In 1978, Frank Barrett, a construction worker in Dawson City, a town in the
northern Yukon, was excavating the site of a new recreation
center when he discovered reels of film poking out from the hard-packed
terrain. He recognized the potential significance of the find and made
official inquiries that ultimately led to careful digs to unearth the
full complement of material, which turned out to be more than five
hundred reels of highly flammable nitrate film. As it turned out, those
reels, from the nineteen-tens and twenties, contained many fiction films
(including ones by D. W. Griffith, Lois Weber, Allan Dwan, Tod Browning,
and other early cinema luminaries) that hadn’t otherwise survived, as
well as newsreel footage from the same period.
That’s where the filmmaker Bill Morrison comes in. In his new film,
“Dawson City: Frozen Time,” currently playing in New York and expanding
to other cities this Friday, Morrison looks at the surviving films and
reconstructs the extraordinary arcs of political and cultural history
that are latent in them. Since the footage was found in Dawson City,
Morrison reconstructs the history of Dawson City as well, its cinematic
history in particular, and discovers that the currents emanating from
the found footage have strange doubles in the history of Dawson City
itself, which, despite its isolation and obscurity, turns out—in his
passionately discerning view—to be a hidden mainspring of modernity.
Morrison launches the story locally, with an American man’s discovery of
gold along the Klondike River, in 1896. Word got out, a claim was staked
for a town, the Mounties displaced the indigenous Hän people to make way
for mining, and boatloads of prospectors arrived from San Francisco and
Seattle. By 1897, the gold rush was in full swing, along with its snares
and hazards. Morrison emphasizes that, of the hundred thousand
travellers who sought their fortune in the Klondike region, seventy
thousand either died en route or returned home—and he uses a comedic
image from Charlie Chaplin’s 1925 masterwork “The Gold Rush” to
illustrate the trip’s terrors.
Relying on footage from the Dawson City find, as well as from other
archival sources, Morrison constructs a vibrant and alluring visual
history. He respects the silence of the silent-film footage and adds no
voice-over; his copious and trenchant commentary appears on the screen
as titles superimposed on the footage, and the only voices in the film
come from a few brief clips that feature recorded sound as well as brief
but informative and hearty interviews with two archivists, Michael Gates
and Kathy Jones-Gates, who played crucial roles in rescuing the Dawson
City footage and ended up marrying each other. (Unfortunately, the
overly insistent music, by Alex Somers, obscures the silence instead of
enhancing it.)
The film locates extraordinary political and cultural tributaries,
marked by archival footage, that arise from the history of Dawson City
and the gold rush. For instance, Morrison notes that Donald Trump’s
grandfather Fred Trump launched his real-estate empire with a
brothel-cum-restaurant in the neighboring gold-rush town of Whitehorse
(and includes a still image of the establishment). Dawson City was a
rowdy home for transient prospectors; it thrived on gambling, grifting,
and prostitution. But, as the gold rush quickly settled to a trickle,
permanent residents purged the town of louche entertainments, which were
quickly replaced by the new medium of movies, which proved extremely
popular.
That hunger for entertainment, and for the new medium, accounts for the
extraordinary diversity of the material in the Dawson City
rediscoveries—not just dramas but newsreels, travelogues, and even
scientific and ethnographic films turn up among the recovered reels.
Morrison tells the strange story of how the reels ended up there. The
remote region didn’t get films until years after their release; as a
result, distributors didn’t want to pay for the return of those films,
which had exhausted their commercial life. Dawson City exhibitors sought
to store the films, but the highly flammable nitrate reels occasionally
combusted spontaneously (Morrison documents the horrific and deadly
history of film-centered fires, with their victims among the viewing
public, as well as their ravages of studios belonging to Thomas Edison
and Alice Guy-Blaché). As a result, many films were dumped in the river,
others were burned in a huge bonfire, and those that remained were
buried deep below the surface of the earth in a permafrost pit.
One newsboy in Dawson City in the late nineteenth century, Sid Grauman,
got his first taste of movies there; he later move to Hollywood, where
he founded, among other movie palaces, Grauman’s Chinese Theatre. A
Dawson City bartender, Alex Pantages, joined with the entertainer
“Klondike Kate” Rockwell to open a movie theatre, and he eventually
became the head of one of the largest American movie-theatre chains.
Jack London, of course, headed north in the gold rush, and stayed only
briefly, but launched his literary career. The New York Rangers and
Madison Square Garden have historical roots in gold-rush entertainments;
even the form of this documentary itself, with its use of archival
photographs, has its roots in a 1957 documentary, “City of Gold,” based
on rediscovered archival Dawson City gold-rush images by Eric Hegg.
But the core of the film, and the supreme display of the intellectual
depth of Morrison’s film-editing virtuosity, involves baseball and
politics. It’s too good a story to spoil in detail; Morrison sets it up
with a wry wink, showing himself on a TV sports broadcast, introducing
footage of the 1917 and 1919 World Series, which he found among the
Dawson City reels. The 1919 Series, of course, is the one that’s
infamous for the “Black Sox” scandal, when players for the Chicago White
Sox were found to have thrown games for the benefit of gamblers, and
Morrison centers the tale on that scandal—and on the images from a game
that he analyzes in slow motion to show how the game-throwing worked.
But, more important, he also links that seemingly isolated event to the
wider politics of the time, as documented in newsreel footage also
discovered in the soil of Dawson City. It’s a tale that involves the
incipient union movement and the collusion of government and business to
repress it. It encompasses the First World War, the Red Scare, protests
in New York, and the deportation of “undesirable” immigrants; and it’s
centered on Judge Kenesaw Mountain Landis, a rigid conservative who, in
the wake of the Black Sox scandal, was appointed the first commissioner
of Major League Baseball. Along the way, Landis kept the game socially
and politically regressive for decades. (Morrison’s ingenious use of
slow motion to analyze the World Series footage film suggests what’s
lacking from the rest of the film: similarly interventionist editing,
whether slow motion or freeze-frames, zoom-ins or iris-ins, to emphasize
and prolong beautiful expressions, gestures, and moods from the found
footage.)
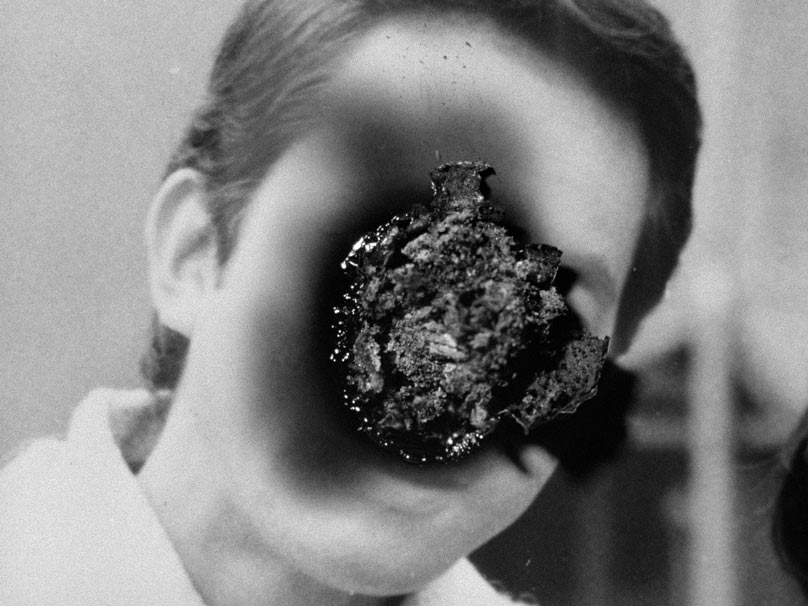
Most of the Dawson City rediscoveries that Morrison deploys have been
damaged by their time in the ground. Rather than restoring the footage,
or trying to elide or correct the damage, Morrison revels in it,
maintaining it onscreen in a way that’s consistent with, and that
reflects, his prior practice in his best-known film to date, “Decasia,”
from 2002. In “Decasia,” Morrison collects archival footage that was
damaged or had deteriorated, and his assemblage of it proves that the
physical degradation of the images, far from rendering them unusable and
unshowable, adds several other layers of expression to them. He showed
that the visual patterns of the image decay are beautiful in themselves,
as a kind of found visual poetry of textures and shapes, and that the
deterioration of the images is an overriding metaphor in itself, one
that reinforces the fragmentary yet miraculous recuperation of lost
time.
“Decasia” is an experimental film in the most literal sense, and the
fruits of that experiment are reflected in “Dawson City,” where most of
the rediscovered footage is mottled, decayed, ravaged—and that menacing
ruin is part of their power. Here, it suggests death in motion, evoking
images that time has rendered cadaverous and— despite the embalming
process of film-processing chemistry—helpless against decomposition.
That decay makes these images look like the undead who return from the
void to bear silent witness to vanished and voiceless lives. In “Dawson
City,” Morrison offers a fiercely precise and discerning look at movies
themselves as embodiments of history. In the process, he retunes our
relationship with the ubiquitous cinematic archive—with the fresh batch
of images that get delivered through the electronic pipeline by the
minute—and with the very question of what’s contained, or what’s hidden,
in the seemingly smooth and seamless flow of a movie.
Over the last decade, entrepreneurial space companies in Southern California have set their sights on such goals aslaunching small satellites, carrying space tourists and colonizing Mars.
As they hire numerous young engineers, those companies and more traditional aerospace giants are finding talent in an unlikely place: a college race-car competition.
Next week, 100 university teams will bring their prototype race cars to the Formula SAE (Society of Automotive Engineers) competition in Lincoln, Neb., where they will be judged on design, manufacturing, performance and business logic.
The aerospace leaders who help judge the contest say it’s also an opportunity to see students explain design and production decisions, present their business cases and adapt on the fly.
“Race cars and rockets are pretty similar,” said Bill Riley, a Formula SAE alumnus from Cornell and competition judge who’s now a senior director of design reliability and vehicle analysis at SpaceX. “It’s lightweight, efficient, elegant engineering. Those basic principles are the same, no matter what you’re designing.”
SpaceX has had “fantastic success” recruiting new hires and interns from Formula SAE teams, as well as from sister competition Baja SAE, which focuses on building an off-road vehicle, and other hands-on engineering competitions, said Brian Bjelde, the Hawthorne company’s vice president of human resources.
Out of the 700 students who intern at SpaceX each year, about 50 or 60 come from Formula SAE. And as of three years ago, about 50% of the company’s 300-person structures team had worked on some sort of project-based design team in college.
“For any candidate, the ones that are most successful at SpaceX have a combination of passion, drive and talent,” Bjelde said. “And to me, [Formula SAE] plays into the passion piece.”
Aaron Cassebeer experienced the highs and lows of competition firsthand 10 years ago as captain of a Lehigh University team that captured several design awards at competitions. But when a hose came loose and spilled oil into the car’s chassis, a few drips landed on the track and the Lehigh team was disqualified.
It all ended well for Cassebeer, though. His work with light, composite materials eventually impressed Scaled Composites, a cutting-edge Mojave aerospace firm. That led to a nine-year career where, among other things, he designed flight controls for an early version of the space plane that Virgin Galactic aims to use to fly tourists to space.
“The type of work I did happens to fit in really well with what Scaled Composites does — design and prototype, over and over again,” Cassebeer said.
The basis of the Formula SAE competition is that a fictional manufacturing company contracts teams to build a prototype race car that is low-cost, high-performance, easy to maintain and reliable.
Industry judges grill students on the design process, scrutinize their cost sheets and inspect the vehicles to make sure they are technically sound. The internal combustion engine car competition is the most popular, though an electric vehicle contest was added in 2013.
Race cars that pass technical inspections get the green light to hit the course for performance trials, testing things such as maneuverability, acceleration and endurance.
During the endurance test, two people drive the car around a course marked by traffic cones for a little more than 13 miles, which can take about half an hour and involves a driver switch. Many teams, such as UCLA’s, have a hard time finding a large, open space for testing, meaning the endurance test could be one of the few times the car runs that long without breaks.
“The great thing about [Formula SAE] is it’s a full production cycle,” said Dolly Singh, SpaceX’s former head of talent acquisition who now serves as chief executive of high-heel designer Thesis Couture. “These kids build the car from scratch. They have to test in a high-pressure situation and see how it performs.”
Preparing for the competition gives students a taste of the grind that goes into meeting real-world project deadlines.
David Hernandez, 21, laughed when asked how many hours he and other members of the Cal Poly Pomona Formula SAE team have spent working on their car.
“Last night, I left early, and that was at 10 p.m.,” said Hernandez, a fourth-year aerospace engineering student.
Cal Poly Pomona has done well in the competition. Last year, the team’s sleek, green vehicle with an aerodynamic wing placed third overall in Lincoln, the highest of any California team there.
The Cal Poly shop, which is on the base floor of an engineering building and is shared with the Baja SAE team and other clubs and project teams, is crammed with tools, machinery and previous years’ cars.
The team’s 2014 car is encased in glass at the front of the engineering school along with a number of trophies. That car placed fourth in Lincoln and ninth in an international Formula SAE competition.
Hernandez applied his software knowledge, acquired through classes and Formula SAE, to his internship last summer at Raytheon Co. He uses the same software to analyze data points from the team’s car.
“There are very few times you feel as passionate about the same thing,” Hernandez said of the group’s camaraderie. “There’s nothing better than this.”
Scaled Composites, which is now part of Northrop Grumman Corp., has mentored a handful of Southern California teams, including UCLA’s, and recruited students in their shops for full-time jobs or internships. Several of the company’s engineers have also volunteered to offer feedback ahead of the competitions.
Scaled Composites is particularly interested in students who work on design and analysis.
“We do look for engineers that are hands-on,” said Kelsey Gould, executive assistant to the company’s vice president of engineering. “They’re really committed to figuring things out on their own.”
As the competition nears, pressure mounts.
Each Saturday for the last few months, about 30 members of the UCLA Formula SAE team pumped up the music in their ground-floor shop on campus and worked almost all day on their car. That’s in addition to the hours they spend there in between classes.
The UCLA team has already made several changes to avoid challenges it ran into last year, when it finished 59th out of 80 teams. A new, tunable muffler has been added that should help the team pass a sound requirement during the technical inspection. Last year, UCLA just barely passed that test by using a special exhaust plug and two mufflers packed with steel wool to deaden the sound.
Students on the team get greater hands-on engineering experience than they might in academic classes, said Owen Hemminger, 20, a mechanical engineering student and financial director of UCLA’s team.
Everyone learns how to use engineering software and do machining in school, “but not to the depth we use it,” he said.
Dan Rivin, 22, said his experience making steering wheels and driver’s seats for UCLA’s cars prepared him for an internship at Northrop Grumman, where he worked extensively with composites.
Last fall, the materials engineering student, who graduated this spring, gave a Northrop recruiter a tour of UCLA’s Formula SAE shop. Later, the recruiter asked Rivin for a resume. After several interviews, he was offered a full-time job with the aerospace giant and will start at the end of this month.
He said his work with Formula SAE came up in a number of interviews. He’s convinced it got him onto recruiters’ radar screens.
“This is very unique in the way that you’re involved in the entire process,” he said. “No one’s holding your hand through the whole thing.”
Repeated nucleotide sequences combined with proteins called telomeres cover chromosome ends and dictate cells lifespan. Many factors can modify telomere length, among them are: nutrition and smoking habits, physical activities and socioeconomic status measured by education level.
The aim of the study was to determine the influence of above mentioned factors on peripheral blood mononuclear cells telomere length.
Methods
Study included 28 subjects (seven male and 21 female, age 18–65 years.), smokers and non-smokers without any serious health problems in past and present. Following a basic medical examination, patients completed the food frequency questionnaire with 17 foods and beverages most common groups and gave blood for testing. PBMC telomere length were measured with qualitative real-time Polymerase Chain Reaction (rtPCR) method and expressed as a T/S ratio.
Results
Among nine food types (cereal, fruits, vegetables, diary, red meat, poultry, fish, sweets and salty snacks) and eight beverages (juices, coffee, tea, mineral water, alcoholic- and sweetened carbonated beverages) only intake of red meat was related to T/S ratio. Individuals with increased consumption of red meat have had higher T/S ratio and the strongest significant differences were observed between consumer groups: “never” and “1–2 daily” (p = 0.02). Smoking habits, physical activity, LDL and HDL concentrations, and education level were not related to telomere length, directly or as a covariates.
Conclusions
Unexpected correlation of telomere length with the frequency of consumption of red meat indicates the need for further in-depth research and may undermine some accepted concepts of adverse effects of this diet on the health status and life longevity.
Telomeres are special structures consisting of repeating DNA chain sequences (TTAGGG) and a complex of few proteins. They are located at the ends of chromosomes and play a role in covering the cell genome and controlling number of cell divisions. Thus, affect cell lifespan. When shortening of telomeres during cell division reaches a critical length, cellular senescence is triggered. Since cellular longevity is affected by telomere length, individuals with longer telomeres should expect higher life expectancy. Very short telomere lengths may activate different repair mechanisms e.g. unlock telomerase – enzyme that can rebuild telomere sequences or ALT (Alternative Lengthening of Telomeres), which can lead to cell immortalization and tumor growth.
Numerous factors can affect shortening and rebuilding of telomeres [1–4], but previous studies did not yield a clear answer to the question what is a relationship between telomere length and some disorders [5, 6] or life expectancy [7, 8].
Diet is a common variable that can have significant impact on human health. Compliance with dietary pyramid is required for maintaining wellbeing. At the top of the pyramid is red meat, which should be eaten with moderation, preferably two or three times a week. Red meat is a good source of high amounts of protein and vitamins, especially B1, B12, PP and easily assimilable iron. Excessive consumption of red meat is accompanied by an increased ingestion of dietary fat with low level of polyunsaturated fatty acids (PUFA), and toxic substances formed during thermal treatment of meat. It may also affect the serum lipid profile while raising LDL concentration – which is widely recognized as a risk factor for cardiovascular diseases [9]. Several studies have shown that high red meat consumption can increase the incidence of colorectal and breast cancer [10–14], and DNA damage. Greater intake of red meat can induce DNA damage and may have an impact on the “Telomere Length” (TL). Main sources of DNA damage are oxidative stress [15] and inflammation. Heme iron from meat can cause DNA damage in vitro through lipid peroxidation products [16]. Increased intake of saturated fatty acids (SFA) may induce oxidative stress and thus enhance DNA-damage [17, 18].
The aim of this 3-year prospective observational study was to determine the effect of diet, smoking habit, physical activity and education on telomere length of peripheral blood mononuclear cells (PBMC). Results of a cross-sectional analysis of baseline data are presented.
Materials and methods
Study population
The study included 28 individuals, (21 females and seven males). A detailed description of the study population is presented in Table . Inclusion criteria were: age 18–65 years, smoking habit: never smoker and current smoker, no significant abnormalities on physical examination, signed informed consent form to participate in the study. Exclusion criteria: previous or ongoing major diseases including proliferative diseases and mental health disorders, pregnancy (excluded by pregnancy urine test), running disease during the follow-up to severe or poor prognosis.
Characteristics of study population
Study design
Patients enrolled to the study, after a routine physical examination, were asked to fill out a questionnaire. This questionnaire was especially developed by the authors for the study. To simplify the filling, questions with different answers (checkbox) were used. The questionnaire consisted of three parts concerning: nutrition habits, food and beverages types and physical activity. It was filled out offhand during a visit, in the presence of a physician or nurse, for additional help. After completing the survey, anthropometric measurements were conducted and detailed information about smoking habit was obtained from smokers. Previous laboratory test results (up to 12 months before enrollment) were obtained from patients’ medical records. At the end of the visit, blood was collected to determine telomere length.
Telomere measurement
Telomere length was assessed as a relative average telomere length (T/S ratio) by PCR according to the method described by Cawthon R.M [19]. Firstly, 9 mL of venous blood was collected into EDTA tubes. Peripheral blood mononuclear cells (PBMC) were isolated from human peripheral blood by density gradient centrifugation using Histopaque® 1077 solution (Sigma Aldrich, Saint Louis, MO) according to the manufacturer’s recommendations. Afterwards, the PBMCs were washed three times in PBS and stored at −80 °C until further analysis. DNA was isolated from PBMC using QIAamp DNA Blood Mini Kit (Qiagen) according to the manufacturer's protocol. The concentration and quality of DNA obtained were assessed by spectrophotometry (Picodrop). After collecting enough samples telomere length was assessed by quantitive real-time PCR.
The primer sequences for the amplification reaction in order to determine the length of telomeres:
The primer sequences for the amplification of the reference gene 36B4
36B4F 5'CAGCAAGTGGGAAGGTGTAATCC3’
36B4R 5'CCCATTCTATCATCAACGGGTACAA3’
The reaction was carried out in triplicate. In order to perform a standard curve, dilution series of DNA were prepared (concentration range from 0.6 ng/μL to 5 ng/μL). The real-time PCR was on a 7900 HT Fast Real-Time PCR System (Applied Biosystems).
Precise reaction conditions for PCR (primer concentration, reaction time and temperature) were determined empirically. The specificity of the PCR reaction was checked based on melting curves, obtained at the end of each PCR.
Statistical analysis
All data are presented as mean ± standard deviation or median and range. Differences between groups with normal distribution were calculated with t-test, ANOVA and adequate post-hoc tests. Survey data not normally distributed were assessed with nonparametric tests. ANCOVA models were used to adjust potential preexisting differences e.g. the effect of age or smoking habit on telomere length. All analyses were performed using the STATISTICA (data analysis software system), version 12. StatSoft, Inc. (2014) http://www.statsoft.com.
Results
Diet
Results of analysis of diet survey are shown in Table . This survey has been limited to provide eating times of a specific food per unit of time (day or week) due to the difficulty in determining the accurate food portion size. It was assumed that subjects have eaten average portion size. Available food frequency questionnaire (FFQ) proved to be too long and complicated. The survey was constructed in a comprehensible form, easy to be filled-up by all subjects and assess the average intake of groups of products (food and drinks) on a basis of daily nutrition. The survey used quantitative research methods to identify 6 “frequency consumption groups”:
F0
never
F1
once weekly or less,
F2
once daily in 2–3 days of week,
F3
once daily in 4–6 days of week,
F4
1–2x daily (at least one meal),
F5
3–5x daily (every meal),
Description of the consumption of various food and drink groups
We found no association between telomere length and the number of meals eaten per day. Eating breakfast - important for the proper diet - turned out to be irrelevant to telomeres. Neither the beginning nor the end of the daily diet had any effect on telomeres though shown its impact on external appearance. After analysis of obtained data it was found that only red meat consumption was associated with the relative length of telomeres (T/S ratio) (Table ). The detailed relationship between consumption groups is shown in Fig. . Post-hoc analysis (HSD test) showed significant difference between group F0 and F3 (# p < 0.05). ANCOVA model indicated, that there was no significant interaction between age as covariate and red meat consumption and after correction of means, value F = 4.62 was still significant (p = 0.0078). Similarly, no effect on HDL and LDL cholesterol levels were found (F = 4.24, p = 0.010, F = 3.98, p = 0.014, respectively). The study could not confirm any relationship between types and quantities of beverages or other food groups and the length of PBMC telomeres, although other authors found such associations [20].
PBMC telomere length differences between red meat consumption groups.
Other data
Age, anthropometric data (BMI, WHR) and cholesterol levels (LDL, HDL) did not correlate with T/S ratio.
The additional aim of this study was to determine the influence of cigarette smoking on telomere length, but there was no difference between active smokers and non-smokers. In the group of smokers, daily and total burden of cigarette smoking were not correlated with T/S ratio and red meat consumption.
Physical activity, a necessary element of a healthy lifestyle was not related to telomere status. Study conditions exceed the possibilities of using more objective but time- and cost-intensive methods for determining the level of physical activity. Survey data allowed to divide participants into five groups of physical activity depending on the frequency and time of physical activity:
None - total lack or medical contraindications for exercise
Low - till 30 min/week
Moderate - above 30 min/week, but less than 4x a week
Increased - above 30 min/week and at least 4x a week
Intensive - practicing an amateur sport with regular training
We found no differences among particular levels and T/S ratio.
Four levels of education were identified among participants (Table ). Participants were divided into two groups – with and without higher education. PBMC telomere length T/S ratio between these groups did not differ significantly (p = 0.26) (Table ).
Relative telomere length (T/S ratio) of study population and compared subgroups
Discussion
This study established a relationship between the relative length of telomeres in peripheral blood mononuclear cells and the frequency of eating red meat. This finding differs from those published by Lee YJ et al. [21] on the impact of dietary patterns on telomere length. This study showed that diet rich with red meat can decrease leucocyte telomere length 10 years after receiving diet data. Our participants had had blood samples collected just after filling out food frequency questionnaire. Hence we analyzed the relationship without any time shift. Our study population was a little younger (18–65 vs. 40–69 at baseline) and eating habits differ between Poland and Korea. Similarly to Lee YJ et al., a relationship was observed in colonocytes of patients who consume higher amounts of red meat [22] but not in those who ate white meat. As mentioned in the introduction, substances that enter the body along with red meat (lipids, heme iron, N-nitroso compounds) can damage the genetic material. This process is well researched in cells directly related to the digestion of red meat products, in terms particularly of carcinogenesis [23–25] can damage the genetic material. Cooking, frying and especially grilling generates substances with mutagenic activity: heterocyclic amines (HCA), polycyclic aromatic hydrocarbons (PAH), lipid peroxides, wherein the amount is dependent on the temperature of meat processing [26]. Increased consumption of processed meat correlates positively with the likelihood of breast cancer [27, 28] and negatively with leucocyte telomere length [29]. Telomere sequences may also be the site of DNA damage [15]. However, some lipid peroxidation products can reduce the risk of carcinogenesis [30]. Carnosine, a dipeptide found in red meat may have a protective effect on telomeres [31]. There is also a published study indicating the negative influence of diet devoid of meat on health status, especially increased incidence of cancer and mental health disorders [32]. This finding can support the concept of positive effects of red meat on health and is also consistent with the results of our study. The positive relationship between diet rich in red meat and the occurrence of tumors of distant organs from the digestive tract may be due to activity of red meat derivatives in the whole body. Peripheral blood mononuclear cells seem to be a good material for the analysis of the impact of red meat derivatives on the body. They are easy to isolate and count. They circulate all over the body and are exposed to the nutrient. Analysis of genetic material derived from these cells allows detection of factors that can influence changes in the genome of other tissues [33].
Our study on a small group of people managed to demonstrate the relationship between the frequency of consumption of red meat and telomere length. Although no attempt was made to estimate the amount of food products. Some studies indicate the risk of underestimating the amount of food products when using the food frequency questionnaires [34]. Micronutrients (e.g. vitamins) can be related to telomere biology, although there are large discrepancies in publications [35–39]. Our study included healthy subjects without symptoms of vitamin deficiency and who were not taking vitamin supplement. At baseline we did not measure micronutrient levels, assuming that there will not be any differences between physiological values in healthy subjects.
Age-related telomere shortening also occurs in PBMC, but there is a large variation in individual - reduction, stabilization and even increase in length [40] and it is still not fully explained [41]. Intake of food rich in small-to-medium-chain saturated fatty acids (SMSFA: milk, butter, cheese) may be associated with PBMC telomere length – inversely relative [42]. In our study we did not find such a relation (dairy products p = 0.81). Small amounts of SMSFA contained in the meat or used for its preparation (e.g. frying with use of butter) can be one of the TL-modifying factors mentioned above. Although high levels of LDL and HDL concentrations are associated with increased risk of cardiovascular diseases, we did not find any association between these parameters and telomere length. Similar findings were noted in other publications [43].
The study did not confirm negative effect of smoking on telomere length. This finding is probably associated with insufficient sample size. Statistical analysis also excluded the effects of smoking as a covariate modifying the TL among red meat consumers. The observation study continues and we expect changes after its completion.
Physical activity of participants did not correlate with telomere length. Two study participants with the highest physical activity had longer telomere length than others, but this difference could not be included in statistical calculations. This may suggest that only intense physical effort as opposed to mild or moderate may modify the biology of telomeres [44, 45]. Body mass index (BMI) can be associated with telomere length and there are studies in large groups of people defining the rate of TL change per BMI unit [46, 47]. We did not find any anthropometric associations – straight or reverse. Adjusting data with BMI or WHR as continuous factors did not significantly change red meat diet impact on PBMC telomere length.
Many studies indicate the relationship between TL and education level [48–50]. Less educated people are on lower incomes, often consume poor-quality foods (stale or processed) [51] containing harmful substances, which damage the genetic material. Our participants did not differ in TL among education levels, mentioned studies were based on the analysis of large populations where identifying weak dependence is easier and effect of covariates is smaller. Additionally - in contrast to our study - tests were performed among groups of people with similar age.
Conclusions
In conclusion, our study findings are at the baseline of further observations of TL changes in response to food and behavior factors. Although we found a relatively strong relationship, it should be treated as a guide for further research on a larger group of people.
Abbreviations
ALT, Alternative Lengthening of Telomeres; ANCOVA, analysis of covariance; ANOVA, analysis of variance; BMI, Body Mass Index; CI, coefficient interval; EDTA, ethylenediaminetetraacetic acid; FFQ, food frequency questionnaire; HCA, heterocyclic amines; HDL, high-density lipoprotein; HSD, honest significant difference; LDL, low-density lipoprotein; PAH, polycyclic aromatic hydrocarbons; PBMC, peripheral blood mononuclear cells; PUFA, polyunsaturated fatty acids; rtPCR, quantitive real-time polymerase chain reaction; SD, standard deviation; SFA, saturated fatty acids; SMSFA, small-to-medium-chain saturated fatty acids; T/S, telomere to single (copy gene); TL, telomere length; WHR, Waist-Hip Ratio
Acknowledgments
The authors would like to thank Bożena Szymańska and Hanna Jerczyńska from Central Laboratory of Medical University of Lodz.
Funding
This study was partially supported by grants no. 503/8-071-03/503-01 and no. 503/1-000-00/503-16 from the Medical University of Lodz.
Availability of data and materials
The datasets analysed during the current study available from the corresponding author on reasonable request.
Authors’ contributions
MK and DN were responsible for study design, data acquisition and statistical analysis. MOE and MP were responsible for cell isolation and laboratory assays. MK, DN and MOE drafted the manuscript. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Not applicable.
Ethics approval and consent to participate
The investigation was conducted in accordance with the ethical standards. The study protocol was approved by the Ethical Committee of the Medical University of Lodz (reference number: RNN/535/13/KB). All participants were informed about the study protocol and asked to sign a written consent form.
Notes
This paper was supported by the following grant(s):
Uniwersytet Medyczny w Lodzi 503/8-071-03/503-01 to Marek Kasielski.
1. Starkweather AR, Alhaeeri AA, Montpetit A, Brumelle J, Filler K, Montpetit M, Mohanraj L, Lyon DE, Jackson-Cook CK. An integrative review of factors associated with telomere length and implications for biobehavioral research. Nurs Res. 2014;63:36–50. doi: 10.1097/NNR.0000000000000009.[PMC free article][PubMed][Cross Ref]
2. von Zglinicki T. Oxidative stress shortens telomeres. Trends Biochem Sci. 2002;27:339–44. doi: 10.1016/S0968-0004(02)02110-2.[PubMed][Cross Ref]
3. Huzen J, Wong LSM, van Veldhuisen DJ, Samani NJ, Zwinderman AH, Codd V, Cawthon RM, Benus GFJD, van der Horst ICC, Navis G, Bakker SJL, Gansevoort RT, de Jong PE, Hillege HL, van Gilst WH, de Boer RA, van der Harst P. Telomere length loss due to smoking and metabolic traits. J Intern Med. 2014;275:155–63. doi: 10.1111/joim.12149.[PubMed][Cross Ref]
4. Bailey SM, Brenneman MA, Goodwin EH. Frequent recombination in telomeric DNA may extend the proliferative life of telomerase-negative cells. Nucleic Acids Res. 2004;32:3743–51. doi: 10.1093/nar/gkh691.[PMC free article][PubMed][Cross Ref]
5. Liu M, Huo YR, Wang J, Wang C, Liu S, Liu S, Wang J, Ji Y. Telomere shortening in Alzheimer's disease patients. Ann Clin Lab Sci. 2016;46:260–5.[PubMed]
6. Zhu X, Han W, Xue W, Zou Y, Xie C, Du J, Jin G. The association between telomere length and cancer risk in population studies. Sci Rep. 2016;6:22243. doi: 10.1038/srep22243.[PMC free article][PubMed][Cross Ref]
7. Boonekamp JJ, Simons MJP, Hemerik L, Verhulst S. Telomere length behaves as biomarker of somatic redundancy rather than biological age. Aging Cell. 2013;12:330–2. doi: 10.1111/acel.12050.[PubMed][Cross Ref]
8. Bischoff C, Petersen HC, Graakjaer J, Andersen-Ranberg K, Vaupel JW, Bohr VA, Kolvraa S, Christensen K. No association between telomere length and survival among the elderly and oldest old. Epidemiology (Cambridge, Mass) 2006;17:190–4. doi: 10.1097/01.ede.0000199436.55248.10.[PubMed][Cross Ref]
9. Fornes NS, Martins IS, Hernan M, Velasquez-Melendez G, Ascherio A. Frequency of food consumption and lipoprotein serum levels in the population of an urban area. Brazil, Revista de saude publica. 2000;34:380–7. doi: 10.1590/S0034-89102000000400011.[PubMed][Cross Ref]
10. Chun YJ, Sohn S-K, Song HK, Lee SM, Youn YH, Lee S, Park H. Associations of colorectal cancer incidence with nutrient and food group intakes in korean adults: a case–control study. Clin Nutr Res. 2015;4:110–23. doi: 10.7762/cnr.2015.4.2.110.[PMC free article][PubMed][Cross Ref]
11. Bishop KS, Erdrich S, Karunasinghe N, Han DY, Zhu S, Jesuthasan A, Ferguson LR. An investigation into the association between DNA damage and dietary fatty acid in men with prostate cancer. Nutrients. 2015;7:405–22. doi: 10.3390/nu7010405.[PMC free article][PubMed][Cross Ref]
12. Guo J, Wei W, Zhan L. Red and processed meat intake and risk of breast cancer: a meta-analysis of prospective studies. Breast Cancer Res Treat. 2015;151:191–8. doi: 10.1007/s10549-015-3380-9.[PubMed][Cross Ref]
13. Ferrucci LM, Sinha R, Graubard BI, Mayne ST, Ma X, Schatzkin A, Schoenfeld PS, Cash BD, Flood A, Cross AJ. Dietary meat intake in relation to colorectal adenoma in asymptomatic women. Am J Gastroenterol. 2009;104:1231–40. doi: 10.1038/ajg.2009.102.[PMC free article][PubMed][Cross Ref]
14. Wie G-A, Cho Y-A, Kang H-h, Ryu K-A, Yoo M-K, Kim Y-A, Jung K-W, Kim J, Lee J-H, Joung H. Red meat consumption is associated with an increased overall cancer risk: a prospective cohort study in Korea. Br J Nutr. 2014;112:238–47. doi: 10.1017/S0007114514000683.[PubMed][Cross Ref]
15. Sun L, Tan R, Xu J, LaFace J, Gao Y, Xiao Y, Attar M, Neumann C, Li G-M, Su B, Liu Y, Nakajima S, Levine AS, Lan L. Targeted DNA damage at individual telomeres disrupts their integrity and triggers cell death. Nucleic Acids Res. 2015;43:6334–47. doi: 10.1093/nar/gkv598.[PMC free article][PubMed][Cross Ref]
16. Bastide NM, Chenni F, Audebert M, Santarelli RL, Taché S, Naud N, Baradat M, Jouanin I, Surya R, Hobbs DA, Kuhnle GG, Raymond-Letron I, Gueraud F, Corpet DE, Pierre, Fabrice HF. A central role for heme iron in colon carcinogenesis associated with red meat intake. Cancer Res. 2015;75:870–9. doi: 10.1158/0008-5472.CAN-14-2554.[PubMed][Cross Ref]
17. Gutierrez-Mariscal FM, Perez-Martinez P, Delgado-Lista J, Yubero-Serrano EM, Camargo A, Delgado-Casado N, Cruz-Teno C, Santos-Gonzalez M, Rodriguez-Cantalejo F, Castaño JP, Villalba-Montoro JM, Fuentes F, Perez-Jimenez F, Lopez-Miranda J. Mediterranean diet supplemented with coenzyme Q10 induces postprandial changes in p53 in response to oxidative DNA damage in elderly subjects. Age (Dordr) 2012;34:389–403. doi: 10.1007/s11357-011-9229-1.[PMC free article][PubMed][Cross Ref]
18. Meza-Miranda ER, Camargo A, Rangel-Zuñiga OA, Delgado-Lista J, Garcia-Rios A, Perez-Martinez P, Tasset-Cuevas I, Tunez I, Tinahones FJ, Perez-Jimenez F, Lopez-Miranda J. Postprandial oxidative stress is modulated by dietary fat in adipose tissue from elderly people. Age (Dordr) 2014;36:507–17. doi: 10.1007/s11357-013-9579-y.[PMC free article][PubMed][Cross Ref]
20. Marcon F, Siniscalchi E, Crebelli R, Saieva C, Sera F, Fortini P, Simonelli V, Palli D. Diet-related telomere shortening and chromosome stability. Mutagenesis. 2012;27:49–57. doi: 10.1093/mutage/ger056.[PMC free article][PubMed][Cross Ref]
21. Lee J-Y, Jun N-R, Yoon D, Shin C, Baik I. Association between dietary patterns in the remote past and telomere length. Eur J Clin Nutr. 2015. [PubMed]
22. O'Callaghan NJ, Toden S, Bird AR, Topping DL, Fenech M, Conlon MA. Colonocyte telomere shortening is greater with dietary red meat than white meat and is attenuated by resistant starch. Clinical nutrition (Edinburgh, Scotland) 2012;31:60–4. doi: 10.1016/j.clnu.2011.09.003.[PubMed][Cross Ref]
23. Toden S, Bird AR, Topping DL, Conlon MA. High red meat diets induce greater numbers of colonic DNA double-strand breaks than white meat in rats: attenuation by high-amylose maize starch. Carcinogenesis. 2007;28:2355–62. doi: 10.1093/carcin/bgm216.[PubMed][Cross Ref]
24. Gilsing AMJ, Fransen F, de Kok, Theo M, Goldbohm AR, Schouten LJ, de Bruïne, Adriaan P, van Engeland M, van den Brandt, Piet A, de Goeij, Anton FPM, Weijenberg MP. Dietary heme iron and the risk of colorectal cancer with specific mutations in KRAS and APC. Carcinogenesis. 2013;34:2757–66. doi: 10.1093/carcin/bgt290.[PubMed][Cross Ref]
25. Hogervorst JGF, de Bruijn-Geraets D, Schouten LJ, van Engeland M, Theo MCM, Goldbohm RA, van den Brandt, Piet A, Weijenberg MP. Dietary acrylamide intake and the risk of colorectal cancer with specific mutations in KRAS and APC. Carcinogenesis. 2014;35:1032–8. doi: 10.1093/carcin/bgu002.[PubMed][Cross Ref]
26. Gilsing AMJ, Berndt SI, Ruder EH, Graubard BI, Ferrucci LM, Burdett L, Weissfeld JL, Cross AJ, Sinha R. Meat-related mutagen exposure, xenobiotic metabolizing gene polymorphisms and the risk of advanced colorectal adenoma and cancer. Carcinogenesis. 2012;33:1332–9. doi: 10.1093/carcin/bgs158.[PMC free article][PubMed][Cross Ref]
27. Mourouti N, Kontogianni MD, Papavagelis C, Plytzanopoulou P, Vassilakou T, Psaltopoulou T, Malamos N, Linos A, Panagiotakos DB. Meat consumption and breast cancer: a case–control study in women. Meat Sci. 2015;100:195–201. doi: 10.1016/j.meatsci.2014.10.019.[PubMed][Cross Ref]
28. Inoue-Choi M, Sinha R, Gierach GL, Ward MH. Red and processed meat, nitrite, and heme iron intakes and postmenopausal breast cancer risk in the NIH-AARP Diet and Health Study, International journal of cancer. Journal international du cancer. 2015. [PMC free article][PubMed]
29. Nettleton JA, Diez-Roux A, Jenny NS, Fitzpatrick AL, Jacobs DR Jr, Dietary patterns, food groups, and telomere length in the Multi-Ethnic Study of Atherosclerosis (MESA)., Am J Clin Nutr. 2008;88:1405–1412. [PMC free article][PubMed]
30. Pizzimenti S, Menegatti E, Berardi D, Toaldo C, Pettazzoni P, Minelli R, Giglioni B, Cerbone A, Dianzani MU, Ferretti C, Barrera G. 4-hydroxynonenal, a lipid peroxidation product of dietary polyunsaturated fatty acids, has anticarcinogenic properties in colon carcinoma cell lines through the inhibition of telomerase activity. J Nutr Biochem. 2010;21:818–26. doi: 10.1016/j.jnutbio.2009.06.005.[PubMed][Cross Ref]
31. Shao L, Li Q-h, Tan Z. l-Carnosine reduces telomere damage and shortening rate in cultured normal fibroblasts. Biochem Biophys Res Commun. 2004;324:931–6. doi: 10.1016/j.bbrc.2004.09.136.[PubMed][Cross Ref]
32. Burkert NT, Muckenhuber J, Großschädl F, Rásky E, Freidl W. Nutrition and health - the association between eating behavior and various health parameters: a matched sample study. PLoS One. 2014;9 doi: 10.1371/journal.pone.0088278.[PMC free article][PubMed][Cross Ref]
33. Diaz-Rua R, Keijer J, Caimari A, van Schothorst, Evert M, Palou A, Oliver P. Peripheral blood mononuclear cells as a source to detect markers of homeostatic alterations caused by the intake of diets with an unbalanced macronutrient composition. J Nutr Biochem. 2015;26:398–407. doi: 10.1016/j.jnutbio.2014.11.013.[PubMed][Cross Ref]
34. Lee K-Y, Uchida K, Shirota T, Kono S. Validity of a self-administered food frequency questionnaire against 7-day dietary records in four seasons. J Nutr Sci Vitaminol. 2002;48:467–76. doi: 10.3177/jnsv.48.467.[PubMed][Cross Ref]
35. Pusceddu I, Herrmann M, Kirsch SH, Werner C, Hubner U, Bodis M, Laufs U, Wagenpfeil S, Geisel J, Herrmann W. Prospective study of telomere length and LINE-1 methylation in peripheral blood cells: the role of B vitamins supplementation. Eur J Nutr. 2015. [PubMed]
36. Shin C, Baik I. Leukocyte telomere length is associated with serum vitamin B12 and homocysteine levels in older adults with the presence of systemic inflammation. Clin Nutr Res. 2016;5:7–14. doi: 10.7762/cnr.2016.5.1.7.[PMC free article][PubMed][Cross Ref]
37. Williams DM, Palaniswamy S, Sebert S, Buxton JL, Blakemore AIF, Hypponen E, Jarvelin M-R. 25-Hydroxyvitamin D Concentration and Leukocyte Telomere Length in Young Adults: Findings From the Northern Finland Birth Cohort 1966. Am J Epidemiol. 1966;183(2016):191–8.[PMC free article][PubMed]
38. Paul L, Jacques PF, Aviv A, Vasan RS, D'Agostino RB, Levy D, Selhub J. High plasma folate is negatively associated with leukocyte telomere length in Framingham Offspring cohort. Eur J Nutr. 2015;54:235–41. doi: 10.1007/s00394-014-0704-1.[PMC free article][PubMed][Cross Ref]
39. Paul L, Cattaneo M, D'Angelo A, Sampietro F, Fermo I, Razzari C, Fontana G, Eugene N, Jacques PF, Selhub J. Telomere length in peripheral blood mononuclear cells is associated with folate status in men. J Nutr. 2009;139:1273–8. doi: 10.3945/jn.109.104984.[PubMed][Cross Ref]
40. Lin Y, Damjanovic A, Metter EJ, Nguyen H, Truong T, Najarro K, Morris C, Longo DL, Zhan M, Ferrucci L, Hodes RJ, Weng N-p. Age-associated telomere attrition of lymphocytes in vivo is co-ordinated with changes in telomerase activity, composition of lymphocyte subsets and health conditions. Clin Sci (Lond) 1979;128(2015):367–77.[PMC free article][PubMed]
41. Steenstrup T, Hjelmborg JVB, Kark JD, Christensen K, Aviv A. The telomere lengthening conundrum--artifact or biology? Nucleic Acids Res. 2013. [PMC free article][PubMed]
42. Song Y, You N-CY, Song Y, Kang MK, Hou L, Wallace R, Eaton CB, Tinker LF, Liu S. Intake of small-to-medium-chain saturated fatty acids is associated with peripheral leukocyte telomere length in postmenopausal women. J Nutr. 2013;143:907–14. doi: 10.3945/jn.113.175422.[PMC free article][PubMed][Cross Ref]
43. Zhang W-G, Zhu S-Y, Zhao D-L, Jiang S-M, Li J, Li Z-X, Fu B, Zhang M, Li D-G, Bai X-J, Cai G-Y, Sun X-F, Chen X-M. The correlation between peripheral leukocyte telomere length and indicators of cardiovascular aging. Heart Lung Circ. 2014;23:883–90. doi: 10.1016/j.hlc.2013.12.016.[PubMed][Cross Ref]
44. Chilton WL, Marques FZ, West J, Kannourakis G, Berzins SP, O'Brien BJ, Charchar FJ. Acute exercise leads to regulation of telomere-associated genes and microRNA expression in immune cells. PLoS One. 2014;9 doi: 10.1371/journal.pone.0092088.[PMC free article][PubMed][Cross Ref]
45. Saßenroth D, Meyer A, Salewsky B, Kroh M, Norman K, Steinhagen-Thiessen E, Demuth I. Sports and exercise at different ages and leukocyte telomere length in later life - data from the Berlin Aging Study II (BASE-II) PLoS One. 2015;10 doi: 10.1371/journal.pone.0142131.[PMC free article][PubMed][Cross Ref]
46. Rode L, Nordestgaard BG, Weischer M, Bojesen SE. Increased body mass index, elevated C-reactive protein, and short telomere length. J Clin Endocrinol Metab. 2014;99:E1671–5. doi: 10.1210/jc.2014-1161.[PubMed][Cross Ref]
47. Müezzinler A, Zaineddin AK, Brenner H. Body mass index and leukocyte telomere length in adults: a systematic review and meta-analysis. Obesity reviews an official journal of the International Association for the Study of Obesity. 2014;15:192–201. doi: 10.1111/obr.12126.[PubMed][Cross Ref]
48. Adler N, Pantell MS, O'Donovan A, Blackburn E, Cawthon R, Koster A, Opresko P, Newman A, Harris TB, Epel E. Educational attainment and late life telomere length in the Health. Aging and Body Composition Study, Brain, behavior, and immunity. 2013;27:15–21. doi: 10.1016/j.bbi.2012.08.014.[PMC free article][PubMed][Cross Ref]
49. Pearce MS, Mann KD, Martin-Ruiz C, Parker L, White M, von Zglinicki T, Adams J. Childhood growth, IQ and education as predictors of white blood cell telomere length at age 49–51 years: the Newcastle Thousand Families Study. PLoS One. 2012;7 doi: 10.1371/journal.pone.0040116.[PMC free article][PubMed][Cross Ref]
50. Steptoe A, Hamer M, Butcher L, Lin J, Brydon L, Kivimäki M, Marmot M, Blackburn E, Erusalimsky JD. Educational attainment but not measures of current socioeconomic circumstances are associated with leukocyte telomere length in healthy older men and women. Brain Behav Immun. 2011;25:1292–8. doi: 10.1016/j.bbi.2011.04.010.[PubMed][Cross Ref]
51. Darmon N, Drewnowski A. Does social class predict diet quality? Am J Clin Nutr. 2008;87:1107–17.[PubMed]
In just its first year, TensorFlow has helped researchers, engineers, artists, students, and many others make progress with everything from language translation to early detection of skin cancer and preventing blindness in diabetics. We're excited to see people using TensorFlow in over 6000 open-source repositories online.
Stardust is a library for rendering information visualizations with GPU (WebGL). Stardust provides an easy-to-use
and familiar API for defining marks and binding data to them. With Stardust, you can render tens of thousands
of markers and animate them in real time without the hassle of managing WebGL shaders and buffers.
<script type="text/javascript">
// Get our canvas element
var canvas = document.getElementById("main-canvas");
var width = 960;
var height = 500;
// Create a WebGL 2D platform on the canvas:
var platform = Stardust.platform("webgl-2d", canvas, width, height);
// ... Load data and render your visualization
</script>
For the tutorial, let’s make some data. You can load data from JSON or CSV files using other libraries such as D3.
var data = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ];
Create a Stardust mark specification:
var circleSpec = Stardust.mark.circle();
Create a mark object using the spec on our WebGL platform:
var circles = Stardust.mark.create(circleSpec, platform);
Stardust: Accessible and Transparent GPU Support for Information Visualization Rendering Donghao Ren, Bongshin Lee, Tobias Höllerer Computer Graphics Forum (Proc. EuroVis), 2017 [ PDF |Video ]
The Competitiveness Council meeting in Brussels this week.
EU Competitiveness Council
In what European science chief Carlos Moedas calls a "life-changing" move, E.U. member states today agreed on an ambitious new open-access (OA) target. All scientific papers should be freely available by 2020, the Competitiveness Council—a gathering of ministers of science, innovation, trade, and industry—concluded after a 2-day meeting in Brussels. But some observers are warning that the goal will be difficult to achieve.
The OA goal is part of a broader set of recommendations in support of open science, a concept that also includes improved storage of and access to research data. The Dutch government, which currently holds the rotating E.U. presidency, had lobbied hard for Europe-wide support for open science, as had Carlos Moedas, the European commissioner for research and innovation.
"We probably don't realize it yet, but what the Dutch presidency has achieved is just unique and huge," Moedas said at a press conference. "The commission is totally committed to help move this forward."
"The time for talking about Open Access is now past. With these agreements, we are going to achieve it in practice," the Dutch state secretary for education, culture, and science, Sander Dekker, added in a statement.
"The means are still somewhat vague but the determination to reach the goal of having all scientific articles freely accessible by 2020 is welcome," says long-time OA advocate Stevan Harnad of the University of Québec in Canada. The decision was also welcomed by the League of European Research Universities (LERU), which called today's conclusions "a major boost for the transition towards an Open Science system."
The council provides few details on how countries can make a full transition to OA in less than 4 years. And given OA's slow march over the past 15 years, some see the target as overly optimistic—if not unrealistic. (LERU calls it "not an easy ambition.") Even the Netherlands, which is considered an OA frontrunner in Europe, until recently had as its official target to reach full OA for Dutch scientific papers by 2024.
But Harnad says the goal is "reachable." What the European Union needs to do is require that its scientific output is deposited in institutional repositories, an option called Green OA. The Dutch government favors Gold OA, in which authors publish in an OA journal; the council does not express a preference for either route.
A spokesperson for the Competitiveness Council admits the 2020 target "may not be an easy task," but stresses the importance of the council's new resolve. "This is not a law, but it's a political orientation for the 28 governments. The important thing is that there is a consensus."
The council's statement is also slightly ambiguous on what exactly should be accomplished by 2020. It calls for "immediate" OA, "without embargoes or with as short as possible embargoes." Many non-OA journals currently allow authors to make their papers available—for instance in an institutional repository—6 or 12 months after publication, but the essence of immediate OA is that a paper is freely available when it gets published. How short journal-imposed embargoes would have to become to qualify as "immediate" OA remains unclear. Harnad says the deposit in an institutional repository should be "immediately upon acceptance for publication (because if the 2019 scientific article output is deposited in 2021, that is not OA in 2020)."
A restored masterpiece unmasks Tokyo's underground gay subculture of the 1960s
A still from Funeral Parade of Roses, 1969. All images courtesy of Cinelicious Pics.
"Each man has his own mask," a voice intones in an art gallery filled with paintings of misshapen, monstrous faces. "Some will wear the same mask for their entire life. Some will wear several masks based on their needs." The voice projects from a reel-to-reel tape recorder on the carpeted ground and it sends Eddie, a gender nonconforming Tokyo bar hostess, into a violent reverie about her childhood trauma. Toshio Masumoto's radical 1969 masterpiece of queer cinema Funeral Parade of Roses, currently re-released in a new restoration, portrays Tokyo's underground LBGT culture as a similar gallery of masks, ones that people wear and occasionally let slip.
Eddie—a tall, slim, fashionable mod who could have stepped right out of a William Klein photoshoot—works in a gay bar (the Genet, no less) by night, entertaining male clientele, and spends the rest of her time with a group of radical leftist filmmakers who quote Jonas Mekas, smoke a lot of marijuana, and have raucous parties. The audience lives inside Eddie's head as she flashes back on her harrowing past to slowly reveal the chaotic whole of her life. Meanwhile, Eddie and her friends live completely in their own world, with almost no interaction with the dominant culture, except the occasional fistfight or protest.
In Noh theater, one of Japan's most important art forms, performers do not "put on" a mask; instead, they become the mask in order to portray the character. As a teenager, abandoned by her father and hated by her mother, Eddie one day looks in the mirror, applies her mother's lipstick, and cries. She kisses her own reflection: finally, the performer has become the mask. "People always wear masks and see masks when they look at others," the voice from the gallery recites, a grim warning for Eddie's future. She faces immediate violence from her mother because of this lipstick incident, and later the characters attend a funeral of one of their own who has committed suicide. It's hard to watch, bringing to mind the atrocious emotional and physical violence trans people have had to face—and, of course, still do.
A still from Funeral Parade of Roses, 1969.
But Masumoto also understands the sensual pleasures of putting on and taking off a mask. Eddie is lovingly filmed in the shower, washing off her makeup; Leda, madame of the Genet, carefully removes her leg hair with a straight razor; Eddie and her friends apply thick stripes of eyeliner in front of the mirror. Naked flesh is fetishized, erotic scenes are shot in close-ups so tight the audience has to work to make out what's happening. Eddie's naked body appears smooth and creamy beneath her lovers' hands, blending into the background as if to suggest infinite pleasure. But sex itself also wears a few masks: it is carnivalesque, as Eddie's sex scenes are occasionally scored by an organ version of "The More We Get Together" and accompanied by dramatic swooping trapeze-like camera movements; and it can be disturbing, as when Eddie's mother and lover are spied upon (a common trope of slasher films in the decades to come).
Funeral Parade of Roses' form follows its function; the audience is ripped out of its fictional universe at several key moments by documentary footage of the actors speaking about their roles, and about their own participation in Tokyo's real-life "gay boy" scene. For instance, during an erotic scene between Eddie and an American bar patron, her head rolling back with pleasure, the frame suddenly pulls back to reveal the cast and crew surrounding the bed, all of them watching Peter (the brilliant first-time actor who plays Eddie) loll around, faking passion for the camera. Matsumoto seems to challenge the audience here: What more is a film than another mask? And fittingly, by the film's end, Eddie's mask has fallen away completely, and she turns from spectator to chilling Oedipal spectacle. Once nearly impossible to see, Funeral Parade of Roses is a dizzying pop experimental epic that bounds off the screen and screams to be heard.
Newly restored from the original camera negative, Funeral Parade of Roses is currently playing at the Quad in New York City, and opens this Friday, June 16, at The Cinefamily in Los Angeles. Additional screenings in the US and Canada continue through the summer.
Dana Reinoos is a writer and former film programmer based in Milwaukee, WI.
The arrangement became much more complicated Friday, when Amazon said it was buying Whole Foods for $13.7 billion. For Instacart, the deal will turn Whole Foods -- its premier partner and investor -- into a subsidiary of its biggest foe.
Instacart has about four years left in a delivery partnership it signed with Whole Foods in 2016, said a person familiar with the matter. The contract made Instacart the exclusive delivery provider for Whole Foods perishables, including produce, deli meats and baked goods, as well as nearly all non-perishable items, the person said. Instacart believes Amazon’s purchase won’t affect the arrangement, said the person, who asked not to be identified because the details are private.
Silicon Valley has made a huge bet on Instacart, despite the dramatic implosion of another grocery-delivery business called Webvan after the dot-com bubble. Instacart was founded in 2012 by Apoorva Mehta, who’s still chief executive officer today. His company has attracted some $700 million in the four years since it started. Sequoia Capital, a major investor in both Webvan and Instacart, doubled down on the younger startup by leading a $400 million funding round a few months ago. Sequoia and Whole Foods declined to comment.
“From the beginning, we’ve been committed to helping grocers compete online,” Instacart wrote in an emailed statement. “That’s more important than ever given Amazon just declared war on every supermarket and corner store in America.”
Since Whole Foods became Instacart’s first national partner in 2014, the two companies have had a tight relationship: Some Whole Foods stores have cashiers dedicated to Instacart orders, as well as special in-store shoppers and staging areas for bagging online orders. They deepened the relationship in 2016 with the long-term contract. Bloomberg reported last year that the retailer also invested more than $30 million in the startup. Whole Foods wasn’t granted access to Instacart’s private financial disclosures as part of the investment, nor will Amazon receive such information, said the person familiar with the matter.
Instacart generates revenue from commissions on orders from 160 retail partners, delivery fees from customers, advertising on its site and coupons. Whole Foods accounts for less than 10 percent of Instacart’s revenue, said the person, without clarifying whether that includes delivery fees or other sales generated from those transactions. This year’s investment led by Sequoia valued the San Francisco startup at $3.4 billion.
Amazon sells fresh produce and household items in more than 20 U.S. cities and abroad. Instacart operates in 69 U.S. markets. If Amazon chooses to continue relying on Instacart for delivery at some stores, the startup could prove itself to be a valuable partner, said Guru Hariharan, a former Amazon manager and founder of Boomerang Commerce Inc., a company that designs software for large retailers.
“Instacart’s core value proposition is last-mile delivery at scale, something Amazon has always struggled with,” Hariharan said. “The key for Instacart is to morph itself into a service that is additive, not competitive for the big giant, Amazon.”
If the relationship falls apart, Instacart may be able to bolster its original pitch about the perils of Amazon to lure other retail partners. Most grocers don’t have the resources to build their own online delivery systems, said Brian Frank, who invests in food-tech companies through his FTW Ventures fund.
“While Instacart could lose their crown jewel of Whole Foods, they may gain in a swell of demand from the rest of the market, and even more mid-range and budget stores coming to them for services to try and compete with Amazon,” Frank said.
After tanking up on “pruno,” a bootleg prison wine, eight maximum-security inmates at the Utah State prison in Salt Lake County tried to shake off more than just the average hangover. Their buzz faded into double vision, weakness, trouble swallowing, and vomiting. Tests confirmed that the detainees came down with botulism from their cellblock science experiment. In secret, a prison moonshiner mixed grapefruit, oranges, powdered drink mix, canned fruit, and water in a plastic bag. For the pièce de résistance, he added a baked potato filched from a meal tray weeks earlier and peeled with his fingernails. After days of fermentation and anticipation, the brewer filtered the mash through a sock, and then doled out the hooch to his fellow yardbirds.
The party was short-lived. The potato was a big mistake.
Investigators traced botulism spores to the humble spud. Within hours of the first swig, botulinum toxin infiltrated the prisoners’ nerve cells, causing weakness and paralysis. Three of the men required a breathing tube and ventilator to prevent suffocation. All eight victims received an experimental antitoxin from the Centers for Disease Control and Prevention, and thanks to meticulous supportive care, none died. But recovery from botulism takes weeks to months; the body must regrow new nerve endings to replace the poisoned ones. All told, the hospital bill topped their bar tab—more than $500,000 in fees alone, not including added expenses for transportation, security, and public health investigation.
Botulinum toxin, a protein produced by the bacterium Clostridium botulinum, could be “the most poisonous poison” there is, as writer Carl Lamanna called it in an article for Science, in 1959. First weaponized by Imperial Japan in the 1930s, and later, Nazi Germany, the United States, the Soviet Union, Syria, Iran, Iraq, and North Korea, a single gram of toxin could theoretically kill more than a million people if dispersed into the air and inhaled. But before botulinum toxin became a bioweapon and a smoother of crow's feet as the drug Botox, botulism was historically a foodborne malady, and the toxin lurked in sausage and cured meats.
Botulism, the illness caused by toxin exposure, first received scientific attention in rural Germany in the late 18th century. Officials in Stuttgart saw an increase in “sausage poisoning” in the wake of the Napoleonic wars, possibly due to poor sanitation and widespread poverty. In the 1820s, a young German physician named Justinus Kerner was the first scientist to publish an accurate and comprehensive description of the disease. He analyzed more than 200 cases of suspected sausage poisoning. He fed extracts of these “sour” sausages to animals and described the classic symptoms of botulism. Muscle weakness leading to drooped eye lids, difficulty swallowing, and respiratory failure; altered autonomic nerve function leading to vomiting, pupil dilation, and dry mouth. Brazenly, he sampled a few drops of this extract himself—he survived, though it caused a “great drying out of the palate and pharynx,” a harbinger of Botox’s modern application in treating uncontrollable salivation for those with amyotrophic lateral sclerosis, or Lou Gehrig’s disease. Grateful citizens dubbed the scientist “Wurst-Kerner,” for his pioneering contributions to public health and sausagery. In 1870, another German physician renamed the illness “botulism” after the Latin word “botulus,” or sausage.
For centuries, people dried, smoked, fermented, canned, and neglected their food, naïve to the microbial threat festering within. This changed in the late 19th and early 20th centuries as science moved from the laboratory into the kitchen. In 1895, Émile van Ermengem isolated a spore-forming bacterium from the remnants of a salted ham that killed three musicians in a Belgian outbreak. He confirmed that Kerner’s mysterious sausage—or ham—poison was made by a microbe. Under very specific growth conditions, the active form of the bacterium could be coaxed to grow and produce toxin; under other conditions, the bacterium would retreat into a dormant, or spore form that does not do so.
Early 20th century researchers found Clostridium botulinum spores nearly anywhere: in soil, rivers, lakes, oceans, on vegetable surfaces, and in fish and animal intestines. Laboratory tests demonstrated that spores are durable: they withstand even boiling. When introduced into an optimal, low-oxygen environment—like the inside of a jar or can of food—spores germinate and make the toxin. Given the ubiquity of botulinum spores in the environment, it is surprising that outbreaks were not more frequent.
As food science matured into its own discipline, botulism outbreaks resulting from commercially canned foods dwindled. Food producers could stop toxin production by manipulating temperature, acidity, salt content, moisture, oxygen concentration, and food preservatives such as nitrates or nitrites. Pressure-cooking freshly canned goods at 250 degrees Fahrenheit destroys spores in 20 minutes, enabling safe long-term storage.
Modern foodborne outbreaks occur when botulism control methods are deliberately, or inadvertently, ignored. Homemade foods are now the leading cause of the disease in the U.S., which is not surprising, as only 59 percent of home canners preserving botulism-friendly low acid vegetables actually use a pressure sterilizing process, according to a National Center for Home Food Preservation survey. Fortunately, botulism remains rare nationwide: between 1990 and 2000, 160 outbreaks afflicted only 263 people. And advances in medical care, including antitoxin availability and intensive care units, have decreased the fatality rate from 60 percent in the first half of the 20th century to about 5 percent now.
But food safety improvements pioneered in the last century occasionally fail the most vulnerable consumers. Young babies now account for most botulism cases reported in the U.S. The cause of infant botulism remains unknown. Infants’ digestive systems are hospitable to Clostridium botulinum, perhaps because their gut bacteria and digestive juices are still immature. Ingested spores activate and produce toxin that is absorbed into the body. Afflicted babies become constipated and “floppy” as the relaxed paralysis takes hold. Like adults, they may require breathing support on a ventilator, but most recover. Early investigators identified honey as a possible spore source in about 20 percent of victims, but most cases remain unexplained—some have wondered whether spore-laden household dust could be the culprit.
Although botulism caused floppy babies for centuries, the first case report of infant botulism was published only in 1976. Around this time, American epidemiologists uncovered another botulism mystery: a geographic one. California, Oregon, Washington, and Alaska accounted for the majority of foodborne outbreaks from 1950 to 1996. They found one answer in Alaska.
For generations, indigenous Alaskans prepared traditional foods using available resources and recipes inherited from their ancestors. To preserve meat, they buried fresh animal parts in cool clay-lined pits to undergo controlled microbial decay under a layer of moss or grass. The final product is complex in flavor, rich in nutrients, portable, and safe from scavengers—no cooking needed! Scandanavians historically used a similar process to make gravlax, which literally translates to “grave salmon.” We now know that traditional preserved meats like seal, whale (“muktuk”), beaver tail (“stink tail”), and salmon heads (“stink heads”) can nurture Clostridium botulinum, much like Kerner’s sausage.
In the far North, as in Europe, foodborne botulism is nothing new. In 1913, explorer Vilhjalmur Stefansson reported a suspected botulism outbreak of “white whale poisoning” that killed eight Inuit. Alaskan botulism rates skyrocketed in the 1970’s and 80’s while remaining steady nationwide. This trend was likely caused by changes in food preservation practices, though better record keeping and detection of the illness probably contributed. As Alaska modernized, “stink” chefs substituted breathable earthen pits or animal skins with readily sourced vessels made of wood, glass, or plastic. New containers facilitate fast indoor fermentation without the hassle of digging. Better living through chemistry? Perhaps not. Investigators suspect that these well-sealed containers create a warm, oxygen-deprived environment more hospitable to botulinum spores.
In response to the botulism epidemic, Alaskan tribal and public health officials launched an educational campaign encouraging citizens to return to the traditional meat preservation methods of their forebears. Their message is counterintuitive—who could imagine that burying meat in the ground is less harmful than sealing it in a clean bucket? Some are heeding the advice, as Alaskan foodborne botulism is at its lowest since the 1960’s, despite remaining more than 800 times the national average. Declining popularity of “stink” foods could also be contributing to the decline. Nonetheless, the Alaskan botulism experience serves as a culinary “I told you so” to younger generations. Sometimes, you shouldn’t mess with the recipe.
Much like native Alaskan cuisine, prison brewing has a storied tradition. The recipe is simple: All you need is a carbohydrate (sugar or starch), a spirit of adventure, and time. Pruno owes its name to the dried prunes historically used as a sugar source. Natural airborne yeasts, or those “back-slopped” from a prior batch, ferment the carbohydrate into alcohol. This is hastened by heating. Prison brewers will steep bags of young pruno in hot water and swaddle them in blankets for insulation. Carbohydrate choice is limited only by resources and creativity: potatoes, fresh fruit, fruit cocktail, raisins, prunes, sugar packets, ketchup, yams, jello, honey, corn, rice, bread, jelly, cake frosting, and hard candies have all been used.
Pruno causes headaches for drinkers and wardens alike, as corrections officials struggle to balance inmate nutrition with order. Tipsy prisoners are more likely to brawl. In 2002, the Los Angeles Times reported that the maximum-security state prison in Lancaster, California banned fresh fruit from the lunches delivered to each inmate’s cell in order to discourage pruno brewing, though prisoners continued to receive at least 15 servings of fresh fruit each week under observation in the cafeteria. Given nutritional needs and the availability of sugar sources, one official lamented, “It’s pretty much an unwinnable battle.”
Lukewarm pruno, low in acid, salt, and oxygen, is a paradise for C. botulinum. Spores can contaminate the brew in any number of ways, but in the case of the 2011 Utah outbreak, epidemiologists fingered the baked potato. Similar potato-borne pruno outbreaks occurred in California state prisons in Riverside County in 2004 and Monterey County in 2005, and twice in Pinal County, Arizona in 2012. In the outside world, improperly baked potatoes cause occasional restaurant botulism outbreaks. These episodes often involve potatoes baked in aluminum foil, as foil insulates the durable C. botulinum spores from lethal cooking temperatures. When the wrapped potatoes are removed from the oven, the stressed—but intact—spores germinate to produce toxin in the moist, warm, airtight environment.
The long-recognized relationship between baked potatoes and botulism earned the troublesome tuber a classification as a “potentially hazardous food” in the Food and Drug Administration’s Food Code. Potatoes, like C. botulinum, grow in the soil, and botulinum spores seem quite at home on their surface. Proper cooking and storage kills spores and inhibits toxin formation. In the case of the Utah outbreak, spores probably germinated in the warm, sealed container during the “undetermined number of weeks” the potato spent in hiding prior to being used in pruno. In response to multiple botulism outbreaks from potato-based pruno, the Arizona State Prison Complex-Eynman banned potatoes from prison meals.
Food and drink have been cohabitating with C. botulinum as long as humans have been sealing them in containers. With safe prepared food on every supermarket shelf, it is easy to forget that civilization had to learn the fundamental lessons of food storage the hard way—through sausage and white whale poisoning. As local food sourcing grows in popularity, more environmentally and health conscious Americans are surrendering their Oscar Meyer for the home pickled, smoked, canned, dried, and fermented foods of generations past. As they rediscover the richness, independence, and simplicity of do-it-yourself cuisine, they must not forget the lessons of Kerner, van Ermengem, and the early pioneers of food microbiology.
In the 20th century, government oversight of commercial meat production undoubtedly saved lives. Botulism outbreaks are now headline-grabbing events, rather than just another day in Stuttgart. Though today, many aspiring restaurateurs and meat curers feel stifled by the rigorous certification process required by local and federal food safety inspectors before they can legally sling their salami to the public. Under the current system, regulators set standards, and producers must prove that their products meet them.
Underground Meats, a Wisconsin meat curer and culinary sibling of Forequarter, a James Beard semi-finalist restaurant, proposes an innovative solution. With more than $49,000 raised on the fundraising website Kickstarter, underground meatmaster Jonny Hunter aims to develop and publish an open-source food safety plan for the production dry-cured salami. This plan, known as a “Hazard Analysis and Critical Control Points,” proves to regulators that a recipe is safe. In the artisan salami world, HACCP’s are typically closely guarded industry secrets, given the time, money, and scientific resources invested in their development.
Hunter aims to “make our local food more accessible and safe.” To stifle harmful bacteria, Underground Meats employs a strategy of acidity changes, controlled drying, and addition of nitrates to directly kill any remaining bugs including C. botulinum. “Nitrate-free” and “no nitrite added” meats, Hunter adds, are a “huge hoax,” as they are made with celery powder—an alternative source of nitrates, albeit not labeled as such. “We believe food safety information should not be proprietary. If someone has a better idea about how a process can limit food borne illness, that information should be free for everyone to access.” He continues, “Open source could be a great model in increasing the food safety knowledge in this community and I hope it is one that sticks.” Somewhere in Sausage Heaven, Justinus Kerner is smiling.
Over time, changes in cooking and food storage trends periodically reinvent man’s relationship with botulism. Be it canned corn or muktuk, the basics of botulism control—careful attention to salt and water balance, moisture, acidity, temperature, and oxygen content—stay the same. C. botulinum is no feral beast: it is a creature of habit, though fortunately, a rare one. Adherence to time-vetted recipes and practices can prevent a trip to the intensive care unit.
So the next time your buddy offers you a cup of room-temperature pruno, politely decline. If you really got a hankerin’, at least make sure he skipped the potato.
After it's all over, your lights will be just as bright, and your refrigerator just as cold. But very soon the ampere -- the SI base unit of electrical current -- will take on an entirely new identity,* and NIST scientists are at work on an innovative, quantum-based measurement system that will be consistent with the impending change.
It won't be a minute too soon. The ampere (A) has long been a sort of metrological embarrassment. For one thing, its 70-year-old formal definition, phrased as a hypothetical, cannot be physically realized as written:
The ampere is that constant current which, if maintained in two straight parallel conductors of infinite length, of negligible circular cross-section, and placed 1 meter apart in vacuum, would produce between these conductors a force equal to 2 x 10–7 newton per meter of length.
For another, the amp's status as a base unit is problematic. It is the only electrical unit among the seven SI base units. So you might logically expect that all other electrical units, including the volt and the ohm, will be derived from it. But that's not the case. In fact, the only practical way to realize the ampere to a suitable accuracy now is by measuring the nominally "derived" volt and ohm using quantum electrical standards and then calculating the ampere from those values.**
In 2018, however, the ampere is slated to be re-defined in terms of a fundamental invariant of nature: the elementary electrical charge (e).*** Direct ampere metrology will thus become a matter of counting the transit of individual electrons over time.
One promising way to do so is with a nanoscale technique called single-electron transport (SET) pumping. Specially adapted at NIST for this application, it involves applying a gate voltage that prompts one electron from a source to tunnel across a high-resistance junction barrier and onto an "island" made from a microscopic quantum dot. (See animation above.)
The presence of this single extra electron on the dot electrically blocks any other electron from tunneling across until a gate voltage induces the first electron to move off the island, through another barrier, and into a drain. When the voltage returns to its initial value, another electron is allowed to tunnel onto the island; repeating this cycle generates a steady, measurable current of single electrons.
There can be multiple islands in a very small space. The distance from source to drain is a few micrometers, and the electron channels are a few tens of nanometers wide and 200 nm to 300 nm long. And the energies involved are so tiny that that device has to be cooled to about 10 millikelvin in order to control and detect them reliably.
Conventional, metallic SET devices, says NIST quantum-ampere project member Michael Stewart, can move and count single electrons with an uncertainty of a few parts in 108 -- in the uncertainty range of other electrical units -- at a rate of tens of millions of cycles per second. "But the current in a single SET pump is on the order of picoamperes [10-12 A]," he says, "and that's many orders of magnitude too low to serve as a practical standard."
So Stewart, colleague Neil Zimmerman, and co-workers are experimenting with ways to produce a current 10,000 times larger. By using all-silicon components instead of conventional metal/oxide materials, they believe that they will be able to increase the frequency at which the pump can be switched into the gigahertz range. And by running 100 pumps in parallel and combining their output, the researchers anticipate getting to a current of about 10 nanoamperes (10-9 A). Another innovation under development may allow them to reach a microampere (10-6 A), in the range that is needed to develop a working current standard.
"At present, we are testing three device configurations of different complexity," Stewart says, "and we're trying to balance the fabrication difficulties with how accurate they can be."
In addition to its use as an electrical current standard, a low-uncertainty, high-throughput SET pump would have two other significant benefits. The first is that it might be combined with ultra-miniature quantum standards for voltage or resistance into a single, quantum-based measurement suite that could be delivered to factory floors and laboratories. The overall effort to provide such standards for all the SI base units is known as "NIST-on-a-Chip," and is an ongoing priority of NIST's Physical Measurement Laboratory.
The other advantage is that an SET pump could be used in conjunction with voltage and resistance standards to test Ohm's Law. Dating from the 1820s, it states that the amount of current (I) in a conductor is equal to the voltage (V) divided by the resistance (R): I=V/R. This relationship has been the basis for countless millions of electrical devices over the past two centuries. But metrologists are interested in testing Ohm's law with components which rely on fundamental constants. An SET pump could provide an all-quantum mechanical environment for doing so.
In a separate effort, scientists at NIST's Boulder location are experimenting with an alternative technology that determines current by measuring the quantum "phase-slips" they engender while traveling through a very narrow superconducting wire. That work will be the subject of a later report.
* In 2018, the base units of the International System of Units (SI) are scheduled to be re-defined in terms of physical constants, with major changes in the kilogram, ampere, kelvin, and mole.
** Josephson voltage and quantum Hall effect resistance can be determined via quantum constants to uncertainties of parts per billion or less.
*** The charge of a single electron will be fixed at a value of 1.60217X × 10-19 ampere-second, where "X" will be specified at the time of the redefinition. One ampere-second is the same as one coulomb.
Tweak the create-react-app webpack config(s) without using 'eject' and without creating a fork of the react-scripts.
All the benefits of create-react-app without the limitations of "no config". You can add plugins, loaders whatever you need.
All you have to do is create your app using create-react-app and then rewire it.
⚠️Please Note:
By doing this you're breaking the "guarantees" that CRA provides. That is to say you now "own" the configs. No support will be provided. Proceed with caution.
1) Install react-app-rewired
$ npm install react-app-rewired --save-dev
2) Create a config-overrides.js file in the root directory
/* config-overrides.js */module.exports=functionoverride(config, env) {//do stuff with the webpack config...return config;
}
Al Jarvis was 16 when he started working at a McDonald’s in Saginaw, a city in Michigan, in 1965. His first customer ordered an All-American: a burger, fries, and shake for 52¢. Soon Jarvis was working 50 hours a week and catching up on sleep at school. He skipped college to manage restaurants. By 1977 he was advising McDonald’s franchisees and helping with store openings across the state. One day in 1980, as he was unpacking his garment bag, his young son asked, “Daddy, where do you live?” So the next year he bought a McDonald’s in Hastings, southeast of Grand Rapids. Over the years he hired hundreds of employees, saw dozens of menu items come and go, and spent four or five hours a day, five or six days a week, watching over the counter and grills from his vantage at the fry station.
Jarvis looked forward to celebrating 50 years with McDonald’s this past May. And then, six months short of that milestone, he sold his restaurants. “I wanted to get the hell out,” he says one recent morning as he sits in the Hastings McDonald’s, sipping a skinny vanilla McCafé Latte. Such “foo-foo coffee,” as he calls espresso and its variants, is partly why he bailed: He loves the taste, but the complexities of making it came to epitomize his disillusionment with McD’s. “The service times went up because of the expansion of the menu,” he says. “I think they went a little overboard. It was difficult in the kitchen. When I would come down Apple Street behind the restaurant and see cars backed up at the drive-thru, my stomach would just knot up. The people were different, the company was different. It became very frustrating.”
“Big Al” Jarvis
Photographer: Ryan Lowry for Bloomberg Businessweek
There are 5,000 McDonald’s franchisees around the world. They run 82 percent of the chain’s 36,000-plus restaurants and generate a third of its $27.4 billion in annual revenue. The average franchisee has six outlets; Jarvis had two, including one he built in Gun Lake, near Hastings. A lanky 67-year-old known around Hastings as Big Al, he likes to say he has ketchup in his blood. His watch is embossed with the Golden Arches logo. “McDonald’s was awful good to me,” he says. “I believe in the brand.” But like many of his fellow operators, he wonders whether executives at headquarters will figure out how to innovate while staying true to the chain’s promise of serving good-tasting food fast. Jarvis’s experience suggests the answer is no, and unlike current franchisees, who are reluctant to speak on the record because they don’t want to provoke HQ, Jarvis is free to say what others can’t or won’t.
“I don’t think they know what they want to do,” he says of McDonald’s top executives. “They’re saying, ‘Let’s go back to basics,’ then they’re doing these customized burgers, and they’re talking about all-day breakfast.” He shakes his head. “I feel sorry for the managers and the crew. That’s not our niche. We make burgers and fries.”
For the first time in at least three decades, McDonald’s this year will close more restaurants in the U.S. than it opens, for a net loss of 59 locations. Same-store sales in the U.S., where McDonald’s gets 30 percent of its revenue, have declined in eight of the past 10 quarters. It’s a number that Wall Street watches closely. The company’s shares have underperformed the Standard & Poor’s 500-stock index for the last three calendar years.
McDonald’s has gussied up its restaurants, stuffed tortillas with baby kale, and promised to rid its chicken of antibiotics, all to little avail. This year it promoted a sirloin burger in ads bringing back the Hamburglar character as a hipster with chin stubble and a Zorro mask; the company recently said the sandwich didn’t meet sales expectations. The sirloin burger was only the latest would-be hit that flopped.
At the same time, a glut of new menu items has slowed service to the point that McDonald’s drive-thru waits in 2013 grew to their longest since at least 1998, according to QSR, a restaurant industry magazine. Slowness at McDonald’s is, of course, sacrilege. If nothing else, the chain has always been known for speed. Ever since the days of owner Ray Kroc, it’s been a growing network of continuously improved assembly lines delivering the exact same food in the exact same form as quickly as possible.
And it’s not like people are tired of burgers. Smashburger, In-N-Out Burger, BurgerFi, and Five Guys Burgers & Fries are all expanding. So is Shake Shack, which has grown from a cart in a Manhattan park in 2001 to 71 locations (each estimated to ring up, on average, about twice the sales of a McDonald’s store in the U.S.) and which saw a January 2015 initial public offering. In Chicago, customers wait in line for three hours for the cheeseburgers at haute diner Au Cheval.
McDonald’s is also trying to compete with Starbucks, Chick-fil-A, and Jamba Juice. Rare is the food trend that the company won’t try to prefix with Mc. “They’re doing too much,” says Bob Goldin, executive vice president at researcher Technomic. “And they don’t seem to be the best at anything anymore.” Franchisees polled recently by industry analyst Mark Kalinowski registered their gloomiest six-month outlook in the survey’s 12-year history.
This summer, McDonald’s raised hourly worker wages at company-owned stores to at least $1 above the local minimum. That may be a good or bad move, depending on one’s views of the free market. Either way, it put pressure on independent operators to follow suit, which hardly renewed their affection for the suits at headquarters. Steve Easterbrook, the 48-year-old Brit who became chief executive officer in March, has named an executive to strengthen ties with franchisees. In an e-mail, McDonald’s spokeswoman Becca Hary said, “We have a strong working relationship with our independent franchisees, and together we are standing strong and working to turn around McDonald’s business.”
In early September, McDonald’s announced it would start offering all-day breakfast across the U.S. Customers will soon be able to order a limited selection of breakfast items past the usual 10:30 a.m. cutoff. That will require changes in the restaurants, such as finding room on the grills for eggs and in the fryer baskets for hash browns when most customers are ordering burgers and fries. Those changes cost money—including a potential $500 to $5,000 for equipment—that will fall mostly on franchisees. Customers will be displeased to learn that some of their favorite items, such as Egg McMuffins, won’t be available after 10:30 everywhere. It all depends on a particular outlet’s capacity, staffing, and configuration of kitchen equipment. Serving food at McDonald’s scale is an intricate ballet, and adding complexity can lead to longer lines. “I’m not going to miss that at all,” Jarvis says.
“They’re saying, ‘Let’s go back to basics,’ then they’re doing these customized burgers, and they’re talking about all-day breakfast”
The franchise Jarvis bought in 1981 sits on State Highway M-43 just west of downtown Hastings. Lined up on either side of the road are Burger King, Wendy’s, Pizza Hut, KFC, Subway, Biggby Coffee, and a handful of other chains. There’s an auto parts store where Jarvis’s main rival three decades ago, Burger Chef, once stood.
He won’t say what he paid for his store, but he had to take a Small Business Administration loan at the Jimmy Carter-era interest rate of 16 percent. And the store was a fixer-upper, losing money in a state where a healthy McDonald’s could bring in $750,000 to $900,000 in annual revenue, as much as $2.4 million in today’s dollars. Employees were “hanging out windows smoking cigarettes, giving free food to their friends,” he says. Even the coffee was terrible—no one was keeping the coffee-making gear clean.
At least the menu was blessedly simple, with about a third of today’s 100-plus items. “Back then, you could crank out a lot of burgers with 10-to-1 meat,” Jarvis says, referring to boxes of 10 burger patties per pound. He quarterbacked his staff from the fry station near the center of the store, becoming a stickler for following McDonald’s exacting standards for preparing food. “French fries were our bread and butter,” he says. “I wanted a fry person who, when the fries were seven minutes old in the fry basket, they would throw them away. It’s in the manual.”
He supported the local 4-H and joined the Kiwanis club, the country club, and a bowling league. He’s still in the bowling league (175 average, high game 256) but not the country club. “I found out the country club wasn’t as good for eaters as the bowling league,” he says.
Jarvis thought he could get the store into the black in six months; it took 18. One of his worst years was in the late 1980s, after the local Burger Chef went out of business. Without a rival down the block, “we didn’t have to work as hard,” he says. Service suffered. Customers went to Kalamazoo and Grand Rapids to try other restaurants. “I like competition,” he says. “It keeps families in town.”
Photographer: Jamie Chung for Bloomberg Businessweek
By the ’90s, things were better, and annual sales were rising by the double digits. At headquarters in suburban Chicago, he says, “I was a hero.” He was also becoming a bit of a recalcitrant, shunning company meetings and conventions so he could mind his store: “I was more interested in building my own business.”
McDonald’s franchisees can be a cranky bunch, chafing under corporate dictates even as they embrace the brand. Some of the tension comes from conflicting agendas between headquarters and store operators. Although the company owns only 18 percent of its stores worldwide, it owns or controls the land and buildings for the vast majority. McDonald’s charges franchisees rent ranging from 8.5 percent to 15 percent of revenue, depending on location and other factors. It also collects a 4 percent royalty on sales, and franchisees contribute to national and local advertising funds.
So while McDonald’s focuses on the stores’ top line, operators worry about what’s left after paying rent, royalties, payroll, and other expenses. Generally, they do well. Jarvis declines to discuss his income, but it’s not unusual for owners to make six figures, according to Arturs Kalnins, a management professor at Cornell who studies franchising. An owner who regularly works in a McDonald’s can collect a manager salary of $108,000 on top of the store profit, he says.
The calculus gets more complicated when McDonald’s insists on, say, a new product such as McCafé coffee, requiring a $15,000 to $20,000 espresso machine. The franchisee, not the company, pays for it. On bigger projects such as store remodelings, the company sometimes shares the cost.
Everyone’s happy so long as a given investment attracts enough business to recoup the costs. Jarvis was delighted in 1998, after he paid to replace his original restaurant with one next door that included an enormous indoor playground. Families with little kids loved it.
The same year, McDonald’s expanded into its 114th country (Sri Lanka, FYI) and opened its 12,472nd U.S. location. But domestic sales were lackluster and franchisees restless. Customers were opting for what they saw as better-tasting burgers at Wendy’s and Burger King. Analysts urged McDonald’s to consider what else it could sell.
Even during those off years, Jarvis says his store did fine by adhering to Kroc’s QSCV doctrine: quality, service, cleanliness, and value. Jarvis says he leaned heaviest on the Q. “If I go to a restaurant and wait a few minutes and have a great meal, I’ll overlook a little more time,” he says. “If I have a bad meal, I’m never going back.”
In 2013, McDonald’s rolled out the McWrap. Executives hoped the salad-in-a-tortilla—years in the making—would entice millennials who were gravitating toward carnitas and fajita-veggie burrito bowls at Chipotle. Jarvis liked the taste and novelty of McWraps, but he didn’t like how tricky they were to prepare. Corporate policy allots a 90-second window for serving each customer, no matter the order, which Jarvis found impossible with the McWrap. “I was happy with three minutes,” he says.
It took 20 seconds alone to steam a McWrap tortilla. Chicken had to be chopped and stuffed inside, along with sauce, bacon, lettuce, tomato, and cucumbers, depending on which of the nine varieties of McWrap a customer ordered. The whole thing then had to be rolled tight enough to fit into a slim cardboard box designed to make McWraps easier to eat while driving. Tortilla rolling turned out to be an inexact science. Sometimes the finished wraps were too big for the boxes and had to be rerolled. Fitting them in quickly and consistently “was a nightmare,” says Annette Snyder, who’s been general manager in the Hastings McDonald’s for more than 30 years. McWraps are now off the menu at about half of the stores in the U.S., including the one in Hastings.
McWrap was just the latest concoction to bog down Jarvis’s kitchen. His restaurant had been slowing since 2005, as McDonald’s expanded the menu with new salads, McGriddles, Fruit N’ Yogurt Parfaits, the Big N’ Tasty burger, and other items—some of which sold, some not, Jarvis says. McCafé beverages, which premiered across the U.S. in 2009—lattes, cappuccinos, mochas—were especially troublesome. Orders backed up as staffers changed 5-gallon bags of whole and skim milk at least once a day and juggled ingredients for dozens of drink variations on a single machine. Jarvis didn’t have room for two. “The drinks are all very good, but you have one machine, and it only makes the drinks so fast,” Snyder says. “It has really slowed things down.” McDonald’s says McCafé beverages have added $125,000 in annual revenue per restaurant.
The Dollar Menu, introduced in 2002, helped bring in customers during the Great Recession. But as beef and other commodity costs went up, Jarvis raised prices of some dollar items to $1.10 and $1.20—as is a franchisee’s prerogative—and “got harassed about it” by the company. “We were just losing money,” he says. And whether franchisees turned a profit or not, they had to pay royalties on the revenue.
At McDonald’s behest, Jarvis tried to keep his store open 24 hours in 2009. He figured he needed $100 an hour of revenue to break even, but he was getting only $15 or $20 from 2 a.m. to 4 a.m. He tried the always-open experiment twice and gave up both times after a few months. He did, however, like headquarters’ idea of adding a second drive-thru. Vehicles in the single lane had been backing up onto the highway. The new lane, which cost him $100,000 to build, paid for itself within a year. But even with the two lanes, lines of vehicles started building up again as his employees scrambled to make skinny vanilla McLattes.
By early 2014, after several years of slowing sales growth, Jarvis decided enough was enough. That March, during his annual operator’s review, he told McDonald’s he intended to sell both his stores.
Even with two drive-thru lanes, the lines built up again as employees scrambled to make skinny vanilla McLattes
“No business or brand has a divine right to succeed,” McDonald’s CEO Easterbrook said in a widely viewed company webcast on May 4. “The reality is, our recent performance has been poor.”
McDonald’s is still the biggest chain in the $222 billion U.S. fast-food market. And it has rallied from tough times before, most notably in 2003, under the “Plan to Win.” The company then de-emphasized opening stores in favor of luring more customers to existing outlets with better food and surroundings. It changed how its burgers were cooked to make them juicier. It also added items it said customers demanded: McGriddles, juice, and other nonsoda drinks, along with salads. It focused on friendlier and faster service and introduced its first global advertising campaign, “I’m lovin’ it.”
In his webcast and conference calls with analysts, Easterbrook said he wants McDonald’s to respond more quickly to food trends while improving service—by simplifying the company itself, reducing menu items, and shifting more day-to-day control to franchisees. McDonald’s is toasting buns longer, experimenting with delivery, rolling out a mobile app, gradually shifting to “cage-free” eggs, and testing touchscreen kiosks for customized burger orders. The kiosks have been favorably received in France and China. All-day breakfast could increase sales by as much as 2.5 percent, according to notes from an August presentation to franchisees by Mike Andres, McDonald’s U.S. president.
Easterbrook also plans to sell 3,500 of McDonald’s 6,700 company-owned stores to franchisees over the next three years. The company then would own about 10 percent of its restaurants. Burger King, by comparison, owns less than 1 percent of its stores; Subway, not a single one. McDonald’s would collect rent and royalties from those restaurants without having to manage them.
Investor Larry Robbins, CEO of Glenview Capital Management, has urged the company to spin off its property holdings into a real estate investment trust. Such a REIT—which McDonald’s executives haven’t ruled out—might unlock billions in cash the company could bestow on shareholders via stock buybacks and special dividends. Or the spinoff could distract management from efforts to boost sales and streamline restaurants, says Bloomberg Intelligence analyst Jennifer Bartashus. And if the stores don’t perform well, McDonald’s and its franchisees could be stuck paying rent under long-term leases.
Jarvis stands in the parking lot of one of his old stores
Photographer: Ryan Lowry for Bloomberg Businessweek
Maybe there’s nothing McDonald’s can do to restore its mojo. With 69 million customers a day around the world, it’s hardly about to go out of business. Perhaps it will simply muddle on, generating royalties and rent as the Chipotles and Panera Breads of the world steal its customers. Cornell’s Kalnins offers an alternate possibility: that the retirement of people Jarvis’s age will make room for a younger, more energetic wave of franchisees.
The buyer of Jarvis’s outlets is Keith Berg, 41, a second-generation franchisee who already owns two locations. He says Jarvis ran “great stores,” so he hasn’t changed much yet. He retained Snyder, the general manager in Hastings. After asking employees what equipment they needed, he bought two digital labeling systems that help keep track of expiration dates on parfaits, salads, pies, and other prepared items. He plans to remodel the outside of the Hastings store and bought a machine that will let workers steam more buns and tortillas at once. “We need to continue to be a quick-service restaurant and also keep in mind what customers are asking for,” he says. For all-day breakfast—which customers have demanded for years—he says he’ll consider adding a worker or two at the grill for the lunch rush.
Jarvis says he’s put on weight because he’s not running around in his stores anymore. He visits the Hastings location most days to get a foo-foo coffee and see old employees and customers.
If he were McDonald’s CEO, he says, he’d get rid of the bagels, wraps, and salads and move the foo-foo drinks to standalone McCafés in strip malls. He likes the idea of using kiosks for custom ordering, which he says should improve order accuracy and reduce arguments with customers.
His final day as a franchisee was a Tuesday last November. He went to the Hastings restaurant that evening to meet Berg. They counted uniforms and emptied the safe of Jarvis’s cash. Berg wrote Jarvis a check for the inventory; Jarvis posed for a farewell photo with Snyder. He didn’t leave till after midnight. His eyes well up at the memory. “It’s like I sold my family,” he says.
ORLANDO, Fla. - Yvette Quinn was convinced the list of aerospace engineers she discovered in a neighbor’s trash a few weeks ago was solid gold for international con men.
The Navy veteran said she was concerned because the list of scientists had secret and top secret clearance along with their Social Security numbers in plain view.
“Nothing less, nothing less," Quinn told WKMG News 6, “and that was scary.”
Scary, she said, because all of it, including test results of early aerospace models and drones, was just sitting there, ripe for the taking.
What Quinn didn’t realize was the photos and manuals from the NASA space program jammed into those piles of papers would be the most important find of all.
Charles Jeffrey, a top space flight memorabilia appraiser for the American Space Museum in Titusville, said the find of the Gemini –Titan II press manual and the Titan manual tucked away in the stacks of photos was “history.”
“Yeah, you have history,” Jeffrey told WKMG News 6 on Monday. “They were designing some of the very first unmanned aircraft drones.”
The black-and-white photographs and test results were owned by G.H. Hampton, an aerospace engineer with Martin Marietta.
Some of the documents, including a NASA Causeway pass for the STS-96 shuttle launch dated May 27, 1999, are handwritten and signed by Hampton.
Hampton apparently had access to rare NASA photos and artists' renderings, including a 1960s-era rendering of a lunar excursion vehicle that caught Jeffrey’s eye.
“One of the earliest designs for a vehicle to land on the moon is this lunar excursion model,” Jeffrey told WKMG-News 6. We have the exact model at the American Space Museum.”
Jeffrey said he had never seen the rendering before.
On Tuesday, News 6 traveled to the American Space Museum in Titusville to document the handcrafted wood model’s similarity to the artist's rendering.
It was a match.
WKMG general manager Jeff Hoffman approved donation of the Titan manuals along with rare color and black-and-white artists’ renderings, which included a prototype for the space shuttle, a Mars spacecraft and the most prized item of all: the rare rendering of the lunar excursion model.
The director of the Space Museum, Tara Dixon Engel, said many of the unique materials donated to the museum are rescued from the trash.
“We are so grateful to you guys," Engel told News 6,” for taking the time to bring it out here and for talking to an expert to get a feel for exactly what this is.”
Jeffrey said the items were worth just over $1,200.
The additional materials involving the drone tests at Martin Marietta “could be worth thousands,” he said.
If you have space memorabilia you would like to donate or have appraised, the Space Museum has a special appraisal day set aside later this month.
The branch rtl_mjit_branch is used for development of RTL
(register transfer language) VM insns and MRI JIT (MJIT in
brief) of the RTL insns
The last branch merge point with the trunk is always the head of the
branch rtl_mjit_branch_base
The branch rtl_mjit_branch will be merged with the trunk from
time to time and correspondingly the head of the branchrtl_mjit_branch_base will be the last merge point with the trunk
The major goal of RTL insns introduction is an implementation of IR
for Ruby code analysis and optimizations
The current stack based insns are an inconvenient IR for such goal
Secondary goal is faster interpretation of VM insns
Stack based insns create additional memory traffic. Let us
consider Ruby code a = b + c. Stack insns vs RTL insns for
the code:
Stack based insns are shorter but usually require more
insns than RTL ones for the same Ruby code
We save time on memory traffic and insn dispatching
In some cases, RTL insns can be the same number as stack-based
insns as typical Ruby code contains a lot of calls. In such
cases, executing RTL insns will be slower executing stack insns
RTL insn operands
What could be an operand:
only temporaries
temporaries and locals
temporaries and locals even from higher levels
above + instance variables
above + class variables, globals
Using only temporaries has little sense as it will produce code
with practically the same number insns which are longer
Decoding overhead of numerous type operands will be not
compensated by processing smaller number of insns
The complicated operands also complicate optimizations and MJIT
Currently we use only temporaries and locals as preliminary
experiments show that it is the best approach
Practically any RTL insn might be an ISEQ call. Therefore we need
to provide a solution to put a result at the destination operand
as the call will always put it on the stack
If RTL insn is actually an ISEQ call, we change a return PC. So
the next insn executed after call will be an insn moving the result
on the stack to the insn destination
To decrease memory overhead, the move insn is a part of the
original insn
For example, in the case of a call in "plus <cont insn>, <call data>, dst, op1, op2" the next executed insn will be
"<cont insn> <call data>, dst, op1, op2"
RTL insn combining and specialization
Immediate value specialization (e.g. plusi - addition with
immediate fixnum)
Frequent insn sequences combining (e.g. bteq - comparison and
branch if the operands are equal)
Speculative insn generation
Some initially generated insns during their execution can be transformed
into speculative ones
Speculation is based on operand types (e.g. plus can be
transformed into an integer plus) and on the operand values
(e.g. no multi-precision integers)
Speculative insns can be transformed into unchanging regular
insns if the speculation is wrong
Speculation insns have a code checking the speculation correctness
Speculation will be more important for JITed code performance
Two approaches to generate RTL insns:
The simplest way is to generate RTL insns from the stack
insns
A faster approach is to generate directly from MRI parse
tree nodes.
We use the later approach as it makes MRI faster
RTL insns status and future work
It mostly works (make check reports no regressions)
Still a lot of work should be done for performance analysis and
performance tuning work
There are a lot of changed files but major changes are in:
insns.def: New definitions of RTL insns
rtl_exec.c: Most of code executing RTL insns
compile.c: Translations of the parse tree into RTL insns. The
file is practically rewritten but I tried to use the
same structure and function names
A few possible approaches in JIT implementation:
JIT specialized for a specific language (e.g. luajit, rujit)
Pro: achievability of very fast compilation
Con: a lot of efforts to implement decent optimizations and
multi-target generation
Using existing VMs with JIT or JIT libraries: Oracle JVM and Graal, IBM OMR,
different JavaScript JITs, libjit
Pro: saving a lot of efforts
Cons: Big dependency on code which is hard to control.
Less optimized code than MRI generated by used C compilers
(even with using JVM server compiler).
Most of the JITs are already used for Ruby implementation
Using JITs frameworks of existing C compilers: GCC JIT, LLVM JIT
engines
Pro: saving a lot of efforts in generating highly optimized
code for multiple targets. No new dependencies as C
compilers are used for building MRI
Cons: Unstable interfaces. An LLVM JIT is already used by
Rubicon. A lot of efforts in preparation of code used by
RTL insns (an environment)
Using existing C compilers
Pro: Very stable interface. The simplest approach to
generate highly optimized code for multiple targets (minimal
changes to MRI). Small efforts to prepare the environment.
Portability (e.g. GCC or LLVM can be used). No new dependencies.
Easy JITed code debugging. Rich optimization set of
industrial C compilers has a potential to generate a
better code especially if we manage to provide profile
info to them
Con: Big JIT code compilation time because of time spent on
lexical, syntax, semantic analysis and optimizations not
tailored for the speedy work
The above is just a very brief analysis resulting in me to use the
last approach. It is the simplest one and adequate for long running
Ruby programs like Ruby on Rails
MJIT is a method JIT (one more reason for the name)
An important organization goal is to minimize the JIT compilation time
To simplify JIT implementation the environment (C code header needed
to C code generated by MJIT) is just vm.c file
A special Ruby script minimize the environment
* Removing about 90% declarations
MJIT has a several threads (workers) to do parallel compilations
One worker prepares a precompiled code of the minimized header
It starts at the MRI execution start
One or more workers generate PIC object files of ISEQs
They start when the precompiled header is ready
They take ISEQs from a priority queue unless it is empty.
They translate ISEQs into C-code using the precompiled header,
call CC and load PIC code when it is ready
MJIT put ISEQ in the queue when ISEQ is called or right after
generating ISEQ for AOT (Ahead Of Time compilation)
MJIT can reorder ISEQs in the queue if some ISEQ has been called many
times and its compilation did not start yet or we need the ISEQ code
for AOT
MRI reuses the machine code if it already exists for ISEQ
All files are stored in /tmp. On modern Linux /tmp is a file
system in memory
The machine code execution can stop and switch to the ISEQ
interpretation if some condition is not satisfied as the machine
code can be speculative or some exception raises
Speculative machine code can be canceled, and a new mutated
machine code can be queued for creation
It can happen when insn speculation was wrong
There is a constraint on the mutation number. The default
value can be changed by a MJIT option. The last mutation will
contain the code without any speculation insns
There are more speculations in JIT code than in the interpreter mode:
Global speculation about tracing
Global speculation about absence of basic type operations redefinition
Speculation about equality of EP (environment pointer)
and BP (basic stack pointer)
When a global speculation becomes wrong, all currently executed JIT
functions are canceled and the corresponding ISEQs continue their
execution in the interpreter mode
It is implemented by checking a special control frame flag after
each call which can affect a global speculation
In AOT mode, ISEQ JIT code creation is queued
right after the ISEQ creation and ISEQ JIT code is always tried to be
executed first. In other words, VM waits the creation of JIT code
if it is not available
Now AOT probably has a sense mostly for big long running programs
MJIT options can be given on the command line or by environment
variable RUBYOPT (the later probably will be removed in the future)
MJIT status
It is on very early stages of the development and only ready for
usage of few small and simple Ruby programs
make test has no issues
The compilation of small ISEQ takes about 50-70 ms on modern
x86-64 CPUs
No Ruby program real time execution slow down because of MJIT
Depending on a MJIT option, GCC or LLVM is used
Some benchmarks are faster with GCC, some are faster with
LLVM Clang
There are a few factors (mostly relation between compilation
speed and generated code quality) making hard to predict the
outcome
As GCC and LLVM are ABI compatible you can compile MRI by GCC
and use LLVM for MJIT or vise verse
MJIT is switched on by -j option
Some other useful MJIT options:
-j:v helps to see how MJIT works: what ISEQs and when are
compiled
-j:p prints a final profile about how frequently ISEQs were
executed in the interpreter and JIT mode
-j:a switches NJIT on in AOT mode
-j:s saves the precompiled header and all C files and object
files in /tmp after MRI finish
-j:t=N defines number of threads used by MJIT to compile
ISEQs in parallel (default N is 1)
Use ruby option --help to see all MJIT options
MJIT future works
A lot of things should be done to use MJIT. Here are the high
priority ones:
Make it working for make check
Generation of optimized C code:
The ultimate goal is to provide possibility of inlining on
paths Ruby->C->Ruby where Ruby means C code generated by MJIT
for user defined Ruby methods and C means MRI C code implementing
some predefined Ruby methods (e.g. times for Number)
More aggressively speculative C code generation with more
possibilities for C compiler optimizations, e.g. speculative
constant usage for C compiler constant folding, (conditional) constant
propagation, etc.
Translations of Ruby temporaries and locals into C locals and
saving them on MRI thread stack in case of deoptimization
Direct calls of C functions generated for ISEQs by MJIT
(another form of speculations)
Transition from static inline functions to extern inline
for GCC and Clang to permit the compilers themselves decide
about inlining profitability
Pass profile info through hot/cold function attributes
May be pass more detail info through C compiler profile
info format in the future
Implement ISEQ JIT code unloading in the case ISEQ cancellation
Tuning MJIT for faster compilation and less waiting time
Implementing On Stack Replacement (OSR)
OSR is a replacement of still executed byte code ISEQ by JIT
generated machine code for the ISEQ
It is a low priority task as it is usable now only for ISEQs
with while-statements
Tailor MJIT for a server environment
Reuse the same ISEQ JIT code for different running MRI instances
Use a crypto-hash function to search JIT code for given pair
(PCH hash, ISEQ hash)
MJIT vulnerability
Prevent adversary from changing C compiler
Prevent adversary from changing MJIT C and object files
Prevent adversary from changing MJIT headers
Use crypto hash function to check the header authenticity
Update: 15th June, 2017
MJIT is reliable enough to run some benchmarks to evaluate its
potential
All measurements are done on Intel 3.9GHz i3-7100 with 32GB memory
under x86-64 Fedora Core25
For the performance comparison I used the following implementations:
v2 - Ruby MRI version 2.0
base - Ruby MRI (2.5 development) version on which rtl_mjit branch
is based
rtl - rtl_mjit branch as of 31th May without using JIT
mjit - as above but with using MJIT with GCC 6.3.1 with -O2
Have a side project which is an analytics web application based on 100k+ records. I was initially thinking to get a small payment from each user. But it appears to me that - information provided can be easily scrapped from site (if someone really wants) and it won't make sense.
So I am thinking of revenue model based on ads. At its 'full' potential web application can draw a million visits per month (in 2-3 years may be).
Adrevenue calculators show adrevenue of $2000 dollars for a million visits[0] with 2 pages/visit and $1 RPM.
How realistic are these adrevenue calculators ?
Can anybody share their experience with real numbers and insights.
“Perhaps no 20th-century children’s books blur the boundaries between art and propaganda in such compelling ways” as early Soviet children’s literature, says Andrea Immel, Curator of the Cotsen Children’s Library at Princeton University. The Cotsen holds nearly 1,000 of these books, published between 1917 and the start of World War II. The collection demonstrates how then-new Soviet ideologies were communicated to the younger generation—even if the idea of indoctrinating children with colorful books wasn’t itself new.
“While it’s tempting to imagine that the Soviet experience was unprecedented because of overthrow of the tsar, it is possible to find other historical moments when reformers or radicals believed that the key to a better future was to provide children with books communicating superior values,” says Immel, citing John Newbery, known as the Father of Children’s Literature. “In the 1760s, he published out of the conviction that English society was corrupt and that one of the best ways to turn the tide was to bring up children differently.”
However, Immel notes, there was one crucial difference. “The Soviets were keenly aware of needing to leap ahead as quickly as possible, creating at the same time a new breed of men,” she says. “And so the tremendous artistic firepower that could be harnessed in the Soviet Union of the 1920s brilliantly made the hard, unglamorous work of agriculture or electrification heroic and patriotic.”
80,000 horses, a rhyming tale about the Volkhov Hydroelectric Plant, 1925.
The shift away from filling children’s books with fairy tales was no accident. In their place, literature for children was focused on practical concerns and industry. The 1930 book Kak svekla sakharom stala (How the Beet Became Sugar) illustrates and describes the sugar production process: “Work is happening night and day. Night and day, sugar is being made from beets.” In 80,000 loshadeĭ (80,000 Horses), the story of the Volkhov Hydroelectric Plant—the first in Russia and named after Lenin—is told in rhyme. Some of the books even created work themselves. The 1930 title Shimpanze i martyshka (Chimpanzee and Marmoset) provides instructions on how the reader can make a toy monkey.
Illustrations from How the Beet Became Sugar, 1930.
The readership of these books wasn’t limited to the Soviet Union either. Immel corresponded with a writer from Kolkata who fondly remembers books from the Soviet children’s publisher Raduga. In the archive Immel discovered Millionnyĭ Lenin (The Millionth Lenin), by Lev Zilov, in which two boys from India participate in an uprising against the Raj. They flee the country and have a series of adventures that take them to the Soviet Union. There, they watch a parade before Lenin’s tomb and don warm clothing (while retaining their turbans). “It had never occurred to me that Raduga books had been translated into South Asian languages or that South Asian people would be represented in Soviet children’s books,” Immel says.
Final pages of The Millionth Lenin, depicting two children from India who become Soviets, 1926.
There are also books about glorious achievements, such as pilot Georgiĭ Baĭdukov’s nonstop flight over the North Pole in the mid-1930s. But by this time, there had been a political shift that changed the way that children’s books looked. Throughout the 1920s, the aesthetics of the books were diverse, and included the influence of the Russian avant-garde, including the work of well-known writers and artists. In 1934, the All-Union Soviet Congress of Writers declared that socialist realism was the only acceptable artistic style. Over the years, some writers and artists escaped into exile. Others did not.
Mochin the Pioneer’s Heroism, a story about a Young Pioneer helping the Red Army, illustrated by Vera Ermolaeva, 1931.
In 1931, artist Vera Ermolaeva illustrated the book Podvig pionera Mochina (Mochin the Pioneer’s Heroism). In the story, a Young Pioneer—the Soviet Union’s more militaristic answer to the Boy Scouts—helps the Red Army in Tajikistan. But by the end of the decade, both Ermolaeva and the book’s author, Aleksandr Ivanovich Vvedenskiĭ, fell victim to one of Stalin’s purges.
Memories of Soviet children’s literature linger today. Immel recounts a story of a Russian colleague who visited her and spotted some Raduga pamphlets. “He knew exactly what they were, being old friends from his childhood,” she says. “He picked up the copy of Kornei Chukovsky’s Barmelai, illustrated by Mstislav Dobuzhinski, and began reciting it from memory.”
Atlas Obscura delved into the Cotsen’s Soviet literature holdings for a selection of children’s titles from the 1920s and 1930s.
Cover and illustration from Chimpanzee and Marmoset, which contains instructions about how to stitch a toy, 1930.Across the Pole to America, Georgiĭ Baĭdukov’s account of his nonstop flight over the North Pole, 1938.Cover and illustration from A Book for Children About Lenin, 1926.Red Army, 1929.The Five-Year Plan, 1930.Illustrations from We Are Many, a book about Soviet children living in the city, 1932.
Added tf.layers.conv3d_transpose layer for spatio temporal deconvolution.
Added tf.Session.make_callable(), which provides a lower overhead means of running a similar step multiple times.
Added ibverbs-based RDMA support to contrib (courtesy @junshi15 from Yahoo).
RNNCell objects now subclass tf.layers.Layer. The strictness described
in the TensorFlow 1.1 release is gone: The first time an RNNCell is used,
it caches its scope. All future uses of the RNNCell will reuse variables from
that same scope. This is a breaking change from the behavior of RNNCells
in TensorFlow versions <= 1.0.1. TensorFlow 1.1 had checks in place to
ensure old code works correctly with the new semantics; this version
allows more flexible uses of RNNCell but can lead to subtle errors if
using code meant for TensorFlow <= 1.0.1. For example, writing:MultiRNNCell([lstm] * 5) will now build a 5-layer LSTM stack where each
layer shares the same parameters. To get 5 layers each with their own
parameters, write: MultiRNNCell([LSTMCell(...) for _ in range(5)]).
If at all unsure, first test your code with TF 1.1; ensure it raises no
errors, and then upgrade to TF 1.2.
TensorForest Estimator now supports SavedModel export for serving.
Support client-provided ClusterSpec's and propagate them to all workers to enable the creation of dynamic TensorFlow clusters.
TensorFlow C library now available for Windows.
We released a new open-source version of TensorBoard.
SavedModel CLI tool available to inspect and execute MetaGraph in SavedModel
RNNCells' variable names have been renamed for consistency with Keras layers.
Specifically, the previous variable names "weights" and "biases" have
been changed to "kernel" and "bias", respectively.
This may cause backward incompatibility with regard to your old
checkpoints containing such RNN cells, in which case you can use the toolcheckpoint_convert script
to convert the variable names in your old checkpoints.
Many of the RNN functions and classes that were in the tf.nn namespace
before the 1.0 release and which were moved to tf.contrib.rnn have now
been moved back to the core namespace. This includesRNNCell, LSTMCell, GRUCell, and a number of other cells. These
now reside in tf.nn.rnn_cell (with aliases in tf.contrib.rnn for backwards
compatibility). The original tf.nn.rnn function is now tf.nn.static_rnn,
and the bidirectional static and state saving static rnn functions are also
now back in the tf.nn namespace.
Notable exceptions are the EmbeddingWrapper, InputProjectionWrapper andOutputProjectionWrapper, which will slowly be moved to deprecation
in tf.contrib.rnn. These are inefficient wrappers that should often
be replaced by calling embedding_lookup or layers.dense as pre- or post-
processing of the rnn. For RNN decoding, this functionality has been replaced
with an alternative API in tf.contrib.seq2seq.
Intel MKL Integration (https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture). Intel developed a number of
optimized deep learning primitives: In addition to matrix multiplication and
convolution, these building blocks include:
Direct batched convolution
Pooling: maximum, minimum, average
Normalization: LRN, batch normalization
Activation: rectified linear unit (ReLU)
Data manipulation: multi-dimensional transposition (conversion), split,
concat, sum and scale.
Deprecations
TensorFlow 1.2 may be the last time we build with cuDNN 5.1. Starting with
TensorFlow 1.3, we will try to build all our prebuilt binaries with cuDNN 6.0.
While we will try to keep our source code compatible with cuDNN 5.1, it will
be best effort.
Breaking Changes to the API
org.tensorflow.contrib.android.TensorFlowInferenceInterface now throws exceptions where possible and has simplified method signatures.
Changes to contrib APIs
Added tf.contrib.util.create_example.
Added bilinear interpolation to tf.contrib.image.
Add tf.contrib.stateless for random ops with custom seed control.
MultivariateNormalFullCovariance added to contrib/distributions/
tensorflow/contrib/rnn undergoes RNN cell variable renaming for
consistency with Keras layers. Specifically, the previous variable names
"weights" and "biases" are changed to "kernel" and "bias", respectively.
This may cause backward incompatibility with regard to your old
checkpoints containing such RNN cells, in which case you can use thecheckpoint_convert script
to convert the variable names in your old checkpoints.
Added tf.contrib.kernel_methods module with Ops and estimators for primal
(explicit) kernel methods in TensorFlow.
Bug Fixes and Other Changes
In python, Operation.get_attr on type attributes returns the Python DType
version of the type to match expected get_attr documentation rather than the
protobuf enum.
Changed MIN_SDK version to 8.0 when building iOS libraries.
Fixed LIBXSMM integration.
Make decode_jpeg/decode_png/decode_gif handle all formats, since users frequently try to decode an image as the wrong type.
Improve implicit broadcasting lowering.
Improving stability of GCS/Bigquery clients by a faster retrying of stale transmissions.
Remove OpKernelConstruction::op_def() as part of minimizing proto dependencies.
VectorLaplaceDiag distribution added.
Android demo no longer requires libtensorflow_demo.so to run (libtensorflow_inference.so still required)
Added categorical_column_with_vocabulary_file.
Introduce ops for batching/unbatching tensors across Session::Run() calls.
Changed hooks lists to immutable tuples, and now allow any iterable for the associated arguments.
Introduce TFDecorator.
Added an Mfcc op for speech feature generation.
Improved DirectSession::Run() overhead and error checking. Feeding a value of the wrong type will now synchronously raise an INVALID_ARGUMENT error instead of asynchronously raising an INTERNAL error. Code that depends on the (undefined) behavior when feeding a tensor of the wrong type may need to be updated.
Added unreduced NONE, and reduced MEAN options for losses. Removed "WEIGHTED_" prefix from other Reduction constants.
assertAllClose now handles dicts.
Added Gmock matcher for HloInstructions.
Add var name to errors on variable restore.
Added an AudioSpectrogram op for audio feature generation.
Added reduction arg to losses.
tf.placeholder can represent scalar shapes and partially known.
Remove estimator_spec(mode) argument.
Added an AudioSpectrogram op for audio feature generation.
TensorBoard disables all runs by default if there are more than 40 runs.
Removed old doc generator code.
GCS file system integration now supports domain buckets, e.g gs://bucket.domain.com/path.
Add tf.summary.text for outputting text to TensorBoard.
The "run" command of tfdbg's command-line interface now supports filtering of tensors by node name, op type and tensor dtype.
tf.string_to_number now supports int64 and float64 outputs.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
4F2E4A2E, Aaron Schumacher, Abhi Agg, admcrae, Adriano Carmezim, Adrià Arrufat,
agramesh1, Akimitsu Seo, Alan Mosca, Alex Egg, Alex Rothberg, Alexander Heinecke,
Alexander Matyasko, Alexandr Baranezky, Alexandre Caulier, Ali Siddiqui, Anand Venkat,
Andrew Hundt, Androbin, Anmol Sharma, Arie, Arno Leist, Arron Cao, AuréLien Geron, Bairen Yi,
Beomsu Kim, Carl Thomé, cfperez, Changming Sun, Corey Wharton, critiqjo, Dalei Li, Daniel
Rasmussen, Daniel Trebbien, DaríO Hereñú, David Eng, David Norman, David Y. Zhang, Davy Song, ddurham2,
Deepak Subburam, Dmytro Kyrychuk, Dominic Rossi, Dominik SchlöSser, Dustin Tran,
Eduardo Pinho, Egil Martinsson, Elliot Saba, Eric Bigelow, Erik Smistad, Evan Klitzke,
Fabrizio Milo, Falcon Dai, Fei Gao, FloopCZ, Fung Lam, Gautam, GBLin5566, Greg Peatfield,
Gu Wang, Guenther Schmuelling, Hans Pabst, Harun Gunaydin, Huaizheng, Ido Shamay, Ikaro
Silva, Ilya Edrenkin, Immexxx, James Mishra, Jamie Cooke, Jay Young, Jayaram Bobba,
Jianfei Wang, jinghua2, Joey Meyer, John Maidens, Jonghoon Jin, Julian Villella,
Jun Kim, Jun Shi, Junwei Pan, jyegerlehner, Karan Desai, Karel Van De Plassche,
Kb Sriram, KhabarlakKonstantin, Koan-Sin Tan, krivard, Kwotsin, Leandro Gracia Gil,
Li Chen, Liangliang He, Louie Helm, lspvic, Luiz Henrique Soares, LáSzló Csomor,
Mark Wong, Mathew Wicks, Matthew Rahtz, Maxwell Paul Brickner, Michael Hofmann, Miguel
Flores Ruiz De Eguino, MikeTam1021, Mortada Mehyar, Mycosynth, Namnamseo,
Nate Harada, Neven Miculinic, Nghia Tran, Nick Lyu, Niranjan Hasabnis, Nishidha, Oleksii
Kuchaiev, Oyesh Mann Singh, Panmari, Patrick, Paul Van Eck, Piyush Chaudhary, Quim Llimona,
Raingo, Richard Davies, Ruben Vereecken, Sahit Chintalapudi, Sam Abrahams, Santiago Castro,
Scott Sievert, Sean O'Keefe, Sebastian Schlecht, Shane, Shubhankar Deshpande, Spencer Schaber,
Sunyeop Lee, t13m, td2014, Thomas H. P. Andersen, Toby Petty, Umang Mehta,
Vadim Markovtsev, Valentin Iovene, Vincent Zhao, Vit Stepanovs, Vivek Rane, Vu Pham, wannabesrevenge,
weipingpku, wuhaixutab, wydwww, Xiang Gao, Xiaolin Lin, xiaoyaozhuzi, Yaroslav Bulatov, Yi Liu,
Yoshihiro Sugi, Yuan (Terry) Tang, Yuming Wang, Yuxin Wu, Zader Zheng, Zhaojun Zhang, zhengjiajin,
ZhipengShen, Ziming Dong, zjj2wry
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
Added Java API support for Windows.
Added tf.spectral module. Moved existing FFT ops to tf.spectral while
keeping an alias in the old location (tf.*).
Added 1D, 2D and 3D Fourier transform ops for real signals to tf.spectral.
Added a tf.bincount function.
Added Keras 2 API to contrib.
Added a new lightweight queue-like object - RecordInput.
Bring tf.estimator.* into the API. Non-deprecated functionality from tf.contrib.learn.Estimator is moved to tf.estimator.Estimator with cosmetic changes.
Docker images: TF images on gcr.io and Docker Hub are upgraded to ubuntu:16.04.
Added the following features to TensorFlow Debugger (tfdbg):
Ability to inspect Python source file against TF ops and tensors (command print_source / ps)
New navigation bar in Curses-based UI
NodeStepper (command invoke_stepper) now uses intermediate tensor dumps. It also uses TensorHandles as direct feeds during successive cont calls for improved performance and reduced memory consumption.
Initial release of installation guides for Java, C, and Go.
Added Text Dashboard to TensorBoard.
Deprecations
TensorFlow 1.1.0 will be the last time we release a binary with Mac GPU support. Going forward, we will stop testing on Mac GPU systems. We continue to welcome patches that maintain Mac GPU support, and we will try to keep the Mac GPU build working.
Changes to contrib APIs
The behavior of RNNCells is now stricter due to the transition towards making RNNCells act more like Keras layers.
If an RNNCell is used twice in two different variable scopes, an error is raised describing how to avoid this behavior.
If an RNNCell is used in a variable scope with existing conflicting variables, an error is raised showing that the RNNCell must be constructed with argument reuse=True.
Java: Support for loading models exported using the SavedModel API (courtesy @EronWright).
Go: Added support for incremental graph execution.
Fix a bug in the WALS solver when single-threaded.
Added support for integer sparse feature values in tf.contrib.layers.sparse_column_with_keys.
Fixed tf.set_random_seed(0) to be deterministic for all ops.
Stability improvements for the GCS file system support.
Improved TensorForest performance.
Added support for multiple filename globs in tf.matching_files.
LogMessage now includes a timestamp as beginning of a message.
Added MultiBox person detector example standalone binary.
Android demo: Makefile build functionality added to build.gradle to fully support building TensorFlow demo in Android on Windows.
Android demo: read MultiBox priors from txt file rather than protobuf.
Added colocation constraints to StagingArea.
sparse_matmul_op reenabled for Android builds.
Restrict weights rank to be the same as the broadcast target, to avoid ambiguity on broadcast rules.
Upgraded libxsmm to 1.7.1 and applied other changes for performance and memory usage.
Fixed bfloat16 integration of LIBXSMM sparse mat-mul.
Improved performance and reduce memory usage by allowing ops to forward input buffers to output buffers and perform computations in-place.
Improved the performance of CPU assignment for strings.
Speed up matrix * vector multiplication and matrix * matrix with unknown shapes.
C API: Graph imports now support input remapping, control dependencies, and returning imported nodes (see TF_GraphImportGraphDefWithReturnOutputs())
Multiple C++ API updates.
Multiple TensorBoard updates including:
Users can now view image summaries at various sampled steps (instead of just the last step).
Bugs involving switching runs as well as the image dashboard are fixed.
Removed data download links from TensorBoard.
TensorBoard uses a relative data directory, for easier embedding.
TensorBoard automatically ignores outliers for domain calculation, and formats proportional values consistently.
Multiple tfdbg bug fixes:
Fixed Windows compatibility issues.
Command history now persists across runs.
Bug fix in graph validation related to tf.while_loops.
Java Maven fixes for bugs with Windows installation.
Backport fixes and improvements from external keras.
Keras config file handling fix.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
A. Besir Kurtulmus, Adal Chiriliuc, @akash, Alec-Desouza, Alex Rothberg, Alex
Sergeev, Alexander Heinecke, Allen Guo, Andreas Madsen, Ankesh Anand, Anton
Loss, @Aravind, @Arie, Ashutosh Das, AuréLien Geron, Bairen Yi, @bakunyo, Ben
Visser, Brady Zhou, Calpa Liu, Changming Sun, Chih Cheng Liang, Christopher
Berner, Clark Zinzow, @Conchylicultor, Dan Ellis, Dan J, Dan Jarvis, Daniel
Ylitalo, Darren Garvey, David Norman, David Truong, @DavidNorman, Dimitar
Pavlov, Dmitry Persiyanov, @Eddie, @elirex, Erfan Noury, Eron Wright, Evgeny
Mazovetskiy, Fabrizio (Misto) Milo, @fanlu, Fisher Coder, Florian Courtial,
Franck Dernoncourt, Gagan Goel, Gao, Xiang, @Gautam, Gefu Tang, @guilherme,
@guschmue, Hannah Provenza, Hans Pabst, @hartb, Hsiao Yi, Huazuo Gao, Igor
ChorążEwicz, Ivan Smirnov, Jakub Kolodziejczyk, Jason Gavris, Jason Morton, Jay
Young, Jayaram Bobba, Jeremy Sawruk, Jiaming Liu, Jihun Choi, @jiqiu, Joan Thibault,
John C F, Jojy George Varghese, Jon Malmaud, Julian Berman, Julian Niedermeier,
Junpeng Lao, Kai Sasaki, @Kankroc, Karl Lessard, Kyle Bostelmann, @Lezcano, Li
Yi, Luo Yun, @lurker, Mahmoud-Abuzaina, Mandeep Singh, Marek Kolodziej, Mark
Szepieniec, Martial Hue, Medhat Omr, Memo Akten, Michael Gharbi, MichaëL Defferrard,
Milan Straka, @MircoT, @mlucool, Muammar Ibn Faisal, Nayana Thorat, @nghiattran,
Nicholas Connor, Nikolaas Steenbergen, Niraj Patel, Niranjan Hasabnis, @Panmari,
Pavel Bulanov, Philip Pries Henningsen, Philipp Jund, @polonez, Prayag Verma, Rahul
Kavi, Raphael Gontijo Lopes, @rasbt, Raven Iqqe, Reid Pryzant, Richard Shin, Rizwan
Asif, Russell Kaplan, Ryo Asakura, RüDiger Busche, Saisai Shao, Sam Abrahams, @sanosay,
Sean Papay, @seaotterman, @selay01, Shaurya Sharma, Sriram Narayanamoorthy, Stefano
Probst, @taknevski, @tbonza, @teldridge11, Tim Anglade, Tomas Reimers, Tomer Gafner,
Valentin Iovene, Vamsi Sripathi, Viktor Malyi, Vit Stepanovs, Vivek Rane, Vlad Firoiu,
@wangg12, @will, Xiaoyu Tao, Yaroslav Bulatov, Yi Liu, Yuan (Terry) Tang, @Yufeng,
Yuming Wang, Yuxin Wu, Zafar Takhirov, Ziming Dong
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Bug Fixes and Other Changes
Change GraphConstructor to not increase the version when importing, but instead take the min of all versions.
Google Cloud Storage fixes.
Removed tf.core and tf.python modules from the API. These were never intended to be exposed. Please use the same objects through top-level tf module instead.
Major Features and Improvements
XLA (experimental): initial release of XLA, a domain-specific compiler for TensorFlow graphs, that targets CPUs and GPUs.
TensorFlow Debugger (tfdbg): command-line interface and API.
New python 3 docker images added.
Made pip packages pypi compliant. TensorFlow can now be installed by pip install tensorflow command.
Several python API calls have been changed to resemble NumPy more closely.
Android: person detection + tracking demo implementing Scalable Object
Detection using Deep Neural Networks.
Add new Android image stylization demo based on "A Learned Representation For Artistic Style", and add YOLO object detector support.
Breaking Changes to the API
To help you upgrade your existing TensorFlow Python code to match the API changes below, we have prepared a conversion script.
TensorFlow/models have been moved to a separate github repository.
Division and modulus operators (/, //, %) now match Python (flooring)
semantics. This applies to tf.div and tf.mod as well. To obtain forced
integer truncation based behaviors you can use tf.truncatediv
and tf.truncatemod.
tf.divide() is now the recommended division function. tf.div() will
remain, but its semantics do not respond to Python 3 or from future
mechanisms.
tf.reverse() now takes indices of axes to be reversed. E.g.tf.reverse(a, [True, False, True]) must now be written astf.reverse(a, [0, 2]). tf.reverse_v2() will remain until 1.0 final.
tf.mul, tf.sub and tf.neg are deprecated in favor of tf.multiply,tf.subtract and tf.negative.
tf.pack and tf.unpack are deprecated in favor of tf.stack andtf.unstack.
TensorArray.pack and TensorArray.unpack are getting deprecated in favor ofTensorArray.stack and TensorArray.unstack.
The following Python functions have had their arguments changed to use axis
when referring to specific dimensions. We have kept the old keyword arguments
for compatibility currently, but we will be removing them well before the
final 1.0.
tf.listdiff has been renamed to tf.setdiff1d to match NumPy naming.
tf.inv has been renamed to be tf.reciprocal (component-wise reciprocal)
to avoid confusion with np.inv which is matrix inversion
tf.round now uses banker's rounding (round to even) semantics to match NumPy.
tf.split now takes arguments in a reversed order and with different
keywords. In particular, we now match NumPy order astf.split(value, num_or_size_splits, axis).
tf.sparse_split now takes arguments in reversed order and with different
keywords. In particular we now match NumPy order astf.sparse_split(sp_input, num_split, axis). NOTE: we have temporarily
made tf.sparse_split require keyword arguments.
tf.concat now takes arguments in reversed order and with different keywords. In particular we now match NumPy order as tf.concat(values, axis, name).
tf.image.decode_jpeg by default uses the faster DCT method, sacrificing
a little fidelity for improved speed. One can revert to the old
behavior by specifying the attribute dct_method='INTEGER_ACCURATE'.
tf.complex_abs has been removed from the Python interface. tf.abs
supports complex tensors and should be used instead.
In the C++ API (in tensorflow/cc), Input, Output, etc. have moved
from the tensorflow::ops namespace to tensorflow.
Template.var_scope property renamed to .variable_scope
SyncReplicasOptimizer is removed and SyncReplicasOptimizerV2 renamed to SyncReplicasOptimizer.
tf.zeros_initializer() and tf.ones_initializer() now return a callable
that must be called with initializer arguments, in your code replacetf.zeros_initializer with tf.zeros_initializer().
SparseTensor.shape has been renamed to SparseTensor.dense_shape. Same forSparseTensorValue.shape.
Replace tf.scalar_summary, tf.histogram_summary, tf.audio_summary, tf.image_summary with tf.summary.scalar, tf.summary.histogram, tf.summary.audio, tf.summary.image, respectively. The new summary ops take name rather than tag as their first argument, meaning summary ops now respect TensorFlow name scopes.
Replace tf.train.SummaryWriter and tf.train.SummaryWriterCache with tf.summary.FileWriter and tf.summary.FileWriterCache.
Removes RegisterShape from public API. Use C++ shape function registration
instead.
Deprecated _ref dtypes from the python API.
In the C++ API (in tensorflow/cc), Input, Output, etc. have moved
from the tensorflow::ops namespace to tensorflow.
Change arg order for {softmax,sparse_softmax,sigmoid}_cross_entropy_with_logits to be (labels, predictions), and force use of named args.
tf.nn.rnn_cell.* and most functions in tf.nn.rnn.* (with the exception of dynamic_rnn and raw_rnn) are temporarily in tf.contrib.rnn. They will be moved back into core for TF 1.2.
tf.nn.sampled_softmax_loss and tf.nn.nce_loss have both changed their API such that you need to switch the inputs, labels to labels, inputs parameters.
The shape keyword argument of the SparseTensor constructor changes its name to dense_shape between Tensorflow 0.12 and Tensorflow 1.0.
Bug Fixes and Other Changes
Numerous C++ API updates.
New op: parallel_stack.
Introducing common tf io compression options constants for
RecordReader/RecordWriter.
Add sparse_column_with_vocabulary_file, to specify a feature column that
transform string features to IDs, where the mapping is defined by a vocabulary
file.
Added index_to_string_table which returns a lookup table that maps indices to
strings.
Add string_to_index_table, which returns a lookup table that matches strings
to indices.
Add a ParallelForWithWorkerId function.
Add string_to_index_table, which returns a lookup table that matches strings
to indices.
Support restore session from checkpoint files in v2 in contrib/session_bundle.
Added a tf.contrib.image.rotate function for arbitrary angles.
Added tf.contrib.framework.filter_variables as a convenience function to
filter lists of variables based on regular expressions.
make_template() takes an optional custom_getter_ param.
Added comment about how existing directories are handled byrecursive_create_dir.
Added an op for QR factorizations.
Divides and mods in Python API now use flooring (Python) semantics.
Android: pre-built libs are now built nightly.
Android: cmake/gradle build for TensorFlow Inference library undercontrib/android/cmake
Android: Much more robust Session initialization code.
Android: TF stats now exposed directly in demo and log when debug mode is
active
Android: new/better README.md documentation
saved_model is available as tf.saved_model.
Empty op is now stateful.
Improve speed of scatter_update on the cpu for ASSIGN operations.
Change reduce_join to treat reduction_indices in the same way as other reduce_ ops.
Move TensorForestEstimator to contrib/tensor_forest.
Enable compiler optimizations by default and allow configuration in configure.
tf.divide now honors the name field.
Make metrics weight broadcasting more strict.
Add new queue-like StagingArea and new ops: stage and unstage.
Enable inplace update ops for strings on CPU. Speed up string concat.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Aaron Hu, Abhishek Aggarwal, Adam Michael, Adriano Carmezim, @AfirSraftGarrier,
Alexander Novikov, Alexander Rosenberg Johansen, Andrew Gibiansky, Andrew Hundt,
Anish Shah, Anton Loss, @b0noI, @BoyuanJiang, Carl Thomé, Chad Kennedy, Comic
Chang, Connor Braa, Daniel N. Lang, Daniel Trebbien,
@danielgordon10, Darcy Liu, Darren Garvey, Dmitri Lapin, Eron Wright, Evan
Cofer, Fabrizio Milo, Finbarr Timbers, Franck Dernoncourt, Garrett Smith,
@guschmue, Hao Wei, Henrik Holst, Huazuo Gao, @Ian, @Issac, Jacob Israel,
Jangsoo Park, Jin Kim, Jingtian Peng, John Pope, Kye Bostelmann, Liangliang He,
Ling Zhang, Luheng He, Luke Iwanski, @lvli, Michael Basilyan, Mihir Patel,
Mikalai Drabovich, Morten Just, @newge, Nick Butlin, Nishant Shukla,
Pengfei Ni, Przemyslaw Tredak, @rasbt, @Ronny, Rudolf Rosa, @RustingSword,
Sam Abrahams, Sam Putnam, @SeongAhJo, Shi Jiaxin, @skavulya, Steffen MüLler,
@TheUSER123, @tiriplicamihai, @vhasanov, Victor Costan, Vit Stepanovs,
Wangda Tan, Wenjian Huang, Xingdong Zuo, Yaroslav Bulatov, Yota Toyama,
Yuan (Terry) Tang, Yuxin Wu
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
TensorFlow now builds and runs on Microsoft Windows (tested on Windows 10,
Windows 7, and Windows Server 2016). Supported languages include Python (via a
pip package) and C++. CUDA 8.0 and cuDNN 5.1 are supported for GPU
acceleration. Known limitations include: It is not currently possible to load
a custom op library. The GCS and HDFS file systems are not currently
supported. The following ops are not currently implemented:
Dequantize, QuantizeAndDequantize, QuantizedAvgPool,
QuantizedBatchNomWithGlobalNormalization, QuantizedBiasAdd, QuantizedConcat,
QuantizedConv2D, QuantizedMatmul, QuantizedMaxPool,
QuantizeDownAndShrinkRange, QuantizedRelu, QuantizedRelu6, QuantizedReshape,
QuantizeV2, RequantizationRange, and Requantize.
New checkpoint format becomes the default in tf.train.Saver. Old V1
checkpoints continue to be readable; controlled by the write_version
argument, tf.train.Saver now by default writes out in the new V2
format. It significantly reduces the peak memory required and latency
incurred during restore.
Added a new library for library of matrix-free (iterative) solvers for linear
equations, linear least-squares, eigenvalues and singular values in
tensorflow/contrib/solvers. Initial version has lanczos bidiagonalization,
conjugate gradients and CGLS.
Added gradients for matrix_solve_ls and self_adjoint_eig.
Large cleanup to add second order gradient for ops with C++ gradients and
improve existing gradients such that most ops can now be differentiated
multiple times.
Added a solver for ordinary differential equations,tf.contrib.integrate.odeint.
New contrib module for tensors with named axes, tf.contrib.labeled_tensor.
Visualization of embeddings in TensorBoard.
Breaking Changes to the API
BusAdjacency enum replaced with a protocol buffer DeviceLocality. PCI bus
indexing now starts from 1 instead of 0, and bus_id==0 is used where
previously BUS_ANY was used.
Env::FileExists and FileSystem::FileExists now return a tensorflow::Status
instead of a bool. Any callers to this function can be converted to a bool
by adding .ok() to the call.
The C API type TF_SessionWithGraph has been renamed to TF_Session,
indicating its preferred use in language bindings for TensorFlow.
What was previously TF_Session has been renamed to TF_DeprecatedSession.
Renamed TF_Port to TF_Output in the C API.
Removes RegisterShape from public API. Use C++ shape function registration instead.
indexing now starts from 1 instead of 0, and bus_id==0 is used where
previously BUS_ANY was used.
Most RNN cells and RNN functions now use different variable scopes to be
consistent with layers (tf.contrib.layers). This means old checkpoints
written using this code will not load after this change without providingSaver a list of variable renames. Examples of variable scope changes
include RNN -> rnn in tf.nn.rnn, tf.nn.dynamic_rnn and moving fromLinear/Matrix -> weights and Linear/Bias -> biases in most RNN cells.
Deprecated tf.select op. tf.where should be used instead.
SparseTensor.shape has been renamed to SparseTensor.dense_shape. Same forSparseTensorValue.shape.
Env::FileExists and FileSystem::FileExists now return atensorflow::Status instead of a bool. Any callers to this function can be
converted to a bool by adding .ok() to the call.
C API: Type TF_SessionWithGraph has been renamed to TF_Session, indicating
its preferred use in language bindings for TensorFlow. What was previouslyTF_Session has been renamed to TF_DeprecatedSession.
C API: Renamed TF_Port to TF_Output.
C API: The caller retains ownership of TF_Tensor objects provided toTF_Run, TF_SessionRun, TF_SetAttrTensor etc.
Move Summary protobuf constructors to tf.summary submodule.
Deprecate histogram_summary, audio_summary, scalar_summary,image_summary, merge_summary, and merge_all_summaries.
Combined batch_* and regular version of linear algebra and FFT ops. The
regular op now handles batches as well. All batch_* Python interfaces were
removed.
tf.all_variables, tf.VARIABLES and tf.initialize_all_variables renamed
to tf.global_variables, tf.GLOBAL_VARIABLES andtf.global_variables_initializer respectively.
tf.zeros_initializer() and tf.ones_initializer() now return a callable
that must be called with initializer arguments, in your code replacetf.zeros_initializer with tf.zeros_initializer()
Bug Fixes and Other Changes
Use threadsafe version of lgamma function.
Fix tf.sqrt handling of negative arguments.
Fixed bug causing incorrect number of threads to be used for multi-threaded
benchmarks.
Performance optimizations for batch_matmul on multi-core CPUs.
Improve trace, matrix_set_diag, matrix_diag_part and their gradients to
work for rectangular matrices.
Support for SVD of complex valued matrices.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
@a7744hsc, Abhi Agg, @admcrae, Adriano Carmezim, Aki Sukegawa, Alex Kendall,
Alexander Rosenberg Johansen, @amcrae, Amlan Kar, Andre Simpelo, Andreas Eberle,
Andrew Hundt, Arnaud Lenglet, @b0noI, Balachander Ramachandran, Ben Barsdell,
Ben Guidarelli, Benjamin Mularczyk, Burness Duan, @c0g, Changming Sun,
@chanis, Corey Wharton, Dan J, Daniel Trebbien, Darren Garvey, David Brailovsky,
David Jones, Di Zeng, @DjangoPeng, Dr. Kashif Rasul, @drag0, Fabrizio (Misto)
Milo, FabríCio Ceschin, @fp, @Ghedeon, @guschmue, Gökçen Eraslan, Haosdent
Huang, Haroen Viaene, Harold Cooper, Henrik Holst, @hoangmit, Ivan Ukhov, Javier
Dehesa, Jingtian Peng, Jithin Odattu, Joan Pastor, Johan Mathe, Johannes Mayer,
Jongwook Choi, Justus Schwabedal, Kai Wolf, Kamil Hryniewicz, Kamran Amini,
Karen Brems, Karl Lattimer, @kborer, Ken Shirriff, Kevin Rose, Larissa Laich,
Laurent Mazare, Leonard Lee, Liang-Chi Hsieh, Liangliang He, Luke Iwanski,
Marek Kolodziej, Moustafa Alzantot, @MrQianjinsi, @nagachika, Neil Han, Nick
Meehan, Niels Ole Salscheider, Nikhil Mishra, @nschuc, Ondrej Skopek, OndřEj
Filip, @OscarDPan, Pablo Moyano, Przemyslaw Tredak, @qitaishui, @Quarazy,
@raix852, Philipp Helo, Sam Abrahams, @SriramRamesh, Till Hoffmann, Tushar Soni,
@tvn, @tyfkda, Uwe Schmidt, Victor Villas, Vit Stepanovs, Vladislav Gubarev,
@wujingyue, Xuesong Yang, Yi Liu, Yilei Yang, @youyou3, Yuan (Terry) Tang,
Yuming Wang, Zafar Takhirov, @zhongyuk, Ziming Dong, @guotong1988
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
CUDA 8 support.
cuDNN 5 support.
HDFS Support.
Adds Fused LSTM support via cuDNN 5 in tensorflow/contrib/cudnn_rnn.
Improved support for NumPy style basic slicing including non-1 strides,
ellipses, newaxis, and negative indices. For example complicated expressions
like foo[1, 2:4, tf.newaxis, ..., :-3:-1, :] are now supported. In addition
we have preliminary (non-broadcasting) support for sliced assignment to
variables. In particular one can write var[1:3].assign([1,11,111]).
Deprecated tf.op_scope and tf.variable_op_scope in favor of a unified tf.name_scope and tf.variable_scope. The new argument order of tf.variable_scope is incompatible with previous versions.
Introducing core/util/tensor_bundle module: a module to efficiently
serialize/deserialize tensors to disk. Will be used in TF's new checkpoint
format.
Added tf.svd for computing the singular value decomposition (SVD) of dense
matrices or batches of matrices (CPU only).
Added gradients for eigenvalues and eigenvectors computed usingself_adjoint_eig or self_adjoint_eigvals.
Eliminated batch_* methods for most linear algebra and FFT ops and promoted
the non-batch version of the ops to handle batches of matrices.
Tracing/timeline support for distributed runtime (no GPU profiler yet).
C API gives access to inferred shapes with TF_GraphGetTensorNumDims andTF_GraphGetTensorShape.
Shape functions for core ops have moved to C++ viaREGISTER_OP(...).SetShapeFn(...). Python shape inference RegisterShape calls
use the C++ shape functions with common_shapes.call_cpp_shape_fn. A future
release will remove RegisterShape from python.
Bug Fixes and Other Changes
Documentation now includes operator overloads on Tensor and Variable.
tensorflow.__git_version__ now allows users to identify the version of the
code that TensorFlow was compiled with. We also havetensorflow.__git_compiler__ which identifies the compiler used to compile
TensorFlow's core.
Improved multi-threaded performance of batch_matmul.
LSTMCell, BasicLSTMCell, and MultiRNNCell constructors now default tostate_is_tuple=True. For a quick fix while transitioning to the new
default, simply pass the argument state_is_tuple=False.
DeviceFactory's AddDevices and CreateDevices functions now return
a Status instead of void.
Int32 elements of list(type) arguments are no longer placed in host memory by
default. If necessary, a list(type) argument to a kernel can be placed in host
memory using a HostMemory annotation.
uniform_unit_scaling_initializer() no longer takes a full_shape arg,
instead relying on the partition info passed to the initializer function when
it's called.
The NodeDef protocol message is now defined in its own file node_def.protoinstead of graph.proto.
ops.NoGradient was renamed ops.NotDifferentiable. ops.NoGradient will
be removed soon.
dot.h / DotGraph was removed (it was an early analysis tool prior
to TensorBoard, no longer that useful). It remains in history
should someone find the code useful.
re2 / regexp.h was removed from being a public interface of TF.
Should users need regular expressions, they should depend on the RE2
library directly rather than via TensorFlow.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Abid K, @afshinrahimi, @AidanGG, Ajay Rao, Aki Sukegawa, Alex Rothberg,
Alexander Rosenberg Johansen, Andrew Gibiansky, Andrew Thomas, @Appleholic,
Bastiaan Quast, Ben Dilday, Bofu Chen, Brandon Amos, Bryon Gloden, Cissp®,
@chanis, Chenyang Liu, Corey Wharton, Daeyun Shin, Daniel Julius Lasiman, Daniel
Waterworth, Danijar Hafner, Darren Garvey, Denis Gorbachev, @DjangoPeng,
Egor-Krivov, Elia Palme, Eric Platon, Fabrizio Milo, Gaetan Semet,
Georg Nebehay, Gu Wang, Gustav Larsson, @haosdent, Harold Cooper, Hw-Zz,
@ichuang, Igor Babuschkin, Igor Macedo Quintanilha, Ilya Edrenkin, @ironhead,
Jakub Kolodziejczyk, Jennifer Guo, Jihun Choi, Jonas Rauber, Josh Bleecher
Snyder, @jpangburn, Jules Gagnon-Marchand, Karen Brems, @kborer, Kirill Bobyrev,
Laurent Mazare, Longqi Yang, Malith Yapa, Maniteja Nandana, Martin Englund,
Matthias Winkelmann, @mecab, Mu-Ik Jeon, Nand Dalal, Niels Ole Salscheider,
Nikhil Mishra, Park Jiin, Pieter De Rijk, @raix852, Ritwik Gupta, Sahil Sharma,
Sangheum Hwang, @SergejsRk, Shinichiro Hamaji, Simon Denel, @Steve, @suiyuan2009,
Tiago Jorge, Tijmen Tieleman, @tvn, @tyfkda, Wang Yang, Wei-Ting Kuo, Wenjian
Huang, Yan Chen, @YenChenLin, Yuan (Terry) Tang, Yuncheng Li, Yunfeng Wang, Zack
Polizzi, @zhongzyd, Ziming Dong, @perhapszzy
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
Added support for C++ shape inference
Added graph-construction C API
Major revision to the graph-construction C++ API
Support makefile build for iOS
Added Mac GPU support
Full version of TF-Slim available as tf.contrib.slim
Added k-Means clustering and WALS matrix factorization
Bug Fixes and Other Changes
Allow gradient computation for scalar values.
Performance improvements for gRPC
Improved support for fp16
New high-level ops in tf.contrib.{layers,metrics}
New features for TensorBoard, such as shape display, exponential smoothing
Faster and more stable Google Cloud Storage (GCS) filesystem support
Support for zlib compression and decompression for TFRecordReader and TFRecordWriter
Support for reading (animated) GIFs
Improved support for SparseTensor
Added support for more probability distributions (Dirichlet, Beta, Bernoulli, etc.)
Added Python interfaces to reset resource containers.
Many bugfixes and performance improvements
Many documentation fixes
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Alex Rothberg, Andrew Royer, Austin Marshall, @BlackCoal, Bob Adolf, Brian Diesel, Charles-Emmanuel Dias, @chemelnucfin, Chris Lesniewski, Daeyun Shin, Daniel Rodriguez, Danijar Hafner, Darcy Liu, Kristinn R. Thórisson, Daniel Castro, Dmitry Savintsev, Kashif Rasul, Dylan Paiton, Emmanuel T. Odeke, Ernest Grzybowski, Gavin Sherry, Gideon Dresdner, Gregory King, Harold Cooper, @heinzbeinz, Henry Saputra, Huarong Huo, Huazuo Gao, Igor Babuschkin, Igor Macedo Quintanilha, Ivan Ukhov, James Fysh, Jan Wilken Dörrie, Jihun Choi, Johnny Lim, Jonathan Raiman, Justin Francis, @lilac, Li Yi, Marc Khoury, Marco Marchesi, Max Melnick, Micael Carvalho, @mikowals, Mostafa Gazar, Nico Galoppo, Nishant Agrawal, Petr Janda, Yuncheng Li, @raix852, Robert Rose, @Robin-des-Bois, Rohit Girdhar, Sam Abrahams, satok16, Sergey Kishchenko, Sharkd Tu, @shotat, Siddharth Agrawal, Simon Denel, @sono-bfio, SunYeop Lee, Thijs Vogels, @tobegit3hub, @Undo1, Wang Yang, Wenjian Huang, Yaroslav Bulatov, Yuan Tang, Yunfeng Wang, Ziming Dong
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
Python 3.5 support and binaries
Added iOS support
Added support for processing on GPUs on MacOS
Added makefile for better cross-platform build support (C API only)
fp16 support and improved complex128 support for many ops
Higher level functionality in contrib.{layers,losses,metrics,learn}
More features to Tensorboard
Improved support for string embedding and sparse features
The RNN api is finally "official" (see, e.g., tf.nn.dynamic_rnn,tf.nn.rnn, and the classes in tf.nn.rnn_cell).
TensorBoard now has an Audio Dashboard, with associated audio summaries.
Bug Fixes and Other Changes
Turned on CuDNN Autotune.
Added support for using third-party Python optimization algorithms (contrib.opt).
Google Cloud Storage filesystem support.
HDF5 support
Add support for 3d convolutions and pooling.
Update gRPC release to 0.14.
Eigen version upgrade.
Switch to eigen thread pool
tf.nn.moments() now accepts a shift argument. Shifting by a good estimate
of the mean improves numerical stability. Also changes the behavior of theshift argument to tf.nn.sufficient_statistics().
Performance improvements
Many bugfixes
Many documentation fixes
TensorBoard fixes: graphs with only one data point, Nan values,
reload button and auto-reload, tooltips in scalar charts, run
filtering, stable colors
Tensorboard graph visualizer now supports run metadata. Clicking on nodes
while viewing a stats for a particular run will show runtime statistics, such
as memory or compute usage. Unused nodes will be faded out.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Aaron Schumacher, Aidan Dang, Akihiko ITOH, Aki Sukegawa, Arbit Chen, Aziz Alto, Danijar Hafner, Erik Erwitt, Fabrizio Milo, Felix Maximilian Möller, Henry Saputra, Sung Kim, Igor Babuschkin, Jan Zikes, Jeremy Barnes, Jesper Steen Møller, Johannes Mayer, Justin Harris, Kashif Rasul, Kevin Robinson, Loo Rong Jie, Lucas Moura, Łukasz Bieniasz-Krzywiec, Mario Cho, Maxim Grechkin, Michael Heilman, Mostafa Rahmani, Mourad Mourafiq, @ninotoshi, Orion Reblitz-Richardson, Yuncheng Li, @raoqiyu, Robert DiPietro, Sam Abrahams, Sebastian Raschka, Siddharth Agrawal, @snakecharmer1024, Stephen Roller, Sung Kim, SunYeop Lee, Thijs Vogels, Till Hoffmann, Victor Melo, Ville Kallioniemi, Waleed Abdulla, Wenjian Huang, Yaroslav Bulatov, Yeison Rodriguez, Yuan Tang, Yuxin Wu, @zhongzyd, Ziming Dong, Zohar Jackson
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
Added a distributed runtime using GRPC
Move skflow to contrib/learn
Better linear optimizer in contrib/linear_optimizer
Random forest implementation in contrib/tensor_forest
CTC loss and decoders in contrib/ctc
Basic support for half data type
Better support for loading user ops (see examples in contrib/)
Allow use of (non-blocking) Eigen threadpool with TENSORFLOW_USE_EIGEN_THREADPOOL define
Add an extension mechanism for adding network file system support
TensorBoard displays metadata stats (running time, memory usage and device used) and tensor shapes
Bug Fixes and Other Changes
Utility for inspecting checkpoints
Basic tracing and timeline support
Allow building against cuDNN 5 (not incl. RNN/LSTM support)
Added instructions and binaries for ProtoBuf library with fast serialization and without 64MB limit
Added special functions
bool-strictness: Tensors have to be explicitly compared to None
Shape strictness: all fed values must have a shape that is compatible with the tensor they are replacing
run() now takes RunOptions and RunMetadata, which enable timing stats
Fixed lots of potential overflow problems in op kernels
Various performance improvements, especially for RNNs and convolutions
Many bugfixes
Nightly builds, tutorial tests, many test improvements
New examples: transfer learning and deepdream ipython notebook
Added tutorials, many documentation fixes.
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Abhinav Upadhyay, Aggelos Avgerinos, Alan Wu, Alexander G. de G. Matthews, Aleksandr Yahnev, @amchercashin, Andy Kitchen, Aurelien Geron, Awni Hannun, @BanditCat, Bas Veeling, Cameron Chen, @cg31, Cheng-Lung Sung, Christopher Bonnett, Dan Becker, Dan Van Boxel, Daniel Golden, Danijar Hafner, Danny Goodman, Dave Decker, David Dao, David Kretch, Dongjoon Hyun, Dustin Dorroh, @e-lin, Eurico Doirado, Erik Erwitt, Fabrizio Milo, @gaohuazuo, Iblis Lin, Igor Babuschkin, Isaac Hodes, Isaac Turner, Iván Vallés, J Yegerlehner, Jack Zhang, James Wexler, Jan Zikes, Jay Young, Jeff Hodges, @jmtatsch, Johnny Lim, Jonas Meinertz Hansen, Kanit Wongsuphasawat, Kashif Rasul, Ken Shirriff, Kenneth Mitchner, Kenta Yonekura, Konrad Magnusson, Konstantin Lopuhin, @lahwran, @lekaha, @liyongsea, Lucas Adams, @makseq, Mandeep Singh, @manipopopo, Mark Amery, Memo Akten, Michael Heilman, Michael Peteuil, Nathan Daly, Nicolas Fauchereau, @ninotoshi, Olav Nymoen, @panmari, @papelita1234, Pedro Lopes, Pranav Sailesh Mani, RJ Ryan, Rob Culliton, Robert DiPietro, @ronrest, Sam Abrahams, Sarath Shekkizhar, Scott Graham, Sebastian Raschka, Sung Kim, Surya Bhupatiraju, Syed Ahmed, Till Hoffmann, @timsl, @urimend, @vesnica, Vlad Frolov, Vlad Zagorodniy, Wei-Ting Kuo, Wenjian Huang, William Dmitri Breaden Madden, Wladimir Schmidt, Yuan Tang, Yuwen Yan, Yuxin Wu, Yuya Kusakabe, @zhongzyd, @znah.
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Bug Fixes and Other Changes
Added gfile.Open and gfile.Copy, used by input_data.py.
Fixed Saver bug when MakeDirs tried to create empty directory.
GPU Pip wheels are built with cuda 7.5 and cudnn-v4, making them
required for the binary releases. Lower versions of cuda/cudnn can
be supported by installing from sources and setting the options
during ./configure
Fix dataset encoding example for Python3 (@danijar)
Fix PIP installation by not packaging protobuf as part of wheel,
require protobuf 3.0.0b2.
Fix Mac pip installation of numpy by requiring pip >= 1.10.1.
Improvements and fixes to Docker image.
Major Features and Improvements
Allow using any installed Cuda >= 7.0 and cuDNN >= R2, and add support
for cuDNN R4
Added a contrib/ directory for unsupported or experimental features,
including higher level layers module
Added an easy way to add and dynamically load user-defined ops
Built out a good suite of tests, things should break less!
Added MetaGraphDef which makes it easier to save graphs with metadata
Added assignments for "Deep Learning with TensorFlow" udacity course
Bug Fixes and Other Changes
Added a versioning framework for GraphDefs to ensure compatibility
Enforced Python 3 compatibility
Internal changes now show up as sensibly separated commits
Open-sourced the doc generator
Un-fork Eigen
Simplified the BUILD files and cleaned up C++ headers
TensorFlow can now be used as a submodule in another bazel build
New ops (e.g., *fft, *_matrix_solve)
Support for more data types in many ops
Performance improvements
Various bugfixes
Documentation fixes and improvements
Breaking Changes to the API
AdjustContrast kernel deprecated, new kernel AdjustContrastv2 takes and
outputs float only. adjust_contrast now takes all data types.
adjust_brightness's delta argument is now always assumed to be in [0,1]
(as is the norm for images in floating point formats), independent of the
data type of the input image.
The image processing ops do not take min and max inputs any more, casting
safety is handled by saturate_cast, which makes sure over- and underflows
are handled before casting to data types with smaller ranges.
For C++ API users: IsLegacyScalar and IsLegacyVector are now gone fromTensorShapeUtils since TensorFlow is scalar strict within Google (for
example, the shape argument to tf.reshape can't be a scalar anymore). The
open source release was already scalar strict, so outside Google IsScalar
and IsVector are exact replacements.
The following files are being removed from tensorflow/core/public/:
For C++ API users: TensorShape::ShortDebugString has been renamed toDebugString, and the previous DebugString behavior is gone (it was
needlessly verbose and produced a confusing empty string for scalars).
GraphOptions.skip_common_subexpression_elimination has been removed. All
graph optimizer options are now specified viaGraphOptions.OptimizerOptions.
ASSERT_OK / EXPECT_OK macros conflicted with external projects, so they
were renamed TF_ASSERT_OK, TF_EXPECT_OK. The existing macros are
currently maintained for short-term compatibility but will be removed.
The non-public nn.rnn and the various nn.seq2seq methods now return
just the final state instead of the list of all states.
tf.scatter_update now no longer guarantees that lexicographically largest
index be used for update when duplicate entries exist.
tf.image.random_crop(image, [height, width]) is nowtf.random_crop(image, [height, width, depth]), and tf.random_crop works
for any rank (not just 3-D images). The C++ RandomCrop op has been replaced
with pure Python.
Renamed tf.test.GetTempDir and tf.test.IsBuiltWithCuda totf.test.get_temp_dir and tf.test.is_built_with_cuda for PEP-8
compatibility.
parse_example's interface has changed, the old interface is accessible inlegacy_parse_example (same for related functions).
New Variables are not added to the same collection several times even if
a list with duplicates is passed to the constructor.
The Python API will now properly set the list member of AttrValue in
constructed GraphDef messages for empty lists. The serialization of some
graphs will change, but the change is both forwards and backwards compatible.
It will break tests that compare a generated GraphDef to a golden serializedGraphDef (which is discouraged).
Thanks to our Contributors
This release contains contributions from many people at Google, as well as:
Akiomi Kamakura, Alex Vig, Alexander Rosenberg Johansen, Andre Cruz, Arun Ahuja,
Bart Coppens, Bernardo Pires, Carl Vondrick, Cesar Salgado, Chen Yu,
Christian Jauvin, Damien Aymeric, Dan Vanderkam, Denny Britz, Dongjoon Hyun,
Eren Güven, Erik Erwitt, Fabrizio Milo, G. Hussain Chinoy, Jim Fleming,
Joao Felipe Santos, Jonas Meinertz Hansen, Joshi Rekha, Julian Viereck,
Keiji Ariyama, Kenton Lee, Krishna Sankar, Kristina Chodorow, Linchao Zhu,
Lukas Krecan, Mark Borgerding, Mark Daoust, Moussa Taifi,
Nathan Howell, Naveen Sundar Govindarajulu, Nick Sweeting, Niklas Riekenbrauck,
Olivier Grisel, Patrick Christ, Povilas Liubauskas, Rainer Wasserfuhr,
Romain Thouvenin, Sagan Bolliger, Sam Abrahams, Taehoon Kim, Timothy J Laurent,
Vlad Zavidovych, Yangqing Jia, Yi-Lin Juang, Yuxin Wu, Zachary Lipton,
Zero Chen, Alan Wu, @brchiu, @emmjaykay, @jalammar, @Mandar-Shinde,
@nsipplswezey, @ninotoshi, @panmari, @prolearner and @rizzomichaelg.
We are also grateful to all who filed issues or helped resolve them, asked and
answered questions, and were part of inspiring discussions.
Major Features and Improvements
Python 3.3+ support via changes to python codebase and ability
to specify python version via ./configure.
Some improvements to GPU performance and memory usage:convnet benchmarks
roughly equivalent with native cudnn v2 performance. Improvements mostly due
to moving to 32-bit indices, faster shuffling kernels. More improvements to
come in later releases.
Bug Fixes
Lots of fixes to documentation and tutorials, many contributed
by the public.
271 closed issues on github issues.
Backwards-Incompatible Changes
tf.nn.fixed_unigram_candidate_sampler changed its default 'distortion'
attribute from 0.0 to 1.0. This was a bug in the original release
that is now fixed.
Passmgr is a simple password manager which allows to securely store
passphrases and retrieve them via commandline.
Usage of passmgr:
-add
store new credentials
-appTTL int
time in seconds after which the application quits if there is no user interaction (default 120)
-clipboardTTL int
time in seconds after which the clipboard is reset (default 15)
-del
delete stored credentials
-file string
specify the passmgr store (default "/home/david/.passmgr_store")
In its default mode (no arguments), passmgr allows to select stored passphrases
which are then copied to the clipboard for a limited amount of time in order
to be pasted into a passphrase field. After this time, the clipboard is erased.
Example:
$ passmgr
[passmgr] master passphrase for /home/david/.passmgr_store:
n) User URL
1) urld github.com
2) david@example.com facebook.com
3) david@example.com twitter.com
4) other@example.com google.com
Choose a command [(S)elect/(a)dd/(d)elete/(q)uit] s
Select: 1
Passphrase copied to clipboard!
Clipboard will be erased in 6 seconds.
......
Passphrase erased from clipboard.
All credentials are stored AES256-GCM encrypted in a single file which by default
is located in the users home directory.
The encryption key for this file is derived from a master passphrase using scrypt.
In 1962 Random House published a first novel by a thirty-two-year-old American living in Paris named Harry Mathews. The Conversions is an adventure story about a man trying to decipher the meaning of carvings on an ancient weapon, and it unfolds in a succession of bizarre anecdotes and obscure quotations, with an appendix in German. One particularly trying passage is written in a language once popular with schoolchildren that involves adding arag before most vowels. Furthermore is faragurtharaggermaragore and indulgences is araggindaragulgearaggencearagges.
The book was considered groundbreaking by a certain literary set. Terry Southern called it a “startling piece of work,” and George Plimpton published a seventy-page excerpt in The Paris Review. Mathews’s agent Maxine Groffsky, then in her first job after college in the editorial department at Random House, says that reading The Conversions was like “seeing Merce Cunningham for the first time.” But it baffled most of the reading public, including the poor Time critic who complained that the symbolism “spreads through the novel like crab grass.”
Mathews is one of American literature’s great idiosyncratic figures. His friend Georges Perec, who once wrote a novel without using the letter e, has accused him of following “rules from another planet.” He is usually identified as the sole American member of the Oulipo, a French writers’ group whose stated purpose is to devise mathematical structures that can be used to create literature. He has also been associated with the New York School of avant-garde writers, which included his friends John Ashbery and Kenneth Koch. After forty-five years of congenital allergy to convention, he rightfully belongs to the experimentalist tradition of Kafka, Beckett, and Joyce, even though his classical, witty style has won him comparisons to Nabokov, Jane Austen, and Evelyn Waugh. Yet while he enjoys the attention of thousands of cultishly enthusiastic French readers, Mathews remains relatively unknown in his native land and language. “When I go into an English bookstore, I always ask the same question,” a Frenchman told me with the sly smile that infects all Mathews fans. “‘Do you have Tlooth?’”
Tlooth, Mathews’s second novel, came out in 1966. It begins with a baseball game at a Siberian prison camp. His next book, The Sinking of the Odradek Stadium (1975), is considered by many to be his masterpiece. Twenty-five publishers rejected it, which isn’t entirely surprising given that half of it is written in an invented pidgin English. Mathews used an Oulipian mathematical scheme to create the plot of his fourth novel, Cigarettes (1987). His last two novels are deceptively straightforward. The Journalist (1994) is the diary of a man obsessed by his diary. My Life in CIA (2005), an “autobiographical novel,” begins reassuringly as a memoir only to devolve into the preposterous, ending with the protagonist Harry Mathews tending sheep in the Alps after attempting murder by ski pole.
In reality, the self-described refugee from the Upper East Side has lived in Paris on and off since the fifties, though he does spend summers in the Alps and he says “there are sheep nearby.” Mathews was born in Manhattan in 1930, the only child of an architect and a cold-water-flats heiress. After dutifully attending Princeton for two years, he dropped out and joined the navy, then eloped at nineteen with the artist Niki de Saint Phalle. He finished his studies at Harvard, majoring in music, and in 1952 moved to Paris where he briefly studied conducting before deciding to write poetry full time. In 1956 Mathews met Ashbery, who was in France on a Fulbright scholarship. The poet introduced him to the works of Raymond Roussel, the early-twentieth-century French avant-gardist. After reading Roussel, Mathews turned to prose.
A novelist, poet, essayist, and translator, Mathews is also the author of many short works, including Twenty Lines a Day (1988), the result of more than a year spent following Stendhal’s dictum to write “twenty lines a day, genius or not,” and Singular Pleasures (1983), a series of sixty-one vignettes describing masturbation scenes. A volume of his collected short stories, The Human Country, was published in 2002.
Mathews and his second wife, the French writer Marie Chaix, split their time between France, New York City, and Key West, Florida. This interview took place over several afternoons in the pleasantly worn living room of Mathews’s apartment on the rue de Grenelle in Paris. A ceramic sculpture by Saint Phalle sat on the mantelpiece next to smoky mirrored walls. Tall, courteous, cigar-smoking, Mathews wore an unusual vest, faintly Indian. A long silver chain hung from his velvet pants, suggesting a pocket watch, though it was later revealed to be an enormous key ring. Mathews speaks with the nearly extinct mid-Atlantic accent that can carry off rather and alas. Then again, as an adult of the seventies, he will occasionally talk about sex (“fucking”) in a casual way that might surprise younger generations.
At one point we were interrupted by deafening honks. Mathews chuckled and said, “I can tell you exactly what that’s about.” He pointed out the window to a bus that was unable to make the turn onto the narrow street because of an illegally parked car. “See the no-parking sign in front of the car? It says zone de giration de bus. Where they came up with that, I have no idea. Bus gyration zone. Never has that formulation been used on earth before!”
INTERVIEWER
Do you have an audience in mind when you’re writing?
HARRY MATHEWS
I’ve always said that my ideal reader would be someone who after finishing one of my novels would throw it out the window, presumably from an upper floor of an apartment building in New York, and by the time it had landed would be taking the elevator down to retrieve it.
I suppose I must have had dreams of greater recognition, but I’ve always had the audience I wanted, and that was the audience that reads poetry. What I want is enthusiasm among friends and their friends, people who I know are serious readers.
INTERVIEWER
When did you start writing?
MATHEWS
My first serious work was a poem I wrote at the age of eleven. I went to a boys’ school in New York called St. Bernard’s. I had a wonderful English teacher who created a special class in Latin and in English poetry for me and a few other pupils. One day in class I wrote my first poem. He read it and gazed out of the window with an expression that, to me, said, What have I done? WASP private schools weren’t meant to produce poets, but doctors, lawyers, businessmen, and so forth. He could clearly see that I was hooked.
INTERVIEWER
Do you remember the poem?
MATHEWS
“It was a sad autumnal morn, / The earth was but a mass of clay; / Of foliage the trees were shorn, / Leaving their branches dull and gray.”
When I got to boarding school, I was addicted to poetry. I remember one week I wrote something like eight poems in eight different styles imitating Wordsworth, Swinburne, and Tennyson, among others. I incurred the total disapproval of my teachers and classmates. I was roundly condemned.
INTERVIEWER
Why?
MATHEWS
Because of the idiotic thing that aspiring young writers are usually told: write about yourself. Don’t imitate literary models. Of course, imitating literary models is the best thing one can do. Like painters—they make copies of classical masterpieces. I was cowed, so I wrote a couple of poems about my own experiences, which were close to doggerel. Then I started sneaking back toward more literary, more derivative work. There was a generous, brilliant man who taught at Groton named John Pick, and we became friends. He had written one of the first books on Gerard Manley Hopkins. I went to his study one evening, and he read me “The Love Song of J. Alfred Prufrock” and my life was never the same after that. There was no attempt to make a visible, logical sequence in the poem. By the time I was thirteen, I knew the work of Stravinsky and Bartók. They too had abandoned what passed for logic in music, which was harmonic organization of the work. It had never occurred to me that that could happen in writing.
Actually my first great aesthetic excitement came from classical music, starting with Wagner. I suppose Wagner is an artist as unlike me as you could imagine. And nevertheless, the obsessive romantic passion that those operas inspired in me is something that is behind all my writing, even though it’s totally suppressed and censored. Can I tell you a joke? What is the question to which the answer is 9 W?
INTERVIEWER
I give up.
MATHEWS
Mr. Wagner, do you write your name with a V?
INTERVIEWER
What did you like to read as a child?
MATHEWS
At first I was read to. My grandfather had taught Greek and Latin at Columbia, and he read to me from a book that had abbreviated versions of The Odyssey and The Iliad—plus a lot of classic fairy tales, which, as you know, are extremely disturbing. Then I began reading on my own. I read mostly Westerns. My parents approved of that, because at least they were books. But when I got into comic books, they disapproved. I would read them by flashlight under the covers. No one realized in those days that 1930s Action Comics and DC Comics, Superman and Batman, would become legendary in American culture. They taught me a great deal about narrative—lots of invention and no pretense of realism.