pullover@echo "Putting on socks."
If we execute the Makefile, we get the following output:
$ make dressPutting on underpants.Putting on trousers.Putting on shirt.Putting on pullover.Putting on socks.Putting on shoes.Putting on jacket.All done. Let's go outside!
Noticed how the steps are in the correct order?
By plainly writing down the dependencies between the steps, make helps us to execute them correctly.
Each build step has the following structure:
target: [dependencies]<shell command to execute><shell command to execute>...
The first target in a Makefile will be executed by default when we call make.
The order of the targets does not matter.
Shell commands must be indented with a tab.
Add an @ sign to suppress output of the command that is executed.
If target isn't a file you want to build, please add .PHONY <target> at the end of the build step.
Common phony targets are: clean, install, run,...
install:npm install.PHONY: install
Otherwise, if somebody creates an install directory, make will silently fail, because the build target already exists.
Congratulations! You've learned 90% of what you need to know about make.
Real Makefiles can do much more! They will only build the files that have changed instead of doing a full rebuild.
And they will do as much as possible in parallel.
For the launch of AMD’s Ryzen Threadripper processors, one of the features being advertised was Game Mode. This was a special profile under the updated Ryzen Master software that was designed to give the Threadripper CPU more performance in gaming, at the expense of peak performance in hard CPU tasks. AMD’s goal, as described to us, was to enable the user to have a choice: a CPU that can be fit for both CPU tasks and for gaming at the flick of a switch (and a reboot) by disabling half of the chip.
Initially, we interpreted this via one of AMD’s slides as half of the threads (simultaneous multi-threading off), as per the exact wording. However, in other places AMD had stated that it actually disables half the cores: AMD returned to us and said it was actually disabling one of the two active dies in the Threadripper processor. We swallowed our pride and set about retesting the effect of Game Mode.
It’s not very often we have to retract some of our content at AnandTech – research is paramount. However in this instance a couple of things led to confusion. First was assumption related: in the original piece, we had assumed that AMD was making Game mode available through both the BIOS and through the Ryzen Master software. Second was communication: AMD had described Game Mode (and specifically, the Legacy Compatibility Mode switch it uses) at the pre-briefing at SIGGRAPH as having half the threads, but offered in diagrams that it was half the cores.

Based on the wording, we had interpreted that this was the equivalent of SMT being disabled, and adjusted the BIOS as such. After our review went live, AMD published and also reached out to us to inform of the error: where we had tested the part of Game Mode that deals with legacy core counts, we had disabled SMT rather than disabling a die and made the 16C/32T into to a 16C/16T system rather than an 8C/16T system. We were informed that the settings that deal with this feature are more complex than simply SMT being disabled, and as such was being offered primarily through Ryzen Master.

From AMD's Gaming Blog. Emphasis ours.
So for this review, we’re going to set the record straight, and test Threadripper in its Game Mode 8C/16T version. The previous review will be updated appropriately.
For Ryzen Threadripper, AMD has defined two modes of operation depending on the use case. The first is Creator Mode, which is enabled by default. This enables full cores, full threads, and gives the maximum available bandwidth across the two active Threadripper silicon dies in the package, at the expense of some potential peak latency. In our original review, we measured the performance of Creator Mode in our benchmarks as the default setting, but also looked into the memory latency.
Each die can communicate to all four memory channels, but is only directly connected to two memory channels. Depending on where the data in DRAM is located, a core may have to search in near memory (the two channels closest) or far memory (the two channels over). This is commonly referred to a non-uniform memory architecture (NUMA). In a unified memory system (UMA), such as Creator mode, the system sees no difference between near memory and far memory, citing a single latency value for both which is typically the average between the near latency and the far latency. At DDR4-2400, we recorded this as 108 nanoseconds.

Game Mode does two things over Creator Mode. First, it changes the memory from UMA to NUMA, so the system can determine between near and far memory. At DDR4-2400, that 108ns ‘average’ latency becomes 79ns for near memory and 136ns for far memory (as per our testing). The system will ensure to use up all available near memory first, before moving to the higher latency far memory.
Second, Game Mode disables the cores in one of the silicon dies. This isn’t a full shutdown of the 8-core Zeppelin die, just the cores. The PCIe lanes, the DRAM channels and the various IO are still active, but the cores themselves are power gated such that the system does not use them or migrate threads to them. In essence, the 16C/32T processor becomes 8C/16T, but with quad-channel memory and 60 PCIe lanes still: the 1950X becomes an uber 1800X, and the 1920X becomes an uber 1600X. The act of disabling dies is called ‘Legacy Compatibility Mode’, which ensures that all active cores have access to near memory at the expensive of immediate bandwidth but enables games that cannot handle more than 20 cores (some legacy titles) to run smoothly.

The core count on the left is the absolute core count, not the core count in Game Mode. Which is confusing.
Some users might see paying $999 for a processor then disabling almost half of it as a major frustration (insert something about Intel integrated graphics). AMD’s argument is that the CPU is still good for gaming, and can offer a better gaming experience when given the choice. However if we consider the mantra surrounding these big processors around gaming adaptability: the ability to stream, transcode and game at the same time. It’s expected that in this mega-tasking (Intel’s term) scenario, having a beefy CPU helps even though there will be some game losses. Moving down to only 8 cores is likely to make this worse, and the only situation Game Mode assists is for a user who purely wants a gaming machine but quad-channel memory and all the PCIe lanes. There’s also a frequency argument – in a dual die configuration, active threads can be positioned at thermally beneficial points of the design to ensure the maximum frequency. Again, AMD reiterates that it offers choice, and users who want to stick with all or half the cores are free to do so, as this change in settings would have been available in BIOS even if AMD did not give a quick button to it.

As always, the proof is in the pudding. If there’s a significant advantage to gaming, then Game Mode will be a plus point in AMD’s cap.
With regards how the memory and memory latency operates, Game Mode still incorporates NUMA, ensuring near memory is used first. The memory latency results are still the same as we tested before:

For the 1950X in the two modes, the results are essentially equal until we hit 8MB, which is the L3 cache limit per CCX. After this, the core bounces out to main memory, where the Game mode sits around 79ns when it probes near memory while the Creator mode is at 108 ns average. By comparison the Ryzen 5 1600X seems to have a lower latency at 8MB (20ns vs 41 ns), and then sits between the Creator and Game modes at 87 ns. It would appear that the bigger downside of Creator mode in this way is the fact that main memory accesses are much slower than normal Ryzen or in Game mode.
If we crank up the DRAM frequency to DDR4-3200 for the Threadripper 1950X, the numbers change a fair bit:

Click for larger image
Up until the 8MB boundary where L3 hits main memory, everything is pretty much equal. At 8MB however, the latency at DDR4-2400 is 41ns compared to 18ns at DDR4-3200. Then out into full main memory sees a pattern: Creator mode at DDR4-3200 is close to Game Mode at DDR4-2400 (87ns vs 79ns), but taking Game mode to DDR4-3200 drops the latency down to 65ns.
In our last review, we put the CPU in NUMA mode and disabled SMT. Both of the active dies were still active, although each thread had full CPU resources, and each set of CPUs would communicate to the nearest memory, however there would be potential die-to-die communication and more potential for far-memory access.
In this new testing, we use Ryzen Master to Game Mode, which enables NUMA and disables one of the silicon dies giving 8 cores and 16 threads.
It’s been about a year since I’ve started using Elixir. Originally, I intended to use the language only for blogging purposes, thinking it could help me better illustrate benefits of Erlang Virtual Machine (EVM). However, I was immediately fascinated with what the language brings to the table, and very quickly introduced it to the Erlang based production system I have been developing at the time. Today, I consider Elixir as a better alternative for the development of EVM powered systems, and in this posts I’ll try to highlight some of its benefits, and also dispell some misconceptions about it.
EVM has many benefits that makes it easier to build highly-available, scalable, fault-tolerant, distributed systems. There are various testimonials on the Internet, and I’ve blogged a bit about some advantages of Erlang here and here, and the chapter 1 of my upcoming book Elixir in Action presents benefits of both Erlang and Elixir.
Long story short, Erlang provides excellent abstractions for managing highly-scalable, fault-tolerant systems, which is particularly useful in concurrent systems, where many independent or loosely-dependent tasks must be performed. I’ve been using Erlang in production for more than three years, to build a long-polling based HTTP push server that in peak time serves over 2000 reqs/sec (non-cached). Never before have I written anything of this scale nor have I ever developed something this stable. The service just runs happily, without me thinking about it. This was actually my first Erlang code, bloated with anti-patterns, and bad approaches. And still, EVM proved to be very resilient, and run the code as best as it could. Most importantly, it was fairly straightforward for me to work on the complex problem, mostly owing to Erlang concurrency mechanism.
However, despite some great properties, I never was (and I’m still not) quite comfortable programming in Erlang. The coding experience somehow never felt very fluent, and the resulting code was always burdened with excessive boilerplate and duplication. The problem was not the language syntax. I did a little Prolog back in my student days, and I liked the language a lot. By extension, I also like Erlang syntax, and actually think it is in many ways nicer and more elegant than Elixir. And this is coming from an OO developer who spent most of his coding time in languages such as Ruby, JavaScript, C# and C++.
The problem I have with Erlang is that the language is somehow too simple, making it very hard to eliminate boilerplate and structural duplication. Conversely, the resulting code gets a bit messy, being harder to write, analyze, and modify. After coding in Erlang for some time, I thought that functional programming is inferior to OO, when it comes to efficient code organization.
This is where Elixir changed my opinion. After I’ve spent enough time with the language, I was finally able to see benefits and elegance of functional programming more clearly. Now I can’t say anymore that I prefer OO to FP. I find the coding experience in Elixir much more pleasant, and I’m able to concentrate on the problem I’m solving, instead of dealing with the language’s shortcomings.
Before discussing some benefits of Elixir, there is an important thing I’d like to stress: Elixir is not Ruby for Erlang. It is also not CoffeeScript, Clojure, C++ or something else for Erlang. Relationship between Elixir and Erlang is unique, with Elixir being often semantically very close to Erlang, but in addition bringing many ideas from different languages. The end result may on surface look like Ruby, but I find it much more closer to Erlang, with both languages completely sharing the type system, and taking the same functional route.
So what is Elixir? To me, it is an Erlang-like language with improved code organization capabilities. This definition differs from what you’ll see on the official page, but I think it captures the essence of Elixir, when compared to Erlang.
Let me elaborate on this. In my opinion, a programming language has a couple of roles:
Erlang and Elixir are completely identical in first two roles - they target the same “thing” (EVM), and they both take a functional approach. It is in role three where Elixir improves on Erlang, and gives us additional tools to organize our code, and hopefully be more efficient in writing production-ready, maintainable code.
Much has been said about Elixir on the Internet, but I especially like two articles from Devin Torres which you can find here and here. Devin is an experienced Erlang developer, who among other things wrote a popular poolboy library, so it’s worth reading what he thinks about Elixir.
I’ll try not to repeat much, and avoid going into many mechanical details. Instead, let’s do a brief tour of main tools that can be used for better code organization.
Metaprogramming in Elixir comes in a couple of flavors, but the essence is the same. It allows us to write concise constructs that seems as if they’re a part of the language. These constructs are in compile-time then transformed into a proper code. On a mechanical level, it helps us remove structural duplication - a case where two pieces of code share the same abstract pattern, but they differ in many mechanical details.
For example, a following snippet presents a sketch of a module models a User record:
defmodule User do
#initializer
def new(data) do ... end
# getters
def name(user) do ... end
def age(user) do ... end
# setters
def name(value, user) do ... end
def age(value, user) do ... end
endSome other type of record will follow this pattern, but contain different fields. Instead of copy-pasting this pattern, we can use Elixir defrecord macro:
defrecord User, name: nil, age: 0Based on the given definition, defrecord generates a dedicated module that contains utility functions for manipulating our User record. Thus, the common pattern is stated only in one place (the code of defrecord macro), while the particular logic is relieved of mechanical implementation details.
Elixir macros are nothing like C/C++ macros. Instead of working on strings, they are something like compile-time Elixir functions that are called in the middle of parsing, and work on the abstract syntax tree (AST), which is a code represented as Elixir data structure. Macro can work on AST, and spit out some alternative AST that represents the generated code. Consequently, macros are executed in compile-time, so once we come to runtime, the performance is not affected, and there are no surprise situations where some piece of code can change the definition of a module (which is possible for example in JavaScript or Ruby).
Owing to macros, most of Elixir, is actually implemented in Elixir, including constructs such as if, unless, or unit testing support. Unicode support works by reading UnicodeData.txt file, and generating the corresponding implementation of Unicode aware string function such as downcase or upcase. This in turn makes it easier for developers to contribute to Elixir.
Macros also allow 3rd party library authors to provide internal DSLs that naturally fit in language. Ecto project, that provides embedded integrated queries, something like LINQ for Elixir, is my personal favorite that really showcases the power of macros.
I’ve seen people sometimes dismissing Elixir, stating they don’t need metaprogramming capabilities. While extremely useful, metaprogramming can also become very dangerous tool, and it is advised to carefully consider their usage. That said, there are many features that are powered by metaprogramming, and even if you don’t write macros yourself, you’ll still probably enjoy many of these features, such as aforementioned records, Unicode support, or integrated query language.
This seemingly simple operator is so useful, I “invented” its Erlang equivalent even before I was aware it exists in Elixir (or other languages for that matter).
Let’s see the problem first. In Erlang, there is no pipeline operator, and furthermore, we can’t reassign variables. Therefore, typical Erlang code will often be written with following pattern:
State1 = trans_1(State),
State2 = trans_2(State1),
State3 = trans_3(State2),
...This is a very clumsy code that relies on intermediate variables, and correct passing of the last result to the next call. I actually had a nasty bug because I accidentally used State6 in one place instead of State7.
Of course, we can go around by inlining function calls:
trans_3(
trans_2(
trans_1(State)
)
)As you can see, this code can soon get ugly, and the problem is often aggravated when transformation functions receive additional arguments, and the number of transformation increases.
The pipeline operator makes it possible to combine various operations without using intermediate variables:
state
|> trans_1
|> trans_2
|> trans_3The code reads like the prose, from top to bottom, and highlights one of the strengths of FP, where we treat functions as data transformers that are combined in various ways to achieve the desired result.
For example, the following code computes the sum of squares of all positive numbers of a list:
list
|> Enum.filter(&(&1 > 0)) # take positive numbers
|> Enum.map(&(&1 * &1)) # square each one
|> Enum.reduce(0, &(&1 + &2)) # calculate sumThe pipeline operator works extremely well because the API in Elixir libraries follows the “subject (noun) as the first argument” convention. Unlike Erlang, Elixir takes the stance that all functions should take the thing they operate on as the first argument. So String module functions take string as the first argument, while Enum module functions take enumerable as the first argument.
Protocols are the Elixir way of providing something roughly similar to OO interfaces. Initially, I wasn’t much impressed with them, but as the time progressed, I started seeing many benefits they bring. Protocols allow developers to create a generic logic that can be used with any type of data, assuming that some contract is implemented for the given data.
An excellent example is the Enum module, that provides many useful functions for manipulating with anything that is enumerable. For example, this is how we iterate an enumerable:
Enum.each(enumerable, fn -> ... end)Enum.each works with different types such as lists, or key-value dictionaries, and of course we can add support for our own types by implementing corresponding protocol. This is resemblant of OO interfaces, with an additional twist that it’s possible to implement a protocol for a type, even if you don’t own its source code.
One of the best example of protocol usefulness is the Stream module, which implements a lazy, composable, enumerable abstraction. A stream makes it possible to compose various enumerable transformations, and then generate the result only when needed, by feeding the stream to some function from the Enum module. For example, here’s the code that computes the sum of squares of all positive numbers of a list in a single pass:
list
|> Stream.filter(&(&1 > 0))
|> Stream.map(&(&1 * &1))
|> Enum.reduce(0, &(&1 + &2)) # Entire iteration happens here in a single passIn lines 2 and 3, operations are composed, but not yet executed. The result is a specification descriptor that implements an Enumerable protocol. Once we feed this descriptor to some Enum function (line 3), it starts producing values. Other than supporting protocol mechanism, there is no special laziness support from Elixir compiler.
The final important piece of puzzle is the tool that help us manage projects. Elixir comes bundled with the mix tool that does exactly that. This is again done in an impressively simple manner. When you create a new project, only 7 files are created (including .gitignore and README.md) on the disk. And this is all it takes to create a proper OTP application. It’s an excellent example of how far can things be simplified, by hiding necessary boilerplate and bureaucracy in the generic abstraction.
Mix tool supports various other tasks, such as dependency management. The tool is also extensible, so you can create your own specific tasks as needed.
The list doesn’t stop here, and there are many other benefits Elixir gives us. Many of these do include syntactical changes from Erlang, such as support for variable rebinding, optional parentheses, implicit statement endings, nullability, short circuits operators, …
Admittedly, some ambiguity is introduced due to optional parentheses, as illustrated in this example:
abs -1 + 5 # same as abs(-1 + 5)However, I use parentheses (except for macros and zero arg functions), so I can’t remember experiencing this problem in practice.
In general, I like many of the decision made in this department. It’s nice to be able to write if without obligatory else. It’s also nice that I don’t have to consciously think which character must I use to end the statement.
Even optional parentheses are good, as they support DSL-ish usage of macros, making the code less noisy. Without them, we would have to add parentheses when invoking macros:
defrecord User, name: nil, age: 0 # without parentheses
defrecord(User, [name: nil, age: 0]) # with parenthesesStill, I don’t find these enhancements to be of crucial importance. They are nice finishing touches, but if this was all Elixir had to offer, I’d probably still use pure Erlang.
Much has been said in this article, and yet I feel that the magic of Elixir is far from being completely captured. The language preference is admittedly something subjective, but I feel that Elixir really improves on Erlang foundations. With more than three years of production level coding in Erlang, and about a year of using Elixir, I simply find Elixir experience to be much more pleasant. The resulting code seems more compact, and I can be more focused on the problem I’m solving, instead of wrestling with excessive noise and boilerplate.
It is for similar reasons that I like EVM. The underlying concurrency mechanisms makes it radically easier for me to tackle complexity of a highly loaded server-side system that must constantly provide service and perform many simultaneous tasks.
Both Elixir and EVM raise the abstraction bar, and help me tackle complex problems with greater ease. This is why I would always put my money behind Elixir/EVM combination as the tools of choice for building a server-side system. YMMV of course.
Security Keys are (generally) USB-connected hardware fobs that are capable of key generation and oracle signing. Websites can “enroll” a security key by asking it to generate a public key bound to an “appId” (which is limited by the browser based on the site's origin). Later, when a user wants to log in, the website can send a challenge to the security key, which signs it to prove possession of the corresponding private key. By having a physical button, which must be pressed to enroll or sign, operations can't happen without user involvement. By having the security keys encrypt state and hand it to the website to store, they can be stateless(*) and robust.
(* well, they can almost be stateless, but there's a signature counter in the spec. Hopefully it'll go away in a future revision for that and other reasons.)
The point is that security keys are unphishable: a phisher can only get a signature for their appId which, because it's based on the origin, has to be invalid for the real site. Indeed, a user cannot be socially engineered into compromising themselves with a security key, short of them physically giving it to the attacker. This is a step up from app- or SMS-based two-factor authentication, which only solves password reuse. (And SMS has other issues.)
The W3C standard for security keys is still a work in progress, but sites can use them via the FIDO API today. In Chrome you can load an implementation of that API which forwards requests to an internal extension that handles the USB communication. If you do that, then there's a Firefox extension that implements the same API by running a local binary to handle it. (Although the Firefox extension appears to stop working with Firefox 57, based on reports.)
Google, GitHub, Facebook and Dropbox (and others) all support security keys this way. If you administer a G Suite domain, you can require security keys for your users. (“G Suite” is the new name for Gmail etc on a custom domain.)
But, to get all this, you need an actual security key, and probably two of them if you want a backup. (And a backup is a good idea, especially if you plan on dropping your phone number for account recovery.) So I did a search on Amazon for “U2F security key” and bought everything on the first page of results that was under $20 and available to ship now.
Brand: Yubico, Firmware: Yubico, Chip: NXP, Price: $17.99, Connection: USB-A
Yubico is the leader in this space and their devices are the most common. They have a number of more expensive and more capable devices that some people might be familiar with, but this one only does U2F. The sensor is a capacitive so a light touch is sufficient to trigger it. You'll have no problems with this key, but it is the most expensive of the under $20 set.
Brand: Thetis, Firmware: Excelsecu, Chip: ?, Price: $13.95, Connection: USB-A
This security key is fashioned more like a USB thumb drive. The plastic inner part rotates within the outer metal shell and so the USB connector can be protected by it. The button is in the axis and is clicky, rather than capacitive, but doesn't require too much force to press. If you'll be throwing your security key in bags and worry about damaging them then perhaps this one will work well for you.
A minor nit is that the attestation certificate is signed with SHA-1. That doesn't really matter, but it suggests that the firmware writers aren't paying as much attention as one would hope. (I.e. it's a brown M&M.)
Brand: Feitian, Firmware: Feitian, Chip: NXP, Price: $16.99, Connection: USB-A, NFC
This one is very much like the Yubico, just a little fatter around the middle. Otherwise, it's also a sealed plastic body and capacitive touch sensor. The differences are a dollar and NFC support—which should let it work with Android. However, I haven't tested this feature.
I don't know what the opposite of a brown M&M is, but this security key is the only one here that has its metadata correctly registered with the FIDO Metadata Service.
Brand: U2F Zero, Firmware: Conor Patrick, Chip: Atmel, Price: $8.99, Connection: USB-A
I did bend the rules a little to include this one: it wasn't immediately available when I did the main order from Amazon. But it's the only token on Amazon that has open source firmware (and hardware designs), and that was worth waiting for. It's also the cheapest of all the options here.
Sadly, I have to report that I can't quite recommend it because, in my laptop (a Chromebook Pixel), it's not thick enough to sit in the USB port correctly: Since it only has the “tongue” of a USB connector, it can move around in the port a fair bit. That's true of the other tokens too, but with the U2F Zero, unless I hold it just right, it fails to make proper contact. Since operating it requires pressing the button, it's almost unusable in my laptop.
However, it's fine with a couple of USB hubs that I have and in my desktop computer, so it might be fine for you. Depends how much you value the coolness factor of it being open-source.
Brand: KEY-ID, Firmware: Feitian(?), Chip: ?, Price: $12.00, Connection: USB-A
I photographed this one while plugged in in order to show the most obvious issue with this device: everyone will know when you're using it! Whenever it's plugged in, the green LED on the end is lit up and, although the saturation in the photo exaggerates the situation a little, it really is too bright. When it's waiting for a touch, it starts flashing too.
In addition, whenever I remove this from my desktop computer, the computer reboots. That suggests an electrical issue with the device itself—it's probably shorting something that shouldn't be shorted, like the USB power pin to ground, for example.
While this device is branded “KEY-ID”, I believe that the firmware is done by Feitian. There are similarities in certificate that match the Feitian device and, if you look up the FIDO certification, you find that Feitian registered a device called “KEY-ID FIDO® U2F Security Key”. Possibly Feitian decided against putting their brand on this.
(Update: Brad Hill, at least, reports no problems with these when using a MacBook.)
Brand: HyperFIDO, Firmware: Feitian(?), Chip: ?, Price: $13.75, Connection: USB-A
By observation, this is physically identical to the KEY-ID device, save for the colour. It has the same green LED too (see above).
However, it manages to be worse. The KEY-ID device is highlighted in Amazon as a “new 2017 model”, and maybe this an example of the older model. Not only does it cause my computer to reliably reboot when removed (I suffered to bring you this review, dear reader), it also causes all devices on a USB hub to stop working when plugged in. When plugged into my laptop it does work—as long as you hold it up in the USB socket. The only saving grace is that, when you aren't pressing it upwards, at least the green LED doesn't light up.
Brand: HyperFIDO, Firmware: Feitian(?), Chip: ?, Price: $9.98, Connection: USB-A
This HyperFIDO device is plastic so avoids the electrical issues of the KEY-ID and HyperFIDO Mini, above. It also avoids having an LED that can blind small children.
However, at least on the one that I received, the plastic USB part is only just small enough to fit into a USB socket. It takes a fair bit of force to insert and remove it. Also the end cap looks like it should be symmetrical and so able to go on either way around, but it doesn't quite work when upside down.
Once inserted, pressing the button doesn't take too much force, but it's enough to make the device bend worryingly in the socket. It doesn't actually appear to be a problem, but it adds a touch of anxiety to each use. Overall, it's cheap and you'll know it.
Those are the devices that matched my initial criteria. But, sometimes, $20 isn't going to be enough I'm afraid. These are some other security keys that I've ended up with:
Brand: Yubico, Firmware: Yubico, Chip: NXP?, Price: $50 (direct from Yubico), Connection: USB-C
If you have a laptop that only has USB-C ports then a USB-A device is useless to you. Currently your only option is the Yubikey 4C at $50 a piece. This works well enough: the “button” is capacitive and triggers when you touch either of the contacts on the sides. The visual indicator is an LED that shines through the plastic at the very end.
Note that, as a full Yubikey, it can do more than just being a security key. Yubico have a site for that.
Many people lacking USB-A ports will have a Touch Bar, which includes a fingerprint sensor and secure element. One might spy an alternative (and cheaper solution) there. GitHub have published SoftU2F which does some of that but, from what I can tell, doesn't actually store keys in the secure element yet. However, in time, there might be a good answer for this.
Brand: Yubico, Firmware: Yubico, Chip: NXP?, Price: $50 (direct from Yubico), Connection: USB-A
Another $50 security key from Yubico, but I've included it because it's my preferred form-factor: this key is designed to sit semi-permanently inside the USB-A port. The edge is a capacitive touch sensor so you can trigger it by running your finger along it.
It does mean that you give up a USB port, but it also means that you've never rummaging around to find it.
(Note: newer Nanos look slightly different. See Yubico's page for a photo of the current design.)
PlanGrid provides premium medical, dental, and vision coverage for full-time employees and their dependents.
We offer Clipper cards to all full-time employees, so they save on fares while helping to save the environment.
We work hard, but strongly encourage everyone to take the time to recharge with generous vacation policies.
We believe in sharing our success. All full-time employees receive equity as part of their total compensation.
PlanGrid is headquartered in San Francisco’s Mission District, just one block from BART. Our office is wheelchair accessible.
Catered lunches are provided multiple times each week, and HQ is well-stocked with delicious drinks, snacks, and treats.
Reasonable Scala compiler (rsc) is an experimental Scala compiler
focused on compilation speed. This project is developed by Eugene Burmako
and his team at Twitter.
At Twitter, we have one of the biggest Scala codebases on the planet,
and compilation time is consistently among the top asks from our engineers.
With rsc, we seek to foster innovation in compilation performance,
openly prototyping performance-focused designs and making our findings
available to the Scala community at large.
Our project is inspired by the work of Martin Odersky and Grzegorz Kossakowski. Martin showed us that in this day and age it is still possible towrite a Scala compiler from scratch. Greg showed us thatcompiling Scala can be blazingly fast.
We believe that it possible to achieve dramatic compilation speedups (5-10x) for typical Scala codebases, and we are currently well on track to realizing this vision.
It is too early to say this definitively. We are planning to start small with a trivial subset of Scala and then gradually add features, carefully measuring their impact on compilation performance. Ideally, we would like to make it possible for Scala programmers to easily reason about compilation performance cost of various Scala features and idioms.
Not all Scala programs will be compatible with Reasonable Scala, so aScalafix migration may be required
to use rsc. However, all Reasonable Scala programs will be compatible with
Scala, so codebases that have been migrated will be crosscompilable.
Details will become clearer down the line, but keep in mind that we are
a large Scala shop, so we take compatibility extremely seriously.
We are planning to open source Reasonable Scala compiler in the near future. For now, star our project on GitHub and stay tuned for updates.
(Submitted on 15 Aug 2017)
Abstract: A decentralized online quantum cash system, called qBitcoin, is given. We design the system which has great benefits of quantization in the following sense. Firstly, quantum teleportation technology is used for coin transaction, which prevents an owner of a coin from keeping the original coin data after sending the coin to another. This was a main problem in systems using classical information and a blockchain was introduced to solve this issue. In qBitcoin, the double-spending problem never happens and its security is guaranteed theoretically by virtue of quantum information theory. Making a bock is time consuming and the system of qBitcoin is based on a quantum chain, instead of blocks. Therefore a payment can be completed much faster than Bitcoin. Moreover we employ quantum digital signature so that it naturally inherits properties of peer-to-peer (P2P) cash system as originally proposed in Bitcoin.
























