This is the introduction of a multipart series. It is to give a high level overview without really deeply diving into any individual component.
Vectorized emulation, why do I do this to myself?
![Why]()
| Date | Info |
|---|
| 2018-10-14 | Initial |
Follow me at @gamozolabs on Twitter if you want notifications when new blogs come up, or I think you can use RSS or something if you’re still one of those people.
All benchmarks done here are on a single Xeon Phi 7210 with 96 GiB of RAM. This comes out to about $4k USD, but if you cheap out on RAM and buy used Phis you could probably get the same setup for $1k USD.
This machine has 64 cores and 256 hardware threads. Using AVX-512 I run 4096 32-bit VMs at a time ((512 / 32) * 256).
All performance numbers in this article refer to the machine running at 100% on all cores.
| Term | Inology |
|---|
| Lane | A single component in a larger vector (often 32-bit throughout this document) |
| VM | A single VM, in terms of vectorized emulation it refers to a single lane of a vector |
In this blog I’m going to introduce you to a concept I’ve been working on for almost 2 years now. Vectorized emulation. The goal is to take standard applications and JIT them to their AVX-512 equivalent such that we can fuzz 16 VMs at a time per thread. The net result of this work allows for high performance fuzzing (approx 40 billion to 120 billion instructions per second [the 2 trillion clickbait number is theoretical maximum]) depending on the target, while gathering differential coverage on code, register, and memory state.
By gathering more than just code coverage we are able to track state of code deeper than just code coverage itself, allowing us to fuzz through things like memcmp() without any hooks or static analysis of the target at all.
Further since we’re running emulated code we are able to run a soft MMU implementation which has byte-level permissions. This gives us stronger-than-ASAN memory protections, making bugs fail faster and cleaner.
My history with fuzzing tools starts off effectively with my hypervisor for fuzzing, falkervisor. falkervisor served me well for quite a long time, but my work rotated more towards non-x86 targets, which it did not support. With a demand for emulation I made modifications to QEMU for high-performance fuzzing, and ultimately swapped out their MMU implementation for my own which has byte-level permissions. This new byte-level permission model allowed me to catch even the smallest memory corruptions, leading to finding pretty fun bugs!
More and more after working with QEMU I got annoyed. It’s designed for whole systems yet I was using it for fuzzing targets that were running with unknown hardware and running from dynamically dumped memory snapshots. Due to the level of abstraction in QEMU I started to get concerned with the potential unknowns that would affect the instrumentation and fuzzing of targets.
I developed my first MIPS emulator. It was not designed for performance, but rather purely for simple usage and perfect single stepping. You step an instruction, registers and memory get updated. No JIT, no intermediate registers, no flushing or weird block level translation changes. I eventually made a JIT for this that maintained the flush-state-every-instruction model and successfully used it against multiple targets. I also developed an ARM emulator somewhere in this timeframe.
When early 2017 rolls around I’m bored and want to buy a Xeon Phi. Who doesn’t want a 64-core 256-thread single processor? I really had no need for the machine so I just made up some excuse in my head that the high bandwidth memory on die would make reverting snapshots faster. Yeah… like that really matters? Oh well, I bought it.
While the machine was on the way I had this idea… when fuzzing from a snapshot all VMs initially start off fuzzing with the exact same state, except for maybe an input buffer and length being changed. Thus they do identical operations until user-controlled data is processed. I’ve done some fun vectorization work before, but what got me thinking is why not just emit vpaddd instead of add when JITting, and now I can run 16 VMs at a time!
Alas… the idea was born
Snapshot fuzzing is fundamental to this work and almost all fuzzing work I have done from 2014 and beyond. It warrants its own blog entirely.
Snapshot fuzzing is a method of fuzzing where you start from a partially-executed system state. For example I can run an application under GDB, like a parser, put a breakpoint after the file/network data has been read, and then dump memory and register state to a core dump using gcore. At this point I have full memory and register state for the application. I can then load up this core dump into any emulator, set up memory contents and permissions, set up register state, and continue execution. While this is an example with core dumps on Linux, this methodology works the same whether the snapshot is a core dump from GDB, a minidump on Windows, or even an exotic memory dump taken from an exploit on a locked-down device like a phone.
All that matters is that I have memory state and register state. From this point I can inject/modify the file contents in memory and continue execution with a new input!
It can get a lot more complex when dealing with kernel state, like file handles, network packets buffered in the kernel, and really anything that syscalls. However in most targets you can make some custom rigging using strace to know which FDs line up, where they are currently seeked, etc. Further a full system snapshot can be used instead of a single application and then this kernel state is no longer a concern.
The benefits of snapshot fuzzing are performance (linear scaling), high levels of introspection (even without source or symbols), and most importantly… determinism. Unless the emulator has bugs snapshot fuzzing is typically deterministic (sometimes relaxed for performance). Find some super exotic race condition while snapshot fuzzing? Well, you can single step through with the same input and now you can look at the trace as a human, even if it’s a 1 in a billion chance of hitting.
Since the 90s many computer architectures have some form of SIMD (vectorized) instruction set. SIMD stands for single instruction multiple data. This means that a single instruction performs an operation (typically the same) on multiple different pieces of data. SIMD instruction sets fall under names like MMX, SSE, AVX, AVX512 for x86, NEON for ARM, and AltiVec for PPC. You’ve probably seen these instructions if you’ve ever looked at a memcpy() implementation on any 64-bit x86 system. They’re the ones with the gross 15 character mnemonics and registers you didn’t even know existed.
For a simple case lets talk about standard SSE on x86. Since x86_64 started with the Pentium 4 and the Pentium 4 had up to SSE3 implementations, almost any x86_64 compiler will generate SSE instructions as they’re always valid on 64-bit systems.
SSE provides 128-bit SIMD operations to x86. SSE introduced 16 128-bit registers named xmm0 through xmm15 (only 8 xmm registers on 32-bit x86). These 128-bit registers can be treated as groups of different sized smaller pieces of data which sum up to 128 bits.
- 4 single precision floats
- 2 double precision floats
- 2 64-bit integers
- 4 32-bit integers
- 8 16-bit integers
- 16 8-bit integers
Now with a single instruction it is possible to perform the same operation on multiple floats or integers. For example there is an instruction paddd, which stands for packed add dwords. This means that the 128-bit registers provided are treated as 4 32-bit integers, and an add operation is performed.
Here’s a real example, adding xmm0 and xmm1 together treating them as 4 individual 32-bit integer lanes and storing them back into xmm0
paddd xmm0, xmm1
| Register | Dword 1 | Dword 2 | Dword 3 | Dword 4 |
|---|
| xmm0 | 5 | 6 | 7 | 8 |
| xmm1 | 10 | 20 | 30 | 40 |
| xmm0 (result) | 15 | 26 | 37 | 48 |
Cool. Starting with AVX these registers were expanded to 256-bits thus allowing twice the throughput per instruction. These registers are named ymm0 through ymm15. Further AVX introduced three operand form instructions which allow storing a result to a different register than the ones being used in the operation. For example you can do vpaddd ymm0, ymm1, ymm2 which will add the 8 individual 32-bit integers in ymm1 and ymm2 and store the result into ymm0. This helps a lot with register scheduling and prevents many unnecessary movs just to save off registers before they are clobbered.
AVX-512 is a continuation of x86’s SIMD model by expanding from 16 256-bit registers to 32 512-bit registers. These registers are named zmm0 through zmm31. Further AVX-512 introduces 8 new kmask registers named k0 through k7 where k0 has a special meaning.
The kmask registers are used to perform masking on instructions, either by merging or zeroing. This makes it possible to loop through data and process it while having conditional masking to disable operations on a given lane of the vector.
The syntax for the common instructions using kmasks are the following:
vpaddd zmm0 {k1}, zmm1, zmm2
chart simplified to show 4 lanes instead of 16
| Register | Dword 1 | Dword 2 | Dword 3 | Dword 4 |
|---|
| zmm0 | 9 | 9 | 9 | 9 |
| zmm1 | 1 | 2 | 3 | 4 |
| zmm2 | 10 | 20 | 30 | 40 |
| k1 | 1 | 0 | 1 | 1 |
| zmm0 (result) | 11 | 9 | 33 | 44 |
or
vpaddd zmm0 {k1}{z}, zmm1, zmm2
chart simplified to show 4 lanes instead of 16
| Register | Dword 1 | Dword 2 | Dword 3 | Dword 4 |
|---|
| zmm0 | 9 | 9 | 9 | 9 |
| zmm1 | 1 | 2 | 3 | 4 |
| zmm2 | 10 | 20 | 30 | 40 |
| k1 | 1 | 0 | 1 | 1 |
| zmm0 (result) | 11 | 0 | 33 | 44 |
The first example uses k1 as the kmask for the add operation. In this case the k1 register is treated as a 16-bit number, where each bit corresponds to each of the 16 32-bit lanes in the 512-bit register. If the corresponding bit in k1 is zero, then the add operation is not performed and that lane is left unchanged in the resultant register.
In the second example there is a {z} suffix on the kmask register selection, this means that the operation is performed with zeroing rather than merging. If the corresponding bit in k1 is zero then the resultant lane is zeroed out rather than left unchanged. This gets rid of a dependency on the previous register state of the result and thus is faster, however it might not be suitable for all applications.
The k0 mask is implicit and does not need to be specified. The k0 register is hardwired to having all bits set, thus the operation is performed on all lanes unconditionally.
Prior to AVX-512 compare instructions in SIMD typically yielded all ones in a given lane if the comparision was true, or all zeroes if it was false. In AVX-512 comparison instructions are done using kmasks.
vpcmpgtd k2 {k1}, zmm10, zmm11
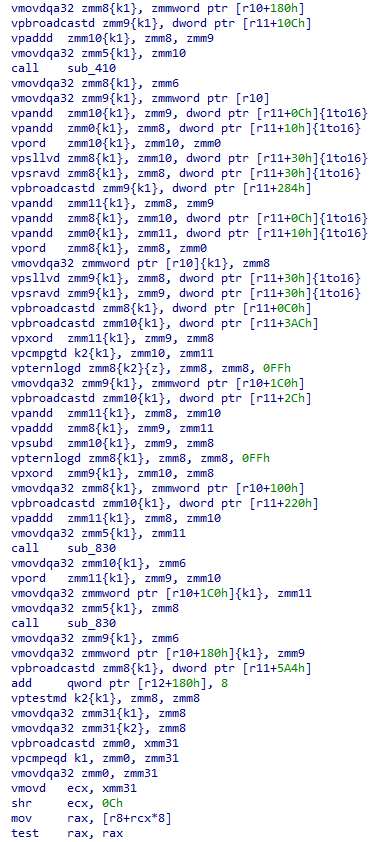
You may have seen this instruction in the picture at the start of the blog. What this instruction does is compare the 16 dwords in zmm10 with the 16 dwords in zmm11, and only performs the compare on lanes enabled by k1, and stores the result of the compare into k2. If the lane was disabled due to k1 then the corresponding bit in the k2 result will be zero. Meaning the only set bits in k2 will be from enabled lanes which were greater in zmm10 than in zmm11. Phew.
Now that you’ve made it this far you might already have some gears turning in your head telling you where this might be going next.
Since with snapshot fuzzing we start executing the same code, we are doing the same operations. This means we can convert the x86 instructions to their vectorized counterparts and run 16 VMs at a time rather than just one.
Let’s make up a fake program:
moveax,5movebx,10addeax,ebxsubeax,20
How can we vectorize this code?
; Register allocation:; eax = zmm0; ebx = zmm1vpbroadcastdzmm0,dwordptr[memorycontainingconstant5]vpbroadcastdzmm1,dwordptr[memorycontainingconstant10]vpadddzmm0,zmm0,zmm1vpsubdzmm0,zmm0,dwordptr[memorycontainingconstant20]{1to16}
Well that was kind of easy. We’ve got a few new AVX concepts here. We’re using the vpbroadcastd instruction to broadcast a dword value to all lanes of a given ZMM register. Since the Xeon Phi is bottlenecked on the instruction decoder it’s actually faster to load from memory than it is to load an immediate into a GPR, move this into a XMM register, and then broadcast it out.
Further we introduce the {1to16} broadcasting that AVX-512 offers. This allows us to use a single dword constant value with in our example vpsubd. This broadcasts the memory pointed to to all 16 lanes and then performs the operation. This saves one instruction as we don’t need an explicit vpbroadcastd.
In this case if we executed this code with any VM state we will have no divergence (no VMs do anything different), thus this example is very easy. It’s pretty much a 1-to-1 translation of the non-vectorized x86 to vectorized x86.
Alright, let’s try one a bit more complex, this time let’s work with VMs in different states:
becomes
; Register allocation:; eax = zmm0vpadddzmm0,zmm0,dwordptr[memorycontainingconstant10]{1to16}
Let’s imagine that the value in eax prior to execution is different, let’s say it’s [1, 2, 3, 4] for 4 different VMs (simplified, in reality there are 16).
| Register | Dword 1 | Dword 2 | Dword 3 | Dword 4 |
|---|
| zmm0 | 1 | 2 | 3 | 4 |
| const | 10 | 10 | 10 | 10 |
| zmm0 (result) | 11 | 12 | 13 | 14 |
Oh? This is exactly what AVX is supposed to do… so it’s easy?
So you might have noticed we’ve dodged a few things here that are hard. First we’ve ignored memory operations, and second we’ve ignored branches.
Lets talk a bit about AVX memory
With AVX-512 we can load and store directly from/to memory, and ideally this memory is aligned as 512-bit registers are whole 64-byte cache lines. In AVX-512 we use the vmovdqa32 instruction. This will load an entire aligned 64-byte piece of memory into a ZMM register ala vmovdqa32 zmm0, [memory], and we can store with vmovdqa32 [memory], zmm0. Further when using kmasks with vmovdqa32 for loads the corresponding lane is left unmodified (merge masking) or zeroed (zero masking). For stores the value is simply not written if the corresponding mask bit is zero.
That’s pretty easy. But this doesn’t really work well when we have 16 unique VMs we’re running with unique address spaces.
… or does it?
VM memory interleaving
Since most VM memory operations are not affected by user input, and thus are the same in all VMs, we need a way to organize the 16 VMs memory such that we can access them all quickly. To do this we actually interleave all 16 VMs at the dword level (32-bit). This means we can perform a single vmovdqa32 to load or store to memory for all 16 VMs as long as they’re accessing the same address.
This is pretty simple, just interleave at the dword level:
chart simplified to show 4 lanes instead of 16
| Guest Address | Host Address | Dword 1 | Dword 2 | Dword 3 | … | Dword 16 |
|---|
| 0x0000 | 0x0000 | 1 | 2 | 3 | … | 33 |
| 0x0004 | 0x0040 | 32 | 74 | 55 | … | 45 |
| 0x0008 | 0x0080 | 24 | 24 | 24 | … | 24 |
All we need to do is take the guest address, multiply it by 16, and then vmovdqa32 from/to that address. It once again does not matter what the contents of the memory are for each VM and they can differ. The vmovdqa32 does not care about the memory contents.
In reality the host address is not just the guest address multiplied by 16 as we need some translation layer. But that will get it’s own entire blog. For now let’s just assume a flat, infinite memory model where we can just multiply by 16.
So what are the limitations of this model?
Well when reading bytes we must read the whole dword value and then shift and mask to extract the specific byte. When writing a byte we need to read the memory first, shift, mask, and or in the new byte, and write it out. And when doing non-aligned operations we need to perform multiple memory operations and combine the values via shifting and masking. Luckily compilers (and programmers) typically avoid these unaligned operations and they’re rare enough to not matter much.
So far everything we have talked about does not care about the values it is operating on at all, thus everything has been easy so far. But in reality values do matter. There are 3 places where divergence matters in this entire system:
- Loads/stores with different addresses
- Branches
- Exceptions/faults
Loads/stores with different addresses
Let’s knock out the first one real quick, loads and stores with different addresses. For all memory accesses we do a very quick horizontal comparison of all the lanes first. If they have the same address then we take a fast path and issue a single vmovdqa32. If their addresses differ than we simply perform 16 individual memory operations and emulate the behavior we desire. It technically can get a bit better as AVX-512 has scatter/gather instructions which allow the CPU to do this load/storing to different addresses for us. This is done with a base and an offset, with 32-bits it’s not possible to address the whole address space we need. However with 64-bit vectorization (8 64-bit VMs) we can leverage scatter/gather instructions to their fullest and all loads and stores just become a fast path with one vmovdqa32, or a slow (but fast) path where we use a single scatter/gather instruction.
Branches
We’ve avoided this until now for a reason. It’s the single hardest thing in vectorized emulation. How can we possibly run 16 VMs at a time if one branches to another location. Now we cannot run a AVX-512 instruction as it would be invalid for the VMs which have gone down a different path.
Well it turns out this isn’t a terribly hard problem on AVX-512. And when I say AVX-512 I mean specifically AVX-512. Feel free to ponder why this might be based on what you’ve learned is unique to AVX-512.
…
…
…
Okay it’s kmasks. Did you get it right? Well kmasks save our lives. Remember the merging kmasks we talked about which would disable updates to a given lane of a vector and ignore writes to a given lane if it is not enabled in the kmask?
Well by using a kmask register on all JITted AVX-512 instructions we can simply change the kmask to disable updates on a given VM.
What this allows us to do is start execution at the same location on all 16 VMs as they start with the same EIP. On all branches we will horizontally compare the branch targets and compute a new kmask value to use when we continue execution on the new branch.
AVX-512 doesn’t have a great way of extracting or broadcasting arbitrary elements of a vector. However it has a fast way to broadcast the 0th lane in a vector ala vpbroadcastd zmm0, xmm0. This takes the first lane from xmm0 and broadcasts it to all 16 lanes in zmm0. We actually never stop following VM #0. This means VM #0 is always executing, which is important for all of the horizontal compares that we talk about. When I say horizontal compare I mean a broadcast of the VM#0 and compare with all other VMs.
Let’s look in-detail at the entire JIT that I use for conditional indirect branches:
; IL operation is Beqz(val, true_target, false_target);; val - 16 32-bit values to conditionally branch by; true_target - 16 32-bit guest branch target addresses if val == 0; false_target - 16 32-bit guest branch target addresses if val != 0;; IL pseudocode:;; if val == 0 {; goto true_target;; } else {; goto false_target;; };; Register usage; k1 - The execution kmask, this is the kmask used on all JITted instructions; k2 - Temporary kmask, just used for scratch; val - Dynamically allocated zmm register containing val; ttgt - Dynamically allocated zmm register containing true_target; ftgt - Dynamically allocated zmm register containing false_target; zmm0 - Scratch register; zmm31 - Desired branch target for all lanes; Compute a kmask `k2` which contains `1`s for the corresponding lanes; for VMs which are enabled by `k1` and also have a non-zero value.; TL;DR: k2 contains a mask of VMs which will be taking `ftgt`vptestmdk2{k1},val,val; Store the true branch target unconditionally, while not clobbering; VMs which have been disabledvmovdqa32zmm31{k1},ttgt; Store the false branch target for VMs not taking the branch; Note the use of k2vmovdqa32zmm31{k2},ftgt; At this point `zmm31` contains the targets for all VMs. Including ones; that previously got disabled.; Broadcast the target that VM #0 wants to take to all lanes in `zmm0`vpbroadcastdzmm0,xmm31; Compute a new kmask of which represents all VMs which are going to; the same location as VM #0vpcmpeqdk1,zmm0,zmm31; ...; Now just rip out the target for VM #0 and translate the guest address; into the host JIT address and jump there.; Or break out and generate the JIT if it hasn't been hit before
The above code is quite fast and isn’t a huge performance issue, especially as we’re running 16 VMs at a time and branches are “rare” with respect to expensive operations like memory loads and stores.
One thing that is important to note is that zmm31 always contains the last desired branch target for a given VM. Even after it has been disabled. This means that it is possible for a VM which has been disabled to come back online if VM #0 ends up going to the same location.
Lets go through a more thorough example:
; Register allocation:; ebx - Pointer to some user controlled buffer; ecx - Length of controlled buffer; Validate buffer sizecmpecx,4jne.end; Fallthrough.next:; Check some magic from the buffercmpdwordptr[ebx],0x13371337jne.end; Fallthrough.next2:; Conditionally jump to end, for clarityjmp.end.end:
And the theoretical vectorized output (not actual JIT output):
; Register allocation:; zmm10 - ebx; zmm11 - ecx; k1 - The execution kmask, this is the kmask used on all JITted instructions; k2 - Temporary kmask, just used for scratch; zmm0 - Scratch register; zmm8 - Scratch register; zmm31 - Desired branch target for all lanes; Compute kmask register for VMs which have `ecx` == 4vpcmpeqdk2{k1},zmm11,dwordptr[memorycontaining4]{1to16}; Update zmm31 to reference the respective branch targetvmovdqa32zmm31{k1},addressof.end; By default we go to endvmovdqa32zmm31{k2},addressof.next; If `ecx` == 4, go to .next; Broadcast the target that VM #0 wants to take to all lanes in `zmm0`vpbroadcastdzmm0,xmm31; Compute a new kmask of which represents all VMs which are going to; the same location as VM #0vpcmpeqdk1,zmm0,zmm31; Branch to where VM #0 is going (simplified)jmpwhere_vm0_wants_to_go.next:; Magicially load memory at ebx (zmm10) into zmm8vmovdqa32zmm8,complex_mmu_operation_and_stuff; Compute kmask register for VMs which have packet contents 0x13371337vpcmpeqdk2{k1},zmm8,dwordptr[memorycontaining0x13371337]{1to16}; Go to .next2 if memory is 0x13371337, else go to .endvmovdqa32zmm31{k1},addressof.end; By default we go to endvmovdqa32zmm31{k2},addressof.next2; If contents == 0x13371337 .next2; Broadcast the target that VM #0 wants to take to all lanes in `zmm0`vpbroadcastdzmm0,xmm31; Compute a new kmask of which represents all VMs which are going to; the same location as VM #0vpcmpeqdk1,zmm0,zmm31; Branch to where VM #0 is going (simplified)jmpwhere_vm0_wants_to_go.next2:; Everyone still executing is unconditionally going to .endvmovdqa32zmm31{k1},addressof.end; Broadcast the target that VM #0 wants to take to all lanes in `zmm0`vpbroadcastdzmm0,xmm31; Compute a new kmask of which represents all VMs which are going to; the same location as VM #0vpcmpeqdk1,zmm0,zmm31.end:
Okay so what does the VM state look like for a theoretical version (simplified to 4 VMs):
Starting state, all VMs enabled with different memory contents (pointed to by ebx) and different packet lengths:
| Register | VM 0 | VM 1 | VM 2 | VM 3 |
|---|
| ecx | 4 | 3 | 4 | 4 |
| memory | 0x13371337 | 0x13371337 | 3 | 0x13371337 |
| K1 | 1 | 1 | 1 | 1 |
First branch, all VMs with ecx != 4 are disabled and are pending branches to .end, VM #1 falls off
| Register | VM 0 | VM 1 | VM 2 | VM 3 |
|---|
| ecx | 4 | 3 | 4 | 4 |
| memory | 0x13371337 | 0x13371337 | 3 | 0x13371337 |
| K1 | 1 | 0 | 1 | 1 |
| Zmm31 | .next | .end | .next | .next |
Second branch, VMs without 0x13371337 in memory are pending branches to .end, VM #2 falls off
| Register | VM 0 | VM 1 | VM 2 | VM 3 |
|---|
| ecx | 4 | 3 | 4 | 4 |
| memory | 0x13371337 | 0x13371337 | 3 | 0x13371337 |
| K1 | 1 | 0 | 0 | 1 |
| Zmm31 | .next2 | .end | .end | .next2 |
Final branch, everyone ends up at .end, all VMs are enabled again as they’re following VM #0 to .end
| Register | VM 0 | VM 1 | VM 2 | VM 3 |
|---|
| ecx | 4 | 3 | 4 | 4 |
| memory | 0x13371337 | 0x13371337 | 3 | 0x13371337 |
| K1 | 1 | 1 | 1 | 1 |
| Zmm31 | .end | .end | .end | .end |
Branch summary
So we saw branches will disable VMs which do not follow VM #0. When VMs are disabled all modifications to their register states or memory states are blocked by hardware. The kmask mechanism allows us to keep performance up and not use different JITs based on different branch states.
Further, VMs can come back online if they were pending to go to a location which VM #0 eventually ends up going to.
Exceptions/faults
These are really just glorified branches with a VM exit to save the input and memory/register state related to the crash. No reason to really go in depth here.
Okay we’ve covered all the very high level details of how vectorized emulation is possible but that’s just academic thought. It’s pointless unless it accomplishes something.
At this point all of the next topics are going to be their own blogs and thus are only lightly touched on
Differential coverage is a special type of coverage that we are able to gather with this vectorized emulation model. This is the most important aspect of all of this tooling and is the main reason it is worth doing.
Since we are running 16 VMs at a time we are able to very cheaply (a few cycles) do a horizontal comparison with other VMs. Since VMs are deterministic and only have differing user-controlled inputs any situation where VMs have different branches, different register states, different memory states, etc is when the user input directly or indirectly caused a change in behavior.
I would consider this to be the holy grail of coverage. Any affect the input has on program state we can easily and cheaply detect.
How differential coverage combats state explosion
If we wanted to track all register states for all instructions the state explosion would be way too huge. This can be somewhat capped by limiting the amount of state each instruction can generate. For example instead of storing all unique register values for an instruction we could simply store the minimums and maximums, or store up to n unique values, etc. However even when limited to just a few values per instruction, the state explosion is too large for any real application.
However, since most memory and register states are not influenced by user input, with differential coverage we can greatly reduce the amount of instructions which state is stored on as we only store state that was influenced by user data.
This works for code coverage as well, for example if we hit a printf with completely uncontrolled parameters that would register as potentially hundreds of new blocks of coverage. With differential coverage all of this state can be ignored.
While the focus of this tool is not performance, the performance costs of updating databases on every instruction is not feasible. By filtering only instructions which have user-influenced data we’re able to perform much more complex operations in the case that new coverage was detected.
For example all of my register loads and stores start with a horizontal compare and a quick jump out if they all match. If one differs it’s a rare enough occasion that it’s feasible to spend a few more cycles to do a hash calculation based on state and insertion into the global input and coverage databases. Without differential coverage I would have to unconditionally do this every instruction.
Since the soft MMU deserves a blog entirely on it’s own, we’ll just go slightly into the details.
As mentioned before, we interleave memory at the dword level, but for every byte there is also a corresponding permission byte. In memory this looks like 16 32-bit dwords representing the permissions, followed by 16 32-bit dwords containing their corresponding memory contents. This allows me to read a 64-byte cache line with the permissions which are checked first, followed by reading the 64-byte cache line directly following with the contents.
For permissions: the read, write, and execute bits are completely separate. This allows more exotic memory models like execute-only memory.
Since permissions are at the byte level, this means we can punch a one-byte hole anywhere in memory and accessing that byte would cause a fault. For some targets I’ll do special modifications to permissions and punch holes in unused or padding fields of structures to catch overflows of buffers contained inside structures.
Further I have a special read-after-write (RaW) bit, which is used to mark memory as uninitialized. Memory returned from allocators is marked as RaW and thus will fault if ever read before written to. This is tracked at the byte level and is one of the most useful features of the MMU. We’ll talk about how this can be made fast in a subsequent blog.
Performance is not the goal of this project, however the numbers are a bit better than expected from the theorycrafting.
In reality it’s possible to hit up to 2 trillion emulated instructions per second, which is the clickbait title of this blog. However this is on a 32-deep unrolled loop that is just adding numbers and not hitting memory. This unrolling makes the branch divergence checking costs disappear, and integer operations are almost a 1-to-1 translation into AVX-512 instructions.
For a real target the numbers are more in the 40 billion to 120 billion emulated instructions per second range. For a real target like OpenBSD’s DHCP client I’m able to do just over 5 million fuzz cases per second (fuzz case is one DHCP transaction, typically 1 or 2 packets). For this specific target the emulation speed is 54 billion instructions per second. This is while gathering PC-level coverage and all register and memory divergence coverage.
I’ve been working on this tooling for almost 2 years now and it’s been usable since month 3. It’s my primary tool for fuzzing and has successfully found bugs in various targets. Sadly most of these bugs are not public yet, but soon.
This tool was used to find a remote bluescreen in Windows Firewall: CVE-2018-8206 (okay technically I found it first manually, but was able to find it with the fuzzer with a byte flipper even though it has much more complex constraints)
It was also used to find a theoretical OOB in OpenBSD’s dhclient: dhclient bug . This is a fun one as really no tradtional fuzzer would find this as it’s an out-of-bounds by 1 inside of a structure.
Description of the IL used, as it’s got some specific designs for vectorized emulation
Internal details of the MMU implementation
Showing the power of differential coverage by looking a real example of fuzzing an HTTP parser and having a byte flipper quickly (under 5 seconds) find the basic “VERB HTTP/number.number\r\n". No magic, no `strings` feedback, no static analysis. Just a useless fuzzer with strong harnessing.
Talk about the new IL which handles graphs and can do cross-block optimizations
Showing better branch divergence handling via post-dominator analysis and stepping VMs until they sync up at a known future merge point
![]()











 by [Jason Scott](https://www.flickr.com/people/54568729@N00)](http://farm6.staticflickr.com/5503/9636183501_06db9682aa_z_d.jpg)

This makes it very expensive for an employer to pay their employees well, and explains very well why salaries are so low in France.
Something else to note is also employment laws, which are way more strict in France and makes it either extremely expansive or just impossible to fire someone, the cost of hiring seems to be way too high for startups, which are business why high risks already.