↧
Linux 4.13 support for TLS record layer in kernel space
↧
Introduction to HTML Components
HTML Components (HTC), introduced in Internet Explorer 5.5, offers a powerful new way to author interactive Web pages. Using standard DHTML, JScript and CSS knowledge, you can define custom behaviors on elements using the “behavior” attribute. Let’s create a behavior for a simple kind of “image roll-over” effect. For instance, save the following as “roll.htc”:
<PUBLIC:ATTACH EVENT="onmouseover" ONEVENT="rollon()" />
<PUBLIC:ATTACH EVENT="onmouseout" ONEVENT="rollout()" />
<SCRIPT LANGUAGE="JScript">
tmpsrc = element.src;
function rollon() {
element.src = tmpsrc + "_rollon.gif"
}
function rollout() {
element.src = tmpsrc + ".gif";
}
rollout();
</SCRIPT>
This creates a simple HTML Component Behavior that swaps the image’s source when the user rolls over and rolls off of the mentioned image. You can “attach” such a behavior to any element using the CSS attribute, “behavior”.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <BODY> <IMG STYLE="behavior: url(roll.htc)" SRC="logo"> </BODY> </HTML>
The benefit of HTML Components is that we can apply them to any element through simple CSS selectors. For instance:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<STYLE>
.RollImg {
behavior: url(roll.htc);
}
</STYLE>
</HEAD>
<BODY>
<IMG CLASS="RollImg" SRC="logo">
<IMG CLASS="RollImg" SRC="home">
<IMG CLASS="RollImg" SRC="about">
<IMG CLASS="RollImg" SRC="contact">
</BODY>
</HTML>
This allows us to reuse them without having to copy/paste code. Wonderful! This is known as an Attached Behavior, since it is directly attached to an element. Once you’ve mastered these basic Attached Behaviors, we can move onto something a bit more fancy, Element Behaviors. With Element Behaviors, you can create custom element types and create custom programmable interfaces, allowing us to build a library of custom components, reusable between pages and projects. Like before, Element Behaviors consist of an HTML Component, but now we have to specify our component in <PUBLIC:COMPONENT>.
<PUBLIC:COMPONENT TAGNAME="ROLLIMG">
<PUBLIC:ATTACH EVENT="onmouseover" ONEVENT="rollon()" />
<PUBLIC:ATTACH EVENT="onmouseout" ONEVENT="rollout()" />
<PUBLIC:PROPERTY NAME="basesrc" />
</PUBLIC:COMPONENT>
<img id="imgtag" />
<SCRIPT>
img = document.all['imgtag'];
element.appendChild(img);
function rollon() {
img.src = element.basesrc + "_rollon.gif";
}
function rollout() {
img.src = element.basesrc + ".gif";
}
rollout();
</SCRIPT>
I’ll get to the implementation of ROLLIMG in a bit, but first, to use a custom element, we use the special <?IMPORT> tag which allows us to import a custom element into an XML namespace.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML XMLNS:CUSTOM> <HEAD> <?IMPORT NAMESPACE="CUSTOM" IMPLEMENTATION="RollImgComponent.htc"> </HEAD> <BODY> <CUSTOM:ROLLIMG BASESRC="logo"> <CUSTOM:ROLLIMG BASESRC="home"> <CUSTOM:ROLLIMG BASESRC="about"> <CUSTOM:ROLLIMG BASESRC="contact"> </BODY> </HTML>
The ROLLIMG fully encapsulates the behavior, freeing the user of having to “know” what kind of element to use the Attached Behavior on! The implementation of the Custom Element Behavior might seem a bit complex, but it’s quite simple. When Internet Explorer parses a Custom Element, it synchronously creates a new HTML Component from this “template” and binds it to the instance. We also have two “magic global variables” here: “element” and “document”. Each instance of this HTML Component gets its own document, the children of which are reflowed to go inside the custom element. “element” refers to the custom element tag in the outer document which embeds the custom element. Additionally, since each custom element has its own document root, that means that it has its own script context, and its own set of global variables.
We can also set up properties as an API for the document author to use when they use our custom element.
Here, we use an img tag as a “template” of sorts, add it to our custom element’s document root.
After IE puts it together, the combined DOM sort of looks like this:
<CUSTOM:ROLLIMG BASESRC="logo"> <IMG ID="imgtag" SRC="logo.gif"> </CUSTOM:ROLLIMG> <CUSTOM:ROLLIMG BASESRC="home"> <IMG ID="imgtag" SRC="home.gif"> </CUSTOM:ROLLIMG> ...
Unfortunately, this has one final flaw. Due to the natural cascading nature of CSS Stylesheets, such “implementation details” will leak through. For instance, if someone adds a <STYLE>IMG { background-color: red; }</STYLE>, this will affect our content. While this can sometimes be a good thing if you want to develop a styleable component, it often results in undesirable effects. Thankfully, Internet Explorer 5.5 adds a new feature, named “Viewlink”, which encapsulates not just the implementation of your HTML Component, but the document as well. “Viewlink” differs from a regular component in that instead of adding things as children of our element, we instead can provide a document fragment which the browser will “attach” to our custom element in a private, encapsulated manner. The simplest way to do this is to just use our HTML Component’s document root.
<PUBLIC:COMPONENT TAGNAME="ROLLIMG">
<PUBLIC:ATTACH EVENT="onmouseover" ONEVENT="rollon()" />
<PUBLIC:ATTACH EVENT="onmouseout" ONEVENT="rollout()" />
<PUBLIC:PROPERTY NAME="basesrc" />
</PUBLIC:COMPONENT>
<img id="imgtag" />
<SCRIPT>
defaults.viewLink = document;
var img = document.all['imgtag'];
function rollon() {
img.src = element.basesrc + "_rollon.gif";
}
function rollout() {
img.src = element.basesrc + ".gif";
}
rollout();
</SCRIPT>
Using the “defaults.viewLink” property, we can set our HTML Component’s private document fragment as our viewLink, rendering the children but without adding them as children of our element. Perfect encapsulation.
…
…
*cough* OK, obviously it’s 2017 and Internet Explorer 5.5 isn’t relevant anymore. But if you’re a Web developer, this should have given you some pause for thought. The modern Web Components pillars: Templates, Custom Elements, Shadow DOM, and Imports, were all features originally in IE5, released in 1999.
Now, it “looks outdated”: uppercase instead of lowercase tags, the “on”s everywhere in the event names, but that’s really just a slight change of accent. Shake off the initial feeling that it’s cruft, and the actual meat is all there, and it’s mostly the same. Sure, there’s magic XML tags instead of JavaScript APIs, and magic globals instead of callback functions, but that’s nothing more than a slight change of dialect. IE says tomato, Chrome says tomato.
Now, it’s likely you’ve never heard of HTML Components at all. And, perhaps shockingly, a quick search at the time of this article’s publishing shows nobody else does at all.
Why did IE5’s HTML Components never quite catch on? Despite what you might think, it’s not because of a lack of open standards. Reminder, a decent amount of the web API, today, started from Internet Explorer’s DHTML initiative. contenteditable, XMLHttpRequest, innerHTML were all carefully, meticulously reverse-engineered from Internet Explorer. Internet Explorer was the dominant platform for websites — practically nobody designed or even tested websites for Opera or Netscape. I can remember designing websites that used IE-specific features like DirectX filters to flip images horizontally, or the VML
And it’s not because of a lack of evangelism or documentation. Microsoft was trying to push DHTML and HTML Components hard. Despite the content being nearly 20 years old at this point, documentation on HTML Components and viewLink is surprisingly well-kept, with diagrams and images, sample links and all, archived without any broken links. Microsoft’s librarians deserve fantastic credit on that one.
For any browser or web developer, please go read the DHTML Dude columns. Take a look at the breadth of APIs available on display, and go look at some examplecomponents on display. Take a look at the persistence API, or dynamic expression properties. Besides the much-hyped-but-dated-in-retrospect XML data binding tech, it all seems relatively modern. Web fonts? IE4. CSS gradients? IE5.5. Vector graphics? VML (which, in my opinion, is a more sensible standard than SVG, but that’s for another day.)
So, again I ask, why did this never catch on? I’m sure there are a variety of complex factors, probably none of which are technical reasons. Despite our lists of “engineering best practices” and “blub paradoxes“, computer engineering has, and always will be, dominated by fads and marketing and corporate politics.
The more important question is a bigger one: Why am I the first one to point this out? Searching for “HTML Components” and “Viewlink” leads to very little discussion about them online, past roughly 2004. Microsoft surely must have been involved in the Web Components Working Group. Was this discussed at all?
Pop culture and fads pop in and fade out over the years. Just a few years ago, web communities were excited about Object.observe before React proved it unnecessary. Before node.js’s take on “isomorphic JavaScript” was solidified, heck, even before v8cgi / teajs, an early JavaScript-as-a-Server project, another bizarre web framework known as Aptana Jaxer was doing it in a much more direct way.
History is important. It’s easier to point and laugh and ignore outdated technology like Internet Explorer. But tech, so far, has an uncanny ability to keep repeating itself. How can we do a better job paying attention to things that happened before us, rather than assuming it was all bad?
↧
↧
HomeBrew Analytics – top 1000 packages installed over last year
nodegitwgetyarnpython3pythonmysqlcoreutilsopensslpostgresqlimagemagickmongodbpkg-configchromedriverawscliautomakevimyoutube-dllibtoolcmakereadlinegomavenlibyamlautoconfwatchmanredisffmpegherokurbenvgradletmuxrubyopenssl@1.1libksbazshpidofnginxselenium-server-standalonecarthagetreejqdockernmaphtopnvmpyenvgccgnupghomebrew/php/php71ansiblebash-completionsbtcurlterraformgraphvizwineboostzsh-completionsmercurialelasticsearchunrargit-lfshomebrew/science/opencvthe_silver_searchernode@6protobufkubernetes-clihomebrew/php/composermacvimbashdnsmasqqtmariadbanthomebrew/php/php70ruby-buildscalagdbsqlitephantomjshugoelixirlibxml2fishwatchswiftlintghostscriptimagemagick@6rabbitmqp7zipflowhomebrew/php/php56neovim/neovim/neovimlibav --with-libvorbis --with-libvpx --with-freetype --with-fdk-aac --with-opushttpiedocker-composemonoctagspandocbazelgnupg2libpnglibffiqt5tigllvmhomebrew/dupes/zlibmemcachedhomebrew/science/rmysql@5.6ackxzdocker-machinejpegsdl2midnight-commanderethereum/ethereum/ethereumpyenv-virtualenvcapstoneputtyhubthefuckemacs --with-cocoagnutlsemacssubversionhighlightreattach-to-user-namespaceideviceinstallerhomebrew/science/octavetomcatlibimobiledevice --HEADssh-copy-idjenkinscertbotvim --with-override-system-vifzfgcc@4.9dos2unixrustpackergraphicsmagicklibtiffcocoapodsmtrdoxygengo-delve/delve/delvevim --with-luagroovywinetricksfreetypegnu-sedapache-sparkpcretesseractswiggnuplotnode --without-npmsdlhomebrew/science/opencv3nginx --with-http2git-flowhomebrew/php/php71-xdebuggcc --without-multilibpvboost-pythongawkgmpqemucairoluadocker-machine-driver-xhyvecloudfoundry/tap/cf-clizsh-syntax-highlightingsocatnumpyhomebrew/php/php70-mcryptzeromqcaskhomebrew/php/php71 --with-httpd24homebrew/fuse/ntfs-3gautojumpandroid-platform-toolsgeckodriverhomebrew/science/hdf5tbbhomebrew/php/php56-mcryptmobile-shellmacvim --with-override-system-vimgettextlibxsltglibhomebrew/php/php56-xdebugkotlinnode@4gdbmhadoopwiresharkeigenhomebrew/php/php71-mcryptkubernetes-helmexiftoolcaskformula/caskformula/inkscapearia2homebrew/php/php56 --with-httpd24libeventbinutilszlibbisonrenamesnappyqt@5.5popplerlynxerlangmitmproxyopenvpntorcowsayicu4caws-elasticbeanstalkios-webkit-debug-proxyhomebrew/php/php70-xdebugjenvpyqtripgrepclochomebrew/php/php70 --with-httpd24sdl_imagecurl --with-opensslgnu-sed --with-default-namesmasparallelandroid-sdkglogspeedtest_clishellchecksdl_mixerbowersdl_ttfmpvfindutilshomebrew/apache/httpd24 --with-privileged-ports --with-http2glidegnu-tarpostgisntfs-3gkafkaportmidifreetdsmysql-connector-cirssileveldbexercismhomebrew/science/opencv3 --HEAD --with-contrib --with-python3fswatchyasmkibanalibdvdcssgflagsaircrack-nggdpangoportaudiohomebrew/php/php70-intlhttrackhomebrew/php/phpunitboot2dockermcryptcassandraclang-formatnodebrewdirenvs3cmdperllibusbjmetergdalethereum/ethereum/cpp-ethereumd12frosted/emacs-plus/emacs-plusleiningengit-flow-avhwebphomebrew/php/php71-intlterminal-notifierfortuneopensshlmdbgrafanafontconfigsoxsyncthingopen-mpicolordiffpwgenhomebrew/science/openblashomebrew/science/matplotlibswagger-codegenmd5sha1sumconsulguetzliiperfhomebrew/apache/httpd24watchman --HEADlibimobiledeviceglfwrsynchomebrew/php/php-cs-fixergtk+libmagicgifsicleslpivotal/tap/springbootvaultsshfslibavlibunistringinfluxdbiperf3homebrew/php/php56-intlscipynetcatpecohaskell-stackunisonneovim/neovim/neovim --HEADnanopstreelogstashgstreamerglewlibgcryptsdl2_imageelasticsearch@2.4kopsrpmgreppyqt5xcprojgslopamunixodbcsqlmapthriftvapor/tap/vapormplayerzhomebrew/php/php71-opcachemosquittolibzipgtk+3nkfopenexrgit-extrasninjadpkglftpbash-git-promptsdl2_mixerpassproxychains-ngmuttmedia-infoopenconnectminicomnpthsdl2_ttfccachescreenneovimvim --with-python3ncdumakev8geoipnasmgiflibhomebrew/php/phpmyadminvagrant-completiongnuplot --with-cairo --without-lua --with-wxmac --with-pdflib-lite --with-x11ruby-installhomebrew/science/opencv3 --with-contrib --with-python3harfbuzzfontforgebrew-cask-completionupxhomebrew/fuse/sshfsapktoolrlwraplrzszlibrsvgszipwxpythonmoreutilsghcocamlvalgrindpostgresql@9.5chrubygnuplot --with-x11libiconvatoolscreenfetchadnshomebrew/php/php71-redisdiff-so-fancysiegeapr-utilhomebrew/science/opencv3 --with-contribfigletzookeeperethereum/ethereum/cpp-ethereum --develhomebrew/php/php71-imagickhomebrew/php/php70-opcachelibuvcrystal-langcodeclimate/formulae/codeclimategrcdocker-completioncurl --with-nghttp2mysql@5.5sbclgpg-agentfftwmycliisl@0.12asciinemaw3mhomebrew/php/php55 --with-httpd24libmemcachedgcc@5aspellgcc@4.8rethinkdbpostgresql@9.4little-cms2xctoolpypyopusneo4jlibvorbisaprdockutilhomebrew/php/php56-imagickpyenv-virtualenvwrapperhtop-osxiftopmkvtoolnixideviceinstaller --HEADhomebrew/php/php70-imagickwrkhomebrew/science/opencv3 --with-python3lamesparksmpegctophomebrew/dupes/rsynccmatrixgnu-tar --with-default-namesplantumlsphinx-dochomebrew/php/php56-rediskoekeishiya/formulae/kwmtrashhomebrew/dupes/opensshneofetchpngquantmd5deepoptipngcabextractfindutils --with-default-namesfacebook/fb/buckyou-gethydrawxmaclibsodiumpgclihomebrew/dupes/grepcsshxgrep --with-default-namesgit-duet/tap/git-duetautoenvantigenlolcatgeditshadowsocks-libevffmpeg --with-fdk-aac --with-libass --with-sdl2 --with-x265 --with-freetype --with-libvorbis --with-libvpx --with-opusdart-lang/dart/dart --with-content-shell --with-dartiumfreetds --with-unixodbcswi-prologaxeltypesafe-activatorgnu-getoptsmartmontoolshomebrew/php/php71-mongodbmpv --with-bundlenwallix/awless/awlesse2fsprogsiproute2macdfu-utilpygtkgobject-introspectionlibssh2casperjsios-deployvim --with-override-system-vi --with-luahandbrakehomebrew/php/php70-mongodbonigurumahomebrew/science/vtketcdtidy-html5flexhomebrew/php/php70-redishashcathomebrew/php/php55uncrustifybash-completion@2siplibusb-compatswiftformatpinentry-macoclint/formulae/oclintrangeraspnet/dnx/dnvmgeossconshomebrew/php/php56-opcachehomebrew/php/php-code-sniffermackupwine --develrailwaycat/emacsmacport/emacs-mactomcat@7shared-mime-infoimagemagick --with-webphomebrew/php/drushjpegoptimsolrtcptraceroutetesseract --with-all-languagesgdk-pixbuflibplisttmatehomebrew/php/php56-memcachedgnuplot --with-aquatermhomebrew/php/php71-pdo-pgsqlweechatsshuttlenodenvhomebrew/nginx/nginx-full --with-rtmp-modulehomebrew/php/php71-memcachedsubversion --with-javaeugenmayer/dockersync/unoxzsh-autosuggestionsgourcewakeonlansonar-scannerazure-cliwireshark --with-qtbfgext4fusewebpackopenshift-cliintltooljeffreywildman/virt-manager/virt-managermsgpackmarkdownluajitgnuradiocscopecabal-installunzipalgol68gxhyvemecabffmpeg --with-fdk-aac --with-libass --with-opencore-amr --with-openjpeg --with-rtmpdump --with-schroedinger --with-sdl2 --with-tools --with-freetype --with-frei0r --with-libvorbis --with-libvpx --with-opus --with-speex --with-theorabinwalkcpanminushomebrew/science/opencv3 --with-contrib --without-python --with-python3autosshactivemqtypescriptipcalcjpeg-turbosphinxbyobuhaproxyhivehomebrew/php/php71-apcuosquerydinkypumpkin/get_iplayer/get_iplayerhomebrew/dupes/libiconvhomebrew/fuse/ext4fuseaugeashomebrew/php/php56-apcuqcachegrinddocker-compose-completionjasperpinentryjmeter --with-pluginsarp-scanfabrichomebrew/php/php56-mongodblinksrbenv-gemsetjanssonarcheymecab-ipadiclibsndfileffmpeg --with-sdl2ossp-uuidsonarqubencursescouchdbgit-cryptfdupeshomebrew/science/pillowhpingtransmissiondiffutilshomebrew/dupes/apple-gcc42jemallocgrpcpigzgrunt-cligrailsdbusispellterragruntzenitynode-buildparitytech/paritytech/parity --stablex264jlhonora/lsusb/lsusbavrdudempg123flywaylz4xmlstarletlastpass-cli --with-pinentryhomebrew/dupes/screenlibdnetfpinggnu-which --with-default-namestldrnumpy --with-python3libvpxfacebook/fb/fbsimctl --HEADlibevhomebrew/php/php56-mongodex2jarhomebrew/science/opencv3 --HEAD --with-contribhomebrew/apache/httpd24 --with-privileged-portsgzipgnu-indent --with-default-namesthoughtbot/formulae/rcmgnuplot --with-qt@5.7boost --c++11clispnetpbmosx-cross/avr/avr-libccppchecktcpreplaycaddyxpdfffmpeg --with-libvpxbazaarmacvim --with-luadart-lang/dart/dartclamavstunnelfasdusbmuxdhomebrew/php/php70-apcuelinksinfercryptoppliboggvitorgalvao/tiny-scripts/cask-repairgmp@4homebrew/php/wp-climpfrethereum/ethereum/soliditymkvtoolnix --with-qtflactcl-tkgitlab-ci-multi-runnerpngcrushddrescuehomebrew/science/netcdfzplugprotobuf@2.5fcrackzipldidboost-python --with-python3kafkacatpoliposwiftgenicdiffglmprivoxyhhvm/hhvm/hhvmrepohomebrew/php/php56-memcachelibmpclibassuanraggi/ale/openssl-osx-carclonehomebrew/php/php70-memcachedwebkit2pnghomebrew/versions/logstash24koekeishiya/formulae/khdnghttp2android-ndkelmxhyve --HEADgperftoolsoath-toolkitsupervisorchiselsourcekittenhomebrew/nginx/openrestyvim --with-python3 --with-luaterminatorlibsasslibgpg-errorx265c-areslibxmlsec1reaverpsshastylecvsgoaccesslibressljohnscala@2.11ruby@2.2librdkafkalessconanrtmpdumpmegatoolshomebrew/science/samtoolstelegrafdialogtestsslmpv --HEAD --with-bundle --with-libdvdreadjettyhomebrew/php/php55-xdebugmpichfreetds@0.91libgit2lzlibhomebrew/science/pymolhomebrew/dupes/grep --with-default-nameswireshark --with-qt5gnuplot --with-aquaterm --with-x11homebrew/apache/mod_wsgiminiupnpcmacvim --with-override-system-vim --with-lua --with-luajitsslscanwdiff --with-gettextlibassipythonmongodb@3.2homebrew/php/php55-mcrypthomebrew/science/opencv3 --HEAD --with-contrib --with-javagistpy2caironode@0.12pypy3homebrew/php/php70-pdo-pgsqlcodekitchen/dinghy/dinghymicrocalcgpacpercona-serverammonite-replpidcatqt@5.7pre-commitprocmailfdk-aacpandoc-citeprocshopify/shopify/themekitmakedependberkeley-dbqpdfaws-sdk-cppaws-shellnet-snmpkops --HEADdark-modepcre2ettercapdocker-machine-completionpx4/px4/gcc-arm-none-eabicartr/qt4/qtpidginruby@2.3squidmit-schemetaskmpv --with-libcacasaltstackelasticsearch@1.7ngrepipmitoolosrf/simulation/gazebo8pdf2htmlexgiter8m-clishtooltheorafltkradare2tcpflowsource-highlightimagemagick --with-x11gdrivem4rbenv-default-gemstexinfojosegonzalez/php/composerpixmanpercona-toolkitofflineimapcntlmasciidochyperlibcouchbasemacvim --with-override-system-vim --with-luagit-credential-managerre2clnavtmux --HEADlua@5.1guilezbarcmusberkeley-db@4git-standupjrubyarpingimagesnaphomebrew/php/brew-php-switchermashape/kong/konggruntlibvirtstowmysql-utilitiesgodephbasezopfliexpecthunspellhomebrew/php/php-versionfilebeatv8@3.15homebrew/php/xdebug-osxlibpqxxtomcat@8.0niktoclooggoogleruniversal-ctags/universal-ctags/universal-ctags --HEADlibmicrohttpdautoconf-archivehomebrew/php/php54jeffreywildman/virt-manager/virt-viewerblackfireio/blackfire/blackfire-agentlibtasn1expatvegetahomebrew/nginx/nginx-fulllastpass-clihomebrew/dupes/makeinstantclienttap/instantclient/instantclient-basicmpdprotobuf@2.6rocksdbglobalzsh --without-etcdirhomebrew/php/php56-phalconqrencodep11-kitarangodbiterate-ch/cyberduck/duckccatwine --without-x11sasschomebrew/dupes/nanodocker-machine-nfsfreerdpcloudfoundry/tap/bosh-clibradp/vv/vvhomebrew/science/pcllcovlzippyqt --with-pythontestdiskhomebrew/apache/abhomebrew/dupes/ncursesgnupg@1.4libpcapmultitaildutilibtermkeyffmpeg --with-libvorbis --with-libvpxgit-reviewgracehomebrew/php/php53jsoncppautogensloccountbindqt --with-qtwebkitsanemat/font/rictyforemosttexi2htmlgradle@2.14doctlgst-plugins-goodhomebrew/php/php56-pdo-pgsqlnugetprometheusgaugecartr/qt4/qt-legacy-formulaencahomebrew/science/root6qt5 --with-qtwebkitgst-plugins-badvim --with-lua --with-luajitd12frosted/emacs-plus/emacs-plus --HEADthoughtbot/formulae/parityhomebrew/php/php71 --with-pearpurescriptlzoncftpatkmkvtoolnix --with-qt5freeglutgit-colahomebrew/php/php71-yamlethereum/ethereum/cpp-ethereum --devel --successfulta-liblibtensorflowassimpgripminioffmpeg --with-fdk-aac --with-libass --with-tools --with-x265 --with-freetype --with-libvorbis --with-libvpxlibxml2 --with-pythonflake8shopify/shopify/yarnsysdigemscriptenrdesktopplanckdfu-programmerpygobject3ipfsopenjpegopen-ocdplatformiojosegonzalez/php/php56phrase/brewed/phraseappgnu-indenthomebrew/dupes/tcl-tksfmlrhinodmdminimal-racketsysbenchgit --with-brewed-openssl --with-brewed-curlgit-quick-statsgo@1.7gcc@6ios-simgit-townuber/alt/cerberushomebrew/boneyard/pyqtrpm2cpiogiborbenv-bundlerhomebrew/science/bedtoolspython --with-tcl-tkcgalboost-python --without-python --with-python3ghqhomebrew/science/glpklibconfiged --with-default-namesopenssl --universalsphinx --with-mysqlmvnvmamazon-ecs-clihomebrew/versions/v8-315↧
Watsi launches universal health coverage, funded by YC Research
We’re excited to announce that we’re expanding Watsi to provide health coverage! Together, Watsi Crowdfunding and Watsi Coverage will help create a world where everyone has access to care — whether that’s by raising money through crowdfunding or enrolling in health coverage.
Five years ago, in a Costa Rican town called Watsi, one of our founders met a woman on a hot, crowded bus who was asking passengers for donations to fund her son's healthcare.
Inspired by that woman, we created Watsi to help people access healthcare. We started by launching our crowdfunding platform, which has processed more than $9M from 23,154 donors and funded healthcare for 13,772 patients.

One of those patients is Witcheldo from Haiti. Watsi donors contributed $1,500 to the cost of open-heart surgery to treat a life-threatening cardiac condition—a condition he developed due to a case of untreated strep throat.
If Witcheldo had access to health coverage, his strep throat could have been treated with an antibiotic for a few dollars. Cases like his inspired us to explore different models of providing health coverage, including community-based health insurance.

In the countries where we work, universal health coverage is a top priority, but it’s prohibitively expensive because up to 40% of healthcare funding is lost to inefficiencies. These inefficiencies stem from administering complex systems with pen and paper, which drives up costs and results in errors, fraud, and a lack of insight into the quality of care.

We met one government insurance administrator who couldn’t verify whether the claims she received were for patients enrolled in the insurance program, because doing so would require manually digging through thousands of enrollment records – so she approved every claim. As a result, the system was teetering on bankruptcy, requiring the government to increase premiums, and forcing members to drop out.

We believe low-income countries have an opportunity to leapfrog the inefficiencies of traditional health coverage by building their national programs with technology. Recognizing this opportunity, YC Research gave us funding to build technology that makes it easy to administer health coverage.

With their support, a few of us moved to rural Uganda and spent three months living in a convent alongside the nuns who own and operate the local clinic. We developed our system with direct input from the community, local stakeholders, and global experts.

In six weeks, we coded a mobile app to run the system and opened enrollment in March 2017. To date, 98% of the community has signed up, bringing the program’s membership to 5,880 people. Once enrolled, members can access care at the clinic. Our app streamlines enrolling members, verifying their identity with their thumbprint when they visit the clinic, collecting data on the care they receive, and reimbursing the provider for their costs.

The primary benefit of automating health coverage from end-to-end is improved efficiency. For example, our mobile app has reduced the time it takes to enroll new members and process claims from weeks to minutes. And by surfacing real-time data, we have insight into the cost and quality of care, making it possible to do things like identify unnecessary prescriptions and ensure treatment guidelines are followed. Currently, the cost of care is just $0.78 per member per month.

193 of the world's governments share a goal to achieve universal health coverage by 2030. If we prove our system can make health coverage more affordable, we believe governments will adopt our technology to accelerate progress towards universal health coverage. But most importantly, when we think back to that woman on the bus, we’re excited to be one step closer to ensuring she never has to worry about affording the care her son needs to get healthy.
We hope you’ll support our journey towards making healthcare a reality for everyone by donating to a Watsi patient.
↧
Spyware Dolls and Intel's VPro
Back in February, it was reported that a "smart" doll with wireless capabilities could be used to remotely spy on children and was banned for breaching German laws on surveillance devices disguised as another object.

For a number of years now there has been growing concern that the management technologies in recent Intel CPUs (ME, AMT and vPro) also conceal capabilities for spying, either due to design flaws (no software is perfect) or backdoors deliberately installed for US spy agencies, as revealed by Edward Snowden. In a 2014 interview, Intel's CEO offered to answer any question, except this one.
The LibreBoot project provides a more comprehensive and technical analysis of the issue, summarized in the statement "the libreboot project recommends avoiding all modern Intel hardware. If you have an Intel based system affected by the problems described below, then you should get rid of it as soon as possible" - eerily similar to the official advice German authorities are giving to victims of Cayla the doll.
All those amateur psychiatrists suggesting LibreBoot developers suffer from symptoms of schizophrenia have had to shut their mouths since May when Intel confirmed a design flaw (or NSA backdoor) in every modern CPU had become known to hackers.
Bill Gates famously started out with the mission to put a computer on every desk and in every home. With more than 80% of new laptops based on an Intel CPU with these hidden capabilities, can you imagine the NSA would not have wanted to come along for the ride?
Four questions everybody should be asking
- If existing laws can already be applied to Cayla the doll, why haven't they been used to alert owners of devices containing Intel's vPro?
- Are exploits of these backdoors (either Cayla or vPro) only feasible on a targeted basis, or do the intelligence agencies harvest data from these backdoors on a wholesale level, keeping a mirror image of every laptop owner's hard desk in one of their data centers, just as they already do with phone and Internet records?
- How long will it be before every fast food or coffee chain with a "free" wifi service starts dipping in to the data exposed by these vulnerabilities as part of their customer profiling initiatives?
- Since Intel's admissions in May, has anybody seen any evidence that anything is changing though, either in what vendors are offering or in terms of how companies and governments outside the US buy technology?
Share your thoughts
This issue was recently raised on the LibrePlanet mailing list. Please feel free to join the list and click here to reply on the thread.
↧
↧
Ask HN: What's the worst Oracle can do to OpenJDK?
| Ask HN: What's the worst Oracle can do to OpenJDK? | ||
| 119 points by yaanoncoward7 hours ago | hide | past | web | 50 comments | favorite | ||
| I've recently started a project using Java. From a technical perspective and after careful analysis of alternative technologies, for what I am doing it currently is the right choice. But with the Google-Oracle lawsuit, Oracle laying off the Sun team, and my professional experience, I really have to convince myself building anything on top of a technology stack where they are such a powerful player. I understand that OpenJDK is GPLed with class path exception, but is that enough? Could Oracle somehow sabotage OpenJDK into oblivion? What's the most probable steps Google, IBM and RedHat could take if Oracle pulls the plug on Java, or worse, plays some dirty legal tricks? I know my concerns are vague but I wonder if people who know better could share their thoughts? | ||

↧
Scaling Your Org with Microservices [slides]
Co-presented with Charity Majors
Description
Ask people about their experience rolling out microservices, and one theme dominates: engineering is the easy part, people are super hard! Everybody knows about Conway’s Law, everybody knows they need to make changes to their organization to support a different product model, but what are those changes? How do you know if you’re succeeding or failing, if people are struggling and miserable or just experiencing the discomfort of learning new skills? We’ll talk through real stories of pain and grief as people modernize their team and their stack.
Detailed review by Tanya Reilly
Video recording of talk
Tweets
↧
Show HN: Play – A simple cli audio player
README.md
Play audio files from terminal.

Quick Start
- Download the rep or clone the rep: git clone https://git@github.com:roecrew/play.git
- brew install portaudio
- brew install libsndfile
- brew install glfw3
- brew install glew
- make
- ./play a.wav
Flags
-v ... opens visualization window
-l ... loops audio
Supported Filetypes
↧
Bitcoin's Academic Pedigree

The July/August issue of acmqueue is out now
Networks
Jacob Loveless
Years ago I squandered most of my summer break locked inside my apartment, tackling an obscure problem in network theory (the bidirectional channel capacity problem). I was convinced that I was close to a breakthrough. (I wasn't.) Papers were everywhere, intermingled with the remnants of far too many 10¢ Taco Tuesday wrappers.
A good friend stopped by to bring better food, lend a mathematical hand, and put an end to my solitary madness. She listened carefully while I jumped across the room grabbing papers and incoherently babbling about my "breakthrough."
Then she somberly grabbed a pen and wrote out the flaw that I had missed, obliterating the proof.
I was stunned and heartbroken. She looked up and said, "But this is great, because what you've done here is define the problem more concretely." She continued with a simple truth that I've carried with me ever since:
"Most times, defining the problem is harder and more valuable than finding the answer. The world needs hard, well-defined problems. Generally, only one or two people work together on an answer—but hundreds work on a well-defined problem."
And so, dear reader, this is where I would like to begin. Unlike most articles in acmqueue, this one isn't about a new technique or an exposition on a practitioner's solution. Instead, this article looks at the problems inherent in building a more decentralized Internet. Audacious? Yes, but this has become a renewed focus in recent years, even by the father of the Web himself (see Tim Berners-Lee's Solid project4). Several companies and open-source projects are now focusing on different aspects of the "content-delivery" problem. Our company Edgemesh (https://edgemesh.com) is working on peer-enhanced client-side content acceleration, alongside other next-generation content-delivery networks such as Peer5 (https://peer5.com) and Streamroot (https://streamroot.io), both of which are focused on video delivery. Others, such as the open-source IPFS (InterPlanetary File System; https://ipfs.io) project are looking at completely new ways of defining and distributing and defining "the web."
Indeed, the concept of a better Internet has crept into popular media. In season 4 of HBO's sitcom Silicon Valley, the protagonist Richard Hendricks devises a new way to distribute content across the Internet in a completely distributed manner using a P2P (peer-to-peer) protocol. "If we could do it, we could build a completely decentralized version of our current Internet," Hendricks says, "with no firewalls, no tolls, no government regulation, no spying. Information would be totally free in every sense of the word." The story line revolves around the idea that thousands of users would allocate a small portion of their available storage on their mobile devices, and that the Pied Piper software would assemble the storage across these devices in a distributed storage "cloud." Then, of course, phones explode and hilarity ensues.
The core idea of a distributed Internet does make sense, but how would it be built? As I learned in my self-imposed solitary confinement so long ago, before diving into possible solutions, you need to define the problems more clearly.
Problems of a Distributed Internet
In his 2008 acmqueue article "Improving Performance on the Internet," Tom Leighton, cofounder of Akamai, the largest content-distribution network in the world, outlined four major architectures for content distribution: centralized hosting, "big data center" CDNs (content-delivery networks), highly distributed CDNs, and P2P networks. Of these, Leighton noted that:
"P2P can be thought of as taking the distributed architecture to its logical extreme, theoretically providing nearly infinite scalability. Moreover, P2P offers attractive economics under current network pricing structures."11
He then noted what others have found in the past, that although the P2P design is theoretically the most scalable, there are several practical issues, specifically throughput, availability, and capacity.
Throughput
The most commonly noted issue is the limited uplink capacity of edge devices, as noted by Leighton in his 2008 article:
P2P faces some serious limitations, most notably because the total download capacity of a P2P network is throttled by its total uplink capacity. Unfortunately, for consumer broadband connections, uplink speeds tend to be much lower than downlink speeds: Comcast's standard high-speed Internet package, for example, offers 6 Mbps for download but only 384 Kbps for upload (one-sixteenth of download throughput).11
This limitation is not as acute today as it was nearly a decade ago when upload speeds in the U.S. hovered around .5 Mbps. Figure 1 shows the current upload and download as taken from Speedtest.net (http://www.speedtest.net/reports/). These data points show that global "last-mile" throughput rates are nearly 30 times their 2008 counterparts. Is this enough? Would a peer with an upload rate at the lower quartile of these metrics (~4 Mbps) suffice? This question has been thoroughly explored in regard to actual webpage load time.

When Mike Belshe (of Google SPDY fame) looked at the relationship between end-client bandwidth and page-load time, he discovered that "bandwidth doesn't matter (much)."3 Once the client's available bandwidth reached 5 Mbps, the impact on the end user's page load is negligible. Figure 2 shows page-load time as a function of client bandwidth, assuming a fixed RTT (round-trip time) of 60 ms.

Availability
The next major hurdle for the distributed Internet is peer availability. Namely, are there enough peers, and are they online and available for enough time to provide value? In the past ten years the edge device count has certainly increased, but has it increased enough? Looking at "Internet Trends 2017,"14 (compiled by Mary Meeker of the venture capital firm KPCB), you can see how much the "available peer" count has increased over the past ten years from mobile alone (see figure 3).

Today roughly 49 percent of the world's population is connected10—around 3.7 billion people, many with multiple devices—so that's a big pool of edge devices. Peter Levine of the venture capital firm Andressen Horowitz has taken us out a few years further and predicted that we will shortly be going beyond billions and heading toward trillions of devices.12
You can get a sense of scale by looking at an Edgemesh network for a single e-commerce customer's website with a global client base, shown in figures 4 and 5.


It's probably safe to say there are enough devices online, but does the average user stay online long enough to be available? What is "long enough" for a peer to be useful?
A sensible place to start might be to want peers to be online long enough for any peer to reach any other peer anywhere on the globe. Given that, we can set some bounds.
The circumference of the earth is approximately 40,000 km. The rule of thumb is that light takes 4.9 microseconds to move 1 km through fiber optics. That would mean data could circumnavigate the globe in about one-fifth of a second (196 milliseconds). Oh, if wishing only made it so, but as Stanford Unversity's Stuart Cheshire points out in "It's the Latency, Stupid,"6 the Internet operates at least a factor of two slower than this. This 2x slowdown would mean it would take approximately 400 milliseconds to get around the globe. Unfortunately, I have spent some time in telecom—specifically in latency-optimized businesses13—and I think this time needs to be doubled again to account for global transit routing; thus, the data can go around the world in some 800 milliseconds. If users are online and available for sub-800 millisecond intervals, this may become problematic. Since most decentralized solutions would require the user to visit the content (e.g., be on the website), the real question is, what is the average page-view time for users across the globe?
Turns out it is 3 minutes 36 seconds,24 or 216,000 milliseconds.
To double-check this, I took all peer-session times (amount of time Edgemesh peers were online and connected to the mesh) across the Edgemesh user base for the past six months (figure 6). The average was right in line at 3 minutes 47 seconds.

In either case, if the node stays online just long enough to download a single web page, that would be enough time for the data to circumnavigate the globe 270 times, certainly long enough to contact a peer anywhere on Earth.
Capacity
If enough users are online for a long enough duration, and they have an acceptable egress throughput (upload bandwidth), all that remains is the question of whether there is enough spare capacity (disk space) available to provide a functional network.
If we assume a site has 20 percent of its users on mobile and 80 percent of its users on desktops—and further expand this to 500 MB of available capacity per desktop user and 50 MB per mobile user (the lower end of browser-available storage pools)—we can extract an estimated required mesh size to achieve a given cache hit rate if the requested content follows a Zipf distribution.1 Figure 7 shows estimated mesh size required for variable cache hit rates for .5 TB, 1 TB, and 2 TB active caches. These numbers certainly seem reasonable for a baseline. Essentially, a website with 500 GB of static content (about 16 million average web images) would need an online capacity of 2 million distinct nodes to achieve a theoretical offload of 100 percent of its traffic to a P2P mesh (approximately an 8:1 ratio of images to users).

Enabling a Distributed Internet
Now that we've better defined the problems and established the theoretical feasibility of a new solution, it's time to look at the technology available to bring to bear on the problem. To start, we can constrain our focus a bit. Implementations such as IPFS focus on distributing the entire content base, allowing you to free yourself from the restrictions of web servers and DNS entirely. This is a fantastic wholesale change, but the tradeoff is that it will require users to dramatically modify how they access content.
Since a peer-to-peer design is dependent on the total network size, this model has difficulty growing until it reaches critical mass. At Edgemesh we wanted to focus on enhancing existing web-content delivery transparently (e.g., in the browser) without requiring any changes to the user experience. This means ensuring that the technology abides by the following three restrictions:
• For users, the solution should be transparent.
• For developers, the solution should require zero infrastructure changes.
• For operations, the solution should be self-managing.
The next question is where exactly to focus.
Fully enabling peer-enhanced delivery of all content is difficult and dangerous (especially allowing for peer-delivered JavaScript to be executed). Is there an 80 percent solution? Trends posted by HTTP Archive reveal that static components (images/video/fonts/CSS) make up roughly 81 percent of the total page weight,9 as shown in figure 8.

Given these details, let's narrow the focus to enabling/enhancing edge delivery of these more traditional CDN assets and the associated challenges of moving and storing data.
Moving data: Building a new network (overlay)
To support peer-to-peer distribution, an overlay network needs to be developed to allow the peer-to-peer connections to operate within the larger existing Internet infrastructure. Luckily, such a stack is available: WebRTC (Real-Time Communications19). Started in earnest in 2011 by Google, WebRTC is an in-browser networking stack that enables peer-to-peer communication. WebRTC is primarily employed by voice and video applications (Google Hangouts/Dua/Allo, Slack, Snapchat, Amazon Chime, WhatsApp, Facebook Messenger) to facilitate peer-to-peer video- and audioconferencing.
WebRTC is a big deal; in June 2016 (only five years later) Google provided several key milestones7 from stats it collected (with some additional updates at the end of 201625):
• Two billion Chrome browsers with WebRTC.
• One billion WebRTC audio/video minutes per week on Chrome.
• One petabyte of DataChannel traffic per week on Chrome (0.1 percent of all web traffic).
• 1,200 WebRTC-based companies and projects (it was 950 in June).
• Five billion mobile app downloads that include WebRTC.
WebRTC support exists in the major browsers (Chrome, Firefox, Edge, and now Safari2). Comparing WebRTC's five-year adoption against other VoIP-style protocols shows the scale (see figure 9).8

WebRTC is a user-space networking stack. Unlike HTTP, which is dependent on TCP for transfer, WebRTC has its roots in a much older protocol—SCTP (Stream Control Transmission Protocol)—and encapsulates this in UDP (User Datagram Protocol). This allows for much lower latency transfer, removes head-of-line blocking, and, as a separate network stack, allows WebRTC to use significantly more bandwidth than HTTP alone.
SCTP is a little like the third wheel of the transport layer of the OSI (Open Systems Interconnection) model—we often forget it's there but it has some very powerful features. Originally introduced to support signaling in IP networks,22 SCTP quickly found adoption in next-generation networks (IMS and LTE).
WebRTC leverages SCTP to provide a reliable, message-oriented delivery transport (encapsulated in UDP or TCP, depending on the implementation5). Alongside SCTP, WebRTC leverages two additional major protocols: DTLS (Datagram Transport Layer Security) for security (a derivative of SSL) and ICE (Interactive Connectivity Establishment) to allow for support in NAT (network address translation) environments (e.g., firewall traversal).
The details of the ICE protocol and how it works with signaling servers (e.g., STUN and TURN) are beyond the scope of this article, but suffice it to say that WebRTC has all the necessary plumbing to enable real peer-to-peer networking.
A simple example is a WebRTC Golang implementation by Serene Han.21 Han's chat demo allows you to pass the SDP (Session Description Protocol) details between two machines (copy paste signaling) to enable peer-to-peer chat. To run this yourself (assuming you have a Docker instance locally), simply do the following:
docker run —it golang bash
Then in the Docker instance, this one-liner will get you set up:
apt-get update && apt-get install libx11-dev -y && \ go get github.com/keroserene/go-webrtc && \ cd /go/src/github.com/keroserene/go-webrtc && \ go run demo/chat/chat.go
If you prefer a browser-native starting point, look at simple-peer module,20 originally from Feross Aboukhadijeh's work with WebTorrent (https://webtorrent.io).
Storing data: Browser storage options and asset interception
The next step is finding a method both to intercept standard HTTP requests and to develop a system for storing peer-to-peer delivered assets. For the request-intercept problem, you have to look no further than the service worker.18 The service worker is a new feature available in most browsers that allows for a background process to run in the browser. Like a web worker (which can be used as a proxy for threads), a service worker has restrictions on how it can interact and exchange data with the DOM (Document Object Model).
The service worker does, however, have a powerful feature that was originally developed to support offline page loads: the Fetch API16 . The Fetch API allows a service worker to intercept request and response calls, similar to an HTTP proxy. This is illustrated in figure 10.

With the service worker online, you can now intercept traditional HTTP requests and offload these requests to the P2P network. The last remaining component will be a browser local storage model where P2P-accelerated content can be stored and distributed. Although no fewer than five different storage options exist in the browser, the IndexedDB17 implementation is the only storage API available within a service-worker context and the DOM context (where the WebRTC code can execute, which is why Edgemesh chose it as the storage base). Alternatively, the CacheStorage API may also be used within the service-worker context.15
Implementing a Distributed Internet
We have a theoretically viable model to support peer-to-peer content delivery. We have a functional network stack to enable ad-hoc efficient peer-to-peer transfer and access to an in-browser storage medium. And so, the game is afoot!
Figure 11 is a flowchart of the Edgemesh P2P-accelerated content-delivery system. The figure shows where the service-worker framework will enable asset interception, and WebRTC (aided by a signal server) will facilitate browser-to-browser asset replication.

Returning, then, to Mike Belshe's research, we can start to dig into some of the key areas to be optimized. Unlike bandwidth, where adding incrementally more bandwidth above 5 Mbps has negligible impact on page-load time, latency (RTT) dramatically increases page-load time, as shown in figure 12.3

WebRTC is already an efficient protocol, but the peer-selection process presents opportunities for further latency reduction. For example, if you are located in New York, providing a peer in Tokyo is likely a nonoptimal choice. Figure 13 shows a sampling of WebRTC latency distributions for a collection of sessions across the Edgemesh networks. Can we do better?

A simple optimization might be to prefer peers that reside in the same network, perhaps identified by the AS (autonomous system)23 number of each peer. Even this simple optimization can cut the average latency by a factor of two. Figure 14 shows performance increase by intra-AS routing preference.

Another optimization is choosing which assets to replicate into a peer. For example, if a user is currently browsing the landing page of a site, we can essentially precache all the images for the next pages, effectively eliminating the latency altogether. This is a current area of research for the team at Edgemesh, but early solutions have already shown significant promise. Figure 15 shows the effective render time for Edgemesh-enabled clients (accelerated) and non-Edgemesh enabled clients (standard) for a single customer domain. The average page-load time has been reduced by almost a factor of two.

This is most clearly seen when most of the page content can be effectively precached, as shown in the page-load time statistics of figure 16.

Conclusion
It had been a few days since I'd been outside, and a few more since I would make myself presentable. For the previous few weeks the team and I had been locked inside the office around the clock, essentially rewriting the software from scratch. We thought it would take a week, but we were now three months into 2017. The growing pile of empty delivery bags resting atop the ad-hoc whiteboard tables we were using was making it difficult to make out exactly what the big change was. We were convinced this was the breakthrough we had been looking for (turns out it was), and that this version would be the one that cracked the problem wide open. I was head down trying to get my parts to work, and I was lost. Then I heard the knock at the door. She came in and sat down, patiently moving aside the empty pizza boxes while I babbled on about our big breakthrough and how I was stuck.
Then, just like she had nearly two decades earlier, she grabbed the marker and said:
"Honey, I think I see the issue. You haven't properly defined the problem. Most times, defining the problem is harder and more valuable than finding the answer. So, what exactly are you trying to solve?"
The world is more connected than it ever has been before, and with our pocket supercomputers and IoT (Internet of Things) future, the next generation of the web might just be delivered in a peer-to-peer model. It's a giant problem space, but the necessary tools and technology are here today. We just need to define the problem a little better.
References
1. Adamic, L. A., Huberman, B. A. 2002. Zipf's law and the Internet. Glottometrics 3: 143-150; http://www.hpl.hp.com/research/idl/papers/ranking/adamicglottometrics.pdf.
2. Apple Inc. Safari 11.0; https://developer.apple.com/library/content/releasenotes/General/WhatsNewInSafari/Safari_11_0/Safari_11_0.html.
3. Belshe, M. 2010. More bandwidth doesn't matter (much); https://docs.google.com/.
4. Berners-Lee, T. Solid; https://solid.mit.edu/.
5. BlogGeek.Me. 2014. Why was SCTP selected for WebRTC's data channel; https://bloggeek.me/sctp-data-channel/.
6. Cheshire, S. 1996-2001. It's the latency, stupid; http://www.stuartcheshire.org/rants/latency.html.
7. Google Groups. 2016. WebRTC; https://groups.google.com/forum/#!topic/discuss-webrtc/I0GqzwfKJfQ.
8. Hart, C. 2017. WebRTC: one of 2016's biggest technologies no one has heard of. WebRTC World; http://www.webrtcworld.com/topics/webrtc-world/articles/428444.
9. HTTP Archive; http://httparchive.org/trends.php.
10. Internet World Stats. 2017. World Internet usage and population statistics—March 31, 2017; http://www.internetworldstats.com/stats.htm.
11. Leighton, T. 2008. Improving performance on the Internet. acmqueue 6(6); http://queue.acm.org/detail.cfm?id=1466449.
12. Levine, P. 2016. The end of cloud computing. Andreessen Horowitz; http://a16z.com/2016/12/16/the-end-of-cloud-computing/.
13. Loveless, J. 2013. Barbarians at the gateways. acmqueue 11(8); http://queue.acm.org/detail.cfm?id=2536492.
14. Meeker, M. 2017. Internet trends 2017—code conference. KPCB; http://www.kpcb.com/internet-trends.
15. Mozilla Developer Network. 2017. CacheStorage; https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage.
16. Mozilla Developer Network. 2017. FetchAPI; https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API.
17. Mozilla Developer Network. 2017. IndexedDB API; https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API.
18. Mozilla Developer Network. 2017. Using service workers; https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API/Using_Service_Workers.
19. Real-time communication in web browsers (rtcweb) Charter for Working Group; http://datatracker.ietf.org/wg/rtcweb/charter/.
20. Simple WebRTC video/voice and data channels. Github; https://github.com/edgemesh/simple-peer.
21. WebRTC for Go. Github; https://github.com/keroserene/go-webrtc.
22. Wikipedia. Signalling System No. 7; https://en.wikipedia.org/wiki/Signalling_System_No._7.
23. Wikipedia. Autonomous system; https://en.wikipedia.org/wiki/Autonomous_system_(Internet).
24. Wolfgang Digital. 2016. E-commerce KPI benchmarks; https://www.wolfgangdigital.com/uploads/general/KPI_Infopgrahic_2016.jpg.
25. YouTube. 2016. WebRTC; https://youtu.be/OUfYFMGtPQ0?t=16504.
Jacob Loveless is chief executive officer at Edgemesh Corporation, the premier edge-network acceleration platform. Prior to Edgemesh, Loveless served as CEO of Lucera Financial Infrastructures, a global network service provider for financial institutions. He was a partner at Cantor Fitzgerald and Company, responsible for running the firm's global low-latency trading operations for nearly 10 years. Prior to Wall Street, he was a senior engineer and consultant for the Department of Defense, focused on large-scale data-analysis programs and distributed networks. Loveless focuses primarily on low-latency networks and distributed computing. His prior ACM articles are available at http://queue.acm.org/detail.cfm?id=2536492 and http://queue.acm.org/detail.cfm?id=2534976.
Copyright © 2017 held by owner/author. Publication rights licensed to ACM.

Originally published in Queue vol. 15, no. 4—
see this item in the ACM Digital Library
Related:
Theo Schlossnagle - Time, but Faster
A computing adventure about time through the looking glass
Neal Cardwell, Yuchung Cheng, C. Stephen Gunn, Soheil Hassas Yeganeh, Van Jacobson - BBR: Congestion-Based Congestion Control
Measuring bottleneck bandwidth and round-trip propagation time
Josh Bailey, Stephen Stuart - Faucet: Deploying SDN in the Enterprise
Using OpenFlow and DevOps for rapid development
Amin Vahdat, David Clark, Jennifer Rexford - A Purpose-built Global Network: Google's Move to SDN
A discussion with Amin Vahdat, David Clark, and Jennifer Rexford
Comments
(newest first)
![]()
© 2017 ACM, Inc. All Rights Reserved.
↧
↧
Chinese man jailed for selling VPN software

China’s crackdown on VPNs appears to be continuing apace after it emerged that a man has been jailed for selling VPN software online.
Deng Jiewei, a 26-year old man from the city of Dongguan, in Guangdong province, close to Hong Kong, had been selling VPN software through his own small independent website. Online records from the China’s Supreme People’s Court (SPC) database [in Chinese] show that he has been convicted of the offence of “illegal control of a computer system”, under Article 285 of China’s Criminal Law. He has subsequently been sentenced to nine months imprisonment.
9 months in jail for a $2,000 profit
Details of his prosecution, which have been reported on the WhatsonWeibo website, note that he set up a ‘dot com’ website in October 2016 through which users could download two types of VPN software. This software enabled users to get around China’s Great Firewall censorship system and enjoy their right to free access to the internet.
Deng had reported made a profit of just US$2,125 from sales which suggests that, despite his lengthy sentence, he had not sold a great number of VPN connections.
His sentence, which was handed down in January but has only recently come to light, appears to be part of a concerted effort by the Chinese Communist regime to crack down even harder on internet freedoms in the run up to this year’s National Congress meeting.
VPN crackdown well underway
As we have reported regularly, China has announced a VPN ban which will officially come into place in February 2018. Whilst it is not yet entirely clear how the regime plans to enforce the ban, they have already taken a number of steps to make it harder for Chinese people to access VPNs.
As well as shutting down a number of local VPNs, they have also targeted various local e-commerce sites which sold VPNs either directly or indirectly. Meanwhile, Apple is also cooperating with the Communist Party by removing many VPN apps from their Chinese App store.
For Chinese people, a VPN is their only real means of accessing the internet uninhibited by the Communist Party’s censorship apparatus and without the risk of the wide-scale online surveillance programmes which watch what every Chinese citizen is doing online at all times. With online anonymity also being targeted of late, if VPNs do disappear, it will make freedom of speech and access to information a great deal harder.
People worried by prison sentence
Understandably, Chinese people are less than impressed with the prison sentence handed down to Deng Jiewei. The story has been shared more than 10,000 on the Chinese social media site Weibo. Some questioned how selling VPNs could be an offence under Article 285 of China’s criminal law, asking “How can using a VPN be defined as ‘intruding into computer systems?”
They suggested this law could perhaps be applied to all VPN users, with another commenter noting that “I am scared we could all be arrested now.” “The dark days are coming”, said another and on the face of it, this gloomy premonition appears to be correct.
Until efforts to ban VPNs in China come into force, it will be difficult to see how effective they can be. But the challenge appears to be akin to holding back the tide.
At the moment, VPNs are still popular in China as they still offer the best means of escaping the restriction of online censorship and surveillance. Recent tests suggested that VyprVPN offered the fastest connection speeds for Chinese internet users. But they are not the only VPN that works in China and you can read our rundown of the best providers here.
Despite the threat of imprisonment, the sale and use of VPNs are not going to go away as the people’s desire for online freedom and information will always trump the oppressive measures of the Communist Party regime.
↧
Ethical Hacking Course: Wireless Lab Session

For wireless hacking we will first of all put our wireless card into monitor mode and the command is –
airmon -ng start wlan0
We can check that it has been started by doing ifconfig. We are actually running this on a physical machine because not all wireless cards can be used for wireless hacking. So one should have the right hardware to do this.
airodump
The airodump command goes out and checks the network traffic. We will use the command –
airodump –ng wlan0mon
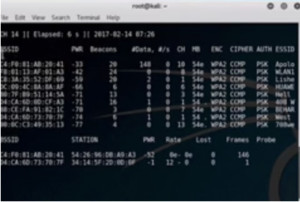
Figure1. airodump output
Here we can see the MAC addresses, the BSSIDs and other information of all the different WAPs in the region. Out of these we will attack WLAN1. For this we will isolate that. We will open another window and run the following command –
airodump -ng -c <channel> –bssid <bssid> -w dump1 wlan0mon
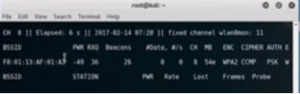
Figure2. airodump for wlan1
Now we are monitoring the one we want to crack. For demo purpose we will log on to the network using the iPhone. While logging we can see the handshake come through on the right hand side of the first line of our output. Now open up another terminal and do ‘ls’. It will show that there are dump files. These files are split into four files i.e. .cap, .csv, kismet and .netxml. We will run a crack on the dump to see if there are any handshakes.
aircrack -ng <filename>
We can see that there is no handshake. So now we will try to get a handshake to be activated on that card by logging in the network again. Now check the dump again. This time we have the handshake –
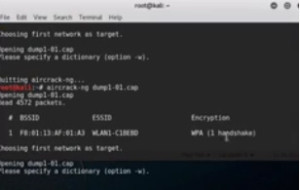
Figure3. aircrack output showing handshake
As it is WPA encryption we will use a dictionary. Here is the command –
aircrack -ng -w words.txt dump-01.cap
Here words.txt is the dictionary which has the key in it. The key is found –
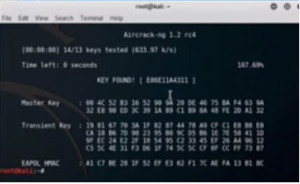
Figure4. aircrack key found
This shows that we have successfully cracked the network.
Ethical Hacking Tutorial – Wireless Lab Session Video:
↧
HSBC is killing my business, piece by piece
I set up my own company in 2012. After decades of working for other people I felt the time was right. I had the experience and the contacts to make it viable and I was willing to put in the monumental effort needed to embark on such a venture. It was a nerve wracking decision, but more than anything it was exciting. In April 2012 Photon Storm Ltd was incorporated and began trading.
After talking with my accountant we decided to open an HSBC Business Account here in the UK. The process was problem free. They provided me with a company debit card and standard banking services. I did my part, ensuring we were always in credit and never needing to borrow any money. My accountants looked after the paperwork, keeping everything up to date. And we’ve been profitable and maintained a healthy positive bank balance since day one.
Everything was going great until Thursday August 10th 2017. I tried to login to our internet banking to pay a freelancer and was met with this message:
At first I assumed it was just a mistake. Maybe the anti-fraud team were being a little overzealous and wanted to check some card payments? I called them immediately. After bouncing through multiple departments I finally end-up talking with HSBC Safeguarding. They tell me they can’t give any more information, cannot un-suspend the account and would need to call me the following week.
However, the alarm bells were already ringing. I knew exactly who the Safeguarding team were because I had talked to them earlier in the year after receiving their scary letter. The letter said they needed to conduct a business review or they would be forced to suspend my account. That’s not the kind of letter you ignore. So I duly responded and completed my business review with them. This was 2 months before the account was suspended, back in June.
Safeguarding is a process that HSBC is taking all of its accounts through in order to better understand how they are used. It’s the fallout of HSBC receiving a record $1.9 billion fine as a result of a US Senate ruling where they were found guilty of allowing money laundering to “drug kingpins and rogue nations”.
It involves them asking all kinds of questions related to what you do and the comings and goings on your account. Who are the people and companies paying you, and being paid by you? What work was invoice X for? Do you have any large sums of money coming in or going out? Which countries do you work with? Why do you hold the bank balance you do? and so on.
It takes around an hour and although marketed as offering me protection against financial crime, what it was really doing was checking I’m not a drug cartel or rogue nation. I am of course neither of these things, but I appreciate they had to check, so I answered every question as fully as I could. I was told that if they needed more information they would be in touch, otherwise it was all fine.
Fast forward to August 10th and clearly things are not “fine” at all.
My business earns income via two streams:
1) Game development. A client will request a game, usually as part of a marketing campaign and we build it. Sometimes we supply everything: the concept, art, coding and support. And other times the client will handle the design in-house and we provide the programming that glues it all together.
2) Our second method of income is from our open source software. We publish and maintain an HTML5 game framework called Phaser. The core library itself is completely free but we make money from the sale of plugins and books via our shop, as well as our Patreon.
All of this was explained to HSBC during our business review.
Then they drop the bombshell
So I wait patiently and anxiously for HSBC to ring. At the appointed time someone from the Safeguarding team calls and explains that they want to conduct the entire business review again, from scratch. No definitive reason was given as to why they needed to do this. It sounded like they were unhappy with the level of questioning asked the first time around.
Frustrated but wanting to resolve this as quickly as possible I comply and go through the entire review again, answering in even more detail than before, to make it painfully clear what we do and where our money comes from.
The second review ends. I’m told that the information is to be sent off to another department who check it, and if they want more details they’ll “be in touch”. I’d heard this same line before, back in June and I no longer trusted them. I begin calling every day to check on progress. It starts taking up to 40 minutes to get through. Clearly they’re dealing with a lot more customers now. Every time they tell me the same thing, that the “other” department hasn’t looked at it yet, but they’ll be in touch if they need more information and “your account will remain suspended in the meantime”.
No-one will admit it’s a mistake that this was even happening. No-one will tell me why they didn’t ever call to ask for more details back in June after the first review. No-one will tell me why they suspended the account without even notifying me in writing. I’ve been wrongfully lumped in with all of those who perhaps didn’t reply to their initial warnings and I have to just sit and wait it out. I’ve filed complaints via their official channels which have so farelicited no response at all.
This has been going on for weeks. At the time of writing our account has been suspended for nearly 1 month and I’m still no closer to understanding how much longer it will be.
Also, it appears I am not alone:
One part of the above article in particular stood out to me:
“Inhibiting an account is always a last resort, so to get to that stage we will have done everything we can to contact the customer and get the information we need,” said Amanda Murphy, head of commercial banking for HSBC UK.
Like hell they did.
Because our account is suspended all direct debits linked to it automatically fail. All services that store our debit card and try to charge it also fail. We are unable to transfer any money out of our business account, which means we cannot pay ourselves, our freelancers, or any of our suppliers.
Like most people I’ve been in the situation before where I didn’t have much money. Running on fumes come the end of the month, eagerly awaiting my salary. But I have never been in the situation where I have all the money I need, that I spent years working hard to earn and save, but cannot access a penny of it.
It’s a uniquely frustrating feeling being this powerless.
Everything starts to break
An interesting thing happens when you run a business that relies on internet services to operate but have no means of paying them: It starts to break. Not all at once, but in small pieces. Like a stress fracture that grows bigger over time. Here is a small section of my inbox to give you an idea of the scale of the problem after a few weeks:
The first to die was GitHub. We have a bunch of private repositories and if you don’t pay your GitHub bill they eventually close access to the private repos until the account is settled. We store our entire web site in a private repo, so we had to pull some funds from our rapidly dwindling personal account to cover it, otherwise we literally couldn’t update our site.
Then Apple failed. This was a strange one — it appears you actually need a valid payment card associated with your Apple account or you cannot download free apps or update existing ones. Every time you try it just asks you to re-enter payment details. Not a show-stopper, but frustrating all the same.
And so it carries on. Photoshop, Trello, Beanstalk, Slack, GoDaddy, Basecamp, SendGrid — you name it, when the bill is past due, they all eventually fail. Some of them fail more gracefully than others. Adobe at least give you 30 days to resolve the issue before turning your software off. SendGrid give you just 48 hours to “avoid the suspension and / or limitation of your SendGrid services.”.
I don’t blame any of these organisations for doing this. I have no personal relationship with them, they don’t know me from Adam. I’m just another failed bank card to them, draining their systems. They don’t understand my situation and to be fair they don’t have to care even if they did.
My web server is hosted with UK Fast, who I do have a client relationship with and was able to explain what is happening to them. So far they have been excellent and it’s only because of them that my web site is even still running and generating my only source of income right now.
But bigger services will start to fail soon. Broadband, the phone line, Vodafone, the water and electricity providers that supply the office I work from. Even the office rent is due next month. Where possible I’ve told everyone I can what is going on but it can’t last for ever.
Most harrowing of all I’ve been unable to pay a member of staff what he is owed. I pushed a personal credit card to the limit just to send him some money via TransferWise but he has had to find other employment while this mess gets sorted out. I don’t blame him at all, I would do the same thing in his situation as I’ve a mortgage to pay, a family to feed and bills too. It’s incredibly frustrating knowing the money I need to solve all of this is right there, but untouchable.
Hints and Tips for your bank screwing up
I figured that at the very least I would try and offer some words of advice based on the back of what’s happening right now:
- Don’t bank with HSBC. If you’re about to start a small business, think twice. The banking service is perfectly fine, but when something out of the ordinary happens they move like dinosaurs.
- Don’t keep all your business funds with the same bank. This one is a lot harder to arrange and can complicate your accounting, but I’d say it’s worth the hassle. Make sure you’ve enough funds set-aside in an entirely separate account, with an entirely different institution, to cover what you need for a month or more. I wish I had.
- If you can pay for an internet service for a year, do so. Most services offer discounts if you pre-pay anyway, so it saves money, but it would also protect you against temporary payment problems in the future, unless of course you’re incredibly unlucky and they land at the same time your yearly payment is due. Our DropBox account was paid for the year thankfully, so our files remained intact.
- If you don’t need a service, cancel it, or do it yourself. When everything started failing I was surprised to see a couple of subscriptions I had that weren’t even needed any longer. The payments were quite tiny but I didn’t need to be spending the money at all, so at least I got to cancel those. It’s also made me question the need for a couple of services I have that I could spend some time and do myself locally (git repo hosting for private projects for a single team is a good example of this)
- Keep control of your DNS with a provider separate to your web host. Although it’s a horrendous situation to be in, should you be forced into it at least you can update your DNS to point to a new host. This isn’t always possible if they manage DNS for you as well, but if your business relies on your site for income it’s a safe thing to do.
- Be able to redirect payments to another bank account. This was an absolute life saver for me. All of our shop sales are handled via Gumroad and we were able to change the account they pay in to each week away from the business one and into our personal one. It’s going to be a nightmare to unpick when this mess is over, but it was that or don’t buy any food. The groceries won. We also get money from advertising, affiliates and Patreon into our PayPal account. A massive shout-out to PayPal for being so excellent. They were able to issue us with a MasterCard (linked to our PayPal balance, not a credit card) and allow us to transfer money into our personal account, instead of the business one. This was quite literally the only way we managed to pay our mortgage this month. PayPal, thank you. Your support was fantastic. I only wish HSBC were more like you.
- If you run a small business ask yourself this: What would happen if your account was frozen and you couldn’t access a single penny in it? How would you cope? It’s an unusual predicament, but clearly not a rare one.
What next?
I really don’t know. Our account is still suspended. HSBC are still a brick wall of silence. The only income we have at the moment is from shop sales, Patreon and donations. It’s barely enough to cover our living costs, but thanks to some superb thriftiness from my wife, we’re making it work. Just. We are literally being saved by the income from our open source project, but unless HSBC hurry up, it won’t be enough to save my company as well.
I cannot wait for this nightmare to be over. Once it is, I cannot wait to transfer my business away from HSBC. Assuming I still have one left to transfer.
Until then, opening Photoshop this morning summed it up well:
↧
With Android Oreo, Google is introducing Linux kernel requirements

Android may be a Linux-based operating system, but the Linux roots are something that few people pay much mind. Regardless of whether it is known or acknowledged by many people, the fact remains that Android is rooted in software regarded as horrendously difficult to use and most-readily associated with the geekier computer users, but also renowned for its security.
As is easy to tell by comparing versions of Android from different handset manufacturers, developers are -- broadly speaking -- free to do whatever they want with Android, but with Oreo, one aspect of this is changing. Google is introducing a new requirement that OEMs must meet certain requirements when choosing the Linux kernel they use.
See also:
Until now, as pointed out by XDA Developers, OEMs have been free to use whatever Linux kernel they wanted to create their own version of Android. Of course, their builds still had to pass Google's other tests, but the kernel number itself was not an issue. Moving forward, Android devices running Oreo must use at least kernel 3.18, but there are more specific requirements to meet as well.
Google explains on the Android Source page:
Android O mandates a minimum kernel version and kernel configuration and checks them both in VTS as well as during an OTA. Android device kernels must enable the kernel .config support along with the option to read the kernel configuration at runtime through procfs.
The company goes on to detail the Linux kernel version requirements:
- All SoCs productized in 2017 must launch with kernel 4.4 or newer.
- All other SoCs launching new Android devices running Android O must use kernel 3.18 or newer.
- Regardless of launch date, all SoCs with device launches on Android O remain subject to kernel changes required to enable Treble.
- Older Android devices released prior to Android O but that will be upgraded to Android O can continue to use their original base kernel version if desired.
The main reason for introducing the Linux kernel mandate is security -- and it's hard to argue with that.
↧
↧
Miscellaneous Arduino bits and pieces
I wrote most of the stuff you'll find here mainly for my own benefit, so that I won't forget what I've learned so far. Stored on my website is probably the safest place to keep it so I thought others may as well take a look as I learn about Arduino. Hopefully, anyone with more experience who happens to land on the site will point out any errors & pitfalls.
↧
Switching Your Site to HTTPS on a Shoestring Budget
Google's Search Console team recently sent out an email to site owners with a warning that Google Chrome will take steps starting this October to identify and show warnings on non-secure sites that have form inputs.
Here's the notice that landed in my inbox:

If your site URL does not support HTTPS, then this notice directly affects you. Even if your site does not have forms, moving over to HTTPS should be a priority, as this is only one step in Google's strategy to identify insecure sites. They state this clearly in their message:
The new warning is part of a long term plan to mark all pages served over HTTP as "not secure".

The problem is that the process of installing SSL certificates and transitioning site URLs from HTTP to HTTPS—not to mention editing all those links and linked images in existing content—sounds like a daunting task. Who has time and wants to spend the money to update a personal website for this?
I use GitHub Pages to host a number sites and projects for free—including some that use custom domain names. To that end, I wanted to see if I could quickly and inexpensively convert a site from HTTP to HTTPS. I wound up finding a relatively simple solution on a shoestring budget that I hope will help others. Let's dig into that.
Enforcing HTTPS on GitHub Pages
Sites hosted on GitHub Pages have a simple setting to enable HTTPS. Navigate to the project's Settings and flip the switch to enforce HTTPS.

But We Still Need SSL
Sure, that first step was a breeze, but it's not the full picture of what we need to do to meet Google's definition of a secure site. The reason is that enabling the HTTPS setting neither provides nor installs a Secure Sockets Layer (SSL) certificate to a site that uses a custom domain. Sites that use the default web address provided by GitHub Pages are fully secure with that setting, but those of us that use a custom domain have to go the extra step of securing SSL at the domain level.
That's a bummer because SSL, while not super expensive, is yet another cost and likely one you may not want to incur when you're trying to keep costs down. I wanted to find a way around this.
We Can Get SSL From a CDN ... for Free!
This is where Cloudflare comes in. Cloudflare is a Content Delivery Network (CDN) that also provides distributed domain name server services. What that means is that we can leverage their network to set up HTTPS. The real kicker is that they have a free plan that makes this all possible.
It's worth noting that there are a number of good posts here on CSS-Tricks that tout the benefits of a CDN. While we're focused on the security perks in this post, CDNs are an excellent way to help reduce server burden and increase performance.
From here on out, I'm going to walk through the steps I used to connect Cloudflare to GitHub Pages so, if you haven't already, you can snag a free account and follow along.
Step 1: Select the "+ Add Site" option
First off, we have to tell Cloudflare that our domain exists. Cloudflare will scan the DNS records to verify both that the domain exists and that the public information about the domain are accessible.

Step 2: Review the DNS records
After Cloudflare has scanned the DNS records, it will spit them out and display them for your review. Cloudflare indicates that it believes things are in good standing with an orange cloud in the Status column. Review the report and confirm that the records match those from your registrar. If all is good, click "Continue" to proceed.

Step 3: Get the Free Plan
Cloudflare will ask what level of service you want to use. Lo and behold! There is a free option that we can select.

Step 4: Update the Nameservers
At this point, Cloudflare provides us with its server addresses and our job is to head over to the registrar where the domain was purchased and paste those addresses into the DNS settings.

It's not incredibly difficult to do this, but can be a little unnerving. Your registrar likely has instructions for how to do this. For example, here are GoDaddy's instructions for updating nameservers for domains registered through their service.
Once you have done this step, your domain will effectively be mapped to Cloudflare's servers, which will act as an intermediary between the domain and GitHub Pages. However, it is a bit of a waiting game and can take Cloudflare up to 24 hours to process the request.
If you are using GitHub Pages with a subdomain instead of a custom domain, there is one extra step you are required to do. Head over to your GitHub Pages settings and add a CNAME record in the DNS settings. Set it to point to <your-username>.github.io, where <your-username> is, of course, your GitHub account handle. Oh, and you will need to add a CNAME text file to the root of your GitHub project which is literally a text file named CNAME with your domain name in it.
Here is a screenshot with an example of adding a GitHub Pages subdomain as a CNAME record in Cloudflare's settings:

Step 5: Enable HTTPS in Cloudflare
Sure, we've technically already done this in GitHub Pages, but we're required to do it in Cloudflare as well. Cloudflare calls this feature "Crypto" and it not only forces HTTPS, but provides the SSL certificate we've been wanting all along. But we'll get to that in just a bit. For now, enable Crypto for HTTPS.

Turn on the "Always use HTTPS" option:

Now any HTTP request from a browser is switched over to the more secure HTTPS. We're another step closer to making Google Chrome happy.
Step 6: Make Use of the CDN
Hey, we're using a CDN to get SSL, so we may as well take advantage of its performance benefits while we're at it. We can speed up performance by reducing files automatically and extend browser cache expiration.
Select the "Speed" option in the settings and allow Cloudflare to auto minify our site's web assets:

We can also set the expiration on browser cache to maximize performance:

By moving the expiration out date a longer than the default option, the browser will refrain itself from asking for a site's resources with each and every visit—that is, resources that more than likely haven't been changed or updated. This will save visitors an extra download on repeat visits within a month's time.
Step 7: Make External Resource Secure
If you use external resources on your site (and many of us do), then those need to be served securely as well. For example, if you use a Javascript framework and it is not served from an HTTP source, that blows our secure cover as far as Google Chrome is concerned and we need to patch that up.
If the external resource you use does not provide HTTPS as a source, then you might want to consider hosting it yourself. We have a CDN now that makes the burden of serving it a non-issue.
Step 8: Activate SSL
Woot, here we are! SSL has been the missing link between our custom domain and GitHub Pages since we enabled HTTPS in the GitHub Pages setting and this is where we have the ability to activate a free SSL certificate on our site, courtesy of Cloudflare.
From the Crypto settings in Cloudflare, let's first make sure that the SSL certificate is active:

If the certificate is active, move to "Page Rules" in the main menu and select the "Create Page Rule" option:

...then click "Add a Setting" and select the "Always use HTTPS" option:

After that click "Save and Deploy" and celebrate! We now have a fully secure site in the eyes of Google Chrome and didn't have to touch a whole lot of code or drop a chunk of change to do it.
In Conclusion
Google's push for HTTPS means front-end developers need to prioritize SSL support more than ever, whether it's for our own sites, company sites, or client sites. This move gives us one more incentive to make the move and the fact that we can pick up free SSL and performance enhancements through the use of a CDN makes it all the more worthwhile.
Have you written about your adventures moving to HTTPS? Let me know in the comments and we can compare notes. Meanwhile, enjoy a secure and speedy site!
↧
Run your own OAuth2 server
This is how ORY Hydra works
I originally built ORY Hydra because all other OAuth2 servers forced their user management on me. But I had a user management in place already, and did not want to migrate away from it. Some of the providers allowed me to integrate with LDAP or SAML, but this was not implemented in my user management.
ORY Hydra defines a consent flow which let's you implement the bridge between ORY Hydra and your user management easily using only a few lines of code. If you want, you could say that ORY Hydra translates the user information you provide to OAuth2 Access Tokens and OpenID Connect ID Tokens, which are then reusable across all your applications (web app, mobile app, CRM, Mail, ...) and also by third-party developers.
↧
Collection of generative models in Tensorflow
README.md
Tensorflow implementation of various GANs and VAEs.
Pytorch version
Pytorch Version is now availabel at https://github.com/znxlwm/pytorch-generative-model-collections
Generative Adversarial Networks (GANs)
Lists
Variants of GAN structure

Results for mnist
Network architecture of generator and discriminator is the exaclty sames as in infoGAN paper.
For fair comparison of core ideas in all gan variants, all implementations for network architecture are kept same except EBGAN and BEGAN. Small modification is made for EBGAN/BEGAN, since those adopt auto-encoder strucutre for discriminator. But I tried to keep the capacity of discirminator.
The following results can be reproduced with command:
python main.py --dataset mnist --gan_type <TYPE> --epoch 25 --batch_size 64Random generation
All results are randomly sampled.
Conditional generation
Each row has the same noise vector and each column has the same label condition.
InfoGAN : Manipulating two continous codes
Results for fashion-mnist
Comments on network architecture in mnist are also applied to here.
Fashion-mnist is a recently proposed dataset consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. (T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, Ankle boot)
The following results can be reproduced with command:
python main.py --dataset fashion-mnist --gan_type <TYPE> --epoch 40 --batch_size 64Random generation
All results are randomly sampled.
Conditional generation
Each row has the same noise vector and each column has the same label condition.
Without hyper-parameter tuning from mnist-version, ACGAN/infoGAN does not work well as compared iwth CGAN.
ACGAN tends to fall into mode-collapse.
infoGAN tends to ignore noise-vector. It results in that various style within the same class can not be represented.
InfoGAN : Manipulating two continous codes
Some results for celebA
(to be added)
Variational Auto-Encoders (VAEs)
Lists
Variants of VAE structure

Results for mnist
Network architecture of decoder(generator) and encoder(discriminator) is the exaclty sames as in infoGAN paper. The number of output nodes in encoder is different. (2x z_dim for VAE, 1 for GAN)
The following results can be reproduced with command:
python main.py --dataset mnist --gan_type <TYPE> --epoch 25 --batch_size 64Random generation
All results are randomly sampled.
Results of GAN is also given to compare images generated from VAE and GAN. The main difference (VAE generates smooth and blurry images, otherwise GAN generates sharp and artifact images) is cleary observed from the results.
Conditional generation
Each row has the same noise vector and each column has the same label condition.
Results of CGAN is also given to compare images generated from CVAE and CGAN.
Results for fashion-mnist
Comments on network architecture in mnist are also applied to here.
The following results can be reproduced with command:
python main.py --dataset fashion-mnist --gan_type <TYPE> --epoch 40 --batch_size 64Random generation
All results are randomly sampled.
Results of GAN is also given to compare images generated from VAE and GAN.
Conditional generation
Each row has the same noise vector and each column has the same label condition.
Results of CGAN is also given to compare images generated from CVAE and CGAN.
Results for celebA
(to be added)
Folder structure
The following shows basic folder structure.
├── main.py # gateway
├── data
│ ├── mnist # mnist data (not included in this repo)
│ | ├── t10k-images-idx3-ubyte.gz
│ | ├── t10k-labels-idx1-ubyte.gz
│ | ├── train-images-idx3-ubyte.gz
│ | └── train-labels-idx1-ubyte.gz
│ └── fashion-mnist # fashion-mnist data (not included in this repo)
│ ├── t10k-images-idx3-ubyte.gz
│ ├── t10k-labels-idx1-ubyte.gz
│ ├── train-images-idx3-ubyte.gz
│ └── train-labels-idx1-ubyte.gz
├── GAN.py # vainilla GAN
├── ops.py # some operations on layer
├── utils.py # utils
├── logs # log files for tensorboard to be saved here
└── checkpoint # model files to be saved here
Acknowledgements
This implementation has been based on this repository and tested with Tensorflow over ver1.0 on Windows 10 and Ubuntu 14.04.
↧
↧
Writing a SQLite clone from scratch in C
Writing a sqlite clone from scratch in C
- What format is data saved in? (in memory and on disk)
- When does it move from memory to disk?
- Why can there only be one primary key per table?
- How does rolling back a transaction work?
- How are indexes formatted?
- When and how does a full table scan happen?
- What format is a prepared statement saved in?
In short, how does a database work?
I’m building a clone of sqlite from scratch in C in order to understand, and I’m going to document my process as I go.
↧
The Wonderful World of Webpack
Monday, 04 September 2017
Webpack is a JavaScript module bundler, or so the blurb goes. This is an apt name for it. However, what I would like to do in this article, is to expand on the true power of Webpack.
This article will not explain how to use Webpack. Rather, explain the reasoning behind it, and what makes it more special than just a bundler.
Webpack is still a Bundler
One of the main reasons for tools like Webpack is to solve the dependency problem. The dependency problem that is caused by modules within JavaScript; specifically Node.js.
Node.js allows you to modularise code. Modularisation of code causes an issue with dependencies. Cyclic dependencies can occur-e.g., A -> B -> A referencing. What tools like Webpack can do, is build an entire dependency graph of all of your referenced modules. With this graph, analysis can occur to help you alleviate the stress of such a dependency graph.
Webpack can take multiple entry points into your code, and spit out an output that has bundled your dependency graph into one or more files.
Webpack is so much more
For me, what makes webpack so special is the great extension points it provides.
Loaders
Loaders are what I like to refer to as mini-transpilers. They take a file of any kind - e.g., TypeScript, CoffeeScript, JSON, etc. - and produce JavaScript code for later addition to the dependency graph Webpack is building.
The power of loaders is that they are not in short supply. Loaders are an extension point. You can create your own loader, and there are 100's of default and 3rd party loaders out there.
For example, could there be a point where we would ever want to take a statically typed language like C#, and transpile this into JavaScript for Webpack to understand?
The limits are boundless with loaders. Loaders can be chained, configured, filtered out based on file type, and more.
Custom Loader Example
As the webpack documentation explains, a loader is just a node module exporting a function. A loader is as simple as a defined node module that exports a function:
module.exports = function(src) {
return src + '\n'
+ 'window.onload = function() { \n'
+ ' console.log("This is from the loader!"); \n'
+ '}';
};This is a trivial example of what a loader is. All this loader is doing is appending a function to write to the console on window load for the current browser session.
With this idea in mind, it becomes apparant that we now have the power to take any source input, and interpret it in anyway we want. So coming back to our previous example, we could take C# as the input, and create a parser that transpiles it into native JavaScript that Webpack expects.
A C# to JavaScript transpiler is a bit far-fetched, and in all honesty slightly pointless, but I hope you appreciate how we can leverage loaders in Webpack to make it more than a bundler.
Plugins
Plugins allow the customisation of Webpack on a more broader scope than file by file like loaders. Plugins are where you can add extra functionality to the core of Webpack. For example, you can add a plugin for minification; Extract certain text from output such as CSS; Use plugins for compression, and so on.
Plugins work by having access to the Webpack compiler itself. They have access to all the compilation steps that can and may occur, and can modify those steps. This means a plugin can modify what files get produced, what files to add as assets, ans so on.
A small example of a plugin is the following:
file: './my-custom-plugin.js'
function MyCustomPlugin() {}
MyCustomPlugin.prototype.apply = function(compiler) {
compiler.plugin('emit', displayCurrentDate);
compiler.plugin('after-emit', displayCurrentDate)
}
function displayCurrentDate(compilation, callback) {
console.log(Date());
callback();
}
module.exports = MyCustomPlugin;
In this example, we are adding two event handlers to two separate event hooks in the Webpack compiler. The outcome of this is one date that is printed to console just before the assets are emitted to the output directory, and one date after the assets have been emitted.
This plugin can be used in the main Webpack configuration:
var MyCustomPlugin = require('my-custom-plugin');
var webpackConfig = {
...
plugins: [
new MyCustomPlugin()
]
}
This plugin will now run on the emit and after-emit stages of the compilation process. A good list of compiler event hooks are available on the Webpack website.
The importance of plugins, once again, is that they are an extension point. The way Webpack has been designed is to allow the user to fully extend the core of Webpack. There are many plugins to choose from, and a lot are 3rd party.
With this in mind, a plugin could take all your assets that you require, and compress them with an algorithm. In fact, there is already a plugin for this very thing.
Summary
Webpack is a module bundler, that is what the label says. It takes your dependency graph, and outputs a browser readable format.
However, webpack can be so much more.
What if we could take C# code, and transpile it into JavaScript? What if we could take a YAML configuration file, and create a working program just out of configuration? What if we took an image, and automatically made it cropped and greyscaled?
I think if you start thinking of Webpack as more of a transpiler, not just a bundler, the true power of Webpack can be seen.
Thanks for reading and hope this helps.
↧
“Google: it is time to return to not being evil”
I have known Google longer than most. At Opera, we were the first to add their search into the browser interface, enabling it directly from the search box and the address field. At that time, Google was an up-and-coming geeky company. I remember vividly meeting with Google’s co-founder Larry Page, his relaxed dress code and his love for the Danger device, which he played with throughout our meeting. Later, I met with the other co-founder of Google, Sergey Brin, and got positive vibes. My first impression of Google was that it was a likeable company.
Our cooperation with Google was a good one. Integrating their search into Opera helped us deliver a better service to our users and generated revenue that paid the bills. We helped Google grow, along with others that followed in our footsteps and integrated Google search into their browsers.
However, then things changed. Google increased their proximity with the Mozilla foundation. They also introduced new services such as Google Docs. These services were great, gained quick popularity, but also exposed the darker side of Google. Not only were these services made to be incompatible with Opera, but also encouraged users to switch their browsers. I brought this up with Sergey Brin, in vain. For millions of Opera users to be able to access these services, we had to hide our browser’s identity. The browser sniffing situation only worsened after Google started building their own browser, Chrome.
Now, we are making the Vivaldi browser. It is based on Chromium, an open-source project, led by Google and built on WebKit and KHTML. Using Google’s services should not call for any issues, but sadly, the reality is different. We still have to hide our identity when visiting services such as Google Docs.
And now things have hit a new low.
As the biggest online advertising company in the world, Google is often the first choice for businesses that want to promote their products or services on the Internet. Being excluded from using Google AdWords could be a major problem, especially for digital companies.
Recently, our Google AdWords campaigns were suspended without warning. This was the second time that I have encountered this situation. This time, however, timing spoke volumes.
I had several interviews where I voiced concerns about the data gathering and ad targeting practices – in particular, those of Google and Facebook. They collect and aggregate far too much personal information from their users. I see this as a very serious, democracy-threatening problem, as the vast targeting opportunities offered by Google and Facebook are not only good for very targeted marketing, but also for tailored propaganda. The idea of the Internet turning into a battlefield of propaganda is very far away from the ideal.
Two days after my thoughts were published in an article by Wired, we found out that all the campaigns under our Google AdWords account were suspended – without prior warning. Was this just a coincidence? Or was it deliberate, a way of sending us a message?
When we reached out to Google to resolve the issue, we got a clarification masqueraded in the form of vague terms and conditions, some of which, they admitted themselves, were not a “hard” requirement. In exchange for being reinstated in Google’s ad network, their in-house specialists dictated how we should arrange content on our own website and how we should communicate information to our users.
We made effort to understand their explanations and to work with them on their various unreasonable demands (some of which they don’t follow themselves, by the way). After almost three months of back-and-forth, the suspension to our account has been lifted, but only when we bent to their requirements.
A monopoly both in search and advertising, Google, unfortunately, shows that they are not able to resist the misuse of power. I am saddened by this makeover of a geeky, positive company into the bully they are in 2017. I feel blocking competitors on thin reasoning lends credence to claims of their anti-competitive practices. It is also fair to say that Google is now in a position where regulation is needed. I sincerely hope that they’ll get back to the straight and narrow.
↧