In order to understand trends in the field, I find it helpful to think of developments in deep learning as being driven by three major frontiers that limit the success of artificial intelligence in general and deep learning in particular. Firstly, there is the available computing power and infrastructure, such as fast GPUs, cloud services providers (have you checked out Amazon's new EC2 P2 instance ?) and tools (Tensorflow, Torch, Keras etc), secondly, there is the amount and quality of the training data and thirdly, the algorithms (CNN, LSTM, SGD) using the training data and running on the hardware. Invariably behind every new development or advancement, lies an expansion of one of these frontiers.
Much of the progress we have seen this year is driven by an expansion of the former two frontiers; we now have systems that are able to recognize images and speech with an accuracy that rivals that of humans and there is an abundance of data and tools to develop them. However, almost all of these systems rely on supervised learning and thereby on the ready availability of labelled data sets. The many revolutionary results we have seen in 2016, be they in medical imaging, self-driving cars or machine translation also point to the fact that moving along the axes of data and compute power will lead to diminishing marginal returns.
This means that the greatest yields can be reaped from pushing the third frontier forward, to develop algorithms that can learn from raw unlabelled data such as video or text. 2016 has seen major developments on the research front (which to anyone trying to keep up sometimes seems like a feverish frenzy) and Yann LeCunn outlines the major ones in this presentation; reinforcement learning and adversarial training.
Deep Reinforcement Learning
For an excellent overview of deep reinforcement learning have a look at Andrej Karpathy's excellent introduction . The basic set up is quite simple; we have an agent that can perform a range of permissible actions which lead to an outcome that is judged by a reward function with either a reward or a penalty. Let's take the game of Pong, here an agent has two available actions; going UP or DOWN, the outcome is whether the ball went past the opponent or the agent misses the ball and a reward or a penalty are assigned respectively.

The state of the art approach to tackling RL problems are Policy Gradients, which in combination with Monte Carlo Tree Search were employed by Google DeepMind's AlphaGo system to famously beat the Go world champion Lee Sedol . Contrary to what one might expect, Policy Gradients are surprisingly straightforward, the network receives as input a certain number of games which consist of a sequence of frames, actions taken by the agents and the result (win/lose) and then apply backpropagation to update the network parameter so as to make actions leading to a win-result more likely than those leading to a lose-result.
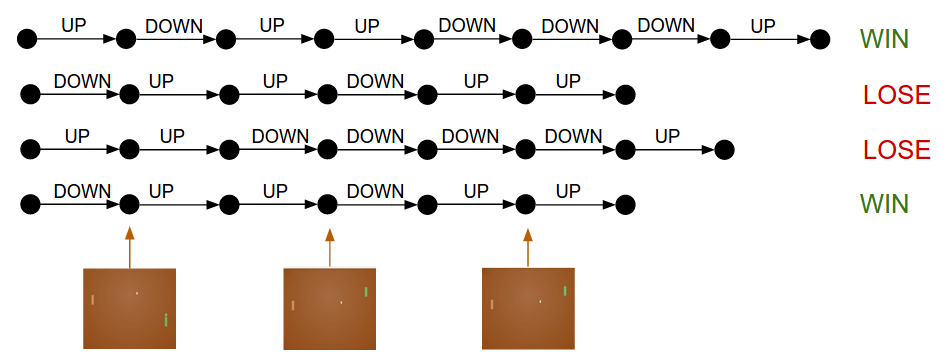
As far as algorithmic ingenuity goes, this is pretty much all there is to it. With all the hype surrounding AlphaGo's victory this year, its success is just as much if not more attributable to data, compute power and infrastructure advancements than algorithmic wizardry.
On the other hand, the success of RL and the fact that it does not require expensively labelled data also led to the infrastructure frontier being pushed ahead a little further this year through the introduction of various simulation platforms such as OpenAI's gym / universe platforms or DeepMind's collaboration with Blizzard to go beyond Pong and to release StarCraft 2 as simulation environment. The fact that anyone could now train their self-driving car algorithm in GTA V is a significant step forward in the real world application and spread of reinforcement learning approaches.
However, researchers in the RL community caution that learning to play games is not a straight path towards broader AI. Hal Daume raises the concerns in an excellent post "Whence your reward function" that games offer simple clear cut reward functions with frequent and small rewards that point both humans and machines in the right direction, our Pong example from above being an excellent case in point. What, however, if you are trying to train an industrial robot and the 'good boy'/'bad boy' reward is only dispensed at the end of 10 billion frames and positive rewards are only achieved at the end of a complex chain of actions in a large action space? Hal leaves us with a couple of hints at solutions that we should bear in mind as we look towards advancements on the algorithmic frontier in 2017 and beyond. An important development in this regard is the paper " Learning to Reinforcement Learn " in which the authors present an approach to deep meta-reinforcement learning which enables RL methods to rapidly adapt to new task and thereby reduces the amount of data required to train the algorithm on the new task.
Generative Models
There was another major development on the algorithmic front this year which might bring us closer to the holy grail of unsupervised learning, namely the rise of Generative Adversarial Networks (GANs). Although already introduced in 2014 by Ian Goodfellow, it wasn't until the publication of a paper detailing a deep convolutional architecture this year that it really took off. In brief, a GAN consists of two networks; a generator (G) and a discriminator (D), given a set of training examples, G will generate outputs and D will classify them as either being from the same distribution as the training examples or not. In doing so D is optimized so as to be able to discriminate between examples from the training example and from the generator network which in turn is optimized to fool D into classifying its output as being drawn from the training examples.

After such training G can now generate samples with properties very similar to those of the training examples. For a more in-depth introduction see this tutorial by Jonh Glover over at Aylien.
The paper " Generative Adversarial Text to Image Synthesis " presents an impressive examples of what GAN's are able to accomplish. The authors train a GAN to convert text descriptions into images.

Most recently, GANs were used to generate 3D Shapes from 2D views of various objects . Unfortunately, GANs tend to be devilishly hard to train, although several tricks on how to overcome these difficulties have been proposed by OpenAI . Given these impressive capabilities, many leaders in industry are hopeful that GANs will be able to overcome hitherto intractable problems by severing the dependence on traditional supervised learning methods. Yann LeCun, for instance, believes that GANs will pave the way towards an AI with predictive abilities that will endow virtual assistants and chatbots with the necessary 'common sense' to be able to interact with humans in a more natural way.
Another class of generative models that have made a splash this year are at the root of DeepMinds voice generation model WaveNet , the image generation model PixelRNN and PixelCNN and the video generation model VPN (Video Pixel Network) .
At their core, these generative models learn the joint probability of, for instance, all pixels in an image and then predict the next pixel given all the previously generated ones. It is easy to see how this applies to sound waves and video frames.

Continued Openness in AI development
The fact that much of the research surveyed above is coming out of private companies and non-profit organizations outside of academia is indicative of another trend that has manifested itself more palpably this year; the new openness in AI development.
Let's summarize:
Facebook has released the designs of high-powered new server for running AI systems , its research branch FAIR is publishing outstanding research at a breakneck pace , Elon Musk and other tech luminaries have funded OpenAI with a billion dollars which apart from their research is opening up the simulation environment universe to the public , Google is expending significant resources to both push ahead deep learning research and open source libraries such as tensorflow, similarly Amazon open sourced t heir Deep Scalable Sparse Tensor Network Engine (DSSTNE) , Uber launches an AI research lab and recently even Apple announced that it will start releasing its AI research results to the public. On the data front we have similar magnanimity with several dominant players publishing the kind of large and well labelled data sets essential to training deep neural networks, a few notable ones include the Youtube video dataset with 500.000 hours of video-level labels and Yahoo's 13.5TB of data , which includes 110B events describing anonymized user-news item interactions from 20M users on various Yahoo properties.
Now, there are several factors driving this development. The first wider force driving this openness is the attempt by each player to commoditize the others advantage, Google, for instance, has the data and the infrastructure, they can publish their research and software without endangering their competitive advantage, while making it harder for the competition to maintain a lead based on proprietary algorithmic advancements. On the other end of the spectrum there are organizations, like OpenAI, trying to break the data monopoly and dislodge incumbents by positioning themselves as a non-profit partner for those like many car companies with lots of data, but no in-house deep learning expertise.
Secondly, for companies such as Google or Amazon, the software and data sets they open source is a complement to their cloud computing infrastructure products with Google offering a convenient way to run your systems with tensorflow in the Google cloud and Amazon likewise expanding AWS to make it simple to run DSSTNE .
Finally, competition for talent has never been fiercer, not only among tech giants, but also between the private sector and academia from which most deep learning researchers and practitioners hail and in which they are still very much entrenched. The best AI talent simply wants to collaborate and communicate with the wider community by being able to openly publish their research. This fact together with the realization that they might have some catching up to do might be what finally coaxed Apple out its famous secrecy into opening up their AI research.
Partnerships & Acquisitions
Another way these companies gobble up talent is through acquisitions. This year alone Salesforce acquired MetaMind and Prediction.IO, Uber snatched up Geometric Intelligence, Amazon the chatbot company Angel.ai and Intel made a splash with its two acquisition of Nervana Systems a startup creating computing infrastructure for deep learning and Movidius a computer vision company and General Motors bought Crew Automation a self-driving car startup.

But far from being mere acquihires, these acquisitions make eminent sense if view through our data/infrastructures/algorithms framework. Many startups simply do not have access to the kind and volume of data necessary to reap maximum value from their technology. Sure you can buy data sets, but there is a difference between some off-the-shelf data set from a distribution that might differ from your ultimate application domain and being embedded in, say, Salesforce's CRM suite with a staggering amount of data being available right from your application domain.
Acquisitions only make sense if the resulting whole is more valuable than the sum of its part. In few other business domains is this more acutely the case than in deep learning and AI. Integrating MetaMind's impressive deep learning capabilities into the world's largest CRM system to simplify or outright solve a host of menial task such as prioritizing leads or automatically resolving cases is an incredible value multiplier.
Every one of these startups is now doing things that would not have possible had they not joined forces with the company that acquired them.
In many cases, where an acquisition does not make sense, the benefits of collaboration can be realized through partnerships. We see this especially in the healthcare field where several new partnerships between technology companies with deep learning expertise and healthcare institutions were being formed this year. NVIDIA kicked things of this year by announcing its partnership with Mass General Hospital Clinical Data Science Center to "improve the detection, diagnosis, treatment and management of diseases". On the other side of the Atlantic DeepMind and the radiotherapy department at the University College London teamed up to develop deep learning-powered tools to automatically identify cancerous cells for radiology machines. The data sharing agreement between these parties includes data on 1.6 million patients stretching back 5 years.
Indeed, radiology seems like the obvious starting point for deep learning's foray into healthcare; Imaging Advantage the largest platform provider of cloud based radiology service partnered with MIT/Harvard researchers to deliver a deep learning-based product to help radiologists read X-Rays. The company has reportedly collected around 7 billion images and is used in 450 radiology facilities in the US.
Again, the main source of synergy in these partnerships is the fact that technology partners are able to train their deep learning algorithms with highly-specialized, high-quality data right from the application domain which makes it possible to achieve better results than if they had been using publicly available scans.
Hardware & Chips
I want to finish off this review by taking a look at the infrastructure at the heart of the deep learning revolution and the two companies who seem poised to drive its success in the future; NVIDIA and Intel. While NVIDIA remains the undisputed market leader in GPUs for deep learning, Intel has taken important steps to close the gap. Early in the year commentators were wondering "AI Is Super Hot, so Where Are All the Chip Firms That Aren’t Named Nvidia?" , it seems, however, like Intel wasn't going to be outstripped so easily acquiring first Nervana Systems to lay the ground work for a general deep learning infrastructure and then Movidius to gain high-performance SoC platforms for accelerating computer vision applications. In addition to that, Intel Capital will invest 250 million in autonomous driving over the next two years cementing their commitment to an AI-centered future of the company. We will have to wait until the new year, however, before the first fruits of Intel's acquisitions will reach the market in the form of deep learning chips .
In the meantime NVIDIA is harvesting the fruit of their enormous head start coming as the result of a 2 billion dollar R&D programme. In April they announced a new chip, the Pascal architecture-based Tesla P100 GPU , as well as the world's first deep learning supercomputer, the DGX-1 which uses 8x 16GB Tesla GPUs to provide the throughput of 250 CPU-based servers, networking, cables and racks, all in a single box.
These impressive new products and the increasing competition in the hardware space could prove to be a boon to cash strapped startups as costs for sophisticated deep learning infrastructure becomes cheaper and more readily available. If, furthermore, startups manage to find opportunities for partnerships that will give them access to abundant and high quality data, we might see more dominance from independent players and a contravening trend to the industry consolidation that has been driven by a few tech giant's insatiable appetite for AI companies. Another factor, as we have seen, to reduce data dependence is to come up with algorithms that are increasingly capable to work with raw, unlabelled data or to generate it on demand. So going into the new year we will keep our eyes on the exciting research in the areas of generative methods and reinforcement learning.
I hope you enjoyed this little whirlwind tour of forces commingling to make this a very exciting year in deep learning.