Want to see Paris? Ever been to Warsaw? Studied the ancient sites in Rome or Athens?
When I was a young student, I just couldn’t wait to visit many places in Europe I had read so much about but never seen. On my travels, I came across people who were not so different to me, but I also learned to appreciate the little quirks that made them British, Italian, Spanish... I felt my mind broaden in ways I could not have imagined. I felt European.
Now I want every 18-year-old European to have a chance to experience this too, to make new friends from all over Europe and feel this common European identity. We already managed to get 20 000 tickets for 2018!
But I need your help if I’m going to persuade the EU to offer every European an Interrail ticket when they turn 18.
Share your experience with me and let’s make Europe yours.
Update 03/06/18(The Quartz API has undergone some radical changes over the years. We’re updating our popular Core Graphics series to work well with the current version of Swift, so here is an update to the first installment.)
Mac and iOS developers have a number of different programming interfaces to get stuff to appear on the screen. UIKit and AppKit have various image, color and path classes. Core Animation lets you move layers of stuff around. OpenGL lets you render stuff in 3-space. SpriteKit lets you animate. AVFoundation lets you play video.
Core Graphics, also known by its marketing name “Quartz,” is one of the oldest graphics-related APIs on the platforms. Quartz forms the foundation of most things 2-D. Want to draw shapes, fill them with gradients and give them shadows? That’s Core Graphics. Compositing images on the screen? Those go through Core Graphics. Creating a PDF? Core Graphics again.
CG (as it is called by its friends) is a fairly big API, covering the gamut from basic geometrical data structures (such as points, sizes, vectors and rectangles) and the calls to manipulate them, stuff that renders pixels into images or onto the screen, all the way to event handling. You can use CG to create “event taps” that let you listen in on and manipulate the stream of events (mouse clicks, screen taps, random keyboard mashing) coming in to the application.
OK. That last one is weird. Why is a graphics API dealing with user events? Like everything else, it has to do with History. And knowing a bit of history can explain why parts of CG behave like they do.
Just a PostScript In History
Back in the mists of time (the 1980s, when Duran Duran was ascendent), graphics APIs were pretty primitive compared to what we have today. You could pick from a limited palette of colors, plot individual pixels, lay down lines and draw some basic shapes like rectangles and ellipses. You could set up clipping regions that told the world, “Hey, don’t draw here,” and sometimes you had some wild features like controling how wide lines could be. Frequently there were “bit-blitting” features for copying blocks of pixels around. QuickDraw on the Mac had a cool feature called regions that let you create arbitrarily-shaped areas and use them to paint through, clip, outline or hit-test. But in general, APIs of the time were very pixel oriented.
In 1985, Apple introduced the LaserWriter, a printer that contained a microprocessor that was more powerful than the computer it was hooked up to, had 12 times the RAM, and cost twice as much. This printer produced (for the time) incredibly beautiful output, due to a technology called PostScript.
PostScript is a stack-based computer language from Adobe that is similar to FORTH. PostScript, as a technology, was geared for creating vector graphics (mathematical descriptions of art) rather than being pixel based. An interpreter for the PostScript language was embedded in the LaserWriter so when a program on the Mac wanted to print something, the program (or a printer driver) would generate program code that was downloaded into the printer and executed.
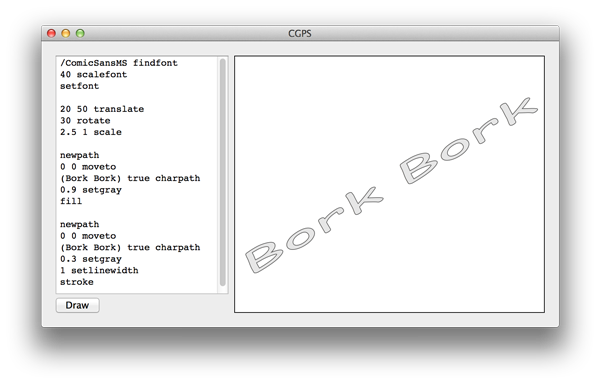
Here’s an example of some PostScript code and the resulting image:
Representing the page as a program was a very important design decision. This allowed the program to represent the contents of the page algorithmically, so the the device that executed the program would be able to draw the page at its highest possible resolution. For most printers at the time, this was 300dpi. For others, 1200dpi. All from the same generated program.
In addition to rendering pages, PostScript is Turing-complete, and can be treated as a general-purpose programming language. You could even write a web server.
Companion CuBEs
When the NeXT engineers were designing their system, they chose PostScript as their rendering model. Display PostScript, a.k.a. DPS, extended the PostScript model so that it would work for a windowed computer display. Deep in the heart of it, though, was a PostScript interpreter. NeXT applications could implement their screen drawing in PostScript code, and use the same code for printing. You could also wrap PostScript in C functions (using a program called pswrap) to call from application code.
Display PostScript was the foundation of user interaction. Events (mouse, keyboard, update, etc.) went through the DPS system and then were dispatched to applications.
NeXT wasn’t the only windowing system to use PostScript at the time. Sun’s NeWS (capitalization aside, no relation to NeXT) had an embedded PostScript interpreter that drove the user’s interaction with the system.
Gallons of Quartz
Why don’t OS X and iOS use Display PostScript? Money, basically. Adobe charged a license fee for Display PostScript. Also, Apple is well known for wanting to own as much of their technology stack as possible. By implementing the PostScript drawing model, but not actually using PostScript, they could avoid paying the license fees and also own the core graphics code.
It’s commonly said that Quartz is “based on” PDF, and in a sense that’s true. PDF (Adobe’s Portable Document Format) is the PostScript drawing model without the arbitrary programmability. Quartz was designed that the typical use of the API would map very closely to what PDF supports, making the creation of PDFs nearly trivial on the platform.
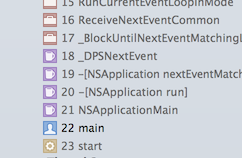
The same basic mechanisms were kept, even though Display PostScript was replaced by Quartz, including the event handling. Check out frame 18 from this Cocoa stack trace. DPS Lives!
Basic Architecture
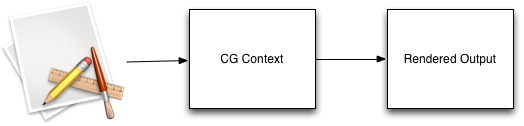
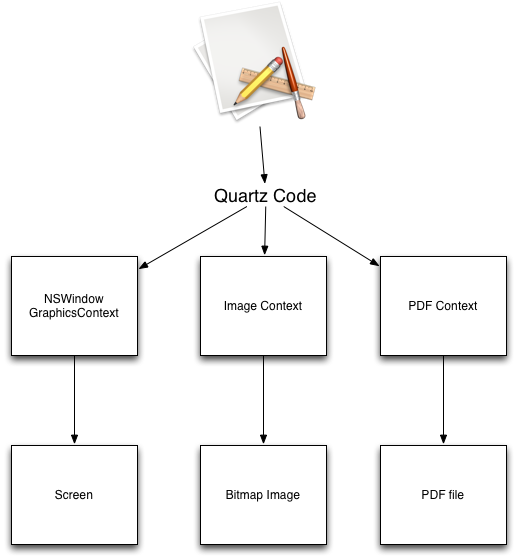
I’ll be covering more aspects in Quartz in detail in the coming weeks, but one of the big take-aways is that the code you call to “draw stuff” is abstracted away from the actual rendering of the graphics. “Render” here could be “make stuff appear in an NSView,” or “make stuff appear in a UIImage,” or even “make stuff appear in a PDF.”
All your CG drawing calls are executed in a “context,” which is a collection of data structures and function pointers that controls how the rendering is done.
There are a number of different contexts, such as (on the Mac) NSWindowGraphicsContext. This particular context takes the drawing commands issued by your code and then lays down pixels in a chunk of shared memory in your application’s address space. This memory is also shared with the window server. The window server takes all of the window surfaces from all the running applications and layers them together onscreen.
Another CG context is an image context. Any drawing code you run will lay down pixels in a bitmap image. You can use this image to draw into other contexts or save to the file system as a PNG or JPEG. There is a PDF context as well. The drawing code you run doesn’t turn into pixels; instead it turns into PDF commands and is saved to a file. Later on, a PDF viewer (such as Adobe Acrobat or Mac Preview) can take those PDF commands and render them into something viewable.
Coming up
Next time, a closer look at contexts, and some of the convenience APIs layered over Core Graphics.
Rihanna, photographed in February, denounced an ad on Snapchat that made light of domestic violence. The company's stock closed down by week's end.
Mamadou Diop/APhide caption
toggle caption
Mamadou Diop/AP
Singer Rihanna denounced an ad that appeared on Snapchat making a game of domestic violence that featured photographs of her and Chris Brown. And the social media app's stock price went tumbling.
"Now SNAPCHAT I know you already know you ain't my fav app out there," Rihanna said in a statement posted Thursday on rival social media platform Instagram, where she has 61 million followers. "I'd love to call it ignorance, but I know you ain't that dumb! You spent money to animate something that would intentionally bring shame to DV victims and made a joke of it!!!"
The ad was for the mobile game "Would You Rather," which asks users a series of questions, sometimes offensive. The ad said, "Would you rather slap Rihanna" or "punch Chris Brown."
In 2009, Brown pleaded guilty to felony assault after Rihanna accused him of beating her and trying to push her out of a car. Photos emerged of her with a bruised face.
Snapchat had already yanked the ad Monday and issued an apology. But the ad reappeared on social media as users circulated it and questioned its content.
"Just awful," Chelsea Clinton tweeted. "Awful that anyone thinks this is funny. Awful that anyone thinks this is appropriate. Awful that any company would approve this."
Apparently Snapchat agreed.
"This advertisement is disgusting and never should have appeared on our service," a Snapchat spokesperson said in a statement. "We are so sorry we made the terrible mistake of allowing it through our review process. We are investigating how that happened so that we can make sure it never happens again."
Snapchat has an automated ad-buying platform. But company policy states, "All ads are subject to our review and approval." It also says it prohibits "Shocking, sensational, or disrespectful content."
In her Instagram post, Rihanna went on to say, "This isn't about my personal feelings, cause I don't have much of them...but all the women, children and men that have been victims of DV in the past and especially the ones who haven't made it out yet...you let us down! Shame on you. Throw the whole app-oligy away."
Investors apparently heeded the call and threw away some stock. Snap Inc's stock prices fell around 4 percent later Thursday, wiping out nearly $800 million from its market value, reports CNN. By Friday, it had rebounded some, but closed the week with a 1 percent loss.
Snapchat has experience with the kind of influence celebrities can wield. Last month after Snapchat changed its layout, Kylie Jenner, one of its most popular users, tweeted that she was no longer using the app.
The company's stock quickly fell 6 percent, erasing more than a billion dollars from its market value, said CNN.
Would you believe me if I claimed that an algorithm that has been on the books as "optimal" for 46 years, which has been analyzed in excruciating detail by geniuses like Knuth and taught in all computer science courses in the world, can be optimized to run 10 times faster?
A couple of years ago, I fell into some interesting company and became the author of an open source HTTP accelerator called Varnish, basically an HTTP cache to put in front of slow Web servers. Today Varnish is used by Web sites of all sorts, from Facebook, Wikia, and Slashdot to obscure sites you have surely never heard of.
Having spent 15 years as a lead developer of the FreeBSD kernel, I arrived in user land with a detailed knowledge of what happens under the system calls. One of the main reasons I accepted the Varnish proposal was to show how to write a high-performance server program.
Because, not to mince words, the majority of you are doing that wrong. Not just wrong as in not perfect, but wrong as in wasting half, or more, of your performance.
The first user of Varnish, the large Norwegian newspaper VG, replaced 12 machines running Squid with three machines running Varnish. The Squid machines were flat-out 100 percent busy, while the Varnish machines had 90 percent of their CPU available for twiddling their digital thumbs.a
The really short version of the story is that Varnish knows it is not running on the bare metal but under an operating system that provides a virtual-memory-based abstract machine. For example, Varnish does not ignore the fact that memory is virtual; it actively exploits it. A 300-GB backing store, memory mapped on a machine with no more than 16 GB of RAM, is quite typical. The user paid for 64 bits of address space, and I am not afraid to use it.
One particular task, inside Varnish, is expiring objects from the cache when their virtual lifetimers run out of sand. This calls for a data structure that can efficiently deliver the smallest keyed object from the total set.
A quick browse of the mental catalog flipped up the binary-heap card, which not only sports an O(log2(n)) transaction performance, but also has a meta-data overhead of only a pointer to each object—which is important if you have 10 million+ objects.
Careful rereading of Knuth confirmed that this was the sensible choice, and the implementation was trivial: "Ponto facto, Cæsar transit," etc.
On a recent trip by night-train to Amsterdam, my mind wandered, and it struck me that Knuth might be terribly misleading on the performance of the binary heap, possibly even by an order of magnitude. On the way home, also on the train, I wrote a simulation that proved my hunch right.
Before any fundamentalist CS theoreticians choke on their coffees: don't panic! The P vs. NP situation is unchanged, and I have not found a systematic flaw in the quality of Knuth et al.'s reasoning. The findings of CS, as we know it, are still correct. They are just a lot less relevant and useful than you think—at least with respect to performance.
The oldest reference to the binary heap I have located, in a computer context, is J.W.J. Williams' article published in the June 1964 issue of Communications of the ACM, titled "Algorithm number 232 - Heapsort."2,b The trouble is, Williams was already out of touch, and his algorithmic analysis was outdated even before it was published.
In an article in the April 1961 of CACM, J. Fotheringham documented how the Atlas Computer at Manchester University separated the concept of an address from a memory location, which for all practical purposes marks the invention of VM (virtual memory).1 It took quite some time before virtual memory took hold, but today all general-purpose, most embedded, and many specialist operating systems use VM to present a standardized virtual machine model (i.e., POSIX) to the processes they herd.
It would of course be unjust and unreasonable to blame Williams for not realizing that Atlas had invalidated one of the tacit assumptions of his algorithm: only hindsight makes that observation possible. The fact is, however, 46 years later most CS-educated professionals still ignore VM as a matter of routine. This is an embarrassment for CS as a discipline and profession, not to mention wasting enormous amounts of hardware and electricity.
Performance simulation
Enough talk. Let me put some simulated facts on the table. The plot in figure 1 shows the runtime of the binary heap and of my new B-heap version for 1 million items on a 64-bit machine.c (My esteemed FreeBSD colleague Colin Percival helpfully pointed out that the change I have made to the binary heap is very much parallel to the change from binary tree to B-tree, so I have adopted his suggestion and named my new variant a B-heap.d)
The x-axis is VM pressure, measured in the amount of address space not resident in primary memory, because the kernel paged it out to secondary storage. The left y-axis is runtime in seconds (log-scale), and the right Y-axis shows the ratio of the two runtimes: (binary heap / B-heap).
Let's get my "order of magnitude" claim out of the way. When we zoom in on the left side (figure 2), we see that there is indeed a factor 10 difference in the time the two algorithms take when running under almost total VM pressure: only 8 to 10 pages of the 1,954 pages allocated are in primary memory at the same time.
Did you just decide that my order of magnitude claim was bogus, because it is based on only an extreme corner case? If so, you are doing it wrong, because this is pretty much the real-world behavior seen.
Creating and expiring objects in Varnish are relatively infrequent actions. Once created, objects are often cached for weeks if not months, and therefore the binary heap may not be updated even once per minute; on some sites not even once per hour.
In the meantime, we deliver gigabytes of objects to clients' browsers, and since all these objects compete for space in the primary memory, the VM pages containing the binheap that are not accessed get paged out. In the worst case of only nine pages resident, the binary heap averages 11.5 page transfers per operation, while the B-heap needs only 1.14 page transfers. If your server has SSD (solid state drive) disks, that is the difference between each operation taking 11 or 1.1 milliseconds. If you still have rotating platters, it is the difference between 110 and 11 milliseconds.
At this point, is it wrong to think, "If it runs only once per minute, who cares, even if it takes a full second?"
We do, in fact, care because the 10 extra pages needed once per minute loiter in RAM for a while, doing nothing for their keep—until the kernel pages them back out again, at which point they get to pile on top of the already frantic disk activity, typically seen on a system under this heavy VM pressure.e
Next, let us zoom in on the other end of the plot (figure 3). If there is no VM pressure, the B-heap algorithm needs more comparisons than the binary sort, and the simple parent-to-child / child-to-parent index calculation is a tad more involved: so, instead of a runtime of 4.55 seconds, it takes 5.92 seconds, a whopping 30 percent slower—almost 350 nanoseconds slower per operation.
So, yes, Knuth and all the other CS dudes had their math figured out right.
If, however, we move left on the curve, then we find, at a VM pressure of four missing pages (= 0.2 percent) the B-heap catches up, because of fewer VM page faults; and it gradually gets better and better, until as we saw earlier, it peaks at 10 times faster.
That was assuming you were using an SSD disk, which can do a page operation in 1 millisecond—pretty optimistic, in particular for the writes. If we simulate a mechanical disk by setting the I/O time to a still-optimistic 10 milliseconds instead (figure 4), then B-heap is 10 percent faster as soon as the kernel steals just a single page from our 1,954-page working set and 37 percent faster when four pages are missing.
So what is a B-heap, anyway?
The only difference between a binary heap and a B-heap is the formula for finding the parent from the child, or vice versa.
The traditional n -> {2n, 2n+1} formula leaves us with a heap built of virtual pages stacked one over the next, which causes (almost) all vertical traversals to hit a different VM page for each step up or down in the tree, as shown in figure 5, with eight items per page. (The numbers show the order in which objects are allocated, not the key values.)
The B-heap builds the tree by filling pages vertically, to match the direction we traverse the heap (figure 6). This rearrangement increases the average number of comparison/swap operations required to keep the tree invariant true, but ensures that most of those operations happen inside a single VM page and thus reduces the VM footprint and, consequently, VM page faults.
Two details are worth noting:
* Once we leave a VM page through the bottom, it is important for performance that both child nodes live in the same VM page, because we are going to compare them both with their parent.
* Because of this, the tree fails to expand for one generation every time it enters a new VM page in order to use the first two elements in the page productively.
In our simulated example, failure to do so would require five pages more.
If that seems unimportant to you, then you are doing it wrong: try shifting the B-heap line 20 KB to the right in figures 2 and 3, and think about the implications.
The parameters of my simulation are chosen to represent what happens in real life in Varnish, and I have not attempted to comprehensively characterize or analyze the performance of the B-heap for all possible parameters. Likewise, I will not rule out that there are smarter ways to add VM-clue to a binary heap, but I am not inclined to buy a ticket on the Trans-Siberian Railway in order to find time to work it out.
The order of magnitude of difference obviously originates with the number of levels of heap inside each VM page, so the ultimate speedup will be on machines with small pointer sizes and big page sizes. This is a pertinent observation, as operating system kernels start to use superpages to keep up with increased I/O throughput.
So why are you, and I, still doing it wrong?
There used to be an (in)famous debate, "Quicksort vs. Heapsort," centering on the fact that the worst-case behavior of the former is terrible, whereas the latter has worse average performance but no such "bad spots." Depending on your application, that can be a very important difference.
We lack a similar inquiry into algorithm selection in the face of the anisotropic memory access delay caused by virtual memory, CPU caches, write buffers, and other facts of modern hardware.
Whatever book you learned programming from, it probably had a figure within the first five pages diagramming a computer much like that shown in figure 7. That is where it all went pear-shaped: that model is totally bogus today.
It is, amazingly, the only conceptual model used in computer education, despite the fact that it has next to nothing to do with the execution environment on a modern computer. And just for the record: by modern, I mean VAX 11/780 or later.
The past 30 or 40 years of hardware and operating-systems development seems to have only marginally impinged on the agenda in CS departments' algorithmic analysis sections, and as far as my anecdotal evidence, it has totally failed to register in the education they provide.
The speed disparity between primary and secondary storage on the Atlas Computer was on the order of 1:1,000. The Atlas drum took 2 milliseconds to deliver a sector; instructions took approximately 2 microseconds to execute. You lost around 1,000 instructions for each VM page fault.
On a modern multi-issue CPU, running at some gigahertz clock frequency, the worst-case loss is almost 10 million instructions per VM page fault. If you are running with a rotating disk, the number is more like 100 million instructions.f
What good is an O(log2(n)) algorithm if those operations cause page faults and slow disk operations? For most relevant datasets an O(n) or even an O(n^2) algorithm, which avoids page faults, will run circles around it.
Performance analysis of algorithms will always be a cornerstone achievement of computer science, and like all of you, I really cherish the foldout chart with the tape-sorts in volume 3 of The Art of Computer Programming. But the results coming out of the CS department would be so much more interesting and useful if they applied to real computers and not just toys like ZX81, C64, and TRS-80. Q
Notes
a. This pun is included specifically to inspire Stan Kelly-Bootle.
b. How wonderful must it have been to live and program back then, when all algorithms in the world could be enumerated in an 8-bit byte?
c. Page size is 4 KB, each holding 512 pointers of 64 bits. The VM system is simulated with dirty tracking and perfect LRU page replacement. Paging operations set to 1 millisecond. Object key values are produced by random(3). The test inserts 1 million objects, then alternately removes and inserts objects 1 million times, and finally removes the remaining 1 million objects from the heap. Source code is at http://phk.freebsd.dk/B-Heap.
d. Does CACM still enumerate algorithms, and is eight bits still enough?
e. Please don't take my word for it: applying queuing theory to this situation is a very educational experience.
f. And below the waterline there are the flushing of pipelines, now useless and in the way, cache content, page-table updates, lookaside buffer invalidations, page-table loads, etc. It is not atypical to find instructions in the "for operating system programmers" section of the CPU data book, which take hundreds or even thousands of clock cycles, before everything is said and done.
References
1. Fotheringham, J. 1961. Dynamic storage allocation in the Atlas Computer, including an automatic use of a backing store. Communications of the ACM 4(10): 435-436; http://doi.acm.org/10.1145/366786.366800.
2. Williams, J. W. J. 1964. Algorithm 232 - Heapsort. Communications of the ACM 7(6): 347-348.
Poul-Henning Kamp ([email protected]) has programmed computers for 26 years and is the inspiration behind bikeshed.org. His software has been widely adopted as "under the hood" building blocks in both open source and commercial products. His most recent project is the Varnish HTTP-accelerator, which is used to speed up large Web sites such as Facebook.
Ulan Degenbaev, Jochen Eisinger, Manfred Ernst, Ross McIlroy, Hannes Payer - Idle-Time Garbage-Collection Scheduling Taking advantage of idleness to reduce dropped frames and memory consumption
Neil Gunther, Paul Puglia, Kristofer Tomasette - Hadoop Superlinear Scalability The perpetual motion of parallel performance
Robert Sproull, Jim Waldo - The API Performance Contract How can the expected interactions between caller and implementation be guaranteed?
There really is no reason to suspect that my experience encountering this error is related to a problem on my system because I do not maintain any conflicting configurations on my pc. No matter what browser I use, I still get this error. I've visited their site before with no problem, however it almost seems like now it is a regular occurrence to come across this error.
I have ample reason to believe this has to do with a problem on their website, specifically with regard to website maintenance, or lack there of...
Try telling HSN that, and you might just get a variety of responses depending upon whom you speak with, but you can rest assure that no matter whom it is at HSN, they're all experts...(Pun intended of course)...
A. Bit Miffed | Sun, 14 Sep 2014 23:15:38 UTC
It's rare to see this kind of hubris in a computer publication. But, oh well. When quantum computers become the norm, we'll see an article that Poul-Henning Kamp was doing it wrong.
asd | Tue, 22 May 2012 04:53:47 UTC
buy more ram bros
iitg | Mon, 12 Dec 2011 09:44:22 UTC
I think some said "buy more ram" in the comment above, that wont be of much help as we are talking about an algorithm which minimises disk access as well as cache miss! Nice article.
Dutch Uncle | Thu, 30 Jun 2011 16:02:25 UTC
Lots of people have been paying attention to memory hierarchy for a long time. I worked for SyncSort on IBM mainframe data sorting and manipulation utilities. I can assure you that every single execution of the SyncSort utility started with an analysis pass that included comparing the effective size of data key indices to the available cache reported by the processor, as well as comparing the available RAM to the total data set size, in order to tune the operation into the best number of iterations of the best sized chunks of data. In the universe, things do happen outside of one's personal knowledge.
Sepp | Fri, 25 Mar 2011 13:34:37 UTC
An interesting comparison of Varnish, Apache Traffic Server (another proxy cache) and G-WAN (an application server with C scripts):
Apache Traffic Server is an HTTP proxy and cache server created by Inktomi, and distributed as a commercial product before Inktomi was acquired by Yahoo.
Yahoo says that it uses TS in to serve more than 30 Billion objects per day. They also say that TS is a "product of literally hundreds of developer-years".
Tom | Wed, 05 Jan 2011 19:56:36 UTC
You have rediscovered the principles of spacial and temporal locality, one of the key things taught in any basic algorithms class. Thinking that it has anything to do with something as specific as virtual memory or hard disks shows your ignorance of computer architecture, modern or otherwise. Imagine swapping tapes back in the day.
Roma Agrawal likes to stroke concrete. Her snaps from a holiday in Italy are of arches and bricks (“so many different types of arches,” she enthuses, “so many different types of bricks”). A typical leisure activity – “a few weekends of good geeky fun” – is building a large Lego model of Big Ben. The man who is now her husband, whom she initially disparaged to her friends as “Flirtman”, wooed her by sending daily emails on a “Bridge of the Day”. (“An example of why you should do a proper damping analysis,” read the first, which was about the Tacoma Narrows Bridge collapse of 1940.) “When we realised the geeky fascination we both had,” she says, “we clicked.”
She loves buildings, construction, materials, the ways in which things stand up, how they’re built and the stories of how they got to be there, the interactions of humanity, matter and mathematics that give us skyscrapers and bridges. Also more modest structures. “I wake up in a warm home. Why is it not sinking or falling down? Every minute of the day its structure is working. Who are the people behind that?”
Engineers, is the answer, of which she is one, having discovered the profession best suited to her passions. She feels her job doesn’t get the credit it deserves. “People appreciate that they live in a warm building or have bridges to cross,” she says, “but they don’t appreciate how they came to be there. You can live in a city that works really well, and a country that works really well, but you only hear about engineering when it goes wrong. ‘Engineering works’ are the reason trains are delayed.” And, while the identity of the architect of the Shard in London, Renzo Piano, is well known, its engineers are not. They were a company called WSP, with Agrawal one of the team.
Her sense that engineering is undervalued has motivated her to proselytise for it, giving talks in schools, going on TV and now writing a book, Built, which seeks to share her enthusiasm with the general reader. She says: “I’m trying to engage people who don’t even know they’re interested in buildings” – which, as we all live in and around them, should be all of us. So the book explains as simply as possible the basics of columns, beams and arches, before moving on to more complex stories, such as the ingenious way in which engineers dealt with Mexico City’s vast stone cathedral sinking into the soggy ground underneath it.
She tells the human stories behind great structures. Although it might seem a sane and reasonable business, the world’s great engineers, she believes, were “very eccentric characters, all very tenacious, the sort who were cheeky at school and didn’t do what their parents wanted them to do”. For example the “mischievous and lively minded” Fazlur Khan, born in 1929 in Dhaka in what is now Bangladesh, who went on to invent the exoskeleton, which is how really tall buildings like the Burj Khalifa in Dubai stand up.
The Northumbria University footbridge in Newcastle that Agrawal helped design. Photograph: Alamy Stock Photo
She believes that there was a time, the 19th century, when engineering generated fascination, excitement and respect, when bridges, tunnels and railways were reshaping cities and countries. It was also a perilous pursuit, as untried techniques were pushed up to and beyond the limit. She describes how Henry Bessemer, inventor of the process that revolutionised steel production, nearly blew himself up; how floods killed many workers while building the tunnel under the Thames that Marc Brunel and his son Isambard Kingdom designed. The younger engineer was himself nearly one of the casualties. In those days engineering “was like going to war – you expected people to die.”
One of her most memorable tales is of the construction of the Brooklyn Bridge, whose chief engineer, John Augustus Roebling, died of tetanus after he injured himself on site. His son Washington took over, only to be made seriously ill by the effects of working inside the caissons – large chambers submerged into the river, to keep the water away from the construction work. The air in the caissons was kept at high pressure to resist the water, which caused “caisson disease” – joint pain, part paralysis and depression – what divers would later call the bends.
Washington’s wife, Emily, gradually took over, acting at first as her husband’s representative, before becoming the de facto leader of the project. She had previously taught herself engineering alongside her husband and set about understanding every technical aspect of the bridge. She also showed what Washington called “her remarkable talent as a peacemaker”, her ability to manage the competing egos of investors, politicians, officials, contractors and labourers. At a time when, as Agrawal says, “a woman’s presence on a construction site was unheard of”, she brought into being one of the greatest engineering works of her time.
Agrawal traces her interests to her early childhood in New York, to the thrill and thrall of skyscrapers, and a curiosity about the ways that things go together. This continued after she moved to Mumbai with her family, and then to Oxford to study physics. It was only when she did a summer job in the physics department, and saw engineers designing specialist equipment, that she realised she wanted to be one.
She was inspired, in particular, by the design of a metal holder for a lens, a simple enough task, as she says, except that it would have to work at -70C. As metal contracts in the cold more than glass, this would cause the lens to crack if it wasn’t done right. “It dawned,” she says, “that the process of design traces every single stage” – not just the equipment, but the cases in which it is carried around.
There are many types of engineer to choose from – electrical, aeronautical, civil – but she chose to be a structural engineer, a designer of the structure of buildings, perhaps because of the early impact of those American towers. She studied engineering at Imperial College London and went to work at WSP, where she helped design a footbridge for Northumbria University in Newcastle and assisted with the foundations of the Shard and the open steel structure at its top. She also worked on a Georgian house in Mayfair and an addition to the Victorian Crystal Palace station in London. She now works for Aecom, a global engineering company that covers most aspects of designing and running buildings.
Brooklyn Bridge under construction… In Built, Agrawal tells the New York landmark’s memorable backstory. Photograph: Museum of the City of New York/Getty Images
Her urge is towards simplicity and clarity. She likes it when you can see how a building works – the big diamond pattern on the outside of the Gherkin, for example, which gives it rigidity and strength. She liked working with Renzo Piano’s office: “My understanding is that Piano’s father was a joiner, so he pays a lot of attention to putting things together. I loved that.” She hopes that, once they’ve read Built, people will be able to look out of the windows of an underground train, see the metal rings of the tunnel and think: I know how that works.
She also realises that, in construction, “there are thousands of people involved and they all want different things”. They might be concerned with cost, aesthetics, the environment or the structure, all of which have to be brought together. If building can therefore be fraught with difficulty, Agrawal makes it sound like a remarkably serene process. “You have to think of all the aspects really early,” is her secret for a peaceful project, “so it doesn’t become a battle.”
The understanding that engineering is not just about getting calculations and details right, but is also about collaborating with other people, is one reason why the great peacemaker Emily Warren Roebling is a hero to Agrawal. And that she was a woman in what is still a very male business. Agrawal knows what this is like: she has been in meetings where she was the only woman among 21 people, has been mistaken for a secretary or the junior of a male colleague, who was in fact junior to her, been asked to make tea and take minutes, had to discuss business in site huts lined with pictures of naked women, and found the women’s toilets on building sites either locked or used by men. There may be no protective site clothing in her size, so she got into the habit of bringing her own.
“It has got better,” she says. “There’s a more welcoming environment, but there’s still a long way to go.” She hopes that Built will help the process by shining light on the unsung women of engineering. One is Isambard Brunel’s sister Sophia, “the great engineer we never had”, who was more technically gifted than her brother, but was denied the opportunity to put her skills into practice. “I have the feeling,” Agrawal says, “that there were very entrepreneurial women around, but their stories have been lost.”
Other engineers who have written about their work tend to stress their role in working with architects to create unprecedented structures and forms. Peter Rice, who helped design the Pompidou Centre, is one. Cecil Balmond, one of the creators of the Orbit sculpture for the 2012 London Olympics, is another. Agrawal, at the age of 34, is not one of these structural auteurs. Collaborative and unpretentious, she just very much likes what she does, and wants other people – especially girls and women – to know how good it is, too.
•Built: The Hidden Stories Behind Our Structures is published by Bloomsbury (£20). To order a copy for £17 go to guardianbookshop.com or call 0330 333 6846. Free UK p&p over £10, online orders only. Phone orders min p&p of £1.99
This blog post was most directly provoked by this tweet from my friend Rob Conery, explaining why he’s giving up contributing on Stack Overflow.
However, it’s been a long time coming. A while ago I started writing a similar post, but it got longer and longer without coming to any conclusion. I’m writing this one with a timebox of one hour, and then I’ll post whatever I’ve got. (I may then reformat it later.)
I’m aware of the mixed feelings many people have about Stack Overflow. Some consider it to be completely worthless, but I think more people view it as “a valuable resource, but a scary place to contribute due to potential hostility.” Others contribute on a regular basis, occasionally experiencing or witnessing hostility, but generally having a reasonable time.
This post talks about my experiences and my thoughts on where Stack Overflow has a problem, where I disagree with some of the perceived problems, and what can be done to improve the situation. This is a topic I wish I’d had time to talk about in more detail with the Stack Overflow team when I visited them in New York in February, but we were too busy discussing other important issues.
For a lot of this post I’ll talk about “askers” and “answerers”. This is a deliberate simplification for the sake of, well, simplicity. Many users are both askers and answerers, and a lot of the time I’ll write comments with a view to being an answerer, but without necessarily ending up writing an answer. Although any given user may take on different roles even in the course of an hour, for a single post each person usually has a single role. There are other roles of course “commenter on someone else’s answer” for example – I’m not trying to be exhaustive here.
Differences in goals and expectations
Like most things in life, Stack Overflow works best when everyone has the same goal. We can all take steps towards that goal together. Conversely, when people in a single situation have different goals, that’s when trouble often starts.
On Stack Overflow, the most common disconnect is between these two goals:
Asker: minimize the time before I’m unblocked on the problem I’m facing
Answerer: maximize the value to the site of any given post, treating the site as a long-lasting resource
In my case, I have often have a sub-goal of “try to help improve the diagnostic skill of software engineers so that they’re in a better position to solve their own problems.”
As an example, consider this question – invented, but not far-fetched:
Random keeps giving me the same numbers. Is it broken?
This is a low-quality question, in my view. (I’ll talk more about that later.) I know what the problem is likely to be, but to work towards my goal I want the asker to improve the question – I want to see their code, the results etc. If I’m right about the problem (creating multiple instances of System.Random in quick succession, which will also use the same system-time-based seed), I’d then almost certainly be able to close the question as a duplicate, and it could potentially be deleted. In its current form, it provides no benefit to the site. I don’t want to close the question as a duplicate without seeing that it really is a duplicate though.
Now from the asker’s perspective, none of that is important. If they know that I have an idea what the problem might be, their perspective is probably that I should just tell them so they can be unblocked. Why take another 10 minutes to reproduce the problem in a good question, if I can just give them the answer now? Worse, if they do take the time to do that and then I promptly close their question as a duplicate, it feels like wasted time.
Now if I ignored emotions, I’d argue that the time wasn’t wasted:
The asker learned that when they ask a clearer question, they get to their answer quicker. (Assuming they follow the link to the duplicate and apply it.)
The asker learned that it’s worth searching for duplicate questions in their research phase, as that may mean they don’t need to ask the question at all.
But ignoring emotions is a really bad idea, because we’re all human. What may well happen in that situation – even if I’ve been polite throughout – is that the asker will decide that Stack Overflow is full of “traffic cop” moderators who only care about wielding power. I could certainly argue that that’s unfair – perhaps highlighting myactual goals – but that may not change anyone’s mind.
So that’s one problem. How does the Stack Overflow community agree what the goal of site is, and then make that clearer to users when they ask a question? It’s worth noting that the tour page (which curiously doesn’t seem to be linked from the front page of the site any more) does include this text:
With your help, we’re working together to build a library of detailed answers to every question about programming.
I tend to put it slightly differently:
The goal of Stack Overflow is to create a repository of high-quality questions, and high-quality answers to those questions.
Is that actually a shared vision? If askers were aware of it, would that help? I’d like to hope so, although I doubt that it would completely stop all problems. (I don’t think anything would. The world isn’t a perfect place.)
Let’s move onto another topic where I disagree with some people: low-quality questions.
Yes, there are low-quality questions
I assert that even if it can’t be measured in a totally objective manner, there are high-quality questions and low-quality questions (and lots in between).
I view a high-quality question in the context of Stack Overflow as one which:
Asks a question, and is clear in what it’s asking for. It should be reasonably obvious whether any given attempted answer does answer the question. (That’s separate to whether the answer is correct.)
Avoids irrelevancies. This can be hard, but I view it as part of due diligence: if you’re encountering a problem as part of writing a web-app, you should at least try to determine whether the context of a web-app is relevant to the problem.
Is potentially useful to other people. This is where avoiding irrelevant aspects is important. Lots of people need to parse strings as dates; relatively few will need to parse strings as dates using framework X version Y in conjunction with a client written in COBOL, over a custom and proprietary network protocol.
Explains what the asker has already tried or researched, and where they’ve become stuck.
Where appropriate (which is often the case) contains a minimal example demonstrating the problem.
Is formatted appropriately. No whole-page paragraphs, no code that’s not formatted as code, etc.
There are lots of questions which meet all those requirements, or at least most of them.
I think it’s reasonable to assert that such a question is of higher quality than a question which literally consists of a link to a photo of a homework assignment, and that’s it. Yes, I’ve seen questions like that. They’re not often quite that bad, but if we really can’t agree that that is a low-quality question, I don’t know what we can agree on.
Of course, there’s a huge spectrum in between – but I think it’s important to accept that there are such things as low-quality questions, or at least to debate it and find out where we disagree.
Experience helps write good questions, but isn’t absolutely required
I’ve seen a lot of Meta posts complaining that Stack Overflow is too hard on newcomers, who can’t be expected to write a good question.
I would suggest that a newcomer who accepts the premise of the site and is willing to put in effort is likely to be able to come up with at least a reasonable question. It may take them longer to perform the research and write the question, and the question may well not be as crisp as one written by a more experienced developer in the same situation, but I believe that on the whole, newcomers are capable of writing questions of sufficient quality for Stack Overflow. They may not be aware of what they need to do or why, but that’s a problem with a different solution than just “we should answer awful questions which show no effort because the asker may be new to tech”.
One slightly separate issue is whether people have the diagnostic skills required to write genuinely good questions. This is a topic dear to my heart, and I really wish I had a good solution, but I don’t. I firmly believe that if we can help programmers become better at diagnostics, then that will be of huge benefit to them well beyond asking better Stack Overflow questions.
Some regular users behave like jerks on Stack Overflow, but most don’t
I’m certainly not going to claim that the Stack Overflow community is perfect. I have seen people being rude to people asking bad questions – and I’m not going to excuse that. If you catch me being rude, call me out on it. I don’t believe that requesting improvements to a question is rude in and of itself though. It can be done nicely, or it can be done meanly. I’m all for raising the level of civility on Stack Overflow, but I don’t think that has to be done at the expense of site quality.
I’d also say that I’ve experienced plenty of askers who react very rudely to being asked for more information. It’s far from one way traffic. I think I’ve probably seen more rudeness in this direction than from answerers, in fact – although the questions usually end up being closed and deleted, so anyone just browsing the site casually is unlikely to see that.
My timebox is rapidly diminishing, so let me get to the most important point. We need to be nicer to each other.
Jon’s Stack Overflow Covenant
I’ve deliberately called this my covenant, because it’s not my place to try to impose it on anyone else. If you think it’s something you could get behind (maybe with modifications), that’s great. If Stack Overflow decides to adopt it somewhere in the site guidelines, they’re very welcome to take it and change it however they see fit.
Essentially, I see many questions as a sort of transaction between askers and answerers. As such, it makes sense to have a kind of contract – but that sounds more like business, so I’d prefer to think of a covenant of good faith.
As an answerer, I will…
Not be a jerk.
Remember that the person I’m responding to is a human being, with feelings.
Assume that the person I’m responding to is acting in good faith and wants to be helped.
Be clear that a comment on the quality of a question is not a value judgement on the person asking it.
Remember that sometimes, the person I’m responding to may feel they’re being judged, even if I don’t think I’m doing that.
Be clear in my comments about how a question can be improved, giving concrete suggestions for positive changes rather than emphasizing the negative aspects of the current state.
Be clear in my answers, remembering that not everyone has the same technical context that I do (so some terms may need links etc).
Take the time to present my answer well, formatting it as readably as I can.
As an asker, I will…
Not be a jerk.
Remember that anyone who responds to me is a human being, with feelings.
Assume that any person who responds to me is acting in good faith and trying to help me.
Remember that I’m asking people to give up their time, for free, to help me with a problem.
Respect the time of others by researching my question before asking, narrowing it down as far as I can, and then presenting as much information as I think may be relevant.
Take the time to present my question well, formatting it as readably as I can.
I hope that most of the time, I’ve already been following that. Sometimes I suspect I’ve fallen down. Hopefully by writing it out explicitly, and then reading it, I’ll become a better community member.
I think if everyone fully took something like this on board before posting anything on Stack Overflow, we’d be in a better place.
Enlarge/ Ian Read, chairman and chief executive officer of Pfizer Inc.
As drug giant Pfizer Inc. hiked the price of dozens of drugs in 2017, it also jacked up the compensation of CEO Ian Read by 61 percent, putting his total compensation at $27.9 million, according to financial filings reported by Bloomberg.
Pfizer’s board reportedly approved the compensation boost because they saw it as a “compelling incentive” to keep Read from retiring. He turns 65 in May. As part of the deal, Read has to stay on through at least next March and is barred from working with a competitor for a minimum of two years after that.
According to Bloomberg, Read’s compensation included in part a salary of $1.96 million, a $2.6 million bonus, $13.1 million in equity awards linked to financial goals and stock price, as well as an $8 million special equity award that will vest if the company’s average stock return goes above 25 percent for 30 consecutive trading days before the end of 2022.
In 2016, Read’s compensation totaled $17.3 million.
The 61 percent raise comes after a string of separate reports noting drug price increases by Pfizer. In January, FiercePharma reported an analysis finding that Pfizer implemented 116 price hikes just between this past December 15 and January 3 of this year. The list price increases ranged from 3 percent to 9.46 percent. The analysts noted that Pfizer increased the price of 20 drugs by 9.44 percent. Those included Viagra, Pristiq, Lipitor, and Zoloft, which are available as generics, as well as Chantix.
Additionally, Pfizer had increased the prices of 91 drugs by an average of 20 percent in just the first half of 2017, according to data first reported by Financial Times. That included two waves of price hikes, one in January and the other on June 1.
That echoes the pattern seen in 2016, 2015, and 2014, according to a report by STAT. In June of 2016, Pfizer raised the list prices of its medicines by an average of 8.8 percent. That followed an average 10.4 percent raise in list prices in January of that year.
In response to the price hikes reported earlier this year, a Pfizer spokesperson told FiercePharma that the company “takes a measured and responsible approach to pricing.” The spokesperson added that Pfizer provides assistance programs to some eligible patients with financial hardships. However, such discount and assistance programs don't spare insurance companies from picking up larger tabs, which contributes to higher premiums and system-wide costs.
Pfizer did not immediately respond to a request for comment from Ars.
The price hikes come amid a national outrage over the high prices of medications and healthcare overall. A recent analysis published in JAMA compared healthcare spending in the US to 10 other high-income countries. It found that the US paid nearly twice as much but performed less well. The main drivers of higher prices, researchers found, were high administrative costs and devices and pricy medicines.
Ivory is an embedded domain-specific language for safer systems programming.
That’s a mouthful. Lets break that down:
Embedded: Ivory is implemented as a library of the Haskell programming language. Ivory programs are written using Haskell syntax and types.
Domain-specific Language: Ivory is not a general purpose programming language. It aims to be a good language for writing a restricted subset of programs.
Safer: Ivory gives strong guarantees of type and memory safety, and has features which allow the programmer to specify other safety properties.
Systems Programming: Ivory is well suited for writing programs which interact directly with hardware and do not require dynamic memory allocation.
You can consider Ivory to be a lot like a restricted version of the C programming language, embedded in Haskell.
Ivory is embedded in the Haskell language: this means that Ivory reuses the syntax and type system of Haskell. It is best if you are comfortable with the Haskell language before learning Ivory. In particular, Ivory uses modern extensions to the Haskell language, such as DataKinds and TypeOperators.
In this example, we tell Ivory about an external procedure called puts in stdio.h. The puts procedure takes an IString (the Ivory type for strings) as an argument, and returns a Sint32 (a signed 32 bit integer).
Then, we create a procedure called main which takes no arguments and returns nothing of interest. The procedure body makes a call to puts, supplying the string "hello, world\n" as an argument. The underscore in call_ indicates the result of the procedure is discarded.
After the call, the next statement in main is retVoid, which causes the procedure to exit.
Fibonacci
fib_loop ::Def ('[Ix 1000] :-> Uint32)
fib_loop = proc "fib_loop"$ \ n -> body $do
a <- local (ival 0)
b <- local (ival 1)
n `times` \ _ ->do
a' <- deref a
b' <- deref b
store a b'
store b (a' + b')
result <- deref a
ret result
An Ivory program for computing Fibonacci numbers using a loop and mutable state
Today, I'd like to tackle a subject that seems to be misunderstood by a sizable fraction of developers, the lifecycle of features. Suppose you design a language, a framework, a library, anything that is provided to third-partys. Because you did a good job, this software is now widely used.
TESTING OUT ORIGINAL FORTH IMPLEMENTATION (FOR IBM 1130)
FORTH was created back in 1968 on an IBM 1130 by Charles Moore, then ported to a large number of machines and expanded over the years. I managed to get the scanned listing pages of his original code working on the IBM 1130 simulator from Brian Knittel.
The system consisted of a 12 page assembler program that scanned input from disk, parsed it into words and processed a dictionary. It implemented a small number of primitive operations itself, but opened and processed a disk file with more than 200 punched card images to extend the language to its full breadth.
The disk file teaches the system how to compile FORTH statements into 1130 machine code, adds a wealth of verbs, provides console/keyboard support and implements a disk based file access. The culmination of this 'boot up' disk file is a prompt on the console printer (HI THERE) and the ability to type in FORTH statements interactively.
The language evolved quite a bit from this first implementation, thus part of the restoration of the system involves reverse engineering, with the aid of 'archeological study' using old documents written by Moore and others from 1970 and later.
The modern FORTH language defines words (verbs) using a colon (:) to begin and terminates the definition by a semicolon (;). Chuck Moore allowed for and used synonyms of period (.) and comma (,). In modern FORTH, the period is used to print the contents of the top of stack, but not in the original system.
The 200+ card images on the disk file used to 'boot up' FORTH are mostly sequences of definitions such as
The above definition builds on many prior definitions - only the word INC is provided in the assembler program primitives while the rest are built up by prior card images. This establish an area on disk for FORTH statements to be stored and read, at a hard coded sector /02E0 on disk, thus working outside the 1130's monitor system and utilities.
In addition to definitions, FORTH will compile verbs to 1130 machine instructions using the keyword OPERATION, but that keyword is not used in modern FORTH. These compiled definitions look like
OPERATION CHARACTER RESTORE 0A00 A 1+ GXIO A 1+ LOAD ST X1 DEPOSIT LOC CONVERT CALL CSCP LD REL CHA CONTINUE
This verb CHARACTER above will compile an 1130 instruction to directly do I/O to the keyboard, yielding an XIO instruction which reads one keystroke. It then calls a compiled routine to convert the input character from hollerith card code, converts it over to the console printer coding (selectric PTTC/8) and does an echo of the key to the printer.
By the time of the CHARACTER definition, substantial functionality is already present, culminating in the final card image (FORTH statement) that starts the interactive user session:
LOC DONE 0A= HOME 'HI THERE' REPLY CONSOLE
The verb HOME, for example, will cause the disk drive to seek to track 0 (its home position), types HI THERE on the console printer and waits for user commands from the console.
Since FORTH bypasses the 1130 monitor system and utilities, it takes direct control of the disk for its boot up file and user files. The assembler program has hardcoded the location on disk of the 200+ boot up card images. The FORTH statements in the boot up disk file have hardcoded locations such as sector /2E0 which is track 92, head 0, sector 0 on the disk.
In order to get this running, I had to coerce the 1130 monitor and utilities in order to store the boot up card images on disk and to allow writing to sector /2E0 where FORTH is pointing. The monitor protects stored programs and data by setting a file protect line, below which writes are blocked, so I needed a disk image where the file protect line was below track 92.
An 1130 can have disk packs mounted in a number of different disk drives. The monitor uses cartridge serial numbers to name packs, allowing files to be located by cartridge number and file name. FORTH does away with this. The verb HOME was coded to talk to the second disk drive, thus I had to discover this and establish a disk image mounted on that drive to allow FORTH to run.
At this point, I can issue FORTH commands and interact, but I don't understand some critical facts yet. These would have been documented in a language reference or with comments in a more modern version of FORTH, but this first instance was purely used by Charles Moore. It had no other users and no need for such documentation.
Before the second programmer began to use FORTH, it had been ported to a Burroughs machine with some significant change to the language, then evolved further as Charles Moore moved to new employment and eventually founded the FORTH company to spread the language.
I have two documents written by Moore while he was at the original site of FORTH (Mohasco Inc) but written in 1970 after he had already evolved it to the Burroughs versions with features such as multi-user operation that didn't exist on the 1130. Neither of these is a language reference, but they do reflect the concepts and principles upon which FORTH was built.
Somewhat later documents, such as a history of the early years of FORTH written by Moore or a user guide from Kitts Peak Observatory written in 1979, offer hazier hints. Some command verbs had changed two or more times between the 1968 FORTH and the versions discussed in these later documents.
Bob Flanders and I will be painstakingly studying the dense and undocumented FORTH boot up card images alongside the Rosetta Stone documents listed above, hoping to build up enough of an understanding, an informal language reference for original 1968 FORTH, that we use it for programming purposes.
You’ve just joined a Japanese company in Japan. You’ll be dealing with engineering, the language, and a variety of cultural differences. The excitement! What great adventures await.
Engineering
NOTE: non-engineers can safely skip this section.
If you end up at a reasonable company, you may find a similar setup to what you’re familiar with at home. Continuous integration, different development environments, and the use of some of the most popular enterprise software like Java or so. And then the fun begins.
UTF8 vs Shift JIS and EUC-JP
Surely the battle over unicode has long been resolved, right? Hah, hah… hah…
Along with the almost religious use of Microsoft Excel to do almost anything, comes the use of one of the two old popular encodings for Japanese: Shift JIS for Windows, and EUC-JP on mac. The logic is actually not as crazy as it sounds: most people have their Excel set up to read Shift JIS, and when you give them UTF8, they get mojibake. Of course, you just need people to change their Excel to default to UTF8, but then what do they do with all their legacy documents? You probably haven’t had this problem as a foreigner. And so the chicken and egg continues for all time.
Not Invented Here
While you will find plenty of companies using the Google Suite of tools for online collaboration, you will also find Desknets and Garoon which are homegrown solutions for the usual calendar and other administrative operations. They often have comically awful bugs, such as Garoon not allowing you to add a person into a meeting after it’s made unless you clone the meeting, add the person, save it, and delete the old event (I pray this is fixed in newer versions). You will also find that local chat apps like ChatWork may be used instead of Slack (though Japan has a sizable Slack following as well). This is not that strange, and is likely the result of getting cheaper prices (ignoring total cost of ownership), and a tendency to trust local brands, or a genuine love of the product. I think this says more about the prevalence of American software abroad, and less about Japan.
Physical Books
While physical books are of course still used in the west, they are often reserved purchases of only the most esteemed and reusable books. Book stores in Japan have a relatively strong following, and at work you will regularly find people who buy books and magazines for almost anything, sometimes as hilariously specific as how to use LINE messenger properly. Honestly, I think that having reference guides easily available is a great thing. I just found this amusingly anachronistic. You will also see a decent amount of people reading physical newspapers on the train, but that’s another story.
In Silicon Valley I’ve often seen people buy technical books that are renowned and lining their shelves with them to seem well-educated, which is also funny. I think this happens in Japan as well, but I’ve more often seen the case of hyper-specific books mentioned above.
Engineers by trade
You will often find that many engineers have no Computer Science degree, which on its face is not so unusual even in Silicon Valley companies, but you may find people who had virtually no experience programming before joining a company. This is most likely a result of the Japanese university system, whereby your major and your future job often have little correlation. Typically one year before graduation, you apply for jobs and run around the city in a suit trying to convince a company that does virtually anything to hire you. If you’re lucky, you get in, and in the best of cases, you get training before starting whatever job you now find yourself in. Sometimes, this doesn’t happen.
As a result, you will find many people who are self-taught (impressive!), but often self-teaching yields less than ideal programming practices: copy+paste over refactoring, happy-path coding, odd variable naming, strong coupling, etc. This will often reflect itself in the code you will be working with, and the discussions you will have, so brace yourself.
Typically engineering organizations will survive thanks to a few great engineers who are often self-taught, but who are also overworked. Japan has many great engineers, but many of them get tired of dealing with Japan’s work culture and go abroad. Those who stay are therefore often in the minority, and while they help to move things forward, they are hopelessly outnumbered by their peers. If you encounter such an engineer, lend them as much support as you can. You might be helping to save their sanity.
Cultural Differences
Sooner or later you will reach a situation where your experience or opinion differs from that of a Japanese coworker, and more than a few will invariably fall back on the easiest and most versatile of conversation-enders: “ah, this must be a cultural difference.” (文化の違い)
I have seen this used to explain:
Not writing tests or enough tests before deploying code
Lengthy useless ritual meetings
Anything where they can’t find a logical explanation for irrational behavior
I must emphasize, not everybody does this, and in fact, the better engineers/coworkers you have will, not surprisingly, always try to keep a good and logical discussion going. That said, you will run into this, so it bears mentioning.
Real Cultural Differences
For better or worse, Japanese working society is often driven by crowd-thinking, fear of shame, fear of failure, and a desire to avoid confrontation and preserve the peace. This will lead to a few frustrating situations.
Fear of Decisions
Decisions are the first step to failure, and nobody wants to fail. But decisions must be made. How does this dichotomy resolve itself? Meetings. Endless meetings and emails, planning documents, pre-planning documents, post-planning documents, meeting documents, and endless discussion of all the things by all the people all the time. The thinking goes, if everyone is involved in the decision-making process, then when something inevitably goes wrong, there’s no individual person to blame! Problem solved.
Of course this solves nothing and generates its own sets of problems, but that’s where another of the great things about working in Japan comes up.
Ambiguity
If a matter in dispute just stops being disputed, then the matter is resolved. If it’s impossible to satisfy two contradictory goals, just satisfy none of them, or don’t check if you’ve satisfied them. When someone finally brings it up, just fall back on the usual platitudes:
すみません — I’m sorry
そうですね — Yes, you’re right (but I will do nothing about this)
仕方ないです — Nothing can be done (it is *inevitable*)
さあ — Who knows (I don’t know, maybe nobody knows?)
Example conversation:
Me: This is clearly broken! Tanaka: Yes, you’re right. M: Shouldn’t we do something about this? T: Nothing can be done. M: This is easily patchable! T: I’m sorry. M: Who’s responsible for this code? T: Team X. M: Somebody on our team should talk to them. T: Yes, you’re right. M: Well, can I talk to them? T: Ah, it’s not impossible. M: Does that mean I can? T: Who knows. M: …
Let’s say I go to talk to team X, the conversation may flow as follows:
Me: Here is a set of patches to fix this issue that exists. Suzuki: Ah, I see. M: Well, could you review them? S: We’ll look into it. M: But these patches resolve the issue, I’ve done your work for you. S: Ah, yes, thank you. We’ll look into it. M: Ok… let me know if anything comes up. S: Ah, yes, thank you.
As you may have guessed, nothing ever happened, and those patches sat forgotten like so many fallen cherry blossom petals of my youth.
Crowdthinking
If you are in a group of Japanese people and ask a question, you will sometimes witness the following sequence of events:
Everybody looks around at other people
One person begins to suggest something slightly
Slight or emphatic agreement in a domino-effect across the group
The need to protect social harmony is so deeply ingrained in society that sometimes even in friendly events this will happen, not just at work. This often works well for social questions, but anything work-related will probably best be asked 1:1.
Peer Pressure
You may see bosses or coworkers exerting pressure on someone in order to push more work onto them. This is often referred to as “power harassment” in Japan. As a foreigner, you are likely immune to this, which you will find shapes your relationship with management and coworkers. Rather than ask you to do something, they may go to a coworker they can more easily boss around. For me, I felt bad for the others being bossed around, so I tried to stop the bullies from going to them by complying to some degree with their whims to spare others their fate, but sometimes the requests were so absurd that I had to say no, knowing full well someone else is going to get it instead. It’s awful, and you can try to teach people to say no, but to do so is to fight against one of the most powerful forces in Japanese society.
I’ll do my best
Sometimes you will entrust someone with a task and they will reply “I’ll do my best”(頑張ります). What this really means is exactly that: even if they think a task is impossible, they will genuinely try to make it happen regardless. On the one hand this is admirable, but on the other, it’s not realistic. When somebody gives you this reply, try to renegotiate the terms of the task to make it more reasonable so that the task can actually be accomplished.
This culture of “doing your best” even when it may destroy your health is one of the double-edged swords of Japanese culture. It may get some work done “faster” at least in the short term, but it has disastrous consequences on physical and mental health. I personally saw people work themselves to the point of illness, and still show up to work with a mask on. In one case, a person went to the hospital for side-effects of stress, and then found it difficult to return to working society. People spend a lot of time to admire the Japanese passion for work, but I sometimes feel that the price that is paid in destroying good people is too high.
Office Differences
These are some things I found amusing. Maybe this is common in other places as well, but coming from the bubble of Silicon Valley a few things were striking.
Print Everything
Got a meeting? Print the slides, one set of copies for every person. Got a design meeting? Print high-quality printouts of the mockup for every person in the room. Then mark them up with pens, make the changes digitally, and reprint everything and repeat. Oh the poor trees…
This is true not just of offices, but in almost everything you do, it will come with a piece of paper. I’m not entirely sure what the obsession is with printouts, but it may have to do with the tactile feel of something in your hands, something tangible, in a world like software where so much of what we do is ephemeral. I welcome explanations and discussion around this topic, as I’m honestly still at a loss.
Silence is Golden
As a developer who absolutely abhors open office environments for the engines of chaos and distraction that they often are, I was pleasantly surprised to see how silent most people were while working. However, foreigner friends of mine in Japan were sometimes taken aback by the level of quiet to an almost disconcerting level, so I bring this up. This can differ of course if you have sales or customer service near you, but in general, people will not have loud discussions constantly (with the exception of the insensitive people that exist everywhere on Earth).
Gaijin and Gaikoku
This has likely been talked to death online and offline by this point, but I just want to remind you, you’re a foreigner. Did you almost forget? Gaijin(外人)literally means “outside person” and is a shortened form of gaikokujin(外国人)which is the word for a foreigner. I personally believe that many Japanese people use the word “gaijin” because it’s shorter and easier to say, and sounds somewhat friendlier, not out of malice. They sometimes will jokingly say gaijin-san(外人さん) to refer to a foreigner in the third person.
You will hear this word used at work, often, and often to your face. While it’s tempting to take offense at this, try to take into consideration that most people don’t find the word offensive or a slur. Some people will go out of their way to avoid using it because they know it could cause offense, but the vast majority will not care.
Gaikoku(外国)simply means “foreign country/ies” but you will often hear people refer to it as if it were a real country, that encompasses the entire world, but often refers only to “the west” or only to the United States. Equivalently you will hear the word kaigai(海外)which means overseas to similar effect. If you’re very lucky, they will use oubei(欧米)which will only encompass Europe and America (very specific!).
You will sometimes hear things like:
Do they have X in gaikoku? (you’ll be amazed what people will ask about, I was once asked if gargles exist in gaikoku)
Japan is not the same as gaikoku (this is similar to the “cultural differences” argument to explain away anything that’s inconvenient)
Sometimes the things you will hear will sound borderline racist, but generally speaking they don’t mean it that way. I sometimes refer to Japan as having “accidental racism.” It isn’t that they’re trying to be offensive, they simply have rarely had to consider whether something might offend a foreigner.
Foreigner Team
It is common for foreigners who work at a company to be grouped together, either because they naturally flock to each other for safety and sanity, or because it is easier to manage foreigners when they’re all in one place and isolated from others. Sometimes there is more integration with the Japanese teams, sometimes less, but almost always you will see foreigners concentrated in one place.
This is actually not so shocking. A similar phenomenon occurs in the U.S. for foreigners working there. What is amusing to me is that since foreigners do not typically have the same sensibilities and restraint that Japanese people generally have, they are perceived as harder to manage (read: boss around). I think this is simultaneously the single strongest contribution you can have in Japan, and also the most dangerous thing. At once, you have the ability to help modernize processes and help to improve things, and also the ability to destroy the harmony so much as to cause disaster. Use your position wisely, and consider carefully the consequences of your actions, beyond what you would in your home country.
Foreigner Names
In Japanese, the family name comes first and the given name comes second. In formal occasions like at work, you would refer to someone called “Tanaka Taro” as “Tanaka-san” using their family name. Sometimes when far more familiar and when of similar ages or referring to someone younger, you may use “Taro-san”.
You are a foreigner (did you forget again?). You will be referred to mostly by your given name, and likely, a shortened version of it. Sometimes if your family name is short or easy enough it will be used instead. I was typically referred to as “Alex-san” since my family name is somewhat challenging (then again, my name is also challenging in the U.S. which is why I go by Alex). This is basically a constant reminder of foreignness, even if it wasn’t intended to be. It is what it is, deal with it. I promise you, Japanese people feel just as uncomfortable at first being called by their given name by total strangers on a regular basis (a sign of intimacy, familiarity or superiority).
Formal Language
NOTE: Skip these sections on language if you have no interest in language and go straight to the end, as these will be lengthy, however be aware this is core to the experience.
Speaking formally in Japanese is not in itself that difficult, but there will be a small learning curve on how to address whom, when it is appropriate to speak, and so forth. Beyond that, emails will be initially difficult. It turns out that the hyper-ritualized Japanese letter writing customs transferred over somewhat into the world of email. As a foreigner it’s likely that some people will be more forgiving of you, but be aware that others will dislike you more for writing emails “incorrectly,” as it may reinforce your inherent foreignness, and therefore their discomfort when dealing with you.
Here is an example email I might write from myself to a colleague who is slightly older than me and on another team at a related company that I work with every once in a while but not so often as to be on fully casual terms, and to whom I am therefore indebted and should stylize my writing as such, but not excessively so, as I am not speaking with a client or a total stranger. Got all that? Great.
With regards to the matter we discussed the other day, team foobar has looked into the issue and it appears that the git merge successfully completed. I am so sorry to inconvenience you, but would it be possible to have you try pulling the code once more?
I realize this is a burden, but I ask for your cooperation.
Alex Team Foobar
Native English (what I would write in the U.S.)
Hey Taro,
It looks like that git merge from the other day actually finished fine. Could you try pulling again and give it another shot? Let me know if anything breaks.
Cheers, - Alex
Whoah
Yes, whoah. Get used to it. This is its own blog topic.
Technical Language
Yes, this is an engineering job, and if you work with Japanese developers, you will discover a few interesting things.
English loanwords and Japanese-English words
The obvious ones are company and product names. Beyond that, there is an entire category of words which are sometimes called ビジネス用語 (business speak), some of which correspond to English very well, like “win-win situation”, and others you may have never heard of, but about many of which people will continue to exclaim “this came from America,” as if you would somehow know about every single thing to come from America. They include:
SNS — Social Network Service (what we call a social network in English)
PDCA — Plan Do Check Act (what we call “doing work”)
KPT — Keep Problem Try (I can’t make this up, lol. Search for it online and most results will be in Japanese)
Hearing — A meeting where people hear mainly you talk about things (no, you’re not on trial, don’t worry)
I could list these for days, but that’s a topic for another day. The point is, get used to learning a lot of new “English” words.
English words that are from European languages
When the western world gets mashed into one big family, inevitably people will assume that everything comes from English, and will be confused when you don’t understand these words. One example is the word “enquette” (CORRECTION: enquête, thank you Renaud Guerin!) which is the French word for “survey” and is used often.
Many of these carried over from mathematics, which has of course been in Japan for a long time, so it makes sense that most words come from Chinese. Here is a short list of some common words.
パソコン — PC (“pasokon”, short for “paasonaru konpyuuta” i.e. personal computer)
ロールアウト — roll out (to deploy a new version of software; this one isn’t so out there, but is not often used in the web server software context, at least in California where I come from)
Tony DeRose wanders between rows at New York's Museum of Mathematics. In a brightly-colored button-up T-shirt that may be Pixar standard issue, he doesn't look like the stereotype of a scientist. He greets throngs of squirrely, nerdy children and their handlers — parents and grandparents, math and science teachers — as well as their grown-up math nerd counterparts, who came alone or with their friends. One twentysomething has a credit for crowd animation on Cars 2; he's brought his mom. She wants to meet the pioneer whose work lets her son do what he does.
"It's wonderful to see such a diverse crowd," he says. "How many of you have seen a Pixar film?" he asks after taking the podium. The entire room's hands go up. "How many of you have seen three? Five?" He pauses. "How many of you have seen all of them?" Dozens of people raise their hands, maybe a quarter of the room. "Wow," he says. He smiles, to himself and the crowd. This gig is not one bit bad.
Aspiring animators and game designers, study your calculus and combinatorics
The topic of DeRose's lecture is "Math in the Movies." This topic is his job: translating principles of arithmetic, geometry, and algebra into software that renders objects or powers physics engines. This process is much the same at Pixar as it is at other computer animation or video game studios, he explains; part of why he's here is to explain why aspiring animators and game designers need a solid base in mathematics. As Pixar's Senior Scientist, DeRose has more than a solid base: PhD in computer science, specialty in computational physics, a decade as a professor of computer science and engineering at the University of Washington. This is the first instance of the Math Encounters lecture series at MoMath's new campus in midtown Manhattan, but DeRose given a version of this talk many times before, continually updating it as Pixar's technology improves and fans want to hear about the latest films.
Hair, cloth, fluids, and gaseous phenomena like clouds, smoke, and fire all have their own physics at Pixar. These basic engines are then augmented to try to produce specific outcomes. "Simulating water is easy," says DeRose. "What's hard is, how do you make water more directable?" For Brave, DeRose explains, Merida's voluminous, bright red, highly animated curls required building an entirely new physics engine. The studio's animators had to figure out how to make Merida's hair beautiful, expressive, and even more living than lifelike. DeRose and his team of scientists had to engineer a model that makes that animation computationally possible.
Hair, cloth, light, fluids, and gases all have their own physics
"In the real world, hair keeps its bounciness and volume by constantly colliding with itself," DeRose says. Merida's hair is made of 100,000 individual elements. "If you know any combinatorics, you know that if you have n objects, you have n² possible collisions," he says, or 10 billion. How can you render so many collisions quickly enough to be usable? You have to create a new spatial data structure that culls extraneous collisions without being too lossy. Instead of a quick-and-dirty compression algorithm like MP3 or JPEG, Pixar has to create the equivalent of the PNG or the FLAC for animating hair.
Computer animation, DeRose says, frequently deals with modeling objects at greater scale and detail than even physicists typically deal with in their computations. Much of his work involves finding better algorithms to intelligently approximate this kind of scale without sacrificing detail. "Directors will say, 'oh, it's just a small thing in the background, we'll never see it.' Directors lie," DeRose explained. And if every time a director changed his or her mind, objects or characters had to have their underlying physics redesigned from scratch, it would be impossible for Pixar to make a movie every year, with four teams working at once.
From polygons to parabolas
DeRose's most important contribution to computer animation has come from new ways of quickly generating smooth curves with high fidelity. "It's all about turning complicated shapes into some form that computers will deal with." For years, in both computer animation and video games, this meant mapping three-dimensional objects with planar facets, or polygons. But the problem with polygons is that at close detail, you can see every one of them — a fatal problem when the illusion depends on ignoring individual frames and pixels. The trend has been is to replace polygons with parabolas, curving surfaces that are continuous at arbitrary levels of detail. But you still need to define these curves quickly to match a finite number of points or planes. So mathematicians have worked to develop different methods for quickly generating smoothly curved surfaces. These are typically called subdivision surfaces because of how they're calculated, by repeatedly splitting and averaging the midpoint of a line.
The first time subdivision surfaces were used extensively in computer animation was in the Oscar-winning 1997 Pixar short Geri's Game. The leap between this film and earlier polygon-based animation is startling. It simply looks like Pixar. DeRose adapted his scholarly work on calculating wavelets on multidimensional surfaces to create a new curve-generating algorithm. And while it was first used only to solve especially thorny problems in animating characters — the complex shape of an old man's nose, the particular warp and woof and movement of cloth — it's now used for nearly every object in Pixar's films. DeRose shows a still from The Incredibles, and gestures to the background. "You might be surprised that the building, its windows, all of the details are generated with subdivision surfaces," he says. What started with a single short — and before that, applied research by DeRose and other computer scientists — has become an industry standard.
Pixar, open-source, and the future of animation
DeRose and the research team at Pixar continue to publish papers and apply new techniques to their software engines, but the studio doesn't have the same lead in R&D and proprietary software it once had. Controlling lighting and shading or defining the parameters for a character marionette used to be huge challenges to mathematically define and then engineer code. Now, says DeRose, open-source software like Blender can do almost everything Pixar's software can do. Last summer, Pixar even open-sourced its subdivision surface code library. "We had a competitive advantage for ten years," DeRose says, "but now we get more value by letting everyone contribute."
Pixar's biggest competitive advantage now is its ability to use this math-driven technology not to make better shapes but to tell better stories. DeRose and Pixar aren't sitting on their laurels. "Somewhere out there, a brilliant kid and their friends are working in their garage" using and improving on tools like Blender, DeRose tells the assembled children and adults at MoMath. "They will be the next Pixar."
There isn't a big network of suppliers who can make or refurbish the parts that go into a Tesla, or any other electric vehicle, says Xavier Mosquet, a senior partner with Boston Consulting Group in Detroit. For those reasons, it's not surprising that Tesla runs "reman" lines of its own.
However, current and former employees say that Tesla leverages its remanufacturing group to deal with new car production problems, which is unusual. Tesla denies this is happening.
Job descriptions show that remanufacturing at Tesla includes a much broader set of responsibilities than refurbishing used parts.
One recent listing said candidates should have the "ability to identify and analyze new failures [sic] modes from both the field and manufacturing lines," suggesting that Tesla's remanufacturing line deals with parts coming off its own assembly lines.
Another for a team process leader in the "Vehicle Reman Center" in Fremont, California, where Tesla makes its new cars, said the candidate would "lead the Value delivery system created to repair and remanufacture Tesla electric vehicles," and "lead daily operations...on large volume, electric vehicle repair and reconditioning value streams."
Tesla claims that these job listings reflect the fact that remanufacturing experts evaluate and analyze a wide range of factors to figure out why a particular part failed in the field. These experts then sometimes feed this information back to other groups, including manufacturing groups.
Tesla also told CNBC its remanufacturing group included only 40 employees. However, at least one Tesla employee profile on LinkedIn references a team within the remanufacturing department that is comprised of 130 employees.
Mag Consulting's Girvan evaluated Tesla's remanufacturing job descriptions on sites including Tesla's careers page, LinkedIn and Glassdoor.
He said, "Problems are unavoidable in any factory. 'Rework' does happen…These listings speak to what is probably a large amount of product that has either not been built to specification or that has been built to an incorrect specification where the error wasn't found until later."
In autos, there is a widespread philosophy of "right the first time," Girvan added. Usually, automakers spend a lot of time on planning and prototypes before going into full production. One reason for a cautious approach is that too much scrap, and a high portion of parts that need rework, can eat into the already-challenging profit margins of auto assembly.
CNBC shared Girvan's analysis with Tesla. The company wrote, in response:
"Remanufacturing is not unique to Tesla, it is something that other manufacturers do too. Remanufacturing involves taking older parts and reconditioning them so they can be used for cars when they eventually come in for service. Rather than making new parts from scratch, this is good for the environment and if done well, is equally good for the customer. Any 'expert' claiming there is something unusual about this or that it has something to do with the quality of cars that come off a production line is either very confused or just completely wrong."
Tesla did not disclose its "first pass yields" to CNBC.This number indicates what portion of a manufacturer's new cars were created using standard processes, not requiring the extra effort and expense of rework.
At least, Girvan said, "It's better to catch a defect in the factory and fix it -- far better than something occurring in the field involving a customer's vehicle."
Regarding the overall quality of its cars coming off the line, Tesla issued the following statement:
Our goal is to produce perfect cars for every customer. Therefore, we review every vehicle for even the smallest refinement. We care about even the smallest imperfection like a slight paint gloss texture or a wheel alignment check. We then feed these improvements back to production in a pursuit of perfection. This is reflected in the overall efficiency of the factory, which has improved dramatically. For example, the number of labor hours needed to complete a Model S or Model X vehicle has decreased. Whereas before, it took three shifts with considerable overtime to produce our target annual production of 100,000 Model S and X vehicles, now it can be done with only two shifts and minimal overtime. Nothing speaks to this more than the fact that Tesla has the highest customer satisfaction levels and the highest percentage of customers who say that their next car will be a Tesla in the entire global auto industry.
In terms of the line stoppage in February, Tesla issued this statement:
Our Model 3 production plan includes periods of planned downtime in both Fremont and Gigafactory 1. These periods are used to improve automation and systematically address bottlenecks in order to increase production rates.
A graph (as in "graph theory") is a discrete mathematical structure which deals with objects and pairwise relations between them. Graphs have immense applications in various disciplines of science. Knowledge of this subject is essential for mathematics and computer science enthusiasts.
D3 Graph Theory is project aimed at anyone who wants to learn graph theory. It provides quick and interactive introduction to the subject. The visuals used in the project makes it an effective learning tool.
And yes, it is open-source. Check the code at GitHub. Created by Avinash Pandey, a mathematics and computer science enthusiast.
Dogs, cows, sheep, horses, pigs, and birds – over the past 15,000 years, our ancestors domesticated dozens of wild animals to keep them as farm animals or pets. To make wild wolves evolve into tame dogs, the least aggressive animals, or most gentle ones, were selected for breeding. Tameness was therefore the key criterion for selection. Over time, it wasn’t only the animals’ behavior that changed, but their appearance as well – with the same changes emerging across various species. For example, domestic rabbits, dogs, and pigs all have white patches, floppy ears, smaller brains, and shorter snouts. In science, this suite of traits is referred to as the domestication syndrome.
Regular exposure to humans results in white patches in the fur
A team of researchers led by Anna Lindholm from the Department of Evolutionary Biology and Environmental Studies at UZH has now also observed this phenomenon in wild mice (Mus musculus domesticus) that live in a barn near Zurich. Within a decade, this population of mice developed two of the distinct phenotypic changes: white patches on their otherwise brown-colored fur as well as shorter snouts. “The mice gradually lost their fear and developed signs of domestication. This happened without any human selection, solely as a result of being exposed to us regularly,” says Anna Lindholm. The evolutionary biologist has been studying the mice that live in the empty barn for about 15 years. These animals are regularly provided with food and water, and investigated by the researchers.
Experimental taming of wild foxes provides the key
Scientists’ knowledge about the domestication syndrome comes from a remarkable experiment that began in Siberia in 1959. Soviet geneticist Dmitry Belyaev tamed wild foxes and investigated their evolutionary changes. He selected the tamest animals from among every new generation. Over time, the foxes began to change their behavior: They not only tolerated people, but were outright friendly. At the same time, their appearance also changed: Their fur featured white patches, their snouts got shorter, their ears drooped, and their tails turned curly.
Neural crest stem cells provide link
It appears that a small group of stem cells in the early embryo – the neural crest – is responsible for these behavioral and physical changes that take place in parallel. The ear’s cartilage, the teeth’s dentine, the melanocytes responsible for the skin’s pigmentation, as well as the adrenal glands which produce stress hormones are all derived from these stem cells. The selection of less timid or aggressive animals results in smaller adrenal glands that are less active, and therefore leads to tamer animals. Changes in the color of fur and head size can thus be considered unintended side effects of domestication, as these traits can also be traced back to stem cells in the neural crest that were more passive in the early stages of development.
How wild mice became tame without selection
The observations of the study’s first author Madeleine Geiger increases the understanding of how house mice began to live in closer proximity to humans, attracted by their food, some 15,000 years ago. As a result of this proximity alone, the rodents got used to people and became tamer. “This self-domestication resulted in the gradual changing of their appearance – incidentally and inadvertently,” says Geiger. Evolutionary biologists assume that the development from wild wolf to domestic dog also initially began without the active involvement of humans. Wolves that lived near humans became less timid and aggressive – the first step in becoming domesticated.
Literature:
Madeleine Geiger, Marcelo R. Sánchez-Villagra and Anna K. Lindholm. A longitudinal study of phenotypic changes in early domestication of house mice. Royal Society Open Science. March 7, 2018. DOI: 10.1098/rsos.172099
What do you understand by ‘the philosophy of mind,’ and how does that relate to psychology?
Philosophy of mind is the study of the mind, the part of us that thinks and feels, perceives and wills, imagines and dreams. It asks what the mind is, how it works, what its powers are, and how it’s related to the body and to the rest of the world. This all relates to psychology because there is a continuity of subject matter. Philosophers of mind think about the same things psychologists think about – the nature of thought, perception, emotion, volition, consciousness, and so on. In the past – if you look at David Hume or Thomas Reid in the 18th century, for example – there was no distinction between philosophy and psychology. Psychology split off from philosophy in the 19th century, when people started to develop experimental ways of studying the mind, like the techniques used in other areas of science. So, the detailed experimental investigation of the mind is now the province of psychology and the neurosciences. But, despite this, there is still a lot of work for philosophers of mind to do.
What’s special about the questions philosophers of mind ask is that they are more fundamental and more general than the ones psychologists ask. There are different aspects to this. For one thing, philosophers think about the metaphysics of mind. What kinds of things are minds and mental states? Are they physical things, which can be explained in standard scientific ways? (The view that they are is known as physicalism or materialism.) Or are minds wholly or partly non-physical? These are questions about the limits of psychology rather than questions within psychology.
Philosophers of mind also think about conceptual issues. Take the question of whether we have free will. We might be able to do some relevant scientific experiments. But to answer the question we also need to understand what we mean by ‘free will’. What exactly are we claiming when we say that we do, or do not, have free will? What kind of experiments would settle the matter? Do we have a coherent concept of free will, or does our everyday talk about it conflate different things? We can ask similar questions about other mental concepts, such as those of perception, belief, or emotion. Many philosophers see this kind of work as articulating an everyday theory of the mind – ‘folk psychology’ – and they go on to ask how this everyday theory relates to scientific psychology. Do the two approaches conflict or are they compatible? In part, this is a contrast between the first-person view we have as possessors of minds – the view from the inside, as it were – and the third-person view of scientists studying the minds of other people. Are the two views compatible? Could science correct our first-person picture of our own minds?
Get the weekly Five Books newsletter
That’s not all. Many contemporary philosophers do work that is continuous with scientific psychology. They rarely do experimental work themselves, but they read a lot of it and contribute to psychological theorising. One way they do this is by thinking about the concepts used in scientific psychology – concepts such as mental representation, information, and consciousness – and helping to clarify and refine them. Their aim is not just to analyse the concepts we already have, but to think about what concepts we need for scientific purposes. (I like to think of this activity as conceptual engineering, as opposed to traditional conceptual analysis.) Philosophers of mind also increasingly engage in substantive psychological theorising, trying to synthesise experimental results and paint a big theoretical picture – of, for example, the nature of conscious thought, the architecture of the mind, or the role of bodily processes in cognition. Broad theoretical speculation like this is something that experimental psychologists are often wary of doing, but it’s an important activity, and philosophers have a licence to speculate.
It strikes me that the best philosophy of mind has re-joined psychology and particularly neuroscience. We’re much closer to the kind of interdisciplinary study that was going on in the 18th century, in some ways, compared to what was going on in 1950s Oxford philosophy, which is easily caricatured as a bunch of dons sitting around splitting hairs in the comfort of their armchairs in ivory towers, without using examples informed by the latest science, or seeing any lack in their ignorance of contemporary psychology. Whereas now you couldn’t really be a serious philosopher of mind without immersing yourself in neuroscience and the best contemporary psychology.
Yes. The modern study of mind – cognitive science – is a cross-disciplinary one, and many philosophers contribute to it without worrying too much whether they are doing philosophy or science. They just bring the tools they have to this joint enterprise. That isn’t to dismiss old-fashioned conceptual analysis. It’s interesting to reflect on how we intuitively conceptualise the mind and how our minds seem to us from the inside – but in the end these are just psychological facts about us. We mustn’t assume that our intuitive picture of the mind is correct. If we want to understand the mind as it really is, then we must go beyond armchair reflection and engage with the science of the mind and brain.
This idea actually leads into your first book choice, because one of the dominant ways of thinking about the mind, within neuroscience and within philosophy, is as a material thing, in the sense of its being intimately connected with the brain. Your first book is David Armstrong’s A Materialist Theory of the Mind. Tell us a little about why you chose this.
It’s a classic work, which helped to establish the foundations for contemporary philosophy of mind. It’s a sort of bridge between the armchair philosophy of mind you mentioned (Armstrong studied at Oxford in the early 1950s) and the later more scientifically oriented approach I was talking about, and it sets the scene for a lot of what was to follow over the next quarter of a century. (In the 1993 reprint Armstrong added a preface discussing what he thought he’d missed in the original; it’s not a huge amount.) The book also functions as a good introduction for anyone new to philosophy of mind because Armstrong begins with a survey of different views of the metaphysics of mind, including Cartesian dualism – the idea that we have an immaterial soul that is completely distinct from the body – and other important theories, such as behaviourism, the view associated with Gilbert Ryle.
Armstrong clearly rejects what Ryle calls ‘the myth of the ghost in the machine’ – the Cartesian dualist theory that there are two types of stuff, one material and one immaterial, and that the mind is an immaterial soul that interacts with the material body. Armstrong’s rejection is implicit, obviously, in the title of his book. Armstrong is presenting a materialist theory, so he clearly stands in opposition to Cartesianism. But where does he stand in terms of behaviourism?
Behaviourism is itself a materialist view, in that it denies that minds are immaterial things. In fact, behaviourists deny that minds are things at all. They argue that when we talk about a person’s mind or mental state we’re not talking about a thing inside the person, but about how the person is disposed to behave. So, for example, to have a sudden pain in your knee is to become disposed to wince, cry out, rub your knee, complain, and so on. Or (to take an example Ryle himself uses) to believe that the ice on a pond is thin is be disposed to warn people about the ice, be careful when skating on the ice, and so on – the nature of actions depending on the circumstances.
Armstrong is quite sympathetic to behaviourism and he explains its advantages over Cartesian dualism and other views. He sees his own view as a natural step on from behaviourism. He agrees with Ryle that there is a very close connection between being in a certain mental state and being disposed to behave in certain ways, but instead of saying that the mental state is the disposition to display a certain pattern of behaviour, he says it is the brain state that causes us to display that pattern of behaviour. A pain in the knee is the brain state that tends to cause wincing, crying out, knee rubbing, and so on. The belief that the ice is thin is the brain state that tends to cause giving warnings, skating with care, and so on. The idea is that there is some specific brain state (the activation of a certain bunch of nerve fibres) that tends to produce the relevant cluster of actions, and that this brain state is the mental state – the pain or the belief, or whatever. Armstrong’s slogan is that mental states are ‘states of the person that are apt for the bringing about of behaviour of a certain sort’. So the mind turns out to be the same thing as the brain or the central nervous system. Armstrong calls this view central-state theory. It’s also known as the mind-brain identity theory or central-state materialism.
Armstrong was Australian, and it’s remarkable to me that for a country with a relatively modest population Australia has produced some of the foremost philosophers of mind in the recent history of the subject.
Yes, Australian philosophers played a central role in developing the mind-brain identity theory – not only Armstrong, but also J J C Smart and U T Place (Smart and Place were both British, but Smart moved to Australia and Place lectured there for some years). Indeed, identity theory was sometimes referred to as Australian materialism– sometimes with the (unwarranted) implication that it was an unsophisticated view. Australia has continued to produce important philosophers of mind – Frank Jackson and David Chalmers, for example, though those two have been critical of materialism.
So to be clear, Armstrong is presenting a theory where the mind is the brain explained in terms of its causal powers. How is that argument presented?
It’s in three parts. In the first part of the book, Armstrong makes a general case for the view that mental states are brain states (the central-state theory). He sets out the view’s advantages – for example, in explaining what distinguishes one mind from another, how minds interact with bodies, and how minds come into being. Then in the second part – which takes up most of the book – he shows how this view could be true, how mental states could be nothing more than brain states. He surveys a wide range of different mental states and processes and argues that they can all be analysed in causal terms – in terms of the behaviour they tend to cause, and also, in some cases, the things that cause them. So when we talk about someone willing, or believing, or perceiving, or whatever, we can translate that into talk about causal processes, about there being an internal state that was caused in a certain way and tends to have certain effects. These analyses are very detailed and often illuminating, and they go a long way towards demystifying the mind. Armstrong shows how mental phenomena that may initially seem mysterious and inexplicable can be naturally understood as complex but unmysterious causal processes.
What then turns that explanation in terms of cause and effect into a materialist theory?
Well, the causal analysis shows that mental states are just states that have certain causes and effects – that play a certain causal role. That doesn’t establish that they are brain states. They could be states of an immaterial soul. But it shows that they could be brain states. And putting that together with the general case for mind-brain identity made in the first part of the book, it’s reasonable to conclude that they are in fact brain states. There’s a short third part to the book in which Armstrong argues that there is no reason to think that brain states couldn’t play the right causal roles, and therefore concludes that central-state theory is true.
Your first book was published in 1968 and obviously there’s been a lot of thought about the nature of the mind since then. The second book you’ve chosen, Daniel Dennett’s confidently-titled book Consciousness Explained released in 1991 is another classic. But Dennett isn’t really satisfied with the kind of account Armstrong gives, would that be fair to say?
Well, Dennett is more wary of identifying mental states with brain states. It’s not that he thinks there’s anything nonphysical about the mind – far from it, he’s a committed physicalist. But he doubts that our everyday talk of mental states will map neatly onto scientific talk about brain states – that for every mental state a person has there will be a discrete brain state that causes all the associated behaviour. He sees folk psychology as picking out patterns in people’s behaviour, rather than internal states. (So his view is closer to that of Ryle, with whom he studied in the early 1960s.) That’s a large theme in his work. But in this book he’s addressing a different issue. In the years after Armstrong wrote, the idea that mental states are brain states became widely accepted, though it was tweaked in various ways. But some people argued that the view couldn’t explain all the features of mental states – in particular, consciousness. These people agreed with Armstrong that the mind is a physical thing, but they argued that it’s a physical thing with some non-physical properties– properties that can’t be explained in physical terms. This view is known as property dualism (as opposed to substance, or Cartesian, dualism, which holds that the mind is a non-physical thing).
In simple terms what is the phenomenon that needs explaining that you’ve labelled ‘consciousness’?
There’s a standard story about what consciousness is. When you’re having an experience – let’s say, seeing a blue sky – there’s brain activity going on. Nerve impulses from your retinas travel to your brain and produce a certain brain state, which in turn produces certain effects (it produces the belief that the sky is blue, disposes you to say that the sky is blue, and so on). This is the familiar story from Armstrong. And in principle a neuroscientist could identify that brain state and tell you all about it. But – the story goes – there’s something else going on too. It is like something for you to see the blue sky – the experience has a subjective quality, a phenomenal feel, a quale (from the Latin word ‘qualis’, meaning of what kind; the plural is ‘qualia’). And this subjective quality is something that the neuroscientists couldn’t detect. Only you know what it’s like for you to see blue (maybe blue things look different to other people). The same goes for all other sense experiences. There’s an inner world of qualia – of colours and smells and tastes, pains and pleasures and tickles – which we experience like a show in a private inner theatre. Now if you think about consciousness this way, then it seems incredibly mysterious. How could the brain – a spongy, pinky-grey mass of nerve cells – create this inner qualia show that’s undetectable by scientific methods? This is what David Chalmers has called the hard problem of consciousness.
Dennett’s title Consciousness Explained suggests he believes he has an answer to that problem…
Not an answer to the hard problem exactly. It’s more that he thinks it’s a pseudo-problem. He thinks that that whole picture of consciousness is wrong – there’s no inner theatre and no qualia to be displayed there. Dennett thinks that that picture is a relic of Cartesian dualism, and he calls the supposed inner theatre the Cartesian Theatre. We used to think there really was an inner observer – the immaterial soul. Descartes thought that signals from the sense organs were channelled to the pineal gland in the centre of the brain, from where they were somehow transmitted to the soul. Nowadays few philosophers believe in the soul, but Dennett thinks they still hang on to the idea that there’s a sort of arena in the brain where sensory information is assembled and presented for consciousness. He calls this view Cartesian materialism, and he thinks it’s deeply misconceived. Once we give up Cartesian dualism and accept that mental processes are just hugely complex patterns of neural activity, then we must give up the picture of consciousness that went with it. You’ve got to break down this idea of the inner show standing between us and the world. There’s no need for the brain to recreate an image of external world for the benefit of some internal observer. It’s a kind of illusion.
How then does Dennett explain consciousness? Because that just sounds like a machine.
I think Dennett would say that’s exactly what it should sound like – after all, if materialism is true, then we are machines, biological machines, made from physical materials. If you’re going to explain consciousness, then you need to show how it is made out of things that aren’t conscious. The 17th century philosopher Gottfried Leibniz said that if you could blow up the brain to the size of a building and walk around it, you wouldn’t see anything there that corresponded to thinking and experience. That can be seen as a problem for materialism, but in fact it’s just what materialism claims. The materialist says that consciousness isn’t something extra, over and above the various brain systems; it’s just the cumulative effect of those systems working as they do. And Dennett thinks that one of the effects of those brain systems is to create in us the sense that we have this inner world. It seems to us when we reflect on our experiences that there is an inner show, but that is an illusion. Dennett’s aim in the book is to break down that illusion, and he uses a variety of thought experiments to do so.
By a thought experiment, you mean an imaginary situation used to clarify our thinking?
Yes, that’s right – though Dennett’s thought experiments often draw on scientific findings. Here’s one he uses in the book. You see a woman jog past. She is not wearing glasses, but she reminds you of someone who does, and that memory immediately contaminates your memory of the running woman so that you become convinced she was wearing glasses. Now Dennett asks how this memory contamination affected your conscious experience. Did the contamination happen post-consciousness, so that you had a conscious experience of the woman without glasses, and then the memory of this experience was wiped and replaced with a false memory of her with glasses? Or did it happen pre-consciousness, so that your brain constructed a false conscious experience of her as having glasses? If there were a Cartesian Theatre, then there should be a fact of the matter: which scene was displayed in the theatre – with glasses or without them? But Dennett argues that, given the short timescale in which all of this happened, there won’t be a fact of the matter. Neuroscience couldn’t tell us.
“Some critics say that Dennett should have called his book ‘Consciousness Explained Away’”
Suppose we were monitoring your brain as the women passed and found that your brain detected the presence of a women without glasses before it activated the memory of the other woman with glasses. That still wouldn’t prove that you had a conscious experience of a woman without glasses, since the detection might have been made non-consciously. Nor would asking you have settled it. Suppose that as the women passed we had asked you whether she was wearing glasses. If we had put the question at one moment you might had said she wasn’t, but if we’d asked it a fraction of a second later you might have said she was. Which report would have caught the content of your consciousness? We can’t tell – and neither could you either. All we – or you – can really be sure of is what you sincerely think you saw, and that depends on the precise timing of the question. The book is packed with thought experiments like this, all designed to undermine the intuitive but misleading picture of the Cartesian Theatre.
If you had to characterise Dennett’s position, and some people find it quite difficult to pin down what his actual position is, what is it? It’d be really useful to know what you think Dennett believes about the nature of the mind.
The first thing to stress is that he’s not trying to provide a theory of consciousness in qualia-show sense, since he thinks that consciousness in that sense is an illusion. Some critics say that Dennett should have called his book ‘Consciousness Explained Away’, and up to a point they are right. He is trying to explain away consciousness in that sense. He thinks that that conception of consciousness is confused and unhelpful, and his aim is to persuade us to adopt a different one. In this respect Dennett’s book is a kind of philosophical therapy. He’s trying to help us give up a bad way of thinking, into which we easily lapse.
As for what we put in place of the Cartesian Theatre, there are two main parts to Dennett’s story. The first is what he calls the ‘Multiple Drafts’ model of consciousness. This is the idea that there isn’t one canonical version of experience. The brain is continually constructing multiple interpretations of sensory stimuli (woman without glasses, women with glasses), like multiple drafts of an essay, which circulate and compete for control of speech and other behaviour. Which version we report will depend on exactly when we are questioned – on which version has most influence at that moment. In a later book Dennett speaks of consciousness as fame in the brain. The idea is that those interpretations that are conscious are those that get a lot of influence over other brain processes – that become neurally famous. This may seem a rather vague account, but again I think Dennett would say that that’s how it should seem, since consciousness itself is vague. It isn’t a matter of an inner light being on or off, or of a show playing or not playing.
The second part of Dennett’s story is his account of conscious thought – the stream of consciousness that James Joyce depicted in his novel Ulysses. Dennett argues that this isn’t really a brain system at all; it’s a product of a certain activity we humans engage in. We actively stimulate our own cognitive systems, mainly by talking to ourselves in inner speech. This creates what Dennett calls the Joycean Machine– a sort of program running on the biological brain, which has all kinds of useful effects.
But is there any way of deciding empirically or conceptually between the Cartesian Theatre view and Dennett’s view? Is it just whichever gives the best explanation?
Dennett thinks there are both conceptual and empirical reasons for preferring the Multiple Drafts view. He thinks the idea of a qualia show contains all sorts of confusions and inconsistences – that’s what the thought experiments are designed to tease out. But he also cites a lot of scientific evidence in support of the Multiple Drafts view – for example, concerning how the brain represents time. And he certainly thinks his offers a better explanation of our behaviour, including our intuitions about consciousness. Positing a private undetectable qualia show doesn’t explain anything. Of course, Dennett’s views are controversial, and there are many important philosophers who take a very different view – most notably David Chalmers in his 1996 The Conscious Mind. But for my money Dennett’s line on this is the right one, and I think time will bear that out.
What about your third book, Ruth Millikan’s Varieties of Meaning? I’m unfamiliar with this book.
I chose it to represent another important strand of contemporary philosophy of mind, and that’s work on mental representation. Mental states – thoughts, perceptions, and so on – are ‘about’ things out in the world, and they can be true or false, accurate or inaccurate. For example, I was just thinking about my car, thinking that it is parked outside. Philosophers call this property of aboutness intentionality, and they say that what a mental state is about is its intentional content. Like consciousness, intentionality poses a problem for materialist theories. If mental states are brain states, how do they come to have intentional content? How can a brain state be about something, and how can it be true or false? Many materialists think the answer involves positing mental representations. We’re familiar with physical things that are representations of other things – words and pictures, for example. And the idea is that some brain states are representations, perhaps like sentences in a brain language (‘Mentalese’). Then the next question is how brain states can be representations. A lot of work in contemporary philosophy of mind has been devoted to this task of building a theory of mental representation. There are many books on this topic I could have chosen – by Fred Dretske, for example, or Jerry Fodor. But Ruth Millikan’s work on this is, in my view, some of the best and most profound, and this book, which is based on a series of lectures she gave in 2002, is a good introduction to her views.
Is this the same as meaning? How do mental representations of some kind acquire meaning for us?
Yes, the problem is how mental representations come to mean, or signify, or stand for, things. If there’s a brain language, how do words and sentences of that language get their meaning? As the title indicates, Millikan thinks there are many varieties of meaning. To begin with, she argues that there is a natural form of meaning which is the foundation of it all. We say that dark clouds mean rain, that tracks on the ground mean that pheasants have been there, that geese flying south mean that winter is coming, and so on. There is a reliable connection, or mapping, between occurrences of the two things, which makes the first a sign of the second. You can get information about the second from the first. Millikan calls these natural signs. Other philosophers, including Paul Grice and Fred Dretske, have discussed natural meaning like this, but Millikan’s account of it improves on previous work in various ways, and I think it’s the best around. So this is one basic form of meaning, but it is limited. One thing is a sign of another – carries information about it – only if the other thing really is there. Clouds mean rain only if rain is actually coming. Tracks means pheasants only if they were made by pheasants, and so on. So natural signs, unlike our thoughts and perceptions, cannot be false, cannot misrepresent.
So mental representations are different from natural signs?
Yes, they are what Millikan calls intentional signs. But normally they are natural signs too. Roughly speaking (Millikan’s account is very subtle and I’m cutting corners), an intentional sign is a sign that is used with the purpose of conveying some information to a recipient. Take a sentence of English, rather than a mental representation. (Sentences of human language are also intentional signs, as are animal calls.) Take ‘Rain is coming’. We say this with the purpose of alerting someone to the fact that rain is coming, and we can do this successfully only if rain is coming. (I can’t alert you to the fact that rain is coming if it’s not.) So if we succeed in our purpose, the sentence we produce will be a natural sign that rain is coming, just as dark clouds are. There’s a reliable connection between the two things. Now if we utter the sentence in error, when rain isn’t coming, then of course it won’t be a natural sign that rain is coming. However, it will still be an intentional sign that rain is coming in virtue of the fact that we used it with thepurpose of signifying to someone that rain is coming. (Millikan argues that intentional signs are always designed for some recipient or consumer.) Roughly, then, an intentional sign of something is a sign whose purpose is to be a natural sign of it.
But how then can mental representations have meaning? We don’t use them for a purpose.
No, but our brains do. Millikan has a thoroughly evolutionary approach to the mind. Evolution has built biological mechanisms to do certain things – to have certain purposes or functions. (This doesn’t mean that evolution had intentions and intelligence, just that the mechanisms were naturally selected for because they did these things, rather than because of other things they did.) And the idea is that the mind is composed of a vast array of systems designed to perform specific tasks – detecting features of the world, interpreting them, reacting to them, and selecting actions to perform. These systems pass information to each other using representations which are designed to serve as natural signs of certain things – and which are thus intentional signs of those things. In very general terms, then, the view is that mental representations derive their meaning from the purposes with which they are used. This sort of view is called a teleological theory of meaning. (‘Teleological’ comes from the Greek word ‘telos’, meaning purpose or end.)
What about non-human animals? Does Millikan have a view on them?
Oh yes. As I said, Millikan takes an evolutionary approach to the mind. She thinks that in order to understand how our minds represent things we need to look at the evolution of mental representation, and she devotes a whole section of the book to this, with lots of information about animal psychology and fascinating observations of animal behaviour. Millikan thinks that the basic kind of intentional signs are what she calls pushmi-pullyu signs, which simultaneously represent what is happening and how to react to it. An example is the rabbit-thump. When a rabbit thumps its hind foot, this signals to other rabbits both that danger is present and that they should take cover. The sign is both descriptive and directive, and if used successfully, it will be a natural sign both of what is happening now and of what will happen next. Millikan thinks that the bulk of mental representations are of this kind; they represent both what is happening and what response to make. This enables creatures to take advantage of opportunities for purposive action as they present themselves. But creatures whose minds have only pushmi-pullyu representations are limited in their abilities – they can’t think ahead, can’t check they have reached their goals, and can get trapped in behavioural loops.
“This isn’t an easy book. You’ll have to work at it, and you may need to re-read the book several times. But it repays the effort”
Millikan argues that more sophisticated behavioural control requires splitting off the descriptive and directive roles, so that the creature has separate representations of objects and of its goals, expressed in a common mental code, and she devotes two chapters of the book to exploring how this might have happened. Finally, she argues that even with these separate representations, non-human animals are still limited in what they can represent. They can only represent things that have practical significance for them – things relevant in some way to their needs. We, on the other hand, can represent things that have no practical value for us. We can think about distant times and places, and about things we’ll never need or encounter. Millikan describes us as collectors of ‘representational junk’ – though, of course, it’s this collecting of theoretical knowledge that enables us to do science and history and philosophy and so on. To represent this kind of theoretical information, Millikan argues, a new representational medium was needed with a certain kind of structure, and she thinks that this was provided by language. It is language that has enabled us to collect representational junk and do all the wonderful things we do with it.
Does Millikan discuss language and linguistic meaning too?
Yes. In fact, there’s another section of the book on what she calls ‘outer intentional signs’ (animal calls and linguistic signs). Millikan argues that linguistic signs emerge from natural signs and that they are normally read in exactly the same way as natural signs. We read the word ‘pheasant’ as we read pheasant tracks on the ground, as a natural sign of pheasants. We don’t need to think about what the speaker intended or had in mind. This view has some surprising consequences, which Millikan traces out. One of them is that we can directly perceive things through language. When we hear someone say ‘Johnny’s arrived’, we perceive Johnny just as if we were to hear his voice or see his face, Millikan argues. The idea is that the words are a natural sign of Johnny just as the sound of his voice or the pattern of light reflected from his face is. They are all just ways of picking up information about Johnny’s whereabouts. Of course, there is processing involved in getting from the sound of the words to a belief about Johnny, but Millikan argues that the processes involved are not fundamentally different from those involved in sense perception. It’s a controversial view, but it fits in with the wider views about perception and language that she develops.
I should perhaps say that this isn’t an easy book. Millikan writes clearly, but the discussion is complex and subtle. You’ll have to work at it, especially if you’re new to the subject, and you may need to re-read the book several times. But it repays the effort. It’s packed full of insights, and you’ll come away with a much deeper understanding of how our minds latch onto the world.
Now let’s move on to the fourth book, The Architecture of Mind by Peter Carruthers. This is a book with a different approach to the mind?
To some extent. It’s a work of substantive psychological theorising. Carruthers makes the case for the thesis of massive modularity– the view that the mind is composed of numerous separate subsystems, or modules, each of which has a specialised function. This view has been popular with people working in evolutionary psychology, since it explains how the human mind could have developed from simpler precursors by adding or repurposing specific modules. Carruthers argues that this view offers the best explanation of a host of experimental data.
And why did you choose this particular book?
First, it’s an excellent example of what philosophy can contribute to psychology. Carruthers surveys a huge range of scientific work from across the cognitive sciences and fits it together into a big picture. As I said, this is something experimental psychologists are often wary of doing, because it means going beyond their own particular area of expertise. Second, the massive modularity thesis is an important one, and Carruthers’s version of it is the most detailed and persuasive one I’ve met. Third, because of the way Carruthers argues for his views, drawing on masses of empirical data from neuroscience, cognitive psychology, social psychology, it is a very informative work. Even if you completely disagree with Carruthers’s conclusions, you will learn a vast amount from this book.
What exactly does Carruthers mean by a mental ‘module’?
This notion of a mental module was made famous by Jerry Fodor in his 1983 book, The Modularity of Mind. As I said, a module is a specialist system for performing some specific task – say, for processing visual information. Fodor had a strict conception of what a module was. In particular, he thought of modules as encapsulated– they couldn’t draw on information from other cognitive systems, except for certain specific inputs. Fodor thought that sensory processes were modular in this way, but he denied that central, conceptual processes were – processes of belief formation, reasoning, decision making and so on. Indeed, he couldn’t see how these processes could possibly be modular, since in order to make judgements and decisions we need to draw on information from a variety of sources. Obviously, if the mind is massively modular, then it can’t be so in Fodor’s sense, and Carruthers proposes a looser definition which, among other things, drops the claim that modules can’t share information. He argues that evolution equipped animals with numerous modules like this, each dedicated to a specific task that was important for survival. There are suites of these modules, he thinks: learning modules, for forming beliefs about direction, time, number, food availability, social relations, and other topics; motivational modules, for generating different kinds of desire, emotion, and social motivation; memory modules for storing different kinds of information, and so on. He argues that the human mind has these modules too, together with various additional ones, including a language module and modules for reasoning about people’s minds, living things, physical objects, and social norms.
What is the argument for thinking that the mind is massively modular in this way?
Carruthers has several arguments. One is evolutionary. This is how complex systems evolve. Nature builds them bit by bit from simpler components, which can be modified without disrupting the whole system. This is true of genes, cells, organs, and whole organisms, and we should expect it to be true of minds too. Another argument is from animals. Carruthers argues that the minds of non-human animals are modular, and since our minds evolved from such minds, they will have retained their basic modular structure, with various new modules added on. A third argument turns on considerations of computability. Carruthers argues that the mind is a computational system; it works by manipulating symbols in something like a language of thought. And for these computations to be tractable, they can’t be done by a general system that draws on all potentially relevant information. It would just take too long. Instead, there must be specialised computational systems – modules – that each access only a limited amount of the information available in the wider system. This doesn’t mean that the modules can’t share information, just that they don’t share much of it. Of course, these are arguments only for the general principle of massive modularity; the arguments for the existence of the specific modules come later in the book.
But if our minds are collections of modules designed to deal with specific survival problems, how do we manage to do so many other things? I assume evolution didn’t equip us with modules for doing science, or making art, or playing football.
This is the big challenge for the massive modularity view. How can a collection of specialist modules support flexible, creative, and scientific thinking of the kind we are capable of? We can think about things that are not of immediate practical importance, we can combine concepts from different domains, and we learn to think in new and creative ways. How can we do this if our minds are modular? Carruthers devotes a lot of the book to answering this challenge in its various forms. It’s a long story, but the core idea is that these abilities involve co-opting systems that originally evolved for other purposes. Language plays a crucial role in the story, since it can combine outputs from different modules, and Carruthers argues that flexible and creative thinking involves rehearsing utterances and other actions in imagination, using mechanisms that originally developed for guiding action. (You’ll notice that this picks up a theme from Dennett and Millikan – that language is key to the distinctive powers of the human mind.) Carruthers thinks that we are conscious of things we mentally rehearse, so this is at the same time an account of the nature of conscious thought. It’s a very attractive account in its own right – another reason to read the book – and you might endorse even if you are sceptical of the modular picture that goes with it. Carruthers has developed his account of conscious thought further in his most recent book The Centred Mind.
Doesn’t Carruthers story about modules sound a little speculative? It’s not as though we can open up the brain and view the modular systems. Is there any empirical consequence for this kind of theorising?
The modules might not be evident from the anatomy. Carruthers isn’t claiming that each module is localised to a specific brain region. A module might be spread out across several regions, as the circulatory system is spread out across the body. But the modular theory should generate many testable predictions. For example, we should find distinctive patterns of response under experimental conditions (say, when a task places heavy demands on one module but not on another), distinctive kinds of breakdown (as when a stroke damages one module but leaves others intact), and distinctive patterns of activation in neuroimaging studies. What Carruthers is doing is setting out a research programme for cognitive science, and it’s only by pursuing the programme that we’ll find out whether it’s a good one. Does the programme lead us to new insights and new discoveries? This is very from far armchair conceptual analysis.
And finally, what did you choose for your last book?
Andy Clark’s, Supersizing the Mind. It’s about how the mind is embodied and extended. Clark is a fascinating philosopher, and he’s always been a bit ahead of the field. He’s played the role of alerting philosophers to the latest developments in cognitive science and AI, such as connectionism, dynamical systems theory, and predictive coding. If you want to know what philosophers of mind will be thinking about in five or ten years’ time, look at what Andy Clark is thinking about today.
To me Andy Clark’s theory of the extended mind is fascinating because it’s an example of the philosopher who, a bit like Dennett, causes us to rethink something we thought we understood. It’s also a very attractive picture that he presents of the way in which things we might not have thought of as parts of our mind, really are parts of our mind.
Yes. One way to think of it is in terms of a contrast between two models of the mind. Both are physicalist, but they differ as to the range of physical processes that make up the mind. One is what Clark calls the Brainbound model. This sees the mind confined to the brain, sealed away in the skull. It is the view that Armstrong has – it’s in the name ‘central-state materialism’, where ‘central’ means the central nervous system. In this model, the brain does all the processing work and the body has an ancillary role, sending sensory data to the brain and receiving the brain’s commands. This means that there’s a lot of work for the brain to do. It needs to model the external world in great detail and calculate precisely how to move the body in order to achieve its goals. This contrasts with what Clark calls the ‘Extended Model.’ This sees mental processes as involving the wider body and external artefacts. One aspect of this concerns the role of the body in cognition. The brain can offload some of the work onto the body. For example, our bodies are designed to do some things automatically, in virtue of their structure and dynamics. Walking is an example. So the brain doesn’t need to issue detailed muscular commands for these activities but can just monitor and tweak the process as it unfolds. Another example is that instead of constructing a detailed internal model of the world, the brain can simply probe the world with the sense organs as and when it needs information – using the world as its own model, as the roboticist Rodney Brooks puts it. So the work of controlling behaviour is not all done in the head but involves interaction and feedback between brain and body. Clark lists many examples of this, with data from psychology, neuroscience, and robotics.
There’s a more familiar element of this theory that suggests storage outside the brain could potentially be part of the mind, which is a fascinating idea.
Yes, that’s the other aspect of the Extended model. Mental processes don’t only involve the body but can also extend out into external objects and artefacts. This was an idea made famous by a 1998 article ‘The extended mind’, which Clark co-wrote with David Chalmers and which is included in the book. (Chalmers also contributed a foreword to the book, giving his later thoughts on the topic.) The argument involves what’s called the Parity Principle. This is the claim that if an external object performs a certain function that we’d regard as a mental function if it were performed by a bit of the brain, then that external object is a part of your mind. It’s what a thing does that matters, not where it’s located. Take memory. Our memories store our beliefs (for example, about names or appointments), which we can access as needed to guide our behaviour. Now suppose someone has a memory impairment, and they write down bits of information in a notebook which they carry around with them and consult regularly. Then the notebook is functioning like their memory used to, and the bits of information in it function as beliefs. So, the argument goes, we should think of the notebook as literally part of the person’s mind and its contents as among their mental states. This view may seem counterintuitive, but it isn’t all that far from where we started with Armstrong and the claim that mental states can be defined in terms of their causal roles – what work they do within the mind/brain system. The new claim is just that these causal roles can be played by things outside the brain. It also fits in nicely with Carruthers’s massive modularity. If the brain is itself composed of modules, then why couldn’t there be further modules or subsystems external to the brain? These external modules would need to have interfaces with the brain, of course – in the case of the notepad this would be through the person’s eyes and fingers. But, as Clark notes, internal modules will need interfaces too.
That explains in some ways the psychological phenomenon that people have when they lose a key address book or family album, they really have lost something that is crucial to their mental functioning.
Yes. Of course, this only applies to things that are closely integrated with your brain processes, things that you carry with you, that you consult regularly. Clark doesn’t claim that anything you consult is part of your mind – a book that you look at only once a year, say.
Could a room, or a bookshelf play the same role?
Yes, I think it could. Clark talks about how we construct cognitive niches– external environments that serve to guide and structure our activities. For example, the arrangement of materials and tools in a workplace might act like a workflow diagram, guiding the workers’ activities. Clark has a nice historical example of this from the Elizabethan theatre. The physical layout of the stage and scenery, combined with a schematic plot summary, enabled actors to master lengthy plays in a short time. We see this with elderly people too. As a person’s mental faculties decline, they become more and more dependent upon the cognitive niche they have created in their own home, and if you take them out of that niche and put them in an institution, they may become unable to do even simple everyday things.
The suggestion is then that an elderly person’s wardrobe and bedside table are actually part of their mind?
Yes. Or rather, the suggestion is that there is a perspective from which they can be seen that way. Clark isn’t dogmatic about this. The point is that the Extended model offers a perspective from which we see patterns and explanations that aren’t visible from the narrower Brainbound perspective. Again, this is nudging us away from this Cartesian view of the mind as something locked away from the world. We have an intuitive picture of our minds as private inner worlds, somehow separate from the physical world, but modern philosophy of mind is increasingly dismantling that picture.
With your book choices there’s a whole interesting set of different ways of thinking about ourselves. So, Armstrong is reacting primarily against Cartesian mind/body dualism, which sees the mind as an immaterial substance. Dennett is rejecting the inner cinema picture of the mind and urging us to rethink what it means to be conscious. Millikan is exploring how our thoughts and perceptions evolved from simpler, more basic signs and representations. Carruthers is suggesting that our mental processes are the product of different systems working with a degree of independence to produce what we think of as our single experience. And Clark is switching us again to thinking that we think too narrowly about the mind, that another way of understanding mental activities is to see it as extending far beyond the skull potentially. It’s a very interesting range of books that you’ve chosen.
Maybe there’s a metaphor of Dennett’s that can help us sum this up. Dennett talks about consciousness as a user illusion. He’s thinking of the graphical user interface on a computer, where you have an image of a desktop with files, folders, a waste bin, and so on, and you can do things by moving the icons around – deleting a file by dragging it to the waste bin, for example. Now these icons and operations correspond to things inside the computer – to complex data structures and ultimately to millions of microsettings in the hardware – but they do so only in a very simplified, metaphorical way. So the interface is a kind of illusion. But it’s a helpful illusion, which enables us to use the computer in an intuitive way, without needing any knowledge of its programming or hardware. Dennett suggests that our awareness of own minds is a bit like this. My mind seems to me to be a private world populated with experiences, images, thoughts, and emotions, which I can survey and control. And Dennett’s idea is that this is a kind of user illusion too. It is useful; it gives us some access to what is going in our brains and some control over it. But it represents the states and processes there only in a very simplified, schematic way. I think that’s right. And what these books are doing, and what a lot of modern philosophy of mind is doing, is deconstructing this user illusion, showing us how it is created and how it relates to what is actually happening as our brains interact with our bodies and the world around us.
Five Books aims to keep its book recommendations and interviews up to date. If you are the interviewee and would like to update your choice of books (or even just what you say about them) please email us at editor@fivebooks.com
Five Books interviews are expensive to produce. If you've enjoyed this interview, please support us by donating a small amount, or by visiting our site before you make purchases from Amazon. Since we are enrolled in their affiliate program, we receive a small percentage of any product you buy, at no extra cost to you.
This report examines the intersection of two subjects, China and artificial intelligence, both of which are already difficult enough to comprehend on their own. It provides context for China’s AI strategy with respect to past science and technology plans, and it also connects the consistent and new features of China’s AI approach to the drivers of AI development (e.g. hardware, data, and talented scientists). In addition, it benchmarks China’s current AI capabilities by developing a novel index to measure any country’s AI potential and highlights the potential implications of China’s AI dream for issues of AI safety, national security, economic development, and social governance.
The author, Jeffrey Ding, writes, “The hope is that this report can serve as a foundational document for further policy discussion and research on the topic of China’s approach to AI.” The report draws from the author’s translations of Chinese texts on AI policy, a compilation of metrics on China’s AI capabilities compared to other countries, and conversations with those who have consulted with Chinese companies and institutions involved in shaping the AI scene. To access the report, click here.
"The airlines are pretty clear that they want every consumer protection law repealed or not enforced," said Paul Hudson, president of Flyersrights.org, a nonprofit group with more than 60,000 members. "I'm concerned that they would try to repeal the few consumer-protection regulations that are out there."
HIP allows developers to convert CUDA code to portable C++. The same source code can be compiled to run on NVIDIA or AMD GPUs.
Key features include:
HIP is very thin and has little or no performance impact over coding directly in CUDA or hcc "HC" mode.
HIP allows coding in a single-source C++ programming language including features such as templates, C++11 lambdas, classes, namespaces, and more.
HIP allows developers to use the "best" development environment and tools on each target platform.
The "hipify" tool automatically converts source from CUDA to HIP.
Developers can specialize for the platform (CUDA or hcc) to tune for performance or handle tricky cases
New projects can be developed directly in the portable HIP C++ language and can run on either NVIDIA or AMD platforms. Additionally, HIP provides porting tools which make it easy to port existing CUDA codes to the HIP layer, with no loss of performance as compared to the original CUDA application. HIP is not intended to be a drop-in replacement for CUDA, and developers should expect to do some manual coding and performance tuning work to complete the port.
Repository branches:
The HIP repository maintains several branches. The branches that are of importance are:
master branch: This is the stable branch. All stable releases are based on this branch.
developer-preview branch: This is the branch were the new features still under development are visible. While this maybe of interest to many, it should be noted that this branch and the features under development might not be stable.
Release tagging:
HIP releases are typically of two types. The tag naming convention is different for both types of releases to help differentiate them.
release_x.yy.zzzz: These are the stable releases based on the master branch. This type of release is typically made once a month.
preview_x.yy.zzzz: These denote pre-release code and are based on the developer-preview branch. This type of release is typically made once a week.
The HIP API includes functions such as hipMalloc, hipMemcpy, and hipFree. Programmers familiar with CUDA will also be able to quickly learn and start coding with the HIP API.
Compute kernels are launched with the "hipLaunchKernel" macro call. Here is simple example showing a
snippet of HIP API code:
The HIP kernel language defines builtins for determining grid and block coordinates, math functions, short vectors,
atomics, and timer functions. It also specifies additional defines and keywords for function types, address spaces, and
optimization controls. (See the HIP Kernel Language for a full description).
Here's an example of defining a simple 'vector_square' kernel.
The HIP Runtime API code and compute kernel definition can exist in the same source file - HIP takes care of generating host and device code appropriately.
HIP Portability and Compiler Technology
HIP C++ code can be compiled with either :
On the NVIDIA CUDA platform, HIP provides header file which translate from the HIP runtime APIs to CUDA runtime APIs. The header file contains mostly inlined
functions and thus has very low overhead - developers coding in HIP should expect the same performance as coding in native CUDA. The code is then
compiled with nvcc, the standard C++ compiler provided with the CUDA SDK. Developers can use any tools supported by the CUDA SDK including the CUDA
profiler and debugger.
On the AMD ROCm platform, HIP provides a header and runtime library built on top of hcc compiler. The HIP runtime implements HIP streams, events, and memory APIs,
and is a object library that is linked with the application. The source code for all headers and the library implementation is available on GitHub. HIP developers on ROCm can use AMD's CodeXL for debugging and profiling.
Thus HIP source code can be compiled to run on either platform. Platform-specific features can be isolated to a specific platform using conditional compilation. Thus HIP
provides source portability to either platform. HIP provides the hipcc compiler driver which will call the appropriate toolchain depending on the desired platform.
Examples and Getting Started:
A sample and blog that uses hipify to convert a simple app from CUDA to HIP:
cd samples/01_Intro/square# follow README / blog steps to hipify the application.
A sample and blog demonstrating platform specialization:
cd samples/01_Intro/bit_extract
make
More Examples
The GitHub repository HIP-Examples contains a hipified version of the popular Rodinia benchmark suite.
The README with the procedures and tips the team used during this porting effort is here: Rodinia Porting Guide
Tour of the HIP Directories
include:
hip_runtime_api.h : Defines HIP runtime APIs and can be compiled with many standard Linux compilers (hcc, GCC, ICC, CLANG, etc), in either C or C++ mode.
hip_runtime.h : Includes everything in hip_runtime_api.h PLUS hipLaunchKernel and syntax for writing device kernels and device functions. hip_runtime.h can only be compiled with hcc.
hcc_detail/** , nvcc_detail/** : Implementation details for specific platforms. HIP applications should not include these files directly.
hcc.h : Includes interop APIs for HIP and HCC
bin: Tools and scripts to help with hip porting
hipify : Tool to convert CUDA code to portable CPP. Converts CUDA APIs and kernel builtins.
hipcc : Compiler driver that can be used to replace nvcc in existing CUDA code. hipcc will call nvcc or hcc depending on platform, and include appropriate platform-specific headers and libraries.
hipexamine.sh : Script to scan directory, find all code, and report statistics on how much can be ported with HIP (and identify likely features not yet supported)
doc: Documentation - markdown and doxygen info
Reporting an issue
Use the GitHub issue tracker.
If reporting a bug, include the output of "hipconfig --full" and samples/1_hipInfo/hipInfo (if possible).
—In many ways, George Pla is the embodiment of the American dream.
The son of Mexican immigrants, Mr. Pla moved to Los Angeles’s Boyle Heights neighborhood at 5 years old. One of five children growing up on the $100 a month his father earned doing construction work in the 1950s, Pla says he always dreamed of attending “the college on the hill.”
That college was California State University, Los Angeles, a mid-tier public university that he credits with his rapid ascent up the income ladder.
Follow Stories Like This
Get the Monitor stories you care about delivered to your inbox.
“Without Cal State L.A., I’m nowhere,” says Pla, who initially got his foot in the door at an East Los Angeles community college. After two years he transferred to Cal State, where he graduated in 1972 before going on to get a graduate degree in public finance from the University of Southern California.
Today, Pla is the founder and CEO of a nationally recognized civil engineering firm, Cordoba Corp. He employs more than 200 people and builds major infrastructure projects for California’s transportation, education, water, and energy sectors. With a base salary of more than $1 million a year, Pla’s story and others like it are held up as the pinnacle of the American Dream. His alma mater, Cal State, Los Angeles, launches more low-income kids into the top income bracket than Harvard, according to a new study by a group of high-level academics working under the title The Equality of Opportunity Project.
For decades, “working-class” colleges like Cal State have been one of the more reliable engines of economic mobility. And, the new research shows, public higher education systems like those in California, Texas, and New York still push low-income kids into the top echelon of earners at far higher rates than the eight Ivy League colleges, plus the University of Chicago, Stanford, Massachusetts Institute of Technology, and Duke University. (The researchers called this the "Ivy-Plus.")
Sixty percent of Ivy-Plus students from the lowest income bracket reach the top, but the mid-tier colleges beat them on the upward-mobility metric because they accept so many more poor students, and those students still reach the top income bracket at comparable rates. For example, 51 percent of the State University of New York, Stony Brook’s, lowest-quintile students make it to the top economic quintile.
But now, authors of the report – Mobility Report Cards: The Role of Colleges in Intergenerational Mobility – say those successes are being significantly hampered. Over the past 15 years, the number of low-income students enrolling at mid-tier universities has been on a downward slide. As such, they say, their new data serves as a timely warning to policymakers and educators for the need to bolster support for high-performing mid-tier institutions. Furthermore, they say, it highlights the need to study what makes top performing public systems so successful so their models can be replicated across the country.
“What we've seen is that the colleges that we identify as being very good by our metric, which in many cases includes these mid-tier public schools are in most cases declining in terms of access,” says Robert Fluegge, a pre-doctoral research fellow at Stanford University, who worked on the study. “They've seen the proportion of poor students decline pretty substantially, and I think that that's a bit worrisome, given that these are the colleges that are really doing well for poor students.”
Top five schools for mobility
The research, based on administrative data of 30 million American college students between 1999 and 2013, showed the colleges with the top five upward mobility rates in the nation: Cal State LA was first (9.9 percent). The State University of New York (SUNY), Stony Brook (8.4 percent); City University of New York’s system (CUNY) (7.2 percent); California’s Glendale Community College (7.1 percent); and University of Texas, El Paso (6.8 percent), rounded out the top five. To put those numbers in perspective, the average upward mobility rate across all US colleges is less than 2 percent.
Pla was pleased to see that his alma mater topped the upward mobility rankings, but as someone who has stayed philanthropically involved with the state’s higher education system, he knows firsthand that it’s getting harder for people from backgrounds like his to find their way into such schools.
“Thank God that public education used to be accessible and affordable, and we have really got to fight to keep it that way,” Pla says. "I think an institution like Cal State is absolutely golden.”
Indeed, the study’s sample group revealed a bittersweet picture. On the upside, America’s poorest students are attending college at record rates. Overall college attendance for low-income students over the study’s sample period climbed about 2 percentage points, according to John N. Friedman, an associate professor of economics and international and public affairs at Brown University and co-author of the research. However, at the same time, their access to schools that improve students' upward economic mobility fell by 2.5 percentage points.
“What our research really points out is that not all community colleges are created equally,” Professor Friedman says. “There are important differences both in the fraction of students from poor families and in the outcomes across different community colleges, and I think it's probably very important, whether you go to a Cal State university or to another California community college.”
Alma mater as predictor of earnings
In other words, access is everything. Friedman says that what particularly stands out to him is that once a low-income student gains access to a good college, whether an Ivy League or a good mid-tier, there’s very little difference in their performance compared with those of their peers from wealthy backgrounds.
“One of the really striking findings of the study was, that you would in some sense really rather know where somebody went to college rather than how much money their parents make, if you wanted to guess how much money they were going to make in the future,” Mr. Fluegge adds.
The need to bolster and spread access to quality secondary education is highlighted by America’s continual downward trend in upward mobility. Children born in the 1940s had a 90 percent likelihood they would grow up to earn more than their parents, for those born in 1980, it’s a 50/50 prospect, according to another paper by the Equality of Opportunity Project, released late last year.
And the implications for America’s severe income inequality are substantial. As David Leonhardt points out in The New York Times, the earnings gap between four-year college graduates and the rest of the population has boomed in recent decades. The unemployment rate for college graduates is only 2.5 percent, compared with a national average close to 5 percent.
The broad consensus among education watchers is that rising tuition costs along with massive state budget cuts are the main culprits. For Friedman, the research is a solid start, although follow-ups looking at the effects of things like budget cuts, students’ college preparedness, and education policies that enable easy transfers from community colleges to universities, just as Pla did when he went to Cal State, are needed.
“By identifying these schools and drawing attention to them hopefully it'll lead to follow-up research where we can identify what makes the City University of New York or the Cal State systems so outstanding in a way that we can find a model to replicate at other schools.”
Editor's note: An earlier version of this story incorrectly stated that David Leonhardt was a professor at New York University Steinhardt.