![]()
Download & Documentation
Zig is an open-source programming language designed for robustness,optimality, and clarity. Zig is aggressively pursuing
its goal of overthrowing C as the de facto language for system programming. Zig intends
to be so practical that people find themselves using it even if they dislike it.
This is a massive release, featuring 6 months of work and
changes from 36 different contributors.
I tried to give credit
where credit is due, but it's inevitable I missed some contributions as I had
to go through 1,345 commits to type up these release notes. I apologize in
advance for any mistakes.
Special thanks to my patrons who provide financial support. You're making Zig sustainable.
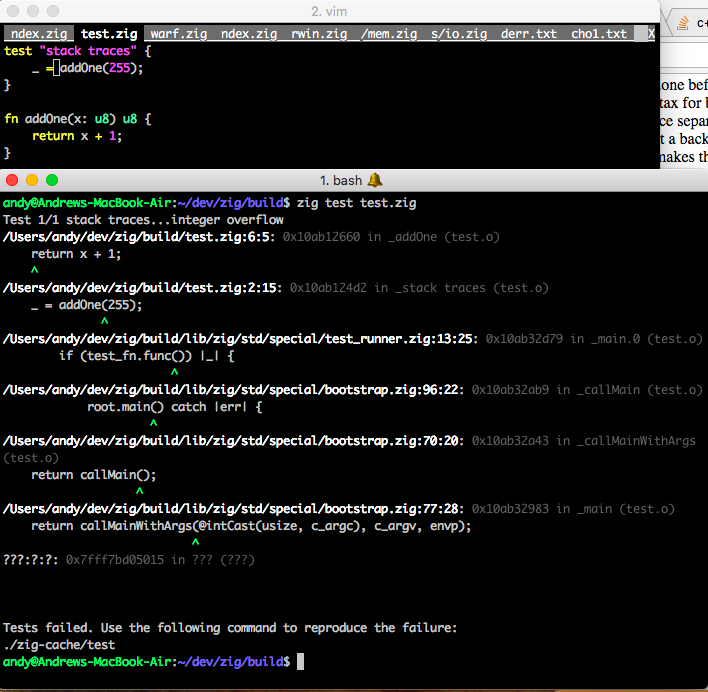
Stack Traces on All Targets
Zig uses LLVM's debug info API to emit native debugging information on all targets.
This means that you can use native debugging tools on Zig code, for example:
- MSVC on Windows
- lldb on MacOS
- gdb and valgrind on Linux
In addition, Zig's standard library can read its own native debug information. This
means that crashes produce stack traces, and errors produceError Return Traces.
MacOS
![]()
This implementation is able to look at the executable's own memory to find out where the .o
files are, which have the DWARF info.
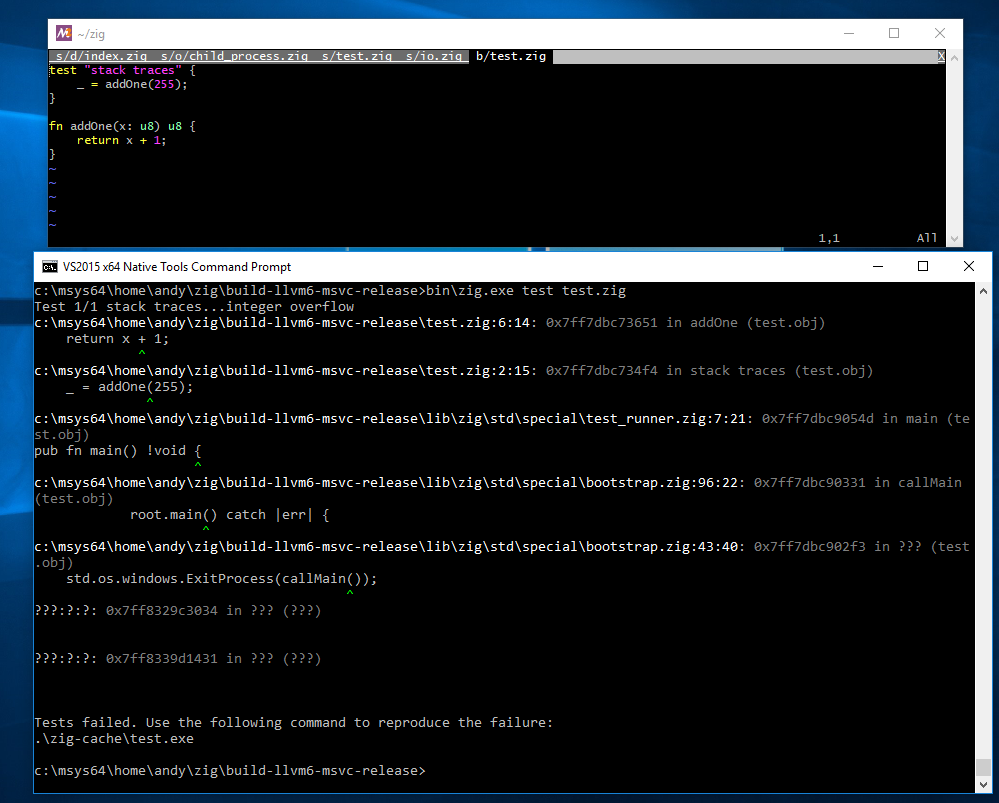
Windows
![]()
Thanks to Sahnvour for implementing the PE parsing
and starting the effort to PDB parsing. I picked up where he left off and finished Windows stack traces.
Thanks to Zachary Turner from the LLVM project for helping me understand the PDB format. I still owe
LLVM some PDB documentation patches in return.
Similar to on MacOS, a Windows executable in memory has location information pointing to a .pdb file which
contains debug information.
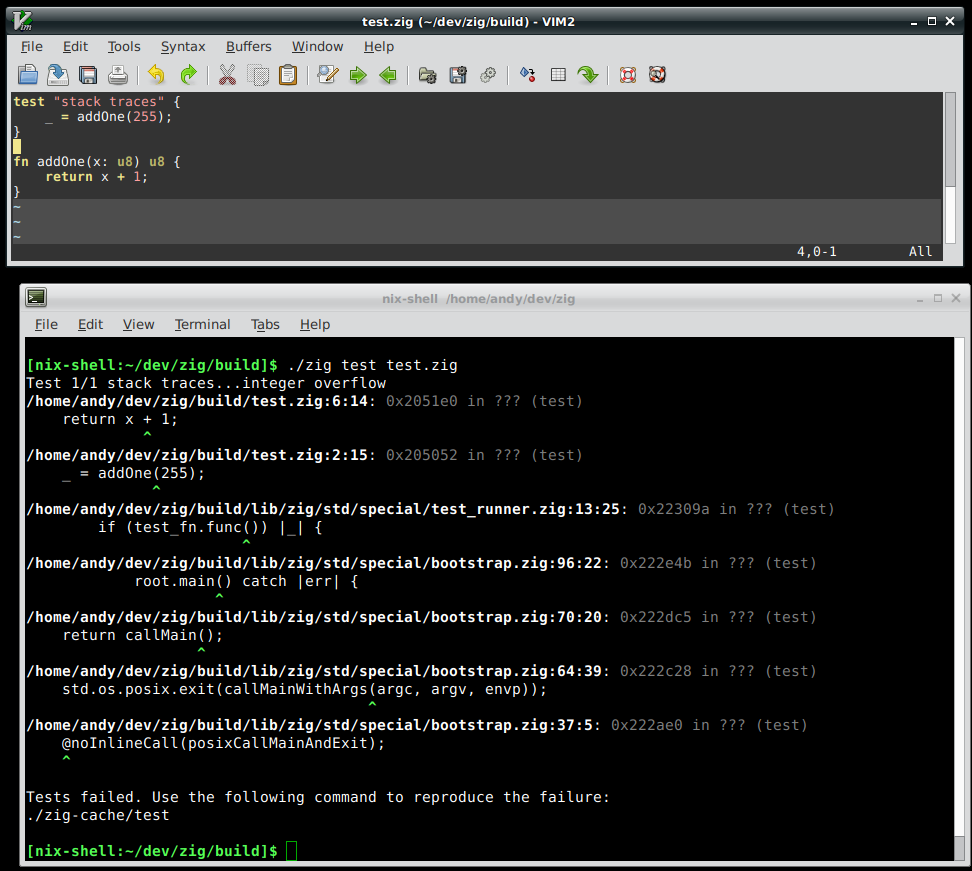
Linux
![]()
Linux stack traces worked in 0.2.0. However now std.debug.dumpStackTrace& friends use ArenaAllocator backed byDirectAllocator. This has the downside of failing to print a stack trace
when the system is out of memory, but for the more common use case when the system is not
out of memory, but the debug info cannot fit in std.debug.global_allocator,
now stack traces will work. This is the case for the self hosted compiler.
There is a proposal tommap() debug info rather than using read().
See also Compatibility with Valgrind.
zig fmt
Thanks to Jimmi Holst Christensen's dilligent work, the Zig standard library now supports parsing Zig code.
This API is used to implement zig fmt, a tool that reformats code to fit the
canonical style.
As an example, zig fmt will change this code:
test"fmt" {const a = []u8{1, 2, 3,4, 5,6,7 };switch (0) { 0 => {}, 1 => unreachable, 2,3 => {}, 4...7 => {}, 1 + 4 * 3 + 22 => {}, else => { const a = 1; const b = a; }, }
foo(a, b, c, d, e, f, g,);
}
...into this code:
test"fmt" {const a = []u8{1, 2,3, 4, 5, 6,7,
};switch (0) {0 => {},1 => unreachable,2, 3 => {},4...7 => {},1 + 4 * 3 + 22 => {},else => {const a = 1;const b = a;
},
}
foo(
a,
b,
c,
d,
e,
f,
g,
);
}
It does not make any decisions about line widths. That is left up to the user.
However, it follows certain cues about when to line break. For example, it will put the
same number of array items in a line as there are in the first one. And it will
put a function call all on one line if there is no trailing comma, but break every
parameter into its own line if there is a trailing comma.
Thanks to Marc Tiehuis, there are currently two editor plugins that integrate with zig fmt:
zig fmt is only implemented in the self-hosted compiler,
which is not finished yet, so in order to use it one
must follow the README instructions to build the self-hosted compiler from source.
Theimplementation of the self-hosted parser
is an interesting case study of avoiding recursion by using an explicit stack. It is essentially a
hand-written recursive descent parser, but with heap allocations instead of recursion. When Jimmi
originally implemented the code, we thought that we could not solve the unbounded stack growth problem
of recursion. However, since then, I prototyped several solutions that provide the ability to have
recursive function calls without giving up statically known upper bound stack growth. SeeRecursion Status for more details.
Automatic formatting can be disabled in source files with a comment like this:
test"this is left alone" { }
zig fmt is written using the standard library's event-based I/O abstractions andasync/await syntax, which means that it is
multi-threaded with non-blocking I/O. A debug build of zig fmt on my laptop
formats the entire Zig standard library in 2.1 seconds, which is 75,516 lines per second.
See Concurrency Status for more details.
zig run
zig run file.zig can now be used to execute a file directly.
Thanks to Marc Tiehuis for the initial implementation of this feature. Marc writes:
On a POSIX system, a shebang can be used to run a zig file directly. An
example shebang would be #!/usr/bin/zig run. You may not be able pass
extra compile arguments currently as part of the shebang. Linux for example
treats all arguments after the first as a single argument which will result
in an 'invalid command'.
Note: there is a proposal
to change this to zig file.zig to match the interface of other languages,
as well as enable the common pattern #!/usr/bin/env zig.
Zig caches the binary generated by zig run so that subsequent invocations have low
startup cost. See Build Artifact Caching for more details.
Automated Static Linux x86_64 Builds of Master Branch
Zig now supports building statically against musl libc.
On every master branch push, the continuous integration server creates a static Linux build of zig
and updates the URL https://ziglang.org/builds/zig-linux-x86_64-master.tar.xz to redirect to it.
In addition, Zig now looks for libc and Zig std lib at runtime. This makes static builds the easiest
and most reliable way to start using the latest version of Zig immediately.
Windows has automated static builds of master branchvia AppVeyor.
MacOS static CI builds arein progress
and should be available soon.
During this release cycle, two design flaws were fixed, which led to a chain reaction
of changes that I called Pointer Reform, resulting in a more consistent syntax with
simpler semantics.
The first design flaw was that the syntax for pointers was ambiguous if the pointed
to type was a type. Consider this 0.2.0 code:
const assert = @import("std").debug.assert;comptime {var a: i32 = 1;const b = &a;@compileLog(@typeOf(b));
*b = 2;
assert(a == 2);
}
This works fine. The value printed from the@compileLog statement is &i32.
This makes sense because b is a pointer to a.
Now let's do it with a type:
const assert = @import("std").debug.assert;comptime {var a: type = i32;const b = &a;@compileLog(b);
*b = f32;
assert(a == f32);
}
$ zig build-obj test.zig
| &i32test.zig:6:5:error:found compile log statement
@compileLog(b);^test.zig:7:5:error:attempt to dereference non-pointer type 'type'
*b = f32;^
It doesn't work in 0.2.0, because the & operator worked differently fortype than other types. Here, b is the type &i32 instead of a pointer to a type which is how we wanted to use it.
This prevented other things from working too; for example if you had a[]type{i32, u8, f64} and you tried to use a for loop,
it crashed the compiler because internally a for loop uses the &
operator on the array element.
The only reasonable solution to this is to have different syntax for the address-of operator and
the pointer operator, rather than them both being &.
So pointer syntax becomes *T, matching syntax from most other languages such as C.
Address-of syntax remains &foo, again matching common address-of syntax such as in C.
This leaves one problem though.
With this modification, the syntax *foo becomes ambiguous with the syntax for
dereferencing. And so dereferencing syntax is changed to a postfix operator: foo.*.
This matches post-fix indexing syntax: foo[0], and in practice ends up harmonizing
nicely with other postfix operators.
The other design flaw is a problem that has plagued C since its creation: the pointer type doesn't tell you how many items
there are at the address. This is now fixed by having two kinds of pointers in Zig:
*T - pointer to exactly one item.- Supports deref syntax:
ptr.*
[*]T - pointer to unknown number of items.- Supports index syntax:
ptr[i] - Supports slice syntax:
ptr[start..end] T must have a known size, which means that it cannot bec_void or any other @OpaqueType().
Note that this causes pointers to arrays to fall into place, as a single-item pointer
to an array acts as a pointer to a compile-time known number of items:
*[N]T - pointer to N items, same as single-item pointer to array.- Supports index syntax:
array_ptr[i] - Supports slice syntax:
array_ptr[start..end] - Supports len property:
array_ptr.len
Consider how slices fit into this picture:
[]T - pointer to runtime-known number of items.- Supports index syntax:
slice[i] - Supports slice syntax:
slice[start..end] - Supports len property:
slice.len
This makes Zig pointers significantly less error prone. For example, it fixed issue #386,
which demonstrates how a pointer to an array in Zig 0.2.0 is a footgun when passed as a parameter.
Meanwhile in 0.3.0, equivalent code is nearly impossible to get wrong.
For consistency with the postfix pointer dereference operator, optional unwrapping syntax is
now postfix as well:
0.2.0: ??x
0.3.0: x.?
And finally, to remove the last inconsistency of optional syntax, the ?? operator
is now the keyword orelse. This means that Zig now has the property thatall control flow occurs exclusively via keywords.
There is a plan for one more pointer type,
which is a pointer that has a null-terminated
number of items. This would be the type of the parameter to strlen for example.
Although this will make the language bigger by adding a new type, it allows Zig to delete a feature
in exchange, since it will makeC string literals unnecessary.
String literals will both have a compile-time known length and be null-terminated; therefore they
will implicitly cast to
slices as well as null-terminated pointers.
There is one new issue caused by Pointer Reform. Because C does not have the concept of
single-item pointers or unknown-length pointers (or non-null pointers),
Zig must translate all C pointers as ?[*]T. That is, a pointer to
an unknown number of items that might be null. This can cause some friction when using C APIs,
which is unfortunate because Zig's types are perfectly compatible with C's types, but
.h files are unable to adequately describe pointers. Although it would be much safer to
translate .h files offline and fix their prototypes, there isa proposal to add a C pointer type.
This new pointer type should never be used on purpose, but would be used when auto-translating C code.
It would simply have C pointer semantics, which means it would be just as much of a footgun as C pointers are.
The upside is that it would make interaction with C APIs go back to being perfectly seamless.
Default Float Mode is now Strict
In response to an overwhelming consensus, floating point operations use Strict mode by default.
Code can use @setFloatMode to
override the mode on a per-scope basis.
Thanks to Marc Tiehuis for implementing the change.
Remove this
this was always a weird language feature. An identifier which referred to the thing in the
most immediate scope, which could be a module, a type, a function, or even a block of code.
The main use case for it was for anonymous structs to refer to themselves. This use case is solved
with a new builtin function, @This(),
which always returns the innermost struct or union that the builtin call is inside.
The "block of code" type is removed from Zig, and the first argument of@setFloatMode is removed.@setFloatMode now always refers to the current scope.
Remove Explicit Casting Syntax
Previously, these two lines would have different meanings:
exportfnfoo(x: u32) void {const a: u8 = x;const b = u8(x);
}
The assignment to a would give error: expected type 'u8', found 'u32',
because not all values of u32 can fit in a u8. But the
assignment to b was "cast harder" syntax, and Zig would truncate bits,
with a safety check to ensure that the mathematical meaning of the integer was preserved.
Now, both lines are identical in semantics. There is no more "cast harder" syntax.
Both cause the compile error because implicit casts are only allowed when it is
completely unambiguous how to get from one type to another, and the transformation is
guaranteed to be safe. For other casts, Zig has builtin functions:
- @bitCast - change type but maintain bit representation
- @alignCast - make a pointer have more alignment
- @boolToInt - convert true to 1 and false to 0
- @bytesToSlice - convert a slice of bytes to a slice of another type
- @enumToInt - obtain the integer tag value of an enum or tagged union
- @errSetCast - convert to a smaller error set
- @errorToInt - obtain the integer value of an error code
- @floatCast - convert a larger float to a smaller float
- @floatToInt - obtain the integer part of a float value
- @intCast - convert between integer types
- @intToEnum - obtain an enum value based on its integer tag value
- @intToError - obtain an error code based on its integer value
- @intToFloat - convert an integer to a float value
- @intToPtr - convert an address to a pointer
- @ptrCast - convert between pointer types
- @ptrToInt - obtain the address of a pointer
- @sliceToBytes - convert a slice of anything to a slice of bytes
- @truncate - convert between integer types, chopping off bits
Some are safe; some are not. Some perform language-level assertions; some do not.
Some are no-ops at runtime; some are not. Each casting function is documented independently.
Having explicit and fine-grained casting like this is a form of intentional redundancy.
Casts are often the source of bugs, and therefore it is worth double-checking a cast to verify that
it is still correct when the type of the operand changes. For example, imagine that we have the following
code:
fnfoo(x: i32) void {var i = @intCast(usize, x);
}
Now consider what happens when the type of x changes to a pointer:
test.zig:2:29:error:expected integer type, found '*i32'
var i = @intCast(usize, x);^
Although we technically know how to convert a pointer to an integer,
because we used
@intCast, we are forced to inspect the cast and change
it appropriately. Perhaps that means changing it to
@ptrToInt, or perhaps
the entire function needs to be reworked in response to the type change.
Direct Parameter Passing
Previously, it was illegal to pass structs and unions by value in non-extern
functions. Instead one would have to have the function accept a const pointer
parameter. This was to avoid the ambiguity that C programs face - having to make the decision about
whether by-value or by-reference was better. However, there were some problems with this. For example,
when the parameter type is inferred, Zig would automatically convert to a const
pointer. This caused problems in generic code, which could not distinguish between a type which is
a pointer, and a type which has been automatically converted to a pointer.
Now, parameters can be passed directly:
const assert = @import("std").debug.assert;const Foo = struct {
x: i32,
y: i32,
};fncallee(foo: Foo) void {
assert(foo.y == 2);
}test"pass directly" {
callee(Foo{ .x = 1, .y = 2 });
}
I have avoided using the term "by-value" because the semantics of this kind of parameter passing
are different:
- Zig is free to pass the parameter by value - perhaps if it is smaller than some number of bytes -
or pass it by reference.
- To the callee, the value appears to be a value and is immutable.
- The caller guarantees that the bytes of the parameter will not change for the duration of the
call. This means that it is unsound to pass a global variable in this way if that global variable
is mutated by the callee. There is anopen issue
which explores adding runtime safety checks for this.
Because of these semantics, there's a clear flow chart for whether to accept a parameter asT or *const T:
- Use
T, unless one of the following is true:- The function depends on the address of the parameter.
- The parameter may alias
another parameter or global variable.
Now that we have this kind of parameter passing, Zig's implicit cast
from T to *const T is less important.
One might even make the case that such a cast is dangerous. Therefore we havea proposal to remove it.
There is one more area that needs consideration with regards to direct parameter passing,
and that is with coroutines. The problem is that if a reference to a stack variable is
passed to a coroutine, it may become invalid after the coroutine suspends.
This is a design flaw in Zig that will
be addressed in a future version. See Concurrency Status for more details.
Note that extern functions are bound by the C ABI,
and therefore none of this applies to them.
Rewrite Rand Functions
Marc Tiehuis writes:
We now use a generic Rand structure which abstracts the core functions
from the backing engine.
The old Mersenne Twister engine is removed and replaced instead with
three alternatives:
- Pcg32
- Xoroshiro128+
- Isaac64
These should provide sufficient coverage for most purposes, including a
CSPRNG using Isaac64. Consumers of the library that do not care about
the actual engine implementation should use DefaultPrng and DefaultCsprng.
Error Return Traces across async/await
One of the problems with non-blocking programming is that stack traces
and exceptions are less useful, because the actual stack trace points back
to the event loop code.
In Zig 0.3.0, Error Return Traces
work across suspend points. This means you can use try as the main
error handling strategy, and when an error bubbles up all the way, you'll still be able to find out
where it came from:
const std = @import("std");const event = std.event;const fs = event.fs;test"unwrap error in async fn" {var da = std.heap.DirectAllocator.init();defer da.deinit();const allocator = &da.allocator;var loop: event.Loop = undefined;try loop.initMultiThreaded(allocator);defer loop.deinit();const handle = tryasync<allocator> openTheFile(&loop);defercancel handle;
loop.run();
}
asyncfnopenTheFile(loop: *event.Loop) void {const future = (async fs.openRead(loop, "does_not_exist.txt") catchunreachable);const fd = (await future) catchunreachable;
}
$ zig test test.zig
Test 1/1 unwrap error in async fn...attempt to unwrap error: FileNotFoundstd/event/fs.zig:367:5: 0x22cb15 in ??? (test)
return req_node.data.msg.Open.result;^std/event/fs.zig:374:13: 0x22e5fc in ??? (test)
return await (async openPosix(loop, path, flags, os.File.default_mode) catch unreachable);^test.zig:22:31: 0x22f34b in ??? (test)
const fd = (await future) catch unreachable;^std/event/loop.zig:664:25: 0x20c147 in ??? (test)
resume handle;^std/event/loop.zig:543:23: 0x206dee in ??? (test)
self.workerRun();^test.zig:17:13: 0x206178 in ??? (test)
loop.run();^
Tests failed. Use the following command to reproduce the failure:
zig-cache/test
Note that this output contains 3 components:
- An error message:
attempt to unwrap error: FileNotFound - An error return trace. The error was first returned at
fs.zig:367:5
and then returned at fs.zig:374:13. You could go look at those source locations
for more information. - A stack trace. Once the error came back from
openRead, the code tried tocatchunreachable which caused the panic. You can see that the stack
trace does, in fact, go into the event loop as described above.
It is important to note in this example, that the error return trace survived despite
the fact that the event loop is multi-threaded, and any one of those threads could be the worker
thread that resumes an async function at the await point.
This feature is enabled by default for Debug and ReleaseSafe builds, and disabled for ReleaseFast
and ReleaseSmall builds.
This is just the beginning of an exploration of what debugging non-blocking behavior
could look like in the future of Zig. See Concurrency Status for more details.
New Async Call Syntax
Instead of async(allocator) call(), now it isasync<allocator> call().
This fixes syntax ambiguity when leaving off the allocator,
and fixes parse failure when call is a field access.
This sets a precedent for using <> to pass arguments
to a keyword. This will affect enum, union, fn, andalign (see #661).
ReleaseSmall Mode
Alexandros Naskos contributed a new build mode.
$ zig build-exe example.zig --release-small
- Medium runtime performance
- Safety checks disabled
- Slow compilation speed
- Small binary size
New builtins: @typeInfo and @field
Alexandros Naskos bravely dove head-first into the deepest, darkest parts of the Zig
compiler and implemented an incredibly useful builtin function:@typeInfo.
This function accepts a type as a parameter, and returns a compile-time known
value of this type:
pubconst TypeInfo = union(TypeId) {
Type: void,
Void: void,
Bool: void,
NoReturn: void,
Int: Int,
Float: Float,
Pointer: Pointer,
Array: Array,
Struct: Struct,
ComptimeFloat: void,
ComptimeInt: void,
Undefined: void,
Null: void,
Optional: Optional,
ErrorUnion: ErrorUnion,
ErrorSet: ErrorSet,
Enum: Enum,
Union: Union,
Fn: Fn,
Namespace: void,
BoundFn: Fn,
ArgTuple: void,
Opaque: void,
Promise: Promise,pubconst Int = struct {
is_signed: bool,
bits: u8,
};pubconst Float = struct {
bits: u8,
};pubconst Pointer = struct {
size: Size,
is_const: bool,
is_volatile: bool,
alignment: u32,
child: type,pubconst Size = enum {
One,
Many,
Slice,
};
};pubconst Array = struct {
len: usize,
child: type,
};pubconst ContainerLayout = enum {
Auto,
Extern,
Packed,
};pubconst StructField = struct {
name: []constu8,
offset: ?usize,
field_type: type,
};pubconst Struct = struct {
layout: ContainerLayout,
fields: []StructField,
defs: []Definition,
};pubconst Optional = struct {
child: type,
};pubconst ErrorUnion = struct {
error_set: type,
payload: type,
};pubconst Error = struct {
name: []constu8,
value: usize,
};pubconst ErrorSet = struct {
errors: []Error,
};pubconst EnumField = struct {
name: []constu8,
value: usize,
};pubconst Enum = struct {
layout: ContainerLayout,
tag_type: type,
fields: []EnumField,
defs: []Definition,
};pubconst UnionField = struct {
name: []constu8,
enum_field: ?EnumField,
field_type: type,
};pubconst Union = struct {
layout: ContainerLayout,
tag_type: ?type,
fields: []UnionField,
defs: []Definition,
};pubconst CallingConvention = enum {
Unspecified,
C,
Cold,
Naked,
Stdcall,
Async,
};pubconst FnArg = struct {
is_generic: bool,
is_noalias: bool,
arg_type: ?type,
};pubconst Fn = struct {
calling_convention: CallingConvention,
is_generic: bool,
is_var_args: bool,
return_type: ?type,
async_allocator_type: ?type,
args: []FnArg,
};pubconst Promise = struct {
child: ?type,
};pubconst Definition = struct {
name: []constu8,
is_pub: bool,
data: Data,pubconst Data = union(enum) {
Type: type,
Var: type,
Fn: FnDef,pubconst FnDef = struct {
fn_type: type,
inline_type: Inline,
calling_convention: CallingConvention,
is_var_args: bool,
is_extern: bool,
is_export: bool,
lib_name: ?[]constu8,
return_type: type,
arg_names: [][] constu8,pubconst Inline = enum {
Auto,
Always,
Never,
};
};
};
};
};
This kicks open the door for compile-time reflection, especially when combined with the fact that
Jimmi Holst Christensen implemented @field,
which performs field access with a compile-time known name:
const std = @import("std");const assert = std.debug.assert;test"@field" {const Foo = struct {
one: i32,
two: bool,
};var f = Foo{
.one = 42,
.two = true,
};const names = [][]constu8{ "two", "one" };
assert(@field(f, names[0]) == true);
assert(@field(f, names[1]) == 42);@field(f, "one") += 1;
assert(@field(f, "on" ++ "e") == 43);
}
This has the potential to be abused, and so the feature should be used carefully.
After Jimmi implemented @field, he improved the implementation of @typeInfo and fixed several bugs. And now, the combination of
these builtins is used to implement struct printing in userland:
const std = @import("std");const Foo = struct {
one: i32,
two: *u64,
three: bool,
};pubfnmain() void {var x: u64 = 1234;var f = Foo{
.one = 42,
.two = &x,
.three = false,
};
std.debug.warn("here it is: {}\n", f);
}
Output:
here it is: Foo{ .one = 42, .two = u64@7ffdda208cf0, .three = false }
See std/fmt/index.zig:15
for the implementation.
Now that we have @typeInfo, there is one more question to answer:
should there be a function which accepts a TypeInfo value, and makes
a type out of it?
This hypothetical feature is called @reify, and it's ahot topic. Although undeniably powerful and
useful, there is concern that it would be too powerful, leading to complex meta-programming
that goes against the spirit of simplicity that Zig stands for.
Improve cmpxchg
@cmpxchg is removed. @cmpxchgStrong and @cmpxchgWeak are added.
The functions have operand type as the first parameter.
The return type is ?T where T is the operand type.
New Type: f16
Ben Noordhuis implemented f16. This is guaranteed to be
IEEE-754-2008 binary16 format, even on systems that have no hardware support,
thanks to the additions to compiler_rt that Ben contributed. He also added support
for f16 to std.math functions such as isnormal
and fabs.
All Integer Sizes are Primitives
Zig 0.2.0 had primitive types for integer bit widths of 2-8, 16, 29, 32, 64, 128.
Any number other than that, and you had to use @IntType to create the type.
But you would get a compile error if you shadowed one of the above bit widths that already existed, for example with
constu29 = @IntType(false, 29);
Needless to say, this situation was unnecessarily troublesome (#745). And so now
arbitrary bit-width integers can be referenced by using an identifier ofi or u followed by digits. For example, the identifieri7 refers to a signed 7-bit integer.
u0 is a 0-bit type, which means:
@sizeOf(u0) == 0- No actual code is generated for loads and stores of this type of value.
- The value of a
u0 as always the compile-time known value of 0.
i0doesn't make sense
and will probably crash the compiler.
Although Zig defines arbitrary integer sizes to support all primitive operations, if you try to use,
for example, multiplication on 256-bit integers:
test"large multiplication" {var x: u256 = 0xabcd;var y: u256 = 0xefef;var z = x * y;
}
Then you'll get an error like this:
LLVM ERROR: Unsupported library call operation!
Zig isn't supposed to be letting LLVM leak through here, but that's a separate issue.
What's happening is that normally if a primitive operation such as multiplication of
integers cannot be lowered to a machine instruction, LLVM will emit a library call to
compiler_rt to perform the operation. This works for up to 128-bit multiplication,
for example. However compiler_rt does not define an arbitrary precision multiplication
library function, and so LLVM is not able to generate code.
It is planned to submit a patch
to LLVM which adds the ability to emit a lib call for situations like this, and then
Zig will include the arbitrary precision multiplication function in Zig's compiler_rt.
In addition to this, Zig 0.3.0 fixesa bug where@IntType was silently wrapping the bit count parameter if it was greater
than pow(2, 32).
Improved f128 Support
Marc Tiehuis & Ben Noordhuis solved the various issues that prevented f128 from being generally useful.
- Fix hex-float parsing. -Marc Tiehuis (#495)
- Add compiler-rt functions to support
f128. -Marc Tiehuis__floatunditf__floatunsitf__floatunsitf__floatuntitf__floatuntisf__trunctfdf2__trunctfsf2__floattitf__floattidf__floattisf
- Alignment fix and allow rudimentary f128 float printing. -Marc Tiehuis
- Fix f128 remainder division bug. The modulo operation computed rem(b+rem(a,b), b) which produces -1
for a=1 and b=2. Switch to a - b * trunc(a/b) which produces the expected result, 1. -Ben Noordhuis (#1137)
Build Artifact Caching
Zig now supports global build artifact caching. This feature is one of those things that
you can generally ignore, because it "just works" without any babysitting.
By default, compilations are not cached. You can enable the global cache for a compilation
by using --cache on:
andy@xps:~/tmp$ time zig build-exe hello.zig
real 0m0.414s
user 0m0.369s
sys 0m0.049s
andy@xps:~/tmp$ time zig build-exe hello.zig --cache on
/home/andy/.local/share/zig/stage1/artifact/hkGO0PyaOKDrdg2wyhV1vRy0ATyTaT0s0ECa2BiHFJfsb9RDVKK_r3qwHI5gaEfv/hello
real 0m0.412s
user 0m0.377s
sys 0m0.038s
andy@xps:~/tmp$ time zig build-exe hello.zig --cache on
/home/andy/.local/share/zig/stage1/artifact/hkGO0PyaOKDrdg2wyhV1vRy0ATyTaT0s0ECa2BiHFJfsb9RDVKK_r3qwHI5gaEfv/hello
real 0m0.012s
user 0m0.009s
sys 0m0.003s
When the cache is on, the output is not written to the current directory. Instead, the output
is kept in the cache directory, and the path to it is printed to stdout.
This is off by default, because this is an uncommon use case. The real benefit of build artifact
caching comes in 3 places:
- zig run, where it is enabled by default:
andy@xps:~/tmp$ time zig run hello.zig
Hello, world!
real 0m0.553s
user 0m0.500s
sys 0m0.055s
andy@xps:~/tmp$ time zig run hello.zig
Hello, world!
real 0m0.013s
user 0m0.007s
sys 0m0.006s
- zig build, so that your build
script only has to build once.
-
When building an executable or shared library, Zig must build
compiler_rt.o andbuiltin.o from source, for the given target. This usually only has to be done
once ever, which is why other compilers such as gcc ship with these components already built.
The problem with that strategy is that you have to build a special version of the compiler for
cross-compiling. With Zig, you can always build for any target, on any target.So caching these artifacts provides a happy solution.
The cache is perfect; there are no false positives. You could even fix a bug in memcpy
in the system's libc, and Zig will detect that its own code has (indirectly) been updated,
and invalidate the cache entry.
If you use zig build-exe, Zig will still create a zig-cache directory
in the current working directory in order to store an intermediate .o file.
This is because on MacOS, the intermediate .o file stores the debug information, and therefore
it needs to stick around somewhere sensible for Stack Traces to work.
Likewise, if you use zig test, Zig will put the test binary in the zig-cache
directory in the current working directory. It's useful to leave the test binary here so that the
programmer can use a debugger on it or otherwise inspect it.
The zig-cache directory is cleaner than before, however. For example, thebuiltin.zig file is no longer created there. It participates in the global caching system,
just like compiler_rt.o. You can use zig builtin to see the contents of@import("builtin").
Compatibility with Valgrind
I noticed that valgrind does not see Zig's debug symbols (#896):
pubfnmain() void {
foo().* += 1;
}fnfoo() *i32 {return@intToPtr(*i32, 10000000);
}
==24133== Invalid read of size 4
==24133== at 0x2226D5: ??? (in /home/andy/downloads/zig/build/test)
==24133== by 0x2226A8: ??? (in /home/andy/downloads/zig/build/test)
==24133== by 0x222654: ??? (in /home/andy/downloads/zig/build/test)
==24133== by 0x2224B7: ??? (in /home/andy/downloads/zig/build/test)
==24133== by 0x22236F: ??? (in /home/andy/downloads/zig/build/test)
After digging around, I was able to reproduce the problem using only Clang and LLD:
static int *foo(void) {
return (int *)10000000;
}
int main(void) {
int *x = foo();
*x += 1;
}
If this C code is built with Clang and linked with LLD, Valgrind has the same issue
as with the Zig code.
I sent a message
to the Valgrind mailing list, and theysuggested
submitting a bug fix to Valgrind.
That's a good idea. I'm a little busy with Zig development though - anybody else want to take
a crack at it?
In the meantime, Zig now has a --no-rosegment flag, which works around the bug.
It should only be used for this purpose; the flag will likely be removed once Valgrind fixes
the issue upstream and enough time passes that the new version becomes generally available.
$ zig build-exe test.zig --no-rosegment
$ valgrind ./test
==24241== Invalid read of size 4
==24241== at 0x221FE5: main (test.zig:2)
Zig is now on Godbolt Compiler Explorer
Marc Tiehuis added Zig support, and then worked with theCompiler Explorer team to get it
merged upstream and deployed.
The command line API that Compiler Explorer uses is covered by Zig's main test suite
to ensure that it continues working as the language evolves.
zig init-lib and init-exe
zig init-lib can be used to initialize azig build
project in the current directory which will create a simple library:
$ zig init-lib
Created build.zig
Created src/main.zig
Next, try `zig build --help` or `zig build test`
$ zig build test
Test 1/1 basic add functionality...OK
All tests passed.
Likewise, zig init-exe initializes a simple application:
$ zig init-exe
Created build.zig
Created src/main.zig
Next, try `zig build --help` or `zig build run`
$ zig build run
All your base are belong to us.
The main Zig test suite tests this functionality so that it will not regress as Zig continues to evolve.
Concurrency Status
Concurrency is now solved. That is, there is a concrete plan for how concurrency will work in Zig,
and now it's a matter of implementing all the pieces.
First and foremost, Zig supports low-level control over hardware.
That means that it has atomic primitives:
...and it means that you can directly spawn kernel threads using standard library functions:
const std = @import("std");const assert = std.debug.assert;const builtin = @import("builtin");const AtomicRmwOp = builtin.AtomicRmwOp;const AtomicOrder = builtin.AtomicOrder;test"spawn threads" {var shared_ctx: i32 = 1;const thread1 = try std.os.spawnThread({}, start1);const thread2 = try std.os.spawnThread(&shared_ctx, start2);const thread3 = try std.os.spawnThread(&shared_ctx, start2);const thread4 = try std.os.spawnThread(&shared_ctx, start2);
thread1.wait();
thread2.wait();
thread3.wait();
thread4.wait();
assert(shared_ctx == 4);
}fnstart1(ctx: void) u8 {return0;
}fnstart2(ctx: *i32) u8 {
_ = @atomicRmw(i32, ctx, AtomicRmwOp.Add, 1, AtomicOrder.SeqCst);return0;
}
On POSIX targets, when you link against libc, the standard library uses
pthreads; otherwise it uses its own lightweight kernel thread implementation.
You can use mutexes, signals, condition variables, and all those things.
Anything you can accomplish in C, you can accomplish in Zig.
However, the standard library provides a higher level concurrency abstraction,
designed for optimal performance, debuggability, and structuring code to closely
model the problems that concurrency presents.
The abstraction is built on two language features: stackless coroutines andasync/await
syntax. Everything else is implemented in userland.
std.event.Loop creates a kernel thread pool matching the number
of logical CPUs. It can then be used for non-blocking I/O that will be dispatched across
the thread pool, using the platform-native API:
This is a competitor to libuv, except multi-threaded.
Once you have an event loop, all of the std.event API becomes available to use:
std.event.Channel - Many producer, many consumer, thread-safe, runtime configurable buffer size.
When buffer is empty, consumers suspend and are resumed by producers. When buffer is full, producers suspend and are resumed by consumers.std.event.Future - A value that many consumers can await.std.event.Group - A way to await multiple async operations.std.event.Lock - Ensures only one thread gets access to a resource, without blocking a kernel thread.std.event.RwLock - Same as Lock except allows multiple readers to access data simultaneously.std.event.fs - File system operations based onasync/await syntax.std.event.tcp - Network operations based onasync/await syntax.
All of these abstractions provide convenient APIs based on async/await
syntax, making it practical for API users to model their code with maximally efficient concurrency.
None of these abstractions block or use mutexes; when an API user must suspend, control flow
goes to the next coroutine waiting to run, if any. If no coroutines are waiting to run,
the application will sit idly, waiting for an event from the respective platform-native API
(e.g. epoll on Linux).
As an example, here is a snippet from a test in the standard library:
asyncfntestFsWatch(loop: *Loop) !void {const file_path = try os.path.join(loop.allocator, test_tmp_dir, "file.txt");defer loop.allocator.free(file_path);const contents =\\line 1\\line 2 ;const line2_offset = 7;tryawaittryasync fs.writeFile(loop, file_path, contents);const read_contents = tryawaittryasync fs.readFile(loop, file_path, 1024 * 1024);
assert(mem.eql(u8, read_contents, contents));var watch = try fs.Watch(void).create(loop, 0);defer watch.destroy();
assert((tryawaittryasync watch.addFile(file_path, {})) == null);const ev = tryasync watch.channel.get();var ev_consumed = false;deferif (!ev_consumed) cancel ev;const fd = tryawaittryasync fs.openReadWrite(loop, file_path, os.File.default_mode);
{defer os.close(fd);tryawaittryasync fs.pwritev(loop, fd, [][]constu8{"lorem ipsum"}, line2_offset);
}
ev_consumed = true;switch ((tryawait ev).id) {
WatchEventId.CloseWrite => {},
WatchEventId.Delete => @panic("wrong event"),
}const contents_updated = tryawaittryasync fs.readFile(loop, file_path, 1024 * 1024);
assert(mem.eql(u8, contents_updated,\\line 1\\lorem ipsum ));
}
You can see that even though Zig is a language with manual memory management that insists on handling
every possible error, it manages to be quite high level using these event-based APIs.
Now, there are some problems to solve:
- The way that canceling a coroutine works is currently unsound. - I know how to fix this, but it'll have to be in 0.4.0. Unfortunately it's causing occasional
test failures.
- Lack of a guarantee about whether an async function call allocates memory or not. - In theory, there are many cases where Zig should be able to guarantee that
an async function call will not allocate memory for the coroutine frame. However in practice, using
LLVM's coroutines API, it will always result in an allocation.
- LLVM's coroutines implementation is buggy -
Right now Zig sadly is forced to disable optimizations for
async functions because
LLVM has a bug
where Mem2Reg turns correct coroutine frame spills back into incorrect
parameter references. - LLVM's coroutines implementation is slow - When I analyzed the compilation
speed of Zig, even with optimizations off, LLVM takes up over 80% of the time. And for the zig behavioral
tests, even though coroutines are a tiny percent of the code, LLVM's coroutine splitting pass takes
up 30% of that time.
And so, the plan is to rework coroutines, without using any of LLVM's coroutines API. Zig will implement
coroutines in the frontend, and LLVM will see only functions and structs. This ishow Rust does it,
and I think it was a strong choice.
The coroutine frame will be in a struct, and so Zig will know the size of it at compile-time, and
it will solve the problem of guaranteeing allocation elision - the async callsite
will simply have to provide the coroutine frame pointer in order to create the promise.
This will also be relevant for recursion; stackless function calls do not count against the
static stack size upper bound calculation. See Recursion Status for
more details.
Self-Hosted Compiler Status
The self-hosted compiler is well underway.Here's a 1 minute demo of the self-hosted compiler watching source files and rebuilding.
The self-hosted compiler cannot do much more than Hello World at the moment, but
it's being constructed from the ground up to fully take advantage of multiple cores
and in-memory caching. In addition, Zig's error system and other safety features
are making it easy to write reliable, robust code. Between stack traces, error return
traces, and runtime safety checks, I barely even need a debugger.
Marc Tiehuis contributed a Big Integer library,
which the self-hosted compiler is using for integer literals and compile-time math operations.
Writing the self-hosted compiler code revealed to me how coroutines should work in Zig.
All the little details and ergonomics are clear to me now. And so before I continue any further on the
self-hosted compiler, I will use this knowledge to rework coroutines and solve the problems with them.
See Concurrency Status for more details.
As a reminder, even when the self-hosted compiler is complete, Zig will forever be stuck
with the stage1 C++ compiler code. See The Grand Bootstrapping Plan for more details.
The self-hosted compiler is successfully sharing some C++ code with the stage1 compiler.
For example the libLLVM C++ API wrapper is built into a static library, which then exports a C API wrapper.
The self-hosted compiler links against this static library in order to make libLLVM C++ API calls via the
C API wrapper. In addition, the Microsoft Visual Studio detection code requires the Windows COM API,
which is also C++, and so a similar strategy is used. I think it's pretty neat that the build system
builds a static library once and then ends up linking against it twice - one for each of the two compiler stages!
Recursion Status
I've said before that
recursion is one of the enemies of perfect software, because it represents a way that a
program can fail with no foolproof way of preventing it. With recursion, pick any stack size
and I'll give you an input that will crash your program. Embedded developers are all too
familiar with this problem.
It's always possible to rewrite code using an explicit stack using heap allocations,
and that's exactly what Jimmi did in the self-hosted parser.
On the other hand, when recursion fits the problem, it's significantly more clear and
maintainable. It would be a real shame to have to give it up.
I researched different ways that Zig could keep recursion, even when we
introduce statically known stack upper bound size.
I came up with a proof of concept for@newStackCall,
a builtin function that calls a function using an explicitly provided new stack.
You can find a usage example in the documentation by following that link.
This works, and it does break call graph cycles, but it would be a little bit awkward to use.
Because if you allocate an entire new stack, it has to be big enough for the rest of the
stack upper bound size, but in a recursive call, which should be only one stack frame,
it would overallocate every time.
So that's why I think that the actual solution to this problem is Zig's stackless coroutines.
Because Zig's coroutines are stackless, they are the perfect solution for recursion (direct
or indirect). With the reworking of coroutines, it will be possible to put the coroutine
frame of an async function anywhere - in a struct, in the stack, in a global variable -
as long as it outlives the duration of the coroutine. See Concurrency
for more details.
So - although recursion is not yet solved, we know enough to know that recursion is OK to use in Zig.
It does suffer from the stack overflow issue today, but in the future we will have a compile error
to prevent call graph cycles. And then this hypothetical compile error will be solved by using@newStackCall or stackless functions (but probably stackless functions).
Once recursion is solved, if stackless functions turn out to be the better solution,
Zig will remove @newStackCall from the language, unless someone demonstrates
a compelling use case for it.
For now, use recursion whenever you want; you'll know when it's time to update your code.
WebAssembly Status
The pieces for web assembly are starting to come together.
Ben Noordhuis fixed support for --target-arch wasm32 (#1094).
LLVM merged my patch to make WebAssembly
a normal (non-experimental) target. But they didn't do it before the LLVM 7 release. So
Zig 0.3.0 will not have WebAssembly support by default, but 0.4.0 will.
That being said, the static builds of Zig provided by ziglang.org have the WebAssembly
target enabled.
Apart from this, there appears to bean issue with Zig's WebAssembly linker.
Once this is solved, all that is left is to use WebAssembly in real life use cases, to work
out the ergonomics, and solve the inevitable issues that arise.
Documentation
The language reference documentation now contains no JavaScript. The code blocks
are pre-formatted with std.zig.Tokenizer. The same is true for these
release notes.
The builtin.zig example code in the documentation is now automatically updated from
the output of Zig, so the docs can't get out of date for this.
In addition to the above, the following improvements were made to the documentation:
Standard Library API Changes
std.mem.SplitIterator is now publicstd.math.atan2 is now publicstd.os.linux now makes public all the syscall numbers and syscall functionsstd.math.cast handles signed integers- added
std.zig.parse - added
std.zig.parseStringLiteral - added
std.zig.render - added
std.zig.ast - added
std.zig.Token - added
std.zig.Tokenizer - added
std.io.readLine - replace
File.exists with File.access. -Marc Tiehuis - rename
std.rand.Rand to std.rand.Random - added common hash/checksum functions. -Marc Tiehuis
- SipHash64, SipHash128
- Crc32 (fast + small variants)
- Adler32
- Fnv1a (32, 64 and 128 bit variants)
- Add Hmac function -Marc Tiehuis
- Added timestamp, high-perf. timer functions -tgschultz
std.os.time.sleepstd.os.time.posixSleepstd.os.time.timestampstd.os.time.miliTimestampstd.os.time.Timer
- Added complex number support. -Marc Tiehuis
std.math.complex.Complexstd.math.complex.absstd.math.complex.acosstd.math.complex.acoshstd.math.complex.argstd.math.complex.asinstd.math.complex.asinhstd.math.complex.atanstd.math.complex.atanhstd.math.complex.conjstd.math.complex.cosstd.math.complex.coshstd.math.complex.expstd.math.complex.logstd.math.complex.powstd.math.complex.projstd.math.complex.sinhstd.math.complex.sinstd.math.complex.sqrtstd.math.complex.tanhstd.math.complex.tanstd.math.complex.ldexp_cexp
- Added more slice manipulation functions. Thanks Braedon Wooding for the original PR. (#944)
std.mem.trimLeftstd.mem.trimRightstd.mem.trimRightstd.mem.lastIndexOfScalarstd.mem.lastIndexOfAnystd.mem.lastIndexOfstd.mem.endsWith
- Added
std.atomic.Stack - Added
std.atomic.Queue - Added
std.os.spawnThread. It works on all targets. On Linux, when linking libc, it uses pthreads, and when not linking libc, it makes syscalls directly. - Add JSON decoder. -Marc Tiehuis
std.json.Tokenstd.json.StreamingParserstd.json.TokenStreamstd.json.validatestd.json.ValueTreestd.json.ObjectMapstd.json.Valuestd.json.Parser - A non-stream JSON parser which constructs a tree of Value's.
- Added
std.SegmentedList - Removed functions from
std.Buffer. Instead users should use std.io.BufferOutStream.- Removed
std.Buffer.appendFormat - Removed
std.Buffer.appendByte - Removed
std.Buffer.appendByteNTimes
- Add arbitrary-precision integer to std. -Marc Tiehuis
std.math.big.Intstd.math.big.Limbstd.math.big.DoubleLimbstd.math.big.Log2Limb
std.os.Dir gains Windows support.std.os.File.access no longer depends on shlwapi.dll on Windows.std.os.path.dirname returns null instead of empty slice when there
is no directory component. This makes it harder to write bugs. (#1017)- Reading from a file can return
error.IsDir. - Added
std.math.floatMantissaBits and std.math.floatExponentBits -Marc Tiehuis std.mem.Allocator allows allocation of any 0 sized type, not just void. -Jimmi Holst Christensen.- Added
std.os.cpuCount - Added
std.sort.asc and std.sort.desc -Marc Tiehuis std.fmt.format add * for formatting things as pointers. (#1285)std.fmt.format add integer binary output format. -Marc Tiehuis (#1313)- Added
std.mem.secureZero. -Marc TiehuisThis is identical to mem.set(u8, slice, 0) except that it will never
be optimized out by the compiler. Intended usage is for clearing
secret data.
The resulting assembly has been manually verified in --release-* modes.
It would be valuable to test the 'never be optimized out' claim in tests
but this is harder than initially expected due to how much Zig appears
to know locally. May be doable with @intToPtr, @ptrToInt to get around
known data dependencies but I could not work it out right now.
std.fmt.format handles non-pointer struct/union/enums. Adds support for printing structs
via reflection. (#1380)- Many
std.os file functions no longer require an allocator. They rely onPATH_MAX, because even Windows, Linux, and MacOS syscalls will fail for paths longer
than PATH_MAX. - Add
std.crypto.chaCha20IETF and std.crypto.chaCha20With64BitNonce. -Shawn Landden & Marc Tiehuis - Add poly1305 and x25519 crypto primitives. -Marc Tiehuis
These are translated from monocypher which
has fairly competitive performance while remaining quite simple.
Initial performance comparision:
Zig:
Poly1305: 1423 MiB/s
X25519: 8671 exchanges per second
Monocypher:
Poly1305: 1567 MiB/s
X25519: 10539 exchanges per second
There is room for improvement and no real effort has been made at all in
optimization beyond a direct translation. - Removed deprecated, unused Windows functions
std.os.windows.CryptAcquireContextAstd.os.windows.CryptReleaseContextstd.os.windows.CryptGenRandom
Thank you contributors!
- Tesla Ice Zhang fixed typos in the Zig grammar documentation and created The IntelliJ IDEA plugin for the Zig programming language
- Jay Weisskopf cleaned up the Zig documentation
- hellerve finished the Mac OS dir entry iterator code
- Raul Leal fixed an undeclared identifier error in readUntilDelimiterBuffer and incorrect number of parameters in readUntilDelimiterAlloc (#877)
- Wander Lairson Costa fixed the build process to find libxml2 and zlib correctly. (#847)
- tgschultz added more linux syscalls and constants to the std lib.
- tgschultz fixed compiler errors around Darwin code.
- Harry Eakins added readability improvements and a bug-fix to the standard library
crypto throughput test.
- tgschultz Added DirectAllocator support for alignments bigger than os.page_size on posix systems. (#939)
- Braedon Wooding& Josh Wolfe Added UTF-8 encoding and decoding support. (#954)
- Alexandros Naskos Fixed a bug where comptime was being incorrectly applied across function definition boundaries. (#972)
- Braedon Wooding worked towards unifying the
std.ArrayList and std.HashMap APIs regarding iteration. (#981) - Braedon Wooding added documentation for arg types and error inference.
- tgschultz added custom formatter support to
std.fmt.format. - isaachier Fixed const-ness of buffer in
std.Buffer.replaceContents method (#1065) - isaachier Fixed error handling in
std.Buffer.fromOwnedSlice. (#1082) - Arthur Elliott Added
std.ArrayList.setOrError so you can set a value without growing the underlying buffer, with range safety checks. - marleck55 std/fmt: Use lowercase k for kilo in base 1000 (#1090)
- tgschultz added C string to fmt by using
{s}. (#1092) - Alexandros Naskos Fixed optional types of zero bit types. (#1110)
- Jay Weisskopf Made
zig version compliant with SemVer with regards
to the git revision metadata. - Sahnvour fixed a compilation error on windows introduced by pointer reform.
- Bodie Solomon Fixed zig not finding std lib files on Darwin when the executable is a symlink. (#1117)
- Isaac Hier Fixed the increment operation for the comptime value
-1. - Isaac Hier Fixed the compiler's internal path joining function when the dirname is empty.
- tgschultz Fixed standard library regressions from updated syntax. (#1162)
- Isaac Hier Improved the compile error for when the RHS of a shift is too large for the LHS. (#1168)
- Jay Weisskopf Fixed version detection for out-of-source builds.
- Isaac Hier Fixed an assertion crash on enum switch values
- wilsonk Fixed a build error in the crypto throughput test (#1211)
- Bas van den Berg Fixed
std.ArrayList.insert and added tests. (#1232) - tgschultz Added
std.ArrayList.swapRemove. (#1230) - Eduardo Sánchez Muñoz fixed bad code generated when an extern function returns a small struct. (#1234)
- Bas van den Berg fixed aligned reallocation. (#1237)
- Bas van den Berg improved realloc on fixed buffer allocator. (#1238)
- Wink Saville gave ArrayList tests consistent names. (#1253)
- Wink Saville added
std.ArrayList.swapRemoveOrError. (#1254) - Jay Weisskopf Fixed minor documentation errors (#1256)
- kristopher tate Added more
std.os.posix constants. - kristopher tate Made tests skippable by returning
error.SkipZigTest - Nathan Sharp Added
std.io.PeekStream and std.io.Slicestream.SliceStream is a read-only stream wrapper around a slice of bytes. It
allows adapting algorithms which work on InStreams to in-memory data.
PeekStream is a stream wrapper which allows "putting back" bytes into
the stream so that they can be read again. This will help make
look-ahead parsers easier to write.
- dbandstra added int writing functions to OutStream, and skipBytes function to InStream (#1300)
- dbandstra add SliceOutStream, rename SliceStream to SliceInStream (#1301)
- Matthew D. Steele added "Comments" section to language reference (#1309)
- kristopher tate Windows: Call RtlGenRandom() instead of CryptGetRandom() (#1319)
- kristopher tate Add builtin function @handle() (#1297)
- kristopher tate better support for `_` identifier (#1204, #1320)
- Matthew D. Steele Fix the start-less-than-end assertion in std.rand.Random.range (#1325)
- Matthew D. Steele Fix a type error in std.os.linux.getpid() (#1326)
- Matthew D. Steele Add thread ID support to std.os.Thread (#1316)
- Shawn Landdendoc: @addWithOverflow also returns if overflow occured
- Shawn Landdenadded a red-black tree implementation to std
- Wink Saville fixed @atomicRmw not type checking correctly.
- prazzb Fixed LLVM detection at build time for some linux distros. (#1378)
- tgschultz fixed handling of [*]u8 when no format specifier is set. (#1379)
- Shawn Landden do not use an allocator when we don't need to because of the existance of PATH_MAX
- Raul Leal Allow implicit cast from
*[N]T to ?[*]T (#1398) - kristopher tate Added a test for writing u64 integers (#1401)
- tgschultz Fixed compile error when passing enum to fmt
- tgschultz Implemented tagged union support in
std.fmt.format (#1432) - Raul Leal Allow implicit cast from
*T and [*]T to ?*c_void - kristopher tate correct version comparison for detecting msvc (fixes #1438)
- kristopher tate allow bytes to be printed-out as hex (#1358)
- Shawn Landden updated incorrect documentation comments (#1456)
- hfcc Added compilation error when a non-float is given to
@floatToInt - kristopher tate X25519: Fix createPublicKey signature and add test (#1480)
- Sahnvour Fixes a path corruption when compiling on windows. (#1488)
- Bas van den Berg Add capacity and appendAssumeCapacity to ArrayList
- emekoifixed WriteFile segfault
- kristopher tate fixed handling of file paths with spaces in the cache
- Wink Saville fixed build failures of FileOutStream/FileInStream from syntax changes
- emekoifixed compiling on mingw (#1542)
- Raul Leal added builtin functions:
@byteOffsetOf and @bitOffsetOf. - Christian Wesselhoeft fixed BufferOutStream import - it is defined in io.zig.
- Wink Saville fixed a typo in a doc comment
- Wink Saville fixed a build issue with GCC 8
- Wink Saville refactored some parsing code in the self-hosted compiler
- Jay Weisskopf improved the help output of the command line interface
Miscellaneous Improvements
- LLVM, Clang, and LLD dependencies are updated to 7.0.0.
- Greatly increased test coverage.
- std.os - getting dir entries works on Mac OS.
- allow integer and float literals to be passed to var params. See #623
- add @sqrt built-in function. #767
- The compiler exits with error code instead of abort() for file not found.
- Add @atomicLoad builtin.
- stage1 compiler defaults to installing in the build directory
- ability to use async function pointers
- Revise self-hosted command line interface
- Add exp/norm distributed random float generation. -Marc Tiehuis
- On linux,
clock_gettime uses the VDSO optimization, even
for static builds. - Better error reporting for missing libc on Windows. (#931)
- Improved fmt float-printing. -Marc Tiehuis
- Fix errors printing very small numbers
- Add explicit scientific output mode
- Add rounding based on a specific precision for both decimal/exp modes.
- Test and confirm exp/decimal against libc for all
f32 values. Various
changes to better match libc.
- The crypto throughput test now uses the new
std.os.time module. -Marc Tiehuis - Added better support for unpure enums in tranlate C. -Jimmi Holst Christensen (#975)
- Made container methods that can be
const, const. -Jimmi Holst Christensen - Tagged union field access prioritizes members over enum tags. (#959)
std.fmt.format supports {B} for human readable bytes using SI prefixes.- Zig now knows the C integer sizes for OpenBSD. Thanks to Jan Schreib for this information. (#1016)
- Renamed integer literal type and float literal type to
comptime_int and comptime_float. -Jimmi Holst Christensen - @canImplicitCast is removed. Nobody will miss it.
- Allow access of
array.len through a pointer. -Jimmi Holst Christensen - Optional pointers follow const-casting rules. Any
*T -> ?*T cast
is allowed implicitly, even when it occurs deep inside the type, and the cast
is a no-op at runtime. - Add i128 compiler-rt div/mul support. -Marc Tiehuis
- Add target C int type information for msp430 target. #1125
- Add
__extenddftf2 and __extendsftf2 to zig's compiler-rt. - Add support for zig to compare comptime array values. -Jimmi Holst Christensen (#1167)
- Support
--emit in test command. -Ben Noordhuis (#1175) - Operators now throw a compiler error when operating on undefined values. -Jimmi Holst Christensen (#1185)
- Always link against compiler_rt even when linking libc. Sometimes libgcc is missing things we need,
so we always link compiler_rt and rely on weak linkage to allow libgcc to override.
- Add compile error notes for where struct definitions are. (#1202)
- Add @popCount.
- Cleaner output from zig build when there are compile errors.
- new
builder.addBuildOption API. -Josh Wolfe - Add compile error for disallowed types in extern structs. (#1218)
- build system: add
-Dskip-release option to test faster. -Andrew Kelley & Jimmi Holst Christensen - allow
== for comparing optional pointers. #658 - allow implicit cast of undefined to optional
- switch most windows calls to use W versions instead of A. (#534)
- Better anonymous struct naming. This makes anonymous structs inherit the name of the
function they are in only when they are the return expression. Also document the behavior
and provide examples. (#1243)
- compile error for @noInlineCall on an inline fn (#1133)
- stage1: use os_path_resolve instead of os_path_real to canonicalize imports.
This means that softlinks can represent different files,
but referencing the same absolute path different ways
still references the same import.
- rename
--enable-timing-info to -ftime-report to match clang, and
have it print llvm's internal timing info. - Binary releases now include the LICENSE file.
- Overhaul standard library api for getting random integers. -Josh Wolfe (#1578)
Bug Fixes
- fix incorrect compile error on inferred error set from async function #856
- fix
promise->T syntax not parsed #857 - fix crash when compile error in analyzing @panic call
- fix compile time array concatenation for slices #866
- fix off-by-one error in all standard library crypto functions. -Marc Tiehuis
- fix use-after-free in BufMap.set() - Ben Noordhuis #879
- fix llvm assert on version string with git sha -Ben Noordhuis #898
- codegen: fix not putting llvm allocas together
- fix calling convention at callsite of zig-generated fns
- inline functions now must be stored in const or comptime var. #913
- fix linux implementation of self exe path #894
- Fixed looking for windows sdk when targeting linux. -Jimmi Holst Christensen
- Fixed incorrect exit code when build.zig cannot be created. -Ben Noordhuis
- Fix os.File.mode function. -Marc Tiehuis
- Fix OpqaueType usage in exported c functions. -Marc Tiehuis
- Added
memmove to builtin.o. LLVM occasionally generates a dependency on this function. - Fix
std.BufMap logic. -Ben Noordhuis - Fix undefined behavior triggered by fn inline test
- Build system supports LLVM_LIBDIRS and CLANG_LIBDIRS. -Ben Noordhuis
- The Zig compiler does exit(1) instead of abort() for file not found.
- Add compile error for invalid deref on switch target. (#945)
- Fix printing floats in release mode. -Marc Tiehuis (#564, #669, #928)
- Fix @shlWithOverflow producing incorrect results when used at comptime (#948)
- Fix labeled break causing defer in same block to fail compiling (#830)
- Fix compiler crash with functions with empty error sets. -Jimmi Holst Christensen (#762, #818)
- Fix returning literals from functions with inferred error sets. -Jimmi Holst Christensen (#852)
- Fix compiler crash for
.ReturnType and @ArgType on unresolved types. -Jimmi Holst Christensen (#846) - Fix compiler-rt ABI for x86_64 windows
- Fix extern enums having the wrong size. -Jimmi Holst Christensen (#970)
- Fix bigint multi-limb shift and masks. -Marc Tiehuis
- Fix bigint shift-right partial shift. -Marc Tiehuis
- translate-c: fix typedef duplicate definition of variable. (#998)
- fix comptime code modification of global const. (#1008)
- build: add flag to LLD to fix gcc 8 build. (#1013)
- fix AtomicFile for relative paths. (#1017)
- fix compiler assert when trying to unwrap return type
type. -Jimmi Holst Christensen - fix crash when evaluating return type has compile error. (#1058)
- Fix Log2Int type construction. -Marc Tiehuis
- fix std.os.windows.PathFileExists specified in the wrong DLL (#1066)
- Fix structs that contain types which require comptime. (#586)
Now, if a struct has any fields which require comptime,
such as type, then the struct is marked as requiring
comptime as well. Same goes for unions.
This means that a function will implicitly be called
at comptime if the return type is a struct which contains
a field of type type.
- fix assertion failure when debug printing comptime values
- fix @tagName handling specified enum values incorrectly. (#976, #1080)
- fix ability to call mutating methods on zero size structs. (#838)
- disallow implicit casts that break rules for optionals. (#1102)
- Fix windows x86_64 i128 ABI issue. -Marc Tiehuis
- Disallow opaque as a return type of function type syntax. (#1115)
- Fix compiler crash for invalid enums. (#1079, #1147)
- Fix crash for optional pointer to empty struct. (#1153)
- Fix comptime
@tagName crashing sometimes. (#1118) - Fix coroutine accessing freed memory. (#1164)
- Fix runtime libc detection on linux depending on locale. (#1165)
- Fix await on early return when return type is struct.
- Fix iterating over a void slice. (#1203)
- Fix crash on
@ptrToInt of a *void (#1192) - fix crash when calling comptime-known undefined function ptr. #880, #1212
- fix
@setEvalBranchQuota not respected in generic fn calls. #1257 - Allow pointers to anything in extern/exported declarations (#1258) -Jimmi Holst Christensen
- Prevent non-export symbols from clobbering builtins. (#1263)
- fix generation of error defers for fns inside fns. (#878)
- Fixed windows getPos. -Jimmi Holst Christensen
- fix logic for determining whether param requires comptime (#778, #1213)
- Fixed bug in LLD crashing when linking twice in the same process. (#1289)
- fix assertion failure when some compile errors happen
- add compile error for non-inline for loop on comptime type
- add compile error for missing parameter name of generic function
- add compile error for ignoring return value of while loop bodies (#1049)
- fix tagged union initialization with a runtime void (#1328)
- translate-c: fix for loops and do while loops with empty body
- fix incorrectly generating an unused const fn global (#1277)
- Fix builtin alignment type. -Marc Tiehuis (#1235)
- fix handling multiple extern vars with the same name
- fix llvm assertion failure when building std lib tests for macos (#1417)
- fix false negative determining if function is generic
- fix
@typeInfo unable to distinguish compile error vs no-payload (#1421, #1426) - fix crash when var in inline loop has different types (#917, #845, #741, #740)
- add compile error for function prototype with no body (#1231)
- fix invalid switch expression parameter. (#604)
- Translate-c: Check for error before working on while loop body. -Jimmi Holst Christensen (#1445)
- use the sret attribute at the callsite when appropriate. Thanks to Shawn Landden for the
original pull request. (#1450)
- ability to
@ptrCast to *void. (#960) - compile error instead of segfault for unimplemented feature. (#1103)
- fix incorrect value for inline loop. (#1436)
- compile errors instead of crashing for unimplemented minValue/maxValue builtins
- add compile error for comptime control flow inside runtime block (#834)
- update throughput test to new File API (#1468)
- fix compile error on gcc 7.3.0. Only set -Werror for debug builds, and only for zig itself, not for
embedded LLD. (#1474)
- stage1: fix emit asm with explicit output file (#1473)
- stage1: fix crash when invalid type used in array type (#1186)
- stage1 compile error instead of crashing for unsupported comptime ptr cast (#955)
- stage1: fix tagged union with no payloads (#1478)
- Add compile error for using outer scoped runtime variables from a fn defined inside it. (#876)
- stage1: improve handling of generic fn proto type expr. (#902)
- stage1: compile error instead of incorrect code for unimplemented C ABI. (#1411, #1481)
- add support for partial C ABI compatibility on x86_64. (#1411, #1264)
- fix crash when var init has compile error and then the var is referenced (#1483)
- fix incorrect union const value generation (#1381)
- fix incorrect error union const value generation (#1442)
- fix tagged union with only 1 field tripping assertion (#1495)
- add compile error for merging non- error sets (#1509)
- fix assertion failure on compile-time
@intToPtr of function - fix tagged union with all void payloads but meaningful tag (#1322)
- fix alignment of structs. (#1248, #1052, #1154)
- fix crash when pointer casting a runtime extern function
- allow extern structs to have stdcallcc function pointers (#1536)
- add compile error for non-optional types compared against null (#1539)
- add compile error for
@ptrCast 0 bit type to non-0 bit type - fix codegen for
@intCast to u0 - fix @bytesToSlice on a packed struct (#1551)
- fix implicit cast of packed struct field to const ptr (#966)
- implementation for bitcasting extern enum type to c_int (#1036)
- add compile error for slice.*.len (#1372)
- fix optional pointer to empty struct incorrectly being non-null (#1178)
- better string literal caching implementation
We were caching the ConstExprValue of string literals,
which works if you can never modify ConstExprValues.
This premise is broken with `comptime var ...`.
So I implemented an optimization in ConstExprValue
arrays, where it stores a Buf * directly rather
than an array of ConstExprValues for the elements,
and then similar to array of undefined, it is
expanded into the canonical form when necessary.
However many operations can happen directly on theBuf *, which is faster.
Furthermore, before a ConstExprValue array is expanded
into canonical form, it removes itself from the string
literal cache. This fixes the issue, because before an
array element is modified it would have to be expanded.
See #1076
- add compile error for casting const array to mutable slice (#1565)
- fix
std.fmt.formatInt to handle upcasting to base int size - fix comptime slice of pointer to array (#1565)
- fix comptime string concatenation ignoring slice bounds (#1362)
- stage1: unify 2 implementations of pointer deref. I found out there were accidentally
two code paths in zig ir for pointer dereference. So this should fix a few bugs. (#1486)
- add compile error for slice of undefined slice (#1293)
- fix @compileLog having unintended side effects. (#1459)
- fix translate-c incorrectly translating negative enum init values (#1360)
- fix comptime bitwise operations with negative values (#1387, #1529)
- fix self reference through fn ptr field crash (#1208)
- fix crash on runtime index into slice of comptime type (#1435)
- fix implicit casting to
*c_void (#1588) - fix variables which are pointers to packed struct fields (#1121)
- fix crash when compile error evaluating return type of inferred error set. (#1591)
- fix zig-generated DLLs not properly exporting functions. (#1443)
This Release Contains Bugs
Zig has known bugs.
The first release that will ship with no known bugs will be 1.0.0.
Roadmap
- Redo coroutines without using LLVM Coroutines and rework the semantics. See #1363 and #1194.
- Tuples instead of var args. #208
- Well-defined copy-eliding semantics. #287
- Self-hosted compiler. #89
- Get to 100% documentation coverage of the language
- Auto generated documentation. #21
- Package manager. #943
Active External Projects Using Zig
Thank you financial supporters!
Special thanks to those who donate monthly. We're now at $1,349 of the $3,000 goal. I hope this release helps to show how much time I've been able to dedicate to the project thanks to your support.
- Lauren Chavis
- Raph Levien
- Stevie Hryciw
- Andrea Orru
- Harry Eakins
- Filippo Valsorda
- jeff kelley
- Martin Schwaighofer
- Brendon Scheinman
- Ali Anwar
- Adrian Sinclair
- David Joseph
- Ryan Worl
- Tanner Schultz
- Don Poor
- Jimmy Zelinskie
- Thomas Ballinger
- David Hayden
- Audun Wilhelmsen
- Tyler Bender
- Matthew
- Mirek Rusin
- Peter Ronnquist
- Josh Gentry
- Trenton Cronholm
- Champ Yen
- Robert Paul Herman
- Caius
- Kelly Wilson
- Steve Perkins
- Clement Rey
- Eduard Nicodei
- Christopher A. Butler
- Colleen Silva-Hayden
- Wesley Kelley
- Jordan Torbiak
- Mitch Small
- Josh McDonald
- Jeff
- Paul Merrill
- Rudi Angela
- Justin B Alexander
- Ville Tuulos
- shen xizhi
- Ross Cousens
- Lorenz Vandevelde
- Ivan
- Jay Weisskopf
- William L Sommers
- Gerdus van Zyl
- Anthony J. Benik
- Brian Glusman
- Furkan Mustafa
- Le Bach
- Jordan Guggenheim
- Tyler Philbrick
- Marko Mikulicic
- Brian Lewis
- Matt Whiteside
- Elizabeth Ryan
- Thomas Lopatic
- Patricio Villalobos
- joe ardent
- John Goen
- Luis Alfonso Higuera Gamboa
- Jason Merrill
- Andriy Tyurnikov
- Sanghyeon Seo
- Neil Henning
- aaronstgeorge@gmail.com
- Raymond Imber
- Artyom Kazak
- Brian Orr
- Frans van den Heuvel
- Jantzen Owens
- David Bremner
- Veit Heller
- Benoit Jauvin-Girard
- Chris Rabuse
- Jeremy Larkin
- Rasmus Rønn Nielsen
- Aharon sharim
- Stephen Oates
- Quetzal Bradley
- Wink Saville
- S.D.
- George K
- Jonathan Raphaelson
- Chad Russell
- Alexandra Gillis
- Pradeep Gowda
- david karapetyan
- Lewis
- stdev
- Wojciech Miłkowski
- Jonathan Wright
- Ernst Rohlicek
- Alexander Ellis
- bb010g
- Pau Fernández
- Krishna Aradhi
- occivink
- Adrian Hatch
- Deniz Kusefoglu
- Dan Boykis
- Hans Wennborg
- Matus Hamorsky
- Ben Morris
- Tim Hutt
- Gudmund Vatn
- Tobias Haegermarck
- Martin Angers
- Christoph Müller
- Johann Muszynski
- Fabio Utzig
- Eigil Skjæveland
- Harry
- moomeme
- xash
- bowman han
- Romain Beaumont
- Nate Dobbins
- Paul Anderson
- Jon Renner
- Karl Syvert Løland
- Stanley Zheng
- myfreeweb
- Dennis Furey
- Dana Davis
- Ansis Malins
- Drew Carmichael
- Doug Thayer
- Henryk Gerlach
- Dylan La Com
- David Pippenger
- Matthew Steele
- tumdum
- Alex Alex
- Andrew London
- Jirka Grunt
- Dillon A
- Yannik
- VilliHaukka
- Chris Castle
- Antonio D'souza
- Silicon
- Damien Dubé
- Dbzruler72
- McSpiros
- Francisco Vallarino
- Shawn Park
- Simon Kreienbaum
- Gregoire Picquot
- Silicas
- James Haggerty
- Falk Hüffner
- allan
- Ahmad Tolba
- jose maria gonzalez ondina
- Adrian Boyko
- Benedikt Mandelkow
- Will Cassella
- Michael Weber
Thank you Andrea Orru for sending me a giant box of Turkish Delight
![]()
![]()