Our team thought about how to recognize this “fingerprint” of difficult parking as a feature to train on. In this case, we aggregate the difference between when a user should have arrived at a destination if they simply drove to the front door, versus when they actually arrived, taking into account circling, parking, and walking. If many users show a large gap between these two times, we expect this to be a useful signal that parking is difficult.
From there, we continued to develop more features that took into account, for any particular destination, dispersion of parking locations, time-of-day and date dependence of parking (e.g. what if users park close to a destination in the early morning, but further away at busier hours?), historical parking data and more. In the end, we decided on roughly twenty different features along these lines for our model. Then it was time to tune the model performance.
Model Selection & Training
We decided to use a standard logistic regression ML model for this feature, for a few different reasons. First, the behavior of logistic regression is well understood, and it tends to be resilient to noise in the training data; this is a useful property when the data comes from crowdsourcing a complicated response variable like difficulty of parking. Second, it’s natural to interpret the output of these models as the probability that parking will be difficult, which we can then map into descriptive terms like “Limited parking” or “Easy.” Third, it’s easy to understand the influence of each specific feature, which makes it easier to verify that the model is behaving reasonably. For example, when we started the training process, many of us thought that the “fingerprint” feature described above would be the “silver bullet” that would crack the problem for us. We were surprised to note that this wasn’t the case at all — in fact, it was features based on the dispersion of parking locations that turned out to be one of the most powerful predictors of parking difficulty.
Results
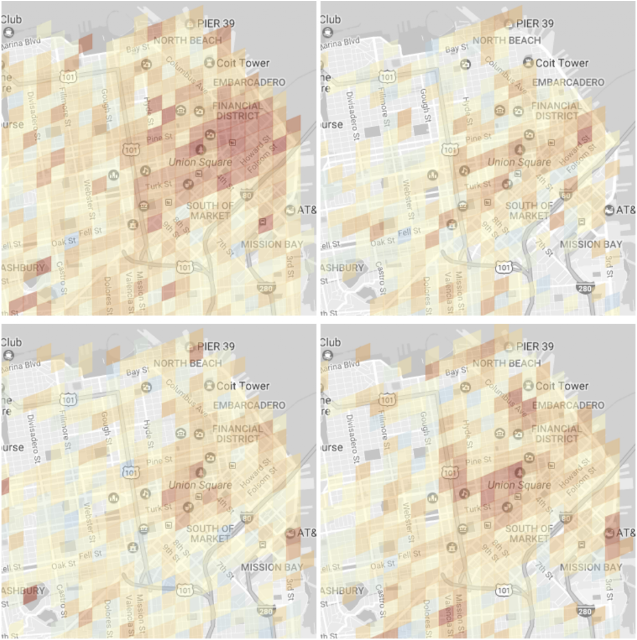
With our model in hand, we were able to generate an estimate for difficulty of parking at any place and time. The figure below gives a few examples of the output of our system, which is then used to provide parking difficulty estimates for a given destination. Parking on Monday mornings, for instance, is difficult throughout the city, especially in the busiest financial and retail areas. On Saturday night, things are busy again, but now predominantly in the areas with restaurants and attractions.
Output of our parking difficulty model in the Financial District and Union Square areas of San Francisco. Red denotes a higher confidence that parking is difficult. Top row: a typical Monday at ~8am (left) and ~9pm (right). Bottom row: the same times but on a typical Saturday.
We’re excited about the opportunities to continue to improve the model quality based on user feedback. If we are able to better understand parking difficulty, we will be able to develop new and smarter forms of parking assistance — we’re very excited about future applications of ML to help make transportation more enjoyable!